深度学习应用篇-自然语言处理-命名实体识别[9]:BiLSTM+CRF实现命名实体识别、实体、关系、属性抽取实战项目合集(含智能标注)【上篇】

【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化算法、卷积模型、序列模型、预训练模型、对抗神经网络等

专栏详细介绍:【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化算法、卷积模型、序列模型、预训练模型、对抗神经网络等
本专栏主要方便入门同学快速掌握相关知识。后续会持续把深度学习涉及知识原理分析给大家,让大家在项目实操的同时也能知识储备,知其然、知其所以然、知何由以知其所以然。
声明:部分项目为网络经典项目方便大家快速学习,后续会不断增添实战环节(比赛、论文、现实应用等)
专栏订阅:
- 深度学习入门到进阶专栏
- 深度学习应用项目实战篇
深度学习应用篇-自然语言处理-命名实体识别[9]:BiLSTM+CRF实现命名实体识别、实体、关系、属性抽取实战项目合集(含智能标注)
1.命名实体识别介绍
**命名实体识别(Named Entity Recoginition, NER)**旨在将一串文本中的实体识别出来,并标注出它所指代的类型,比如人名、地名等等。具体地,根据MUC会议规定,命名实体识别任务包括三个子任务:
- 实体名:人名、地名、机构名等
- 时间表达式:日期、时间、持续时间等
- 数字表达式:百分比、度量衡、钱、基数等
我们来看这句话,百度于2021年3月23日正式回香港上市,这句话中"百度"是个机构名,"香港"是个地名,"2021年3月23日"是个日期,命名实体识别任务能够通过建模的方式来帮助我们自动地发现这些实体。
命名实体识别是一项比较关键的NLP任务,具有广泛的应用场景,例如在对话意图理解(NLU)中,通过提取出相应的实体词,能够帮助系统更加准确地理解用户的需求,比如根据用户的问题提取出"天气",“北京”,"今天"这样的词汇,大概率就能知道用户在问些什么;在微博场景中,应用命名实体识别提取出微博短文中重要的实体词,也有利于微博信息的汇总,或者事件热度的统计。
NER任务一般会被建模成序列标注任务,也就是说,模型的输入是待识别的一串文本序列,模型的输出就是该文本序列对应的标签序列,不同于文本分类任务,这是一种序列到序列的任务。我们来举个例子:
| 姚 | 明 | 担 | 任 | 中 | 国 | 篮 | 协 | 主 | 席 |
|---|---|---|---|---|---|---|---|---|---|
| B-Person | I-Person | O | O | B-Organization | I-Organization | I-Organization | I-Organization | O | O |
这句话中的每个字分别对应着一个标签, 模型的输入就是上边的文本,模型的输出就是下面的标签序列,我们通过这样的标签序列就能识别出原始文本中的实体。
具体地,上边这串文本中,“姚明"对应着Person实体,其中"姚"字是"Person"实体的起始字,所以设置标签为"B-person”,其中标签前边的B代表Begin这个单词;“明"字是"Person"实体的中间字,所以设置标签为"I-Person”,其中标签前边的I代表Intermediate这个单词。 “中国篮协"对应这Organization实体,相应标签"B-Organization"和"I-Organization"的解读和Person实体是一致的。最后的标签"O"代表"other”,表示其他实体类型的标签。
看到这里,相信你已经知道,本节的NER任务要建模完成一件什么事情了,即建模一个序列到序列的模型来找出文本中蕴含的实体。
2.BiLSTM+CRF实现命名实体识别
