第二章:unity性能优化之drawcall优化-1
目录
前言:
一、什么是drawcall
二、如何合批
1、什么是合批?
2、静态批处理
1、什么是静态批处理:
2、静态合批的规则
3、动态批处理
4、GPU Instancing
1、GPU instancing的定义
2、编写支持GPU instancing Shader步骤
5、Scriptable Render Pipeline Batch(SRP Batch)
1、SRP Batch的定义
2、SRP Batch工作原理
3、SRP Batch规则
4、支持SRP Batch的管线
总结:
前言:
有时候内存并不是我们的瓶颈,可能渲染drawcall过多是我们的压力,drawcall过多的最直接后果是程序可能卡,耗电量大等表现。
移动端的程序不比PC端,留给程序员的优化空间比较小,一般对于相应的渲染指标都比较苛刻。那么设定多少个Drawcall是一个比较合理的标准呢,一般情况下,我们应该尽可能将控制在Drawcall在200平均值一下,对于效果特别要求的可以在250左右,不建议超过这个数
在讲解drawcall之前,我们先讲解下什么是Drawcall
一、什么是drawcall
drawcall是cpu对图形绘制接口的调用,CPU通过调用图形库(directx/opengl)接口,命令GPU进行渲染操作。
CPU和GPU之间的数据是通过命令冲区commandBuffer进行传输的。命令缓冲区包含了一个队列,由CPU向其中添加命令,GPU去读取命令,添加和读取的命令都是相互独立的。当CPU需要渲染一个对象时,就可以向命令缓冲区中添加命令,而当GPU完成上一个渲染任务后,就会从命令缓冲区中再取出一条命令并执行它。在渲染绘制过程有很多命令,drawcall就是其中一种。
我们经常认为,Drawcall是通常认为GPU是Drawcall产生的瓶颈,其实不然,真正的元凶是CPU。
在每次调用DrawCall之前,CPU需要向GPU发送很多内容,包括数据、状态和命令等。在这一阶段,CPU需要完成很多工作,例如检查渲染状态等。而一旦CPU完成了这些准备工作,GPU就可以开始本次渲染。GPU的渲染能力很强,渲染速度往往快于CPU提交命令的速度,相对来说CPU与GPU命令交互的过程是非常耗时,CPU在等待GPU指令返回之前这期间什么都做不了。如果DrawCall的数量太多,CPU就会把大量时间花费在提交DrawCall上,造成CPU的过载。
比如:我们渲染10个模型,如果每次渲染时都调用一次Drawcall,那么总共需要调用10次Drawcall;如果10个模型能够合并调用,那么只需要调用一次drawcall,减少了CPU与GPU的指令交互的时间,性能不言而喻,自然就提升了许多。
既然drawcall是主要的性能瓶颈,那么如何减少Drawcall呢?合批(Draw Call Batching)就是最终的解决办法。
二、如何合批
1、什么是合批?
将多个渲染对象的CPU渲染指令统一一起来向GUP提交,将多个独立Drawcall合并成给
一个drawcall的指令方式。
绘制调用批处理是一种组合mesh的绘制调用优化方法,以便Unity可以在较少的绘制调用中render mesh 。Unity提供以下内置的绘制调用批处理方法:
静态批处理(Static batching)
动态批处理(Dynamic batching)
SRP Batcher (只在UPR或SRP项目中有效)
对于合批是有些限定的,基本规则如下:
1)带有如MeshRender、TrailRender、LineRender、ParticleSystem、SpriteRender组
件的mesh支持合批。
2)带有SkinMeshRender和 布料模拟的mesh是不能合批。
GPU Instancing
2、静态批处理
1、什么是静态批处理:
静态批处理是一种绘制调用批处理方法,它结合了不移动的mesh以减少绘制调用。
它将组合的mesh转换为世界空间,并为它们构建一个共享的顶点和索引缓冲区。然
后,对于可见模型,Unity执行一系列简单的绘制调用,每个调用之间几乎没有状态变
化。
静态批处理不会减少绘制调用的数量,而是减少它们之间的渲染状态更改的数量。静
态批处理比动态批处理更有效,因为静态批处理不会转换CPU上的顶点。
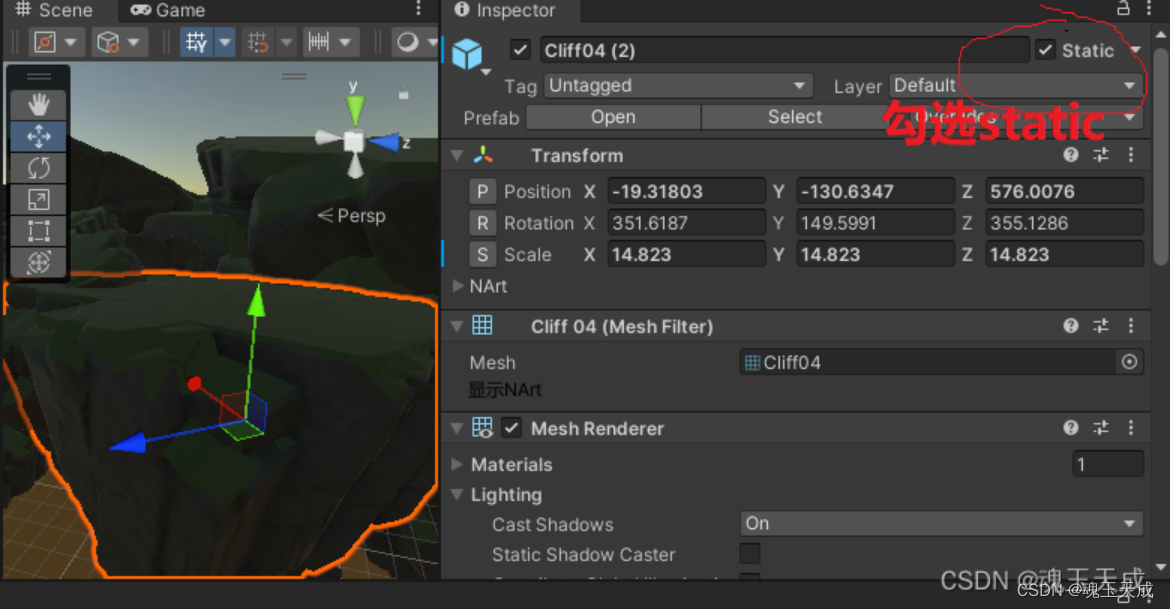
对于静态mesh,Unity将其组合并一起渲染。将场景的物件勾选static就是告诉编辑器,该Game Object对象不能被移动并且需要合批。
如图:
2、静态合批的规则
1)必须符合合批的基本规则
2)必须是static类型的mesh,不能移动的mesh
3)mesh是一样的并且材质相同,有meshRender组件
4)在大多数平台上,批处理限制为 64k 个顶点和 64k 个索引(OpenGLES 上为 48k 个索
引,在 macOS 上为 32k 个索引)如果超过会合批成另外个mesh
5)合批的mesh如果Scale不同无法合批,合批会被打断
