实现PyTorch/ONNX自定义节点操作的TensorRT部署
参考一
下面是基本步骤:
- 加载训练好的bev transformer网络权重参数:
import torch
from model import Modelmodel = Model()
model.load_state_dict(torch.load("path/to/weights"))
- 定义新的自定义操作:
import torch
from torch.autograd import Functionclass CustomOp(Function):@staticmethoddef forward(ctx, input, weight):# 这里实现自定义操作的前向传递output = ...ctx.save_for_backward(input, weight)return output@staticmethoddef backward(ctx, grad_output):# 这里实现自定义操作的反向传递input, weight = ctx.saved_tensorsgrad_input = ...grad_weight = ...return grad_input, grad_weight
- 将自定义操作应用于transformer模块的网络层:
import torch.nn as nnclass Transformer(nn.Module):def __init__(self):super(Transformer, self).__init__()self.self_attn = CustomOp() # 将自定义操作应用于transformer模块的网络层def forward(self, x):output = self.self_attn(x, weight)return output
- 加载模型和权重参数,并转换为ONNX格式:
import onnx
from onnx import TensorProto, helper# 将模型和权重参数转换为ONNX格式
input_shape = (1,3,224,224)
input_names = ['input']
output_names = ['output']
x = torch.randn(input_shape)
torch.onnx.export(model, x, 'model.onnx', input_names=input_names, output_names=output_names)# 加载ONNX模型
model = onnx.load("model.onnx")# 新增自定义操作,并将其插入ONNX模型
op_def = helper.make_node("CustomOp",inputs=["input", "weight"],outputs=["output"]
)
model.graph.node.append(op_def)# 修改输入和输出张量的数据类型为float32
for i in range(len(model.graph.input)):model.graph.input[i].type.tensor_type.elem_type = TensorProto.FLOAT
for i in range(len(model.graph.output)):model.graph.output[i].type.tensor_type.elem_type = TensorProto.FLOAT# 保存修改后的ONNX模型
onnx.save(model, "model_custom_op.onnx")
这样,我们就获得了带有自定义操作的ONNX模型。
参考二
首先,我们需要将原始PyTorch模型转换为ONNX格式,这可以通过以下代码完成:
import torch
import onnx
import onnxruntime# Load the model
model = torch.load("model.pt")# Set the model to evaluation mode
model.eval()# Dummy input for the model
input_names = ["input"]
output_names = ["output"]
dummy_input = torch.randn(1, 3, 224, 224)# Export the model to ONNX
onnx_path = "model.onnx"
torch.onnx.export(model, dummy_input, onnx_path, input_names=input_names, output_names=output_names, opset_version=12)
接下来,我们需要使用ONNX库加载模型,并替换转换器模块的网络层。我们可以使用ONNX的Graph和Model API来实现这个过程。
import onnx
from onnx import numpy_helper
from onnx import ModelProto
import onnx.tools# Load the ONNX model
model_path = 'model.onnx'
onnx_model = onnx.load(model_path)# Find the Transformer module in the ONNX graph
for node in onnx_model.graph.node:if 'Transformer' in node.name:transformer_node = node# Find the weights of the Transformer module
for initializer in onnx_model.graph.initializer:if transformer_node.name in initializer.name:transformer_weights = numpy_helper.to_array(initializer)# Replace the Transformer module with custom node
from onnx.helper import make_node
custom_node = make_node(op_type='CustomOp', inputs=transformer_node.input, outputs=transformer_node.output, name=transformer_node.name)
onnx_model.graph.node.remove(transformer_node)
onnx_model.graph.node.append(custom_node)# Save the modified ONNX model
onnx.checker.check_model(onnx_model)
onnx.save(onnx_model, 'custom_model.onnx')
在代码中,我们首先加载了ONNX模型,然后遍历图寻找我们想要替换的Transformer模块。然后,我们在图中找到该层的权重,并使用其创建一个新的自定义节点,然后通过删除已有的Transformer节点,并将自定义节点添加到图中来替换它。最后,我们将修改后的模型保存为新的ONNX文件。
接下来,我们需要使用TensorRT来加载我们的自定义模型并运行推理。在TensorRT中使用自定义操作需要实现自定义插件。TensorRT提供了C++ API和Python API来实现自定义插件。这里我们将介绍如何使用Python API来实现自定义插件。
首先,我们需要实现我们的自定义操作。我们可以使用C ++编写自定义操作,然后使用Python API将其转换为TensorRT插件。这里,我们将为您提供一个示例代码,以了解如何将PyTorch中的自定义操作转换为TensorRT插件。
// Sample code for a custom operation to replace the Transformer module in PyTorch#include "NvInfer.h"
#include "NvInferPlugin.h"int main(int argc, char** argv) {// Create a new logger for TensorRTauto logger = nvinfer1::createLogger(nvinfer1::ILogger::Severity::kINFO);// Create a TensorRT builder and networkauto builder = nvinfer1::createInferBuilder(logger);auto network = builder->createNetwork();// Define the input tensor shapenvinfer1::Dims input_shape;input_shape.nbDims = 4;input_shape.d[0] = 1;input_shape.d[1] = 3;input_shape.d[2] = 224;input_shape.d[3] = 224;// Define the input tensorauto input = network->addInput("input", nvinfer1::DataType::kFLOAT, input_shape);// Define the output tensor shapenvinfer1::Dims output_shape;output_shape.nbDims = 4;output_shape.d[0] = 1;output_shape.d[1] = 3;output_shape.d[2] = 224;output_shape.d[3] = 224;// Define the output tensorauto output = network->addOutput("output", nvinfer1::DataType::kFLOAT, output_shape);// Create a new plugin layerauto plugin_factory = getPluginRegistry()->getPluginFactory("CustomOp");std::vector<nvinfer1::PluginField> plugin_fields;nvinfer1::PluginFieldCollection plugin_field_collection;plugin_field_collection.nbFields = static_cast<int>(plugin_fields.size());plugin_field_collection.fields = plugin_fields.data();auto plugin_layer = plugin_factory->createPlugin("CustomOp", &plugin_field_collection);// Add the plugin layer to the networknvinfer1::IPluginV2Layer* plugin = network->addPluginV2(&input, 1, *plugin_layer);// Build the TensorRT engineauto engine = builder->buildCudaEngine(*network);// Serialize the engine to a filenvinfer1::IHostMemory* serialized_engine = engine->serialize();std::ofstream engine_file("engine.trt", std::ios::binary);engine_file.write(static_cast<char*>(serialized_engine->data()), serialized_engine->size());// Destroy the objectsserialized_engine->destroy();engine->destroy();plugin_layer->destroy();network->destroy();builder->destroy();logger->destroy();return 0;
}
这里,我们定义了一个新的TensorRT Builder和Network,然后添加了我们的自定义OP。请注意,我们在创建自定义层时使用了PluginFactory,这需要从TensorRT插件注册表获取。PluginFactory需要插件类型名称来创建自定义插件。
接下来,我们使用以下代码将C ++插件转换为Python插件。
import tensorrt as trt
import numpy as np# Define our custom plugin layer with an instance normalization operation
class CustomOpLayer(trt.PluginLayer):def __init__(self, context, max_batch_size, *args, **kwargs):super().__init__(context, max_batch_size)def get_plugin_fields(self):# Define the plugin fieldsfields = [trt.PluginField("norm", np.array([1.0], dtype=np.float32), trt.PluginFieldType.FLOAT32)]# Return the plugin fieldsreturn fieldsdef get_output_type(self, idx, input_types):# Return the output types of the plugin layerreturn input_types[0]def plugin_op(self):# Implement the custom plugin operationreturn input_tensor * self.normdef create_plugin():# Create the plugin layerlayer = CustomOpLayer()# Return the plugin layerreturn layer# Register the plugin with TensorRT
trt.init_libnvinfer_plugins(logger, '')
plugin_registry = trt.get_plugin_registry()
plugin_creator = plugin_registry.get_plugin_creator("CustomOp", "1", "")
