【深度学习】【Image Inpainting】Generative Image Inpainting with Contextual Attention
Generative Image Inpainting with Contextual Attention
DeepFillv1 (CVPR’2018)
论文:https://arxiv.org/abs/1801.07892
论文代码:https://github.com/JiahuiYu/generative_inpainting
论文摘录
文章目录
- 效果一览
- 摘要
- 介绍
- 论文贡献
- 相关工作
- Image Inpainting
- Global and local Wasserstein GANs
- Spatially discounted reconstruction loss
- Image Inpainting with Contextual Attention
- Contextual Attention
- Unified Inpainting Network
- 训练
- 模型大小和速度
- 结论
效果一览
自然场景、人脸、纹理:

摘要
最近基于深度学习的方法在绘制图像中大块缺失区域的挑战性任务上显示出了有希望的结果。这些方法可以生成视觉上可信的图像结构和纹理,但往往会产生扭曲的结构或与周围区域不一致的模糊纹理。
这主要是由于卷积神经网络在明确地从distant spatial locations借用或复制信息时无效。另一方面,当需要从周围区域借用纹理时,传统的纹理和斑块合成方法尤其适用。
基于这些观察结果,我们提出了一种新的基于深度生成模型的方法,该方法不仅可以合成新的图像结构,还可以在网络训练中明确地利用周围图像特征作为参考来进行更好的预测。该模型是一个前馈、全卷积神经网络,可以在测试时间内处理任意位置的多个孔和不同大小的图像。在包括人脸(CelebA, CelebA- hq),纹理(DTD)和自然图像(ImageNet, Places2)在内的多个数据集上的实验表明,我们提出的方法比现有的方法产生更高质量的图像绘制结果。
介绍
Filling missing pixels of an image ,通常称为image inpainting or completion,是计算机视觉中的一项重要任务。它在照片编辑、基于图像的渲染和计算摄影中有许多应用[3,25,30,31,36,41]。图像绘制的核心挑战在于为缺失区域合成视觉上真实和语义上合理的像素,这些像素与现有区域一致(The core challenge of image inpainting lies in synthesizing visually realistic and semantically plausible pixels for the missing regions that are coherent with existing ones.)。
PS. 都会谈到早期基于diffusion和patch的工作,不能生成新的对象,比如脸部不能生成嘴巴,现在基于GAN的方式是更优的。
早期的工作[3,14]尝试使用类似于纹理合成texture synthesis[10,11]的思路来解决这个问题,即从低分辨率到高分辨率开始匹配和复制背景补丁到孔中,或者从孔边界传播。这些方法在背景绘制任务中效果很好,并且在实际应用中得到了广泛的应用[3]。然而,由于他们假设缺失的补丁可以在背景区域的某个地方找到,他们无法在具有挑战性的情况下产生新的图像内容,因为在绘制区域涉及复杂的,非重复的结构(例如面孔,物体)。此外,这些方法不能捕获高级语义。
深度卷积神经网络(CNN)和生成式对抗网络(GAN)[12]的快速发展启发了最近的研究[17,27,32,41],他们将inpainting定义为一个条件图像生成问题 conditional image generation problem ,其中高级识别和低级像素合成被制定为卷积编码器-解码器网络。与对抗网络联合训练,以促进生成和现有像素之间的一致性。这些作品被证明在高度结构化的图像中产生可信的新内容,如面孔、物体和场景。
不幸的是,这些基于cnn的方法经常会产生边界伪影boundary artifacts,扭曲的结构distorted structures和与周围区域不一致的模糊纹理blurry textures inconsistent with surrounding areas。我们发现这可能是由于卷积神经网络在模拟远距离上下文信息(distant contextual information)和空洞区域之间的长期相关性方面的有效性出现了问题。例如,为了允许一个像素受到64像素外内容的影响,它需要至少6层3 × 3的卷积,膨胀因子为2或equivalent [17,42]。然而,dilated convolution从规则和对称网格中采样特征,因此可能无法权衡感兴趣的特征。请注意,最近的一项工作[40]试图通过优化已知区域中生成的补丁和匹配补丁之间的纹理相似性来解决外观差异。虽然提高了视觉质量,但这种方法被数百次梯度下降迭代所拖慢,并且在gpu上处理分辨率为512 × 512的图像需要几分钟。
我们提出了一种统一的前馈生成网络,该网络具有新颖的上下文注意层。我们提出的网络包括两个阶段。第一阶段是用重建损失训练一个简单的dilated convolutional network 来粗略地列出遗漏的内容( to rough out the missing contents)。 contextual attention 在第二阶段被整合。上下文注意力的核心思想是使用已知补丁的特征作为卷积滤波器来处理生成的补丁。它是通过卷积来设计和实现的,用于将生成的补丁与已知的上下文补丁进行匹配,通过channel-wise softmax 来加权相关补丁,并通过去卷积来重建具有上下文补丁的生成补丁。上下文注意力模块还具有 spatial propagation layer ,以鼓励注意力的空间连贯性。为了让网络能产生新内容(hallucinate novel contents),我们有另一个与上下文注意力通路平行的卷积通路。这两条路径被聚合并馈送到单个解码器中以获得最终输出。整个网络是以重建损失和两个Wasserstein GAN损失进行端到端训练的[1,13],其中一个critic 关注全局图像,而另一个则关注缺失区域的局部补丁。
论文贡献
1、我们提出了一种新的上下文注意力层(novel contextual attention layer ),以明确地关注遥远空间位置(distant spatial locations)的相关特征块。
2、我们介绍了几种技术,包括修复网络增强( inpainting network enhancements)、全局和局部WGAN[13](global and local WGANs)以及空间折扣重建损失(spatially discounted reconstruction loss ),以在当前最先进的生成图像修复网络[17]的基础上提高训练稳定性和速度。因此,我们能够在一周内而不是两个月内对网络进行训练。
博客上一篇读到的:

