Python 高级编程之正则表达式(八)
文章目录
- 一、概述
- 二、正则表达式语法
- 1)字符匹配
- 2)字符集合
- 3)定位符
- 4)分组
- 1、定义分组
- 2、引用分组
- 3、命名分组
- 三、Python 的 re 模块
- 1)re.match() 方法
- 2)re.search() 方法
- 3)re.match() 与 re.search() 的区别
- 4)re.findall() 方法
- 5)re.finditer() 方法
- 6)re.sub() 方法
- 7)re.compile() 方法
- 8)re.split() 方法
一、概述
**正则表达式(Regular Expression)**是一种文本模式,用于匹配字符串中的模式。它可以用于很多任务,例如文本搜索和替换,数据提取,数据验证等。
-
在 Python 中,可以使用
re模块来支持正则表达式。正则表达式使用特殊的字符来表示不同的模式,例如 . 匹配任意字符,\d 匹配数字,^ 匹配字符串开头,$ 匹配字符串结尾等。 -
通过使用正则表达式,可以很方便地对字符串进行匹配,搜索和替换等操作。使用正则表达式的时候,需要先编写一个匹配模式,然后使用 re 模块中的函数来执行实际的匹配操作。
总的来说,正则表达式是一种强大且高效的文本处理工具,可以用于解决很多实际问题。
二、正则表达式语法
正则表达式(Regular Expression,简称 regex 或 regexp)是一种用来匹配文本模式的工具,它可以用来搜索、替换和验证文本。正则表达式由一些特殊字符和普通字符组成,这些字符表示了一些模式。
下面是一些常见的正则表达式语法:
1)字符匹配
- 普通字符:表示自身,例如 “a” 表示字符 a。
- 元字符(特殊字符):表示某种特殊含义,例如 “.” 表示匹配任意字符,“\d” 表示匹配数字,“\w” 表示匹配字母、数字、下划线。
示例:
import re# 匹配 "abc" 字符串
pattern = "abc"
text = "abc"
result = re.match(pattern, text)
print(result) # <re.Match object; span=(0, 3), match='abc'># 匹配任意字符
pattern = "."
text = "abc"
result = re.match(pattern, text)
print(result) # <re.Match object; span=(0, 1), match='a'># 匹配数字
pattern = "\d"
text = "123"
result = re.match(pattern, text)
print(result) # <re.Match object; span=(0, 1), match='1'># 匹配字母、数字、下划线
pattern = "\w"
text = "abc_123"
result = re.match(pattern, text)
print(result) # <re.Match object; span=(0, 1), match='a'>
2)字符集合
- 方括号:表示匹配方括号中任意一个字符,例如 “[abc]” 表示匹配字符 a、b、c 中的任意一个。
- 范围符号:表示匹配某个范围内的字符,例如 “[a-z]” 表示匹配小写字母 a 到 z 中的任意一个。
- 量词:“”, “+”, “?”: 表示重复次数,“” 表示重复0次或多次,“+” 表示重复1次或多次,“?” 表示重复0次或1次。
"{m,n}": 表示重复次数的范围,例如 “{2,4}” 表示重复2到4次。
示例:
import re# 匹配方括号中任意一个字符
pattern = "[abc]"
text = "a"
result = re.match(pattern, text)
print(result) # <re.Match object; span=(0, 1), match='a'># 匹配小写字母 a 到 z 中的任意一个
pattern = "[a-z]"
text = "a"
result = re.match(pattern, text)
print(result) # <re.Match object; span=(0, 1), match='a'># 重复0次或多次
pattern = "a*"
text = "aaa"
result = re.match(pattern, text)
print(result) # <re.Match object; span=(0, 3), match='aaa'># 重复1次或多次
pattern = "a+"
text = "aaa"
result = re.match(pattern, text)
print(result) # <re.Match object; span=(0, 3), match='aaa'># 重复0次或1次
pattern = "a?"
text = "aaa"
result = re.match(pattern, text)
print(result) # <re.Match object; span=(0, 1), match='a'># 重复2到4次
pattern = "a{2,4}"
text = "aaaa"
result = re.match(pattern, text)
print(result) # <re.Match object; span=(0, 4), match='aaaa'>
3)定位符
"^": 表示匹配开头。"$": 表示匹配结尾。"\b": 表示匹配单词边界。
import re# 匹配开头
pattern = "^a"
text = "abc"
result = re.match(pattern, text)
print(result) # <re.Match object; span=(0, 1), match='a'># 匹配结尾
pattern = "c$"
text = "abc"
result = re.search(pattern, text)
print(result) # <re.Match object; span=(2, 3), match='c'># 匹配单词边界
pattern = r"\bcat\b"
text = "cat sat on the mat"
result = re.search(pattern, text)
print(result) # <re.Match object; span=(0, 3), match='cat'>
4)分组
"()", "(?:)": 表示分组,可以对一个子表达式进行分组。"|": 表示或关系。
1、定义分组
使用圆括号 () 来定义分组,分组可以嵌套,每个分组都有一个唯一的编号,从左到右按照左括号的顺序编号。
import re
pattern = r"(\d{3})-(\d{4})-(\d{4})"
result = re.search(pattern, "Tel: 010-1234-5678")
print(result.group(0)) # 010-1234-5678
print(result.group(1)) # 010
print(result.group(2)) # 1234
print(result.group(3)) # 5678
2、引用分组
可以在正则表达式中使用 \n 引用第 n 个分组,其中 n 是分组的编号。
