WRAN翻译
基于小波的图像超分辨残差注意力网络
Wavelet-based residual attention network for image super-resolution
代码: https://github.com/xueshengke/WRANSR-keras
摘要: 图像超分辨率技术是图像处理和计算机视觉领域的一项基础技术。近年来,深度学习在许多超分辨率方法上取得了显著进展。然而,我们发现大多数集中都是在设计更深更广的体系结构以提升图像超分辨质量,代价是计算量及速度。在本文中,我们提出了基于小波变换的图像超分辨的残差注意力网络。具体来说,我们网络的输入和标签是由二维小波变换生成的四个系数,通过将低频和高频细节明确地分离成四个通道,降低了网络的训练难度。我们提出多核卷积层作为网络的基本模块,它可以自适应聚合来自不同大小接受域的特征。我们采用残差注意力模块,包含通道注意和空间注意模块。因此,我们的方法可以以一种轻量级的方式关注通道和空间维度中更关键的底层模式。大量的实验验证了我们的WRAN的计算效率,并证明了与最先进的SR方法相比具有竞争力的结果。
关键词:超分辨、小波变换、多核卷积、通道注意、空间注意
1 简介
单图像超分辨率(Single image super-resolution, SR)是计算机视觉领域中一种重要的图像处理技术,即从相应的低分辨率(LR)版本恢复高分辨率(HR)图像。基于深度学习的图像SR近年来得到了广泛的关注[1-7]。它已经扩展到各种现实世界的应用,如医学成像[8-12]、视频监控[13-17]、遥感[18,19]、图像分类的先决条件[20,21]、检测[22]、识别[23,24]、去噪[25]等。
图像SR是出了名的具有挑战性,被称为是病态的,因为一个特定的LR图像对应多个对应的HR。这导致SR的解决方案通常是可处理的。在实际应用中,一般不存在每个HR图像的精确LR图像。因此,我们假设下采样的HR图像通过双三次插值[26]被认为是LR。从这个角度来看,一些细节不可避免地会丢失,将图像SR视为其逆过程。
许多SR方法采用预上采样的方法,即在将LR图像插值到与HR图像大小相同,然后传递到网络进行训练[27,28]。这种方式的优点是可以用传统的方法(如双三次插值)在网络开始时进行上采样。这样可以大大减轻训练难度。此外,这些模型可以处理具有任意(甚至分数阶)比例因子的输入图像,而不修改其结构。但是,预上采样方法存在噪声放大、失真等问题。由于大多数操作是在HR空间中执行的,其计算负担(时间和内存)比那些在网络末端使用特定可学习层(如反卷积或亚像素卷积[29])的上采样后方法要重得多[30-32]。
为了弥补这一缺陷,我们进一步应用小波变换,它被认为是一种有效的算子,将图像分解为高频(HF)纹理细节和低频(LF)信息。具体地说,LR图像首先通过使用双三次插值将其提升为所需维数的粗HR图像。然后利用小波变换得到四个系数。通过这种方式,高频和低频分量被明确地分离为四个通道,这有助于训练我们的模型。另外,对于I bic∈R h ×w,经过小波变换后,得到I w∈R h/2 ×w/2 ×4,这意味着图像在两个方向上被减半,然后分成四个通道。从经验上来说,四张一半大小的图像比一张大图像更容易训练。注意小波变换及其逆运算都是可逆的,不会造成信息损失。[33-35]已经在图像SR问题中引入了小波变换。
一般情况下,卷积神经网络能够有效地从输入数据中提取层次特征。受inception 框架[36]的启发,我们提出了一种新的多尺度特征提取的类型结构,即多核卷积层,作为模型的基本模块。我们使用不同的核大小(1 × 1,3 × 3和5 × 5)进行卷积,通过多条路径同时提取特征。然后进一步聚合这些路径的特征,从而融合来自不同接受域的不同模式,进一步提高SR性能。
近年来,对cnn中通道间关系的研究较多。Hu等人[37]提出了“squeeze-and-excitation”(SE)块,该块通过显式建模通道之间的相互作用来调整通道特征表示。由于其在分类精度方面有了实质性的性能提升,并且额外的计算成本很小,Zhang et al.[38]将SE块引入到图像SR中,显著增强了他们的模型的表示能力,使得SR结果得到了令人印象深刻的改善。受SE块[37]的启发,Woo等人提出了CBAM[39],不仅将SE块升级为通道注意力,还进一步提出了空间注意力。以这种方式,CBAM在决定关注特性中的“哪个通道”和“何处”方面扮演着关键角色。然而,据我们所知,CBAM仅在检测和分类任务上取得了显著进展。
在本文中,我们首先将该框架集成到图像SR任务中。我们称之为残差注意力模块(RAB)。与SE block和CBAM类似,我们的RAB也是轻量级的;也就是说,它给我们的模型增加了负的计算负担。为此,我们的方法可以在通道和空间维度上自适应地增强所需要的特征,抑制不必要的特征。这可以有效地提高图像SR的重建质量。
本文的主要贡献包括:
- 采用二维小波变换生成的四个系数作为输入,在训练前将粗内容和清晰细节明确分离。这可以帮助我们在不丢失信息的情况下缓解网络的学习困难。相应地,我们的模型生成4个通道,然后进行二维小波逆变换,得到完整的残差图像。
- 我们采用多核卷积层作为基本模组。具体来说,feature map通过多个具有不同内核大小的卷积层的路径,从不同大小的接受域提取不同的底层模式。然后将它们沿通道维度连接起来,并聚合到与该模块的输入相同的宽度。
- 我们利用残差注意块,包括通道注意和空间注意模块,在通道和空间维度上进行自适应特征细化。它们可以无缝地集成到一般的cnn中,并增加微不足道的计算成本。另外,残差注意块非常适合小波子带,因为小波子带本质上包含各种类型的特征。
2 相关工作
2.1 针对超分辨的小波变换
作为一种传统的图像处理技术,小波变换在图像SR中得到了广泛的应用。Ji等[40,41]利用多帧预测小波系数中缺失的细节来实现超分辨率。Anbarjafari和Demirel[42]直接采用双三次插值上采样小波子带生成SR结果。由于部分小波系数通常是稀疏的,因此可以结合稀疏编码方法来细化图像细节[43,44]。然而,由于训练数据有限和模式规模不可扩展,上述方法不能产生最先进的SR结果,特别是与那些充分利用海量数据和复杂架构的深度学习相关方法相比。
Guo等人提出了将小波变换与ResNet[45]相结合的DWSR[33]。它预测的是残差小波子带而不是HR子带,因为稀疏输出有助于稳定训练和鲁棒收敛。Huang等人提出了用于人脸超分辨率的小波- srnet[34]。提出了训练过程中多尺度因子的统一框架,并提出了小波预测损失的额外监督。受U-Net[46]的启发,Liu等人提出了MWCNN[35],其中池化(非池化)操作被(逆)二维小波变换代替。由于小波变换是可逆的,因此可以保证该算子后不会发生信息丢失。然而,大量的小波变换操作过度分解特征映射,导致大量冗余通道,在训练过程中不利于梯度反向传播。详细的讨论将在第3.6节中提出。
2.2 基于深度学习的超分辨
深度学习在图像超分辨率方面取得了显著的进展。Dong等首先提出SRCNN[27],这是一个简单的端到端训练的三层CNN。该方法在重建图像质量方面明显优于传统的SR方法。从经验上看,增加CNN的深度和宽度会提高其代表性。Kim等人提出了VDSR[28],使用20个卷积层来获得更大的接受域。采用残差学习和梯度裁剪策略帮助稳定训练,避免梯度消失问题。DRCN[47]还开发了一个具有递归学习的深层结构,共共享参数16次,可以有效提取更高层次的上下文信息。为了减少计算负担,Lai等人提出了LapSRN[30],采用拉普拉斯金字塔结构,在附加监督的情况下逐步升级中间图像。MemNet[31]在DenseNet[48]的基础上,用递归网代替了正常卷积。Tai等人宣称,一个块中的局部连接表示短期记忆,而先前块的传入连接表示长期记忆。为了简化SR网络的结构,EDSR[49]废弃批处理归一化层。Lim等人报道,尽管批量归一化在其他高级视觉任务(如分类、检测和分割)中已被证明是有效的,但它却阻碍了图像SR的质量。因此,Lim等人设计了带有256个滤波器的64层网络,以进一步提高EDSR的学习能力。此外,为了重用计算,× 3/ × 4比例模型采用预先训练的× 2模型作为初始化,而不是从头开始训练。Haris等人提出了DBPN[50],它由一对迭代的上/下采样层组成。他们创造性地提供了一个反馈方案,允许投影错误在LR和HR空间之间传递。为了充分利用中间特征映射,RDN[32]将残差学习和密集连接策略分别以局部和全局的方式集成。网络内部有多个跳跃连接,可以自适应融合层次特征,梯度信息可以充分在网络中传播。除了SRCNN之外,上述方法不可避免地需要大量的参数,并且需要大量的内存和时间来训练它们。
2.3 注意力机制
与人类感知相似[51,52],注意机制在计算机视觉任务中起着重要的作用。人类视觉系统的特点是不能一次处理整个视觉。相比之下,人类利用一系列不完整的瞥见来选择性地更好地捕捉显著的视觉信息。通常,注意力被认为是一个指导,将可用的计算资源重新分配到输入中最有信息的部分[37]。
最近,一些研究将注意机制纳入到提高cnn在高级视觉任务中的表现。Wang等人首先提出残差注意网络[54],该网络采用编码器-解码器风格的注意力方案进行分类。自底向上/自顶向下的架构创建了一个软掩模来复制,从而自适应地增强或抑制特征。Hu等人提出了SE块[37],在残差块后使用原始的面向信道的注意来提高分类精度。为了考虑在spa维度上的特征图集中在哪里,Woo等人提出了CBAM[39],它提供了通道和空间注意力模块,可以很容易地纳入主流cnn。他们的模型在大规模数据集的图像检测任务中非常有效。
然而,针对图像采用注意力结构的研究很少,SR. Zhang等人提出了RCAN[38],将通道注意力模块置于残差块中,从而捕获丰富的高频特征,并根据信道之间的相互依赖性自适应缩放。RCAN模型中含有大量的通道注意模块,这些模块在模型中被过度使用。此外,RCAN缺乏用于提取层次特征的连续卷积层,而这是一般cnn的基本功能。
3 提出的方法
3.1 小波变换
小波变换作为一种传统的图像处理技术,在图像分析中得到了广泛的应用。图2给出了二维离散小波变换的基本原理。图像X首先通过低通滤波器GLG_LGL和高通滤波器GHG_HGH,然后沿列进行半采样。之后,两条路径分别通过low-pass和high-pass滤波器,并进一步沿行进行半采样。最后输出四个系数,表示为{A, V, H, D}。在本文中,我们在整个实验中使用“哈尔”核。
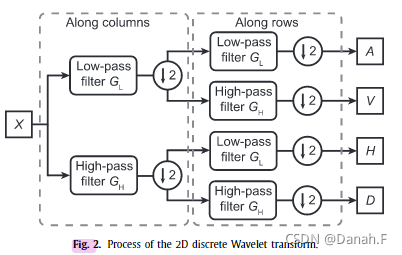
图2 二维离散小波变换的过程
图3为基于“Haar”核的二维(逆)小波变换示例。如图所示,图像X被分解为A、V、H、D四个子波段,由原始图像的平均、垂直、水平和对角线信息细节组成。另外,每个子带的大小是x的一半。注意小波变换及其逆运算都是可逆的,没有信息损失。因此,利用小波逆变换可以很容易地生成完整的残差图像。
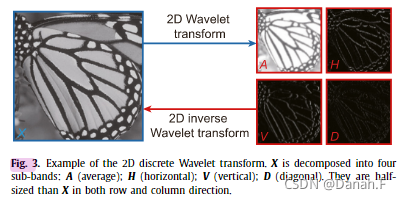
图3 二维离散小波变换的示例,X被分解为四个子波段A(平均)、V(垂直)、H(水平)、D(对角)。他们在行列向上都是X的一半。
在小波变换的帮助下,我们的模型学会了预测4个半大小的通道,这些通道近似于小波变换产生的4个系数对残差SR图像的影响。由于在四个通道中保留了不同的底层模式,而不是在一个大图像中,我们的模型的学习难度可以显著降低。在第3.6节中,图7揭示了在我们的网络中没有必要使用多个小波变换操作。
3.2 网络结构

