count(0)、count(1)和count(*)、count(列名) 的区别
当我们对一张数据表中的记录进行统计的时候,习惯都会使用 count 函数来统计,但是 count 函数传入的参数有很多种,比如 count(1)、count(*)、count(字段) 等。
到底哪种效率是最好的呢?是不是 count(*) 效率最差?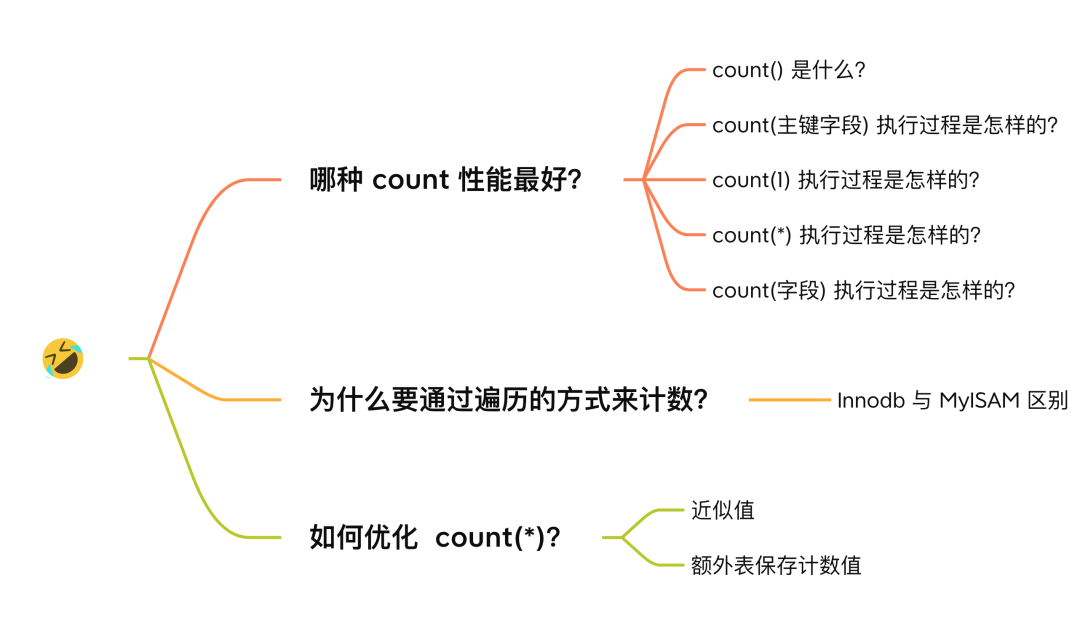
一. 哪种 count 性能最好?
哪种 count 性能最好?
我先直接说结论:

要弄明白这个,我们得要深入 count 的原理,以下内容基于常用的 innodb 存储引擎来说明。
count() 是什么?
count() 是一个聚合函数,函数的参数不仅可以是字段名,也可以是其他任意表达式,该函数作用是统计符合查询条件的记录中,函数指定的参数不为 NULL 的记录有多少个。
假设 count() 函数的参数是字段名,如下:
select count(name) from t_order;
这条语句是统计「 t_order 表中,name 字段不为 NULL 的记录」有多少个。也就是说,如果某一条记录中的 name 字段的值为 NULL,则就不会被统计进去。
再来假设 count() 函数的参数是数字 1 这个表达式,如下:
select count(1) from t_order;
这条语句是统计「 t_order 表中,1 这个表达式不为 NULL 的记录」有多少个。
1 这个表达式就是单纯数字,它永远都不是 NULL,所以上面这条语句,其实是在统计 t_order 表中有多少个记录。
count(主键字段) 执行过程是怎样的?
在通过 count 函数统计有多少个记录时,MySQL 的 server 层会维护一个名叫 count 的变量。
server 层会循环向 InnoDB 读取一条记录,如果 count 函数指定的参数不为 NULL,那么就会将变量 count 加 1,直到符合查询的全部记录被读完,就退出循环。最后将 count 变量的值发送给客户端。
InnoDB 是通过 B+ 树来保存记录的,根据索引的存储方式又分为聚簇索引和二级索引(即聚簇索引和非聚簇索引。聚簇索引通常与表的主键相关联),它们区别在于,聚簇索引的叶子节点存放的是实际数据,而二级索引的叶子节点存放的是主键值,而不是实际数据。
用下面这条语句作为例子:
//id 为主键值
select count(id) from t_order;
如果表里只有主键索引,没有二级索引时,那么,InnoDB 循环遍历聚簇索引,将读取到的记录返回给 server 层,然后读取记录中的 id 值,就会根据 id 值判断是否为 NULL,如果不为 NULL,就将 count 变量加 1。
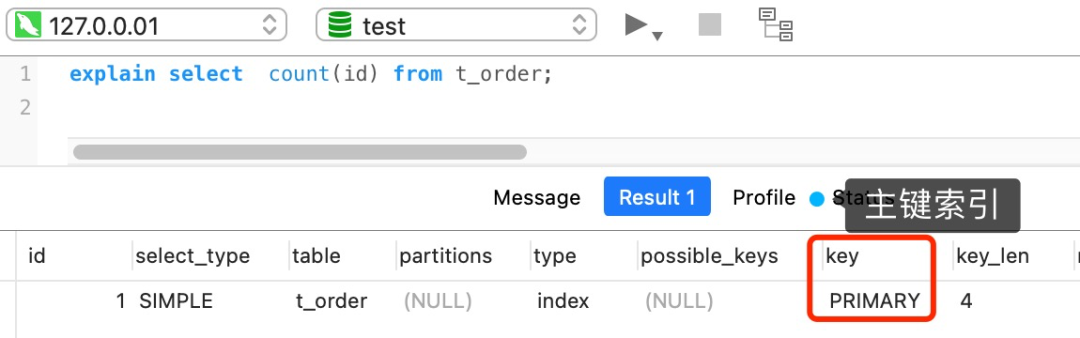
但是,如果表里有二级索引时,InnoDB 循环遍历的对象就不是聚簇索引,而是二级索引。
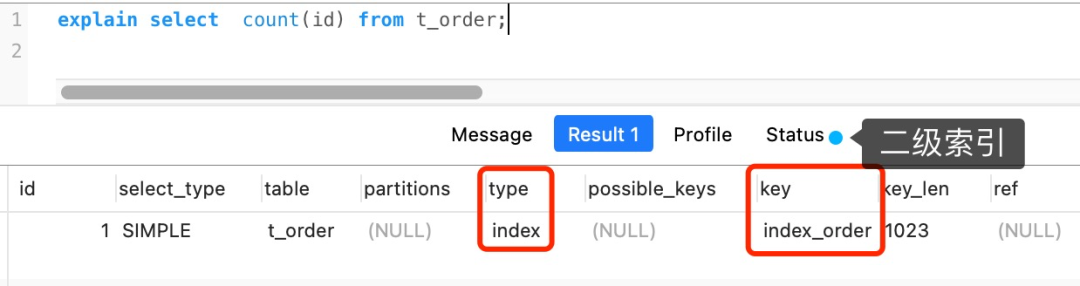 这是因为相同数量的二级索引记录可以比聚簇索引记录占用更少的存储空间,所以二级索引树比聚簇索引树小,这样遍历二级索引的 I/O 成本比遍历聚簇索引的 I/O 成本小,因此「优化器」优先选择的是二级索引。
这是因为相同数量的二级索引记录可以比聚簇索引记录占用更少的存储空间,所以二级索引树比聚簇索引树小,这样遍历二级索引的 I/O 成本比遍历聚簇索引的 I/O 成本小,因此「优化器」优先选择的是二级索引。
count(1) 执行过程是怎样的?
用下面这条语句作为例子:
select count(1) from t_order;
如果表里只有主键索引,没有二级索引时。
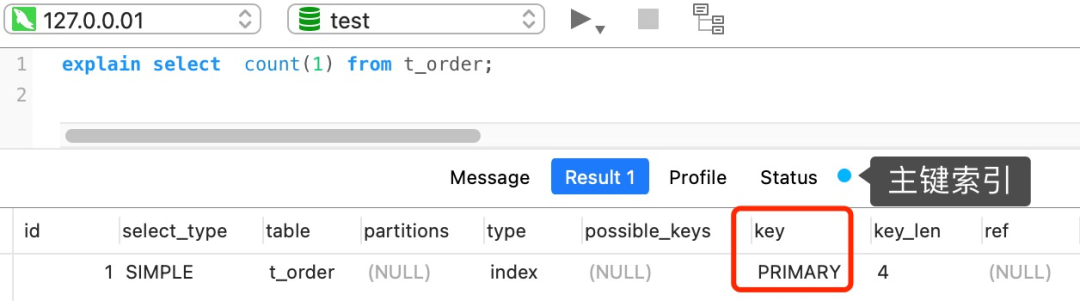
