Zookeeper(一)
简介
设计模式角度
Zookeeper:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。
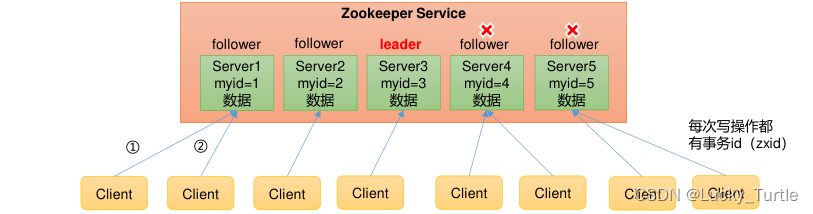
1)Zookeeper:一个领导者(Leader),多个跟随者(Follower)组成的集群。
2)集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。所以Zookeeper适合安装奇数台服务器。
3)全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的。
4)更新请求顺序执行,来自同一个Client的更新请求按其发送顺序依次执行。
5)数据更新原子性,一次数据更新要么成功,要么失败。
6)实时性,在一定时间范围内,Client能读到最新数据。
数据结构
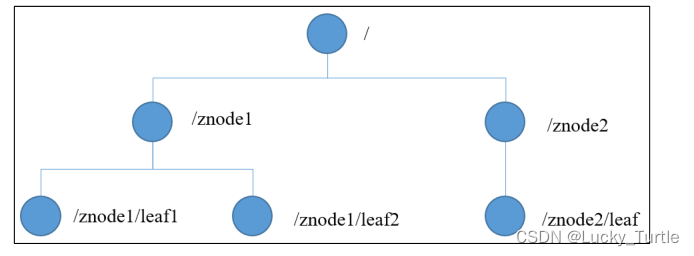
整体上可以看作是一棵树,每个节点称做一个 ZNode。每一个 ZNode 默认能够存储 1MB 的数据,每个 ZNode 都可以通过其路径唯一标识。
应用场景
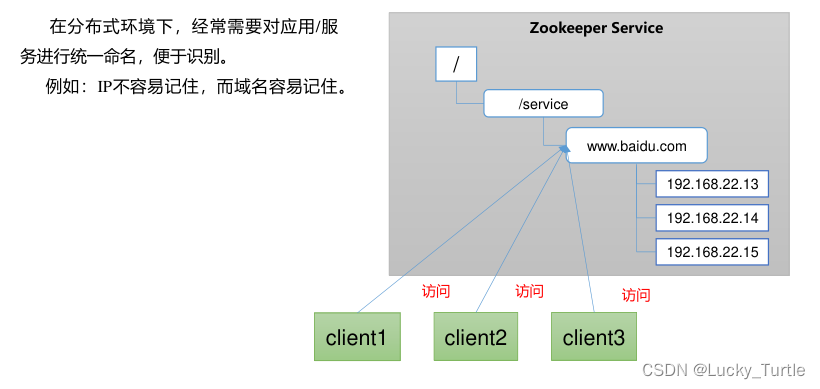
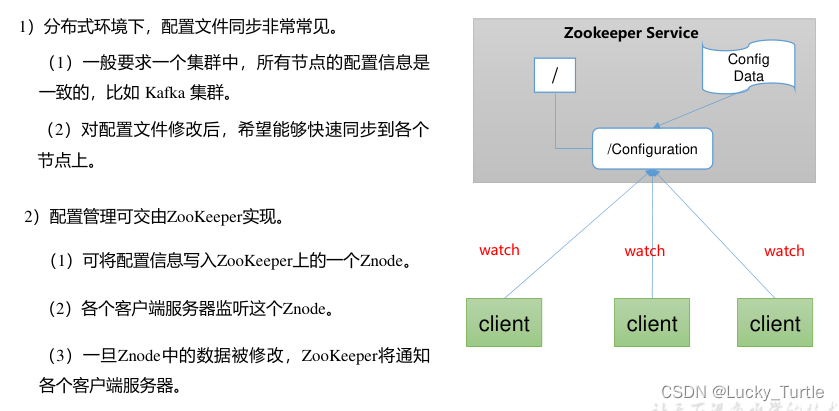
提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等。

