bert中文文本摘要代码(1)
bert中文文本摘要代码
- 写在最前面
- 关于BERT
- 使用transformers库进行微调
- load_data.py
- 自定义参数
- collate_fn函数
- BertDataset类
- 主函数
- tokenizer.py
- 创建词汇表
- encode函数
- decode函数
写在最前面
熟悉bert+文本摘要的下游任务微调的代码,方便后续增加组件实现idea
代码来自:
https://github.com/jasoncao11/nlp-notebook/tree/master
已跑通,略有修改
关于BERT
BERT模型参数的数量取决于具体实现,在Google发布的BERT模型中,大概有1.1亿个模型参数。
通常情况下,BERT的参数是在训练期间自动优化调整的,因此在使用预训练模型时不需要手动调节模型参数。
如果想微调BERT模型以适应特定任务,可以通过改变学习率、正则化参数和其他超参数来调整模型参数。在这种情况下,需要进行一些实验以找到最佳的参数配置。
使用transformers库进行微调
主要包括:
- Tokenizer:使用提供好的Tokenizer对原始文本处理,得到Token序列;
- 构建模型:在提供好的模型结构上,增加下游任务所需预测接口,构建所需模型;
- 微调:将Token序列送入构建的模型,进行训练。
本文主要为第一part
load_data.py
这段代码是BERT中读取数据的部分,主要实现了将数据集读取为PyTorch的数据集格式,包括对数据进行padding和collate操作。
自定义参数
-
训练集、测试集地址
TRAIN_DATA_PATH = ‘./data/train.tsv’
DEV_DATA_PATH = ‘./data/dev.tsv’ -
最大文字长度、批数据大小
MAX_LEN = 512
BATCH_SIZE = 8
# -*- coding: utf-8 -*-
import csv
import torch
import torch.utils.data as tud
from torch.nn.utils.rnn import pad_sequence
from tokenizer import TokenizerTRAIN_DATA_PATH = './data/train.tsv'
DEV_DATA_PATH = './data/dev.tsv'
MAX_LEN = 512
BATCH_SIZE = 8
collate_fn函数
这段代码用于对数据进行批处理(batching)和填充(padding)。具体来说,它将输入和标签序列列表中的所有张量进行填充,使它们的长度都等于batch中的最大长度,并将它们堆叠成一个4维张量。使用的填充值为0或-1或-100(具体取决于输入和标签的类型)。这样得到的一个batch数据可以被输入到神经网络中进行训练。
- 通过迭代batch_data中的每一个instance来进行数据的padding填充。将处理后的张量添加到对应的列表中,将这些张量作为输入传递到模型中进行推理。
instance是指输入数据中的一个单独的样本实例,包含了四个标志(input_ids、token_type_ids、token_type_ids_for_mask和labels)的信息。torch.tensor()是将上述列表转化为 PyTorch 张量类的函数,dtype=torch.long指定张量的数据类型为 64 位整型。- input_ids 表示输入文本中每个词的编码,token_type_ids 表示每个词属于哪个句子。
pad_sequence函数将每个batch数据中的tensor进行长度补全,补全元素为padding_value。
def collate_fn(batch_data):"""DataLoader所需的collate_fun函数,将数据处理成tensor形式Args:batch_data: batch数据Returns:"""# list初始化input_ids_list, token_type_ids_list, token_type_ids_for_mask_list, labels_list = [], [], [], []for instance in batch_data:# 按照batch中的最大数据长度,对数据进行padding填充input_ids_temp = instance["input_ids"]token_type_ids_temp = instance["token_type_ids"]token_type_ids_for_mask_temp = instance["token_type_ids_for_mask"]labels_temp = instance["labels"]input_ids_list.append(torch.tensor(input_ids_temp, dtype=torch.long))token_type_ids_list.append(torch.tensor(token_type_ids_temp, dtype=torch.long))token_type_ids_for_mask_list.append(torch.tensor(token_type_ids_for_mask_temp, dtype=torch.long))labels_list.append(torch.tensor(labels_temp, dtype=torch.long))# 使用pad_sequence函数,会将list中所有的tensor进行长度补全,补全到一个batch数据中的最大长度,补全元素为padding_valuereturn {"input_ids": pad_sequence(input_ids_list, batch_first=True, padding_value=0),"token_type_ids": pad_sequence(token_type_ids_list, batch_first=True, padding_value=0),"token_type_ids_for_mask": pad_sequence(token_type_ids_for_mask_list, batch_first=True, padding_value=-1),"labels": pad_sequence(labels_list, batch_first=True, padding_value=-100)}
BertDataset类
BertDataset类继承了torch.utils.data.Dataset类,实现了
__init__、__len__和__getitem__三个函数用于初始化数据集,获取数据集长度,以及获取指定位置的数据。
在__init__函数中,将原始数据读取后进行分词,并将得到的数据以字典形式保存到self.data_set中;
其中,摘要为tsv文件的第一列数据,原文为第二列数据。

