Hive提升篇-Hive修改事务
简介
Hive 默认是不允许数据更新操作的,毕竟它不擅长,即使在0.14版本后,做一些额外的配置便可开启Hive数据更新操作。而在海量数据场景下做update、delete之类的行级数据操作时,效率并不如意。
简单使用
修改HIVE_HOME/conf/hive-site.xml,添加如下配置
<property><name>hive.support.concurrency</name><value>true</value>
</property>
<property><name>hive.exec.dynamic.partition.mode</name><value>nonstrict</value>
</property>
<property><name>hive.txn.manager</name><value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
</property>
<property><name>hive.compactor.initiator.on</name><value>true</value>
</property>
<property><name>hive.compactor.worker.threads</name><value>1</value>
</property>建表
create table if not exists accountInfo(
id int,
name string,
age int
)
clustered by (id) into 4 buckets
stored as orc TBLPROPERTIES ('transactional'='true');
建表须知
1 注意存储格式按ORC方式
2 进行数据分桶
3 添加表属性:‘transactional’=‘true’
分发配置到其他hive节点。
测试如下
插入测试数据
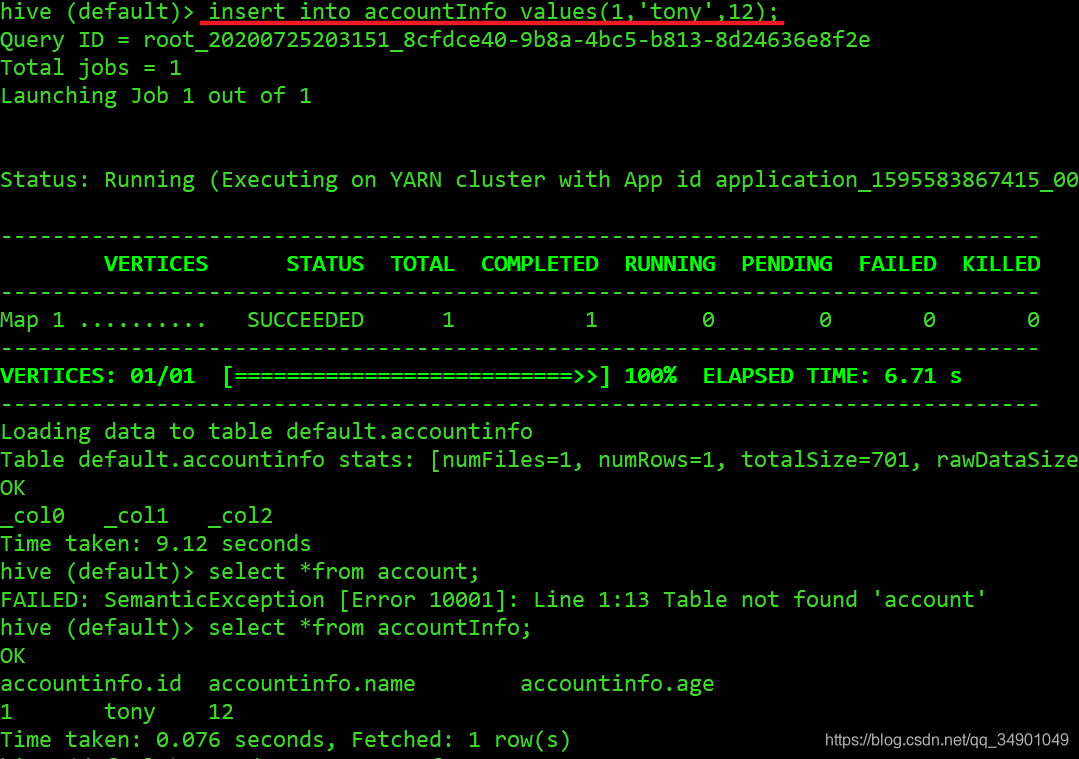
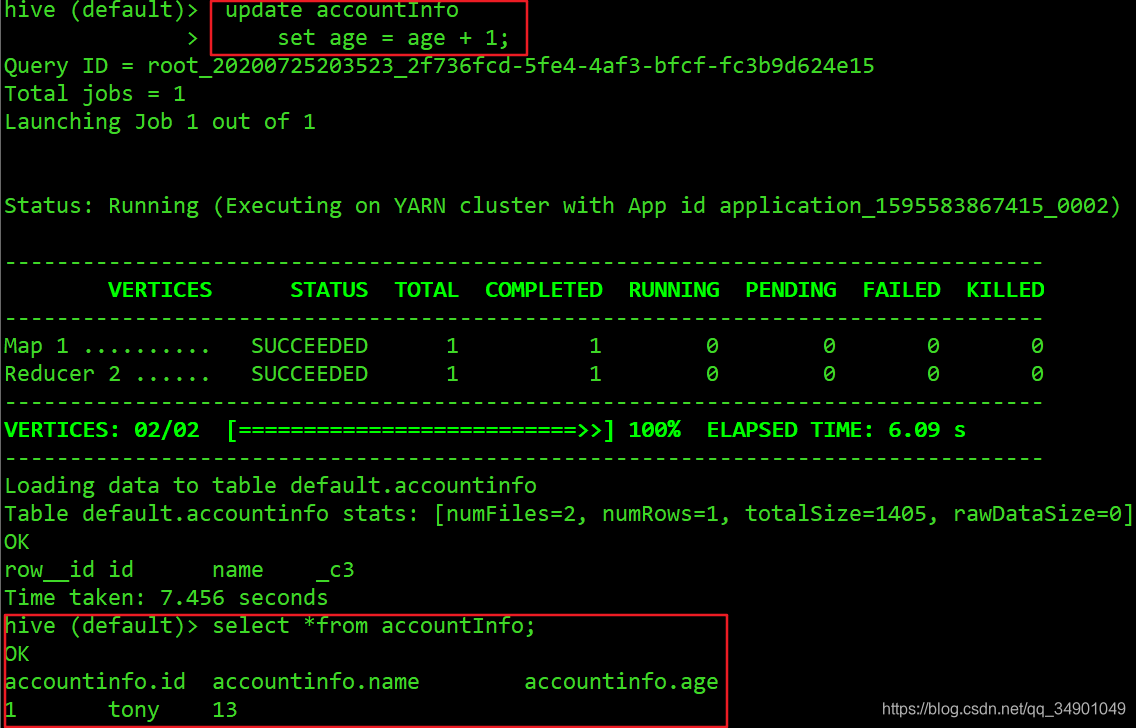
更新数据(此处配置了Hive on Tez)
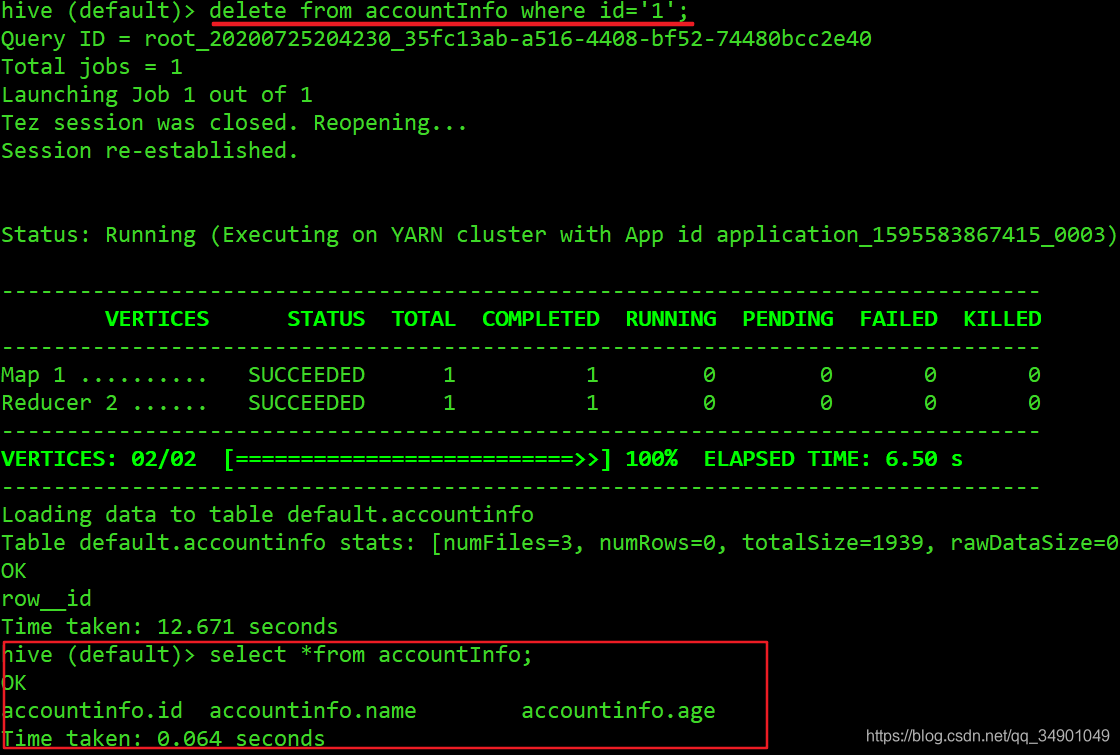
数据删除
hive作为数仓常用技术工具,更多的是用于数据的存储分析,而比较少涉及到数据更新。并且在OLAP场景下并不适合做原有数据更新,更不用说行级别的细粒度操作。记得在一些状态更新场景下会有缓慢渐变维的运用,可即使如此也要运用拉链表保存历史数据,很少将原有数据直接覆盖;你不知道被覆盖的数据蕴含着怎样的价值。
而在一些海量OLTP场景中,也会运用Hbase去替代传统RDB架构;若在运用中伴有大量的数据更新操作,我想Hbase会是不错的选择。
Hive事务原理简介
Apache Hive 0.13 版本引入了事务特性,能够在 Hive 表上实现 ACID 语义,包括 INSERT/UPDATE/DELETE/MERGE 语句、增量数据抽取等。Hive 3.0 又对该特性进行了优化,包括改进了底层的文件组织方式,减少了对表结构的限制,以及支持条件下推和向量化查询。Hive 事务表的介绍和使用方法可以参考 Hive Wiki 和 各类教程,本文将重点讲述 Hive 事务表是如何在 HDFS 上存储的,及其读写过程是怎样的。
文件结构
插入数据
1 2 3 4 5 6 7 | CREATE TABLE employee (id int, name string, salary int)
STORED AS ORC TBLPROPERTIES ('transactional' = 'true');INSERT INTO employee VALUES
(1, 'Jerry', 5000),
(2, 'Tom', 8000),
(3, 'Kate', 6000);
|
INSERT 语句会在一个事务中运行。它会创建名为 delta 的目录,存放事务的信息和表的数据。
1 2 3 | /user/hive/warehouse/employee/delta_0000001_0000001_0000 /user/hive/warehouse/employee/delta_0000001_0000001_0000/_orc_acid_version /user/hive/warehouse/employee/delta_0000001_0000001_0000/bucket_00000 |
目录名称的格式为 delta_minWID_maxWID_stmtID,即 delta 前缀、写事务的 ID 范围、以及语句 ID。具体来说:
- 所有 INSERT 语句都会创建
delta目录。UPDATE 语句也会创建delta目录,但会先创建一个delete目录,即先删除、后插入。delete目录的前缀是 delete_delta; - Hive 会为所有的事务生成一个全局唯一的 ID,包括读操作和写操作。针对写事务(INSERT、DELETE 等),Hive 还会创建一个写事务 ID(Write ID),该 ID 在表范围内唯一。写事务 ID 会编码到
delta和delete目录的名称中; - 语句 ID(Statement ID)则是当一个事务中有多条写入语句时使用的,用作唯一标识。
再看文件内容,_orc_acid_version 的内容是 2,即当前 ACID 版本号是 2。它和版本 1 的主要区别是 UPDATE 语句采用了 split-update 特性,即上文提到的先删除、后插入。这个特性能够使 ACID 表支持条件下推等功能,具体可以查看 HIVE-14035。bucket_00000 文件则是写入的数据内容。由于这张表没有分区和分桶,所以只有这一个文件。事务表都以 ORC 格式存储的,我们可以使用 orc-tools 来查看文件的内容:
1 2 3 4 | $ orc-tools data bucket_00000
{"operation":0,"originalTransaction":1,"bucket":536870912,"rowId":0,"currentTransaction":1,"row":{"id":1,"name":"Jerry","salary":5000}}
{"operation":0,"originalTransaction":1,"bucket":536870912,"rowId":1,"currentTransaction":1,"row":{"id":2,"name":"Tom","salary":8000}}
{"operation":0,"originalTransaction":1,"bucket":536870912,"rowId":2,"currentTransaction":1,"row":{"id":3,"name":"Kate","salary":6000}}
|
输出内容被格式化为了一行行的 JSON 字符串,我们可以看到具体数据是在 row 这个键中的,其它键则是 Hive 用来实现事务特性所使用的,具体含义为:
operation0 表示插入,1 表示更新,2 表示删除。由于使用了 split-update,UPDATE 是不会出现的;originalTransaction是该条记录的原始写事务 ID。对于 INSERT 操作,该值和currentTransaction是一致的。对于 DELETE,则是该条记录第一次插入时的写事务 ID;bucket是一个 32 位整型,由BucketCodec编码,各个二进制位的含义为:- 1-3 位:编码版本,当前是
001; - 4 位:保留;
- 5-16 位:分桶 ID,由 0 开始。分桶 ID 是由 CLUSTERED BY 子句所指定的字段、以及分桶的数量决定的。该值和
bucket_N中的 N 一致; - 17-20 位:保留;
- 21-32 位:语句 ID;
- 举例来说,整型
536936448的二进制格式为00100000000000010000000000000000,即它是按版本 1 的格式编码的,分桶 ID 为 1;
- 1-3 位:编码版本,当前是
rowId是一个自增的唯一 ID,在写事务和分桶的组合中唯一;currentTransaction当前的写事务 ID;row具体数据。对于 DELETE 语句,则为null。
我们可以注意到,文件中的数据会按 (originalTransaction, bucket, rowId) 进行排序,这点对后面的读取操作非常关键。
这些信息还可以通过 row__id 这个虚拟列进行查看:
1 | SELECT row__id, id, name, salary FROM employee; |
输出结果为:
1 2 3 | {"writeid":1,"bucketid":536870912,"rowid":0} 1 Jerry 5000
{"writeid":1,"bucketid":536870912,"rowid":1} 2 Tom 8000
{"writeid":1,"bucketid":536870912,"rowid":2} 3 Kate 6000
|
增量数据抽取 API V2
Hive 3.0 还改进了先前的 增量抽取 API,通过这个 API,用户或第三方工具(Flume 等)就可以利用 ACID 特性持续不断地向 Hive 表写入数据了。这一操作同样会生成 delta 目录,但更新和删除操作不再支持。
1 2 3 4 5 6 | StreamingConnection connection = HiveStreamingConnection.newBuilder().connect();
connection.beginTransaction();
connection.write("11,val11,Asia,China".getBytes());
connection.write("12,val12,Asia,India".getBytes());
connection.commitTransaction();
connection.close();
|
更新数据
1 | UPDATE employee SET salary = 7000 WHERE id = 2; |
这条语句会先查询出所有符合条件的记录,获取它们的 row__id 信息,然后分别创建 delete 和 delta 目录:
1 2 3 | /user/hive/warehouse/employee/delta_0000001_0000001_0000/bucket_00000 /user/hive/warehouse/employee/delete_delta_0000002_0000002_0000/bucket_00000 /user/hive/warehouse/employee/delta_0000002_0000002_0000/bucket_00000 |
delete_delta_0000002_0000002_0000/bucket_00000 包含了删除的记录:
1 | {"operation":2,"originalTransaction":1,"bucket":536870912,"rowId":1,"currentTransaction":2,"row":null}
|
delta_0000002_0000002_0000/bucket_00000 包含更新后的数据:
1 | {"operation":0,"originalTransaction":2,"bucket":536870912,"rowId":0,"currentTransaction":2,"row":{"id":2,"name":"Tom","salary":7000}}
|
DELETE 语句的工作方式类似,同样是先查询,后生成 delete 目录。
合并表
MERGE 语句和 MySQL 的 INSERT ON UPDATE 功能类似,它可以将来源表的数据合并到目标表中:
1 2 3 4 5 6 7 8 9 | CREATE TABLE employee_update (id int, name string, salary int); INSERT INTO employee_update VALUES (2, 'Tom', 7000), (4, 'Mary', 9000);MERGE INTO employee AS a USING employee_update AS b ON a.id = b.id WHEN MATCHED THEN UPDATE SET salary = b.salary WHEN NOT MATCHED THEN INSERT VALUES (b.id, b.name, b.salary); |
这条语句会更新 Tom 的薪资字段,并插入一条 Mary 的新记录。多条 WHEN 子句会被视为不同的语句,有各自的语句 ID(Statement ID)。INSERT 子句会创建 delta_0000002_0000002_0000 文件,内容是 Mary 的数据;UPDATE 语句则会创建 delete_delta_0000002_0000002_0001 和 delta_0000002_0000002_0001 两个文件,删除并新增 Tom 的数据。
1 2 3 4 | /user/hive/warehouse/employee/delta_0000001_0000001_0000 /user/hive/warehouse/employee/delta_0000002_0000002_0000 /user/hive/warehouse/employee/delete_delta_0000002_0000002_0001 /user/hive/warehouse/employee/delta_0000002_0000002_0001 |
压缩
随着写操作的积累,表中的 delta 和 delete 文件会越来越多。事务表的读取过程中需要合并所有文件,数量一多势必会影响效率。此外,小文件对 HDFS 这样的文件系统也是不够友好的。因此,Hive 引入了压缩(Compaction)的概念,分为 Minor 和 Major 两类。
Minor Compaction 会将所有的 delta 文件压缩为一个文件,delete 也压缩为一个。压缩后的结果文件名中会包含写事务 ID 范围,同时省略掉语句 ID。压缩过程是在 Hive Metastore 中运行的,会根据一定阈值自动触发。我们也可以使用如下语句人工触发:
