ChatGPT原理简介
承接上文GPT前2代版本简介
GPT3的基本思想
GPT2没有引起多大轰动,真正改变NLP格局的是第三代版本。
GPT3训练的数据包罗万象,上通天文下知地理,所以它会胡说八道,会说的贼离谱,比如让你穿越到唐代跟李白对诗,不在一个频道上,他说的你理解不了,你说的他理解不了。
GPT3太泛了,把世界上所有的东西都给训练了,不受约束条件的、无法无天,给它发一个指令,它抗拒指令,按照自己的思维模式去做,比如我问一个问题,接下来你用python代码的方式来回答我,它可能不按照这个模式来,不受我的约束。
这就是GPT3,不按照我们自己的思维去做我们自己的事情,也是给后面的ChatGPT做了一个铺垫。
GPT3 三种模式对比
-
Zero-shot
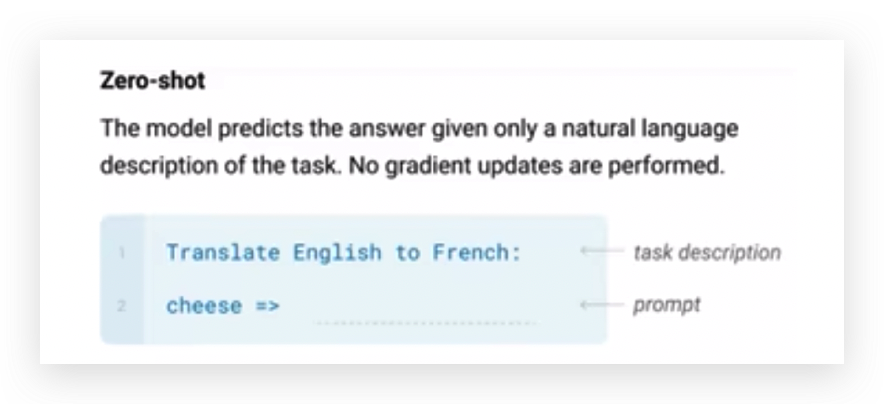
不管我输入什么,后面都会加上提示,比如把英文转换成法语,接下来就输出了法语。
-
One-shot

