【chatGPT4结对编程】chatGPT4教我做图像分类
开始接触深度学习
大语言模型火了之后,我也想过是否要加入深度学习的行业当中来,一开始的想法就是AI大模型肯定会被各大厂垄断,我们作为普通应用型软件工程师直接调用api就完事,另外对自己的学历也自卑(刚刚够线的二本)。因此有一段时间,专门尝试去折腾chatGPT的各种应用,不过始终觉得不够,有很多疑问: 这些通用的人工机器人是如何工作的呢?GPT4的1750亿参数到底是指什么?为何指定一个不同的prompt,相同的问题答案会差别这么大?为何它的代码能力这么强?我有太多的疑问,我觉得AI颠覆了我的认知,我从业10多年了,为何现在才开始接触AI呢?我想了解大模型背后的原理,我也想做这些cool的事情,10多年的CURD太没意思了。
那么问题来了,我该怎么入门深度学习呢?
在京东搜索深度学习,排名前2名的书籍是:《深度学习》和《动手学深度学习》,对比了下发现动手学深度学习是大神李沐编撰的,有对应的在线书籍,B站上有视频课程,github上有代码样例,这么高质量的作品,居然这一切都是免费的,还有什么理由不入坑呢,因此我果断加入深度学习的队列。
每天上一节课持续有1个多月了,目前学到30节课了,但目前我感觉还未真正上手,要掌握原理,需要的掌握背景知识太多了:微积分、线性代数、概率论等,毕业10多年后的我,自觉连初高中的数学都不一定能完全搞定,要学习起来真的觉得很痛苦。
实践比赛Classify Leaves
学完第二阶段开始第二次实践比赛,比赛题目是《Classify Leaves》给叶子图像分类,有了上一次的房价预测比赛实践之后,大致知道深度学习的流程:
- 读取数据预处理
- 设置超参数
- 训练和验证(验证用于进行超参数调整)
- 跑测试集后保存
图像分类与房价预测不同之处:
- 房价预测是表格数据,图像分类是图像数据
- 另外房价预测使用简单的线模型即可,图像预测需要使用卷积神经网络
- 房价预测对非熟知数据预处理对最后结果影响比较大,分类数据比较简单预处理简单。
查看数据格式
数据样例如下:包含3个文件和一个图片文件夹。
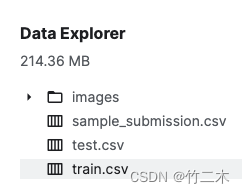
-
训练数据train.csv如下表格,包含了2列:image表示图片文件路径,label图片所属分类。
image| label
—|—
images/0.jpg|maclura_pomifera
images/1.jpg|maclura_pomifera
images/2.jpg|maclura_pomifera
images/3.jpg|maclura_pomifera
…|… -
sample_submission.csv 是提交样例,样例数据格式与训练数据集一样。
-
test.csv 是测试数据,训练好模型后,使用测试数据跑出结果提交,测试数据只有一列:image, label需要我们使用训练好的模型进行预测,然后提交预测后的结果。
导入包
from torch.utils.data import DataLoader
import torch
from torch import nn
from d2l import torch as d2l
import os
import pandas as pd
from torchvision.io import read_image
from torch.utils.data import Dataset
from torchvision import transforms
import matplotlib.pyplot as plt
from PIL import Image
import torchvision.models as models
from numpy import random
数据预处理
自定义数据读取
自己实现Dataset来读取图片分类数据
class CustomImageDataset(Dataset):def __init__(self, annotations_file, img_dir, dict_label, transform=None, target_transform=None):self.img_labels = pd.read_csv(annotations_file)self.img_dir = img_dirself.transform = transformself.target_transform = target_transformself.dict_label = dict_labeldef __len__(self):return len(self.img_labels)def __getitem__(self, idx):img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])image = Image.open(img_path)if self.dict_label != None:label = self.img_labels.iloc[idx, 1]if self.transform:image = self.transform(image)if self.target_transform:label = self.target_transform(label)if self.dict_label != None: #通过这个来判断是否是测试数据的读取return image, torch.tensor(self.dict_label[label],dtype=torch.long)return image # 测试数据没有label
读取数据并初始化
# 直接读取csv列数据,用于处理列数据label的与处理,主要用于将数字分类和文本分类相互映像转换
train_data_csv = pd.read_csv('data/train.csv')
# 读取图片,用于输出提交结果
test_data_csv = pd.read_csv('data/test.csv')
# 读取所有文本分类
all_text_labels = train_data_csv['label']
# 去重
uni_text_labels = all_text_labels.unique()
# 数字映射文本分类字典
dict_num2text_labels = {}
# 文本映射数字分类字典
dict_text2num_labels = {}
# 分类打乱,有点多此一举
random.shuffle(uni_text_labels)
num_classes = 0 # 分类总数
# 相互映射
for label in uni_text_labels:dict_num2text_labels[num_classes] = labeldict_text2num_labels[label] = num_classesnum_classes += 1print(f"dict_num2text_labels:{dict_num2text_labels} ")
print(f"dict_text2num_labels:{num_classes} ")
# 训练集,图片转换成tensor
transform_train = transforms.Compose([transforms.Resize((224, 224)),transforms.RandomHorizontalFlip(p=0.5), #随机水平翻转 选择一个概率transforms.ToTensor()
])
# 测试集,图片转换成tensor
transform_test = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor()
])training_data = CustomImageDataset("data/train.csv", "data/", dict_text2num_labels,transform = transform_train)
test_data = CustomImageDataset("data/test.csv", "data/", None, transform = transform_test)
模型定义和超参数
使用深度学习神经网络框架定义
model = models.resnet34(pretrained=True)
model.eval()
# 设置输出分类数
model.fc = nn.Sequential(nn.Linear(model.fc.in_features, num_classes))
# 批次大小, 学习率,训练次数、权重
batch_size,lr, num_epochs,weight_decay = 32, 3e-4, 20, 1e-3
k折交叉训练
由于数据集合比较小,使用k折交叉读取数据训练
import time
from sklearn.model_selection import KFold
from torch.utils.data import DataLoader, Dataset, random_split, Subset
import torch.optim as optim# 计算验证集
