消息中间件----内存数据库 Redis7(第3章 Redis 命令)
Redis 根据命令所操作对象的不同,可以分为三大类:对 Redis 进行基础性操作的命令,
对 Key 的操作命令,对 Value 的操作命令。
3.1 Redis 基本命令
首先通过 redis-cli 命令进入到 Redis 命令行客户端,然后再运行下面的命令。
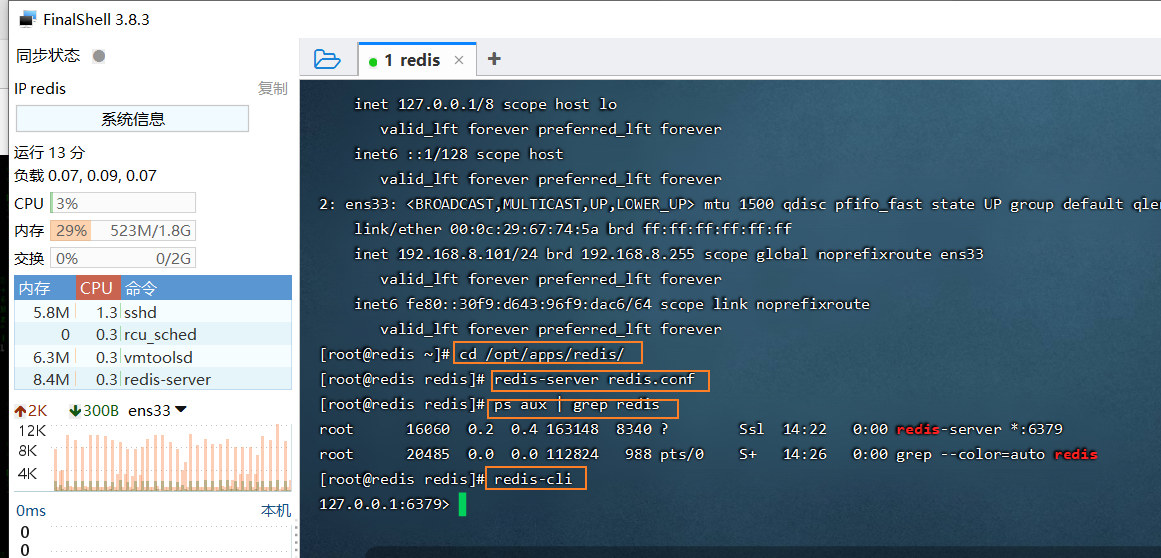
3.1.1 心跳命令 ping
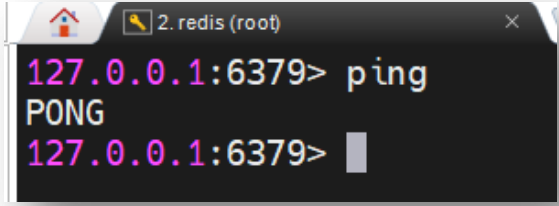
键入 ping 命令,会看到 PONG 响应,则说明该客户端与 Redis 的连接是正常的。该命令
亦称为心跳命令。
自己操作
3.1.2 读写键值命令
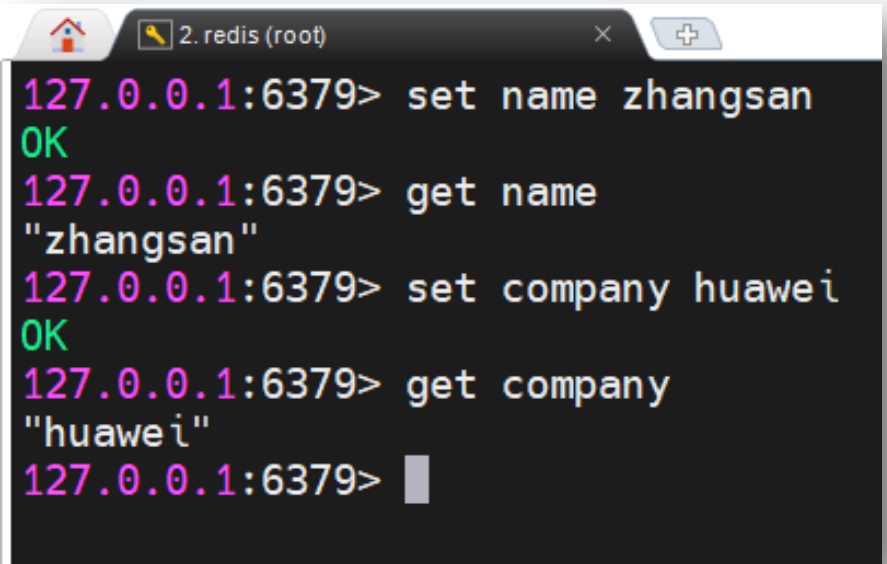
set key value 会将指定 key-value 写入到 DB。get key 则会读取指定 key 的 value 值。关于
更多 set 与 get 命令格式,后面会详细学习。
自己操作
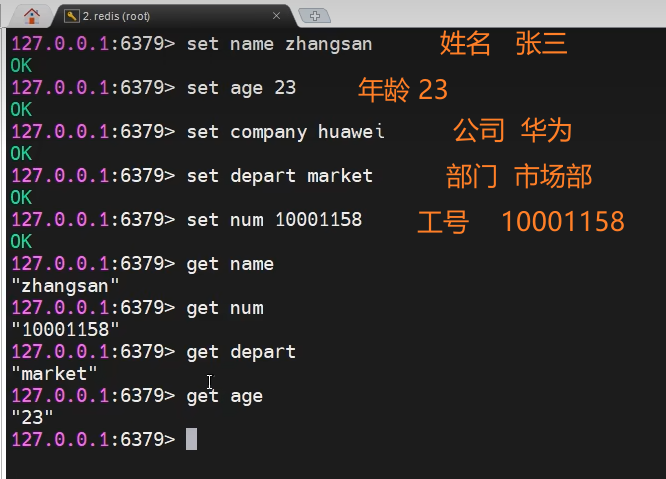
补:安装redis-desktop-manager-0.8.8.384
1)说明
Redis Desktop Manager是一款简单快速、跨平台的Redis桌面管理工具,也被称作Redis可视化工具;支持命令控制台操作,以及常用,查询key,rename,delete等操作。
2)安装方法
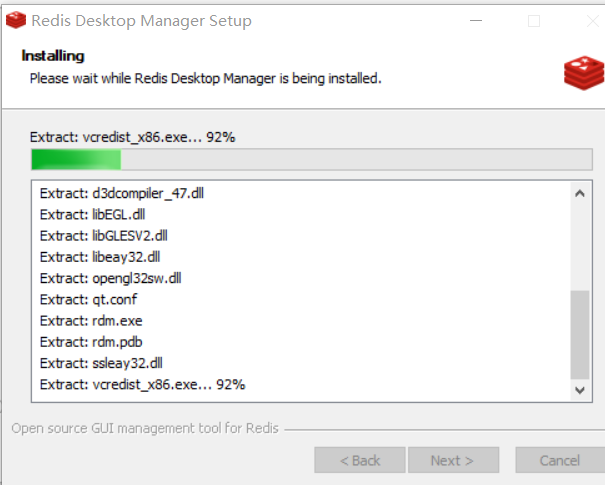
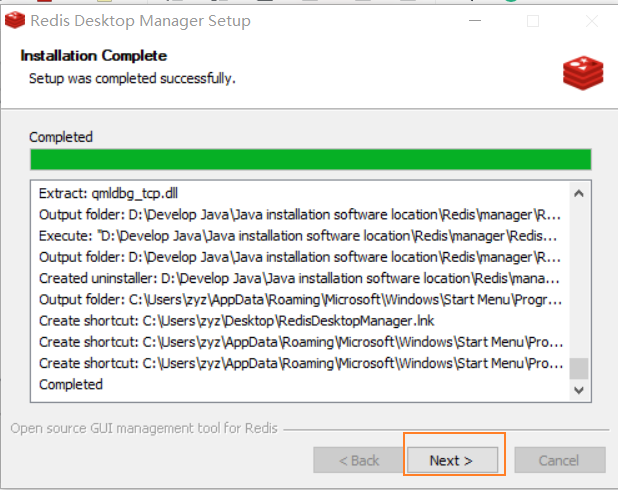
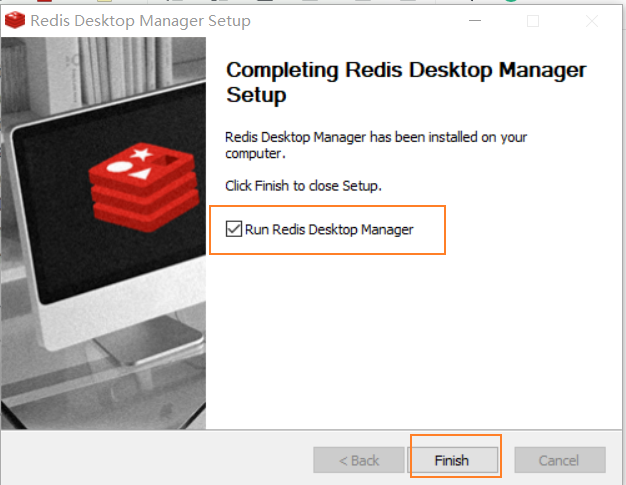
3)使用方法
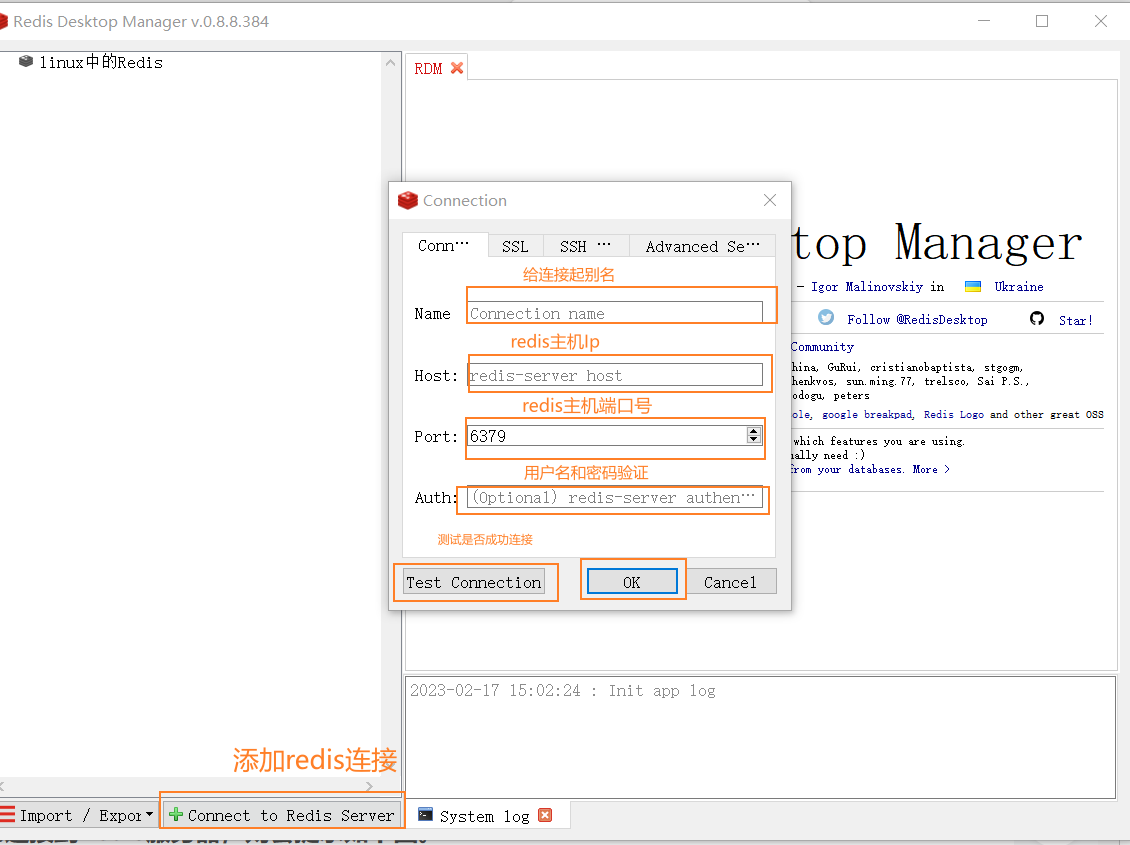
如果没有链接通的话 请查找我的另一篇文章https://blog.csdn.net/m0_59281987/article/details/129090004
