【LSTM】读取时间序列数据 | 时间序列数据的小批量划分方法
由于序列数据本质上是连续的,因此我们在处理数据时需要解决这个问题。当序列过长而不能被模型一次性全部处理时,我们希望能拆分这样的序列以便模型方便读取。
Q:怎样随机生成一个具有n个时间步的mini batch的特征和标签?
A:从随机偏移量开始拆分序列,以同时获得覆盖性和随机性。(内容参考了李沐老师的动手学深度学习,简化这个问题,仅进行序列的切分,不区分特征和标签,二者逻辑基本一样)
0 数据展示及问题
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RUJs8Qwo-1686137669642)(【LSTM】读取时间序列数据-时间序列数据的小批量划分方法/image-20230607152658840.png)]](https://img-blog.csdnimg.cn/73309497d34941ec94bfda78f5ce7534.png)
时间序列数据包含4个特征:温度、湿度、降水、气压,有60000条左右记录。
目标:根据24h内温度,预测下一个24h内的温度。
如果直接把这个dataframe丢到dataloader里会怎样呢。比如按照batch_size=24进行划分,使一组数据包含24个记录。
df = pd.read_csv('../data/2013-2022-farm/farm.csv')
dataloader = torch.utils.data.DataLoader(df.iloc[:, 1:].values, batch_size=24, shuffle=True)
结果如下:
for data in dataloader:print(data)print()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gvRWmJam-1686137669643)(【LSTM】读取时间序列数据-时间序列数据的小批量划分方法/image-20230607153154154.png)]](https://img-blog.csdnimg.cn/3720c4e9ac2b4147ab8c798557157a5b.png)
可以看到,这样处理后,得到的序列实际上只有2529个,完全没有好好地利用整个序列。
而且data代表的其实不是一个小batch,而是一条序列数据。
1 随机抽样
1.1 实现
每个样本都是在原始的长序列上任意捕获的子序列。先给出整体代码,然后进行解释。
def seq_data_iter_random(data, batch_size, num_steps):# 随机初始化位置对data进行切割得到新的data列表data = data[random.randint(0, num_steps - 1):]# 能够得到的子序列数目num_subseqs = (len(data) - 1) // num_steps# 创建一个新的列表, 用于记录子序列的开始位置initial_indices = list(range(0, num_subseqs * num_steps, num_steps))# 随机打乱各个子序列的顺序random.shuffle(initial_indices)# 总批量个数等于:子序列个数 / 小批量大小num_batches = num_subseqs // batch_size# 每次取batch_size个数据for i in range(0, batch_size * num_batches, batch_size):# 取batch_size个数值,取出该批量的子序列的开始位置initial_indices_per_batch = initial_indices[i:i + batch_size]X = [data[j: j + num_steps] for j in initial_indices_per_batch]yield torch.tensor(X)
使用示例,本质上是一个迭代器:
df = pd.read_csv('../data/2013-2022-farm/farm.csv')
data = df.iloc[:, 1:].values
for X in seq_data_iter_random(data, 32, 24):print(X)
1、在步长内随机初始化位置对data进行切割
data = data[random.randint(0, num_steps - 1):]
因为不同的随机偏移量可以得到不同的子序列,这样能够提高覆盖性。

