Yolov5s算法从训练到部署
文章目录
- PyTorch GPU环境搭建
- 查看显卡CUDA版本
- Anaconda安装
- PyTorch环境安装
- PyCharm中验证
- 训练算法模型
- 克隆Yolov5代码工程
- 制作数据集
- 划分训练集、验证集
- 修改工程
- 相关文件配置
- 预训练权重文件配置
- 数据文件配置
- 模型文件配置
- 超参数配置
- 测试训练出来的算法模型
- 量化转换算法模型
- pt转onnx
- onnx转rknn
- 部署到RK系列板子
本文主要介绍的是使用PyTorch开源神经网络框架GPU版本训练自己制作数据集的Yolov5s目标检测算法,并量化转化为瑞芯微RK系列搭载的NPU加速单元可以推理的rknn格式模型全流程。
PyTorch GPU环境搭建
使用Anaconda虚拟Python环境,在此环境上安装相应显卡驱动版本的PyTorch GPU版本,在PyCharm上训练测试。
查看显卡CUDA版本
显卡型号可以去设备管理器中查看,显卡驱动以及CUDA版本可以在cmd输入以下命令查看:
nvidia-smi
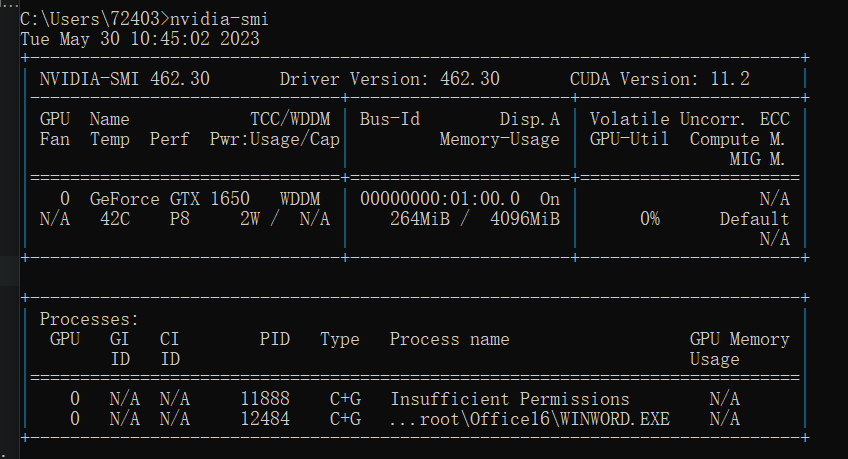
可以根据结果看到驱动版本以及CUDA版本,这个CUDA版本要记好,是最高支持的CUDA版本,安装PyTorch时,要安装CUDA版本以下的,根据我的情况,我在接下来要安装CUDA11.2以下版本的PyTorch。
Anaconda安装
去Anaconda官网下载就好,Anaconda | The World’s Most Popular Data Science Platform,,傻瓜式安装。
PyTorch环境安装
上一步Anaconda安装好后,会在开始栏中有Anaconda终端 Anaconda Prompt,后面会经常使用,可以在桌面上创建一个快捷方式,打开。
可以使用如下命令查看有哪些环境存在:
conda env list
新装的肯定只有一个base环境,我们可以再创建一个pytorch虚拟环境来专门安装PyTorch,我的理解是Anaconda相当于VMware一样,WMware是虚拟出操作系统,Anaconda是虚拟出不同的Python环境,我们当然可以在Anaconda下创建多个环境来安装不同版本的PyTorch。
创建一个名叫pytorch(随意)的Python3.8的虚拟环境:
conda create -n pytorch python=3.8
当安装好之后呢,就会多出来一个与base并列的pytorch环境,切换到此环境上:
conda activate pytorch
下面就到了安装PyTorch-GPU的环境了,可能会出现各种各样的问题,出现的问题也都不一样,主要还是因为PyTorch包在国外。
给环境换国内源;
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
conda config --set show_channel_urls yes
生成的配置在系统用户.condarc文件下,也可直接更改此文件。
然后去PyTorch官网PyTorch去找适合自己显卡CUDA版本的安装命令,最新版可能没有适合的版本,去历史版本中Previous PyTorch Versions | PyTorch去寻找,
我发现这一版本挺合适:
conda install pytorch==1.10.1 torchvision==0.11.2 torchaudio==0.10.1 cudatoolkit=10.2 -c pytorch
一定不要把后面的 '-c pytorch (有的版本还有-c conda-forge)'也复制下来,因为这样还是在国外源中下载。pytorch虚拟环境中运行:
conda install pytorch==1.10.1 torchvision==0.11.2 torchaudio==0.10.1 cudatoolkit=10.2
这里总结下可能出现的问题以及解决办法:
- 安装过程中不能科学上网
- 可能要安装的版本镜像内没有,换其他镜像
- 当前网络频繁访问镜像,被拒绝访问了,换一个网络试试
- 实在安装不成功也可离线安装
PyCharm中验证
在官网中傻瓜式安装,安装免费社区版就已经够用了。
新建一个工程后,选择在Anaconda里已经安装了PyTorch的虚拟环境:
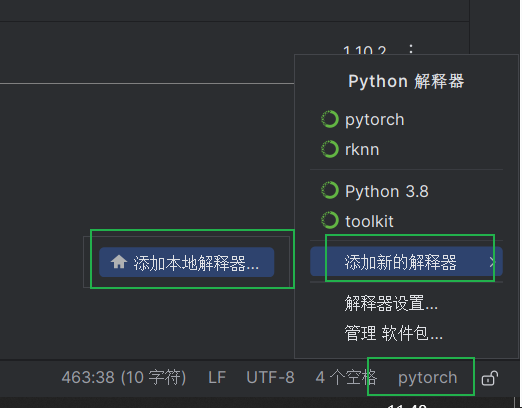
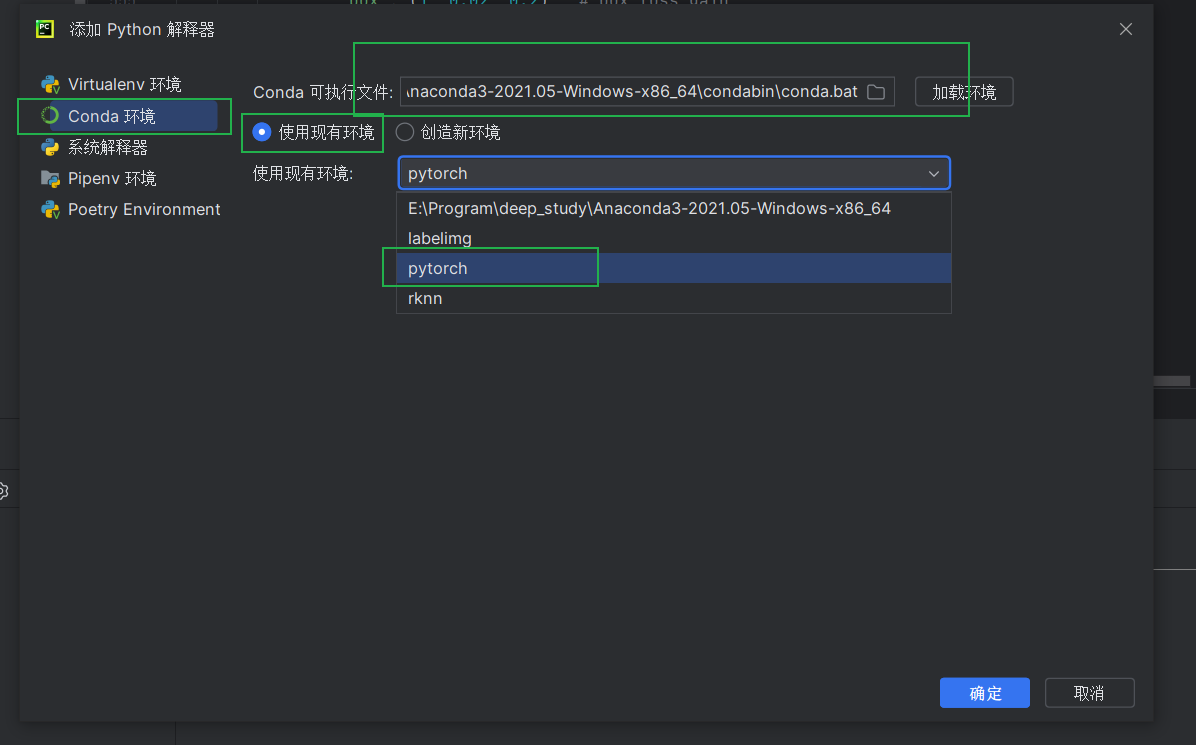
验证脚本:
import torch
print(torch.cuda.is_available())
print(torch.backends.cudnn.is_available())
print(torch.cuda_version)
print(torch.backends.cudnn.version())
如果打印的是false,也就是没调用GPU版本的,很有可能是安装了有cpuonly的模块,使用 conda list查看,如果有,用 conda uninstall cpuonly 就好了!