1 | ALTER TABLE employee COMPACT 'minor'; |
以上文中的 MERGE 语句的结果举例,在运行了一次 Minor Compaction 后,文件目录结构将变为:
1 2 | /user/hive/warehouse/employee/delete_delta_0000001_0000002 /user/hive/warehouse/employee/delta_0000001_0000002 |
在 delta_0000001_0000002/bucket_00000 文件中,数据会被排序和合并起来,因此文件中将包含两行 Tom 的数据。Minor Compaction 不会删除任何数据。
Major Compaction 则会将所有文件合并为一个文件,以 base_N 的形式命名,其中 N 表示最新的写事务 ID。已删除的数据将在这个过程中被剔除。row__id 则按原样保留。
1 | /user/hive/warehouse/employee/base_0000002 |
需要注意的是,在 Minor 或 Major Compaction 执行之后,原来的文件不会被立刻删除。这是因为删除的动作是在另一个名为 Cleaner 的线程中执行的。因此,表中可能同时存在不同事务 ID 的文件组合,这在读取过程中需要做特殊处理。
读取过程
我们可以看到 ACID 事务表中会包含三类文件,分别是 base、delta、以及 delete。文件中的每一行数据都会以 row__id 作为标识并排序。从 ACID 事务表中读取数据就是对这些文件进行合并,从而得到最新事务的结果。这一过程是在 OrcInputFormat 和 OrcRawRecordMerger 类中实现的,本质上是一个合并排序的算法。
以下列文件为例,产生这些文件的操作为:插入三条记录,进行一次 Major Compaction,然后更新两条记录。1-0-0-1 是对 originalTransaction - bucketId - rowId - currentTransaction 的缩写。
1 2 3 4 5 6 7 | +----------+ +----------+ +----------+ | base_1 | | delete_2 | | delta_2 | +----------+ +----------+ +----------+ | 1-0-0-1 | | 1-0-1-2 | | 2-0-0-2 | | 1-0-1-1 | | 1-0-2-2 | | 2-0-1-2 | | 1-0-2-1 | +----------+ +----------+ +----------+ |
合并过程为:
- 对所有数据行按照 (
originalTransaction,bucketId,rowId) 正序排列,(currentTransaction) 倒序排列,即:1-0-0-11-0-1-21-0-1-1- …
2-0-1-2
- 获取第一条记录;
- 如果当前记录的
row__id和上条数据一样,则跳过; - 如果当前记录的操作类型为 DELETE,也跳过;
- 通过以上两条规则,对于
1-0-1-2和1-0-1-1,这条记录会被跳过;
- 通过以上两条规则,对于
- 如果没有跳过,记录将被输出给下游;
- 重复以上过程。
合并过程是流式的,即 Hive 会将所有文件打开,预读第一条记录,并将 row__id 信息存入到 ReaderKey 类型中。该类型实现了 Comparable 接口,因此可以按照上述规则自定义排序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | public class RecordIdentifier implements WritableComparable<RecordIdentifier> {private long writeId;private int bucketId;private long rowId;protected int compareToInternal(RecordIdentifier other) {if (other == null) { return -1; }if (writeId != other.writeId) { return writeId < other.writeId ? -1 : 1; }if (bucketId != other.bucketId) { return bucketId < other.bucketId ? - 1 : 1; }if (rowId != other.rowId) { return rowId < other.rowId ? -1 : 1; }return 0;}
}public class ReaderKey extends RecordIdentifier {private long currentWriteId;private boolean isDeleteEvent = false;public int compareTo(RecordIdentifier other) {int sup = compareToInternal(other);if (sup == 0) {if (other.getClass() == ReaderKey.class) {ReaderKey oth = (ReaderKey) other;if (currentWriteId != oth.currentWriteId) { return currentWriteId < oth.currentWriteId ? +1 : -1; }if (isDeleteEvent != oth.isDeleteEvent) { return isDeleteEvent ? -1 : +1; }} else {return -1;}}return sup;}
}
|
然后,ReaderKey 会和文件句柄一起存入到 TreeMap 结构中。根据该结构的特性,我们每次获取第一个元素时就能得到排序后的结果,并读取数据了。
1 2 3 4 5 6 | public class OrcRawRecordMerger {private TreeMap<ReaderKey, ReaderPair> readers = new TreeMap<>();public boolean next(RecordIdentifier recordIdentifier, OrcStruct prev) {Map.Entry<ReaderKey, ReaderPair> entry = readers.pollFirstEntry();}
}
|
选择文件
上文中提到,事务表目录中会同时存在多个事务的快照文件,因此 Hive 首先要选择出反映了最新事务结果的文件集合,然后再进行合并。举例来说,下列文件是一系列操作后的结果:两次插入,一次 Minor Compaction,一次 Major Compaction,一次删除。
1 2 3 4 5 | delta_0000001_0000001_0000 delta_0000002_0000002_0000 delta_0000001_0000002 base_0000002 delete_delta_0000003_0000003_0000 |
