数据库监控与调优【九】—— 索引数据结构
索引数据结构-B-Tree索引、Hash索引、空间索引、全文索引
二叉树查找
对于相同深度的节点,左侧的节点总是比右侧的节点小。在搜索时,如果要搜索的值key大于根节点(图中6),就会在右侧子树里查找;key小于根节点(图中6),就会在左侧子树里查找;
比如查找图中2,先找到根节点6,然后使用2与6对比,小于6,在左侧查找。然后再将2与3对比,小于3在左侧查找,然后将2与2对比,相等,故找到节点2。
只需要三次找到就能找到节点2。
并且对于图中这样一棵树,由于它的深度是3,不管哪个元素,最多只需要3次查找就能找到对应的节点。

但是假设是下面图中的二叉树,如果想要搜索的值key是8,则需要5次查找。
并且对于图中这样一棵树,由于它的深度是5,则最多需要5次查找就能找到对应的节点。

从上可以知道,两个二叉树都是6个节点,但是查询效率是不一样的。后面的二叉树比前面的性能要差一些。
因为下面的二叉树不够平衡导致的,所谓的不够平衡,就是一棵二叉树,左侧的节点和右侧的节点严重不一致。
于是,就有了平衡二叉树的概念。也叫AVL树。
在普通二叉搜索树上增加了一个约束,每个节点的左子树和右子树的高度差不超过1。
平衡二叉搜索树(AVL树)
- 每个节点的左子树和右子树的高度差不超过1
- 可以看到上面前面的二叉树就是一个平衡二叉搜索树,它的左子树和右子树的高度差都是小于等于1。
- 但是上面后面的二叉树就不是一个平衡二叉搜索树,比如2节点的左子树高度是0,右子树高度是4,超过1了。
- 对于n个节点,树的深度是log2n,查询的时间复杂度是O(log2n)
- 对于一个有64个节点的平衡二叉树,最多只需要查找6次就能找到任意一个节点
- 但是假设n非常大,比如10000,那么这个树的深度依然比较高,这意味着查询的次数也会很多
- 于是,就出现,如果不是一个二叉树,而是一个m叉树。
- 比如,5叉树,一个节点存在五个子节点,这样树的深度就可以变小一些。当我们像定位某个节点的时候,查询的次数就减少了
- 就产生了B-Tree树
B-Tree树(Balance Tree)
-
读作B Tree,不是B减Tree,不是减,是杠
-
B-Tree全称Balance Tree,意思是平衡多路搜索树
-
下面图展示3阶的B-Tree,阶是构建B-Tree的一个参数,可以认为是一个数字,阶越大,表示一个节点的子节点越多。
-
图中指针指向子节点对应的磁盘块。
-
关键字可以想象成表的主键或者索引。
-
数据指的是关键字所对应的数据,可以理解为表里面某一行的数据。
-
比如图中17 Data,就可以理解为主键等于17的那一条数据,也可以理解为有一个索引,这个索引字段的值为17,Data是17对应的数据
-
假设要搜索主键等于5的数据,首先找到根节点里面的关键字17和35,进行比较后发现5小于17,就可以通过P1指针定位到磁盘块2,而磁盘块2里面的关键字是8和12,进行比较后发现5小于8,于是通过磁盘块2P1指针找到磁盘块5,最后在磁盘块5里面就可以找到这条数据了。