训练算法模型
这里以训练口罩算法模型为例。
克隆Yolov5代码工程
去github仓库克隆GitHub - ultralytics/yolov5 at v5.0这个版本即可。
把工程下repuirements.txt依赖包安装一下:
pip install -r requirements.txt -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
阿里云 http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
豆瓣(douban) http://pypi.douban.com/simple/
清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/
制作数据集
首先要准备含有检测目标(戴口罩和不带口罩)的图片集,这里我使用OpenCV库写了一个小工具,显示摄像头实时视频流,按下空格键就会保存当前图片帧数据以当前时间戳的方式命名(不会造成重复)保存到指定文件夹。
/************************************************************************************************************** @Description: 从videoUrl中按下空格截取图片到directory目录中,以时间戳命名*** @param {string} &videoUrl 视频流*** @param {string} &directory 截取图片保存目录*** @return {void}***********************************************************************************************************/
void capture_imgs(const std::string &videoUrl, const std::string &directory)
{cv::Mat frame;int key;datetime_t dt;string imgName;char buf1[DATETIME_FMT_BUFLEN];cv::VideoCapture capture;if(videoUrl.size()&&videoUrl.front()=='0'){capture.open(atoi(videoUrl.c_str()));}else{capture.open(videoUrl);}if (!capture.isOpened()){printf("could not read this video file...\n");return;}int fps = capture.get(cv::CAP_PROP_FPS);int delay = 1;if (fps){delay = 1000 / fps;cout << "delay:" << delay << endl;cout << "fps:" << fps << endl;}mkdir(directory.c_str());while (1){if (capture.read(frame)){imshow(videoUrl, frame);key = waitKey(1);if (key == 27){break;}else if (key == 32) // 空格{dt = datetime_now();imgName = datetime_fmt_iso(&dt, buf1);string filePath = directory + imgName;filePath.pop_back();filePath += ".jpg";filePath = regex_replace(filePath, regex(":"), "-");printf("imgname:%s\n", filePath.c_str());if (imwrite(filePath, frame)){printf("save success!\n");}else{printf("save fail!\n");}}}else{capture.release(); // 必须加release释放,否则会内存泄漏cout << "未获取到帧数据,重新获取打开" << endl;if (videoUrl.size() && videoUrl.front() == '0'){capture.open(atoi(videoUrl.c_str()));}else{capture.open(videoUrl);}}}
}
然后使用labelImg目标检测标注工具生成这些图片的标签文件,注意labelImg必须是Python3.9的版本,我们可以使用Anaconda虚拟出来一个,手动绘制图片内所有戴口罩或不带口罩区域,然后选择标签,绘制出图片区域内所有目标,切换下一张图片后,会自动生成Yolov5s支持的YOLO格式标签文件。标注界面如下图所示:

YOLO标签格式为:<object-class> <x> <y> <width> <height>,object-class是目标类型的整形索引,x、y是目标的中心坐标,width、height是目标的宽和高。这些坐标是通过归一化处理,其中x、width是使用原图的width进行归一化处理;而y、height是使用原图的height进行归一化处理得到的。以上图生成的标签为例,生成的标签为:1 0.576302 0.344907 0.096354 0.184259,说明如下表所示:
| 1 | 0.576302 | 0.344907 | 0.096354 | 0.184259 |
|---|---|---|---|---|
| 标签的类别 | 框的中心横坐标与图像宽度之比 | 框的中心横坐标与图像宽度之比 | 框的宽度 | 框的高度 |
结构:
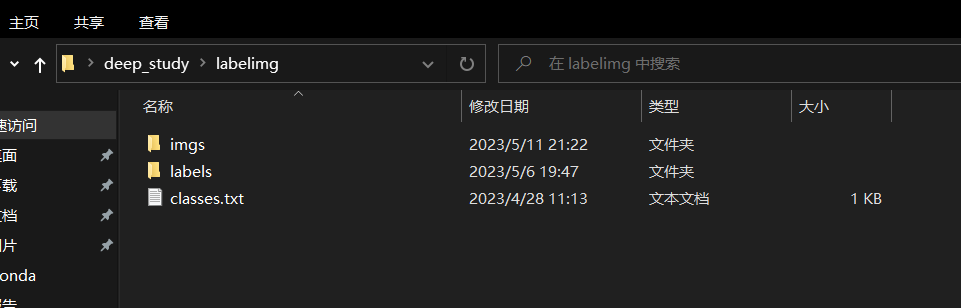
imgs:要标注的图片存放目录
labels:生成的标签文件存放目录
classes.txt:标签目录,增加这个的好处是在labelImg中可以直接选择,而不用在再输入标签。
划分训练集、验证集
把生成的标签文件与图像集还要划分为训练集与验证集,这里我写了一个脚本使用随机种子数按照训练集与验证集以3:1的比例随机划分,我看网上有些教程需要先将yolo格式(txt)转为voc格式(xml),再用代码直接将voc格式转为yolo并直接划分训练集与验证集,不然会出错,我认为完全没有这个必要,我也验证过,下面的代码就是yolo直接划分,没有一点问题,就算是手动不用程序划分也是没问题的。
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
from shutil import copyfile
import shutil
classes = ["no_mask", "mask"]
TRAIN_RATIO = 75 #训练集所占比例
def clear_hidden_files(path):dir_list = os.listdir(path)for i in dir_list:abspath = os.path.join(os.path.abspath(path), i)if os.path.isfile(abspath): #文件if i.startswith("._"):os.remove(abspath)else: #文件夹clear_hidden_files(abspath)
def convert(size, box):dw = 1. / size[0]dh = 1. / size[1]x = (box[0] + box[1]) / 2.0y = (box[2] + box[3]) / 2.0w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn (x, y, w, h)
def convert_annotation(image_id):in_file = open('./data/source/voc/%s.xml' % image_id) #voc格式out_file = open('./data/source/yolo/%s.txt' % image_id, 'w') #yolo格式tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):difficult = obj.find('difficult').textcls = obj.find('name').textif cls not in classes or int(difficult) == 1:continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))bb = convert((w, h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')in_file.close()out_file.close()wd = os.getcwd()
data_base_dir = os.path.join(wd, "./data/")
if not os.path.isdir(data_base_dir):os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, "source/")
if not os.path.isdir(work_sapce_dir):os.mkdir(work_sapce_dir)
image_dir = os.path.join(work_sapce_dir, "imgs/")
if not os.path.isdir(image_dir):print("没有图片文件夹!\n")exit(0)
clear_hidden_files(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, "yolo/")
if not os.path.isdir(yolo_labels_dir):print("没有yolo标签文件夹")exit(0)
clear_hidden_files(yolo_labels_dir)yolov5_images_dir = os.path.join(data_base_dir, "images/")
if os.path.isdir(yolov5_images_dir):shutil.rmtree(yolov5_images_dir)
os.mkdir(yolov5_images_dir)
clear_hidden_files(yolov5_images_dir)yolov5_labels_dir = os.path.join(data_base_dir, "labels/")
if os.path.isdir(yolov5_labels_dir):shutil.rmtree(yolov5_labels_dir)
os.mkdir(yolov5_labels_dir)
clear_hidden_files(yolov5_labels_dir)yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")
if not os.path.isdir(yolov5_images_train_dir):os.mkdir(yolov5_images_train_dir)
clear_hidden_files(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, "verify/")
if not os.path.isdir(yolov5_images_test_dir):os.mkdir(yolov5_images_test_dir)
clear_hidden_files(yolov5_images_test_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")
if not os.path.isdir(yolov5_labels_train_dir):os.mkdir(yolov5_labels_train_dir)
clear_hidden_files(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "verify/")
if not os.path.isdir(yolov5_labels_test_dir):os.mkdir(yolov5_labels_test_dir)
clear_hidden_files(yolov5_labels_test_dir)train_file = open(os.path.join(wd, "yolov5_train.txt"), 'w')
verify_file = open(os.path.join(wd, "yolov5_verify.txt"), 'w')
# train_file.close()
# verify_file.close()
# train_file = open(os.path.join(wd, "yolov5_train.txt"), 'a')
# verify_file = open(os.path.join(wd, "yolov5_verify.txt"), 'a')
list_imgs = os.listdir(image_dir) # list image filesfor i in range(0, len(list_imgs)):path = os.path.join(image_dir, list_imgs[i])if os.path.isfile(path):image_path = image_dir + list_imgs[i]image_name = list_imgs[i](nameWithoutExtention, extention) = os.path.splitext(image_name)label_name = nameWithoutExtention + '.txt'label_path = os.path.join(yolo_labels_dir, label_name)else: #如果不存在图片文件,就不再找标签continue#随机划分prob = random.randint(1, 100)print("Probability: %d" % prob)if (prob < TRAIN_RATIO): # train datasetif os.path.exists(label_path):train_file.write(image_path + '\n')copyfile(image_path, yolov5_images_train_dir + image_name)copyfile(label_path, yolov5_labels_train_dir + label_name)else: # verify datasetif os.path.exists(label_path):verify_file.write(image_path + '\n')copyfile(image_path, yolov5_images_test_dir + image_name)copyfile(label_path, yolov5_labels_test_dir + label_name)
train_file.close()
verify_file.close()
生成的文件结构如下图所示:

