Elasticsearch 文本分析器(下)
字符过滤器
注意:字符过滤器用于在将字符流传递给分词器之前对其进行预处理
html_strip HTML元素替换过滤器
此过滤器会替换掉HTML标签,且会转换HTML实体 如:& 会被替换为 &。
{"tokenizer": "keyword","char_filter": ["html_strip"],"text": "<p>I'm so <b>happy</b>!</p>"
}
解析结果:
[ \nI'm so happy!\n ]
因为是 p 标签,所以有前后的换行符。如果使用<span>标签就不会有换行符了。
可配参数说明
- escaped_tags
(可选,字符串数组)不包含尖括号 ( < >) 的 HTML 元素数组。当从文本中剥离 HTML 时,过滤器会跳过这些 HTML 元素。例如,设置 [ “p” ] 将会跳过 <p> HTML 元素。
自定义字符过滤器
{"settings": {"analysis": {"analyzer": {"my_analyzer": {"tokenizer": "keyword","char_filter": ["my_custom_html_strip_char_filter"]}},"char_filter": {"my_custom_html_strip_char_filter": {"type": "html_strip","escaped_tags": ["b"]}}}}
}
自定义字符过滤器 my_custom_html_strip_char_filter ,以 html_strip 过滤器为基础,设置了跳过 b 标签不过滤。
mapping 键值替换过滤器
配置键和值的映射,每当遇到与键相同的字符串时,它就会用与该键关联的值替换它们
{"tokenizer": "keyword","char_filter": [{"type": "mapping","mappings": ["0 => 零","1 => 壹","2 => 贰","3 => 叁","4 => 肆","5 => 伍","6 => 陆","7 => 柒","8 => 捌","9 => 玖"]}],"text": "9527就是你的终身代号"
}
解析结果:
{"tokens": [{"token": "玖伍贰柒就是你的终身代号","start_offset": 0,"end_offset": 12,"type": "word","position": 0}]
}
可配参数说明
- mappings
(必需*,字符串数组)映射数组,每个元素的形式为key => value. - mappings_path
(必需*,字符串)包含映射的文件的路径key => value。
此路径必须是绝对路径或相对于config位置的路径,并且文件必须是 UTF-8 编码的。文件中的每个映射必须用换行符分隔。
以上两个参数二选一即可。
pattern_replace 正则替换过滤器
{"tokenizer": "keyword","char_filter": [{"type": "pattern_replace","pattern": "(\\d{3})(\\d{4})(\\d{4})","replacement":"$1****$3"}],"text": "13199838273"
}
解析结果:
{"tokens": [{"token": "131****8273","start_offset": 0,"end_offset": 11,"type": "word","position": 0}]
}
看到结果你就知道我们示例的作用了,关于写法可以看看可配参数的说明。
可配参数说明
- pattern
必需,Java正则表达式。 - replacement
替换字符串,用 $1…$9来表示正则表达式匹配的内容。注意,我们的示例中每一个正则匹配都用了()括号扩起来。 - flags
Java 正则表达式标志。
常用分词器
分析器只能配置一个分词器,所以很多分词器的名称和分析器的名称是一致的
标准分词器
standard词器提供基于语法的分词(基于 Unicode 文本分割算法)并且适用于大多数语言。
POST _analyze
{"tokenizer": "standard","text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
解析结果:
[ The, 2, QUICK, Brown, Foxes, jumped, over, the, lazy, dog's, bone ]
如果仔细对比,你还是能发现和 standard 分析器处理结果的区别的。
我们来试试中文
{"tokenizer": "standard","text": "我是中国人"
}
解析结果:
[我,是,中,国,人]
分词是分词了,但是貌似不符合我们的要求,关于中文的分词我们后面再说。
可配参数说明
- max_token_length
单个词语的最大长度。如果词语长度超过该长度,则按max_token_length间隔将其拆分。默认为255。
自定义分词器
PUT /person1
{"settings": {"analysis": {"analyzer": {"my_analyzer": {"tokenizer": "my_tokenizer"}},"tokenizer": {"my_tokenizer": {"type": "standard","max_token_length": 5}}}}
}
注意配置参数:我们配置了一个自定义的分词器 my_tokenizer ,以 standard 为基础类型,然后配置了一个自定义的分析器 my_analyzer,设置该分析器的分词器为 my_tokenizer 。
letter 字母分词器
只要遇到不是字母的字符,分词器就会将文本分解。它对大多数欧洲语言都做得很好,但对一些亚洲语言来说就很糟糕,因为在这些语言中单词没有用空格分隔。
POST _analyze
{"tokenizer": "letter","text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
解析结果:
[ The, QUICK, Brown, Foxes, jumped, over, the, lazy, dog, s, bone]
lowercase 小写分词器
其作用和 letter 分词器一样,只是会将字母转换为小写。此处我们就不贴示例了。
classic 经典分词器
适用于英语文档。此分词器具有对首字母缩写词、公司名称、电子邮件地址和 Internet 主机名进行特殊处理的启发式方法。然而,这些规则并不总是有效,分词器对除英语以外的大多数语言都不能很好地工作
POST _analyze
{"tokenizer": "standard","text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone. email: abc@cormm.com"
}
解析结果:
{"tokens": [{"token": "The","start_offset": 0,"end_offset": 3,"type": "<ALPHANUM>","position": 0},{"token": "2","start_offset": 4,"end_offset": 5,"type": "<ALPHANUM>","position": 1},{"token": "QUICK","start_offset": 6,"end_offset": 11,"type": "<ALPHANUM>","position": 2},{"token": "Brown","start_offset": 12,"end_offset": 17,"type": "<ALPHANUM>","position": 3},{"token": "Foxes","start_offset": 18,"end_offset": 23,"type": "<ALPHANUM>","position": 4},{"token": "jumped","start_offset": 24,"end_offset": 30,"type": "<ALPHANUM>","position": 5},{"token": "over","start_offset": 31,"end_offset": 35,"type": "<ALPHANUM>","position": 6},{"token": "the","start_offset": 36,"end_offset": 39,"type": "<ALPHANUM>","position": 7},{"token": "lazy","start_offset": 40,"end_offset": 44,"type": "<ALPHANUM>","position": 8},{"token": "dog's","start_offset": 45,"end_offset": 50,"type": "<APOSTROPHE>","position": 9},{"token": "bone","start_offset": 51,"end_offset": 55,"type": "<ALPHANUM>","position": 10},{"token": "email","start_offset": 57,"end_offset": 62,"type": "<ALPHANUM>","position": 11},{"token": "abc@cormm.com","start_offset": 64,"end_offset": 77,"type": "<EMAIL>","position": 12}]
}
关于与 standard 分词器的区别,可以自行验证一下。
可配参数说明
- max_token_length
单个词语的最大长度。如果词语长度超过该长度,则按max_token_length间隔将其拆分。默认为255。
path_hierarchy 路径层次分词器
POST _analyze
{"tokenizer": "path_hierarchy","text": "/one/two/three"
}
解析结果:
[ /one, /one/two, /one/two/three ]
可配参数说明
- delimiter
用作路径分隔符的字符。默认为 / - replacement
用于分隔符的可选替换字符。默认为delimiter. - buffer_size
单次读取到术语缓冲区的字符数。默认为1024. 术语缓冲区将按此大小增长,直到所有文本都被消耗掉。建议不要更改此设置。 - reverse:是否反转,默认为false。
- skip
要跳过的初始标记数。默认为0.
示例2
拆分 - 字符,并将它们替换为 / 并跳过前两个标记
PUT /person1
{"settings": {"analysis": {"analyzer": {"my_analyzer": {"tokenizer": "my_tokenizer"}},"tokenizer": {"my_tokenizer": {"type": "path_hierarchy","delimiter": "-","replacement": "/","skip": 2}}}}
}
{"analyzer": "my_analyzer","text": "one-two-three-four-five"
}
解析结果:
[ /three, /three/four, /three/four/five ]
如果设置 reverse 为 true
[ one/two/three/, two/three/, three/ ]
uax_url_email 电子邮件分词器
{"tokenizer": "uax_url_email","text": "Email me at john.smith@global-international.com"
}
解析结果:
[ Email, me, at, john.smith@global-international.com ]
可配参数说明
- max_token_length
单个词语的最大长度。如果词语长度超过该长度,则按max_token_length间隔将其拆分。默认为255。
令牌过滤器
令牌过滤器,是在标记之后执行。es 提供的令牌过滤器非常多,我们只列一些可能会有用的来说一说。
uppercase 大写过滤器
{"tokenizer" : "standard","filter" : ["uppercase"],"text" : "the Quick FoX JUMPs"
}
解析结果
[ THE, QUICK, FOX, JUMPS ]
lowercase 小写过滤器
{"tokenizer" : "standard","filter" : ["lowercase"],"text" : "THE Quick FoX JUMPs"
}
解析结果:
[ the, quick, fox, jumps ]
stemmer 词干过滤器
{"tokenizer": "standard","filter": [ "stemmer" ],"text": "fox running and jumping jumped"
}
解析结果:
[ fox, run, and, jump, jump ]
注意标记提取了词干。比如:jumping 和 jumped 提取为了 jump 。
可配参数说明
- language
(可选,字符串)用于词干标记的依赖于语言的词干提取算法。可以设置很多语言,我们常用的也就 english(默认:英语)german 德语、spanish 西班牙语等等,但还是不包括中文。
stop 停用词过滤器
该过滤器默认将如下词语作为停用词:
a, an, and, are, as, at, be, but, by, for, if, in, into, is,
it, no, not, of, on, or, such, that, the, their, then, there,
these, they, this, to, was, will, with
{"tokenizer": "standard","filter": [ "stop" ],"text": "a quick fox jumps over the lazy dog"
}
解析结果:
[ quick, fox, jumps, over, lazy, dog ]
cjk_bigram 中日韩双字母标记过滤器
此过滤器支持中日韩的文字,但标记只对文字进行两两组合,严格上说对中文的支持也不是十分好。
{"tokenizer" : "standard","filter" : ["cjk_bigram"],"text" : "我们都是中国人"
}
解析结果:
{"tokens": [{"token": "我们","start_offset": 0,"end_offset": 2,"type": "<DOUBLE>","position": 0},{"token": "们都","start_offset": 1,"end_offset": 3,"type": "<DOUBLE>","position": 1},{"token": "都是","start_offset": 2,"end_offset": 4,"type": "<DOUBLE>","position": 2},{"token": "是中","start_offset": 3,"end_offset": 5,"type": "<DOUBLE>","position": 3},{"token": "中国","start_offset": 4,"end_offset": 6,"type": "<DOUBLE>","position": 4},{"token": "国人","start_offset": 5,"end_offset": 7,"type": "<DOUBLE>","position": 5}]
}
除去我们以上介绍的,ES 的令牌过滤器还有很多,我们就不过多说明了,因为他们大多数都是不支持中文的。
相关文章:
)
Elasticsearch 文本分析器(下)
字符过滤器 注意:字符过滤器用于在将字符流传递给分词器之前对其进行预处理 html_strip HTML元素替换过滤器 此过滤器会替换掉HTML标签,且会转换HTML实体 如:& 会被替换为 &。 {"tokenizer": "keyword","…...