BiLSTM + CRF是一种经典的命名实体识别(NER)模型方案,这在后续很多的模型improvment上都有启发性。如果你有了解NER任务的兴趣或者任务,或者完全出于对CRF的好奇,建议大家静心读一读这篇文章。
本篇文章会将重点放到条件随机场(CRF)上边,因为这是实现NER任务很重要的一个组件,也是本篇文章最想向你推荐的特色。但是如果你 对长短时记忆网络(LSTM)也不是很熟悉,那你也不用担心,笔者会去解释LSTM的用法,它的输入和输出等等内容,以保证你可以顺畅的读下去,领悟到这个模型的精髓。
2.1使用BiLSTM+CRF实现NER
为方便直观地看到BiLSTM+CRF是什么,我们先来贴一下BiLSTM+CRF的模型结构图,如图1所示。
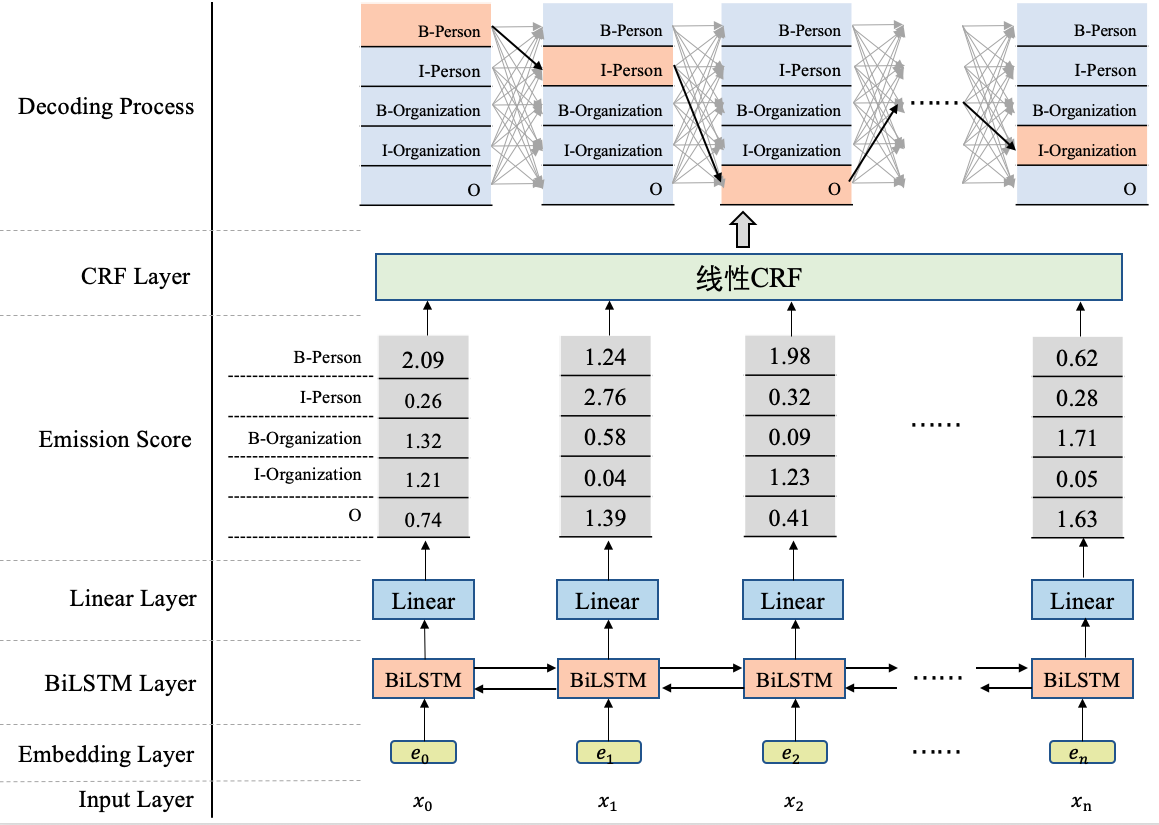
从图1可以看到,在BiLSTM上方我们添加了一个CRF层。具体地,在基于BiLSTM获得各个位置的标签向量之后,这些标签向量将被作为发射分数传入CRF中,发射这个概念是从CRF里面带出来的,后边在介绍CRF部分会更多地提及,这里先不用纠结这一点。
这些发射分数(标签向量)传入CRF之后,CRF会据此解码出一串标签序列。那么问题来了,从图1最上边的解码过程可以看出,这里可能对应着很多条不同的路径,例如:
- B-Person, I-Person, O, …, I-Organization
- B-Organization, I-Person, O, …, I-Person
- B-Organization, I-Organization, O, …, O
CRF的作用就是在所有可能的路径中,找出得出概率最大,效果最优的一条路径,那这个标签序列就是模型的输出。
我们来总结一下,使用BiLSTM+CRF模型架构实现NER任务,大致分为两个阶段:使用BiLSTM生成发射分数(标签向量),基于发射分数使用CRF解码最优的标签路径。
2. 回归CRF建模原理本身
本节将开始聚焦在CRF原理本身进行讲解,力图为读者展现一个清楚明白,基础本质的CRF。那现在开始这趟学习之旅吧,相信你一定会有所收获。
2.1 线性CRF的定义
通常我们会使用线性链CRF来建模NER任务,所以本实验将聚焦在线性链CRF来探讨。那什么是线性链CRF呢,我们来看下李航老师在《统计学习方法》书中的定义:
设 X = [ x 1 , x 2 , . . . , x n ] , Y = [ y 1 , y 2 , . . . , y n ] X=[x_1, x_2, ..., x_n],Y=[y_1, y_2, ..., y_n] X=[x1,x2,...,xn],Y=[y1,y2,...,yn] 均为线性链表示的随机变量序列,若在给定随机变量序列的 X X X的条件下,随机变量序列 Y Y Y的条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X)构成条件随机场,即满足马尔可夫性:
P ( y i ∣ X , y 1 , . . . , y i − 1 , y i + 1 , . . . , y n ) = P ( y i ∣ X , y i − 1 , y i + 1 ) i = 1 , 2 , . . . , n ( 在 i = 1 和 n 时只考虑单边 ) \begin{align} P(y_i|X, y_{1},...,y_{i-1},y_{i+1},...,y_n) &= P(y_i|X,y_{i-1},y_{i+1}) \\ i &= 1,2,...,n (在i=1和n时只考虑单边) \end{align} P(yi∣X,y1,...,yi−1,yi+1,...,yn)i=P(yi∣X,yi−1,yi+1)=1,2,...,n(在i=1和n时只考虑单边)
则称 P ( Y ∣ X ) P(Y|X) P(Y∣X)为线性链条件随机场。
