深度学习Week15-common.py文件解读(YOLOv5)
目录
简介
一.基本组件
1.1autopad
1.2Conv
1.3 Focus
1.4Bottleneck
1.5BottleneckCSP
1.6 C3
1.7 SPP
1.8Concat
1.9Contract、Expand
二、重要类
2.1非极大值抑制(NMS)
2.2AutoShape
2.3 Detections
2.4 Classify
三、实验
🍨 本文为[🔗365天深度学习训练营]内部限免文章(版权归 *K同学啊* 所有)
🍖 作者:[K同学啊]
这周接着详细解析小白YOLOv5全流程-训练+实现数字识别_牛大了2022的博客-CSDN博客_yolov5识别数字,之前入门教大家下载配置环境,如果没有的话请参考这篇的文章深度学习Week11-调用官方权重进行检测(YOLOv5)_yolov5权重_牛大了2022的博客-CSDN博客
📌 本周任务:将YOLOv5s网络模型中的C3模块按照下图方式修改,并跑通YOLOv5。
💫 任务提示:仅需修改./models/common.yaml文件。
简介
common.py文件位置在./models/commonpy
需要导入的基础包和配置:
import ast # 抽象语法树
import contextlib #为with语句分配资源的实用程序
import json #用于json和Python数据之间的相互转换
import math # 数学函数模块
import platform #获取操作系统的信息
import warnings #警告程序员关于语言或库功能的变化的方法
import zipfile #zip格式编码的压缩和解压缩
from collections import OrderedDict, namedtuple #集合模块
from copy import copy # 数据拷贝模块 分浅拷贝和深拷贝
from pathlib import Path # Path将str转换为Path对象 使字符串路径易于操作的模块
from urllib.parse import urlparse #urllib为http请求库,parse 用来编码和解码import cv2 # opencv-python
import numpy as np # numpy数组操作模块
import pandas as pd # panda数组操作模块
import requests # Python的HTTP客户端库
import torch # pytorch深度学习框架
import torch.nn as nn ## 专门为神经网络设计的模块化接口
from IPython.display import display
from PIL import Image # 图像基础操作模块
from torch.cuda import amp # 混合精度训练模块from utils import TryExcept
from utils.dataloaders import exif_transpose, letterbox
from utils.general import (LOGGER, ROOT, Profile, check_requirements, check_suffix, check_version, colorstr,increment_path, is_notebook, make_divisible, non_max_suppression, scale_boxes, xywh2xyxy,xyxy2xywh, yaml_load)
from utils.plots import Annotator, colors, save_one_box
from utils.torch_utils import copy_attr, smart_inference_mode一.基本组件
1.1autopad
根据输入的卷积核计算该卷积模块所需的pad值。
def autopad(k, p=None, d=1): # kernel, padding, dilation# Pad to 'same' shape outputsif d > 1:k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-sizeif p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn p1.2Conv
最基础的模块组成: 卷积层 + BN层 + 激活函数。
class Conv(nn.Module):# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)default_act = nn.SiLU() # default activationdef __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):super().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):return self.act(self.conv(x))其中有一个特殊函数 fuseforward ,这是一个前向加速推理模块,在前向传播过程中,通过融合conv + bn层,达到加速推理的作用,一般用于测试或验证阶段。
1.3 Focus
将输入图像切为4份(即宽高各减半),再聚合到通道处。
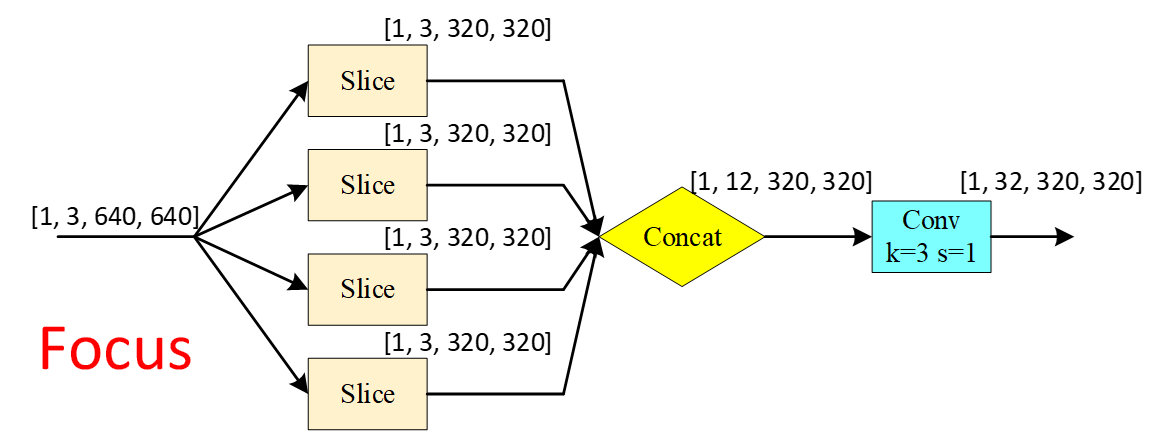
class Focus(nn.Module):# Focus wh information into c-spacedef __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groupssuper().__init__()self.conv = Conv(c1 * 4, c2, k, s, p, g, act=act)# self.contract = Contract(gain=2)def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)return self.conv(torch.cat((x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]), 1))# return self.conv(self.contract(x))
1.4Bottleneck
由1x1conv、3x3conv、残差块组成。
class Bottleneck(nn.Module):# Standard bottleneckdef __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_, c2, 3, 1, g=g)self.add = shortcut and c1 == c2def forward(self, x):return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))1.5BottleneckCSP
由Bottleneck模块和CSP结构组成。
class BottleneckCSP(nn.Module):# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworksdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)self.cv4 = Conv(2 * c_, c2, 1, 1)self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)self.act = nn.SiLU()self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))def forward(self, x):y1 = self.cv3(self.m(self.cv1(x)))y2 = self.cv2(x)return self.cv4(self.act(self.bn(torch.cat((y1, y2), 1))))1.6 C3
一种简化版的BottleneckCSP, 由三个卷积块和N个Bottleneck组成。
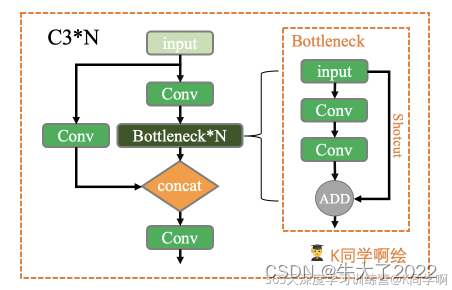
class C3(nn.Module):# CSP Bottleneck with 3 convolutionsdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))def forward(self, x):return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))1.7 SPP
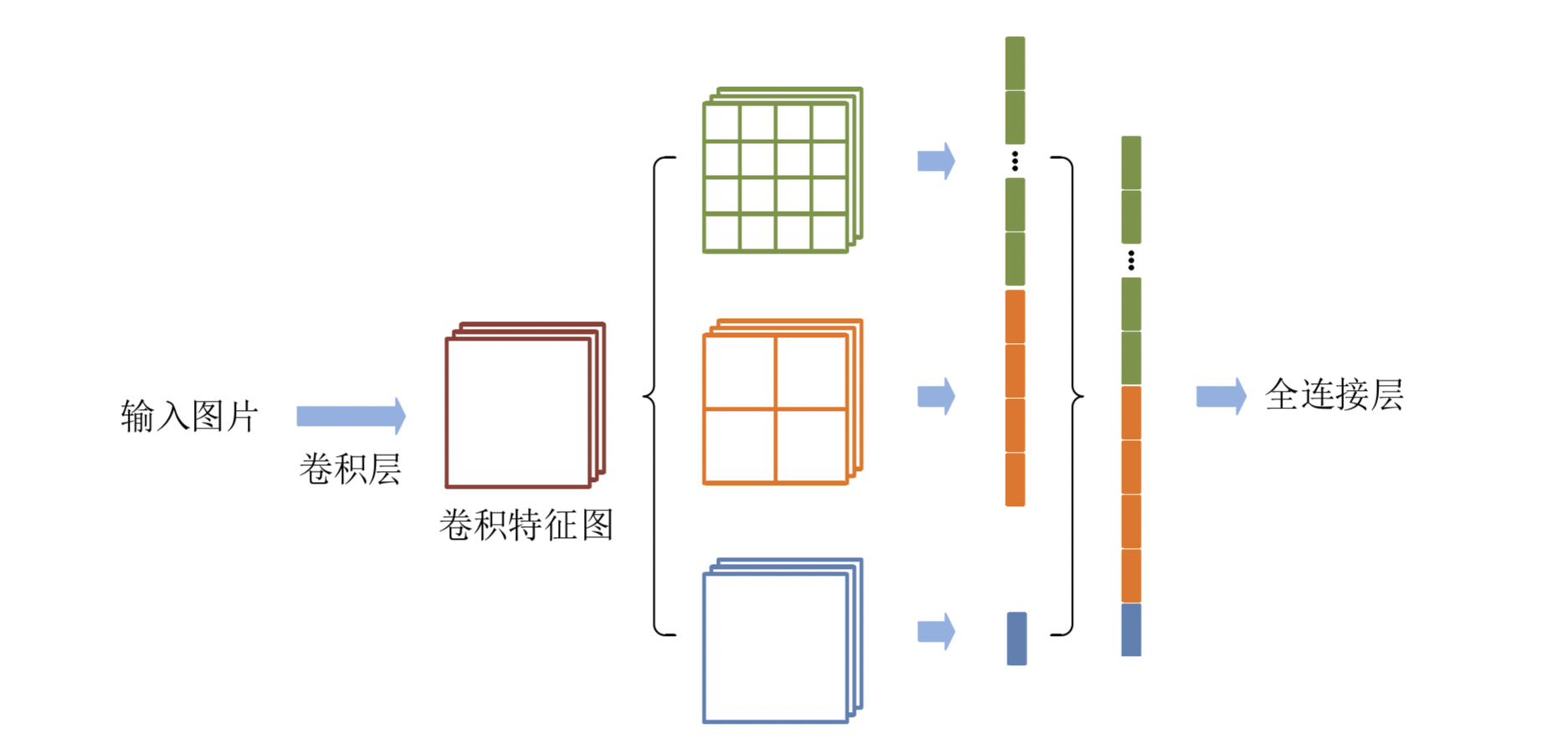
空间金字塔池化,将更多不同分辨率的特征进行融合,得到更多的信息。
经典的空间金字塔池化模块首先将输入的卷积特征分成不同的尺寸,然后每个尺寸提取固定维度的特征,最后将这些特征拼接成一个固定的维度,如图1所示。输入的卷积特征图的大小为(w,h),第一层空间金字塔采用4×4的刻度对特征图进行划分,其将输入的特征图分成了16个块,每块的大小为(w/4, h/4);第二层空间金字塔采用2×2刻度对特征图进行划分,其将特征图分为4个快,每块大小为(w/2,h/2);第三层空间金字塔将整张特征图作为一块,进行特征提取操作,最终的特征向量为21=16+4+1维。
