Redis的使用规范小建议
Redis 核心技术与实战 笔记
作者: 蒋德钧
毕竟,高性能和节省内存,是我们的两个目标,只有规范地使用Redis,才能真正实现这两个目标。如果说之前的内容教会了你怎么用,那么今天的内容,就是帮助你用好Redis,尽量不出错。
好了,话不多说,我们来看下键值对的使用规范。
键值对使用规范
关于键值对的使用规范,我主要想和你说两个方面:
- key 的命名规范,只有命名规范,才能提供可读性强、可维护性好的 key,方便日常管理;
- value 的设计规范,包括避免bigkey、选择高效序列化方法和压缩方法、使用整数对象共享池、数据类型选择。
规范一:key 的命名规范
一个 Redis 实例默认可以支持 16 个数据库,我们可以把不同的业务数据分散保存到不同的数据库中。
但是,在使用不同数据库时,客户端需要使用 SELECT 命令进行数据库切换,相当于增加了一个额外的操作。
其实,我们可以通过合理命名 key,减少这个操作。具体的做法是,把业务名作为前缀,然后用冒号分隔,再加上具体的业务数据名。这样一来,我们可以通过 key 的前缀区分不同的业务数据,就不用在多个数据库间来回切换了。
我给你举个简单的小例子,看看具体怎么命名 key。
比如说,如果我们要统计网页的独立访客量,就可以用下面的代码设置 key,这就表示,这个数据对应的业务是统计 unique visitor(独立访客量),而且对应的页面编号是 1024。
uv:page:1024
这里有一个地方需要注意一下。key 本身是字符串,底层的数据结构是 SDS。SDS 结构中会包含字符串长度、分配空间大小等元数据信息。从 Redis 3.2 版本开始,当 key 字符串的长度增加时,SDS 中的元数据也会占用更多内存空间。
所以,我们在设置 key 的名称时,要注意控制 key 的长度。否则,如果 key 很长的话,就会消耗较多内存空间,而且,SDS 元数据也会额外消耗一定的内存空间。
SDS 结构中的字符串长度和元数据大小的对应关系如下表所示:

为了减少 key 占用的内存空间,我给你一个小建议:对于业务名或业务数据名,可以使用相应的英文单词的首字母表示,(比如 user 用 u 表示,message 用 m),或者是用缩写表示(例如 unique visitor 使用 uv)。
规范二:避免使用 bigkey
Redis 是使用单线程读写数据,bigkey 的读写操作会阻塞线程,降低 Redis 的处理效率。所以,在应用 Redis 时,关于 value 的设计规范,非常重要的一点就是避免 bigkey。
bigkey 通常有两种情况。
-
情况一:键值对的值大小本身就很大,例如 value 为 1MB 的 String 类型数据。为了避免 String 类型的 bigkey,在业务层,我们要尽量把 String 类型的数据大小控制在 10KB 以下。
-
情况二:键值对的值是集合类型,集合元素个数非常多,例如包含 100 万个元素的 Hash 集合类型数据。为了避免集合类型的 bigkey,我给你的设计规范建议是,尽量把集合类型的元素个数控制在 1 万以下。
当然,这些建议只是为了尽量避免 bigkey,如果业务层的 String 类型数据确实很大,我们还可以通过数据压缩来减小数据大小;如果集合类型的元素的确很多,我们可以将一个大集合拆分成多个小集合来保存。
这里,还有个地方需要注意下,Redis 的 4 种集合类型 List、Hash、Set 和 Sorted Set,在集合元素个数小于一定的阈值时,会使用内存紧凑型的底层数据结构进行保存,从而节省内存。例如,假设 Hash 集合的 hash-max-ziplist-entries 配置项是 1000,如果 Hash 集合元素个数不超过 1000,就会使用 ziplist 保存数据。
紧凑型数据结构虽然可以节省内存,但是会在一定程度上导致数据的读写性能下降。所以,如果业务应用更加需要保持高性能访问,而不是节省内存的话,在不会导致 bigkey 的前提下,你就不用刻意控制集合元素个数了。
规范三:使用高效序列化方法和压缩方法
为了节省内存,除了采用紧凑型数据结构以外,我们还可以遵循两个使用规范,分别是使用高效的序列化方法和压缩方法,这样可以减少 value 的大小。
Redis 中的字符串都是使用二进制安全的字节数组来保存的,所以,我们可以把业务数据序列化成二进制数据写入到 Redis 中。
但是,不同的序列化方法,在序列化速度和数据序列化后的占用内存空间这两个方面,效果是不一样的。比如说,protostuff 和 kryo 这两种序列化方法,就要比 Java 内置的序列化方法(java-build-in-serializer)效率更高。
此外,业务应用有时会使用字符串形式的 XML 和 JSON 格式保存数据。
这样做的好处是,这两种格式的可读性好,便于调试,不同的开发语言都支持这两种格式的解析。
缺点在于,XML 和 JSON 格式的数据占用的内存空间比较大。为了避免数据占用过大的内存空间,我建议使用压缩工具(例如 snappy 或 gzip),把数据压缩后再写入 Redis,这样就可以节省内存空间了。
规范四:使用整数对象共享池
整数是常用的数据类型,Redis 内部维护了 0 到 9999 这 1 万个整数对象,并把这些整数作为一个共享池使用。
换句话说,如果一个键值对中有 0 到 9999 范围的整数,Redis 就不会为这个键值对专门创建整数对象了,而是会复用共享池中的整数对象。
这样一来,即使大量键值对保存了 0 到 9999 范围内的整数,在 Redis 实例中,其实只保存了一份整数对象,可以节省内存空间。
基于这个特点,我建议你,在满足业务数据需求的前提下,能用整数时就尽量用整数,这样可以节省实例内存。
那什么时候不能用整数对象共享池呢?主要有两种情况。
第一种情况是,如果 Redis 中设置了 maxmemory,而且启用了 LRU 策略(allkeys-lru 或 volatile-lru 策略),那么,整数对象共享池就无法使用了。 这是因为,LRU 策略需要统计每个键值对的使用时间,如果不同的键值对都共享使用一个整数对象,LRU 策略就无法进行统计了。
第二种情况是,如果集合类型数据采用 ziplist 编码,而集合元素是整数,这个时候,也不能使用共享池。因为 ziplist 使用了紧凑型内存结构,判断整数对象的共享情况效率低。
好了,到这里,我们了解了和键值对使用相关的四种规范,遵循这四种规范,最直接的好处就是可以节省内存空间。接下来,我们再来了解下,在实际保存数据时,该遵循哪些规范。
数据保存规范
规范一:使用 Redis 保存热数据
为了提供高性能访问,Redis 是把所有数据保存到内存中的。
虽然 Redis 支持使用 RDB 快照和 AOF 日志持久化保存数据,但是,这两个机制都是用来提供数据可靠性保证的,并不是用来扩充数据容量的。而且,内存成本本身就比较高,如果把业务数据都保存在 Redis 中,会带来较大的内存成本压力。
所以,一般来说,在实际应用 Redis 时,我们会更多地把它作为缓存保存热数据,这样既可以充分利用 Redis 的高性能特性,还可以把宝贵的内存资源用在服务热数据上,就是俗话说的“好钢用在刀刃上”。
规范二:不同的业务数据分实例存储
虽然我们可以使用 key 的前缀把不同业务的数据区分开,但是,如果所有业务的数据量都很大,而且访问特征也不一样,我们把这些数据保存在同一个实例上时,这些数据的操作就会相互干扰。
你可以想象这样一个场景:假如数据采集业务使用 Redis 保存数据时,以写操作为主,而用户统计业务使用 Redis 时,是以读查询为主,如果这两个业务数据混在一起保存,读写操作相互干扰,肯定会导致业务响应变慢。
那么,我建议你把不同的业务数据放到不同的 Redis 实例中。这样一来,既可以避免单实例的内存使用量过大,也可以避免不同业务的操作相互干扰。
规范三:在数据保存时,要设置过期时间
对于 Redis 来说,内存是非常宝贵的资源,而且,Redis 通常用于保存热数据。热数据一般都有使用的时效性。所以,在数据保存时,我建议你根据业务使用数据的时长,设置数据的过期时间。
不然的话,写入 Redis 的数据会一直占用内存,如果数据持续增多,就可能达到机器的内存上限,造成内存溢出,导致服务崩溃。
规范四:控制 Redis 实例的容量
Redis 单实例的内存大小都不要太大,根据我自己的经验值,建议你设置在 2~6GB 。这样一来,无论是 RDB 快照,还是主从集群进行数据同步,都能很快完成,不会阻塞正常请求的处理。
命令使用规范
最后,我们再来看下在使用 Redis 命令时要遵守什么规范。
规范一:线上禁用部分命令
Redis 是单线程处理请求操作,如果我们执行一些涉及大量操作、耗时长的命令,就会严重阻塞主线程,导致其它请求无法得到正常处理,这类命令主要有 3 种。
- KEYS,按照键值对的 key 内容进行匹配,返回符合匹配条件的键值对,该命令需要对 Redis 的全局哈希表进行全表扫描,严重阻塞 Redis 主线程;
- FLUSHALL,删除 Redis 实例上的所有数据,如果数据量很大,会严重阻塞 Redis 主线程;
- FLUSHDB,删除当前数据库中的数据,如果数据量很大,同样会阻塞 Redis 主线程。
所以,我们在线上应用 Redis 时,就需要禁用这些命令。具体的做法是,管理员用 rename-command 命令在配置文件中对这些命令进行重命名,让客户端无法使用这些命令。
当然,你还可以使用其它命令替代这 3 个命令。
- 对于 KEYS 命令来说,你可以用 SCAN 命令代替 KEYS 命令,分批返回符合条件的键值对,避免造成主线程阻塞;
- 对于 FLUSHALL、FLUSHDB 命令来说,你可以加上 ASYNC 选项,让这两个命令使用后台线程异步删除数据,可以避免阻塞主线程。
规范二:慎用 MONITOR 命令
Redis 的 MONITOR 命令在执行后,会持续输出监测到的各个命令操作,所以,我们通常会用 MONITOR 命令返回的结果,检查命令的执行情况。
但是,MONITOR 命令会把监控到的内容持续写入输出缓冲区。如果线上命令的操作很多,输出缓冲区很快就会溢出了,这就会对 Redis 性能造成影响,甚至引起服务崩溃。
所以,除非十分需要监测某些命令的执行(例如,Redis 性能突然变慢,我们想查看下客户端执行了哪些命令),你可以偶尔在短时间内使用下 MONITOR 命令,否则,我建议你不要使用 MONITOR 命令。
规范三:慎用全量操作命令
对于集合类型的数据来说,如果想要获得集合中的所有元素,一般不建议使用全量操作的命令(例如 Hash 类型的 HGETALL、Set 类型的 SMEMBERS)。这些操作会对 Hash 和 Set 类型的底层数据结构进行全量扫描,如果集合类型数据较多的话,就会阻塞 Redis 主线程。
如果想要获得集合类型的全量数据,我给你三个小建议。
- 第一个建议是,你可以使用 SSCAN、HSCAN 命令分批返回集合中的数据,减少对主线程的阻塞。
- 第二个建议是,你可以化整为零,把一个大的 Hash 集合拆分成多个小的 Hash 集合。这个操作对应到业务层,就是对业务数据进行拆分,按照时间、地域、用户 ID 等属性把一个大集合的业务数据拆分成多个小集合数据。例如,当你统计用户的访问情况时,就可以按照天的粒度,把每天的数据作为一个 Hash 集合。
- 最后一个建议是,如果集合类型保存的是业务数据的多个属性,而每次查询时,也需要返回这些属性,那么,你可以使用 String 类型,将这些属性序列化后保存,每次直接返回 String 数据就行,不用再对集合类型做全量扫描了。
小结
这节课,我围绕 Redis 应用时的高性能访问和节省内存空间这两个目标,分别在键值对使用、命令使用和数据保存三方面向你介绍了 11 个规范。
我按照强制、推荐、建议这三个类别,把这些规范分了下类,如下表所示:

我来解释一下这 3 个类别的规范。
- 强制类别的规范:这表示,如果不按照规范内容来执行,就会给 Redis 的应用带来极大的负面影响,例如性能受损。
- 推荐类别的规范:这个规范的内容能有效提升性能、节省内存空间,或者是增加开发和运维的便捷性,你可以直接应用到实践中。
- 建议类别的规范:这类规范内容和实际业务应用相关,我只是从我的经历或经验给你一个建议,你需要结合自己的业务场景参考使用。
我再多说一句,你一定要熟练掌握这些使用规范,并且真正地把它们应用到你的 Redis 使用场景中,提高 Redis 的使用效率。
我总结的 Redis 使用规范分为两大方面,主要包括业务层面和运维层面。业务层面主要面向的业务开发人员:1、key 的长度尽量短,节省内存空间
2、避免 bigkey,防止阻塞主线程
3、4.0+版本建议开启 lazy-free
4、把 Redis 当作缓存使用,设置过期时间
5、不使用复杂度过高的命令,例如SORT、SINTER、SINTERSTORE、ZUNIONSTORE、ZINTERSTORE
6、查询数据尽量不一次性查询全量,写入大量数据建议分多批写入
7、批量操作建议 MGET/MSET 替代 GET/SET,HMGET/HMSET 替代 HGET/HSET
8、禁止使用 KEYS/FLUSHALL/FLUSHDB 命令
9、避免集中过期 key
10、根据业务场景选择合适的淘汰策略
11、使用连接池操作 Redis,并设置合理的参数,避免短连接
12、只使用 db0,减少 SELECT 命令的消耗
13、读请求量很大时,建议读写分离,写请求量很大,建议使用切片集群运维层面主要面向的是 DBA 运维人员:1、按业务线部署实例,避免多个业务线混合部署,出问题影响其他业务
2、保证机器有足够的 CPU、内存、带宽、磁盘资源
3、建议部署主从集群,并分布在不同机器上,slave 设置为 readonly
4、主从节点所部署的机器各自独立,尽量避免交叉部署,对从节点做维护时,不会影响到主节点
5、推荐部署哨兵集群实现故障自动切换,哨兵节点分布在不同机器上
6、提前做好容量规划,防止主从全量同步时,实例使用内存突增导致内存不足
7、做好机器 CPU、内存、带宽、磁盘监控,资源不足时及时报警,任意资源不足都会影响 Redis 性能
8、实例设置最大连接数,防止过多客户端连接导致实例负载过高,影响性能
9、单个实例内存建议控制在 10G 以下,大实例在主从全量同步、备份时有阻塞风险
10、设置合理的 slowlog 阈值,并对其进行监控,slowlog 过多需及时报警
11、设置合理的 repl-backlog,降低主从全量同步的概率
12、设置合理的 slave client-output-buffer-limit,避免主从复制中断情况发生
13、推荐在从节点上备份,不影响主节点性能
14、不开启 AOF 或开启 AOF 配置为每秒刷盘,避免磁盘 IO 拖慢 Redis 性能
15、调整 maxmemory 时,注意主从节点的调整顺序,顺序错误会导致主从数据不一致
16、对实例部署监控,采集 INFO 信息时采用长连接,避免频繁的短连接
17、做好实例运行时监控,重点关注 expired_keys、evicted_keys、latest_fork_usec,这些指标短时突增可能会有阻塞风险
18、扫描线上实例时,记得设置休眠时间,避免过高 OPS 产生性能抖动
相关文章:
Redis的使用规范小建议
Redis 核心技术与实战 笔记 作者: 蒋德钧 毕竟,高性能和节省内存,是我们的两个目标,只有规范地使用Redis,才能真正实现这两个目标。如果说之前的内容教会了你怎么用,那么今天的内容,就是帮助你用…...

