华为OD机试之打印机队列(Java源码)
打印机队列
题目描述
有5台打印机打印文件,每台打印机有自己的待打印队列。
因为打印的文件内容有轻重缓急之分,所以队列中的文件有1~10不同的代先级,其中
数字越大优先级越高
打印机会从自己的待打印队列中选择优先级最高的文件来打印。
如果存在两个优先级一样的文件,则选择最早进入队列的那个文件。
现在请你来模拟这5台打印机的打印过程。
输入描述
每个输入包含1个测试用例,
每个测试用例第一行给出发生事件的数量N(0 < N < 1000)。
接下来有 N 行,分别表示发生的事件。共有如下两种事件:
- “IN P NUM”,表示有一个拥有优先级 NUM 的文件放到了打印机 P 的待打印队列中。(0< P <= 5, 0 < NUM <= 10);
- “OUT P”,表示打印机 P 进行了一次文件打印,同时该文件从待打印队列中取出。(0 < P <= 5)。
输出描述
- 对于每个测试用例,每次”OUT P”事件,请在一行中输出文件的编号。
- 如果此时没有文件可以打印,请输出”NULL“。
- 文件的编号定义为”IN P NUM”事件发生第 x 次,此处待打印文件的编号为x。编号从1开始。
用例
| 输入 | 7 IN 1 1 IN 1 2 IN 1 3 IN 2 1 OUT 1 OUT 2 OUT 2 |
| 输出 | 3 4 NULL |
| 说明 | 无 |
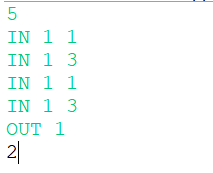
| 输入 | 5 IN 1 1 IN 1 3 IN 1 1 IN 1 3 OUT 1 |
| 输出 | 2 |
| 说明 | 无 |
源码和解析
解析:
1.可以使用有序列表对该题进行求解,但是这种每次添加任务队列都需要解决排序的问题,可以考虑在打印任务时再看是否有序,若无序,则可以排队,若有序,则直接输出首个任务,且直接移出这个任务。
2.另外一种方式就是使用大根堆去解决这个问题
示例代码方式一:
import java.util.ArrayList;
import java.util.Comparator;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Scanner;public class T35 {static class Task {int num;int priority;int taskId;public Task(int num, int priority, boolean isFinished,int taskId) {super();this.num = num;this.priority = priority;this.taskId = taskId;}@Overridepublic String toString() {return "Task [num=" + num + ", priority=" + priority+ ", taskId=" + taskId + "]\n";}}// 按输入的设备编号进行分堆 存放在不同的map中 键是打印机编号 值为该打印机的任务信息static Map<Integer, List<Task>> taskMap = new HashMap<Integer, List<Task>>();static List<Integer> pList = new ArrayList<>();// 记录设备的id集// 后面就不用keyset去遍历map了static boolean isOrdered = false;public static void main(String[] args) {Scanner scanner = new Scanner(System.in);int num = scanner.nextInt();int id = 0;for (int i = 0; i < num; i++) {id++;String op = scanner.next();int p = scanner.nextInt();int priority = 0;if (op.equals("IN")) {priority = scanner.nextInt();}if (!taskMap.containsKey(p)) {List<Task> tasks = new ArrayList<T35.Task>();taskMap.put(p, tasks);pList.add(p);}Task task = new Task(p, priority, false, id);if (op.equals("IN")) {taskMap.get(p).add(task);isOrdered = false;} else {if (!isOrdered)sort();List<Task> tasksItem = taskMap.get(p);Task t = tasksItem.size() == 0 ? null : tasksItem.get(0);if (t != null) {tasksItem.remove(0);}System.out.println((t == null ? "NULL" : t.taskId));}}}// 排序public static void sort() {isOrdered = true;for (int p : pList) {taskMap.get(p).sort(new Comparator<Task>() {@Overridepublic int compare(Task o1, Task o2) {// 优先级降序 高的排前面 方便取值if (o1.priority > o2.priority) {return -1;} else if (o1.priority < o2.priority) {return 1;}// 优先级一样 任务顺序排序if (o1.taskId < o2.taskId) {return -1;} else if (o1.taskId > o2.taskId) {return 1;}return 0;}});}}
}执行示意图如下:

大根堆解法
解析
例如输入
10
IN 1 2
IN 1 1
IN 1 4
IN 1 2
IN 1 4
IN 1 3
IN 1 5
OUT 1
OUT 2
OUT 2
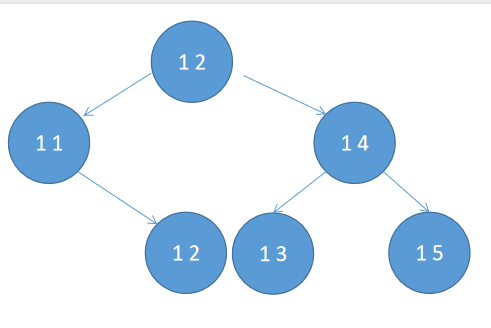
形成的节点信息如下
那么在移出时就
OUT 1 针对 1 5 这个节点
OUT 1 查找到 1 5这个节点 无比他大 比他小的 那么只能是1 5 节点的父节点 1 4
OUT 1 查找到 1 4 节点是已完成的 那么可能就是1 3 节点 若1 3节点已完成 则可能是1 2 节点 若 1 2 节点已完成 则可能是其左节点1 1 若 1 1节点已完成 则看其左节点 若 1 1 节点未完成 则看其左节点
注意:这里并非是完全排序好的大根堆,而是依据节点的添加顺序形成的堆
源码示例 大根堆
import java.util.HashMap;
import java.util.Map;
import java.util.Scanner;public class T35 {static class Task {int devId; // 设备编号int priority;int taskId;boolean isFinished;Task leftTask; // 左节点Task rightTask; // 右节点Task parenTask;// 父节点@Overridepublic String toString() {return "Task [devId=" + devId + ", priority=" + priority+ ", taskId=" + taskId + "]\n";}}// 按输入的设备编号进行分堆 存放在不同的map中 键是打印机编号 值为该打印机的任务信息static Map<Integer, Task> taskMap = new HashMap<Integer, Task>();static Task objTask = null;public static void main(String[] args) {Scanner scanner = new Scanner(System.in);int num = scanner.nextInt();int id = 0;for (int i = 0; i < num; i++) {id++;String op = scanner.next();int devId = scanner.nextInt();int priority = 0;if (op.equals("IN")) {priority = scanner.nextInt();}Task task = new Task();task.devId = devId;task.priority = priority;task.taskId = id;if (op.equals("IN")) {if (!taskMap.containsKey(devId)) {taskMap.put(devId, task);System.out.println("挂载跟节点:" + task.taskId);} else {// 挂载节点handle(devId, task);}} else {// 出节点objTask = null;find(taskMap.get(devId));if (objTask == null)System.out.println("NULL");}}}// 找到目标设备要出的那个public static void find(Task task) {if (task.isFinished == false) {// 自己未完成 那么可能到右侧if (task.rightTask != null && task.rightTask.isFinished == false) {find(task.rightTask);// 找右侧子节点 这种是不可能找左侧子节点的} else {// 到自己task.isFinished = true;objTask = task;System.out.println(task.taskId);// 输出任务id}} else {// 当前已完成 那么只有可能是其左侧节点if (task.leftTask != null)find(task.leftTask);}}public static void handle(int devId, Task task) {Task rootTask = taskMap.get(devId);mount(rootTask, task);}// 遍历节点 进行挂载public static void mount(Task task, Task objTask) {if (task.priority < objTask.priority) {// 挂载右侧if (task.rightTask != null) {mount(task.rightTask, objTask);} else {task.rightTask = objTask;System.out.println("节点" + objTask.taskId + "挂载在节点"+ task.taskId + "右侧");}} else {// 挂载左侧if (task.leftTask != null) {mount(task.leftTask, objTask);} else {task.leftTask = objTask;System.out.println("节点" + objTask.taskId + "挂载节点" + task.taskId+ "左侧");}}}
}大根堆代码运行示意图:

相关文章:
华为OD机试之打印机队列(Java源码)
打印机队列 题目描述 有5台打印机打印文件,每台打印机有自己的待打印队列。 因为打印的文件内容有轻重缓急之分,所以队列中的文件有1~10不同的代先级,其中 数字越大优先级越高 打印机会从自己的待打印队列中选择优先级最高的文件来打印。 如…...

