2W字正则表达式基础知识总结,这一篇就够了!!(含前端常用案例,建议收藏)
正则表达式 (Regular Expression,简称 RE 或 regexp ) 是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符")
正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。
主流的开发语言都内置或者通过第三方库支持利用正则表达式进行字符串操作
第一个正则表达式
下面这个范例使用正则表达式从字符串中找出手机号
var str = "my phone is: 13888888888";var patt1 = /\d{3,4}-?\d{3,4}-?\d{2,4}/;document.write(str.match(patt1));运行上面的范例,输出结果如下
13888888888听说过正则表达式的人都知道正则表达式能用来匹配、查找、替换文本,不管怎样,我们一定使用过简单的正则表达式
Windows 上的文件查找
例如,我们在 Windows 里里面使用 问号(?)和 星号()通配符来查找硬盘上的文件,知道问号(?) 可以代表文件名中的单个字符,而星号()可以表示任意数量的字符
像 data?.dat 这样的模式将查找下列文件:
data1.datdata2.datdatax.datdataN.dat使用 * 字符代替 ? 字符可以扩大查找范文,data*.dat 匹配下列所有文件:
data.datdata1.datdata2.datdata12.datdatax.datdataXYZ.dat这种方法很有用,因为简单易记,完成查找文件这种工作绰绰有余了
正则表达式
像 data*.dat 和 data?.dat 这样的字符串就是正则表达式,但正则表达式不止于此
正则表达式功能强大,而且更加灵活,可以通过简单的办法来实现强大的功能
比如下图这个正则表达式
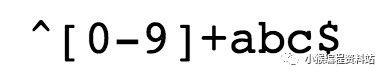
匹配以 任意数量数字开头的以 abc 结尾的字符串
^ 匹配开头,意思是字符串要从行首开始,且第一个字符就是数字 (0到9任意)
[0-9]+ 匹配多个数字: [0-9] 匹配单个数字,+ 表示前面的数字出现一次以上
abc 表示匹配 abc 三个字符
$ 匹配结尾,表示字符串要此结尾(可能是一行结束或者文本结束 abc$ 匹配以 abc 结尾
范例
匹配以数字开头,并以 abc 结尾的字符串
var str = "456xyz";var patt1 = /^[0-9]+xyz$/;document.write(str.match(patt1));匹配的结果如下
456xyz为什么使用正则表达式?
各种开发语言的字符串数据类型通常都提供了简单的查找和替换能力,但这种查找替换要给予确定的查找字符,比如只能一次查找 food 而不能一次查找以 f 或 g 开头的以 ood 结尾的 food 或 good。
但我们日常开发中却迫切希望能一次性查找出所有 food 或者 good。这时候正则表达式就孕育而生了。
正则表达式而已使用 (f|d)ood 一次性找出所有 food 或 good 单词,可以用 1\d{10} 找出所有的手机号
这就是正则表达式,它的能力就是这么强大
通常来说,有了正则表达式,我们可以:
测试字符串内的模式
例如,可以测试输入字符串,以查看字符串内是否出现电话号码模式或信用卡号码模式。这称为数据验证
替换文本
可以使用正则表达式来识别文档中的特定文本,完全删除该文本或者用其他文本替换它
基于模式匹配从字符串中提取子字符串
可以查找文档内或输入域内特定的文本
例如,我们可能需要搜索整个网站,删除过时的材料,以及替换某些 html 格式标记,在这种情况下,可以使用正则表达式来确定在每个文件中是否出现该材料或该 HTML 格式标记,将受影响的文件列表缩小到包含需要删除或更改的材料的那些文件,然后可以使用正则表达式来删除过时的材料。最后,可以使用正则表达式来搜索和替换标记
历史
正则表达式的"祖先"可以一直上溯至对人类神经系统如何工作的早期研究
Warren McCulloch 和 Walter Pitts 这两位神经生理学家研究出一种数学方式来描述这些神经网络
1956 年, 一位叫 Stephen Kleene 的数学家在 McCulloch 和 Pitts 早期工作的基础上,发表了一篇标题为"神经网事件的表示法"的论文,引入了正则表达式的概念
正则表达式就是用来描述他称为"正则集的代数"的表达式,因此采用"正则表达式"这个术语
随后,发现可以将这一工作应用于使用 Ken Thompson 的计算搜索算法的一些早期研究,Ken Thompson 是 Unix 的主要发明人
正则表达式的第一个实用应用程序就是 Unix 中的 qed 编辑器
剩下的历史,就众所周知了,从那时起直至现在正则表达式都是基于文本的编辑器和搜索工具中的一个重要部分
应用领域
目前,正则表达式已经在很多软件中得到广泛的应用,包括 *nix(Linux, Unix等)、HP 等操作系统,php、C#、Java 等开发环境,以及很多的应用软件中,都可以看到正则表达式的影子
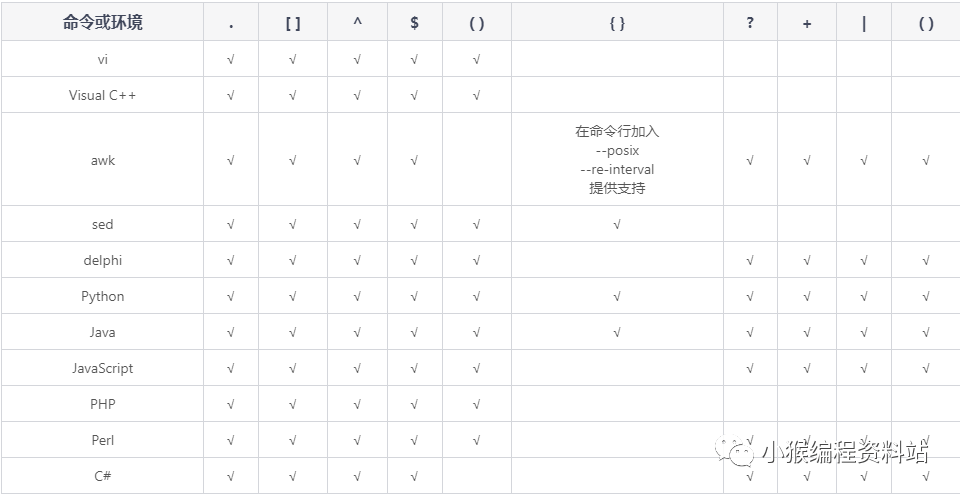
正则表达式语法支持情况
下表列出了流行的开发语言或工具对正则表达式语法的支持情况
正则表达式 - 语法
现在我们来学习正则表达式的语法,正则表达式的语法很简单,也很复杂
正则表达式( regular expression )描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等
构造正则表达式的方法和创建数学表达式的方法一样,也就是用多种元字符与运算符可以将小的表达式结合在一起来创建更大的表达式
正则表达式的组件可以是单个的字符、字符集合、字符范围、字符间的选择或者所有这些组件的任意组合
正则表达式是由普通字符(例如字符 a 到 z)以及特殊字符(称为"元字符")组成的文字模式
模式描述在搜索文本时要匹配的一个或多个字符串
正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配
普通字符
普通字符包括没有显式指定为元字符的所有可打印和不可打印字符
这包括所有大写和小写字母、所有数字、所有标点符号和一些其它符号
非打印字符
非打印字符也可以是正则表达式的组成部分
下表列出了表示非打印字符的转义序列:
字符 | 描述 |
\cx | 匹配由 x 指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符 x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符 |
\f | 匹配一个换页符。等价于 \x0c 和 \cL |
\n | 匹配一个换行符。等价于 \x0a 和 \cJ |
\r | 匹配一个回车符。等价于 \x0d 和 \cM |
\s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v] |
\S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v] |
\t | 匹配一个制表符。等价于 \x09 和 \cI |
\v | 匹配一个垂直制表符。等价于 \x0b 和 \cK |
特殊字符
所谓特殊字符,就是一些有特殊含义的字符,如上面说的 tw*e 中的 *,简单的说就是表示任何字符串的意思
如果要查找字符串中的 * 符号,则需要对 * 进行转义,即在其前加一个 fly\*e 匹配 fly*e
许多元字符要求在试图匹配它们时特别对待,若要匹配这些特殊字符,必须首先使字符"转义",即,将反斜杠字符\放在它们前面
下表列出了正则表达式中的特殊字符
特别字符 | 描述 |
$ | 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 '\n' 或 '\r'。要匹配 $ 字符本身,请使用 \$ |
( ) | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 ( 和 ) |
* | 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 * |
+ | 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 + |
. | 匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 . |
[ | 标记一个中括号表达式的开始。要匹配 [,请使用 [ |
? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 \? |
\ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, 'n' 匹配字符 'n'。'\n' 匹配换行符。序列 '\' 匹配 "\",而 '(' 则匹配 "(" |
^ | 匹配输入字符串的开始位置,除非在方括号表达式中使用,此时它表示不接受该字符集合。要匹配 ^ 字符本身,请使用 \^ |
{ | 标记限定符表达式的开始。要匹配 {,请使用 { |
| | 指明两项之间的一个选择。要匹配 |,请使用 \| |
限定符
限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配
有 * 或 + 或 ? 或 {n} 或 {n,} 或 {n,m} 共6种
正则表达式的限定符有
字符 | 描述 |
* | 匹配前面的子表达式零次或多次 例如,zo 能匹配 "z" 以及 "zoo"。 等价于 {0,} |