Git操作方法
目录 Git是什么 Git特点 Git作用 Git原理 集中式 分布式 Git安装 修改语言 Git操作 1.初始化Git仓库 2.提交工作区的内容到版本库 3.查看版本记录 4.版本回退 5.版本前进 Git 命令 通用操作 工作状态 版本回退 版本前进 远程仓 1.GitHub 2.GitLab 3.码云…...

CorelDRAW矢量绘图2023中文版下载
市面上的矢量绘图工具虽然很多,但权威又专业的却不多,选到不好用的工具,会极大的影响自己创作,CorelDRAW简称cdr,是一款功能强大的矢量图制作软件,一说到矢量图制作,大家都会不由自主地想到cdr。…...

Java-API简析_java.lang.Float类(基于 Latest JDK)(浅析源码)
【版权声明】未经博主同意,谢绝转载!(请尊重原创,博主保留追究权) https://blog.csdn.net/m0_69908381/article/details/131129886 出自【进步*于辰的博客】 其实我的【Java-API】专栏内的博文对大家来说意义是不大的。…...
pycharm的基本使用
废话文学 本人记录笔记始终遵循“能动手绝不动脑,能动脑绝不动手”的基本原则。不会的操作,跟着笔记干就完事了,还动啥脑袋?留着脑细胞刷抖音擦边小姐姐他不香吗? 什么是IDE IDE即【集成开发环境】,Inte…...
为什么要使用微软的 Application Framework?
我是荔园微风,作为一名在IT界整整25年的老兵,今天来看一下我们为什么要使用微软的 Application Framework? 虽然Application Framework 并不是新观念,它们却在最近数年才成为 PC 平台上软件开发的主流工具。面向对象语言是具体实…...

Python爬虫基础知识点