plugin = plugin_creator.create_plugin('CustomOp', trt.PluginFieldCollection())
在代码中,我们定义了一个自定义层,该层包含一个实例归一化操作,并重写了基类中的get_plugin_fields,get_output_type和plugin_op方法。然后,我们通过使用get_plugin_registry来注册自定义插件,并使用get_plugin_creator和create_plugin方法来创建TensorRT插件。
现在,我们已经成功地将PyTorch模型转换为带有自定义操作的ONNX模型,并使用TensorRT API将其转换为可用于推理的TensorRT引擎和插件。我们可以使用如下代码来加载TensorRT引擎并运行推理:
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit# Load the serialized engine
serialized_engine = open("engine.trt", "rb").read()# Create a TensorRT runtime
runtime = trt.Runtime(trt.Logger(trt.Logger.WARNING))# Deserialize the engine
engine = runtime.deserialize_cuda_engine(serialized_engine)# Create a TensorRT execution context
context = engine.create_execution_context()# Allocate device memory for inputs and outputs
input = cuda.mem_alloc(1 * 3 * 224 * 224 * 4)
output = cuda.mem_alloc(1 * 3 * 224 * 224 * 4)# Load the input data to device memory
input_data = np.zeros((1, 3, 224, 224), dtype=np.float32)
cuda.memcpy_htod(input, input_data.ravel())# Run inference on the device
context.execute(1, [int(input), int(output)])# Copy the output data from device memory to host memory
output_data = np.empty((1, 3, 224, 224), dtype=np.float32)
cuda.memcpy_dtoh(output_data.ravel(), output)# Print the output data
print(output_data)
在代码中,我们首先使用TensorRT运行时和序列化引擎初始化TensorRT引擎。然后,我们为输入和输出分配设备内存,并将输入数据加载到设备内存中。最后,我们在设备上运行推理,并将输出数据从设备内存复制到主机内存。
这样就可以实现PyTorch自定义操作的TensorRT部署了。
参考三
以下是一个示例代码,用于将transformer模块的网络层融合为一个自定义的ONNX节点,并使用TensorRT插件实现。
首先,需要安装必要的Python库和TensorRT。以下是安装TensorRT的步骤:
- 下载TensorRT并解压到合适的位置:https://developer.nvidia.com/nvidia-tensorrt-download
- 安装TensorRT Python库:
pip install tensorrt - 安装TensorRT Python插件库:
pip install tensorrt-plugin
接下来,使用以下代码将transformer模块的网络层融合为一个自定义的ONNX节点:
import onnx
from onnx import helper, numpy_helper, shape_inference# Load the trained model
model_file = 'model.pt'
model = torch.load(model_file)# Get the weights of the transformer module
transformer_weights = model.transformer.state_dict()# Create the inputs and outputs for the new custom node
inputs = [helper.make_tensor_value_info('input', onnx.TensorProto.FLOAT, ['batch_size', 'seq_len', 'hidden_size']),helper.make_tensor_value_info('weights', onnx.TensorProto.FLOAT, ['num_layers', '3', 'hidden_size', 'hidden_size']),helper.make_tensor_value_info('bias', onnx.TensorProto.FLOAT, ['num_layers', '3', 'hidden_size']),
]
outputs = [helper.make_tensor_value_info('output', onnx.TensorProto.FLOAT, ['batch_size', 'seq_len', 'hidden_size'])
]# Create the new custom node
custom_node = helper.make_node('MyTransform',inputs=['input', 'weights', 'bias'],outputs=['output'],
)# Create the new ONNX graph with the custom node
graph_def = onnx.GraphProto()
graph_def.node.extend([custom_node])
graph_def.input.extend(inputs)
graph_def.output.extend(outputs)# Set the shape information for the inputs and outputs
graph_def = shape_inference.infer_shapes(graph_def)# Add the weights to the graph
for name, weight in transformer_weights.items():tensor = numpy_helper.from_array(weight.numpy(), name=name)graph_def.initializer.append(tensor)# Save the new ONNX graph
onnx_file = 'model.onnx'
onnx.save(graph_def, onnx_file)
注意,这里假设已经使用PyTorch训练好了一个transformer模型并保存为model.pt文件,需要将其加载到内存中。此外,在新的ONNX图中,使用了自定义节点MyTransform,需要在后续代码中实现这个节点。
接下来,使用TensorRT插件实现自定义节点。以下是示例代码:
import tensorrt as trt
import numpy as np# Define the custom plugin and create a TensorRT plugin registry
class MyTransformPlugin(trt.IPluginV2DynamicExt):def __init__(self, weights, bias):self.weights = weightsself.bias = biasdef get_plugin_type(self):return 'MyTransform'def get_plugin_version(self):return '1'def get_output_dtype(self, idx, layer):return trt.DataType.FLOATdef get_output_dimensions(self, idx, inputs, outputs, network):return inputs[0].shapedef configure_plugin(self, inputs, outputs, layers, max_batch_size):self.batch_size = inputs[0].shape[0]self.seq_len = inputs[0].shape[1]self.hidden_size = inputs[0].shape[2]self.num_layers = self.weights.shape[0]self.stream = Nonedef enqueue(self, inputs, outputs, bindings, workspace, stream):self.stream = streaminput_buf = inputs[0].as_gpu_tensor() # [batch_size, seq_len, hidden_size]weights_buf = self.weights.as_gpu_tensor() # [num_layers, 3, hidden_size, hidden_size]bias_buf = self.bias.as_gpu_tensor() # [num_layers, 3, hidden_size]output_buf = outputs[0].as_gpu_tensor() # [batch_size, seq_len, hidden_size]# Use CUDA kernel to perform the transformationcuda_module = None # Load the CUDA module herecuda_module.my_transform(input_buf, weights_buf, bias_buf, output_buf, self.batch_size, self.seq_len, self.hidden_size, self.num_layers, stream.handle)def get_workspace_size(self, max_batch_size):return 0def destroy(self):passdef clone(self):return MyTransformPlugin(self.weights, self.bias)plugin_registry = trt.PluginRegistry()# Register the plugin with the TensorRT plugin registry
def register_plugin():plugin_creator = trt.PluginCreator(name='MyTransform', plugin_version='1', plugin_creator=MyTransformPlugin)plugin_registry.register_creator(plugin_creator, 'MyTransform')register_plugin()# Load the ONNX model with the custom node
onnx_file = 'model.onnx'
model_stream = open(onnx_file, 'rb')
model_proto = onnx.load(model_stream)# Create the TensorRT engine from the ONNX model
trt_logger = trt.Logger()
builder = trt.Builder(trt_logger)
builder.max_batch_size = 1
builder.fp16_mode = True
engine = builder.build_engine(model_proto, plugin_registry)
参考四
这个问题涉及到多个步骤,我尝试简单介绍一下:
- 加载模型权重参数
使用PyTorch加载模型权重参数,尤其是transformer层的权重参数,可以使用以下代码:
import torchmodel = MyModel() # 假设MyModel是你的模型
state_dict = torch.load("model_weights.pth")
model.load_state_dict(state_dict)
- 定义自定义op
在PyTorch中定义自定义op的方式是通过继承torch.autograd.Function类并实现forward和backward方法。例如,以下是一个简单的自定义op示例:
import torchclass MyCustomOp(torch.autograd.Function):@staticmethoddef forward(ctx, input_tensor, weight_tensor):# 前向传递的逻辑output_tensor = input_tensor.mm(weight_tensor.t())ctx.save_for_backward(input_tensor, weight_tensor)return output_tensor@staticmethoddef backward(ctx, grad_output):# 反向传递的逻辑input_tensor, weight_tensor = ctx.saved_tensorsgrad_input = grad_output.mm(weight_tensor)grad_weight = grad_output.t().mm(input_tensor)return grad_input, grad_weight
在这个例子中,自定义op将输入张量input_tensor与权重张量weight_tensor相乘,并返回结果。在反向传递中,它计算输入张量和权重张量同时对梯度的贡献。
- 使用自定义op替换transformer层
为了使用自定义op替换transformer层,你需要知道transformer层的具体实现。在PyTorch中,transformer层通常是一个torch.nn.TransformerEncoderLayer对象,它包含了多个子层,如self-attention层和全连接层。你需要将这些子层替换为自定义op。
以下是一个示例代码,假设你要将transformer层的全连接层替换为自定义op:
import torch.nn as nnclass MyModel(nn.Module):def __init__(self):super(MyModel, self).__init__()self.transformer = nn.TransformerEncoderLayer(d_model=512, nhead=8)self.custom_op = MyCustomOp.applydef forward(self, x):# 获取transformer层的各个子层self_attn = self.transformer.self_attnlinear1 = self.transformer.linear1dropout = self.transformer.dropoutlinear2 = self.transformer.linear2norm1 = self.transformer.norm1norm2 = self.transformer.norm2# 使用自定义op替换linear2层x = self_attn(x, x, x)[0]x = linear1(x)x = dropout(x)x = self.custom_op(x, linear2.weight)x = norm1(x)x = x + linear2.biasx = norm2(x)# 返回输出return x
在这个例子中,注意到我们使用了MyCustomOp.apply而不是直接调用MyCustomOp。这是因为PyTorch要求自定义op使用apply方法来处理前向和反向传递逻辑。
- 将PyTorch模型转换为ONNX模型
使用PyTorch将模型导出为ONNX格式,可以使用以下代码:
import torch.onnxmodel = MyModel() # 假设MyModel是你的模型
input_shape = (1, 512) # 假设输入张量的形状为(1, 512)
output_path = "my_model.onnx"
model.eval()# 导出为ONNX模型
x = torch.randn(input_shape)
torch.onnx.export(model, x, output_path, input_names=["input"], output_names=["output"])
在这个例子中,我们使用torch.onnx.export方法将PyTorch模型导出为ONNX模型。注意要将模型设置为eval模式并提供模型输入和输出的名称。
- 使用TensorRT加载自定义op
使用TensorRT加载ONNX模型需要使用TensorRT的C++ API。以下是一个简单的示例代码,假设你要使用TensorRT加载带有自定义op的ONNX模型:
#include "NvInfer.h"
#include "NvOnnxParser.h"using namespace nvinfer1;
using namespace nvonnxparser;void loadModelWithCustomOp(const std::string& model_path)
{// 创建TensorRT builder、network和ONNX解析器IBuilder* builder = createInferBuilder(gLogger);INetworkDefinition* network = builder->createNetwork();IParser* parser = createParser(*network, gLogger);// 解析ONNX模型并检查是否成功if (!parser->parseFromFile(model_path.c_str(), 1)){std::cerr << "Failed to parse ONNX model" << std::endl;exit(EXIT_FAILURE);}// 注册自定义opconst char* op_name = "MyCustomOp";const char* plugin_name = "MyCustomOpPlugin";MyCustomOpPluginCreator plugin_creator;plugin_creator.setPluginName(plugin_name);bool registered = parser->registerPlugin(op_name, &plugin_creator);if (!registered){std::cerr << "Failed to register custom op" << std::endl;exit(EXIT_FAILURE);}// 创建推理引擎builder->setMaxBatchSize(1);builder->setMaxWorkspaceSize(1 << 30);ICudaEngine* engine = builder->buildCudaEngine(*network);// 释放资源parser->destroy();network->destroy();builder->destroy();engine->destroy();
}
在这个例子中,我们使用createParser方法创建ONNX解析器,并使用parseFromFile方法从文件中解析ONNX模型。然后,我们使用MyCustomOpPluginCreator类创建自定义op的插件,并使用registerPlugin方法注册自定义op。最后,我们使用buildCudaEngine方法创建推理引擎。
注意到我们需要为自定义op编写一个插件,并将其注册到ONNX解析器中。这是因为自定义op并不是TensorRT原生支持的操作。插件的编写和注册需要额外的代码,我在这里就不展开了。如果你想知道更多细节,可以参阅TensorRT的官方文档和代码示例。
希望这些代码能够帮助你解决问题!
参考五
对于这个问题,需要进行以下步骤:
- 安装必要的库和工具
首先需要安装一些必要的库和工具,包括PyTorch、ONNX、TensorRT等。可以通过以下命令安装:
pip install torch==1.6.0 onnx==1.7.0 tensorrt==7.2.2.3 pycuda==2020.1
- 加载训练好的模型权重
使用PyTorch加载训练好的模型权重,并将其转换为ONNX格式。可以参考以下代码:
import torch
import onnx# 加载PyTorch模型
model = torch.load('model.pth')# 转换为ONNX格式
dummy_input = torch.randn(1, 3, 224, 224)
input_names = ['input']
output_names = ['output']
torch.onnx.export(model, dummy_input, 'model.onnx', input_names=input_names, output_names=output_names, opset_version=11)
- 定义自定义节点
定义一个自定义节点来融合Transformer的所有子层。可以参考以下代码:
import onnx
from onnx import helper, shape_inference, TensorProtoclass TransformerFusion(helper.Node):def __init__(self, transformer_inputs, transformer_outputs, name=None):super().__init__('TransformerFusion', transformer_inputs, transformer_outputs, name=name)def transformer_fusion(inputs, outputs, name=None):node = TransformerFusion(inputs, outputs, name=name)return node
- 加载模型并替换子层
使用ONNX API加载模型,并使用自定义节点替换Transformer的所有子层。可以参考以下代码:
# 加载ONNX模型
model = onnx.load('model.onnx')# 替换Transformer的所有子层
for node in model.graph.node:if node.op_type == 'MultiHeadAttention':# 替换MultiHeadAttention子层inputs = []for i in range(len(node.input)):if i == 0:inputs.append(node.input[i])else:inputs.append('dummy')outputs = node.outputtransformer_fusion_node = transformer_fusion(inputs, outputs)model.graph.node.remove(node)model.graph.node.extend([transformer_fusion_node])elif node.op_type == 'LayerNormalization':# 替换LayerNormalization子层inputs = []for i in range(len(node.input)):if i == 0:inputs.append(node.input[i])else:inputs.append('dummy')outputs = node.outputtransformer_fusion_node = transformer_fusion(inputs, outputs)model.graph.node.remove(node)model.graph.node.extend([transformer_fusion_node])# 推断模型形状
onnx.checker.check_model(model)
onnx.shape_inference.infer_shapes(model)
- 导出有自定义op的ONNX模型
使用ONNX API导出带有自定义op的ONNX模型。可以参考以下代码:
# 导出有自定义op的ONNX模型
onnx.save(model, 'model_fused.onnx')
- 使用TensorRT进行推断
使用TensorRT进行推断。可以参考以下代码:
import pycuda.driver as cuda
import pycuda.autoinit
import numpy as np
import tensorrt as trt# 定义TensorRT logger
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)# 加载TensorRT引擎
def load_engine():with open('model.plan', 'rb') as f, trt.Runtime(TRT_LOGGER) as runtime:engine = runtime.deserialize_cuda_engine(f.read())return engine# 创建TensorRT上下文
def create_context():engine = load_engine()context = engine.create_execution_context()return engine, context# 推断函数
def infer(context, inputs):inputs = [inp.astype(np.float32) for inp in inputs]outputs = [np.empty(output.shape, dtype=np.float32) for output in outputs]stream = cuda.Stream()bindings = []for inp in inputs:bindings.append(int(inp.gpudata))for out in outputs:bindings.append(int(out.gpudata))context.execute_async_v2(bindings=bindings, stream_handle=stream.handle)stream.synchronize()return [out.get() for out in outputs]
- 完整示例代码
import torch
import onnx
from onnx import helper, shape_inference, TensorProto
import pycuda.driver as cuda
import pycuda.autoinit
import numpy as np
import tensorrt as trt# 定义自定义节点
class TransformerFusion(helper.Node):def __init__(self, transformer_inputs, transformer_outputs, name=None):super().__init__('TransformerFusion', transformer_inputs, transformer_outputs, name=name)def transformer_fusion(inputs, outputs, name=None):node = TransformerFusion(inputs, outputs, name=name)return node# 加载PyTorch模型
model = torch.load('model.pth')# 转换为ONNX格式
dummy_input = torch.randn(1, 3, 224, 224)
input_names = ['input']
output_names = ['output']
torch.onnx.export(model, dummy_input, 'model.onnx', input_names=input_names, output_names=output_names, opset_version=11)# 加载ONNX模型
model = onnx.load('model.onnx')# 替换Transformer的所有子层
for node in model.graph.node:if node.op_type == 'MultiHeadAttention':# 替换MultiHeadAttention子层inputs = []for i in range(len(node.input)):if i == 0:inputs.append(node.input[i])else:inputs.append('dummy')outputs = node.outputtransformer_fusion_node = transformer_fusion(inputs, outputs)model.graph.node.remove(node)model.graph.node.extend([transformer_fusion_node])elif node.op_type == 'LayerNormalization':# 替换LayerNormalization子层inputs = []for i in range(len(node.input)):if i == 0:inputs.append(node.input[i])else:inputs.append('dummy')outputs = node.outputtransformer_fusion_node = transformer_fusion(inputs, outputs)model.graph.node.remove(node)model.graph.node.extend([transformer_fusion_node])# 推断模型形状