6)相同顶线信息和UV的才能一起合批:
如:Unity可以对使用顶点位置、顶点法线和一个UV的mesh进行批处理,但不能与顶点
坐标、顶点法线、UV0、UV1和顶点切线的mesh一起批处理
7)mesh顶点数必须大于0
8)Mesh Renderer component组件不使用具有DisableBatching标记设置为true的着色器的
任何材质。
9)不同的贴图信息的无法合批。如:烘焙的光照贴图不相同的mesh无法合批在一起
10)模型的GameObject必须是active状态
11)位置不相邻的中间夹杂着不同材质的其他物体,不会批处理。
12)动态改变Render.material会造成一个新的material拷贝,应该使用render.shareMaterial
保证材质共享,否则不能合批。
3、动态批处理
1、动态合批的定义
对于足够小的mesh,这将在CPU上变换它们的顶点,将相似的顶点分组在一起,并在一
次绘制调用中渲染它们。
Unity build-in的调用批处理比手动合并mesh有几个优点;最值得注意的是,Unity仍然可
以单独剔除mesh。然而dynamic batch会导致一些CPU开销。
2、动态合批规则:
1)Unity 无法将动态批处理应用于包含超过 900 个顶点属性和 300 个顶点的网格。
这是因为网格的动态批处理具有每个顶点的开销。例如,如果您的着色器使用顶点
位置、顶点法线和单个 UV,则 Unity 最多可以批处理 300 个顶点。但是,如果您
的着色器使用顶点位置、顶点法线、UV0、UV1 和顶点切线,则 Unity 只能批处理 180
个顶点。
2)Unity 无法将动态批处理应用于在其变换组件中包含镜像的对象。例如,如果一个对
象的比例为 1,而另一个游戏对象的缩放比例为 –1,Unity 无法将它们批处理在一
起。
3)如果对象使用不同的material实例,Unity 无法将它们批处理在一起,即使它们本质
上是相同的。Shadow cast是个例外,仅管Shadow casters使用不同的材质,但是只
要它们的材质中给Shadow Caster Pass使用的参数是相同的,他们也能够进行
Dynamic batching。
4)具有lightmap的GameObject具有其他渲染器参数。这意味着,如果要批量光照贴图
游戏对象,它们必须指向相同的光照贴图位置。
5)Unity 无法将dynamic batch完全应用于使用多pass的Shader的对象。
6)几乎所有 Unity 着色器都支持Forward render中的多个光源。为了实现这一点,他们
为每个光源处理一个额外的render pass。Unity 仅对第一个pass进行批处理。它无法
dynamic batch附加的每个光源的所产生的pass 进行合批处理。
7)旧版延迟渲染路径,不支持动态批处理,因为它在两个渲染通道中绘制对象。第一遍
是轻量级预传递,第二遍渲染对象。
4、GPU Instancing
1、GPU instancing的定义
GPU Instancing是一种drawcall优化方法,它在一次绘图调用中使用相同材质render mesh 的
多个副本。多个mesh的副本都称为Instance。这对于绘制场景中多次出现的对象非常有用,
例如树或灌木丛。GPU实例化在同一drawcall中渲染相同的mesh。
每个实例可以具有不同的属性,例如“Color或“Scale”。要对材质使用GPU实例,请在
material 中Inspector中属性中选择"Enable GPU instacing”选项。、
是否是所有的都支持GPU Instancing?答案肯定不是。只有在支持GPU Instancing的shader才有可能
2、编写支持GPU instancing Shader步骤
shader编写一定需要经历如下几步:
Shader"MyGPUInstance"{Properties{...}SubShader{...Pass{...CGPROGRAM#pragma vertex vert#pragma fragment frag#pragma multi_compile_instancing //第一步...struct a2v{...UNITY_VERTEX_INPUT_INSTANCE_ID //第二步};struct v2f{...UNITY_VERTEX_INPUT_INSTANCE_ID //第二步};v2f vert(a2v v){v2f o;UNITY_SETUP_INSTANCE_ID(v); //这里第三步UNITY_TRANSFER_INSTANCE_ID(v,o); //第三步...return o;}fixed4 frag(v2f i):SV_Target{UNITY_SETUP_INSTANCE_ID(i); //最后一步...}ENDCG}}FallBack"Diffuse"
}并且在材质面中勾选 Eanble GPU Instancing选项。如图:

5、Scriptable Render Pipeline Batch(SRP Batch)
1、SRP Batch的定义
SRP Batcher是一个渲染循环(loop),可以让相同的shader Variant的材质的GameObject能够进行合批,加速你的CPU渲染。
SRP Batcher 通过批处理(batching)一系列绑定(Bind)和绘制(Draw)GPU 命令,来减少DrawCalls之间的GPU设置(工作量)。也就是之前一堆绑定和绘制的GPU命令,能够集合的集合起来,不需要一步步设置,而来减少CPU与GPU交互次数,从而减少CPU执行的时间。
2、SRP Batch工作原理
传统的合批方法是减少绘制的对象。相反,SRP Batch是减少渲染的状态和执行过程。
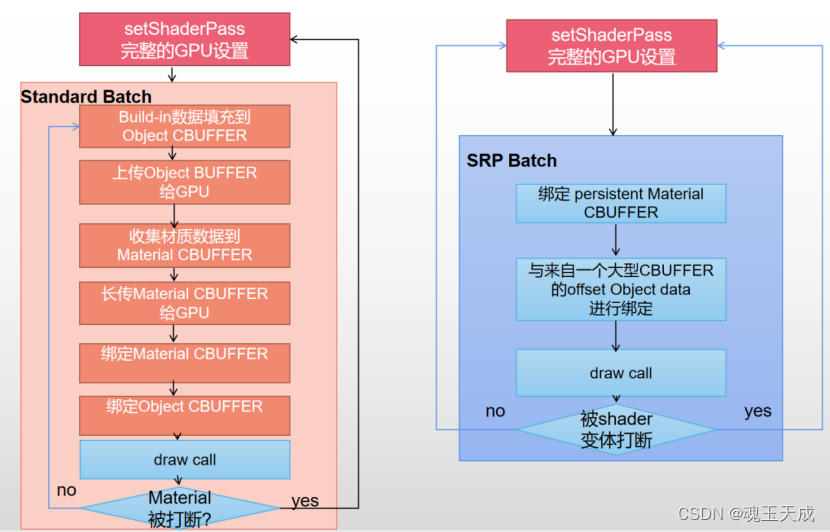
我们看到在内置渲染管线中我们需要设置Meterial和Object CBUFFER,如果材质参数不同,会被打断;但是对于SRP渲染管线,只有变体不同时,才会被打断合批。
3、SRP Batch规则:
- GameObject必须包含mesh或者 skinned mesh。它不能是粒子。
- Game Object没有使用MaterialPropertyBlocks设置材质信息
- Shader必须兼容SRP
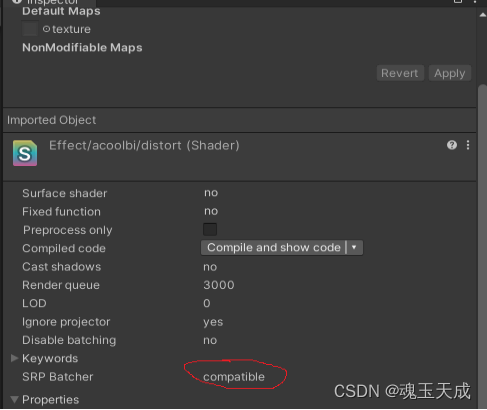
4、支持SRP Batch的管线
| 功能 | 内置渲染管线 | 通用渲染管线 (URP) | 高清渲染管线 (HDRP) | Custom Scriptable Render Pipeline (SRP) |
| SRP Batcher | 否 | 是 | 是 | 是 |
总结:
对于合批,我们应该实际情况做出选择,它们的合批效率从高到低依次是static->GPU instancing-->Dynamic->SRP。我们知道合批的基本条件是同一个模型,并且是同一份材质信息(动态合批和SRP可以不同)。我们不仅要了解合批的规则,我们也要了解合批限制与在什么情况下被中断,同时要了解他们的优劣,才能选择合适的合批方式。
由于篇幅原因,该篇主要讲解内容是drawcall 在什么情况产生的以及 减少drawcal的常用方法。下篇我会以项目的具体内容角度讲解如何对drawcall细致优化。
相关文章:
第二章:unity性能优化之drawcall优化-1
目录 前言: 一、什么是drawcall 二、如何合批 1、什么是合批? 2、静态批处理 1、什么是静态批处理: 2、静态合批的规则 3、动态批处理 4、GPU Instancing 1、GPU instancing的定义 2、编写支持GPU instancing Shader步骤 5、…...

