大数据课程D7——hadoop的YARN
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州
▲ 本章节目的
⚪ 了解YARN的概念和结构;
⚪ 掌握YARN的资源调度流程;
⚪ 了解Hadoop支持的资源调度器:FIFO、Capacity、Fair;
⚪ 掌握YARN的完全分布式结构和常见问题;
⚪ 掌握YARN的服役新节点操作;
一、简介
1. 概述
1. Another Resource Negotiator - 迄今另一个资源调度器) - 负责任务管理和资源调度。
2. YARN是Hadoop2.X开始出现的,也是Hadoop2.X中最重要的特性之一。也正是因为YARN的出现,导致Hadoop1.X和Hadoop2.X不兼容。
3. 产生原因:
a. 内部原因:
Ⅰ. 在Hadoop1.X中,没有YARN的说法,此时MapReduce分为主进程JobTracker和从进程TaskTracker。JobTracker只允许存在1个,容易出现单点故障。
Ⅱ. JobTracker负责对外接收任务,接收到任务之后需要将任务拆分成子任务(MapTask和ReduceTask)。JobTracker拆分完任务之后,将子任务分配给从进程TaskTracker。JobTracker会监控每一个TaskTracker的执行情况。在官方文档中,每一个JobTracker最多能够管理4000个TaskTracker。如果TaskTracker数量过多,导致JobTracker的效率成别下降,甚至于导致JobTracker的崩溃。
b. 外部原因:
Ⅰ. Hadoop产生的时候,市面上并没有太多的大数据框架,因此Hadoop在刚开始涉及的时候,只考虑MapReduce的资源调度问题。
Ⅱ. 后来随着大数据的发展,产生了越来越多的计算框架,很大一部分的框架都是围绕着Hadoop使用,因为Hadoop没有考虑其他框架的资源调度问题,所以这些计算框架就产生了资源调度冲突。
4. YARN的结构:
a. 主进程ResourceManager:
Ⅰ. 负责对外接收请求
Ⅱ. 负责管理NodeManager
Ⅲ. 负责管理ApplicationMaster
b. 从进程NodeManager:
Ⅰ. 执行任务。
Ⅱ. 负责管理本节点上的资源。
c. 辅助进程ApplicationMaster:负责管理具体的子任务。
2. 流程
1. 当ResourceManager收到客户端提交的任务之后,会先将这个任务临时存储下来,等待NodeManager的心跳。
2. 当ResourceManager收到NodeManager的心跳之后,会在心跳响应中将Job任务返回给NodeManager。
3. NodeManager通过心跳响应之后,收到任务之后,就会在本节点内部开启一个ApplicationMaster进程,然后将Job任务交给这个ApplicationMaster处理。
4. ApplicationMaster收到任务之后,会将Job任务来进行拆分,拆分成子任务。例如,如果是一个MapReduce程序,那么拆分成MapTask和ReduceTask。
5. 拆分完成之后,ApplicationMaster会给ResourceManager发送请求申请资源。
6. ResourceManager收到请求之后,将请求交给内部组件ResourceScheduler处理。
7. ResourceScheduler收到请求之后,会将资源的描述封装成一个Container对象返回给ApplicationMaster。
8. ApplicationMaster收到资源之后,会对资源进行二次拆分,分配给具体的子任务,然后将子任务分配到不同的NodeManager上执行,并且ApplicationMaster还会监控这些子任务的执行。
9. 如果子任务执行失败,那么ApplicationMaster监控到之后,会自动的重启这个失败的子任务,或者会自动的将失败的子任务分配到其他的节点上重新执行。
10. 当Job任务结束之后,ApplicationMaster会ResourceManager发送请求,同时请求注销自己。