操作受限的线性表——栈
本文主要内容:本文主要讲解栈的基本概念、基本操作和栈的顺序、链式实现。 目录 栈一、栈的基本概念1、基本概念2、基本操作 二、栈的顺序存储结构1、顺序栈的实现2、顺序栈的基本运算1)初始化2)判栈空3)进栈4)出栈5&a…...
父类指针访问子类成员变量(需要dynamic_cast))
C++基类指针或引用指向或引用派生类对象(实现动态多态四种手段)父类指针访问子类成员变量(需要dynamic_cast)
文章目录 背景多态示例:父类指针指向子类对象父类指针指向子类对象,如何通过父类指针访问到子类特定的成员变量实现动态多态的四种手段:基类的指针或引用指向或引用一个派生类对象(new或不new) 背景 比如有父类Animal…...
WTM框架运行报错0308010C:digital envelope routines::unsupported
WTM框架运行报错0308010C:digital envelope routines::unsupported 错误描述报错原因解决方式 错误描述 我所使用WTM搭建的程序是选择的.net5.0Vue前后端分离的方式,项目结构选择的是“各层分离的多个项目”;本人并非初次使用WTM平台框架搭建项目&#…...
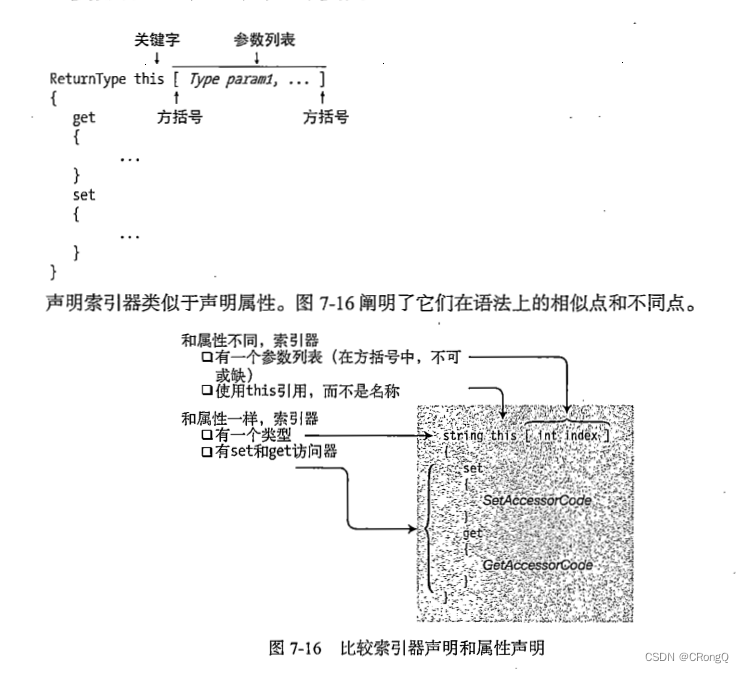
(二)CSharp-索引器
1、索引器定义 什么是索引器 索引器(indexer)是这样一种成员:它使对象能够用与数组相同的方式(即使用下标)进行索引 索引器的声明参见 C# 语言定义文档注意:没有静态索引器 索引器是一组 get 和 set 访问…...