class SPP(nn.Module):# Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729def __init__(self, c1, c2, k=(5, 9, 13)):super().__init__()c_ = c1 // 2 # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])def forward(self, x):x = self.cv1(x)with warnings.catch_warnings():warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warningreturn self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))1.8Concat
按照某个维度进行concat,常用来合并前后两个feature map(也是上周提到的yolov5s结构图中的Concat)
class Concat(nn.Module):# Concatenate a list of tensors along dimensiondef __init__(self, dimension=1):super().__init__()self.d = dimensiondef forward(self, x):return torch.cat(x, self.d)1.9Contract、Expand
用于改变feature map的维度,Contract将feature map的w和h维度(缩小)的数据收缩到channel维度上(放大),Expand将channel维度(变小)的数据扩展到W和H维度(变大)。
class Contract(nn.Module):# Contract width-height into channels, i.e. x(1,64,80,80) to x(1,256,40,40)def __init__(self, gain=2):super().__init__()self.gain = gaindef forward(self, x):b, c, h, w = x.size() # assert (h / s == 0) and (W / s == 0), 'Indivisible gain's = self.gainx = x.view(b, c, h // s, s, w // s, s) # x(1,64,40,2,40,2)x = x.permute(0, 3, 5, 1, 2, 4).contiguous() # x(1,2,2,64,40,40)return x.view(b, c * s * s, h // s, w // s) # x(1,256,40,40)class Expand(nn.Module):# Expand channels into width-height, i.e. x(1,64,80,80) to x(1,16,160,160)def __init__(self, gain=2):super().__init__()self.gain = gaindef forward(self, x):b, c, h, w = x.size() # assert C / s ** 2 == 0, 'Indivisible gain's = self.gainx = x.view(b, s, s, c // s ** 2, h, w) # x(1,2,2,16,80,80)x = x.permute(0, 3, 4, 1, 5, 2).contiguous() # x(1,16,80,2,80,2)return x.view(b, c // s ** 2, h * s, w * s) # x(1,16,160,160)二、重要类
下面的几个函数都是属于模型的扩展模块。yolov5的作者将搭建模型的函数功能写的很齐全。不光包含搭建模型部分,还考虑到了各个方面其他的功能,比如给模型搭载nms功能、给模型封装成包含前处理、推理、后处理的模块(预处理 + 推理 + nms)、二次分类等等功能。
2.1非极大值抑制(NMS)
非极大抑制,保留哪些框.
class NMS(nn.Module):"""在yolo.py中Model类的nms函数中使用NMS非极大值抑制 Non-Maximum Suppression (NMS) module给模型model封装nms 增加模型的扩展功能 但是我们一般不用 一般是在前向推理结束后再调用non_max_suppression函数"""conf = 0.25 # 置信度阈值 confidence thresholdiou = 0.45 # iou阈值 IoU thresholdclasses = None # 是否nms后只保留特定的类别 (optional list) filter by classmax_det = 1000 # 每张图片的最大目标个数 maximum number of detections per imagedef __init__(self):super(NMS, self).__init__()def forward(self, x):""":params x[0]: [batch, num_anchors(3个yolo预测层), (x+y+w+h+1+num_classes)]直接调用的是general.py中的non_max_suppression函数给model扩展nms功能"""return non_max_suppression(x[0], self.conf, iou_thres=self.iou, classes=self.classes, max_det=self.max_det)2.2AutoShape
给模型封装成包含前处理、推理、后处理的模块(预处理 + 推理 + nms) (代码很长,参考看)
class AutoShape(nn.Module):# YOLOv5 input-robust model wrapper for passing cv2/np/PIL/torch inputs. Includes preprocessing, inference and NMSconf = 0.25 # NMS confidence thresholdiou = 0.45 # NMS IoU thresholdagnostic = False # NMS class-agnosticmulti_label = False # NMS multiple labels per boxclasses = None # (optional list) filter by class, i.e. = [0, 15, 16] for COCO persons, cats and dogsmax_det = 1000 # maximum number of detections per imageamp = False # Automatic Mixed Precision (AMP) inferencedef __init__(self, model, verbose=True):super().__init__()if verbose:LOGGER.info('Adding AutoShape... ')copy_attr(self, model, include=('yaml', 'nc', 'hyp', 'names', 'stride', 'abc'), exclude=()) # copy attributesself.dmb = isinstance(model, DetectMultiBackend) # DetectMultiBackend() instanceself.pt = not self.dmb or model.pt # PyTorch modelself.model = model.eval()if self.pt:m = self.model.model.model[-1] if self.dmb else self.model.model[-1] # Detect()m.inplace = False # Detect.inplace=False for safe multithread inferencem.export = True # do not output loss valuesdef _apply(self, fn):# Apply to(), cpu(), cuda(), half() to model tensors that are not parameters or registered buffersself = super()._apply(fn)if self.pt:m = self.model.model.model[-1] if self.dmb else self.model.model[-1] # Detect()m.stride = fn(m.stride)m.grid = list(map(fn, m.grid))if isinstance(m.anchor_grid, list):m.anchor_grid = list(map(fn, m.anchor_grid))return self@smart_inference_mode()def forward(self, ims, size=640, augment=False, profile=False):# Inference from various sources. For size(height=640, width=1280), RGB images example inputs are:# file: ims = 'data/images/zidane.jpg' # str or PosixPath# URI: = 'https://ultralytics.com/images/zidane.jpg'# OpenCV: = cv2.imread('image.jpg')[:,:,::-1] # HWC BGR to RGB x(640,1280,3)# PIL: = Image.open('image.jpg') or ImageGrab.grab() # HWC x(640,1280,3)# numpy: = np.zeros((640,1280,3)) # HWC# torch: = torch.zeros(16,3,320,640) # BCHW (scaled to size=640, 0-1 values)# multiple: = [Image.open('image1.jpg'), Image.open('image2.jpg'), ...] # list of imagesdt = (Profile(), Profile(), Profile())with dt[0]:if isinstance(size, int): # expandsize = (size, size)p = next(self.model.parameters()) if self.pt else torch.empty(1, device=self.model.device) # paramautocast = self.amp and (p.device.type != 'cpu') # Automatic Mixed Precision (AMP) inferenceif isinstance(ims, torch.Tensor): # torchwith amp.autocast(autocast):return self.model(ims.to(p.device).type_as(p), augment=augment) # inference# Pre-processn, ims = (len(ims), list(ims)) if isinstance(ims, (list, tuple)) else (1, [ims]) # number, list of imagesshape0, shape1, files = [], [], [] # image and inference shapes, filenamesfor i, im in enumerate(ims):f = f'image{i}' # filenameif isinstance(im, (str, Path)): # filename or uriim, f = Image.open(requests.get(im, stream=True).raw if str(im).startswith('http') else im), imim = np.asarray(exif_transpose(im))elif isinstance(im, Image.Image): # PIL Imageim, f = np.asarray(exif_transpose(im)), getattr(im, 'filename', f) or ffiles.append(Path(f).with_suffix('.jpg').name)if im.shape[0] < 5: # image in CHWim = im.transpose((1, 2, 0)) # reverse dataloader .transpose(2, 0, 1)im = im[..., :3] if im.ndim == 3 else cv2.cvtColor(im, cv2.COLOR_GRAY2BGR) # enforce 3ch inputs = im.shape[:2] # HWCshape0.append(s) # image shapeg = max(size) / max(s) # gainshape1.append([y * g for y in s])ims[i] = im if im.data.contiguous else np.ascontiguousarray(im) # updateshape1 = [make_divisible(x, self.stride) for x in np.array(shape1).max(0)] if self.pt else size # inf shapex = [letterbox(im, shape1, auto=False)[0] for im in ims] # padx = np.ascontiguousarray(np.array(x).transpose((0, 3, 1, 2))) # stack and BHWC to BCHWx = torch.from_numpy(x).to(p.device).type_as(p) / 255 # uint8 to fp16/32with amp.autocast(autocast):# Inferencewith dt[1]:y = self.model(x, augment=augment) # forward# Post-processwith dt[2]:y = non_max_suppression(y if self.dmb else y[0],self.conf,self.iou,self.classes,self.agnostic,self.multi_label,max_det=self.max_det) # NMSfor i in range(n):scale_boxes(shape1, y[i][:, :4], shape0[i])return Detections(ims, y, files, dt, self.names, x.shape)2.3 Detections
对推理结果进行处理(代码很长,参考看)
class Detections:# YOLOv5 detections class for inference resultsdef __init__(self, ims, pred, files, times=(0, 0, 0), names=None, shape=None):super().__init__()d = pred[0].device # devicegn = [torch.tensor([*(im.shape[i] for i in [1, 0, 1, 0]), 1, 1], device=d) for im in ims] # normalizationsself.ims = ims # list of images as numpy arraysself.pred = pred # list of tensors pred[0] = (xyxy, conf, cls)self.names = names # class namesself.files = files # image filenamesself.times = times # profiling timesself.xyxy = pred # xyxy pixelsself.xywh = [xyxy2xywh(x) for x in pred] # xywh pixelsself.xyxyn = [x / g for x, g in zip(self.xyxy, gn)] # xyxy normalizedself.xywhn = [x / g for x, g in zip(self.xywh, gn)] # xywh normalizedself.n = len(self.pred) # number of images (batch size)self.t = tuple(x.t / self.n * 1E3 for x in times) # timestamps (ms)self.s = tuple(shape) # inference BCHW shapedef _run(self, pprint=False, show=False, save=False, crop=False, render=False, labels=True, save_dir=Path('')):s, crops = '', []for i, (im, pred) in enumerate(zip(self.ims, self.pred)):s += f'\nimage {i + 1}/{len(self.pred)}: {im.shape[0]}x{im.shape[1]} ' # stringif pred.shape[0]:for c in pred[:, -1].unique():n = (pred[:, -1] == c).sum() # detections per classs += f"{n} {self.names[int(c)]}{'s' * (n > 1)}, " # add to strings = s.rstrip(', ')if show or save or render or crop:annotator = Annotator(im, example=str(self.names))for *box, conf, cls in reversed(pred): # xyxy, confidence, classlabel = f'{self.names[int(cls)]} {conf:.2f}'if crop:file = save_dir / 'crops' / self.names[int(cls)] / self.files[i] if save else Nonecrops.append({'box': box,'conf': conf,'cls': cls,'label': label,'im': save_one_box(box, im, file=file, save=save)})else: # all othersannotator.box_label(box, label if labels else '', color=colors(cls))im = annotator.imelse:s += '(no detections)'im = Image.fromarray(im.astype(np.uint8)) if isinstance(im, np.ndarray) else im # from npif show:im.show(self.files[i]) # showif save:f = self.files[i]im.save(save_dir / f) # saveif i == self.n - 1:LOGGER.info(f"Saved {self.n} image{'s' * (self.n > 1)} to {colorstr('bold', save_dir)}")if render:self.ims[i] = np.asarray(im)if pprint:s = s.lstrip('\n')return f'{s}\nSpeed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {self.s}' % self.tif crop:if save:LOGGER.info(f'Saved results to {save_dir}\n')return cropsdef show(self, labels=True):self._run(show=True, labels=labels) # show resultsdef save(self, labels=True, save_dir='runs/detect/exp', exist_ok=False):save_dir = increment_path(save_dir, exist_ok, mkdir=True) # increment save_dirself._run(save=True, labels=labels, save_dir=save_dir) # save resultsdef crop(self, save=True, save_dir='runs/detect/exp', exist_ok=False):save_dir = increment_path(save_dir, exist_ok, mkdir=True) if save else Nonereturn self._run(crop=True, save=save, save_dir=save_dir) # crop resultsdef render(self, labels=True):self._run(render=True, labels=labels) # render resultsreturn self.imsdef pandas(self):# return detections as pandas DataFrames, i.e. print(results.pandas().xyxy[0])new = copy(self) # return copyca = 'xmin', 'ymin', 'xmax', 'ymax', 'confidence', 'class', 'name' # xyxy columnscb = 'xcenter', 'ycenter', 'width', 'height', 'confidence', 'class', 'name' # xywh columnsfor k, c in zip(['xyxy', 'xyxyn', 'xywh', 'xywhn'], [ca, ca, cb, cb]):a = [[x[:5] + [int(x[5]), self.names[int(x[5])]] for x in x.tolist()] for x in getattr(self, k)] # updatesetattr(new, k, [pd.DataFrame(x, columns=c) for x in a])return newdef tolist(self):# return a list of Detections objects, i.e. 'for result in results.tolist():'r = range(self.n) # iterablex = [Detections([self.ims[i]], [self.pred[i]], [self.files[i]], self.times, self.names, self.s) for i in r]# for d in x:# for k in ['ims', 'pred', 'xyxy', 'xyxyn', 'xywh', 'xywhn']:# setattr(d, k, getattr(d, k)[0]) # pop out of listreturn xdef print(self):LOGGER.info(self.__str__())def __len__(self): # override len(results)return self.ndef __str__(self): # override print(results)return self._run(pprint=True) # print resultsdef __repr__(self):return f'YOLOv5 {self.__class__} instance\n' + self.__str__()class Proto(nn.Module):# YOLOv5 mask Proto module for segmentation modelsdef __init__(self, c1, c_=256, c2=32): # ch_in, number of protos, number of maskssuper().__init__()self.cv1 = Conv(c1, c_, k=3)self.upsample = nn.Upsample(scale_factor=2, mode='nearest')self.cv2 = Conv(c_, c_, k=3)self.cv3 = Conv(c_, c2)def forward(self, x):return self.cv3(self.cv2(self.upsample(self.cv1(x))))class Classify(nn.Module):# YOLOv5 classification head, i.e. x(b,c1,20,20) to x(b,c2)def __init__(self, c1, c2, k=1, s=1, p=None, g=1): # ch_in, ch_out, kernel, stride, padding, groupssuper().__init__()c_ = 1280 # efficientnet_b0 sizeself.conv = Conv(c1, c_, k, s, autopad(k, p), g)self.pool = nn.AdaptiveAvgPool2d(1) # to x(b,c_,1,1)self.drop = nn.Dropout(p=0.0, inplace=True)self.linear = nn.Linear(c_, c2) # to x(b,c2)def forward(self, x):if isinstance(x, list):x = torch.cat(x, 1)return self.linear(self.drop(self.pool(self.conv(x)).flatten(1)))
2.4 Classify
二级分类,比如要做识别人脸面部表情,先要识别出人脸,如果想识别出人的面部表情,就需要二级分类进一步检测。
class Classify(nn.Module):# YOLOv5 classification head, i.e. x(b,c1,20,20) to x(b,c2)def __init__(self, c1, c2, k=1, s=1, p=None, g=1): # ch_in, ch_out, kernel, stride, padding, groupssuper().__init__()c_ = 1280 # efficientnet_b0 sizeself.conv = Conv(c1, c_, k, s, autopad(k, p), g)self.pool = nn.AdaptiveAvgPool2d(1) # to x(b,c_,1,1)self.drop = nn.Dropout(p=0.0, inplace=True)self.linear = nn.Linear(c_, c2) # to x(b,c2)def forward(self, x):if isinstance(x, list):x = torch.cat(x, 1)return self.linear(self.drop(self.pool(self.conv(x)).flatten(1)))三、实验
要求:
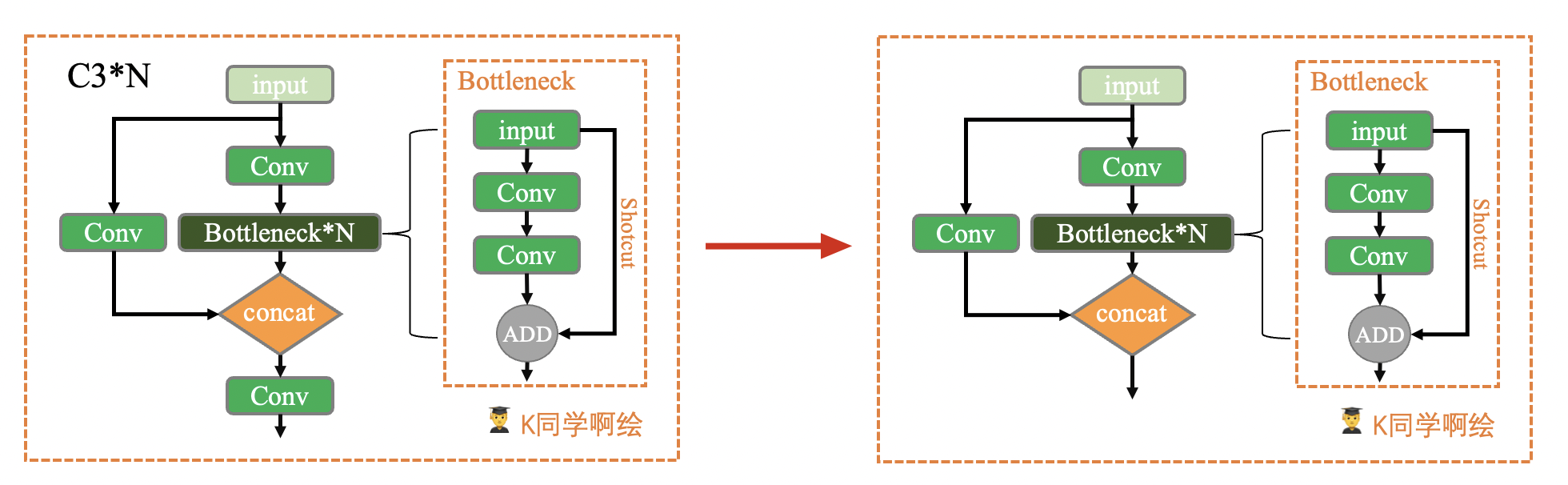
应该是移除cv3卷积层即可,注释掉
class C3(nn.Module):# CSP Bottleneck with 3 convolutionsdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))def forward(self, x):return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))相关文章:
深度学习Week15-common.py文件解读(YOLOv5)
目录 简介 一.基本组件 1.1autopad 1.2Conv 1.3 Focus 1.4Bottleneck 1.5BottleneckCSP 1.6 C3 1.7 SPP 1.8Concat 1.9Contract、Expand 二、重要类 2.1非极大值抑制(NMS) 2.2AutoShape 2.3 Detections 2.4 Classify 三、实验 …...
qemu的snapshot快照功能的详细使用介绍
快照功能还是蛮有趣的,就是资料比较少,这边万能菜道人特意整理了一下。参考内容:QEMU checkpoint(snapshot) 使用-pudn.comKVM&QEMU学习笔记(二)-蒲公英云 (dandelioncloud.cn)在线迁移存储 - 爱码网 (likecs.com)…...
谷歌关键词优化多少钱【2023年调研】
本文主要分享Google关键词排名优化的一些成本调研,方便大家参考。 本文由光算创作,有可能会被剽窃和修改,我们佛系对待这种行为吧。 今年2023年了,谷歌关键词优化到底要多少钱? 答案是:价格在2w~25w左右…...