+ | 匹配前面的子表达式一次或多次 例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,} |
? | 匹配前面的子表达式零次或一次 例如,"do(es)?" 可以匹配 "do" 或 "does" 中的 "does" 或 "doxy" 中的 "do" ? 等价于 {0,1} |
{n} | n 是一个非负整数。匹配确定的 n 次 例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o |
{n,} | 至少匹配 n 次 n 是一个非负整数。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+'。'o |
{n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o |
由于章节编号在大的输入文档中会很可能超过九,所以您需要一种方式来处理两位或三位章节编号
限定符给您这种能力
面的正则表达式匹配编号为任何位数的章节标题:
/Chapter [1-9][0-9]*/请注意,限定符出现在范围表达式之后。因此,它应用于整个范围表达式,在本例中,只指定从 0 到 9 的数字(包括 0 和 9)
这里不使用 + 限定符,因为在第二个位置或后面的位置不一定需要有一个数字
也不使用 ?字符,因为它将章节编号限制到只有两位数
我们需要至少匹配 Chapter 和空格字符后面的一个数字
如果知道章节编号被限制为只有 99 章,可以使用下面的表达式来至少指定一位但至多两位数字
/Chapter [0-9]{1,2}/上面的表达式的缺点是,大于 99 的章节编号仍只匹配开头两位数字
另一个缺点是 Chapter 0 也将匹配
只匹配两位数字的更好的表达式如下:
/Chapter [1-9][0-9]?/或
/Chapter [1-9][0-9]{0,1}/*、+限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个 ? 就可以实现非贪婪或最小匹配
例如,可能搜索 html 文档,以查找括在 H1 标记内的章节标题。该文本在您的文档中如下:
<h1>Chapter1 - 介绍正则表达式</h1>贪婪: 下面的表达式匹配从开始小于符号 (<) 到关闭 H1 标记的大于符号 (>) 之间的所有内容
/<.*>/非贪婪: 如果您只需要匹配开始和结束 H1 标签,下面的非贪婪表达式只匹配 <h1>
/<.*?>/如果只想匹配开始的 h1 标签,表达式则是:
/<\w+?>/通过在*、+或?限定符之后放置?,该表达式从"贪心"表达式转换为"非贪心"表达式或者最小匹配
定位符
定位符使您能够将正则表达式固定到行首或行尾
它们还使您能够创建这样的正则表达式,这些正则表达式出现在一个单词内、在一个单词的开头或者一个单词的结尾
定位符用来描述字符串或单词的边界,^和$分别指字符串的开始与结束,\b描述单词的前或后边界,\B表示非单词边界
正则表达式的定位符有
字符 | 描述 |
^ | 匹配输入字符串开始的位置 如果设置了 RegExp 对象的 Multiline 属性,^ 还会与 \n 或 \r 之后的位置匹配 |
$ | 匹配输入字符串结尾的位置 如果设置了 RegExp 对象的 Multiline 属性,$ 还会与 \n 或 \r 之前的位置匹配 |
\b | 匹配一个字边界,即字与空格间的位置 |
\B | 非字边界匹配 |
注意
不能将限定符与定位符一起使用,由于在紧靠换行或者字边界的前面或后面不能有一个以上位置,因此不允许诸如^*之类的表达式。
若要匹配一行文本开始处的文本,请在正则表达式的开始使用 ^ 字符
不要将^的这种用法与中括号表达式内的用法混淆
若要匹配一行文本的结束处的文本,请在正则表达式的结束处使用 $ 字符
若要在搜索章节标题时使用定位点,下面的正则表达式匹配一个章节标题,该标题只包含两个尾随数字, 并且出现在行首:
/^Chapter [1-9][0-9]{0,1}/真正的章节标题不仅出现行的开始处,而且它还是该行中仅有的文本
它即出现在行首又出现在同一行的结尾
下面的表达式能确保指定的匹配只匹配章节而不匹配交叉引用
通过创建只匹配一行文本的开始和结尾的正则表达式,就可做到这一点
/^Chapter [1-9][0-9]{0,1}$/匹配字边界稍有不同,但向正则表达式添加了很重要的能力
字边界是单词和空格之间的位置
非字边界是任何其他位置。下面的表达式匹配单词 Chapter 的开头三个字符,因为这三个字符出现字边界后面:
/\bCha/\b 字符的位置是非常重要的
如果它位于要匹配的字符串的开始,它在单词的开始处查找匹配项
如果它位于字符串的结尾,它在单词的结尾处查找匹配项
例如,下面的表达式匹配单词 Chapter 中的字符串 ter,因为它出现在字边界的前面:
/ter\b/下面的表达式匹配 Chapter 中的字符串 apt,但不匹配 aptitude 中的字符串 apt:
/\Bapt/字符串 apt 出现在单词 Chapter 中的非字边界处,但出现在单词 aptitude 中的字边界处 对于\B非字边界运算符,位置并不重要,因为匹配不关心究竟是单词的开头还是结尾
选择
用圆括号将所有选择项括起来,相邻的选择项之间用 | 分隔
但用圆括号会有一个副作用,是相关的匹配会被缓存,此时可用 ?: 放在第一个选项前来消除这种副作用
其中 ?: 是非捕获元之一,还有两个非捕获元是 ?= 和 ?! ,这两个还有更多的含义,前者为正向预查,在任何开始匹配圆括号内的正则表达式模式的位置来匹配搜索字符串,后者为负向预查,在任何开始不匹配该正则表达式模式的位置来匹配搜索字符串
反向引用
对一个正则表达式模式或部分模式两边添加圆括号将导致相关匹配存储到一个临时缓冲区中,所捕获的每个子匹配都按照在正则表达式模式中从左到右出现的顺序存储
缓冲区编号从 1 开始,最多可存储 99 个捕获的子表达式
每个缓冲区都可以使用 \n 访问,其中 n 为一个标识特定缓冲区的一位或两位十进制数
可以使用非捕获元字符 ?:、?= 或 ?! 来重写捕获,忽略对相关匹配的保存
反向引用的最简单的、最有用的应用之一,是提供查找文本中两个相同的相邻单词的匹配项的能力
以下面的句子为例:
Isis the cost ofof gasoline going up up?上面的句子很显然有多个重复的单词
如果能设计一种方法定位该句子,而不必查找每个单词的重复出现,那该有多好
下面的正则表达式使用单个子表达式来实现这一点:
查找重复的单词:
var str = "Is is the cost of of gasoline going up up";var patt1 = /\b([a-z]+) \1\b/;document.write(str.match(patt1));捕获的表达式,正如[a-z]+指定的,包括一个或多个字母
正则表达式的第二部分是对以前捕获的子匹配项的引用,即,单词的第二个匹配项正好由括号表达式匹配
\1指定第一个子匹配项
字边界元字符确保只检测整个单词。否则,诸如 "is issued" 或 "this is" 之类的词组将不能正确地被此表达式识别
正则表达式后面的全局标记g指定将该表达式应用到输入字符串中能够查找到的尽可能多的匹配
表达式的结尾处的不区分大小写i标记指定不区分大小写
多行标记指定换行符的两边可能出现潜在的匹配
反向引用还可以将通用资源指示符 (URI) 分解为其组件
假定您想将下面的 URI 分解为协议(ftp、http 等等)、域地址和页/路径:
https://www.fly63.com:80/yufei/html/html-basic-index.html.html下面的正则表达式提供该功能:
var str = "https://www.fly63.com:80/html/html-basic-index.html";var patt1 = /(\w+):\/\/([^/:]+)(:\d*)?([^# ]*)/;arr = str.match(patt1);for (var i = 0; i < arr.length ; i++) {document.write(arr[i]);document.write("<br>");}第一个括号子表达式捕获 Web 地址的协议部分
该子表达式匹配在冒号和两个正斜杠前面的任何单词
第二个括号子表达式捕获地址的域地址部分
子表达式匹配 / 和 : 之外的一个或多个字符
第三个括号子表达式捕获端口号(如果指定了的话)
该子表达式匹配冒号后面的零个或多个数字
只能重复一次该子表达式
最后,第四个括号子表达式捕获 Web 地址指定的路径和 / 或页信息
该子表达式能匹配不包括 # 或空格字符的任何字符序列
将正则表达式应用到上面的 URI,各子匹配项包含下面的内容:
第一个括号子表达式包含 "https"
第二个括号子表达式包含 "www.fly63.com"
第三个括号子表达式包含 ":80"
第四个括号子表达式包含 "/yufei/html/html-basic-index.html"
正则表达式 - 元字符 ( meta char)
要写出正则表达式,一定要知道表达式中可以使用哪些字符,代表哪些意思,这些字符就是元字符
下表列出了所有语言几乎都支持的元字符列表以及它们的行为
字符 | 描述 |
\ | 将下一个字符标记为一个特殊字符、或一个原义字符、或一个 向后引用、或一个八进制转义符 例如,'n' 匹配字符 "n"。'\n' 匹配一个换行符 序列 '\' 匹配 "\" 而 "(" 则匹配 "(" |
^ | 匹配输入字符串的开始位置 如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 '\n' 或 '\r' 之后的位置 |
$ | 匹配输入字符串的结束位置 如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 '\n' 或 '\r' 之前的位置 |
