flink watermark介绍及watermark的窗口触发机制
Flink的三种时间
在谈watermark之前,首先需要了解flink的三种时间概念。在flink中,有三种时间戳概念:Event Time 、Processing Time 和 Ingestion Time。其中watermark只对Event Time类型的时间戳有用。这三种时间概念分别表示:
Processing time
处理时间,指执行算子操作的机器的当前时间。当基于处理时间运行时,所有关于时间的操作(如时间窗口)都将使用执行算子操作的主机的本地时间。例如,当时间窗口为一小时,如果应用程序在9:15 am开始运行,则第一个窗口将包括在9:15 am到10:00 am之间被处理的事件,下一个窗口将包含在10:00 am到11:00 am之间被处理的事件,依此类推。
处理时间是最简单的时间概念,不需要流和机器之间的协调。它提供了最佳的性能和最低的延迟。但是,在分布式和异步环境中,处理时间不能提供确定性,因为它容易受到上流系统(例如从消息队列)到达Flink的速度、flink内部operators之间交互的速度,以及中断(调度或其他情况)等因素的影响。
Event Time
事件时间,是每个event在其生产设备上产生的时间,即元素在到达flink之前,本身就自带的时间戳。
所以说,Event Time的时间戳取决于数据,而与其他时间无关。使用Event Time,必须在从执行环境中先引入EventTime的时间属性。如:
java
复制代码
val env = StreamExecutionEnvironment.getExecutionEnvironment // 从调用时刻开始给env创建的每一个stream追加时间特征 env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
然后通过Dstream的assignTimestampsAndWatermarks方法指定event time时间戳,具体操作不做赘述。
在理想情况下,事件时间是有序的。但实际上,由于分布式操作,以及网络延迟等原因,event可能不是按照event time的顺序到达的。所以flink对处理乱序数据的方案是提供一个允许延迟时间,在允许延迟时间内到达的元素将会重新触发一次计算。这个延迟时间时相对event time而不是其他时间的,而event time不是由flink决定的,那么如何判断当前的event time到底时多少呢?flink通过一个watermark来确定与维护当前event time的最大值。这也是本文将会在后面重点解释的。
Ingestion time
Ingestion time是event进入Flink的时间,即执行source操作时的时间。
Ingestion time从概念上讲介于Event Time和Processing time之间。
与Processing time相比 ,它花费的资源会稍微多一些,但结果却更可预测。由于 Ingestion time使用稳定的时间戳(仅在addSource处分配了一次),因此对记录的不同窗口操作将引用相同的时间戳,而在Processing time中,每个窗口操作都会更新事件的Processing time,所以可能一个上游窗口中的记录会分配给不同的下游窗口(基于本地系统时钟和任何可能的延误)。
与Event Time相比,Ingestion time程序无法处理任何乱序事件或迟到的数据,但是程序不必指定如何生成watermarks。
下图为三种时间语义的图解:

watermark
用我自己的语言总结,在flink的窗口计算中,的watermark就是触发窗口计算的一种机制。 那么,watermark到底是以怎样的一种形式存在的呢?实际上,watermark就是一种特殊的event,它被参杂在Dstream中,watermark由flink的某个操作生成后,就在整个程序中随event一同流转,如下图所示:

以下是watermark的代码,可以看出watermark的就是一个流元素,仅包含一个时间戳属性:
java
复制代码
public final class Watermark extends StreamElement { /** The watermark that signifies end-of-event-time. */ public static final Watermark MAX_WATERMARK = new Watermark(Long.MAX_VALUE); // ------------------------------------------------------------------------ /** The timestamp of the watermark in milliseconds. */ private final long timestamp; /** * Creates a new watermark with the given timestamp in milliseconds. */ public Watermark(long timestamp) { this.timestamp = timestamp; }
watermark的窗口触发机制
watermark会根据数据流中event的时间戳发生变化。通常情况下,event都是乱序的,不按时间排序的。watermark的计算逻辑为:当前最大的 event time - 最大允许延迟时间(MaxOutOfOrderness)。在同一个分区内部,当watermark大于或者等于窗口的结束时间时,才能触发该窗口的计算,即watermark>=windows endtime。如下图所示:

根据上图分析: MaxOutOfOrderness = 5s,窗口的大小为:10s。 watermark分别为:12:08、12:15、12:30 计算逻辑为:WM(12:08)=12:13 - 5s;WM(12:15)=12:20 - 5s;WM(12:30)=12:35 - 5s
- 对于 [12:00,12:10) 窗口,需要在WM=12:15时,才能被触发计算,参与计算的event为:event(12:07)/event(12:01)/event(12:07)/event(12:09),event(12:10)/event(12:12)/event(12:12)/event(12:13)/event(12:20)/event(12:14)/event(12:15)不参与计算,因为还未到窗口时间,也就是event time 为 [12:00,12:10] 窗口内的event才能参与计算。 注意,如果过了这个窗口期,再收到 [12:00,12:10] 窗口内的event,就算超过了最大允许延迟时间(MaxOutOfOrderness),不会再参与计算,也就是数据被强制丢掉了。
- 对于 [12:10,12:20] 和 [12:20,12:30] 窗口,会在WM=12:30时,被同时触发计算,参与**[12:10,12:20]** 窗口计算的event为:event(12:10)/event(12:12)/event(12:12)/event(12:13)/event(12:14)/event(12:15)/event(12:15)/event(12:18);参与 [12:20,12:30] 窗口计算的event为:event(12:20)/event(12:20);在这个过程中event(12:05)会被丢弃,不会参与计算,因为已经超了最大允许延迟时间(MaxOutOfOrderness)
迟到的事件
在介绍watermark时,提到了现实中往往处理的是乱序event,即当event处于某些原因而延后到达时,往往会发生该event time < watermark的情况,所以flink对处理乱序event的watermark有一个允许延迟的机制,这个机制就是最大允许延迟时间(MaxOutOfOrderness),允许在一定时间内迟到的event仍然视为有效event。
并行流的Watermarks
watermark可以在source处生成(也可以在source后通过其他算子生成,如map、filter等),如果source有多个并行度,那么每个并行度会单独生成一个watermark,这些watermark定义了各分区的event time。 当并行度发生变化(即上游的一个分区可能被下游多个分区使用时),每个分区的watermark是会广播至下游的每个分区的,如一些聚合多个流的操作,如 keyBy(…) 或者partition(…),此类操作的watermark是在所有输入流中取最小的watermark。当带有watermark的流通过此类算子时,会根据每个分区的watermark来更新watermark。
举个例子:当上游并行度数为4,下游的某个分区的窗口中的watermark如下:

-
当已到达的watermark分别为2、4、3、6时,窗口中的watermark为2,触发watermark为2的对应窗口计算,并将watermark=2广播至下游。
-
当第一个窗口的watermark被更新为4时,所有分区中已到达最小的watermark是3,则将窗口的watermark更新为3,触发对应窗口的计算,并将watermark=3广播至下游。
-
当第二个分区的watermark被更新为7,所有分区中已到达最小的watermark还是3,不做处理。
-
当第三个分区的watermark被更新为6,所有分区中已到达最小的watermark是4,则将窗口的watermark更新为4,触发对应窗口的计算,并将watermark=4广播至下游。
下图显示了event和watermark在一个并行流的示例,以及算子如何跟踪事件时间的:

watermark分配器
当watermark完全基于event time时,如果没有元素到达,则watermark不会被更新,这就说明,当一段时间没有元素到达,则在这个时间间隙内,watermark不会增加,那么也不会触发窗口计算。显然,如果这段时间很长的话,那么该窗口中已经到达的元素将会等待很久才会被输出计算结果。
为了避免这种情况,可以使用周期性的watermark分配器(AssignerWithPeriodicWatermarks 下面马上提到),这些分配器不仅仅基于event time进行分配。比如,可以使用一个分配器,当一段时间没有接收到新的event时,则将当前时间作为watermark。
watermark的两种分配器,flink生成watermark有两种机制:
- AssignerWithPeriodicWatermarks :分配时间戳并定期生成watermark(可以取决于event time,或基于处理时间)。
- AssignerWithPunctuatedWatermarks:分配时间戳并根据每一个元素生成watermark(每来一个元素都进行一次判断,相更消耗性能)
通常情况下会使用第一种机制,原因除了更节省性能外,在上面的分配器中也有提到。
下面分别对两种机制进行介绍。
AssignerWithPeriodicWatermarks
对每个元素都调用extractTimestamp方法获取时间戳,并维护一个最大时间戳。通过ExecutionConfig.setAutoWatermarkInterval(...)定义生成watermark的间隔(每n毫秒) 。根据这个间隔,周期性调用分配器的getCurrentWatermark()方法,为watermark分配值。
在flink自带的BoundedOutOfOrdernessGenerator分配器中, getCurrentWatermark是定期将当前watermark更新为最大时间戳减去允许延迟时间的值。
以下是两个使用AssignerWithPeriodicWatermarks 生成的时间戳分配器的简单示例:
java
复制代码
/** * This generator generates watermarks assuming that elements arrive out of order, * but only to a certain degree. The latest elements for a certain timestamp t will arrive * at most n milliseconds after the earliest elements for timestamp t. */ class BoundedOutOfOrdernessGenerator extends AssignerWithPeriodicWatermarks[MyEvent] { val maxOutOfOrderness = 3500L // 3.5 seconds var currentMaxTimestamp: Long = _ override def extractTimestamp(element: MyEvent, previousElementTimestamp: Long): Long = { val timestamp = element.getCreationTime() currentMaxTimestamp = max(timestamp, currentMaxTimestamp) timestamp } override def getCurrentWatermark(): Watermark = { // return the watermark as current highest timestamp minus the out-of-orderness bound new Watermark(currentMaxTimestamp - maxOutOfOrderness) } } /** * This generator generates watermarks that are lagging behind processing time by a fixed amount. * It assumes that elements arrive in Flink after a bounded delay. */ class TimeLagWatermarkGenerator extends AssignerWithPeriodicWatermarks[MyEvent] { val maxTimeLag = 5000L // 5 seconds override def extractTimestamp(element: MyEvent, previousElementTimestamp: Long): Long = { element.getCreationTime } override def getCurrentWatermark(): Watermark = { // return the watermark as current time minus the maximum time lag new Watermark(System.currentTimeMillis() - maxTimeLag) } }
AssignerWithPunctuatedWatermarks
根据每个元素的event time生成watermark,通过extractTimestamp(...)方法为元素分配时间戳,通过checkAndGetNextWatermark(...)检查元素的watermark并更新watermark。
checkAndGetNextWatermark(...)方法的第二个参数是extractTimestamp(...) 返回的时间戳,根据这个时间戳决定是否要生成watermark。每当checkAndGetNextWatermark(...) 方法返回一个非空watermark,并且该watermark大于上一个watermark时,就会更新watermark。
java
复制代码
class PunctuatedAssigner extends AssignerWithPunctuatedWatermarks[MyEvent] { override def extractTimestamp(element: MyEvent, previousElementTimestamp: Long): Long = { element.getCreationTime } override def checkAndGetNextWatermark(lastElement: MyEvent, extractedTimestamp: Long): Watermark = { if (lastElement.hasWatermarkMarker()) new Watermark(extractedTimestamp) else null } }
相关文章:
flink watermark介绍及watermark的窗口触发机制
Flink的三种时间 在谈watermark之前,首先需要了解flink的三种时间概念。在flink中,有三种时间戳概念:Event Time 、Processing Time 和 Ingestion Time。其中watermark只对Event Time类型的时间戳有用。这三种时间概念分别表示: …...

Spring Cloud: 云原生微服务实践
文章目录 1. Spring Cloud 简介2. Spring Cloud Eureka:服务注册与发现在Spring Cloud中使用Eureka 3. Spring Cloud Config:分布式配置中心在Spring Cloud中使用Config 4. Spring Cloud Hystrix:熔断器在Spring Cloud中使用Hystrix 5. Sprin…...

存bean和取bean
准备工作存bean获取bean三种方式 准备工作 bean:一个对象在多个地方使用。 spring和spring boot:spring和spring boot项目;spring相当于老版本 spring boot本质还是spring项目;为了方便spring项目的搭建;操作起来更加简单 spring…...

