2023爱分析 · 数据科学与机器学习平台厂商全景报告 | 爱分析报告

报告编委
黄勇
爱分析合伙人&首席分析师
孟晨静
爱分析分析师
目录
1. 研究范围定义
2. 厂商全景地图
3. 市场分析与厂商评估
4. 入选厂商列表
研究范围
经济新常态下,如何对海量数据进行分析挖掘以支撑敏捷决策、适应市场的快速变化,正成为企业数字化转型的关键。机器学习算法能识别数据模型,基于规律完成学习、推理和决策,正广泛的应用在金融、消费品与零售、制造业、能源业、政府与公共服务等行业的各种业务场景中,如精准营销、智能风控、产品研发、设备监管、智能排产、流程优化等。企业传统的机器学习虽然能有效支撑业务决策,但由于严重依赖数据科学家,其技术门槛高、建模周期长的特点正成为企业实现数据驱动的阻碍。
数据科学与机器学习平台是指覆盖数据采集、数据探索、数据处理、特征工程、模型构建、模型训练、模型部署与发布、模型管理与运营等建模全流程的平台,提供一站式建模服务,能显著提升建模效率、降低建模门槛。数据科学与机器学习平台能支持并赋能企业各业务场景实现智能决策,帮助企业打造数据驱动型组织。
本报告对数据科学与机器学习平台市场进行重点研究,面向金融、消费品与零售、制造与能源、政府与公共服务等行业企业,以及人工智能软件与服务提供商的数据部门、业务部门负责人,通过对业务场景的需求定义和代表厂商的能力评估,为企业数据科学与机器学习平台的建设规划、厂商选型提供参考。
厂商入选标准
本次入选报告的厂商需同时符合以下条件:
- 厂商的产品服务满足市场分析的厂商能力要求;
- 近一年厂商具备一定数量以上的付费客户(参考第3章市场分析部分);
- 近一年厂商在特定市场的收入达到指标要求(参考第3章市场分析部分)。
2. 厂商全景地图
爱分析基于对甲方企业和典型厂商的调研以及桌面研究,遴选出在数据科学与机器学习市场中具备成熟解决方案和落地能力的入选厂商。

