5.1 合并数据
5.1 合并数据
- 5.1.1 堆叠合并数据
- 1、横向堆叠 concat()
- 2、纵向堆叠 concat()和append()
- 5.1.2 主键合并数据 merge()和join()
- 5.1.3 重叠合并数据 combine_first()
5.1.1 堆叠合并数据
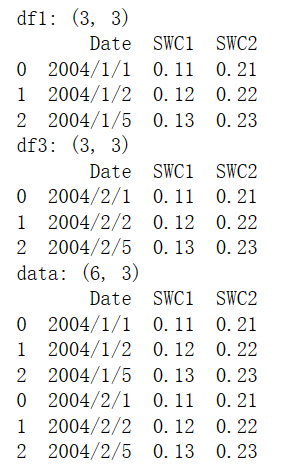
堆叠就是简单地把两个表拼在一起,也被称作轴向连接、绑定或连接。依照连接轴的方向,数据堆叠可以分为横向堆叠和纵向堆叠。
1、横向堆叠 concat()
横向堆叠,即将两个表在X轴向拼接在一起,可以使用concat函数完成,concat函数的基本语法如下。
pandas.concat(objs, axis=0, join=‘outer’, join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, copy=True)

当axis=1的时候,concat做行对齐,然后将不同列名称的两张或多张表合并。当两个表索引不完全一样时,可以使用join参数选择是内连接还是外连接。在内连接的情况下,仅仅返回索引重叠部分。在外连接的情况下,则显示索引的并集部分数据,不足的地方则使用空值填补。
横向堆叠外连接示例如下:
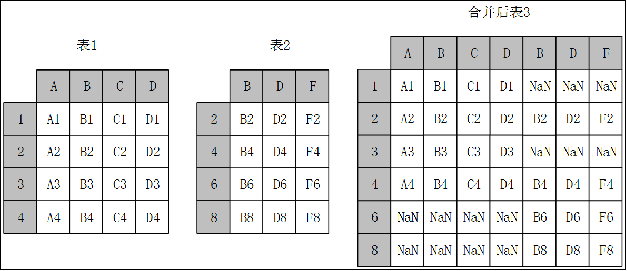
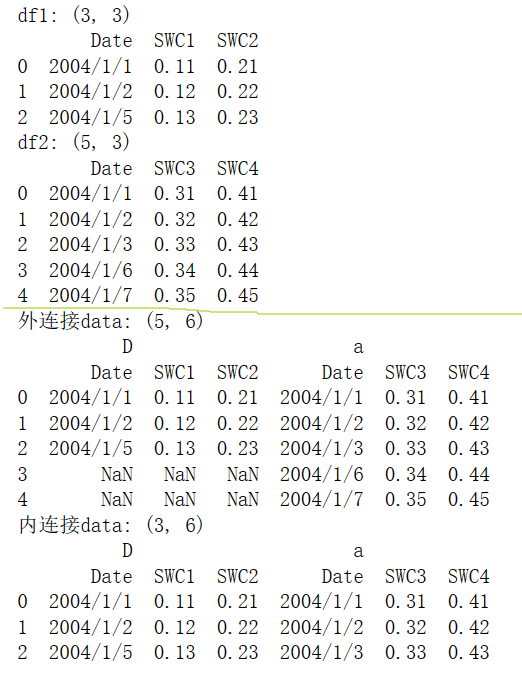
## 1、横向堆叠 concat()
import numpy as np
import pandas as pd
path1 = 'E:/Input/5_1_swc12.csv'
path2 = 'E:/Input/5_1_swc34.csv'
df1 = pd.read_csv(path1)
print("df1:", df1.shape)
print(df1)
df2 = pd.read_csv(path2)
print("df2:", df2.shape)
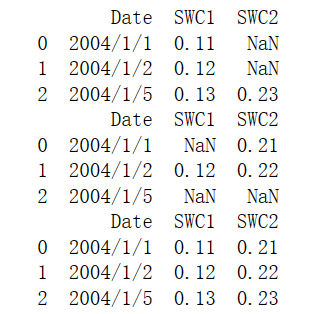
print(df2)outer_data = pd.concat([df1,df2], axis = 1, join='outer',keys = 'Date')
print("外连接data:", outer_data.shape)
print(outer_data)
inner_data = pd.concat([df1,df2], axis = 1, join='inner', keys = 'Date')
print("内连接data:", inner_data.shape)
print(inner_data)
Notes: 当两张表完全一样时,不论join参数取值是inner或者outer,结果都是将两个表完全按照X轴拼接起来。
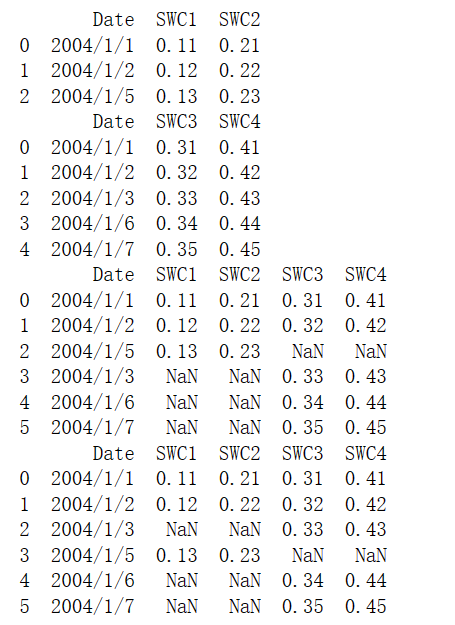
2、纵向堆叠 concat()和append()
(1)concat()
使用concat函数时,在默认情况下,即axis=0时,concat做列对齐,将不同行索引的两张或多张表纵向合并。在两张表的列名并不完全相同的情况下,可join参数取值为inner时,返回的仅仅是列名交集所代表的列,取值为outer时,返回的是两者列名的并集所代表的列,纵向堆叠外连接示例如图所示。
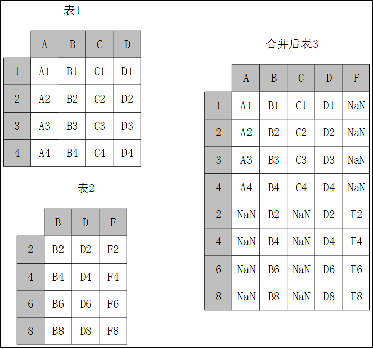
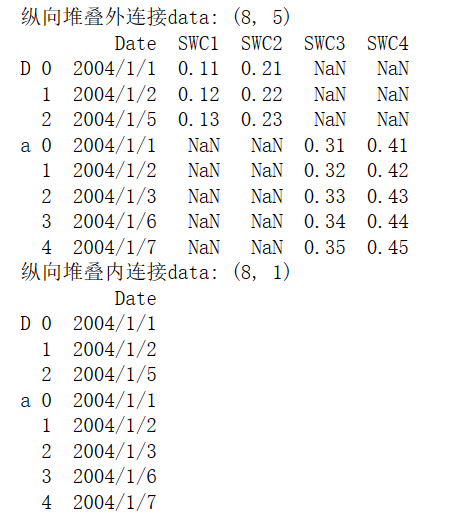
outer_data = pd.concat([df1,df2], axis = 0, join='outer',keys = 'Date')
print("纵向堆叠外连接data:", outer_data.shape)
print(outer_data)
inner_data = pd.concat([df1,df2], axis = 0, join='inner', keys = 'Date')
print("纵向堆叠内连接data:", inner_data.shape)
print(inner_data)
Notes: 当两张表完全一样时,不论join参数取值是inner或者outer,结果都是将两个表完全按照Y轴拼接起来。
(2)append() #append方法已弃用,并将在未来的版本中从pandas中删除。
append方法也可以用于纵向合并两张表。但是append方法实现纵向表堆叠有一个前提条件,那就是两张表的列名需要完全一致。
pandas.DataFrame.append(self, other, ignore_index=False, verify_integrity=False)。

