不可错过的SQL优化干货分享-sql优化、索引使用

本文是向大家介绍在sql调优的几个操作步骤,它能够在日常遇到慢sql时有分析优化思路,能够让开发者更好的了解sql执行的顺序和原理。
一、前言
在日常开发中,我们经常遇到一些数据库相关的问题,比方说:
SQL已经走了索引了,为什么还是会耗时很长?
索引越建越多了,但是好像都是合理的,因为需求就是需要各种查询,但是索引过多又会降低写入的效率,怎么更加合理的建立索引?
为某个业务场景建立了某个索引,想当然的会生效,搞不清楚为啥没有完全覆盖?
索引包含了排序字段,为什么还是fileSort?
批量处理大量数据如何优化?
二、SQL优化步骤
1、通过查SQL日志等定位那些执行效率较低的SQL语句。
2、explain 分析SQL的执行计划。

常见字段
type | 执行链接类型,常见的比如ALL表示全表扫描,const表示常量匹配通过索引可以确认一条数据,rang范围查询、ref使用非唯一索引匹配数据,ref_or_null表示使用唯一索引匹配,index_merge表示使用了索引合并 |
possible_keys | 可能用到的索引 |
key | 用到的索引 |
key_len | 使用到的索引长度,按照字段的类型字节数计算。比方说一个BIGINT类型则为8. Varchar比较特殊。 比方说可以为空的utf8mb4编码的Varchar(32) 占用key_len = 32 * 4 + 2 +1。 2字节用于标示长度,1字节用于标示是否为空。 |
rows | 扫描行数,引擎层通过索引过滤后剩余的数据行数(剩余的数据需要在server层进行非索引过滤)。 |
Extra | 额外信息,通常用于判断Mysql怎么使用该索引 |
filtered | 符合所有查询条件的返回的结果占rows列的百分比,只是一个抽样统计 的结果,并不一定准确。 (100%则表示完全走索引过滤,通过索引过滤后的数据完全符合查询结果。) |
查询语句常出现的Extra类型
空 | 什么都没显示,说明完全使用了索引,但是需要回表 |
using index | 覆盖索引,说明完全使用了索引,并且不需要回表 |
using where | 部分用到索引 |
using index condition | 使用到了ICP,利用到索引现有的数据在引擎层过滤数据 |
using filesort | 排序没有通过索引排序,出现filesort且rows比较大的情况,则需要优化 |
using temporary | 使用到了临时表,如果执行过程需要根据查询到的数据做一些聚合分组,而数据量较大时,会使用临时表。比如group by、distinct没走索引时 |
using union Using intersect Using sort_union | 索引合并: 指字段分别有索引,采用索引查询合并数据的方式优化 使用到了索引合并联合访问算法 select * from table where filed1=1 or filed2=2 使用到了索引合并交叉访问算法 select * from table where filed1=1 and filed2>2 使用到了索引合并排序访问算法 select * from table where filed1<1 or filed2>2 |
需要重点关注 type、rows、filtered、extra。
type 由上至下,效率越来越高
ALL 全表扫描。
index 索引全扫描。
range 索引范围扫描,常用语<,<=,>=,between,in等操作。
ref 使用非唯一索引扫描或唯一索引前缀扫描,返回单条记录,常出现在关联查询中。
eq_ref 类似ref,区别在于使用的是唯一索引,使用主键的关联查询。
const/system 单条记录,系统会把匹配行中的其他列作为常数处理,如主键或唯一索引查询。
null MySQL不访问任何表或索引,直接返回结果。
虽然上至下,效率越来越高,但是根据cost模型,假设有两个索引idx1(a, b, c), idx2(a, c),SQL为"select * from t where a = 1 and b in (1, 2) order by c";如果走idx1,那么是type为range,如果走idx2,那么type是ref;当需要扫描的行数,使用idx2大约是idx1的5倍以上时,会用idx1,否则会用idx2。
extra
Using filesort:MySQL需要额外的一次传递,以找出如何按排序顺序检索行。通过根据联接类型浏览所有行并为所有匹配WHERE子句的行保存排序关键字和行的指针来完成排序。然后关键字被排序,并按排序顺序检索行。
Using temporary:使用了临时表保存中间结果,性能特别差,需要重点优化。
Using index:表示相应的 select 操作中使用了覆盖索引(Coveing Index),避免访问了表的数据行,效率不错!如果同时出现 using where,意味着无法直接通过索引查找来查询到符合条件的数据。
Using index condition:MySQL5.6之后新增的ICP,using index condtion就是使用了ICP(索引下推),在存储引擎层进行数据过滤,而不是在服务层过滤,利用索引现有的数据减少回表的数据。
3、show profile 分析
了解SQL执行的线程的状态及消耗的时间。
默认是关闭的,开启语句“set profiling = 1;”
SHOW PROFILES;
SHOW PROFILE FOR QUERY #{id};
4、trace 工具
trace分析优化器如何选择执行计划,通过trace文件能够进一步了解为什么optimizer选择A执行计划而不选择B执行计划。
set optimizer_trace="enabled=on";
set optimizer_trace_max_mem_size=1000000;
select * from information_schema.optimizer_trace;
5、确定问题并采用相应的措施
优化索引
优化SQL语句:修改SQL、IN 查询分段、时间查询分段、基于上一次数据过滤