onnx.checker.check_model(model)
onnx.shape_inference.infer_shapes(model)# 导出有自定义op的ONNX模型
onnx.save(model, 'model_fused.onnx')# 创建TensorRT上下文
def create_context():with open('model.plan', 'rb') as f, trt.Runtime(TRT_LOGGER) as runtime:engine = runtime.deserialize_cuda_engine(f.read())context = engine.create_execution_context()return engine, context# 推断函数
def infer(context, inputs):inputs = [inp.astype(np.float32) for inp in inputs]outputs = [np.empty(output.shape, dtype=np.float32) for output in outputs]stream = cuda.Stream()bindings = []for inp in inputs:bindings.append(int(inp.gpudata))for out in outputs:bindings.append(int(out.gpudata))context.execute_async_v2(bindings=bindings, stream_handle=stream.handle)stream.synchronize()return [out.get() for out in outputs]# 加载TensorRT引擎
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
engine, context = create_context()# 准备输入数据
input_data = np.random.randn(1, 3, 224, 224).astype(np.float32)
outputs = [np.empty(shape, dtype=np.float32) for shape in engine.get_binding_shape(1)]# 进行推断
trt_outputs = infer(context, [input_data])# 验证推断结果
for i, trt_output in enumerate(trt_outputs):np.testing.assert_allclose(outputs[i], trt_output, atol=1e-3)
参考六
这是一个比较复杂的问题,需要详细的代码和步骤来回答。以下是一个大体的解决方案:
Step 1. 融合所有层并替换为自定义node
你需要先使用Python和ONNX Runtime执行以下步骤:
-
加载训练好的CNN Transformer网络权重参数,并将其转换为ONNX模型。
-
将ONNX模型中所有transformer层的节点融合成一个节点。
-
将融合后的节点替换为自定义node,并添加相应的属性和输入/输出。
-
导出新的ONNX模型。
这里给出一个简单的示例代码,假设模型的输入和输出都是固定的:
import onnx
from onnx import helper, shape_inference, TensorProto
from onnx import numpy_helper# 加载模型
model_path = 'model.onnx'
model = onnx.load(model_path)# 获取输入和输出张量的名称和形状
input_name = model.graph.input[0].name
input_shape = model.graph.input[0].type.tensor_type.shape.dim
output_name = model.graph.output[0].name
output_shape = model.graph.output[0].type.tensor_type.shape.dim# 获取transformer层节点
transformer_node = []
for node in model.graph.node:if node.op_type == 'Transformer':transformer_node.append(node)# 融合所有transformer层节点
inputs = [helper.make_tensor_value_info('input', TensorProto.FLOAT, input_shape)]
outputs = [helper.make_tensor_value_info('output', TensorProto.FLOAT, output_shape)]
for node in transformer_node:inputs.append(node.input[0])outputs.append(node.output[0])
merge_node = helper.make_node('CustomTransformerOp', inputs, outputs, name='Merged_Transformer'
)# 替换所有transformer层节点为融合节点
new_nodes = []
for node in model.graph.node:if node not in transformer_node:new_nodes.append(node)else:new_nodes.append(merge_node)# 更新输入和输出节点的张量名称和形状
model.graph.input[0].name = 'input'
model.graph.input[0].type.tensor_type.shape.dim[0].dim_param = 'batch_size'
model.graph.output[0].name = 'output'
model.graph.output[0].type.tensor_type.shape.dim[0].dim_param = 'batch_size'# 更新ONNX模型
model.graph.node[:] = new_nodes
onnx.checker.check_model(model)
onnx.save(model, 'merged_model.onnx')
Step 2. 加载新的ONNX模型并使用TensorRT API生成plugin
我们需要使用C++代码加载新的ONNX模型,并使用TensorRT API生成plugin。这里需要TensorRT-7.0.0以上版本。
-
使用ONNX Parser加载新的ONNX模型。
-
声明自定义node的plugin。
-
实现自定义node的plugin,并注册到TensorRT。
-
构建一个TensorRT engine并运行推理。
以下是一个简单的示例代码,其中假设我们已经定义了CustomTransformerPlugin类和相应的实现:
#include <iostream>
#include <fstream>
#include <sstream>
#include <cmath>
#include <cuda_runtime_api.h>
#include <NvInfer.h>
#include <NvInferPlugin.h>
#include <NvOnnxParser.h>using namespace std;
using namespace nvinfer1;
using namespace nvonnxparser;
using namespace plugin;// 声明自定义transformer plugin
class CustomTransformerPlugin : public IPluginV2DynamicExt {public:// 构造函数CustomTransformerPlugin(const int hidden_size);// 使用weights加载模型参数CustomTransformerPlugin(const void* data, size_t length);// 返回plugin名称const char* getPluginType() const override;// 返回plugin版本const char* getPluginVersion() const override;// 返回plugin能力const PluginFieldCollection* getFieldNames() override;// 复制pluginIPluginV2DynamicExt* clone() const override;// 返回plugin输出大小DimsExprs getOutputDimensions(int outputIndex, const DimsExprs* inputs,int nbInputs, IExprBuilder& exprBuilder) override;// 设置plugin数据类型void setDataType(DataType type) override;// 返回plugin数据类型DataType getDataType() const override;// 返回plugin输出格式bool supportsFormatCombination(int pos, const PluginTensorDesc* inOut,int nbInputs, int nbOutputs) override;// 初始化pluginvoid configurePlugin(const DynamicPluginTensorDesc* in, int nbInputs,const DynamicPluginTensorDesc* out, int nbOutputs) override;// 返回plugin输出格式size_t getWorkspaceSize(const PluginTensorDesc* inputs, int nbInputs,const PluginTensorDesc* outputs, int nbOutputs) const override;// 运行推理int enqueue(const PluginTensorDesc* inputDesc, const PluginTensorDesc* outputDesc,const void* const* inputs, void* const* outputs, void* workspace,cudaStream_t stream) override;// 返回plugin序列化数据大小size_t getSerializationSize() const override;// 序列化pluginvoid serialize(void* buffer) const override;// 清空pluginvoid destroy() override;private:const int mHiddenSize; // transformer隐藏层大小DataType mDataType; // plugin数据类型
};// 实现plugin
CustomTransformerPlugin::CustomTransformerPlugin(const int hidden_size): mHiddenSize(hidden_size), mDataType(DataType::kFLOAT) {}CustomTransformerPlugin::CustomTransformerPlugin(const void* data, size_t length): mDataType(DataType::kFLOAT) {// 从weights中加载模型参数
}const char* CustomTransformerPlugin::getPluginType() const {return "CustomTransformerPlugin";
}const char* CustomTransformerPlugin::getPluginVersion() const {return "1";
}const PluginFieldCollection* CustomTransformerPlugin::getFieldNames() {static PluginFieldCollection fields;return &fields;
}IPluginV2DynamicExt* CustomTransformerPlugin::clone() const {return new CustomTransformerPlugin(mHiddenSize);
}DimsExprs CustomTransformerPlugin::getOutputDimensions(int outputIndex, const DimsExprs* inputs, int nbInputs,IExprBuilder& exprBuilder) {DimsExprs output(inputs[0]);output.d[2] = exprBuilder.operation(DimensionOperation::kPROD, *output.d[2], *exprBuilder.constant(mHiddenSize));return output;
}void CustomTransformerPlugin::setDataType(DataType type) {mDataType = type;
}DataType CustomTransformerPlugin::getDataType() const {return mDataType;
}bool CustomTransformerPlugin::supportsFormatCombination(int pos, const PluginTensorDesc* inOut,int nbInputs, int nbOutputs) {if (inOut[pos].format != TensorFormat::kLINEAR) {return false;}return true;
