Hive窗口函数详细介绍
文章目录
- Hive窗口函数概述
- 样本数据
- 表结构
- 表数据
- 窗口函数
- 窗口聚合函数
- count()
- SQL演示
- sum()
- SQL演示
- avg()
- SQL演示
- min()
- SQL演示
- max()
- SQL演示
- 窗口分析函数
- first_value() 取开窗第一个值
- 应用场景
- SQL演示
- last_value()取开窗最后一个值
- 应用场景
- SQL演示
- lag(col, n, default_val):往前第n行数据
- 应用场景
- SQL演示
- lead(col, n, default_val):往后第n行数据
- cume_dist:统计大于或小于当前值数量/总数
- 应用场景
- SQL演示
- 窗口排序函数
- rank():为查询结果中的行返回排名-非连续编号
- 应用场景
- SQL演示
- dense_rank():为查询结果中的行返回排名-连续编号
- 应用场景
- SQL演示
- ntile:将结果集分成指定的桶数
- 应用场景
- SQL演示
- row_number:排名函数
- 应用场景
- SQL演示
- 开窗后后只取最新一条数据
- percent_rank:计算查询结果集中每个行相对于其组内排名的百分比
- 应用场景
- SQL演示
Hive窗口函数概述
Hive 窗口函数是一种高级查询技术,用于对分组数据进行聚合计算,并且可以在数据分组内对每行数据进行排序和取值范围的过滤。与普通的聚合函数(如 SUM、MAX 等)不同的是,窗口函数可以同时获取每个数据行内的计算结果和数据群组/分区内部的排名、比例等信息,同时避免了使用 self-join 等操作来完成计算,使得运算效率更高。
Hive 窗口函数常用的包括 COUNT()、SUM()、AVG()、RANK()、DENSE_RANK()、ROW_NUMBER()、 FIRST_VALUE()、LAST_VALUE() 和 CUME_DIST() 等,对于不同的计算场景和需求可以选择不同的窗口函数进行聚合计算。
窗口函数通常包含以下核心要素:
- PARTITION BY:指定数据分组字段。
- ORDER BY:指定相对排序的字段。
- ROWS BETWEEN:指定窗口函数计算的行范围。
通过使用这些要素的组合方案,可以实现多种数据分组、排序、聚合和计算需求,大大拓展了 SQL 查询的功能和应用范围。
样本数据
表结构
CREATE TABLE IF NOT EXISTS article_data(article_id INT comment '文章id', release_time STRING comment '文章发布时间', article_word_count INT comment '文章字数',author STRING comment '文章作者'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
表数据
INSERT INTO article_data VALUES
(1, '2022-01-01 09:30:00', 1000, 'Tom'),
(2, '2022-01-02 10:00:00', 1200, 'Bob'),
(3, '2022-01-03 11:00:00', 800, 'Alice'),
(4, '2022-01-04 12:00:00', 1500, 'Jack'),
(5, '2022-01-05 13:00:00', 2000, 'Lucy'),
(6, '2022-01-06 14:00:00', 900, 'Tom'),
(7, '2021-12-27 15:00:00', 700, 'Bob'),
(8, '2022-01-08 16:00:00', 1300, 'Alice'),
(9, '2022-01-13 17:00:00', 1800, 'Jack'),
(10, '2022-01-19 18:00:00', 1100, 'Lucy'),
(11, '2022-01-07 19:00:00', 1700, 'Tom'),
(12, '2022-01-09 20:00:00', 800, 'Bob'),
(13, '2022-01-16 21:00:00', 600, 'Alice'),
(14, '2022-01-22 22:00:00', 1500, 'Jack'),
(15, '2022-01-25 23:00:00', 2000, 'Lucy'),
(16, '2022-01-26 10:30:00', 900, 'Tom'),
(17, '2022-01-13 11:30:00', 1900, 'Bob'),
(18, '2022-01-02 12:30:00', 1000, 'Alice'),
(19, '2022-01-14 13:30:00', 1300, 'Jack'),
(20, '2022-01-17 14:30:00', 1700, 'Lucy'),
(21, '2022-01-14 13:30:00', 1800, 'Jack'),
(22, '2022-01-17 14:30:00', 2500, 'Lucy');
查询
0: jdbc:hive2://bigdata:2181,bigdata-2> select * from article_data;
+--------------------------+----------------------------+----------------------------------+----------------------+
| article_data.article_id | article_data.release_time | article_data.article_word_count | article_data.author |
+--------------------------+----------------------------+----------------------------------+----------------------+
| 1 | 2022-01-01 09:30:00 | 1000 | Tom |
| 2 | 2022-01-02 10:00:00 | 1200 | Bob |
| 3 | 2022-01-03 11:00:00 | 800 | Alice |
| 4 | 2022-01-04 12:00:00 | 1500 | Jack |
| 5 | 2022-01-05 13:00:00 | 2000 | Lucy |
| 6 | 2022-01-06 14:00:00 | 900 | Tom |
| 7 | 2021-12-27 15:00:00 | 700 | Bob |
| 8 | 2022-01-08 16:00:00 | 1300 | Alice |
| 9 | 2022-01-13 17:00:00 | 1800 | Jack |
| 10 | 2022-01-19 18:00:00 | 1100 | Lucy |
| 11 | 2022-01-07 19:00:00 | 1700 | Tom |
| 12 | 2022-01-09 20:00:00 | 800 | Bob |
| 13 | 2022-01-16 21:00:00 | 600 | Alice |
| 14 | 2022-01-22 22:00:00 | 1500 | Jack |
| 15 | 2022-01-25 23:00:00 | 2000 | Lucy |
| 16 | 2022-01-26 10:30:00 | 900 | Tom |
| 17 | 2022-01-13 11:30:00 | 1900 | Bob |
| 18 | 2022-01-02 12:30:00 | 1000 | Alice |
| 19 | 2022-01-14 13:30:00 | 1300 | Jack |
| 20 | 2022-01-17 14:30:00 | 1700 | Lucy |
| 21 | 2022-01-14 13:30:00 | 1800 | Jack |
| 22 | 2022-01-17 14:30:00 | 2500 | Lucy |
+--------------------------+----------------------------+----------------------------------+----------------------+
窗口函数
窗口聚合函数
count()
在 Hive 中,COUNT() 是一种聚合函数,用于计算某列中非 NULL 值的数量。Hive 支持 COUNT() 作为窗口函数,可以结合 OVER() 应用于专业计算中。
COUNT() 窗口函数的语法如下:
COUNT(expression) OVER([PARTITION BY partition_expression, ... ][ORDER BY order_expression [ASC | DESC], ... ][window_frame]
)
其中,expression 表示需要计数的列或表达式,也可以是通配符(*),表示计数整个行。PARTITION BY 和 ORDER BY 子句用于对计数的分组和排序。WINDOWING 子句用于指定窗口的边界。
COUNT() 窗口函数的使用方法与普通的 COUNT() 函数类似,但是由于其结合了窗口函数,因此可以实现更加灵活高效的数据分析工作。在使用 COUNT() 窗口函数时,我们可以指定多个 PARTITION BY 和 ORDER BY 子句,从而对不同的数据进行分组和排序。同时,通过使用 WINDOWING 子句,我们可以更加灵活地确定窗口的边界,以适应实际的数据分析需求。
SQL演示
select article_id,release_time,article_word_count,author,# 所有行作为一个窗口count(author) over() as a,# 根据author分组,返回分组后文章总数count(author) over(partition by author) as a1,# 根据author分组,按照release_time排序,返回当前时间发布文章总数count(author) over(partition by author order by release_time) as a2,# 根据author分组,按照release_time排序,按当前数据行+前1行+后2行的行作为窗口(算上当前数据一共4行,根据分组排序后的数据进行计算行范围)count(author) over(partition by author order by release_time rows between 1 preceding and 2 following) as a3,# 根据author分组,按照release_time排序,从分组后第一行到最后一行作为窗口,与a1结果相同count(author) over(partition by author order by release_time rows between unbounded preceding and unbounded following) as a4,# 根据author分组,按照release_time排序,从第一行到当前行的前一行作为窗口count(author) over(partition by author order by release_time rows between unbounded preceding and 1 preceding) as a5,# 根据author分组,按照release_time排序,从第一行到当前行作为窗口count(author) over(partition by author order by release_time rows between unbounded preceding and current row) as a6,# 根据author分组,按照release_time排序,从当前行到最后一行作为窗口count(author) over(partition by author order by release_time rows between current row and unbounded following) as a7,# 根据author分组,按照release_time排序,从当前行后一行到最后一行作为窗口count(author) over(partition by author order by release_time rows between 1 following and unbounded following) as a8,# 根据author分组,按照release_time排序,从当前行后一行到当前后两行行作为窗口count(author) over(partition by author order by release_time rows between 1 following and 2 following) as a9from article_data;
结果
+-------------+----------------------+---------------------+---------+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+
| article_id | release_time | article_word_count | author | a | a1 | a2 | a3 | a4 | a5 | a6 | a7 | a8 | a9 |
+-------------+----------------------+---------------------+---------+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+
| 18 | 2022-01-02 12:30:00 | 1000 | Alice | 22 | 4 | 1 | 3 | 4 | 0 | 1 | 4 | 3 | 2 |
| 3 | 2022-01-03 11:00:00 | 800 | Alice | 22 | 4 | 2 | 4 | 4 | 1 | 2 | 3 | 2 | 2 |
| 8 | 2022-01-08 16:00:00 | 1300 | Alice | 22 | 4 | 3 | 3 | 4 | 2 | 3 | 2 | 1 | 1 |
| 13 | 2022-01-16 21:00:00 | 600 | Alice | 22 | 4 | 4 | 2 | 4 | 3 | 4 | 1 | 0 | 0 |
| 1 | 2022-01-01 09:30:00 | 1000 | Tom | 22 | 4 | 1 | 3 | 4 | 0 | 1 | 4 | 3 | 2 |
| 6 | 2022-01-06 14:00:00 | 900 | Tom | 22 | 4 | 2 | 4 | 4 | 1 | 2 | 3 | 2 | 2 |
| 11 | 2022-01-07 19:00:00 | 1700 | Tom | 22 | 4 | 3 | 3 | 4 | 2 | 3 | 2 | 1 | 1 |
| 16 | 2022-01-26 10:30:00 | 900 | Tom | 22 | 4 | 4 | 2 | 4 | 3 | 4 | 1 | 0 | 0 |
| 7 | 2021-12-27 15:00:00 | 700 | Bob | 22 | 4 | 1 | 3 | 4 | 0 | 1 | 4 | 3 | 2 |
| 2 | 2022-01-02 10:00:00 | 1200 | Bob | 22 | 4 | 2 | 4 | 4 | 1 | 2 | 3 | 2 | 2 |