修改工程
相关文件配置
预训练权重文件配置
Yolov5又分为Yolov5s、Yolov5m、Yolov5l、Yolov5x,按照其所含的残差结构的个数依次增多,网络的特征提取、融合能力不断加强,检测精度得到提高,但相应的检测花费的时间和消耗的资源也依次在增加。因为训练出的算法模型最终是要部署到嵌入式神经网络处理器上,考虑到其算力性能以及系统实时性等多方面的考量,最终选择Yolov5s版本来进行。使用预训练权重呢,一般是为了缩短网络的训练时间,达到更好的精度。
我们去GitHub Releases · ultralytics/yolov5 (github.com)找到对应版本的预训练权重 yolov5s.pt,放到weights目录下。
数据文件配置
在data下找到voc.yaml,复制一份再命名为mask.yaml,将其修改为:
# download command/URL (optional)
#download: bash data/scripts/get_voc.sh# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: divide_yoloData/data/images/train/
val: divide_yoloData/data/images/verify/# number of classes
nc: 2# class names
names: [ 'no_mask', 'mask']
注释到下载字段,train字段存放训练集图片目录,val字段存放验证集图片目录,刚开始很好奇不用配置标签目录,我的理解是会自动寻找labels目录。
模型文件配置
在models目录下找到yolov5s.yaml,复制一份命名为mask.yaml,把nc字段修改为2即可。
超参数配置
找到train.py的main函数入口,修改几个超参数,模型主要参数解析如下:
opt模型主要参数解析:--weights:初始化的权重文件的路径地址--cfg:模型yaml文件的路径地址--data:数据yaml文件的路径地址--hyp:超参数文件路径地址--epochs:训练轮次--batch-size:喂入批次文件的多少--img-size:输入图片尺寸--rect:是否采用矩形训练,默认False--resume:接着打断训练上次的结果接着训练--nosave:不保存模型,默认False--notest:不进行test,默认False--noautoanchor:不自动调整anchor,默认False--evolve:是否进行超参数进化,默认False--bucket:谷歌云盘bucket,一般不会用到--cache-images:是否提前缓存图片到内存,以加快训练速度,默认False--image-weights:使用加权图像选择进行训练--device:训练的设备,cpu;0(表示一个gpu设备cuda:0);0,1,2,3(多个gpu设备)--multi-scale:是否进行多尺度训练,默认False--single-cls:数据集是否只有一个类别,默认False--adam:是否使用adam优化器--sync-bn:是否使用跨卡同步BN,在DDP模式使用--local_rank:DDP参数,请勿修改--workers:最大工作核心数--project:训练模型的保存位置--name:模型保存的目录名称--exist-ok:模型目录是否存在,不存在就创建
将预训练权重的相对路径放到这里:
parser.add_argument('--weights', type=str, default='weights/yolov5s.pt', help='initial weights path')
将数据文件、模型文件分别放到这里:
parser.add_argument('--cfg', type=str, default='models/mask.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/mask.yaml', help='data.yaml path')
epochs训练次数、batch-size每次投入的图片次数、workers CPU的核心数,都要根据自己的电脑配置情况改。
超参数配置完成后,就可以开始训练了,如果报错可能是以下问题:
-
在utils路径下找到datasets.py这个文件,将里面的81行里面的参数num_workers改成0
-
添加SPPF类,需要到github下载yolov5-6.0,打开文件找到models文件下的common.py,到里面复制SPPF类,并将这段代码(下面)复制到自己项目文件的models/common.py里去,放在了149的SPP类之后。
class SPPF(nn.Module):# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocherdef __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))super().__init__()c_ = c1 // 2 # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_ * 4, c2, 1, 1)self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)def forward(self, x):x = self.cv1(x)with warnings.catch_warnings():warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warningy1 = self.m(x)y2 = self.m(y1)return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
然后就可以愉快的去玩耍,让电脑吭哧吭哧的训练模型了。
如果想要停止后接着上次的结果继续训练,当然也是可以的,好像就算更新过数据集后也是可以接着训练的,步骤:
- 找到exp数值最大的目录下的opt.yaml文件,修改你想改的配置(epochs、batch-size等)
- 把超参数 --resume 改为True
测试训练出来的算法模型
训练结束后可以在终端输入以下命令启用tensorbord查看训练结果:
tensorboard --logdir=runs
打开网址就可以看到,里面有很多图表,很多也看不懂什么意思。
训练好的模型在 runs/train/exp数字最大/weights 的目录下,有最后一次(last)和最好的(best)两个模型。
在detect.py下可以测试算法,–weights 配置为算法模型文件的路径,–source 配置为要推理的数据来源,可以为图片、电脑摄像头(0)、RTSP网络摄像头等。
测了一下训练出来的还是还不错的。