Tokenizer.encode是Hugging Face库中的一个方法,用于处理自然语言处理任务中的输入数据,将文本转换成数字序列。
该方法使用预训练的词汇表(或者根据需要自动生成)来将单词或子词转换成其对应的编码表示。编码后的文本可以作为输入传递给深度学习模型,以便进行训练或推断。

在__getitem__函数中,根据给定索引idx返回self.data_set中对应位置的字典。
在__len__函数中,根据可迭代的数据集data_set返回该长度。
class BertDataset(tud.Dataset):def __init__(self, data_path):super(BertDataset, self).__init__()self.data_set = []with open (data_path, 'r', encoding='utf8') as rf:r = csv.reader(rf, delimiter='\t')next(r)for row in r:summary = row[0]content = row[1]input_ids, token_type_ids, token_type_ids_for_mask, labels = Tokenizer.encode(content, summary, max_length=MAX_LEN)self.data_set.append({"input_ids": input_ids, "token_type_ids": token_type_ids, "token_type_ids_for_mask": token_type_ids_for_mask,"labels": labels})def __len__(self):return len(self.data_set)def __getitem__(self, idx):return self.data_set[idx]
主函数
通过tud.DataLoader函数将BertDataset转换为PyTorch的DataLoader格式,即可用于训练模型。
traindataset = BertDataset(TRAIN_DATA_PATH)
traindataloader = tud.DataLoader(traindataset, BATCH_SIZE, shuffle=True, collate_fn=collate_fn)valdataset = BertDataset(DEV_DATA_PATH)
valdataloader = tud.DataLoader(valdataset, BATCH_SIZE, shuffle=False, collate_fn=collate_fn)# for batch in valdataloader:
# print(batch["input_ids"])
# print(batch["input_ids"].shape)
# print('------------------')# print(batch["token_type_ids"])
# print(batch["token_type_ids"].shape)
# print('------------------')# print(batch["token_type_ids_for_mask"])
# print(batch["token_type_ids_for_mask"].shape)
# print('------------------')# print(batch["labels"])
# print(batch["labels"].shape)
# print('------------------')
tokenizer.py
定义Tokenizer类,用于处理文本生成任务中的分词和索引映射操作。
创建词汇表
读取BERT模型的词汇表文件,并创建了一些方便的数据结构,用于在文本生成任务中进行分词和索引映射操作。
注意:使用的是BERT模型的中文版本,并且已经下载了相应的预训练模型文件。
- 打开"vocab.txt"文件,该文件是BERT模型的词汇表文件,包含了模型所使用的所有词汇及其对应的索引。
- 逐行读取文件内容,并将每个词汇和其对应的索引存储在一个名为word2idx的字典中。方便通过词汇找到对应的索引。
- 定义一些常用的特殊标记的索引,如"[CLS]“、”[SEP]“和”[UNK]",标记在BERT模型中有特殊的含义,用于表示句子的起始、结束和未知词汇等。
- 创建idx2word字典,用于将索引映射回对应的词汇。可以通过索引找到对应的词汇。
# -*- coding: utf-8 -*-
import unicodedataclass Tokenizer():with open("./bert-base-chinese/vocab.txt", encoding="utf-8") as f:lines = f.readlines()word2idx = {}for index, line in enumerate(lines):word2idx[line.strip("\n")] = indexcls_id = word2idx['[CLS]']sep_id = word2idx['[SEP]']unk_id = word2idx['[UNK]']idx2word = {idx: word for word, idx in word2idx.items()}
encode函数
将输入的文本转换为BERT模型所需的输入编码。
第一个文本(first_text):
- 转换为小写形式。
- Unicode规范化,将文本中的字符进行标准化处理,将其中的字符规范化为NFD形式。
- 将每个词汇转换为对应的索引,如果词汇不在词汇表中,则使用未知词汇(unk_id)的索引表示。
- 在开头插入特殊标记"[CLS]"的索引(cls_id)。
- 在词汇索引序列的末尾添加特殊标记"[SEP]"的索引(sep_id)。
如果还有第二个文本(second_text)作为输入,则进行类似的处理。
(但第二个文本不需要在开始插入"[CLS]"?)
最终,该方法返回两个文本的编码结果,即第一个文本和第二个文本的词汇索引序列。如果没有第二个文本,则返回的第二个文本的编码结果为空列表。这样,可以将输入文本转换为适合输入到BERT模型的编码表示形式。