配合AI刷leetcode 实现1170
题目如下: 1170. 比较字符串最小字母出现频次 难度中等 75 定义一个函数 f(s),统计 s 中(按字典序比较)最小字母的出现频次 ,其中 s 是一个非空字符串。 例如,若 s "dcce",那么…...

English Learning - L3 作业打卡 Lesson5 Day36 2023.6.9 周五
English Learning - L3 作业打卡 Lesson5 Day36 2023.6.9 周五 引言🍉句1: So next time you are on a train, look around and see what other people are reading, but dont jump to any conclusions.成分划分弱读连读爆破语调 🍉句2: You will probab…...

前端框架笔记
Vue.js的安装 安装Vue.js有两种方法: (1)类似于Bootstrap或jQuery,直接通过HTML文件中的标签引用。为了方便开发者使用,Vue.js提供了相关的CDN,通过如下代码可以引用最新版本的Vue.js: <sc…...

详细设计文档
1. 引言 1.1 目的 1.2 范围 1.3 定义、缩略语和缩写 1.4 参考文献 1.5 概述 2. 系统架构设计 2.1 总体架构 2.2 模块划分 2.3 数据流程设计 2.4 接口设计 3. 模块详细设计 3.1 登录模块详细设计 3.1.1 类设计 3.1.2 方法设计 3.1.3 数据库表设计 3.1.4 界面设计 3.2 文章管理模…...
)
Java011——Java数据类型转换(基本数据类型)
回顾:Java八大基本数据类型 大类 类型名称 关键字 占用内存 取值范围 --------------------------------------------------------------------------------------------|字节型 byte 1 字节 -128~127 整型 |短整型 short 2 字节 -32768~32…...
mybatis-plus用法(二)
(5条消息) mybatis-plus用法(一)_渣娃工程师的博客-CSDN博客 AR模式 ActiveRecord模式,通过操作实体对象,直接操作数据库表。与ORM有点类似。 示例如下 让实体类User继承自Model package com.example.mp.po; import com.bao…...