为了让它更好的理解我说的意思,我给它举了一个例子。
举一个例子,这个例子作为输入,我让你干什么,我给你举一个例子,你回答的时候可以参考这个例子。
这些例子都是我写到输入对话框中,一起给到模型,模型基于我写的例子,再往下输出。
-
Few-shot
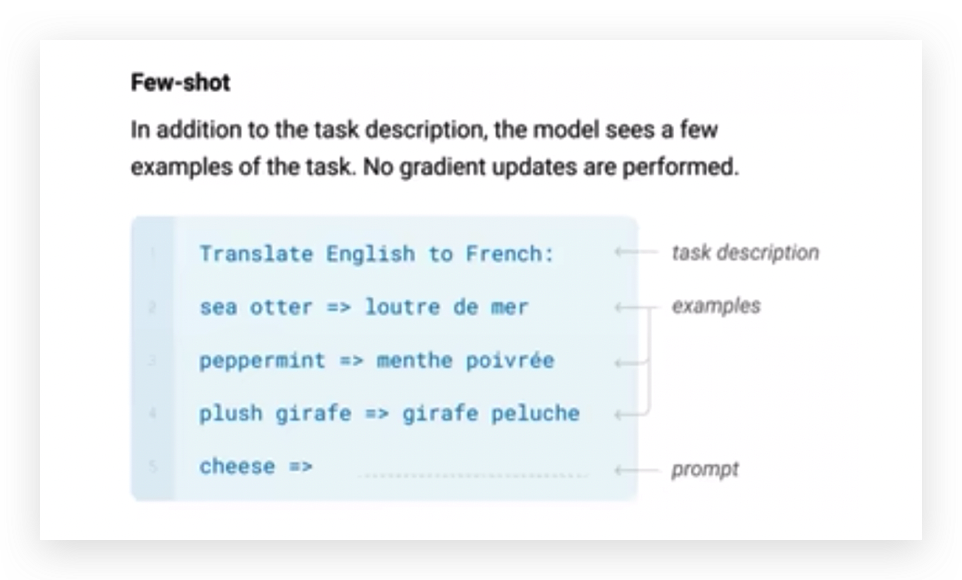
Few-shot是举多个例子。
这就是GPT3的基本思想。
Few-shot像在下游任务中又做了个简单的训练,比如举了三个例子,即三条数据,相当于把下游任务融入到了这个任务当中。
GPT3本质上还是一个生成式模型,它不需要下游任务,下游任务可以放到Few-shot或放到One-shot中。
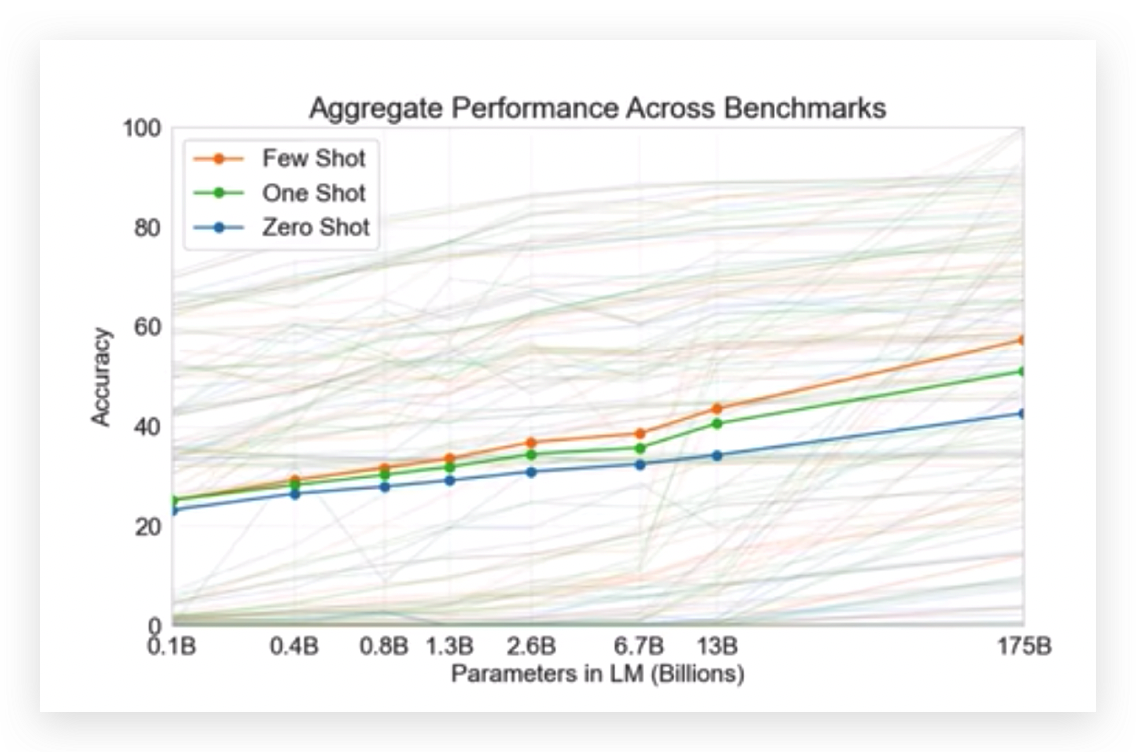
横轴表示语言模型的大小, One-shot和Few-shot之间还是存在差异的,尤其是模型越大的时候,差异越明显,Few-shot效果更好一些。
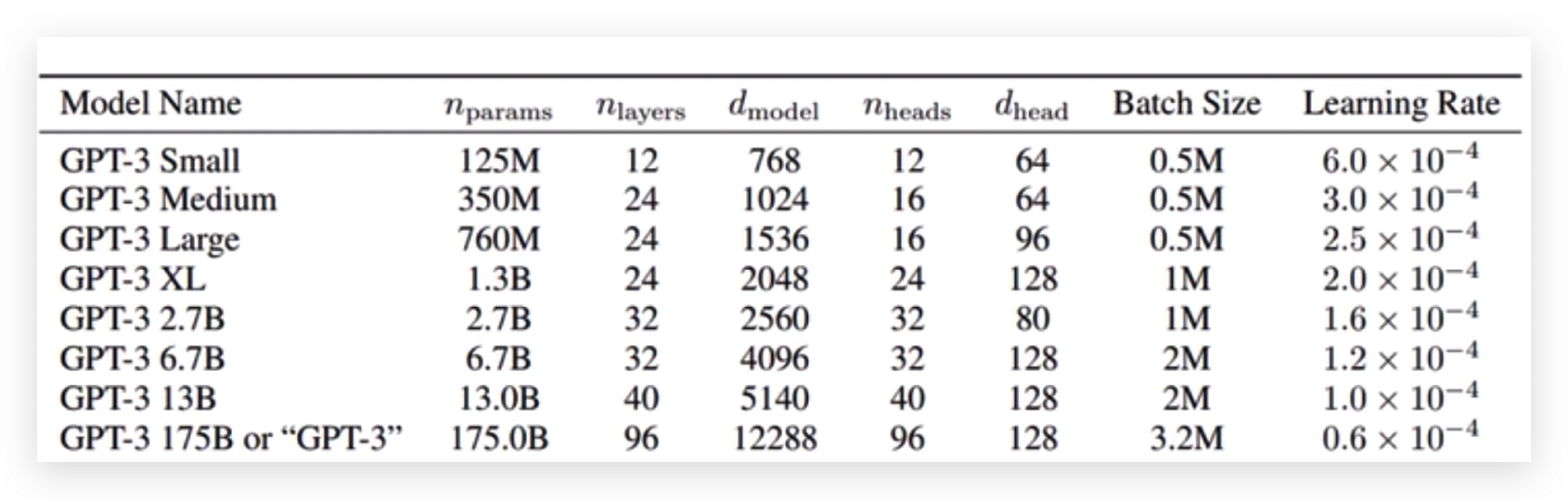
GPT3网络结构没有什么亮眼的,就是把Transformer做的更大了。
NLP哪家强,就看谁的模型更大,谁的数据更多。
OpenAI训练的GPT-3 1750亿个权重参数,每批次的训练数据大小是3.2M,这么大的量级,目前只有OpenAI大型GPU集群才能玩的转。
准备训练数据
准备数据不难,但数据又多又干净才不容易准备。
OpenAI对收集到的数据有质量的判断,对于网页的爬取会设计一些算法去评估哪些网页要求比较低或可信度比较低的,它会把这些网页过滤掉,只爬一些有价值的网页。
GPT三代算法告诉我们一件事,这种生成式语言模型能解决一切的事情,即以不变应万变。以后的趋势是GPT这个系列一家独大,可能再过10年NLP的其他分支就不存在了,因为一个通用大模型可以解决所有的事情,干嘛还要每个NLP分支做自己的东西呢。
CODEX
程序猿一般都是面向百度、Google编程,而GPT面向github编程。
使用GPT-3模型,训练数据是所有的github数据,进行重新训练(注意不是微调)。
github和OpenAI都是微软的,所以CODEX拿到github的数据很容易,然后进行清洗和训练。
10年之内不用考虑程序猿能否被替代,因为ChatGPT以及现在的GPT还不能解决特别多的实际任务。
举例说明什么是有监督学习?
小时候家里没钱买电脑,就经常上网吧,我爸就教育我不要去网吧,我特别理解我爸,我还没嫌他穷呢他还嫌我上网吧。我爸教育我,你这么做是不对的,我爸给了明确的标签,有了标准答案,我下次去网吧的时候,就会想一想是我不对,不是我爸不对,那这次我就不去网吧了,这是一个有监督学习。
人工的给了一些标注,在预训练模型基础之上继续去学一学正确的说话逻辑,学一学怎样正确的回答问题。
ChatGPT提出的第一件事情就是不能再用无监督去做了,无监督不确定的东西太多了,它生出来的东西是好是坏都不好说,所以要限制它,它的语言能力已经非常强了,我们现在要让它继续去完成我们的任务,学我们说的话,办我们说的事,所以ChatGPT是有监督训练。
模型越大、参数越大并不是越好,文本模型越大,参数越多,结果越专一,越专一的结果可能并不是想要的,比如随便问一句话,永远回复的一样。
训练模型,希望模型学人类说话的逻辑,说人话办人事,让机器更像人,更符合人的逻辑的给你解释这些东西,而不是像原来的GPT3只是纯生成的模型,那下一步应该怎么办?
大家在问ChatGPT问题的时候,后面加一个提示,这些提示是经常问的问题,这些问题由人工标注,人工来回答。有了输入和输出,接下来训练GPT3.5模型,继续在它无监督的基础上再去做这个有监督任务,有监督学习就是我们希望它输出啥,就用这样的数据去训练它。

无监督学习任务中不可能有一个学习的过程,而有监督首先要解决的就是敏感话题,比如跳楼是一个不好的,得告诉你不要去跳楼。
-
第一个要标注答案,不要是有“毒”的东西
-
第二个应该是跟我们聊天近似的,要一些有感情的东西,而不是像专家一样教育我
这得需要有监督去做,通过有监督解决无监督解决不了的事情,要说人话、办人事。
强化学习
先来玩个游戏,来了解下什么是强化学习,

