hadoop考试应急
概述
四大特点:大量化、快速化、多元化、价值化
关键技术:采集、存储管理、处理分析、隐私和安全
计算模式:批处理、流、图、查询分析计算
Hadoop处理架构
了解就好
- 2007年,雅虎在Sunnyvale总部建立了M45——一个包含了4000个处理器和1.5PB容量的Hadoop集群系统

启动haoop: Start-all.sh查看状态: jps
NameNod:负责协调数据存储
DataNod:存储被拆分的数据块
JobTracker:协调计算
TaskTracker:负责完成JobTrack的计算
SecondaryNameNod 帮助NameNod收集系统运行数据
Hadoop特点:
-
高可靠性
-
高效性
-
高可扩展性
-
高容错性
-
成本低
-
运行在Linux平台上
-
支持多种编程语言
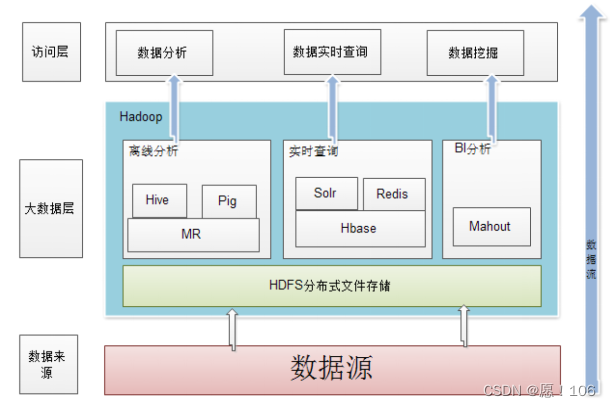
HDFS
计算机集群结构
分布式文件系统把文件存储在多个计算机节点上、所有的计算机节点构成一个集群
相比多个处理器和专用高级硬件的并行化处理装置 大大降低的成本开销
图无需记忆,仅仅帮助理解
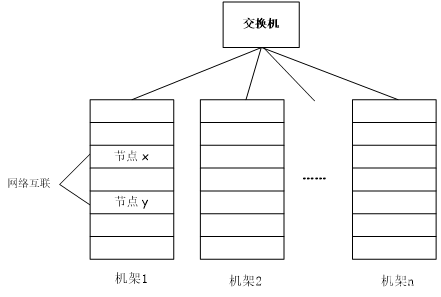
分布式文件系统的结构
由: MasterNode NameNode SlaveNode DataNode构成
图无需记忆,仅仅帮助理解
HDFS实现目标:
-
廉价设备
流数据读写
大数据集
简单文件模型
跨平台
HDFS 局限:
无法 多用户写入和修改任意文件
不适 低延迟数据访问
很难高效存储打大量小文件
HDFS默认一个块64MB
寻址方式:
从NameNode中找到构成目标文件的数据快的位置列表、从位置列表中得到存储各数据块的数据节点位置,数据节点找到文件返回给客户端
HDFS采用抽象数据块好处
-
支持大规模文件存储
一个大文件会被拆分成小文件分发到各个节点、所以文件大小不受单个节点影响
简化系统设计
适合数据备份
每个文件都可以冗余存储到各个节点、提高了容错性
三个副本如何存储
第一个副本:放置在上传文件的数据节点;如果是集群外提交,则随机挑选一台磁盘不太满、CPU不太忙的节点
第二个副本:放置在与第一个副本不同的机架的节点上
第三个副本:与第一个副本相同机架的其他节点上
更多副本:随机节点
NameNod & DataNode
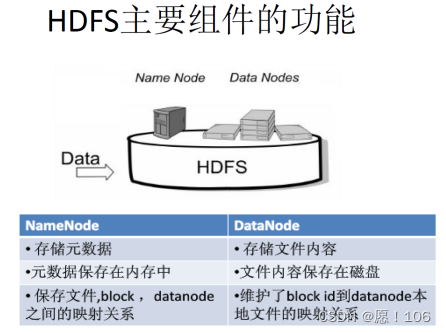
FsImage
-
维护整个系统的所有目录和文件信息
-
保存了最新的元数据检查点、包含了整个系统的所有目录和文件信息(扩展)
EditLog
- 存储了对所有文件 操作(编辑、删除、添加……) 的日志
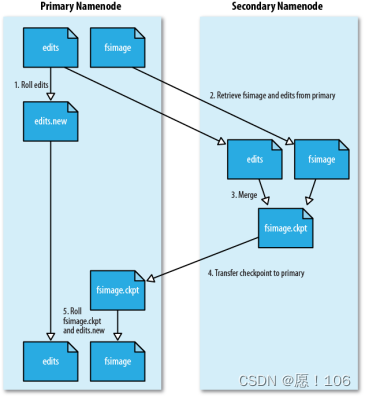