安装
mv zoo_sample.cfg zoo.cfg
#打开 zoo.cfg 文件,修改 dataDir 路径:
dataDir=/opt/module/zookeeper-3.5.7/zkDatamkdir zkData
操作 Zookeeper
#启动 Zookeeper
bin/zkServer.sh start
#查看进程是否启动
jps
#查看状态
bin/zkServer.sh status
#启动客户端
bin/zkCli.sh
#退出客户端
quit
#停止 Zookeeper
bin/zkServer.sh stop
配置参数
1)tickTime = 2000:通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
2)initLimit = 10:LF初始通信时限
3)syncLimit = 5:LF同步通信时限
Leader和Follower之间通信时间如果超过syncLimit * tickTime,Leader认为Follwer死
掉,从服务器列表中删除Follwer。
4)dataDir:保存Zookeeper中的数据
注意:默认的tmp目录,容易被Linux系统定期删除,所以一般不用默认的tmp目录。
5)clientPort = 2181:客户端连接端口,通常不做修改。
Zookeeper 集群
集群安装
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/
1)配置服务器编号
在/opt/module/zookeeper-3.5.7/zkData 目录下创建一个 myid 的文件
vi myid
#2
拷贝配置好的 zookeeper 到其他机器上
xsync zookeeper-3.5.7
配置zoo.cfg文件
打开 zoo.cfg 文件
打开 zoo.cfg 文件
[atguigu@hadoop102 conf]$ vim zoo.cfg
修改数据存储路径配置
dataDir=/opt/module/zookeeper-3.5.7/zkData
增加如下配置
#######################cluster##########################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
配置参数解读
server.A=B:C:D
A 是一个数字,表示这个是第几号服务器;
集群模式下配置一个文件 myid,这个文件在 dataDir 目录下,这个文件里面有一个数据
就是 A 的值,Zookeeper 启动时读取此文件,拿到里面的数据与 zoo.cfg 里面的配置信息比
较从而判断到底是哪个 server。
B 是这个服务器的地址;
C 是这个服务器 Follower 与集群中的 Leader 服务器交换信息的端口;
D 是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的
Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
同步 zoo.cfg 配置文件
xsync zoo.cfg
ZK 集群启动停止脚本
#!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 启动 ------------
ssh
$i
"/opt/module/zookeeper-3.5.7/bin/zkServer.sh
start"
done
};;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 停止 ------------
ssh
$i
"/opt/module/zookeeper-3.5.7/bin/zkServer.sh
stop"
done
};;
"status"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 状态 ------------
ssh
$i
"/opt/module/zookeeper-3.5.7/bin/zkServer.sh
status"
done
};;
esac
启动
zk.sh start
停止
zk.sh stop
节点数据
(1)czxid:创建节点的事务 zxid
每次修改 ZooKeeper 状态都会产生一个 ZooKeeper 事务 ID。事务 ID 是 ZooKeeper 中所有修改总的次序。每次修改都有唯一的 zxid,如果 zxid1 小于 zxid2,那么 zxid1 在 xid2 之前发生。
(2)ctime:znode 被创建的毫秒数(从 1970 年开始)
(3)mzxid:znode 最后更新的事务 zxid
(4)mtime:znode 最后修改的毫秒数(从 1970 年开始)
(5)pZxid:znode 最后更新的子节点 zxid
(6)cversion:znode 子节点变化号,znode 子节点修改次数
(7)dataversion:znode 数据变化号
(8)aclVersion:znode 访问控制列表的变化号
(9)ephemeralOwner:如果是临时节点,这个是 znode 拥有者的 session id。如果不是临时节点则是 0。
(10)dataLength:znode 的数据长度
(11)numChildren:znode 子节点数量
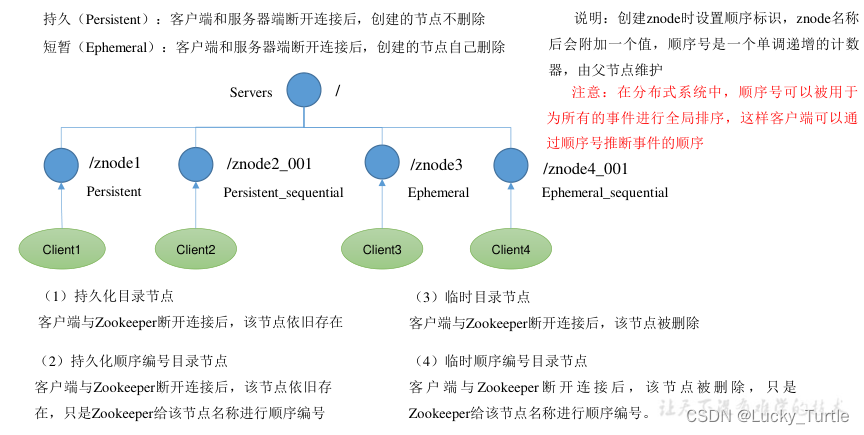
节点类型
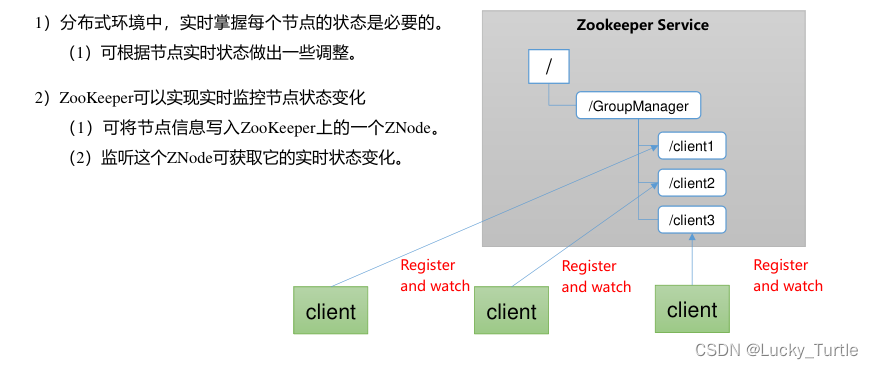
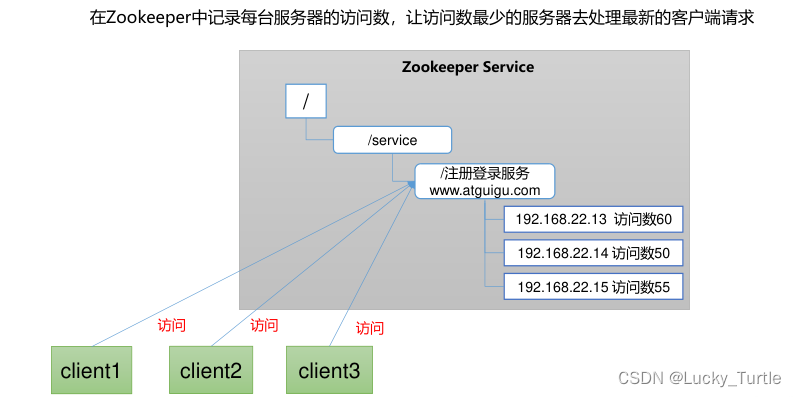
监听器原理
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、节点删除、子目
录节点增加删除)时,ZooKeeper 会通知客户端。监听机制保证 ZooKeeper 保存的任何的数据的任何改变都能快速的响应到监听了该节点的应用程序。