分享一个国内免费的ChatGPT网站,手机电脑通用,免费无限制,支持AI绘画
背景 ChatGPT作为一种基于人工智能技术的自然语言处理工具,近期的热度直接沸腾🌋。 作为一个AI爱好者,翻遍了各大基于ChatGPT的网站,终于找到一个免费!免登陆!手机电脑通用!国内可直接对话的C…...

【面向对象编程1】——类和对象——如桃花来
目录索引 面向过程和面向对象的区别:面向过程:面向对象:总结: 类和对象:定义类:语法: 创建对象:实例演示: 魔法方法:__init __方法:__ del __方法…...
chat聊天系统消息消费时遇到的问题及优化思路(二)
1、前言 考虑下面几个条件下如何提升kafka的消费速度 消息要求严格有序,如chat聊天消息业务处理速度慢,如处理一条数据需要100ms分片不合理,如有的分区很闲,有的分区消息数量积压 2、解决方案 1、顺序问题 关于消息消费时存在…...

js正则中的match()
在前端开发中,正则表达式是一大利器。所以我们这次就来讨论下match()方法。 match本身是JavaScript语言中字符串对象的一个方法,该方法的签名是 match([string] | [RegExp]) 它的参数既可以是一个字符串,也可以是一个正则表达式。该方法绝…...
Apache 配置和应用
目录 构建虚拟 Web 主机 Options指令解释 Options指令常用选项 AllowOverride指令解释: 地址限制策略: httpd服务支持的虚拟主机类型包括以下三种: 基于域名的虚拟主机 1.为虚拟主机提供域名解析 2.为虚拟主机准备网页文档 3.添加虚拟…...

实现PyTorch/ONNX自定义节点操作的TensorRT部署
参考一 下面是基本步骤: 加载训练好的bev transformer网络权重参数: import torch from model import Modelmodel Model() model.load_state_dict(torch.load("path/to/weights"))定义新的自定义操作: import torch from torc…...

Shamir 秘密共享、GMW和BGW方案
一、Shamir秘密共享 Shamir秘密共享方案是一种将秘密拆分成多份并分配给多个参与者保存,只有在满足特定条件下才能恢复原始秘密的密码学方案。它具有良好的容错性、加法同态性和无条件安全性等特点。 具体地,Shamir秘密共享方案可以概括为以下步骤&…...

Day56【动态规划】583.两个字符串的删除操作、72.编辑距离
583.两个字符串的删除操作 力扣题目链接/文章讲解 视频讲解 1、确定 dp 数组下标及值含义 dp[i][j]:以下标 i 为结尾的字符串 word1,和以下标 j 为结尾的字符串 word2,想要达到相等,所需要删除元素的最少次数为 dp[i][j] 2、…...