图1显示了我们网络的总体结构。模型的输入Ibicw∈Rh/2×w/2×4I^w_{bic}∈R^{h/2 ×w/2 ×4}Ibicw∈Rh/2×w/2×4是应用于双三次LR图像Ibic∈Rh×wI_{bic}∈R^{h×w}Ibic∈Rh×w的二维小波变换的四个系数,正如前面提到过,它们在行和列维度上都是一半大小,在训练前被分成四个通道。首先,我们使用卷积层从输入中提取浅层特征:
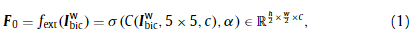
式中C(·)为卷积层,其中5 × 5为核大小,通道C = 64;σ(·)表示Leaky整流单元(ReLU)层。由于小波变换的特性,IbicwI^w_{bic}Ibicw固有地包含负像素,因此我们采用Leaky的ReLU(负斜率α = 0.1)用于非线性激活。请注意,为了简单的符号,忽略了偏差。
我们的模型主体由L个连续的相同块组成,每个块包含一个多核卷积层、一个通道注意模块和一个空间注意模块。在每个块中,我们使用跳过连接来帮助信息流。因此,我们有
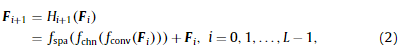
式中,fconv(⋅)f_{conv}(·)fconv(⋅)、fchn(⋅)f_{chn}(·)fchn(⋅)、fspa(⋅)f_{spa}(·)fspa(⋅)分别表示多核卷积函数、信道注意函数和空间注意函数。请注意,每个块的输出与它的输入具有相同的维数。
为了克服深度网络结构中普遍存在的梯度消失问题,我们将这些块的所有输出沿通道维连接起来,即:
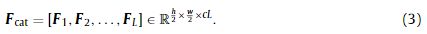
为此,在正演计算中充分利用了浅层到深层的特征图,并将梯度信息有效地反向传播到网络前端。从经验上看,这个框架可以在训练中实现更好的融合。
在融合多个块的特征后,我们利用瓶颈结构将这些特征映射进一步缩小到一个紧凑的尺寸,瓶颈结构包括两个3 × 3卷积层和一个Leaky的ReLU激活层,如图1所示:
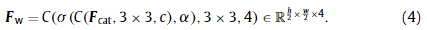
训练网络的目的是使输出FwF_wFw能很好地逼近真实残差图像IHR−IbicI_{HR}-I_{bic}IHR−Ibic上小波变换的四个系数。同样,我们有