path1 = 'E:/Input/5_1_swc12.csv'
path3 = 'E:/Input/5_1_swc12_副本.csv'
df1 = pd.read_csv(path1)
print("df1:", df1.shape)
print(df1)
df3 = pd.read_csv(path3)
print("df3:", df3.shape)
print(df3)data = df1.append(df3)
print("data:", data.shape)
print(data)
5.1.2 主键合并数据 merge()和join()
主键合并,即通过一个或多个键将两个数据集的行连接起来,类似于SQL中的JOIN。针对同一个主键存在两张包含不同字段的表,将其根据某几个字段一一对应拼接起来,结果集列数为两个元数据的列数和减去连接键的数量。
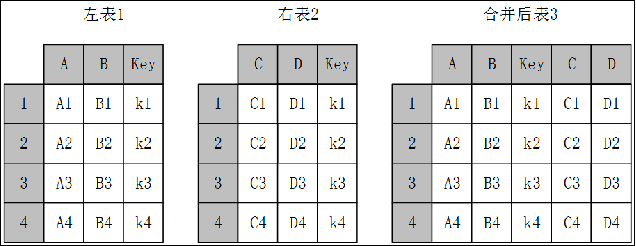
(1)merge函数
和数据库的join一样,merge函数也有左连接(left)、右连接(right)、内连接(inner)和外连接(outer),但比起数据库SQL语言中的join和merge函数还有其自身独到之处,例如可以在合并过程中对数据集中的数据进行排序等。
pandas.merge(left, right, how=‘inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=(‘_x’, ‘_y’), copy=True, indicator=False)
可根据merge函数中的参数说明,并按照需求修改相关参数,就可以多种方法实现主键合并。

# 5.1.2 主键合并数据 merge()
# df1 = pd.read_csv(path1)
print(df1)
# df2 = pd.read_csv(path2)
print(df2)
# 合并
# data = pd.merge(df1, df2, on='Date', how = 'outer') # 与下面一样
data = pd.merge(df1, df2, left_on='Date', right_on='Date',how = 'outer')
print(data)
# 合并并根据连接键排序
data = pd.merge(df1, df2, on='Date', how = 'outer',sort = True)
print(data)
(1)join函数
join方法也可以实现部分主键合并的功能,但是join方法使用时,两个主键的名字必须相同。
pandas.DataFrame.join(self, other, on=None, how=‘left’, lsuffix=‘’, rsuffix=‘’, sort=False)

5.1.3 重叠合并数据 combine_first()
数据分析和处理过程中若出现两份数据的内容几乎一致的情况,但是某些特征在其中一张表上是完整的,而在另外一张表上的数据则是缺失的时候,可以用combine_first方法进行重叠数据合并,其原理如下。
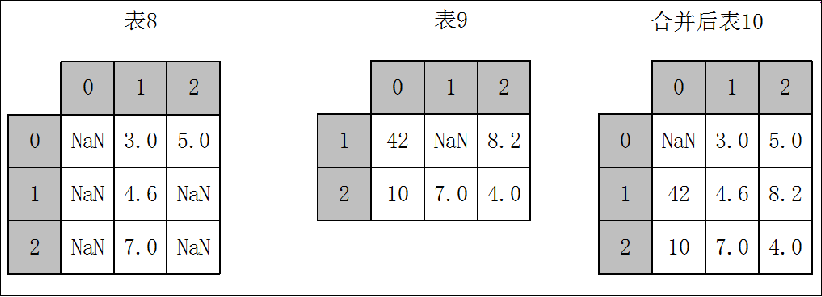
pandas.DataFrame.combine_first(other)

# 5.1.3 重叠合并数据
path5 = 'E:/Input/5_1_swc12 - 副本.csv'
path6 = 'E:/Input/5_1_swc12 - 副本 (2).csv'
df5 = pd.read_csv(path5)
print(df5)
df6 = pd.read_csv(path6)
print(df6)
# 合并
data = df5.combine_first(df6)
print(data)
相关文章:
5.1 合并数据
5.1 合并数据 5.1.1 堆叠合并数据1、横向堆叠 concat()2、纵向堆叠 concat()和append() 5.1.2 主键合并数据 merge()和join()5.1.3 重叠合并数据 combine_first() 5.1.1 堆叠合并数据 堆叠就是简单地把两个表拼在一起,也被称作轴向连接、绑定或连接。依照连接轴的方…...