那么,InnoDB 循环遍历聚簇索引(主键索引),将读取到的记录返回给 server 层,但是不会读取记录中的任何字段的值,因为 count 函数的参数是 1,不是字段,所以不需要读取记录中的字段值。参数 1 很明显并不是 NULL,因此 server 层每从 InnoDB 读取到一条记录,就将 count 变量加 1。
可以看到,count(1) 相比 count(主键字段) 少一个步骤,就是不需要读取记录中的字段值,所以通常会说 count(1) 执行效率会比 count(主键字段) 高一点。
但是,如果表里有二级索引时,InnoDB 循环遍历的对象就二级索引了。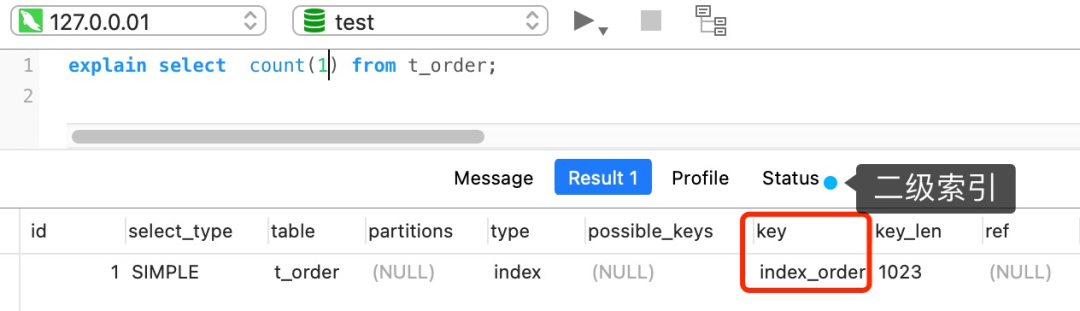
count(*) 执行过程是怎样的?
看到 * 这个字符的时候,是不是大家觉得是读取记录中的所有字段值?
对于 selete * 这条语句来说是这个意思,但是在 count(*) 中并不是这个意思。
count(\*) 其实等于 count(0),也就是说,当你使用 count(*) 时,MySQL 会将 * 参数转化为参数 0 来处理。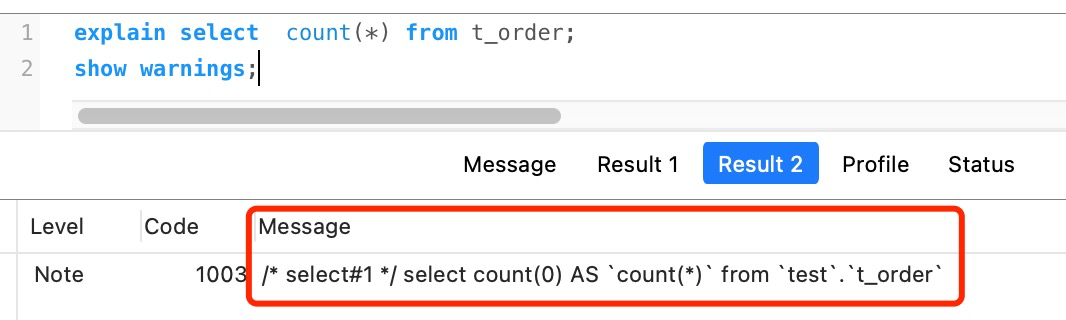
所以,count(*) 执行过程跟 count(1) 执行过程基本一样的,性能没有什么差异。
在 MySQL 5.7 的官方手册中有这么一句话:
InnoDB handles SELECT COUNT(\*) and SELECT COUNT(1) operations in the same way. There is no performance difference.
翻译:InnoDB以相同的方式处理SELECT COUNT(\*)和SELECT COUNT(1)操作,没有性能差异。
而且 MySQL 会对 count(*) 和 count(1) 有个优化,如果有多个二级索引的时候,优化器会使用key_len 最小的二级索引进行扫描。
只有当没有二级索引的时候,才会采用主键索引来进行统计。
count(字段) 执行过程是怎样的?
count(字段) 的执行效率相比前面的 count(1)、 count(*)、 count(主键字段) 执行效率是最差的。
用下面这条语句作为例子:
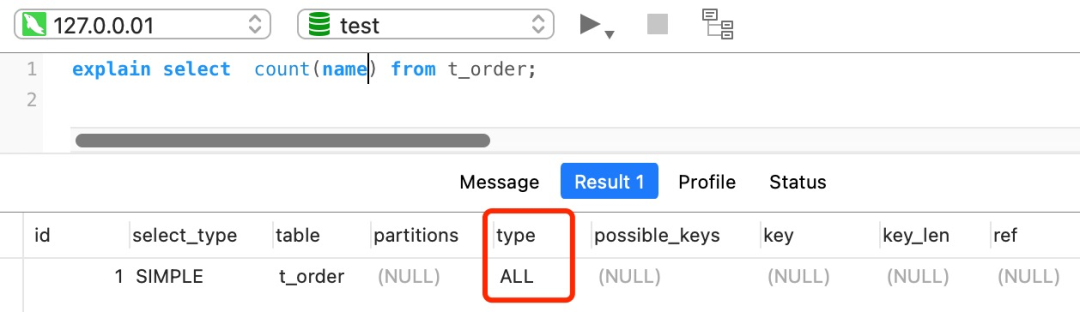
//name不是索引,普通字段
select count(name) from t_order;
对于这个查询来说,会采用全表扫描的方式来计数,所以它的执行效率是比较差的。
小结
count(1)、 count(*)、 count(主键字段)在执行的时候,如果表里存在二级索引,优化器就会选择二级索引进行扫描。
所以,如果要执行 count(1)、 count(*)、 count(主键字段) 时,尽量在数据表上建立二级索引,这样优化器会自动采用 key_len 最小的二级索引进行扫描,相比于扫描主键索引效率会高一些。
再来,就是不要使用 count(字段) 来统计记录个数,因为它的效率是最差的,会采用全表扫描的方式来统计。如果你非要统计表中该字段不为 NULL 的记录个数,建议给这个字段建立一个二级索引。
二. 为什么要通过遍历的方式来计数?
你可以会好奇,为什么 count 函数需要通过遍历的方式来统计记录个数?
