pytorch 测量模型运行时间,GPU时间和CPU时间,model.eval()介绍
文章目录
- 1. 测量时间的方式
- 2. model.eval(), model.train(), torch.no_grad()方法介绍
- 2.1 model.train()和model.eval()
- 2.2 model.eval()和torch.no_grad()
- 3. 模型推理时间方式
- 4. 一个完整的测试模型推理时间的代码
- 5. 参考:
1. 测量时间的方式
time.time()
time.perf_counter()
time.process_time()
time.time() 和time.perf_counter() 包括sleep()time 可以用作一般的时间测量,time.perf_counter()精度更高一些
time.process_time()当前进程的系统和用户CPU时间总和的值
测试代码:
def show_time():print('我是time()方法:{}'.format(time.time()))print('我是perf_counter()方法:{}'.format(time.perf_counter()))print('我是process_time()方法:{}'.format(time.process_time()))t0 = time.time()c0 = time.perf_counter()p0 = time.process_time()r = 0for i in range(10000000):r += itime.sleep(2)print(r)t1 = time.time()c1 = time.perf_counter()p1 = time.process_time()spend1 = t1 - t0spend2 = c1 - c0spend3 = p1 - p0print("time()方法用时:{}s".format(spend1))print("perf_counter()用时:{}s".format(spend2))print("process_time()用时:{}s".format(spend3))print("测试完毕")
测试结果:
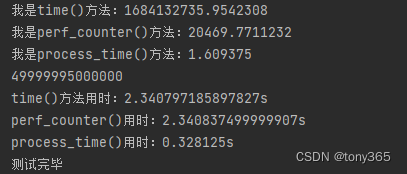
更详细解释参考
Python3.7中time模块的time()、perf_counter()和process_time()的区别
2. model.eval(), model.train(), torch.no_grad()方法介绍
2.1 model.train()和model.eval()
我们知道,在pytorch中,模型有两种模式可以设置,一个是train模式、另一个是eval模式。
model.train()的作用是启用 Batch Normalization 和 Dropout。在train模式,Dropout层会按照设定的参数p设置保留激活单元的概率,如keep_prob=0.8,Batch Normalization层会继续计算数据的mean和var并进行更新。
model.eval()的作用是不启用 Batch Normalization 和 Dropout。在eval模式下,Dropout层会让所有的激活单元都通过,而Batch Normalization层会停止计算和更新mean和var,直接使用在训练阶段已经学出的mean和var值。
在使用model.eval()时就是将模型切换到测试模式,在这里,模型就不会像在训练模式下一样去更新权重。但是需要注意的是model.eval()不会影响各层的梯度计算行为,即会和训练模式一样进行梯度计算和存储,只是不进行反向传播。
2.2 model.eval()和torch.no_grad()
在讲model.eval()时,其实还会提到torch.no_grad()。
torch.no_grad()用于停止autograd的计算,能起到加速和节省显存的作用,但是不会影响Dropout层和Batch Normalization层的行为。
如果不在意显存大小和计算时间的话,仅仅使用model.eval()已足够得到正确的validation的结果;而with torch.zero_grad()则是更进一步加速和节省gpu空间。因为不用计算和存储梯度,从而可以计算得更快,也可以使用更大的batch来运行模型。
3. 模型推理时间方式
在测量时间的时候,与一般测试不同,比如下面的代码不正确:
start = time.time()
result = model(input)
end = time.time()
而应该采用:
torch.cuda.synchronize()
start = time.time()
result = model(input)
torch.cuda.synchronize()
end = time.time()
因为在pytorch里面,程序的执行都是异步的。
如果采用代码1,测试的时间会很短,因为执行完end=time.time()程序就退出了,后台的cu也因为python的退出退出了。