FsImage EditLog 的备份(其备份在secondaryNamenode上)
-
NameNode暂停使用EditLog,创建 EditLong.new.
-
secondaryNamenode 获取到NameNode上的fsimage 和 editlog(通过get方式)
-
secondaryNamenode 将fsimage存入内存,一条一条执行editlog中的更新操作,将fsimage和editlog合并
-
SecondaryNameNode 通过(post方式)将 Fsimage发送到 NameNode上
-
Namenode 用Editlog.new 替代 Editlog
数据节点出错
-
每个数据节点会定期的向NameNode发送“心跳”(报告自己的状态)
-
当数据节点出错,“心跳”将停止、这时数据节点就会被标记为“宕机”,NameNode将不再向该节点发送任何I/O
-
由于数据节点不可用可能会出现数据块的副本数量小于****冗余因子****
-
当系统检测到莫数据节点出现 3.这种情况,就会为该节点生成新的副本
建议看视频:15分钟左右
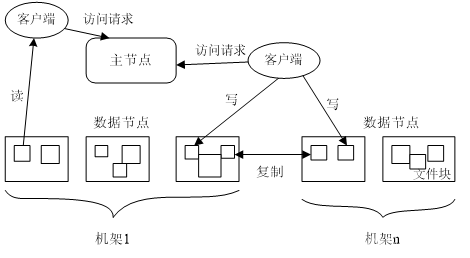
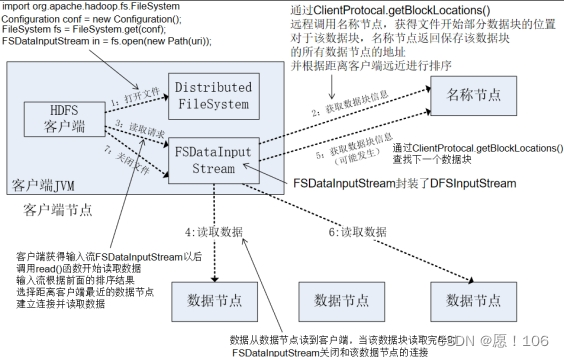
读数据的过程
和寻址方式有一定 类似
重要
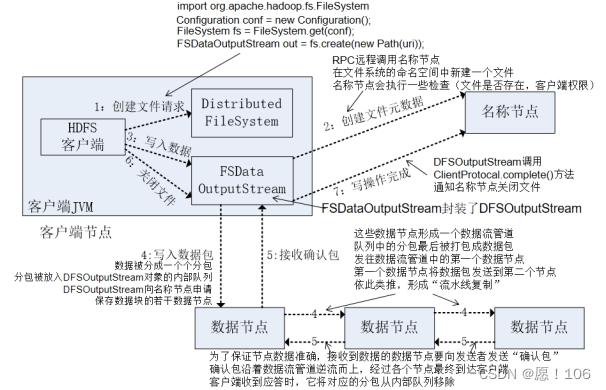
写数据的过程
HDFS常用命名
建议命名头使用 hadoop fs
运用
Hdfs dfs -ls <指定路径>显示指定路径的所有文件Hdfs dfs -madir <指定路径>创建指定路径下的指定name的文件夹…… -put <本地文件> <目标位置>…… -get <目标文件> <指定位置>复制文件到本地文件系统hadoop fs -copyFromLocal <localsrc> <dst>将本地源文件<localsrc>复制到路径<dst>指定的文件或文件夹中…… -cat <指定文件>查看指定文件
MapReduce
-
MapReduce将计算过程抽象到了两个函数:Map和Reduce
-
MapReduce采用“分而治之”策略,将大量数据分割成片,这些片可以被map处理
-
MapReduce计算向数据靠拢因为: 移动数据需要大量网络传输开销
-
I MapReduce 采用Master/slave 架构,及一master和若干slave。
- Master上运行JobTracker,slave上运行TaskTracker
- JobTracker:协调计算
- TaskTracker:负责完成JobTrack的计算
Habse
Habse是对bigtable的实现