ps:图中磁盘块3也有3个子节点,只是图中没有画。
B-Tree树特性
-
根节点的子节点个数2<=x<=m,m是树的阶
- 假设m=3,则根节点可以有2-3个孩子
-
中间节点的子节点个数m/2<=y<=m
- 假设m=3,中间节点至少有2个孩子,最多3个孩子
-
每个中间节点包含n个关键字,n=子节点个数-1,且按升序排序
- 如果中间节点有3个子节点,则里面会有2个关键字,且按升序排序
-
Pi(i=1,…n+1)为指向子树根节点的指针,其中P[1]指向关键字小于Key[1]的子树,P[i]指向关键字属于(Key[i-1],Key[i])的子树,P[n+1]指向关键字大于Key[n]的子树
-
每个节点包含n个关键字则就会有n+1个指针
-
P1、P2、P3为指向子树根节点的指针,P1指向关键字小于Key1的树;P2指向Key1-Key2之间的子树;P3指向大于Key2的树
-
B-Tree树总结
通过B-Tree树可以有效的把树的高度降下来。树的阶越大树的高度越低,查询的次数也会越少。
B+Tree树
-
读作B加Tree
-
B+Tree树是B-Tree树基础上的一种优化
-
MySQL里面的InnoDB存储引擎就是使用B+Tree树实现其索引结构
-
假设查找图中主键等于8的数据,先通过根节点将8和5、28进行对比,发现8大于5小于28,于是使用P1指针找到磁盘块2。接着再用8与5、10对比,发现8大于5小于10。于是使用磁盘块2里面的P1指针找到数据8

B-Tree和B+Tree的差异
-
B+Tree有n个子节点的节点中含有n个关键字
- B-Tree是n个子节点的节点有n-1个关键字
- 上图B-Tree里面3个子节点只包含了2个关键字,而B+Tree里面3个子节点只包含了3个关键字
-
B+Tree中,所有叶子节点中包含了全部关键字的信息,且叶子节点按照关键字的大小自小而大的顺序链接,构成一个有序链表(最显著的差异)
- B-Tree的叶子节点不包括全部关键字
- 比如图中B+Tree根节点里面的5、28、65会在中间节点里面展示出来,中间节点里面的5、10、20又会在叶子节点里面展示出来。
- 且叶子节点里面包含所有关键字的信息,不管哪一个父节点里面的关键字在叶子节点里面都会记录一份
-
B+Tree中,非叶子节点仅用于索引,不保存数据记录,记录存放在叶子节点中
- B-Tree中,非叶子节点既保存索引,也保存数据记录
B-Tree VS B+Tree
- where id = 5这种情况都是查询了3次,查询过程区别不大
- 但是由于B+Tree的中间节点只用来索引,所以对于相同的空间B+Tree里面存储的关键字更多,于是,B+Tree相对就更加矮胖一些,所以磁盘IO的次数就少一些。
- 由于B-Tree的中间节点也存储数据,所以它的查询效率不是很稳定,最好的情况是在根节点就直接查询到数据了,而最差的情况是下叶子节点才能找到数据。而B+Tree不管什么时候都必须要到叶子节点才能获得数据,这是因为B+Tree里面非叶子节点不存储数据只是用来索引。
- where id between 5 and 10
- B-Tree需要先查5,再查6…最后查10,最后再把结果组成到一起返回。
- B+Tree只需要先查5,然后通过5这个叶子节点的有序链表依次遍历,一直遍历到10即可,不需要像B-Tree一样挨个查再组装数据
- 所以B+Tree对于范围查询的性能要比B-Tree好
InnoDB存储方式
- 使用B+Tree索引
- 主键索引:叶子节点存储主键以及主键对应的数据内容
- 非主键索引(二级索引、辅助索引):叶子节点存储索引以及数据对应的主键
- 故如果sql查询是根据非主键索引查询,先是通过主键索引查询主键,再通过主键查询数据
MyISAM存储方式
- 使用B+Tree索引
- 主键索引/非主键索引的叶子节点都是存储指向数据块的指针
- 也就是说MyISAM存储方式里面,索引和数据是分开存储的
InnoDB VS MyISAM
- InnoDB:聚簇索引
- MyISAM:非聚簇索引
Hash索引