3、我们的统一前馈生成网络在各种具有挑战性的数据集上实现了高质量的修复结果,包括CelebA人脸[28]、CelebAHQ人脸[22]、DTD纹理[6]、ImageNet[34]和Places2[43]。
相关工作
Image Inpainting
传统的基于扩散或补丁的方法,如[2,4,10,11],通常使用变分算法或补丁相似性来将信息从背景区域传播到空穴。这些方法适用于平稳纹理,但仅限于自然图像等非平稳数据。Simakov等人[36]提出了一种基于双向补丁相似性的方案,以更好地为非平稳视觉数据建模,用于重新定位和修复应用。然而,密集计算补丁相似性[36]是一项非常昂贵的操作,这阻碍了这种方法的实际应用。为了应对这一挑战,提出了一种称为PatchMatch[3]的快速最近邻场算法,该算法对包括修复在内的图像编辑应用具有重要的实用价值。
最近,深度学习和基于GAN的方法已经成为图像修复的一种很有前途的范例。最初的努力[23,39]训练卷积神经网络用于小区域的去噪和修复。上下文编码器[32]首先训练用于修复大洞的深度神经网络。它被训练来完成128×128图像中64×64的中心区域,以“2像素的重建损失和生成对抗性损失”作为目标函数。最近,Iizuka等人[17]通过引入全局和局部鉴别器作为对抗性损失对其进行了改进。全局鉴别器评估完成的图像整体上是否连贯,而局部鉴别器聚焦于以生成区域为中心的小区域,以增强局部一致性。此外,Iizuka等人[17]在修复网络中使用扩张卷积来取代上下文编码器中采用的通道式全连接层,这两种技术都被提出用于增加输出神经元的感受野。同时,也有一些研究集中在生成性人脸修复。Yeh等人[41]在受损图像的潜在空间中搜索最接近的编码,并进行解码以获得完整的图像。李等人[27]介绍了用于人脸完成的额外人脸解析损失。然而,这些方法通常需要后处理步骤,例如图像混合操作,以增强孔边界附近的颜色一致性。 PS 这也是痛点。
一些工作[37,40]遵循了图像风格化[5,26]的思想,将修复表述为一个优化问题。例如,Yang等人[40]提出了一种基于图像内容和纹理约束的联合优化的多尺度神经补丁合成方法,该方法不仅保留了上下文结构,而且通过匹配和调整深度分类网络中具有最相似中层特征相关性的补丁来产生高频细节。这种方法显示出有希望的视觉结果,但由于优化过程,速度非常慢。
在深度卷积神经网络中,已经有许多关于学习空间注意力的研究。在这里,我们选择回顾与所提出的上下文注意力模型相关的一些有代表性的模型。Jaderberg等人[19]首次提出了一种用于对象分类任务的参数空间注意力模块,称为空间变换网络(STN)。
该模型具有定位模块,用于预测全局仿射变换到扭曲特征的参数。然而,该模型假设全局变换,因此不适合对逐片注意力进行建模。周等人[44]引入了一种外观流来预测偏移向量,该偏移向量指定了输入视图中的哪些像素应该被移动以重建目标视图,用于新的视图合成。根据我们的实验,这种方法被证明对匹配相同物体的相关视图是有效的,但对预测从背景区域到洞的流场是无效的。最近,Dai等人[8]和Jeon等人[20]提出学习空间注意或主动卷积核。这些方法可以在训练过程中更好地利用信息来变形卷积核形状,但当我们需要从背景中借用确切的特征时,这些方法可能仍然受到限制。