def evaluate_accuracy_gpu(net, data_iter, device=None):"""Compute the accuracy for a model on a dataset using a GPU.Defined in :numref:`sec_lenet`"""if isinstance(net, nn.Module):net.eval() # Set the model to evaluation modeif not device:device = next(iter(net.parameters())).device# No. of correct predictions, no. of predictionsmetric = d2l.Accumulator(2)with torch.no_grad():for X, y in data_iter:if isinstance(X, list):# Required for BERT Fine-tuning (to be covered later)X = [x.to(device) for x in X]else:X = X.to(device)y = y.to(device)metric.add(d2l.accuracy(net(X), y), d2l.size(y))return metric[0] / metric[1]
# 训练
def train_ch6(net, train_iter, test_iter, num_epochs, lr,weight_decay, device):"""Train a model with a GPU (defined in Chapter 6).Defined in :numref:`sec_lenet`"""def init_weights(m):if type(m) == nn.Linear or type(m) == nn.Conv2d:nn.init.xavier_uniform_(m.weight)net.apply(init_weights)print('training on', device)net.to(device)optimizer = torch.optim.Adam(net.parameters(), lr=lr, weight_decay=weight_decay)#optimizer = torch.optim.SGD(net.parameters(), lr=lr, weight_decay=weight_decay)loss = nn.CrossEntropyLoss()animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],legend=['train loss', 'train acc', 'test acc'])timer, num_batches = d2l.Timer(), len(train_iter)for epoch in range(num_epochs):# Sum of training loss, sum of training accuracy, no. of examplesmetric = d2l.Accumulator(3)net.train()for i, (X, y) in enumerate(train_iter):timer.start()optimizer.zero_grad()X, y = X.to(device), y.to(device)y_hat = net(X)l = loss(y_hat, y)l.backward()optimizer.step()with torch.no_grad():metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])timer.stop()train_l = metric[0] / metric[2]train_acc = metric[1] / metric[2]if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i + 1) / num_batches,(train_l, train_acc, None))test_acc = evaluate_accuracy_gpu(net, test_iter)animator.add(epoch + 1, (None, None, test_acc))print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, 'f'test acc {test_acc:.3f}')print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec 'f'on {str(device)}')# 定义 k 折交叉验证参数
k_folds = 5