3.1.3 DB 切换 select
Redis 默认有 16 个数据库。这个在 Redis Desktop Manager(RDM)图形客户端中可以直观地看到。
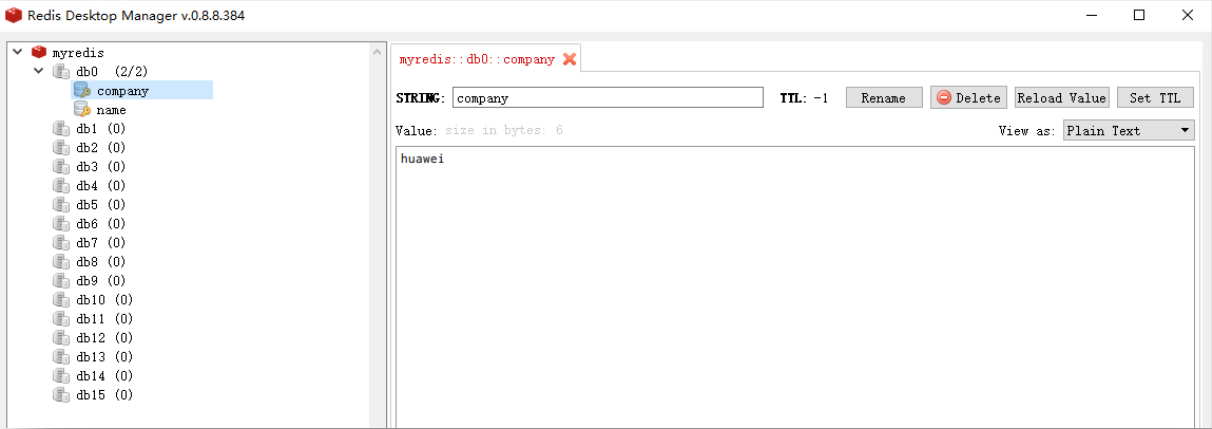
默认使用的是 0 号 DB,可以通过 select db 索引来切换 DB。例如,如下命令会切换到DB3,并会将 age-23 写入到 DB3 中。
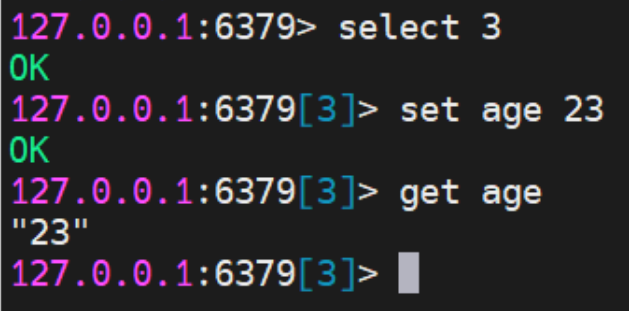
并且这个结果在 RDM 中是可以直观地看到的。
3.1.4 查看 key 数量 dbsize
dbsize 命令可以查看当前数据库中 key 的数量。
从以上查看情况看,DB0 中有 2 个 key,DB1 中没有 key,DB3 中有 1 个 key。
3.1.5 删除当前库中数据 flushdb
flushdb 命令仅仅删除的是当前数据库中的数据,不影响其它库。
3.1.6 删除所有库中数据命令 flushall
flushall 命令可以删除所有库中的所有数据。所以该命令的使用一定要慎重。
3.1.7 退出客户端命令
使用 exit 或 quit 命令均可退出 Redis 命令行客户端。
3.2 Key 操作命令
Redis 中存储的数据整体是一个 Map,其 key 为 String 类型,而 value 则可以是 String、
Hash 表、List、Set 等类型。
3.2.1 keys
格式:KEYS pattern
功能:查找所有符合给定模式 pattern 的 key,pattern 为正则表达式。
说明:KEYS 的速度非常快,但在一个大的数据库中使用它可能会阻塞当前服务器的服
务。所以生产环境中一般不使用该命令,而使用 scan 命令代替。
3.2.2 exists
格式:EXISTS key
功能:检查给定 key 是否存在。
说明:若 key 存在,返回 1 ,否则返回 0 。
3.2.3 del
格式:DEL key [key ...]