我前面将的案例都是基于 Innodb 存储引擎来说明的,但是在 MyISAM 存储引擎里,执行 count 函数的方式是不一样的,通常在没有任何查询条件下的 count(*),MyISAM 的查询速度要明显快于 InnoDB。
使用 MyISAM 引擎时,执行 count 函数只需要 O(1 )复杂度,这是因为每张 MyISAM 的数据表都有一个 meta 信息有存储了row_count值,由表级锁保证一致性,所以直接读取 row_count 值就是 count 函数的执行结果。
而 InnoDB 存储引擎是支持事务的,同一个时刻的多个查询,由于多版本并发控制(MVCC)的原因,InnoDB 表“应该返回多少行”也是不确定的,所以无法像 MyISAM一样,只维护一个 row_count 变量。
举个例子,假设表 t_order 有 100 条记录,现在有两个会话并行以下语句:
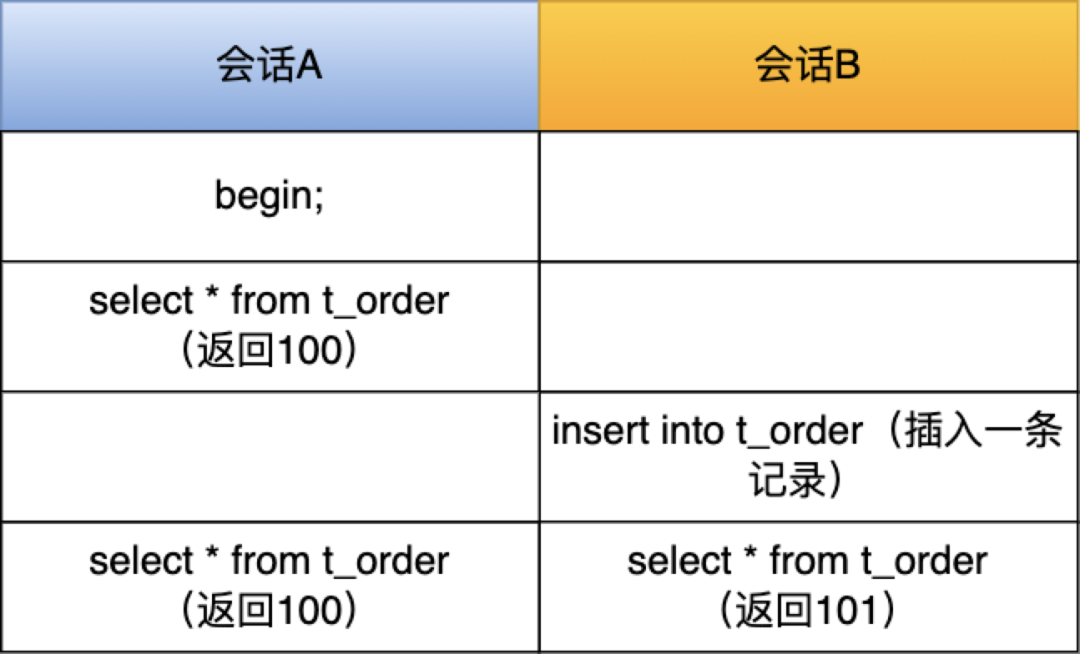
在会话 A 和会话 B的最后一个时刻,同时查表 t_order 的记录总个数,可以发现,显示的结果是不一样的。所以,在使用 InnoDB 存储引擎时,就需要扫描表来统计具体的记录。
而当带上 where 条件语句之后,MyISAM 跟 InnoDB 就没有区别了,它们都需要扫描表来进行记录个数的统计。
三. 如何优化 count(*)?
如果对一张大表经常用 count(*) 来做统计,其实是很不好的。
比如下面我这个案例,表 t_order 共有 1200+ 万条记录,我也创建了二级索引,但是执行一次 select count(*) from t_order 要花费差不多 5 秒!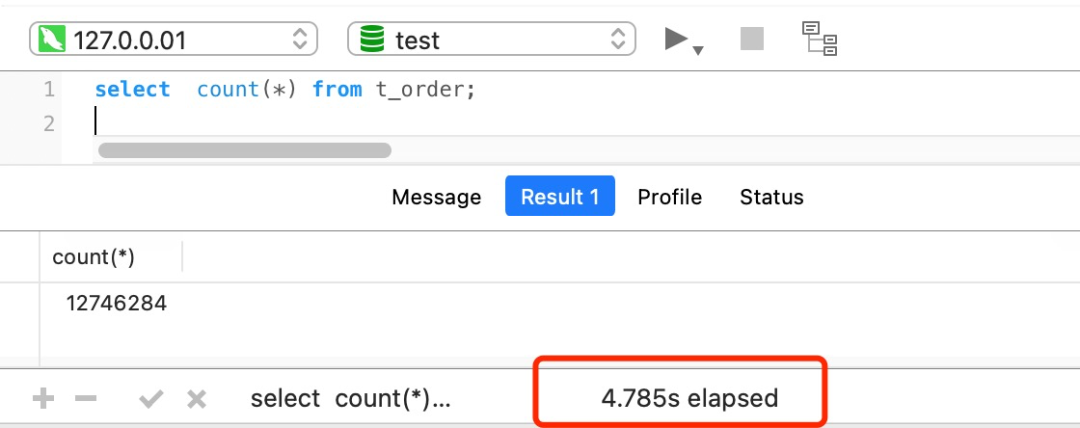
面对大表的记录统计,我们有没有什么其他更好的办法呢?
*第一种,近似值*
如果你的业务对于统计个数不需要很精确,比如搜索引擎在搜索关键词的时候,给出的搜索结果条数是一个大概值。
这时,我们就可以使用 show table status 或者 explain 命令来表进行估算。
执行 explain 命令效率是很高的,因为它并不会真正的去查询,下图中的 rows 字段值就是 explain 命令对表 t_order 记录的估算值。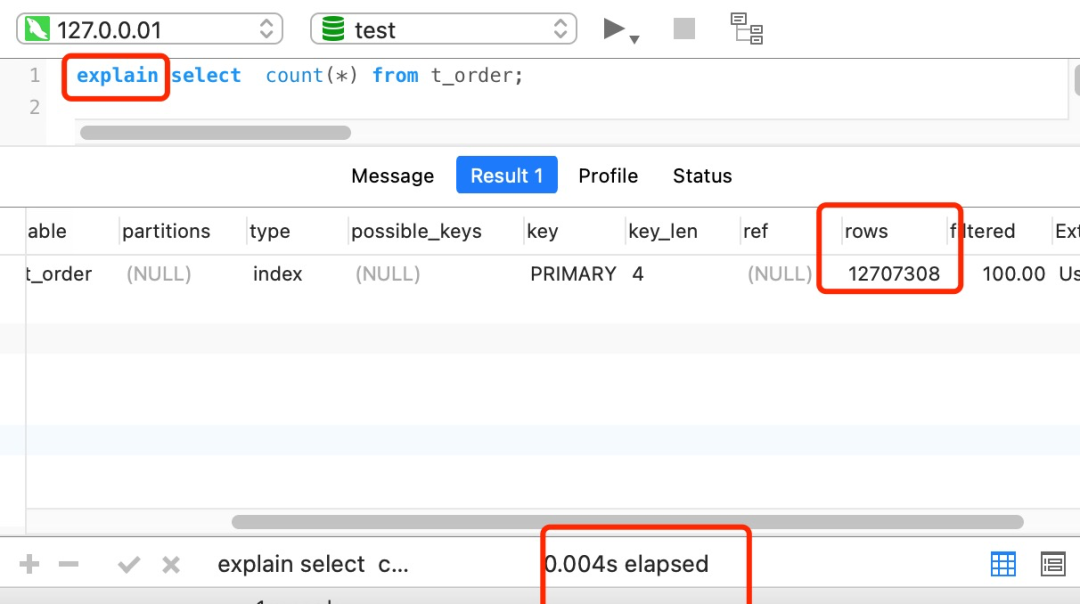
第二种,额外表保存计数值
如果是想精确的获取表的记录总数,我们可以将这个计数值保存到单独的一张计数表中。
当我们在数据表插入一条记录的同时,将计数表中的计数字段 + 1。也就是说,在新增和删除操作时,我们需要额外维护这个计数表。
四. 总结
1、从执行结果上分析:
(1)、count(0)、count(1)和count(*)不会过滤空值
(2)、count(列名)会过滤空值
2、从执行效率上分析:
count(*)=count(0)=count(1)>count(主键字段)>count(非主键字段)
相关文章:
count(0)、count(1)和count(*)、count(列名) 的区别
当我们对一张数据表中的记录进行统计的时候,习惯都会使用 count 函数来统计,但是 count 函数传入的参数有很多种,比如 count(1)、count(*)、count(字段) 等。 到底哪种效率是最好的呢?是不是 count(*) 效率最差? 一.…...