Python爬虫是使用Python编写的程序,可以自动抓取互联网上的数据。常用的Python爬虫框架包括Scrapy、BeautifulSoup、Requests等。Python爬虫可以应用于众多场合,如大数据分析、信息监测、数据挖掘和机器学习等领域。那么新手应该如何学习python爬虫呢&am…...

K8s运维备忘
1.服务器集群搭建: VagrantFile中加入以下代码,创建3个虚拟机: Vagrant.configure("2") do |config| (1..3).each do |i| config.vm.define "k8s-node#{i}" do |node| # 设置虚拟机的Box …...
)
激光雷达+rtk+rgb联合使用(4)
因为一直在忙一些乱七八糟的事情,就没顾得上继续写,想着快速收尾算了。 前面写到,我在点云的匹配上花了大量的时间,不断的调参数,换方法,一共几百个点云,想着先每50个匹配一次,得到几…...

【K8S系列】快速初始化⼀个最⼩集群
序言 走得最慢的人,只要不丧失目标,也比漫无目的地徘徊的人走得快。 文章标记颜色说明: 黄色:重要标题红色:用来标记结论绿色:用来标记一级重要蓝色:用来标记二级重要 希望这篇文章能让你不仅有…...
Exploit/CVE-2010-0738
打开JBoss的潘多拉魔盒:JBoss高危漏洞分析 *本文中涉及到的相关漏洞已报送厂商并得到修复,本文仅限技术研究与讨论,严禁用于非法用途,否则产生的一切后果自行承担。 前言 JBoss是一个基于J2EE的开放源代码应用服务器࿰…...
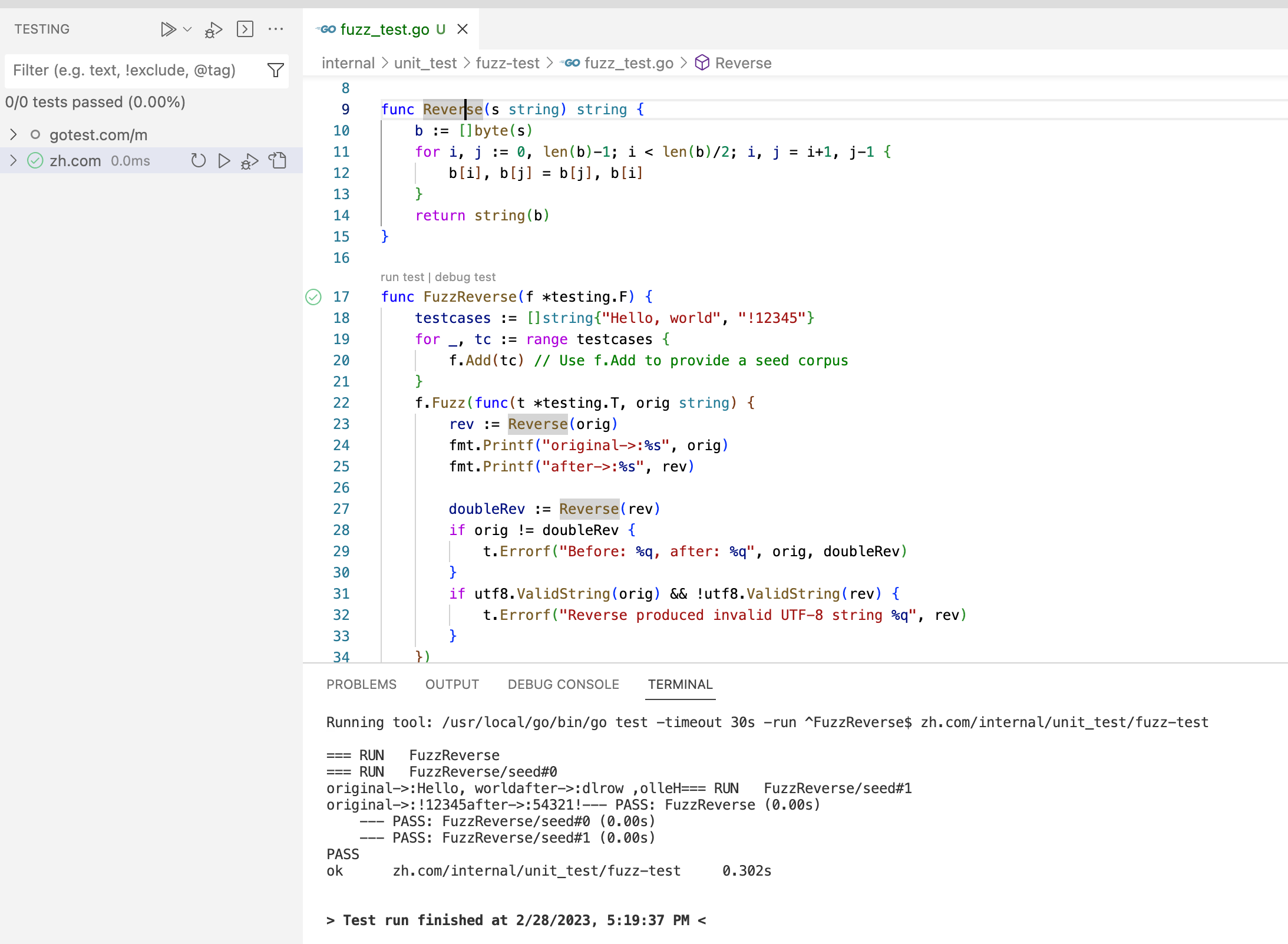
Go单元测试及框架使用
Go自带测试框架 单元测试 建议Go 语言推荐测试文件和源代码文件放在一块,测试文件以 _test.go 结尾。函数名必须以 Test 开头,后面一般跟待测试的函数名参数为 t *testing.T 简单测试用例定义如下: func TestXXXX(t *testing.T) {// ...}…...