其中idWT(·)为离散小波反变换函数。需要注意的是,我们采用了全局残差学习方法,即在模型的末端添加一个从IbicI_{bic}Ibic到我们的模型末端的长跳过连接,这样我们的网络就可以学习预测残差成分,而不是直接预测HR图像。作为通用策略,这有助于鲁棒的训练和快速融合。
3.3 多核卷积层
受初始结构[36]的启发,我们采用多核卷积层作为基本模块,如图4所示。具体来说,输入经过四个路径,这四个路径是不同核大小的卷积层(1 × 1,3 × 3,5 × 5,和{3 × 3,5 × 5}):
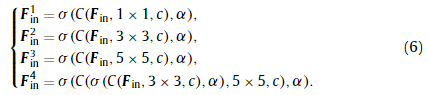
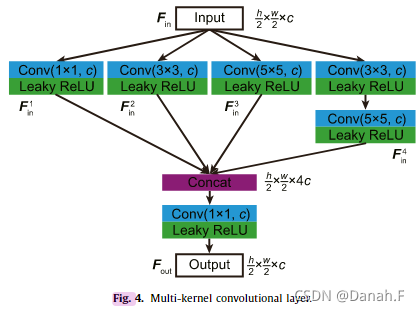
图4 多核卷积层
后沿着通道维度连接四个部分,然后是一个1 × 1的卷积层,聚合特征到与输入相同的宽度:
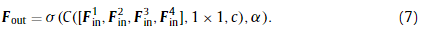
每个卷积层都伴随着一个Leaky的ReLU激活层以保持非线性。与Inception结构[55-57]使用分裂-转换-合并策略相似,我们的网络利用不同大小的接受域和多条路径,具有较强的特征提取能力。尽管多核学习在高级视觉问题(如分类、分割和检测)中得到了广泛的应用,但在低级别视觉问题(如超分辨率)中却很少被采用。
3.4 通道注意力模块
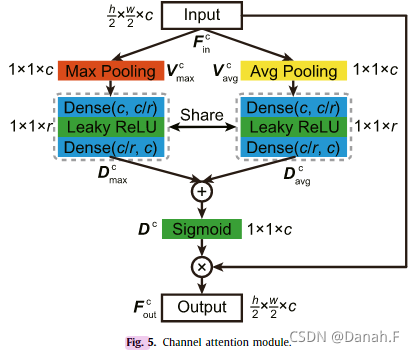
图5给出了通道注意模块[39]的结构,该模块利用了特征图的通道相互依赖关系。本模块着重于哪些通道在计算中是重要的。分别通过最大池化操作和平均池化操作对输入特征FincF^c_{in}Finc进行压缩,聚合空间维度上的上下文信息,生成两个向量:
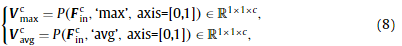
其中,’ max ‘和’ avg '分别表示最大池化和平均池化,axis =[0,1]表示在特征FincF^c_{in}Finc的前两个维度执行池化。然后将两个向量前向传播到两个参数共享的全连接层,分别获得两个特征向量。向量中的每个值都可以被视为对应通道的描述符:
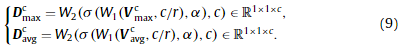
这里,对于两个特征向量,w1(·)和w2(·)是共享的。隐藏层大小设置为c/r,以减少参数开销,其中r为缩减比。在这个方案中,通道之间的关系可以通过琐碎的计算得到利用。描述向量DavgcD^c_{avg}Davgc和DavgcD^c_{avg}Davgc由元素求和合并,然后是一个s形激活层:
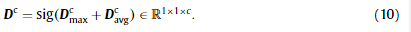
最后,将描述向量DcD^cDc以元素积的形式应用于该模块的输入;也就是说,每个描述符乘以一个特征图,写为

◦表示元素方面的产品。请注意,输入和输出具有相同的维度。因此,该模块可以很容易地集成到通用cnn中。
3.5 空间注意力模块
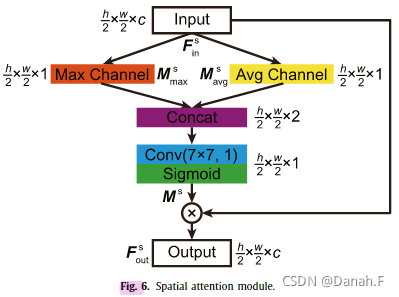
图6显示了空间注意模块[39]的结构,它使用了特征的空间关系。与通道注意不同,空间注意关注的是特征图中信息部分“在哪里”。输入特征FincF^c_{in}Finc在通道轴上分别通过最大池化操作和平均池化操作进行压缩,生成两个2D注意映射:
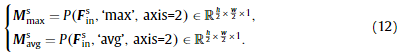
然后它们通过7 × 7核大小的卷积层进行连接和融合。采用Sigmoid函数引入非线性,将注意力映射归一化为[0,1]:
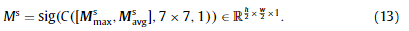
类似于通道注意,这个注意力特征图最终是在元素上与该模块的输入相乘;即,map中的每个值乘以所有特征地图对应位置上的元素:

请注意,输入和输出具有相同的维度。因此,该模块可以很容易地集成到通用CNN中。
3.6 讨论
许多方法采用均方误差(l2l_2l2损失)作为代价函数,使SR结果接近于地面真实的HR图像。然而,这些方法通常产生模糊或过度平滑的输出,并错过一些文本细节。与更能容忍小误差的l2l_2l2损失相比,平均绝对误差(MAE) (l1l_1l1损失)能有效地惩罚小值,并在整个训练阶段保持更好的收敛性。因此,我们采用l1l_1l1损失来训练我们的网络:
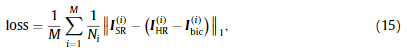
其中ISR(i)I^{(i)}_{SR}ISR(i)和IHR(i)−Ibic(i)I^{(i)}_{HR}-I^{(i)}_{bic}IHR(i)−Ibic(i)分别表示第I张输出残差图像和ground-truth残差图像,Ni表示第I张图像的像素总个数,M表示一个训练批的图像个数。
图7是经过两次小波变换处理的图像。显然,经过第一次小波变换后,原始图像被明显地分为四个通道,分别表示平均、垂直、水平和对角细节。然而,第二个小波变换并不有效,因为在最后一步中执行了相同的分割过程。大多数子信道接近或等于零,这对进一步训练没有帮助。
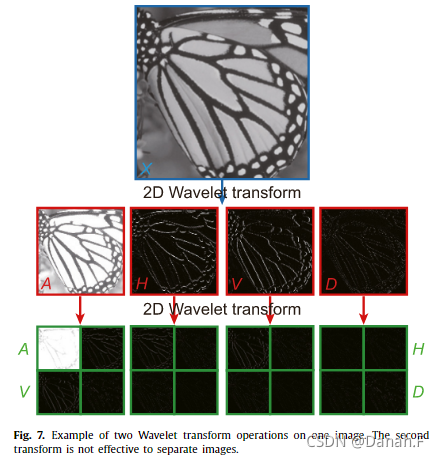
图7.对一个图像的两个小波变换操作的例子。第二种变换不能有效地分离图像。
这与使用多级小波cnn (MWCNN)的[35]相反。我们认为,MWCNN在其全卷积网络中主要采用小波变换来代替池化和非池化算子,因为(逆)小波变换本质上是可逆的(没有信息丢失),并且直接将图像的维数减半(双倍)。在我们的网络中,我们只使用了一个(逆)小波变换,并将其作为输入数据(标签)的预处理。由于小波变换没有可训练的参数,因此在训练阶段不需要计算它们。
请注意,在一个块中安排三个模块的顺序是至关重要的:多核卷积、信道注意和空间注意。根据CBAM[39],将以上三个模块按顺序排列比并行处理要好。此外,他们声称通道优先级比空间优先级表现出稍好的性能。由于其结构仅对高视觉任务(如检测和分类)有效,我们需要验证其对图像sr的影响。在4.4节中,我们将分别进行实验验证三个模块的贡献。
由Sergey等人提出的批处理归一化(BN)是一种减少网络中协变量间移位的有效技术。具体地说,它对每个小批执行,并引入额外的参数以保持表示能力。因为BN可以重新校准中间特征并且缓解梯度消失,所以在较高的学习率下加速训练是可行的,且模型对初始化不敏感。
但是Lim等人[49]认为BN损害了图像的比例信息,限制了模型的范围灵活性。通过去除BN层,EDSR减少了大量内存,设计了一个大模型,以提高SR的性能。在本文中,我们采用了这种经验,并消除了网络中的BN层。
4 实验
我们的源代码是Tensorflow[59]与Keras实现,并可在线获得。所有实验都在CentOS 7 Linux服务器上执行,该服务器配备两个Intel Xeon® E5 cpu、256gb内存和两个NVIDIA Tesla P4 (8GB) gpu。
4.1 数据集和指标
我们使用DIV2K数据集[60],它包含丰富的2K分辨率的高质量图像。具体来说,它被分为800个训练图像和100个验证图像。我们使用800张图片来训练我们的网络,但出于速度考虑,只选择10张图片进行验证。采用数据增广方案,防止过拟合。训练图像随机旋转90°,180°,或270°,并翻转水平或垂直。在测试阶段,我们选择了四种常用的基准数据集:Set5[61]、Set14[62]、B100[63]和Urban100[64]。所有训练图像被裁剪为96 × 96大小,没有重叠。对应的下采样图像分别为48 × 48、32 × 32、24 × 24,尺度因子为2、3、4。通过双三次插值重新缩放到原始大小后,再通过二维小波变换进行处理,作为网络的输入。同样,利用残差图像(5)的二维小波变换结果作为ground truth进行训练。注意,2D(逆)小波变换算子没有可训练的参数,因此它们不包含在我们的训练过程中。我们只是在训练前准备训练数据和标签对(IbicwI^w_{bic}Ibicw,FwF_wFw)。通过采用较小的图像尺寸,该模型在训练阶段收敛速度快,占用内存少。
我们知道,有一些方法是处理RGB颜色空间的图像,也有一些方法是处理YCbCr空间的图像。目前,对于哪种方案更好还没有达成普遍的共识。在本文中,为了公平比较,我们在YCbCr空间的Y通道上执行所有图像。Cb和Cr通道通过双三次插值直接放大。结合Y通道提取的SR结果,可以获得更好的彩色图像。
在本文中,我们使用峰值信噪比(PSNR),这是评价重建图像质量的常用指标。在数学上,PNSR的定义如下:
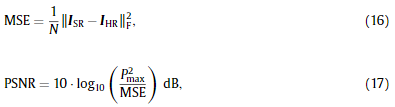
其中P max表示图像中的最大像素值(通常等于1.0)。此外,我们采用结构相似度指数(SSIM)[65]来衡量超分辨率的质量。它的范围是0到1,值越大越好。
4.2 训练细节
给出了如下一些训练配置。批量大小设置为64。epoch的数目是200个。在每个epoch,需要500次迭代才能从增广数据生成批。我们设置初始学习速率λ = 1e−3,每40个epoch后它将乘以0.1,直到它达到最小1e-8。Adam[66]优化器取值为β1 = 0.9、β2 = 0.999,取值为ϵ\epsilonϵ = 1 e−8。此外,我们部署了早停范式;即在连续20个时间段内,如果检测到验证中的PSNR没有改善,则训练过程将提前终止。
每个卷积的内核大小已经在前一节中描述过。每次卷积运算都采用零填充,以保持输入输出特征映射的大小一致。我们设置块数L = 8,通道宽度c = 64,Leaky ReLU α的负斜率为0.1、且减速比r = 4为最佳性能。详细的参数选择将在4.3节中报告。
更多超参数设置可以在Github的源代码中找到。
4.3 参数选择