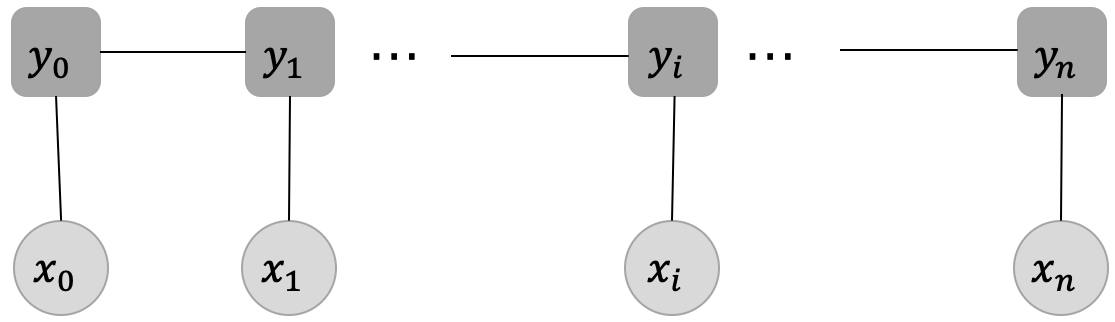
同学们看到这个定义,或许会有些疑惑,但是不用着急,我们来探讨下这个定义。图2展示了一种经典的线性链CRF的结构图,从这张结构图来理解这个定义,主要包含两个点:
- 确保输入序列 X X X和输出序列 Y Y Y是线性序列
- 每个标签 y i y_i yi的产生,只与这些因素有关系:当前位置的输入 x i x_i xi, y i y_i yi直接相连的两个邻居 y i − 1 y_{i-1} yi−1和 y i + 1 y_{i+1} yi+1,与其他的标签和输入没有关系。
这样的定义,其实帮助我们减小了建模CRF的代价。
2.2 发射分数和转移分数
上边我们探讨了线性链CRF的定义以及它的一种经典图结构,接下来我们继续回到我们建模的命名实体任务上来。
在图2中, x = [ x 0 , x 1 , . . . , x i , . . . , x n ] x=[x_0, x_1, ... , x_i, ... , x_n] x=[x0,x1,...,xi,...,xn]代表输入变量,对应到我们当前任务就是输入文本序列, y = [ y 0 , y 1 , . . . , y i , . . . , y n ] y=[y_0, y_1, ..., y_i, ..., y_n] y=[y0,y1,...,yi,...,yn]代表相应的标签序列,
其中,每个输入 x i x_i xi均对应着一个标签 y i y_i yi,这一步对应的就是发射分数,它指示了当前的输入 x i x_i xi应该对应什么样的标签;在每个标签 y i y_i yi之间也存在连线,它表示当前位置的标签 y i y_i yi向下一个位置的标签 y i + 1 {y_{i+1}} yi+1的一种转移。举个例子,假设当前位置的标签是"B-Person",那下一个位置就很有可能是"I-Person"标签,即标签"B-Person"向"I-Person"转移的概率会比较大。
这里我们带出了建模CRF过程中两个重要的概念:发射分数和转移分数,下边我们来看看他们是什么。
2.2.1 发射分数
前边我们在第2节已经提到过发射分数了,即BiLSTM后产生的标签向量。如果大家对这部分内容已经很熟悉,完全可以跳过这部分。图3以矩阵的形式展示了发射分数的生成过程。
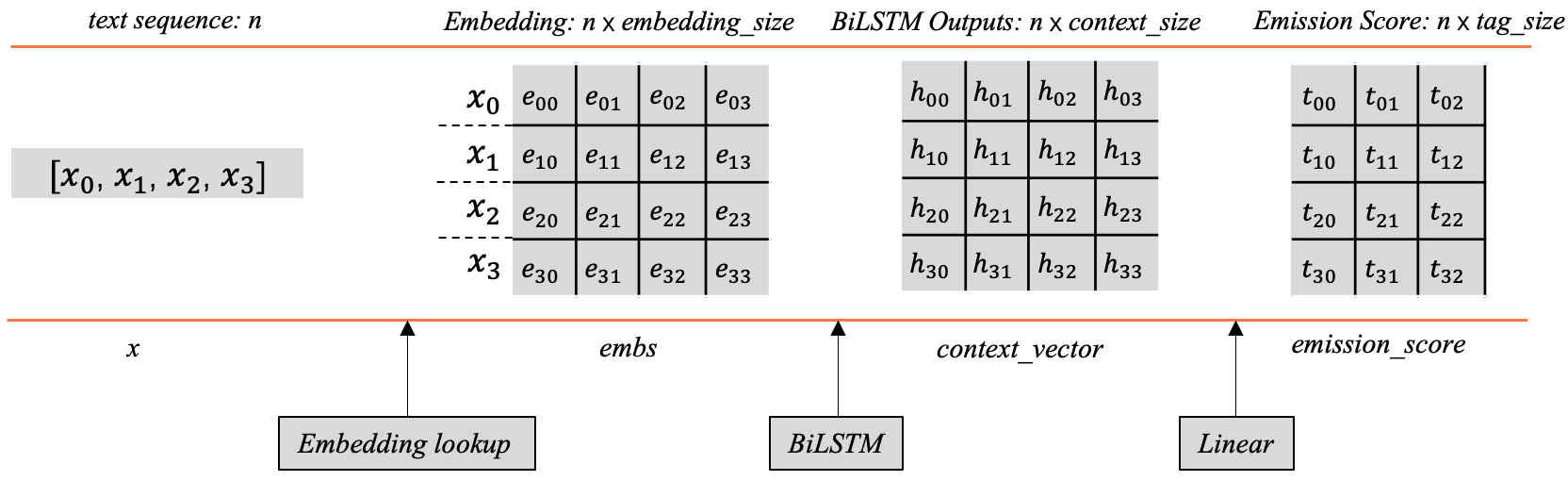
当给定的文本序列 x = [ x 1 , x 2 , x 3 , . . . , x n ] x=[x_1, x_2, x_3,..., x_n] x=[x1,x2,x3,...,xn]映射为对应词向量之后,将会得到一个shape为 [ n , e m b e d d i n g _ s i z e ] [n, embedding\_size] [n,embedding_size]的词向量矩阵 e m b s embs embs,其中每对应一个字词(图5样例只使用了4个词),例如 x 0 x_0 x0对应的词向量是 [ e 00 , e 01 , e 02 , e 03 ] [e_{00}, e_{01}, e_{02}, e_{03}] [e00,e01,e02,e03]。
然后将 e m b s embs embs传入BiLSTM后,每个词的位置都会产生一个上下文向量,所有的向量组合之后会得到一个向量矩阵 c o n t e x t _ v e c t o r context\_vector context_vector,其中每行代表对应单词经过BiLSTM后的上下文向量。
这里的每个位置的上下文向量可以用来指导当前位置应该输出的标签信息,但这里有个问题,这个输出向量的维度并不是标签的数量,它不能直接用来指示应该输出什么标签。一般的做法是在后边加一层线性层,将这个上下文向量的维度映射为标签的数量,这样的话就会生成前边所讲的标签向量,其中的每个元素分别对应着相应标签的分数,根据这个分数可以用来指导最终标签的输出。