| 12 | 2022-01-09 20:00:00 | 800 | Bob | 22 | 4 | 3 | 3 | 4 | 2 | 3 | 2 | 1 | 1 |
| 17 | 2022-01-13 11:30:00 | 1900 | Bob | 22 | 4 | 4 | 2 | 4 | 3 | 4 | 1 | 0 | 0 |
| 4 | 2022-01-04 12:00:00 | 1500 | Jack | 22 | 5 | 1 | 3 | 5 | 0 | 1 | 5 | 4 | 2 |
| 9 | 2022-01-13 17:00:00 | 1800 | Jack | 22 | 5 | 2 | 4 | 5 | 1 | 2 | 4 | 3 | 2 |
| 19 | 2022-01-14 13:30:00 | 1300 | Jack | 22 | 5 | 4 | 4 | 5 | 2 | 3 | 3 | 2 | 2 |
| 21 | 2022-01-14 13:30:00 | 1800 | Jack | 22 | 5 | 4 | 3 | 5 | 3 | 4 | 2 | 1 | 1 |
| 14 | 2022-01-22 22:00:00 | 1500 | Jack | 22 | 5 | 5 | 2 | 5 | 4 | 5 | 1 | 0 | 0 |
| 5 | 2022-01-05 13:00:00 | 2000 | Lucy | 22 | 5 | 1 | 3 | 5 | 0 | 1 | 5 | 4 | 2 |
| 22 | 2022-01-17 14:30:00 | 2500 | Lucy | 22 | 5 | 3 | 4 | 5 | 1 | 2 | 4 | 3 | 2 |
| 20 | 2022-01-17 14:30:00 | 1700 | Lucy | 22 | 5 | 3 | 4 | 5 | 2 | 3 | 3 | 2 | 2 |
| 10 | 2022-01-19 18:00:00 | 1100 | Lucy | 22 | 5 | 4 | 3 | 5 | 3 | 4 | 2 | 1 | 1 |
| 15 | 2022-01-25 23:00:00 | 2000 | Lucy | 22 | 5 | 5 | 2 | 5 | 4 | 5 | 1 | 0 | 0 |
+-------------+----------------------+---------------------+---------+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+
sum()
Hive 窗口函数 SUM() 可以用于计算指定列的数值总和。相比于 GROUP BY 子句,窗口函数能够避免对查询结果进行分组,因此在某些查询场景下拥有更高的效率和扩展性。
下面是 SUM() 函数的语法:
SUM(expression) OVER (partition_clause [order_clause] [windowing_clause])
其中参数 expression 可以是任意 Hive 支持的表达式,例如列名、数值常数、函数返回值等。partition_clause 和 order_clause 分别用于指定分组和排序规则,可以省略。windowing_clause 用于指定窗口函数的计算范围,可以是 RANGE 或 ROWS 两种模式,具体使用方式可以参见 Hive 官方文档。
SQL演示
与count()类似,参考count()
avg()
Hive 窗口函数 AVG() 可以用于计算指定列的平均值。它的语法如下:
AVG(expr) OVER ([PARTITION BY col_list][ORDER BY col_list][ROWS BETWEEN frame_start AND frame_end]
)
其中:
-
expr:指定需要求平均值的列或表达式,可以是数字类型或者能够隐式转换成数字类型的表达式。 -
PARTITION BY col_list:可选项,指定针对哪些列进行分组,计算每个分组的平均值。如果省略,则针对整张表计算平均值。 -
ORDER BY col_list:可选项,指定按照哪些列进行排序。如果省略,则使用表的默认排序顺序。 -
ROWS BETWEEN frame_start AND frame_end:可选项,指定针对当前行向前或向后多少行进行平均值的计算。语法格式如下:ROWS BETWEEN frame_start PRECEDING AND frame_end FOLLOWING其中,
frame_start和frame_end可以是以下几个值:UNBOUNDED PRECEDING:表示窗口从前面第一行开始。CURRENT ROW:表示窗口当前行。UNBOUNDED FOLLOWING:表示窗口到后面最后一行结束。<value> PRECEDING/FOLLOWING:表示窗口从当前行前面/后面的第<value>行开始。
如果省略
ROWS BETWEEN子句,则将默认使用RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING,即使用所有分组内的行来计算平均值。
需要注意的是,AVG() 窗口函数在计算平均值时会自动忽略 NULL 值。如果所有行都是 NULL,则返回 NULL 值。
SQL演示
与count()类似,参考count()
min()
Hive 窗口函数 MIN() 可以用于计算指定列的最小值。它的语法如下:
MIN(expr) OVER ([PARTITION BY col_list][ORDER BY col_list][ROWS BETWEEN frame_start AND frame_end]
)
其中,参数 expr 是要计算最小值的列或表达式。而 PARTITION BY、ORDER BY 和 ROWS BETWEEN 则用于指定窗口函数的分区、排序和行范围。
SQL演示
与count()类似,参考count()
max()
Hive 窗口函数 MAX() 可以用于计算指定列的最大值。它的语法如下:
MAX(expr) OVER ([PARTITION BY col_list][ORDER BY col_list][ROWS BETWEEN frame_start AND frame_end]
)
其中:
-
expr:指定需要求最大值的列或表达式,可以是任意类型。 -
PARTITION BY col_list:可选项,指定针对哪些列进行分组,如果不设置,则会把所有行视为同一个组。 -
ORDER BY col_list:可选项,用于对每个组内的数据进行排序,以便计算窗口边界。如果不设置,则会按照输入顺序进行计算。 -
ROWS BETWEEN frame_start AND frame_end:可选项,指定窗口边界,用于计算窗口函数的取值范围。默认情况下,窗口边界为 UNBOUNDED PRECEDING 和 CURRENT ROW,即从当前行往前取所有行。可以通过设置 frame_start 和 frame_end 来指定边界,常用的设置包括:ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING:取所有行。ROWS BETWEEN frame_start AND CURRENT ROW:取当前行及之前的 frame_start 行。ROWS BETWEEN frame_start AND frame_end:取 frame_start 和 frame_end 之间的行。
SQL演示
与count()类似,参考count()
窗口分析函数
first_value() 取开窗第一个值
Hive中的FIRST_VALUE函数是一种分析函数,用于返回查询结果集中第一个数据值。使用FIRST_VALUE函数时,相应的ORDER BY子句应该指定所查询结果记录应该按照哪个字段排序。当查询结果集进行分组时,需要使用PARTITION BY子句对结果进行分组形成记录集。
FIRST_VALUE()函数的语法如下:
FIRST_VALUE(expr) OVER ([PARTITION BY partition_expression, ...]ORDER BY sort_expression [ASC | DESC], ...
)
其中,expr是计算第一个值的表达式, [PARTITION BY] 和 [ORDER BY]块表示按特定的列分区和排序,与ROW_NUMBER()、DENSE_RANK()和NTILE()函数中的语法相同。
应用场景
FIRST_VALUE()函数在数据分析和数据挖掘领域应用广泛,特别是在以下场景下会显得很有用:
-
计算人员历史数据:当你需要查找数据集中的某个员工最早的时间戳(或者其他值)时,可以使用FIRST_VALUE()函数。这通常用于跟踪员工的属性或异动状况。
-
排序:使用FIRST_VALUE()函数可以轻松地查找数据集中的最低或最高值,并按照特定的条件进行排序。这对于有效的数据汇总和高效的报告制作非常有帮助。
-
按行计算:使用根据PARTITION BY和ORDER BY条件定义的窗口为每行计算FIRST_VALUE()函数将会很有用,特别是在处理复杂的多行数据时。
-
设置目标:在需要对数据集进行目标设定和位置指示时,FIRST_VALUE()函数同样十分有用。例如,你可以计算竞技选手的第一次比赛得分,然后以此为基础来设置未来的比赛目标。
FIRST_VALUE()函数是非常有用的Hive分析函数,适用于计算相对时间戳,计算排序和目标设定等情况。它可以方便地追踪数据集中的员工属性和更具体的数据值,帮助人们更好地处理和管理数据。
SQL演示
select article_id,release_time,article_word_count,author,# 根据author分组,按照release_time排序,进行开窗,取第一条数据的article_word_count字段first_value(article_word_count) over(partition by author order by release_time) as a1,# 根据author分组,按照release_time排序,按当前数据行+前1行+后2行的行作为窗口(算上当前数据一共4行,取第一值)first_value(article_word_count) over(partition by author order by release_time rows between 1 preceding and 2 following) as a2,# 根据author分组,按照release_time排序,从分组后第一行到最后一行作为窗口,取第一个值first_value(article_word_count) over(partition by author order by release_time rows between unbounded preceding and unbounded following) as a3,# 根据author分组,按照release_time排序,从第一行到当前行的前一行作为窗口,取第一个值first_value(article_word_count) over(partition by author order by release_time rows between unbounded preceding and 1 preceding) as a4,# 根据author分组,按照release_time排序,从第一行到当前行作为窗口first_value(article_word_count) over(partition by author order by release_time rows between unbounded preceding and current row) as a5,# 根据author分组,按照release_time排序,从当前行到最后一行作为窗口first_value(article_word_count) over(partition by author order by release_time rows between current row and unbounded following) as a6,# 根据author分组,按照release_time排序,从当前行后一行到最后一行作为窗口first_value(article_word_count) over(partition by author order by release_time rows between 1 following and unbounded following) as a7,# 根据author分组,按照release_time排序,从当前行后一行到当前后两行行作为窗口first_value(article_word_count) over(partition by author order by release_time rows between 1 following and 2 following) as a8
from article_data;
结果
+-------------+----------------------+---------------------+---------+-------+-------+-------+-------+-------+-------+-------+-------+
| article_id | release_time | article_word_count | author | a1 | a2 | a3 | a4 | a5 | a6 | a7 | a8 |
+-------------+----------------------+---------------------+---------+-------+-------+-------+-------+-------+-------+-------+-------+
| 18 | 2022-01-02 12:30:00 | 1000 | Alice | 1000 | 1000 | 1000 | NULL | 1000 | 1000 | 800 | 800 |
| 3 | 2022-01-03 11:00:00 | 800 | Alice | 1000 | 1000 | 1000 | 1000 | 1000 | 800 | 1300 | 1300 |
| 8 | 2022-01-08 16:00:00 | 1300 | Alice | 1000 | 800 | 1000 | 1000 | 1000 | 1300 | 600 | 600 |
| 13 | 2022-01-16 21:00:00 | 600 | Alice | 1000 | 1300 | 1000 | 1000 | 1000 | 600 | NULL | NULL |
| 1 | 2022-01-01 09:30:00 | 1000 | Tom | 1000 | 1000 | 1000 | NULL | 1000 | 1000 | 900 | 900 |
| 6 | 2022-01-06 14:00:00 | 900 | Tom | 1000 | 1000 | 1000 | 1000 | 1000 | 900 | 1700 | 1700 |
| 11 | 2022-01-07 19:00:00 | 1700 | Tom | 1000 | 900 | 1000 | 1000 | 1000 | 1700 | 900 | 900 |
| 16 | 2022-01-26 10:30:00 | 900 | Tom | 1000 | 1700 | 1000 | 1000 | 1000 | 900 | NULL | NULL |
| 7 | 2021-12-27 15:00:00 | 700 | Bob | 700 | 700 | 700 | NULL | 700 | 700 | 1200 | 1200 |
| 2 | 2022-01-02 10:00:00 | 1200 | Bob | 700 | 700 | 700 | 700 | 700 | 1200 | 800 | 800 |