Arnold图像置乱的MATLAB实现
这件事情的起因是这样的,我需要研究一下各种图像置乱的算法。然后在知乎上找到了一篇关于Arnold变化的文章,但是呢,这个人实际上是卖资料,代做大作业的。详细的代码根部不给你,则给我气坏了,必须要手动实现…...
ASP.NET Core
1. 入口文件 一个应用程序总有一个入口文件,是应用启动代码开始执行的地方,这里往往也会涉及到应用的各种配置。当我们接触到一个新框架的时候,可以从入口文件入手,了解入口文件,能够帮助我们更好地理解应用的相关配置…...
javascript基础二十二:举例说明你对尾递归的理解,有哪些应用场景
一、递归 递归(英语:Recursion) 在数学与计算机科学中,是指在函数的定义中使用函数自身的方法 在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数 其核心思想是把一个大型…...
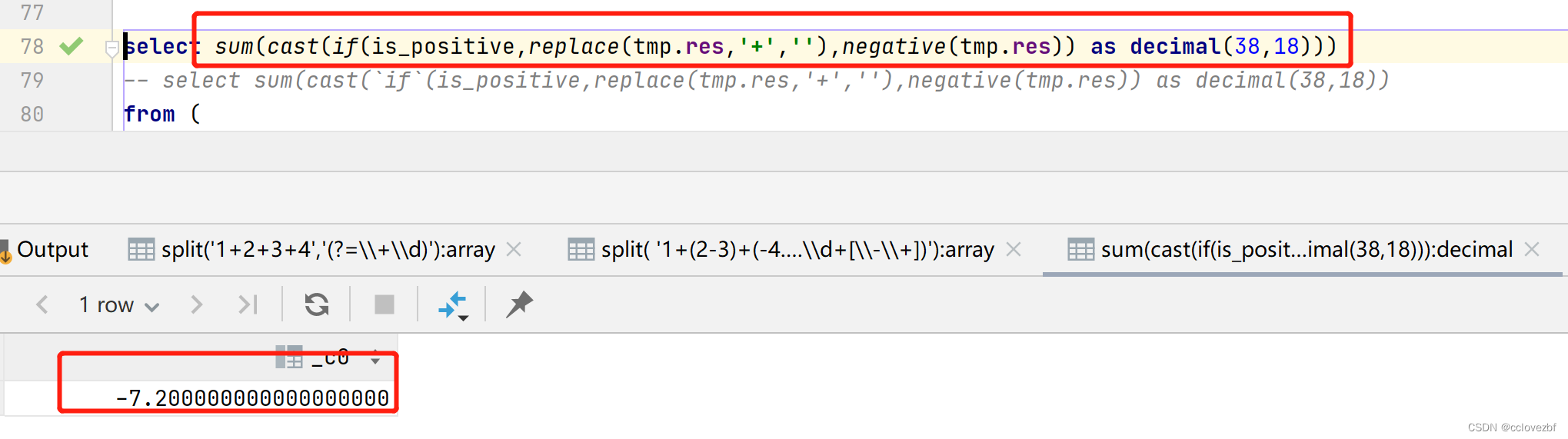
hive中如何计算字符串中表达式
比如 select 1(2-3)(-4.1-3.1)-(4-3)-(-3.34.3)-1 col ,1(2-3)(-4.1-3.1)-(4-3)-(-3.34.3)-1 result \ 现在的需求式 给你一个字符串如上述col 你要算出result。 前提式 只有和-的运算,而且只有嵌套一次 -(4-3)没有 -(-4(3-(31)))嵌套多次。 第一步我们需要将运…...

如何将maven项目改为springboot项目?
将 Maven 项目转换为 Spring Boot 项目需要进行以下步骤: 1. 在 Maven 项目中添加 Spring Boot 的依赖。可以通过在 pom.xml 文件中添加以下依赖来实现: <dependency> <groupId>org.springframework.boot</groupId> <artifactId>…...
:哈希查找)
Java与查找算法(5):哈希查找
一、哈希查找 哈希查找,也称为散列查找,是一种基于哈希表的查找算法。哈希表是一种数据结构,它将键(key)映射到值(value),使得查找某个键对应的值的时间复杂度为O(1)。哈希查找的过…...
Vercel部署个人博客
vercel 部署静态资源网站极其方便简单,并且有可观的访问速度,最主要的是免费部署。 如果你还没有尝试的话,强烈建议去使用一下。 演示博客演示http://202271.xyz/?vercel vercel 介绍 注册账号 进入Vercel官网https://vercel.com&#x…...
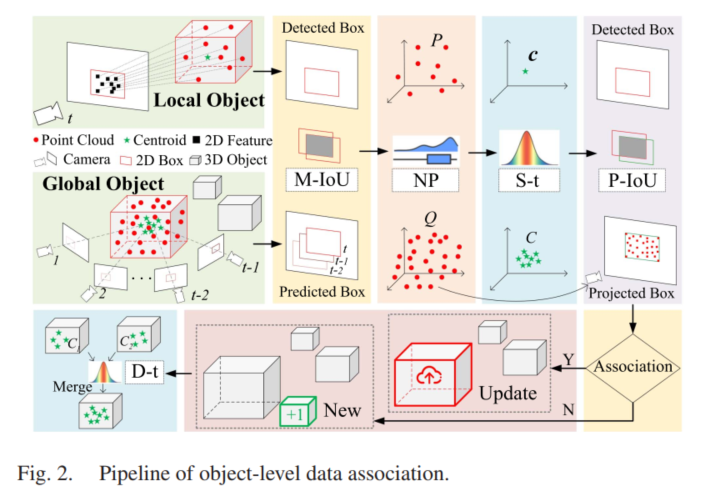
【论文阅读】An Object SLAM Framework for Association, Mapping, and High-Level Tasks
一、系统概述 这篇文章是一个十分完整的物体级SLAM框架,偏重于建图及高层应用,在前端的部分使用了ORBSLAM作为基础框架,用于提供点云以及相机的位姿,需要注意的是,这篇文章使用的是相机,虽然用的是点云这个…...