Habse是一个稀疏、多维、排序的映射表。根据行键排序
表的索引是行键、列族、列限定符、时间戳确定
Habse存储的是 字符串,没有数据类型
更新操作时不会删除旧的版本(总版本数达到建立表时所设立的版本数时会删除最旧的版本)
habse功能组件
- 库函数
- 一个Master主服务器
- 许多region(区域、分区)服务器
region服务器:存储和维护Master服务器分配给自己region、处理客户端请求
Master服务器:管理维护Habse表分区信息、维护region队列、分配region、维持整体Habse
region
-
一个region 1G-2G
-
同一个Region不会被拆分到多个Region服务器上
-
每个Region服务器可以有10-1000Region及 10G–1T
region定位
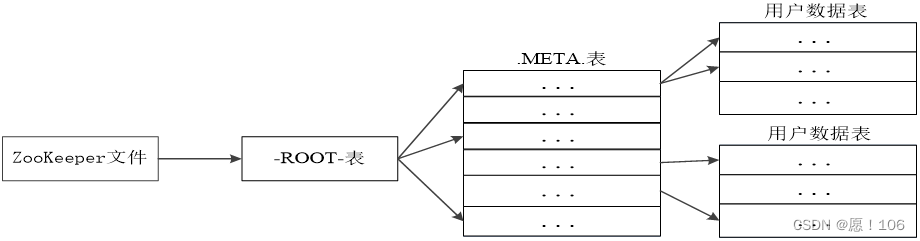
原数组表(META表)存放region和region服务器的映射关系
当数据Habse表过大时,META也会被分成多个region
Root表记录元数据的具体位置,其只有一个region
zookeepre记录root表位置
- HBase有三层结构
计算方式
假设.META.表的每行(一个映射条目)在内存中大约占用1KB,并且每个Region限制为128MB,那么,上面的三层结构可以保存的用户数据表的Region数目的计算方法是:
root最多有 128MB/1kB = 2^17行
每个mate最大只有 128MB/1kB = 2^17行
所有最多只能存2^17 * 2^17
HLong工作原理
采用预写式日志,及先写日志在存入数据
Habse 命令
启动Habse、先启动hadoop(start-all.sh)再启动habse
start-habse.sh
通过habse shell打开habse 的shell界面
通过exit退出shell界面
stop-habse.sh停止habse
创建表
create 'student','name','sex',{NAME=>'course',VERSIONS=>2}
插入数据
put 'student','95001','name','xiaog'put 'student','95001','name','xiaoming'
列族下可以再分
put 'student','95001','course:math','31'
删除指定数据
delete 'student','95001','name'
删除指定一行
deleteall 'student','95001'
查看指定一行
get 'studet','95001'
查看指定版本数据
get 'student','95001',{COLUMN=>'name',VERSIONS=>1}
查看整个表
scan 'student'
停用表
disable 'student'
删除表
drop 'student'eixt
Hive
因为使用java编程效率比较低、提供一种利用sql的语言进行查询
操作
Hive可以用自带的derby来存储元数据
启动 hadoop在启动hive
start-all.shhive数据类型;
TINYINT 1个字节
SMALLINT 2个字节
INT 4个字节
BIGINT 8个字节
FLOAT 4个字节
Double 8个
ARRAY:有序字段
MAP: 无序字段
STRUCT:一组命名的字段
与sql不同的是hive有时需要指定分隔符和数据位置
指定分隔符
row format delimited fields terminated by ','
指定是数据位置
location '/C/……'
分区,不能在创建表中写
partitioned by(city string,state string)
创建数据库
create database if not exists hive;
使用数据库
use hive
创建表
create table if not exists hiveusr(
name string comment 'username',
sex string,
course int)创建外部表关键字external
create external if not exists usr2(
name string,
address struct<street:string,city:string,QQ:string,weixi:string>,
identyfy map<int,tinytin>
ff map<int,int>)
row format delimited filds terminated by ','
location '/usr/....'增加列
alter table hiveusr add columns(age int);
删除列
alter table hiveusr replace columns(age int);导入数据
load data local inpath 'usr/local/....' overwrite table hiveusr.
如果数据在本地要加上local关键字,利用overwrite可以让追加效果变成覆盖插入数据
insert overwrite table hivesur values('xx','man','1')从其他表中导入
insert overwirte table hivesur select name,age,course from stu where (条件)
map<int,int>)
row format delimited filds terminated by ‘,’
location ‘/usr/…’
增加列
alter table hiveusr add columns(age int);
删除列
alter table hiveusr replace columns(age int);
导入数据
load data local inpath ‘usr/local/…’ overwrite table hiveusr.
如果数据在本地要加上local关键字,利用overwrite可以让追加效果变成覆盖
插入数据
insert overwrite table hivesur values(‘xx’,‘man’,‘1’)
从其他表中导入
insert overwirte table hivesur select name,age,course from stu where (条件)
相关文章:
hadoop考试应急
概述 四大特点:大量化、快速化、多元化、价值化 关键技术:采集、存储管理、处理分析、隐私和安全 计算模式:批处理、流、图、查询分析计算 Hadoop处理架构 了解就好 2007年,雅虎在Sunnyvale总部建立了M45——一个包含了4000…...