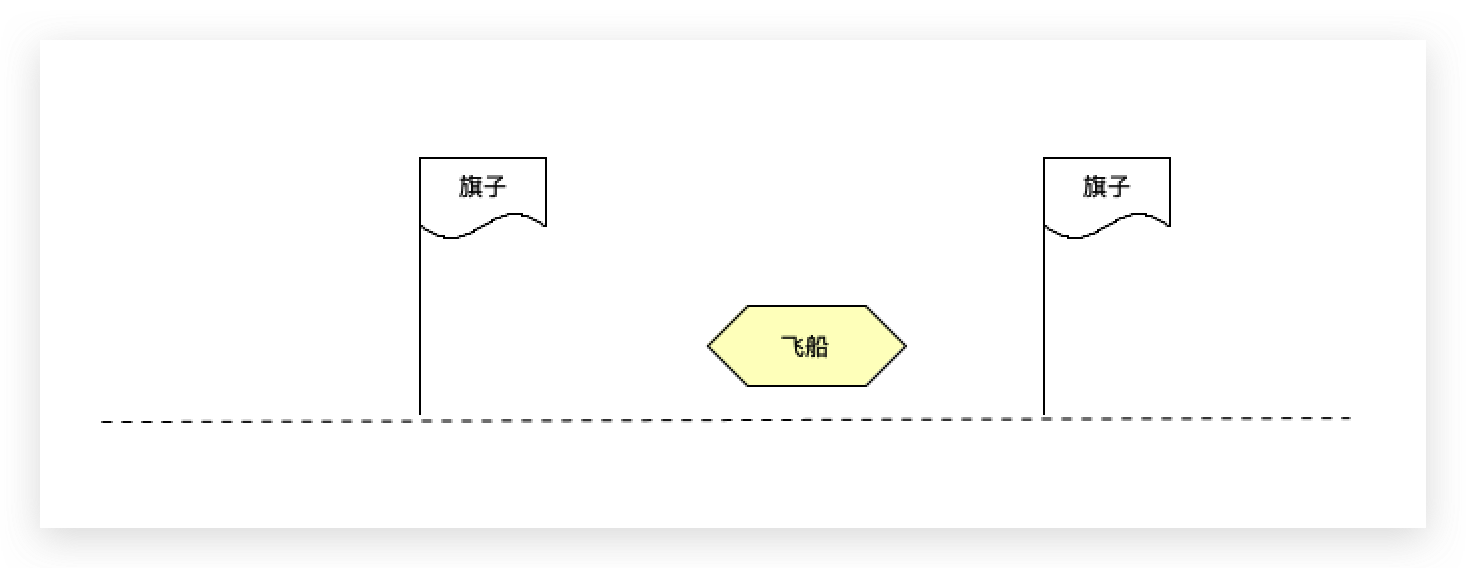
右边有一个飞船,想降落在2个旗子当中,某一时刻的飞船可以往左走,也可以往右走,那飞船应该往哪边走?
上图中的飞船想要落到两个棋子中间需要往左走,飞船往左走的时候给它一个奖励,表示走对了,如果往右走了,奖励就很低,表示走错了。
飞船降落的过程,不要把它想象成一个连续的,当它是离散的,比如它是由1000个step组成,每一个step都有当前的一个状态 当前位置以及action(action表示接下来往那边走)这些属性。
我们所关注的东西,并不是一个片面的,即并不是每一步走的怎么样,而是要看最终的一个累加的结果。