具体地,线性层这里只是做了这样的一个线性变换: y = X W + b y = XW+b y=XW+b,显然,这里的 X X X就是 c o n t e x t _ v e c t o r context\_vector context_vector, y y y是相应的 e m i s s i o n _ s c o r e emission\_score emission_score, W 和 b W和b W和b是线性层的可学习参数。
前边提到, c o n t e x t _ v e c t o r context\_vector context_vector的shape为 [ n , c o n t e x t _ s i z e ] [n,context\_size] [n,context_size],那么线性层的 W W W的shape应该是 [ c o n t e x t _ s i z e , t a g _ s i z e ] [context\_size, tag\_size] [context_size,tag_size],经过以上公式的线性变换,就可以得到发射分数 e m i s s i o n _ s c o r e emission\_score emission_score,其中每个字词对应一行的标签分数(图3中只设置了三列,代表一共有3个标签),例如, x 0 x_0 x0对第一个标签的分数预测为 t 00 t_{00} t00,对第二个标签的分数预测为 t 01 t_{01} t01,对第三个标签的分数预测为 t 02 t_{02} t02,依次类推。
2.2.2 转移分数
下面我们来聊聊转移分数,这个转移分数表示一个标签向另一个标签转移的分数,分数越高,转移概率就越大,反之亦然。图4展示了记录转移分数的矩阵。
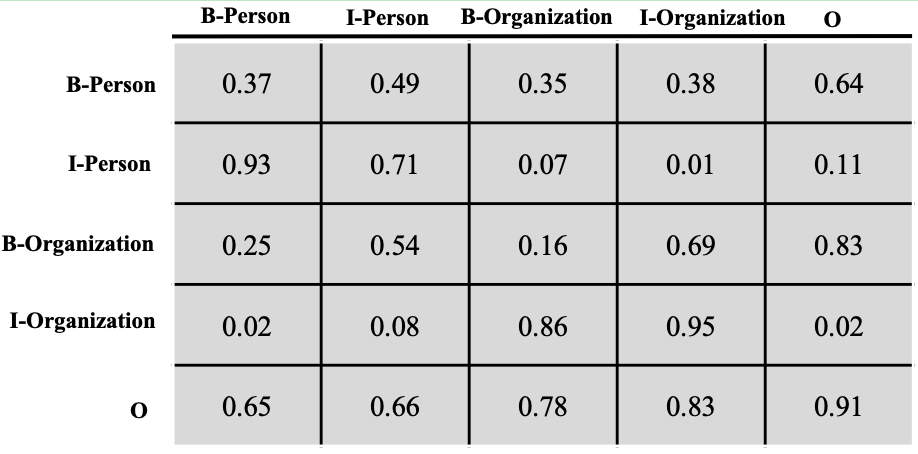
让我们从列到行地来看下这个转移矩阵 T T T,B-Person向I-Person转移的分数为0.93,B-Person向I-Organization转移的分数为0.02,前者的分数远远大于后者。I-Person向I-Person转移的概率是0.71,I-Organization向I-Organization转移的分数是0.95,因为一个人或者组织的名字往往包含多个字,所以这个概率相对是比较高的,这其实也是很符合我们直观认识的。
假设我们现在有个标签序列:B-Person, I-Person, O, O,B-Organization, I-Organization。那么这个序列的转移分数可按照如下方式计算:
S e q t = T I − P e r s o n , B − P e r s o n + T O , I − P e r s o n + T O , O + T O , B − O r g a n i z a t i o n + T B − O r g a n i z a t i o n , I − O r g a n i z a t i o n Seq_t = T_{I-Person,B-Person} + T_{O,I-Person} + T_{O,O} + T_{O,B-Organization} + T_{B-Organization, I-Organization} Seqt=TI−Person,B−Person+TO,I−Person+TO,O+TO,B−Organization+TB−Organization,I−Organization
这个转移分数矩阵是CRF中的一个可学习的参数矩阵,它的存在能够帮助我们显示地去建模标签之间的转移关系,提高命名实体识别的准确率。
2.3 其余内容见下一篇文章(字数限制)
更多文章请关注公重号:汀丶人工智能