import re
pattern = r"(\w+) \1"
result = re.search(pattern, "hello hello world")
print(result.group(0)) # hello hello
print(result.group(1)) # hello
3、命名分组
除了使用编号引用分组,还可以使用 (?Ppattern) 语法给分组命名。
import re
pattern = r"(?P<first>\w+) (?P<last>\w+)"
result = re.search(pattern, "John Smith")
print(result.group(0)) # John Smith
print(result.group("first")) # John
print(result.group("last")) # Smith
以上仅是正则表达式语法的一部分,实际上正则表达式还包括很多高级的语法,比如反向引用、零宽度断言等。上面讲使用到了Python 的re模式,接下来细讲这个模块。
三、Python 的 re 模块
Python标准库中的re模块是用于正则表达式操作的模块,提供了正则表达式的编译、匹配、查找、替换等功能。下面是re模块的一些常用方法:
1)re.match() 方法
re.match()函数从字符串的起始位置开始匹配正则表达式,如果匹配成功,就返回一个匹配对象。如果匹配不成功,就返回 None。
re.match() 的语法格式如下:
re.match(pattern, string, flags=0)
参数:
pattern是正则表达式string是要匹配的字符串flags是可选参数,用于指定匹配模式。
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志:
| 修饰符 | 描述 |
|---|---|
re.I | 使匹配对大小写不敏感 |
re.M | 多行匹配,影响 ^ 和 $ |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
下面是一个简单的例子:
import repattern = r"hello"
string = "hello world"match_obj = re.match(pattern, string)if match_obj:print("匹配成功")
else:print("匹配失败")
在这个例子中,正则表达式 pattern 是 “hello”,要匹配的字符串是 “hello world”。由于正则表达式和字符串的开头都是 “hello”,所以匹配成功。
re.match() 返回的是一个匹配对象。如果匹配成功,可以使用匹配对象的方法和属性来获取匹配结果,如 group() 方法可以返回匹配的字符串,start() 和 end() 方法可以返回匹配的起始位置和结束位置,等等。如果匹配不成功,调用这些方法和属性会出现异常。
start()返回匹配开始的位置end()返回匹配结束的位置span()返回一个元组包含匹配 (开始,结束) 的位置
下面是一个获取匹配结果的例子:
import repattern = r"hello"
string = "hello world"match_obj = re.match(pattern, string)if match_obj:print("匹配成功")print(match_obj.group()) # helloprint(match_obj.start()) # 0print(match_obj.end()) # 5print(match_obj.span()) # (0, 5)
else:print("匹配失败")
2)re.search() 方法
re.search()方法在字符串中搜索正则表达式的第一个匹配项,并返回一个匹配对象。如果没有找到匹配项,就返回 None。
re.search() 的语法格式如下:
re.search(pattern, string, flags=0)
其中,pattern 是正则表达式,string 是要匹配的字符串,flags 是可选参数,用于指定匹配模式。匹配模式在上面有具体讲解。
下面是一个简单的例子:
import repattern = r"hello"
string = "world hello"match_obj = re.search(pattern, string)if match_obj:print("匹配成功")
else:print("匹配失败")
在这个例子中,正则表达式 pattern 是 “hello”,要匹配的字符串是 “world hello”。由于字符串中包含 “hello”,所以匹配成功。
3)re.match() 与 re.search() 的区别
Python re 模块中的
re.match()和re.search()方法都用于在字符串中查找匹配的模式。但是它们之间有一些区别。
re.match()方法从字符串的起始位置开始匹配,如果起始位置不匹配,则返回 None。因此,re.match() 只能匹配到字符串的开头。re.search()方法在字符串中查找匹配的模式,可以匹配到字符串中任意位置的模式。
另外,两个方法返回的匹配对象也有一些区别:
re.match()方法返回第一个匹配的对象,如果没有匹配到任何内容,则返回 None。re.search()方法返回第一个匹配的对象,如果没有匹配到任何内容,则返回 None。
如果要匹配整个字符串,通常建议使用 re.match() 方法;如果要匹配字符串中的一部分,或者不确定匹配的位置,通常建议使用 re.search() 方法。
下面是一个例子,展示了两个方法之间的区别:
import repattern = r"hello"
string = "world hello"# 使用 re.match() 方法
match_obj = re.match(pattern, string)
if match_obj:print("re.match() 匹配成功")print(match_obj.group()) # 输出 "None"# 使用 re.search() 方法
match_obj = re.search(pattern, string)
if match_obj:print("re.search() 匹配成功")print(match_obj.group()) # 输出 "hello"
在这个例子中,正则表达式 pattern 是 “hello”,要匹配的字符串是 “world hello”。由于字符串的开头不是 “hello”,所以 re.match() 方法无法匹配,返回 None;而 re.search() 方法可以在字符串中找到 “hello”,匹配成功。
4)re.findall() 方法
re.findall()方法用于在字符串中查找正则表达式匹配的所有子串,并返回一个列表。如果没有匹配项,返回一个空列表。
re.findall() 方法的语法格式如下:
re.findall(pattern, string, flags=0)
其中,pattern 是正则表达式,string 是要匹配的字符串,flags 是可选参数,用于指定匹配模式。匹配模式在上面有具体讲解。
下面是一个简单的例子:
import repattern = r"\d+"