改用其他实现方式:ES、数仓等
数据碎片处理
三、 案例分析
案例1、最左匹配
索引
KEY `idx_shopid_orderno` (`shop_id`,`order_no`)
SQL语句
select * from t where order_no = ''
查询匹配从左往右匹配,要使用order_no索引,必须查询条件携带shop_id或索引(shop_id, order_no)调换前后顺序。
案例2、隐式转换
索引
KEY `idx_mobile` (`mobile`)
SQL语句
select * from user where mobile = 12345678901
隐式转换相当于在索引上做运算,会让索引失效。mobile是字符类型,使用了数字,应该使用字符串匹配,否则MySQL会用到隐式替换,导致索引失效。
案例3、大分页
索引
KEY `idx_a_b_c` (`a`, `b`, `c`)
SQL语句
select * from t where a = 1 and b = 2 order by c desc limit 10000, 10;
对于大分页的场景,可以优先让产品优化需求,如果没有优化的,有如下两种优化方式,
一种是把上一次的最后一条数据,也即上面的c传过来,然后做“c < xxx”处理,但是这种一般需要改接口协议,并不一定可行。
另一种是采用延迟关联的方式进行处理,减少SQL回表,但是要记得索引需要完全覆盖才有效果,SQL改动如下
select t1.* from t t1, (select id from t where a = 1 and b = 2 order by c desc limit 10000, 10) t2 where t1.id = t2.id;
案例4、in + order by
索引
KEY `idx_shopid_status_created` (`shop_id`, `order_status`, `created_at`)
SQL语句
select * from order where shop_id = 1 and order_status in (1, 2, 3) order by created_at desc limit 10
in查询在MySQL底层是通过 n*m 的方式去搜索,类似union,但是效率比union高。
in查询在进行cost代价计算时(代价 = 元组数 * IO平均值),是通过将in包含的数值,一条条去查询获取元组数的,因此这个计算过程会比较的慢,所以MySQL设置了个临界值(eq_range_index_dive_limit),5.6之后超过这个临界值后该列的cost就不参与计算了。因此会导致执行计划选择不准确。默认是200,即in条件超过了200个数据,会导致in的代价计算存在问题,可能会导致Mysql选择的索引不准确。
处理方式,可以(order_status, created_at)互换前后顺序,并且调整SQL为延迟关联。
案例5、范围查询阻断,后续字段不能走索引
索引
KEY `idx_shopid_created_status` (`shop_id`, `created_at`, `order_status`)
SQL语句
select * from order where shop_id = 1 and created_at > '2021-01-01 00:00:00' and order_status = 10
范围查询还有“IN、between”
案例6、不等于、不包含不能用到索引的快速搜索。(可以用到ICP)
select * from order where shop_id = 1 and order_status not in (1, 2);
select * from order where shop_id = 1 and order_status != 1;
在索引上,避免使用NOT、!=、<>、!<、!>、NOT EXISTS、NOT IN、NOT LIKE等
案例7、优化器选择不使用索引的情况
如果要求访问的数据量很小,则优化器还是会选择辅助索引,但是当访问的数据占整个表中数据的蛮大一部分时(一般是20%左右),优化器会选择通过聚集索引来查找数据。
select * from order where order_status = 1
查询出所有未支付的订单,一般这种订单是很少的,即使建了索引,也没法使用索引。
案例8、复杂查询
select sum(amt) from t where a = 1 and b in (1, 2, 3) and c > '2020-01-01';
select * from t where a = 1 and b in (1, 2, 3) and c > '2020-01-01' limit 10;
如果是统计某些数据,可能改用数仓进行解决;
如果是业务上就有那么复杂的查询,可能就不建议继续走SQL了,而是采用其他的方式进行解决,比如使用ES等进行解决。
案例9、asc和desc混用
select * from t where a = 1 order by b desc, c asc;
desc 和 asc 混用时会导致索引失效;
案例10、大数据
对于推送业务的数据存储,可能数据量会很大,如果在方案的选择上,最终选择存储在MySQL上,并且做7天等有效期的保存。
那么需要注意,频繁的清理数据,会照成数据碎片,需要联系DBA进行数据碎片处理。
相关文章:
不可错过的SQL优化干货分享-sql优化、索引使用
本文是向大家介绍在sql调优的几个操作步骤,它能够在日常遇到慢sql时有分析优化思路,能够让开发者更好的了解sql执行的顺序和原理。一、前言在日常开发中,我们经常遇到一些数据库相关的问题,比方说:SQL已经走了索引了&a…...
vue3:直接修改reative的值,页面却不响应,这是什么情况?
目录 前言 错误示范: 解决办法: 1.使用ref 2.reative多套一层 3.使用Object.assign 前言: 今天看到有人在提问,问题是这样的,我修改了reative的值,数据居然失去了响应性,页面毫无变化&…...

