实现一个简单的Database10(译文)
- GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源。
- GreatSQL是MySQL的国产分支版本,使用上与MySQL一致。
- 作者: 花家舍
- 文章来源:GreatSQL社区原创
前文回顾
- 实现一个简单的Database系列
译注:cstack在github维护了一个简单的、类似sqlite的数据库实现,通过这个简单的项目,可以很好的理解数据库是如何运行的。本文是第十篇,主要是实现B-tree中叶子节点分裂
Part 10 叶子节点分裂
我们 B-Tree 只有一个节点,这看起来不太像一棵标准的 tree。为了解决这个问题,需要一些代码来实现分裂叶子节点。在那之后,需要创建一个内部节点,使其成为两个新的叶子节点的父节点。
基本上,我们这个系列的文章的目标是从这里开始的:
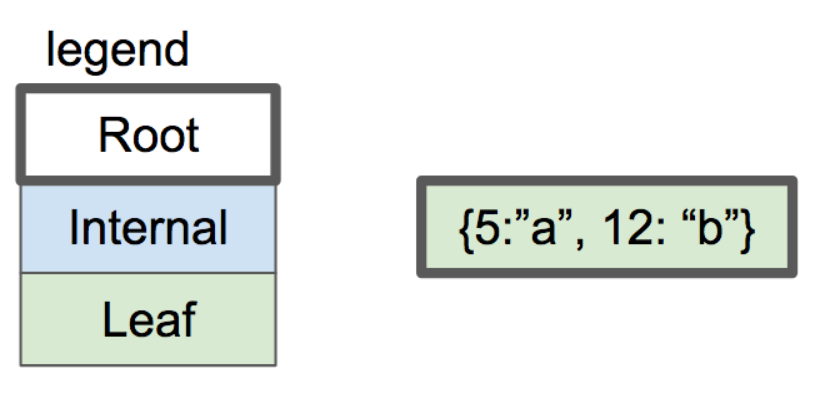
one-node btree
到这样:
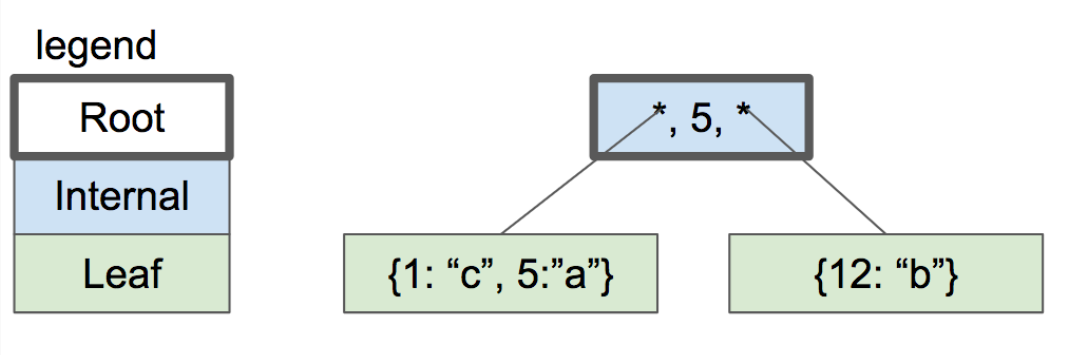
two-level btree
首先中的首先,先把处理节点写满错误移除掉:
void leaf_node_insert(Cursor* cursor, uint32_t key, Row* value) {void* node = get_page(cursor->table->pager, cursor->page_num);uint32_t num_cells = *leaf_node_num_cells(node);if (num_cells >= LEAF_NODE_MAX_CELLS) {// Node full
- printf("Need to implement splitting a leaf node.\n");
- exit(EXIT_FAILURE);
+ leaf_node_split_and_insert(cursor, key, value);
+ return;}
ExecuteResult execute_insert(Statement* statement, Table* table) {void* node = get_page(table->pager, table->root_page_num);uint32_t num_cells = (*leaf_node_num_cells(node));
- if (num_cells >= LEAF_NODE_MAX_CELLS) {
- return EXECUTE_TABLE_FULL;
- }Row* row_to_insert = &(statement->row_to_insert);uint32_t key_to_insert = row_to_insert->id;分裂算法(Splitting Algorithm)
简单的部分结束了。以下是我们需要做的事情的描述(出自:SQLite Database System: Design and Implementation) 原文:If there is no space on the leaf node, we would split the existing entries residing there and the new one (being inserted) into two equal halves: lower and upper halves. (Keys on the upper half are strictly greater than those on the lower half.) We allocate a new leaf node, and move the upper half into the new node. 翻译:如果在叶子节点中已经没有空间,我们需要将驻留在节点中的现有条目和新条目(正在插入)分成相等的两半:低半部分和高半部分(在高半部分中的键要严格大于低半部分中的键)。我们分配一个新的节点,将高半部分的条目移到新的节点中。
现在来处理旧节点并创建一个新的节点:
+void leaf_node_split_and_insert(Cursor* cursor, uint32_t key, Row* value) {
+ /*
+ Create a new node and move half the cells over.
+ Insert the new value in one of the two nodes.
+ Update parent or create a new parent.
+ */
+
+ void* old_node = get_page(cursor->table->pager, cursor->page_num);
+ uint32_t new_page_num = get_unused_page_num(cursor->table->pager);
+ void* new_node = get_page(cursor->table->pager, new_page_num);
+ initialize_leaf_node(new_node);接下来,拷贝节点中每一个单元格到新的位置:
+ /*
+ All existing keys plus new key should be divided
+ evenly between old (left) and new (right) nodes.
+ Starting from the right, move each key to correct position.
+ */
+ for (int32_t i = LEAF_NODE_MAX_CELLS; i >= 0; i--) {
+ void* destination_node;
+ if (i >= LEAF_NODE_LEFT_SPLIT_COUNT) {
+ destination_node = new_node;
+ } else {
+ destination_node = old_node;
+ }
+ uint32_t index_within_node = i % LEAF_NODE_LEFT_SPLIT_COUNT;
+ void* destination = leaf_node_cell(destination_node, index_within_node);
+
+ if (i == cursor->cell_num) {
+ serialize_row(value, destination);
+ } else if (i > cursor->cell_num) {
+ memcpy(destination, leaf_node_cell(old_node, i - 1), LEAF_NODE_CELL_SIZE);
+ } else {
+ memcpy(destination, leaf_node_cell(old_node, i), LEAF_NODE_CELL_SIZE);
+ }
+ }更新节点中头部标记的单元格的数量(更新node’s header)
+ /* Update cell count on both leaf nodes */
+ *(leaf_node_num_cells(old_node)) = LEAF_NODE_LEFT_SPLIT_COUNT;
+ *(leaf_node_num_cells(new_node)) = LEAF_NODE_RIGHT_SPLIT_COUNT;然后我们需要更新节点的父节点。如果原始节点是一个根节点(root node),那么他就没有父节点。这种情况中,创建一个新的根节点来作为它的父节点。这里做另外一个存根(先不具体实现):
+ if (is_node_root(old_node)) {
+ return create_new_root(cursor->table, new_page_num);
+ } else {
+ printf("Need to implement updating parent after split\n");
+ exit(EXIT_FAILURE);