功能:删除给定的一个或多个 key 。不存在的 key 会被忽略。
说明:返回被删除 key 的数量。
3.2.4 rename
格式:RENAME key newkey
功能:将 key 改名为 newkey。
说明:当 key 和 newkey 相同,或者 key 不存在时,返回一个错误。当 newkey 已经
存在时, RENAME 命令将覆盖旧值。改名成功时提示 OK ,失败时候返回一个错误。
3.2.5 move
格式:MOVE key db
功能:将当前数据库的 key 移动到给定的数据库 db 当中。
说明:如果当前数据库(源数据库)和给定数据库(目标数据库)有相同名字的给定 key ,
或者 key 不存在于当前数据库,那么 MOVE 没有任何效果。移动成功返回 1 ,失败
则返回 0 。
3.2.6 type
格式:TYPE key
功能:返回 key 所储存的值的类型。
说明:返回值有以下六种
none (key 不存在)
string (字符串)
list (列表)
set (集合)
zset (有序集)
hash (哈希表)
3.2.7 expire 与 pexpire
格式:EXPIRE key seconds
功能:为给定 key 设置生存时间。当 key 过期时(生存时间为 0),它会被自动删除。
expire 的时间单位为秒,pexpire 的时间单位为毫秒。在 Redis 中,带有生存时间的 key
被称为“易失的”(volatile)。
说明:生存时间设置成功返回 1。若 key 不存在时返回 0 。rename 操作不会改变 key
的生存时间。
3.2.8 ttl 与 pttl
格式:TTL key
功能:TTL, time to live,返回给定 key 的剩余生存时间。
说明:其返回值存在三种可能:
当 key 不存在时,返回 -2 。
当 key 存在但没有设置剩余生存时间时,返回 -1 。
否则,返回 key 的剩余生存时间。ttl 命令返回的时间单位为秒,而 pttl 命令
返回的时间单位为毫秒。
3.2.9 persist
格式:PERSIST key
功能:去除给定 key 的生存时间,将这个 key 从“易失的”转换成“持久的”。
说明:当生存时间移除成功时,返回 1;若 key 不存在或 key 没有设置生存时间,则返回 0。
3.2.10 randomkey
格式:RANDOMKEY
功能:从当前数据库中随机返回(不删除)一个 key。
说明:当数据库不为空时,返回一个 key。当数据库为空时,返回 nil。
3.2.11 scan
格式:SCAN cursor [MATCH pattern] [COUNT count] [TYPE type]
功能:用于迭代数据库中的数据库键。其各个选项的意义为:
cursor:本次迭代开始的游标。
pattern :本次迭代要匹配的 key 的模式。
count :本次迭代要从数据集里返回多少元素,默认值为 10 。
type:本次迭代要返回的 value 的类型,默认为所有类型。
SCAN 命令是一个基于游标 cursor 的迭代器:SCAN 命令每次被调用之后,都会向用户返回返回一个包含两个元素的数组, 第一个元素是用于进行下一次迭代的新游标,而第二个元素则是一个数组, 这个数组中包含了所有被迭代的元素。用户在下次迭代时需要使用这个新游标作为 SCAN 命令的游标参数,以此来延续之前的迭代过程。当SCAN 命令的游标参数被设置为 0 时,服务器将开始一次新的迭代。如果新游标返回 0 表示迭代已结束。
说明:使用间断的、负数、超出范围或者其他非正常的游标来执行增量式迭代不会造成服务器崩溃。
当数据量很大时,count 的数量的指定可能会不起作用,Redis 会自动调整每次的遍历数目。由于 scan 命令每次执行都只会返回少量元素,所以该命令可以用于生产环境,而不会出现像 KEYS 命令带来的服务器阻塞问题。
增量式迭代命令所使用的算法只保证在数据集的大小有界的情况下迭代才会停止,换句话说,如果被迭代数据集的大小不断地增长的话,增量式迭代命令可能永远也无法完成一次完整迭代。即当一个数据集不断地变大时,想要访问这个数据集中的所有元素就需要做越来越多的工作, 能否结束一个迭代取决于用户执行迭代的速度是否比数据集增长的速度更快。
相关命令:另外还有 3 个 scan 命令用于对三种类型的 value 进行遍历。
hscan:属于 Hash 型 Value 操作命令集合,用于遍历当前 db 中指定 Hash 表的
所有 field-value 对。
sscan:属于 Set 型 Value 操作命令集合,用于遍历当前 db 中指定 set 集合的所
有元素
zscan:属于 ZSet 型 Value 操作命令集合,用于遍历当前 db 中指定有序集合的
所有元素(数值与元素值)
3.3 String 型 Value 操作命令
Redis 存储数据的 Value 可以是一个 String 类型数据。
String 类型的 Value 是 Redis 中最基
本,最常见的类型。String 类型的 Value 中可以存放任意数据,包括数值型,甚至是二进制
的图片、音频、视频、序列化对象等。一个 String 类型的 Value 最大是 512M 大小。
3.3.1 set
格式:SET key value [EX seconds | PX milliseconds] [NX|XX]
功能:SET 除了可以直接将 key 的值设为 value 外,还可以指定一些参数。
EX seconds:为当前 key 设置过期时间,单位秒。等价于 SETEX 命令。
PX milliseconds:为当前 key 设置过期时间,单位毫秒。等价于 PSETEX 命令。
NX:指定的 key 不存在才会设置成功,用于添加指定的 key。等价于 SETNX 命令。
XX:指定的 key 必须存在才会设置成功,用于更新指定 key 的 value。
说明:如果 value 字符串中带有空格,则该字符串需要使用双引号或单引号引起来,否
则会认为 set 命令的参数数量不正确,报错。
3.3.2 setex 与 psetex
格式:SETEX/PSETEX key seconds value
功能:set expire,其不仅为 key 指定了 value,还为其设置了生存时间。setex 的单位为
秒,psetex 的单位为毫秒。
说明:如果 key 已经存在, 则覆写旧值。该命令类似于以下两个命令,不同之处是,
SETEX 是一个原子性操作,关联值和设置生存时间两个动作会在同一时间内完成,该命
令在 Redis 用作缓存时,非常实用。
SET key value
EXPIRE key seconds # 设置生存时间
3.3.3 setnx
格式:SETNX key value
功能:SET if Not eXists,将 key 的值设为 value ,当且仅当 key 不存在。若给定的 key
已经存在,则 SETNX 不做任何动作。成功,返回 1,否则,返回 0。
说明:该命令等价于 set key value nx
3.3.4 getset
格式:GETSET key value
功能:将给定 key 的值设为 value ,并返回 key 的旧值。
说明:当 key 存在但不是字符串类型时,返回一个错误;当 key 不存在时,返回 nil 。
3.3.5 mset 与 msetnx
格式:MSET/MSETNX key value [key value ...]
