搭建hadoop高可用集群(二)
搭建hadoop高可用集群(一)
- 配置hadoop
- hadoop-env.sh
- workers
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
- yarn-site.xml
- /etc/profile
- 拷贝
- 集群首次启动
- 1、先启动zk集群(自动化脚本)
- 2、在hadoop151,hadoop152,hadoop153启动JournalNode
- 3、在hadoop151格式化
- 4、在hadoop151启动namenode服务
- 5、在hadoop152机器上同步namenode信息
- 6、在hadoop152上启动namenode服务
- 7、关闭所有dfs有关的服务
- 8、格式化zk
- 9、启动dfs
- 10、启动yarn
- 安装成功
配置hadoop
解压完后,单独配置这6个文件
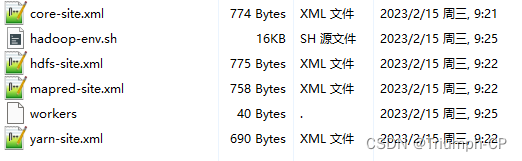
hadoop-env.sh
第54行
export JAVA_HOME=/opt/soft/jdk180export HDFS_NAMENODE_USER=rootexport HDFS_DATANODE_USER=rootexport HDFS_SECONDARYNAMENODE_USER=rootexport HDFS_JOURNALNODE_USER=rootexport HDFS_ZKFC_USER=rootexport YARN_RESOURCEMANAGER_USER=rootexport YARN_NODEMANAGER_USER=root
workers
填入ip
hadoop151
hadoop152
hadoop153
hadoop154
core-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://gky</value><description>逻辑名称,必须与hdfs-site.xml中的dfs.nameservice值保持一致</description></property><property><name>hadoop.tmp.dir</name><value>/opt/soft/hadoop313/tmpdata</value><description>namenode上本地的hadoop临时文件夹</description></property><property><name>hadoop.http.staticuser.user</name><value>root</value><description>默认用户</description></property><property><name>hadoop.proxyuser.root.hosts</name><value>*</value><description></description></property><property><name>hadoop.proxyuser.root.groups</name><value>*</value><description></description></property><property><name>io.file.buffer.size</name><value>131072</value><description>读写文件的buffer大小为:128k</description></property><property><name>ha.zookeeper.quorum</name><value>hadoop151:2181,hadoop152:2181,hadoop153:2181</value>//改成自己的ip<description>zookeeper队列</description></property><property><name>ha.zookeeper.session-timeout.ms</name><value>10000</value><description>hadoop连接zookeeper的超时时长设置为10s</description></property>
</configuration>
hdfs-site.xml
<configuration><property><name>dfs.replication</name><value>3</value><description>hadoop中每一个block文件的备份数量</description></property><property><name>dfs.namenode.name.dir</name><value>/opt/soft/hadoop313/data/dfs/name</value><description>namenode上存储hdfs名字空间元数据的目录</description></property><property><name>dfs.datanode.data.dir</name><value>/opt/soft/hadoop313/data/dfs/data</value><description>datanode上数据块的物理存储位置目录</description></property><property><name>dfs.namenode.secondary.http-address</name><value>hadoop151:9869</value><description></description></property><property><name>dfs.nameservices</name><value>gky</value><description>指定hdfs的nameservice,需要和core-site.xml中保持一致</description></property><property><name>dfs.ha.namenodes.gky</name><value>nn1,nn2</value><description>gky为集群的逻辑名称,映射两个namenode逻辑</description></property><property><name>dfs.namenode.rpc-address.gky.nn1</name><value>hadoop151:9000</value><description>namenode1的RPC通信地址</description></property><property><name>dfs.namenode.http-address.gky.nn1</name><value>hadoop151:9870</value><description>namenode1的http通信地址</description></property><property><name>dfs.namenode.rpc-address.gky.nn2</name><value>hadoop152:9000</value><description>namenode2的RPC通信地址</description></property><property><name>dfs.namenode.http-address.gky.nn2</name><value>hadoop152:9870</value><description>namenode2的http通信地址</description></property><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://hadoop151:8485;hadoop152:8485;hadoop153:8485/gky</value><description>指定NameNode的edits元数据的共享存储位置(JournalNode列表)</description></property><property><name>dfs.journalnode.edits.dir</name><value>/opt/soft/hadoop313/data/journaldata</value><description>指定JournalNode在本地磁盘存放数据的位置</description></property><!-- 容错 --><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value><description>开启NameNode故障自动切换</description></property><property><name>dfs.client.failover.proxy.provider.gky</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value><description>失败后自动切换的实现方式</description></property><property><name>dfs.ha.fencing.methods</name><value>sshfence</value><description>防止脑裂的处理</description></property><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value><description>使用sshfence隔离机制,需要ssh免密登录</description></property><property><name>dfs.permissions.enabled</name><value>false</value><description>关闭HDFS操作权限验证</description></property><property><name>dfs.image.transfer.bandwidthPerSec</name><value>1048576</value><description></description></property><property><name>dfs.block.scanner.volume.bytes.per.second</name><value>1048576</value><description></description></property>