3. 市场分析与厂商评估
爱分析对本次数据科学与机器学习平台项目的市场分析如下。同时,针对参与此次报告的部分代表厂商,爱分析撰写了厂商能力评估。
数据科学与机器学习平台
市场定义:
数据科学与机器学习平台是指覆盖数据采集、数据探索、数据处理、特征工程、模型构建、模型训练、模型部署与发布、模型管理与运营等建模全流程的平台,提供一站式建模服务,能显著提升建模效率、降低建模门槛。
甲方终端用户:
金融、消费品与零售、制造与能源、政府与公共服务等行业企业,以及人工智能软件与服务提供商的数据科学家、风控建模人员、营销建模人员、业务分析人员、模型应用人员
甲方核心需求:
企业对机器学习的应用越来越广泛。一方面,数据量的激增、算法的突破以及CPU、GPU、DPU等多种算力技术的发展,为以机器学习为基础的数据挖掘、计算机视觉、自然语言处理、生物特征识别等技术在企业的应用奠定了技术基础;另一方面,市场环境的快速变化对企业决策敏捷性要求增强,不仅推动企业将机器学习模型应用到营销、广告、风控、生产等更多业务场景,也对模型精度、模型开发敏捷性以及模型应用广度提出更高要求。然而,机器学习技术门槛高、建模周期长,难以满足企业通过基于机器学习模型提升经营效率的需求。
数据科学与机器学习平台具备工具丰富集成、建模效率提升以及模型资产复用等特点,能充分满足企业对智能应用的需求,正成为企业智能化基础设施的必要构成。
不同企业对数据科学与机器学习平台的需求不同,其差异取决于企业自身机器学习建模能力和对算法的需求。
1、对于金融、消费品与零售、制造与能源、政府与公共服务等行业企业
除大型金融机构外,传统企业普遍不具备机器学习建模能力。大型金融机构数据科学团队人才完善,对机器学习算法的探索和应用更前沿,如将机器学习模型应用在精准营销、智能风控、产品研发、客户体验管理等多个场景中。但更多的传统企业面临IT人才缺失、尚未开始智能化应用或处于局部试验的初期阶段。传统企业对数据科学与机器学习平台的需求主要体现在以下四个方面:
1)降低机器学习建模门槛,使非专业建模人员也能掌握机器学习建模技术,赋能业务。传统机器学习建模技术门槛高,需要组建专门的数据科学团队,包括数据工程师、数据科学家、开发工程师等,人力成本高昂。传统企业希望能降低机器学习建模门槛,如平台能实现数据自动处理、自动特征工程、图形化建模或自动建模等功能,使非专业的业务人员也能快速开展建模工作,广泛赋能业务,实现普惠AI。
2)提供定制化算法、模型部署和运营服务,快速创造业务价值。传统行业多具备行业特性,行业垂直场景下的模型开发耗时耗力,而且传统企业对AI智能应用的探索尚处于初期,更倾向“小步快跑”,因此购买定制化算法能节约人力、实现快速产出以及验证AI智能应用效果。企业需要厂商提供定制化算法服务、模型在硬件平台和操作系统平台的部署服务以及模型运营服务。
3)缩短建模周期,提高业务敏捷响应度。以金融行业为例,金融企业的产品、服务、风控模型均需随着客户行为改变而持续迭代更新。但传统的机器学习建模周期长达数月,无法敏捷响应业务需求。企业需要数据科学与机器学习平台内置丰富的行业算法、模型模板、案例等,供建模人员直接调用,加速模型训练;或是提供一键部署功能,实现模型在生产环境的快速部署。
4)提供咨询服务,提升模型质量。对于具备一定机器学习建模能力的金融机构,需要厂商提供建模咨询支持,协助企业完成数据准备、模型训练、模型部署等环节,提升模型质量。
2、对于人工智能软件与服务提供商
对于中小企业或是刚开始试点智能应用的企业,相较于数据科学与机器学习平台需要的组织、人才、流程上的变革与支持,采购适用于特定场景的AI智能应用是性价比更高、更迅捷的解决方案。人工智能软件与服务商如算法服务商、ISV即面向此类需求,提供模型和智能应用服务。以算法服务商为例,尽管具备专业的数据科学团队,但中小型企业的算法需求多样且个性化,如虽然都是AI视觉算法,智慧城市、智慧工业下的应用场景如安全帽识别、产品瑕疵识别的模型却截然不同,需要基于业务数据集、业务思路分别进行训练。这使得算法服务商常常面临严格的算法交付周期和算法精度要求。具体而言,人工智能软件与服务提供商对数据科学与机器学习平台的核心需求主要体现在以下四个方面:
1)提高机器学习建模效率。软件开发公司、算法提供商面临严格的交付周期,但在传统AI应用开发方式下,数据接入、数据处理、模型训练等一系列建模流程都需要人工操作,建模周期长。其中数据接入环节因开源算法工具对不同类型的数据兼容性较差,需人工将原始数据转化为开源算法所支持的数据类型;数据标注环节往往通过人工完成,并且部分领域的标注过程严重依赖专业知识,整体数据准备将耗费数周时间;模型部署中对模型的集成、监控和更新需要大量的调研和实施工作,单个模型部署到上线需要3-5个月。企业需要完善的数据科学工具和建模功能,支持实现数据采集、数据准备、特征工程、模型训练、模型部署等建模全流程,提高建模效率。