功能:同时设置一个或多个 key-value 对。
说明:如果某个给定 key 已经存在,那么 MSET 会用新值覆盖原来的旧值,如果这不
是你所希望的效果,请考虑使用 MSETNX 命令:它只会在所有给定 key 都不存在的情
况下进行设置操作。MSET/MSETNX 是一个原子性(atomic)操作,所有给定 key 都会在同
一时间内被设置,某些给定 key 被更新而另一些给定 key 没有改变的情况不可能发生。
该命令永不失败。
3.3.6 mget
格式:MGET key [key ...]
功能:返回所有(一个或多个)给定 key 的值。
说明:如果给定的 key 里面,有某个 key 不存在,那么这个 key 返回特殊值 nil 。
因此,该命令永不失败。
3.3.7 append
格式:APPEND key value
功能:如果 key 已经存在并且是一个字符串, APPEND 命令将 value 追加到 key 原
来的值的末尾。如果 key 不存在, APPEND 就简单地将给定 key 设为 value ,就像
执行 SET key value 一样。
说明:追加 value 之后, key 中字符串的长度。
3.3.8 incr 与 decr
格式:INCR key 或 DECR key
功能:increment,自动递增。将 key 中存储的数字值增一。
decrement,自动递减。将 key 中存储的数字值减一。
说明:如果 key 不存在,那么 key 的值会先被初始化为 0,然后再执行增一/减一操作。
如果值不能表示为数字,那么返回一个错误提示。如果执行正确,则返回增一/减一后
的值。
3.3.9 incrby 与 decrby
格式:INCRBY key increment 或 DECRBY key decrement
功能:将 key 中存储的数字值增加/减少指定的数值,这个数值只能是整数,可以是负
数,但不能是小数。
说明:如果 key 不存在,那么 key 的值会先被初始化为 0,然后再执行增/减操作。如
果值不能表示为数字,那么返回一个错误提示。如果执行正确,则返回增/减后的值。
3.3.10 incrbyfloat
格式:INCRBYFLOAT key increment
功能:为 key 中所储存的值加上浮点数增量 increment 。
说明:与之前的说明相同。没有 decrbyfloat 命令,但 increment 为负数可以实现减操作
效果。
3.3.11 strlen
格式:STRLEN key
功能:返回 key 所储存的字符串值的长度。
说明:当 key 储存的不是字符串值时,返回一个错误;当 key 不存在时,返回 0 。
3.3.12 getrange
格式:GETRANGE key start end
功能:返回 key 中字符串值的子字符串,字符串的截取范围由 start 和 end 两个偏移量决定,包括 start 和 end 在内。
说明:end 必须要比 start 大。支持负数偏移量,表示从字符串最后开始计数,-1 表示最后一个字符,-2 表示倒数第二个,以此类推。
3.3.13 setrange
格式:SETRANGE key offset value
功能:用 value 参数替换给定 key 所储存的字符串值 str,从偏移量 offset 开始。
说明:当 offset 值大于 str 长度时,中间使用零字节\x00 填充,即 0000 0000 字节填充;对于不存在的 key 当作空串处理。
3.3.14 位操作命令
名称中包含 BIT 的命令,都是对二进制位的操作命令,例如,setbit、getbit、bitcount、bittop、bitfield,这些命令不常用。
3.3.15 典型应用场景
Value 为 String 类型的应用场景很多,这里仅举这种典型应用场景的例子:
(1) 数据缓存
Redis 作为数据缓存层,MySQL 作为数据存储层。应用服务器首先从 Redis 中获取数据,
如果缓存层中没有,则从 MySQL 中获取后先存入缓存层再返回给应用服务器。
(2) 计数器
在 Redis 中写入一个 value 为数值型的 key 作为平台计数器、视频播放计数器等。每个有效客户端访问一次,或视频每播放一次,都是直接修改 Redis 中的计数器,然后再以异步方式持久化到其它数据源中,例如持久化到 MySQL。
(3) 共享 Session
对于一个分布式应用系统,如果将类似用户登录信息这样的 Session 数据保存在提供登录服务的服务器中,那么如果用户再次提交像收藏、支付等请求时可能会出现问题:在提供收藏、支付等服务的服务器中并没有该用户的 Session 数据,从而导致该用户需要重新登录。对于用户来说,这是不能接受的。
此时,可以将系统中所有用户的 Session 数据全部保存到 Redis 中,用户在提交新的请求后,系统先从 Redis 中查找相应的 Session 数据,如果存在,则再进行相关操作,否则跳转到登录页面。这样就不会引发“重新登录”问题。
(4) 限速器
现在很多平台为了防止 DoS(Denial of Service,拒绝服务)攻击,一般都会限制一个 IP不能在一秒内访问超过 n 次。而 Redis 可以可以结合 key 的过期时间与 incr 命令来完成限速功能,充当限速器。
注意,其无法防止 DDoS(Distributed Denial of Service,分布式拒绝服务)攻击。
// 客户端每提交一次请求,都会执行下面的代码
// 等价于 set 192.168.192.55 1 ex 60 nx
// 指定新 ip 作为 key 的缓存过期时间为 60 秒
Boolean isExists = redis.set(ip, 1, “EX 60”, “NX”);
if(isExists != null || redis.incr(ip) <= 5) {// 通过
} else { // 限流
}3.4 Hash 型 Value 操作命令
Redis 存储数据的 Value 可以是一个 Hash 类型。Hash 类型也称为 Hash 表、字典等。
Hash 表就是一个映射表 Map,也是由键-值对构成,为了与整体的 key 进行区分,这里
的键称为 field,值称为 value。注意,Redis 的 Hash 表中的 field-value 对均为 String 类型。
3.4.1 hset
格式:HSET key field value
功能:将哈希表 key 中的域 field 的值设为 value 。
说明:如果 key 不存在,一个新的哈希表被创建并进行 HSET 操作。如果域 field 已
经存在于哈希表中,旧值将被覆盖。如果 field 是哈希表中的一个新建域,并且值设置
成功,返回 1 。如果哈希表中域 field 已经存在且旧值已被新值覆盖,返回 0 。
3.4.2 hget
格式:HGET key field
功能:返回哈希表 key 中给定域 field 的值。
说明:当给定域不存在或是给定 key 不存在时,返回 nil 。
3.4.3 hmset
格式:HMSET key field value [field value ...]
功能:同时将多个 field-value (域-值)对设置到哈希表 key 中。
说明:此命令会覆盖哈希表中已存在的域。如果 key 不存在,一个空哈希表被创建并执行 HMSET 操作。如果命令执行成功,返回 OK 。当 key 不是哈希表(hash)类型时,返回一个错误。
3.4.4 hmget
格式:HMGET key field [field ...]
功能:按照给出顺序返回哈希表 key 中一个或多个域的值。
说明:如果给定的域不存在于哈希表,那么返回一个 nil 值。因为不存在的 key 被当
作一个空哈希表来处理,所以对一个不存在的 key 进行 HMGET 操作将返回一个只带有 nil 值的表。
3.4.5 hgetall
格式:HGETALL key
功能:返回哈希表 key 中所有的域和值。
说明:在返回值里,紧跟每个域名(field name)之后是域的值(value),所以返回值的长度
是哈希表大小的两倍。若 key 不存在,返回空列表。若 key 中包含大量元素,则该命
令可能会阻塞 Redis 服务。所以生产环境中一般不使用该命令,而使用 hscan 命令代替。
3.4.6 hsetnx
格式:HSETNX key field value
功能:将哈希表 key 中的域 field 的值设置为 value ,当且仅当域 field 不存在。
说明:若域 field 已经存在,该操作无效。如果 key 不存在,一个新哈希表被创建并执行 HSETNX 命令。
3.4.7 hdel
格式:HDEL key field [field ...]