</configuration>
mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value><description>job执行框架:local,classic or yarn</description><final>true</final></property><property><name>mapreduce.application.classpath</name><value>/opt/soft/hadoop313/etc/hadoop:/opt/soft/hadoop313/share/hadoop/common/lib/*:/opt/soft/hadoop313/share/hadoop/common/*:/opt/soft/hadoop313/share/hadoop/hdfs/*:/opt/soft/hadoop313/share/hadoop/hdfs/lib/*:/opt/soft/hadoop313/share/hadoop/mapreduce/*:/opt/soft/hadoop313/share/hadoop/mapreduce/lib/*:/opt/soft/hadoop313/share/hadoop/yarn/*:/opt/soft/hadoop313/share/hadoop/yarn/lib/*</value></property><property><name>mapreduce.jobhistory.address</name><value>hadoop151:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop151:19888</value></property><property><name>mapreduce.map.memory.mb</name><value>1024</value><description>map阶段的task工作内存</description></property><property><name>mapreduce.reduce.memory.mb</name><value>2048</value><description>reduce阶段的task工作内存</description></property>
</configuration>
yarn-site.xml
<configuration><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value><description>开启resourcemanager高可用</description></property><property><name>yarn.resourcemanager.cluster-id</name><value>yrcabc</value><description>指定yarn的集群中的id</description></property><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value><description>指定resourcemanager的名字</description></property><property><name>yarn.resourcemanager.hostname.rm1</name><value>hadoop153</value><description>设置rm1的名字</description></property><property><name>yarn.resourcemanager.hostname.rm2</name><value>hadoop154</value><description>设置rm2的名字</description></property><property><name>yarn.resourcemanager.webapp.address.rm1</name><value>hadoop153:8088</value><description></description></property><property><name>yarn.resourcemanager.webapp.address.rm2</name><value>hadoop154:8088</value><description></description></property><property><name>yarn.resourcemanager.zk-address</name><value>hadoop151:2181,hadoop152:2181,hadoop153:2181</value><description>指定zk集群地址</description></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value><description>运行mapreduce程序必须配置的附属服务</description></property><property><name>yarn.nodemanager.local-dirs</name><value>/opt/soft/hadoop313/tmpdata/yarn/local</value><description>nodemanager本地存储目录</description></property><property><name>yarn.nodemanager.log-dirs</name><value>/opt/soft/hadoop313/tmpdata/yarn/log</value><description>nodemanager本地日志目录</description></property><property><name>yarn.nodemanager.resource.memory-mb</name><value>2048</value><description>resource进程的内存</description></property><property><name>yarn.nodemanager.resource.cpu-vcores</name><value>2</value><description>resource工作中所能使用机器的内核数</description></property><property><name>yarn.scheduler.minimum-allocation-mb</name><value>256</value><description></description></property><property><name>yarn.log-aggregation-enable</name><value>true</value><description>yarn的日志能不能合并</description></property><property><name>yarn.log-aggregation.retain-seconds</name><value>86400</value><description>yarn的合并日志保存的时间(多少秒)</description></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value><description></description></property><property><name>yarn.application.classpath</name><value>/opt/soft/hadoop313/etc/hadoop:/opt/soft/hadoop313/share/hadoop/common/lib/*:/opt/soft/hadoop313/share/hadoop/common/*:/opt/soft/hadoop313/share/hadoop/hdfs/*:/opt/soft/hadoop313/share/hadoop/hdfs/lib/*:/opt/soft/hadoop313/share/hadoop/mapreduce/*:/opt/soft/hadoop313/share/hadoop/mapreduce/lib/*:/opt/soft/hadoop313/share/hadoop/yarn/*:/opt/soft/hadoop313/share/hadoop/yarn/lib/*</value><description></description></property><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value><description></description></property>
</configuration>/etc/profile
#HADOOP_HOME
export HADOOP_HOME=/opt/soft/hadoop313
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/lib
拷贝
将配置好的文件拷贝到另外三台机器中
scp -r ./hadoop313/ root@hadoop151:/opt/softscp -r ./hadoop313/ root@hadoop152:/opt/softscp -r ./hadoop313/ root@hadoop153:/opt/softscp -r ./hadoop313/ root@hadoop154:/opt/soft
scp -r /etc/profile root@hadoop151:/etc
scp -r /etc/profile root@hadoop152:/etc
scp -r /etc/profile root@hadoop153:/etc
scp -r /etc/profile root@hadoop154:/etc
集群首次启动
1、先启动zk集群(自动化脚本)
2、在hadoop151,hadoop152,hadoop153启动JournalNode
hdfs --daemon start journalnode
可以用脚本查看三台机器的启动状态