这是目标函数,希望全局奖励越高越好。
不关注每一步怎么样,而是看全局,飞船完成一个完整的过程之后总的奖励,这就是强化学习基本的思想。
有这样一个序列,{s1,a1,s2,a2,....,st,at},表示飞船在每一个step的状态和action,
类似于见人(s1)说人话(a1),见鬼(s2)说鬼话(a2)。
那每一步如何走才能得到更多的奖励呢,这就需要训练神经网络了。
把a1输入到神经网络中,不需要知道a1是人还是鬼,神经网络输出这个状态下的预测结果是什么。
或者把这个图片作为输入到神经网络中,
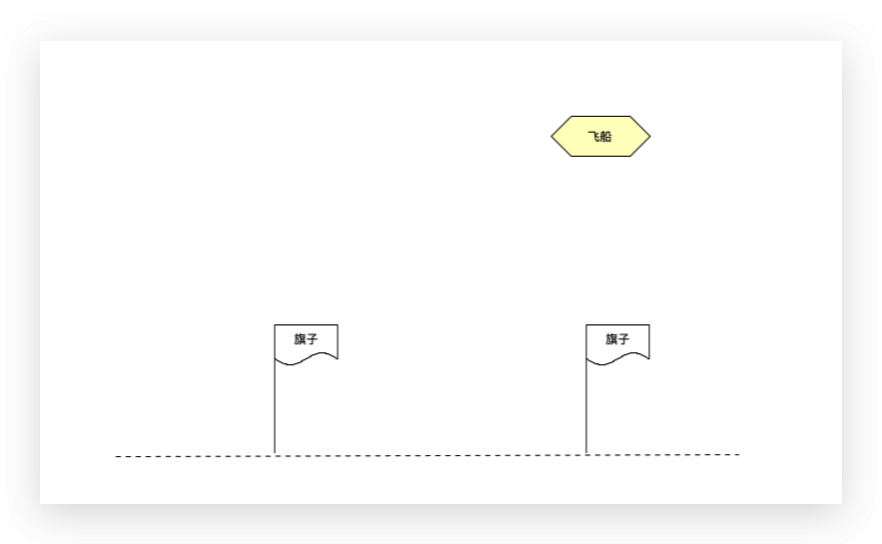
神经网络会告诉飞船往左走。
状态和动作可以跟神经网络联系在一起,动作做的对做的准奖励才高。
为了让奖励做的高,神经网络的权重参数要不断更新。
通过奖励最高这种机制来训练神经网络,让神经网络知道输入一个状态,怎么样输出一个好的答案。
在ChatGPT中,状态是你输入的一句话,action是输出的一句话。
象棋、围棋等游戏也都可以设置奖励,阿法尔狗大战李世石就是用强化学习来做的。
用强化学习,得需要有什么?
得有一个奖励,得知道这一步到底做的对不对,做的不对的话,再改正,所以需要单独训练一个可以预测奖励的模型。
输入一句话到奖励模型,输出一个reward(奖励值)。
为什么ChatGPT没有用纯的监督学习来训练?不用强化学习行不行?
-
什么是监督学习
比如我上网吧,我爸给我一顿揍,这是监督学习,我爸告诉我,我干这件事情是错的。
我爸揍我的强弱程度决定了这件事我是错的多还是错的少,这是监督学习,直接告诉你这件事情是对的还是错的。
-
什么是强化学习?
我去网吧了,我爸回家哭了,我没哭,我寻思我爸咋哭了,是不是我哪做的不对?是不是以后不上网吧就行了呢? 强化学习并不是哪件事情是对还是错,而是告诉你,你做的这个东西,可能是好的,可能也是不好的,但没有告诉你有多不好或有多坏,你接下来怎么去更新并不是一个固定的机制,需要我去思考的,不是固定的。
再比如导师给你安排了一个项目,但没有说具体该怎么做。
导师说:你态度不端正,思考问题的方式不行。
说你不对,但没有告诉你哪块不对,也没有告诉你这个项目第一步怎么做,第二步怎么做,不会告诉你具体的每一件事。
如果导师告诉你就是有监督学习,你输入一个东西,我告诉你答案,但是没有锻炼到你。
你回到家去思考,想到一个解决方式,就先这么改进吧,改进完之后,给导师看,导师又给一顿骂,在反复找导师的过程中会思考一个问题,怎么做更迎合导师的思维。
强化学习并不是一个固定的输入输出模式,怎么做能让输出的东西更符合想要的答案,强化学习不是给你的一个答案,而给的是导师的满意程度。
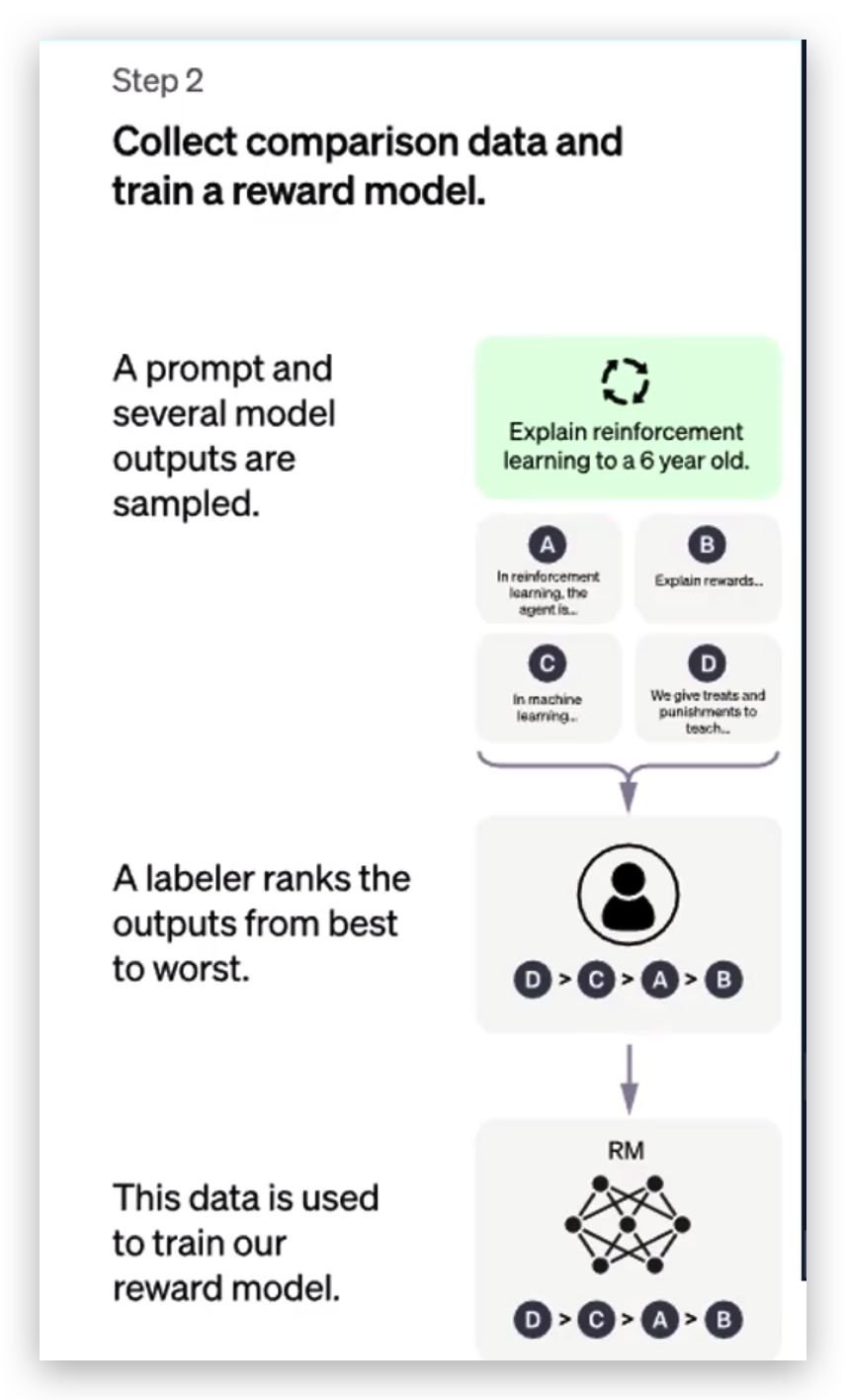
需要额外再训练一个奖励模型,第一步少不了人工标注。
比如随便问一个问题“你瞅啥?”,产生四种答案:瞅你咋滴、没瞅啥、我就随便看看、你说啥。
导师对4个答案打分,对于每一个输出都要人工打分,人工打分之后,再做一个排序操作。
人工打分需要知道什么样的打分高,什么样的打分低。
怎么训练奖励模型,输入一句话,输出一个分值?
正常的语言模型要输出接下来预测的每一个词的概率,比如一共有3万个词,每个词的概率是多少。 奖励模型不是这样了,它把最后的输出层改了,去预测一个得分值。
奖励模型还是基于Transformer去做的,只是以前是一个分类任务,3万个词,预测每个词的得分,现在变成了预测一个得分值。
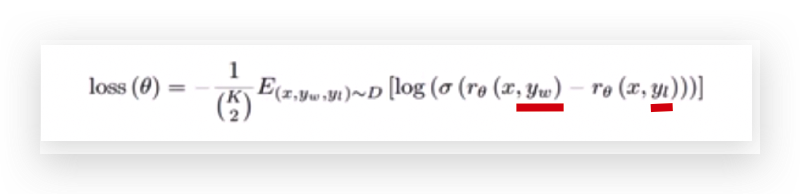
通过这个损失函数去猜怎么训练的,这个奖励模型是一个小的6亿参数的GPT。
x是“你瞅啥”,
Yw是得分最高的那一个,
Yl是得分较低的那一个,
w是“瞅你咋滴”,
l是“我就随便看看”。
得分最高和最低两者差异越大越好,
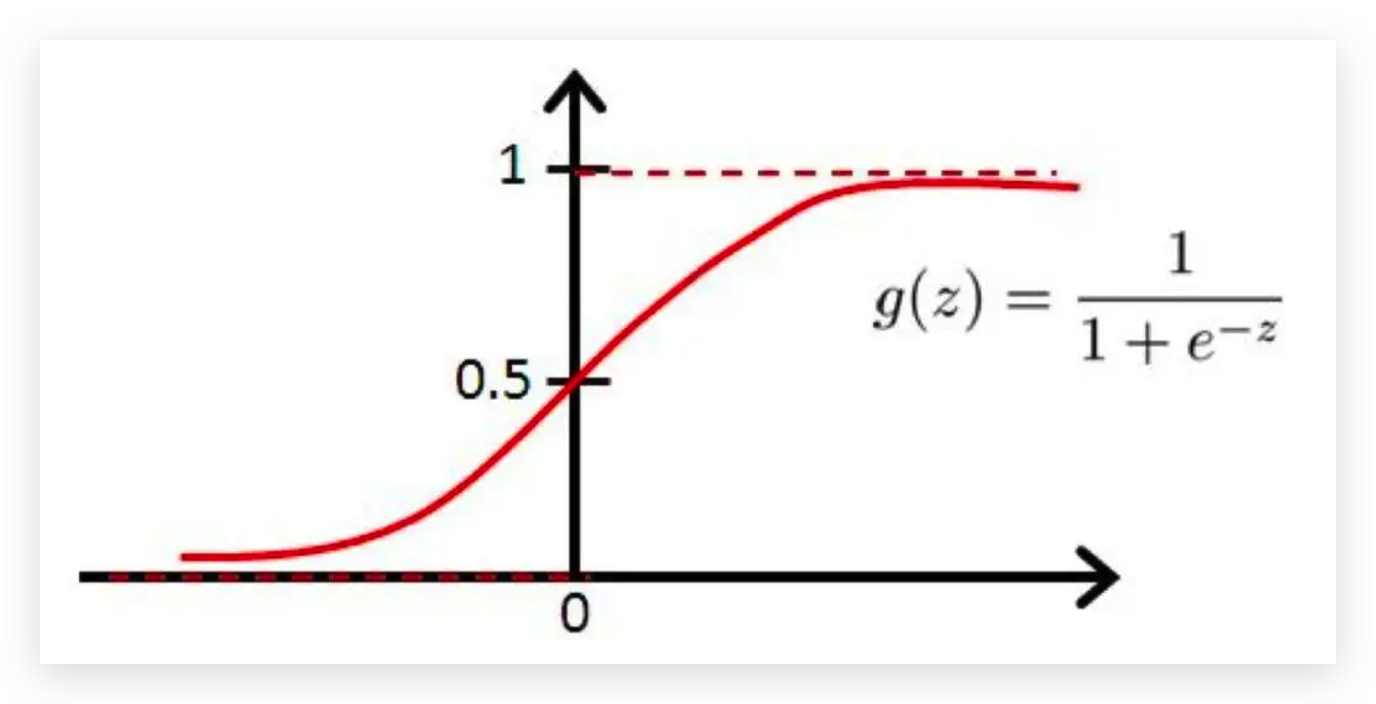
sigmod函数,差异越大,得到的结果越接近1。 得分高的和得分低的没啥差异的化,可能就接近0,效果就越差。
传入log对数函数中,越接近1的,损失越小,越接近0的 ,损失越大。
标注分高的和标注分低的,起码在奖励得分上要高出一个等级,越高越好。 输入和输出是由人工标注的。
比如k=4,表示4句话,比如选“瞅你咋滴”和"随便看看"以及"没瞅啥","你说啥",从中选择2个, 所有的输出结果都是由人工标注的,在所有标注中任选其中的2个,k个里面选2个来计算,损失越低越好。
奖励模型怎么去做,首先人工标注,想要的,得分高点;不想要的,得分低点。
奖励模型并不需要特别大的模型,若是1750亿权重参数的模型,验证集准确率很低,效果一般,小版本6亿参数的模型却恰恰好。
继续训练这个模型得到一个初始化模型,最后的一个圈层 当中正常是要做一个多分类,现在把多分类用FC预测一个得分值。
往ChatGPT模型中输入“你瞅啥”,输出“没瞅啥”,
输出的东西要往奖励模型中传入,奖励模型会帮你输出一个分数,分数低的话,要更新ChatGPT模型的权重参数。
通过强化学习的方式就可以无限制的更新我们的模型了, 奖励模型会判断你输入给我的东西是不是我想要的,是我想要的,分高一点,不是我想要的,分低一点, 根据分的高低更新ChatGPT。
比如经过了一个epoch(一个epoch等于使用训练集中的全部样本训练一次的过程)之后,ChatGPT更新了一次,奖励模型也要进行更新,交替训练,交替更新,这就是强化学习当中的基本思想。
ChatGPT和奖励模型都是在原始的GPT中衍生过来的。
我们需要的模型就是通过RL来更新的,模型输出的句子通过奖励模型得到得分,再反馈,而且模型更新一阵后,也需要再更新奖励模型。
目标函数