我们首先通过复制和对最新的最先进的绘画模型[17]进行若干改进来构建基线生成图像绘画网络,该模型在面部、建筑立面和自然图像的绘画图像中显示出有希望的视觉效果。
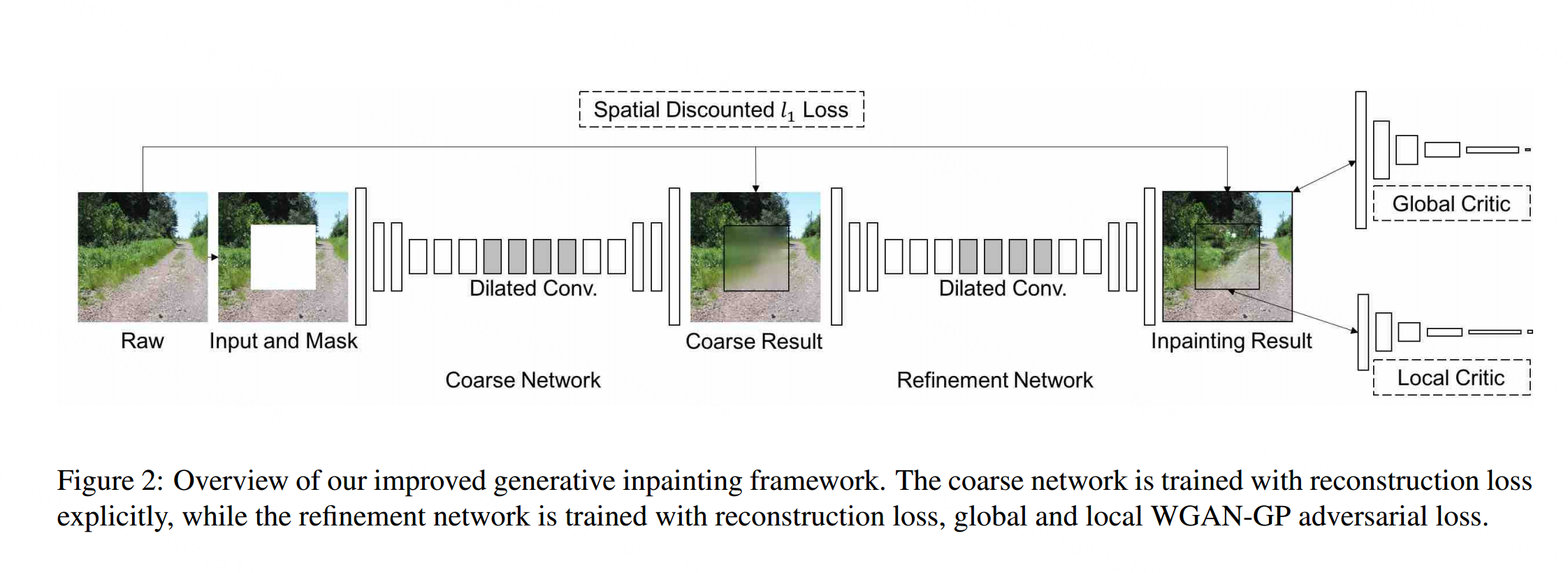
我们改进的模型的网络架构如图2所示。对于训练和推理,我们遵循与[17]相同的输入和输出配置,即生成器网络将填充有洞的白色像素的图像和表示洞区域的二值掩码作为输入对,并输出最终完成的图像。我们将输入与相应的二进制掩模配对,以处理具有可变大小,形状和位置的孔。网络的输入是一张256 × 256的图像,在训练时随机采样一个矩形缺失区域,训练后的模型可以取不同大小的图像,其中有多个孔。
在图像绘制任务中,接受野的大小需要足够大,Iizuka等[17]为此采用了扩展卷积。为了进一步扩大接收域和稳定训练,我们引入了一种两阶段的从粗到细的网络架构,其中第一个网络进行初始粗预测,第二个网络将粗预测作为输入并预测精细结果。粗网络明确地使用重构损失进行训练,而精化网络则同时使用重构损失和GAN损失进行训练。从直观上看,细化网络比缺失区域的原始图像看到了更完整的场景,因此其编码器可以比粗网络学习到更好的特征表示。这种两阶段网络架构在精神上类似于残差学习[15]或深度监督[24]。
此外,为了提高效率,我们的inpainting网络采用了细而深的设计方案,其参数比文献[17]中的网络少。在层实现方面,我们对所有卷积层使用镜像填充,并删除批处理归一化层18。此外,我们使用elu[7]作为激活函数,而不是[17]中的ReLU,并剪辑输出滤波器值,而不是使用tanh或sigmoid函数。此外,我们发现在GAN训练中分离全局和局部特征表示比[17]中的特征连接效果更好。更多的细节可以在补充材料中找到。
Global and local Wasserstein GANs
与之前依赖DCGAN[33]进行对抗性监督的生成式绘画网络[17,27,32]不同,我们建议使用改进版本的WGAN-GP[1,13]。受[17]的启发,我们将WGAN-GP损失附加到第二阶段细化网络的全局和局部输出上,以加强全局和局部一致性。众所周知,WGAN-GP损失在图像生成任务中优于现有的GAN损失,并且当与L1重建损失结合使用时效果很好,因为它们都使用L1距离度量。
PS. WGAN-GP https://blog.csdn.net/xiaoxifei/article/details/87542317 这是一个重要知识点。
WGAN(Wasserstein生成对抗网络)和WGAN-GP(Wasserstein生成对抗网络梯度惩罚)是生成对抗网络(GAN)的改进版本,它们主要通过引入Wasserstein距离来解决传统GAN中存在的训练不稳定和模式崩溃的问题。
区别在于:
损失函数:WGAN使用了Wasserstein距离作为生成器和判别器之间的训练目标。它通过最大化判别器对真实样本的期望输出与生成样本的期望输出之差来衡量两个分布之间的距离。而WGAN-GP在WGAN的基础上,通过引入梯度惩罚项来进一步限制判别器的Lipschitz连续性,使得训练更加稳定。
梯度惩罚:WGAN-GP使用梯度惩罚来替代WGAN中的权重裁剪。在WGAN-GP中,对判别器的输入数据和生成样本之间的随机线性插值进行采样,并计算这些样本对应的判别器梯度的范数。然后将这个范数减去1并求平均,作为生成器和判别器的梯度惩罚项。
训练稳定性:WGAN-GP相对于WGAN具有更好的训练稳定性。它通过梯度惩罚项来强制判别器满足Lipschitz连续性,避免了训练过程中梯度消失或爆炸的问题,从而提高了模型的收敛性和生成样本的质量。
总的来说,WGAN-GP是对WGAN的改进,通过引入梯度惩罚项解决了WGAN在训练稳定性上的一些问题,提高了生成对抗网络的性能和可靠性。
Spatially discounted reconstruction loss
绘画问题涉及到像素的幻觉,因此在任何给定的环境下都可能有许多看似合理的解决方案。在具有挑战性的情况下,看似完整的图像可能具有与原始图像中非常不同的补丁或像素。由于我们使用原始图像作为计算重建损失的唯一基础,因此在这些像素上强制执行重建损失可能会误导卷积网络的训练过程。
直观地说,靠近孔边界的缺失像素比靠近孔中心的那些像素具有更少的模糊性。这与在强化学习中观察到的问题类似。当长期奖励在采样过程中有较大变化时,人们在采样轨迹上使用时间贴现奖励[38]。受此启发,我们使用权重掩模M引入空间贴现重建损失Spatially discounted reconstruction loss。掩模中每个像素的权重计算为γ l,其中l是像素到最近的已知像素的距离。γ在所有实验中都被设置为0.99。
通过以上改进,我们的基线生成绘制模型的收敛速度比[17]快得多,绘制结果也更准确。对于Places2[43],我们将训练时间从[17]报道的11,520 gpu小时(K80)减少到120 gpu小时(GTX 1080),这几乎是100倍的加速。并且,不再需要后处理步骤(图像混合)[17]。
Image Inpainting with Contextual Attention
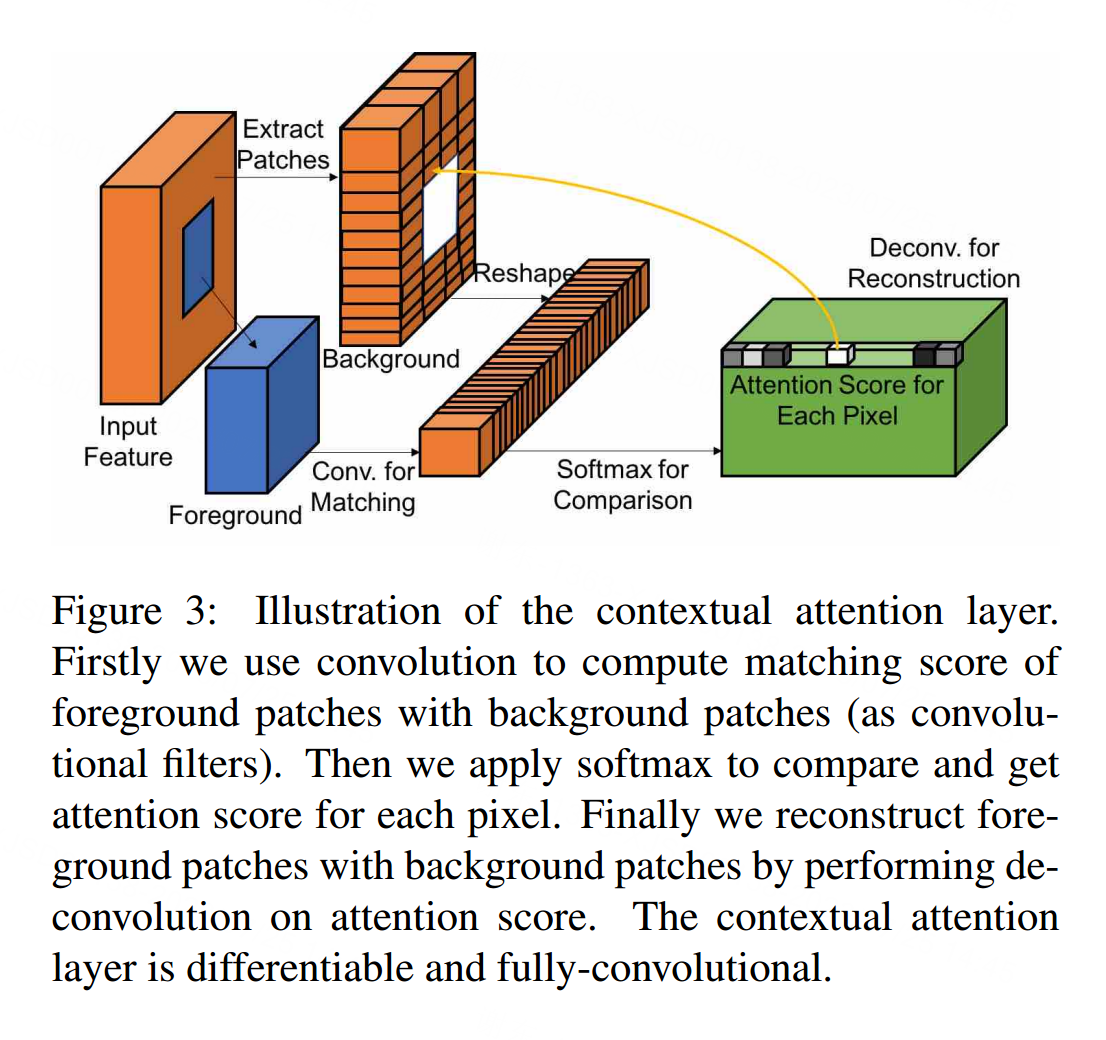
卷积神经网络用局部卷积核逐层处理图像特征,因此不是有效地从遥远的空间位置借用特征。为了克服这种局限性,我们考虑了注意机制,并在深度生成网络中引入了一种新的上下文注意层。在本节中,我们首先讨论上下文注意层的细节,然后讨论如何将其集成到我们unified inpainting network。
Contextual Attention
The contextual attention layer 学习在何处从已知的背景补丁中借用或复制特征信息以生成缺失的补丁。它是可微的,因此可以在深度模型中训练,并且是完全卷积的,这允许在任意分辨率上进行测试。