+ }
+}分配新的页面(Allocating New Pages)
让我们回过头来定义一些函数和常量。当我们创建一个新的叶子节点,我们把它放进一个由get_unused_page_num()函数决定(返回)的页中。
+/*
+Until we start recycling free pages, new pages will always
+go onto the end of the database file
+*/
+uint32_t get_unused_page_num(Pager* pager) { return pager->num_pages; }现在,我们假定在一个数据库中有N个数据页,页编码从 0 到 N-1 的页已经被分配。因此我们总是可以为一个新页分配页 N编码。在我们最终实现删除(数据)操作后,一些页可能会变成空页,并且他们的页编号可能没有被使用。为了更有效率,我们会回收这些空闲页。
叶子节点的大小(Leaf Node Sizes)
为了保持的树的平衡,我们在两个新的节点之间平等的分发单元格。如果一个叶子节点可以hold住 N 个单元格,那么在分裂期间我们需要分发 N + 1 个单元格在两个节点之间(N 个原有的单元格和一个新插入的单元格)。如果 N+1 是奇数,我比较随意地选择了左侧节点获取多的那个单元格。
+const uint32_t LEAF_NODE_RIGHT_SPLIT_COUNT = (LEAF_NODE_MAX_CELLS + 1) / 2;
+const uint32_t LEAF_NODE_LEFT_SPLIT_COUNT =
+ (LEAF_NODE_MAX_CELLS + 1) - LEAF_NODE_RIGHT_SPLIT_COUNT;创建新根节点(Creating a New Root)
这里是“SQLite Database System”描述的创建一个新根节点的过程: 原文:Let N be the root node. First allocate two nodes, say L and R. Move lower half of N into L and the upper half into R. Now N is empty. Add 〈L, K,R〉 in N, where K is the max key in L. Page N remains the root. Note that the depth of the tree has increased by one, but the new tree remains height balanced without violating any B+-tree property. 翻译:设 N 为根节点。先分配两个节点,比如 L 和 R。移动 N 中低半部分的条目到 L 中,移动高半部分条目到 R 中。现在 N 已经空了。增加 〈L, K,R〉到 N 中,这里 K 是 L 中最大 key 。页 N 仍然是根节点。注意这时树的深度已经增加了一层,但是在没有违反任何 B-Tree 属性的情况下,新的树仍然保持了高度上平衡。
此时,我们已经分配了右子节点并移动高半部分的条目到这个子节点。我们的函数把这个右子节点作为输入,并且分配一个新的页面来存放左子节点。
+void create_new_root(Table* table, uint32_t right_child_page_num) {
+ /*
+ Handle splitting the root.
+ Old root copied to new page, becomes left child.
+ Address of right child passed in.
+ Re-initialize root page to contain the new root node.
+ New root node points to two children.
+ */
+
+ void* root = get_page(table->pager, table->root_page_num);
+ void* right_child = get_page(table->pager, right_child_page_num);
+ uint32_t left_child_page_num = get_unused_page_num(table->pager);
+ void* left_child = get_page(table->pager, left_child_page_num);旧的根节点已经被拷贝到左子节点,所以我们可以重用根节点(无需重新分配):
+ /* Left child has data copied from old root */
+ memcpy(left_child, root, PAGE_SIZE);
+ set_node_root(left_child, false);最后我们初始化根节点作为一个新的、有两个子节点的内部节点。
+ /* Root node is a new internal node with one key and two children */
+ initialize_internal_node(root);
+ set_node_root(root, true);
+ *internal_node_num_keys(root) = 1;
+ *internal_node_child(root, 0) = left_child_page_num;
+ uint32_t left_child_max_key = get_node_max_key(left_child);
+ *internal_node_key(root, 0) = left_child_max_key;
+ *internal_node_right_child(root) = right_child_page_num;
+}内部节点格式(Internal Node Format)
现在我们终于创建了内部节点,我们就不得不定义它的布局了。它从通用 header 开始,然后是它包含的 key 的数量,接下来是它右边子节点的页号。内部节点的子节点指针始终比它的 key 的数量多一个。这个 子节点指针存储在 header 中。
+/*
+ * Internal Node Header Layout
+ */
+const uint32_t INTERNAL_NODE_NUM_KEYS_SIZE = sizeof(uint32_t);
+const uint32_t INTERNAL_NODE_NUM_KEYS_OFFSET = COMMON_NODE_HEADER_SIZE;
+const uint32_t INTERNAL_NODE_RIGHT_CHILD_SIZE = sizeof(uint32_t);
+const uint32_t INTERNAL_NODE_RIGHT_CHILD_OFFSET =
+ INTERNAL_NODE_NUM_KEYS_OFFSET + INTERNAL_NODE_NUM_KEYS_SIZE;
+const uint32_t INTERNAL_NODE_HEADER_SIZE = COMMON_NODE_HEADER_SIZE +
+ INTERNAL_NODE_NUM_KEYS_SIZE +
+ INTERNAL_NODE_RIGHT_CHILD_SIZE;内部节点的 body 是一个单元格的数组,每个单元格包含一个子指针和一个 key 。每个 key 都必须是它的左边子节点中包含的最大 key 。
+/*
+ * Internal Node Body Layout
+ */
+const uint32_t INTERNAL_NODE_KEY_SIZE = sizeof(uint32_t);
+const uint32_t INTERNAL_NODE_CHILD_SIZE = sizeof(uint32_t);
+const uint32_t INTERNAL_NODE_CELL_SIZE =
+ INTERNAL_NODE_CHILD_SIZE + INTERNAL_NODE_KEY_SIZE;基于这些常量,下边是内部节点布局看上去的样子:

Our internal node format
注意我们巨大的分支因子(也就是扇出)。因为每个子节点指针/键对儿(child pointer / key pair)太小了,我们可以在每个内部节点中容纳 510 个键和 511 个子指针(也就是每个内部节点可以有510个子节点)。这意味着我们从来不用在查找 key 时遍历树的很多层。
| # internal node layers | max # leaf nodes | Size of all leaf nodes |
|---|---|---|
| 0 | 511^0 = 1 | 4 KB |
| 1 | 511^1 = 512 | ~2 MB |
| 2 | 511^2 = 261,121 | ~1 GB |
| 3 | 511^3 = 133,432,831 | ~550 GB |
实际上,我们不能在每个叶子节点中存储满 4KB 的数据,这是因为存储 header 、 keys 的开销和空间的浪费。 但是我们可以通过从磁盘上加载 4 个 pages (树高四层,每层只需检索一页)来检索大约 500G 的数据。这就是为什么 B-Tree 对数据库来说是很有用的数据结构。
下边是读取和写入一个内部节点的方法:
+uint32_t* internal_node_num_keys(void* node) {
+ return node + INTERNAL_NODE_NUM_KEYS_OFFSET;
+}
+
+uint32_t* internal_node_right_child(void* node) {
+ return node + INTERNAL_NODE_RIGHT_CHILD_OFFSET;
+}
+
+uint32_t* internal_node_cell(void* node, uint32_t cell_num) {
+ return node + INTERNAL_NODE_HEADER_SIZE + cell_num * INTERNAL_NODE_CELL_SIZE;
+}
+
+uint32_t* internal_node_child(void* node, uint32_t child_num) {
+ uint32_t num_keys = *internal_node_num_keys(node);
+ if (child_num > num_keys) {
+ printf("Tried to access child_num %d > num_keys %d\n", child_num, num_keys);
+ exit(EXIT_FAILURE);
+ } else if (child_num == num_keys) {
+ return internal_node_right_child(node);
+ } else {
+ return internal_node_cell(node, child_num);
+ }
+}
+
+uint32_t* internal_node_key(void* node, uint32_t key_num) {
+ return internal_node_cell(node, key_num) + INTERNAL_NODE_CHILD_SIZE;
+}对于一个内部节点,最大 key 始终是其右键。对于一个叶子节点,最大 key 就是最大索引键。
+uint32_t get_node_max_key(void* node) {
+ switch (get_node_type(node)) {
+ case NODE_INTERNAL:
+ return *internal_node_key(node, *internal_node_num_keys(node) - 1);
+ case NODE_LEAF:
+ return *leaf_node_key(node, *leaf_node_num_cells(node) - 1);
+ }
+}追踪根节点(Keeping Track of the Root)
我们终于在通用的节点 header 中使用了 is_root 字段。回调它是我们用它来决定怎样来分裂一个叶子节点:
if (is_node_root(old_node)) {return create_new_root(cursor->table, new_page_num);} else {printf("Need to implement updating parent after split\n");exit(EXIT_FAILURE);}
}下面是 getter & setter:
+bool is_node_root(void* node) {
+ uint8_t value = *((uint8_t*)(node + IS_ROOT_OFFSET));
+ return (bool)value;
+}
+
+void set_node_root(void* node, bool is_root) {
+ uint8_t value = is_root;
+ *((uint8_t*)(node + IS_ROOT_OFFSET)) = value;
+}初始化这两种类型的节点(内部节点&叶子节点)应默认设置 is_root 为 false。
void initialize_leaf_node(void* node) {set_node_type(node, NODE_LEAF);
+ set_node_root(node, false);*leaf_node_num_cells(node) = 0;
}+void initialize_internal_node(void* node) {
+ set_node_type(node, NODE_INTERNAL);
+ set_node_root(node, false);
+ *internal_node_num_keys(node) = 0;
+}当创建表的第一个节点时我们需要设置 is_root 为 true 。
// New database file. Initialize page 0 as leaf node.
void* root_node = get_page(pager, 0);
initialize_leaf_node(root_node);
+ set_node_root(root_node, true);
}return table;打印树(Printing the Tree)
为了帮助我们可视化数据库的状态,我们应该更新我们的 .btree 元命令以打印多级树。
我要替换当前的 print_leaf_node() 函数:
-void print_leaf_node(void* node) {
- uint32_t num_cells = *leaf_node_num_cells(node);
- printf("leaf (size %d)\n", num_cells);