【2341. 数组能形成多少数对】
来源:力扣(LeetCode) 描述: 给你一个下标从 0 开始的整数数组 nums 。在一步操作中,你可以执行以下步骤: 从 nums 选出 两个 相等的 整数从 nums 中移除这两个整数,形成一个 数对 请你在 nu…...

[TPAMI‘21] Heatmap Regression via Randomized Rounding
paper: https://arxiv.org/pdf/2009.00225.pdf code: https://github.com/baoshengyu/H3R 总结:本文提出一套编解码方法: 编码:random-round整数化 激活点响应值表征小数部分,使得GT可以通过编码后的heatmap解码得到;…...

pytorch下tensorboard使用[远程服务器]
** 1、安装tensorboard ** pip install tensorboard可以不安装tensorflow,后续会有提示: TensorFlow installation not found - running with reduced feature set. 但是没有影响。 2、创建环境,导出数据 这一步由代码中的writer完成。 …...

CentOS下安装Nginx的详细步骤
1.安装依赖:yum -y install gcc gcc-c make libtool zlib zlib-devel openssl openssl-devel pcre pcre-devel 2.下载Nginx安装包:wget -c https://nginx.org/download/nginx-1.18.0.tar.gz 3.解压,进入解压目录: tar -zxvf nginx-1.18.0.…...

CSS编码规范
本篇文章是基于王叨叨大佬师父维护的文档梳理的,有兴趣可以去看一下原文CSS编码规范。 其实不管是HTML也好,还是CSS也好,有些规范其实是共通的。 1. 命名 class的命名应该偏向语义化,不是为了样式而去命名,而是通过…...

Linux下makefile 编译项目
文章目录1、规划makefile编写2、makefile文件2.1、根目录下common.mk2.2、config.mk2.3、根目录makefile2.4、其他目录下1、规划makefile编写 a、根目录下放三个文件: 1、makefile:是咱们编译项目的入口脚本,编译项目从这里开始,…...
Linux磁盘查看,使用(分区、格式化、挂载)
目录 0、观察磁盘分区状态:lsblk、blkid、parted 0.1 lsblk列出系统上的所有磁盘列表 0.2 blkid列出设备的UUID等参数 0.3 parted列出磁盘的分区表类型与分区信息 1、磁盘分区:gdisk、fdisk 1.1 fdisk 2、磁盘格式化(创建文件系统…...