SQL笔记-存储过程+循环
存储过程循环使用方法 Oracle Oracle中存储过程的循环使用方法如下: DECLAREi NUMBER; BEGINi : 1;WHILE i < 10 LOOPDBMS_OUTPUT.PUT_LINE(i || i);i : i 1;END LOOP; END;其中,DECLARE用于声明变量,BEGIN和END用于标识存储过程的开始…...
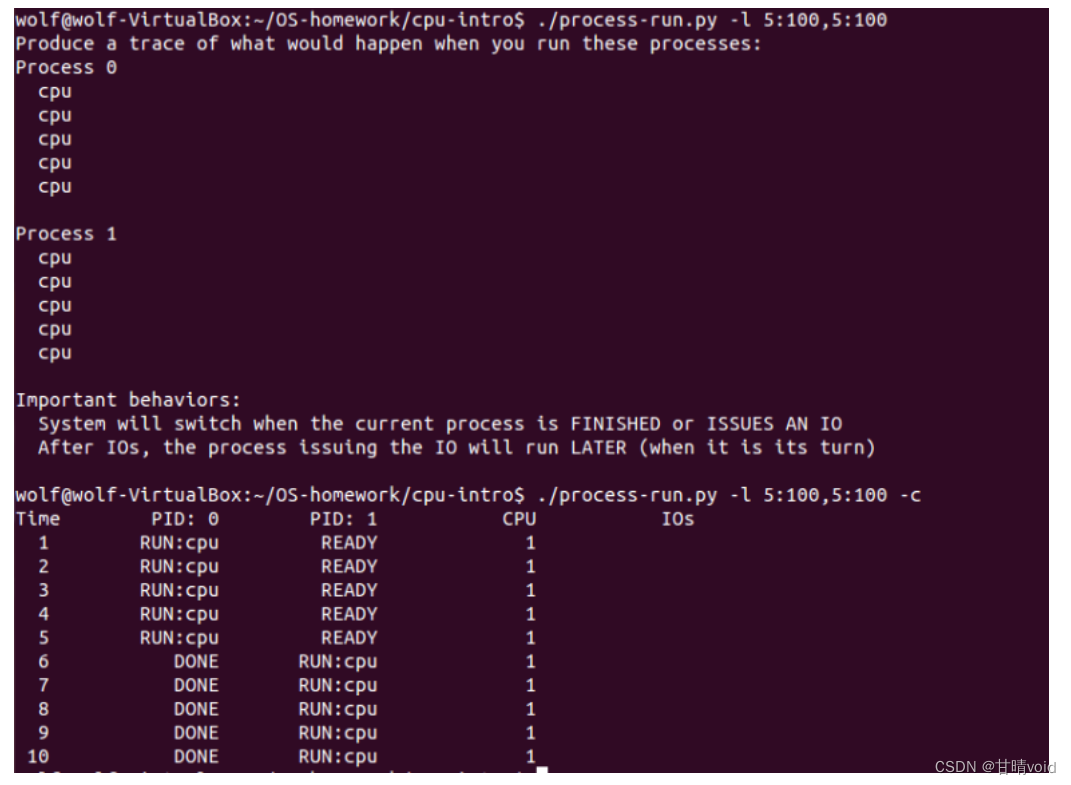
HNU-操作系统OS-作业1(4-9章)
这份文件是OS_homework_1 by计科2102 wolf 202108010XXX 文档设置了目录,可以通过目录快速跳转至答案部分。 第四章 4.1用以下标志运行程序:./process-run.py -l 5:100,5:100。CPU 利用率(CPU 使用时间的百分比)应该是多少?为什么你知道这一点?利用 -c 标记查看你…...

springboot 精华
一、基础 官方文档地址:Spring Boot 注:以下部分例子 有些用到 .properties 方式,有些用 .yml方式,两者可自行学习,这里部分是为了省空间而写 .properties 方式。 1、泛谈 (1)优势 快速构建…...
:新课标I卷)
我用ChatGPT写2023高考语文作文(三):新课标I卷
2023年 新课标I卷 适用地区:山东、福建、湖北、江苏、广东、湖南、河北、浙江 好的故事,可以帮我们更好地表达和沟通,可以触动心灵、启迪智慧;好的故事,可以改变一个人的命运,可以展现一个民族的形象……故…...
HTML 标签的学习
1.HTML 的结构 前端三剑客: HTML CSS JS,本章我们学习的是HTML HTML > 超文本标记语言 HTML代码是由"标签"构成的. 形如 <body>hello</body>标签名 (body) 放到 < > 中大部分标签成对出现. 为开始标签, 为结束标签.少数标签只有开始标签…...
)
计算耗时为微秒的方法(包含:时/分/秒/毫秒/微秒/纳秒)
计算耗时为微秒的方法1 #include<stdio.h> #include <windows.h> int main() {int a[10002];int i 0;double run_time;_LARGE_INTEGER time_start; //开始时间_LARGE_INTEGER time_over; //结束时间double dqFreq; //计时器频率LARGE_INTEGER f; //计时器频率Qu…...