- for (uint32_t i = 0; i < num_cells; i++) {
- uint32_t key = *leaf_node_key(node, i);
- printf(" - %d : %d\n", i, key);
- }
-}实现一个递归函数,可以接受任何节点,然后打印它和它的子节点。它接受一个缩进级别作为参数,缩进级别每次在每次递归时会递增。我还在缩进中添加了一个很小的辅助函数。
+void indent(uint32_t level) {
+ for (uint32_t i = 0; i < level; i++) {
+ printf(" ");
+ }
+}
+
+void print_tree(Pager* pager, uint32_t page_num, uint32_t indentation_level) {
+ void* node = get_page(pager, page_num);
+ uint32_t num_keys, child;
+
+ switch (get_node_type(node)) {
+ case (NODE_LEAF):
+ num_keys = *leaf_node_num_cells(node);
+ indent(indentation_level);
+ printf("- leaf (size %d)\n", num_keys);
+ for (uint32_t i = 0; i < num_keys; i++) {
+ indent(indentation_level + 1);
+ printf("- %d\n", *leaf_node_key(node, i));
+ }
+ break;
+ case (NODE_INTERNAL):
+ num_keys = *internal_node_num_keys(node);
+ indent(indentation_level);
+ printf("- internal (size %d)\n", num_keys);
+ for (uint32_t i = 0; i < num_keys; i++) {
+ child = *internal_node_child(node, i);
+ print_tree(pager, child, indentation_level + 1);
+
+ indent(indentation_level + 1);
+ printf("- key %d\n", *internal_node_key(node, i));
+ }
+ child = *internal_node_right_child(node);
+ print_tree(pager, child, indentation_level + 1);
+ break;
+ }
+}并更新对 print 函数的调用,传递缩进级别为零。
} else if (strcmp(input_buffer->buffer, ".btree") == 0) {printf("Tree:\n");
- print_leaf_node(get_page(table->pager, 0));
+ print_tree(table->pager, 0, 0);return META_COMMAND_SUCCESS;下面是一个对新的打印函数的测例
+ it 'allows printing out the structure of a 3-leaf-node btree' do
+ script = (1..14).map do |i|
+ "insert #{i} user#{i} person#{i}@example.com"
+ end
+ script << ".btree"
+ script << "insert 15 user15 person15@example.com"
+ script << ".exit"
+ result = run_script(script)
+
+ expect(result[14...(result.length)]).to match_array([
+ "db > Tree:",
+ "- internal (size 1)",
+ " - leaf (size 7)",
+ " - 1",
+ " - 2",
+ " - 3",
+ " - 4",
+ " - 5",
+ " - 6",
+ " - 7",
+ " - key 7",
+ " - leaf (size 7)",
+ " - 8",
+ " - 9",
+ " - 10",
+ " - 11",
+ " - 12",
+ " - 13",
+ " - 14",
+ "db > Need to implement searching an internal node",
+ ])
+ end新格式有点简化,所以我们需要更新现有的 .btree 测试:
"db > Executed.",
"db > Executed.",
"db > Tree:",
- "leaf (size 3)",
- " - 0 : 1",
- " - 1 : 2",
- " - 2 : 3",
+ "- leaf (size 3)",
+ " - 1",
+ " - 2",
+ " - 3",
"db > "
])
end这是新测试本身的 .btree 输出:
Tree:
- internal (size 1)- leaf (size 7)- 1- 2- 3- 4- 5- 6- 7- key 7- leaf (size 7)- 8- 9- 10- 11- 12- 13- 14在缩进最小的级别,我们看到根节点(一个内部节点)。它输出的 size 为 1 因为它有一个 key 。缩进一个级别,我们看到叶子节点,一个 key ,和一个叶子节点。根节点中的 key (7)是第一个左子节点中最大的 key 。每个大于7的 key 存放在第二个子节点中。
一个主要问题(A Major Problem)
如果你一直密切关注,你可能会注意到我们错过了一些大事。看看如果我们尝试插入额外一行会发生什么:
db > insert 15 user15 person15@example.com
Need to implement searching an internal node哦吼!是谁写的TODO信息?(作者在故弄玄虚!明明是他自己在 table_find() 函数中把内部节点搜索的功能存根的!)
下次我们将通过在多级树上实现搜索来继续史诗般的 B 树传奇。
Enjoy GreatSQL :)
关于 GreatSQL
GreatSQL是由万里数据库维护的MySQL分支,专注于提升MGR可靠性及性能,支持InnoDB并行查询特性,是适用于金融级应用的MySQL分支版本。
相关链接: GreatSQL社区 Gitee GitHub Bilibili
GreatSQL社区:

社区有奖建议反馈: https://greatsql.cn/thread-54-1-1.html
社区博客有奖征稿详情: https://greatsql.cn/thread-100-1-1.html
社区2022年度勋章获奖名单: https://greatsql.cn/thread-184-1-1.html
(对文章有疑问或者有独到见解都可以去社区官网提出或分享哦~)
技术交流群:
微信&QQ群: QQ群:533341697 微信群:添加GreatSQL社区助手(微信号:wanlidbc )好友,待社区助手拉您进群。
相关文章:
实现一个简单的Database10(译文)
GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源。GreatSQL是MySQL的国产分支版本,使用上与MySQL一致。作者: 花家舍文章来源:GreatSQL社区原创 前文回顾 实现一个简单的Database系列 译注:csta…...
CTF-取证题目解析-提供环境
一、安装 官网下载:Volatility 2.6 Release 1、将windows下载的volatility上传到 kali/home 文件夹里面 3、将home/kali/vol刚刚上传的 移动到use/sbin目录里面 mv volatility usr/local/sbin/ 切换到里面 cd /usr/local/sbin/volatility 输入配置环境echo $PAT…...

计算机基础 | 网络篇 | TCP/IP 四层模型
前沿:撰写博客的目的是为了再刷时回顾和进一步完善,其次才是以教为学,所以如果有些博客写的较简陋,是为了保持进度不得已而为之,还请大家多多见谅。 一、OSI 七层模型 参考文章:OSI 和 TCP/IP 网络分层模型…...