Unified Inpainting Network
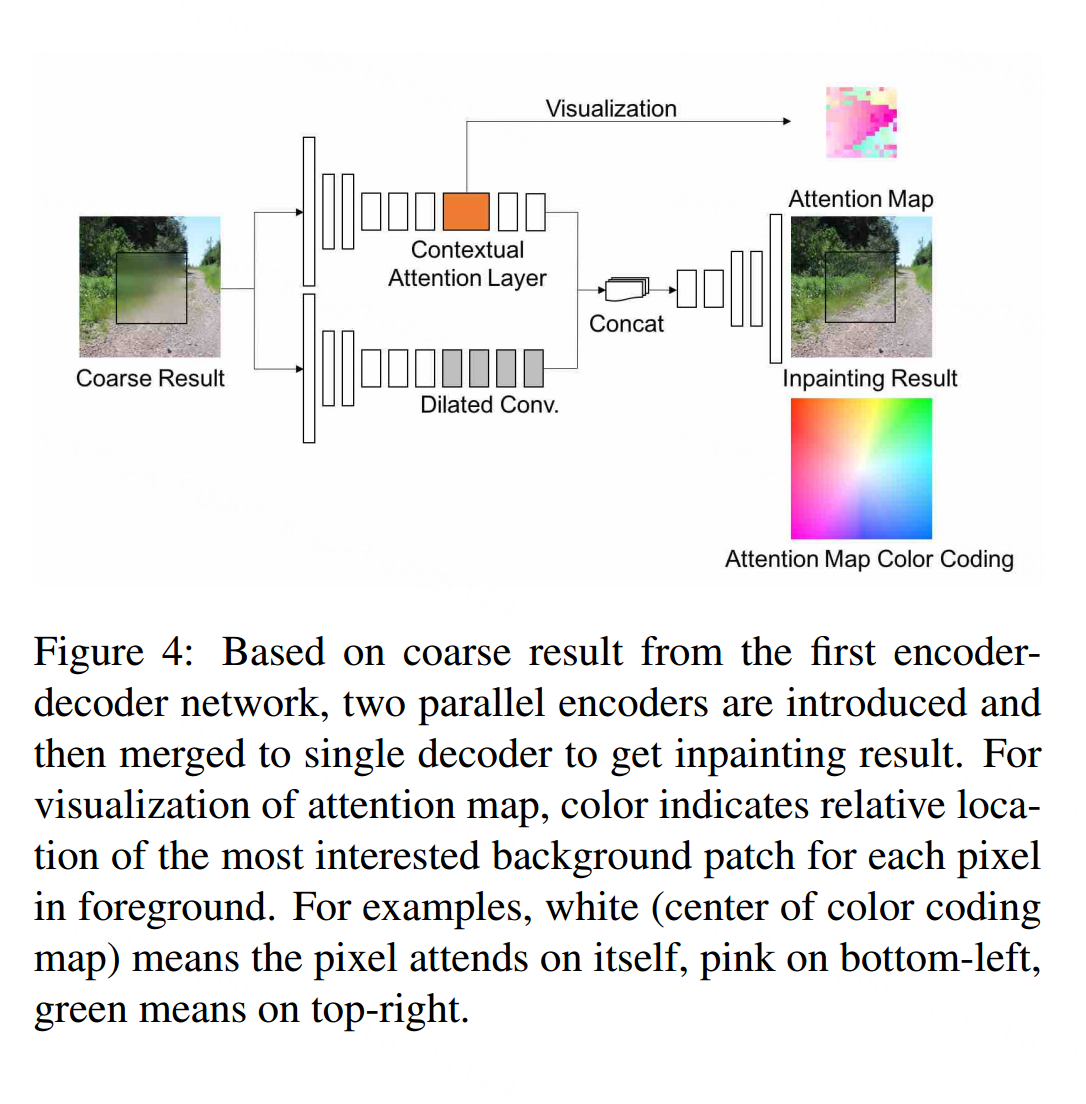
为了集成注意力模块,我们在图2的基础上引入两个并行编码器,如图4所示。底部的编码器通过逐层(扩展)卷积专门关注幻觉内容,而顶部的编码器则试图关注感兴趣的背景特征。来自两个编码器的输出特征被聚合并馈送到一个单个解码器获得最终输出。为了解释上下文注意,我们以图4所示的方式将其可视化。
我们使用颜色来表示每个前景像素最感兴趣的背景补丁的相对位置。例如,白色(颜色编码图的中心)表示像素关注自身,左下角为粉色,右上角为绿色。偏移值根据不同的图像进行不同的缩放,以最好地显示最有趣的范围。
训练