2)满足数据科学家复杂场景建模需求。平台需支持数据科学家在复杂场景下进行灵活建模,如提供丰富的算法,预置主流机器学习框架,支持NoteBook建模方式,以及支持数据科学家在模型训练中手动调参等。
3)对模型开发资源和计算资源进行统一管理,支持计算资源弹性扩容,加速建模计算性能。传统开发模式中重复建设严重,如各项目数据准备、特征工程、模型训练等各自研发,造成模型开发管理资源、计算资源浪费,难以适应大规模智能应用开发需求。另外,机器学习模型训练过程中耗费大量计算资源,而一旦结束训练,计算资源又处于闲置状态。企业需要实现计算资源弹性扩容,满足模型开发不同阶段的计算需求。
4)为多角色的数据科学团队提供协作平台。机器学习建模过程需要数据工程师、数据科学家、数据分析师等多角色共同协作完成,存在反复沟通、协作流程不明确等问题,带来重复性工作。
厂商能力要求:
为满足金融、消费品与零售、制造与能源、政府与公共服务等行业企业,以及人工智能软件与服务提供商等甲方客户的核心需求,厂商需具备以下能力:
1、厂商应具备完善的机器学习模型开发功能,提供包括数据采集、数据准备、特征工程、模型训练、模型部署等功能在内的一站式端到端数据科学与机器学习平台。
1)数据采集方面,平台应具备整合多源异构数据的能力,支持实时接入结构化数据和非结构化数据(如表格、图片、时间序列数据、语音和文本等),并具备基本的ETL能力、数据实时更新和同步能力。
2)数据准备方面,平台应提供丰富的数据清洗、数据探索工具。其中数据清洗环节,应能支持进行数据融合、数据缺失处理、数据分类、数据标注、数据异常处理、数据平滑以及整合非结构化数据和结构化数据等数据清洗工作,减少人工干预。数据探索环节,厂商需具备单变量和多变量统计、聚类分析、地理定位图、相似度度量等分析能力。
3)模型训练环节,针对非专业建模人员,平台应提供简便易用的建模工具,降低机器学习建模门槛。如平台可通过建模全流程可视化降低用户使用门槛,尤其在模型构建环节,应支持以拖拉拽的方式完成建模。针对专业建模人员,平台应具备较高的灵活性和开放性,提供主流开源算法和建模工具。如为专业的数据科学家提供自由灵活的NoteBook建模方式,并预置主流机器学习框架R、TensorFlow、Pytorch、Spark等,以及丰富的机器学习算法。
4)模型部署环节,平台应支持模型一键部署,使建模人员可快速将模型从开发环境部署到生产环境中,并提供API接口供业务人员调用。此外,平台还应提供模型版本管理和模型监控功能,实时监测模型性能,保证模型质量。
5)资源管理方面,平台需能对CPU、GPU资源进行管理和整合,以容器化方式对算力虚拟化,实现弹性扩容、性能加速等功能,且不同部门和项目之间可共享集群资源。
6)平台应具备AutoML能力,包括提供数据自动清洗、智能标注、自动特征工程和自动模型训练等功能,提高建模效率。其中特征工程环节,数据科学与机器学习平台应能实现自动化特征构建、特征选择、特征降维和特征编码;模型训练环节,平台应支持自动化模型选择、自动化调参、自动化超参数搜索、模型自动验证等,减少模型训练时间成本和人力成本。
7)此外,平台还应支持多角色的数据科学团队协作,协同数据工程师、数据科学家、业务人员等不同角色在建模工作流程中的模型注解、讨论、答疑、评论等,使建模过程可追溯、模型可复用,减少重复性工作。
2、厂商需具备垂直行业Know-how能力,为企业提供咨询和实施部署服务。厂商的专业服务能力体现在三个方面:一方面,基于丰富的垂直行业知识和经验积累,厂商能为用户提供行业场景相关的算法、模型模板,或是将行业经验与模型算法相结合,形成诸如精准营销、智能推荐、反欺诈、设备预警等智能业务模型,供用户直接调用;另一方面,厂商能提供建模咨询服务,通过数据科学专家团队规划有效的模型应用到特定业务的运营方案,协助用户完成数据准备、模型训练、模型部署、模型运营等工作,以及将企业既有的数据集经验、特征工程经验、模型经验等提炼形成数字资产,内嵌到平台中。此外,厂商应具备较强的实施部署能力,包括提供定制化模型算法在硬件平台和操作系统平台的部署服务、以及数据科学与机器学习平台的部署服务。
入选标准:
1.符合市场定义中的厂商能力要求;
2.2021Q3至2022Q2该市场付费客户数量≥10个;
3.2021Q3至2022Q2该市场合同收入≥1000万元;
代表厂商评估:

百分点科技
厂商介绍:
北京百分点科技集团股份有限公司(简称“百分点科技”)成立于2009年,是领先的数据科学基础平台及数据智能应用提供商,围绕智慧政务、公共安全、数字产业三大业务板块,为国内外企业和政府客户提供端到端数智化解决方案。
产品服务介绍:
百分点数据科学基础平台围绕数据价值增值过程,提供数据融合治理、数据建模与知识生产、知识应用三大工具集,覆盖从数据集成、数据治理、数据建模、数据分析到数据服务的完整数据价值链条。其中数据建模环节,内置机器学习平台,能一站式、可视化地实现数据准备、特征工程、模型开发与训练、模型部署与发布、模型管理等机器学习建模全流程,帮助企业快速构建数据分析、语义分析、语音分析以及视觉分析应用。
厂商评估:
百分点机器学习平台能实现一站式、可视化机器学习建模全流程管理,具备高效的数据预处理、丰富的模型服务能力。此外,百分点科技具备完善的数据建模上下游数据科学工具,能帮助用户实现“数据——知识——应用”闭环,并在智慧公安、应急管理、客户体验管理等领域沉淀丰富行业经验,能为用户提供端到端解决方案。
- 具备便捷、高效的数据预处理能力。百分点机器学习平台封装了大量预处理算法组件支持对数据的提取、清洗、转化、组合、去重等多种处理操作,尤其分布式数据处理组件,可大幅提升数据预处理速度。此外,百分点机器学习平台还提供文本标注、语音标注、图像标注、视频标注四种标注类型,支持多模态信息抽取和融合。
- 建模全流程可视化,显著降低用户使用门槛。百分点机器学习平台提供从数据接入、数据预处理、特征工程、模型训练、模型评估、模型管理及发布的全流程可视化操作。其中在建模环节,机器学习平台封装大量机器学习算法组件并支持可视化参数配置,用户可零代码操作,通过简单拖拽和连线对算法组件进行组合,进而构建复杂的机器学习框架,以及通过调节、配置参数完成模型创建。在模型训练及评估环节,平台支持模型评估指标以图、表的形式展现,用户可动态查看评估指标,实时掌控模型优度情况。在模型发布后,支持对发布上线的任务进行可视化实时监控,帮助建模人员轻松完成智能监控、定时任务调度。
- 提供丰富的模型服务,简化模型工程化事项。在模型发布方面,提供一键部署功能,自动分配集群资源,实现大数据环境下机器学习模型的稳定运行。模型管理方面,支持模型详细信息查看、多版本对比以及模型复用。此外,百分点科技还提供模型的下发、上报、订阅及评论功能,支持模型的共享和评价,如在全国公安机关警务督察信息研判系统案例中,系统可以将模型下发到省级、市级警务督察部门,并且支持基层干警对模型进行修正或评价,以实现模型快速分享和反馈。
- 具备完善的数据建模上下游数据科学工具,为用户实现“数据——知识——应用”闭环。百分点数据科学基础平台中,数据建模的上游工具包括数据集成、数据治理、数据开发等多种数据融合治理工具,能提高用户数据治理能力、沉淀数据资产。下游工具包括知识生产工具,如指标体系、标签体系、知识图谱构建,基于数据建模帮助企业实现知识生产;以及知识应用工具,如商业智能分析、知识融合分析、领域知识管理等,将知识进一步应用到业务场景中,提升企业经营效率。
- 在智慧公安、应急管理、客户体验管理领域提供端到端解决方案,赋能业务场景应用。百分点科技成立于2009年,在智慧公安、应急管理、客户体验管理等领域沉淀了大量领域know-how和项目经验,能为政府单位用户以及工业、零售快消等行业企业用户提供端到端的解决方案,包括项目咨询、项目开发、项目运营、项目服务等。在服务用户的过程中,百分点科技项目团队包含数据科学家、数据工程师、业务专家等,协同用户一起将数据、模型和工具融入智慧统计、数字营商、经营分析、营销洞察等业务场景中,真正实现业务价值。此外,百分点科技也将行业经验与模型算法相结合,形成销量预测、库存预警、指挥调度、监测预警、风险预测等丰富的智能业务模型,供用户直接调用。
典型客户:
中旅中免、应急管理部、北京市公安局、北京市统计局