kfold = KFold(n_splits=k_folds, shuffle=True)for fold, (train_ids, val_ids) in enumerate(kfold.split(training_data)):print(f'FOLD {fold}')print('--------------------------------')# 根据索引划分训练集和验证集train_subsampler = Subset(training_data, train_ids)val_subsampler = Subset(training_data, val_ids)# 创建数据加载器trainloader = DataLoader(train_subsampler, batch_size=64, shuffle=True, num_workers=2)valloader = DataLoader(val_subsampler, batch_size=64, shuffle=False, num_workers=2)# 训练模型train_ch6(model, trainloader, valloader, num_epochs, lr, weight_decay, d2l.try_gpu())# 保存模型
torch.save(model.state_dict(), f"data/resnet34_SGD_model.state_{time}.pth")
生产预测测试数据保存
# 加载保存到文件的模型
model = models.resnet34(pretrained=True)
model.load_state_dict(torch.load("data/resnet34_SGD_model.state_1685356838.1272397.pth"))
model.eval()
model.cuda()test_dataloader = DataLoader(test_data, batch_size=batch_size, shuffle=False)
preds = []
with torch.no_grad():for i, X in enumerate(test_dataloader):X = X.to(d2l.try_gpu())y_hat = model(X)y_hat = torch.argmax(y_hat, axis=1) #获取最大分类for num_label in y_hat:label_str = dict_num2text_labels[num_label.item()]preds.append(label_str)# 将网络应用于测试集。
# 将其重新格式化以导出到Kaggle
test_data_csv['label'] = preds
submission = pd.concat([test_data_csv['image'], test_data_csv['label']], axis=1)
submission.to_csv('submission.csv', index=False)
使用GPT4的过程
在实现的过程中并不是一帆风顺,GPT4给了很大的帮助,下面是我们的对话。
输出分类参数错误
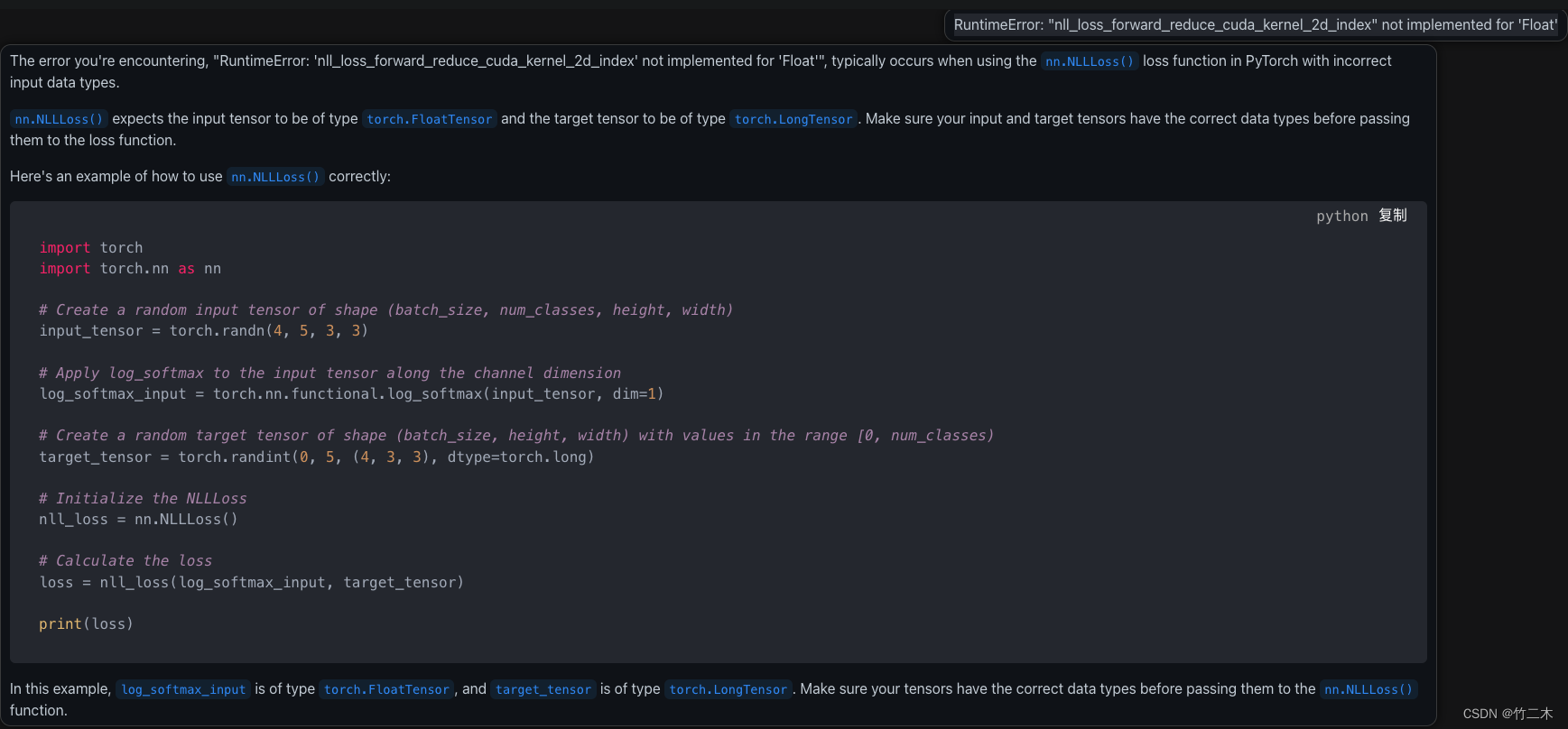
一开始读取分类标签的时候,转换成了tensor 的float类型,导致出现报错:
RuntimeError: “nll_loss_forward_reduce_cuda_kernel_2d_index” not implemented for ‘Float’
直接复制给GPT4,他清晰的告诉了我是因为nn.NLLLoss() 函数输出的是LongTensor类型。
怎么使用模型输出分类
不知道如何使用框架模型,直接提问题。
训练效果不好
深度神经网络训练集的准确率和验证集的差异比较大是什么原因
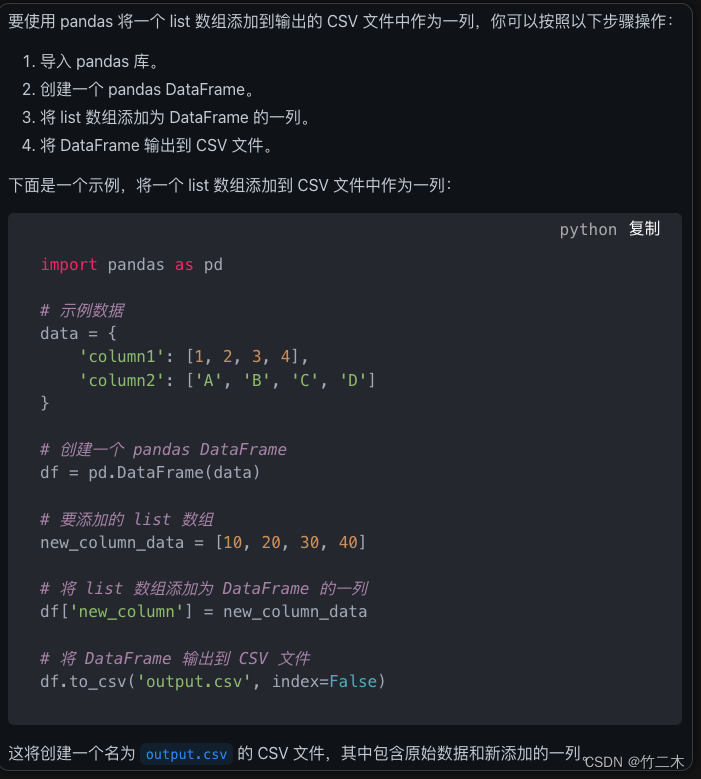
使用pandas输入问题
怎么使用pandas 加一个list数组加入输出csv文件的一列是上
如何使用k折交叉验证法
如何使用k折交叉方法训练图片分类,给定了一个数据集,如何进行k折分别选择测试集合和验证集数据
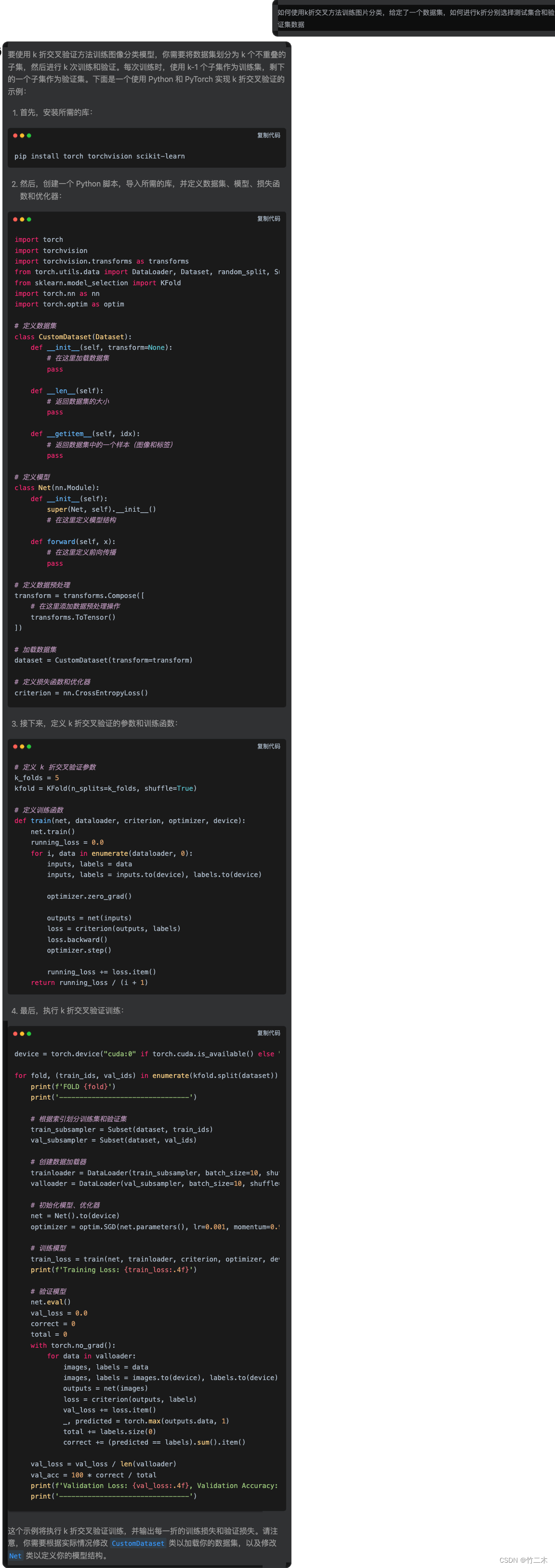
给出了非常详细的样例。
相关文章:
【chatGPT4结对编程】chatGPT4教我做图像分类
开始接触深度学习 大语言模型火了之后,我也想过是否要加入深度学习的行业当中来,一开始的想法就是AI大模型肯定会被各大厂垄断,我们作为普通应用型软件工程师直接调用api就完事,另外对自己的学历也自卑(刚刚够线的二本࿰…...