凸包及其算法
概念 凸包:一个能够将所有给定点围住的最小周长封闭图形。 稳定凸包:在当前组成凸包的点集 V0V_0V0 中新增一个不在凸包上的点,形成新点集 V1V_1V1,若可以使 V1V_1V1 中所有点都在 V1V_1V1 的点的凸包上,则这…...

计算机网络学习笔记(二)物理层
物理层(传输比特0/1)基本概念 物理层下的传输媒体 1. 导引型 同轴电缆,双绞线(绞合可抵御干扰),光纤,电力线 2. 非导引型(调制振幅 频率 相位) 无线电波,微…...

为什么职称要提前准备?
职称反映专业技术人员的学术和技术水平、工作能力的工作成就,具有学衔、岗位两种性质。目前中国现状下,职称主要代表社会地位,就业经验,职称等级越高,越容易得到更高的社会经济和福利待遇。 职称通过申报、评审的形式…...

MyBatis详解1——相关配置
一、什么是MyBatis 1.定义:是一个优秀的持久层框架(ORM框架),它支持自定义 SQL、存储过程以及高级映射。MyBatis是一个用来更加简单的操作和读取数据库的工具。 2.支持的操作方式:xml或者注解实现操作(xm…...
字节青训营——秒杀系统设计学习笔记(三)
限流算法 限流顾名思义,就是对请求或并发数进行限制;通过对一个时间窗口内的请求量进行限制来保障系统的正常运行。如果我们的服务资源有限、处理能力有限,就需要对调用我们服务的上游请求进行限制,以防止自身服务由于资源耗尽而…...