如果采用代码2,代码会同步cu的操作,等待gpu上的操作都完成了再继续成形end = time.time()
4. 一个完整的测试模型推理时间的代码
一般是首先model.eval()不启用 Batch Normalization 和 Dropout, 不启用梯度更新
然后利用mode创建模型,和初始化输入数据(单张图像)
def measure_inference_speed(model, data, max_iter=200, log_interval=50):model.eval()# the first several iterations may be very slow so skip themnum_warmup = 5pure_inf_time = 0fps = 0# benchmark with 2000 image and take the averagefor i in range(max_iter):torch.cuda.synchronize()start_time = time.perf_counter()with torch.no_grad():model(*data)torch.cuda.synchronize()elapsed = time.perf_counter() - start_timeif i >= num_warmup:pure_inf_time += elapsedif (i + 1) % log_interval == 0:fps = (i + 1 - num_warmup) / pure_inf_timeprint(f'Done image [{i + 1:<3}/ {max_iter}], 'f'fps: {fps:.1f} img / s, 'f'times per image: {1000 / fps:.1f} ms / img',flush=True)if (i + 1) == max_iter:fps = (i + 1 - num_warmup) / pure_inf_timeprint(f'Overall fps: {fps:.1f} img / s, 'f'times per image: {1000 / fps:.1f} ms / img',flush=True)breakreturn fps
if __name__ == "__main__":device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# device = 'cpu'print(device)img_channel = 3width = 32enc_blks = [2, 2, 4, 8]middle_blk_num = 12dec_blks = [2, 2, 2, 2]width = 16enc_blks = [1, 1, 1]middle_blk_num = 1dec_blks = [1, 1, 1]net = NAFNet(img_channel=img_channel, width=width, middle_blk_num=middle_blk_num,enc_blk_nums=enc_blks, dec_blk_nums=dec_blks)net = net.to(device)data = [torch.rand(1, 3, 256, 256).to(device)]fps = measure_inference_speed(net, data)print('fps:', fps)
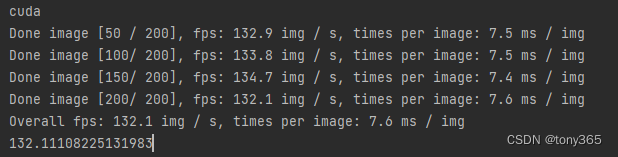
5. 参考:
https://blog.csdn.net/weixin_44317740/article/details/104651434
https://zhuanlan.zhihu.com/p/547033884
https://deci.ai/blog/measure-inference-time-deep-neural-networks/
https://github.com/xinntao/BasicSR
相关文章:
pytorch 测量模型运行时间,GPU时间和CPU时间,model.eval()介绍
文章目录 1. 测量时间的方式2. model.eval(), model.train(), torch.no_grad()方法介绍2.1 model.train()和model.eval()2.2 model.eval()和torch.no_grad() 3. 模型推理时间方式4. 一个完整的测试模型推理时间的代码5. 参考: 1. 测量时间的方式 time.time() time.…...
十三、超时重试机制
目录 超时配置和重试机制 FeignClient 、Ribbon 、 Hystrix三个之间配置优先级的关系 配置常用属性 Ribbon超时和重试配置: Ribbon重试次数计算公式: FeignClient 超时配置: Hystrix超时配置: Hystrix超时计算公式: 超时配…...