39. 组合总和
给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。 candidates 中的 同一个 数字可以 无限制重复被选取 。如…...

100行以内Python能做那些事
Python100 找到一个很好的python教程分享出来---->非本人 B站视频连接 100行以内的Pyhton代码可以做哪些有意思的事 按照难度1-5颗星,分为五个文件夹 希望大家可以补充 关于运行环境的补充 Python3.7 Pycharm社区版2019 关于用到的Python库,有些是自带的&am…...

Android 电源键事件流程分析
Android 电源键事件流程分析 电源按键流程处理逻辑在 PhoneWindowManager.java类中的 dispatchUnhandledKey 方法中 frameworks/base/services/core/java/com/android/server/policy/PhoneWindowManager.java从dispatchUnhandledKey方法开始分析 Overridepublic KeyEvent dis…...

游戏搬砖简述-1
游戏搬砖是一种在游戏中通过重复性的任务来获取游戏内货币或物品的行为。这种行为在游戏中非常普遍,尤其是在一些MMORPG游戏中。虽然游戏搬砖看起来很无聊,但是它确实是一种可以赚钱的方式,而且对于一些玩家来说,游戏搬砖也是一种…...

多线程基础总结
1. 为什么要有多线程? 线程:线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中实际运行单位。 进程:进程是程序的基本执行实体。 什么是多线程? 有了多线程,我们就可以让程序同时做…...
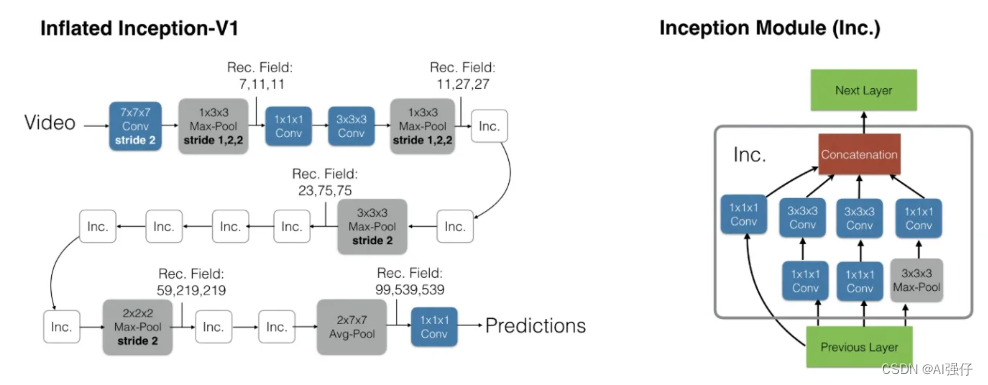
视频理解AI模型分类与汇总
人工智能领域视频模型大体也经历了从传统手工特征,到卷积神经网络、双流网络(2014年-2017年)、3D卷积网络、transformer的发展脉络。为了时序信息,有的模型也结合用LSTM。 视频的技术大多借鉴图像处理技术,只是视频比…...
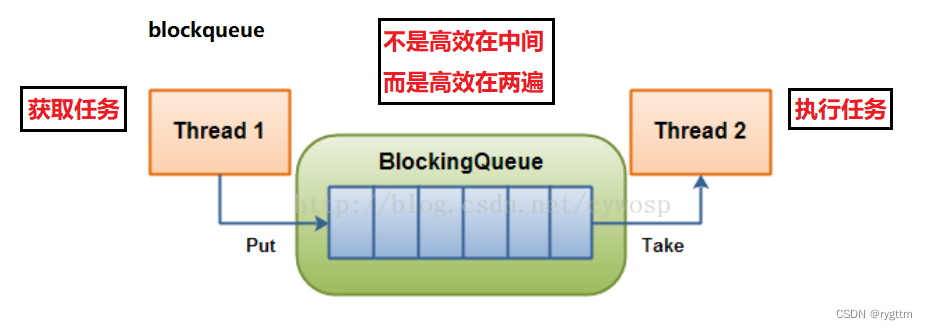
【Linux】多线程 --- 线程同步与互斥+生产消费模型
人生总是那么痛苦吗?还是只有小时候是这样? —总是如此 文章目录 一、线程互斥1.多线程共享资源访问的不安全问题2.提出解决方案:加锁(局部和静态锁的两种初始化/销毁方案)2.1 对于锁的初步理解和实现2.2 局部和全局锁…...