python爬虫入门,10分钟就够了,这可能是我见过最简单的基础教学
一、基础入门 1.1什么是爬虫 爬虫(spider,又网络爬虫),是指向网站/网络发起请求,获取资源后分析并提取有用数据的程序。 从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据&…...

华为OD机试真题 Java 实现【记票统计】【牛客练习题】
一、题目描述 请实现一个计票统计系统。你会收到很多投票,其中有合法的也有不合法的,请统计每个候选人得票的数量以及不合法的票数。 (注:不合法的投票指的是投票的名字不存在n个候选人的名字中!!) 数据范围:每组输入中候选人数量满足 1≤n≤100 ,总票数量满足 1≤…...

.NET并行计算
一段很简答的,模拟多任务并发的测试代码。 private void button_Click(object sender, EventArgs e) { List<Action> actions new List<Action>(); for (int i 0; i < 30; i) { //匿…...
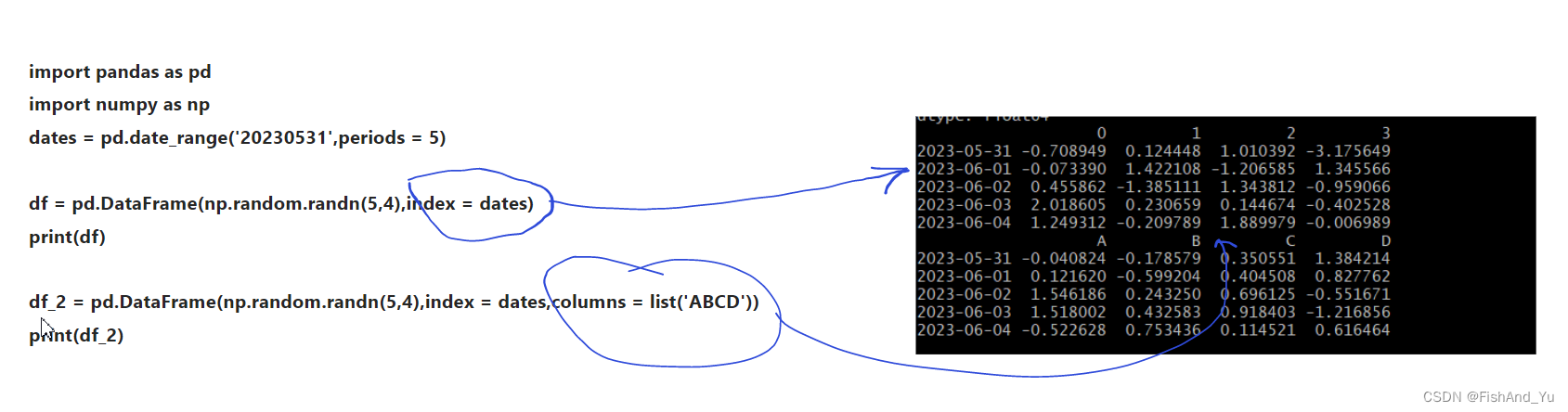
Python:Python编程:金融量化交易
金融量化交易 1. numpy2. scipy3. Pandas3.1 : Series 3.2: DataFrame代码示例 在金融量化交易中,下面几个模块是应用的比较广泛的 numpy (Numberic Python) : 提供大量的数值编程工具,可以方便的处理:向量矩阵等运算,…...