模型大小和速度

结论
我们提出了一个从粗到精的生成图像绘画框架,并引入了我们的基线模型以及一个具有新颖上下文注意模块的完整模型。我们发现上下文注意模块通过学习明确匹配和关注相关背景补丁的特征表示,显著改善了图像绘制结果。作为未来的工作,我们计划将该方法扩展到非常高分辨率的绘画应用,使用类似于gan渐进生长的想法[22]。所提出的绘图框架和上下文关注模块也可以应用于条件图像生成、图像编辑和计算摄影任务,包括基于图像的渲染、图像超分辨率、引导编辑等。
相关文章:
【深度学习】【Image Inpainting】Generative Image Inpainting with Contextual Attention
Generative Image Inpainting with Contextual Attention DeepFillv1 (CVPR’2018) 论文:https://arxiv.org/abs/1801.07892 论文代码:https://github.com/JiahuiYu/generative_inpainting 论文摘录 文章目录 效果一览摘要介绍论文贡献相关工作Image…...
二维深度卷积网络模型下的轴承故障诊断
1.数据集 使用凯斯西储大学轴承数据集,一共有4种负载下采集的数据,每种负载下有10种 故障状态:三种不同尺寸下的内圈故障、三种不同尺寸下的外圈故障、三种不同尺寸下的滚动体故障和一种正常状态 2.模型(二维CNN) 使…...

redis突然变慢问题定位
CPU 相关:使用复杂度过高命令、O(N)的这个N,数据的持久化,都与耗费过多的 CPU 资源有关 内存相关:bigkey 内存的申请和释放、数据过期、数据淘汰、碎片整理、内存大页、内存写时复制都与内存息息相关 磁盘…...
React井字棋游戏官方示例
在本篇技术博客中,我们将介绍一个React官方示例:井字棋游戏。我们将逐步讲解代码实现,包括游戏的组件结构、状态管理、胜者判定以及历史记录功能。让我们一起开始吧! 项目概览 在这个井字棋游戏中,我们有以下组件&am…...

七大经典比较排序算法
1. 插入排序 (⭐️⭐️) 🌟 思想: 直接插入排序是一种简单的插入排序法,思想是是把待排序的数据按照下标从小到大,依次插入到一个已经排好的序列中,直至全部插入,得到一个新的有序序列。例如:…...
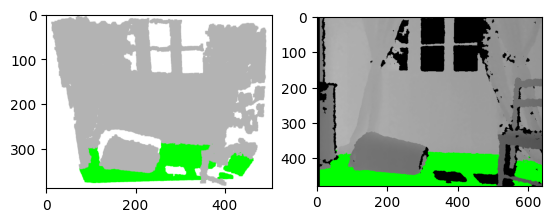
【点云处理教程】03使用 Python 实现地面检测
一、说明 这是我的“点云处理”教程的第3篇文章。“点云处理”教程对初学者友好,我们将在其中简单地介绍从数据准备到数据分割和分类的点云处理管道。 在上一教程中,我们在不使用 Open3D 库的情况下从深度数据计算点云。在本教程中,我们将首先…...
Python 日志记录:6大日志记录库的比较
Python 日志记录:6大日志记录库的比较 文章目录 Python 日志记录:6大日志记录库的比较前言一些日志框架建议1. logging - 内置的标准日志模块默认日志记录器自定义日志记录器生成结构化日志 2. Loguru - 最流行的Python第三方日志框架默认日志记录器自定…...