Different romantic
001 他暗恋上我们班上的一个女生。 He has a crush on a girl in our class. crush n. 迷恋 have a crush on (someone) 暗恋(某人) crush 也可以指“暗恋的对象”。例如,“他在大学曾经暗恋过两个人”,英语就是He had two crushe…...
learn C++ NO.7——C/C++内存管理
引言 现在是5月30日的正午,图书馆里空空的,也许是大家都在午休,也许是现在37摄氏度的气温。穿着球衣的我已经汗流浃背,今天热火战胜了凯尔特人,闯入决赛。以下克上的勇气也激励着我,在省内垫底的大学中&am…...
)
SDUT数据库原理——第十章作业(参考答案)
1. 简述使用检查点方法进行数据恢复的一般步骤。 答: (1)使用检查点方法进行数据恢复,首先从重新开始文件(见P302页图10.3)中找到最后一个检查点记录在日志文件中的地址,由该地址在日志文件中找到最后一个检查点记录。 (2)由该检查点记录得到检查点建立时刻所有正在…...

My Note of Diffusion Models
Diffusion Models Links: https://theaisummer.com/diffusion-models/ Markovian Hierachical VAE rvs: data: x 0 x_{0} x0,representation: x T x_{T} xT ( p ( x 0 , x 1 , ⋯ , x T ) , q ( x 1 , ⋯ , x T ∣ x 0 ) ) (p(x_0,x_1,\cdots,x_T),q(x_1,\cdots,x_{T…...