「HTML和CSS入门指南」canvas 标签详解
什么是 canvas 标签? 在 HTML 中,canvas 标签用于在网页中绘制图形、动画和其他复杂的视觉效果。它是一个独立的标签,并且可以使用 JavaScript 来操纵和渲染其内容。使用 canvas 标签可以帮助您创造交互性更强、生动更具吸引力的用户界面和体验。 canvas 标签的基本语法 以…...

【JS】1699- 重学 JavaScript API - WebSockets API
❝ 前期回顾: 1. Page Visibility API 2. Broadcast Channel API 3. Beacon API 4. Resize Observer API 5. Clipboard API 6. Fetch API 7. Performance API 8. Web Storage API ❞ WebSockets API 提供了一种在客户端和服务器之间建立持久连接的机制,使…...

String s = new String(“xyz“) 创建了几个对象?
这个问题相信每个学习 java 的同学都不陌生,作为一个经典的面试题,到现在工作这么多年了我真是认为挺操蛋的一个问题,在网上到现在你仍然可以看见很多讨论这个问题的人,其中不乏工作很多年的人都有争论,我认为还是有必…...
STL库(1)
STL库(1) vectorvector介绍vector使用初始化元素访问内存扩容插入删除 listlist介绍初始化,元素访问插入删除元素 vector和list区别 vector vector介绍 vector是可以改变大小的数组的容器。其内存结构和数组一样,使用连续的存储…...
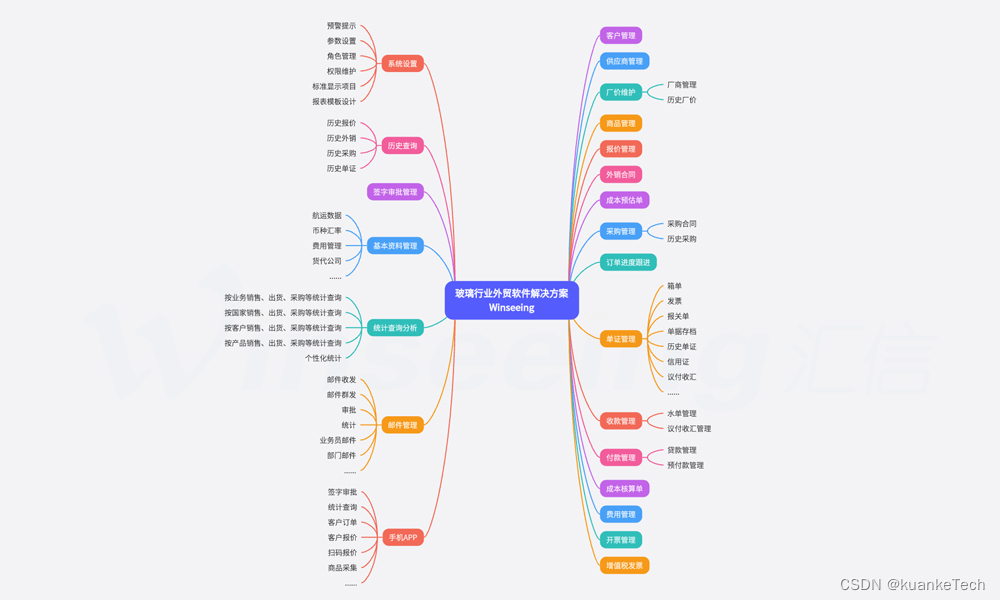
玻璃制品行业丨外贸业务管理难点及解决方案
玻璃作为一种重要的建筑材料,在国际贸易中一直占有一定的份额。随着国外市场需求量的不断增加,对玻璃制品的技术含量要求越来越高,需要在研发方面的投入也逐步加大。由于国际市场竞争激烈,想要做玻璃制品行业的外贸公司࿰…...