3. ResourceScheduler - 资源调度器
1. 在Hadoop中,目前为止,支持3种资源调度器:FIFO(先进先出),Capacity(资源容量)以及Fair(公平)。
2. FIFO(先进先出):
a. 在Hadoop2.X中,默认使用是这个资源调度器,但是Hadoop3.X发生变化。
b. 底层会为维系唯一的队列,任务会先进入队列,然后从队列头获取任务,为这个任务分配资源。如果资源不充足的情况下,后入队的任务就会被阻塞。
3. Capacity(资源容量):
a. 在Hadoop3.X中,默认使用的是这个资源调度器。
b. 这个资源调度器中,可以维系多个队列,每一个队列维系FIFO的规则。默认情况下,这个调度器中只有1个队列default。
c. 如果资源调度器中维系了多个队列,那么可以为每一个队列设置资源分配比。在提交任务的时候,可以将任务提交到不同的队列中。
4. Fair(公平资源):
a. 在这个资源调取其中,也可以维系多个队列。
b. 这个队列中可以保证每一个在时间上是相对公平中 - 即任务在队列中是进行轮询的。
二、完全分布式结构
1. 结构
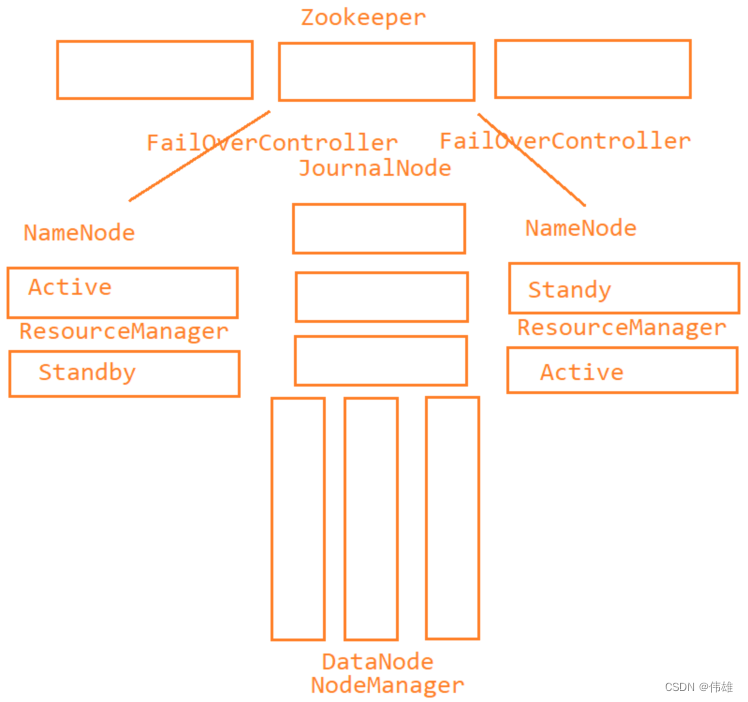
2. 常见问题
1. 在第一次关闭Hadoop之前,先修改stop-dfs.sh和stop-yarn.sh中的内容。将start-dfs.sh中添加的内容放到stop-dfs.sh中,将start-yarn.sh中的内容放到stop-yarn.sh中。
2. 在Hadoop集群中,一定要先启动Zookeeper再启动Hadoop。
3. 以后再次启动Hadoop,只需要通过start-all.sh即可启动。
4. 在执行命令的时候,出现了Name or service not known或者UnknownHost之类的异常,那么先检查主机名是否写对;再检查/etc/hostname或者是/etc/hosts文件是否配置正确。
5. 在进行ssh的时候需要输入密码,需要重新进行免密。
6. 在执行命令的时候,出现了command not found,那么先检查命令是否配置正确;然后再检查/etc/profile中的环境变量是否配置正确;最后确定对/etc/profile文件修改之后是否进行了重新生效source。
7. 在格式化的时候,出现了HA is not enabled/HA is not available之类的异常,那么说明Hadoop和当前系统出现了兼容性问题 - 重装系统。
8. 如果执行命令的时候出现了IllegalArgument之类的异常,那么说明命令或者参数写错了。
9. 如果启动之后,发现缺少了QuorumPeerMain,那么Zookeeper启动失败。
10. 如果启动之后,发现缺少了NameNode/DataNode/JournalNode/ DFSZKFailoverController进程,可以试图通过hdfs --daemon start namenode/datanode/journalnode/zkfc来单独这个进程,例如hdfs --daemon start datanode。
11. 如果启动之后,发现缺少了ResourceManager/NodeManage进程,那么可以试图通过yarn --daemon start resourcemanager/nodemanager来单独启动这个进程,例如yarn --daemon start nodemanager。
12. 如果在启动的时候,出现process already running as xxx,那么先kill -9 xxx,然后再单独重新启动。
13. 在NameNode格式化的时候,如果格式化失败,那么改错之后,先删除掉/home/software/hadoop-3.1.3/tmp/dfs/name目录,再重新格式化。
三、扩展
1. 服役新节点
1. 先修改新节点的主机名
vim /etc/hostname