走进WebGL
什么是 WebGL? WebGL 是一种跨平台、免版税的 API,用于在 Web 浏览器中创建 3D 图形。基于 OpenGL ES 2.0,WebGL 使用 OpenGL 着色语言 GLSL,并提供熟悉的标准 OpenGL API。因为它在 HTML5 Canvas 元素中运行,所以 We…...

Unity 中 Awake 和 Start 时机与 GameObject的关系
Awake和Start很相似,都是在脚本的初始阶段执行 但是有两点重要不同: Awake先执行Awake即便在脚本 disabled (即enabled false)时,也会执行,但是Start就不会执行了 对一个物体: 当初始没有激…...
1月份 GameFi 行业报告
Jan. 2023, DanielData Source: January Monthly GameFi Report在经历了艰难的一年之后,1 月是对加密货币市场最有利的月份。虽然可以说的大部分内容适用于其他看涨周期,但有几个统计数据令 1 月在区块链领域非常有趣。例如&#…...

JVM - 调优
目录 调什么,如何调 内存方面 线程方面 如何调优 调优的目标,策略和冷思考 JVM调优的目标 常见调优策略 JVM调优冷思考 调优经验与内存泄漏分析 JVM调优经验 内存泄露 调什么,如何调 内存方面 JVM需要的内存总大小各块内存分配,新生代、老年代、存活区选…...

flask配置https协议
感谢https://blog.csdn.net/qq_33934427/article/details/127456673,文中多有参考再实践一、要用https协议需要有ca证书,在windows10先下载windows版本openssl,地址如下https://share.weiyun.com/vfjVrMAb我是64位的选择下载完毕安装后配置环…...
Springboot 我随手封装了一个万能的导出excel工具,传什么都能导出
前言 如题,这个小玩意,就是不限制你查的是哪张表,用的是什么类。 我直接一把梭,嘎嘎给你一顿导出。 我知道,这是很多人都想过的, 至少我就收到很多人问过我这个类似的问题。 我也跟他们说了,但…...
【Linux详解】——进程控制(创建、终止、等待、替换)
📖 前言:本期介绍进程控制(创建、终止、等待、替换)。 目录🕒 1. 进程创建🕘 1.1 fork函数初识🕘 1.2 fork的返回值问题🕘 1.3 写时拷贝🕘 1.4 创建多个进程🕒…...
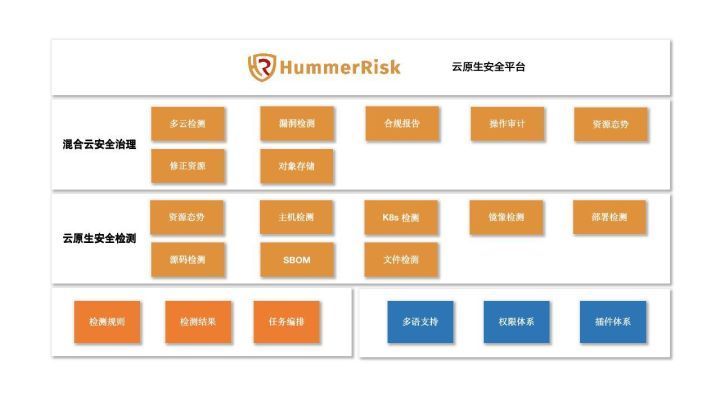
HummerRisk V0.9.1:操作审计增加百度云,增加主机检测规则及多处优化
HummerRisk V0.9.0发布:增加RBAC 资源拓扑图,首页新增检查的统计数据,云检测、漏洞、主机等模块增加规则,对象存储增加京东云,操作审计增加金山云,镜像仓库新增设置别名。 感谢社区中小伙伴们的反馈&#…...
:手写web服务器和线程池)
Rust入门(十六):手写web服务器和线程池
这一章将实现一个手写的 web server 和 多线程的服务器,用到之前学到的所有特性 简单的web server 作为一个 web 服务器,我们首先要能接收到请求,目前市面上的 web 服务大多数都是基于 HTTP 和 HTTPS 协议的,而他们有是基于 TCP…...
数据结构——第二章 线性表(1)——顺序结构
线性表1. 线性表1.1 线性表的定义1.1.1 访问型操作1.1.2 加工型操作1.2 线性表的顺序存储结构1.2.1 定义顺序表数据类型方法11.2.2 定义顺序表数据类型方法21.3 顺序表的基本操作实现1.3.1 顺序表的初始化操作1.3.2 顺序表的插入操作1.3.3 顺序表的删除操作1.3.4 顺序表的更新操…...
YOLO 格式数据集制作
目录 1. YOLO简介 2.分割数据集准备 3.代码展示 整理不易,欢迎一键三连!!! 1. YOLO简介 YOLO(You Only Look Once)是一种流行的目标检测和图像分割模型,由华盛顿大学的 Joseph Redmon 和 Al…...