图8。在缩放系数为4、Set14数据集上,我们的方法在不同的块数L和通道宽度c值下的性能。
图8显示了我们的方法在Set14上在比例因子4下,在不同的块数L和通道宽度c值下的SR性能。正如我们所看到的,通过增加块的数量L,我们的模型表现得更好。这与我们的直觉是一致的,更广泛和更深的网络具有更强的学习能力,因此获得更好的性能。然而,当L > 8时,PSNR变得稳定,因为超深层结构很难训练,也不一定提高性能。此外,随着c的增大,PSNR逐渐增大。但是设置一个大的c意味着参数的数量和计算负担将显著增加。为了平衡模型大小和性能之间的权衡,我们选择c = 64。
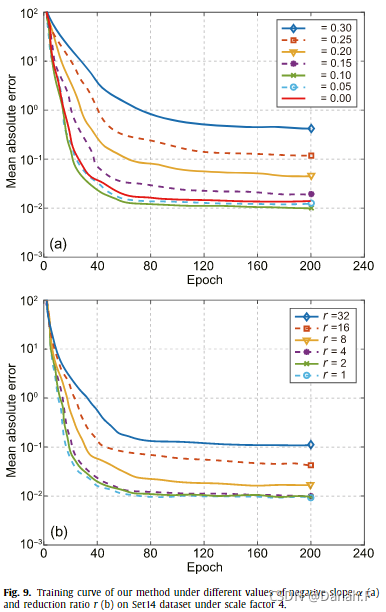
图9所示。在尺度因子4下,我们的方法在Set14数据集负斜率α (a)和折减比r (b)的不同值下的训练曲线。
图9(a)和(b)分别描述了在不同负斜率α和折减比r值下MAE相对epoch的训练损失曲线。从图9(a)可以看出,随着α的增加,收敛速度变慢,最终MAE变大。这是因为ReLU (α = 0)天生具有稀疏效应。但随着α的增大,ReLU逼近恒等函数f(x) = x,稀疏效应逐渐消失。然而,我们发现小的α值有助于模型更好地收敛。这是因为我们的输入图像经过小波变换处理,自然包含了一些负梯度像素。因此,微小的值α = 0.1有利于在正向传递和反向传播中有效保持负信息流。
从图9 (b)可以看出,不同的折减比r值对模型的收敛性有影响。注意,r = 1表示通道注意力模块中描述向量没有降维。当r增大,即描述向量的长度被压缩时,收敛性变差,因为在此期间丢失了一些具有信道重要性的信息。我们选择R = 4以保持最佳性能,因为保存在通道注意模块中的参数的数量是微不足道的。
4.4 消融研究
表1 不同模块组合在我们网络中的效果。在Set5和Set14数据集上给出了比例因子2下的参数个数和PSNR。
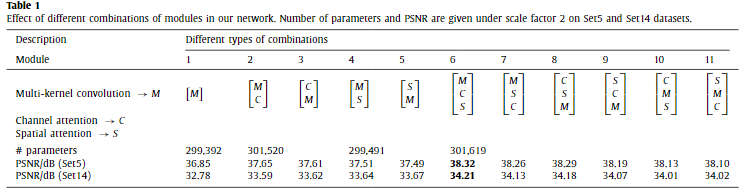
表1比较了我们网络中三个模块不同组合的效果。我们报告了在尺度因子2下Set5和Set14数据集的参数数量和PSNR。显然,通道注意模块和空间注意模块引入的额外参数数量可以忽略不计。从模块1到模块5可以看出,通道注意模块和空间注意模块都显著提高了SR性能,但增加的计算成本微不足道。在模块组合6到11中,我们采用了三个不同顺序的模块。结果表明,将多核卷积设置为块的第一部分可以获得最佳的PSNR。同样,将通道注意和空间注意模块(8和9)结合起来,而不是将它们分开(10和11),会产生更好的表现。由于它们都是轻量级结构(图5和图6),将它们连接起来有助于信息流的前向传递和后向传播,但将它们分开将破坏这一优势。此外,我们发现将通道注意模块置于空间注意模块之前会获得稍好的效果。因此,我们在整个实验中采用该结构作为模块6。
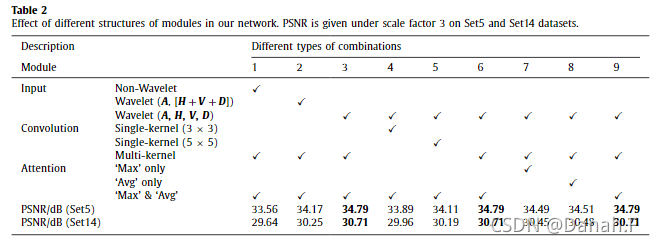
表2比较了我们网络中几个模块不同结构的效果。为了验证小波变换的有效性,我们比较了三种类型的输入数据:1。原始图像;2.LF(A)和HF([H + V + D])部分;3.小波子带(A, H, V, D)。可以看出,随着训练前将输入数据分割成更多的信道,PSNR大幅提高。通过将输入数据分离为平均、水平、垂直和对角子带,小波类型比其他组合获得了最佳的PSNR。作为我们网络中的基本函数,我们证明了不同核大小对sr的有效性。我们比较了三种试验:3 × 3、5 × 5和多核(图4),使用相同的通道数量。结果表明,核大小越大,该方法的性能越好,这与我们的经验一致,即神经网络中较大的接收域有利于高级特征的提取和代表性能力的学习。为了验证注意力模块的影响,我们比较了三种类型的pooling: max, average和max & average。通过单独使用最大池或平均池,我们可以看到它们在PSNR方面显示出相似的结果,并且始终比使用这两种池操作要差一些。结果表明,采用最大池化和平均池化对训练大量图像具有较强的鲁棒性,从而获得了较好的性能。
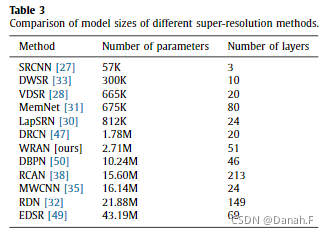
表3总结了几种SR方法的模型尺寸。参数和层数用于比较。直观地说,SRCNN是最简单的方法,因为它只包含三个卷积层。
为了提高性能,DWSR、VDSR和LapSRN顺序地地不断增加参数的数量到10^5并且加深他们的网络至最多24层。MemNet作为两种特殊情况,其参数数量与上述三种情况相近,但具有80层的深度结构;DRCN由20层组成,但需要178万个参数。虽然我们的模型包含51层,有超过270万个参数,但WRAN相对于DBPN和MWCNN要小一些。得益于通道注意结构,RCAN可以堆叠超过200层,但其参数没有显著增加。RDN和EDSR都构建了大规模的模型,导致大量的参数需要学习。因此,与其他SR方法相比,我们的WRAN模型大小被认为是中等的。
4.5 与最先进的SR方法的比较
表4 与其他超分辨率方法相比,我们的方法在四个数据集上的定量结果(粗体数字和下划线数字分别表示最佳结果和次最佳结果)。
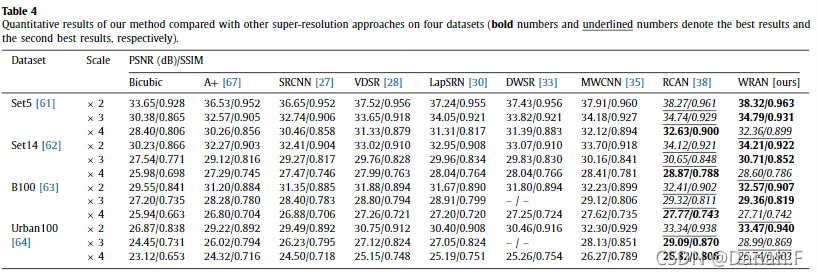
表4给出了在尺度因子2、3和4下,几种SR方法在4个数据集上的定量结果(PSNR/SSIM)。Bicu- bic插值和A+的结果最差,因为它们是常规方法,不需要训练它们的模型。作为第一种基于深度学习的方法,SRCNN在所有情况下都略微提高了PSNR。通过设计深宽结构,VDSR和LapSRN在训练中采用了大量的参数,能够有效地挖掘feature maps中的潜在模式,因此其性能优于SRCNN。与我们的方法类似,DWSR和MWCNN也使用小波变换作为其输入的预处理。这两种方法都具有明显分离低频和高频成分的优点,比以往的方法获得了更好的性能。但是他们在网络中采用了正常的CNN结构,导致其在PSNR和SSIM方面的进步有限。由于RCAN和我们的WRAN都使用通道注意模块,两种方法相对于其他方法取得了最好的效果。在大多数情况下,我们的WRAN报告最好的PSNR,因为我们集成了小波变换、多核卷积和空间注意的优点。然而,RCAN在大规模因子× 4的情况下表现稍微好一些,因为它们构建了一个非常深的网络,比我们的方法的参数数多5倍(表3)。在尺度因子× 4的情况下,bicu- bic输入不可避免地缺乏大量的高频细节,导致小波变换不能有效地分离特征。因此,我们的方法优于其他SR方法,但略低于RCAN方法。
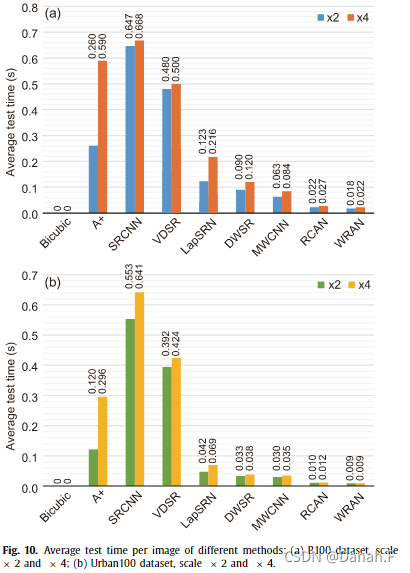
图10表示在尺度因子× 2和× 4条件下,不同方法在B100和Urban100数据集上每幅图像的平均测试时间。值得注意的是,双三次插值被广泛地用作图像sr的基本运算,它简单且不需要参数。因此,我们认为双三次插值不需要测试时间,这里不讨论它。显然,SRCNN由于包含多个卷积层,卷积层计算量较大,尽管SRCNN的参数较少,比其他方法消耗的时间最多。VDSR也需要相当长的测试时间,因为它有20个卷积层,并且像SRCNN一样在大的图像空间中运行。在比例因子× 2和× 4下,A +需要大量的测试时间。由于A +涉及到字典学习和回归,需要处理时间与图像大小成比例,因此该方法在小尺度因子下运行明显更快。通过从小尺度到大尺度以金字塔的方式对图像进行逐步处理,LapSRN比以前的方法执行速度快好几倍。利用小波变换的优势,dwsrr和MWCNN都比LapSRN需要更少的时间。这证明了小波变换的有效性,小波变换会将图像分割成小图像空间。受益于注意力块,RCAN和WRAN是最快的方法(最多12毫秒),这验证了空间和通道注意模块节省了大量的计算成本。