图中buckets是索引字段计算出来的hash值,和对应数据的物理位置组成的哈希表,都知道哈希表是数组+链表的组合,数组存储就是索引字段计算出来的hash值,链表存储的就是对应数据的物理位置。而entries是具体的数据。
这样Hash索引的核心就是哈希表,每条数据都会基于索引字段计算出hashcode存放在buckets中,查询时根据索引字段计算出hashcode从buckets中查询。故正常情况的时间复杂度时O(1)。性能很好。
假设出现了哈希冲突,比如图中阿神和姚半仙的hashcode都是139。当查询条件是姚半仙,会先用姚半仙计算出hashcode得出139,然后到buckets中匹配,找到hashcode是139的指针数组或者是链表,这个需要看数据引擎是如何实现的,之后再通过指针数组或者是链表找到对应的数据。
可以发现在哈希冲突的情况下,性能会降低一些,所以说,使用Hash索引要尽量防止哈希冲突。
Hash索引支持情况
- Memory引擎支持显式定义Hash索引
- InnoDB引擎支持“自适应Hash索引”
- 当InnoDB发现某些索引值使用非常频繁的话,那么它会在内存里面基于B+Tree索引之上再创建一个Hash索引,提升查询效率
- “自适应Hash索引”我们没法直接介入,MySQL官方只提供了一个开关
- 可以使用SHOW VARIABLES LIKE ‘innodb_adaptive_hash_index’;指令查看开关状态,默认是开启的ON状态
- 可以使用SET GLOBAL innodb_adaptive_hash_index = ‘OFF’;指令设置开发状态,正常情况保持默认ON状态即可
- 测试:
- CREATE TABLE t_test_hash ( NAME VARCHAR ( 45 ) NOT NULL, age TINYINT ( 4 ) NOT NULL, KEY USING HASH ( NAME ) ) ENGINE = memory;可以创建成功
- CREATE TABLE t_test_hash ( NAME VARCHAR ( 45 ) NOT NULL, age TINYINT ( 4 ) NOT NULL, KEY USING HASH ( NAME ) ) ENGINE = INNODB;会发现也可以创建成功,但是可以使用SHOW INDEX FROM t_test_hash;语句查看真正的索引是btree索引
空间索引(R-Tree索引)
- 存储GIS数据,基于R-Tree
- 在早期只有MyISAM引擎支持空间索引,但是MySQL 5.7时开始InnoDB支持空间索引
- 目前MySQL对于GIS的支持并不是很完善,所以大部分人都不会用到相关的功能
- 在GIS领域里面,做得比较好的是空间数据库Postgresql(Postgis拓展)
- R-Tree介绍文章参考:https://blog.csdn.net/sjyttkl/article/details/70226192
- 空间索引使用文章参考:https://www.cnblogs.com/oloroso/p/9579720.html
全文索引【了解即可】
- 适应全文搜索的需求
- MySQL 5.7之前,全文索引不支持中文,经常搭配Sphinx
- MySQL 5.7起,内置ngram,支持中文
- ngram官方地址:https://dev.mysql.com/doc/refman/8.0/en/fulltext-search-ngram.html
- 但是由于时代变化,目前来说应对全文搜索的需求,我们更多的会使用一些搜索引擎,比如elasticsearch、solr等,所以全文索引用的不是很多,只需要了解即可
- 全文索引使用文章参考:https://blog.csdn.net/mrzhouxiaofei/article/details/79940958
B-Tree(B+Tree)、Hash索引的特性与限制
B-Tree(B+Tree)特性
- 完全匹配:index(name) => where name = '大目’可以使用索引
- 范围匹配:index(age) => where age > 5可以使用索引
- 前缀匹配:index(name) => where name like '大%'可以使用索引
- 但是%在前面就无法使用索引了
- 即右模糊可以使用索引,左模糊不可以使用索引
B-Tree(B+Tree)限制——最左优先原则
- 创建组合索引index(name,age,sex)
- 查询条件不包括最左列,无法使用索引
- 例如:where age = 5 and sex = 1不包括name,所以无法使用索引
- 跳过了索引中的列,则无法完全使用索引
- 例如:where name = ‘大目’ and sex = 1 => 只能用到name这一列索引,而sex字段因为跳过了age字段无法使用索引
- 查询中有某个列的范围(模糊)查询,则其右边所有列都无法使用索引
- 例如:where name = ‘大目’ and age > 32 and sex = 1 => 只能用到name、age这两列索引
- 查询条件不包括最左列,无法使用索引
- 最左优先原则:指的是索引按照最左优先的方式匹配索引,不满足以上三个条件时都无法完全使用索引
- 因此,当使用B-Tree(B+Tree)索引时,索引列的顺序是非常重要的。