过滤过程为:
- 从 Hive Metastore 中获取所有成功提交的写事务 ID 列表;
- 从文件名中解析出文件类型、写事务 ID 范围、以及语句 ID;
- 选取写事务 ID 最大且合法的那个
base目录,如果存在的话; - 对
delta和delete文件进行排序:minWID较小的优先;- 如果
minWID相等,则maxWID较大的优先; - 如果都相等,则按
stmtID排序;没有stmtID的会排在前面;
- 将
base文件中的写事务 ID 作为当前 ID,循环过滤所有delta文件:- 如果
maxWID大于当前 ID,则保留这个文件,并以此更新当前 ID; - 如果 ID 范围相同,也会保留这个文件;
- 重复上述步骤。
- 如果
过滤过程中还会处理一些特别的情况,如没有 base 文件,有多条语句,包含原始文件(即不含 row__id 信息的文件,一般是通过 LOAD DATA 导入的),以及 ACID 版本 1 格式的文件等。具体可以参考 AcidUtils#getAcidState 方法。
并行执行
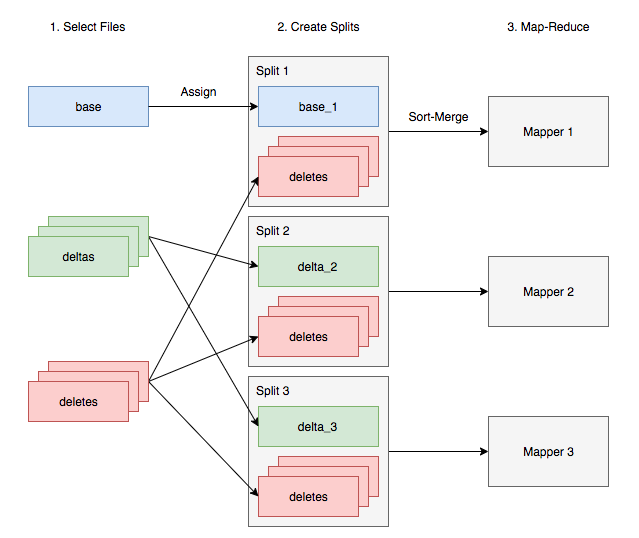
在 Map-Reduce 模式下运行 Hive 时,多个 Mapper 是并行执行的,这就需要将 delta 文件按一定的规则组织好。简单来说,base 和 delta 文件会被分配到不同的分片(Split)中,但所有分片都需要能够读取所有的 delete 文件,从而根据它们忽略掉已删除的记录。
向量化查询
当 向量化查询 特性开启时,Hive 会尝试将所有的 delete 文件读入内存,并维护一个特定的数据结构,能够快速地对数据进行过滤。如果内存放不下,则会像上文提到的过程一样,逐步读取 delete 文件,使用合并排序的算法进行过滤。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | public class VectorizedOrcAcidRowBatchReader {private final DeleteEventRegistry deleteEventRegistry;protected static interface DeleteEventRegistry {public void findDeletedRecords(ColumnVector[] cols, int size, BitSet selectedBitSet);}static class ColumnizedDeleteEventRegistry implements DeleteEventRegistry {}static class SortMergedDeleteEventRegistry implements DeleteEventRegistry {}public boolean next(NullWritable key, VectorizedRowBatch value) {BitSet selectedBitSet = new BitSet(vectorizedRowBatchBase.size);this.deleteEventRegistry.findDeletedRecords(innerRecordIdColumnVector,vectorizedRowBatchBase.size, selectedBitSet);for (int setBitIndex = selectedBitSet.nextSetBit(0), selectedItr = 0;setBitIndex >= 0;setBitIndex = selectedBitSet.nextSetBit(setBitIndex+1), ++selectedItr) {value.selected[selectedItr] = setBitIndex;}}
}
|
事务管理
为了实现 ACID 事务机制,Hive 还引入了新的事务管理器 DbTxnManager,它能够在查询计划中分辨出 ACID 事务表,联系 Hive Metastore 打开新的事务,完成后提交事务。它也同时实现了过去的读写锁机制,用来支持非事务表的情形。
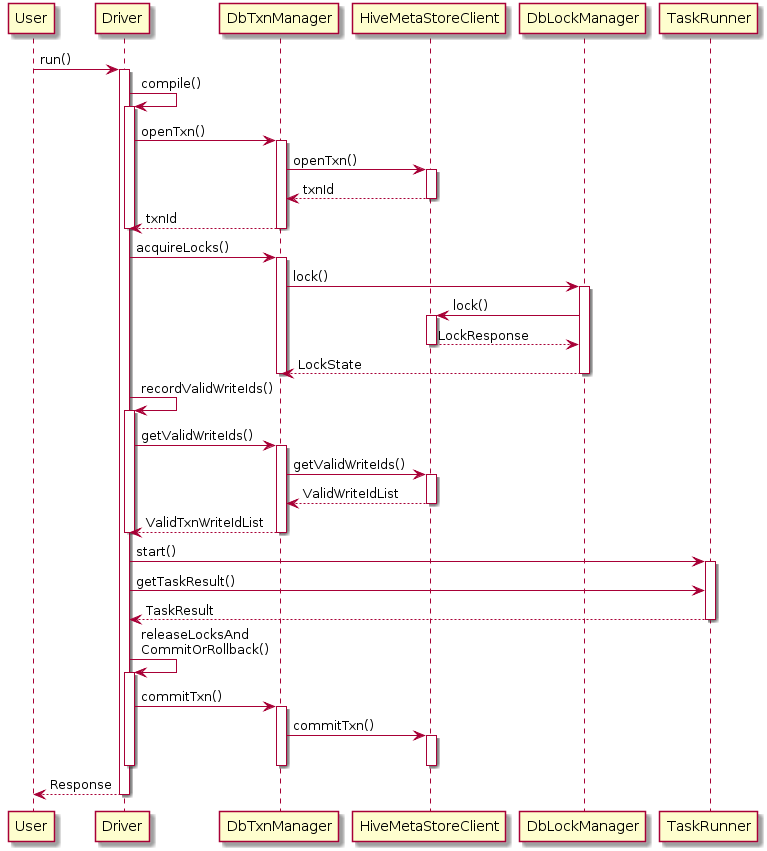
Hive Metastore 负责分配新的事务 ID。这一过程是在一个数据库事务中完成的,从而避免多个 Metastore 实例冲突的情况。
1 2 3 4 5 6 7 8 9 10 11 12 13 | abstract class TxnHandler {private List<Long> openTxns(Connection dbConn, Statement stmt, OpenTxnRequest rqst) {String s = sqlGenerator.addForUpdateClause("select ntxn_next from NEXT_TXN_ID");s = "update NEXT_TXN_ID set ntxn_next = " + (first + numTxns);for (long i = first; i < first + numTxns; i++) {txnIds.add(i);rows.add(i + "," + quoteChar(TXN_OPEN) + "," + now + "," + now + ","+ quoteString(rqst.getUser()) + "," + quoteString(rqst.getHostname()) + "," + txnType.getValue());}List<String> queries = sqlGenerator.createInsertValuesStmt("TXNS (txn_id, txn_state, txn_started, txn_last_heartbeat, txn_user, txn_host, txn_type)", rows);}
} |
PS: 向量化查询
向量化查询执行是Hive特性,可以大大减少典型查询操作(如扫描,过滤器,聚合和连接)的CPU使用率。一个标准的查询执行系统一次处理一行。这涉及在执行的内部循环中长的代码路径和重要的元数据解释。目前Hive也严重依赖于惰性的反序列化,数据列通过一层对象检查器来识别列类型,反序列化数据并在内部循环中确定合适的表达式例程。这些虚拟方法调用层进一步减慢了处理速度。向量化的查询执行通过一次处理1024行的数据块来简化操作。在块内,每一列都被存储为一个向量(一个基本数据类型的数组)。算术和比较等简单操作是通过在紧密循环中快速迭代向量来完成的,在循环内没有或很少有函数调用或条件分支。这些循环以简化的方式进行编译,使用相对较少的指令,并通过有效地使用处理器流水线和高速缓存存储器,以较少的时钟周期完成每条指令
相关文章:
Hive提升篇-Hive修改事务
简介 Hive 默认是不允许数据更新操作的,毕竟它不擅长,即使在0.14版本后,做一些额外的配置便可开启Hive数据更新操作。而在海量数据场景下做update、delete之类的行级数据操作时,效率并不如意。 简单使用 修改HIVE_HOME/conf/hi…...