【React】Hooks
🚩🚩🚩 💎个人主页: 阿选不出来 💨💨💨 💎个人简介: 一名大二在校生,学习方向前端,不定时更新自己学习道路上的一些笔记. 💨💨💨 💎目…...

升级Room引发的惨案!!
kotlin升级 在升级kotlin的时候,直接升级到大版本的kotlin(比如1.7以上),直接报错,只是报错不知道原因。 koltin Release details 后来把koltin版本改成1.6.0,报如下的错,我们才知道gradle是需…...

RPC框架:一文带你搞懂RPC
RPC是什么(GPT答) ChatGPT回答: RPC(Remote Procedure Call)是一种分布式应用程序的编程模型,允许程序在不同的计算机上运行。它以一种透明的方式,将一个程序的函数调用定向到远程系统上的另一个程序,而使…...
电子招标采购系统源码—企业战略布局下的采购寻源
智慧寻源 多策略、多场景寻源,多种看板让寻源过程全程可监控,根据不同采购场景,采取不同寻源策略, 实现采购寻源线上化管控;同时支持公域和私域寻源。 询价比价 全程线上询比价,信息公开透明࿰…...
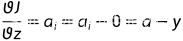
P16 激活函数与Loss 的梯度
参考:https://www.ngui.cc/el/507608.html?actiononClick这里面简单回顾一下PyTorch 里面的两个常用的梯度自动计算的APIautoGrad 和 Backward, 最后结合 softmax 简单介绍一下一下应用场景。目录:1 autoGrad2 Backward3 softmax一 autoGrad输入 x输出损…...
ThinkPHP5美食商城系统
有需要请私信或看评论链接哦 可远程调试 ThinkPHP5美食商城系统一 介绍 此美食商城系统基于ThinkPHP5框架开发,数据库mysql,前端bootstrap。系统角色分为用户和管理员。用户注册登录后可购买美食,个人中心,评论和反馈等ÿ…...
 / <script setup>))
Vue3 - $refs 使用教程,父组件调用获取子组件数据和方法(setup() / <script setup>)
前言 在 Vue2 中父组件使用 $refs 调用子组件数据和方法非常简单,但在 Vue3 中这种方法行不通了。 本文实现了 Vue3 中父组件使用 $refs 获取调用子组件数据和方法教程, 并且提供了 setup() 与 <script setup> 两种 “开发模式” 的示例代码,请根据需要进行选择。 网…...
| 真题+思路+考点+代码+岗位)
华为OD机试 - 众数和中位数(Python)| 真题+思路+考点+代码+岗位
众数和中位数 题目 众数是指一组数据中出现次数多的数 众数可以是多个中位数是指把一组数据从小到大排列,最中间的那个数, 如果这组数据的个数是奇数,那最中间那个就是中位数 如果这组数据的个数为偶数,那就把中间的两个数之和除以 2 就是中位数查找整型数组中元素的众数并…...

一眼万年的 Keychron 无线机械键盘
一眼万年的 Keychron 无线机械键盘 一款好的键盘对于程序员或者喜欢码字的人来说是非常重要的,而最近博主入手了自己的第一款机械键盘——Keychron 无线机械键盘。 机械键盘特点 有独立轴体,通过两个簧接触,来触发信号,价格相对贵…...

自动化测试高频面试题(含答案)
Hello,你们的好朋友来了!今天猜猜我给大家带来点啥干货呢?最近很多小伙伴出去面试的时候经常会被问到跟自动化测试相关的面试题。所以,今天特意给大家整理了一些经常被公司问到的自动化测试相关的面试题。停,咱先收藏起…...