IDEA操作
创建 ZooKeeper 客户端
package com.atguigu.zk;import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
import org.junit.Before;
import org.junit.Test;import java.io.IOException;
import java.util.List;public class zkClient {// 注意:逗号左右不能有空格// private String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181";private String connectString = "localhost:2181";private int sessionTimeout = 2000;private ZooKeeper zkClient;@Beforepublic void init() throws IOException {zkClient = new ZooKeeper(connectString, sessionTimeout, new Watcher() {@Overridepublic void process(WatchedEvent watchedEvent) {// System.out.println("-------------------------------");
// List<String> children = null;
// try {
// children = zkClient.getChildren("/", true);
//
// for (String child : children) {
// System.out.println(child);
// }
//
// System.out.println("-------------------------------");
// } catch (KeeperException e) {
// e.printStackTrace();
// } catch (InterruptedException e) {
// e.printStackTrace();
// }}});}@Testpublic void create() throws KeeperException, InterruptedException {String nodeCreated = zkClient.create("/atguigu", "ss.avi".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);}@Testpublic void getChildren() throws KeeperException, InterruptedException {List<String> children = zkClient.getChildren("/", true);for (String child : children) {System.out.println(child);}// 延时Thread.sleep(Long.MAX_VALUE);}@Testpublic void exist() throws KeeperException, InterruptedException {Stat stat = zkClient.exists("/atguigu", false);System.out.println(stat==null? "not exist " : "exist");}
}客户端向服务端写数据流程
写流程:写入请求发送给Leader节点