@classmethoddef encode(cls, first_text, second_text=None, max_length=512):first_text = first_text.lower()first_text = unicodedata.normalize('NFD', first_text)first_token_ids = [cls.word2idx.get(t, cls.unk_id) for t in first_text]first_token_ids.insert(0, cls.cls_id)first_token_ids.append(cls.sep_id)if second_text:second_text = second_text.lower()second_text = unicodedata.normalize('NFD', second_text)second_token_ids = [cls.word2idx.get(t, cls.unk_id) for t in second_text]second_token_ids.append(cls.sep_id)else:second_token_ids = []对词汇索引序列进行处理,以保证其总长度不超过指定的最大长度(max_length)。
使用循环,不断检查总长度是否超过max_length,并根据情况进行调整。处理逻辑如下:
- 计算当前词汇索引序列的总长度(包括第一个文本和第二个文本),存储在total_length变量中。
- 如果总长度total_length小于等于max_length,则跳出循环,不需要进行截断。
- 删除两个文本中更长的那个,则从倒数第二个位置处删除一个词汇,以减少总长度。
- 经过循环处理后,保证词汇索引序列的总长度不超过max_length。
接下来:
- 创建first_token_type_ids列表,其长度与first_token_ids相同,并且将所有元素设置为0。这用于表示第一个文本中的词汇属于第一个句子。
- 创建first_token_type_ids_for_mask列表,其长度与first_token_ids相同,并且将所有元素设置为1。这用于在遮蔽(mask)操作中标记第一个文本的词汇。
- 创建labels列表,其长度与first_token_ids相同,并且将所有元素设置为-100。这是为了后续任务标签的设置,-100表示忽略该位置的标签。
如果存在第二个文本,则进行进一步处理:
- 创建second_token_type_ids列表,其长度与second_token_ids相同,并且将所有元素设置为1。这用于表示第二个文本中的词汇属于第二个句子。
- 创建second_token_type_ids_for_mask列表,其长度与second_token_ids相同,并且将所有元素设置为0。这用于在遮蔽操作中标记第二个文本的词汇。
- 将第二个文本的词汇索引序列等(second_token_ids),分别添加到第一个文本的词汇索引序列(first_token_ids)末尾等。
最后返回:(文本1、文本2)两个文本的词汇索引序列(first_token_ids)、词汇类型序列(first_token_type_ids)、遮蔽词汇类型序列(first_token_type_ids_for_mask)和标签序列(labels)。这些结果可用于进一步的BERT模型输入。
while True:total_length = len(first_token_ids) + len(second_token_ids)if total_length <= max_length:breakelif len(first_token_ids) > len(second_token_ids):first_token_ids.pop(-2)else:second_token_ids.pop(-2)first_token_type_ids = [0] * len(first_token_ids)first_token_type_ids_for_mask = [1] * len(first_token_ids)labels = [-100] * len(first_token_ids) if second_token_ids:second_token_type_ids = [1] * len(second_token_ids)second_token_type_ids_for_mask = [0] * len(second_token_ids)first_token_ids.extend(second_token_ids)first_token_type_ids.extend(second_token_type_ids)first_token_type_ids_for_mask.extend(second_token_type_ids_for_mask)labels.extend(second_token_ids)return first_token_ids, first_token_type_ids, first_token_type_ids_for_mask, labels
decode函数
将输入的词汇索引序列转换回对应的文本。
首先遍历输入的词汇索引序列(input_ids),对每个索引进行如下操作:
- 通过索引值从idx2word字典中获取对应的词汇。
- 将获取的词汇添加到一个名为tokens的列表中。
最后,代码使用空格将tokens列表中的词汇拼接起来,形成一个字符串。这样,将词汇索引序列转换为对应的文本字符串。
返回转换后的文本字符串。
@classmethoddef decode(cls, input_ids):tokens = [cls.idx2word[idx] for idx in input_ids]return ' '.join(tokens)
相关文章:
bert中文文本摘要代码(1)
bert中文文本摘要代码 写在最前面关于BERT使用transformers库进行微调 load_data.py自定义参数collate_fn函数BertDataset类主函数 tokenizer.py创建词汇表encode函数decode函数 写在最前面 熟悉bert+文本摘要的下游任务微调的代码,方便后续增加组件实现…...