string = "2 apples, 5 bananas, 1 orange"result = re.findall(pattern, string)print(result) # ['2', '5', '1']
在这个例子中,正则表达式 pattern 是 “\d+”,要匹配的字符串是 “2 apples, 5 bananas, 1 orange”。“\d+” 表示匹配一个或多个数字,所以返回的结果是一个包含所有数字的列表。
【注意】
re.findall()方法返回的是一个字符串列表,其中的每个字符串都是一个匹配的子串。如果正则表达式包含分组,返回的列表将包含所有分组匹配的字符串。
5)re.finditer() 方法
re.finditer()方法与re.findall()方法类似,都可以在字符串中使用正则表达式进行匹配,但它返回的不是一个列表,而是一个迭代器,可以通过迭代器逐个访问匹配结果。
re.finditer() 方法的语法格式如下:
re.finditer(pattern, string, flags=0)
其中,pattern 是正则表达式,string 是要匹配的字符串,flags 是可选参数,用于指定匹配模式。
下面是一个简单的例子:
import repattern = r"\d+"
string = "2 apples, 5 bananas, 1 orange"result = re.finditer(pattern, string)for match in result:print(match.group())
在这个例子中,正则表达式 pattern 是 “\d+”,要匹配的字符串是 “2 apples, 5 bananas, 1 orange”。使用 re.finditer() 方法进行匹配,返回的结果是一个迭代器,可以通过 for 循环逐个访问匹配结果。每个匹配结果都是一个 Match 对象,可以使用 match.group() 方法获取匹配的内容。
re.finditer() 方法与 re.findall() 方法的区别在于,
re.findall()方法返回一个包含所有匹配结果的列表,而re.finditer()方法返回一个迭代器,可以逐个访问匹配结果,这在处理大量数据时可以节省内存。
6)re.sub() 方法
re.sub()方法用于在字符串中查找正则表达式匹配的子串,并将其替换为指定的字符串。re.sub() 方法返回替换后的字符串。
re.sub() 方法的语法格式如下:
re.sub(pattern, repl, string, count=0, flags=0)
其中,pattern 是正则表达式,repl 是替换字符串,string 是要进行替换的字符串,count 是可选参数,用于指定最多替换的次数,flags 是可选参数,用于指定匹配模式。
下面是一个简单的例子:
import repattern = r"\s+"
string = "hello world"result = re.sub(pattern, "-", string)print(result) # 'hello-world'
在这个例子中,正则表达式 pattern 是 “\s+”,要匹配的字符串是 “hello world”,“\s+” 表示匹配一个或多个空格。repl 参数是 “-”,表示将匹配到的空格替换为 “-”,结果返回的是 “hello-world”。
【注意】
re.sub()方法并不会改变原始的字符串,而是返回一个新的字符串。如果想要在原始字符串中进行替换,可以将结果赋值给原始字符串变量。
7)re.compile() 方法
re.compile()方法用于将正则表达式编译为一个模式对象,该模式对象可以用于匹配字符串。
re.compile() 方法的语法格式如下:
re.compile(pattern, flags=0)
其中,pattern 是要编译的正则表达式,flags 是可选参数,用于指定匹配模式。
编译后的模式对象可以调用 match()、search()、findall() 和 sub() 等方法进行匹配和替换操作。使用 re.compile() 方法编译正则表达式可以提高多次使用同一模式的效率。
下面是一个简单的例子:
import repattern = r"\d+"
string = "2 apples, 5 bananas, 1 orange"regex = re.compile(pattern)
result = regex.findall(string)print(result) # ['2', '5', '1']
在这个例子中,正则表达式 pattern 是 “\d+”,要匹配的字符串是 “2 apples, 5 bananas, 1 orange”。使用 re.compile() 方法将正则表达式编译为一个模式对象 regex,然后调用 regex.findall() 方法进行匹配,返回的结果是一个包含所有数字的列表。
【注意】如果要使用编译后的正则表达式进行匹配,必须调用相应的模式对象的方法。如果直接在 re 模块中使用正则表达式,Python 会自动将其编译为一个模式对象。
8)re.split() 方法
re.split()方法用于在字符串中使用正则表达式进行分割,并返回一个列表。
re.split() 方法的语法格式如下:
re.split(pattern, string, maxsplit=0, flags=0)
其中,pattern 是正则表达式,string 是要分割的字符串,maxsplit 是可选参数,用于指定最大分割次数,flags 是可选参数,用于指定匹配模式。
下面是一个简单的例子:
import repattern = r"\s+"
string = "hello world"result = re.split(pattern, string)print(result) # ['hello', 'world']
在这个例子中,正则表达式 pattern 是 “\s+”,要分割的字符串是 “hello world”,“\s+” 表示匹配一个或多个空格。re.split() 方法将字符串按照正则表达式进行分割,并返回一个列表,列表中的每个元素都是分割后的子串。
【注意】
re.split()方法不会在分割后的字符串中保留分割符,如果想要保留分割符,可以使用分组语法,例如:
import repattern = r"(\s+)"
string = "hello world"result = re.split(pattern, string)print(result) # ['hello', ' ', 'world']
在这个例子中,正则表达式 pattern 是 “(\s+)”,使用圆括号将 “\s+” 包含起来,表示将空格作为分组进行匹配,re.split() 方法会保留分组匹配的内容。返回的结果是一个列表,列表中的元素是分割后的子串和分组匹配的内容。
Python 的正则表达式常用的语法和方法就先讲解到这里了,更关键还是需要多使用加深印象的。有任何疑问的小伙伴欢迎给我留言哦,后续会持续更新相关技术文章,也可关注我的公众号【大数据与云原生技术分享】进行深入技术交流~
相关文章:
Python 高级编程之正则表达式(八)
文章目录一、概述二、正则表达式语法1)字符匹配2)字符集合3)定位符4)分组1、定义分组2、引用分组3、命名分组三、Python 的 re 模块1)re.match() 方法2)re.search() 方法3)re.match() 与 re.sea…...