- 以上的几个例子都和索引的顺序有关,那么在做性能调优时,我们常常需要根据查询条件看看索引需要的字段,甚至需要额外创建一些使用的列相同但是列顺序不同的索引
Hash索引
- 一般性能比B-Tree(B+Tree)要好一些
- 只要不产生哈希冲突,时间复杂度就是O(1)
Hash索引限制
- Hash索引并不是按照索引值排序,所以无法使用排序
- 这意味着如果查询条件带order by是无法使用Hash索引的
- Hash索引不支持部分索引列匹配查找
- hash(a,b) => where a = 1不走索引
- 这是因为Hash索引是使用索引列的全部内容计算的
- Hash索引只支持等值查询(例如 =、IN),不支持范围查询(例如 >、<、between…and…)、模糊查询(like)
- Hash索引的Hash冲突越严重,性能下降越厉害
创建索引的原则
- 哪些场景建议创建索引
- 哪些场景不建议创建索引
建议创建索引的场景
-
select语句,频繁作为where条件的字段,一般需要创建索引
-- 如果频繁使用first_name字段作为查询条件,就创建索引index(first_name) SELECT * FROM employees WHERE first_name = 'Georgi';-- 如果频繁使用first_name和last_name字段作为查询条件,可以创建索引index(first_name, last_name) -- 如果有一个动态查询,first_name是个必填条件、last_name是个可选条件,创建索引index(last_name, first_name),根据最左前缀原则,WHERE first_name = 'Georgi'无法使用该索引 SELECT * FROM employees WHERE first_name = 'Georgi' AND last_name = 'Cools'; -
update/delete语句,where条件的字段,一般需要创建索引。因为update/delete语句需要先根据where条件查询出数据,再更新或者删除数据
-- 例如以下sql就需要为emp_no创建索引,但是emp_no已经是主键索引就不需要创建了 UPDATE employees SET first_name = 'Jim' WHERE = '100001';-- 例如以下sql就需要为first_name创建索引 DELETE FROM employees WHERE first_name = 'Georgi'; -
需要分组、排序的字段,一般需要创建索引。
-- 例如以下sql就需要为GROUP BY和ORDER BY字段dept_no创建索引 SELECT dept_no, count( * ) FROM dept_emp GROUP BY dept_no; SELECT dept_no, count( * ) FROM dept_emp ORDER BY dept_no; -
distinct所使用的字段,一般需要创建索引。
-- 例如以下sql就需要为first_name字段创建索引 SELECT DISTINCT(first_name) FROM employees; -
字段的值有唯一性约束,一般需要创建索引。而一些索引本身就可以起到唯一性约束的作用,比如唯一索引、主键索引等
-
对于多表查询,连接的字段应创建索引,且类型务必必保持一致,为了避免隐式转换,隐式转换可能会导致索引无法使用
-- 查询工号为100001的雇员待过的部门 -- emp.emp_no和de.emp_no、de.dept_no和d.dept_no的字段类型就需要保持一致,否则就会导致隐式转换,从而可能导致索引无法使用 SELECTemp.*,d.dept_name FROMemployees empLEFT JOIN dept_emp de ON emp.emp_no = de.emp_noLEFT JOIN departments d ON de.dept_no = d.dept_no WHEREde.emp_no = '100001';
不建议创建索引的场景
-
where子句里面用不到的字段。因为索引的作用是为了快速定位到需要查询的数据
-
表的记录非常少。因为即使创建了索引对性能影响并不大
-
有大量重复数据,选择性低。因为此时创建索引的作用是不大的,也不建议创建索引
-
因为索引的选择性越高,查询效率越好,因为可以在查找时过滤更多行,从而提升查询效率
-
这也是唯一索引比普通索引查询效率好的原因
-
而如果存在大量重复数据,那么索引的效率也会越低
-
比如有个人员表,里面的性别字段就不适合创建索引,因为性别字段的值存在大量重复数据,选择性很低。
-
-
-
频繁更新的字段,如果创建索引要考虑其索引维护开销
- 因为在更新或者删除数据的时候,也需要更新索引
- 如果更新频繁的字段而查询很少的话,是不适合创建索引的,因为每次更新数据都要去维护索引信息
ps:创建索引的原则只是参考,不要死守教条
相关文章:
数据库监控与调优【九】—— 索引数据结构
索引数据结构-B-Tree索引、Hash索引、空间索引、全文索引 二叉树查找 对于相同深度的节点,左侧的节点总是比右侧的节点小。在搜索时,如果要搜索的值key大于根节点(图中6),就会在右侧子树里查找;key小于根…...