JAVA常用API - Runtime和System
文章目录 前言 大家好,我是最爱吃兽奶,今天给大家带来JAVA常用API中的Runtime类和System类 那么就让我们一起去看看吧! 一、Rubtime 1.Rubtime是什么? 2.Runtime常用方法 Runtime提供了很多方法,在这里演示两个 public static Runtime getRuntime(): 返回当前运行时环境的…...
ANR实战案例 - FCM拉活启动优化
系列文章目录 提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加 例如:第一章 Python 机器学习入门之pandas的使用 文章目录 系列文章目录前言一、Trace日志分析二、业务分析1.Firebase源码分析2.Firebase官方查看官方文档Dem…...
Kali-linux查看打开的端口
对一个大范围的网络或活跃的主机进行渗透测试,必须要了解这些主机上所打开的端口号。在Kali Linux中默认提供了Nmap和Zenmap两个扫描端口工具。为了访问目标系统中打开的TCP和UDP端口,本节将介绍Nmap和Zenmap工具的使用。 4.4.1 TCP端口扫描工具Nmap 使…...

判断浏览器是否支持webp图片
.WebP是谷歌主导的开放免费的网络图像格式,其核心编码来自VP8也就是同时支持WebP图片和WebM视频等。 这种图像格式追求的并不是无损画质,而是在有损画质的情况下尽可能的压缩图像体积但也尽量降低清晰度下降。 谷歌资助和发展该图像格式最主要的目的就是…...
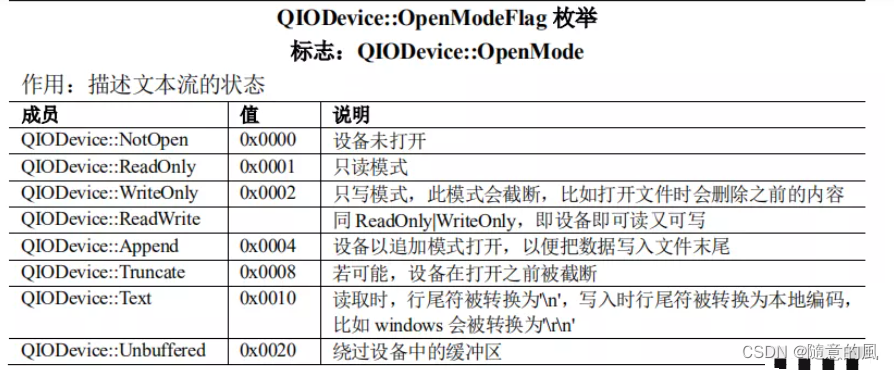
【Qt编程之Widgets模块】-007:QTextStream类及QDataStream类
1 概述 QTextStream和QDataStream都是对流进行操作 QTextStream只能普通类型的流操作像QChar、QString、int…,其实就很类似我们c或者c中读写文件的感觉, QDataStream就厉害了,无论是QTextStream的普通类型的流操作还是一些特殊类型的流操作…...

js对map排序,后端返回有序的LinkedHashMap类型时前端获取后顺序依旧从小到大的解决方法
js对map排序,后端返回有序的LinkedHashMap类型时前端获取后顺序依旧从小到大的解决方法 js对map排序,后端返回有序的LinkedHashMap类型时前端获取后顺序依旧从小到大的解决方法 [{"2020": [{"id": 39,"createTime": &quo…...

JMX vs JFR:谁才是最强大的JVM监控利器?
大家好,我是小米!今天我们来聊一聊JVM监控系统,特别是关于JMX和JFR的使用。你是否有过在线上应用出现性能问题时,无法准确获取关键指标的困扰呢?那么,不妨听听我给大家带来的解决方案。 什么是JMX 首先&a…...

Laravel Collection 基本使用
创建集合 为了创建一个集合,可以将一个数组传入集合的构造器中,也可以创建一个空的集合,然后把元素写到集合中。Laravel 有collect()助手,这是最简单的,新建集合的方法。 $collection collect([1, 2, 3]);默认情况下…...

JUC并发编程19 | 读写锁
有一些关于锁的面试题: 你知道 Java 里面有哪些锁?读写锁的饥饿问题是什么?有没有比读写锁更快的锁?StampedLock知道嘛?(邮戳锁/票据锁)ReentrantReadWriteLock 有锁降级机制? Ree…...

springboot_maven项目怎么引入mybatis
在pom.xml文件中添加mybatis和mybatis-spring-boot-starter的依赖 org.mybatis mybatis ${mybatis.version} org.mybatis.spring.boot mybatis-spring-boot-starter ${mybatis.spring.version} 配置mybatis 在application.properties(或application.yml࿰…...