为何溃坝事故频发,大坝安全如何保障?
随着水利水电工程的重要性日益突显,水库大坝安全越来越受到相关部门的重视。因为大坝的安全直接影响水利工程的功能与作用,因此对大坝安全的监测显得十分必要。大坝安全监测的作用是能够及时掌握大坝的运行状态,及时发现大坝的变形、渗漏等异…...
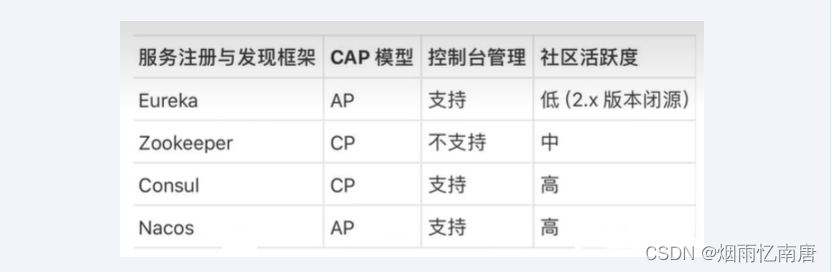
第十九章_手写Redis分布式锁
锁的种类 单机版同一个JVM虚拟机内synchronized或者Lock接口。 分布式多个不同JVM虚拟机,单机的线程锁机制不再起作用,资源类在不同的服务器之间共享了。 一个靠谱分布式锁需要具备的条件和刚需 独占性 :OnlyOne,任何时刻只能有且…...

电路设计【8】原理图中VCC、VDD、VEE、VSS、VBAT各表示什么意思
文章目录 一、名词解析二、应用讲解三、举例分析:为什么stm32vet6中要分出5对VDD VSS?它们分别负责哪些模块的供电? 一、名词解析 (1)VCC:Ccircuit 表示电路的意思, 即接入电路的电压 (2&…...

Volatile、Synchronized、ReentrantLock锁机制使用说明
一、Volatile底层原理 volatile是轻量级的同步机制,volatile保证变量对所有线程的可见性,不保证原子性。 当对volatile变量进行写操作的时候,JVM会向处理器发送一条LOCK前缀的指令,将该变量所在缓存行的数据写回系统内存。由于缓…...

港联证券|AI概念股继续活跃 科创50指数逆势走高
周三,A股市场出现极致分化态势。得益于存储芯片为代表的硬科技股的强势,科创50指数逆势走高。但创业板指、深证成指等主要股指仍然跌跌不休,沪指险守3200点关口。AI概念股继续逆势活跃,国资云、数据方向领涨,算力概念股…...
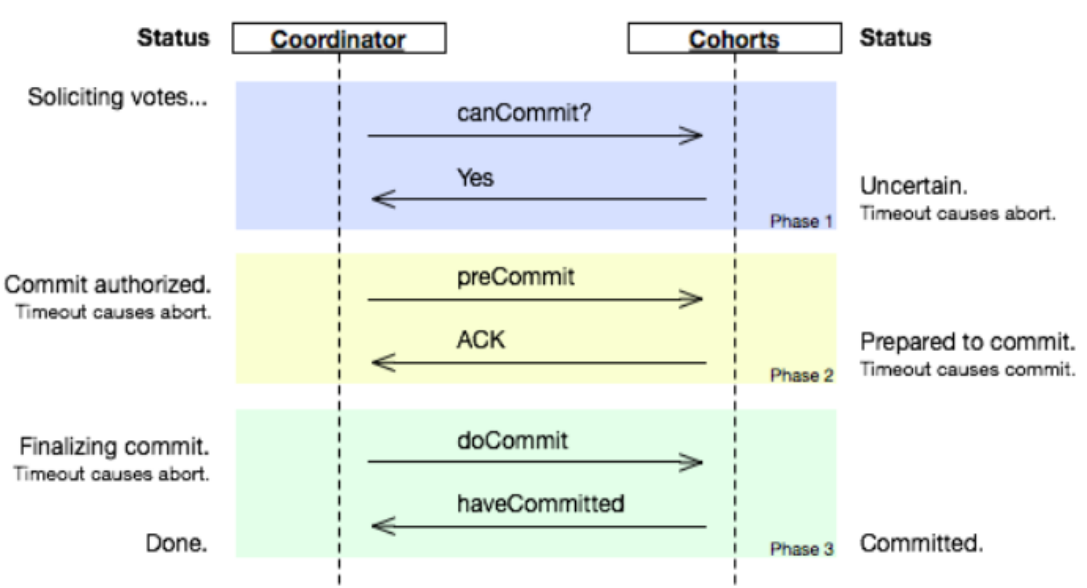
分布式事务一 事物以及分布式事物介绍
一 事务简介 事务(Transaction)是访问并可能更新数据库中各种数据项的一个程序执行单元(unit)。在关系数据库中,一个事务由一组SQL语句组成。事务应该具有4个属性:原子性、一致性、隔离性、持久性。这四个属性通常称为ACID特性。 原子性(at…...
【十四】设计模式~~~行为型模式~~~中介者模式(Java)
【学习难度:★★★☆☆,使用频率:★★★★★】 3.1. 模式动机 建立一种对象与对象之间的依赖关系,一个对象发生改变时将自动通知其他对象,其他对象将相应做出反应。在此,发生改变的对象称为观察目标&#…...