从Vue2 到 Vue3,这些路由差异你需要掌握!
✨ 个人主页:山山而川~xyj ⚶ 作者简介:前端领域新星创作者,专注于前端各领域技术,共同学习共同进步,一起加油! 🎆 系列专栏: vue系列 🚀 学习格言:与其临渊羡…...

Maxwell简介、部署、原理和使用介绍
Maxwell简介、部署、原理和使用介绍 1.Maxwell概述简介 1-1.Maxwell简介 Maxwell是由美国Zendesk公司开源,使用Java编写的MySQL变更数据抓取软件。他会实时监控Mysql数据库的数据变更操作(包括insert、update、delete),并将变…...

20230215_数据库过程_渠道业务清算过程
----2023-0131-清算过程 zhyw.shc_drop_retable(upper(‘xc_qdcn_pgtx_qsqdtype_sja’),‘SHZC’); SQL_STRING:‘create table shzc.xc_qdcn_pgtx_qsqdtype_sja as select * from shzc.xc_qdcn_pgtx_qdtype a where a.in_time ( select max(a.in_time) from shzc.xc_qdcn_pg…...
webpack(高级)--性能优化-代码分离
webpack webpack性能优化 优化一:打包后的结果 上线时的性能优化 (比如分包处理 减少包体积 CDN服务器) 优化二:优化打包速度 开发或者构建优化打包速度 (比如exclude cache-loader等) 大多数情况下我们侧…...

借助docker, 使用verdaccio搭建npm私服
为何要搭建npm私服 搭建npm私服好处多多,网上随便一篇教程搜出来都罗列了诸多好处,譬如: 公司内部开发环境与外网隔离,内部开发的一些库高度隐私不便外传,内网搭建npm服务保证私密性同属内网,可以确保使用npm下载依赖…...
c/c++开发,无可避免的模板编程实践(篇二)
一、开发者需要对模板参数负责 1.1 为您模板参数提供匹配的操作 在进行模板设计时,函数模板或类模板一般只做模板参数(typename T)无关的操作为主,但是也不见得就不会关联模板参数自身的操作,尤其是在一些自定义的数据…...

【2023】【standard-products项目】中查找的问题与解决方案 (未完待续)
10、el-table 判断是多选操作还是单选操作 9、判断数组对象中是否包含某个指定值 需求:修改时数据回填el-select下拉数据,发现当前id在原数组里没有找到,就显示了id值,应该显示name名, 处理:当查找到id…...