#将主机名改为对应的名字,例如hadoop04
2. 进行主机名和IP的映射
vim /etc/hosts
#需要将所有云主机的IP和主机名都进行映射
cd /etc/
#远程拷贝给其他主机
scp -r hosts root@hadoop01:$PWD
scp -r hosts root@hadoop02:$PWD
scp -r hosts root@hadoop03:$PWD
3. 重启
4. 配置免密码互通
ssh-keygen
ssh-copy-id root@hadoop01
ssh hadoop01 --- 如果不需要密码,则输入logout
ssh-copy-id root@hadoop02
ssh hadoop02 --- 如果不需要密码,则输入logout
ssh-copy-id root@hadoop03
ssh hadoop03 --- 如果不需要密码,则输入logout
5. 所有的主机都需要和新添加的节点进行免密
ssh-copy-id root@hadoop04
ssh hadoop04 --- 如果不需要密码,则输入logout
6. 从其他节点拷贝一个Hadoop安装目录到第四个节点上
cd /home/software/
scp -r hadoop-3.1.3 root@hadoop04:$PWD
7. 新添加的节点上,进入Hadoop的安装目录,然后删除对应的目录
cd /home/software/hadoop-3.1.3/
rm -rf tmp
rm -rf logs/
8. 新节点配置环境变量
vim /etc/profile
#在文件末尾添加
export HADOOP_HOME=/home/software/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#保存退出,重新生效
source /etc/profile
9. 启动DataNode
10. 启动YARN
2. Federation HDFS - 联邦HDFS
1. 当前HDFS架构的弊端:
a. NameNode会将元数据维系在内存中。实际开发中,一台服务器大概能腾出50G左右的内存给NameNode来使用,也就意味着一台服务器大概能存储3亿~4亿条元数据,经过计算,意味着NameNode所管理的集群大概能够存储12~15PB的数据。但是在现在的开发中,很多大型企业的数据量已经超过上百PB,原始的NameNode架构就不能满足这个需求。
b. NameNode无法做到程序的隔离。所有的元数据都维系在一个NameNode上,意味着如果某一个任务占用的资源比较多,那么就会影响其他在进行的任务。
c. 所有的请求都只能访问这唯一的一个NameNode,此时NameNode的并发量就成了整个HDFS的并发瓶颈。
2. 在联邦HDFS中,可以利用多个节点同时作为NameNode对外接收请求,在请求之前,需要将HDFS中的路径于NameNode之间来进行映射。每一个路径必须对应某一个NameNode。
3. 在联邦HDFS中,所有的请求不再集中于某一个节点上而是分散到不同的节点上,从而提高了集群的并发量的上限。
4. 因为不同路径分别对应了不同的节点,此时某一个节点上资源被过多的占用,例如节点的磁盘的IO资源占用比较多,并不会影响其他的节点的读写。
5. 因为利用多个NameNode来实现功能,此时元数据也不再集中于一个节点上,而是分散到多个节点上,大大的提高了集群的数据量容纳的上限。
6. 在联邦HDFS中,要求所有的NameNode的BlockPoolID必须一致。
相关文章:
大数据课程D7——hadoop的YARN
文章作者邮箱:yugongshiyesina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 了解YARN的概念和结构; ⚪ 掌握YARN的资源调度流程; ⚪ 了解Hadoop支持的资源调度器:FIFO、Capacity、Fair; ⚪ 掌握YA…...