相关文章:
2023爱分析 · 数据科学与机器学习平台厂商全景报告 | 爱分析报告
报告编委 黄勇 爱分析合伙人&首席分析师 孟晨静 爱分析分析师 目录 1. 研究范围定义 2. 厂商全景地图 3. 市场分析与厂商评估 4. 入选厂商列表 1. 研究范围定义 研究范围 经济新常态下,如何对海量数据进行分析挖掘以支撑敏捷决策、适应市场的快…...

20230215_数据库过程_高质量发展
高质量发展 —一、运营结果 SQL_STRING:‘delete shzc.np_rec_lnpdb a where exists (select * from tbcs.v_np_rec_lnpdbbcv t where a.telnumt.telnum and a.outcarriert.OUTCARRIER and a.incarriert.INCARRIER and a.owncarriert.OWNCARRIER and a.starttimet.STARTTIME …...

【百度 JavaScript API v3.0】LocalSearch 位置检索、Autocomplete 结果提示
地名检索移动到指定坐标 需求 在输入框中搜索,在下拉列表中浮动,右侧出现高亮的列表集。选中之后移动到指定坐标。 技术点 官网地址: JavaScript API - 快速入门 | 百度地图API SDK 开发文档:百度地图JSAPI 3.0类参考 实现 …...

运用Facebook投放,如何制定有效的竞价策略?
广告投放中,我们经常会遇到一个问题,就是不知道什么样的广告适合自己的业务。其实,最简单的方法就是根据我们业务本身进行定位并进行投放。当你了解了广告主所处行业及目标受众后,接下来会针对目标市场进行搜索和定位(…...

大数据框架之Hadoop:HDFS(五)NameNode和SecondaryNameNode(面试开发重点)
5.1NN和2NN工作机制 5.1.1思考:NameNode中的元数据是存储在哪里的? 首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低。因此&am…...

计算机网络 - 1. 体系结构
目录概念、功能、组成、分类概念功能组成分类分层结构概念总结OSI 七层模型应用层表示层会话层传输层网络层数据链路层物理层TCP/IP 四层模型OSI 与 TCP/IP 相同点OSI 与 TCP/IP 不同点为什么 TCP/IP 去除了表示层和会话层五层参考模型概念、功能、组成、分类 概念 …...

银行业上云进行时,OLAP 云服务如何解决传统数仓之痛?
本文节选自《中国金融科技发展概览:创新与应用前沿》,从某国有大行构建大数据云平台的实践出发,解读了 OLAP 云服务如何助力银行实现技术平台化、组件化和云服务化,降低技术应用门槛,赋能业务创新。此外,本…...

特定领域知识图谱融合方案:文本匹配算法之预训练Simbert、ERNIE-Gram单塔模型等诸多模型【三】
特定领域知识图谱融合方案:文本匹配算法之预训练模型SimBert、ERNIE-Gram 文本匹配任务在自然语言处理中是非常重要的基础任务之一,一般研究两段文本之间的关系。有很多应用场景;如信息检索、问答系统、智能对话、文本鉴别、智能推荐、文本数据去重、文本相似度计算、自然语…...

【2023最新教程】从0到1开发自动化测试框架(0基础也能看懂)
一、序言 随着项目版本的快速迭代、APP测试有以下几个特点: 首先,功能点多且细,测试工作量大,容易遗漏;其次,代码模块常改动,回归测试很频繁,测试重复低效;最后&#x…...

linux备份命令小记 —— 筑梦之路
Linux dump命令用于备份文件系统。 dump为备份工具程序,可将目录或整个文件系统备份至指定的设备,或备份成一个大文件。 dump命令只可以备份ext2/3/4格式的文件系统, centos7默认未安装dump命令,可以使用yum install -y dump安…...
配置环境变量和打包时区分开发、测试、生产环境)
vue项目(vue-cli)配置环境变量和打包时区分开发、测试、生产环境
1.打包时区分不同环境在自定义配置Vue-cli 的过程中,想分别通过.env.development .env.test .env.production 来代表开发、测试、生产环境。NODE_ENVdevelopment NODE_ENVtest NODE_ENVproduction本来想使用上面三种配置来区分三个环境,但是发现使用test…...