【P37】JMeter 仅一次控制器(Once Only Controller)
文章目录 一、仅一次控制器(Once Only Controller)参数说明二、测试计划设计2.1、测试计划一2.1、测试计划二 一、仅一次控制器(Once Only Controller)参数说明 可以让控制器内部的逻辑只执行一次;单次的范围是针对某…...

cleanmymac要不要下载装机?好不好用
当我们收到一台崭新的mac电脑,第一步肯定是找到一款帮助我们管理电脑运行的“电脑管家”,监控内存运行、智能清理系统垃圾、清理Mac大文件旧文件、消除恶意软件、快速卸载更新软件、隐私保护、监控系统运行状况等。基本在上mac电脑防护一款CleanMyMac就够…...
:常见的DNS威胁与防御(中科三方))
DNS风险分析及防护研究(五):常见的DNS威胁与防御(中科三方)
DNS是互联网运行重要的基础设施,在全球互联网运转中扮演重要作用。互联网中的每一次访问都开始于一次DNS查询,从而将人们更好辨识的域名转换为数字化的IP地址。随着互联网的快速发展以及网络技术的快速发展,DNS固有的缺陷逐步暴露出来&#x…...

使用geoserver发布shp和tiff数据
一、安装并启动geoserver服务 1.1 下载geoserver 进入官网下载 由于geoserver是使用Java语言开发的,所以运行需要java的环境,不同geoserver的版本号对java的版本要求不同,所以选择版本时需注意对应java的版本要求,由于我本地安…...

谷歌周彦祺:LLM浪潮中的女性科学家多面手丨智源大会嘉宾风采
导读 大模型研发竞赛如火如荼,谷歌紧随OpenAI其后推出PalM2、Gemini等系列模型。Scaling Law是否仍然适用于当下的大模型发展?科技巨头与初创企业在竞争中各有哪些优势和劣势?模型研究者应秉持哪些社会责任? 2023智源大会「基础模…...
Burp模块
Target模块 记录流量 1.Target按主机或域名分类记录 2.HTTP History 按时间顺序记录且会记录很多次 3.Target模块的作用 (1)把握网站的整体情况 (2)对一次工作的域进行分析 (3)分析网站存在的攻击面 …...
)
sql笔记:SQL SERVER字符串填充(标量值函数创建、标量值函数调用)
/*字符串填充 ,如果返回 -1 说明输入参数有错误*/ CREATE FUNCTION [dbo].[uf_pad_string] ( @string_unpadded VARCHAR(100), --123填充前字符串 @pad_char VARCHAR(1), --0 填充的字符串 @pad_count tinyint, --10 填充后字符串长度 @pad_p…...

python使用hTTP方法
Python中可以使用requests库来发送HTTP请求,其中包括GET、POST、PUT、DELETE等方法。下面是一个使用requests库发送HTTP请求的示例: python import requests # 发送GET请求 response requests.get(Example Domain) # 发送POST请求 data {key1: valu…...

JavaSE常用API
1. Math.round(11.5)等于多少?Math.round(- 11.5) 又等于多少? Math.round(11.5)的返回值是 12,Math.round(-11.5)的返回值是-11。四舍五入的原理是在参数上加 0.5然后进行取整。 2. switch 是否能作用在 byte 上,是否能作用在 long 上…...

华为OD机试之模拟商场优惠打折(Java源码)
模拟商场优惠打折 题目描述 模拟商场优惠打折,有三种优惠券可以用,满减券、打折券和无门槛券。 满减券:满100减10,满200减20,满300减30,满400减40,以此类推不限制使用; 打折券&…...

5月VR大数据:Quest 2下跌超1%,其它变化不大
Hello大家好,每月一期的VR内容/硬件大数据统计又和大家见面了。 想了解VR软硬件行情么?关注这里就对了。我们会统计Steam平台的用户及内容等数据,每月初准时为你推送,不要错过喔! 本数据报告包含:Steam VR硬…...
CW32系列模数转换器(ADC)
模数转换器(ADC)的主要功能是将模拟量转换为数字量,方便MCU进行处理。下面以CW32L083为例介绍CW系列的模数转换器的特点和功能,并提供演示实例。 一、概述 CW32L083 内部集成一个 12 位精度、最高 1M SPS 转换速度的逐次逼近型模…...
电动力学专题:电磁场规范不变性与规范自由度
对称性,不变性,相对性,协变形 在现代物理学中常常被认为具有相同的含义(好拗口) 规范与规范的自由度 保证电磁场物理量不改变的情况下,有多组势可供选择,而每组势可以称为一个规范 规范不变性…...

max delay的应用场景与常见问题
max delay与min delay用来约束start points到endpoints点对点的路径长度,set_max_delay约束最大值,set_min_delay约束最小值。 max delay的-from和-to并不局限在get_pins,get_cells和get_clocks同样可以。 set_max_delay 5 -from UFF0/Q -to UFF1/D set_max_delay -from …...