实时数据仓库
1 为什么选择kafka? ① 实时写入,实时读取 ② 消息队列适合,其他数据库受不了 2 ods层 1)存储原始数据 埋点的行为数据 (topic :ods_base_log) 业务数据 (topic :ods_base_db) 2)业务数据的有序性&#x…...

leetcode 1250. 检查「好数组」
给你一个正整数数组 nums,你需要从中任选一些子集,然后将子集中每一个数乘以一个 任意整数,并求出他们的和。 假如该和结果为 1,那么原数组就是一个「好数组」,则返回 True;否则请返回 False。 示例 1&…...

JDK动态代理和CGLib动态代理的区别
原文网址:JDK动态代理和CGLib动态代理的区别_IT利刃出鞘的博客-CSDN博客 简介 本文介绍Java中JDK动态代理和CGLib动态代理的区别。 区别概述 项 JDK动态代理 CGLIB动态代理 接口是否需实现 只能代理实现了接口的类。 可以代理没有实现接口的类。 原理 继承…...

Leetcode.1250 检查「好数组」
题目链接 Leetcode.1250 检查「好数组」 Rating : 1983 题目描述 给你一个正整数数组 nums,你需要从中任选一些子集,然后将子集中每一个数乘以一个 任意整数,并求出他们的和。 假如该和结果为 1,那么原数组就是一个「…...

WMS系统推荐,如何选到适合企业的仓库管理系统
市场上有很多WMS系统,但是现在很多仓库管理系统都在使用WMS系统。那么在选择WMS系统时应该考虑什么呢?明确业务发展特征,准确表达能力目标许多物流企业在选择物流管理系统时,往往会被物流管理系统的整体系统所迷惑,在功…...
C语言的期末复习
🌈博客主页:卿云阁 💌欢迎关注🎉点赞👍收藏⭐️留言📝 🌟本文由卿云阁原创! 🙏作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢&a…...