华为OD机试真题 JavaScript 实现【求解立方根】【牛客练习题】
一、题目描述 计算一个浮点数的立方根,不使用库函数。保留一位小数。 数据范围:∣val∣≤20 。 二、输入描述 待求解参数,为double类型(一个实数) 三、输出描述 输出参数的立方根。保留一位小数。 四、解题思路…...
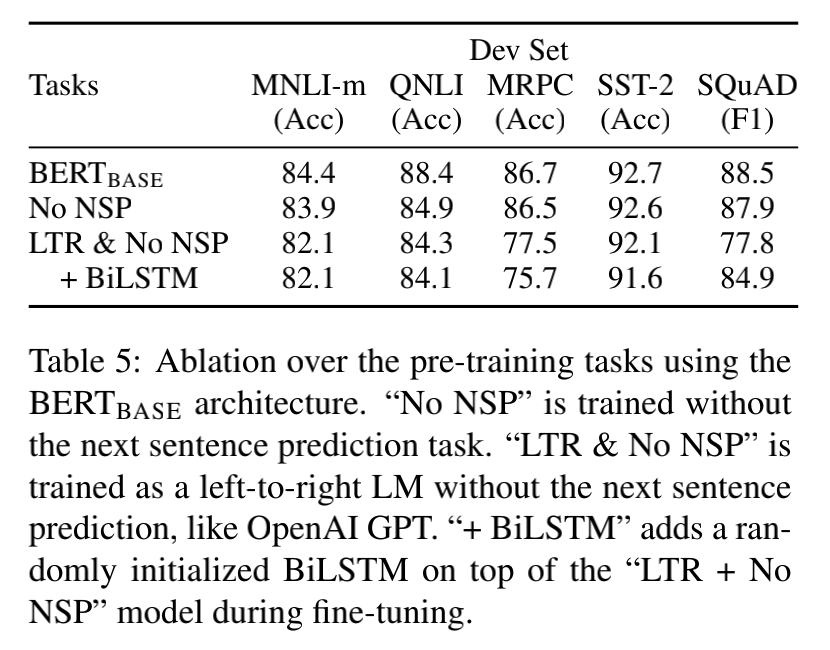
初探BERTPre-trainSelf-supervise
初探Bert 因为一次偶然的原因,自己有再次对Bert有了一个更深层地了解,特别是对预训练这个概念,首先说明,自己是看了李宏毅老师的讲解,这里只是尝试进行简单的总结复述并加一些自己的看法。 说Bert之前不得不说现在的…...