量化转换算法模型
训练出来pt格式的算法模型的Tensor精度是单精度浮点型的float32,而RK系列支持的是整型的uint8,想要最终部署到板子中,还需要进行一系列量化最终转换为rknn格式的算法模型。
pt转onnx
工程下的models/export.py,–weights 配置为算法模型文件的路径,此外还需要修改models/yolo.py文件的后处理部分,将class Detect(nn.Module) 类的子函数forward改为(训练的时候不能改):
def forward(self, x):z = [] # inference outputfor i in range(self.nl):x[i] = self.m[i](x[i]) # convreturn x
然后根据介绍执行脚本即可完成转换。
onnx转rknn
需要用到RKNN Toolkit,RK不同系列板子用到的版本不一样,在Windows、Ubuntu系统都可以完成转换,但windows系统不支持模拟仿真功能不全,所以最好是在Ubuntu上进行。
我是在Ubuntu20.04上安装的,在Anaconda上虚拟出的Python3.8环境中安装所需依赖。
GitHub仓库中doc有pdf中文手册专门讲解Toolkit
在example/onnx/yolov5工程下,把onnx模型路径、带预测图片路径、标签类别、板子平台更改下运行即可完成onnx到rknn的转换。
量化转换后的rknn模型通过Netron神经网络可视化工具可以查看网络结构以及模型参数:
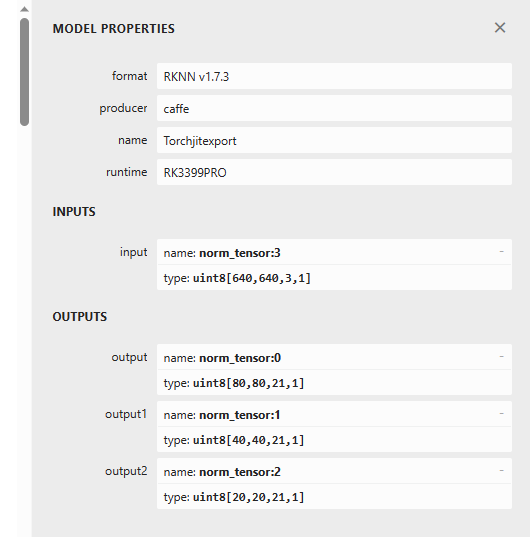
从上图可以看出算法模型已经量化为uint8精度,支持板子Tensor整形精度。
部署到RK系列板子
在GitHub仓库rknpu、rknpu2、RK3399Pro_npu有各自板子适用的python、c++版本npu推理例程。
GitHub - rockchip-linux/rknpu
例程一般都是推理图片的,可以先根据例程把推理流程给熟悉一下给跑通,然后再进行拉取摄像头流实时推理、多流多算法等更进一步的探索。
相关文章:
Yolov5s算法从训练到部署
文章目录 PyTorch GPU环境搭建查看显卡CUDA版本Anaconda安装PyTorch环境安装PyCharm中验证 训练算法模型克隆Yolov5代码工程制作数据集划分训练集、验证集修改工程相关文件配置预训练权重文件配置数据文件配置模型文件配置 超参数配置 测试训练出来的算法模型 量化转换算法模型…...
分布式补充技术 01.AOP技术
01.AOP技术是对于面向对象编程(OOP)的补充。是按照OCP原则进行的编写,(ocp是修改模块权限不行,扩充可以) 02.写一个例子: 创建一个新的java项目,在main主启动类中,写如下代码。 package com.co…...
)
QT 多对一服务插件 CTK开发(五)
CTK在软件的开发过程中可以很好的降低复杂性、使用 CTK Plugin Framework 提供统一的框架来进行开发增加了复用性 将同一功能打包可以提供多个应用程序使用避免重复性工作、可以进行版本控制提供了良好的版本更新迭代需求、并且支持动态热拔插 动态更新、开发更加简单快捷 方便…...