| 12 | 2022-01-09 20:00:00 | 800 | Bob | 700 | 1200 | 700 | 700 | 700 | 800 | 1900 | 1900 |
| 17 | 2022-01-13 11:30:00 | 1900 | Bob | 700 | 800 | 700 | 700 | 700 | 1900 | NULL | NULL |
| 4 | 2022-01-04 12:00:00 | 1500 | Jack | 1500 | 1500 | 1500 | NULL | 1500 | 1500 | 1800 | 1800 |
| 9 | 2022-01-13 17:00:00 | 1800 | Jack | 1500 | 1500 | 1500 | 1500 | 1500 | 1800 | 1300 | 1300 |
| 19 | 2022-01-14 13:30:00 | 1300 | Jack | 1500 | 1800 | 1500 | 1500 | 1500 | 1300 | 1800 | 1800 |
| 21 | 2022-01-14 13:30:00 | 1800 | Jack | 1500 | 1300 | 1500 | 1500 | 1500 | 1800 | 1500 | 1500 |
| 14 | 2022-01-22 22:00:00 | 1500 | Jack | 1500 | 1800 | 1500 | 1500 | 1500 | 1500 | NULL | NULL |
| 5 | 2022-01-05 13:00:00 | 2000 | Lucy | 2000 | 2000 | 2000 | NULL | 2000 | 2000 | 1700 | 1700 |
| 20 | 2022-01-17 14:30:00 | 1700 | Lucy | 2000 | 2000 | 2000 | 2000 | 2000 | 1700 | 2500 | 2500 |
| 22 | 2022-01-17 14:30:00 | 2500 | Lucy | 2000 | 1700 | 2000 | 2000 | 2000 | 2500 | 1100 | 1100 |
| 10 | 2022-01-19 18:00:00 | 1100 | Lucy | 2000 | 2500 | 2000 | 2000 | 2000 | 1100 | 2000 | 2000 |
| 15 | 2022-01-25 23:00:00 | 2000 | Lucy | 2000 | 1100 | 2000 | 2000 | 2000 | 2000 | NULL | NULL |
+-------------+----------------------+---------------------+---------+-------+-------+-------+-------+-------+-------+-------+-------+
last_value()取开窗最后一个值
Hive中的LAST_VALUE函数是一种分析函数,与FIRST_VALUE()函数相反,返回查询结果集中最后一个数据值。在使用LAST_VALUE()函数时,相应的ORDER BY子句应该指定所查询结果记录应该按照哪个字段排序。当查询结果集进行分组时,需要使用PARTITION BY子句对结果进行分组形成记录集。
LAST_VALUE()函数的语法如下:
LAST_VALUE(expr) OVER ([PARTITION BY partition_expression, ...]ORDER BY sort_expression [ASC | DESC], ...
)
其中,expr是计算最后一个值的表达式, [PARTITION BY] 和 [ORDER BY]块表示按特定的列分区和排序,与FIRST_VALUE()函数和其他分析函数中的语法相同。
应用场景
除了上述场景外,LAST_VALUE()函数还在以下场合中得到广泛应用:
-
价格追踪: LAST_VALUE()函数能够帮助跟踪不同商品价格的变化。在分析市场趋势时,需找出每个商品最后报价或最后的交易价格。
-
数据库数据记录: LAST_VALUE() 函数可以在查询一个包含数据记录的表中找出每个记录最后一条数据。例如,一个学生的测试成绩记录可能包含多个测试成绩,但我们仅需找出最后一次测试成绩。
-
历史数据比较: LAST_VALUE()函数可以比较和分析历史数据记录的变化。例如,计算节点或设备的健康状况历史,找出节点最后一天的健康状况或找出设备故障之前的最后一次正常状态。
LAST_VALUE()函数适用于任何需要查找结果集中最后一条数据的场景,例如跟踪价格变化、HTML 页面内容变化检测,或者找到历史资料和数据库记录的最新状态。LAST_VALUE()函数提供了一个实用的方法,以帮助复杂的数据分析和数据挖掘场景中,更快更准确地分析数据。
SQL演示
与first_value()类似,参考first_value()
lag(col, n, default_val):往前第n行数据
Hive 的 LAG 函数是一种窗口函数,可用于计算指定偏移量前某列值的函数。LAG 函数的主要作用是返回结果集中指定列的前 N 行(默认为 1 行)的值,它通常用于计算相邻时间点之间数据的差异或增长率。在使用前,请首先使用ORDER BY排序,以确保当前行的目标列以指定的方式排序。
以下是 LAG 函数的语法:
LAG(column_name, offset, default_value) OVER ([PARTITION BY partition_clause, ...]ORDER BY sort_clause
)
其中,column_name 是需要计算的列名;offset 是指定要查找的列的偏移量(默认值为 1);default_value 是当没有找到值时返回的默认值(默认值为 NULL)。
除此之外,PARTITION BY 子句可用于将行分组为不同的分区,sort_clause 用于指定应按照哪个列对结果进行排序。在使用 LAG 函数时,我们可以通过使用 OVER 子句与 PARTITION BY 和 ORDER BY 子句来编写窗口函数。
- lag(col, n, default_val): 往前第n行数据,没有数据的话用default_value代替
- 第一个参数:取的列
- 第二个参数:往前的行数
- 第三个参数:如果没有数据则返回默认值,默认值的类型需要和列类型匹配,否则不生效
应用场景
Hive 的 LAG 函数可以应用于如下场景:
- 计算数据增长率:可以通过 LAG 函数直接计算某个指标在相邻时间间隔之间的增长率。例如,在一组销售数据中,我们可以通过比较某个产品的前一天和当前的销售额来计算其销售增长率。
- 计算相邻两个时间点之间的差异:可以使用 LAG 函数来计算同一指标在相邻时间点之间的差异。例如,在一组股票交易数据中,我们可以使用 LAG 函数计算当前时点与前一时点之间的差异,从而确定股票价格的变化情况。
LAG 函数可用于对结果集中的数据进行排序、比较、累积或计算增长率等计算场景。它可以提高数据分析和数据挖掘场景中的计算效率,并为用户的数据处理和分析提供了非常实用的工具。
SQL演示
select article_id,release_time,article_word_count,author,# 根据author分组,按照release_time排序,注意第三个参数默认值的类型需要和列类型匹配,否则不生效lag(article_word_count, 1, 0) over(partition by author order by release_time) as a1,# 测试类型不对情况下,默认值'NA'没有设置成功,直接赋值了NULLlag(article_word_count, 2, 'NA') over(partition by author order by release_time rows between unbounded preceding and unbounded following) as a2
from article_data;
结果
+-------------+----------------------+---------------------+---------+-------+-------+
| article_id | release_time | article_word_count | author | a1 | a2 |
+-------------+----------------------+---------------------+---------+-------+-------+
| 18 | 2022-01-02 12:30:00 | 1000 | Alice | 0 | NULL |
| 3 | 2022-01-03 11:00:00 | 800 | Alice | 1000 | NULL |
| 8 | 2022-01-08 16:00:00 | 1300 | Alice | 800 | 1000 |
| 13 | 2022-01-16 21:00:00 | 600 | Alice | 1300 | 800 |
| 1 | 2022-01-01 09:30:00 | 1000 | Tom | 0 | NULL |
| 6 | 2022-01-06 14:00:00 | 900 | Tom | 1000 | NULL |
| 11 | 2022-01-07 19:00:00 | 1700 | Tom | 900 | 1000 |
| 16 | 2022-01-26 10:30:00 | 900 | Tom | 1700 | 900 |
| 7 | 2021-12-27 15:00:00 | 700 | Bob | 0 | NULL |
| 2 | 2022-01-02 10:00:00 | 1200 | Bob | 700 | NULL |
| 12 | 2022-01-09 20:00:00 | 800 | Bob | 1200 | 700 |
| 17 | 2022-01-13 11:30:00 | 1900 | Bob | 800 | 1200 |
| 4 | 2022-01-04 12:00:00 | 1500 | Jack | 0 | NULL |
| 9 | 2022-01-13 17:00:00 | 1800 | Jack | 1500 | NULL |
| 19 | 2022-01-14 13:30:00 | 1300 | Jack | 1800 | 1500 |
| 21 | 2022-01-14 13:30:00 | 1800 | Jack | 1300 | 1800 |
| 14 | 2022-01-22 22:00:00 | 1500 | Jack | 1800 | 1300 |
| 5 | 2022-01-05 13:00:00 | 2000 | Lucy | 0 | NULL |
| 20 | 2022-01-17 14:30:00 | 1700 | Lucy | 2000 | NULL |
| 22 | 2022-01-17 14:30:00 | 2500 | Lucy | 1700 | 2000 |
| 10 | 2022-01-19 18:00:00 | 1100 | Lucy | 2500 | 1700 |
| 15 | 2022-01-25 23:00:00 | 2000 | Lucy | 1100 | 2500 |
+-------------+----------------------+---------------------+---------+-------+-------+
lead(col, n, default_val):往后第n行数据
- lead(col, n, default_val):往后第n行数据,没有数据的话用default_value代替
与lag(col, n, default_val)类似,参考lag(col, n, default_val)
cume_dist:统计大于或小于当前值数量/总数
Hive 的 CUME_DIST 函数是一种窗口函数,它可以计算出一个给定值在排序窗口的累积分布比例。CUME_DIST 函数用于确定一个值在排序结果集中所占的大小位置,通过它,用户可以轻松地计算出整体数据集中某个特定值的排名和比例。
以下是 CUME_DIST 函数的语法:
CUME_DIST() OVER ([PARTITION BY partition_clause, ...]ORDER BY sort_clause
)
其中,PARTITION BY 子句可用于将行分组为不同的分区,sort_clause 用于指定应按照哪个列对结果进行排序。
应用场景
除了上述提到的场景,Hive 的 CUME_DIST 函数还可以应用于以下场景:
-
数据重排:CUME_DIST 函数可以通过返回一个百分比值,表示当前行与排序后所有值之间的比例,帮助用户重排输入表格,使数据按照某个数值属性排序。
-
数据增长率计算:CUME_DIST 函数可以帮助用户计算数据增长率。举例来说,我们可以计算出某个值在排序结果集中的位置,并将其与前一行的值进行比较,从而确定两次采样之间的增长率。
-
相邻两个时间点之间的差异计算:对与时序数据分析相关的场景,CUME_DIST 函数可以用于计算相邻两个时间点之间的差异,并呈现出它们之间的比率差异。
CUME_DIST 函数的应用场景非常广泛,在计算排名、计算占比、计算增长率等数据分析场景中都非常实用,对于数据科学家、数据分析师、商业智能开发人员等实现数据分析任务的用户具有非常大的帮助。
SQL演示
select article_id,release_time,article_word_count,author,# 统计小于等于当前文章字数(包含当前文章)的文章占总文章的比例,这里round的函数是取小数点后2位round( cume_dist() over(order by article_word_count), 2) as a1,# 统计大于等于当前文章字数(包含当前文章)的文章占总文章的比例,这里round的函数是取小数点后2位round(cume_dist() over(order by article_word_count desc), 2) as a2,# 根据author分组,统计小于等于当前文章字数(包含当前文章)的文章占总文章的比例,这里round的函数是取小数点后2位round(cume_dist() over(partition by author order by article_word_count), 2) as a3
from article_data;
结果
+-------------+----------------------+---------------------+---------+-------+-------+-------+
| article_id | release_time | article_word_count | author | a1 | a2 | a3 |
+-------------+----------------------+---------------------+---------+-------+-------+-------+
| 13 | 2022-01-16 21:00:00 | 600 | Alice | 0.05 | 1.0 | 0.25 |
| 3 | 2022-01-03 11:00:00 | 800 | Alice | 0.18 | 0.91 | 0.5 |
| 18 | 2022-01-02 12:30:00 | 1000 | Alice | 0.36 | 0.73 | 0.75 |
| 8 | 2022-01-08 16:00:00 | 1300 | Alice | 0.55 | 0.55 | 1.0 |
| 6 | 2022-01-06 14:00:00 | 900 | Tom | 0.27 | 0.82 | 0.5 |