pynrrd常用操作解析
目录依赖安装官方文档常用操作1. 读部分nrrd.read()nrrd.read_header()nrrd.read_data()2. 写部分nrrd.write()依赖安装 pip install pynrrd官方文档 https://pynrrd.readthedocs.io/en/stable/ 常用操作 1. 读部分 nrrd.read() nrrdpath "your nrrd file path"…...

数据结构:链表基础OJ练习+带头双向循环链表的实现
目录 一.leetcode剑指 Offer II 027. 回文链表 1.问题描述 2.问题分析与求解 (1) 快慢指针法定位链表的中间节点 (2) 将链表后半部分进行反转 附:递归法反转链表 (3) 双指针法判断链表是否回文 二.带头双向循环链表的实现 1.头文件 2.节点内存申请接口和链表初始化接口…...

计算机视觉方向地理空间遥感图像数据集汇总
文章目录1.DSTL卫星图像数据集/Kaggle竞赛2.Swimming Pool and Car Detection/Kaggle竞赛3.SpaceNet Challenge 3数据集4.RarePlanes数据集5.BigEarthNet数据集6.NWPU VHR-10数据集7.UC Merced Land-Use数据集8.Inria Aerial Image Labeling数据集9.RSOD数据集1.DSTL卫星图像数…...
)
信息系统项目管理师真题精选(一)
1.信息系统的( )决定了系统可以被外部环境识别,外部环境或者其他系统可以按照预定的方法使用系统的功能或者影响系统的行为。A.可嵌套性B.稳定性C.开放性D.健壮性2、在实际的生产环境中,( )能使底层物理硬件…...
)
信息系统项目管理师刷题知识点(持续更新)
主要记录自己在备考高项过程中知识点 信息系统项目管理师刷题知识点(按刷题顺序排列) 1.信息技术应用是信息化体系六要素中的龙头,是国家信息化建设的主阵地,集中体现了国家信息化建设的需求和效益。 2.原型化方法也称为快速原型法…...