图11举例说明了Set14和Urban100数据集的三个例子,这些数据集是由几种SR方法在比例因子× 4下生成的。直观地说,图11(b)和©显示了相对较差的重建图像,因为它们包含视觉模糊的纹理。通过利用CNN, SRCNN(图11(d))显示出比前两种方法更清晰的图像。随着模型尺寸的增大和复杂程度的提高,这些方法的重建质量都逐步有所提高(图11(e) - (h))。直观地说,图11(i)和(j)比其他方法说明了最好的SR结果。我们可以看到,RCAN和我们的WRAN成功恢复了一些细节,这是因为我们利用小波变换提前分割低频和高频分量,并在训练过程中采用信道注意和空间注意模块自适应地重新调整特征。
5 结论
本文提出了基于小波的图像sr剩余关注网络(WRAN)。我们采用了轻量级但有效的模块,而不是堆积计算量大、参数大的大尺度模型:信道注意和空间注意,在不牺牲性能的前提下提高图像SR的效率。在训练前,我们使用二维小波变换将一张图像的低频和高频细节明确地分离到四个通道。这样可以减轻我们网络的学习困难。受Inception结构的启发,我们提出了多核卷积层作为基本模块来自适应地聚合来自不同大小接收域的特征。研究结果表明,将基本模态、通道注意和空间注意合理结合,可以进一步提高SR结果。大量的实验表明,我们的WRAN需要相对较少的参数,并产生与最先进的SR方法在定量和定性方面具有竞争力的结果。
相关文章:
WRAN翻译
基于小波的图像超分辨残差注意力网络 Wavelet-based residual attention network for image super-resolution 代码: https://github.com/xueshengke/WRANSR-keras 摘要: 图像超分辨率技术是图像处理和计算机视觉领域的一项基础技术。近年来,…...

ROS学习笔记——第二章 ROS通信机制
主要跟着[1]学习ros::Rate r(1); //错误,应改为ros::Rate r(10);[2]对Topic通信打的比方很形象,便于理解记忆。[3]有整个过程的图片,对于初学者更加友好[4]对发布者的代码注释非常好,方便进一步学习此外CMake官方文档可以查询相关…...
MacOS Pytorch 机器学习环境搭建
学习 Pytorch ,首先要搭建好环境,这里将采用 Anoconda Pytorch PyCharm 来一起构建 Pytorch 学习环境。 1. Anoconda 安装与环境创建 Anoconda 官方介绍:提供了在一台机器上执行 Python/R 数据科学和机器学习的最简单方法。 为什么最简单…...