《metasploit渗透测试魔鬼训练营》学习笔记第六章--客户端渗透
四.客户端攻击 客户端攻击与服务端攻击有个显著不同的标识,就是攻击者向用户主机发送的恶意数据不会直接导致用户系统中的服务进程溢出,而是需要结合一些社会工程学技巧,诱使客户端用户去访问这些恶意数据,间接发生攻击。 4.1客户…...

华为OD机试真题 Java 实现【Linux 发行版的数量】【2023Q1 100分】
一、题目描述 Linux 操作系统有多个发行版,distrowatch.com 提供了各个发行版的资料。这些发行版互相存在关联,例如 Ubuntu 基于 Debian 只开发而 Mint 又基于 Ubuntu 开发,那么我们认为 Mint 同 Debian 也存在关联。 发行版集是一个或多个相关存在关联的操作系统发行版,…...
VMware ESXi 8.0U1a macOS Unlocker OEM BIOS (标准版和厂商定制版)
VMware ESXi 8.0 Update 1a macOS Unlocker & OEM BIOS (标准版和厂商定制版) ESXi 8.0U1 标准版,Dell HPE 联想 浪潮 定制版 请访问原文链接: https://sysin.org/blog/vmware-esxi-8-u1-oem/,查看最新版。原创作品,转载请保…...

AtCoder 第409场初级竞赛 A~E题解
A Conflict 【题目链接】 原题链接:A - Conflict 【考点】 枚举 【题目大意】 找到是否有两人都想要的物品。 【解析】 遍历两端字符串,只有在同时为 o 时输出 Yes 并结束程序,否则输出 No。 【难度】 GESP三级 【代码参考】 #i…...

大数据零基础学习day1之环境准备和大数据初步理解
学习大数据会使用到多台Linux服务器。 一、环境准备 1、VMware 基于VMware构建Linux虚拟机 是大数据从业者或者IT从业者的必备技能之一也是成本低廉的方案 所以VMware虚拟机方案是必须要学习的。 (1)设置网关 打开VMware虚拟机,点击编辑…...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...

论文浅尝 | 基于判别指令微调生成式大语言模型的知识图谱补全方法(ISWC2024)
笔记整理:刘治强,浙江大学硕士生,研究方向为知识图谱表示学习,大语言模型 论文链接:http://arxiv.org/abs/2407.16127 发表会议:ISWC 2024 1. 动机 传统的知识图谱补全(KGC)模型通过…...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...

云原生玩法三问:构建自定义开发环境
云原生玩法三问:构建自定义开发环境 引言 临时运维一个古董项目,无文档,无环境,无交接人,俗称三无。 运行设备的环境老,本地环境版本高,ssh不过去。正好最近对 腾讯出品的云原生 cnb 感兴趣&…...

【VLNs篇】07:NavRL—在动态环境中学习安全飞行
项目内容论文标题NavRL: 在动态环境中学习安全飞行 (NavRL: Learning Safe Flight in Dynamic Environments)核心问题解决无人机在包含静态和动态障碍物的复杂环境中进行安全、高效自主导航的挑战,克服传统方法和现有强化学习方法的局限性。核心算法基于近端策略优化…...

七、数据库的完整性
七、数据库的完整性 主要内容 7.1 数据库的完整性概述 7.2 实体完整性 7.3 参照完整性 7.4 用户定义的完整性 7.5 触发器 7.6 SQL Server中数据库完整性的实现 7.7 小结 7.1 数据库的完整性概述 数据库完整性的含义 正确性 指数据的合法性 有效性 指数据是否属于所定…...

【Nginx】使用 Nginx+Lua 实现基于 IP 的访问频率限制
使用 NginxLua 实现基于 IP 的访问频率限制 在高并发场景下,限制某个 IP 的访问频率是非常重要的,可以有效防止恶意攻击或错误配置导致的服务宕机。以下是一个详细的实现方案,使用 Nginx 和 Lua 脚本结合 Redis 来实现基于 IP 的访问频率限制…...

android13 app的触摸问题定位分析流程
一、知识点 一般来说,触摸问题都是app层面出问题,我们可以在ViewRootImpl.java添加log的方式定位;如果是touchableRegion的计算问题,就会相对比较麻烦了,需要通过adb shell dumpsys input > input.log指令,且通过打印堆栈的方式,逐步定位问题,并找到修改方案。 问题…...