力扣sql简单篇练习(十六)
力扣sql简单篇练习(十六) 1 产品销售分析|| 1.1 题目内容 1.1.1 基本题目信息 1.1.2 示例输入输出 1.2 示例sql语句 SELECT p.product_id,sum(s.quantity) total_quantity FROM Product p INNER JOIN Sales s ON p.product_ids.product_id GROUP BY p.product_id1.3 运行截…...
)
青少年蓝桥杯python组(STEMA中级组)
第一套编程题第一题【编程实现】输入一个字符串(N),输出该字符串的长度。输入描述:输入一个字符串 N输出描述:输出该字符串的长度【样例输入】abcd【样例输出】4N input() print(len(N))第二题【提示信息】小蓝家的灯…...
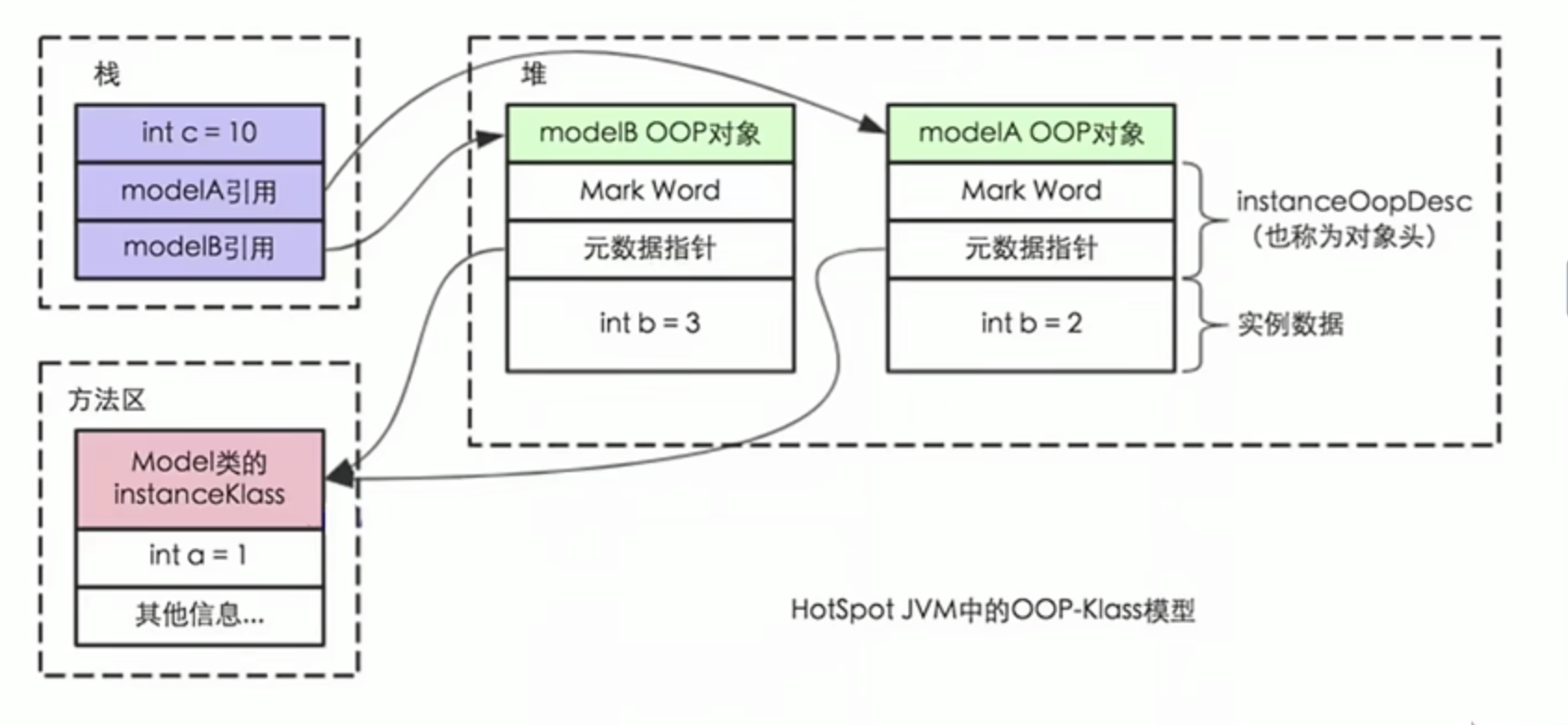
JVM内存结构,Java内存模型,Java对象模型
一.整体方向JVM内存结构是和java虚拟机的运行时区域有关。Java内存模型和java并发编程有关。java对象模型和java对象在虚拟机中的表现形式有关。1.JVM内存结构堆:通过new或者其他指令创建的实例对象,会被垃圾回收。动态分配。虚拟机栈:基本数…...