3、在hadoop151格式化
hdfs namenode -format
4、在hadoop151启动namenode服务
hdfs --daemon start namenode
5、在hadoop152机器上同步namenode信息
hdfs namenode -bootstrapStandby
6、在hadoop152上启动namenode服务
hdfs --daemon start namenode
没启动之前的jps
启动之后

查看namenode节点状态
hdfs haadmin -getServiceState nn2
7、关闭所有dfs有关的服务
stop-dfs.sh
8、格式化zk
hdfs zkfc -formatZK
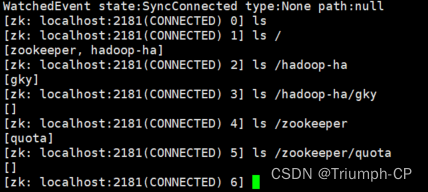
格式化完可以进工作空间
zkCli.sh
9、启动dfs
start-dfs.sh
查看namenode节点状态

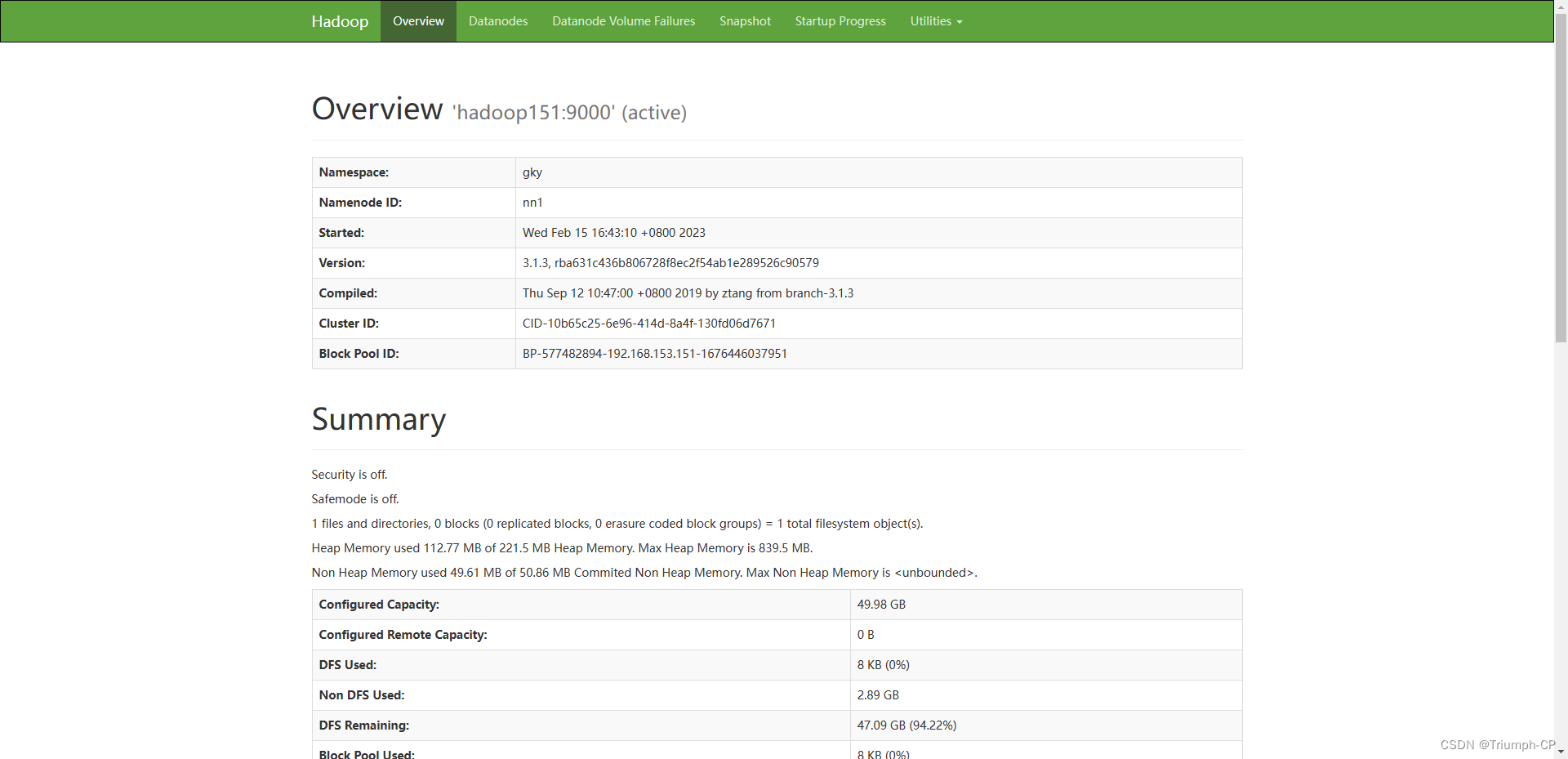
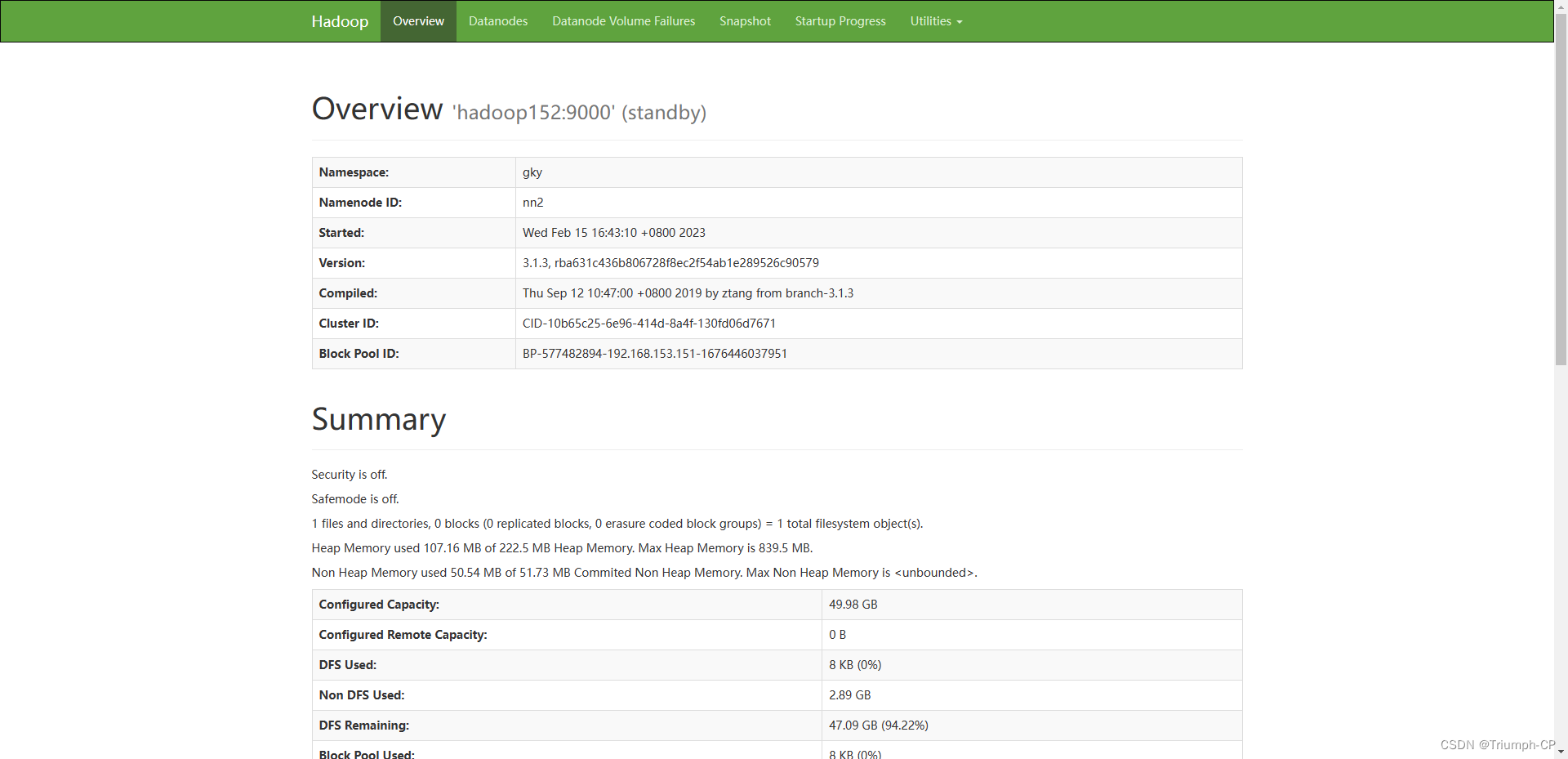
151挂掉后,152会变成active,如果151又上线,它不会变成active,会变成standby
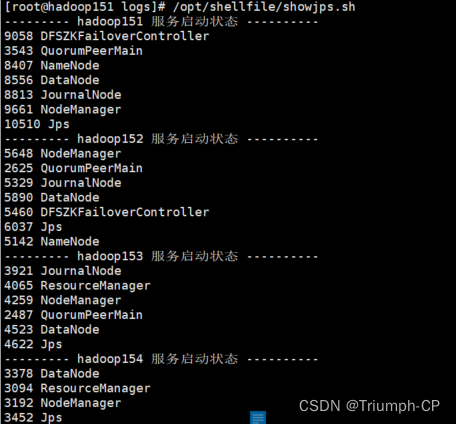
10、启动yarn
start-yarn.sh
查看状态
查看resourcemanager节点状态
yarn rmadmin -getServiceState rm1