以num_steps=5为例,可能产生的切割有:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7Xk3Ub3Q-1686137669643)(【LSTM】读取时间序列数据-时间序列数据的小批量划分方法/image-20230607161433381.png)]](https://img-blog.csdnimg.cn/e99bb81e2fe14b3a848df1e182f15c74.png)
在程序中,步长设为24,执行前后,data从60695变为60684:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KejYc1vz-1686137669643)(【LSTM】读取时间序列数据-时间序列数据的小批量划分方法/image-20230607161558890.png)]](https://img-blog.csdnimg.cn/9089e84096f54e59bc849267a5f0761a.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TJPSXUui-1686137669643)(【LSTM】读取时间序列数据-时间序列数据的小批量划分方法/image-20230607161836583.png)]](https://img-blog.csdnimg.cn/1a2375e244cc40c98f891913d3014855.png)
2、计算能够产生多少个子序列
num_subseqs = (len(data) - 1) // num_steps
结果: ( 60684 − 1 ) ÷ 24 = 2528 (60684 - 1) \div 24 = 2528 (60684−1)÷24=2528
3、创建一个新列表,用于得到子序列开始位置
# 创建一个新的列表, 用于记录子序列的开始位置initial_indices = list(range(0, num_subseqs * num_steps, num_steps))# {list: 2528}[0, 24, 48, 72, 96, 120, 144, 168, 192, 216, ...]# 随机打乱各个子序列的顺序random.shuffle(initial_indices)
4、计算总批量大小
batch_size设置为32
# 总批量个数等于:子序列个数 / 小批量大小num_batches = num_subseqs // batch_size
| 变量 | 大小 | 含义 |
|---|---|---|
| data | (60684, 4) | |
| num_steps | 24 | 步长 |
| num_subseqs | 2528 | 划分产生的子序列数目, d a t a n u m _ s t e p s \frac{data}{num\_steps} num_stepsdata |
| batch_size | 32 | |
| num_batches | 79 | 能产生多少个批量,不足的一个批量的部分直接舍去, n u m _ s u b s e q s n u m _ b a t c h e s \frac{num\_subseqs}{num\_batches} num_batchesnum_subseqs |
5、产生数据
for i in range(0, batch_size * num_batches, batch_size):# 取batch_size个数值,取出该批量的子序列的开始位置initial_indices_per_batch = initial_indices[i:i + batch_size]X = [data[j: j + num_steps] for j in initial_indices_per_batch]yield torch.tensor(X)
循环进行num_batches:
# 每次取batch_size个数据,range (0, 2528, 32)
for i in range(0, batch_size * num_batches, batch_size):
循环体内,每次取batch_size个数值,取出该批量的子序列的开始位置:
initial_indices_per_batch = initial_indices[i:i + batch_size]
# {list: 32}[18456, 17232, 13320, 2904, 51240, 56472, 25056, 17040, 8040, 33936, 30792, 12312, 17328, 8304, 28128, 29976, 46560, 4680, 53928, 39096, 14616, 12240, 57120, 29784, 2784, 4752, 22272, 5040, 42600, 41856, 38232, 20448]
根据子序列的开始位置生成这个batch的子序列数据:
X = [data[j: j + num_steps] for j in initial_indices_per_batch]
yield torch.tensor(X)
1.2 说明
由于在训练过程中会不断地调用seq_data_iter_random迭代器产生数据,而初始时的偏移量是随机的,最终有机会获得所有可能的序列:
随机偏移量切割情况:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zPd85w91-1686137669644)(【LSTM】读取时间序列数据-时间序列数据的小批量划分方法/image-20230607164640835.png)]](https://img-blog.csdnimg.cn/12d3cba76aaf48a3ba4ce9d6802ea0e2.png)
可能获得的序列如下,每次完整运行seq_data_iter_random时,可以产生下述示意图中的一行数据(但每一行中的子序列顺序随机),多次运行可以覆盖所有的情况。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DUKNX0LK-1686137669644)(【LSTM】读取时间序列数据-时间序列数据的小批量划分方法/image-20230607164624333.png)]](https://img-blog.csdnimg.cn/5c815b8947774ff5a19c3c7c1bcc073c.png)
2 顺序分区
保证两个相邻的小批量在原始序列中也是相邻的。保留了拆分的子序列的顺序,因此称为顺序分区。
有一说一我感觉把上面那行shuffle=True改一下不就好了嘛。
注意:不是指在一个小批量里的数据是相邻的,而是两个不同的小批量的相邻访问性质。
2.1 代码实现