功能:删除哈希表 key 中的一个或多个指定域,不存在的域将被忽略。
说明:返回被成功移除的域的数量,不包括被忽略的域。
3.4.8 hexits
格式:HEXISTS key field
功能:查看哈希表 key 中给定域 field 是否存在。
说明:如果哈希表含有给定域,返回 1 。如果不含有给定域,或 key 不存在,返回 0 。
3.4.9 hincrby 与 hincrbyfloat
格式:HINCRBY key field increment
功能:为哈希表 key 中的域 field 的值加上增量 increment 。hincrby 命令只能增加整
数值,而 hincrbyfloat 可以增加小数值。
说明:增量也可以为负数,相当于对给定域进行减法操作。如果 key 不存在,一个新
的哈希表被创建并执行 HINCRBY 命令。如果域 field 不存在,那么在执行命令前,域的值被初始化为 0。对一个储存字符串值的域 field 执行 HINCRBY 命令将造成一个错误。
3.4.10 hkeys 与 hvals
格式:HKEYS key 或 HVALS
功能:返回哈希表 key 中的所有域/值。
说明:当 key 不存在时,返回一个空表。
3.4.11 hlen
格式:HLEN key
功能:返回哈希表 key 中域的数量。
说明:当 key 不存在时,返回 0 。
3.4.12 hstrlen
格式:HSTRLEN key field
功能:返回哈希表 key 中,
与给定域 field 相关联的值的字符串长度(string length)。
说明:如果给定的键或者域不存在, 那么命令返回0 。
3.4.13 应用场景
Hash 型 Value 非常适合存储对象数据。key 为对象名称,value 为描述对象属性的 Map,
对对象属性的修改在 Redis 中就可直接完成。其不像 String 型 Value 存储对象,那个对象是
序列化过的,例如序列化为 JSON 串,对对象属性值的修改需要先反序列化为对象后再修改,
修改后再序列化为 JSON 串后写入到 Redis。
3.5 List 型 Value 操作命令
Redis 存储数据的 Value 可以是一个 String 列表类型数据。即该列表中的每个元素均为
String 类型数据。列表中的数据会按照插入顺序进行排序。不过,该列表的底层实际是一个
无头节点的双向链表,所以对列表表头与表尾的操作性能较高,但对中间元素的插入与删除
的操作的性能相对较差。
3.5.1 lpush/rpush
格式:LPUSH key value [value ...] 或 RPUSH key value [value ...]
功能:将一个或多个值 value 插入到列表 key 的表头/表尾(表头在左表尾在右)
说明:如果有多个 value 值,对于 lpush 来说,各个 value 会按从左到右的顺序依次插
入到表头;对于 rpush 来说,各个 value 会按从左到右的顺序依次插入到表尾。如果 key
不存在,一个空列表会被创建并执行操作。当 key 存在但不是列表类型时,返回一个
错误。执行成功时返回列表的长度。
3.5.2 llen
格式:LLEN key
功能:返回列表 key 的长度。
说明:如果 key 不存在,则 key 被解释为一个空列表,返回 0 。如果 key 不是列表
类型,返回一个错误。
3.5.3 lindex
格式:LINDEX key index
功能:返回列表 key 中,下标为 index 的元素。列表从 0 开始计数。
说明:如果 index 参数的值不在列表的区间范围内(out of range),返回 nil 。
3.5.4 lset
格式:LSET key index value
功能:将列表 key 下标为 index 的元素的值设置为 value 。
说明:当 index 参数超出范围,或对一个空列表(key 不存在)进行 LSET 时,返回一
个错误。
3.5.5 lrange
格式:LRANGE key start stop
功能:返回列表 key 中指定区间[start, stop]内的元素,即包含两个端点。
说明:List 的下标从 0 开始,即以 0 表示列表的第一个元素,以 1 表示列表的第二个元素,以此类推。也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。超出范围的下标值不会引起错误。如果 start 下标比列表的最大下标 还要大,那么 LRANGE 返回一个空列表。如果 stop 下标比最大下标还要大,Redis 将 stop 的值设置为最大下标。
3.5.6 lpushx 与 rpushx
格式:LPUSHX key value 或 RPUSHX key value
功能:将值 value 插入到列表 key 的表头/表尾,当且仅当 key 存在并且是一个列表。
说明:当 key 不存在时,命令什么也不做。若执行成功,则输出表的长度。
3.5.7 linsert
格式:LINSERT key BEFORE|AFTER pivot value
功能:将值 value 插入到列表 key 当中,位于元素 pivot 之前或之后。
说明:当 pivot 元素不存在于列表中时,不执行任何操作,返回-1;当 key 不存在时,
key 被视为空列表,不执行任何操作,返回 0;如果 key 不是列表类型,返回一个错误;
如果命令执行成功,返回插入操作完成之后,列表的长度。
3.5.8 lpop / rpop
格式:LPOP key [count] 或 RPOP key [count]
功能:从列表 key 的表头/表尾移除 count 个元素,并返回移除的元素。count 默认值 1
说明:当 key 不存在时,返回 nil
3.5.9 blpop / brpop
格式:BLPOP key [key ...] timeout 或 BRPOP key [key ...] timeout
功能:BLPOP/BRPOP 是列表的阻塞式(blocking)弹出命令。它们是 LPOP/RPOP 命令的阻
塞版本,当给定列表内没有任何元素可供弹出的时候,连接将被 BLPOP/BRPOP 命令阻
塞,直到等待 timeout 超时或发现可弹出元素为止。当给定多个 key 参数时,按参数 key
的先后顺序依次检查各个列表,弹出第一个非空列表的头元素。timeout 为阻塞时长,
单位为秒,其值若为 0,则表示只要没有可弹出元素,则一直阻塞。
说明:假如在指定时间内没有任何元素被弹出,则返回一个 nil 和等待时长。反之,返
回一个含有两个元素的列表,第一个元素是被弹出元素所属的 key ,第二个元素是被
弹出元素的值。
3.5.10 rpoplpush
格式:RPOPLPUSH source destination
功能:命令 RPOPLPUSH 在一个原子时间内,执行以下两个动作:
将列表 source 中的最后一个元素(尾元素)弹出,并返回给客户端。
将 source 弹出的元素插入到列表 destination ,作为 destination 列表的的头元素。
如果 source 不存在,值 nil 被返回,并且不执行其他动作。如果 source 和 destination
相同,则列表中的表尾元素被移动到表头,并返回该元素,可以把这种特殊情况视作列
表的旋转(rotation)操作。
3.5.11 brpoplpush
格式:BRPOPLPUSH source destination timeout
功能:BRPOPLPUSH 是 RPOPLPUSH 的阻塞版本,当给定列表 source 不为空时,
BRPOPLPUSH 的表现和 RPOPLPUSH 一样。当列表 source 为空时, BRPOPLPUSH 命令
将阻塞连接,直到等待超时,或有另一个客户端对 source 执行 LPUSH 或 RPUSH 命令
为止。timeout 为阻塞时长,单位为秒,其值若为 0,则表示只要没有可弹出元素,则
一直阻塞。
说明:假如在指定时间内没有任何元素被弹出,则返回一个 nil 和等待时长。反之,返
回一个含有两个元素的列表,第一个元素是被弹出元素的值,第二个元素是等待时长。
3.5.12 lrem
格式:LREM key count value
功能:根据参数 count 的值,移除列表中与参数 value 相等的元素。count 的值可以
是以下几种:
count > 0 : 从表头开始向表尾搜索,移除与 value 相等的元素,数量为 count 。
count < 0 : 从表尾开始向表头搜索,移除与 value 相等的元素,数量为 count 的
绝对值。
count = 0 : 移除表中所有与 value 相等的值。
说明:返回被移除元素的数量。当 key 不存在时, LREM 命令返回 0 ,因为不存在
的 key 被视作空表(empty list)。
3.5.13 ltrim
格式:LTRIM key start stop
功能:对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指
定区间之内的元素都将被删除。