如图153是active
当输入 hadoop153:8088或hadoop154:8088时,页面地址都会转到hadoop153:8088
安装成功
上传一个文件,测试wordcount,运行成功,即安装成功

后面hadoop可直接用start-all.sh开启,stop-all.sh关闭;zookeeper可以用脚本一键开启关闭(要注意开启时,要先开启zookeeper)
相关文章:
搭建hadoop高可用集群(二)
搭建hadoop高可用集群(一)配置hadoophadoop-env.shworkerscore-site.xmlhdfs-site.xmlmapred-site.xmlyarn-site.xml/etc/profile拷贝集群首次启动1、先启动zk集群(自动化脚本)2、在hadoop151,hadoop152,hadoop153启动JournalNode…...

CentOS升级内核-- CentOS9 Stream/CentOS8 Stream/CentOS7
官方文档在此 升级原因 当我们安装一些软件(对,我说的就是Kubernetes),可能需要新内核的支持,而CentOS又比较保守,不太升级,所以需要我们手工升级. # 看下目前是什么版本内核 uname -a# 安装公钥 rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org# 添加仓库,如果…...
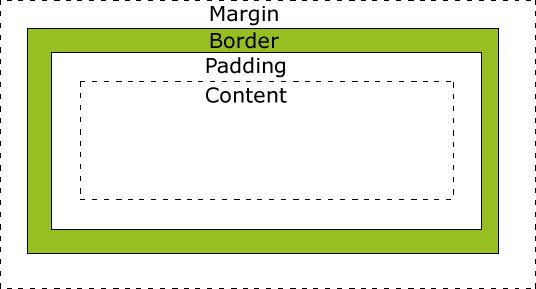
【基础篇】一文掌握css的盒子模型(margin、padding)
1、CSS 盒子模型(Box Model) 所有HTML元素可以看作盒子,在CSS中,"box model"这一术语是用来设计和布局时使用。CSS盒模型本质上是一个盒子,封装周围的HTML元素,它包括:边距,边框,填充,和实际内容。盒模型允许我们在其它元素和周围元素边框之间的空间放置元素…...
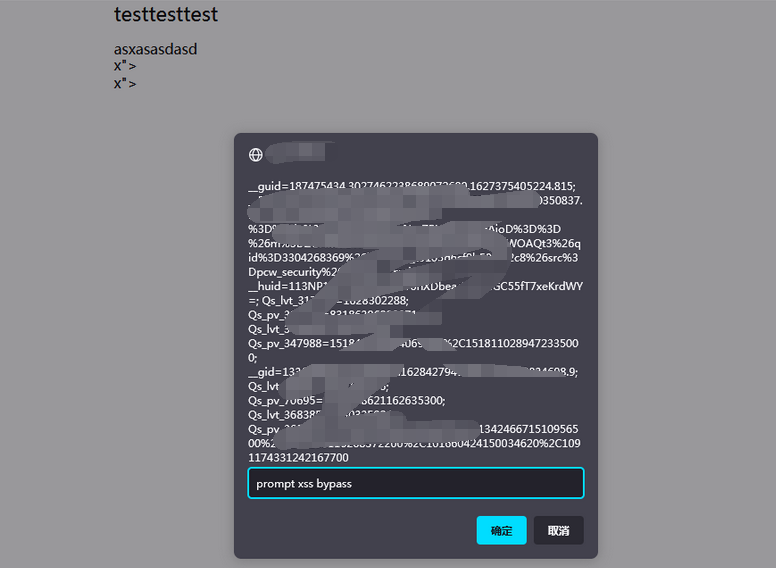
重生之我是赏金猎人-漏洞挖掘(十一)-某SRC储存XSS多次BypassWAF挖掘
0x01:利用编辑器的超链接组件导致存储XSS 鄙人太菜了,没啥高质量的洞呀,随便水一篇文章吧。 在月黑风高的夜晚,某骇客喊我起床挖洞,偷瞄了一下发现平台正好出活动了,想着小牛试刀吧 首先信息收集了一下&a…...

Wails简介
https://wails.io/zh-Hans/docs/introduction 简介 Wails 是一个可让您使用 Go 和 Web 技术编写桌面应用的项目。 将它看作为 Go 的快并且轻量的 Electron 替代品。 您可以使用 Go 的灵活性和强大功能,结合丰富的现代前端,轻松的构建应用程序。 功能…...
)
滑动窗口 AcWing (JAVA)
给定一个大小为 n≤10^6 的数组。 有一个大小为 k 的滑动窗口,它从数组的最左边移动到最右边。 你只能在窗口中看到 k 个数字。 每次滑动窗口向右移动一个位置。 以下是一个例子: 该数组为 [1 3 -1 -3 5 3 6 7],k 为 33。 窗口位置最小值最大…...
vue小案例
vue小案例 组件化编码流程 1.拆分静态组件,按功能点拆分 2.实现动态组件 3.实现交互 文章目录vue小案例组件化编码流程1.父组件给子组件传值2.通过APP组件给子组件传值。3.案例实现4.项目小细节1.父组件给子组件传值 父组件给子组件传值 1.在父组件中写好要传的值&a…...