通过 Python 封装关键词搜索阿里巴巴商品api接口
以下是使用 Python 封装关键词搜索阿里巴巴商品列表数据的步骤: 使用 requests 库向阿里巴巴搜索接口发送 HTTP 请求,可以使用 GET 或 POST 方法,请求参数中应包含搜索关键词、每页展示数量、当前页码等信息。 解析返回的 response 中的 HTM…...
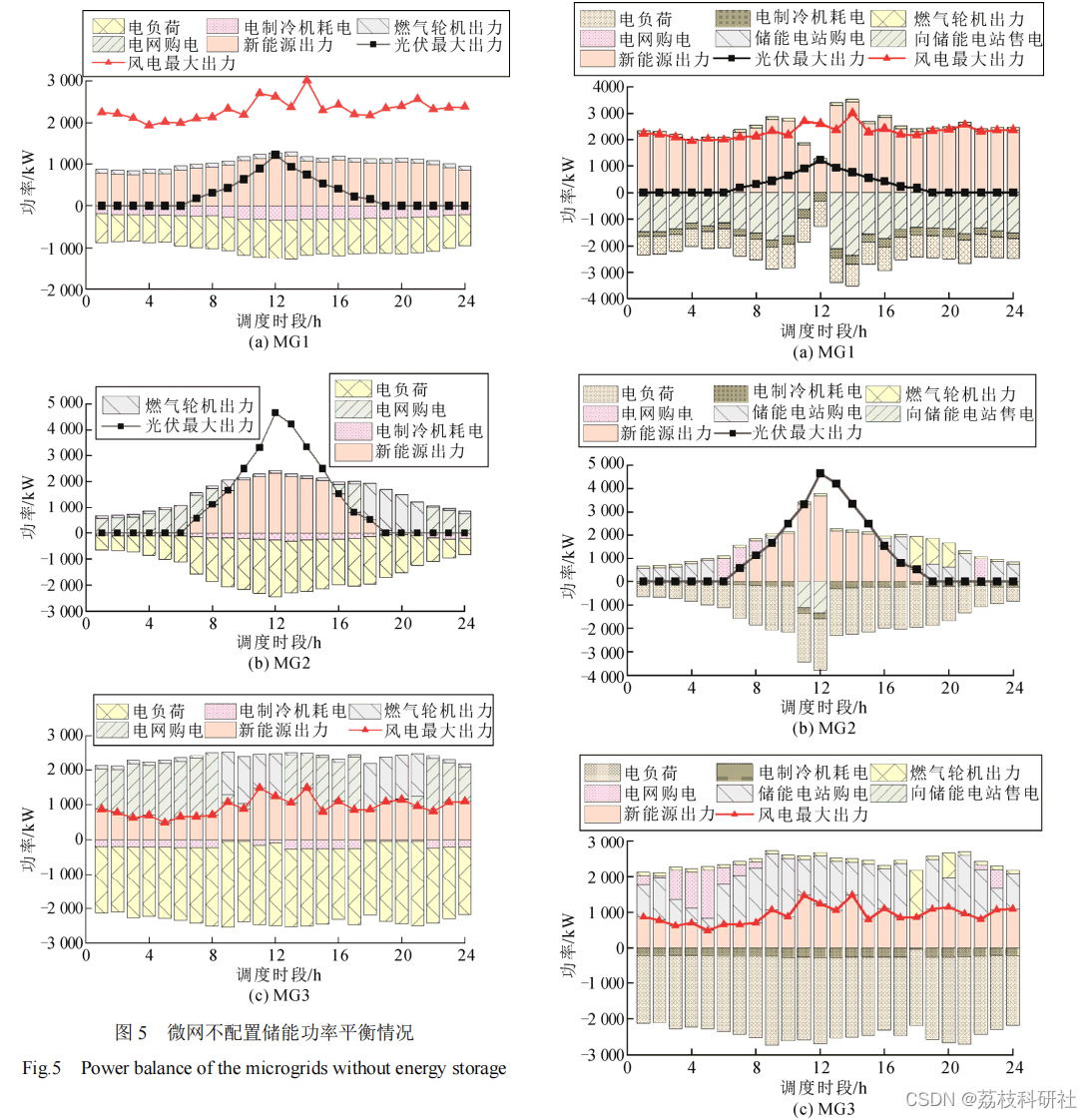
分布式光伏消纳的微电网群共享储能配置策略研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