说明:下标(index)参数 start 和 stop 都以 0 为底,也就是说,以 0 表示列表的第一
个元素,以 1 表示列表的第二个元素,以此类推。也可以使用负数下标,以 -1 表示
列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。当 key 不是列表
类型时,返回一个错误。如果 start 下标比列表的最大下标 end ( LLEN list 减去 1 )还要
大,或者 start > stop , LTRIM 返回一个空列表,因为 LTRIM 已经将整个列表清空。
如果 stop 下标比 end 下标还要大,Redis 将 stop 的值设置为 end 。
3.5.14 应用场景
Value 为 List 类型的应用场景很多,主要是通过构建不同的数据结构来实现相应的业务功能。这里仅对这些数据结构的实现方式进行总结,不举具体的例子。
(1) 栈
通过 lpush + lpop 可以实现栈数据结构效果:先进后出。通过 lpush 从列表左侧插入数
据,通过 lpop 从列表左侧取出数据。当然,通过 rpush + rpop 也可以实现相同效果,只不过
操作的是列表右侧。
(2) 队列
通过 lpush + rpop 可以实现队列数据结构效果:先进先出。通过 lpush 从列表左侧插入数据,通过rpop 从列表右侧取出数据。当然,通过 rpush + lpop 也可以实现相同效果,只不过操作的方向正好相反。
(3) 阻塞式消息队列
通过 lpush + brpop 可以实现阻塞式消息队列效果。作为消息生产者的客户端使用 lpush从列表左侧插入数据,作为消息消费者的多个客户端使用 brpop 阻塞式“抢占”列表尾部数据进行消费,保证了消费的负载均衡与高可用性。brpop 的 timeout 设置为 0,表示只要没有数据可弹出,就永久阻塞。
(4) 动态有限集合
通过 lpush + ltrim 可以实现有限集合。通过 lpush 从列表左侧向列表中添加数据,通过ltrim 保持集合的动态有限性。像企业的末位淘汰、学校的重点班等动态管理,都可通过这种动态有限集合来实现。当然,通过 rpush + ltrim 也可以实现相同效果,只不过操作的方向正好相反。
3.6 Set 型 Value 操作命令
Redis 存储数据的 Value 可以是一个 Set 集合,且集合中的每一个元素均 String 类型。Set与 List 非常相似,但不同之处是 Set 中的元素具有无序性与不可重复性,而 List 则具有有序性与可重复性。
Redis 中的 Set 集合与 Java 中的 Set 集合的实现相似,其底层都是 value 为 null 的 hash表。也正因为此,才会引发无序性与不可重复性。
3.6.1 sadd
格式:SADD key member [member ...]
功能:将一个或多个 member 元素加入到集合 key 当中,已经存在于集合的 member 元素将被忽略。
说明:假如 key 不存在,则创建一个只包含 member 元素作成员的集合。当 key 不是集合类型时,返回一个错误。
3.6.2 smembers
格式:SMEMBERS key
功能:返回集合 key 中的所有成员。
说明:不存在的 key 被视为空集合。若 key 中包含大量元素,则该命令可能会阻塞 Redis服务。所以生产环境中一般不使用该命令,而使用 sscan 命令代替。
3.6.3 scard
格式:SCARD key
功能:返回 Set 集合的长度
说明:当 key 不存在时,返回 0 。
3.6.4 sismember
格式:SISMEMBER key member
功能:判断 member 元素是否集合 key 的成员。
说明:如果 member 元素是集合的成员,返回 1 。如果 member 元素不是集合的成
员,或 key 不存在,返回 0 。
3.6.5 smove
格式:SMOVE source destination member
功能:将 member 元素从 source 集合移动到 destination 集合。
说明:如果 source 集合不存在或不包含指定的 member 元素,则 SMOVE 命令不执行任何操作,仅返回 0 。否则, member 元素从 source 集合中被移除,并添加到destination 集合中去,返回 1。当 destination 集合已经包含 member 元素时, SMOVE命令只是简单地将 source 集合中的 member 元素删除。当 source 或 destination 不是集合类型时,返回一个错误。
3.6.6 srem
格式:SREM key member [member ...]
功能:移除集合 key 中的一个或多个 member 元素,不存在的 member 元素会被忽略,且返回成功移除的元素个数。
说明:当 key 不是集合类型,返回一个错误。
3.6.7 srandmember
格式:SRANDMEMBER key [count]
功能:返回集合中的 count 个随机元素。count 默认值为 1。
说明:若 count 为正数,且小于集合长度,那么返回一个包含 count 个元素的数组,
数组中的元素各不相同。如果 count 大于等于集合长度,那么返回整个集合。如果count 为负数,那么返回一个包含 count 绝对值个元素的数组,但数组中的元素可能
会出现重复。
3.6.8 spop
格式:SPOP key [count]
功能:移除并返回集合中的 count 个随机元素。count 必须为正数,且默认值为 1。
说明:如果 count 大于等于集合长度,那么移除并返回整个集合。
3.6.9 sdiff / sdiffstore
格式:SDIFF key [key ...] 或 SDIFFSTORE destination key [key ...]
功能:返回第一个集合与其它集合之间的差集。差集,difference。
说明:这两个命令的不同之处在于,sdiffstore 不仅能够显示差集,还能将差集存储到指
定的集合 destination 中。如果 destination 集合已经存在,则将其覆盖。不存在的 key 被
视为空集。
3.6.10 sinter / sinterstore
格式:SINTER key [key ...] 或 SINTERSTORE destination key [key ...]
功能:返回多个集合间的交集。交集,intersection。
说明:这两个命令的不同之处在于,sinterstore 不仅能够显示交集,还能将交集存储到
指定的集合 destination 中。如果 destination 集合已经存在,则将其覆盖。不存在的 key
被视为空集。
3.6.11 sunion / sunionstore
格式:SUNION key [key ...] 或 SUNIONSTORE destination key [key ...]
功能:返回多个集合间的并集。并集,union。
说明:这两个命令的不同之处在于,sunionstore 不仅能够显示并集,还能将并集存储到
指定的集合 destination 中。如果 destination 集合已经存在,则将其覆盖。不存在的 key
被视为空集。
3.6.12 应用场景
Value 为 Set 类型的应用场景很多,这里对这些场景仅进行总结。
(1) 动态黑白名单
例如某服务器中要设置用于访问控制的黑名单。如果直接将黑名单写入服务器的配置文件,那么存在的问题是,无法动态修改黑名单。此时可以将黑名单直接写入 Redis,只要有客户端来访问服务器,服务器在获取到客户端 IP后先从 Redis的黑名单中查看是否存在该 IP,如果存在,则拒绝访问,否则访问通过。
(2) 有限随机数
有限随机数是指返回的随机数是基于某一集合范围内的随机数,例如抽奖、随机选人。
通过 spop 或 srandmember 可以实现从指定集合中随机选出元素。
(3) 用户画像
社交平台、电商平台等各种需要用户注册登录的平台,会根据用户提供的资料与用户使用习惯,为每个用户进行画像,即为每个用户定义很多可以反映该用户特征的标签,这些标签就可以使用 sadd 添加到该用户对应的集合中。这些标签具有无序、不重复特征。
同时平台还可以使用 sinter/sinterstore 根据用户画像间的交集进行好友推荐、商品推荐、客户推荐等。
3.7有序 Set 型 Value 操作命令
Redis 存储数据的 Value 可以是一个有序 Set,这个有序 Set 中的每个元素均 String 类型。
有序 Set 与 Set 的不同之处是,有序 Set 中的每一个元素都有一个分值 score,Redis 会根据
score 的值对集合进行由小到大的排序。其与 Set 集合要求相同,元素不能重复,但元素的
score 可以重复。由于该类型的所有命令均是字母 z 开头,所以该 Set 也称为 ZSet。
3.7.1 zadd
格式:ZADD key score member [[score member] [score member] ...]