TreeMap类型实体类数据进行排序
实体类Student类代码如下所示: package com.test.Test11;public class Student implements Comparable<Student>{private int age;private String name;private Double height;public int getAge() {return age;}public void setAge(int age) {this.age age…...
HOOPS助力AVEVA数字化转型:支持多种3D模型格式转换!
行业: 电力和公用事业、化工、造船、能源、采矿业 挑战: 创建大规模复杂资产的客户需要汇集多种类型的数据,以支持初始设计和创建强大的数字双胞胎;现有版本的产品只支持半打CAD格式;有限的内部开发资源限制了增加对新…...
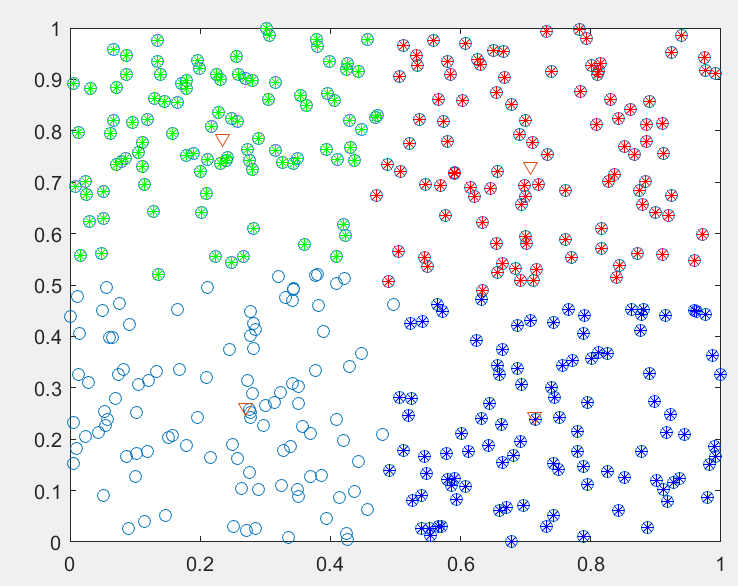
(转载)基于遗传模拟退火的聚类算法(matlab实现)
1 理论基础 1.1 模糊聚类分析 模糊聚类是目前知识发现以及模式识别等诸多领域中的重要研究分支之一。随着研究范围的拓展,不管是科学研究还是实际应用,都对聚类的结果从多方面提出了更高的要求。模糊C-均值聚类(FCM)是目前比较流行的一种聚类方法。该…...

