如何启动和关闭分布式集群
分布式集群是由多个节点组成的系统,可以提供高性能、高可用、高扩展的数据处理能力。本文介绍如何启动和关闭一个包含hadoop、zookeeper、hbase和spark的分布式集群。
目录
启动顺序
关闭顺序
启动和关闭hadoop
启动hadoop
关闭hadoop
查看网页
启动和关闭zookeeper
启动zookeeper
关闭zookeeper
查看状态
启动和关闭hbase
启动hbase
关闭hbase
查看网页
验证hbase
启动和关闭spark
启动spark
关闭spark
启动Spark History Server
查看网页
验证spark
启动顺序
启动分布式集群的顺序是:
- 先启动hadoop
- 再启动zookeeper
- 最后启动hbase和spark
这样可以保证各个组件之间的依赖关系和协调关系。
关闭顺序
关闭分布式集群的顺序是:
- 先关闭hbase和spark
- 再关闭zookeeper
- 最后关闭hadoop
这样可以避免数据丢失和服务异常。
启动和关闭hadoop
hadoop是一个分布式文件系统和计算框架,它提供了存储和处理海量数据的能力。hadoop主要由两个部分组成:HDFS(Hadoop Distributed File System)和YARN(Yet Another Resource Negotiator)。
启动hadoop
启动hadoop之前,需要先初始化hadoop的namenode,这是HDFS的主节点,负责管理元数据。只有在第一次启动时才需要执行这一步,以后就不用了。在namenode所在的节点上执行以下命令:
# 初始化namenode
hadoop namenode -format
然后,在namenode所在的节点上执行以下命令,启动HDFS:
# 启动HDFS
start-dfs.sh
接着,在resourcemanager所在的节点上执行以下命令,启动YARN:
# 启动YARN
start-yarn.sh
最后,可以在任意节点上执行以下命令,查看各个进程是否正常运行:
# 查看进程
jps
也可直接快捷启动HDFS和YARN:
start-all.sh如果输出结果中包含以下进程,则说明启动成功:
- NameNode:HDFS的主节点
- DataNode:HDFS的从节点,负责存储数据块
- ResourceManager:YARN的主节点,负责管理资源和调度任务
- NodeManager:YARN的从节点,负责执行任务
关闭hadoop
关闭hadoop时,只需要在任意节点上执行以下命令即可:
# 关闭hadoop
stop-all.sh
这个命令会自动停止所有的HDFS和YARN进程。
查看网页
如果想要查看hadoop的运行状态和数据情况,可以通过浏览器访问以下网址:
- http://192.168.1.100:9870/:这是namenode的网页界面,可以查看HDFS的概况、文件系统、快照等信息。
- http://192.168.1.100:8088/cluster/:这是resourcemanager的网页界面,可以查看YARN的概况、应用、队列等信息。
其中,192.168.1.100是namenode和resourcemanager所在节点的IP地址,如果你的IP地址不同,请自行替换。
启动和关闭zookeeper
zookeeper是一个分布式协调服务,它提供了一致性、可靠性、原子性等特性,可以用于实现分布式锁、配置管理、服务发现等功能。zookeeper由多个服务器组成一个集群,每个服务器都有一个唯一的ID,并且其中一个服务器会被选举为leader,负责处理客户端的请求。
启动zookeeper
启动zookeeper时,需要在每个服务器上执行以下命令:
# 启动zookeeper
zkServer.sh start
这个命令会在后台运行zookeeper,并输出日志到指定的目录。如果想要在前台运行zookeeper,并查看控制台输出的信息,可以执行以下命令:
# 启动zookeeper并输出日志到控制台
zkServer.sh start-foreground
关闭zookeeper
关闭zookeeper时,需要在每个服务器上执行以下命令:
# 关闭zookeeper
zkServer.sh stop
这个命令会停止zookeeper的进程,并删除相关的文件。
查看状态
查看zookeeper的状态时,有两种方法:
- 在每个服务器上执行以下命令,查看本地的状态:
# 查看本地状态
zkServer.sh status
这个命令会输出本地服务器的ID、角色(leader或follower)、连接数等信息。
- 在任意节点上执行以下命令,查看远程的状态:
# 查看远程状态
nc -v 192.168.1.100 2181
stat
这个命令会连接到指定的服务器(192.168.1.100是服务器的IP地址,2181是zookeeper的默认端口),并发送stat命令,然后输出远程服务器的ID、角色、连接数等信息。
启动和关闭hbase
hbase是一个分布式的列式数据库,它基于HDFS和zookeeper,提供了高性能、高可用、高扩展的数据存储和查询能力。hbase主要由两个部分组成:HMaster和HRegionServer。
启动hbase
启动hbase时,需要先确保hadoop和zookeeper已经启动,并且配置文件中指定了正确的HDFS和zookeeper地址。然后,在任意节点上执行以下命令即可:
# 启动hbase
start-hbase.sh
这个命令会自动启动一个HMaster进程和多个HRegionServer进程。HMaster是hbase的主节点,负责管理元数据和协调任务。HRegionServer是hbase的从节点,负责存储和处理数据。启动hbase时,会根据配置文件中指定的master节点来启动HMaster进程,如果没有指定,则随机选择一个节点。
关闭hbase
关闭hbase时,需要先确保所有的客户端连接已经断开,并且没有正在运行的任务。然后,在任意节点上执行以下命令即可:
# 关闭hbase
stop-hbase.sh
这个命令会自动停止所有的HMaster和HRegionServer进程。关闭hbase时,要保证HMaster节点没有挂掉,否则可能导致数据丢失或服务异常。
查看网页
如果想要查看hbase的运行状态和数据情况,可以通过浏览器访问以下网址:
- http://192.168.1.100:16010/:这是HMaster的网页界面,可以查看hbase的概况、表、快照等信息。
其中,192.168.1.100是HMaster所在节点的IP地址,如果你的IP地址不同,请自行替换。
验证hbase
如果想要验证hbase是否正常工作,可以通过交互式shell来操作hbase。在任意节点上执行以下命令,打开交互式shell:
# 打开交互式shell
hbase shell
然后,在交互式shell中输入各种命令,例如:
# 列出所有表
list# 创建一个表test,有两个列族cf1和cf2
create 'test', 'cf1', 'cf2'# 插入一条数据到test表中,行键为row1,列族为cf1,列为c1,值为v1
put 'test', 'row1', 'cf1:c1', 'v1'# 查询test表中row1行的所有数据
get 'test', 'row1'# 关闭然后删除test表
disable 'test'
drop 'test'
这些命令可以对hbase进行基本的增删改查操作。如果想要了解更多的命令和用法,可以参考官方文档或者输入help命令。
启动和关闭spark
spark是一个分布式的计算框架,它基于HDFS和YARN,提供了高性能、高可用、高扩展的数据处理能力。spark可以运行在多种模式下,例如standalone、yarn、mesos等。在本文中,我将介绍如何在yarn模式下启动和关闭spark。
启动spark
启动spark时,只需要在主节点上执行以下命令即可:
# 启动spark
start-all.sh
这个命令会自动启动一个SparkMaster进程和多个SparkWorker进程。SparkMaster是spark的主节点,负责管理资源和调度任务。SparkWorker是spark的从节点,负责执行任务。启动spark时,会根据配置文件中指定的master节点来启动SparkMaster进程,如果没有指定,则随机选择一个节点。
关闭spark
关闭spark时,只需要在主节点上执行以下命令即可:
# 关闭spark
stop-all.sh
这个命令会自动停止所有的SparkMaster和SparkWorker进程。
启动Spark History Server
Spark History Server是一个可选的组件,它可以提供历史任务的监控和分析功能。如果想要启动Spark History Server,需要在主节点上执行以下命令:
# 启动Spark History Server
start-history-server.sh
这个命令会在后台运行Spark History Server,并输出日志到指定的目录。
查看网页
如果想要查看spark的运行状态和数据情况,可以通过浏览器访问以下网址:
- http://192.168.1.100:8080/:这是SparkMaster的网页界面,可以查看spark的概况、应用、工作、执行器等信息。
- http://192.168.1.100:18080/:这是Spark History Server的网页界面,可以查看历史任务的概况、应用、作业、阶段等信息。
其中,192.168.1.100是主节点的IP地址,如果你的IP地址不同,请自行替换。
验证spark
如果想要验证spark是否正常工作,可以通过提交一个示例程序来测试spark。在任意节点上的spark根目录执行以下命令,提交一个计算圆周率的程序:
# 提交一个计算圆周率的程序
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client ./examples/jars/spark-examples_2.12-3.2.3.jar 10
这个命令会在客户端模式下提交一个程序到yarn上,并输出结果到控制台。如果输出结果中包含以下内容,则说明运行成功:
# 输出结果
Pi is roughly 3.1418
如果想要在集群模式下提交一个程序到yarn上,并在yarn上查看结果,可以执行以下命令:
# 提交一个计算圆周率的程序
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster ./examples/jars/spark-examples_2.12-3.2.3.jar 10
这个命令会在集群模式下提交一个程序到yarn上,并输出结果到日志文件中。可以通过yarn的网页界面或者日志目录来查看结果。
相关文章:

如何启动和关闭分布式集群
分布式集群是由多个节点组成的系统,可以提供高性能、高可用、高扩展的数据处理能力。本文介绍如何启动和关闭一个包含hadoop、zookeeper、hbase和spark的分布式集群。 目录 启动顺序 关闭顺序 启动和关闭hadoop 启动hadoop 关闭hadoop 查看网页 启动和关闭z…...

WLAN基本概述及简单组网配置
WLAN概述 WLAN即Wireless LAN(无线局域网),是指通过无线技术构建的无线局域网络。WLAN广义上是指以无线电波、激光、红外线等无线信号来代替有线局域网中的部分或全部传输介质所构成的网络。 家庭WLAN产品: 家庭Wi-Fi路由器:通过把有线网络信号转换成无线信号,供家庭电…...

响应式Web设计单元测试
响应式Web设计单元测试 一. 单选题 (共8题,40.0分)二. 多选题 (共5题,25.0分)三. 判断题 (共7题,35.0分) 一. 单选题 (共8题,40.0分) …...

linux计划任务管理
1. crond计划任务概述 什么是计划任务,计划任务类似于我们平时生活中的闹钟。 在Linux系统的计划任务服务crond可以满足周期性执行任务的需求。 crond进程每分钟会处理一次计划任务, 计划任务主要是做一些周期性的任务目前最主要的用途是定时备份数据 Schedule on…...

研一,有点迷茫。
作者:阿秀 校招八股文学习网站:https://interviewguide.cn 这是阿秀的第「277」篇原创 小伙伴们大家好,我是阿秀。 最近回答了不少大一大二研一在读的学习圈中学弟学妹的咨询问题,基本都是计算机学习、进度、疑惑等等相关的问题&a…...

【新版】系统架构设计师 - 软件工程
个人总结,仅供参考,欢迎加好友一起讨论 文章目录 架构 - 软件工程考点摘要软件工程概述软件能力成熟度模型软件过程模型瀑布模型原型化模型增量模型螺旋模型喷泉模型V模型迭代与增量的概念CBSD基于构件的模型(构件组装模型/基于构件的软件开发…...

html实现好看的个人介绍,个人主页模板3(附源码)
文章目录 1.设计来源1.1 主界面1.2 关于我界面1.3 教育成就界面1.4 项目演示界面1.5 联系我界面 2.效果和源码2.1 动态效果2.2 源代码2.2 源代码目录 源码下载 作者:xcLeigh 文章地址:https://blog.csdn.net/weixin_43151418/article/details/131263195 …...

某大厂工作3年,被劣驱良了。。。
最近在知乎上看到一个问题:编程界的劣驱良现象有哪些? 要想回答这个问题,首先要定义清楚,什么是「劣」什么是「良」? 如果你认为编程技术牛x就是「良」,编程技术差就是「劣」,那可以清楚的回答…...

爱奇艺大数据加速:从Hive到Spark SQL
01 导语 爱奇艺自2012年开展大数据业务以来,基于大数据开源生态服务建设了一系列平台,涵盖了数据采集、数据处理、数据分析、数据应用等整个大数据流程,为公司的运营决策和各种数据智能业务提供了强有力的支持。随着数据规模的不断增长和计算…...

c++构造函数的多个细节拷问
提问1 能在 构造函数里面调用 虚函数吗? 调用的 是这个类自己的 虚函数吗? 这个问题 等价于 虚函数表什么时候形成的? 回答1 答:在构造函数里面 可以调用虚函数哈 不过是父类的 子类对象还没有创建完成 所以 尽量不要在 构造里…...
Redis入门 - Lua脚本
原文首更地址,阅读效果更佳! Redis入门 - Lua脚本 | CoderMast编程桅杆https://www.codermast.com/database/redis/redis-scription.html Redis 脚本使用 Lua 解释器来执行脚本。 Redis 2.6 版本通过内嵌支持 Lua 环境。执行脚本的常用命令为 EVAL。 …...
Creating Serial Numbers (C#)
此示例展示如何使用Visual C#编写的Add-ins为文件数据卡生成序列号。 注意事项: SOLIDWORKS PDM Professional无法强制重新加载用.NET编写的Add-ins,必须重新启动所有客户端计算机,以确保使用Add-ins的最新版本。 SOLIDWORKS PDM Professio…...

pycharm使用之torch_geometric安装
正式安装之前要先查看一下torch的版本 一、查看torch版本 1、winR ,输入cmd 2、输入python 3、 输入import torch,然后输入torch.__version__,最后回车 可以看到我的torch版本是1.10.0 二、下载合适的版本 1、打开链接 https://pytorch-…...

spring-mvc 工作流程
一、概述 spring-mvc 主要是DispatcherServlet工作流程流程可以分为两块,第一块为DispatcherServlet的加载,第二块为请求处理 二、DispatcherServlet的加载 主要依靠三个对象 DispatcherServletRegistrationBean:实现了ServletContextInit…...