Ficus 第二弹,突破限制器的 Markdown 编辑管理软件!
大家好,我们是 ggG 团队,我们开发的 markdown 笔记管理软件 Ficus Beta 版本正式发布了。详情可以见我们官网,也可以来我们仓库查看。 相对于 Alpha 版本(可以在我们之前的博客中查看),主要有 3 点明显的提…...
基于Springboot+vue+协同过滤+前后端分离+鲜花商城推荐系统(用户,多商户,管理员)+全套视频教程
基于Springbootvue协同过滤前后端分离鲜花商城推荐系统(用户,多商户,管理员)(毕业论文11000字以上,共33页,程序代码,MySQL数据库) 代码下载: 链接:https://pan.baidu.com/s/1mf2rsB_g1DutFEXH0bPCdA 提取码:8888 【运行环境】Idea JDK1.8 Maven MySQL…...
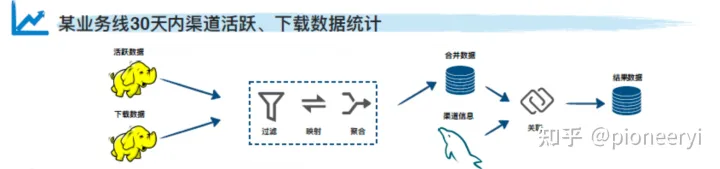
MixQuery系列(一):多数据源混合查询引擎调研