哈工大计算机网络传输层详解之:流水线机制与滑动窗口协议
哈工大计算机网络传输层详解之:流水线机制与滑动窗口协议 哈工大计算机网络课程传输层协议详解之:可靠数据传输的基本原理哈工大计算机网络课程传输层协议详解之:TCP协议哈工大计算机网络课程传输层协议详解之:拥塞控制原理剖析 …...
Unity Mac最新打苹果包流程
作者介绍:铸梦xy。IT公司技术合伙人,IT高级讲师,资深Unity架构师,铸梦之路系列课程创始人。 IOS详细打包流程1.申请APPID2.申请开发证书3.创建描述文件 IOS详细打包流程 1.申请AppID 2.创建证书 3.申请配置文件(又名描…...

【MySQL数据库 | 第二十篇】explain执行计划
目录 前言: explain: 语法: 总结: 前言: 上一篇我们介绍了从时间角度分析MySQL语句执行效率的三大工具:SQL执行频率,慢日志查询,profile。但是这三个方法也只是在时间角度粗略的…...

学Python能做哪些副业?我一般不告诉别人!建议存好
前两天一个朋友找到我吐槽,说工资一发交完房租水电,啥也不剩,搞不懂朋友圈里那些天天吃喝玩乐的同龄人钱都是哪来的?确实如此,刚毕业的大学生工资起薪都很低,在高消费、高租金的城市,别说存钱&a…...
简化 Hello World:Java 新写法要来了
OpenJDK 的 JEP 445 提案正在努力简化 Java 的入门难度。 这个提案主要是引入 “灵活的 Main 方法和匿名 Main 类” ,希望 Java 的学习过程能更平滑,让学生和初学者能更好地接受 Java 。 提案的作者 Ron Pressler 解释:现在的 Java 语言非常…...

【服务器】springboot实现HTTP服务监听
文章目录 前言1. 本地环境搭建1.1 环境参数1.2 搭建springboot服务项目 2. 内网穿透2.1 安装配置cpolar内网穿透2.1.1 windows系统2.1.2 linux系统 2.2 创建隧道映射本地端口2.3 测试公网地址 3. 固定公网地址3.1 保留一个二级子域名3.2 配置二级子域名3.2 测试使用固定公网地址…...

浅谈常见的加密算法及实现
浅谈常见的加密算法及实现 简介: 随着公司业务的发展,系统用户量日益增多,系统安全性问题一直在脑子里反复回旋,以前系统用户少影响面小,安全方面也一直没有进行思考和加固,现如今业务发展了,虽…...
FTP协议详解
简介 FTP(File Transfer Protocol,文件传输协议) 是 TCP/IP 协议组中的协议之一。FTP协议包括两个组成部分,其一为FTP服务器,其二为FTP客户端。其中FTP服务器用来存储文件,用户可以使用FTP客户端通过FTP协…...