这是目标函数,首先要更新的是ChatGPT模型,这是最核心的,模型在更新的过程中,希望x传入这个模型之后得到的奖励越高越好,对应着第一项越大越好,

第一项后面是一个减号, 对于目标函数来说,希望减去的第二项越小越好。
贝塔系数(β)是一个权重, SFT表示有监督渲染出来的模型,把x输入之后,有监督模型会帮我们生成一个结果,强化学习ChatGPT也会生成一个结果,强化学习跟有监督之间的一个pk,两者做了一个除法,输出是一个句子,可以把输出一个句子叫输出一个分布或者输出它的概率分布,这时强化学习认为输入这个句子每个词的概率分布合在一起。
右边是有监督模型,它输出的句子每个词的概率分布合在一起。
计算两个分布之间的差异。
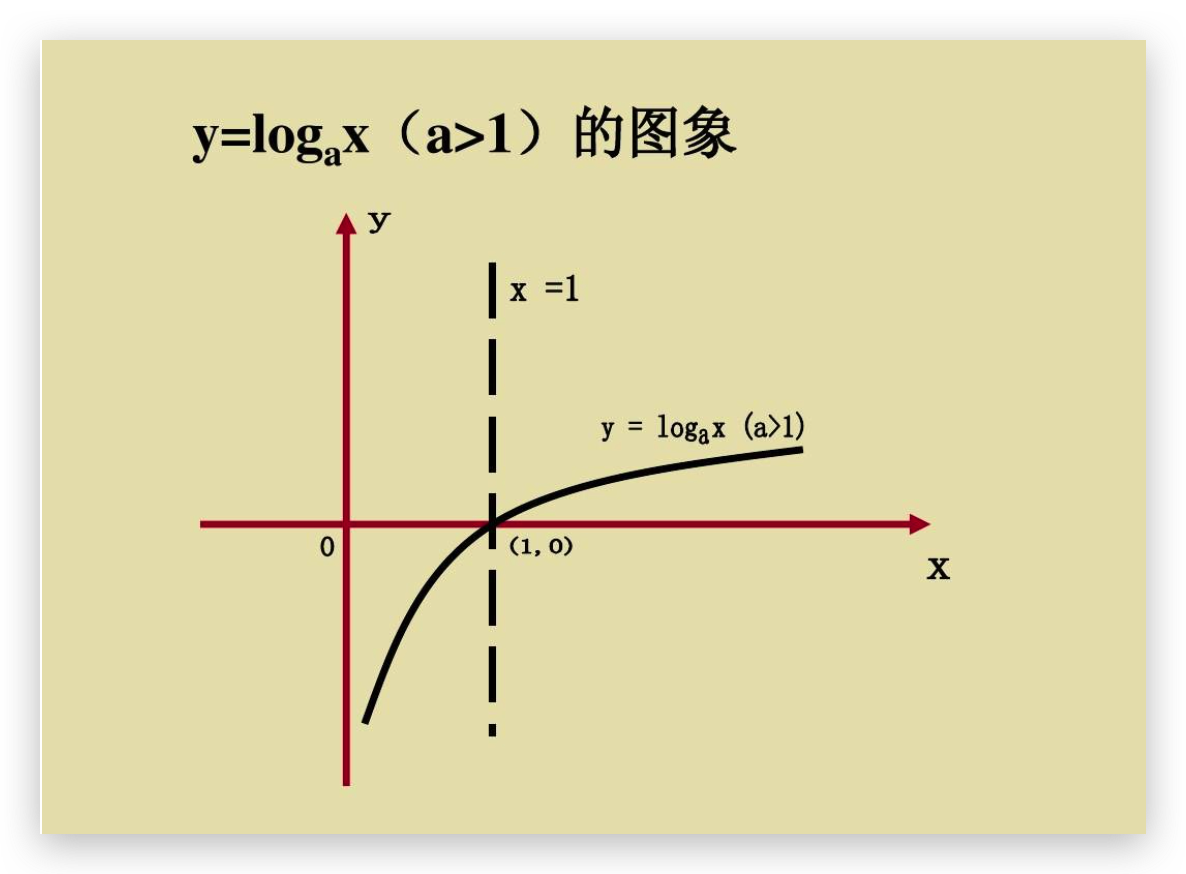
前面是一个对数,对数当中只有为1的时候最小。
除法2/2=1、3/3为1,两者旗鼓相当。
强化学习思维会比较发散,那怎么做才能得分高?可能会尝试很多东西。
类比怎么让导师满意我?我给他转100万和用监督模型学习,结果导师可能都高兴, 但现在越学越离谱了,因为强化学习不太可控,强化学习说你把导师揍一顿,他下次就不敢说你了,会和人工标注的(有监督)差异非常大。
强化学习要探索,我不知道正确答案,但我不按套路出牌,我可以任意去发挥,它很容易发散,比如我从9楼跳下去,它说你从天台跳,9楼可能摔不死。
需要降低强化学习和有监督的差异,强化学习太离谱了,别让它那么离谱,减去这个差异,要以人为主,跟有监督模型(人工标注的)做对比,你要去学怎么样接近人类的思维。