css3--nth-child的用法
目录 使用CSS nth-child选择器基本用法使用公式从零开始关键点结论 使用CSS nth-child选择器 CSS的 :nth-child 选择器是一个强大的工具,允许我们根据它们在父元素中的位置选择元素。这为我们提供了更大的灵活性来控制页面上的元素。 基本用法 基本形式为 :nth-c…...
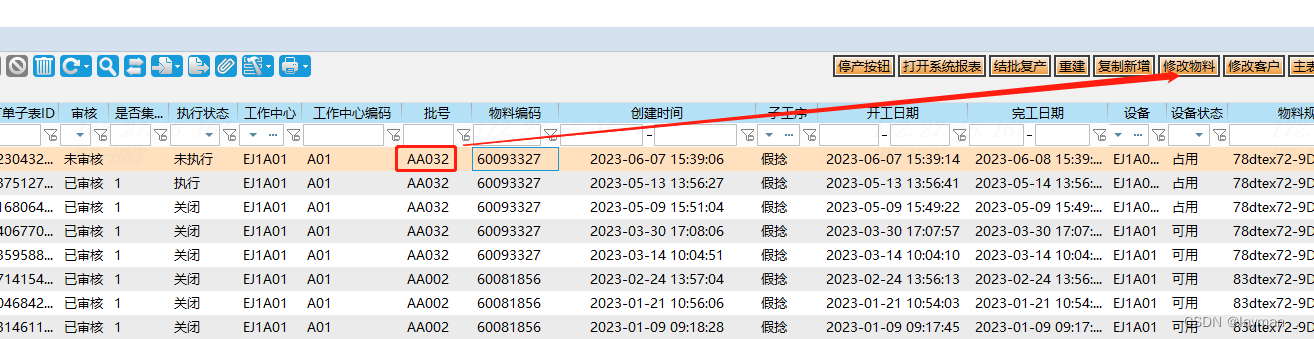
【假捻发加工生产工单下达】
假捻工单是需要下到工作中心的,比如A01机台或者A02机台。 所以下工单之前要先查询A01机台上的最新工单量。 查询结果如下: 她会按照创建时间进行排序,后下的工单排在最前面 (如果下了个新工单,那么前一个工单的执行状态会自动改为关闭。) 因此查询结果,最上面的工单执…...

Go for-range VS for
Go 语言中,for-range 可以用来遍历string、数组(array)、切片(slice)、map和channel,实际使用过程踩了一些坑,所以,还是总结记录下for-range的原理。 首先,go是值传递语言。变量是指针类型,复制指针传递&a…...

大数据教程【01.01】--大数据介绍及开发环境
更多信息请关注WX搜索GZH:XiaoBaiGPT 大数据简介 大数据(Big Data)是指规模庞大、结构复杂、增长速度快且难以使用传统技术处理的数据集合。大数据分析可以帮助企业和组织从海量的数据中提取有价值的信息,用于业务决策、市场分析、…...