JAVA8的新特性——lambda表达式
JAVA8的新特性——lambda表达式 此处,我们首先对于Java8的一些特性作为一个简单介绍 Java 8是Java编程语言的一个重要版本,于2014年发布。Java 8引入了许多新特性和改进,以提高开发效率和性能。以下是Java 8的一些主要新特性: Lam…...
算法修炼之练气篇——练气六层
博主:命运之光 专栏:算法修炼之练气篇 前言:每天练习五道题,炼气篇大概会练习200道题左右,题目有C语言网上的题,也有洛谷上面的题,题目简单适合新手入门。(代码都是命运之光自己写的…...
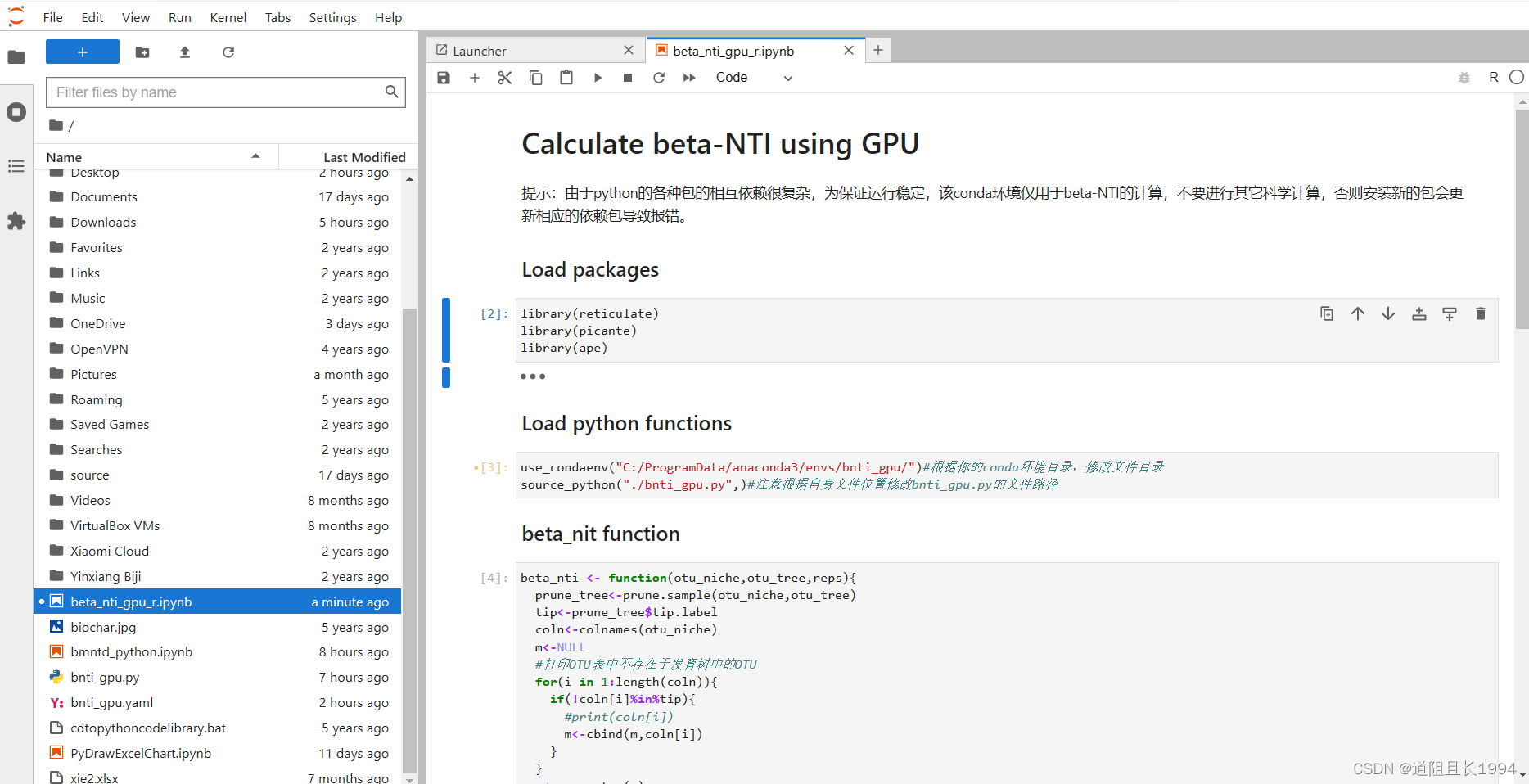
利用GPU并行计算beta-NTI,大幅减少群落构建计算时间
1 先说效果 18个样本,抽平到8500条序列,4344个OTUs,计算beta-NTI共花费时间如下。如果更好的显卡,更大的数据量,节约的时间应该更加可观。 GPU(GTX1050):1分20秒 iCAMP包 的bNTIn.p(…...
Shiro框架漏洞分析与复现
Shiro简介 Apache Shiro是一款开源安全框架,提供身份验证、授权、密码学和会话管理。Shiro框架直观、易用,同时也能提供健壮的安全性,可以快速轻松地保护任何应用程序——从最小的移动应用程序到最大的 Web 和企业应用程序。 1、Shiro反序列…...