3. 3 推荐!实体、关系、属性抽取实战项目合集(含智能标注)
实体、关系、属性抽取实战项目合集(含智能标注)
相关文章:
深度学习应用篇-自然语言处理-命名实体识别[9]:BiLSTM+CRF实现命名实体识别、实体、关系、属性抽取实战项目合集(含智能标注)【上篇】
【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化算法、卷积模型、序列模型、预训练模型、对抗神经网络等 专栏详细介绍:【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化…...
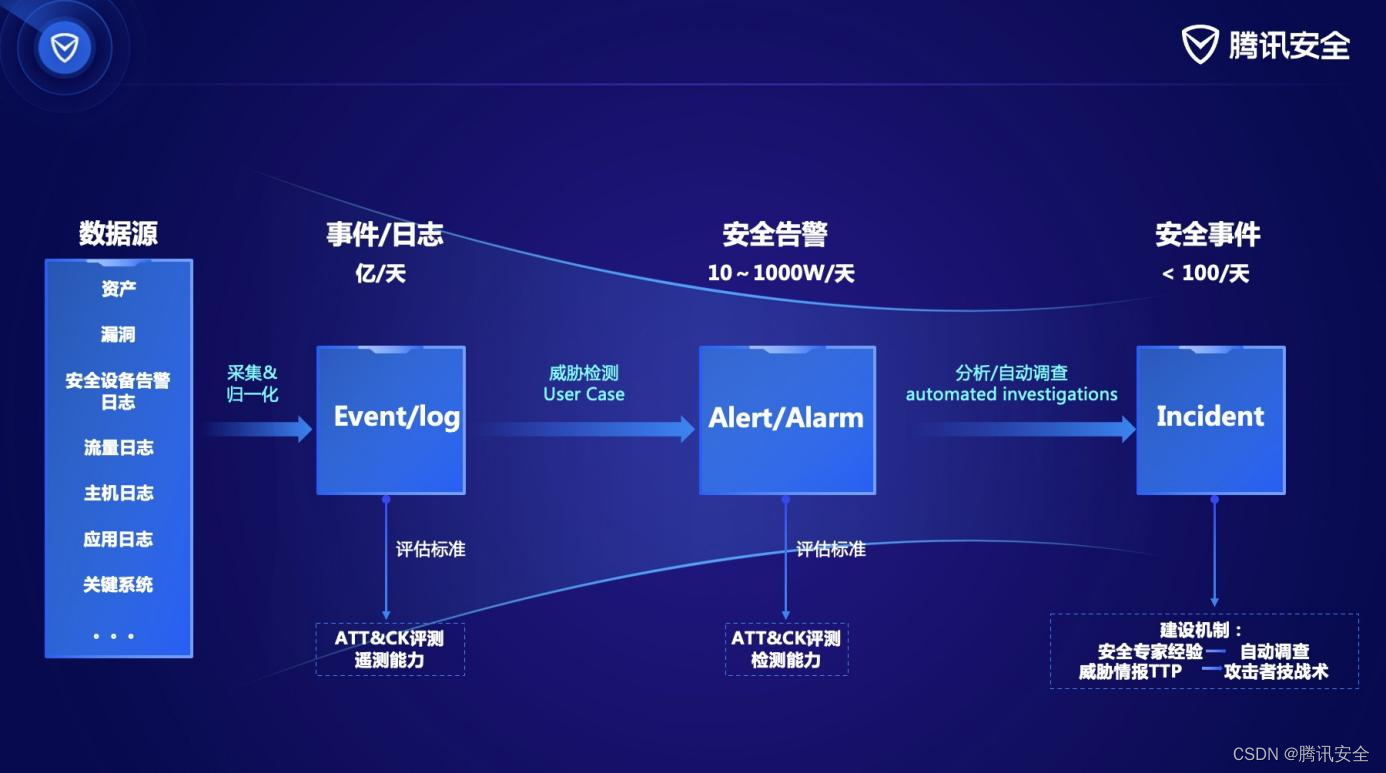
腾讯安全SOC+荣获“鑫智奖”,助力金融业数智化转型
近日,由金科创新社主办,全球金融专业人士协会支持的“2023鑫智奖第五届金融数据智能优秀解决方案评选”榜单正式发布。腾讯安全申报的“SOC基于新一代安全日志大数据平台架构的高级威胁安全治理解决方案”获评“鑫智奖网络信息安全创新优秀解决方案”。 …...