写流程:写入请求发送给Follower节点

服务器动态上下线

Client
public class DistributeClient {// private String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181";private String connectString = "localhost:2181";private int sessionTimeout = 2000;private ZooKeeper zk;public static void main(String[] args) throws IOException, KeeperException, InterruptedException {DistributeClient client = new DistributeClient();// 1 获取zk连接client.getConnect();// 2 监听/servers下面子节点的增加和删除client.getServerList();// 3 业务逻辑(睡觉)client.business();}private void business() throws InterruptedException {Thread.sleep(Long.MAX_VALUE);}private void getServerList() throws KeeperException, InterruptedException {List<String> children = zk.getChildren("/servers", true);ArrayList<String> servers = new ArrayList<>();for (String child : children) {byte[] data = zk.getData("/servers/" + child, false, null);servers.add(new String(data));}// 打印System.out.println(servers);}private void getConnect() throws IOException {zk = new ZooKeeper(connectString, sessionTimeout, new Watcher() {@Overridepublic void process(WatchedEvent watchedEvent) {try {getServerList();} catch (KeeperException e) {e.printStackTrace();} catch (InterruptedException e) {e.printStackTrace();}}});}
}
Server
public class DistributeServer {// private String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181";private String connectString = "localhost:2181";private int sessionTimeout = 2000;private ZooKeeper zk;public static void main(String[] args) throws IOException, KeeperException, InterruptedException {DistributeServer server = new DistributeServer();// 1 获取zk连接server.getConnect();// 2 注册服务器到zk集群server.regist(args[0]);// 3 启动业务逻辑(睡觉)server.business();}private void business() throws InterruptedException {Thread.sleep(Long.MAX_VALUE);}private void regist(String hostname) throws KeeperException, InterruptedException {String create = zk.create("/servers/"+hostname, hostname.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);System.out.println(hostname +" is online") ;}private void getConnect() throws IOException {zk = new ZooKeeper(connectString, sessionTimeout, new Watcher() {@Overridepublic void process(WatchedEvent watchedEvent) {}});}
}
重点
6.1 选举机制
半数机制,超过半数的投票通过,即通过。
(1)第一次启动选举规则:
投票过半数时,服务器 id 大的胜出
(2)第二次启动选举规则:
①EPOCH 大的直接胜出
②EPOCH 相同,事务 id 大的胜出
③事务 id 相同,服务器 id 大的胜出
6.2 生产集群安装多少 zk 合适?
安装奇数台。
生产经验:
10 台服务器:3 台 zk;
20 台服务器:5 台 zk;
100 台服务器:11 台 zk;
200 台服务器:11 台 zk
服务器台数多:好处,提高可靠性;坏处:提高通信延时
6.3 常用命令
ls、get、create、delete
相关文章:
Zookeeper(一)
简介 设计模式角度 Zookeeper:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那…...
Maven(五):Maven的使用——依赖的测试
Maven(五):Maven的使用——依赖的测试 前言一、实验六:测试依赖的范围1、依赖范围1.1 compile 和 test 对比1.2 compile 和 provided 对比1.3 结论 二、实验七:测试依赖的传递性1、依赖的传递性1.1 概念1.2 传递的原则…...
超级独角兽 Databricks 的崛起之路
在数据扩张以及 AI 兴起的时代,数据存储和分析平台拥有巨大价值和能量。 随着互联网数据的爆炸性增长,数据已经成为企业的新型资源,犹如石油般重要。越来越多的企业希望利用各种结构化和非结构化数据来发挥自己的优势。 然而,他…...

python 3.8 + tensorflow 2.4.0 + cuda11.0 的问题
版本匹配 🔗从源代码构建 | TensorFlow 报错:Could not load dynamic library ‘cupti64_110.dll’; dlerror: cupti64_110.dll not found 是因为我电脑中的 cuda 版本以前是 10,现在是 11.4 ,所以需要安装对应版本的 cudatoolk…...
精确定位问题-参考思路)
华为杯”研究生数学建模竞赛2021 年中国研究生数学建模竞赛 E 题: 信号干扰下的超宽带(UWB)精确定位问题-参考思路
一、背景 UWB ( Ultra-Wideband )技术也被称之为“超宽带”,又称之为脉冲无线电技术。这是一 种无需任何载波,通过发送纳秒级脉冲而完成数据传输的短距离范围内无线通信技术,并且信 号传输过程中的功耗仅仅有几十 W 。 UWB 因其独有的特点,使其在军事、物联网等各个领…...