网络安全|渗透测试入门学习,从零基础入门到精通—渗透中的开发语言
目录 前面的话 开发语言 1、html 解析 2、JavaScript 用法 3、JAVA 特性 4、PHP 作用 PHP 能做什么? 5、C/C 使用 如何学习 前面的话 关于在渗透中需要学习的语言第一点个人认为就是可以打一下HTML,JS那些基础知识,磨刀不误砍柴…...

八大排序算法之归并排序(递归实现+非递归实现)
目录 一.归并排序的基本思想 归并排序算法思想(排升序为例) 二.两个有序子序列(同一个数组中)的归并(排升序) 两个有序序列归并操作代码: 三.归并排序的递归实现 递归归并排序的实现:(后序遍历递归) 递归函数抽象分析: 四.非递归归并排序的实现 1.非递归归并排序算法…...

基于SpringBoot+Html的前后端分离的学习平台
✌全网粉丝20W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式🍅 一、项目背景介绍: 在知识大爆炸的现代,怎…...

MySQL实战解析底层---“order by“是怎么工作的
目录 前言 全字段排序 rowid排序 全字段排序 VS rowid排序 前言 在开发应用的时候,一定会经常碰到需要根据指定的字段排序来显示结果的需求以举例市民表为例,假设你要查询城市是“杭州”的所有人名字,并且按照姓名排序返回前1000个人的姓…...

Linux和Shell:开源力量与命令行之美
目录 一、概述二、Linux的简单介绍三、Shell的简单介绍四、Linux和Shell的应用领域五、Shell编程结语: 一、概述 Linux和Shell是开源世界中不可或缺的两个重要组成部分。Linux作为一种自由和开放的操作系统,以其稳定性、安全性和可定制性而备受推崇。而S…...
服务负载均衡Ribbon
服务负载均衡Ribbon Ribbon 介绍Ribbon 案例Ribbon 负载均衡策略Ribbon 负载均衡算法设置自定义负载均衡算法 Ribbon 介绍 Ribbon 是一个的客服端负载均衡工具,它是基于 Netflix Ribbon 实现的。它不像 Spring Cloud 服务注册中心、配置中心、API 网关那样独立部署…...