* | 匹配前面的子表达式零次或多次 例如,zo 能匹配 "z" 以及 "zoo"。 等价于{0,} |
+ | 匹配前面的子表达式一次或多次 例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,} |
? | 匹配前面的子表达式零次或一次 例如,"do(es)?" 可以匹配 "do" 或 "does" 。? 等价于 {0,1} |
{n} | n 是一个非负整数。匹配确定的 n 次 例:'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o |
{n,} | n 是一个非负整数。至少匹配n 次 例:'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+'。'o |
{n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次 例如,"o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o |
? | 当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 "oooo",'o+?' 将匹配单个 "o",而 'o+' 将匹配所有 'o' |
. | 匹配除 "\n" 之外的任何单个字符 要匹配包括 '\n' 在内的任何字符,请使用像"(.|\n)"的模式 |
(pattern) | 匹配 pattern 并获取这一匹配。所获取的匹配可以从产生的 Matches 集合得到,在VBScript 中使用 SubMatches 集合,在JScript 中则使用 $0…$9 属性。要匹配圆括号字符,请使用 '(' 或 ')' |
(?:pattern) | 匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用 "或" 字符 (|) 来组合一个模式的各个部分是很有用。例如, 'industr(?:y|ies) 就是一个比 'industry|industries' 更简略的表达式 |
(?=pattern) | 在任何匹配 pattern 的字符串开始处匹配查找字符串 这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用 例如,'Windows (?=95|98|NT|2000)' 能匹配 "Windows 2000" 中的 "Windows" ,但不能匹配 "Windows 3.1" 中的 "Windows" 预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始 |
(?!pattern) | 在任何不匹配 pattern 的字符串开始处匹配查找字符串 这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用 例如'Windows (?!95|98|NT|2000)' 能匹配 "Windows 3.1" 中的 "Windows",但不能匹配 "Windows 2000" 中的 "Windows" 预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始 |
x|y | 匹配 x 或 y 例如,'z|food' 能匹配 "z" 或 "food"。'(z|f)od' 则匹配 "zod" 或 "fod" |
[xyz] | 匹配所包含的任意一个字符 例如, '[abc]' 可以匹配 "plain" 中的 'a' |
[^xyz] | 匹配未包含的任意字符 例如, '[^abc]' 可以匹配 "plain" 中的'p'、'l'、'i'、'n' |
[a-z] | 匹配指定范围内的任意字符 例如,'[a-z]' 可以匹配 'a' 到 'z' 范围内的任意小写字母字符 |
[^a-z] | 匹配任何不在指定范围内的任意字符 例如,'[^a-z]' 可以匹配任何不在 'a' 到 'z' 范围内的任意字符 |
\b | 匹配一个单词边界,也就是指单词和空格间的位置 例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er' |
\B | 匹配非单词边界 'er\B' 能匹配 "verb is" 中的 'er',但不能匹配 "never" 中的 'er' |
\cx | 匹配由 x 指明的控制字符 x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符 例如, \cM 匹配一个 Control-M 或回车符 |
\d | 匹配一个数字字符,等价于 [0-9] |
\D | 匹配一个非数字字符,等价于 [^0-9] |
\f | 匹配一个换页符,等价于 \x0c 和 \cL |
\n | 匹配一个换行符,等价于 \x0a 和 \cJ |
\r | 匹配一个回车符,等价于 \x0d 和 \cM |
\s | 匹配任何空白字符,包括空格、制表符、换页符,等价于 [ \f\n\r\t\v] |
\S | 匹配任何非空白字符,等价于 [^ \f\n\r\t\v] |
\t | 匹配一个制表符,等价于 \x09 和 \cI |
\v | 匹配一个垂直制表符,等价于 \x0b 和 \cK |
\w | 匹配包括下划线的任何单词字符,等价于'[A-Za-z0-9_]' |
\W | 匹配任何非单词字符,等价于 '[^A-Za-z0-9_]' |
\xn | 匹配十六进制字符,其中 n 为十六进制转义值 十六进制转义值必须为确定的两个数字长 例如,'\x41' 匹配 "A"。'\x041' 则等价于 '\x04' & "1" |
\num | 对所获取的匹配 num 的引用 其中 num 是一个正整数。例如,'(.)\1' 匹配两个连续的相同字符 |
\n | 标识一个八进制转义值或一个向后引用 1. 如果 \n 之前至少 n 个获取的子表达式,则 n 为向后引用 2. 如果 n 为八进制数字 (0-7),则 n 为一个八进制转义值 |
\nm | 标识一个八进制转义值或一个向后引用 1. 如果 \nm 之前至少有 nm 个获得子表达式,则 nm 为向后引用 2. 如果 \nm 之前至少有 n 个获取,则 n 为一个后跟文字 m 的向后引用 3. 如果前面的条件都不满足,若 n 和 m 均为八进制数字 (0-7),则 \nm 将匹配八进制转义值 nm |
\nml | 匹配八进制转义值 nml 其中 n 是八进制数字 (0-3),m 和 l 是八进制数字 (0-7) |
\un | 匹配 Unicode 字符 n n 是四个十六进制数字表示的 Unicode 字符,例如, \u00A9 匹配版权符号 (@) |
正则表达式 - 运算符优先级
正则表达式从左到右进行匹配或查找,并遵循优先级顺序:
相同优先级的从左到右进行匹配或查找
不同优先级的运算先高后低
正则表达式运算符优先级
下表列出了正则表达式的优先级顺序 (从最高到最低)
运算符 | 描述 |
|转义符 | |
(), (?:), (?=), [] | 圆括号和方括号 |
*, +, ?, | 限定符 |
^, $, \任何元字符、任何字符 | 定位点和序列(即:位置和顺序) |
| | 替换,"或"操作字符具有高于替换运算符的优先级 使得"m|food"匹配"m"或"food" 若要匹配"mood"或"food",可以使用括号创建子表达式,比如 "(m|f)oo |
正则表达式 - 匹配规则
我们已经把正则表达式的语法和优先级学的差不多了,现在,我们将学习正则表达式的匹配的规则,了解正则表达式是如何从左往右匹配的
1. 基本模式匹配
我们从最简单的开始。
模式,是正规表达式最基本的元素,它们是一组描述字符串特征的字符
模式可以很简单,由普通的字符串组成,也可以非常复杂,往往用特殊的字符表示一个范围内的字符、重复出现,或表示上下文
例如:
^once这个模式包含一个特殊的字符 ^,表示该模式只匹配那些以 once 开头的字符串
该模式与字符串"once upon a time" 匹配,与 "There once was a man from NewYork"不匹配
正如如 ^ 符号表示开头一样,`$ 符号用来匹配那些以给定模式结尾的字符串
bucket$这个模式与 "Who kept all of this cash in a bucket"匹配,与"buckets"不匹配
字符 ^ 和 $ 同时使用时,表示精确匹配(字符串与模式一样)
例如:
^bucket$只匹配字符串"bucket"
如果一个模式不包括 ^和 $ ,那么它与任何包含该模式的字符串匹配
例如
once与字符串
Thereonce was a man from NewYorkWhokept all of his cash in a bucket.是匹配的
在该模式中的字母 (o-n-c-e) 是字面的字符,也就是说,他们表示该字母本身,数字也是一样的
其它一些稍微复杂的字符,如标点符号和白字符(空格、制表符等),要用到转义序列
所有的转义序列都用反斜杠()打头,例如制表符的转义序列是:\t
所以如果我们要检测一个字符串是否以制表符开头,可以用这个模式:
^\t类似的,用 \n表示 "新行",\r表示回车,其他的特殊符号,可以用在前面加上反斜杠,如反斜杠本身用\表示,句号(.)用 \. 表示,以此类推
2. 字符簇
正则表达式通常用来验证用户的输入
当用户提交一个表单以后,要判断输入的电话号码、地址、EMAIL地址、信用卡号码等是否有效,用普通的基于字面的字符是不够的
所以要用一种更自由的描述我们要的模式的办法,它就是字符簇
要建立一个表示所有元音字符的字符簇,就把所有的元音字符放在一个方括号里:
[AaEeIiOoUu]这个模式与任何元音字符匹配,但只能表示一个字符
用连字号可以表示一个字符的范围
如:
[a-z] //匹配所有的小写字母 [A-Z] //匹配所有的大写字母 [a-zA-Z] //匹配所有的字母 [0-9] //匹配所有的数字 [0-9\.\-] //匹配所有的数字,句号和减号 [ \f\r\t\n] //匹配所有的白字符同样的,这些也只表示一个字符,这是一个非常重要的
如果要匹配一个由一个小写字母和一位数字组成的字符串,比如"z2"、"t6"或"g7",但不是"ab2"、"r2d3" 或"b52"的话,用这个模式:
^[a-z][0-9]$尽管[a-z]代表26个字母的范围,但在这里它只能与第一个字符是小写字母的字符串匹配
前面曾经提到 ^ 表示字符串的开头,但它还有另外一个含义,当在一组方括号里使用 ^ 是,它表示"非"或"排除"的意思,常常用来剔除某个字符
还用前面的例子,我们要求第一个字符不能是数字:
^[^0-9][0-9]$这个模式与"&5"、"g7"及"-2"是匹配的, 但与"12"、"66"是不匹配的
下面是几个排除特定字符的例子:
[^a-z] //除了小写字母以外的所有字符 [^\\\/\^] //除了(\)(/)(^)之外的所有字符 [^\"\'] //除了双引号(")和单引号(')之外的所有字符特殊字符 "." (点,句号)在正则表达式中用来表示除了 "新行" 之外的所有字符
所以模式 "^.5$" 与任何两个字符的、以数字5结尾和以其他非"新行"字符开头的字符串匹配
模式 "." 可以匹配任何字符串,除了空串和只包括一个"新行"的字符串
php的正规表达式有一些内置的通用字符簇
字符簇 | 描述 |
[[:alpha:]] | 任何字母 |
[[:digit:]] | 任何数字 |
[[:alnum:]] | 任何字母和数字 |
[[:space:]] | 任何空白字符 |
[[:upper:]] | 任何大写字母 |
[[:lower:]] | 任何小写字母 |
[[:punct:]] | 任何标点符号 |
[[:xdigit:]] | 任何16进制的数字,相当于[0-9a-fA-F] |
3. 确定重复出现
到现在为止,我们已经知道如何去匹配一个字母或数字,但更多的情况下,可能要匹配一个单词或一组数字
一个单词有若干个字母组成,一组数字有若干个单数组成
跟在字符或字符簇后面的花括号({})用来确定前面的内容的重复出现的次数
字符簇 | 描述 |
^[a-zA-Z_]$ | 所有的字母和下划线 |
^[[:alpha:]] | 所有的3个字母的单词 |
^a$ | 字母 a |
^a{4}$ | aaaa |
^a{2,4}$ | aa,aaa 或 aaaa |
^a{1,3}$ | a,aa 或 aaa |
^a{2,}$ | 包含多于两个a的字符串 |
^a{2,} | 如:aardvark和aaab,但apple不行 |
a{2,} | 如:baad和aaa,但Nantucket不行 |
\t{2} | 两个制表符 |
.{2} | 所有的两个字符 |
这些例子描述了花括号的三种不同的用法:
一个数字{x}的意思是 前面的字符或字符簇只出现x次 ;一个数字加逗号{x,}的意思是 前面的内容出现x或更多的次数 ;两个数字用逗号分隔的数字{x,y}表示 前面的内容至少出现x次,但不超过y次
我们可以把模式扩展到更多的单词或数字:
^[a-zA-Z0-9_]{1,}$ // 所有包含一个以上的字母、数字或下划线的字符串 ^[1-9][0-9]{0,}$ // 所有的正整数 ^\-{0,1}[0-9]{1,}$ // 所有的整数 ^[-]?[0-9]+\.?[0-9]+$ // 所有的浮点数最后一个例子不太好理解,是吗?这么看吧:以一个可选的负号 ([-]?) 开头 (^)、跟着1个或更多的数字([0-9]+)、和一个小数点(.)再跟上1个或多个数字([0-9]+),并且后面没有其他任何东西($)
下面你将知道能够使用的更为简单的方法。
特殊字符?与{0,1}是相等的,它们都代表着: 0个或1个前面的内容 或 前面的内容是可选的
所以刚才的例子可以简化为:
^\-?[0-9]{1,}\.?[0-9]{1,}$特殊字符*与{0,}是相等的,它们都代表着 0 个或多个前面的内容
最后,字符+与{1,}是相等的,表示 1 个或多个前面的内容
所以上面的4个例子可以写成:
^[a-zA-Z0-9_]+$ // 所有包含一个以上的字母、数字或下划线的字符串 ^[1-9][0-9]*$ // 所有的正整数 ^\-?[0-9]+$ // 所有的整数 ^\-?[0-9]+\.?[0-9]*$ // 所有的浮点数正则表达式 - 范例
经过简短的学习,我们已经掌握了正则表达式大部分的语法知识,现在我们通过一些简单的范例来巩固之前的学习
1. 字符串中搜索单个字符
正则表达式的最简单形式是在搜索字符串中匹配其本身的单个普通字符
例如,单字符模式,如 Y,不论出现在搜索字符串中的何处,它总是匹配字母 Y
/Y//7//M/可以将许多单字符组合起来以形成大的表达式
例如,以下正则表达式组合了单字符表达式:Y、8 和 s
/Y8s/注意,正则表达式没有串联运算符,只能在一个字符后面键入另一个字符
2. 字符匹配
句点 (.) 可匹配字符串中的各种打印或非打印字符,但不能匹配换行符 (\n)
例如下面的正则表达式可以匹配 aac、abc、acc、adc 等,以及 a1c、a2c、a-c 和 a#c
/a.c/如果要匹配包含文件名的字符串,则需要在正则表达式中的句点前面加反斜扛 ( \ ),因为句点 (.) 是输入字符串的组成部分
例如,下面的正则表达式匹配 demo.txt
/demo\.txt/3. 中括号表达式
句点(.) 元字符只能匹配 "任何" 单个字符,但我们可能需要匹配列表中的特定字符组,例如,可能需要查找用数字表示的章节标题(Chapter 1、Chapter 2)。这时候就要用到 中括号([]) 元字符
若要创建匹配字符组的一个列表,请在方括号([ 和 ])内放置一个或更多单个字符
当字符括在中括号内时,该列表称为"中括号表达式"
与在任何别的位置一样,普通字符在中括号内表示其本身,即,它在输入文本中匹配一次其本身
大多数特殊字符在中括号表达式内出现时失去它们的意义。不过也有一些例外:
如果 ] 字符不是第一项,它结束一个列表。若要匹配列表中的 ] 字符,请将它放在第一位,紧跟在开始 [ 后面
\ 字符继续作为转义符。若要匹配 \ 字符,请使用 \\
括在中括号表达式中的字符只匹配处于正则表达式中该位置的单个字符
以下正则表达式匹配 Chapter 1、Chapter 2、Chapter 3、Chapter 4 和 Chapter 5
/Chapter [12345]/请注意,单词 Chapter 和后面的空格的位置相对于中括号内的字符是固定的
中括号表达式指定的只是匹配紧跟在单词 Chapter 和空格后面的单个字符位置的字符集
范围字符
若要使用范围代替字符本身来表示匹配字符组,请使用连字符 (-) 将范围中的开始字符和结束字符分开
单个字符的字符值确定范围内的相对顺序
下面的正则表达式包含范围表达式,该范围表达式等效于上面显示的中括号中的列表
/Chapter [1-5]/当以这种方式指定范围时,开始值和结束值两者都包括在范围内
注意,还有一点很重要,按 Unicode 排序顺序,开始值必须在结束值的前面
中括号中的连字符(-)
若要在中括号表达式中包括连字符,请采用下列方法之一:
用反斜扛将它转义:
[\-]将连字符放在中括号列表的开始或结尾
下面的表达式匹配所有小写字母和连字符
[-a-z][a-z-]创建一个范围,在该范围中,开始字符值小于连字符,而结束字符值等于或大于连字符
下面的两个正则表达式都满足这一要求
[!--][!-~]匹配不在中括号内字符
若要查找不在列表或范围内的所有字符,请将插入符号 (^) 放在列表的开头
如果插入字符出现在列表中的其他任何位置,则它匹配其本身
下面的正则表达式匹配1、2、3、4 或 5 之外的任何数字和字符:
/Chapter [^12345]/在上面的示例中,表达式在第九个位置匹配 1、2、3、4 或 5 之外的任何数字和字符。这样,例如,Chapter 7 就是一个匹配项,Chapter 9 也是一个匹配项
上面的表达式可以使用连字符 (-) 来表示:
/Chapter [^1-5]/中括号表达式的典型用途是指定任何大写或小写字母或任何数字的匹配
下面的表达式指定这样的匹配:
/[A-Za-z0-9]/4. 替换和分组
替换使用 | 字符来允许在两个或多个替换选项之间进行选择
例如,可以扩展章节标题正则表达式,以返回比章标题范围更广的匹配项。但是,返回的结果可能不是我们想象的那么简单
替换匹配 | 字符任一侧最大的表达式
可能会认为,下面的表达式匹配出现在行首和行尾、后面跟一个或两个数字的 Chapter 或 Section:
/^Chapter|Section [1-9][0-9]{0,1}$/很遗憾,上面的正则表达式要么匹配行首的单词 Chapter,要么匹配行尾的单词 Section 及跟在其后的任何数字
如果输入字符串是 Chapter 22,那么上面的表达式只匹配单词 Chapter
如果输入字符串是 Section 22,那么该表达式匹配 Section 22
若要使正则表达式更易于控制,可以使用括号来限制替换的范围,即,确保它只应用于两个单词 Chapter 和 Section
但是,括号也用于创建子表达式,并可能捕获它们以供以后使用,这一点在有关反向引用的那一节讲述
通过在上面的正则表达式的适当位置添加括号,就可以使该正则表达式匹配 Chapter 1 或 Section 3
下面的正则表达式使用括号来组合 Chapter 和 Section,以便表达式正确地起作用:
/^(Chapter|Section) [1-9][0-9]{0,1}$/尽管这些表达式正常工作,但 Chapter|Section 周围的括号还将捕获两个匹配字中的任一个供以后使用
由于在上面的表达式中只有一组括号,因此,只有一个被捕获的"子匹配项"
在上面的示例中,我们只需要使用括号来组合单词 Chapter 和 Section 之间的选择
若要防止匹配被保存以备将来使用,请在括号内正则表达式模式之前放置 ?:
下面的修改提供相同的能力而不保存子匹配项:
/^(?:Chapter|Section) [1-9][0-9]{0,1}$/除 ?: 元字符外,两个其他非捕获元字符创建被称为 "预测先行" 匹配的某些内容
正向预测先行使用 ?= 指定,它匹配处于括号中匹配正则表达式模式的起始点的搜索字符串
反向预测先行使用 ?! 指定,它匹配处于与正则表达式模式不匹配的字符串的起始点的搜索字符串
假设我们有一个文档,该文档包含指向 Windows 3.1、Windows 95、Windows 98 和 Windows NT 的引用,再进一步假设,我们可能需要更新该文档,将指向 Windows 95、Windows 98 和 Windows NT 的所有引用更改为 Windows 2000
下面的正则表达式(这是一个正向预测先行的示例)匹配 Windows 95、Windows 98 和 Windows NT:
/Windows(?=95|98|NT)/找到一处匹配后,紧接着就在匹配的文本(不包括预测先行中的字符)之后搜索下一处匹配。例如,如果上面的表达式匹配 Windows 98,将在 Windows 之后而不是在 98 之后继续搜索
其它范例
下表列出了一些正则表达式范例
正则表达式 | 描述 |
/\b([a-z]+) \1\b/gi | 一个单词连续出现的位置 |
/(\w+):\/\/([^/:]+)(:\d)?([^# ])/ | 将一个URL解析为协议、域、端口及相对路径 |
/^(?:Chapter|Section) [1-9][0-9] | 定位章节的位置 |
/[-a-z]/ | a至z共26个字母再加一个-号 |
/ter\b/ | 可匹配chapter,而不能匹配terminal |
/\Bapt/ | 可匹配chapter,而不能匹配aptitude |
/Windows(?=95 |98 |NT )/ | 可匹配Windows95或Windows98或WindowsNT,当找到一个匹配后,从Windows后面开始进行下一次的检索匹配 |
/^\s*$/ | 匹配空行 |
/\d | 验证由两位数字、一个连字符再加 5 位数字组成的 ID 号 |
/<\s(\S+)(\s[^>])?>[\s\S]<\s\/\1\s*>/ | 匹配 html 标记 |
正则表达式 - 前端常用
在表单验证中,使用正则表达式来验证正确与否是一个很频繁的操作,本文收集整理了15个常用的javaScript正则表达式,其中包括用户名、密码强度、整数、数字、电子邮件地址(Email)、手机号码、身份证号、URL地址、 IPv4地址、 十六进制颜色、 日期、 QQ号码、 微信号、车牌号、中文正则。
1 用户名正则
//用户名正则,4到16位(字母,数字,下划线,减号)var uPattern = /^[a-zA-Z0-9_-]{4,16}$/;
//输出 trueconsole.log(uPattern.test("caibaojian"));2 密码强度正则
//密码强度正则,最少6位,包括至少1个大写字母,1个小写字母,1个数字,1个特殊字符var pPattern = /^.*(?=.{6,})(?=.*d)(?=.*[A-Z])(?=.*[a-z])(?=.*[!@#$%^&*? ]).*$/;
//输出 trueconsole.log("=="+pPattern.test("caibaojian#"));3 整数正则
//正整数正则var posPattern = /^d+$/;
//负整数正则var negPattern = /^-d+$/;
//整数正则var intPattern = /^-?d+$/;
//输出 trueconsole.log(posPattern.test("42"));
//输出 trueconsole.log(negPattern.test("-42"));
//输出 trueconsole.log(intPattern.test("-42"));4 数字正则
可以是整数也可以是浮点数
//正数正则var posPattern = /^d*.?d+$/;
//负数正则var negPattern = /^-d*.?d+$/;
//数字正则var numPattern = /^-?d*.?d+$/;
console.log(posPattern.test("42.2"));
console.log(negPattern.test("-42.2"));
console.log(numPattern.test("-42.2"));5 Email正则
//Email正则var ePattern = /^([A-Za-z0-9_-.])+@([A-Za-z0-9_-.])+.([A-Za-z]{2,4})$/;
//输出 trueconsole.log(ePattern.test("99154507@qq.com"));6 手机号码正则
//手机号正则var mPattern = /^1[34578]d{9}$/; //http://caibaojian.com/regexp-example.html//输出 trueconsole.log(mPattern.test("15507621888"));7 身份证号正则
//身份证号(18位)正则
var cP = /^[1-9]d{5}(18|19|([23]d))d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)d{3}[0-9Xx]$/;
//输出 true
console.log(cP.test("11010519880605371X"));8 URL正则
//URL正则var urlP= /^((https?|ftp|file)://)?([da-z.-]+).([a-z.]{2,6})([/w .-]*)*/?$/;
//输出 trueconsole.log(urlP.test("http://caibaojian.com"));9 IPv4地址正则
//ipv4地址正则
var ipP = /^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/;
//输出 true
console.log(ipP.test("115.28.47.26"));10 十六进制颜色正则
//RGB Hex颜色正则var cPattern = /^#?([a-fA-F0-9]{6}|[a-fA-F0-9]{3})$/;//输出 true
console.log(cPattern.test("#b8b8b8"));11 日期正则
//日期正则,简单判定,未做月份及日期的判定
var dP1 = /^d{4}(-)d{1,2}1d{1,2}$/;
//输出 true
console.log(dP1.test("2017-05-11"));
//输出 true
console.log(dP1.test("2017-15-11"));
//日期正则,复杂判定
var dP2 = /^(?:(?!0000)[0-9]{4}-(?:(?:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)$/;
//输出 true
console.log(dP2.test("2017-02-11"));
//输出 false
console.log(dP2.test("2017-15-11"));
//输出 false
console.log(dP2.test("2017-02-29"));12 QQ号码正则
//QQ号正则,5至11位
var qqPattern = /^[1-9][0-9]{4,10}$/;
//输出 true
console.log(qqPattern.test("65974040"));13 微信号正则
//微信号正则,6至20位,以字母开头,字母,数字,减号,下划线
var wxPattern = /^[a-zA-Z]([-_a-zA-Z0-9]{5,19})+$/;
//输出 true
console.log(wxPattern.test("caibaojian_com"));14 车牌号正则
//车牌号正则var cPattern = /^[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领A-Z]{1}[A-Z]{1}[A-Z0-9]{4}[A-Z0-9挂学警港澳]{1}$/;
//输出 trueconsole.log(cPattern.test("粤B39006"));15 包含中文正则
//包含中文正则var cnPattern = /[u4E00-u9FA5]/;
//输出 trueconsole.log(cnPattern.test相关文章:
2W字正则表达式基础知识总结,这一篇就够了!!(含前端常用案例,建议收藏)
正则表达式 (Regular Expression,简称 RE 或 regexp ) 是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符")正则表达式使用单个字符串来描述、匹配一系列匹…...
自学web前端觉得好难,可能你遇到了这些困境
好多人跟我说上学的时候也学过前端,毕业了想从事web前端开发的工作,但自学起来好难,快要放弃了,所以我总结了一些大家遇到的困境,希望对你会有所帮助。 目录 1. 意志是否坚定 2. 没有找到合适自己的老师 3. 为了找…...