(数字图像处理MATLAB+Python)第七章图像锐化-第一、二节:图像锐化概述和微分算子
文章目录 一:图像边缘分析二:一阶微分算子(1)梯度算子A:定义B:边缘检测C:示例D:程序 (2)Robert算子A:定义B:示例C:程序 &a…...

C# | 内存池
内存池 文章目录 内存池前言什么是内存池内存池的优点内存池的缺点 实现思路示例代码结束语 前言 在上一篇文章中,我们介绍了对象池的概念和实现方式。对象池通过重复利用对象,避免了频繁地创建和销毁对象,提高了系统的性能和稳定性。 今天我…...

程序设计入门——C语言2023年5月10日
程序设计入门——C语言 1、window下安装gcc 课程来源:链接: 浙江大学 翁恺 程序设计入门——C语言 学习日期:2023年5月10日 1、window下安装gcc 如果想让gcc在windows下运行,需要将gcc,及对于的lib包,都安装到window…...

【2023华为OD笔试必会25题--C语言版】《03 单入口空闲区域》——递归、数组、DFS
本专栏收录了华为OD 2022 Q4和2023Q1笔试题目,100分类别中的出现频率最高(至少出现100次)的25道,每篇文章包括原始题目 和 我亲自编写并在Visual Studio中运行成功的C语言代码。 仅供参考、启发使用,切不可照搬、照抄,查重倒是可以过,但后面的技术面试还是会暴露的。✨✨…...

系统设计 --- MongoDB亿级数据查询优化策略
系统设计 --- MongoDB亿级数据查询分表策略 背景Solution --- 分表 背景 使用audit log实现Audi Trail功能 Audit Trail范围: 六个月数据量: 每秒5-7条audi log,共计7千万 – 1亿条数据需要实现全文检索按照时间倒序因为license问题,不能使用ELK只能使用…...

Vue2 第一节_Vue2上手_插值表达式{{}}_访问数据和修改数据_Vue开发者工具
文章目录 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染2. 插值表达式{{}}3. 访问数据和修改数据4. vue响应式5. Vue开发者工具--方便调试 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染 准备容器引包创建Vue实例 new Vue()指定配置项 ->渲染数据 准备一个容器,例如: …...

C++中string流知识详解和示例
一、概览与类体系 C 提供三种基于内存字符串的流,定义在 <sstream> 中: std::istringstream:输入流,从已有字符串中读取并解析。std::ostringstream:输出流,向内部缓冲区写入内容,最终取…...

学习STC51单片机32(芯片为STC89C52RCRC)OLED显示屏2
每日一言 今天的每一份坚持,都是在为未来积攒底气。 案例:OLED显示一个A 这边观察到一个点,怎么雪花了就是都是乱七八糟的占满了屏幕。。 解释 : 如果代码里信号切换太快(比如 SDA 刚变,SCL 立刻变&#…...

CSS设置元素的宽度根据其内容自动调整
width: fit-content 是 CSS 中的一个属性值,用于设置元素的宽度根据其内容自动调整,确保宽度刚好容纳内容而不会超出。 效果对比 默认情况(width: auto): 块级元素(如 <div>)会占满父容器…...