def seq_data_iter_sequential(data, batch_size, num_steps, num_features=1):# 从偏移量开始拆分序列offset = random.randint(0, num_steps)# 计算偏移offset后的序列长度num_tokens = ((len(data) - offset - 1) // batch_size) * batch_size# 截取序列Xs = torch.tensor(data[offset: offset + num_tokens])# 变形为第一维度为batch_size大小;Xs = Xs.reshape(batch_size, -1, num_features)# 求得批量总数num_batches = Xs.shape[1] // num_steps# 访问各个batchfor i in range(0, num_steps * num_batches, num_steps):X = Xs[:, i:i + num_steps]yield X
1、随机偏移量
和上述流程比较类似,不再解释
# 从偏移量开始拆分序列offset = random.randint(0, num_steps)# 计算偏移offset后的序列长度num_tokens = ((len(data) - offset - 1) // batch_size) * batch_size# 截取序列Xs = torch.tensor(data[offset: offset + num_tokens])
2、第一维度修改为batch_size大小
Xs = data.reshape(batch_size, -1, num_features)
执行前后:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HcZDt8UW-1686137669644)(【LSTM】读取时间序列数据-时间序列数据的小批量划分方法/image-20230607175223595.png)]](https://img-blog.csdnimg.cn/38ecf0136f4e4de48c204380dcd2d5b3.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xQcUYEQR-1686137669644)(【LSTM】读取时间序列数据-时间序列数据的小批量划分方法/image-20230607175241903.png)]](https://img-blog.csdnimg.cn/a118574bf2504fb09e2611c1a6eb7b7b.png)
可以理解为将一整个序列,先拆分为32个小序列。然后每一个batch从32个小序列中取一个元素。
# 求得批量总数
num_batches = Xs.shape[1] // num_steps
# 1896 // 24 = 79
3、访问各个batch
# 访问各个batch
for i in range(0, num_steps * num_batches, num_steps):X = Xs[:, i:i + num_steps]yield X
2.2 说明
以batch_size = 3, num_steps=2为例,首先将一整个序列折叠为3份。
然后每一个batch顺序地分别从3份中选择两个元素
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9wXoVJHF-1686137669645)(【LSTM】读取时间序列数据-时间序列数据的小批量划分方法/image-20230607191032420.png)]](https://img-blog.csdnimg.cn/a301123cd3a54feb8b095f786e827786.png)
3 封装为Dataloader
class SeqDataLoader:"""加载序列数据的迭代器"""def __init__(self, data, batch_size, num_steps, use_random_iter, num_features=1):if use_random_iter:self.data_iter_fn = self.seq_data_iter_randomelse:self.data_iter_fn = self.seq_data_iter_sequentialself.data = dataself.batch_size, self.num_steps = batch_size, num_stepsself.num_features = num_featuresdef seq_data_iter_random(self, data, batch_size, num_steps, num_features=1):# 随机初始化位置对data进行切割得到新的data列表data = data[random.randint(0, num_steps - 1):]num_subseqs = (len(data) - 1) // num_steps# 创建一个新的列表, 用于记录子序列的开始位置initial_indices = list(range(0, num_subseqs * num_steps, num_steps))# 随机打乱各个子序列的顺序random.shuffle(initial_indices)# 总批量个数等于:子序列个数 / 小批量大小num_batches = num_subseqs // batch_size# 每次取batch_size个数据for i in range(0, batch_size * num_batches, batch_size):# 取batch_size个数值,取出该批量的子序列的开始位置initial_indices_per_batch = initial_indices[i:i + batch_size]X = [data[j: j + num_steps] for j in initial_indices_per_batch]yield torch.tensor(X)def seq_data_iter_sequential(self, data, batch_size, num_steps, num_features=1):# 从偏移量开始拆分序列offset = random.randint(0, num_steps)# 计算偏移offset后的序列长度num_tokens = ((len(data) - offset - 1) // batch_size) * batch_size# 截取序列Xs = torch.tensor(data[offset: offset + num_tokens])# 变形为第一维度为batch_size大小;Xs = Xs.reshape(batch_size, -1, num_features)# 求得批量总数num_batches = Xs.shape[1] // num_steps# 访问各个batchfor i in range(0, num_steps * num_batches, num_steps):X = Xs[:, i:i + num_steps]yield Xdef __iter__(self):return self.data_iter_fn(self.data, self.batch_size, self.num_steps, self.num_features)
使用方法:
dataloader = SeqDataLoader(data, batch_size=32, num_steps=24, use_random_iter=False, num_features=4)