Spring Boot如何实现自定义Spring Boot启动器
Spring Boot如何实现自定义Spring Boot启动器 在Spring Boot中,启动器(Starter)是一组依赖项的集合,它们一起提供了某个特定的功能。使用Spring Boot启动器可以让我们更加方便地集成第三方库和框架,并且可以避免版本冲…...
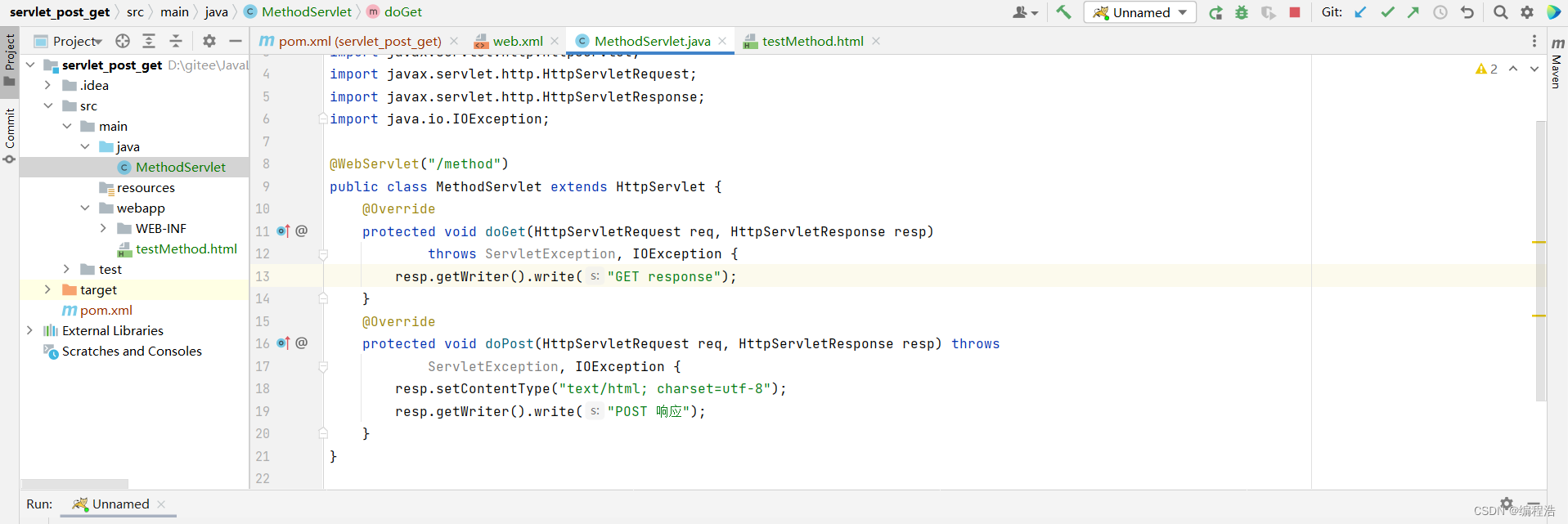
【面试题HTTP中的两种请求方法】GET 和 POST 有什么区别?
GET 和 POST 有什么区别? 1.相同点和最本质的区别1.1 相同点1.2 最本质的区别 2.非本质区别2.1 缓存不同2.2 参数长度限制不同2.3 回退和刷新不同2.4 历史记录不同2.5 书签不同 总结代码示例 GET 和 POST 是 HTTP 请求中最常用的两种请求方法,在日常开发…...
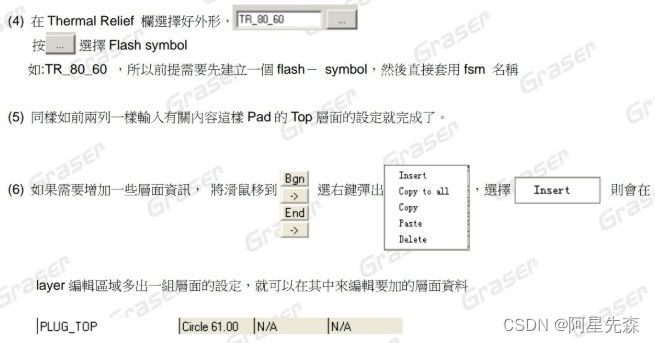
Allegro16.6详细教程(三)
確定Pad的層面 (1)用Single layer mode開關來控制pad type 勾選Single layer mode,則pad為單面孔,比如SMD 不勾選Single layer mode,則pad為通孔,比如:via (2)用滑鼠左鍵點選BEGIN LAYER彈出下面3個欄位 Regular, Thermal Relief, Anti Pad;Regular用於正片,Thermal R…...
离散分布分析示例)
Python3数据分析与挖掘建模(6)离散分布分析示例
1. 离散分布分析示例 相关库: pandas详细用法 numpy详细用法 1.1 引入算法库 # 引入 pandas库 import pandas as pd # 引入 numpy库 import numpy as np# 读取数据 dfpd.read_csv("data/HR.csv")# 查看数据 df Out[6]: satisfaction_level last_eval…...

汇编语言程序设计基础知识二
五、顺序结构 1、程序设计的步骤 1、分析问题 2、建立数据模型 3、设计算法 4、编制程序 5、上机调试 2、流程图的应用 3、程序的基本控制结构 1、顺序结构:程序顺序执行,不发生跳转 2、分支结构:程序在执行过程中发生跳转 3、循环…...

一文详解!Robot Framework Selenium UI自动化测试入门篇
目录 前言: 自动化框架的选择 测试环境的搭建 导入Selenium2Library包 关键字是什么? 创建测试用例 前言: 自动化测试的重要性越来越受到人们的重视,因为它可以提高测试效率、降低测试成本并减少人为错误的出现。为了满足这…...