RabbitMq及其他消息队列
消息队列中间价都有哪些 先进先出 Kafka、Pulsar、RocketMQ、RabbitMQ、NSQ、ActiveMQ Rabbitmq架构 消费推拉模式 客户端消费者获取消息的方式,Kafka和RocketMQ是通过长轮询Pull的方式拉取消息,RabbitMQ、Pulsar、NSQ都是通过Push的方式。 pull类型…...
Toolformer: Language Models Can Teach Themselves to Use Tools
展示了LM可以通过简单的API教自己使用外部工具,并实现两个世界的最佳效果。我们介绍了Toolformer,这是一个经过训练的模型,可以决定调用哪些API,何时调用,传递哪些参数,以及如何将结果最好地纳入未来的标记…...

悲观锁与乐观锁
何谓悲观锁与乐观锁 乐观锁对应于生活中乐观的人总是想着事情往好的方向发展,悲观锁对应于生活中悲观的人总是想着事情往坏的方向发展。这两种人各有优缺点,不能不以场景而定说一种人好于另外一种人。 悲观锁 总是假设最坏的情况,每次去拿数据…...
LeetCode 25. K 个一组翻转链表
原题链接 难度:hard\color{red}{hard}hard 题目描述 给你链表的头节点 headheadhead , kkk 个节点一组进行翻转,请你返回修改后的链表。 kkk 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 kkk 的整数倍…...

朗润国际期货招商:历次科技风头下巨头的博弈
历次科技风头下巨头的博弈 VR/AR、区块链、折叠屏、元宇宙、AIGC五轮科技风头下巨头们都进场了吗? VR/AR硬件 谷歌:2014年入局,推出AR眼镜 百度:未入局 京东:未入局 腾讯:传要开发 亚马逊࿱…...