项目——博客系统
文章目录项目优点项目创建创建相应的目录,文件,表,导入前端资源实现common工具类实现拦截器验证用户登录实现统一数据返回格式实现加盐加密类实现encrypt方法实现decrypt方法实现SessionUtil类实现注册页面实现前端代码实现后端代码实现登录页…...
PHP(14)会话技术
PHP(14)会话技术一、概念二、分类三、cookie技术1. cookie的基本使用2. cookie的生命周期3. cookie的作用范围4. cookie的跨子域5. cookie的数组数据四、session1. session原理2. session基本使用3. session配置4. 销毁session一、概念 HTTP协议是一种无…...

对JAVA 中“指针“理解
对于Java中的指针,以下典型案例会让你对指针的理解更加深刻。 首先对于: 系统自动分配对应空间储存数字 1,这个空间被变量名称b所指向即: b ——> 1 变量名称 空间 明…...

功率放大器在MEMS微结构模态测试研究中的应用
实验名称:功率放大器在MEMS微结构模态测试研究中的应用研究方向:元器件测试测试目的:随着MEMS器件在各个领域中广泛应用,对微结构进行模态测试获得其动态特性参数对微结构的设计、仿真、制造、以及质量控制和评价等方面具有十分重…...
【算法基础】字典树(Trie树)
一、Trie树原理介绍 1. 基本概念 Trie 树,也叫“字典树”。顾名思义,它是一个树形结构。它是一种专门处理字符串匹配的数据结构,用来解决在一组字符串集合中快速查找某个字符串的问题。【高效存储和查找字符串集合的数据结构】,存储形式如下: 2. 用数组来模拟Trie树的…...
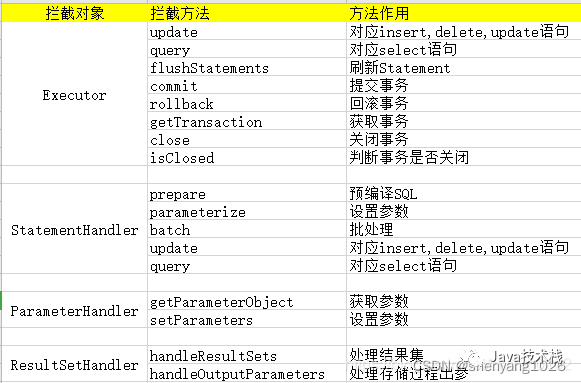
MyBatis 插件 + 注解轻松实现数据脱敏
问题在项目中需要对用户敏感数据进行脱敏处理,例如身份号、手机号等信息进行加密再入库。解决思路就是:一种最简单直接的方式,在所有涉及数据敏感的查询到对插入时进行密码加解密方法二:有方法一到出现对所有重大问题的影响&#…...
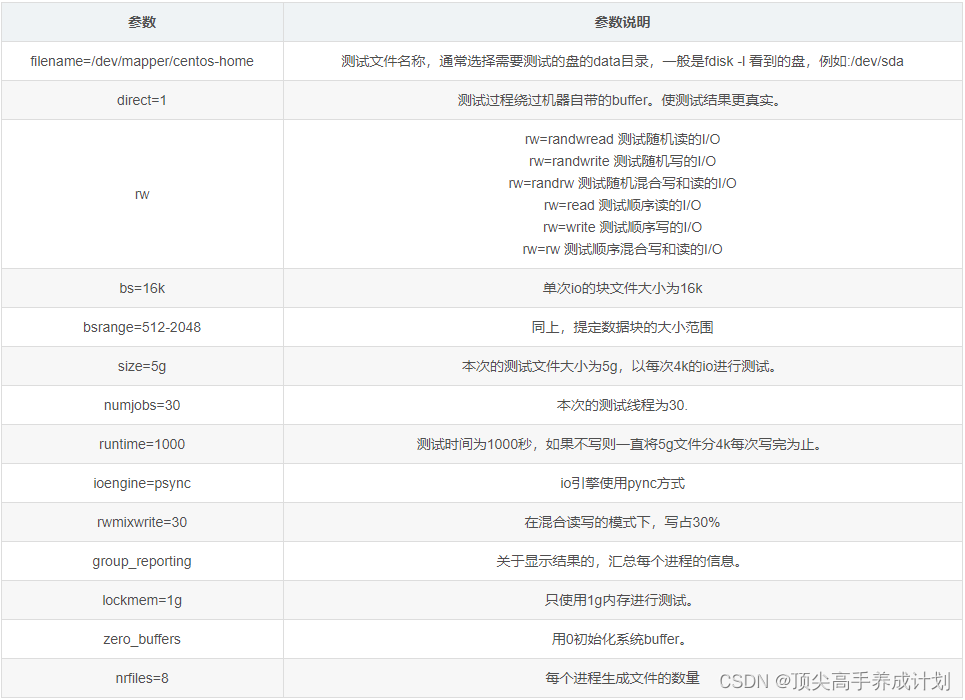
MySQL优化篇-MySQL压力测试
备注:测试数据库版本为MySQL 8.0 MySQL压力测试概述 为什么压力测试很重要?因为压力测试是唯一方便有效的、可以学习系统在给定的工作负载下会发生什么的方法。压力测试可以观察系统在不同压力下的行为,评估系统的容量,掌握哪些是重要的变化…...

CF43A Football 题解
CF43A Football 题解题目链接字面描述题面翻译题面描述题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1样例 #2样例输入 #2样例输出 #2代码实现题目 链接 https://www.luogu.com.cn/problem/CF43A 字面描述 题面翻译 题面描述 两只足球队比赛,现给你进…...

Nginx常用命令及具体应用(Linux系统)
目录 一、常用命令 1、查看Nginx版本命令,在sbin目录下 2、检查配置文件的正确性 3、启动和停止Nginx 4、查看日志,在logs目录下输入指令: 5、重新加载配置文件 二、Nginx配置文件结构 三、Nginx具体应用 1、部署静态资源 2、反向代…...

从零实现Web服务器(三):日志优化,压力测试,实战接收HTTP请求,实战响应HTTP请求
文章目录一、日志系统的运行流程1.1 异步日志和同步日志的不同点1.2 缓冲区的实现二、基于Webbench的压力测试三、HTTP请求报文解析http报文处理流程epoll相关代码服务器接收http请求四、HTTP请求报文响应一、日志系统的运行流程 步骤: 单例模式(局部静态变量懒汉…...
MFC入门
1.什么是MFC?全称是Microsoft Foundation Class Library,我们称微软基础类库。它封装了windows应用程序的各种API以及相关机制的C类库MFC是一个大的类库MFC是一个应用程序框架MFC类库常用的头文件afx.h-----将各种MFC头文件包含在内afxwin.h-------包含了各种MFC窗…...