| 16 | 2022-01-26 10:30:00 | 900 | Tom | 0.27 | 0.82 | 0.5 |
| 1 | 2022-01-01 09:30:00 | 1000 | Tom | 0.36 | 0.73 | 0.75 |
| 11 | 2022-01-07 19:00:00 | 1700 | Tom | 0.73 | 0.36 | 1.0 |
| 7 | 2021-12-27 15:00:00 | 700 | Bob | 0.09 | 0.95 | 0.25 |
| 12 | 2022-01-09 20:00:00 | 800 | Bob | 0.18 | 0.91 | 0.5 |
| 2 | 2022-01-02 10:00:00 | 1200 | Bob | 0.45 | 0.59 | 0.75 |
| 17 | 2022-01-13 11:30:00 | 1900 | Bob | 0.86 | 0.18 | 1.0 |
| 19 | 2022-01-14 13:30:00 | 1300 | Jack | 0.55 | 0.55 | 0.2 |
| 14 | 2022-01-22 22:00:00 | 1500 | Jack | 0.64 | 0.45 | 0.6 |
| 4 | 2022-01-04 12:00:00 | 1500 | Jack | 0.64 | 0.45 | 0.6 |
| 21 | 2022-01-14 13:30:00 | 1800 | Jack | 0.82 | 0.27 | 1.0 |
| 9 | 2022-01-13 17:00:00 | 1800 | Jack | 0.82 | 0.27 | 1.0 |
| 10 | 2022-01-19 18:00:00 | 1100 | Lucy | 0.41 | 0.64 | 0.2 |
| 20 | 2022-01-17 14:30:00 | 1700 | Lucy | 0.73 | 0.36 | 0.4 |
| 15 | 2022-01-25 23:00:00 | 2000 | Lucy | 0.95 | 0.14 | 0.8 |
| 5 | 2022-01-05 13:00:00 | 2000 | Lucy | 0.95 | 0.14 | 0.8 |
| 22 | 2022-01-17 14:30:00 | 2500 | Lucy | 1.0 | 0.05 | 1.0 |
+-------------+----------------------+---------------------+---------+-------+-------+-------+
窗口排序函数
rank():为查询结果中的行返回排名-非连续编号
Hive中的RANK函数用来为查询结果中的行返回排名(rank),即返回一个数值,表示查询结果中每一行所处的排名。和类似的函数(如DENSE_RANK和ROW_NUMBER)不同,RANK函数可能包含重复的排名。
RANK函数的语法如下:
RANK() OVER ([PARTITION BY partition_expression, ... ]ORDER BY sort_expression [ASC | DESC], ...
)
其中,PARTITION BY 是可选的,表示按照某个列进行分区;ORDER BY 是必须指定的,指定用于排序的列,可以附加 ASC(默认)或 DESC 以指定排序顺序。
应用场景
RANK函数通常应用于需要根据某个指标对数据进行排名和分组的场景中,例如:
-
数据分析报告中,当需要统计用户的排名时,可以使用RANK函数来计算用户排名,并将其用于生成报告。
-
电商网站中,使用RANK函数来计算商品销售额排名,可以根据排名来推荐热门商品给用户。
-
银行业务中,使用RANK函数计算贷款申请人的授信额度排名,并据此决定是否批准此申请。
RANK函数可以帮助我们更简单地对大量数据进行排序和排名,并方便地生成带有排名信息的报告和分析结果。
SQL演示
select article_id,release_time,article_word_count,author,# 根据auhtor排序,返回排名rank() over(order by author) as a1,# 根据auhtor分组,release_time排序,返回排名rank() over(partition by author order by release_time) as a2
from article_data;
演示结果
+-------------+----------------------+---------------------+---------+-----+-----+
| article_id | release_time | article_word_count | author | a1 | a2 |
+-------------+----------------------+---------------------+---------+-----+-----+
| 18 | 2022-01-02 12:30:00 | 1000 | Alice | 1 | 1 |
| 3 | 2022-01-03 11:00:00 | 800 | Alice | 1 | 2 |
| 8 | 2022-01-08 16:00:00 | 1300 | Alice | 1 | 3 |
| 13 | 2022-01-16 21:00:00 | 600 | Alice | 1 | 4 |
| 1 | 2022-01-01 09:30:00 | 1000 | Tom | 19 | 1 |
| 6 | 2022-01-06 14:00:00 | 900 | Tom | 19 | 2 |
| 11 | 2022-01-07 19:00:00 | 1700 | Tom | 19 | 3 |
| 16 | 2022-01-26 10:30:00 | 900 | Tom | 19 | 4 |
| 7 | 2021-12-27 15:00:00 | 700 | Bob | 5 | 1 |
| 2 | 2022-01-02 10:00:00 | 1200 | Bob | 5 | 2 |
| 12 | 2022-01-09 20:00:00 | 800 | Bob | 5 | 3 |
| 17 | 2022-01-13 11:30:00 | 1900 | Bob | 5 | 4 |
| 4 | 2022-01-04 12:00:00 | 1500 | Jack | 9 | 1 |
| 9 | 2022-01-13 17:00:00 | 1800 | Jack | 9 | 2 |
| 19 | 2022-01-14 13:30:00 | 1300 | Jack | 9 | 3 |
| 21 | 2022-01-14 13:30:00 | 1800 | Jack | 9 | 3 |
| 14 | 2022-01-22 22:00:00 | 1500 | Jack | 9 | 5 |
| 5 | 2022-01-05 13:00:00 | 2000 | Lucy | 14 | 1 |
| 20 | 2022-01-17 14:30:00 | 1700 | Lucy | 14 | 2 |
| 22 | 2022-01-17 14:30:00 | 2500 | Lucy | 14 | 2 |
| 10 | 2022-01-19 18:00:00 | 1100 | Lucy | 14 | 4 |
| 15 | 2022-01-25 23:00:00 | 2000 | Lucy | 14 | 5 |
+-------------+----------------------+---------------------+---------+-----+-----+
dense_rank():为查询结果中的行返回排名-连续编号
Hive中的DENSE_RANK函数和RANK函数类似,也用来为查询结果中的行返回排名(rank),但DENSE_RANK函数不会包含重复的排名,即如果有两个相同排名的行,DENSE_RANK函数会跳过下一个排名并继续为后续行分配排名。
DENSE_RANK函数的语法与RANK函数相同,如下所示:
DENSE_RANK() OVER ([PARTITION BY partition_expression, ... ]ORDER BY sort_expression [ASC | DESC], ...
)
其中,PARTITION BY 是可选的,表示按照某个列进行分区;ORDER BY 是必须指定的,指定用于排序的列,可以附加 ASC(默认)或 DESC 以指定排序顺序。
应用场景
DENSE_RANK函数在数据分析和报告生成方面有广泛的应用,常见的场景包括:
-
Top-N 分析:使用DENSE_RANK函数来识别销售额、利润等指标排名前 N 的产品或部门,以及排名最高的客户。
-
历史趋势分析:使用DENSE_RANK函数来计算不同时间段的销售额、客户数等指标排名,并分析历史数据的趋势变化。
-
数据分组:使用DENSE_RANK函数来分组数据,并针对每个分组计算采购成本、库存量等指标的排名。
-
数据挖掘:使用DENSE_RANK函数来排名数据挖掘模型中的特征变量,以确定对模型性能影响最大的变量。
DENSE_RANK函数适用于所有需要对数据进行分组、排序和排名的场合,它能够提高数据分析和报告生成的效率,并帮助我们发现数据中的规律和趋势。
SQL演示
select article_id,release_time,article_word_count,author,# 根据auhtor排序,返回排名dense_rank() over(order by author) as a1,# 根据auhtor分组,release_time排序,返回排名dense_rank() over(partition by author order by release_time) as a2
from article_data;
结果
+-------------+----------------------+---------------------+---------+-----+-----+
| article_id | release_time | article_word_count | author | a1 | a2 |
+-------------+----------------------+---------------------+---------+-----+-----+
| 18 | 2022-01-02 12:30:00 | 1000 | Alice | 1 | 1 |
| 3 | 2022-01-03 11:00:00 | 800 | Alice | 1 | 2 |
| 8 | 2022-01-08 16:00:00 | 1300 | Alice | 1 | 3 |
| 13 | 2022-01-16 21:00:00 | 600 | Alice | 1 | 4 |
| 1 | 2022-01-01 09:30:00 | 1000 | Tom | 5 | 1 |
| 6 | 2022-01-06 14:00:00 | 900 | Tom | 5 | 2 |
| 11 | 2022-01-07 19:00:00 | 1700 | Tom | 5 | 3 |
| 16 | 2022-01-26 10:30:00 | 900 | Tom | 5 | 4 |
| 7 | 2021-12-27 15:00:00 | 700 | Bob | 2 | 1 |
| 2 | 2022-01-02 10:00:00 | 1200 | Bob | 2 | 2 |
| 12 | 2022-01-09 20:00:00 | 800 | Bob | 2 | 3 |
| 17 | 2022-01-13 11:30:00 | 1900 | Bob | 2 | 4 |
| 4 | 2022-01-04 12:00:00 | 1500 | Jack | 3 | 1 |
| 9 | 2022-01-13 17:00:00 | 1800 | Jack | 3 | 2 |
| 19 | 2022-01-14 13:30:00 | 1300 | Jack | 3 | 3 |
| 21 | 2022-01-14 13:30:00 | 1800 | Jack | 3 | 3 |
| 14 | 2022-01-22 22:00:00 | 1500 | Jack | 3 | 4 |
| 5 | 2022-01-05 13:00:00 | 2000 | Lucy | 4 | 1 |
| 20 | 2022-01-17 14:30:00 | 1700 | Lucy | 4 | 2 |
| 22 | 2022-01-17 14:30:00 | 2500 | Lucy | 4 | 2 |
| 10 | 2022-01-19 18:00:00 | 1100 | Lucy | 4 | 3 |
| 15 | 2022-01-25 23:00:00 | 2000 | Lucy | 4 | 4 |
+-------------+----------------------+---------------------+---------+-----+-----+
ntile:将结果集分成指定的桶数
Hive中的NTILE函数可以将结果集分成指定的桶数,并对每个桶进行编号。NTILE函数接受一个整数参数,该参数指定将结果集分成的桶数,然后将每个行按顺序分配到这些桶中。 如果无法将每个桶分配给相同数量的行,则在最后的桶中可能会有更少的行。
NTILE函数的语法如下所示:
NTILE(n) OVER ([PARTITION BY partition_expression, ...]ORDER BY sort_expression [ASC | DESC], ...
)
其中,n 是用于分割结果集的桶数,在上面的语法中,[PARTITION BY]和[ORDER BY]与DENSE_RANK函数中的用法相同,不再赘述。
应用场景
NTILE函数通常用于分析数据分布和网格处理。下面是一些NTILE函数的应用场景示例:
- 数据分组:将数据分成多个桶,并将每个桶中的所有行视为一组。这对于按年龄、性别、地理位置等对数据进行分类和分析非常有用。
- 数据挖掘:通过将数据分组成多个桶来构建数据挖掘模型。例如,可以将客户分成不同的组,并使用NTILE函数来确定每个组的重要性。
- 电子商务:将产品分成多个桶,并将产品按其价格带分配到这些桶中。这可以帮助企业了解其销售额的分布和趋势,并更好地管理库存。
- 网络流量管理:将网络流量分成多个桶,以便根据每个桶中的存储器大小和速度限制来管理流量。这有助于保持网络的可靠性和安全性。
NTILE函数适用于需要将结果集分成多个桶,并将每个桶中的所有行视为一组的场景,可以帮助我们更好地理解数据的分布和趋势,进行数据分析和数据挖掘等工作。
SQL演示
select article_id,release_time,article_word_count,author,# 根据auhtor分组,article_word_count排序,分为2组ntile(2) over(partition by author order by article_word_count) as a1,# 根据auhtor分组,article_word_count排序,分为3组ntile(3) over(partition by author order by article_word_count) as a2
from article_data;
结果
+-------------+----------------------+---------------------+---------+-----+-----+
| article_id | release_time | article_word_count | author | a1 | a2 |