配置中心Config
引入依赖<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.0.6.RELEASE</version></parent><properties><spring-cloud.version>Finchley.SR…...
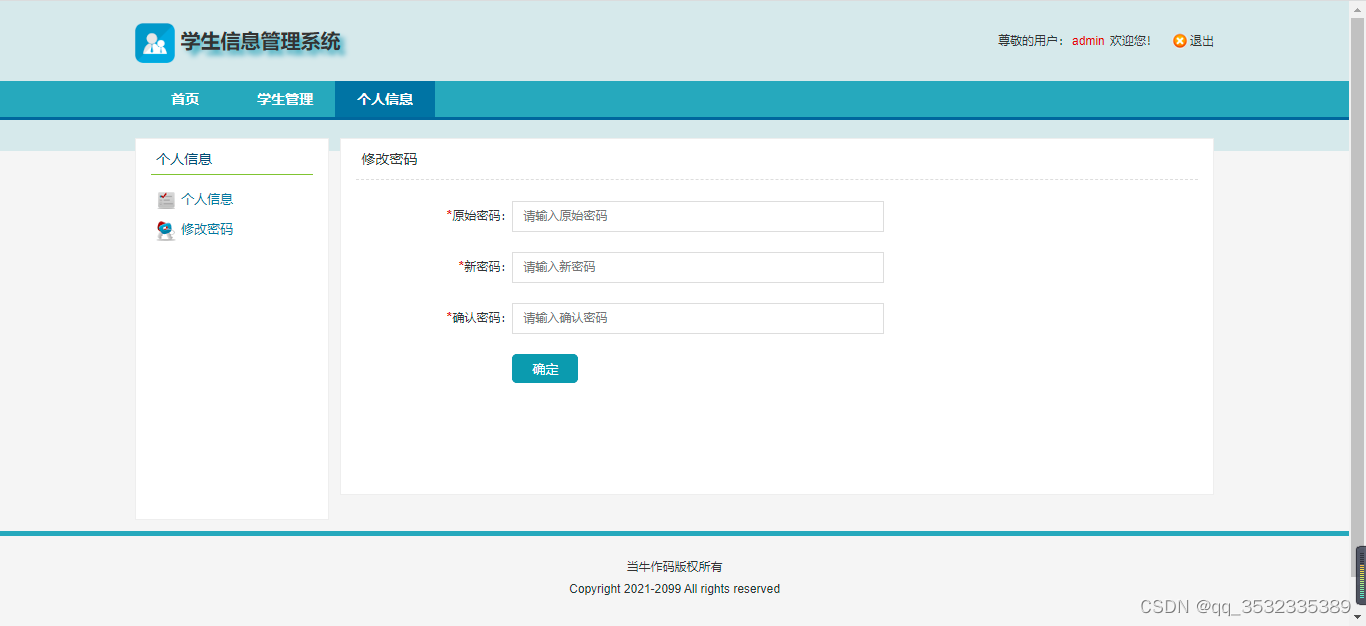
【原创】java+jsp+servlet学生信息管理系统(jdbc+ajax+filter+cookie+分页)
一直想写一个比较基础的JavaWeb项目,然后综合各种技术,方便Java入门者进行学习。学生信息管理系统大家一般接触的比较多,那么就以这个为例来写一个基础项目吧。 需求分析: 使用jspservletmysql开发的学生信息管理系统࿰…...
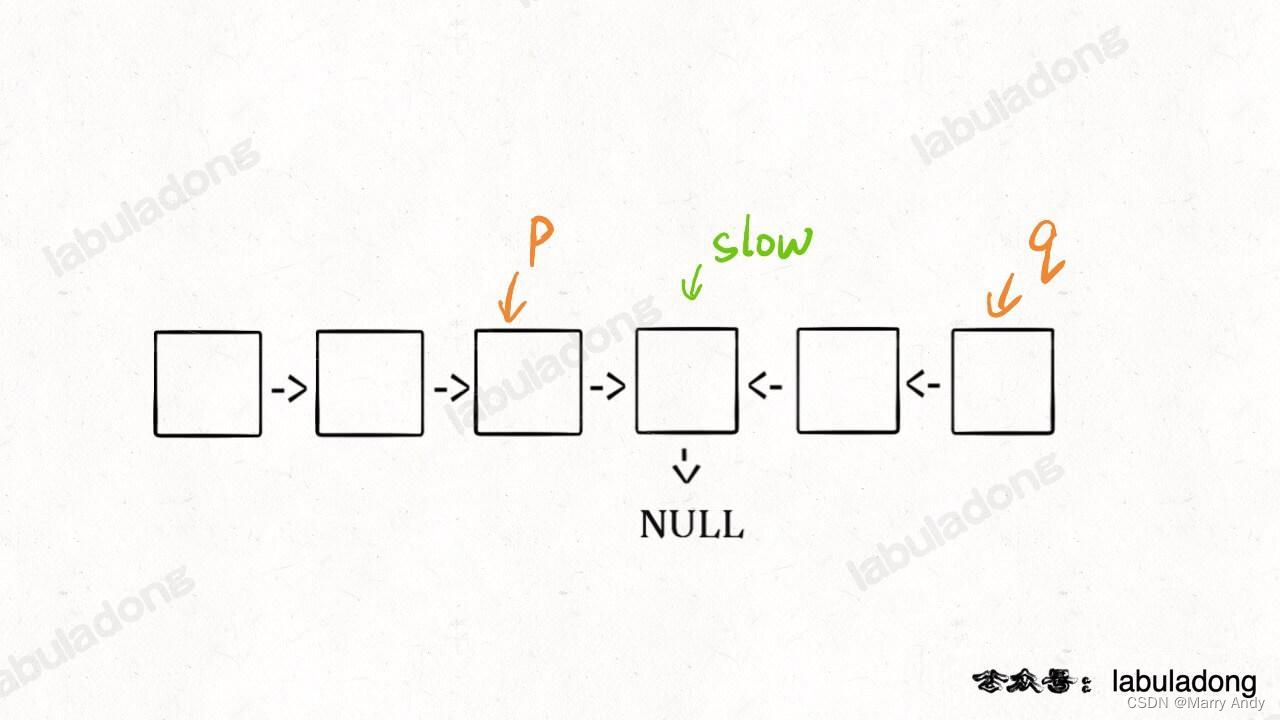
链表题目总结 -- 回文链表
目录一. 从中心开始找最大的回文字符串1. 思路简述2. 代码3. 总结二. 判断是否为回文字符串1. 思路简述2. 代码3.总结三. 判断是否是回文链表1. 思路简述2. 代码3. 总结4. 优化解法一. 从中心开始找最大的回文字符串 题目链接:没有。给定一个字符串s,从…...