hibernate vilidator主要使用注解的方式对bean进行校验
hibernate vilidator主要使用注解的方式对bean进行校验,初步的例子如下所示: package com.learn.validate.domain; import javax.validation.constraints.Min; import org.hibernate.validator.constraints.NotBlank; public class Student { //在需要校…...
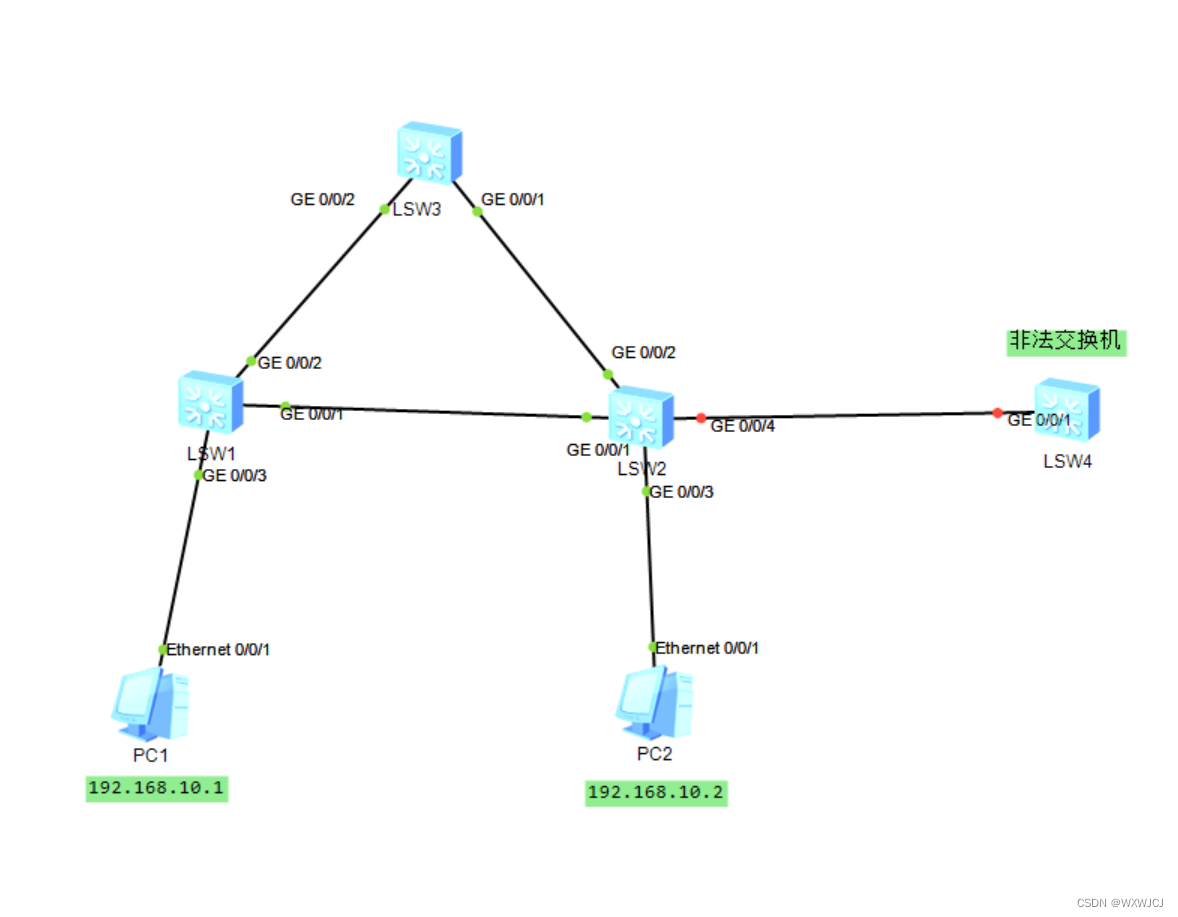
华为HCIP第一天---------RSTP
一、介绍 1、以太网交换网络中为了进行链路备份,提高网络可靠性,通常会使用冗余链路,但是这也带来了网络环路的问题。网络环路会引发广播风暴和MAC地址表震荡等问题,导致用户通信质量差,甚至通信中断。为了解决交换网…...

Jmeter(二) - 从入门到精通 - 创建测试计划(Test Plan)(详解教程)
1.简介 上一篇文章已经教你把JMeter的测试环境搭建起来了,那么这一篇我们就将JMeter启动起来,一睹其芳容,首先我给大家介绍一下如何来创建一个测试计划(Test Plan)。 2.创建一个测试计划(Test Plan&#x…...

Autosar诊断实战系列06-详解Dem中Event的NvM存储
本文框架 前言1. Dem触发NvM存储的基本流程2. Dem触发NvM存储的layout格式及内容2.1 Event在NvM中的layout格式2.2 Event在NvM中的存储内容2.3 Dem中Event与DTC的存储关系3.组合式Event(多个Event对应一个DTC)的存储处理3.1 仅分配一个Memory Entry3.2 检索方式3.3 一对一方式前…...

04 todoList案例
React全家桶 一、案例- TODO List 综合案例 功能描述 动态显示初始列表添加一个 todo删除一个 todo反选一个 todotodo 的全部数量和完成数量全选/全不选 todo删除完成的 todo 1.1 静态组件构建 将资料包中的todos_page/index.html中核心代码添加到Todo.jsx文件中,…...

sqlserver 根据指定字符 解析拼接字符串
DECLARE LotNo NVARCHAR(50)A,B,C DECLARE xml XML ( SELECT <x> REPLACE(LotNo, ,, </x><x>) </x> ) DECLARE ErrorCode NVARCHAR(50) -- 提取 XML 中的值 SELECT value x.value(., VARCHAR(MAX))…...