17.模型的定义
学习要点: 1.默认设置 2.模型定义 本节课我们来开始学习数据库的模型部分的定义和默认值的设置。 一.默认设置 1. 框架可以使用 Eloquent ORM 进行数据库交互,也就是关系对象模型; 2. 在数据库入门阶段,我们已经创建了…...

golang 记录交叉编译sqlite的报错信息 go build -ldflags
go build -ldflags ‘-s -w --extldflags “-static -fpic”’ -o go-web main.go [gos20230512]# CGO_ENABLED1 CCaarch64-linux-gnu-gcc CXXaarch64-linux-gnu-g GOOSlinux GOARCHarm64 go build -ldflags -s -w --extldflags "-static -fpic" -o go-web m…...
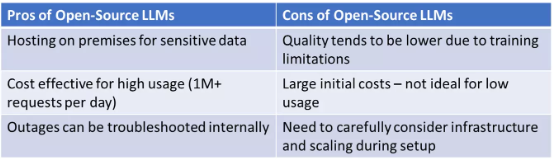
ChatGPT AI使用成本
LLM “经济学”:ChatGPT 与开源模型,二者之间有哪些优劣权衡?谁的部署成本更低? 太长不看版:对于日均请求在 1000 次左右的低频使用场景,ChatGPT 的实现成本低于部署在 AWS 上的开源大模型。但面对每天数以…...
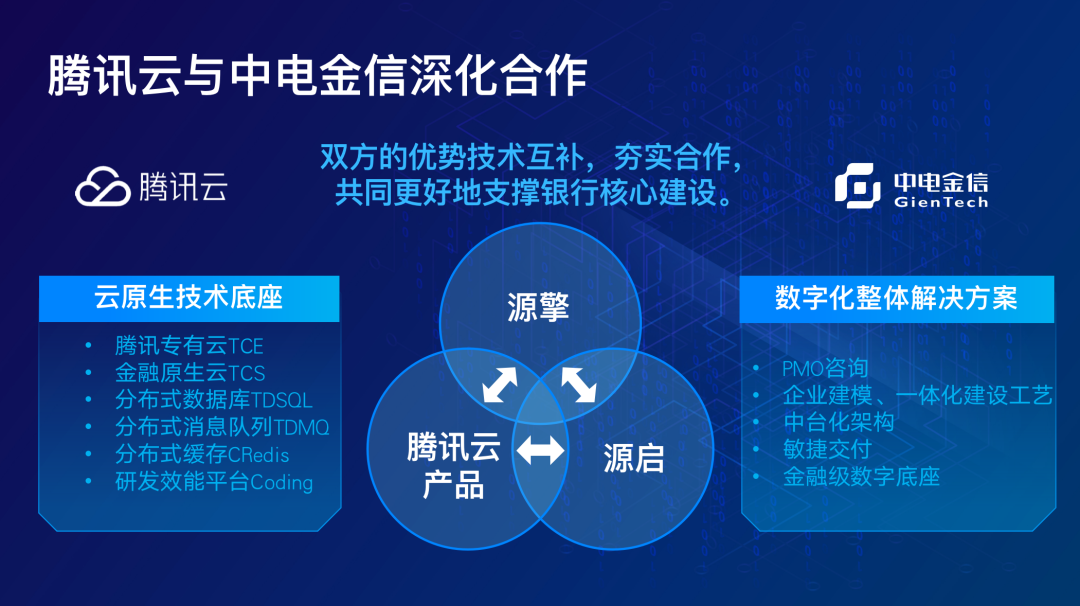
腾讯云与中电金信发布联合核心方案
5月11日,以“聚力革新,行稳致远”为主题的 “腾讯金融云国产化战略峰会”在北京举办,来自金融业、科技侧、研究机构的专家学者同聚一堂,共同探讨银行核心下移方法论以及国产化转型实践等话题。会议期间,中电金信副总经…...
老胡的周刊(第090期)
老胡的信息周刊[1],记录这周我看到的有价值的信息,主要针对计算机领域,内容主题极大程度被我个人喜好主导。这个项目核心目的在于记录让自己有印象的信息做一个留存以及共享。 🎯 项目 privateGPT[2] 为保证数据私密性,…...
2023-数仓常见问题以及解决方案
01 数据仓库现状 小 A 公司创建时间比较短,才刚过完两周岁生日没多久;业务增长速度快,数据迅速增加,同时取数需求激增与数据应用场景对数据质量、响应速度、数据时效性与稳定要求越来越高;但技术能力滞后业务增长&…...