JAVA集合之List >> Arraylist/LinkedList/Vector结构
在Java开发过程中,可能经常会使用到List作为集合来使用,List是一个接口承于Collection的接口,表示着有序的列表。而我们要讨论的是它下面的实现类Arraylist/LinkedList/Vector的数据结构及区别。 ArrayList ArrayList:底层为数组…...
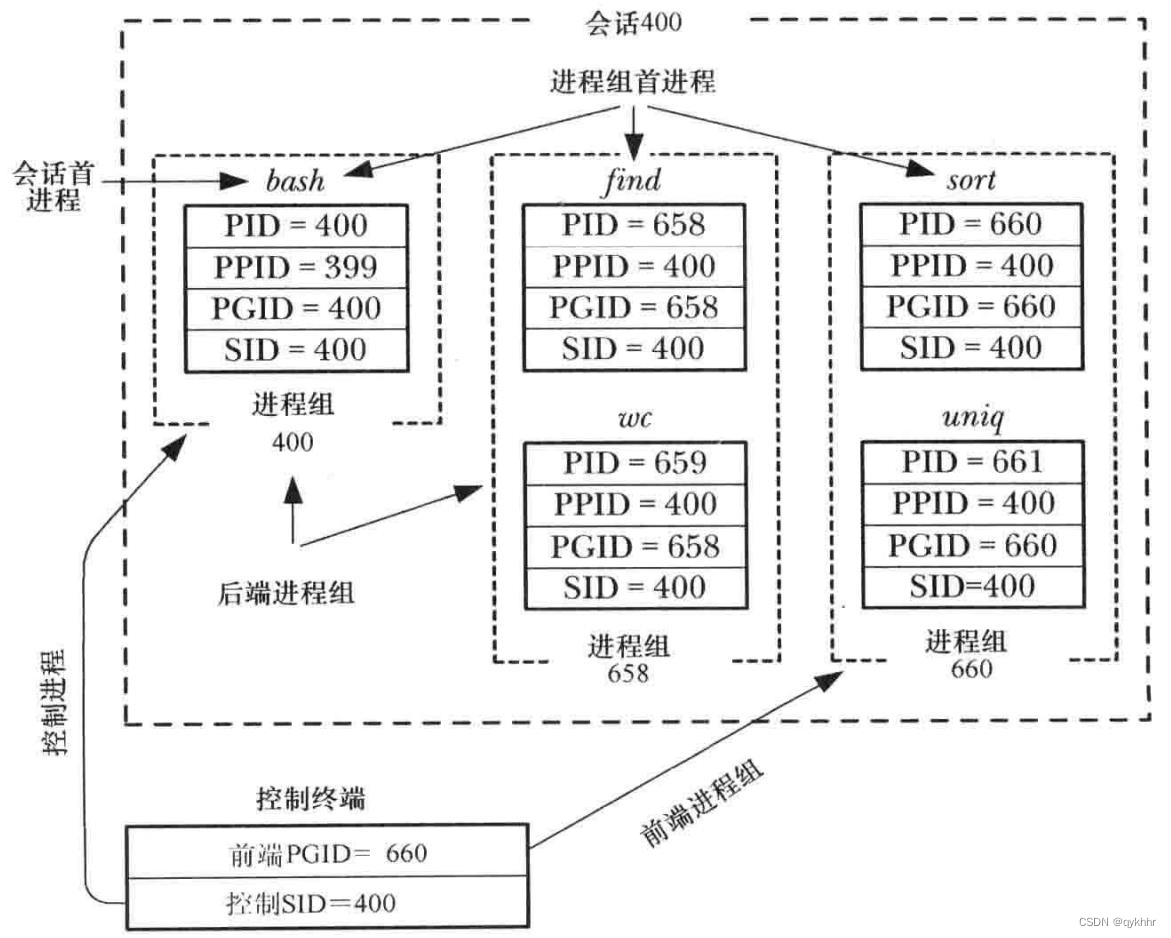
Linux多进程开发
一、进程概述 1、程序和进程 程序是包含一系列信息的文件,这些信息描述了如何在运行时创建一个进程: 二进制格式标识:每个程序文件都包含用于描述可执行文件格式的元信息。内核利用此信息来解释文件中的其他信息。(ELF可执行连…...

三维重建小有基础入门之特征点检测基础
前言:本文将从此篇开始,记录自己从普通CVer入门三维重建的学习过程,可能过程比较坎坷,都在摸索阶段,但争取每次学习都能进一步,提高自己的能力,同时,每篇文章都会按情况相应地推出B站…...
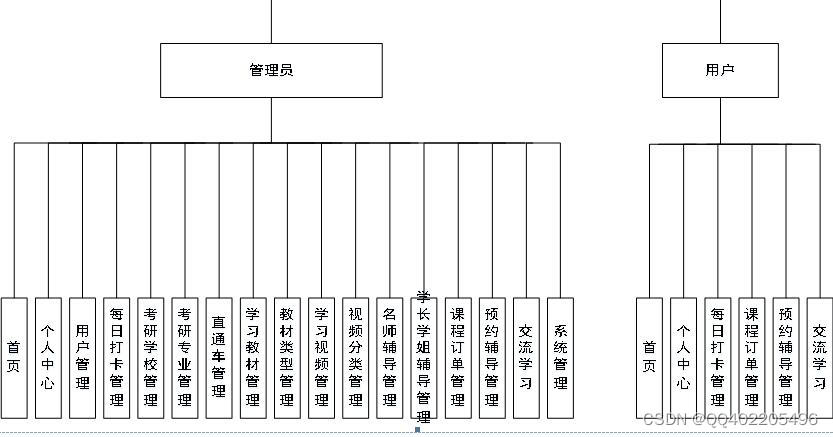
基于node.js+vue+mysql考研辅导学习打卡交流网站系统vscode
语言 node.js 框架:Express 前端:Vue.js 数据库:mysql 数据库工具:Navicat 开发软件:VScode 主要功能包括管理员:首页、个人中心、用户管理、每日打卡管理、考研学校管理、考研专业管理、直通车管理、学习教材管理、…...