【C++】struct 和 class 的区别
欢迎来到博主 Apeiron 的博客,祝您旅程愉快。时止则止,时行则行。动静不失其时,其道光明。 目录 1、缘起 2、示例代码 3、总结 1、缘起 在 C 中,struct 和 class 唯一的区别就在于 默认的访问权限不同。区别如下: …...
活动笔记丨物业行业人效提升与灵活用工新路径
近日,盖雅工场成功举办物业行业人效提升专场交流,来自广深地区央企和民营的领先物业企业和现场服务业的多位代表齐聚深圳招商积余大厦,共同研讨行业人效提升的挑战和实践。 本次闭门交流会聚焦于人效提升,讨论话题包括各自企业在人…...
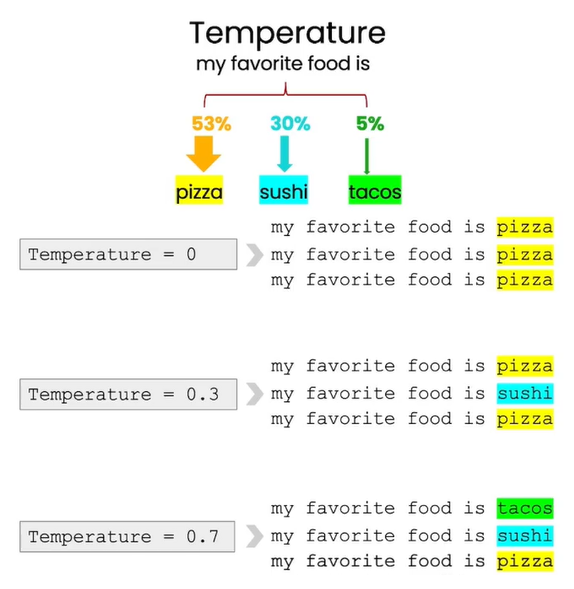
学习笔记:吴恩达ChatGPT提示工程
以下为个人笔记,原课程网址Short Courses | Learn Generative AI from DeepLearning.AI 01 Introduction 1.1 基础LLM 输入 从前有一只独角兽,输出 它和其他独角兽朋友一起住在森林里输入 法国的首都在哪?输出 法国的首都在哪…...
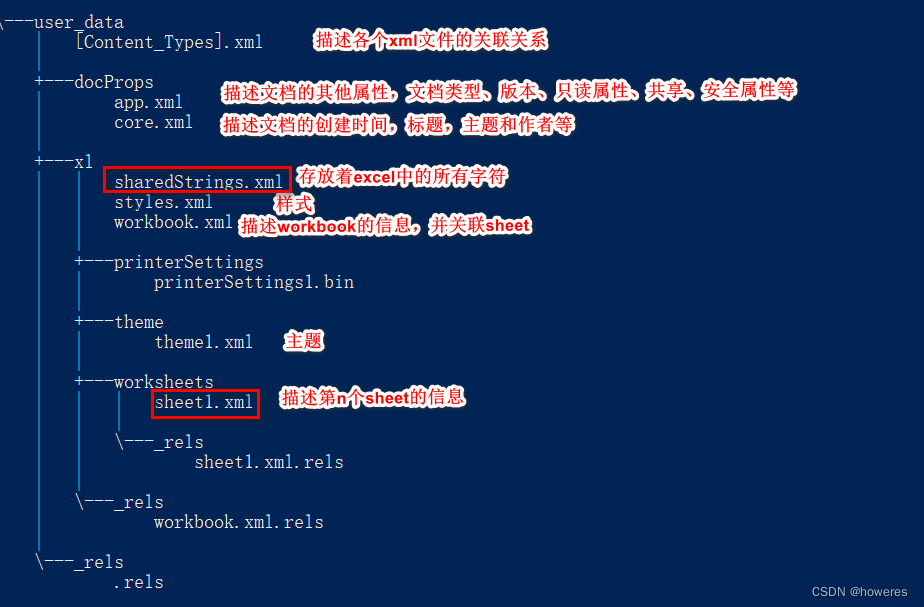
POI in Action
POI 组件依赖 按需引入对应依赖 (给出官方的指引) 组件作用Maven依赖POIFSOLE2 FilesystempoiHPSFOLE2 Property SetspoiHSSFExcel XLSpoiHSLFPowerPoint PPTpoi-scratchpadHWPFWord DOCpoi-scratchpadHDGFVisio VSDpoi-scratchpadHPBFPublisher PUBpoi-scratchpadHSMFOutloo…...