Java 中的访问修饰符有什么区别?
Java 中的访问修饰符用于控制类、类的成员变量和方法的访问权限,主要有以下四种: public:公共访问修饰符,可以被任何类访问。public 修饰的类、成员变量和方法可以在任何地方被访问到。 protected:受保护的访问修饰符…...
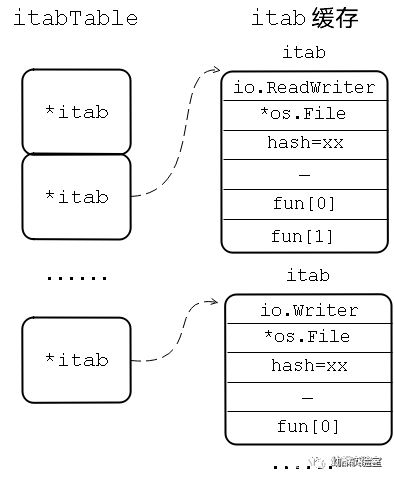
Go基础篇:接口
目录 前言✨一、什么是接口?二、空接口 interface{}1、eface的定义2、需要注意的问题 三、非空接口1、iface的定义2、itab的定义3、itab缓存 前言✨ 前段时间忙着春招面试,现在也算告一段落,找到一家比较心仪的公司实习,开始慢慢回…...

边缘计算:数字时代的新战场
随着数字化时代的到来,云计算已经成为了各行各业不可或缺的技术支持。但是,由于云计算涉及到数据的传输和存储,对于网络带宽和延迟的要求也非常高,这使得云计算难以满足一些低延迟、高实时性要求的场景。在这种情况下,…...
)
PBDB Data Service:Fossil occurrences(化石产出记录)
Fossil occurrences(化石产出记录) 描述摘要1. [Single fossil occurrence(单条化石产出记录)](https://blog.csdn.net/whitedrogen/article/details/130519180)2. [List of fossil occurrences(化石产出记录列表&…...

虾皮Shopee商品详情接口(item_get-根据ID取商品详情)代码封装
item_get-根据ID取商品详情接口 通过代码封装该接口可以拿到商品标题,商品价格,商品促销信息,商品优惠价,商品库存,sku属性,商品图片,desc图片,desc描述,sku图片…...