}void CustomTransformerPlugin::configurePlugin(const DynamicPluginTensorDesc* in, int nbInputs,const DynamicPluginTensorDesc* out, int nbOutputs) {}size_t CustomTransformerPlugin::getWorkspaceSize(const PluginTensorDesc* inputs, int nbInputs,const PluginTensorDesc* outputs, int nbOutputs) const {return 0;
}int CustomTransformerPlugin::enqueue(const PluginTensorDesc* inputDesc, const PluginTensorDesc* outputDesc,const void* const* inputs, void* const* outputs, void* workspace,cudaStream_t stream) {// 实现推理return 0;
}size_t CustomTransformerPlugin::getSerializationSize() const {// 返回序列化数据大小return 0;
}void CustomTransformerPlugin::serialize(void* buffer) const {// 序列化plugin
}void CustomTransformerPlugin::destroy() {// 清空plugin
}
然后是加载新的ONNX模型和生成plugin的完整示例代码:
int main() {// 加载ONNX模型const char* model_path = "merged_model.onnx";size_t size;char* buffer = readBuffer(model_path, size); // 读取ONNX模型数据IRuntime* runtime = createInferRuntime(gLogger);assert(runtime != nullptr);IPluginFactory* plugin_factory = createPluginFactory(gLogger);assert(plugin_factory != nullptr);nvonnxparser::IParser* parser = nvonnxparser::createParser(*plugin_factory, gLogger);assert(parser != nullptr);parser->parse(buffer, size);const int batch_size = 1;const int hidden_size = 512;const int seq_len = 128;const std::string input_name = "input";const std::string output_name = "output";// 注册自定义transformer pluginconst std::string plugin_name = "CustomTransformerPlugin";plugin_factory->registerCreator(plugin_name.c_str(), new PluginCreatorImpl<CustomTransformerPlugin>, true);// 创建engineIBuilder* builder = createInferBuilder(gLogger);assert(builder != nullptr);builder->setMaxBatchSize(batch_size);builder->setMaxWorkspaceSize(1 << 28);builder->setFp16Mode(false);builder->setInt8Mode(false);builder->setStrictTypeConstraints(false);INetworkDefinition* network = builder->createNetworkV2(1U << static_cast<uint32_t>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH));IOptimizationProfile* profile = builder->createOptimizationProfile();ITensor* input_tensor = network->addInput(input_name.c_str(), DataType::kFLOAT, Dims4(batch_size, seq_len, hidden_size));ITensor* output_tensor = network->addOutput(output_name.c_str(), DataType::kFLOAT, Dims4(batch_size, seq_len, hidden_size));// 添加pluginconst auto plugin_creator = getPluginRegistry()->getPluginCreator(plugin_name.c_str(), "1", "");const PluginFieldCollection* plugin_fields = plugin_creator->getFieldNames();std::vector<PluginField> plugin_params;IPluginV2DynamicExt* plugin = plugin_creator->createPlugin("", plugin_fields, plugin_params);ITensor* plugin_outputs[] = {plugin->enqueue(1, &input_tensor, &output_tensor, nullptr, nullptr)};assert(plugin_outputs[0] != nullptr);// 构建engineprofile->setDimensions(input_name.c_str(), OptProfileSelector::kMIN, Dims4(1, 1, hidden_size));profile->setDimensions(input_name.c_str(), OptProfileSelector::kOPT, Dims4(batch_size, seq_len, hidden_size));profile->setDimensions(input_name.c_str(), OptProfileSelector::kMAX, Dims4(batch_size, seq_len, hidden_size));profile->setDimensions(output_name.c_str(), OptProfileSelector::kMIN, Dims4(1, 1, hidden_size));profile->setDimensions(output_name.c_str(), OptProfileSelector::kOPT, Dims4(batch_size, seq_len, hidden_size));profile->setDimensions(output_name.c_str(), OptProfileSelector::kMAX, Dims4(batch_size, seq_len, hidden_size));IOptimizationProfile** profiles = new IOptimizationProfile* {profile};ICudaEngine* engine = builder->buildEngineWithCustomizedOp(*network, *parser, *plugin_factory, *plugin, profiles, 1);assert(engine != nullptr);// 释放资源plugin->destroy();input_tensor->destroy();output_tensor->destroy();network->destroy();parser->destroy();plugin_factory->destroy();builder->destroy();runtime->destroy();free(buffer);return 0;
}
这就是完整的解决方案,需要注意的是,由于自定义node和plugin的实现需要基本的TensorRT知识,这里只是提供了一个简单的示例,具体的实现还需要根据自己的模型和需求进行调整。
参考七
以下是一个用PyTorch实现的简单示例,用于将一个训练好的CNN Transformer模型导出为带有自定义OP的ONNX模型。由于没有提供模型和权重参数,您需要根据您自己的模型和权重参数进行调整。
import torch
import onnx
import onnxruntime as ort
from onnx import helper
from onnx import AttributeProto, TensorProto, GraphProto
import numpy as np# Load trained model
model = torch.load('model.pt')# Set up input and output names
input_names = ['input_ids', 'attention_mask']
output_names = ['output']# Convert PyTorch model to ONNX
dummy_input = (torch.zeros(1, 512), torch.zeros(1, 512))
torch.onnx.export(model=model, args=dummy_input, f='model.onnx', input_names=input_names, output_names=output_names, opset_version=11)# Load ONNX model
onnx_model = onnx.load('model.onnx')# Create a custom ONNX node for the fused CNN Transformer model
custom_node = helper.make_node('CustomCNNTransformer',inputs=['input_ids', 'attention_mask', 'encoder_layer_0_attention_self_query_weight', 'encoder_layer_0_attention_self_query_bias', ...], # Replace with all necessary input namesoutputs=['output'],name='fused_model'
)# Remove original CNN Transformer nodes
graph = onnx_model.graph
for i in range(len(graph.node)):if graph.node[i].op_type == 'EncoderLayer':graph.node.pop(i)# Add custom ONNX node
graph.node.append(custom_node)# Create ONNX tensor for each weight parameter
encoder_layer_0_attention_self_query_weight_tensor = helper.make_tensor('encoder_layer_0_attention_self_query_weight', TensorProto.FLOAT, [512, 512], np.random.rand(512, 512).flatten().tolist())
encoder_layer_0_attention_self_query_bias_tensor = helper.make_tensor('encoder_layer_0_attention_self_query_bias', TensorProto.FLOAT, [512], np.random.rand(512).flatten().tolist())
...# Add ONNX tensor to graph initializers
graph.initializer.extend([encoder_layer_0_attention_self_query_weight_tensor, encoder_layer_0_attention_self_query_bias_tensor, ...])# Export final ONNX model with custom node and weight parameters
onnx.checker.check_model(onnx_model)
onnx.save(onnx_model, 'model_custom.onnx')# Load ONNX model with custom node and weight parameters using ONNXRuntime
session = ort.InferenceSession('model_custom.onnx')
input_data = {'input_ids': np.zeros((1, 512)), 'attention_mask': np.zeros((1, 512))}
outputs = session.run(None, input_data)# Implement custom plugin using TensorRT C++ API
# TODO: Implement custom plugin using TensorRT C++ API
此示例涉及以下步骤:
-
加载已训练好的CNN Transformer模型。
-
使用PyTorch将模型转换为ONNX格式。
-
创建自定义ONNX节点用于融合CNN Transformer模型的所有层,并将其添加到ONNX图中。
-
移除原始CNN Transformer节点。
-
创建ONNX张量以存储融合模型的权重参数,并将它们添加到ONNX图的初始值中。
-
导出包括自定义节点和权重参数的ONNX模型。
-
使用ONNXRuntime加载带有自定义节点和权重参数的ONNX模型。
-
用TensorRT C++ API实现自定义插件。
请注意,此示例仅包括用于将CNN Transformer模型融合为自定义ONNX节点的代码,不包括实现自定义插件的代码。你需要自己编写自定义插件的代码。
相关文章:

实现PyTorch/ONNX自定义节点操作的TensorRT部署
参考一 下面是基本步骤: 加载训练好的bev transformer网络权重参数: import torch from model import Modelmodel Model() model.load_state_dict(torch.load("path/to/weights"))定义新的自定义操作: import torch from torc…...

Shamir 秘密共享、GMW和BGW方案
一、Shamir秘密共享 Shamir秘密共享方案是一种将秘密拆分成多份并分配给多个参与者保存,只有在满足特定条件下才能恢复原始秘密的密码学方案。它具有良好的容错性、加法同态性和无条件安全性等特点。 具体地,Shamir秘密共享方案可以概括为以下步骤&…...

Day56【动态规划】583.两个字符串的删除操作、72.编辑距离
583.两个字符串的删除操作 力扣题目链接/文章讲解 视频讲解 1、确定 dp 数组下标及值含义 dp[i][j]:以下标 i 为结尾的字符串 word1,和以下标 j 为结尾的字符串 word2,想要达到相等,所需要删除元素的最少次数为 dp[i][j] 2、…...

Arnold图像置乱的MATLAB实现
这件事情的起因是这样的,我需要研究一下各种图像置乱的算法。然后在知乎上找到了一篇关于Arnold变化的文章,但是呢,这个人实际上是卖资料,代做大作业的。详细的代码根部不给你,则给我气坏了,必须要手动实现…...
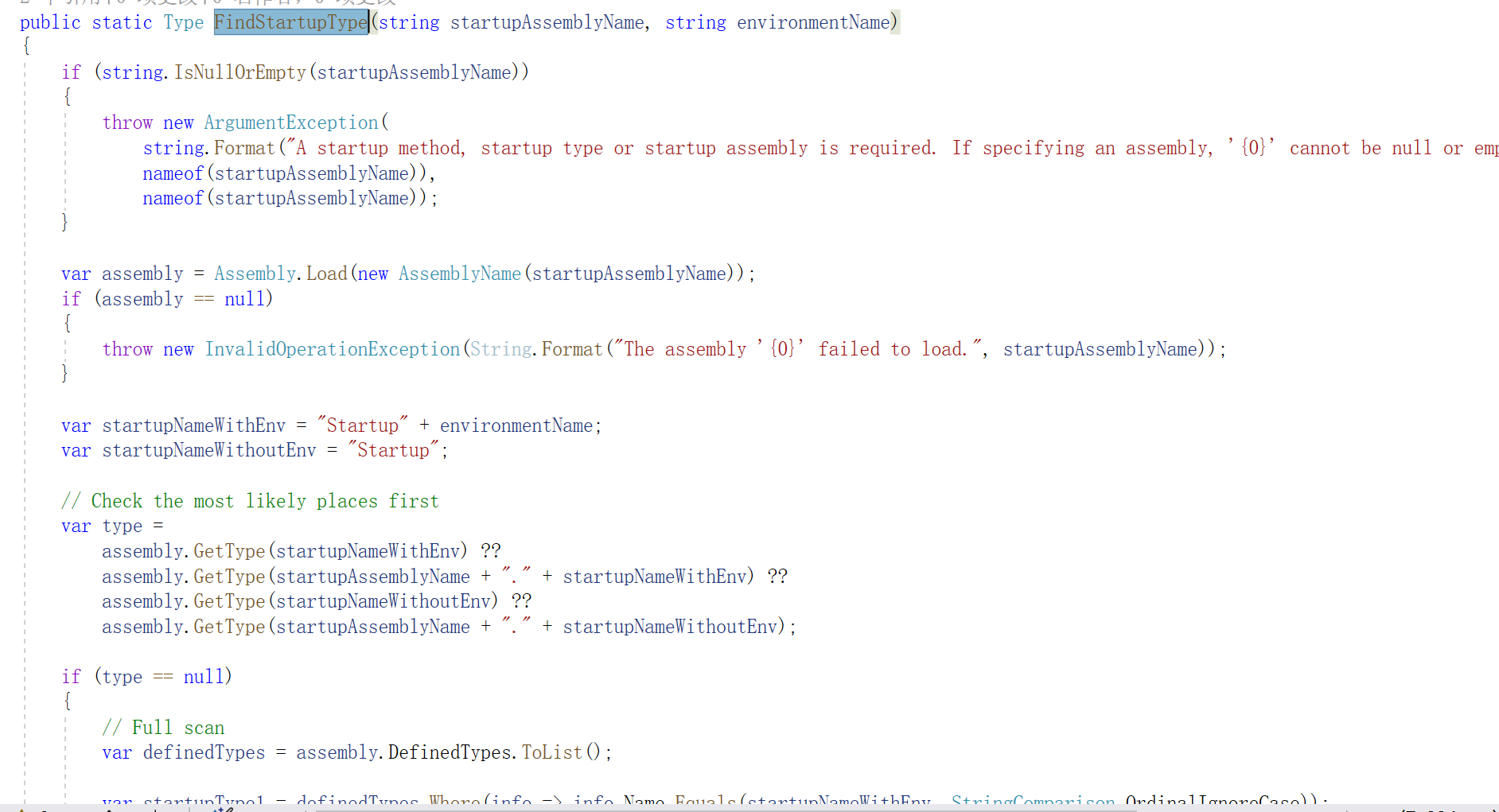
ASP.NET Core
1. 入口文件 一个应用程序总有一个入口文件,是应用启动代码开始执行的地方,这里往往也会涉及到应用的各种配置。当我们接触到一个新框架的时候,可以从入口文件入手,了解入口文件,能够帮助我们更好地理解应用的相关配置…...
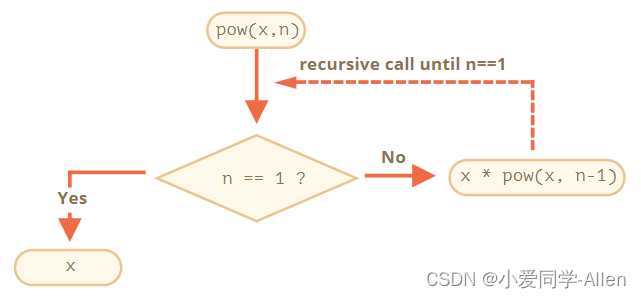
javascript基础二十二:举例说明你对尾递归的理解,有哪些应用场景
一、递归 递归(英语:Recursion) 在数学与计算机科学中,是指在函数的定义中使用函数自身的方法 在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数 其核心思想是把一个大型…...
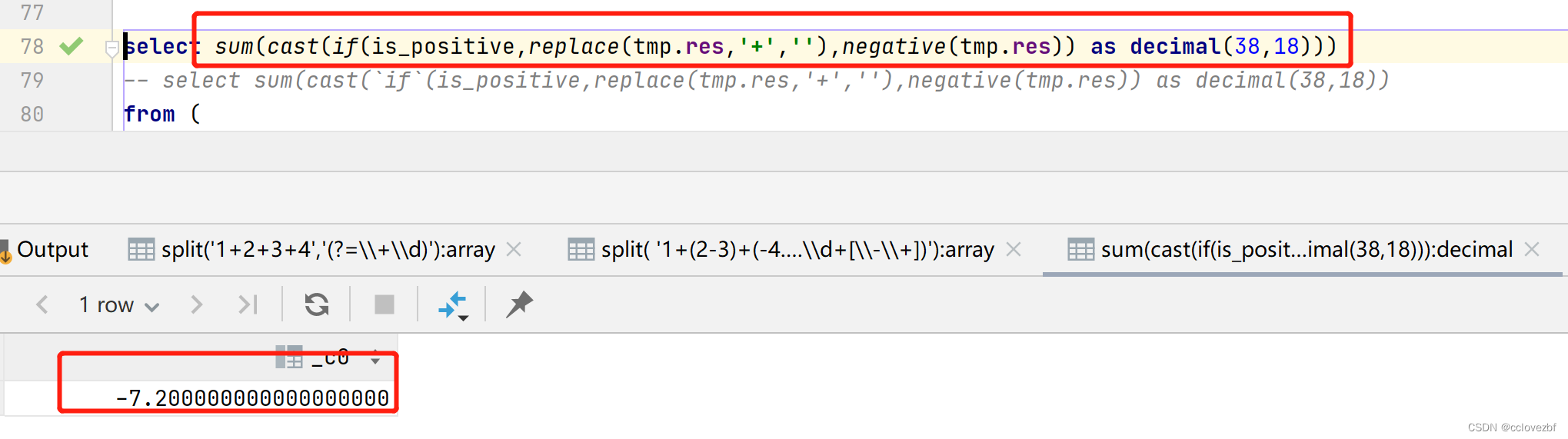
hive中如何计算字符串中表达式
比如 select 1(2-3)(-4.1-3.1)-(4-3)-(-3.34.3)-1 col ,1(2-3)(-4.1-3.1)-(4-3)-(-3.34.3)-1 result \ 现在的需求式 给你一个字符串如上述col 你要算出result。 前提式 只有和-的运算,而且只有嵌套一次 -(4-3)没有 -(-4(3-(31)))嵌套多次。 第一步我们需要将运…...