算法:模拟
1.替换所有的问号 1576. 替换所有的问号 - 力扣(LeetCode) 遍历字符串:通过外层循环逐一检查每个字符。遇到 ? 时处理: 内层循环遍历小写字母(a 到 z)。对每个字母检查是否满足: 与…...

MFC 抛体运动模拟:常见问题解决与界面美化
在 MFC 中开发抛体运动模拟程序时,我们常遇到 轨迹残留、无效刷新、视觉单调、物理逻辑瑕疵 等问题。本文将针对这些痛点,详细解析原因并提供解决方案,同时兼顾界面美化,让模拟效果更专业、更高效。 问题一:历史轨迹与小球残影残留 现象 小球运动后,历史位置的 “残影”…...

【JVM面试篇】高频八股汇总——类加载和类加载器
目录 1. 讲一下类加载过程? 2. Java创建对象的过程? 3. 对象的生命周期? 4. 类加载器有哪些? 5. 双亲委派模型的作用(好处)? 6. 讲一下类的加载和双亲委派原则? 7. 双亲委派模…...
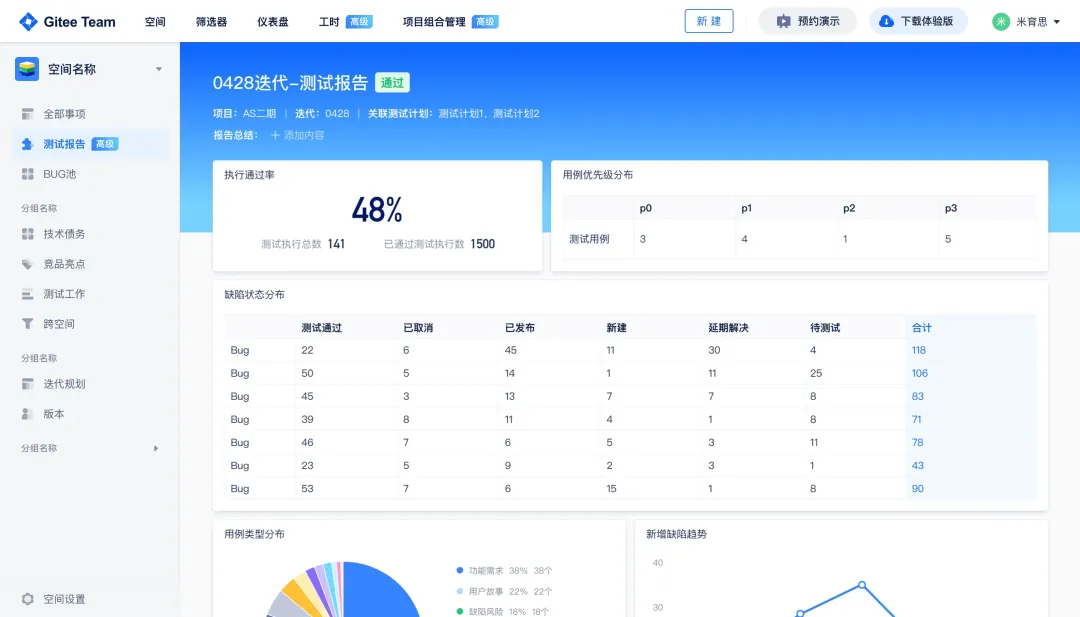
从“安全密码”到测试体系:Gitee Test 赋能关键领域软件质量保障
关键领域软件测试的"安全密码":Gitee Test如何破解行业痛点 在数字化浪潮席卷全球的今天,软件系统已成为国家关键领域的"神经中枢"。从国防军工到能源电力,从金融交易到交通管控,这些关乎国计民生的关键领域…...

Linux 下 DMA 内存映射浅析
序 系统 I/O 设备驱动程序通常调用其特定子系统的接口为 DMA 分配内存,但最终会调到 DMA 子系统的dma_alloc_coherent()/dma_alloc_attrs() 等接口。 关于 dma_alloc_coherent 接口详细的代码讲解、调用流程,可以参考这篇文章,我觉得写的非常…...