最近遇到一些问题的解决方案
最近遇到一些问题的解决方案 SpringBoot前后端分离参数传递方式总结Java8版本特性讲解idea使用git更新代码 : update project removeAll引发得java.lang.UnsupportedOperationException异常Java的split()函数用多个不同符号分割 Aspect注解切面demo 抽取公共组件,使…...

封装hutool工具生成JWT token
private static final String KEY "abcdef";/*** 生成token** param payload 可以存放用户的一些信息,不要存放敏感字段* return*/public static String createToken(Map<String, Object> payload) {//十分重要,不禁用发布到生产环境无…...

【手机】三星手机刷机解决SecSetupWizard已停止
三星手机恢复出厂设置之后,出现SecSetupWizard已停止的解决方案 零、问题 我手上有一部同学给的三星 GT-S6812I,这几天搞了张新卡,多余出的卡就放到这个手机上玩去了。因为是获取了root权限的(直接使用KingRoot就可以࿰…...

GDAL C++ API 学习之路 OGRGeometry 抽象曲线基类 OGRCurve
OGRCurve class "ogrsf_frmts.h" OGRCurve 是 OGR(OpenGIS Simple Features Reference Implementation)几何库中的一个基类,表示曲线几何对象。它是 OGRLineString 和 OGRCircularString 的抽象基类,用于表示曲…...

etcd底层支持的数据库有哪些
etcd底层的数据库可以更换。在当前版本的etcd中,它使用的是BoltDB作为默认的后端存储引擎。但是,etcd提供了接口允许您更换数据库后端,以便根据需要选择更合适的存储引擎。 以下是etcd支持的一些后端数据库选项: BoltDBÿ…...
linux设备驱动的poll与fasync
什么是fasync 在 Linux 驱动程序中,fasync 是一种机制,用于在异步事件发生时通知进程。它允许进程在等待设备事件时,不必像传统的轮询方式那样持续地查询设备状态。 具体来说,当进程调用 fcntl(fd, F_SETFL, O_ASYNC) 函数时&am…...
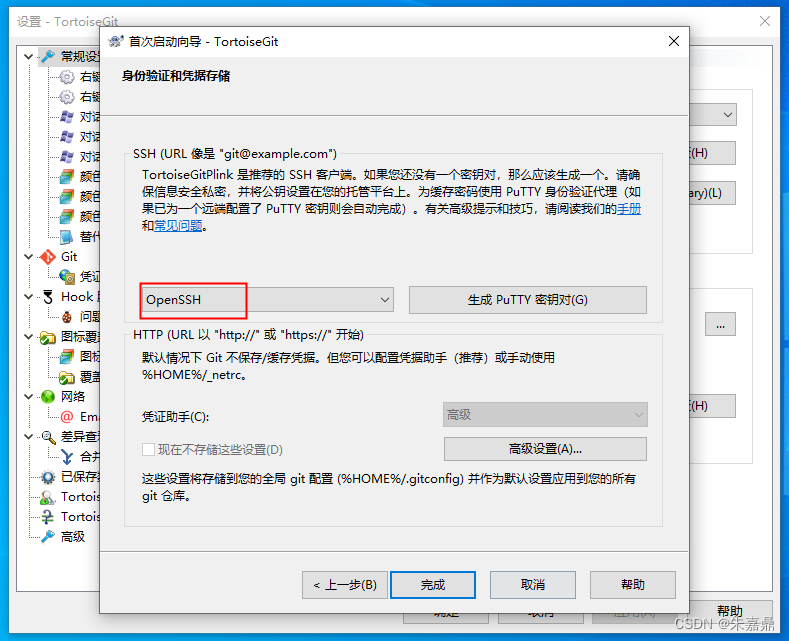
TortoiseGit安装与配置
注:在安装TortoiseGit之前我已经安装了git工具。 二、Git的诞生及环境配置_tortoisegit安装包_朱嘉鼎的博客-CSDN博客 1、TortoiseGit简介 TortoiseGit是基于TortoiseSVN的Git版本的Windows Shell界面。它是开源的,可以完全免费使用。 TortoiseGit 支持…...
)
Java代码打印空心菱形(小练习)
回看基础 利用Java代码打印一个空心菱形 //5. 打印空心菱形 import java.util.Scanner; public class MulForExercise01 {//编写一个 main 方法public static void main(String[] args) {Scanner myScanner new Scanner(System.in);System.out.println("请输入正三角的行…...