如何将maven项目改为springboot项目?
将 Maven 项目转换为 Spring Boot 项目需要进行以下步骤: 1. 在 Maven 项目中添加 Spring Boot 的依赖。可以通过在 pom.xml 文件中添加以下依赖来实现: <dependency> <groupId>org.springframework.boot</groupId> <artifactId>…...
:哈希查找)
Java与查找算法(5):哈希查找
一、哈希查找 哈希查找,也称为散列查找,是一种基于哈希表的查找算法。哈希表是一种数据结构,它将键(key)映射到值(value),使得查找某个键对应的值的时间复杂度为O(1)。哈希查找的过…...
Vercel部署个人博客
vercel 部署静态资源网站极其方便简单,并且有可观的访问速度,最主要的是免费部署。 如果你还没有尝试的话,强烈建议去使用一下。 演示博客演示http://202271.xyz/?vercel vercel 介绍 注册账号 进入Vercel官网https://vercel.com&#x…...
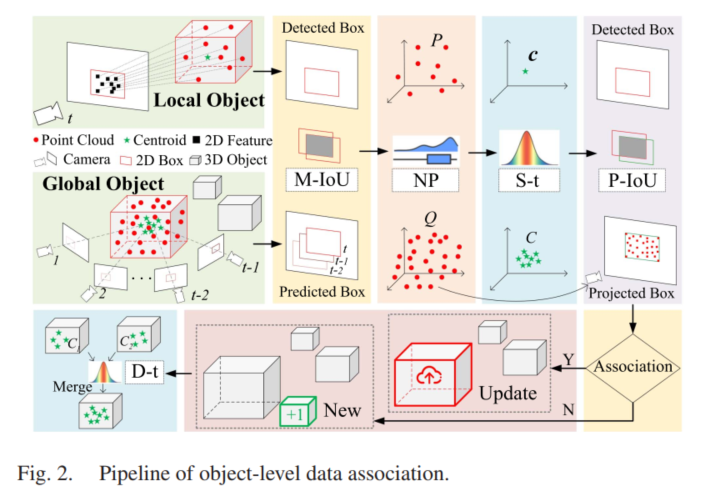
【论文阅读】An Object SLAM Framework for Association, Mapping, and High-Level Tasks
一、系统概述 这篇文章是一个十分完整的物体级SLAM框架,偏重于建图及高层应用,在前端的部分使用了ORBSLAM作为基础框架,用于提供点云以及相机的位姿,需要注意的是,这篇文章使用的是相机,虽然用的是点云这个…...