Rust vs Go:常用语法对比(十三)
题图来自 Go vs. Rust: The Ultimate Performance Battle 241. Yield priority to other threads Explicitly decrease the priority of the current process, so that other execution threads have a better chance to execute now. Then resume normal execution and call f…...

【【51单片机DA转换模块】】
爆改直流电机,DA转换器 main.c #include <REGX52.H> #include "Delay.h" #include "Timer0.h"sbit DAP2^1;unsigned char Counter,Compare; //计数值和比较值,用于输出PWM unsigned char i;void main() {Timer0_Init();whil…...

[SQL挖掘机] - 字符串函数 - substring
介绍: substring函数是在mysql中用于提取字符串的一种函数。它接受一个字符串作为输入,并返回从该字符串中指定位置开始的一部分子串。substring函数可以用于获取字符串中的特定字符或子串,以便进行进一步的处理或分析。 用法: 下面是substring函数的…...
第一百一十六天学习记录:C++提高:STL-string(黑马教学视频)
string基本概念 string是C风格的字符串,而string本质上是一个类 string和char区别 1、char是一个指针 2、string是一个类,类内部封装了char*,管理这个字符串,是一个char型的容器。 特点: string类内部封装了很多成员方…...
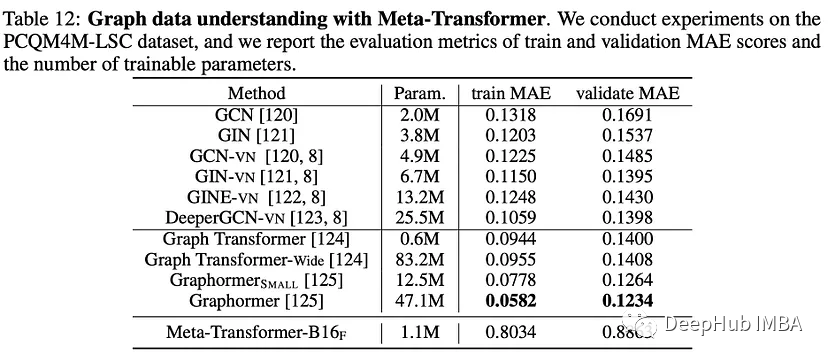
Meta-Transformer 多模态学习的统一框架
Meta-Transformer是一个用于多模态学习的新框架,用来处理和关联来自多种模态的信息,如自然语言、图像、点云、音频、视频、时间序列和表格数据,虽然各种数据之间存在固有的差距,但是Meta-Transformer利用冻结编码器从共享标记空间…...
tinkerCAD案例:24.Tinkercad 中的自定义字体
tinkerCAD案例:24.Tinkercad 中的自定义字体 原文 Tinkercad Projects Tinkercad has a fun shape in the Shape Generators section that allows you to upload your own font in SVG format and use it in your designs. I’ve used it for a variety of desi…...
list与流迭代器stream_iterator
运行代码: //list与流迭代器 #include"std_lib_facilities.h" //声明Item类 struct Item {string name;int iid;double value;Item():name(" "),iid(0),value(0.0){}Item(string ss,int ii,double vv):name(ss),iid(ii),value(vv){}friend ist…...

九耶:冯·诺伊曼体系
冯诺伊曼体系(Von Neumann architecture)是一种计算机体系结构,它由匈牙利数学家冯诺伊曼于1945年提出。冯诺伊曼体系是现代计算机体系结构的基础,几乎所有的通用计算机都采用了这种体系结构。 冯诺伊曼体系的核心思想是将计算机硬…...
探索UCI心脏病数据:利用R语言和h2o深度学习构建预测模型
一、引言 随着机器学习模型在实际应用中的广泛应用,人们对于模型的解释性和可理解性日益关注。可解释性机器学习是指能够清晰、透明地解释机器学习模型决策过程的一种方法和技术。在许多领域中,如医疗诊断、金融风险评估和自动驾驶等,解释模型…...
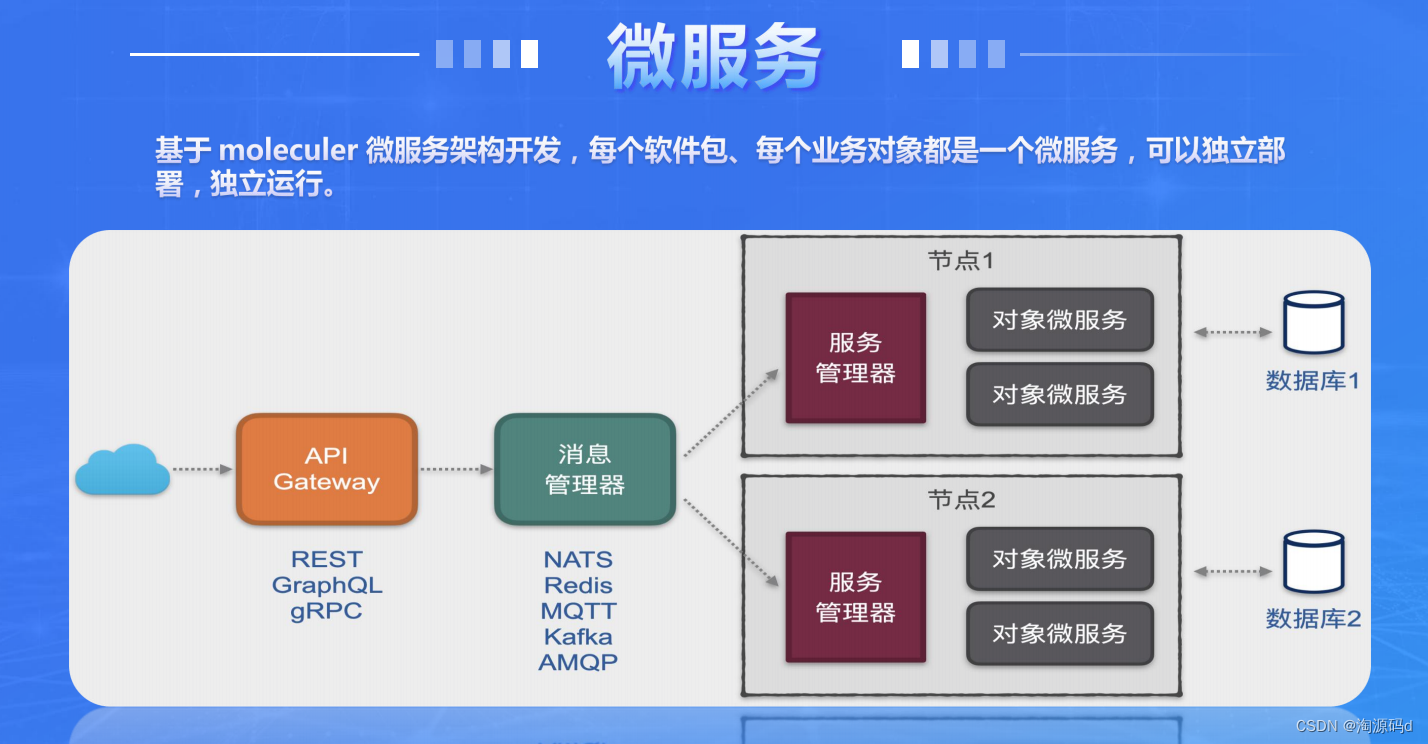
基于 moleculer 微服务架构的智能低代码PaaS 平台源码 可视化开发
低代码开发平台源码 低代码管理系统PaaS 平台 无需代码或通过少量代码就可以快速生成应用程序的开发平台。 本套低代码管理后台可以支持多种企业应用场景,包括但不限于CRM、ERP、OA、BI、IoT、大数据等。无论是传统企业还是新兴企业,都可以使用管理后台…...