阅读笔记3——空洞卷积
空洞卷积 1. 背景 空洞卷积(Dilated Convolution)最初是为解决图像分割的问题而提出的。常见的图像分割算法通常使用池化层来增大感受野,同时也缩小了特征图尺寸,然后再利用上采样还原图像尺寸。特征图先缩小再放大的过程造成了精…...
CSS系统学习总结
目录 CSS边框 CSS背景 CSS3渐变 线性渐变(Linear Gradients)- 向下/向上/向左/向右/对角方向 语法 线性渐变(从上到下) 线性渐变(从左到右) 线性渐变(对角) 使用角度 使用多…...

阿里一面:你做过哪些代码优化?来一个人人可以用的极品案例
前言 在尼恩读者50交流群中,尼恩经常指导小伙伴改简历。 改简历所涉及的一个要点是: 在 XXX 项目中,完成了 XXX 模块的代码优化 另外,在面试的过程中,面试官也常常喜欢针对提问,来考察候选人对代码质量的追…...
Android NFC 标签读写Demo与历史漏洞概述
文章目录前言NFC基础1.1 RFID区别1.2 工作模式1.3 日常应用NFC标签2.1 标签应用2.2 应用实践2.3 标签预览2.4 前台调度NFC开发3.1 NDEF数据3.2 标签的调度3.3 读写Demo3.4 Demo演示历史漏洞4.1 中继攻击4.2 预览伪造4.3 篡改卡片4.4 其它漏洞总结前言 NFC 作为 Android 手机一…...

亿级高并发电商项目-- 实战篇 --万达商城项目 六(编写角色管理、用户权限(Spring Security认证授权)、管理员管理等模块)
专栏:高并发---前后端分布式 👏作者简介:大家好,我是小童,Java开发工程师,CSDN博客博主,Java领域新星创作者 📕系列专栏:前端、Java、Java中间件大全、微信小程序、微信…...

博视像元获近5000万元融资,主攻半导体前道及锂电高端部件供应
这两年各大车企与电池厂商都在快速新建产能,尤其上游原材料成本大增,反映到产业链上巨头都在寻求增效,高端制造技术投入也大幅增长。比如这家,高端工业相机提供商「博视像元」近期宣布完成近5000万的天使加轮融资,投资…...

SpringCloud-断路器Hystrix
一、降级使用1、添加依赖<!--hystrix--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-hystrix</artifactId></dependency>2、启动类添加注解EnableCircuitBreakerSpringBoot…...

JavaScript精简笔记
文章目录基础语法函数1.1、函数的使用预解析对象1.1、创建对象基础语法 函数 1.1、函数的使用 函数在使用时分为两步:声明函数和调用函数 ①声明函数 //声明函数 function 函数名(){//函数体代码 }function 是声明函数的关键字,必须小写由于函数一般是为了实现…...

MySQL常用函数汇总
1 MySQL 字符串函数函数描述实例ASCII(s)返回字符串 s 的第一个字符的 ASCII 码。返回 CustomerName 字段第一个字母的 ASCII 码:SELECT ASCII(CustomerName) AS NumCodeOfFirstCharFROM Customers;CHAR_LENGTH(s)返回字符串 s 的字符数返回字符串 RUNOOB 的字符数S…...
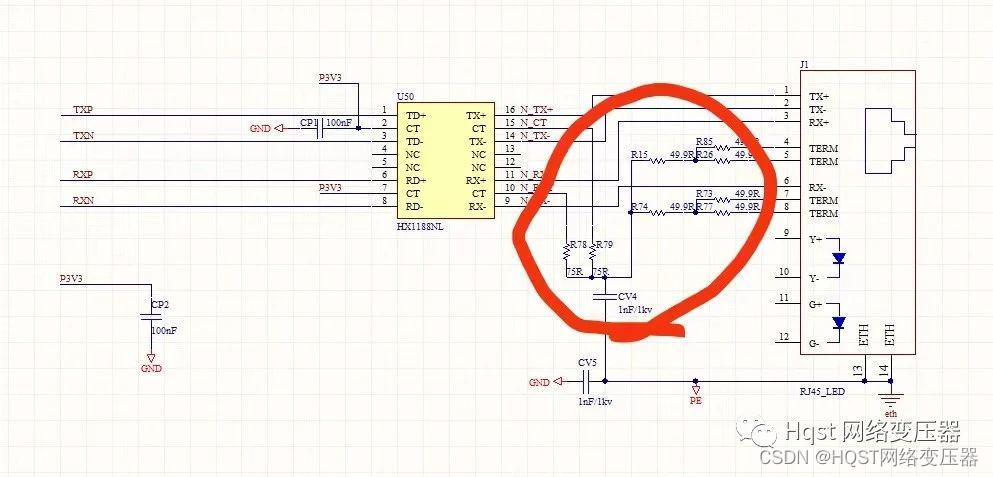
100M网口客户电脑插上网线就断线,自己工厂正常,是什么问题导致?
Hqst(华强盛科技)导读:物联工程师100M网口产品出现客户电脑插上网线就显示断线,无法通信,在自己工厂又正常使用,是什么问题?问:100M 网口, 使用改电路, 产品出…...