背景 存储情况 当前的存储引擎可谓百花齐放,层出不穷。为什么会这样了?因为不存在One for all的存储,不同的存储总有不同的存储的优劣和适用场景。因此,在实际的业务场景中,不同特点的数据会存储到不同的存储引擎里。 业务挑战 然而异构的存储和数据源,却给分析查询带…...
d2l学习——第一章Introduction
x.0 环境配置 使用d2l库,安装如下: conda create --name d2l python3.9 -y conda activate d2lpip install torch1.12.0 torchvision0.13.0 pip install d2l1.0.0b0mkdir d2l-en && cd d2l-en curl https://d2l.ai/d2l-en.zip -o d2l-en.zip u…...
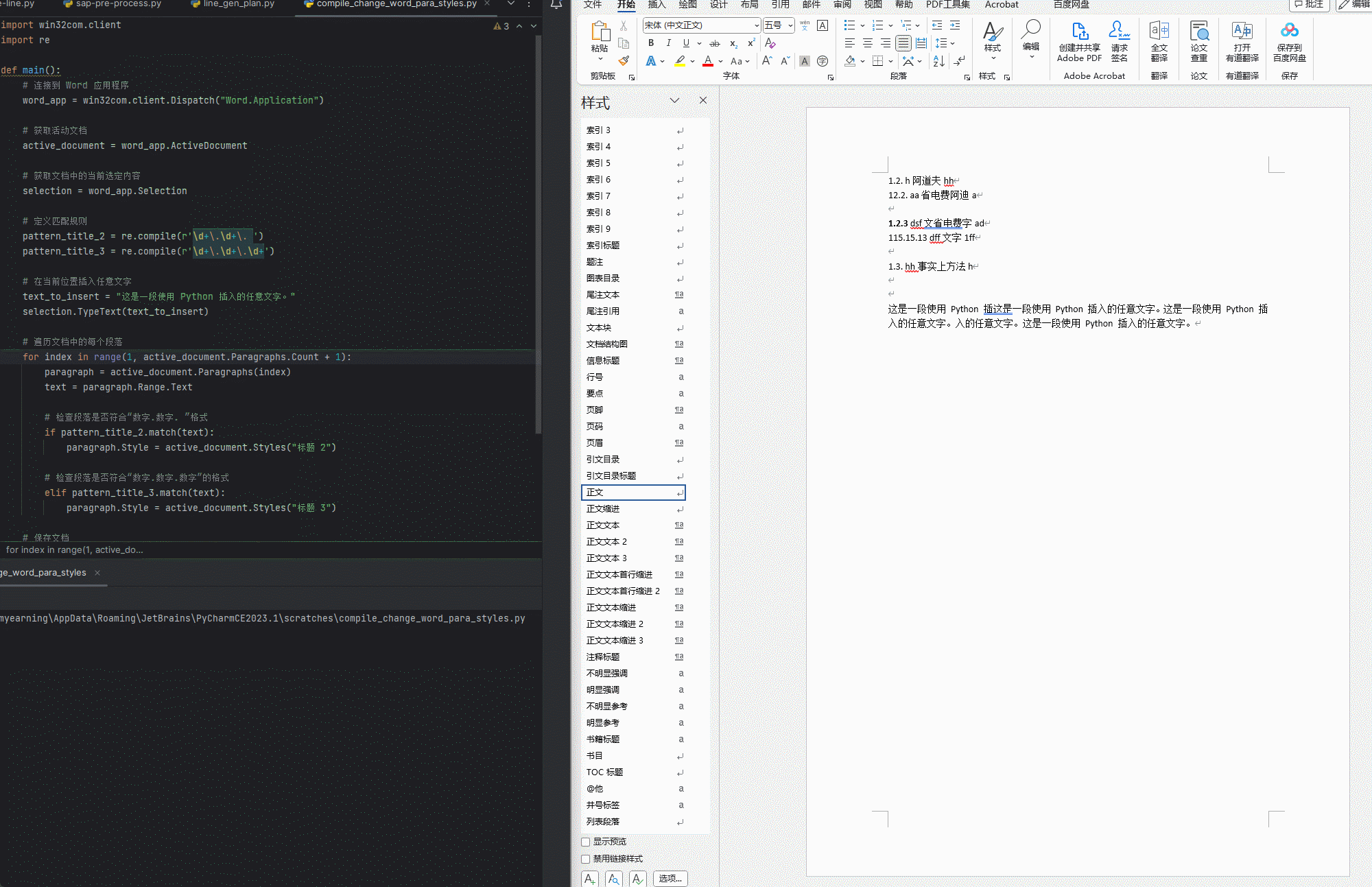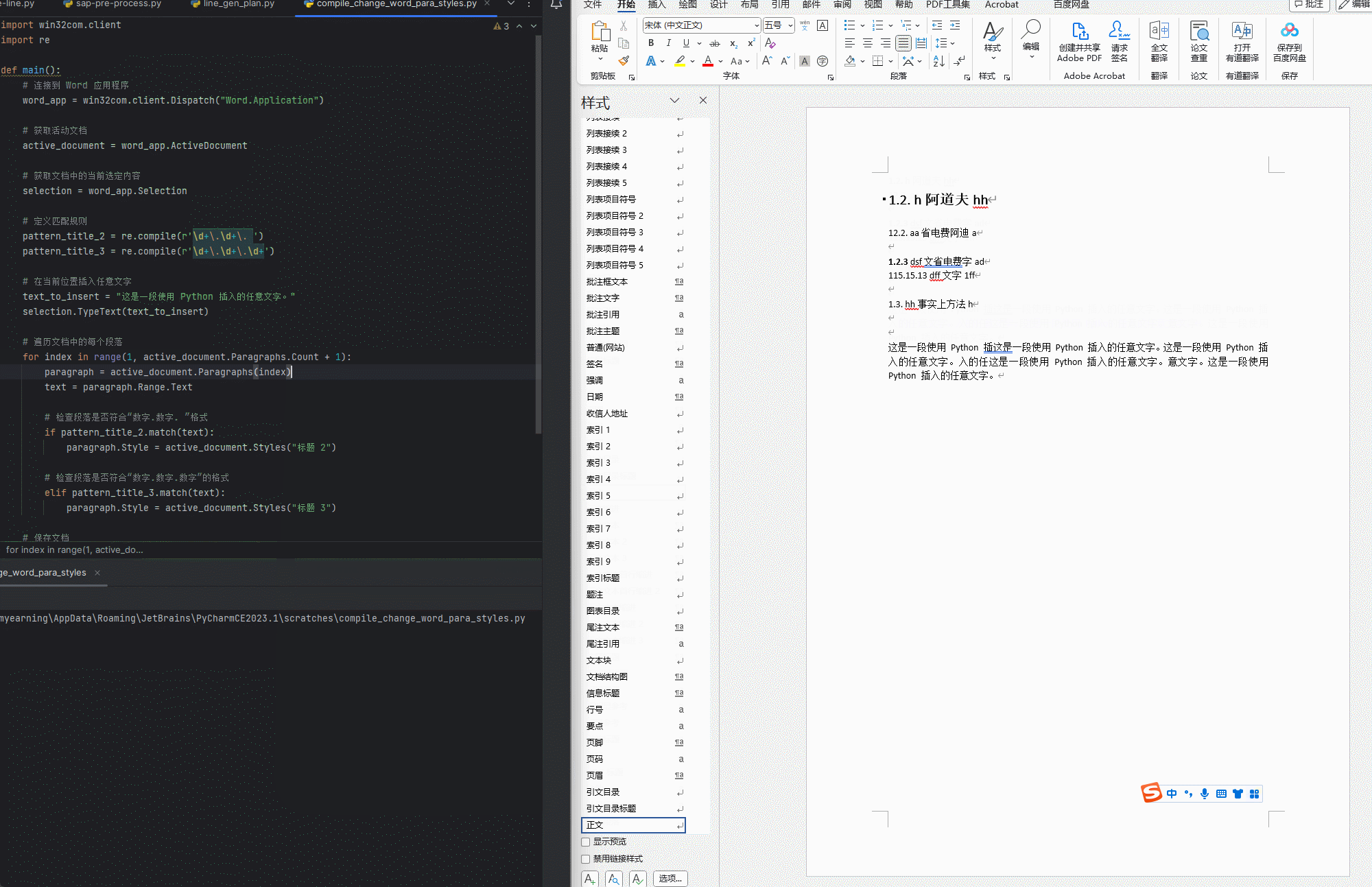