文件阅览功能的实现(适用于word、pdf、Excel、ppt、png...)
需求描述: 需要一个组件,同时能预览多种类型文件,一种类型文件可有多个的文件。 看过各种博主的方案,其中最简单的是利用第三方地址进行预览解析(无需任何插件); 这里推荐三个地址:…...

面试-RabbitMQ常见面试问题
1.什么是RabbitMQ? RabbitMQ是一款基于AMQP协议的消息中间件,消费方并不需要确保提供方的存在,实现服务之间的高度解耦。 基本组成有: Queue:消息队列,存储消息,消息送达队列后转发给指定的消费方Exchange:消息队列交…...

使用VBA在单元格中快速插入Unicode符号
Unicode 符号 Unicode 符号在实际工作中有着广泛的应用,比如用于制作邮件签名、文章排版、演示文稿制作等等。在 Excel 表格中,插入符号可以让表格的排版更加美观,同时也能够帮助用户更清晰地表达意思。 Dingbats Dingbats是一个包含装饰符…...

PyTorch 深度学习 || 专题六:PyTorch 数据的准备
PyTorch 数据的准备 1. 生成数据的准备工作 import torch import torch.utils.data as Data#准备建模数据 x torch.unsqueeze(torch.linspace(-1, 1, 500), dim1) # 生成列向量 y x.pow(3) # yx^3#设置超参数 batch_size 15 # 分块大小 torch.manual_seed(10) # 设置种子点…...

迅为RK3568开发板2800页手册+220集视频
iTOP-3568开发板采用瑞芯微RK3568处理器,内部集成了四核64位Cortex-A55处理器。主频高达2.0Ghz,RK809动态调频。集成了双核心架构GPU,ARM G52 2EE、支持OpenGLES1.1/2.0/3.2OpenCL2.0、Vulkan 1.1、内高性能2D加速硬件。 内置NPU 内置独立NP…...

模拟电子 | 稳压管及其应用
模拟电子 | 稳压管及其应用 稳压二极管工作在反向击穿状态时,其两端的电压是基本不变的。利用这一性质,在电路里常用于构成稳压电路。 稳压二极管构成的稳压电路,虽然稳定度不很高,输出电流也较小,但却具有简单、经济实…...

使用大型语言模(LLM)构建系统(二):内容审核、预防Prompt注入
今天我学习了DeepLearning.AI的 Building Systems with LLM 的在线课程,我想和大家一起分享一下该门课程的一些主要内容。 下面是我们访问大型语言模(LLM)的主要代码: import openai#您的openai的api key openai.api_key YOUR-OPENAI-API-KEY def get_…...

springboot---mybatis操作事务配置的处理
目录 前言: 事务的相关问题 1、什么是事务? 2、事务的特点(ACID) 3、什么时候想到使用事务? 4、通常使用JDBC访问数据库,还是mybatis访问数据库,怎么处理事务? 5、问题中事务处…...
)
浏览器访问 AWS ECS 上部署的 Docker 容器(监听 80 端口)
✅ 一、ECS 服务配置 Dockerfile 确保监听 80 端口 EXPOSE 80 CMD ["nginx", "-g", "daemon off;"]或 EXPOSE 80 CMD ["python3", "-m", "http.server", "80"]任务定义(Task Definition&…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...

让回归模型不再被异常值“带跑偏“,MSE和Cauchy损失函数在噪声数据环境下的实战对比
在机器学习的回归分析中,损失函数的选择对模型性能具有决定性影响。均方误差(MSE)作为经典的损失函数,在处理干净数据时表现优异,但在面对包含异常值的噪声数据时,其对大误差的二次惩罚机制往往导致模型参数…...

【生成模型】视频生成论文调研
工作清单 上游应用方向:控制、速度、时长、高动态、多主体驱动 类型工作基础模型WAN / WAN-VACE / HunyuanVideo控制条件轨迹控制ATI~镜头控制ReCamMaster~多主体驱动Phantom~音频驱动Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation速…...

4. TypeScript 类型推断与类型组合
一、类型推断 (一) 什么是类型推断 TypeScript 的类型推断会根据变量、函数返回值、对象和数组的赋值和使用方式,自动确定它们的类型。 这一特性减少了显式类型注解的需要,在保持类型安全的同时简化了代码。通过分析上下文和初始值,TypeSc…...