强化学习之DQN论文介绍
强化学习之DQN论文介绍DQN摘要介绍问题特点经验回放相关工作实验算法流程结论DQN 摘要 1.基于Q-learning从高维输入学习到控制策略的卷积神经网络。 2.输入是像素,输出是奖励函数。 3.主要训练、学习Atari 2600游戏,在6款游戏中3款超越人类专家。 介绍 …...

使用luaBridge添加自己的C++脚本插件能力
概述 如果我们有一个应用需要频繁的更改业务逻辑,但是基础功能不变,那么我们可以将基础功能作为底层接口,上层的功能按照脚本方式来编写。很多插件都这样的原理,比如我们的浏览器的JS就这样,小程序也是这样的原理,我们使用C++也很容易实现这样的功能。 lua是最小最精致的…...

再拾起博客
一切要从去年12月27日被裁员的那天说起。 那天是星期二,和平常一样,8点20的闹钟响起,但我习惯性的磨蹭到8点40起床,洗漱完成后9点过几分出门,骑车20多分钟几乎是踩点到的公司,正当我坐在工位准备平复心情切…...

Mybatis流式游标查询-大数据DB查询OOM查询问题
问题场景Mysql数据处理类型分以下三种com.mysql.cj.protocol.a.result.ResultsetRowsStatic:普通查询,将结果集一次性全部拉取到内存com.mysql.cj.protocol.a.result.ResultsetRowsCursor:游标查询,将结果集分批拉取到内存&#x…...
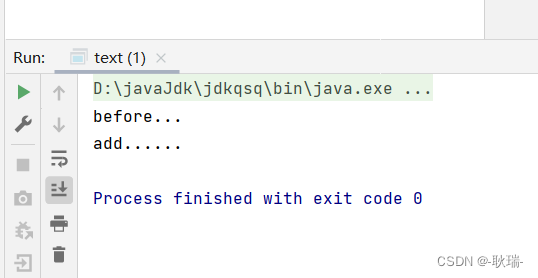
以before为例 完成一个aop代理强化方法案例
观看本文 首先 您需要做好Spring aop的准备工作 具体可以参考我的文章 java Spring aop入门准备工作 首先 我们创建一个包 我这里叫 Aop 然后在Aop包下创建一个类 叫 User 参考代码如下 package Aop;public class User {public void add(){System.out.println("add....…...

好记性不如烂笔头之Java基础复习笔记
未完待续。。。 代码块先于构造方法执行,不管类中有多少个代码块,都会先将所有代码块执行完再执行构造方法和其他方法。类中如果没有自定义的构造方法,那么JVM会提供默认的无参构造方法;如果类中有自定义的构造方法,那…...
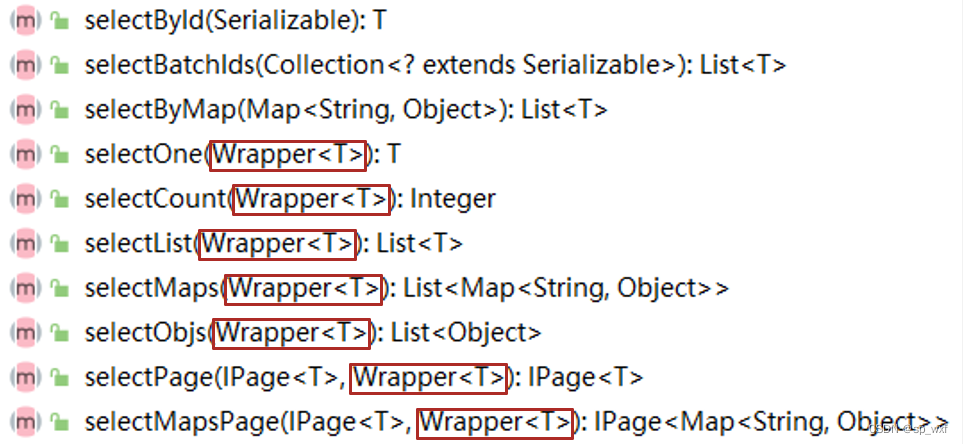
MyBatisPlus
这里写目录标题1.MyBatisPlus概述2.MyBatisPlus的开发步骤2.1 MyBatisPlus的CRUD操作2.2 MyBatisPlus的分页查询3.MyBatisPlus的DQL编程控制(封装sql)3.1 条件查询方式3.1.1 条件查询3.1.2 组合条件3.1.3 Null值处理3.2 查询投影-设置【查询字段、分组、分页】3.2.1 查询结果包…...
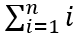
【C语言】编程初学者入门训练(11)
文章目录101. 矩阵相等判定102. 上三角矩阵判定103. 矩阵转置104. 矩阵交换105. 杨辉三角106. 井字棋107. 小乐乐与进制转换108. 小乐乐求和109. 小乐乐定闹钟110. 小乐乐排电梯101. 矩阵相等判定 问题描述:KiKi得到了两个n行m列的矩阵,他想知道两个矩阵…...