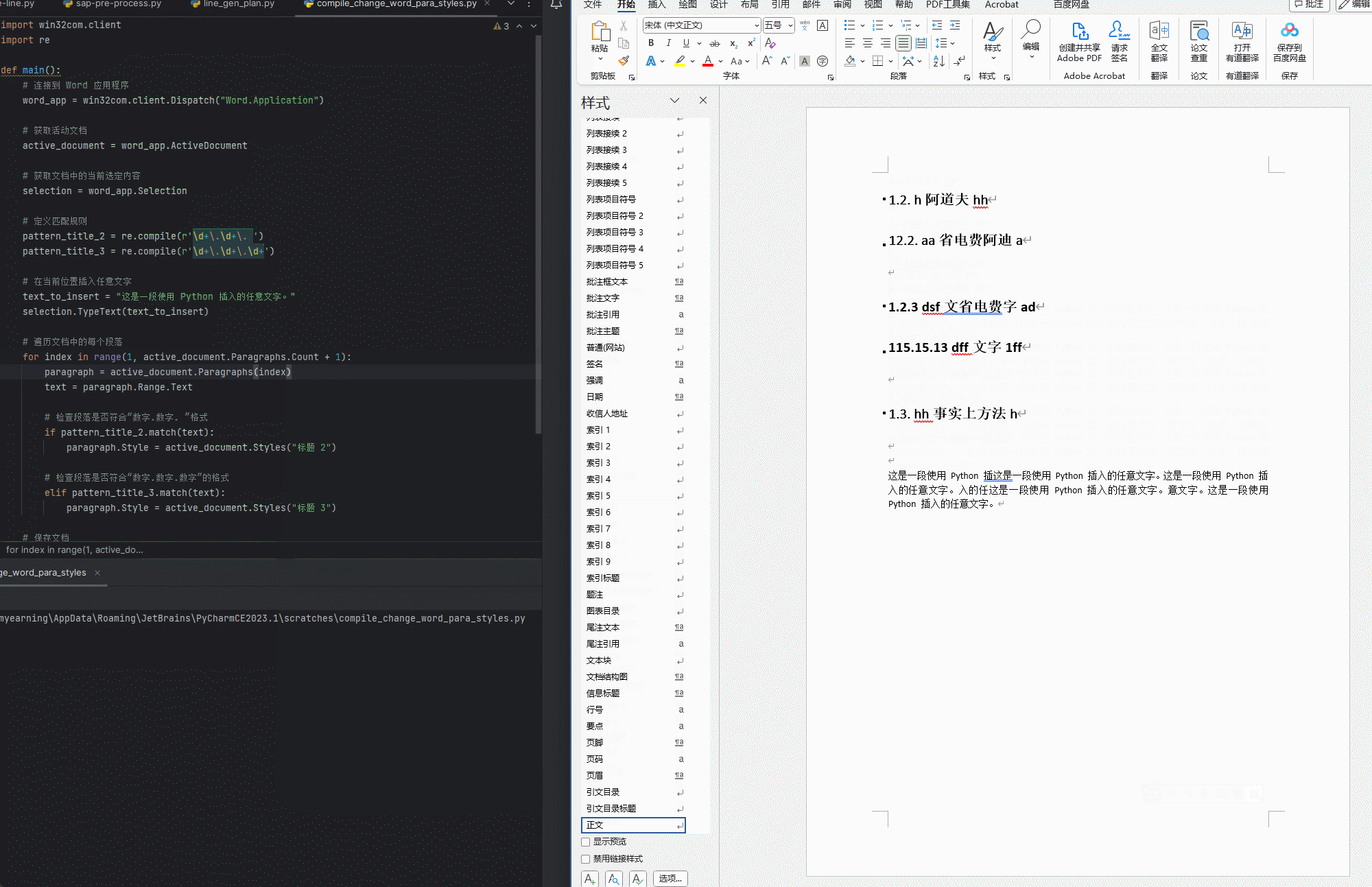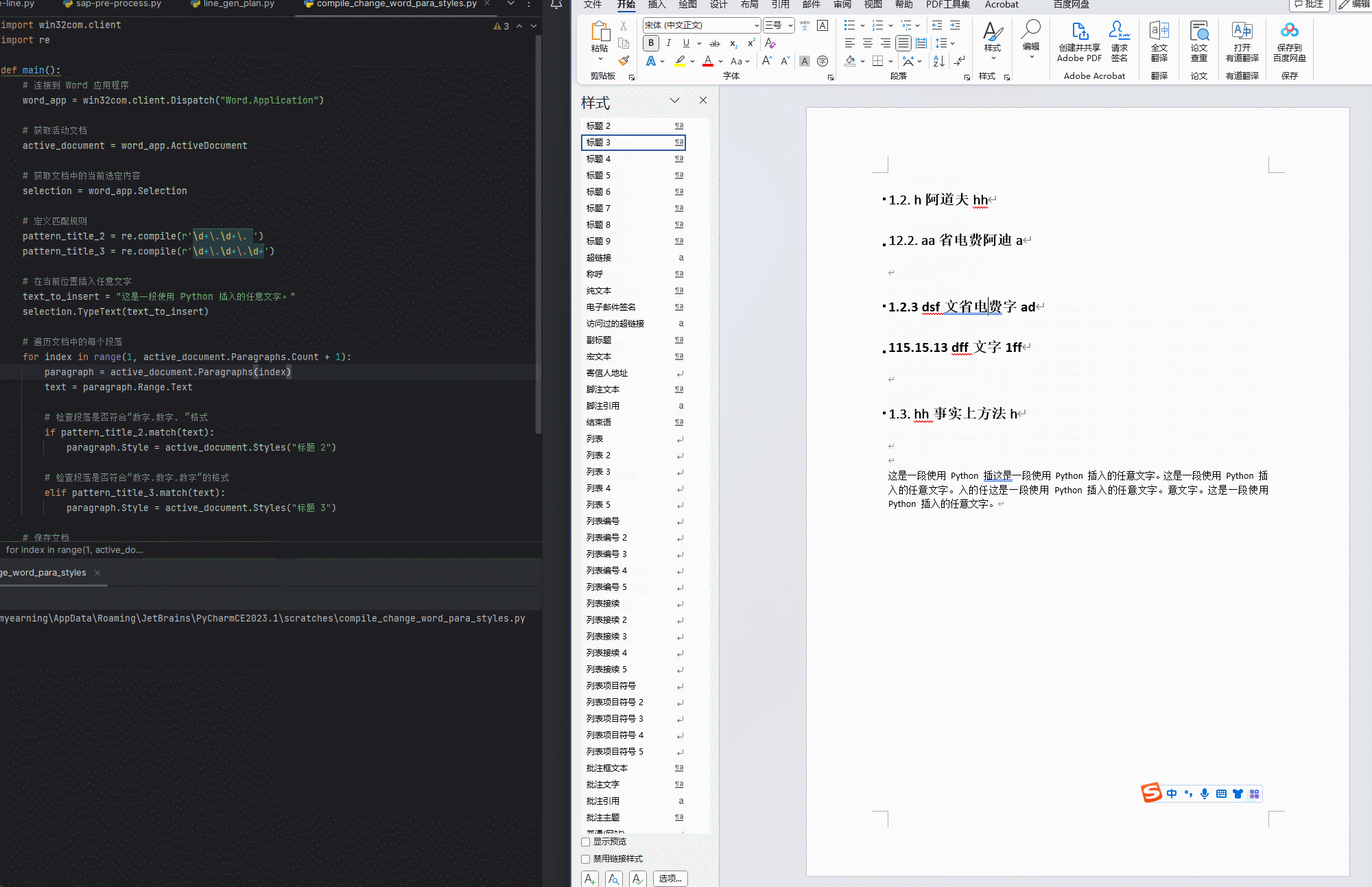
【python】【Word】用正则表达式匹配正文中的标题(未使用样式)并通过win32com指定相应样式
标题的格式 二级标题: 数字.数字. 文字 三级标题:数字.数字.数字 文字 python代码 使用方法 只保留一个需要应用的WORD文档运行程序,逐行匹配 使用效果 代码 import win32com.client import redef compile_change_Word_titlestyle():#…...
)
Matlab实现光伏仿真(附上完整仿真源码)
光伏发电电池模型是描述光伏电池在不同条件下产生电能的数学模型。该模型可以用于预测光伏电池的输出功率,并为优化光伏电池系统设计和控制提供基础。本文将介绍如何使用Matlab实现光伏发电电池模型。 文章目录 1、光伏发电电池模型2、使用Matlab实现光伏发电电池模…...