ASEMI中低压MOS管18N20参数,18N20封装,18N20尺寸
编辑-Z ASEMI中低压MOS管18N20参数: 型号:18N20 漏极-源极电压(VDS):200V 栅源电压(VGS):30V 漏极电流(ID):18A 功耗(PD&#x…...

[NetBackup]客户端安装后server无法连通client
client name处填写客户端主机名,server to use for backups and restores处填写server端名字,与hosts文件内保持一致;source client for restores处填写client主机名,与server端hosts文件中保持一致,与主机实际名称保持…...

黑马Java后端项目实战--在线聊天交友
【课程简介】 越来越多的系统都有消息推送的功能,如聊天室、邮件推送、系统消息推送等; 要实现消息推送就需要服务端在数据有变化时主动推送消息给客户端,本次课程将带大家使用websocket实现消息推送。 【主讲内容】 1.方法:如…...

【实战系列 2】Yapi接口管理平台Getshell-Linux后门权限维持与痕迹清除
文章目录 前言一、网站主页到Getshell二、SSH软链接后门三、Linux权限维持 --隐藏踪迹3.1 隐藏远程SSH登陆记录3.2、ssh软链接后门连接失败的原因以及解决办法3.3、隐藏踪迹-痕迹清楚3.3.1、隐藏历史操作命令3.3.2、隐藏文件/文件夹3.3.3、修改文件时间戳3.3.4、隐藏权限3.3.5、…...
设计模式之抽象工厂模式(C++)
作者:翟天保Steven 版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处 一、抽象工厂模式是什么? 抽象工厂模式是一种创建型的软件设计模式,该模式相当于升级版的工厂模式。 如果…...
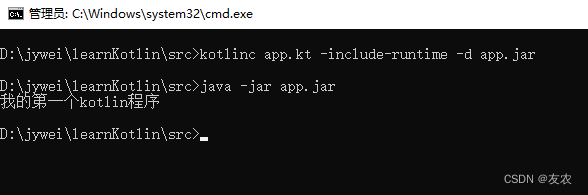
Kotlin新手教程一(Kotlin简介及环境搭建)
目录一、 什么是Kotlin?二、为什么要使用Kotlin?三、使用IntelliJ IDEA搭建Kotlin四、Kotlin使用命令行编译一、 什么是Kotlin? Kotlin 是一种在 Java 虚拟机上运行的静态类型编程语言,它也可以被编译成为 JavaScript 源代码&…...