PMP项目管理未来的发展与趋势
什么是项目管理?关于项目管理的解释主要是基于国际项目管理三大体系不同的解释及本领域权威专家的解释。 项目管理就是以项目为对象的系统管理方法,通过一个临时性的、专门的柔性组织,对项目进行高效率的计划、组织、指导和控制,以…...

深度学习算法面试常问问题(三)
pooling层是如何进行反向传播的? average pooling: 在前向传播中,就是把一个patch的值取平均传递给下一层的一个像素。因此,在反向传播中,就是把某个像素的值平均分成n份 分配给上一层。 max pooling: 在前…...
GEE学习笔记 八十七:python版GEE动态加载地图方法
在Google Earth Engine的python版API更新后,之前使用folium动态加载地图的代码就不能在正常运行,因为整个Google Earth Engine的地图加载服务的URL发生了更新,所以我们也需要更新相关绘制方法。下面我会讲解一种新的绘制方法,大家…...

第三章 SQL错误信息
文章目录第三章 SQL错误信息SQLCODE 0和100SQLCODE -400检索SQL消息文本第三章 SQL错误信息 下表列出了SQL数字错误代码及其错误消息。这些代码作为SQLCODE变量值返回。 注意:虽然本文档将错误代码列为负值,但JDBC和ODBC客户端始终收到正值。例如&…...