3、按键扫描检测处理
说明:本文处理按键的短按、长按检测执行,非矩阵按键 硬件可以类似如下连接即可,无需放置上下拉电阻; 按键动作分长按、短按(弹起时执行)两种 按下不放执行长按,但松开按键时不予执行短按函数 多个按键可以同时操作 按…...
集中式存储和分布式存储
分布式存储是相对于集中式存储来说的,在介绍分布式存储之前,我们先看看什么是集中式存储。不久之前,企业级的存储设备都是集中式存储。所谓集中式存储,从概念上可以看出来是具有集中性的,也就是整个存储是集中在一个系…...
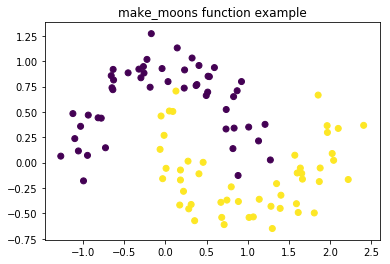
【机器学习数据集】如何获得机器学习的练习数据?
一、scikit-learn自带数据集Scikit-learn内置了很多可以用于机器学习的数据,可以用两行代码就可以使用这些数据。自带的小的数据集为:sklearn.datasets.load_<name>load_bostonBoston房屋价格回归506*13fetch_california_housing加州住房回归20640…...

【编程实践】使用 Kotlin HTTP 框架 Fuel 实现 GET,POST 接口 kittinunf.fuel【极简教程】
目录 Fuel 简介 实现代码 GET网络请求用法(有三种写法...

大数据DataX(一):DataX的框架设计和插件体系
文章目录 DataX的框架设计和插件体系 一、DataX是什么...

软考高级信息系统项目管理师系列之十一:项目进度管理
软考高级信息系统项目管理师系列之十一:项目进度管理 一、进度管理领域输入、输出、工具和技术表二、项目进度管理1.项目进度管理过程2.项目进度管理三、项目进度管理过程1.项目进度管理2.工作包和活动3.活动清单4.活动属性5.项目进度网络图6.资源日历7.活动资源需求8.资源分解…...

vue2版本《后台管理模式》(下)
文章目录前言一、home 页以下都属于home子组件二、header 头部 组件二、Menu 页面三、Bread 面包屑四、Footer五 、分页器: Pageing六、权限管理总结前言 这章…...
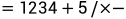
软考中级-程序设计语言
(1)解释器解释源程序时不生成独立的目标代码,源程序和解释程序都参与到程序执行中。(2)编译器编译时生成独立的目标代码,运行时是运行与源程序等价的目标程序,源程序不参与执行。阶段补充&#…...
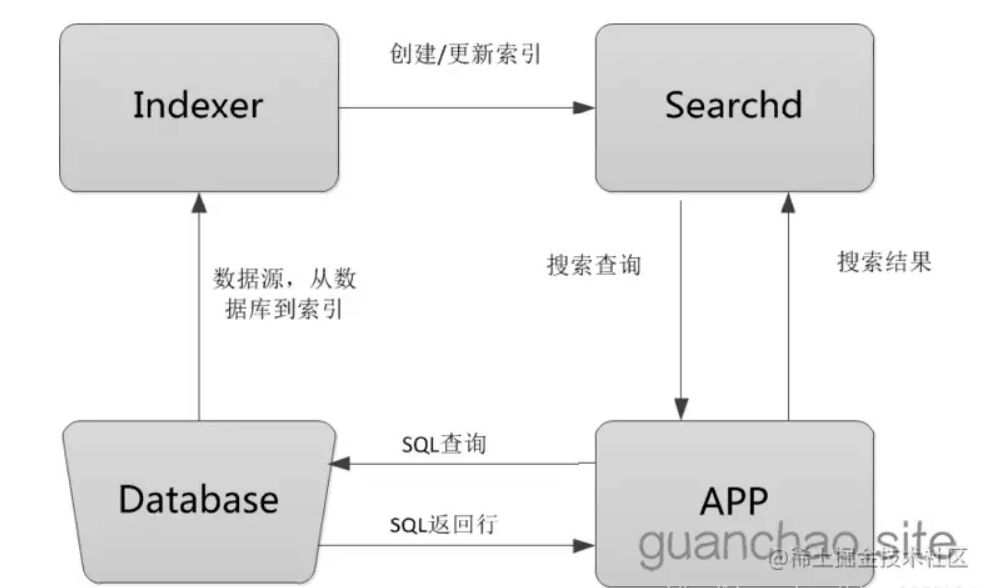
Sphinx : 高性能SQL全文检索引擎
Sphinx是一款基于SQL的高性能全文检索引擎,Sphinx的性能在众多全文检索引擎中也是数一数二的,利用Sphinx,我们可以完成比数据库本身更专业的搜索功能,而且可以有很多针对性的性能优化。 Sphinx的特点 快速创建索引:3分…...