物联网Lora模块从入门到精通(六)OLED显示屏
一、前言 获取到数据后我们常需要在OLED显示屏上显示,本文中我们需要使用上一篇文章(光照与温湿度数据获取)的代码,在其基础上继续完成本文内容。 基础代码: #include <string.h> #include "board.h" #include "hal_ke…...
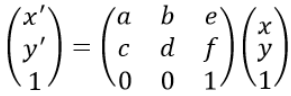
平面坐标变换(单应性变换/Homography变换)
单应性(homography)变换用来描述物体在两个平面之间的转换关系,可以用于描述平移、翻转、缩放、旋转、仿射变换等。其是对应齐次坐标下的线性变换,可以通过矩阵表示: 其中,H为单应性变换矩阵,假设变换前坐标为(x,y)&am…...

大数据项目常识
大数据项目 随着社会的进步,大数据的高需求,高薪资,高待遇,促使很多人都来学习和转行到大数据这个行业。学习大数据是为了什么?成为一名大数据高级工程师。而大数据工程师能得到高薪、高待遇的能力在哪?自…...

Linux系统:常用服务端口
目录 一、理论 1.端口分类 2.传输协议 3.常用端口 一、理论 1.端口分类 一个计算机最多有65535个端口,端口不能重复。Linux 只有 root 用户可以使用1024以下的端口。 表1 端口分类 端口范围说明公认端口(Well-KnownPorts)0 - 1023这类…...

前端和后端分别是什么?
从技术工具来看: 前端:常见的 html5、JavaScript、jQuery... 后端:spring、tomcet、JVM,MySQL... 毕竟,如果这个问题问一个老后端,他掰掰手指可以给你罗列出一堆的名词来,比如设计模式、数据库…...
)
Spring基础知识(一)
目录 1.Spring Framework 2.Spring Framework优点 3.Spring Framework的功能模块 4.Spring配置文件 5.Spring应用配置步骤 6.Spring的IoC是什么 7.IoC的理念 8.IoC体系的好处 9.Spring中的 IoC 容器 10.依赖注入的方式 1.Spring Framework Spring Framework即Spring框…...

零门槛NAS搭建:WinNAS如何让普通电脑秒变私有云?
一、核心优势:专为Windows用户设计的极简NAS WinNAS由深圳耘想存储科技开发,是一款收费低廉但功能全面的Windows NAS工具,主打“无学习成本部署” 。与其他NAS软件相比,其优势在于: 无需硬件改造:将任意W…...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...

突破不可导策略的训练难题:零阶优化与强化学习的深度嵌合
强化学习(Reinforcement Learning, RL)是工业领域智能控制的重要方法。它的基本原理是将最优控制问题建模为马尔可夫决策过程,然后使用强化学习的Actor-Critic机制(中文译作“知行互动”机制),逐步迭代求解…...

逻辑回归:给不确定性划界的分类大师
想象你是一名医生。面对患者的检查报告(肿瘤大小、血液指标),你需要做出一个**决定性判断**:恶性还是良性?这种“非黑即白”的抉择,正是**逻辑回归(Logistic Regression)** 的战场&a…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...

【碎碎念】宝可梦 Mesh GO : 基于MESH网络的口袋妖怪 宝可梦GO游戏自组网系统
目录 游戏说明《宝可梦 Mesh GO》 —— 局域宝可梦探索Pokmon GO 类游戏核心理念应用场景Mesh 特性 宝可梦玩法融合设计游戏构想要素1. 地图探索(基于物理空间 广播范围)2. 野生宝可梦生成与广播3. 对战系统4. 道具与通信5. 延伸玩法 安全性设计 技术选…...

使用 SymPy 进行向量和矩阵的高级操作
在科学计算和工程领域,向量和矩阵操作是解决问题的核心技能之一。Python 的 SymPy 库提供了强大的符号计算功能,能够高效地处理向量和矩阵的各种操作。本文将深入探讨如何使用 SymPy 进行向量和矩阵的创建、合并以及维度拓展等操作,并通过具体…...

视频行为标注工具BehaviLabel(源码+使用介绍+Windows.Exe版本)
前言: 最近在做行为检测相关的模型,用的是时空图卷积网络(STGCN),但原有kinetic-400数据集数据质量较低,需要进行细粒度的标注,同时粗略搜了下已有开源工具基本都集中于图像分割这块,…...