axios中的resolvePromise为什么影响promise状态
axios的取消请求意思很简单,就是在发送请求后不久停止发送请求 本文探讨的是v0.22.0之前的CancelToken API,因为在阅读源码交流的时候发现很多朋友不理解为什么CancelToken中的resolvePromise会影响到实例对象身上的promise状态 即下图所示代码…...

AWS攻略——创建VPC
文章目录创建一个可以外网访问的VPCCIDR主路由表DestinationTarget主网络ACL入站规则出站规则子网创建EC2测试连接创建互联网网关(IGW)编辑路由表知识点参考资料在 《AWS攻略——VPC初识》一文中,我们在AWS默认的VPC下部署了一台可以SSH访问的…...
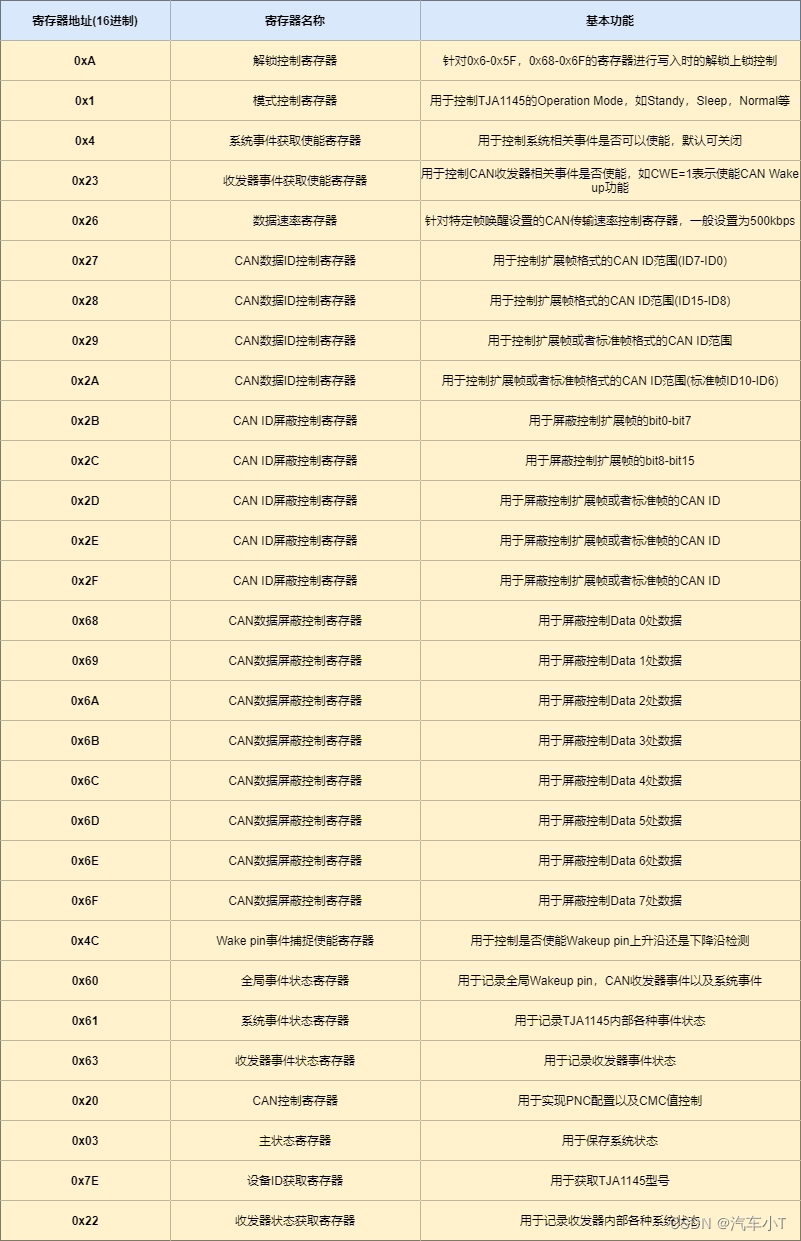
一文搞懂ECU休眠唤醒之利器-TJA1145
前言 首先,小T请教大家几个小小问题,你清楚: 什么是TJA1145吗?你知道休眠唤醒控制基本逻辑是怎么样的吗?TJA1145又是如何控制ECU进行休眠唤醒的呢?使用TJA1145时有哪些注意事项呢? 今天&…...
【Java基础】022 -- Lambda与递归练习
目录 一、Lambda表达式 1、Lambda初体验 2、函数式编程 3、Lambda表达式的标准格式 4、小结 5、Lambda表达式的省略写法 ①、示例代码 ②、小结 6、Lambda表达式的练习 ①、Lambda表达式简化Comparator接口的匿名形式 二、综合练习 1、按照要求进行排序(…...
技研智联云原生容器化平台实践
作者简介:郑建林,现任深圳市技研智联科技有限公司架构师,技术负责人。多年物联网及金融行业经验,对云计算、区块链、大数据等领域有较深入研究及应用。现主要从事 PaaS 平台建设,为公司各业务产品线提供平台底座如技术…...