突破百度网盘限速:从问题诊断到性能优化的实战全攻略
突破百度网盘限速:从问题诊断到性能优化的实战全攻略 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 问题诊断:揭开网盘下载的痛点图谱 场景引入&…...

OpenClaw飞书集成实战:Qwen3-VL:30B智能对话与任务触发
OpenClaw飞书集成实战:Qwen3-VL:30B智能对话与任务触发 1. 为什么选择OpenClaw飞书组合 去年夏天,我接手了一个棘手的任务:团队每天产生上百条会议录音和杂乱无章的文档碎片,需要人工整理成结构化会议纪要。当我尝试用传统RPA工…...

MacBook Pro本地部署OpenClaw:百川2-13B量化模型7×24小时运行方案
MacBook Pro本地部署OpenClaw:百川2-13B量化模型724小时运行方案 1. 为什么选择MacBook Pro部署OpenClaw? 去年冬天,当我第一次尝试在MacBook Pro上部署量化版百川2-13B模型时,身边的朋友都觉得我疯了。"M1芯片能跑得动13B…...
)
基于springboot家庭影像管理系统设计与开发(源码+精品论文+答辩PPT等资料)
博主介绍:CSDN毕设辅导第一人、靠谱第一人、全网粉丝50W,csdn特邀作者、博客专家、腾讯云社区合作讲师、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交…...

三层架构破解小红书数据采集难题:Appium+MitmProxy双引擎实战
三层架构破解小红书数据采集难题:AppiumMitmProxy双引擎实战 【免费下载链接】XiaohongshuSpider 小红书爬取 项目地址: https://gitcode.com/gh_mirrors/xia/XiaohongshuSpider 在小红书内容生态快速发展的今天,数据工程师和产品分析师面临着内容…...
)
Windows 11下保姆级安装Isaac Sim 4.5.0与Isaac Lab避坑全记录(含CUDA 12.8配置)
Windows 11下Isaac Sim 4.5.0与Isaac Lab全流程部署指南(RTX 4090实测版) 对于机器人仿真和AI开发领域的从业者来说,NVIDIA Isaac Sim和Isaac Lab无疑是当前最强大的工具组合之一。然而,当我在自己的RTX 4090显卡上首次尝试部署这…...

终极桌面歌词解决方案:LyricsX 让你的音乐体验全面升级
终极桌面歌词解决方案:LyricsX 让你的音乐体验全面升级 【免费下载链接】Lyrics Swift-based iTunes plug-in to display lyrics on the desktop. 项目地址: https://gitcode.com/gh_mirrors/lyr/Lyrics 在macOS平台上享受音乐时,你是否曾渴望拥有…...

4 大平台 “免费拿” 玩法大拆解,看完不踩坑
现在很多平台都有 “0元领东西” 的活动,玩法不一样,难度也差很多。今天用大白话对比拼dd、淘b、京d、全能锦鲤,简单易懂,看完就知道该选哪个。一、各平台免费拿怎么玩?1. 拼dd(老牌砍价)玩法&a…...

NaViL-9B图文问答入门:Web界面支持拖拽上传+历史记录回溯功能
NaViL-9B图文问答入门:Web界面支持拖拽上传历史记录回溯功能 1. 平台介绍 NaViL-9B是一款原生多模态大语言模型,由专业研究机构开发。它不仅能像传统语言模型一样处理纯文本问答,还具备强大的图片理解能力。这意味着你可以上传一张图片&…...

Gemma-3-12b-it实战教程:极简UI背后隐藏的12B模型内存映射优化策略
Gemma-3-12b-it实战教程:极简UI背后隐藏的12B模型内存映射优化策略 1. 项目概述 Gemma-3-12b-it是一款基于Google Gemma-3-12b-it大模型开发的本地多模态交互工具。这款工具针对12B大模型进行了全维度的CUDA性能优化,支持图片上传和文本提问的流式生成…...