Python 命名规范
Python 命名规范 基本规范 类型公有内部备注Packagepackage_namenone全小写下划线式驼峰Modulemodule_name_module_name全小写下划线式驼峰ClassClassName_ClassName首字母大写式驼峰Methodmethod_nameprotected: _method_name private: __method_name全小写下划线式驼峰Exce…...
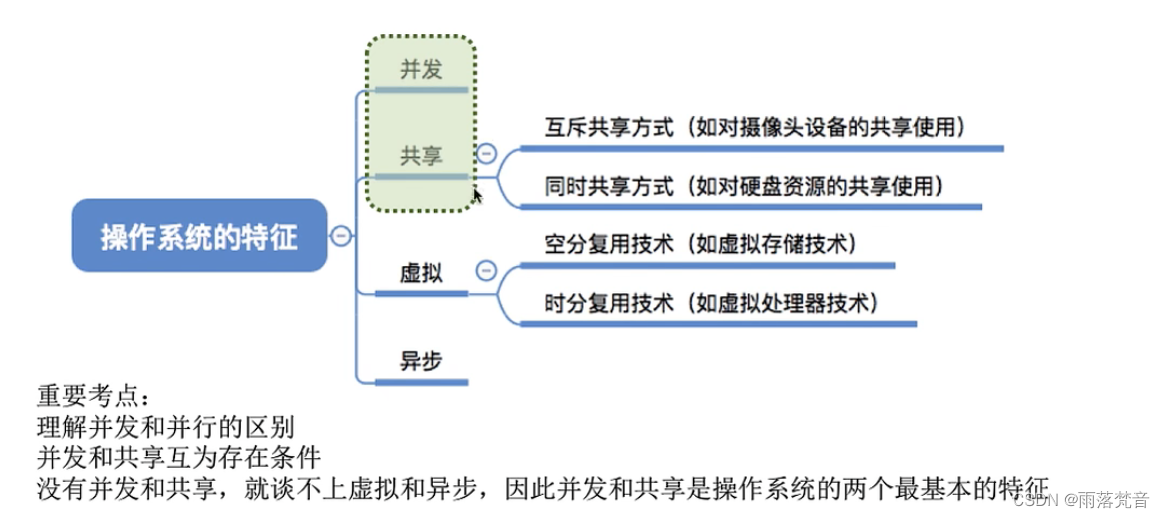
操作系统——2.操作系统的特征
这篇文章,我们来讲一讲操作系统的特征 目录 1.概述 2.并发 2.1并发概念 2.1.1操作系统的并发性 3.共享 3.1共享的概念 3.2共享的方式 4.并发和共享的关系 5.虚拟 5.1虚拟的概念 5.2虚拟小结 6.异步 6.1异步概念 7.小结 1.概述 上一篇文章,我们…...
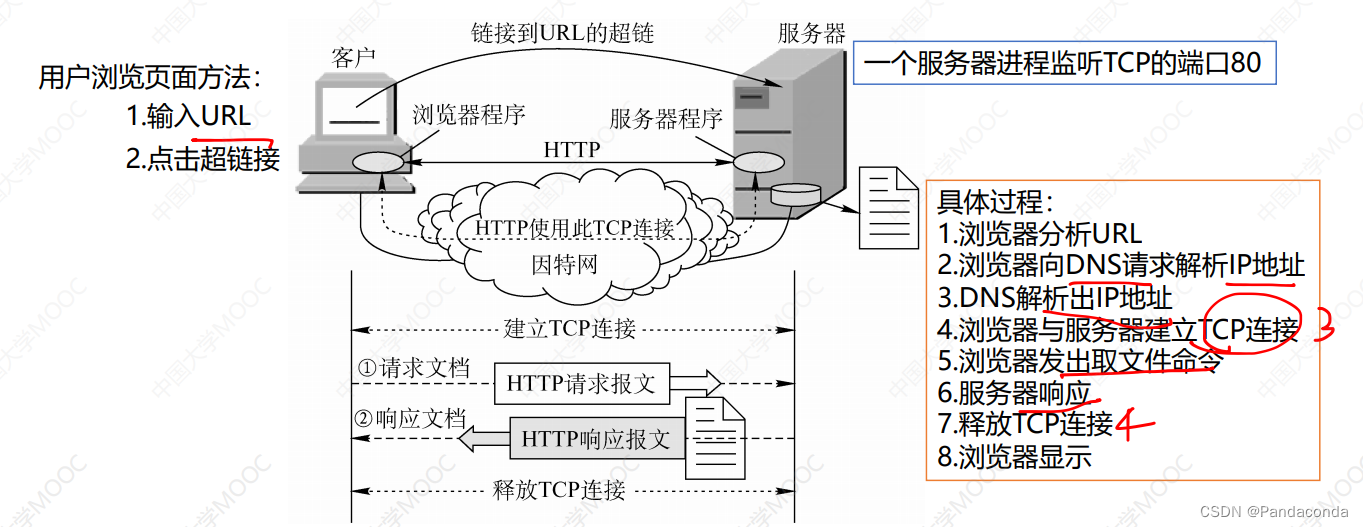
【计算机网络期末复习】第六章 应用层
✍个人博客:https://blog.csdn.net/Newin2020?spm1011.2415.3001.5343 📣专栏定位:为想复习学校计算机网络课程的同学提供重点大纲,帮助大家渡过期末考~ 📚专栏地址:https://blog.csdn.net/Newin2020/arti…...