这个是泛化能力,之前是没有的,额外做了拓展,即做了一个对比实验。
模型能生成你的对话,但模型不仅仅生成对话。
类比你的体育天赋特别好,一般跑步跳远很棒的人,踢足球也是很好的。
加了一些下游任务,在不同的下游任务里面也要预测的好,比如情感分析、机器翻译、文本摘要,在这些例子中也会做的不错,所以叫它泛化能力。
就在当前这个前提上,可能人家又加了一些业务场景,在其他业务场景中也要做的好,这就是一个多目标损失函数 ,而不仅是一项做的好。
强化学习要以人为主,尽可能跟有监督是类似的,最后再结合一个泛化能力,应用到不同的拓展任务当中,效果也要好才行。
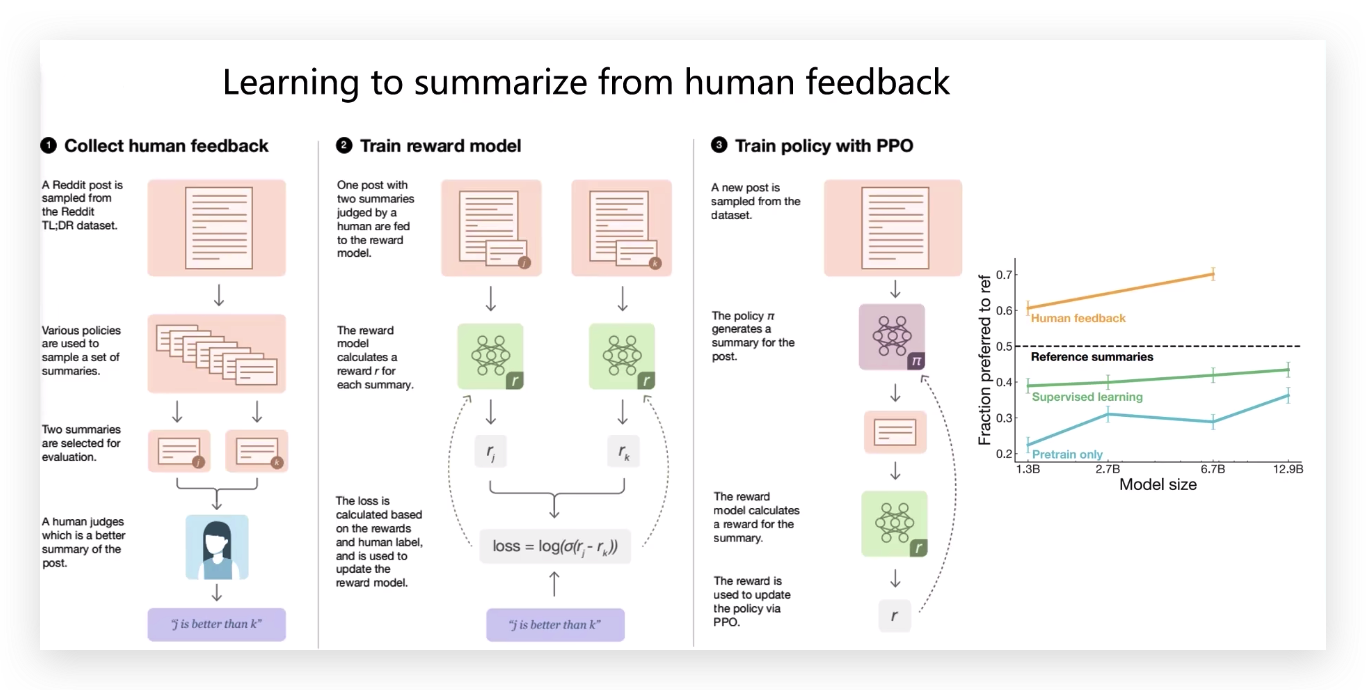
上面所将的ChatGPT思想出自2020年的一篇论文。
它是做文本摘要的,怎么把文本摘要做的好?
第一步:
人工的去收集一些数据,这个文本应该有哪些摘要。
在语言模型当中再加上下游任务。
第二步:
训练一个奖励模型,奖励模型希望得分高的和得分低的差异越大越好,要让模型知道这样一个事。
再用PPO损失函数去渲染整个模型。
OpenAI做了个分析
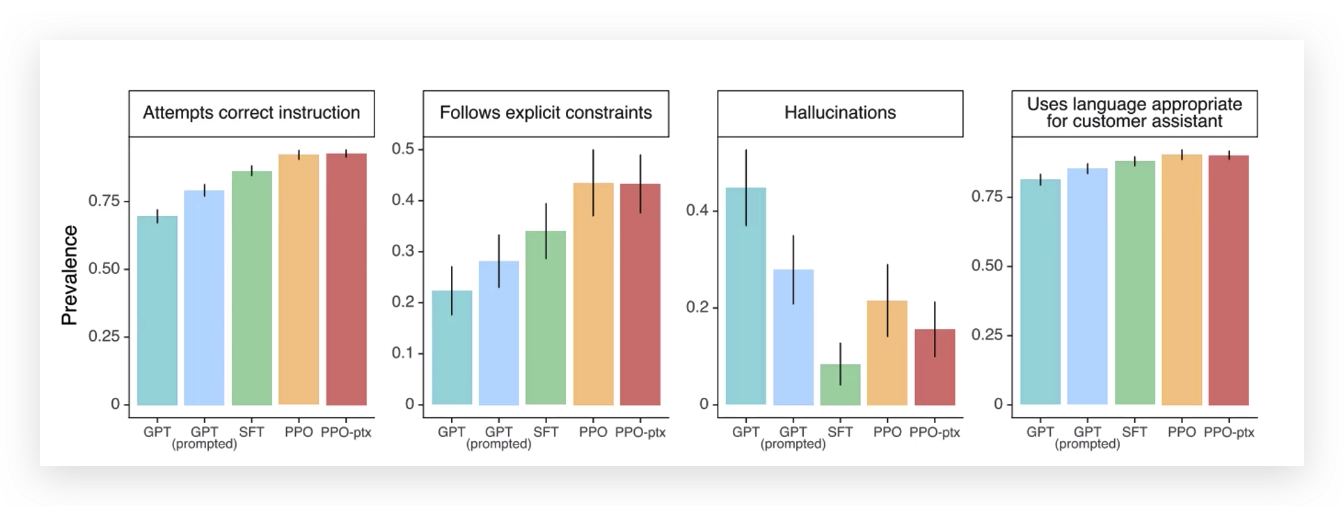
GPT、给GPT加了提示、有监督模型、PPO(强化学习思想)、ptx(泛化能力)这几个模型的对比效果图。
第一个比较维度,问ChatGPT能不能争取有效的回答。
第二个维度,有没有满足限制条件,比如请你用一个女生的口吻来和我说话。
第三个维度,模型输出的有没有太离谱的,为什么解释以人本,其实就是以这个图思考的,
第四个维度,能不能帮我们解决常见的事情,比如充当一个助手。
相关文章:
ChatGPT原理简介
承接上文GPT前2代版本简介 GPT3的基本思想 GPT2没有引起多大轰动,真正改变NLP格局的是第三代版本。 GPT3训练的数据包罗万象,上通天文下知地理,所以它会胡说八道,会说的贼离谱,比如让你穿越到唐代跟李白对诗,不在一…...
从0搭建Hyperledger Fabric2.5环境
Hyperledger Fabric 2.5环境搭建 一.Linux环境准备 # root登录 yum -y install git curl docker docker-compose tree yum -y install autoconf autotools-dev automake m4 perl yum -y install libtool autoreconf -ivf # 安装jq相关包 cd /opt git clone --recursive https…...