xrdp登录显示白屏且红色叉
如上图所示,xrdp登录出现了红色叉加白屏,这是因为不正常关闭导致,解决方法其实挺简单的 #进入/usr/tmp cd /usr/tmp #删除对应用户的kdecache-** 文件(我这里使用的是kde桌面),例如删除ywj用户对应的文件 …...
Docker安装 Mysql 8.x 版本
文章目录 Docker安装 Mysql 8.0.22Mysql 创建账号并授权Mysql 数据迁移同版本数据迁移跨版本数据迁移 Mysql 5.x 版本与 Mysql 8.x版本是两个大版本,这里演示安装Mysql 8.x版本 Docker安装 Mysql 8.0.22 # 下载mysql $ docker pull mysql 默认安装最新…...

【数理知识】刚体 rigid body 及刚体的运动
文章目录 1 刚体2 刚体一般运动1 平移运动2 旋转运动 Ref 1 刚体 刚体是指在运动中和受力作用后,形状和大小不变,而且内部各点的相对位置不变的物体。绝对刚体实际上是不存在的,只是一种理想模型,因为任何物体在受力作用后&#…...
【UE5 多人联机教程】03-创建游戏
效果 步骤 打开“UMG_MainMenu”,增加创建房间按钮的点击事件 添加如下节点 其中,“FUNL Fast Create Widget”是插件自带的函数节点,内容如下: “创建会话”节点指游戏成功创建一个会话后,游戏的其他实例即可发现&am…...

【时间序列预测 】M4
【时间序列预测 】M4 论文题目:The M4 Competition: 100,000 time series and 61 forecasting methods 中文题目: 论文链接: 论文代码: 论文团队: 发表时间: DOI: 引用: 引用数: 摘要…...
:微信小程序授权登录增加多租户可配置界面)
SpringCloud微服务实战——搭建企业级开发框架(五十三):微信小程序授权登录增加多租户可配置界面
GitEgg框架集成weixin-java-miniapp工具包以实现微信小程序相关接口调用功能,weixin-java-miniapp底层支持多租户扩展。每个小程序都有唯一的appid,weixin-java-miniapp的多租户实现并不是以租户标识TenantId来区分的,而是在接口调用时&#…...