原生js手动实现一个多级树状菜单效果(高度可过渡变化) + 模拟el-menu组件实现(简单版)
文章目录 学习链接效果图代码要点 简单模拟el-menu实现TestTree.vueMenu.vueSubMenu.vue 学习链接 vue实现折叠展开收缩动画 - 自己的链接 elment-ui/plus不定高度容器收缩折叠动画组件 - 自己的链接 vue的过渡与动画理解 Vue transition 折叠类动画自动获取隐藏层高度以及…...
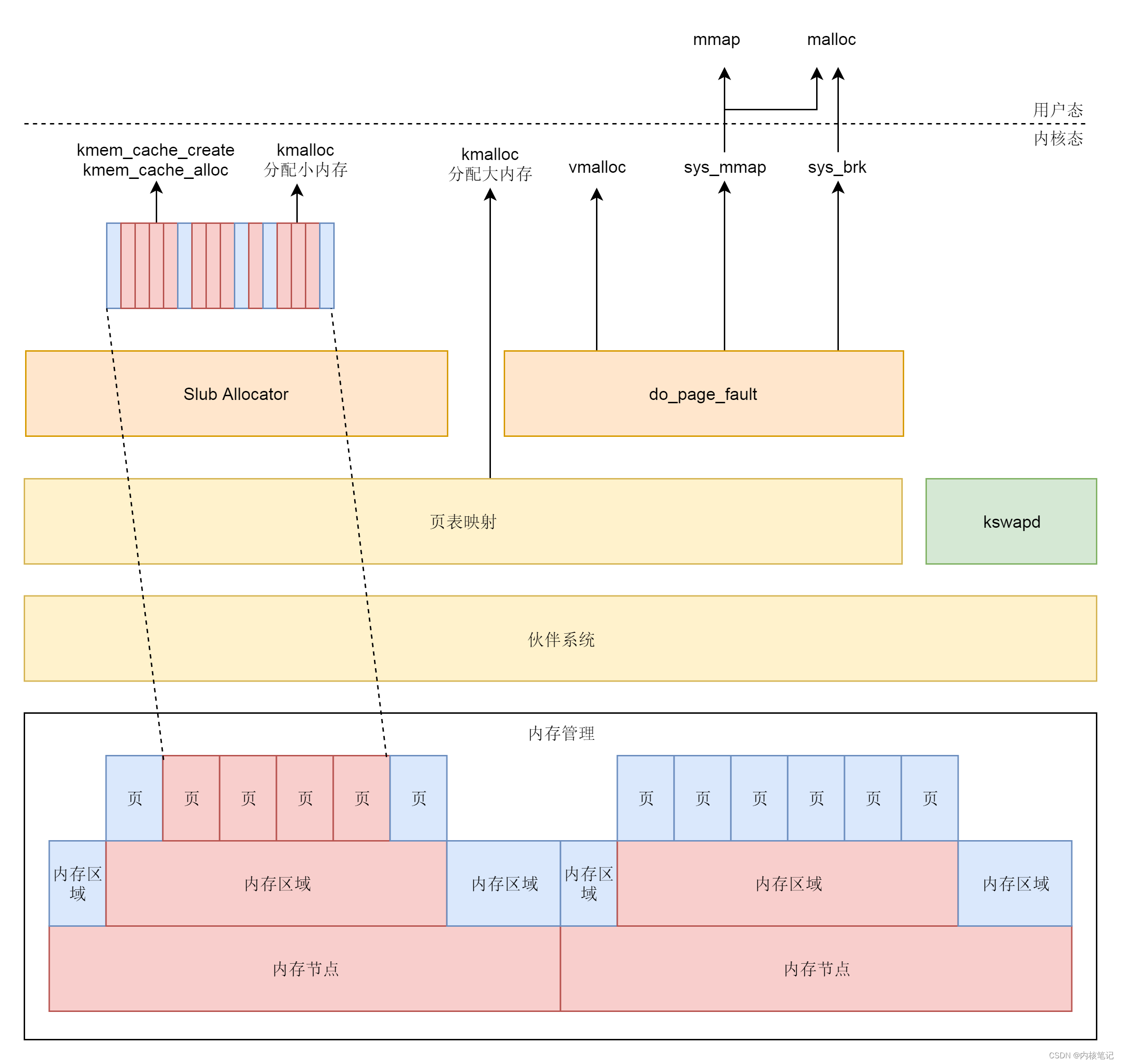
RK3568平台开发系列讲解(Linux内存篇)Linux内存管理框架
🚀返回专栏总目录 文章目录 一、内核态内存分配二、用户态内存分配三、内存篇章更新哪些内容沉淀、分享、成长,让自己和他人都能有所收获!😄 📢本篇我们一起将整个内存管理的体系串起来。 对于内存的分配需求,可能来自内核态,也可能来自用户态。 一、内核态内存分配…...

你的编程能力从什么时候开始突飞猛进?
关于编程能力突飞猛进的原因和如何突破自己,以下是我的建议。 在过去的几年中,编程领域发生了很多变化。新的语言和技术不断涌现,使得程序员们需要不断学习和提高。作为一名程序员,编程能力的提高是非常重要的,有助于…...

滨州高企认定条件
认定为高新技术企业必须同时满足以下条件: (一)企业在申请认定时需要注册一年以上。 (二)公司通过自主开发、转让、赠与、并购等方式,获得对其主要产品(服务)在技术上发挥核心支持作用的知识产权所有权。 (三)对企业主要产品(服…...
Azkaban学习——单机版安装与部署
目录 1.解压改名 2.修改装有mysql的虚拟机的my.cnf文件 3.重启装有mysql的虚拟机 4.Datagrip创建azkaban数据库,执行脚本文件 5.修改/opt/soft/azkaban-exec/conf/azkaban.properties文件 6.修改commonprivate.properties 7.传入mysql-connector-java-8.0.29…...

table标签-移动端适配
封装一个组件,该组件需要根据不同设备屏幕宽度自适应调整展示方式。对于 PC 端,以类似 el-table 的形式展示数据,而移动端则以一个类似 item 的形式展示每行数据。 可以先在组件中判断设备类型,如以下示例代码所示: …...