Python绘制气泡图示例
部分数据来源:ChatGPT 引言 在数据可视化领域中,气泡图是一种能够同时展示三维信息的图表类型,常用于表示数据集中的两个变量之间的关系。Python中提供了许多用于绘制气泡图的可视化库,比如pyecharts。在本篇文章中,我们将介绍如何使用pyecharts库绘制一个简单的气泡图,…...

数学建模经历-程序人生
引言 即将大四毕业(现在大三末),闲来无事(为了冲粽子)就写一篇记录数学建模经历的博客吧。其实经常看到一些大佬的博客里会有什么"程序人生"、"人生感想"之类的专栏,但是由于我只是一个小趴菜没什么阅历因此也就没有写过类似的博客…...

数字电子电路绪论
博主介绍:一个爱打游戏的计算机专业学生 博主主页:夏驰和徐策 所属专栏:程序猿之数字电路 1.科技革命促生互联网时代 科技革命对互联网时代的兴起产生了巨大的推动作用。以下是一些科技革命对互联网时代的促进因素: 1. 计算机技…...

电脑丢失dll文件一键修复需要什么软件?快速修复dll文件的方法
在使用电脑的过程中,我们经常会遇到程序无法正常运行的情况,提示“XXX.dll文件丢失”的错误。这时候,很多人会感到困惑,不知道该如何解决。本文将详细介绍dll文件丢失的各种原因、如何使用dll修复工具进行一键修复dll丢失问题以及…...
你知道微信的转账是可以退回的吗
微信作为当今最受欢迎的即时通讯软件之一,其转账功能得到了广泛的应用。在使用微信转账时,我们可能会遇到一些问题,例如误操作、支付失败或者需要退款等等。 首先需要注意的是,微信转账退回的操作只能在“一天内未确认”时进行。如…...
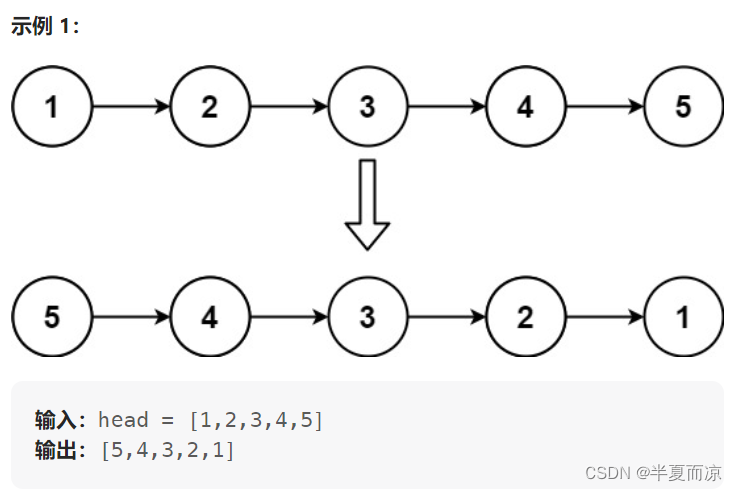
【链表Part01】| 203.移除链表元素、707.设计链表、206.反转链表
目录 ✿LeetCode203.移除链表元素❀ ✿LeetCode707.设计链表❀ ✿LeetCode206.反转链表❀ ✿LeetCode203.移除链表元素❀ 链接:203.移除链表元素 给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val val 的节点ÿ…...

如何使用Postman生成curl?
生成在Lunix系统调接口的curl 直接看图操作 点击</>即可!...

CSS灯光效果,背景黑金效果
先看效果 再看代码: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>灯光效果</title><link href"https://fonts.googleapis.com/css2?familyCinzel:wght700&dis…...
这里推荐几个前端icon网站(动图网站)
1. Loading.ioLoading.io 是一个免费的加载动效(Loading animations)图标库。它提供了多种风格的加载动效图标,包括 SVG、CSS 和 Lottie 动画格式。这些加载图标可以增强用户体验,为网站和应用程序添加更佳的视觉效果。 网站地址:loading.io - Your SVG GIF PNG Ajax Loading…...

【图神经网络】用PyG实现图机器学习的可解释性
Graph Machine Learning Explainability with PyG 框架总览示例:解释器The Explanation ClassThe Explainer Class and Explanation SettingsExplanation评估基准数据集Explainability Visualisation实现自己的ExplainerAlgorithm对于异质图的扩展解释链路预测 总结…...

HarmonyOS ArkTS Ability内页面的跳转和数据传递
HarmonyOS ArkTS Ability的数据传递包括有Ability内页面的跳转和数据传递、Ability间的数据跳转和数据传递。本节主要讲解Ability内页面的跳转和数据传递。 打开DevEco Studio,选择一个Empty Ability工程模板,创建一个名为“ArkUIPagesRouter”的工程为…...