深入解析C++中的extern关键字:跨文件共享变量与函数的终极指南
🚀 C extern 关键字深度解析:跨文件编程的终极指南 📅 更新时间:2025年6月5日 🏷️ 标签:C | extern关键字 | 多文件编程 | 链接与声明 | 现代C 文章目录 前言🔥一、extern 是什么?&…...

在WSL2的Ubuntu镜像中安装Docker
Docker官网链接: https://docs.docker.com/engine/install/ubuntu/ 1、运行以下命令卸载所有冲突的软件包: for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done2、设置Docker…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...

力扣热题100 k个一组反转链表题解
题目: 代码: func reverseKGroup(head *ListNode, k int) *ListNode {cur : headfor i : 0; i < k; i {if cur nil {return head}cur cur.Next}newHead : reverse(head, cur)head.Next reverseKGroup(cur, k)return newHead }func reverse(start, end *ListNode) *ListN…...

Golang——6、指针和结构体
指针和结构体 1、指针1.1、指针地址和指针类型1.2、指针取值1.3、new和make 2、结构体2.1、type关键字的使用2.2、结构体的定义和初始化2.3、结构体方法和接收者2.4、给任意类型添加方法2.5、结构体的匿名字段2.6、嵌套结构体2.7、嵌套匿名结构体2.8、结构体的继承 3、结构体与…...

WEB3全栈开发——面试专业技能点P7前端与链上集成
一、Next.js技术栈 ✅ 概念介绍 Next.js 是一个基于 React 的 服务端渲染(SSR)与静态网站生成(SSG) 框架,由 Vercel 开发。它简化了构建生产级 React 应用的过程,并内置了很多特性: ✅ 文件系…...
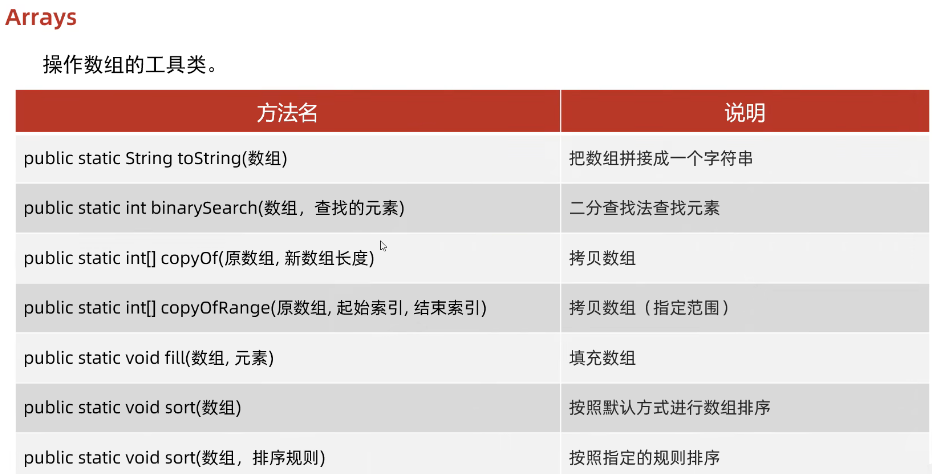
Java数组Arrays操作全攻略
Arrays类的概述 Java中的Arrays类位于java.util包中,提供了一系列静态方法用于操作数组(如排序、搜索、填充、比较等)。这些方法适用于基本类型数组和对象数组。 常用成员方法及代码示例 排序(sort) 对数组进行升序…...

CppCon 2015 学习:Reactive Stream Processing in Industrial IoT using DDS and Rx
“Reactive Stream Processing in Industrial IoT using DDS and Rx” 是指在工业物联网(IIoT)场景中,结合 DDS(Data Distribution Service) 和 Rx(Reactive Extensions) 技术,实现 …...

StarRocks 全面向量化执行引擎深度解析
StarRocks 全面向量化执行引擎深度解析 StarRocks 的向量化执行引擎是其高性能的核心设计,相比传统行式处理引擎(如MySQL),性能可提升 5-10倍。以下是分层拆解: 1. 向量化 vs 传统行式处理 维度行式处理向量化处理数…...