没关系,前端还死不了
前言 网络上的任何事情都可以在《乌合之众》书中找到答案。大众言论没有理性,全是极端,要么封神,要么踩死。不少人喷前端,说前端已死?前端内卷?前端一个月800包吃住? 对此我想说,“…...

OpenSSL-基于IP或域名生成自签名证书脚本
个人名片: 对人间的热爱与歌颂,可抵岁月冗长🌞 Github👨🏻💻:念舒_C.ying CSDN主页✏️:念舒_C.ying 个人博客🌏 :念舒_C.ying 一、安装 需要安装并配置Op…...

如何在C#中创建和使用自定义异常
C#是一种强类型语言,可以捕获和处理各种异常,从而帮助我们发现程序中出现的错误。在程序开发过程中,如果需要找到特定的错误情况并处理,这时就需要创建自定义异常。下面介绍一下如何在C#中创建和使用自定义异常。 1、什么是异常&…...
通过systemctl管理服务
文章目录 通过systemctl管理服务通过systemctl管理单一服务(service unit)使用案例服务启动/关闭/查看的练习关于systemctl命令启动/停止服务后面的后缀名是否加? 通过systemctl查看系统上所有的服务使用案例 通过systemctl管理不同的操作环境(target unit)使用案例…...

深度学习在微纳光子学中的应用
深度学习在微纳光子学中的主要应用方向 深度学习与微纳光子学的结合主要集中在以下几个方向: 逆向设计 通过神经网络快速预测微纳结构的光学响应,替代传统耗时的数值模拟方法。例如设计超表面、光子晶体等结构。 特征提取与优化 从复杂的光学数据中自…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...
指令的指南)
在Ubuntu中设置开机自动运行(sudo)指令的指南
在Ubuntu系统中,有时需要在系统启动时自动执行某些命令,特别是需要 sudo权限的指令。为了实现这一功能,可以使用多种方法,包括编写Systemd服务、配置 rc.local文件或使用 cron任务计划。本文将详细介绍这些方法,并提供…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...

04-初识css
一、css样式引入 1.1.内部样式 <div style"width: 100px;"></div>1.2.外部样式 1.2.1.外部样式1 <style>.aa {width: 100px;} </style> <div class"aa"></div>1.2.2.外部样式2 <!-- rel内表面引入的是style样…...

AI病理诊断七剑下天山,医疗未来触手可及
一、病理诊断困局:刀尖上的医学艺术 1.1 金标准背后的隐痛 病理诊断被誉为"诊断的诊断",医生需通过显微镜观察组织切片,在细胞迷宫中捕捉癌变信号。某省病理质控报告显示,基层医院误诊率达12%-15%,专家会诊…...

A2A JS SDK 完整教程:快速入门指南
目录 什么是 A2A JS SDK?A2A JS 安装与设置A2A JS 核心概念创建你的第一个 A2A JS 代理A2A JS 服务端开发A2A JS 客户端使用A2A JS 高级特性A2A JS 最佳实践A2A JS 故障排除 什么是 A2A JS SDK? A2A JS SDK 是一个专为 JavaScript/TypeScript 开发者设计的强大库ÿ…...

RabbitMQ入门4.1.0版本(基于java、SpringBoot操作)
RabbitMQ 一、RabbitMQ概述 RabbitMQ RabbitMQ最初由LShift和CohesiveFT于2007年开发,后来由Pivotal Software Inc.(现为VMware子公司)接管。RabbitMQ 是一个开源的消息代理和队列服务器,用 Erlang 语言编写。广泛应用于各种分布…...