MySQL 8.0.29 instant DDL 数据腐化问题分析
前言Instant add or drop column的主线逻辑表定义的列顺序与row 存储列顺序阐述引入row版本的必要性数据腐化问题原因分析Bug重现与解析MySQL8.0.30修复方案 前言 DDL 相对于数据库的 DML 之类的其他操作,相对来说是比较耗时、相对重型的操作; 因此对业务的影比较严…...
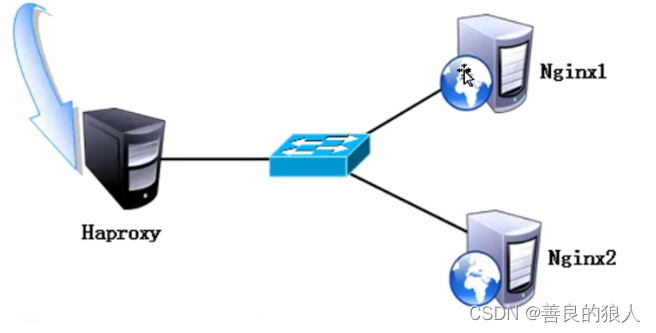
Haproxy搭建负载均衡
Haproxy搭建负载均衡 一、常见的Web集群调度器二、Haproxy介绍1、Haproxy应用分析2、Haproxy的主要特性3、Haproxy负载均衡策略 三、LVS、Nginx、Haproxy之间的区别四、Haproxy搭建Web群集1、Haproxy服务器部署2、节点服务器部署3、测试Web群集 五、日志定义1、方法一2、方法二…...

SpringBoot:SpringBoot启动加载过程 ④
一、思想 我们看到技术上高效简单的使用,其实背后除了奇思妙想的开创性设计,另一点是别人帮你做了复杂繁琐的事情。 二、从官网Demo入手 官网就一行代码。这个就是它的启动代码。 1、SpringBootApplication注解 ①. 三个核心注解的整合。 SpringBootCon…...

抽象轻松JavaScript
真真假假,鬼鬼,谁知道什么是真什么是假 疑点二:什么是真,什么是假 核心:确定一个清晰的目的,可以达到目的就是真,达不到就是假 知道了核心开始举例 考大学,考上大学就是满足目的…...
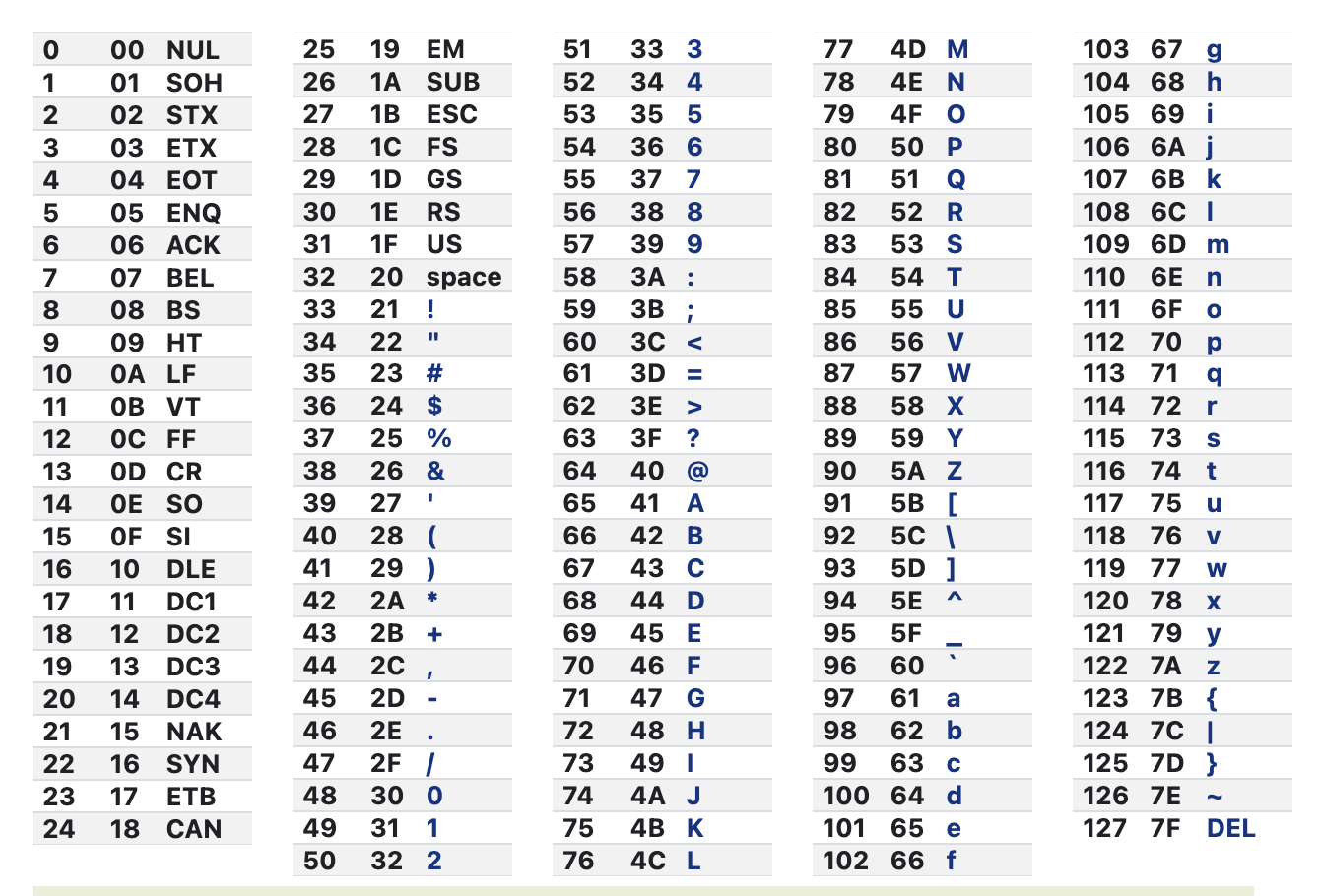
深入理解CSS字符转义行为
深入理解CSS字符转义行为 深入理解CSS字符转义行为 前言为什么要转义?CSS 转义什么是合法css的表达式 左半部分右半部分 练习参考链接 前言 在日常的开发中,我们经常写css。比如常见的按钮: <button class"btn"></button>&am…...
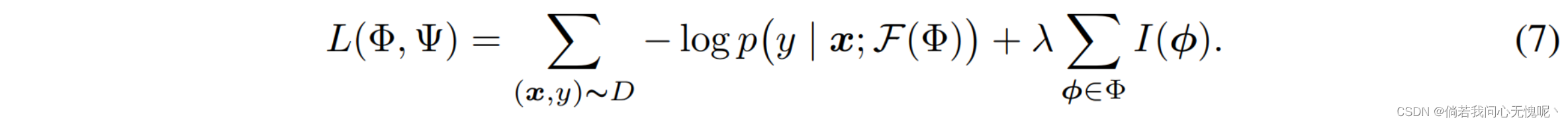
【论文阅读】(2023.05.10-2023.06.03)论文阅读简单记录和汇总
(2023.05.10-2023.06.08)论文阅读简单记录和汇总 2023/05/10:今天状态,复阳大残,下午淋了点雨吹了点风,直接躺了四个小时还是头晕- -应该是阳了没跑了。 2023/06/03:前两周出差复阳,这两周调整作息把自己又…...