+-------------+----------------------+---------------------+---------+-----+-----+
| 13 | 2022-01-16 21:00:00 | 600 | Alice | 1 | 1 |
| 3 | 2022-01-03 11:00:00 | 800 | Alice | 1 | 1 |
| 18 | 2022-01-02 12:30:00 | 1000 | Alice | 2 | 2 |
| 8 | 2022-01-08 16:00:00 | 1300 | Alice | 2 | 3 |
| 16 | 2022-01-26 10:30:00 | 900 | Tom | 1 | 1 |
| 6 | 2022-01-06 14:00:00 | 900 | Tom | 1 | 1 |
| 1 | 2022-01-01 09:30:00 | 1000 | Tom | 2 | 2 |
| 11 | 2022-01-07 19:00:00 | 1700 | Tom | 2 | 3 |
| 7 | 2021-12-27 15:00:00 | 700 | Bob | 1 | 1 |
| 12 | 2022-01-09 20:00:00 | 800 | Bob | 1 | 1 |
| 2 | 2022-01-02 10:00:00 | 1200 | Bob | 2 | 2 |
| 17 | 2022-01-13 11:30:00 | 1900 | Bob | 2 | 3 |
| 19 | 2022-01-14 13:30:00 | 1300 | Jack | 1 | 1 |
| 14 | 2022-01-22 22:00:00 | 1500 | Jack | 1 | 1 |
| 4 | 2022-01-04 12:00:00 | 1500 | Jack | 1 | 2 |
| 9 | 2022-01-13 17:00:00 | 1800 | Jack | 2 | 2 |
| 21 | 2022-01-14 13:30:00 | 1800 | Jack | 2 | 3 |
| 10 | 2022-01-19 18:00:00 | 1100 | Lucy | 1 | 1 |
| 20 | 2022-01-17 14:30:00 | 1700 | Lucy | 1 | 1 |
| 5 | 2022-01-05 13:00:00 | 2000 | Lucy | 1 | 2 |
| 15 | 2022-01-25 23:00:00 | 2000 | Lucy | 2 | 2 |
| 22 | 2022-01-17 14:30:00 | 2500 | Lucy | 2 | 3 |
+-------------+----------------------+---------------------+---------+-----+-----+
row_number:排名函数
Hive中的ROW_NUMBER()函数是一种排名函数,用于为查询结果集中的每个行分配唯一的数字标识符。使用ROW_NUMBER()函数可以方便地对查询结果进行排序、筛选和分组。
ROW_NUMBER()函数的语法如下所示:
ROW_NUMBER() OVER ([PARTITION BY partition_expression, ...]ORDER BY sort_expression [ASC | DESC], ...
)
其中, [PARTITION BY] 和 [ORDER BY]块表示按特定的列分区和排序,与DENSE_RANK()和NTILE()函数中的语法相同。
应用场景
ROW_NUMBER()函数在许多场景中都非常有用,主要有以下几个应用场景:
-
数据排名和排序:使用ROW_NUMBER()函数可以为查询结果集中的每个行分配唯一的数字标识符,方便数据排名和排序。
-
分组分析:ROW_NUMBER()函数常用于为分组数据分配唯一编号,并将它们按照指定的属性分组。这样可以更轻松地进行数据分析和计算。
-
数据分页:ROW_NUMBER()函数可以很方便地用于实现数据分页功能。可以通过设置
FROM和TO参数的值来检索结果集中的某个页面。 -
数据去重:ROW_NUMBER()函数可以用于去重操作。通过使用分区语句,我们可以为重复的记录分配相同的编号,并排除包含相同编号的记录。
-
数据备份:ROW_NUMBER()函数也可以用于为备份数据集生成唯一的编号。例如,在某些情况下,我们可能需要备份某个表并保留其原始编号。
在涉及数据排名、排序、分组、分页、去重、备份等操作时,ROW_NUMBER()函数可以为数据分配唯一编号,方便进行后续处理和分析。
SQL演示
根据作者分区,发布时间进行排序,并为数据添加序号
select article_id,release_time,article_word_count,author,
row_number() over(partition by author order by release_time desc) as data_row
from article_data;
结果,我们发现根据用户分组统计,并在分组内按照发布时间进行排序,并添加了序号
+-------------+----------------------+---------------------+---------+-----------+
| article_id | release_time | article_word_count | author | data_row |
+-------------+----------------------+---------------------+---------+-----------+
| 13 | 2022-01-16 21:00:00 | 600 | Alice | 1 |
| 8 | 2022-01-08 16:00:00 | 1300 | Alice | 2 |
| 3 | 2022-01-03 11:00:00 | 800 | Alice | 3 |
| 18 | 2022-01-02 12:30:00 | 1000 | Alice | 4 |
| 16 | 2022-01-26 10:30:00 | 900 | Tom | 1 |
| 11 | 2022-01-07 19:00:00 | 1700 | Tom | 2 |
| 6 | 2022-01-06 14:00:00 | 900 | Tom | 3 |
| 1 | 2022-01-01 09:30:00 | 1000 | Tom | 4 |
| 17 | 2022-01-13 11:30:00 | 1900 | Bob | 1 |
| 12 | 2022-01-09 20:00:00 | 800 | Bob | 2 |
| 2 | 2022-01-02 10:00:00 | 1200 | Bob | 3 |
| 7 | 2021-12-27 15:00:00 | 700 | Bob | 4 |
| 14 | 2022-01-22 22:00:00 | 1500 | Jack | 1 |
| 19 | 2022-01-14 13:30:00 | 1300 | Jack | 2 |
| 21 | 2022-01-14 13:30:00 | 1800 | Jack | 3 |
| 9 | 2022-01-13 17:00:00 | 1800 | Jack | 4 |
| 4 | 2022-01-04 12:00:00 | 1500 | Jack | 5 |
| 15 | 2022-01-25 23:00:00 | 2000 | Lucy | 1 |
| 10 | 2022-01-19 18:00:00 | 1100 | Lucy | 2 |
| 20 | 2022-01-17 14:30:00 | 1700 | Lucy | 3 |
| 22 | 2022-01-17 14:30:00 | 2500 | Lucy | 4 |
| 5 | 2022-01-05 13:00:00 | 2000 | Lucy | 5 |
+-------------+----------------------+---------------------+---------+-----------+
22 rows selected (32.885 seconds)
开窗后后只取最新一条数据
使用row_number()开窗、排序后,统计序号为1的数据,SQL如下
SELECT *
FROM (SELECT article_id,release_time,article_word_count,author,ROW_NUMBER() OVER(PARTITION BY author ORDER BY release_time DESC) AS data_rowFROM article_data
) AS t
WHERE t.data_row = 1;
结果如下
+---------------+----------------------+-----------------------+-----------+-------------+
| t.article_id | t.release_time | t.article_word_count | t.author | t.data_row |
+---------------+----------------------+-----------------------+-----------+-------------+
| 13 | 2022-01-16 21:00:00 | 600 | Alice | 1 |
| 16 | 2022-01-26 10:30:00 | 900 | Tom | 1 |
| 17 | 2022-01-13 11:30:00 | 1900 | Bob | 1 |
| 14 | 2022-01-22 22:00:00 | 1500 | Jack | 1 |
| 15 | 2022-01-25 23:00:00 | 2000 | Lucy | 1 |
+---------------+----------------------+-----------------------+-----------+-------------+
percent_rank:计算查询结果集中每个行相对于其组内排名的百分比
Hive中的PERCENT_RANK()函数是一种分析函数,用于计算查询结果集中每个行相对于其组内排名的百分比。PERCENT_RANK()函数将结果表示为一个介于0和1之间的小数,0表示排名最低(最少的百分比),1表示排名最高(最多的百分比)。
PERCENT_RANK()函数的语法如下:
PERCENT_RANK() OVER ([PARTITION BY partition_expression, ...]ORDER BY sort_expression [ASC | DESC], ...
)
其中, [PARTITION BY] 和 [ORDER BY]块表示按特定的列分区和排序,与ROW_NUMBER()、DENSE_RANK()和NTILE()函数中的语法相同。
应用场景
PERCENT_RANK()函数主要用途是为数据集中的行计算相对百分比排名。以下是PERCENT_RANK()函数的一些常见用法:
-
数据分析:PERCENT_RANK()函数可以用于评估某些数据在数据集中的相对位置,比如分析薪资、销售额、股价涨跌幅等指标。
-
数据挖掘:PERCENT_RANK()函数可以用于查找最大或最小的数据值,或者识别与数据集中的其他值相对高或低的特定值。
-
数据可视化:PERCENT_RANK()函数可以用于生成柱状图、折线图、热力图等各种数据可视化图表,以便更直观地展示数据排名。
-
数据报告:通过PERCENT_RANK()函数计算分组数据集中每个行的百分比排名,可以更轻松地创建数据报告,提供更多有关数据中某些组的关键洞见。
PERCENT_RANK()函数是一种可以被广泛应用于数据分析和数据挖掘场景的分析函数,可以计算查询结果集中每个行相对于其组内排名的百分比,并提供了丰富的数据分析、可视化和报告功能。
SQL演示
select article_id,release_time,article_word_count,author,row_number() over(partition by author order by article_word_count) as a1,round(percent_rank() over(partition by author order by article_word_count), 2) as a2
from article_data;
结果
+-------------+----------------------+---------------------+---------+-----+-------+
| article_id | release_time | article_word_count | author | a1 | a2 |
+-------------+----------------------+---------------------+---------+-----+-------+
| 13 | 2022-01-16 21:00:00 | 600 | Alice | 1 | 0.0 |
| 3 | 2022-01-03 11:00:00 | 800 | Alice | 2 | 0.33 |
| 18 | 2022-01-02 12:30:00 | 1000 | Alice | 3 | 0.67 |
| 8 | 2022-01-08 16:00:00 | 1300 | Alice | 4 | 1.0 |
| 16 | 2022-01-26 10:30:00 | 900 | Tom | 1 | 0.0 |
| 6 | 2022-01-06 14:00:00 | 900 | Tom | 2 | 0.0 |
| 1 | 2022-01-01 09:30:00 | 1000 | Tom | 3 | 0.67 |
| 11 | 2022-01-07 19:00:00 | 1700 | Tom | 4 | 1.0 |
| 7 | 2021-12-27 15:00:00 | 700 | Bob | 1 | 0.0 |
| 12 | 2022-01-09 20:00:00 | 800 | Bob | 2 | 0.33 |
| 2 | 2022-01-02 10:00:00 | 1200 | Bob | 3 | 0.67 |
| 17 | 2022-01-13 11:30:00 | 1900 | Bob | 4 | 1.0 |
| 19 | 2022-01-14 13:30:00 | 1300 | Jack | 1 | 0.0 |
| 14 | 2022-01-22 22:00:00 | 1500 | Jack | 2 | 0.25 |
| 4 | 2022-01-04 12:00:00 | 1500 | Jack | 3 | 0.25 |
| 9 | 2022-01-13 17:00:00 | 1800 | Jack | 4 | 0.75 |
| 21 | 2022-01-14 13:30:00 | 1800 | Jack | 5 | 0.75 |
| 10 | 2022-01-19 18:00:00 | 1100 | Lucy | 1 | 0.0 |
| 20 | 2022-01-17 14:30:00 | 1700 | Lucy | 2 | 0.25 |
| 5 | 2022-01-05 13:00:00 | 2000 | Lucy | 3 | 0.5 |
| 15 | 2022-01-25 23:00:00 | 2000 | Lucy | 4 | 0.5 |
| 22 | 2022-01-17 14:30:00 | 2500 | Lucy | 5 | 1.0 |
+-------------+----------------------+---------------------+---------+-----+-------+
相关文章:

Hive窗口函数详细介绍
文章目录 Hive窗口函数概述样本数据表结构表数据 窗口函数窗口聚合函数count()SQL演示 sum()SQL演示 avg()SQL演示 min()SQL演示 max()SQL演示 窗口分析函数first_value() 取开窗第一个值应用场景SQL演示 last_value()取开窗最后一个值应用场景SQL演示 lag(col, n, default_val…...

牛客网【c语言练习】
单选题 下面代码段的输出是(-12 ) int main() {int a3; printf("%d\n",(aa-a*a)); } aa-9,此时还是等于3,因为a*a只是运算,并没有赋值;之后再算a-9,运算之前a等于3,运算…...

C++类和对象(上)
文章目录 🦍1. 面向过程和面向对象🦧2. 类的引入🐶3. 类的定义🦮4. 类的访问控制和封装🍖4.1 访问限定符🍖4.2 封装 🐩5. 类的作用域🐅6. 类的实例化🐄7. 类的大小计算&a…...
JavaScript 数据透视表 DHTMLX Pivot Crack
DHTMLX Pivot JavaScript 数据透视表 - 强大的数据汇总和报告 使用我们的高速 JavaScript/HTML5 Pivot 组件可视化您的复杂数据,从而提高您的商业智能。 它可以帮助您以方便的方式汇总大型数据集。 主要特征 纯 JavaScript 库,可轻松与任何服务器端集成…...