[Windows]_[初级]_[创建目录和文件的名字注意事项]
场景 在开发Windows程序时,会出现目录生成了,但是函数无法在目录里创建文件,怎么回事?说明 在之前说过Windows上有些字符是不能作为文件名的[1],但是检查了下出问题的目录名没有非法字符,所以不是这个原因。 把文件的绝对路径打印出来就发现了问题,目录名后边带了空格,…...

「QT」QT5程序设计目录
✨博客主页:何曾参静谧的博客 📌文章专栏:「QT」QT5程序设计 目录 📑【QT的基础知识篇】📑【QT的GUI编程篇】📑【QT的项目示例篇】📑【QT的网络编程篇】📑【QT的数据库编程篇】📑【QT的跨平台编程篇】📑【QT的高级编程篇】📑【QT的开发工具篇】📑【QT的调…...

ConcurrentHashMap核心源码(JDK1.8)
一、ConcurrentHashMap的前置知识扫盲 ConcurrentHashMap的存储结构? 数组 链表 红黑树 二、ConcurrentHashMap的DCL操作 HashMap线程不安全,在并发情况下,或者多个线程同时操作时,肯定要使用ConcurrentHashMap 无论是HashM…...

【Python】文件 读取 写 os模块 shutil模块 pickle模块
目录 1.文件 1.1 读取操作 1.2 写操作 1.3 os:文件管理 1.4 os.path:获取文件属性 1.5 shutil:文件的拷贝删除移动解压缩 1.6 pickle:数据永久存储 1.文件 文件编码 编码是一种规则集合,记录内容和二进制间相互…...

PAT A1087 All Roads Lead to Rome
1087 All Roads Lead to Rome 分数 30 作者 CHEN, Yue 单位 浙江大学 Indeed there are many different tourist routes from our city to Rome. You are supposed to find your clients the route with the least cost while gaining the most happiness. Input Specific…...

浅谈HttpURLConnection所有方法详解
HttpURLConnection 类是 Java 中用于实现 HTTP 协议的基础类,它提供了一系列方法来建立与 HTTP 服务器的连接、发送请求并读取响应信息。下面是 HttpURLConnection 类中常用的方法以及其详细解释: ---------------------------------------------------…...

前端快速创建web3应用模版分享
一、起因 一直以来都有一个创建前端Dapp模版的愿望,一来是工作中也有这样的需要,避免每次都要抽离重复的代码。二来是这样的模版也能帮助其他前端快速了解到web3应用的脚手架以及框架结构。于是决定整理一个模版并开源,希望我的代码能帮助到大…...