《metasploit渗透测试魔鬼训练营》学习笔记第六章--客户端渗透
四.客户端攻击 客户端攻击与服务端攻击有个显著不同的标识,就是攻击者向用户主机发送的恶意数据不会直接导致用户系统中的服务进程溢出,而是需要结合一些社会工程学技巧,诱使客户端用户去访问这些恶意数据,间接发生攻击。 4.1客户…...

华为OD机试真题 Java 实现【Linux 发行版的数量】【2023Q1 100分】
一、题目描述 Linux 操作系统有多个发行版,distrowatch.com 提供了各个发行版的资料。这些发行版互相存在关联,例如 Ubuntu 基于 Debian 只开发而 Mint 又基于 Ubuntu 开发,那么我们认为 Mint 同 Debian 也存在关联。 发行版集是一个或多个相关存在关联的操作系统发行版,…...
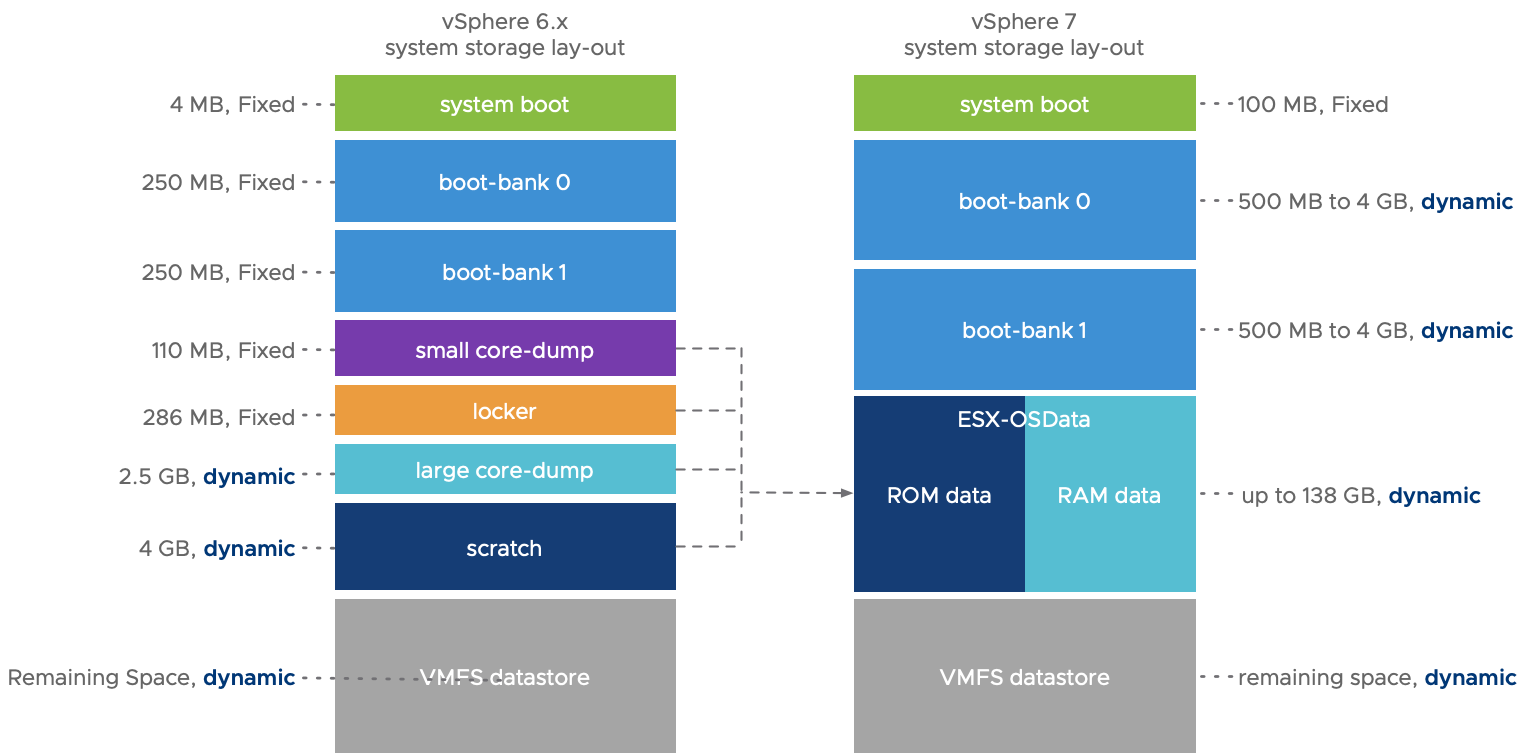
VMware ESXi 8.0U1a macOS Unlocker OEM BIOS (标准版和厂商定制版)
VMware ESXi 8.0 Update 1a macOS Unlocker & OEM BIOS (标准版和厂商定制版) ESXi 8.0U1 标准版,Dell HPE 联想 浪潮 定制版 请访问原文链接: https://sysin.org/blog/vmware-esxi-8-u1-oem/,查看最新版。原创作品,转载请保…...

Effective STL_读书笔记
Effective STL 1. 容器条例01:慎重选择容器类型条例02:不要试图编写独立于容器类型的代码条例03:确保容器中对象的拷贝正确而高效条例04:调用empty而不是检查size()是否为空条例05:区间成员函数优先于与之对应的单元素…...
通过yum:mysql5.6-msyql5.7-mysql8.0升级之路
一 前言 mysql的yum源 https://dev.mysql.com/downloads/repo/yum/ https://dev.mysql.com/get/mysq57-community-release-el7-7.noarch.rpm服务器信息 2c2g40GB [rootlocalhost ~]# cat /etc/redhat-release CentOS Linux release 7.9.2009 (Core) [rootlocalhost ~]# una…...

C语言数据存储 — 整型篇
C语言数据存储 — 整型篇 前言1. 数据类型介绍1.1 类型的基本分类 2. 整型在内存中的存储2.1 原码、反码、补码2.1.1 为什么数据存放在内存中存放的是补码 2.2 大小端介绍2.2.1 什么是大小端?2.2.2 为什么有大端和小端?2.2.3 一道百度系统工程师笔试题 3…...

高级Excel功能教程_编程入门自学教程_菜鸟教程-免费教程分享
教程简介 Excel是办公室自动化中非常重要的一款软件,Excel函数则是Excel中的内置函数。Excel函数共包含11类,分别是数据库函数、日期与时间函数、工程函数、财务函数、信息函数、逻辑函数、查询和引用函数、数学和三角函数、统计函数、文本函数以及用户…...

ChatGPT会取代低代码开发平台吗?
编程作为一种高端技能,向来是高收入高科技的代名词。近期,伴随着ChatGPT在全球的爆火,过去通过窗口“拖拉拽”的所见即所得方式的低代码开发模式,在更加智能和更低成本的AI搅局之下,又面临了更深层次的影响。 低代码平…...

Linux :: 文件内容操作【5】:echo 指令 与 输入重定向、输出重定向、追加重定向在文件内容写入中的简单用法!
前言:本篇是 Linux 基本操作篇章的内容! 笔者使用的环境是基于腾讯云服务器:CentOS 7.6 64bit。 学习集: C 入门到入土!!!学习合集Linux 从命令到网络再到内核!学习合集 说明&#x…...

解锁数据库简洁之道:FastAPI与SQLModel实战指南
在构建现代Web应用程序时,与数据库的交互无疑是核心环节。虽然传统的数据库操作方式(如直接编写SQL语句与psycopg2交互)赋予了我们精细的控制权,但在面对日益复杂的业务逻辑和快速迭代的需求时,这种方式的开发效率和可…...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...

12.找到字符串中所有字母异位词
🧠 题目解析 题目描述: 给定两个字符串 s 和 p,找出 s 中所有 p 的字母异位词的起始索引。 返回的答案以数组形式表示。 字母异位词定义: 若两个字符串包含的字符种类和出现次数完全相同,顺序无所谓,则互为…...

【HTTP三个基础问题】
面试官您好!HTTP是超文本传输协议,是互联网上客户端和服务器之间传输超文本数据(比如文字、图片、音频、视频等)的核心协议,当前互联网应用最广泛的版本是HTTP1.1,它基于经典的C/S模型,也就是客…...

JavaScript基础-API 和 Web API
在学习JavaScript的过程中,理解API(应用程序接口)和Web API的概念及其应用是非常重要的。这些工具极大地扩展了JavaScript的功能,使得开发者能够创建出功能丰富、交互性强的Web应用程序。本文将深入探讨JavaScript中的API与Web AP…...

iview框架主题色的应用
1.下载 less要使用3.0.0以下的版本 npm install less2.7.3 npm install less-loader4.0.52./src/config/theme.js文件 module.exports {yellow: {theme-color: #FDCE04},blue: {theme-color: #547CE7} }在sass中使用theme配置的颜色主题,无需引入,直接可…...

嵌入式常见 CPU 架构
架构类型架构厂商芯片厂商典型芯片特点与应用场景PICRISC (8/16 位)MicrochipMicrochipPIC16F877A、PIC18F4550简化指令集,单周期执行;低功耗、CIP 独立外设;用于家电、小电机控制、安防面板等嵌入式场景8051CISC (8 位)Intel(原始…...
的打车小程序)
基于鸿蒙(HarmonyOS5)的打车小程序
1. 开发环境准备 安装DevEco Studio (鸿蒙官方IDE)配置HarmonyOS SDK申请开发者账号和必要的API密钥 2. 项目结构设计 ├── entry │ ├── src │ │ ├── main │ │ │ ├── ets │ │ │ │ ├── pages │ │ │ │ │ ├── H…...

Windows 下端口占用排查与释放全攻略
Windows 下端口占用排查与释放全攻略 在开发和运维过程中,经常会遇到端口被占用的问题(如 8080、3306 等常用端口)。本文将详细介绍如何通过命令行和图形化界面快速定位并释放被占用的端口,帮助你高效解决此类问题。 一、准…...

k8s从入门到放弃之Pod的容器探针检测
k8s从入门到放弃之Pod的容器探针检测 在Kubernetes(简称K8s)中,容器探测是指kubelet对容器执行定期诊断的过程,以确保容器中的应用程序处于预期的状态。这些探测是保障应用健康和高可用性的重要机制。Kubernetes提供了两种种类型…...