HTTP 1.1响应码
HTTP 1.1响应码 响应码和信息含义HttpURLConnection1XX信息100 Continue服务器准备接受请求主体,客户端应当发送请求主体;这允许客户端在请求中发送大量数据之前询问服务器是否将接受请求N/A101 Switching Protocols服务器接受客户端在Upgrade首部字段中…...
常用设计模式介绍
java设计模式类型创建型模式:将对象的创建与使用分离结构型模式:如何将类和对象按照某种布局组成更大的格局行为型模式:用于描述类或对象之间怎样相互协作共同完成单个对象都无法单独完成的任务23种设计模式介绍1.单例(Singleton&…...

关于货物物品横竖摆放的问题
货车内宽是2.4米。考虑到最多装载,长宽130100的货品,应该横竖摆放。 横竖摆放的数量如何自动计算呢? 采用数学公式,计算如下: 横向摆放数(int)(横长竖高)*数量/4/横长 竖向摆放数数量-横向摆放数 结果如下&#x…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...
Cesium相机控制)
三维GIS开发cesium智慧地铁教程(5)Cesium相机控制
一、环境搭建 <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"> 关键配置点: 路径验证:确保相对路径.…...

【解密LSTM、GRU如何解决传统RNN梯度消失问题】
解密LSTM与GRU:如何让RNN变得更聪明? 在深度学习的世界里,循环神经网络(RNN)以其卓越的序列数据处理能力广泛应用于自然语言处理、时间序列预测等领域。然而,传统RNN存在的一个严重问题——梯度消失&#…...

django filter 统计数量 按属性去重
在Django中,如果你想要根据某个属性对查询集进行去重并统计数量,你可以使用values()方法配合annotate()方法来实现。这里有两种常见的方法来完成这个需求: 方法1:使用annotate()和Count 假设你有一个模型Item,并且你想…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...

PL0语法,分析器实现!
简介 PL/0 是一种简单的编程语言,通常用于教学编译原理。它的语法结构清晰,功能包括常量定义、变量声明、过程(子程序)定义以及基本的控制结构(如条件语句和循环语句)。 PL/0 语法规范 PL/0 是一种教学用的小型编程语言,由 Niklaus Wirth 设计,用于展示编译原理的核…...
)
Typeerror: cannot read properties of undefined (reading ‘XXX‘)
最近需要在离线机器上运行软件,所以得把软件用docker打包起来,大部分功能都没问题,出了一个奇怪的事情。同样的代码,在本机上用vscode可以运行起来,但是打包之后在docker里出现了问题。使用的是dialog组件,…...

九天毕昇深度学习平台 | 如何安装库?
pip install 库名 -i https://pypi.tuna.tsinghua.edu.cn/simple --user 举个例子: 报错 ModuleNotFoundError: No module named torch 那么我需要安装 torch pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple --user pip install 库名&#x…...

服务器--宝塔命令
一、宝塔面板安装命令 ⚠️ 必须使用 root 用户 或 sudo 权限执行! sudo su - 1. CentOS 系统: yum install -y wget && wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh2. Ubuntu / Debian 系统…...

Mysql中select查询语句的执行过程
目录 1、介绍 1.1、组件介绍 1.2、Sql执行顺序 2、执行流程 2.1. 连接与认证 2.2. 查询缓存 2.3. 语法解析(Parser) 2.4、执行sql 1. 预处理(Preprocessor) 2. 查询优化器(Optimizer) 3. 执行器…...