DeepSeek源码深度解析 × 华为仓颉语言编程精粹——从MoE架构到全场景开发生态
前言 在人工智能技术飞速发展的今天,深度学习与大模型技术已成为推动行业变革的核心驱动力,而高效、灵活的开发工具与编程语言则为技术创新提供了重要支撑。本书以两大前沿技术领域为核心,系统性地呈现了两部深度技术著作的精华:…...
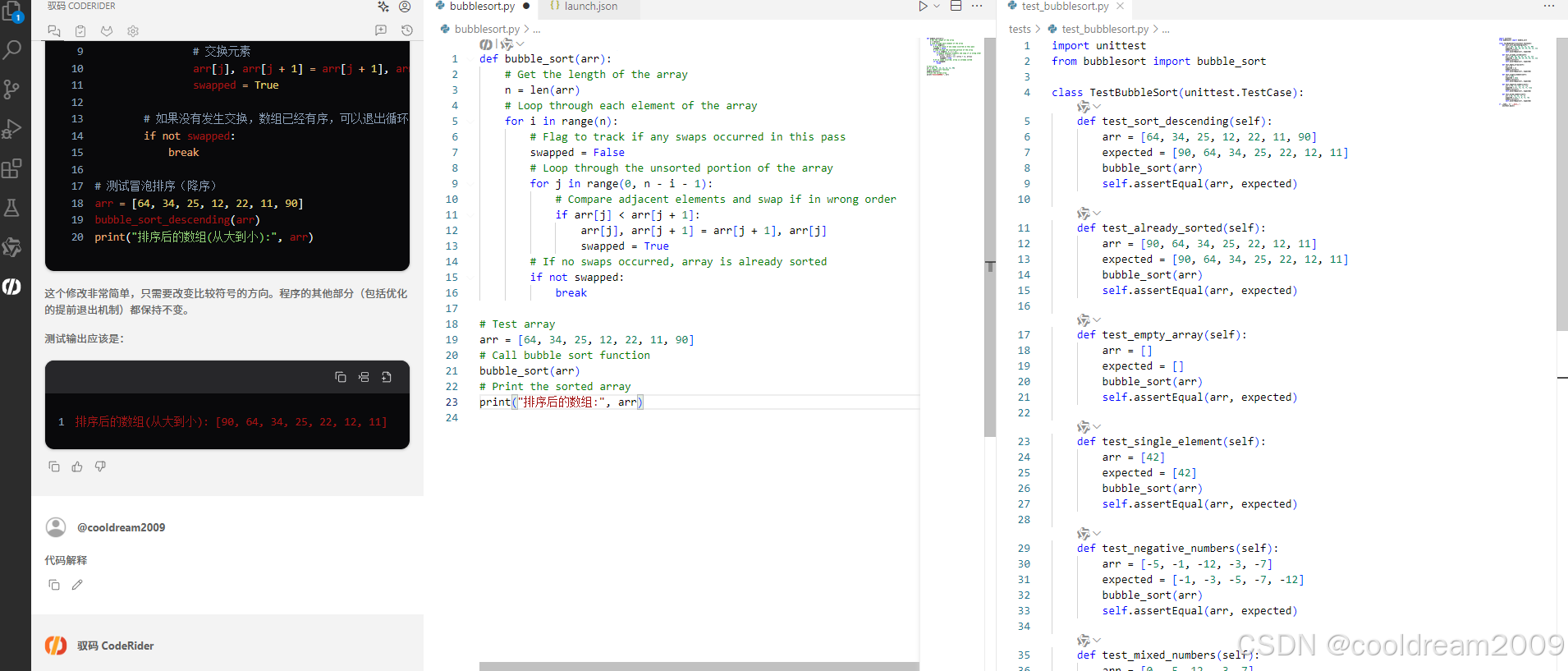
在 Visual Studio Code 中使用驭码 CodeRider 提升开发效率:以冒泡排序为例
目录 前言1 插件安装与配置1.1 安装驭码 CodeRider1.2 初始配置建议 2 示例代码:冒泡排序3 驭码 CodeRider 功能详解3.1 功能概览3.2 代码解释功能3.3 自动注释生成3.4 逻辑修改功能3.5 单元测试自动生成3.6 代码优化建议 4 驭码的实际应用建议5 常见问题与解决建议…...

图解JavaScript原型:原型链及其分析 | JavaScript图解
忽略该图的细节(如内存地址值没有用二进制) 以下是对该图进一步的理解和总结 1. JS 对象概念的辨析 对象是什么:保存在堆中一块区域,同时在栈中有一块区域保存其在堆中的地址(也就是我们通常说的该变量指向谁&…...