从零开始学习无人机 00 硬件配置
遥控器 型号 乐迪Radiolink AT9S Pro 固件更新 对遥控器固件作更新 乐迪Radiolink AT9S Pro 固件更新 光流传感器 型号 思动智能ThoneFlow-3901U 开发文档 Pmw3901光流传感器PX4开发文档 距离传感器 型号 空循环Nooploop TOFSense-F Pro 开发文档 TOFSense-F官方…...
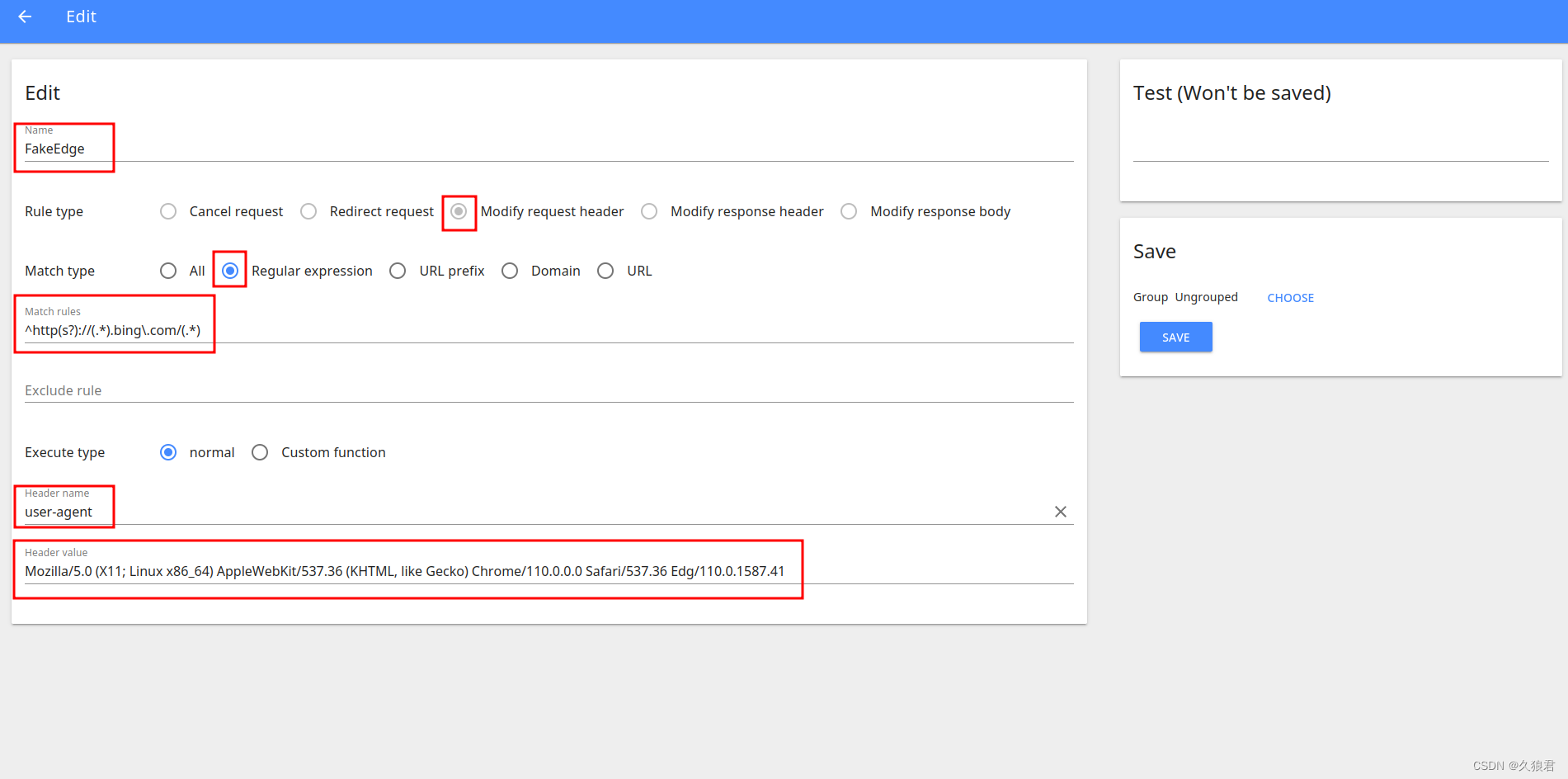
免翻在Chrome上使用新必应(New Bing)聊天机器人
这里不讲如何加入New Bing内测 文章目录免翻使用New Bing用Chrome(非Edge)使用新必应聊天机器人免翻使用New Bing 第一个是免翻,需要一个浏览器插件Header Editor,扩展商店或者百度自行下载安装吧。打开该插件,添加一个规则 为方便填写&…...