Rust每日一练(Leetday0026) 最小覆盖子串、组合、子集
目录 76. 最小覆盖子串 Minimum Window Substring 🌟🌟🌟 77. 组合 Combinations 🌟🌟 78. 子集 Subsets 🌟🌟 🌟 每日一练刷题专栏 🌟 Rust每日一练 专栏 Gola…...

c# 从零到精通-ArrayList-Hashtable的操作
c# 从零到精通-ArrayList-Hashtable的操作 1、ArrayList的操作 using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Collections; namespace Test11 { class Program { static void Main(string[] args) { ArrayList list …...

pnpm带来了什么
首先 pnpm 和 npm yarn 一样是包管理工具,他解决了npm 和 yarn 存在的一些问题 npm3之前每个依赖都是一层嵌套一层的,每个依赖里都有node_modules 用来存放依赖所需的依赖包导致重复下载的依赖包很多,一层层嵌套,嵌套很深&#x…...
图像分类模型嵌入flask中开发PythonWeb项目
图像分类模型嵌入flask中开发PythonWeb项目 图像分类是一种常见的计算机视觉任务,它的目的是将输入的图像分配到预定义的类别中,如猫、狗、花等。图像分类模型是一种基于深度学习的模型,它可以利用大量的图像数据来学习图像的特征和类别之间…...
GIT安装教程(入门)
目录 前言 Git作者 官网 GIT优点 GIT缺点 为什么要使用 Git 下载以及安装步骤 一、官网下载 二、GIT安装步骤 1、安装get程序 2、许可声明 3、选择安装路径 4、选择git组件 5、创建菜单名称 6、 git文件默认编辑器 7、设置新存储库中初始分支的名称 8、调整Pa…...

全志V3S嵌入式驱动开发(触摸屏驱动)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 所谓的触摸屏,其实就是在普通的lcd屏幕之上,再加一层屏而已。这个屏是透明的,这样客户就可以看到下面lcd屏幕的…...

死信队列详解
什么是死信队列? 在消息队列中,执行异步任务时,通常是将消息生产者发布的消息存储在队列中,由消费者从队列中获取并处理这些消息。但是,在某些情况下,消息可能无法正常地被处理和消耗,例如&…...
:北京卷I)
我用ChatGPT写2023高考语文作文(五):北京卷I
2023年 北京卷 I 适用地区:北京 “续航”一词,原指连续航行,今天在使用中被赋予了新的含义,如为青春续航、科技为经济发展续航等。 请以“续航”为题目,写一篇议论文。 要求:论点明确,论据充实&…...
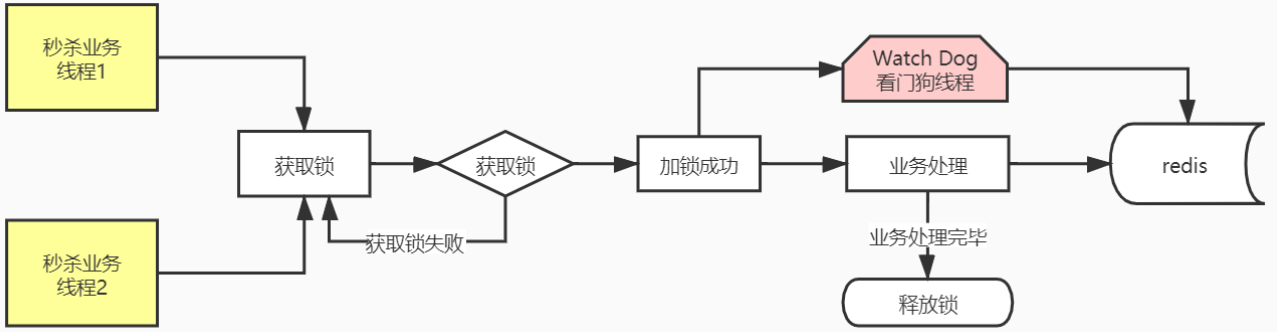
《微服务实战》 第二十八章 分布式锁框架-Redisson
前言 Redisson 在基于 NIO 的 Netty 框架上,充分的利⽤了 Redis 键值数据库提供的⼀系列优势,在Java 实⽤⼯具包中常⽤接⼝的基础上,为使⽤者提供了⼀系列具有分布式特性的常⽤⼯具类。使得原本作为协调单机多线程并发程序的⼯具包获得了协调…...

局部搜索,变邻域搜索算法
目录 局部搜索 02 变邻域搜索算法 局部搜索 1.1 局部搜索是什么玩意儿? 官方一点:局部搜索是解决优化问题的一种启发式算法。对于某些计算起来非常复杂的优化问题,比如各种NP-难问题,要找到最优解需要的时间随问题规模呈指数增长,因此诞生了各种启发式算法来退而求其次…...

软件工程实训——第一天
第一天 前后分离 前端:android 后端:springbootmbatis-plus 高心星 软件工程的思维来开发项目 问题定义 可行性研究 需求分析 概要设计 详细设计 编码 测试 维护 需求分析 1.用户的信息管理 2.新增支出 3.新增收入 4.支出统计 5.收入…...
嵌入式C语言中if/else如何优化详解
观点一(灵剑): 前期迭代懒得优化,来一个需求,加一个if,久而久之,就串成了一座金字塔。 当代码已经复杂到难以维护的程度之后,只能狠下心重构优化。那,有什么方案可以优雅…...