功能:将一个或多个 member 元素及其 score 值加入到有序集 key 中的适当位置。
说明:score 值可以是整数值或双精度浮点数。如果 key 不存在,则创建一个空的有序
集并执行 ZADD 操作。当 key 存在但不是有序集类型时,返回一个错误。如果命令执
行成功,则返回被成功添加的新成员的数量,不包括那些被更新的、已经存在的成员。
若写入的 member 值已经存在,但 score 值不同,则新的 score 值将覆盖老 score。
3.7.2 zrange 与 zrevrange
格式:ZRANGE key start stop [WITHSCORES] 或 ZREVRANGE key start stop [WITHSCORES]
功能:返回有序集 key 中,指定区间内的成员。zrange 命令会按 score 值递增排序,
zrevrange命令会按score递减排序。具有相同 score 值的成员按字典序/逆字典序排列。
可以通过使用 WITHSCORES 选项,来让成员和它的 score 值一并返回。
说明:下标参数从 0 开始,即 0 表示有序集第一个成员,以 1 表示有序集第二个成员,
以此类推。也可以使用负数下标,-1 表示最后一个成员,-2 表示倒数第二个成员,以
此类推。超出范围的下标并不会引起错误。例如,当 start 的值比有序集的最大下标还
要大,或是 start > stop 时,
ZRANGE 命令只是简单地返回一个空列表。再比如 stop 参
数的值比有序集的最大下标还要大,那么 Redis 将 stop 当作最大下标来处理。
若 key 中指定范围内包含大量元素,则该命令可能会阻塞 Redis 服务。所以生产环
境中如果要查询有序集合中的所有元素,一般不使用该命令,而使用 zscan 命令代替。
3.7.3 zrangebyscore 与 zrevrangebyscore
格式:ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count]
功能:返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或
max )的成员。有序集成员按 score 值递增/递减次序排列。具有相同 score 值的成员按
字典序/逆字典序排列。可选的 LIMIT 参数指定返回结果的数量及区间(就像 SQL 中的
SELECT LIMIT offset, count ),注意当 offset 很大时,定位 offset 的操作可能需要遍历整
个有序集,此过程效率可能会较低。可选的 WITHSCORES 参数决定结果集是单单返回
有序集的成员,还是将有序集成员及其 score 值一起返回。
说明:min 和 max 的取值是正负无穷大的。默认情况下,区间的取值使用闭区间 (小
于等于或大于等于),也可以通过给参数前增加左括号“(”来使用可选的开区间 (小于或
大于)。
3.7.4 zcard
格式:ZCARD key
功能:返回集合的长度
说明:当 key 不存在时,返回 0 。
3.7.5 zcount
格式:ZCOUNT key min max
功能:返回有序集 key 中,
score 值在 min 和 max 之间(默认包括 score 值等于 min 或 max )的成员的数量。
3.7.6 zscore
格式:ZSCORE key member
功能:返回有序集 key 中,成员 member 的 score 值。
说明:如果 member 元素不是有序集 key 的成员,或 key 不存在,返回 nil 。
3.7.7 zincrby
格式:ZINCRBY key increment member
功能:为有序集 key 的成员 member 的 score 值加上增量 increment 。increment 值
可以是整数值或双精度浮点数。
说明:可以通过传递一个负数值 increment ,让 score 减去相应的值。当 key 不存在,
或 member 不是 key 的成员时, ZINCRBY key increment member 等同于 ZADD key increment member 。当 key 不是有序集类型时,返回一个错误。命令执行成功,则返回 member 成员的新 score 值。
3.7.8 zrank 与 zrevrank
格式:ZRANK key member 或 ZREVRANK key member
功能:返回有序集 key 中成员 member 的排名。zrank 命令会按 score 值递增排序,
zrevrank 命令会按 score 递减排序。
说明:score 值最小的成员排名为 0 。如果 member 不是有序集 key 的成员,返回 nil 。
3.7.9 zrem
格式:ZREM key member [member ...]
功能:移除有序集 key 中的一个或多个成员,不存在的成员将被忽略。
说明:当 key 存在但不是有序集类型时,返回一个错误。执行成功,则返回被成功移
除的成员的数量,不包括被忽略的成员。
3.7.10 zremrangebyrank
格式:ZREMRANGEBYRANK key start stop
功能:移除有序集 key 中,指定排名(rank)区间内的所有成员。
说明:排名区间分别以下标参数 start 和 stop 指出,包含 start 和 stop 在内。排名区间参数从 0 开始,即 0 表示排名第一的成员, 1 表示排名第二的成员,以此类推。
也可以使用负数表示,-1 表示最后一个成员,-2 表示倒数第二个成员,以此类推。命令执行成功,则返回被移除成员的数量。
3.7.11 zremrangebyscore
格式:ZREMRANGEBYSCORE key min max
功能:移除有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或max )的成员。
说明:命令执行成功,则返回被移除成员的数量。
3.7.12 zrangebylex
格式:ZRANGEBYLEX key min max [LIMIT offset count]
功能:该命令仅适用于集合中所有成员都具有相同分值的情况。当有序集合的所有成员
都具有相同的分值时,有序集合的元素会根据成员的字典序(lexicographical ordering)
来进行排序。即这个命令返回给定集合中元素值介于 min 和 max 之间的成员。如果
有序集合里面的成员带有不同的分值, 那么命令的执行结果与 zrange key 效果相同。
说明:合法的 min 和 max 参数必须包含左小括号“(”或左中括号“[”,其中左小括号“(”
表示开区间, 而左中括号“[”则表示闭区间。min 或 max 也可使用特殊字符“+”和“-”,
分别表示正无穷大与负无穷大。
3.7.13 zlexcount
格式:ZLEXCOUNT key min max
功能:该命令仅适用于集合中所有成员都具有相同分值的情况。该命令返回该集合中元
素值本身(而非 score 值)介于 min 和 max 范围内的元素数量。
3.7.14 zremrangebylex
格式:ZREMRANGEBYLEX key min max
功能:该命令仅适用于集合中所有成员都具有相同分值的情况。该命令会移除该集合中
元素值本身介于 min 和 max 范围内的所有元素。
3.7.15 应用场景
有序 Set 最为典型的应用场景就是排行榜,例如音乐、视频平台中根据播放量进行排序的排行榜;电商平台根据用户评价或销售量进行排序的排行榜等。将播放量作为 score,将作品 id 作为 member,将用户评价积分或销售量作为 score,将商家 id 作为 member。使用zincrby 增加排序 score,使用 zrevrange 获取 Top 前几名,使用 zrevrank 查询当前排名,使用zscore 查询当前排序 score 等。
3.8 benchmark 测试工具
3.8.1 简介
在Redis安装完毕后会自动安装一个redis-benchmark测试工具,其是一个压力测试工具,用于测试 Redis 的性能。
通过 redis-benchmark –help 命令可以查看到其用法:
其选项 options 非常多,下面通过例子来学习常用的 options 的用法。
3.8.2 测试 1
(1) 命令解析
以上命令中选项的意义:
-h:指定要测试的 Redis 的 IP,若为本机,则可省略