基于linux内核的驱动开发
1 字符设备驱动框架 1.1字符设备 定义:只能以一个字节一个字节的方式读写的设备,不能随机的读取设备中中的某一段数据,读取数据需要按照先后顺序。(字符设备是面向字节流的) 常见的字…...

RocketMQ 入门到原理实战全讲明白了!第二章
文章目录1、客户端消息确认机制2、广播模式详解3、消息过滤机制4、顺序消息机制5、延迟消息、批量消息6、事务消息机制7、ACL 权限控制机制8、SpringBoot 整合 RocketMQ9、RocketMQ 客户端注意事项10、MQ 如何保证消息不丢失11、MQ 如何保证消息的顺序性12、MQ 如何保证消息的幂…...

构建本地AI智能体:从LLM工具调用到自动化工作流实战
1. 项目概述:一个能“听懂”你需求的本地AI助手最近在折腾本地大语言模型(LLM)的朋友,可能都绕不开一个痛点:模型本身能力很强,但怎么让它真正“听话”,按照你的具体需求去执行任务?…...

VSCode配置C++开发环境:OpenCV跨平台实战指南
1. 为什么选择VSCode进行C开发? 很多刚接触C开发的同学都会纠结该用什么开发工具。我在刚入门时也试过各种IDE,从Visual Studio到CLion,最后发现VSCode才是最适合跨平台开发的轻量级选择。VSCode不仅免费开源,而且通过插件系统可以…...

研究生整理论文访谈素材2026年实测4款b站视频转文字工具 快速出稿节省一周整理时间
做2026届硕士论文,我前前后后采访了11位行业受访者,加上师门讲座录音,总共有11小时的音视频素材。之前手动逐句听着整理,一天坐满8小时才整理完1.5小时,脖子僵到抬不起来,还经常漏记专业术语,本…...

Atmel maX触控技术解析:从电容传感原理到工业级嵌入式HMI实战
1. 项目概述:从“点按”到“感知”的交互革命在嵌入式人机交互领域,我们早已习惯了物理按键的“咔哒”声和电阻屏的“按压感”。但你是否想过,当一块普通的玻璃或塑料表面,无需任何物理形变,就能精准识别你的手指轻触、…...

3步高效解决方案:Calibre电子书元数据自动化管理
3步高效解决方案:Calibre电子书元数据自动化管理 【免费下载链接】calibre-douban Calibre new douban metadata source plugin. Douban no longer provides book APIs to the public, so it can only use web crawling to obtain data. This is a calibre Douban p…...

Photoshop图层批量导出效率革命:10倍速免费脚本完全指南
Photoshop图层批量导出效率革命:10倍速免费脚本完全指南 【免费下载链接】Photoshop-Export-Layers-to-Files-Fast This script allows you to export your layers as individual files at a speed much faster than the built-in script from Adobe. 项目地址: h…...

从零到一:基于STC单片机与AHT10传感器的低成本温湿度监测方案实现
1. 为什么选择STC单片机与AHT10传感器组合 当你第一次想做一个温湿度监测设备时,可能会被市面上五花八门的方案搞得眼花缭乱。我刚开始接触这个领域时,也踩过不少坑,买过DHT11模块,试过SHT30传感器,最后发现STC单片机A…...

Vue项目打印凭证纸保姆级教程:用JS动态注入@media print样式,告别全局污染
Vue项目动态打印方案实战:精准控制凭证纸与A4布局的JS样式注入技术 在财务系统和ERP开发中,打印功能往往是最容易被忽视却最影响用户体验的环节。传统Vue项目中直接使用media print会遇到一个致命问题——当同一个页面需要支持A4报表和76mm130mm凭证纸两…...

BilibiliDown终极指南:免费跨平台B站视频下载器完整教程
BilibiliDown终极指南:免费跨平台B站视频下载器完整教程 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors…...