QT链接库设置
以windows 平台为例,在.pro 文件中: 1 增加 INCLUDEPATH <头文件路径> DEPENDPATH <头文件路径> 2 LIBS -L<库目录路径> -l<库得名字> 3 设置MT、MTD、MD、MDD运行时库 win32:CONFIG(debug, debug|release): { QMAKE_CFLAGS_…...

零点起飞学Android——期末考试课本复习重点
目录 第一章 认识Android第二章 Android常见界面布局第三章 Android常用基本控件第四章 Android 高级控件第五章 Android菜单和对话框 第一章 认识Android 1. Android 界面设计被称为______。 答案:布局 2. Android中常见的布局包括______、______ 、______ 、____…...
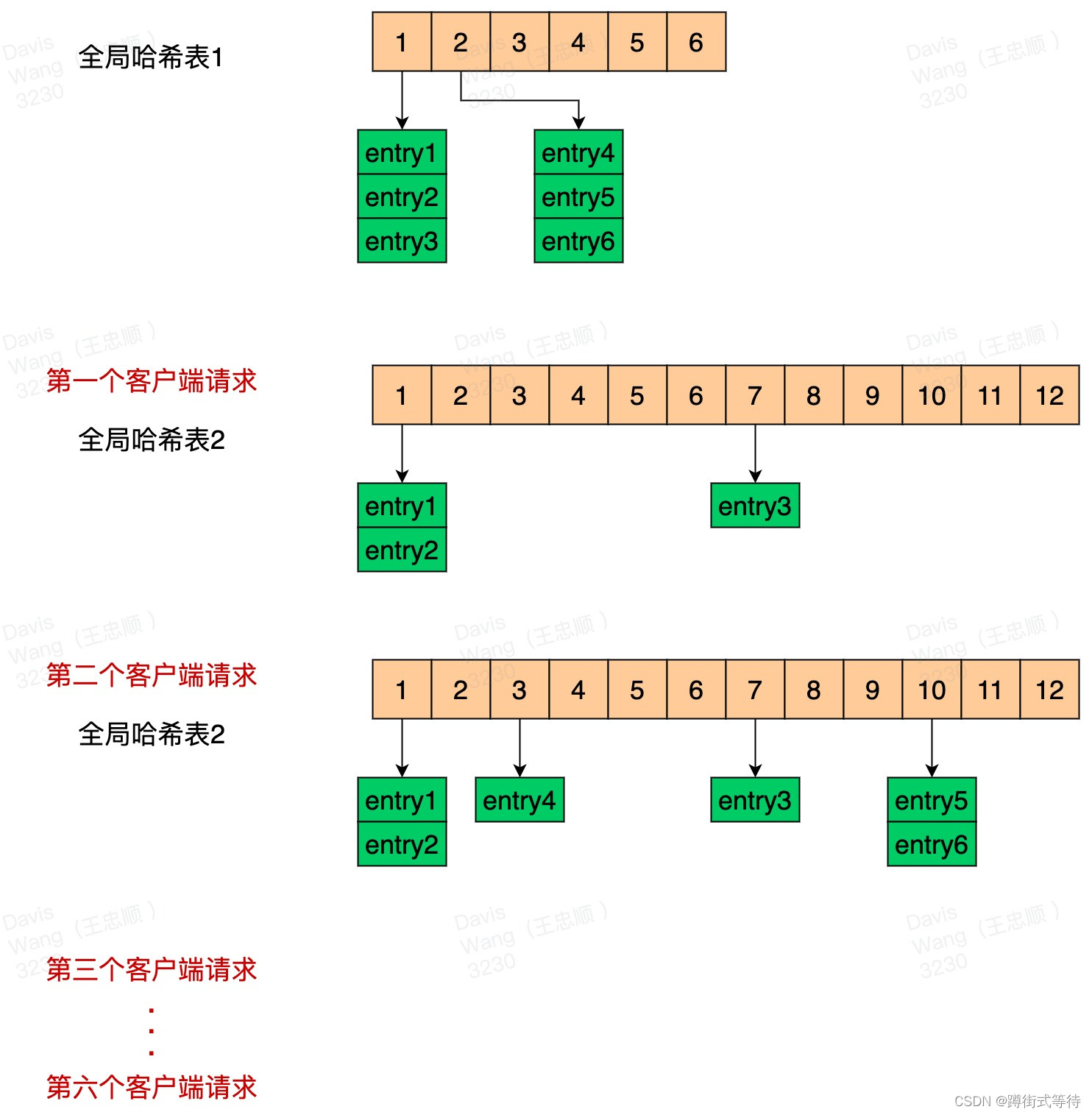
Redis为什么快?
目录 Redis为什么快?渐进式ReHash全局哈希表渐进式ReHash 缓存时间戳 Redis为什么快? 纯内存访问; 单线程避免上下文切换; 渐进式ReHash、缓存时间戳; 前面两个都比较好理解,下面我们主要来说下 渐进式…...
Zabbix从入门到精通以及案例实操系列
1、Zabbix入门 1.1、Zabbix概述 Zabbix是一款能够监控各种网络参数以及服务器健康性和完整性的软件。Zabbix使用灵活的通知机制,允许用户为几乎任何事件配置基于邮件的告警。这样可以快速反馈服务器的问题。基于已存储的数据,Zabbix提供了出色的报告和…...