TypeScript基本教程
TS是JS的超集,所以JS基础的类型都包含在内 起步安装 npm install typescript -g运行tsc 文件名 基础类型 Boolean、Number、String、null、undefined 以及 ES6 的 Symbol 和 ES10 的 BigInt。 1 字符串类型 字符串是使用string定义的 let a: string 123 //普…...

使用Windows API实现本地音频采集
Windows API提供了Winmm(Windows多媒体)库,其中包括了音频设备相关的函数,可以用来实现音频设备的枚举和测试。 下面是一个简单的示例代码,演示了如何使用Winmm库中的waveInGetNumDevs()函数来枚举计算机上的音频输入…...

实用的费曼学习法 | 一些思考
文章目录 一、前言二、费曼学习法CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 大数据与人工智能背景下,最重要的是:捕捉机会和快速学习的能力 一、前言 费曼学习法是美国著名的物理学家,理查德 ∙ \bullet ∙ 费曼总结出来的学习方法。 这个方法的核心是:当你学习了…...

Linux安装Docker配置docker-compose 编排工具【超详细】
一、介绍Docker Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的 Linux或Windows操作系统的机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有…...

iTerm2 + Oh My Zsh 打造舒适终端体验
最终效果图: 因为powerline以及homebrew均需要安装command line tool,网络条件优越的同学在执行本文下面内容之前,可以先安装XCode并打开运行一次(会初始化安装components),省去以后在iterm2中的等待时间。…...
和dia_matrix()的区别)
【scipy.sparse】diags()和dia_matrix()的区别
【scipy.sparse】diags()和dia_matrix()的区别 文章目录【scipy.sparse】diags()和dia_matrix()的区别1. 介绍2. 代码示例2.1 sp.diags()2.1.1 第一种用法(dataoffsets)2.1.2 广播(需要指定shape)2.1.3 只有一条对角线2.2 sp.dia_…...

AI-调查研究-01-正念冥想有用吗?对健康的影响及科学指南
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

什么是EULA和DPA
文章目录 EULA(End User License Agreement)DPA(Data Protection Agreement)一、定义与背景二、核心内容三、法律效力与责任四、实际应用与意义 EULA(End User License Agreement) 定义: EULA即…...

【分享】推荐一些办公小工具
1、PDF 在线转换 https://smallpdf.com/cn/pdf-tools 推荐理由:大部分的转换软件需要收费,要么功能不齐全,而开会员又用不了几次浪费钱,借用别人的又不安全。 这个网站它不需要登录或下载安装。而且提供的免费功能就能满足日常…...

MFC 抛体运动模拟:常见问题解决与界面美化
在 MFC 中开发抛体运动模拟程序时,我们常遇到 轨迹残留、无效刷新、视觉单调、物理逻辑瑕疵 等问题。本文将针对这些痛点,详细解析原因并提供解决方案,同时兼顾界面美化,让模拟效果更专业、更高效。 问题一:历史轨迹与小球残影残留 现象 小球运动后,历史位置的 “残影”…...

作为测试我们应该关注redis哪些方面
1、功能测试 数据结构操作:验证字符串、列表、哈希、集合和有序的基本操作是否正确 持久化:测试aof和aof持久化机制,确保数据在开启后正确恢复。 事务:检查事务的原子性和回滚机制。 发布订阅:确保消息正确传递。 2、性…...