跨境电商新形式下,如何选择市场?
2022年,全球经济已经有增长乏力、通胀高起的趋势,美国等国家的通货膨胀情况令人担忧,不少行业面临更为复杂的外部环境以及严峻的市场挑战。不过,跨境电商行业依旧保持着较高的增长速度,越来越多有远见的卖家将电商事业…...

MySQL的触发器
目录 一.概述 介绍 触发器的特性 操作—创建触发器 操作—new和old 操作—查看触发器 操作—删除触发器 注意事项 一.概述 介绍 触发器,就是一种特殊的存储过程。触发器和存储过程一样是一个能够完成特定功能、存储在数据库服务器上的SQL片段,但是…...

内存映射模块读写文件提高IO性能mmap
内存映射模块读写文件提高IO性能mmap 1.概述 这篇文章介绍下与普通读写文件不同的方式,内存映射读写文件。在什么情况下才会用到内存映射操作文件那,还是要先了解下他。 1.1.内存映射与IO区别 常规操作IO开销 常规的操作文件是经过下面几个环节操作I…...
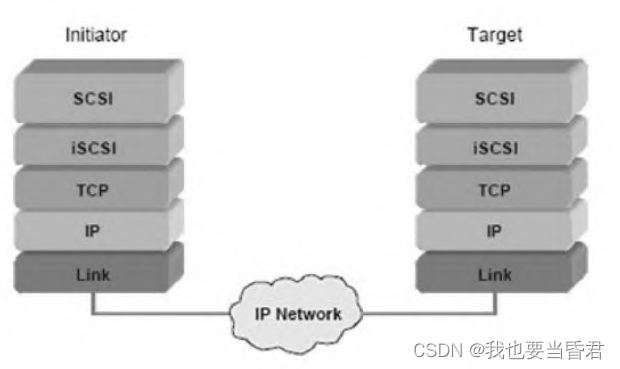
存储硬件与协议
存储硬件与协议存储设备的历史轨迹存储介质的进化3D NAND3D XPointIntel Optane存储接口协议的演变NVMeNVMe-oF网络存储技术1)DAS2)NAS3)SAN4)iSCSIiSCSI层次结构存储设备的历史轨迹 1.穿孔卡2.磁带3.硬盘4.磁盘(软盘…...

智能物流半导体发展
智能物流半导体在国内的发展,国内巨大的人口基数,这将会不断促进智慧物流的发展。智能物流在未来发展的潜力巨大。 关于触屏的设计是界面越简单,越清晰越好,最近设计一个小车控制触屏软件。把小车当前所在信息通过图像显示出来。…...

SAP S/4HANA 概述
智能企业业务技术平台Business Technology Platform提供数据管理和分析,并支持应用程序开发和集成。它还允许我们的客户使用人工智能、机器学习和物联网等智能技术来推动创新。业务网络Business network帮助客户实现跨公司业务流程的数字化。该网络建立在我们的采购…...