Java 9 模块化系统详解
Java 9 模块化系统详解 一、简介1. 引入模块化系统原因2. 模块化系统带来的优势和挑战3. 模块化关键概念 二、模块化基础1. 模块化源代码结构规范2. 模块定义与描述符3. 打包可执行模块 三、模块化系统的高级特性1. 模块发现与解决依赖2. 模块化升级与替换3. 模块化动态访问 四…...
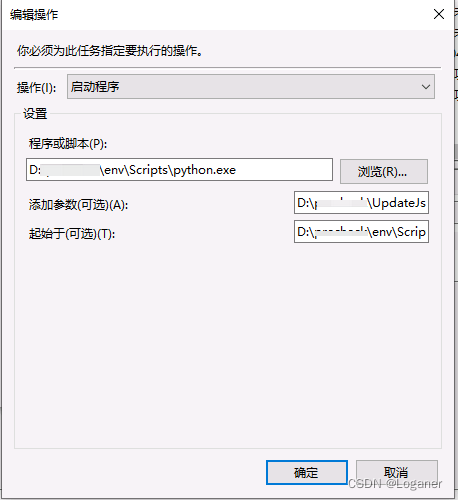
Windows定时执行Python脚本
在Linux环境下我们可以使用crontab工具来定时的执行脚本,可以很轻松的管理各个虚拟环境下的py文件在Windows上可以使用任务计划程序来定时执行我们的脚本 关于这个的基本使用可以查看我前面的博客 https://blog.csdn.net/wyh1618/article/details/125725967?spm10…...

数据科学简介:如何使用 Pandas 库处理 CSV 文件
部分数据来源:ChatGPT 什么是 CSV 文件? CSV ( Comma Separated Values)文件是一种常见的文本文件格式,它通常用于存储结构化数据,因为它可以轻松地转换成电子表格,如Excel。 CSV 文件是以逗号作为分隔符的表格数据。文件中的每行代表一个记录,每列代表一个属性。例如…...
面试专题:java多线程(2)-- 线程池
1.为什么要用线程池? 线程池提供了一种限制和管理资源(包括执行一个任务)。 每个线程池还维护一些基本统计信息,例如已完成任务的数量。 这里借用《Java并发编程的艺术》提到的来说一下使用线程池的好处: 降低资源消…...

IDEA运行Tomcat出现乱码问题解决汇总
最近正值期末周,有很多同学在写期末Java web作业时,运行tomcat出现乱码问题,经过多次解决与研究,我做了如下整理: 原因: IDEA本身编码与tomcat的编码与Windows编码不同导致,Windows 系统控制台…...

Linux 文件类型,目录与路径,文件与目录管理
文件类型 后面的字符表示文件类型标志 普通文件:-(纯文本文件,二进制文件,数据格式文件) 如文本文件、图片、程序文件等。 目录文件:d(directory) 用来存放其他文件或子目录。 设备…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...

【HarmonyOS 5.0】DevEco Testing:鸿蒙应用质量保障的终极武器
——全方位测试解决方案与代码实战 一、工具定位与核心能力 DevEco Testing是HarmonyOS官方推出的一体化测试平台,覆盖应用全生命周期测试需求,主要提供五大核心能力: 测试类型检测目标关键指标功能体验基…...
:爬虫完整流程)
Python爬虫(二):爬虫完整流程
爬虫完整流程详解(7大核心步骤实战技巧) 一、爬虫完整工作流程 以下是爬虫开发的完整流程,我将结合具体技术点和实战经验展开说明: 1. 目标分析与前期准备 网站技术分析: 使用浏览器开发者工具(F12&…...

论文浅尝 | 基于判别指令微调生成式大语言模型的知识图谱补全方法(ISWC2024)
笔记整理:刘治强,浙江大学硕士生,研究方向为知识图谱表示学习,大语言模型 论文链接:http://arxiv.org/abs/2407.16127 发表会议:ISWC 2024 1. 动机 传统的知识图谱补全(KGC)模型通过…...

Map相关知识
数据结构 二叉树 二叉树,顾名思义,每个节点最多有两个“叉”,也就是两个子节点,分别是左子 节点和右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只 有左子节点,有的节点只有…...

laravel8+vue3.0+element-plus搭建方法
创建 laravel8 项目 composer create-project --prefer-dist laravel/laravel laravel8 8.* 安装 laravel/ui composer require laravel/ui 修改 package.json 文件 "devDependencies": {"vue/compiler-sfc": "^3.0.7","axios": …...

在QWebEngineView上实现鼠标、触摸等事件捕获的解决方案
这个问题我看其他博主也写了,要么要会员、要么写的乱七八糟。这里我整理一下,把问题说清楚并且给出代码,拿去用就行,照着葫芦画瓢。 问题 在继承QWebEngineView后,重写mousePressEvent或event函数无法捕获鼠标按下事…...
:观察者模式)
JS设计模式(4):观察者模式
JS设计模式(4):观察者模式 一、引入 在开发中,我们经常会遇到这样的场景:一个对象的状态变化需要自动通知其他对象,比如: 电商平台中,商品库存变化时需要通知所有订阅该商品的用户;新闻网站中࿰…...