【LSTM】读取时间序列数据 | 时间序列数据的小批量划分方法
由于序列数据本质上是连续的,因此我们在处理数据时需要解决这个问题。当序列过长而不能被模型一次性全部处理时,我们希望能拆分这样的序列以便模型方便读取。 Q:怎样随机生成一个具有n个时间步的mini batch的特征和标签? A&…...
K8s in Action 阅读笔记——【12】Securing the Kubernetes API server
K8s in Action 阅读笔记——【12】Securing the Kubernetes API server 12.1 Understanding authentication 在上一章中,我们提到API服务器可以配置一个或多个认证插件(授权插件也是同样的情况)。当API服务器接收到一个请求时,它…...
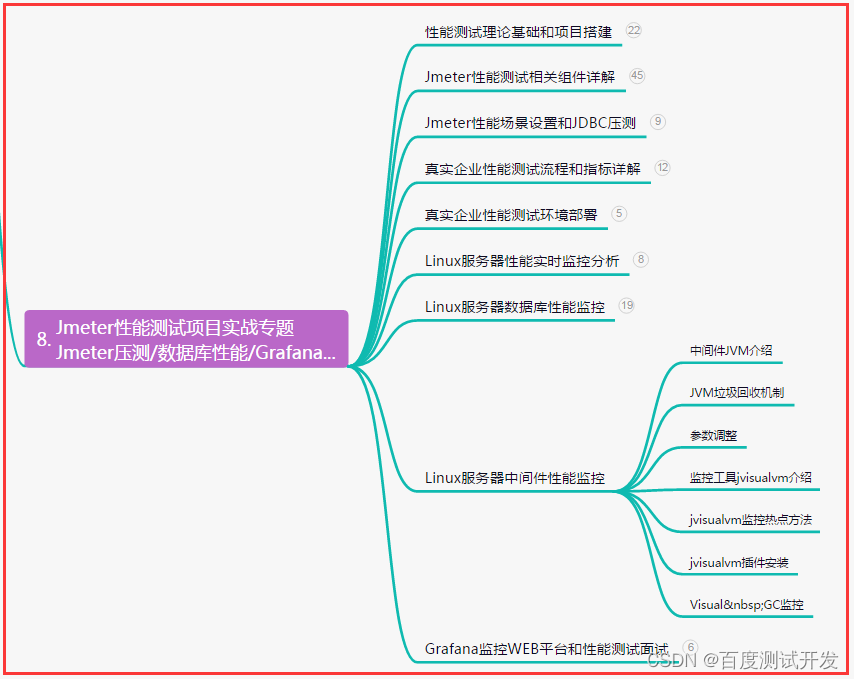
爆肝整理,3个月从功能进阶自动化测试,一跃成测试卷王...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 首先先了解自动化…...

人生这场概率游戏,怎么玩
只会标准答案,是不可救药的愚蠢 那么为了便于理解,我用一些典型的案例来讲解,什么是概率游戏,以及这个游戏,应该怎么玩。 比如典型的相亲,婚恋。人生大事,用标准答案来说,你的意中人…...
Redis笔记
缓存过期时间很重要!redis是单线程的 对于内存过多的3中方案: 惰性删除: 在定时删除的基础上,对于已经过期了的数据,redis的随机选择算法一直没有选中这个数据,所以导致它就一直没被删除,但是…...

centos 安装supervisor并运行网站
前言 之前一直用宝塔的**进程守护管理器【Supervisor】**来启动一些项目,如ThinkPHP、Hyperf的项目,或laravel的一些命令。如果不用宝塔怎么办呢? 一、简介[supervisor] [Supervisor] 是用Python开发的一个client/server服务,是Linux/Unix系统下的一个进程管理工具,不支…...

Nginx server_name 配置说明
Nginx 是一个高性能的反向代理和负载均衡服务器,其核心配置之一是 server 块中的 server_name 指令。server_name 决定了 Nginx 如何根据客户端请求的 Host 头匹配对应的虚拟主机(Virtual Host)。 1. 简介 Nginx 使用 server_name 指令来确定…...

【python异步多线程】异步多线程爬虫代码示例
claude生成的python多线程、异步代码示例,模拟20个网页的爬取,每个网页假设要0.5-2秒完成。 代码 Python多线程爬虫教程 核心概念 多线程:允许程序同时执行多个任务,提高IO密集型任务(如网络请求)的效率…...
)
Typeerror: cannot read properties of undefined (reading ‘XXX‘)
最近需要在离线机器上运行软件,所以得把软件用docker打包起来,大部分功能都没问题,出了一个奇怪的事情。同样的代码,在本机上用vscode可以运行起来,但是打包之后在docker里出现了问题。使用的是dialog组件,…...

【C++进阶篇】智能指针
C内存管理终极指南:智能指针从入门到源码剖析 一. 智能指针1.1 auto_ptr1.2 unique_ptr1.3 shared_ptr1.4 make_shared 二. 原理三. shared_ptr循环引用问题三. 线程安全问题四. 内存泄漏4.1 什么是内存泄漏4.2 危害4.3 避免内存泄漏 五. 最后 一. 智能指针 智能指…...

【Linux系统】Linux环境变量:系统配置的隐形指挥官
。# Linux系列 文章目录 前言一、环境变量的概念二、常见的环境变量三、环境变量特点及其相关指令3.1 环境变量的全局性3.2、环境变量的生命周期 四、环境变量的组织方式五、C语言对环境变量的操作5.1 设置环境变量:setenv5.2 删除环境变量:unsetenv5.3 遍历所有环境…...
Ubuntu系统多网卡多相机IP设置方法
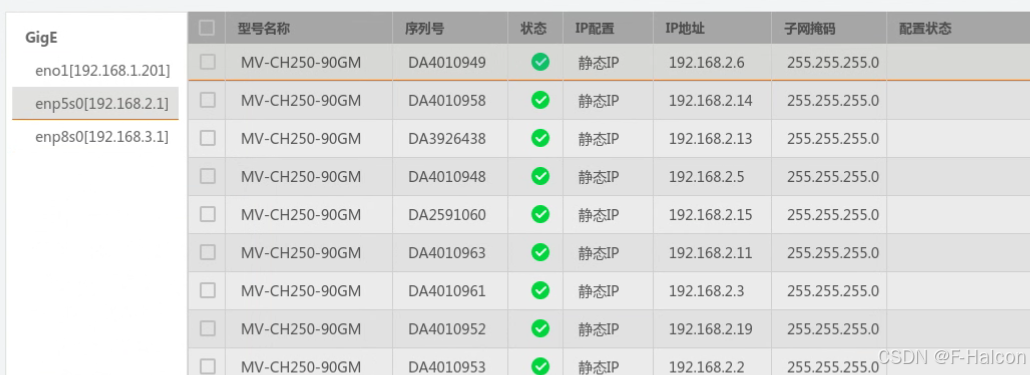
目录 1、硬件情况 2、如何设置网卡和相机IP 2.1 万兆网卡连接交换机,交换机再连相机 2.1.1 网卡设置 2.1.2 相机设置 2.3 万兆网卡直连相机 1、硬件情况 2个网卡n个相机 电脑系统信息,系统版本:Ubuntu22.04.5 LTS;内核版本…...

从物理机到云原生:全面解析计算虚拟化技术的演进与应用
前言:我的虚拟化技术探索之旅 我最早接触"虚拟机"的概念是从Java开始的——JVM(Java Virtual Machine)让"一次编写,到处运行"成为可能。这个软件层面的虚拟化让我着迷,但直到后来接触VMware和Doc…...

WEB3全栈开发——面试专业技能点P7前端与链上集成
一、Next.js技术栈 ✅ 概念介绍 Next.js 是一个基于 React 的 服务端渲染(SSR)与静态网站生成(SSG) 框架,由 Vercel 开发。它简化了构建生产级 React 应用的过程,并内置了很多特性: ✅ 文件系…...

ArcGIS Pro+ArcGIS给你的地图加上北回归线!
今天来看ArcGIS Pro和ArcGIS中如何给制作的中国地图或者其他大范围地图加上北回归线。 我们将在ArcGIS Pro和ArcGIS中一同介绍。 1 ArcGIS Pro中设置北回归线 1、在ArcGIS Pro中初步设置好经纬格网等,设置经线、纬线都以10间隔显示。 2、需要插入背会归线…...

FOPLP vs CoWoS
以下是 FOPLP(Fan-out panel-level packaging 扇出型面板级封装)与 CoWoS(Chip on Wafer on Substrate)两种先进封装技术的详细对比分析,涵盖技术原理、性能、成本、应用场景及市场趋势等维度: 一、技术原…...