非阻塞队列
非阻塞队列 首先我们要简单的理解下什么是非阻塞队列: 与阻塞队列相反,非阻塞队列的执行并不会被阻塞,无论是消费者的出队,还是生产者的入队。 在底层,非阻塞队列使用的是CAS(compare and swap)来实现线程执行的非阻塞…...

RestClient
什么是RestClient RestClient 是 Elasticsearch 官方提供的 Java 低级 REST 客户端,它允许HTTP与Elasticsearch 集群通信,而无需处理 JSON 序列化/反序列化等底层细节。它是 Elasticsearch Java API 客户端的基础。 RestClient 主要特点 轻量级ÿ…...

Vim 调用外部命令学习笔记
Vim 外部命令集成完全指南 文章目录 Vim 外部命令集成完全指南核心概念理解命令语法解析语法对比 常用外部命令详解文本排序与去重文本筛选与搜索高级 grep 搜索技巧文本替换与编辑字符处理高级文本处理编程语言处理其他实用命令 范围操作示例指定行范围处理复合命令示例 实用技…...

golang循环变量捕获问题
在 Go 语言中,当在循环中启动协程(goroutine)时,如果在协程闭包中直接引用循环变量,可能会遇到一个常见的陷阱 - 循环变量捕获问题。让我详细解释一下: 问题背景 看这个代码片段: fo…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个生活电费的缴纳和查询小程序
一、项目初始化与配置 1. 创建项目 ohpm init harmony/utility-payment-app 2. 配置权限 // module.json5 {"requestPermissions": [{"name": "ohos.permission.INTERNET"},{"name": "ohos.permission.GET_NETWORK_INFO"…...

微信小程序云开发平台MySQL的连接方式
注:微信小程序云开发平台指的是腾讯云开发 先给结论:微信小程序云开发平台的MySQL,无法通过获取数据库连接信息的方式进行连接,连接只能通过云开发的SDK连接,具体要参考官方文档: 为什么? 因为…...

基于Java+VUE+MariaDB实现(Web)仿小米商城
仿小米商城 环境安装 nodejs maven JDK11 运行 mvn clean install -DskipTestscd adminmvn spring-boot:runcd ../webmvn spring-boot:runcd ../xiaomi-store-admin-vuenpm installnpm run servecd ../xiaomi-store-vuenpm installnpm run serve 注意:运行前…...
《Docker》架构
文章目录 架构模式单机架构应用数据分离架构应用服务器集群架构读写分离/主从分离架构冷热分离架构垂直分库架构微服务架构容器编排架构什么是容器,docker,镜像,k8s 架构模式 单机架构 单机架构其实就是应用服务器和单机服务器都部署在同一…...
Element-Plus:popconfirm与tooltip一起使用不生效?
你们好,我是金金金。 场景 我正在使用Element-plus组件库当中的el-popconfirm和el-tooltip,产品要求是两个需要结合一起使用,也就是鼠标悬浮上去有提示文字,并且点击之后需要出现气泡确认框 代码 <el-popconfirm title"是…...

CppCon 2015 学习:Simple, Extensible Pattern Matching in C++14
什么是 Pattern Matching(模式匹配) ❝ 模式匹配就是一种“描述式”的写法,不需要你手动判断、提取数据,而是直接描述你希望的数据结构是什么样子,系统自动判断并提取。❞ 你给的定义拆解: ✴ Instead of …...

自定义线程池1.2
自定义线程池 1.2 1. 简介 上次我们实现了 1.1 版本,将线程池中的线程数量交给使用者决定,并且将线程的创建延迟到任务提交的时候,在本文中我们将对这个版本进行如下的优化: 在新建线程时交给线程一个任务。让线程在某种情况下…...