数据结构:递归的种类(Types of Recursion)
目录 尾递归(Tail Recursion) 什么是 Loop(循环)? 复杂度分析 头递归(Head Recursion) 树形递归(Tree Recursion) 线性递归(Linear Recursion)…...
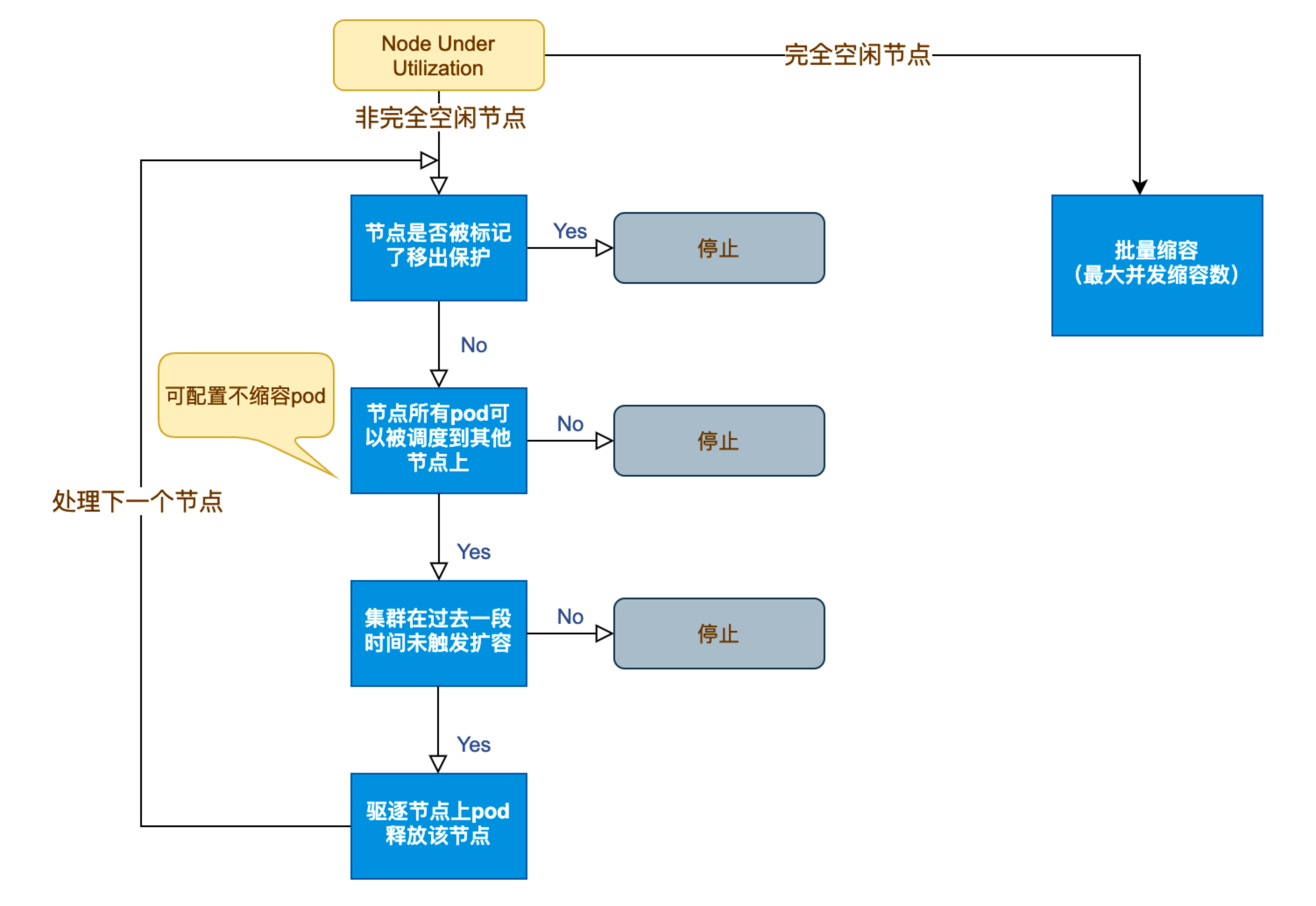
Kubernetes 节点自动伸缩(Cluster Autoscaler)原理与实践
在 Kubernetes 集群中,如何在保障应用高可用的同时有效地管理资源,一直是运维人员和开发者关注的重点。随着微服务架构的普及,集群内各个服务的负载波动日趋明显,传统的手动扩缩容方式已无法满足实时性和弹性需求。 Cluster Auto…...
恶补电源:1.电桥
一、元器件的选择 搜索并选择电桥,再multisim中选择FWB,就有各种型号的电桥: 电桥是用来干嘛的呢? 它是一个由四个二极管搭成的“桥梁”形状的电路,用来把交流电(AC)变成直流电(DC)。…...

[USACO23FEB] Bakery S
题目描述 Bessie 开了一家面包店! 在她的面包店里,Bessie 有一个烤箱,可以在 t C t_C tC 的时间内生产一块饼干或在 t M t_M tM 单位时间内生产一块松糕。 ( 1 ≤ t C , t M ≤ 10 9 ) (1 \le t_C,t_M \le 10^9) (1≤tC,tM≤109)。由于空间…...

AD学习(3)
1 PCB封装元素组成及简单的PCB封装创建 封装的组成部分: (1)PCB焊盘:表层的铜 ,top层的铜 (2)管脚序号:用来关联原理图中的管脚的序号,原理图的序号需要和PCB封装一一…...