【虚拟仿真】Unity3D打包WEBGL实现全屏切换
推荐阅读 CSDN主页GitHub开源地址Unity3D插件分享简书地址我的个人博客 大家好,我是佛系工程师☆恬静的小魔龙☆,不定时更新Unity开发技巧,觉得有用记得一键三连哦。 一、前言 今天实现Unity3D打包WEBGL后实现按钮点击全屏和退出 全屏的实现…...

java对象内存结构分析与大小计算
java对象内存结构Java对象保存在堆中时,由三部分组成:对象头(object header):包括了关于堆对象的布局、类型、GC状态、同步状态和标识哈希码的基本信息。所有java对象都有一个共同的对象头格实例数据(Insta…...
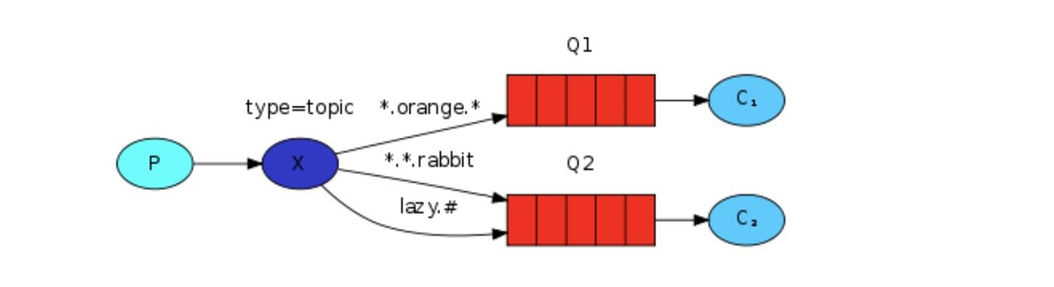
RabbitMQ学习(七):交换器
〇、前言在之前的内容中,我们创建了一个工作队列。我们假设的是工作队列背后,每个任务都恰好交付给一个消 费者(工作进程)。在今天的内容中,我们将做一些完全不同的事情——我们将消息传达给多个消费者。这种模式 称为 “发布/订阅”。为了说…...

cmd命令大全
文章目录变量输入输出逻辑命令符控制语句函数注释变量 在批处理中,变量全部是弱类型的,通常可以当做字符串处理 1.初始化定义 set varthis a var 2.获取变量值 %var% 3.链接 set varcat%var1%%var2% 4.截取 %var:~n,m% n是起点,m是长度&…...

Git的使用方法(保姆级)
一、安装git二、创建凭据 ①打开电脑的凭据管理器git:https://gitee.com是固定写法用户名、密码是你创建gitee的用户名、密码三、在gitee中创建一个仓库四、项目提交到仓库的方法①选择一个项目交由git管理按照步骤一中召唤小黑窗口输入 git init 就可以出现.git文件夹②右键选…...