C语言写网络爬虫总体思路
使用C语言编写爬虫可以实现网络数据的快速获取和处理,适用于需要高效处理海量数据的场景。与其他编程语言相比,C语言具有较高的性能和灵活性,可以进行底层操作和内存管理,适合处理较复杂的网络请求和数据处理任务。 但是…...

CiteSpace关键词聚类图谱实战解析:从数据预处理到可视化解读
CiteSpace关键词聚类图谱实战解析:从数据预处理到可视化解读 作为一名经常和文献数据打交道的科研人员,我深知在浩如烟海的学术文献中快速把握一个领域的研究脉络是多么重要。CiteSpace作为一款强大的文献计量与可视化工具,其关键词聚类图谱功…...

华硕电脑键盘全部失灵
华硕电脑键盘全部失灵前言一、故障排查二、发现问题三、使用方法总结前言 故障情况描述: 键盘无法使用,键盘除开机键外全部失灵,关机后,如果没断电,键盘常亮 打开机器,故障复现,果然是完全失效…...

Gemini3Pro全解析及2026最新AI模型对比
Gemini3Pro全解析及2026最新AI模型对比在2026年AI大模型全面向落地转型的当下,很多用户被Gemini3Pro的多模态优势吸引,却被“gemini3pro国内怎么用”“gemini3pro是免费的吗”等问题困扰,而kulaai.cn能一站式解决这些痛点,同时适配…...

从 “养龙虾” 到 “养章鱼”:AiPy 提前一年走完安全可控路
近日,知道创宇旗下智能体爱派(AiPy) 发布新版本。此次更新中,AiPy 新增支持通过手机QQ、飞书APP远程连接,同时将原有智能体集市升级为 Skills市场,并推出“龙虾伴侣”CLI 工具接口,完成对 OpenC…...

京东商品详情 API 开发实战:JD 商品详情接口调用与返回值解析
在电商API开发中,京东商品详情API是最常用、最核心的接口之一,无论是做比价工具、选品分析、ERP对接,还是第三方服务集成,都离不开它。本文将从实战角度出发,手把手教你完成京东商品详情API的调用、签名生成、数据解析…...

WRF安装解决报错
1.参考链接:https://blog.csdn.net/ME1010/article/details/129914778 2.报错: (1)刚开始在服务器安装,因为没有sudo权限,怕修改环境变量影响了其他人,同时因为安装报错 就在本地安装 &#…...

学习记录贴-day12
今天又是跑了几个实验,加深了对prvaccountant和momentaccountant的差别,然后看了一些基准实验的指标。明天对着这些基准实验看看哪里还有可改进的点。...

Visual StudioProfiler对工作流进行热点分析
热点:消耗了绝大部分CPU计算时间(例如超过50%或更高比例)的那部分代码。Visual Studio 中,使用性能探查器(Profiler)在 Visual Studio 中,使用性能探查器(Profiler)进行热…...

UPF 商用部署:从核心网架构到场景落地的实践指南
在 5G 商用全面铺开的今天,UPF(用户数据面功能实体) 早已不再是藏在核心网里的技术名词,而是决定网络性能、业务体验与行业赋能能力的核心枢纽。作为 5G 核心网中唯一负责用户数据报文处理的网元,UPF 的部署策略直接影…...

南昌本地靠谱的整木定制公司
在南昌,随着人们生活品质的提高,对于家居装修的要求也越来越高,整木定制成为了许多别墅、大平层和高端住宅业主的首选。然而,市场上的整木定制公司众多,如何选择一家靠谱的公司成为了一个难题。今天,就为大…...