苹果Vision Pro将引爆人机交互的重大变革
2023年6月6日,苹果发布了大家期待已久的Vision Pro,Vision Pro是一款专业级MR设备,融合了虚拟现实(VR)和增强现实(AR)技术,可以让用户完全沉浸在高分辨率显示内容中。允许用户以一种全新的方式在其周围的空间中查看APP。用户可以用…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

【杂谈】-递归进化:人工智能的自我改进与监管挑战
递归进化:人工智能的自我改进与监管挑战 文章目录 递归进化:人工智能的自我改进与监管挑战1、自我改进型人工智能的崛起2、人工智能如何挑战人类监管?3、确保人工智能受控的策略4、人类在人工智能发展中的角色5、平衡自主性与控制力6、总结与…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...

微服务商城-商品微服务
数据表 CREATE TABLE product (id bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 商品id,cateid smallint(6) UNSIGNED NOT NULL DEFAULT 0 COMMENT 类别Id,name varchar(100) NOT NULL DEFAULT COMMENT 商品名称,subtitle varchar(200) NOT NULL DEFAULT COMMENT 商…...
)
是否存在路径(FIFOBB算法)
题目描述 一个具有 n 个顶点e条边的无向图,该图顶点的编号依次为0到n-1且不存在顶点与自身相连的边。请使用FIFOBB算法编写程序,确定是否存在从顶点 source到顶点 destination的路径。 输入 第一行两个整数,分别表示n 和 e 的值(1…...

Python 包管理器 uv 介绍
Python 包管理器 uv 全面介绍 uv 是由 Astral(热门工具 Ruff 的开发者)推出的下一代高性能 Python 包管理器和构建工具,用 Rust 编写。它旨在解决传统工具(如 pip、virtualenv、pip-tools)的性能瓶颈,同时…...

用机器学习破解新能源领域的“弃风”难题
音乐发烧友深有体会,玩音乐的本质就是玩电网。火电声音偏暖,水电偏冷,风电偏空旷。至于太阳能发的电,则略显朦胧和单薄。 不知你是否有感觉,近两年家里的音响声音越来越冷,听起来越来越单薄? —…...

搭建DNS域名解析服务器(正向解析资源文件)
正向解析资源文件 1)准备工作 服务端及客户端都关闭安全软件 [rootlocalhost ~]# systemctl stop firewalld [rootlocalhost ~]# setenforce 0 2)服务端安装软件:bind 1.配置yum源 [rootlocalhost ~]# cat /etc/yum.repos.d/base.repo [Base…...

Python+ZeroMQ实战:智能车辆状态监控与模拟模式自动切换
目录 关键点 技术实现1 技术实现2 摘要: 本文将介绍如何利用Python和ZeroMQ消息队列构建一个智能车辆状态监控系统。系统能够根据时间策略自动切换驾驶模式(自动驾驶、人工驾驶、远程驾驶、主动安全),并通过实时消息推送更新车…...

MacOS下Homebrew国内镜像加速指南(2025最新国内镜像加速)
macos brew国内镜像加速方法 brew install 加速formula.jws.json下载慢加速 🍺 最新版brew安装慢到怀疑人生?别怕,教你轻松起飞! 最近Homebrew更新至最新版,每次执行 brew 命令时都会自动从官方地址 https://formulae.…...