LA@特征值和特征向量
文章目录特征值和特征向量例例求解方阵的特征值和特征向量🎈特征多项式特征方程方阵特征值和特征向量的性质证明推论衍生特征值更一般的转置和特征值其他结论(方阵多项式的特征值与方阵本身特征值的关系)特征向量线性相关性特征值和特征向量 许多定量分析模型中,常常…...

3步解锁B站4K视频:bilibili-downloader零基础使用指南
3步解锁B站4K视频:bilibili-downloader零基础使用指南 【免费下载链接】bilibili-downloader B站视频下载,支持下载大会员清晰度4K,持续更新中 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-downloader 还在为无法保存B站4…...

Gemma-3-12B-IT WebUI惊艳效果:Agent框架设计+Tool Calling实现
Gemma-3-12B-IT WebUI惊艳效果:Agent框架设计Tool Calling实现 1. 引言:当大模型拥有“手”和“眼” 想象一下,你正在和一个非常聪明的助手聊天。它能回答你的问题,帮你写代码,甚至能创作故事。但当你问它“现在几点…...
)
告别纯Verilog手搓!用Vivado HLS快速搭建你的第一个CNN加速器(ZYNQ平台实战)
从Verilog到Vivado HLS:ZYNQ平台CNN加速器开发实战指南 在FPGA开发领域,传统RTL设计方法正面临越来越复杂的算法实现挑战。以卷积神经网络(CNN)为例,一个简单的三层网络就可能需要数万行Verilog代码,不仅开发周期漫长,…...

C-index避坑指南:生存分析中90%人会犯的5个评估错误
C-index避坑指南:生存分析中90%人会犯的5个评估错误 在临床研究和生物统计领域,C-index(Harrells concordance index)作为评估生存分析模型预测性能的核心指标,其正确计算与解读直接影响研究结论的可靠性。然而&#x…...

【Java 21记录模式性能优化终极指南】:3个被90%开发者忽略的模式匹配陷阱及提速300%的实战方案
第一章:Java 21记录模式性能优化全景概览Java 21 引入的记录模式(Record Patterns)不仅提升了模式匹配的表达力,更在JVM层面实现了多项关键性能优化。通过与模式匹配(Pattern Matching for instanceof)和解…...

快手数据采集引擎:无水印解析与多源内容整合工具
快手数据采集引擎:无水印解析与多源内容整合工具 【免费下载链接】kuaishou-crawler As you can see, a kuaishou crawler 项目地址: https://gitcode.com/gh_mirrors/ku/kuaishou-crawler 价值定位:重新定义短视频数据采集标准 在数字内容分析与…...

Beyond Compare 5终极激活指南:免费获取永久授权密钥的完整教程
Beyond Compare 5终极激活指南:免费获取永久授权密钥的完整教程 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen Beyond Compare 5作为业界领先的文件对比工具,其强大的功…...

嵌入式轻量级任务调度框架cola_os解析与实践
1. 嵌入式轻量级任务调度框架cola_os深度解析在嵌入式开发中,我们经常面临一个经典困境:对于功能简单、实时性要求不高的多任务场景,使用完整的RTOS显得过于臃肿,而裸机轮询又难以维护。今天要介绍的cola_os正是为解决这个问题而生…...

私域数据安全与合规——企微引流必须注意的5个技术红线
做公域引流到企微,数据安全和合规是技术团队必须重视的问题。一旦踩红线,轻则功能受限,重则企微封禁甚至法律风险。今天梳理5个技术红线及应对方案。红线1:用户隐私数据存储企微API返回的用户信息包含ExternalUserID(外…...

新手零基础入门:用快马生成你的第一个dify对话应用
今天想和大家分享一个特别适合新手入门的实践:用InsCode(快马)平台快速搭建你的第一个dify对话应用。作为一个刚接触AI开发的小白,我发现这个平台真的能省去很多麻烦的配置步骤,特别适合想快速看到成果的新手。 为什么选择dify作为入门&…...