订单服务:订单流程
订单流程 订单流程是指从订单产生到完成整个流转的过程,从而行程了一套标准流程规则。而不同的产品类型或业务类型在系统中的流程会千差万别,比如上面提到的线上实物订单和虚拟订单的流程,线上实物订单与 O2O 订单等,所以需要根据…...

Python的有用知识,一共十三个代码片段,确定不来看看吗
前言 之前发过22个小技巧,今天就来分享分享13个非常有用的代码片段 赶紧码住,看看你都了解吗 1.将两个列表合并成一个字典 假设我们在 Python 中有两个列表,我们希望将它们合并为字典形式,其中一个列表的项作为字典的键&#…...
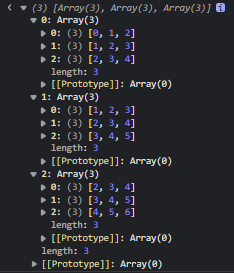
数据结构与算法-数组
前言:几乎所有的编程语言都原生支持数组类型。因为数组是最简单的内存数据结构。创建一个数组:let arr new Array()或let arr new Array(5) // 指定长度或let arr new Array(1,2,3,4,5) // 将数组元素作为参数传给构造函数或let arr [1,2,3,4,5] // …...

PMP证书在哪个行业比较有用?
PMP 各个行业都能用,PMP 的知识体系是通用的,管理层的考试也有借鉴PMP知识的地方。历年考生考的最多的是IT 行业,其他行业也都有分布。PMP认证从国外引进大陆这么多年了,其火热程度依然不减,我个人认为是取决于市场的运…...

Wine零知识学习4 —— Wine编译进阶详解
本系列第3篇文章Wine零知识学习3 —— Winetricks介绍及下载和运行讲述了Wentricks的下载及使用。在Winetricks的使用过程中会发现很多应用下载会出现问题,会提示32位程序无法运行在64位系统上。为什么会出现这个问题?又如何解决此问题?这就是…...
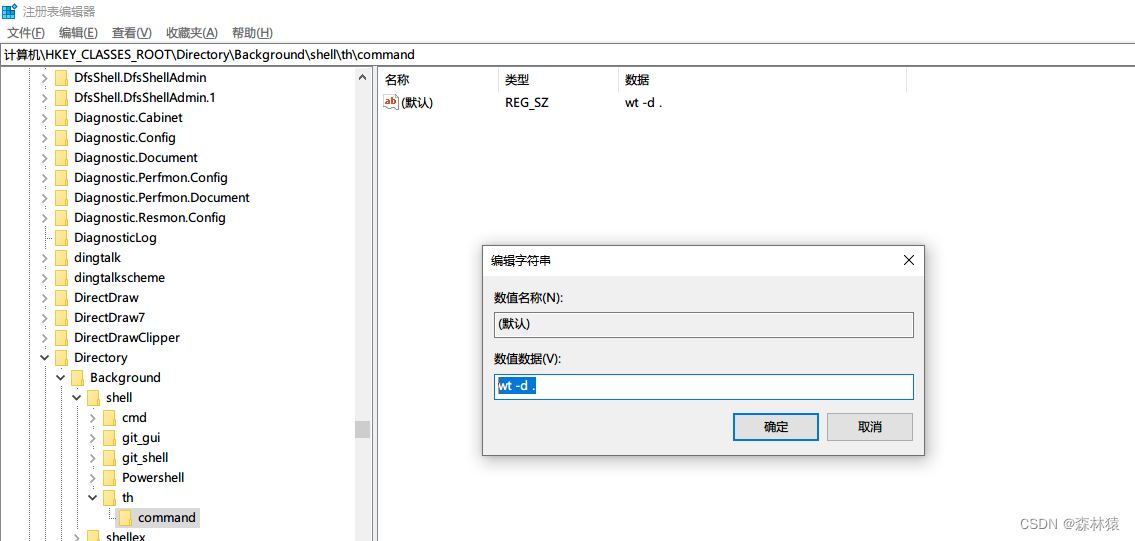
win10-右键打开windows terminal
文章目录windows terminal设置右键打开打开注册表添加一个右键选项新建一个项添加右键的名称和图标右键选项执行的命令测试windows terminal windows 新一代命命令行 设置右键打开 打开注册表 WinR 输入: regedit 定位: 计算机\HKEY_CLASSES_ROOT\Di…...
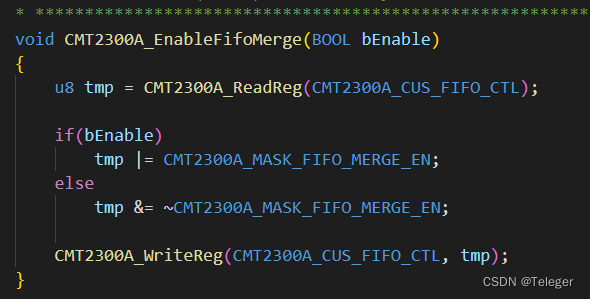
关于使用CMT2300A FIFO缓存区间设置为64Byte的问题
首先请看,CMT2300A 是什么产品,或者说是 模组吗? 请看介绍: https://blog.csdn.net/sishuihuahua/article/details/105095994 以及RFPDK 的使用: 这博客,记录了 RFPDK 的使用,以及遇到的一些问题 我说一下&#…...