水声声波频率如何划分?水声功率放大器可将频率放大到20MHz吗?
水声声波频率如何划分?水声功率放大器可将频率放大到20MHz吗? 现如今我们可以在地球任意地区实现通信,是因为电磁波的作用。但是我们都知道海洋占了全球十分之七面积,电磁波在水下衰减速度太快,无法做到远距离传输&am…...

网络攻防技术--论文阅读--《基于自动数据分割和注意力LSTM-CNN的准周期时间序列异常检测》
英文题目:Anomaly Detection in Quasi-Periodic Time Series based on Automatic Data Segmentation and Attentional LSTM-CNN 论文地址:Anomaly Detection in Quasi-Periodic Time Series Based on Automatic Data Segmentation and Attentional LST…...

C++ 学习 ::【基础篇:08】:C++ 中 struct 结构体的认识【面试考点:C 与 C++ 中结构体的区别】
本系列 C 相关文章 仅为笔者学习笔记记录,用自己的理解记录学习!C 学习系列将分为三个阶段:基础篇、STL 篇、高阶数据结构与算法篇,相关重点内容如下: 基础篇:类与对象(涉及C的三大特性等&#…...

Electron开发:打包和发布 Electron 应用
https://start.spring.io/ 在线数据分析网站 https://tj.aldwx.com/ https://www.spsspro.com/ win10如何分屏 拖到边缘 Electron 环境搭建 https://www.electronjs.org/zh/docs/latest/tutorial/%E6%89%93%E5%8C%85%E6%95%99%E7%A8%8B electron 隐藏菜单 electron 标题栏 设…...

【每日一题Day222】LC1110删点成林 | dfs后序
删点成林【LC1110】 给出二叉树的根节点 root,树上每个节点都有一个不同的值。 如果节点值在 to_delete 中出现,我们就把该节点从树上删去,最后得到一个森林(一些不相交的树构成的集合)。 返回森林中的每棵树。你可以按…...

[ChatGPT] 从 GPT-3.5 到 GPT-5 的进化之路 | ChatGPT和程序员 : 协作 or 取代
⭐作者介绍:大二本科网络工程专业在读,持续学习Java,努力输出优质文章 ⭐作者主页:逐梦苍穹 ⭐如果觉得文章写的不错,欢迎点个关注一键三连😉有写的不好的地方也欢迎指正,一同进步😁…...

6.4 GDP调试多进程程序
目录 GDB调试多进程程序 安装gdb gdb编译 运行gdb 单步运行 从头到尾运行 下一步 运行子进程 同时运行父进程 查看运行的进程 切换进程 退出 GDB调试多进程程序 set follow-fork-mode child 设置GDB调试子进程 set follow-fork-mode parent 设置GDB调试父进…...
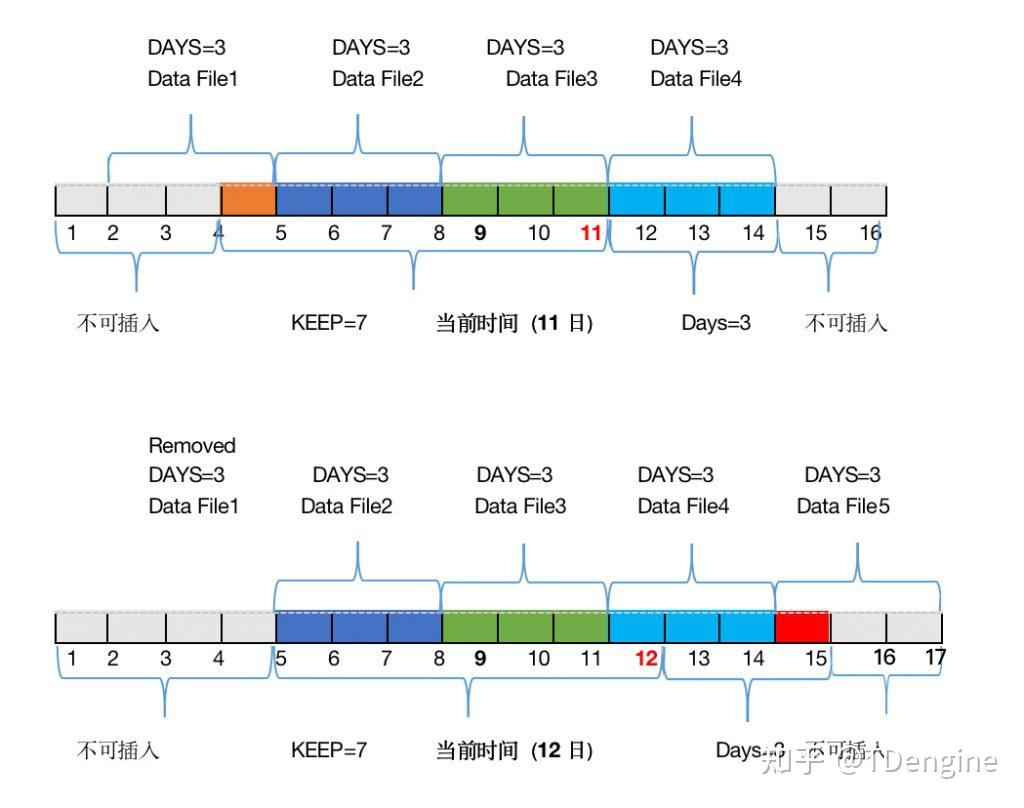
TDengine 时序数据的保留策略
“TDengine除vnode分片之外,还对时序数据按照时间段进行分区。每个数据文件只包含一个时间段的时序数据,时间段的长度由DB的配置参数days决定。这种按时间段分区的方法还便于高效实现数据的保留策略,只要数据文件超过规定的天数(系…...

Java-多线程解析1
一、线程的描述: 1、线程是一个应用程序进程中不同的执行路径比例如:一个WEB服务器,能够为多个用户同时提供请求服务;而 -> 进程是操作系统中正在执行的不同的应用程序,比如:我们可以同时打开系统的word和游戏 2、多…...

PHP 判断用户当前坐标是否在电子围栏内
可以使用射线法判断用户当前坐标点是否在电子围栏内。 具体步骤如下: 1. 将电子围栏的四个角坐标按顺序连接成一个封闭多边形。 2. 从用户当前坐标点向外发射一条射线,判断这条射线与多边形的交点个数。 3. 如果交点个数为奇数,则用户当前…...
Java版本工程管理系统源码企业工程项目管理系统简介
一、立项管理 1、招标立项申请 功能点:招标类项目立项申请入口,用户可以保存为草稿,提交。 2、非招标立项申请 功能点:非招标立项申请入口、用户可以保存为草稿、提交。 3、采购立项列表 功能点:对草稿进行编辑&#x…...

高速缓存(cache)的原理: 了解计算机架构与性能优化
计基之存储器层次结构 Author: Once Day Date: 2023年5月9日 长路漫漫,而今才刚刚启程! 本内容收集整理于《深入理解计算机系统》一书。 参看文档: 捋一捋Cache - 知乎 (zhihu.com)iCache和dCache一致性 - 知乎 (zhihu.com)C…...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

XCTF-web-easyupload
试了试php,php7,pht,phtml等,都没有用 尝试.user.ini 抓包修改将.user.ini修改为jpg图片 在上传一个123.jpg 用蚁剑连接,得到flag...

Leetcode 3576. Transform Array to All Equal Elements
Leetcode 3576. Transform Array to All Equal Elements 1. 解题思路2. 代码实现 题目链接:3576. Transform Array to All Equal Elements 1. 解题思路 这一题思路上就是分别考察一下是否能将其转化为全1或者全-1数组即可。 至于每一种情况是否可以达到…...

阿里云ACP云计算备考笔记 (5)——弹性伸缩
目录 第一章 概述 第二章 弹性伸缩简介 1、弹性伸缩 2、垂直伸缩 3、优势 4、应用场景 ① 无规律的业务量波动 ② 有规律的业务量波动 ③ 无明显业务量波动 ④ 混合型业务 ⑤ 消息通知 ⑥ 生命周期挂钩 ⑦ 自定义方式 ⑧ 滚的升级 5、使用限制 第三章 主要定义 …...

边缘计算医疗风险自查APP开发方案
核心目标:在便携设备(智能手表/家用检测仪)部署轻量化疾病预测模型,实现低延迟、隐私安全的实时健康风险评估。 一、技术架构设计 #mermaid-svg-iuNaeeLK2YoFKfao {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg…...

基于服务器使用 apt 安装、配置 Nginx
🧾 一、查看可安装的 Nginx 版本 首先,你可以运行以下命令查看可用版本: apt-cache madison nginx-core输出示例: nginx-core | 1.18.0-6ubuntu14.6 | http://archive.ubuntu.com/ubuntu focal-updates/main amd64 Packages ng…...

MODBUS TCP转CANopen 技术赋能高效协同作业
在现代工业自动化领域,MODBUS TCP和CANopen两种通讯协议因其稳定性和高效性被广泛应用于各种设备和系统中。而随着科技的不断进步,这两种通讯协议也正在被逐步融合,形成了一种新型的通讯方式——开疆智能MODBUS TCP转CANopen网关KJ-TCPC-CANP…...

零基础设计模式——行为型模式 - 责任链模式
第四部分:行为型模式 - 责任链模式 (Chain of Responsibility Pattern) 欢迎来到行为型模式的学习!行为型模式关注对象之间的职责分配、算法封装和对象间的交互。我们将学习的第一个行为型模式是责任链模式。 核心思想:使多个对象都有机会处…...

用docker来安装部署freeswitch记录
今天刚才测试一个callcenter的项目,所以尝试安装freeswitch 1、使用轩辕镜像 - 中国开发者首选的专业 Docker 镜像加速服务平台 编辑下面/etc/docker/daemon.json文件为 {"registry-mirrors": ["https://docker.xuanyuan.me"] }同时可以进入轩…...

多模态大语言模型arxiv论文略读(108)
CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文标题:CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文作者:Sayna Ebrahimi, Sercan O. Arik, Tejas Nama, Tomas Pfister ➡️ 研究机构: Google Cloud AI Re…...