JVM零基础到高级实战之Java内存区域方法区
JVM零基础到高级实战之Java内存区域方法区 JVM零基础到高级实战之Java内存区域方法区 文章目录 JVM零基础到高级实战之Java内存区域方法区前言JVM内存模型之JAVA方法区总结 前言 JVM零基础到高级实战之Java内存区域方法区 JVM内存模型之JAVA方法区 JAVA方法区是什么…...

SpringCloud-stream一体化MQ解决方案-消费者组
参考资料: 参考demo 参考视频1 参考视频2 官方文档(推荐) 官方文档中文版 关于Kafka和rabbitMQ的安装教程,见本人之前的博客 rocketMq的安装教程 rocketMq仪表盘安装教程 重!!!...
HNU计算机图形学-作业二
HNU计算机图形学-作业二 作业二:纹理和照明前言介绍实施详细信息任务1:加载复杂对象任务2:纹理映射和照明任务3:互动活动和动画额外任务:增强场景的视觉效果(最高20%) 最终实现效果 作业二&…...
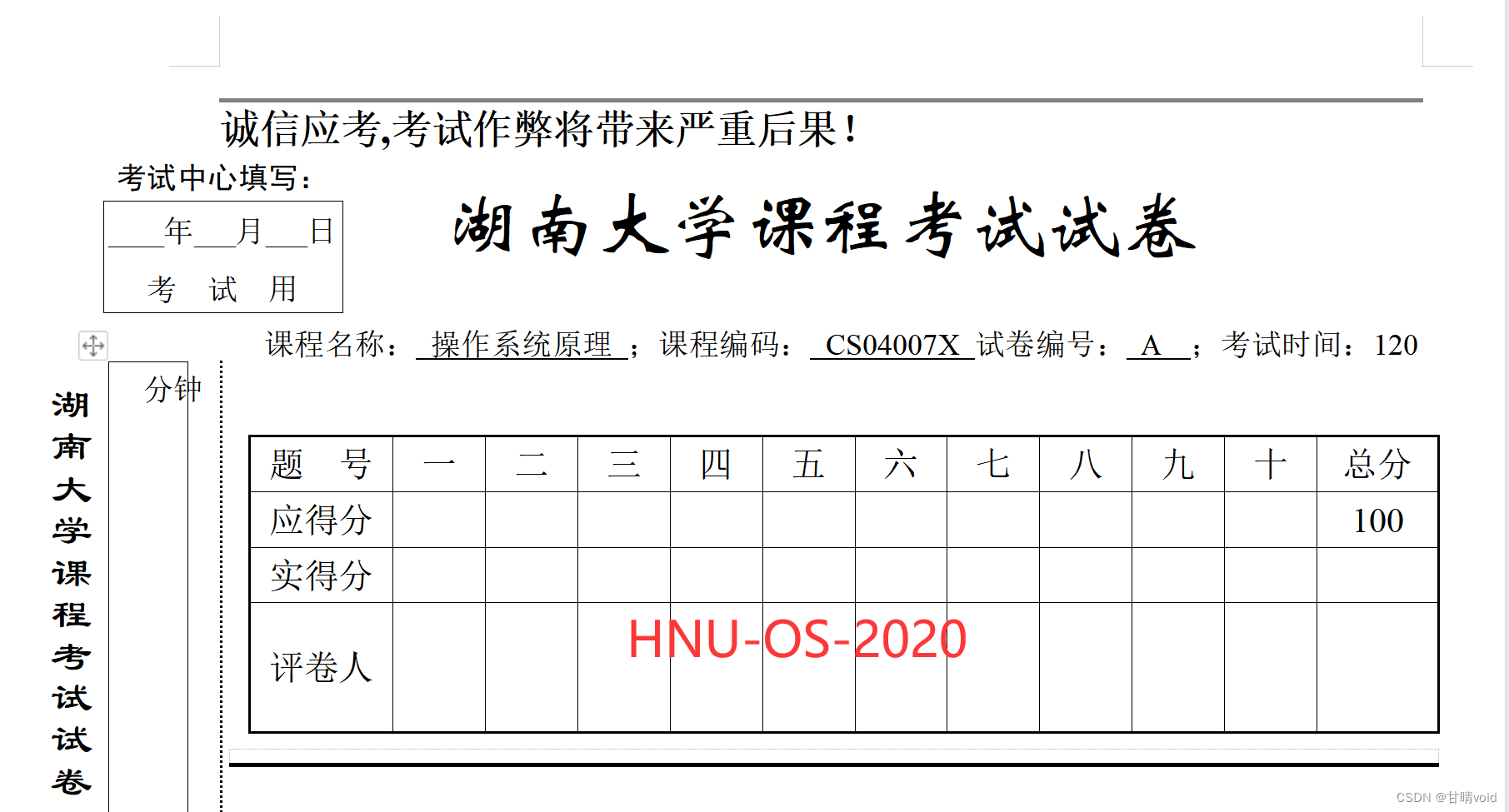
湖南大学OS-2020期末考试解析
【特别注意】 答案来源于@wolf以及网络 是我在备考时自己做的,仅供参考,若有不同的地方欢迎讨论。 【试卷评析】 这张卷子有点老了,部分题目可能有用。如果仔细研究应该会有所收获。 【试卷与答案】 一、选择题(15%) 1.下列关于进程状态转换,不正确的是:C A. …...
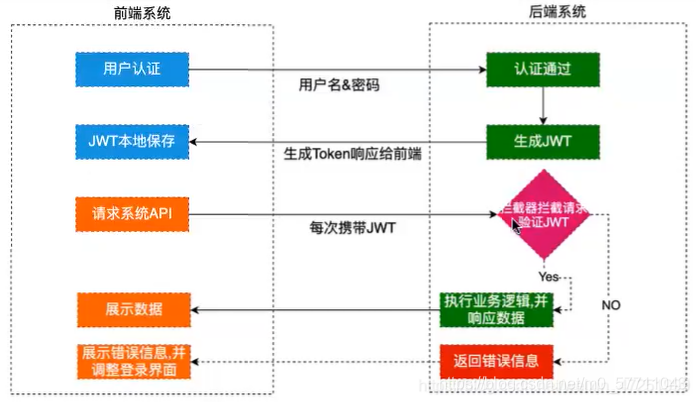
【用户认证】密码加密,用户状态保存,cookie,session,token
相关概念 认证与授权 认证(authentication )是验证你的身份的过程,而授权(authorization)是验证你有权访问的过程 用户认证的逻辑 获取用户提交的用户名和密码根据用户名,查询数据库,获得完…...
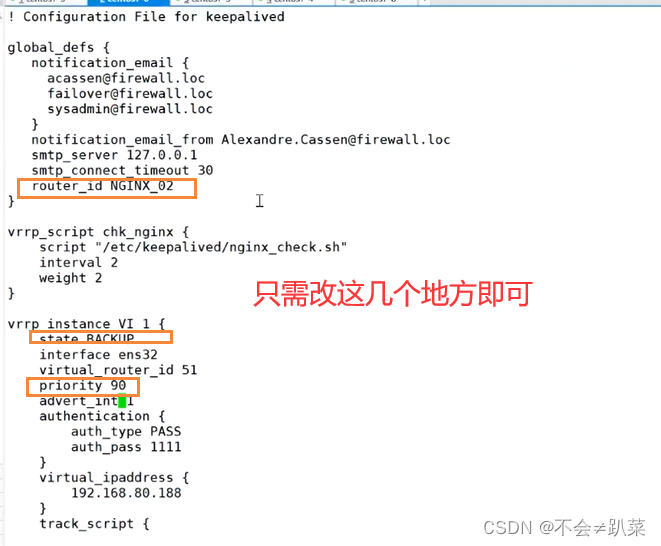
LVS+Keepalivedd
Keepalived 一、Keepalived及其工作原理二、实验非抢占模式的设置 三、脑裂现象四、Nginx高可用模式 一、Keepalived及其工作原理 keepalived是一个基于VRRP协议来实现的LVS服务高可用方案,可用解决静态路由出现的单点故障问题。 在一个LVS服务集群中通常有主服务器…...