每天一道大厂SQL题【Day10】电商分组TopK实战
每天一道大厂SQL题【Day10】电商分组TopK实战 大家好,我是Maynor。相信大家和我一样,都有一个大厂梦,作为一名资深大数据选手,深知SQL重要性,接下来我准备用100天时间,基于大数据岗面试中的经典SQL题&…...
最全的免费录屏工具,这 19 款录屏软件绝对值得你收藏
屏幕录制软件可让您捕获屏幕以与他人共享,创建与产品相关的视频、教程、课程、演示、视频等。这些软件是您能够从网络摄像头和屏幕录制视频。以下是精选的顶级屏幕录像机列表。 适用于 PC 的19 款免费录屏屏幕录像机软件 1)奇客免费录屏 奇客免费录屏&am…...
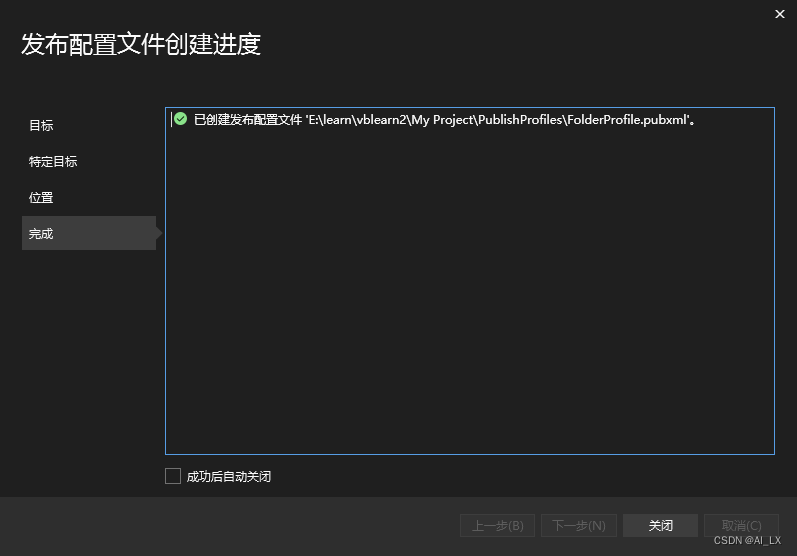
vb.net计算之.net core基础(2)-发布应用
目录 发布程序测试运行运行方式发布程序 首先,将编译配置改为Release 然后,发布应用,在生成菜单下。 选择发布到文件夹 继续选择文件夹 接着,完成 关闭 点击发布标签栏的发布按钮...
微服务项目【商品秒杀接口压测及优化】
生成测试用户 将UserUtils工具类导入到zmall-user模块中,运行生成测试用户信息,可根据自身电脑情况来生成用户数量。 UserUtils: package com.xujie.zmall.utils;import com.alibaba.nacos.common.utils.MD5Utils; import com.fasterxml.j…...