FPGA开发-ddr测试
文章目录 概要整体架构流程技术名词解释技术细节小结 概要 提示:这里可以添加技术概要 例如: 本文以米联科开发板为例,介绍ddr测试相关例程。 整体架构流程 提示:这里可以添加技术整体架构 技术名词解释 提示:这…...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

STM32标准库-DMA直接存储器存取
文章目录 一、DMA1.1简介1.2存储器映像1.3DMA框图1.4DMA基本结构1.5DMA请求1.6数据宽度与对齐1.7数据转运DMA1.8ADC扫描模式DMA 二、数据转运DMA2.1接线图2.2代码2.3相关API 一、DMA 1.1简介 DMA(Direct Memory Access)直接存储器存取 DMA可以提供外设…...

【项目实战】通过多模态+LangGraph实现PPT生成助手
PPT自动生成系统 基于LangGraph的PPT自动生成系统,可以将Markdown文档自动转换为PPT演示文稿。 功能特点 Markdown解析:自动解析Markdown文档结构PPT模板分析:分析PPT模板的布局和风格智能布局决策:匹配内容与合适的PPT布局自动…...

10-Oracle 23 ai Vector Search 概述和参数
一、Oracle AI Vector Search 概述 企业和个人都在尝试各种AI,使用客户端或是内部自己搭建集成大模型的终端,加速与大型语言模型(LLM)的结合,同时使用检索增强生成(Retrieval Augmented Generation &#…...
集成 Mybatis-Plus 和 Mybatis-Plus-Join)
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join 1、依赖1.1、依赖版本1.2、pom.xml 2、代码2.1、SqlSession 构造器2.2、MybatisPlus代码生成器2.3、获取 config.yml 配置2.3.1、config.yml2.3.2、项目配置类 2.4、ftl 模板2.4.1、…...

探索Selenium:自动化测试的神奇钥匙
目录 一、Selenium 是什么1.1 定义与概念1.2 发展历程1.3 功能概述 二、Selenium 工作原理剖析2.1 架构组成2.2 工作流程2.3 通信机制 三、Selenium 的优势3.1 跨浏览器与平台支持3.2 丰富的语言支持3.3 强大的社区支持 四、Selenium 的应用场景4.1 Web 应用自动化测试4.2 数据…...

Ubuntu Cursor升级成v1.0
0. 当前版本低 使用当前 Cursor v0.50时 GitHub Copilot Chat 打不开,快捷键也不好用,当看到 Cursor 升级后,还是蛮高兴的 1. 下载 Cursor 下载地址:https://www.cursor.com/cn/downloads 点击下载 Linux (x64) ,…...

MyBatis中关于缓存的理解
MyBatis缓存 MyBatis系统当中默认定义两级缓存:一级缓存、二级缓存 默认情况下,只有一级缓存开启(sqlSession级别的缓存)二级缓存需要手动开启配置,需要局域namespace级别的缓存 一级缓存(本地缓存&#…...

智能职业发展系统:AI驱动的职业规划平台技术解析
智能职业发展系统:AI驱动的职业规划平台技术解析 引言:数字时代的职业革命 在当今瞬息万变的就业市场中,传统的职业规划方法已无法满足个人和企业的需求。据统计,全球每年有超过2亿人面临职业转型困境,而企业也因此遭…...