越权漏洞讲解
越权漏洞是指系统或应用程序中存在的安全漏洞,允许攻击者以超越其授权范围的方式访问系统资源或执行特权操作。这种漏洞可能会导致严重的安全风险,因为攻击者可以利用它来获取敏感信息、修改系统设置或执行恶意操作。 下面是一些常见的越权漏洞类型和它…...
短视频矩阵源码系统打包.源码
Masayl是一款基于区块链技术的去中心化应用程序开发平台,可帮助开发者快速、便捷地创建去中心化应用程序。Masayl拥有丰富的API和SDK,为开发者们提供了支持。此外,Masayl还采用了高效的智能合约技术,确保应用程序的稳定、安全和高…...

云南LED、LCD显示屏系统建设,户外、室内广告大屏建设方案
LED大屏幕显示系统是LED高清晰数字显示技术、显示单元无缝拼接技术、多屏图像处理技术、信号切换技术、网络技术等科技手段的应用综合为一体,形成一个拥有高亮度、高清晰度、技术先进、功能强大、使用方便的大屏幕投影显示系统。通过大屏幕显示系统,可以…...

Shell脚本:expect脚本免交互
Shell脚本:expect脚本免交互 expect脚本免交互 一、免交互基本概述:1.交互与免交互的区别:2.格式:3.通过read实现免交互:4.通过cat实现查看和重定向:5.变量替换: 二、expect安装:1.…...

王道考研计算机网络第二章知识点汇总
2.1.1物理层基本概念 电气特性和功能特性易混淆,注意区分。电气特性一般指的是某个范围,功能特性一般指的是电平所代表的含义。 2.1.2数据通信基础知识 同步传输是指发送方和接收方节奏是统一的,数据之间是没有间隔的是一个一个的区块。在键…...
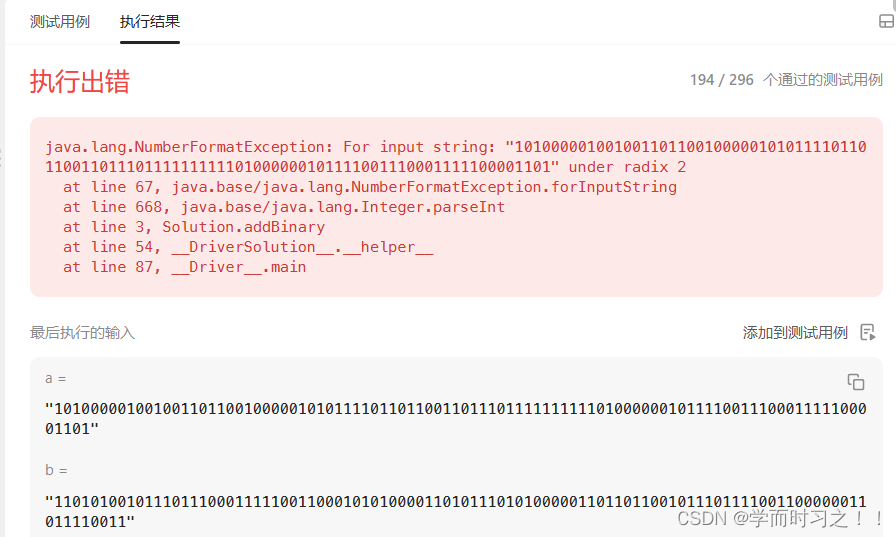
06.05
1.二进制求和 给你两个二进制字符串 a 和 b ,以二进制字符串的形式返回它们的和。 考虑一个最朴素的方法:先将 aaa 和 bbb 转化成十进制数,求和后再转化为二进制数。利用 Python 和 Java 自带的高精度运算,我们可以很简单地写出这…...

【虹科案例】虹科数字化仪在激光雷达大气研究中的应用
01 莱布尼茨研究所使用激光雷达进行大气研究 图 1:在 Khlungsborn 的 IAP 办公室测试各种激光器 大气研究使用脉冲激光束通过测量大气中 100 公里高度的多普勒频移和反向散射光来测量沿光束的温度和风速。返回的光信号非常微弱,会被阳光阻挡,…...
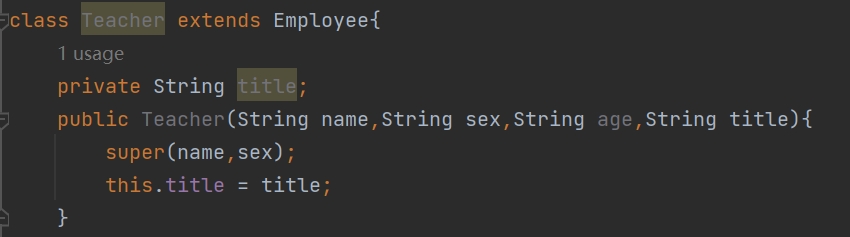
Java抽象类介绍
1 问题 声明一个名为Employee的抽象类,其中包含name(姓名)和sex(性别)两个String类型的私有属性,并声明一个继承于Employee抽象类的子类Teacher。 2 方法 2.1 定义一个抽象类:Employee。 2.2 为Employee类设计一个抽象方法。 2.3实现抽象类Em…...