Stability AI推出Stable Diffusion XL 1.0,文本到图像模型
Stability AI宣布推出Stable Diffusion XL 1.0,这是一个文本到图像的模型,该公司将其描述为迄今为止“最先进的”版本。 Stability AI表示,SDXL 1.0能生成更加鲜明准确的色彩,在对比度、光线和阴影方面做了增强,可生成…...
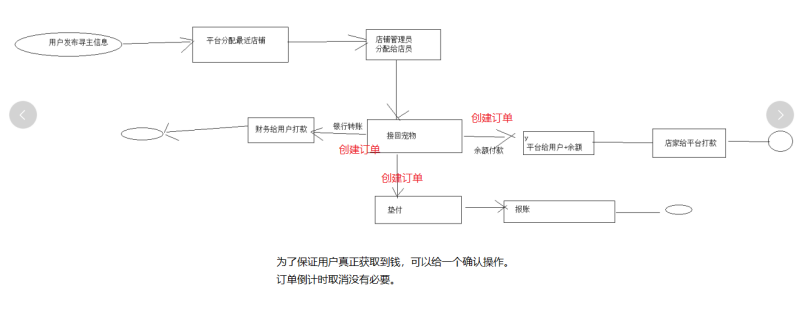
B076-项目实战--宠物上下架 展示 领养 收购订单
目录 上下架功能提供后台宠物列表实现 前台展示前台宠物列表和详情展示店铺展示 领养分析前台后端PetControllerPetServiceImpl 订单需求分析可能产生订单的模块订单模块额外功能 订单设计表设计流程设计 集成基础代码收购订单创建订单前端后端 上下架功能提供 后台宠物列表实…...

【iOS】—— 持久化
文章目录 数据持久化的目的iOS中数据持久化方案数据持久化方式分类内存缓存磁盘缓存 沙盒机制获取应用程序的沙盒路径沙盒目录的获取方式 持久化数据存储方式XML属性列表Preferences偏好设置(UserDefaults)数据库存储什么是序列化和反序列化,…...
详解)
后进先出(LIFO)详解
LIFO 是 Last In, First Out 的缩写,中文译为后进先出。这是一种数据结构的工作原则,类似于一摞盘子或一叠书本: 最后放进去的元素最先出来 -想象往筒状容器里放盘子: (1)你放进的最后一个盘子(…...

测试微信模版消息推送
进入“开发接口管理”--“公众平台测试账号”,无需申请公众账号、可在测试账号中体验并测试微信公众平台所有高级接口。 获取access_token: 自定义模版消息: 关注测试号:扫二维码关注测试号。 发送模版消息: import requests da…...
: K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?)
云原生核心技术 (7/12): K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?
大家好,欢迎来到《云原生核心技术》系列的第七篇! 在上一篇,我们成功地使用 Minikube 或 kind 在自己的电脑上搭建起了一个迷你但功能完备的 Kubernetes 集群。现在,我们就像一个拥有了一块崭新数字土地的农场主,是时…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...

基于FPGA的PID算法学习———实现PID比例控制算法
基于FPGA的PID算法学习 前言一、PID算法分析二、PID仿真分析1. PID代码2.PI代码3.P代码4.顶层5.测试文件6.仿真波形 总结 前言 学习内容:参考网站: PID算法控制 PID即:Proportional(比例)、Integral(积分&…...

SciencePlots——绘制论文中的图片
文章目录 安装一、风格二、1 资源 安装 # 安装最新版 pip install githttps://github.com/garrettj403/SciencePlots.git# 安装稳定版 pip install SciencePlots一、风格 简单好用的深度学习论文绘图专用工具包–Science Plot 二、 1 资源 论文绘图神器来了:一行…...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

Vue2 第一节_Vue2上手_插值表达式{{}}_访问数据和修改数据_Vue开发者工具
文章目录 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染2. 插值表达式{{}}3. 访问数据和修改数据4. vue响应式5. Vue开发者工具--方便调试 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染 准备容器引包创建Vue实例 new Vue()指定配置项 ->渲染数据 准备一个容器,例如: …...

macOS多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用
文章目录 问题现象问题原因解决办法 问题现象 macOS启动台(Launchpad)多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用。 问题原因 很明显,都是Google家的办公全家桶。这些应用并不是通过独立安装的…...

学习STC51单片机31(芯片为STC89C52RCRC)OLED显示屏1
每日一言 生活的美好,总是藏在那些你咬牙坚持的日子里。 硬件:OLED 以后要用到OLED的时候找到这个文件 OLED的设备地址 SSD1306"SSD" 是品牌缩写,"1306" 是产品编号。 驱动 OLED 屏幕的 IIC 总线数据传输格式 示意图 …...