1997. 访问完所有房间的第一天
题目 你需要访问 n 个房间,房间从 0 到 n - 1 编号。同时,每一天都有一个日期编号,从 0 开始,依天数递增。你每天都会访问一个房间。 最开始的第 0 天,你访问 0 号房间。给你一个长度为 n 且 下标从 0 开始 的数组 n…...

通达信交易接口以什么形式执行下单的?
通达信程交易接口 以API形式来执行下单接口,一般不再需要通过接口系统之间进行连接,通过直接调用通达信dll交易函数的方式直接进行交易,包括下单,撤单,查询资金股份、当日委托、当日成交等方面都能很快的执行出来。以a…...

CobaltStrike上线微信通知
CobaltStrike上线微信通知 利用pushplus公众号(每天免费发送200条消息) http://www.pushplus.plus/push1.html 扫码登录后需要复制token 可以测试一下发送一下消息,手机会受到如下消息。可以在微信提示里将消息免打扰关闭(默认…...

喜茶、奈雪的茶“花式”寻生路
配图来自Canva可画 疫情全面开放不少人“阳了又阳”,电解质饮品成为热销品,梨子、橘子、柠檬等水果被卖断货,凉茶、黄桃罐头被抢购一空,喜茶的“多肉大橘”、奈雪的“霸气银耳炖梨”、蜜雪冰城的“棒打鲜橙”、沪上阿姨的“鲜炖整…...