WPF开发txt阅读器7:自定义文字和背景颜色
文章目录 添加控件具体实现代码说明 txt阅读器系列: 需求分析和文件读写目录提取类💎列表控件与目录字体控件绑定书籍管理系统💎用树形图管理书籍 添加控件 除了字体、字体大小之外,文字和背景颜色也会影响阅读观感,…...

Elasticsearch文件存储
分析Elasticsearch Index文件是如何存储的? 主要是想看一下FST文件是以什么粒度创建的? 首先通过kibana找一个索引的shard,此处咱们就以logstash-2023.05.30索引为例 查看下shard分布情况 GET /_cat/shards/logstash-2023.05.30?vindex …...

chatgpt赋能python:如何安装pyecharts
如何安装pyecharts Pyecharts是一个基于echarts的数据可视化工具,它是Python语言的一个库,可以通过Python编程语言进行数据可视化,并且能通过交互式的方式展示出来。 在本文中,我们将介绍如何安装pyecharts,如果您是…...
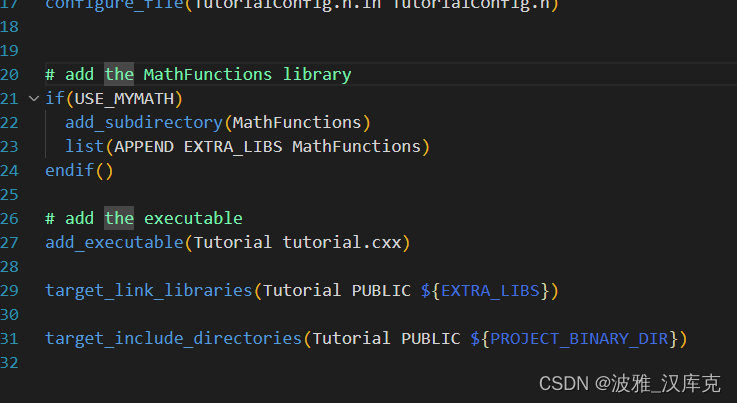
cmake 添加一个库
目录 项目格式 cmake基本语法 设置编译器 添加库 链接库 添加库的头文件 cmake打印字符串 库的cmake文件 cmake生辰库 mian函数中使用 让库成为可选的 cmake基本语法 设置option变量 cmake设置条件链接库 链接库 添加头文件 修改cmake配置文件 修改引用的源码…...

代码随想录二刷 226 翻转二叉树 102 二叉树的层序遍历 101 对称二叉树
226 翻转二叉树 代码如下 func invertTree(root *TreeNode) *TreeNode { if root nil { 采用前序遍历,如果当前节点为空,就返回空 return nil } root.Left,root.Right root.Right, root.Left 交换该节点的…...

Youtu-Parsing快速部署指南:一键启动Web服务,5分钟开始解析文档
Youtu-Parsing快速部署指南:一键启动Web服务,5分钟开始解析文档 1. 引言:为什么选择Youtu-Parsing 在日常工作中,我们经常需要处理各种文档——合同、报告、表格、发票等。传统的手动录入方式不仅效率低下,还容易出错…...

千问3.5-2B部署案例:RTX 4090 D单卡开箱即用,免配置镜像快速上手
千问3.5-2B部署案例:RTX 4090 D单卡开箱即用,免配置镜像快速上手 1. 千问3.5-2B模型简介 千问3.5-2B是Qwen系列中的小型视觉语言模型,它能够同时理解图片内容和处理自然语言。这个模型特别适合需要结合视觉和语言理解的任务场景。 1.1 核心…...
)
工业控制C++安全生命周期管理缺失的5个致命断点(某汽车电池BMS项目因第4点导致ASIL-B降级,完整V模型追溯报告首次公开)
第一章:工业控制C安全生命周期管理缺失的5个致命断点(某汽车电池BMS项目因第4点导致ASIL-B降级,完整V模型追溯报告首次公开) 在高完整性工业控制系统中,C代码的安全生命周期管理远非“编译通过即交付”。某头部车企BMS…...
人工智能创意工作流:Pixel Script Temple 与 AI Agent 协同创作
人工智能创意工作流:Pixel Script Temple 与 AI Agent 协同创作 1. 多智能体协作的艺术革命 当三个专业AI Agent组成创意团队,会产生怎样的化学反应?这套由Pixel Script Temple驱动的协同工作流,正在重新定义数字艺术创作的可能…...

Ostrakon-VL-8B多模态能力解析:图文联合理解在零售场景的体现
Ostrakon-VL-8B多模态能力解析:图文联合理解在零售场景的体现 1. 零售场景中的多模态挑战 现代零售行业面临着复杂的视觉理解需求。传统计算机视觉系统通常只能完成单一任务,比如商品识别或文字提取,而无法同时理解图像中的多种元素及其相互…...

墨语灵犀网络安全知识库:基于AI的威胁情报分析与解读
墨语灵犀网络安全知识库:让AI成为你的安全分析师 最近和几个做安全运营的朋友聊天,他们都在抱怨同一件事:每天面对海量的安全告警和晦涩的漏洞报告,眼睛都快看花了。一份新的漏洞描述扔过来,光是理解它到底在说什么、…...

单例模式全解析:5种写法 + 破坏与防护
文章目录什么是单例模式?实现方式饿汉式懒汉式方式一(线程不安全)方式二(同步方法)方式三(双重检查锁 DCL)枚举什么是单例模式? 保证一个类在全局只有一个实例,并提供一个全局访问点。 适用场…...

<数据集>yolo骑行者识别<目标检测>
数据集下载链接https://blog.csdn.net/qq_53332949/article/details/159770308?spm1011.2415.3001.5331数据集格式:VOCYOLO格式 图片数量:13674张 标注数量(xml文件个数):13674 标注数量(txt文件个数):13674 标注类别数&…...

终极fswatch过滤器配置指南:如何用正则表达式精准控制文件监控范围
终极fswatch过滤器配置指南:如何用正则表达式精准控制文件监控范围 【免费下载链接】fswatch A cross-platform file change monitor with multiple backends: Apple OS X File System Events, *BSD kqueue, Solaris/Illumos File Events Notification, Linux inoti…...

M5Stamp C3 Mate LED驱动库:基于RMT的WS2812B精简控制方案
1. 项目概述M5StampC3LED 是专为 M5Stamp C3 Mate 模块设计的 LED 控制库,其本质是一个轻量级封装层,用于驱动板载的 Adafruit NeoPixel(WS2812B 兼容)RGB LED。该库不直接实现底层时序协议,而是基于 ESP-IDF 或 Ardui…...