TypeScript 学习之泛型
泛型使用 组件不仅能够支持当前的数据类型,同时也能支持未来的数据类型。就需要使用泛型。使用泛型就不会丢失类型信息,使用any会丢失类型信息。 function identity<T>(arg: T): T {return arg; }identity 添加了类型变量T, T 捕获用户传入的类型…...
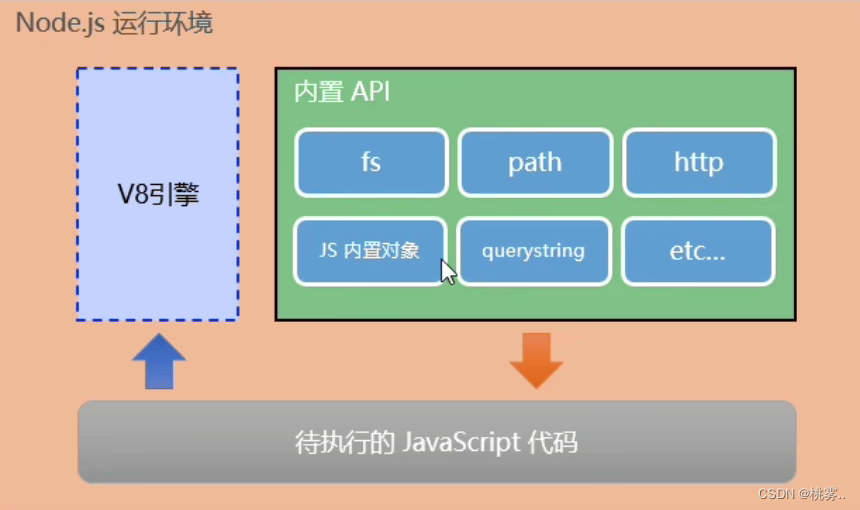
新手学习node.js基础,node.js安装过程,node.js运行环境及javascript运行环境.
学习node.js1.什么是node.js?2.node.js中的javaScript运行环境3.node.js可以做什么?4. node.js学习思路5.node.js环境的安装6.如何在node.js中执行JavaScript代码1.什么是node.js? node.js是一个基于Chrome v8 引擎的JavaScript运行环境(后端) node.js官网 &…...
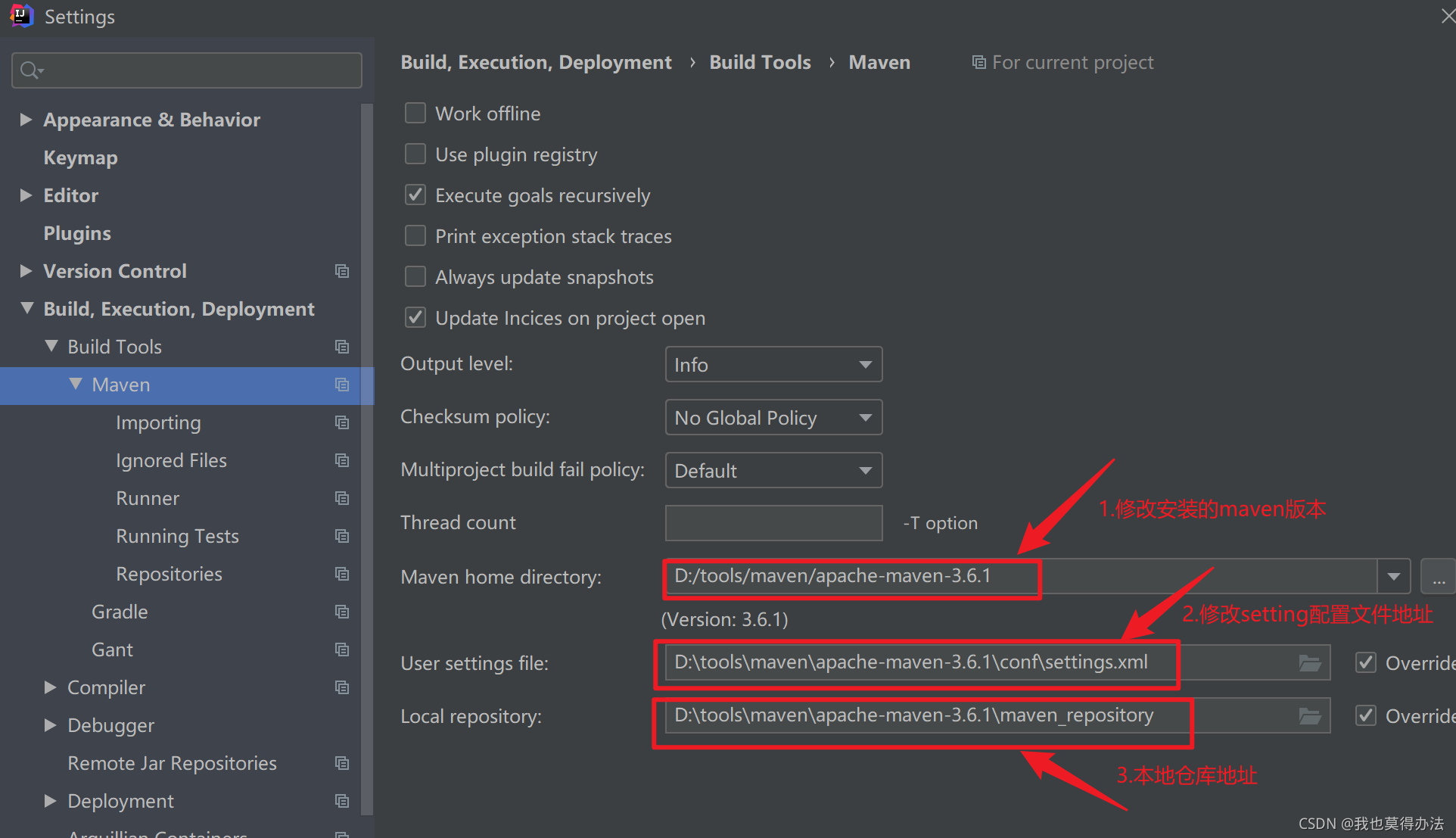
Maven的安装步骤(保姆级安装教程)
一、安装本地Maven 选择你需要的maven版本下载:官网下载传送门 我使用的是3.6.1版本:maven-3.6.1-bin.zip 二、安装 把下载好的maven压缩包解压到一个没有中文,空格或其他特殊字符的文件夹,如: 三、配置环境变量…...

Axure教程(一)——线框图与高保真原型图制作
前面我们学习了制作网页的技能,从这里开始我们来学习前端必备技能,就是用Axure来制作原型图,一方面我们能提前绘制出我们所需的页面,这在我们开发的时候能节省大量的时间,另一方面我们能通过给用户进行体验从而能够发现…...

wholeaked:一款能够追责数据泄露的文件共享工具
关于wholeaked wholeaked是一款功能强大的文件共享工具,该工具基于go语言开发,可以帮助广大系统管理员和安全研究人员在组织发生数据泄露的时候,迅速找出数据泄露的“始作俑者”。 wholeaked可以获取被共享的文件信息以及接收人列表&#x…...

动态规划——股票问题全解
引入 股票问题是一类动态问题,我们需要对其状态进行判定分析来得出答案 但其实,我们只需要抓住两个点,持有和不持有,在这两种状态下分析问题会简单清晰许多 下面将会对各个问题进行分析讲解,来解释什么是持有和不持…...

想做游戏开发要深入c/c++还是c#?
根据题主描述提三点建议: 先选择一个语言、选择一个引擎能入行确保精通一个及已入行的情况下,技多不压身不必想日后的”退而求其次“,现在的事情还没有开始做就想以后,太过虚无及功利了 下面是这三点的详细说明: 【选…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...

【kafka】Golang实现分布式Masscan任务调度系统
要求: 输出两个程序,一个命令行程序(命令行参数用flag)和一个服务端程序。 命令行程序支持通过命令行参数配置下发IP或IP段、端口、扫描带宽,然后将消息推送到kafka里面。 服务端程序: 从kafka消费者接收…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

C++:std::is_convertible
C++标志库中提供is_convertible,可以测试一种类型是否可以转换为另一只类型: template <class From, class To> struct is_convertible; 使用举例: #include <iostream> #include <string>using namespace std;struct A { }; struct B : A { };int main…...

shell脚本--常见案例
1、自动备份文件或目录 2、批量重命名文件 3、查找并删除指定名称的文件: 4、批量删除文件 5、查找并替换文件内容 6、批量创建文件 7、创建文件夹并移动文件 8、在文件夹中查找文件...

UE5 学习系列(三)创建和移动物体
这篇博客是该系列的第三篇,是在之前两篇博客的基础上展开,主要介绍如何在操作界面中创建和拖动物体,这篇博客跟随的视频链接如下: B 站视频:s03-创建和移动物体 如果你不打算开之前的博客并且对UE5 比较熟的话按照以…...

Linux简单的操作
ls ls 查看当前目录 ll 查看详细内容 ls -a 查看所有的内容 ls --help 查看方法文档 pwd pwd 查看当前路径 cd cd 转路径 cd .. 转上一级路径 cd 名 转换路径 …...

鱼香ros docker配置镜像报错:https://registry-1.docker.io/v2/
使用鱼香ros一件安装docker时的https://registry-1.docker.io/v2/问题 一键安装指令 wget http://fishros.com/install -O fishros && . fishros出现问题:docker pull 失败 网络不同,需要使用镜像源 按照如下步骤操作 sudo vi /etc/docker/dae…...

Java多线程实现之Thread类深度解析
Java多线程实现之Thread类深度解析 一、多线程基础概念1.1 什么是线程1.2 多线程的优势1.3 Java多线程模型 二、Thread类的基本结构与构造函数2.1 Thread类的继承关系2.2 构造函数 三、创建和启动线程3.1 继承Thread类创建线程3.2 实现Runnable接口创建线程 四、Thread类的核心…...

rnn判断string中第一次出现a的下标
# coding:utf8 import torch import torch.nn as nn import numpy as np import random import json""" 基于pytorch的网络编写 实现一个RNN网络完成多分类任务 判断字符 a 第一次出现在字符串中的位置 """class TorchModel(nn.Module):def __in…...