太上感应篇
太上感应篇原文 太上曰。祸福无门。惟人自召。善恶之报。如影随形。 是以天地有司过之神。依人所犯轻重。以夺人算。算减则贫耗。多逢忧患。人皆恶之。刑祸随之。吉庆避之。恶星灾之。算尽则死。 又有三台北斗神君。在人头上。录人罪恶。夺其纪算。又有三尸神。在人身中。每…...
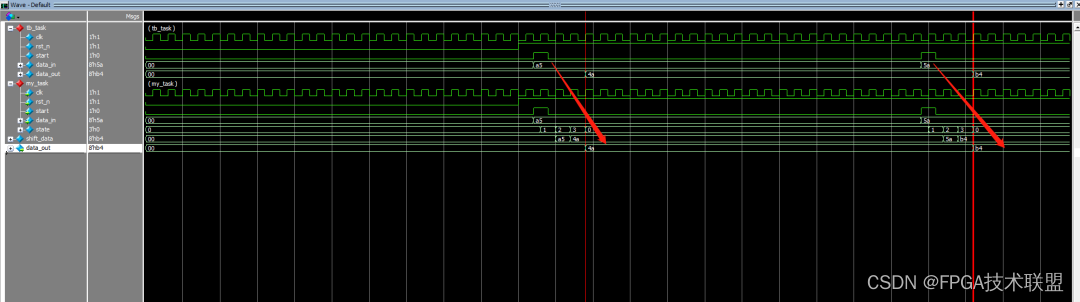
FPGA入门系列17--task
文章简介 本系列文章主要针对FPGA初学者编写,包括FPGA的模块书写、基础语法、状态机、RAM、UART、SPI、VGA、以及功能验证等。将每一个知识点作为一个章节进行讲解,旨在更快速的提升初学者在FPGA开发方面的能力,每一个章节中都有针对性的代码…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

工程地质软件市场:发展现状、趋势与策略建议
一、引言 在工程建设领域,准确把握地质条件是确保项目顺利推进和安全运营的关键。工程地质软件作为处理、分析、模拟和展示工程地质数据的重要工具,正发挥着日益重要的作用。它凭借强大的数据处理能力、三维建模功能、空间分析工具和可视化展示手段&…...

linux arm系统烧录
1、打开瑞芯微程序 2、按住linux arm 的 recover按键 插入电源 3、当瑞芯微检测到有设备 4、松开recover按键 5、选择升级固件 6、点击固件选择本地刷机的linux arm 镜像 7、点击升级 (忘了有没有这步了 估计有) 刷机程序 和 镜像 就不提供了。要刷的时…...

macOS多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用
文章目录 问题现象问题原因解决办法 问题现象 macOS启动台(Launchpad)多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用。 问题原因 很明显,都是Google家的办公全家桶。这些应用并不是通过独立安装的…...

Springcloud:Eureka 高可用集群搭建实战(服务注册与发现的底层原理与避坑指南)
引言:为什么 Eureka 依然是存量系统的核心? 尽管 Nacos 等新注册中心崛起,但金融、电力等保守行业仍有大量系统运行在 Eureka 上。理解其高可用设计与自我保护机制,是保障分布式系统稳定的必修课。本文将手把手带你搭建生产级 Eur…...

Caliper 配置文件解析:config.yaml
Caliper 是一个区块链性能基准测试工具,用于评估不同区块链平台的性能。下面我将详细解释你提供的 fisco-bcos.json 文件结构,并说明它与 config.yaml 文件的关系。 fisco-bcos.json 文件解析 这个文件是针对 FISCO-BCOS 区块链网络的 Caliper 配置文件,主要包含以下几个部…...

【JavaWeb】Docker项目部署
引言 之前学习了Linux操作系统的常见命令,在Linux上安装软件,以及如何在Linux上部署一个单体项目,大多数同学都会有相同的感受,那就是麻烦。 核心体现在三点: 命令太多了,记不住 软件安装包名字复杂&…...

基于Java+MySQL实现(GUI)客户管理系统
客户资料管理系统的设计与实现 第一章 需求分析 1.1 需求总体介绍 本项目为了方便维护客户信息为了方便维护客户信息,对客户进行统一管理,可以把所有客户信息录入系统,进行维护和统计功能。可通过文件的方式保存相关录入数据,对…...

【Android】Android 开发 ADB 常用指令
查看当前连接的设备 adb devices 连接设备 adb connect 设备IP 断开已连接的设备 adb disconnect 设备IP 安装应用 adb install 安装包的路径 卸载应用 adb uninstall 应用包名 查看已安装的应用包名 adb shell pm list packages 查看已安装的第三方应用包名 adb shell pm list…...

苹果AI眼镜:从“工具”到“社交姿态”的范式革命——重新定义AI交互入口的未来机会
在2025年的AI硬件浪潮中,苹果AI眼镜(Apple Glasses)正在引发一场关于“人机交互形态”的深度思考。它并非简单地替代AirPods或Apple Watch,而是开辟了一个全新的、日常可接受的AI入口。其核心价值不在于功能的堆叠,而在于如何通过形态设计打破社交壁垒,成为用户“全天佩戴…...