【C++、数据结构】封装unordered_map和unordered_set(用哈希桶实现)
文章目录📖 前言1. 复用同一个哈希桶⚡1.1 🌀修改后结点的定义1.2 🌀两个容器各自模板参数类型:2. 改造之后的哈希桶⛳3. 哈希桶的迭代器🔥3.1 💥哈希桶的begin()和 end(…...
)
StratoVirt 的 vCPU 拓扑(SMP)
CPU 拓扑用来表示 CPU 在硬件层面的组合方式,本文主要讲解 CPU 拓扑中的 SMP(Symmetric Multi-Processor,对称多处理器系统)架构,CPU 拓扑还包括其他信息,比如:cache 等,这些部分会在…...

在软件开发中正确使用MySQL日期时间类型的深度解析
在日常软件开发场景中,时间信息的存储是底层且核心的需求。从金融交易的精确记账时间、用户操作的行为日志,到供应链系统的物流节点时间戳,时间数据的准确性直接决定业务逻辑的可靠性。MySQL作为主流关系型数据库,其日期时间类型的…...

C++初阶-list的底层
目录 1.std::list实现的所有代码 2.list的简单介绍 2.1实现list的类 2.2_list_iterator的实现 2.2.1_list_iterator实现的原因和好处 2.2.2_list_iterator实现 2.3_list_node的实现 2.3.1. 避免递归的模板依赖 2.3.2. 内存布局一致性 2.3.3. 类型安全的替代方案 2.3.…...

Lombok 的 @Data 注解失效,未生成 getter/setter 方法引发的HTTP 406 错误
HTTP 状态码 406 (Not Acceptable) 和 500 (Internal Server Error) 是两类完全不同的错误,它们的含义、原因和解决方法都有显著区别。以下是详细对比: 1. HTTP 406 (Not Acceptable) 含义: 客户端请求的内容类型与服务器支持的内容类型不匹…...

练习(含atoi的模拟实现,自定义类型等练习)
一、结构体大小的计算及位段 (结构体大小计算及位段 详解请看:自定义类型:结构体进阶-CSDN博客) 1.在32位系统环境,编译选项为4字节对齐,那么sizeof(A)和sizeof(B)是多少? #pragma pack(4)st…...

C++中string流知识详解和示例
一、概览与类体系 C 提供三种基于内存字符串的流,定义在 <sstream> 中: std::istringstream:输入流,从已有字符串中读取并解析。std::ostringstream:输出流,向内部缓冲区写入内容,最终取…...

【碎碎念】宝可梦 Mesh GO : 基于MESH网络的口袋妖怪 宝可梦GO游戏自组网系统
目录 游戏说明《宝可梦 Mesh GO》 —— 局域宝可梦探索Pokmon GO 类游戏核心理念应用场景Mesh 特性 宝可梦玩法融合设计游戏构想要素1. 地图探索(基于物理空间 广播范围)2. 野生宝可梦生成与广播3. 对战系统4. 道具与通信5. 延伸玩法 安全性设计 技术选…...

SiFli 52把Imagie图片,Font字体资源放在指定位置,编译成指定img.bin和font.bin的问题
分区配置 (ptab.json) img 属性介绍: img 属性指定分区存放的 image 名称,指定的 image 名称必须是当前工程生成的 binary 。 如果 binary 有多个文件,则以 proj_name:binary_name 格式指定文件名, proj_name 为工程 名&…...

无人机侦测与反制技术的进展与应用
国家电网无人机侦测与反制技术的进展与应用 引言 随着无人机(无人驾驶飞行器,UAV)技术的快速发展,其在商业、娱乐和军事领域的广泛应用带来了新的安全挑战。特别是对于关键基础设施如电力系统,无人机的“黑飞”&…...
【C++特殊工具与技术】优化内存分配(一):C++中的内存分配
目录 一、C 内存的基本概念 1.1 内存的物理与逻辑结构 1.2 C 程序的内存区域划分 二、栈内存分配 2.1 栈内存的特点 2.2 栈内存分配示例 三、堆内存分配 3.1 new和delete操作符 4.2 内存泄漏与悬空指针问题 4.3 new和delete的重载 四、智能指针…...

【从零开始学习JVM | 第四篇】类加载器和双亲委派机制(高频面试题)
前言: 双亲委派机制对于面试这块来说非常重要,在实际开发中也是经常遇见需要打破双亲委派的需求,今天我们一起来探索一下什么是双亲委派机制,在此之前我们先介绍一下类的加载器。 目录 编辑 前言: 类加载器 1. …...