for X in dataloader:print(X)
4 带有标签和归一化的DataLoader
根据num_steps的数据,预测predict_steps的数据。
获取标签Y的逻辑与上类似,下次填坑。
可使用.normalization函数进行归一化,.reverse_normalization函数复原。
import random
import pandas as pd
import torch.utils.datafrom sklearn.preprocessing import MinMaxScaler# 将时间序列文件分为小批量
class SeqDataLoader:"""加载序列数据的迭代器,根据num_steps的数据,预测predict_steps的数据"""def __init__(self, data, batch_size, num_steps, use_random_iter, num_features=1, predict_steps=1):if use_random_iter:self.data_iter_fn = self.seq_data_iter_randomelse:self.data_iter_fn = self.seq_data_iter_sequentialself.data = dataself.batch_size, self.num_steps, self.predict_steps = batch_size, num_steps, predict_stepsself.num_features = num_featuresself.scaler = MinMaxScaler()self.normalization()def seq_data_iter_random(self, data, batch_size, num_steps, num_features=1, predict_steps=1):# 随机初始化位置对data进行切割得到新的data列表data = data[random.randint(0, num_steps - 1):]# 减去predict_steps以保证子序列可获得对应的标签而不会越界num_subseqs = (len(data) - self.predict_steps) // num_steps# 创建一个新的列表, 用于记录子序列的开始位置initial_indices = list(range(0, num_subseqs * num_steps, num_steps))# 随机打乱各个子序列的顺序random.shuffle(initial_indices)# 总批量个数等于:子序列个数 / 小批量大小num_batches = num_subseqs // batch_size# 每次取batch_size个数据for i in range(0, batch_size * num_batches, batch_size):# 取batch_size个数值,取出该批量的子序列的开始位置initial_indices_per_batch = initial_indices[i:i + batch_size]X = [data[j: j + num_steps] for j in initial_indices_per_batch]Y = [data[j + num_steps: j + num_steps + predict_steps] for j in initial_indices_per_batch]yield torch.tensor(X), torch.tensor(Y)def seq_data_iter_sequential(self, data, batch_size, num_steps, num_features=1, predict_steps=1):# 从偏移量开始拆分序列offset = random.randint(0, num_steps)# 计算偏移offset后的序列长度,减去predict_steps以保证子序列可获得对应的标签而不会越界num_tokens = ((len(data) - offset - predict_steps) // batch_size) * batch_size# 截取序列Xs = torch.tensor(data[offset: offset + num_tokens])# Ys从后一个时间序列开始截取,表示labelYs = torch.tensor(data[offset + num_steps: offset + num_tokens + num_steps])# 变形为第一维度为batch_size大小;Xs = Xs.reshape(batch_size, -1, num_features)Ys = Ys.reshape(batch_size, -1, num_features)# 求得批量总数num_batches = Xs.shape[1] // num_steps# 访问各个batchfor i in range(0, num_steps * num_batches, num_steps):X = Xs[:, i:i + num_steps]Y = Ys[:, i:i + predict_steps]yield X, Ydef __iter__(self):return self.data_iter_fn(self.data, self.batch_size, self.num_steps, self.num_features, self.predict_steps)def normalization(self):self.data = self.scaler.fit_transform(self.data) # 对选定的列进行归一化self.data = self.data.astype('float32')def reverse_normalization(self):self.data = self.scaler.inverse_transform(self.data) # 恢复各列数据
相关文章:
【LSTM】读取时间序列数据 | 时间序列数据的小批量划分方法
由于序列数据本质上是连续的,因此我们在处理数据时需要解决这个问题。当序列过长而不能被模型一次性全部处理时,我们希望能拆分这样的序列以便模型方便读取。 Q:怎样随机生成一个具有n个时间步的mini batch的特征和标签? A&…...
K8s in Action 阅读笔记——【12】Securing the Kubernetes API server
K8s in Action 阅读笔记——【12】Securing the Kubernetes API server 12.1 Understanding authentication 在上一章中,我们提到API服务器可以配置一个或多个认证插件(授权插件也是同样的情况)。当API服务器接收到一个请求时,它…...
爆肝整理,3个月从功能进阶自动化测试,一跃成测试卷王...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 首先先了解自动化…...