1、H5+CSS面试题
1, HTML5中新增了哪些内容?广义上的html5指的是最新一代前端开发技术的总称,包括html5,CSS3,新增的webAPI。Html中新增了header,footer,main,nav等语义化标签,新增了video,audio媒体标签,新增了canvas画布。…...

亚马逊云科技重磅发布《亚马逊云科技汽车行业解决方案》
当今,随着万物智联、云计算等领域的高速发展,创新智能网联汽车和车路协同技术正在成为车企加速发展的关键途径,推动着汽车产品从出行代步工具向着“超级智能移动终端”快速转变。挑战无处不在,如何抢先预判?随着近年来…...
Springboot扩展点之FactoryBean
前言FactoryBean是一个有意思,且非常重要的扩展点,之所以说是有意思,是因为它老是被拿来与另一个名字比较类似的BeanFactory来比较,特别是在面试当中,动不动就问你:你了解Beanfactory和FactoryBean的区别吗…...
新库上线 | CnOpenDataA股上市公司交易所监管措施数据
A股上市公司交易所监管措施数据 一、数据简介 证券市场监管是指证券管理机关运用法律的、经济的以及必要的行政手段,对证券的募集、发行、交易等行为以及证券投资中介机构的行为进行监督与管理。 我国《证券交易所管理办法》第十二条规定,证券交易所应当…...
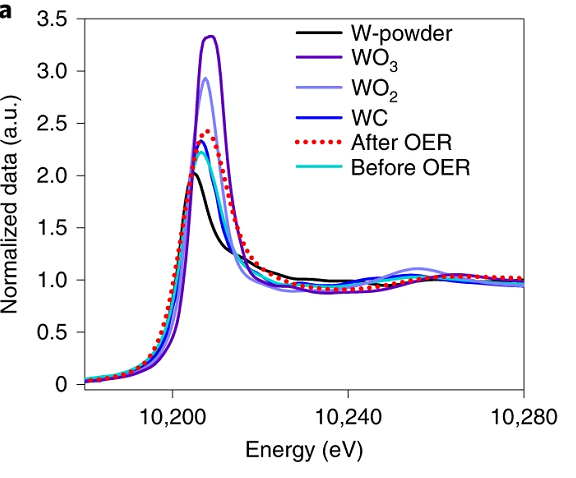
同步辐射XAFS表征方法的应用场景分析
X射线吸收精细结构XAFS表征方法是一种用于研究物质结构和化学环境的分析技术。XAFS 使用 X 射线照射到物质表面,并观察由此产生的 X 光吸收谱。 XAFS 技术通常应用于研究高分子物质、生物分子、纳米结构和其他类型的物质。例如,XAFS 可以用来研究高分子…...

06 antdesign react Anchor 不同页面之间实现锚点
react Anchor 不同页面之间实现锚点一、定义二、使用步骤三、开发流程(一)、组件(二)、页面布局(三)、点击事件(四)、总结说明一、react单页面应用,当前页面的锚点二、react单页面应用,不同页面的锚点思路:锚点只能在当前页面使用,…...

突破性解决方案:用cursor-free-vip开源工具解锁Cursor Pro功能的深度解析
突破性解决方案:用cursor-free-vip开源工具解锁Cursor Pro功能的深度解析 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youv…...

FanControl中文界面深度定制指南:零基础打造个性化风扇控制中心
FanControl中文界面深度定制指南:零基础打造个性化风扇控制中心 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Tr…...

STM32F103C8T6实战:I2C驱动STP23L测距传感器与OLED显示优化
1. 项目背景与硬件选型 第一次接触STM32F103C8T6驱动STP23L测距传感器时,我完全没料到这个蓝色小模块会成为后续多个项目的核心组件。STP23L是一款基于TOF(飞行时间)原理的激光测距传感器,测量范围0.1-3米,精度可达1m…...

Linux硬盘分区管理
硬盘分区管理 大容量的硬盘,分区使用:C盘系统盘,D盘办公,E盘娱乐。 类似于:买了一个房子100平方,隔断:主卧、次卧1、次卧2、厨房、卫生间。识别硬盘设备接口类型设备命名示例说明SATA/SAS/USB/S…...

新手友好:黑丝空姐-造相Z-Turbo镜像的详细操作步骤
新手友好:黑丝空姐-造相Z-Turbo镜像的详细操作步骤 你是不是对AI生成图片很感兴趣,特别是想试试那些能生成特定风格图片的模型?今天要介绍的这个“黑丝空姐-造相Z-Turbo”镜像,就是一个专门用于生成黑丝空姐风格图片的AI模型服务…...

无线网卡选购指南:别再被商家忽悠了,这5个参数才是关键
无线网卡选购指南:别再被商家忽悠了,这5个参数才是关键本文为付费专栏内容,全文约3800字,阅读需12分钟 适合人群:台式机用户、老旧笔记本用户、游戏玩家、NAS玩家前言:为什么你需要单独买无线网卡ÿ…...

重型设备预测性维护:时序数据的摄取与治理架构
重型设备预测性维护:时序数据的摄取与治理架构在工业 4.0 的演进路线中,制造企业对生产设备的管理正在经历深刻的范式转移。传统的“定期维护(Preventive Maintenance)”往往会造成零部件的过度替换与运维人力的浪费;而…...

RimSort:环世界MOD管理神器,让上百个模组有序运行的5大秘诀
RimSort:环世界MOD管理神器,让上百个模组有序运行的5大秘诀 【免费下载链接】RimSort RimSort is an open source mod manager for the video game RimWorld. There is support for Linux, Mac, and Windows, built from the ground up to be a reliable…...

OpenClaw夜间值守:Qwen2.5-VL-7B实现服务器监控截图报警
OpenClaw夜间值守:Qwen2.5-VL-7B实现服务器监控截图报警 1. 为什么需要夜间值守方案 凌晨三点,我的手机突然响起刺耳的警报声——服务器CPU负载飙升至98%。当我手忙脚乱地远程连接服务器时,业务已经中断了15分钟。这次事故让我意识到&#…...

【MinerU】Docker构建实战:从零到一打造内网可用的PDF解析镜像
1. 为什么需要内网可用的PDF解析镜像 最近在帮客户部署一个PDF解析系统时,遇到了一个典型的企业级需求:在内网环境中运行MinerU这个强大的PDF解析工具。你可能要问,为什么不能直接用官方镜像?这里有几个现实问题: 首…...