【性能优化】MySQL百万数据深度分页优化思路分析
业务场景 一般在项目开发中会有很多的统计数据需要进行上报分析,一般在分析过后会在后台展示出来给运营和产品进行分页查看,最常见的一种就是根据日期进行筛选。这种统计数据随着时间的推移数据量会慢慢的变大,达到百万、千万条数据只是时间问…...
交叉编译工具链的安装、配置、使用
一、交叉编译的概念 交叉编译是在一个平台上生成另一个平台上的可执行代码。 编译:一个平台上生成在该平台上的可执行文件。 例如:我们的Windows上面编写的C51代码,并编译成可执行的代码,如xx.hex.在C51上面运行。 我们在Ubunt…...
【C++ 进阶】继承
一.继承的定义格式 基类又叫父类,派生类又叫子类; 二.继承方式 继承方式分为三种: 1.public继承 2.protected继承 3.private继承 基类成员与继承方式的关系共有9种,见下表: 虽然说是有9种,但其实最常用的还…...
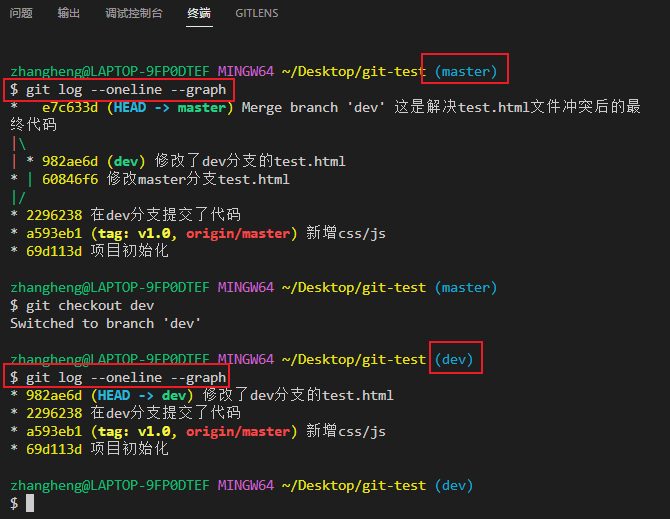
Git使用详细教程
1. cmd面板的常用命令 clear:清屏cd 文件夹名称----进入文件夹cd … 进入上一级目录(两个点)dir 查看当前目录下的文件和文件夹(全拼:directory)Is 查看当前目录下的文件和文件夹touch 文件名----创建文件echo 内容 > 创建文件名----创建文件并写入内容rm 文件名…...

小程序 表单验证
使用 WxValidate.js 插件来校验表单数据 常用实例方法 名称返回类型描述checkForm(e)boolean验证所有字段的规则,返回验证是否通过。valid()boolean返回验证是否通过。size()number返回错误信息的个数。validationErrors()array返回所有错误信息。addMethod(name…...

ubuntu搭建nfs服务centos挂载访问
在Ubuntu上设置NFS服务器 在Ubuntu上,你可以使用apt包管理器来安装NFS服务器。打开终端并运行: sudo apt update sudo apt install nfs-kernel-server创建共享目录 创建一个目录用于共享,例如/shared: sudo mkdir /shared sud…...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...

macOS多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用
文章目录 问题现象问题原因解决办法 问题现象 macOS启动台(Launchpad)多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用。 问题原因 很明显,都是Google家的办公全家桶。这些应用并不是通过独立安装的…...

[Java恶补day16] 238.除自身以外数组的乘积
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 不要使用除法,且在 O(n) 时间复杂度…...

tree 树组件大数据卡顿问题优化
问题背景 项目中有用到树组件用来做文件目录,但是由于这个树组件的节点越来越多,导致页面在滚动这个树组件的时候浏览器就很容易卡死。这种问题基本上都是因为dom节点太多,导致的浏览器卡顿,这里很明显就需要用到虚拟列表的技术&…...

rnn判断string中第一次出现a的下标
# coding:utf8 import torch import torch.nn as nn import numpy as np import random import json""" 基于pytorch的网络编写 实现一个RNN网络完成多分类任务 判断字符 a 第一次出现在字符串中的位置 """class TorchModel(nn.Module):def __in…...

让回归模型不再被异常值“带跑偏“,MSE和Cauchy损失函数在噪声数据环境下的实战对比
在机器学习的回归分析中,损失函数的选择对模型性能具有决定性影响。均方误差(MSE)作为经典的损失函数,在处理干净数据时表现优异,但在面对包含异常值的噪声数据时,其对大误差的二次惩罚机制往往导致模型参数…...

代码随想录刷题day30
1、零钱兑换II 给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。 请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。 假设每一种面额的硬币有无限个。 题目数据保证结果符合 32 位带…...

CVE-2020-17519源码分析与漏洞复现(Flink 任意文件读取)
漏洞概览 漏洞名称:Apache Flink REST API 任意文件读取漏洞CVE编号:CVE-2020-17519CVSS评分:7.5影响版本:Apache Flink 1.11.0、1.11.1、1.11.2修复版本:≥ 1.11.3 或 ≥ 1.12.0漏洞类型:路径遍历&#x…...

Python Ovito统计金刚石结构数量
大家好,我是小马老师。 本文介绍python ovito方法统计金刚石结构的方法。 Ovito Identify diamond structure命令可以识别和统计金刚石结构,但是无法直接输出结构的变化情况。 本文使用python调用ovito包的方法,可以持续统计各步的金刚石结构,具体代码如下: from ovito…...