人生这场概率游戏,怎么玩
只会标准答案,是不可救药的愚蠢 那么为了便于理解,我用一些典型的案例来讲解,什么是概率游戏,以及这个游戏,应该怎么玩。 比如典型的相亲,婚恋。人生大事,用标准答案来说,你的意中人…...
Redis笔记
缓存过期时间很重要!redis是单线程的 对于内存过多的3中方案: 惰性删除: 在定时删除的基础上,对于已经过期了的数据,redis的随机选择算法一直没有选中这个数据,所以导致它就一直没被删除,但是…...

centos 安装supervisor并运行网站
前言 之前一直用宝塔的**进程守护管理器【Supervisor】**来启动一些项目,如ThinkPHP、Hyperf的项目,或laravel的一些命令。如果不用宝塔怎么办呢? 一、简介[supervisor] [Supervisor] 是用Python开发的一个client/server服务,是Linux/Unix系统下的一个进程管理工具,不支…...

Hadoop面试题十道
问题 1:Hadoop是什么? 答案:Hadoop是一个开源的分布式计算框架,用于处理大规模数据集的存储和处理。它基于Google的MapReduce和Google文件系统(GFS)的思想,旨在解决大数据量的处理和分析问题。…...
使用Docker-Compose对Docker容器集群快速编排
目录 一、Docker-Compose1、Docker-Compose使用场景2、Docker-Compose简介3、Docker-Compose安装部署4、YAML 文件格式及编写注意事项5、Docker Compose配置常用字段6、Docker Compose 常用命令7、Docker Compose 文件结构8、docker Compose撰写nginx 镜像9、docker Compose撰写…...
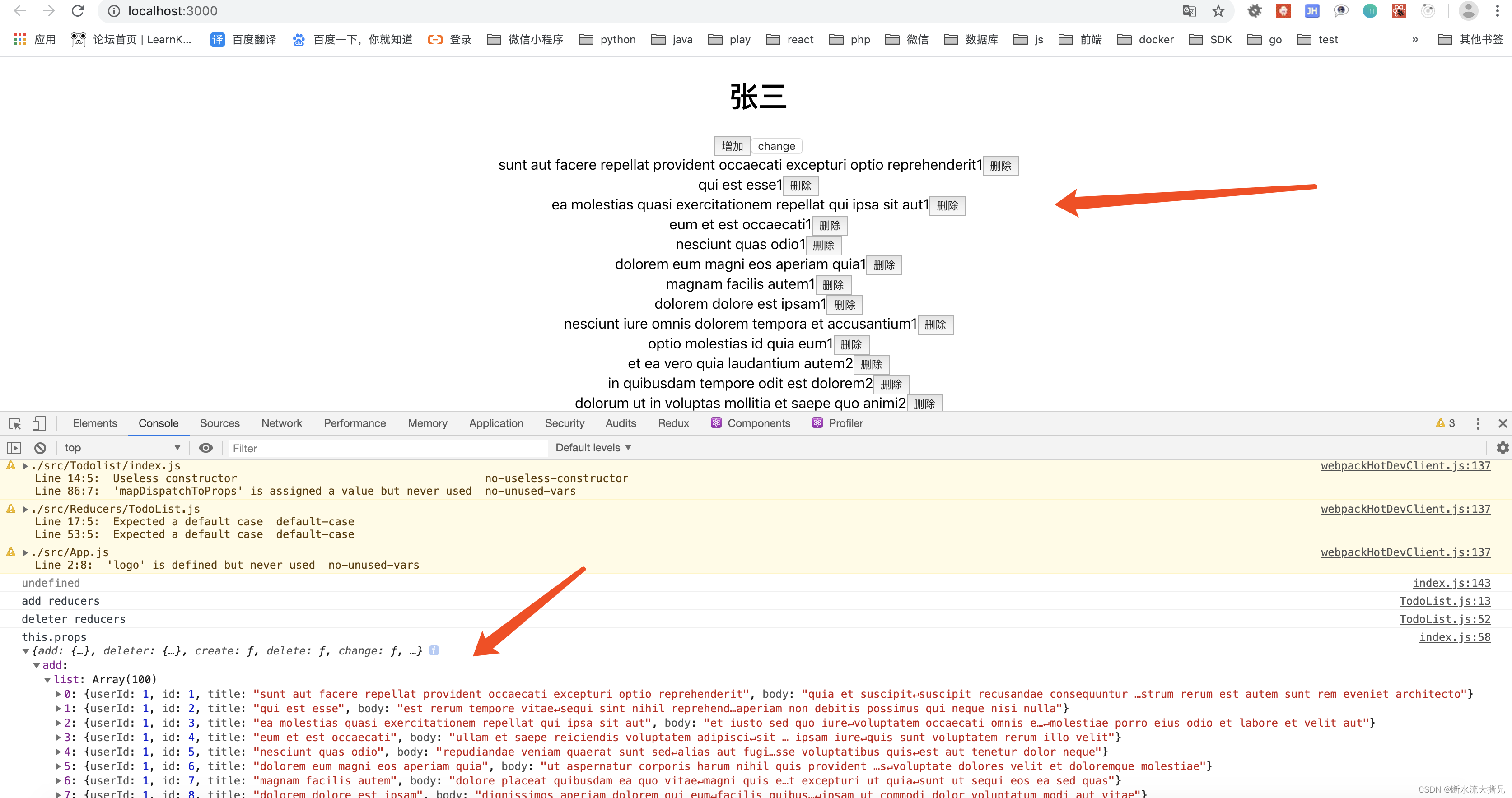
React-Redux 对Todolist修改
在单独使用redux的时候 需要手动订阅store里面 感觉特别麻烦 不错的是react有一个组件可以帮我们解决这个问题, 那就是react-redux。 react-redux提供了Provider 和 connent给我们使用。 先说一下几个重点知道的知识 Provider 就是用来提供store里面的状态 自动getState()co…...