Xstream使用教程
1.Xstream介绍 官网:https://x-stream.github.io/tutorial.html 介绍:XStream 对象序列化和反序列化为 XML的一个JAVA类库。JDK 1.4以上适用。 PS:与JAXB相比,Xstream更好用一些,像XStreamImplicit这种注解,我在JAX…...
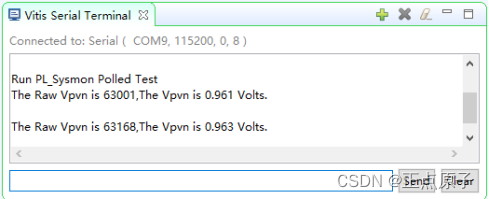
【正点原子FPGA连载】第十一章PL SYSMON测量输入模拟电压 摘自【正点原子】DFZU2EG_4EV MPSoC之嵌入式Vitis开发指南
1)实验平台:正点原子MPSoC开发板 2)平台购买地址:https://detail.tmall.com/item.htm?id692450874670 3)全套实验源码手册视频下载地址: http://www.openedv.com/thread-340252-1-1.html 第十一章PL SYSM…...

纷享销客百思特 | 数字化营销赋能企业新增长沙龙圆满落幕
为进一步帮助企业客户实现数字化转型,纷享销客联合百思特管理咨询集团,于2月10日举办 “数字化营销赋能企业新增长”主题沙龙。本次活动以“新变革新增长”为主题,现场30余位制造企业高管齐聚一堂,共同探讨企业如何在当前复杂的宏…...

oracle查看具体表占用空间 oracle查看表属于哪个用户
文章目录前言oracle查看具体表占用空间1、查看表空间总大小、使用率、剩余空间2、查看具体表的占用空间大小3、查看表空间对应日志文件oracle查看表属于哪个用户1、oracle怎么查看表属于哪个用户2、Oracle查询视图所属用户3、Oracle查询存储过程所属用户总结前言 表空间是数据…...

gopher-os社区贡献指南:从代码提交到功能开发的完整参与流程
gopher-os社区贡献指南:从代码提交到功能开发的完整参与流程 【免费下载链接】gopher-os A proof of concept OS kernel written in Go 项目地址: https://gitcode.com/gh_mirrors/go/gopher-os gopher-os是一个用Go语言编写的操作系统内核概念验证项目&…...

终极指南:Vue-Multiselect 源码架构深度剖析与优秀组件设计模式解析
终极指南:Vue-Multiselect 源码架构深度剖析与优秀组件设计模式解析 【免费下载链接】vue-multiselect Universal select/multiselect/tagging component for Vue.js 项目地址: https://gitcode.com/gh_mirrors/vu/vue-multiselect Vue-Multiselect 是一个功…...

OpenSSF Scorecard安全策略检查:保护代码仓库的终极完整指南
OpenSSF Scorecard安全策略检查:保护代码仓库的终极完整指南 【免费下载链接】scorecard OpenSSF Scorecard - Security health metrics for Open Source 项目地址: https://gitcode.com/gh_mirrors/sc/scorecard OpenSSF Scorecard是一款由Open Source Secu…...

Rack错误处理终极指南:ShowExceptions中间件详解与实战技巧
Rack错误处理终极指南:ShowExceptions中间件详解与实战技巧 【免费下载链接】rack A modular Ruby web server interface. 项目地址: https://gitcode.com/gh_mirrors/ra/rack Rack是Ruby生态系统中最核心的Web服务器接口,为Ruby开发者提供了模块…...

随记 - 2026 年 4 月 3 日
写在前面1111 字 | 感触 | 朋友 | 经历 | 友谊 | 青春 | 爱与被爱正文 这则随记可能没有一个特定的主题,只是最近期的感想。 昨天中午,我送别了远道而来的大学室友。跨越许多省份,从安徽到四川。而他这次来见我们的理由也很朴素。 “只是很久…...
)
【PHP异步I/O配置终极指南】:20年SRE亲授EventLoop选型、Swoole协程适配与ReactPHP性能调优(附压测对比数据)
第一章:PHP异步I/O配置全景认知与演进脉络PHP的异步I/O能力并非原生内置,而是伴随SAPI模型演进、扩展生态成熟及现代协程范式兴起逐步构建的。从早期通过多进程(pcntl_fork)或轮询(stream_select)模拟非阻塞…...

峰值电流控制模式在开关电源中的动态响应优化策略
1. 峰值电流控制模式的核心原理 我第一次接触峰值电流控制模式是在设计一款手机充电器时。当时被它独特的双环控制结构吸引——就像汽车同时配备油门踏板和定速巡航,既能快速响应路况变化,又能保持稳定车速。这种模式通过实时监测电感电流的峰值来动态调…...

37、web常见的攻击方式有哪些?如何防御?
一、先给面试官一个总览Web 常见攻击我通常会从 前端安全、认证安全、传输安全、服务端安全 四类来理解。 前端最常见的是 XSS、CSRF、点击劫持; 认证相关有 SQL 注入、暴力破解、会话劫持; 传输层有 中间人攻击; 工程层面还要关注 文件上传、…...

STM32 串口通信入门:printf 重定向 + 调试技巧
作为STM32新手,串口通信是嵌入式调试的万能钥匙。很多新手调试程序时,只能靠LED亮灭判断运行状态,出错后无从排查;想查看变量、确认函数执行情况,也没有有效方法。串口通信可解决这一问题,通过printf函数&a…...

绕开原厂协议:非侵入式梯控改造的OT架构解耦与状态机设计
摘要: 在机器人跨层调度项目中,架构师常面临特种设备管理方“严禁改动原生电路与读取主板总线”的硬性约束。本文深度拆解如何通过引入边缘设备,实现 OT(操作技术)层面的彻底解耦。重点探讨在非侵入式架构下࿰…...