Yolov8改进---注意力机制:DoubleAttention、SKAttention,SENet进阶版本
目录 🏆🏆🏆🏆🏆🏆Yolov8魔术师🏆🏆🏆🏆🏆🏆 1. DoubleAttention 2. SKAttention 3.总结...
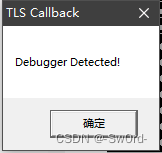
【逆向工程核心原理:TLS回调函数】
TLS 代码逆向分析领域中,TLS(Thread Local Storage,线程局部存储)回调函数(Callback Function)常用反调试。TLS回调函数的调用运行要先于EP代码的执行,该特征使它可以作为一种反调试技术的使用…...
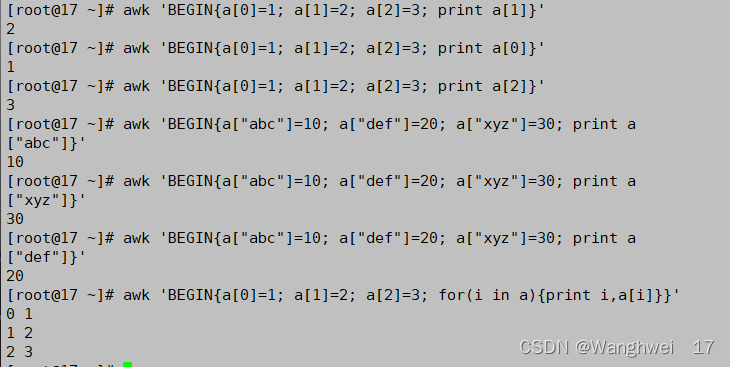
“Shell“Awk命令
文章目录 一.Awk二.Awk按行输出文本三.Awk按字段输出文本四.通过管道,双引号调用shell命令五.总结: 一.Awk Awk的工作原理: 逐行读取文本,默认以空格或tab键为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中&a…...
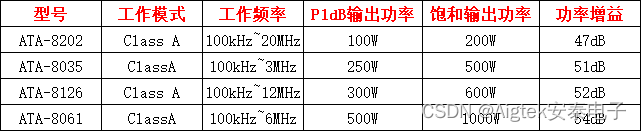
射频放大器的原理和作用(射频放大器和功率放大器的区别)
射频放大器是一种电子电路,用于将输入信号增强到足够高的电平以驱动射频输出负载。其原理和作用如下: 射频放大器的工作原理是利用晶体管的三极管效应,将输入信号放大到足够的电平以驱动输出负载。在射频放大器中,输入信号经过输入…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

【JVM】- 内存结构
引言 JVM:Java Virtual Machine 定义:Java虚拟机,Java二进制字节码的运行环境好处: 一次编写,到处运行自动内存管理,垃圾回收的功能数组下标越界检查(会抛异常,不会覆盖到其他代码…...

【第二十一章 SDIO接口(SDIO)】
第二十一章 SDIO接口 目录 第二十一章 SDIO接口(SDIO) 1 SDIO 主要功能 2 SDIO 总线拓扑 3 SDIO 功能描述 3.1 SDIO 适配器 3.2 SDIOAHB 接口 4 卡功能描述 4.1 卡识别模式 4.2 卡复位 4.3 操作电压范围确认 4.4 卡识别过程 4.5 写数据块 4.6 读数据块 4.7 数据流…...

STM32F4基本定时器使用和原理详解
STM32F4基本定时器使用和原理详解 前言如何确定定时器挂载在哪条时钟线上配置及使用方法参数配置PrescalerCounter ModeCounter Periodauto-reload preloadTrigger Event Selection 中断配置生成的代码及使用方法初始化代码基本定时器触发DCA或者ADC的代码讲解中断代码定时启动…...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

华为OD机试-食堂供餐-二分法
import java.util.Arrays; import java.util.Scanner;public class DemoTest3 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseint a in.nextIn…...

C++ 基础特性深度解析
目录 引言 一、命名空间(namespace) C 中的命名空间 与 C 语言的对比 二、缺省参数 C 中的缺省参数 与 C 语言的对比 三、引用(reference) C 中的引用 与 C 语言的对比 四、inline(内联函数…...

Robots.txt 文件
什么是robots.txt? robots.txt 是一个位于网站根目录下的文本文件(如:https://example.com/robots.txt),它用于指导网络爬虫(如搜索引擎的蜘蛛程序)如何抓取该网站的内容。这个文件遵循 Robots…...

Spring AI 入门:Java 开发者的生成式 AI 实践之路
一、Spring AI 简介 在人工智能技术快速迭代的今天,Spring AI 作为 Spring 生态系统的新生力量,正在成为 Java 开发者拥抱生成式 AI 的最佳选择。该框架通过模块化设计实现了与主流 AI 服务(如 OpenAI、Anthropic)的无缝对接&…...