网页概念、常用浏览器及内核、Web标准
网页、常用浏览器及内核、Web标准一、网页1.1、什么是网页?1.2、什么是HTML?(重点)1.3、网页的形成?二、常用浏览器三、浏览器内核四、Web标准(重点)4.1 为什么需要Web标准?4.2 Web标准的构成一…...
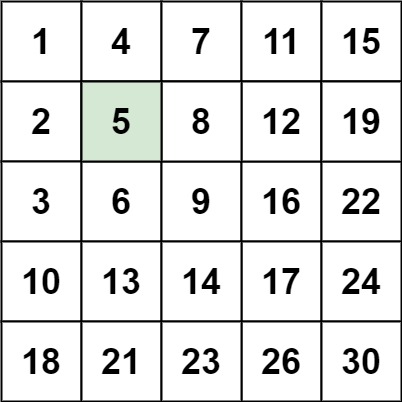
【刷题笔记】--搜索二维矩阵 II
题目: 编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target 。该矩阵具有以下特性: 每行的元素从左到右升序排列。 每列的元素从上到下升序排列。 示例 1: 输入:matrix [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16…...
uni-app实战教程
一、准备 下载HBuilderX编辑器,前往下载注册百度AI账号,创建应用获得Appid和Secret 前往注册百度AI通用物体识别文档 前往查阅Uni-App文档 前往查阅HTML5 文档 前往查阅HTML5文档 前往查阅 二、介绍 开发工具:HBuilderX跨段框架࿰…...

Simulink模型加密二选一:是选‘受保护模型’还是自己写S-Function?一份给嵌入式代码生成者的选择指南
Simulink模型加密实战:受保护模型与S-Function的深度技术选型 在嵌入式系统开发中,Simulink模型往往承载着核心算法和知识产权。当需要与团队协作或交付给客户时,如何在保证模型可用性的同时防止核心逻辑被窥探或篡改?这成为每个嵌…...

告别PDF转换烦恼:Marker让学术文档秒变Markdown的完整指南
告别PDF转换烦恼:Marker让学术文档秒变Markdown的完整指南 【免费下载链接】marker 一个高效、准确的工具,能够将 PDF 和图像快速转换为 Markdown、JSON 和 HTML 格式,支持多语言和复杂布局处理,可选集成 LLM 提升精度,…...

PDF文本高效提取:用pdftotext实现秒级文档内容解析
PDF文本高效提取:用pdftotext实现秒级文档内容解析 【免费下载链接】pdftotext Simple PDF text extraction 项目地址: https://gitcode.com/gh_mirrors/pd/pdftotext 破解PDF提取痛点:为什么你需要专业工具? 每天面对数十份PDF文档却…...

开源字体破局者:思源宋体TTF的免费商用解决方案
开源字体破局者:思源宋体TTF的免费商用解决方案 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 在数字设计领域,寻找兼具专业品质与商业授权的中文字体一直是设…...


Qwen2.5-72B-Instruct-GPTQ-Int4部署教程:vLLM与HuggingFace Transformers对比
Qwen2.5-72B-Instruct-GPTQ-Int4部署教程:vLLM与HuggingFace Transformers对比 1. 模型简介 Qwen2.5-72B-Instruct-GPTQ-Int4是Qwen大语言模型系列的最新版本,具有720亿参数规模。相比前代Qwen2,这个版本在多个方面实现了显著提升ÿ…...

高效处理海量数据——pandas分块读取与内存管理实战
1. 为什么需要分块读取千万级数据? 第一次处理千万级CSV文件时,我盯着16GB的硬盘文件发愁——128GB内存的服务器居然加载到一半就崩溃了。这种场景在金融交易记录、物联网传感器数据、用户行为日志分析中太常见了。pandas默认的read_csv()会一次性把数据…...

Cowabunga Lite完全指南:从入门到精通的iOS个性化解决方案
Cowabunga Lite完全指南:从入门到精通的iOS个性化解决方案 【免费下载链接】CowabungaLite iOS 15 Customization Toolbox 项目地址: https://gitcode.com/gh_mirrors/co/CowabungaLite iOS设备的封闭性常常让用户在个性化定制时感到束手束脚,既想…...

hnswlib高级功能全解:多线程搜索/动态更新/过滤器实战指南
hnswlib高级功能全解:多线程搜索/动态更新/过滤器实战指南 【免费下载链接】hnswlib Header-only C/python library for fast approximate nearest neighbors 项目地址: https://gitcode.com/gh_mirrors/hn/hnswlib hnswlib是一个高效的Header-only C/Python…...

告别‘main分支被拒绝’:用VSCode内置Git图形界面轻松同步远程仓库更新
告别‘main分支被拒绝’:用VSCode内置Git图形界面轻松同步远程仓库更新 当你沉浸在VSCode中编写代码,点击那个熟悉的"推送"按钮时,突然弹出一个红色错误提示——! [rejected] main -> main (non-fast-forward)。这种场景对于依赖…...