初识微信小程序
新建小程序 创建一个新的微信小程序项目: 打开微信开发者工具,点击“新建项目”。 在弹出的窗口中,填写小程序的 AppID、项目名称和项目目录等信息。 点击“确定”按钮,等待微信开发者工具自动下载并安装所需的依赖库和框架。 …...

我们该如何入门编程呢
提醒:以下内容仅做参考,可自行发散。在发布作品前,请把不需要的内容删掉。 随着信息技术的快速发展,编程已经成为一个越来越重要的技能。那么,我们该如何入门编程呢?选择编程语言:选择一种编程…...

App 软件开发《判断6》试卷及答案
App 软件开发《判断6》试卷及答案 文章目录 App 软件开发《判断6》试卷及答案判断题(对的打“√”,错的打“”;共0分)1.”ionic resources --icon"命令用于生成适应不同分辨率的App图标所应用的图片。(✔)2&#…...

MVC工作原理
MVC工作原理 有视图的情况 1.客户端(浏览器)发起请求,DispatcherServlet拦截请求。 2.DispatcherServlet根据请求信息调用HandlerMapping。HandlerMapping根据uri去匹配查询能处理的Handler(也就是我们所说的Controller&#x…...

使用 Redis 统计网站 UV 的方法
使用 Redis 统计网站 UV 的方法(概率算法) 文章目录 前言思路HyperLogLog 使用 Redis 命令操作使用 Java 代码操作 HyperLogLog 实现原理及特点使用 Java 实现 HyperLogLog小结 前言 网站 UV 就是指网站的独立用户访问量Unique Visitor,即相同用户的多次访问需要…...

黑客工具软件大全
黑客工具软件大全100套 给大家准备了全套网络安全梓料,有web安全,还有渗透测试等等内容,还包含电子书、面试题、pdf文档、视频以及相关的网络安全笔记 👇👇👇 《黑客&网络安全入门&进阶学习包》 &a…...

uniapp主题切换功能的第二种实现方式(scss变量+require)
在上一篇 “uniapp主题切换功能的第一种实现方式(scss变量vuex)” 中介绍了第一种如何切换主题,但我们总结出一些不好的地方,例如扩展性不强,维护起来也困难等等,那么接下我再给大家介绍另外一种切换主题的…...

# 蓝牙音频相关知识
蓝牙音频相关知识 文章目录 蓝牙音频相关知识1 音频源2 蓝牙音频编解码器3 一些标准4 蓝牙音频其他相关知识4.1 蓝牙版本4.2 ANC(主动降噪)4.3 音响相关参数4.4 音质评价4.5 HI-Fi声音特点4.6 耳机线材4.7 耳机分类4.8 IP防尘防水等级4.9 噪音与量化噪音…...

【AI作画】使用DiffusionBee with stable-diffusion在mac M1平台玩AI作画
DiffusionBee是一个完全免费、离线的工具。它简洁易用,你只需输入一些标签或文本描述,它就能生成艺术图像。 DiffusionBee下载地址 运行DiffusionBee的硬性要求:MacOS系统版本必须在12.3及以上 DBe安装完成后,去C站挑选自己喜欢…...
所有函数的介绍及使用)
2 STM32库函数 之 通用同步异步收发器(USART、串口)所有函数的介绍及使用
2 STM32库函数 之 通用同步异步收发器(USART、串口)所有函数的介绍及使用 前言一、USART固件库函数预览二、USART固件库函数具体介绍2.1 库函数 USART_DeInit2.2 库函数 USART_Init2.2.1 USART_InitTypeDef structure2.2.2 USART_InitTypeDef 成员 USART…...