适配器模式的运用
文章目录 一、适配器模式的运用1.1 介绍1.2 适配器模式结构1.3 类适配器模式1.3.1 类适配器模式类图1.3.2 代码 1.4 对象适配器模式1.4.1 对象适配器模式类图1.4.2 代码 1.5 应用场景1.6 JDK源码解析1.6.1 字节流到字符流的转换类图1.6.2 部分源码分析1.6.3 总结 一、适配器模式…...

2023/6/8总结
MySQL必知必会 commit 和 rollback 的差异是commit会提交,而rollback不会,就好像是撤回。 使用保留点: 简单的rollback和commit语句就可以写入或者撤销整个事务处理,但是,只是对简单的事务处理才能这样做࿰…...

AI应用架构师必藏:AI系统故障诊断的完美方案
AI应用架构师必藏:AI系统故障诊断的完美方案 ——从数据到模型的全链路故障定位方法论 关键词 AI故障诊断、全链路监控、数据漂移、模型退化、根因分析、可解释AI(XAI)、AIOps 摘要 AI系统的“数据+模型”双驱动特性,让其故障比传统软件更隐蔽——可能是输入数据悄悄“…...

避坑指南:在Win10上用PyCharm训练DeepLabV3+时,如何解决CUDA内存不足和依赖冲突?
Win10PyCharm实战:DeepLabV3训练中的7个致命陷阱与突围策略 当你在Windows 10上用PyCharm跑DeepLabV3模型时,是否遇到过这些场景:训练刚开始就爆显存、PyTorch版本冲突导致报错、修改配置后依然无法识别数据集?这些问题往往让初学…...

终极系统加速指南:AtlasOS四大驱动优化工具完全解析
终极系统加速指南:AtlasOS四大驱动优化工具完全解析 【免费下载链接】Atlas 🚀 An open and lightweight modification to Windows, designed to optimize performance, privacy and security. 项目地址: https://gitcode.com/GitHub_Trending/atlas1/…...

EVA-01效果展示:Qwen2.5-VL-7B对视频关键帧摘要+动作识别+事件检测
EVA-01效果展示:Qwen2.5-VL-7B对视频关键帧摘要动作识别事件检测 1. 引言:当视觉AI披上机甲战袍 想象一下,你有一段长达十分钟的监控视频,需要快速找出其中有人摔倒的片段;或者你手头有一堆产品演示视频,…...

Ruoyi+WebSocket实战:如何绕过安全配置实现即时通讯功能
Ruoyi框架中WebSocket安全配置的深度实践指南 引言:当实时通讯遇上安全框架 在基于Ruoyi框架开发企业级应用时,实时通讯功能的需求日益普遍。想象这样一个场景:你的团队协作平台需要即时消息通知,客服系统要求实时对话能力&#x…...

如何用XcodeBenchmark选择最佳Mac设备:完整成本效益分析教程
如何用XcodeBenchmark选择最佳Mac设备:完整成本效益分析教程 【免费下载链接】XcodeBenchmark XcodeBenchmark measures the compilation time of a large codebase on iMac, MacBook, and Mac Pro 项目地址: https://gitcode.com/gh_mirrors/xc/XcodeBenchmark …...

P3618 误会
题目大意:给你两个字符串a和b,你可以将a中的与b相同子串替换为*,不限制替换次数(可以为0),问你最多可以替换出多少个不同的字符串。解法:KMP套dp QWQ。先做一遍KMP,再做一次简单dpfor(int i1;i<n;i){//v…...

GPT-SoVITS技术优化实战指南:从环境配置到性能调优全解析
GPT-SoVITS技术优化实战指南:从环境配置到性能调优全解析 【免费下载链接】GPT-SoVITS 项目地址: https://gitcode.com/GitHub_Trending/gp/GPT-SoVITS 引言 在AI语音合成领域,GPT-SoVITS作为一款开源项目,为开发者提供了强大的语音…...

高德地图Loca 2.0飞线功能深度测评:与百度地图可视化效果对比
高德地图Loca 2.0飞线功能技术解析与实战指南 地图可视化已成为现代数据展示的重要形式,而飞线功能作为其中的核心特效,能够直观呈现空间数据的流动关系。本文将深入探讨高德地图Loca 2.0的飞线功能实现原理,并与同类解决方案进行技术对比&am…...
’与‘条款内容(content)’结构化解析)
PP-DocLayoutV3应用场景:电力调度规程中‘条款编号(number)’与‘条款内容(content)’结构化解析
PP-DocLayoutV3应用场景:电力调度规程中‘条款编号(number)’与‘条款内容(content)’结构化解析 1. 引言:电力调度规程的结构化挑战 电力调度规程是电网运行的核心指导文件,包含了大量的技术…...