SpringCloudAlibaba整合Sentinel实现流量控制熔断降级
目录 一、概念 二、整合Sentinel控制台 三、Sentinel规则配置 四、@SentinelResource资源保护注解...

nerdctl 入门指南:从安装到容器管理
1. 为什么选择 nerdctl 管理容器? 如果你已经熟悉 Docker 的命令行工具,那么第一次接触 nerdctl 时会感到非常亲切。作为 containerd 生态中的明星工具,nerdctl 提供了与 Docker CLI 高度兼容的操作体验,但底层却采用了更轻量级的…...

开源抢票工具成功率提升指南:从配置到实战的全方位优化
开源抢票工具成功率提升指南:从配置到实战的全方位优化 【免费下载链接】damaihelper 支持大麦网,淘票票、缤玩岛等多个平台,演唱会演出抢票脚本 项目地址: https://gitcode.com/gh_mirrors/dam/damaihelper 你是否曾在开票瞬间眼睁睁…...

像素剧本圣殿从零开始:Windows/Linux双平台Qwen2.5镜像部署步骤详解
像素剧本圣殿从零开始:Windows/Linux双平台Qwen2.5镜像部署步骤详解 1. 项目介绍与核心价值 像素剧本圣殿(Pixel Script Temple)是一款基于Qwen2.5-14B-Instruct模型深度优化的专业剧本创作工具。这个项目将先进的大语言模型能力与独特的8-…...

创新流复用架构:OBS Multi RTMP插件技术方案与商业价值实现
创新流复用架构:OBS Multi RTMP插件技术方案与商业价值实现 【免费下载链接】obs-multi-rtmp OBS複数サイト同時配信プラグイン 项目地址: https://gitcode.com/gh_mirrors/ob/obs-multi-rtmp OBS Multi RTMP插件通过创新的流复用架构,解决了多平…...

终极指南:3个简单步骤免费下载B站4K大会员视频
终极指南:3个简单步骤免费下载B站4K大会员视频 【免费下载链接】bilibili-downloader B站视频下载,支持下载大会员清晰度4K,持续更新中 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-downloader 你是否曾遇到过这样的场景&…...

Citra模拟器终极指南:免费畅玩3DS游戏的完整教程
Citra模拟器终极指南:免费畅玩3DS游戏的完整教程 【免费下载链接】citra A Nintendo 3DS Emulator 项目地址: https://gitcode.com/gh_mirrors/cit/citra 任天堂3DS模拟器Citra是一款开源的高性能游戏模拟工具,让PC用户能够流畅体验《精灵宝可梦》…...

Adobe-GenP: 实现Adobe CC全版本破解的自动化补丁解决方案
Adobe-GenP: 实现Adobe CC全版本破解的自动化补丁解决方案 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe Creative Cloud系列软件作为创意行业的标准工具&am…...

新手开发者的第一课:用快马打造零基础的mc指令学习助手
作为一个刚接触《我的世界》指令系统的玩家,我最初完全搞不懂那些复杂的斜杠命令。直到自己动手做了一个指令查询工具,才发现原来理解指令可以这么简单。今天就来分享如何用InsCode(快马)平台快速打造一个零基础友好的MC指令助手。 为什么需要专门的指令…...

终极硬件指纹伪装指南:如何用EASY-HWID-SPOOFER保护你的数字隐私
终极硬件指纹伪装指南:如何用EASY-HWID-SPOOFER保护你的数字隐私 【免费下载链接】EASY-HWID-SPOOFER 基于内核模式的硬件信息欺骗工具 项目地址: https://gitcode.com/gh_mirrors/ea/EASY-HWID-SPOOFER 在数字时代,你的电脑硬件指纹就像数字世界…...

Android Studio中文语言包:突破本地化困境的社区解决方案
Android Studio中文语言包:突破本地化困境的社区解决方案 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 问题场景&am…...