-p:指定要测试的 Redis 的 port,若为 6379,则可省略
-c:指定模拟有客户端的数量,默认值为 50
-n:指定这些客户端发出的请求的总量,默认值为 100000
-d:指定测试 get/set 命令时其操作的 value 的数据长度,单位字节,默认值为 3。在测试其它命令时该指定没有用处。
以上命令的意义是,使用 100 个客户端连接该 Redis,这些客户端总共会发起 100000个请求,set/get 的 value 为 8 字节数据。
(2) 测试结果分析
该命令会逐个测试所有 Redis 命令,每个命令都会给出一份测试报告,每个测试报告由
四部分构成:
A、测试环境报告
首先就是测试环境:
B、 延迟百分比分布
这是按照百分比进行的统计报告:每完成一次剩余测试量的 50%就给出一个统计数据。
C、 延迟的累积分布
这是按照时间间隔统计的报告:基本是每 0.1 毫秒统计一次。D、总述报告
这是总述性报告。
3.8.3 测试 2
以上命令中选项的意义:
-t:指定要测试的命令,多个命令使用逗号分隔,不能有空格
-q:指定仅给出总述性报告
3.9 简单动态字符串 SDS
3.9.1 SDS 简介
无论是 Redis 的 Key 还是 Value,其基础数据类型都是字符串。例如,Hash 型 Value 的field 与 value 的类型、List 型、Set 型、ZSet 型 Value 的元素的类型等都是字符串。虽然 Redis
是使用标准 C 语言开发的,但并没有直接使用 C 语言中传统的字符串表示,而是自定义了一种字符串。这种字符串本身的结构比较简单,但功能却非常强大,称为简单动态字符串,Simple Dynamic String,简称 SDS。
注意,Redis 中的所有字符串并不都是 SDS,也会出现 C 字符串。C 字符串只会出现在字
符串“字面常量”中,并且该字符串不可能发生变更。
redisLog(REDIS_WARNNING, “sdfsfsafsafds”);
3.9.2 SDS 结构
SDS 不同于 C 字符串。C 字符串本身是一个以双引号括起来,以空字符’\0’结尾的字符序
列。但 SDS 是一个结构体,定义在 Redis 安装目录下的 src/sds.h 中:
struct sdshdr {
// 字节数组,用于保存字符串
char buf[];
// buf[]中已使用字节数量,称为 SDS 的长度
int len;
// buf[]中尚未使用的字节数量
int free;
}例如执行 SET country “China”命令时,键 country 与值”China”都是 SDS 类型的,只不过
一个是 SDS 的变量,一个是 SDS 的字面常量。”China”在内存中的结构如下:
通过以上结构可以看出,SDS 的 buf 值实际是一个 C 字符串,包含空字符’\0’共占 6 个字
节。但 SDS 的 len 是不包含空字符’\0’的。
该结构与前面不同的是,这里有 3 字节未使用空间。
3.9.3 SDS 的优势
C 字符串使用 Len+1 长度的字符数组来表示实际长度为 Len 的字符串,字符数组最后以空字符’\0’结尾,表示字符串结束。这种结构简单,但不能满足 Redis 对字符串功能性、安全性及高效性等的要求。
(1) 防止”字符串长度获取”性能瓶颈
对于 C 字符串,若要获取其长度,则必须要通过遍历整个字符串才可获取到的。对于超长字符串的遍历,会成为系统的性能瓶颈。但,由于 SDS 结构体中直接就存放着字符串的长度数据,所以对于获取字符串长度需要消耗的系统性能,与字符串本身长度是无关的,不会成为 Redis 的性能瓶颈。
(2) 保障二进制安全
C 字符串中只能包含符合某种编码格式的字符,例如 ASCII、UTF-8 等,并且除了字符串末尾外,其它位置是不能包含空字符’\0’的,否则该字符串就会被程序误解为提前结束。而
在图片、音频、视频、压缩文件、office 文件等二进制数据中以空字符’\0’作为分隔符的情况是很常见的。故而在 C 字符串中是不能保存像图片、音频、视频、压缩文件、office 文件等二进制数据的。
但 SDS 不是以空字符’\0’作为字符串结束标志的,其是通过 len 属性来判断字符串是否结束的。所以,对于程序处理 SDS 中的字符串数据,无需对数据做任何限制、过滤、假设,只需读取即可。数据写入的是什么,读到的就是什么。
(3) 减少内存再分配次数
SDS 采用了空间预分配策略与惰性空间释放策略来避免内存再分配问题。空间预分配策略是指,每次 SDS 进行空间扩展时,程序不但为其分配所需的空间,还会为其分配额外的未使用空间,以减少内存再分配次数。而额外分配的未使用空间大小取决于空间扩展后 SDS 的 len 属性值。
如果 len 属性值小于 1M,那么分配的未使用空间 free 的大小与 len 属性值相同。
如果 len 属性值大于等于 1M ,那么分配的未使用空间 free 的大小固定是 1M。
SDS 对于空间释放采用的是惰性空间释放策略。该策略是指,SDS 字符串长度如果缩短,
那么多出的未使用空间将暂时不释放,而是增加到 free 中。以使后期扩展 SDS 时减少内存再分配次数。
如果要释放 SDS 的未使用空间,则可通过 sdsRemoveFreeSpace()函数来释放。
(4) 兼容 C 函数
Redis 中提供了很多的 SDS 的 API,以方便用户对 Redis 进行二次开发。为了能够兼容 C
函数,SDS 的底层数组 buf[]中的字符串仍以空字符’\0’结尾。
现在要比较的双方,一个是 SDS,一个是 C 字符串,此时可以通过 C 语言函数
strcmp(sds_str->buf,c_str)
3.9.4 常用的 SDS 操作函数
下表列出了一些常用的 SDS 操作函数及其功能描述。


3.10 集合的底层实现原理
Redis 中对于 Set 类型的底层实现,直接采用了 hashTable。但对于 Hash、ZSet、List 集
合的底层实现进行了特殊的设计,使其保证了 Redis 的高性能。
3.10.1 两种实现的选择
对于Hash与ZSet集合,其底层的实现实际有两种:压缩列表zipList,与跳跃列表skipList。
这两种实现对于用户来说是透明的,但用户写入不同的数据,系统会自动使用不同的实现。
只有同时满足以配置文件 redis.conf 中相关集合元素数量阈值与元素大小阈值两个条件,使
用的就是压缩列表 zipList,只要有一个条件不满足使用的就是跳跃列表 skipList。例如,对于
ZSet 集合中这两个条件如下:
集合元素个数小于 redis.conf 中 zset-max-ziplist-entries 属性的值,其默认值为 128
每个集合元素大小都小于 redis.conf 中 zset-max-ziplist-value 属性的值,其默认值为 64字节
3.10.2 zipList
(1) 什么是 zipList
zipList,通常称为压缩列表,是一个经过特殊编码的用于存储字符串或整数的双向链表。
其底层数据结构由三部分构成:head、entries 与 end。这三部分在内存上是连续存放的。
(2) head
head 又由三部分构成:
zlbytes:占 4 个字节,用于存放 zipList 列表整体数据结构所占的字节数,包括 zlbytes
本身的长度。
zltail:占 4 个字节,用于存放 zipList 中最后一个 entry 在整个数据结构中的偏移量(字
节)。该数据的存在可以快速定位列表的尾 entry 位置,以方便操作。
zllen:占 2 字节,用于存放列表包含的 entry 个数。由于其只有 16 位,所以 zipList 最多
可以含有的 entry 个数为 216-1 = 65535 个。
(3) entries
entries 是真正的列表,由很多的列表元素 entry 构成。由于不同的元素类型、数值的不
同,从而导致每个 entry 的长度不同。
每个 entry 由三部分构成:
prevlength:该部分用于记录上一个 entry 的长度,以实现逆序遍历。默认长度为 1 字节,
只要上一个 entry 的长度<254 字节,prevlength 就占 1 字节,否则其会自动扩展为 3 字
节长度。
encoding:该部分用于标志后面的 data 的具体类型。如果 data 为整数类型,
固定长度为 1 字节。如果 data 为字符串类型,则 encoding 长度可能会是 1 字节、2 字
节或 5 字节。data 字符串不同的长度,对应着不同的 encoding 长度。
data:真正存储的数据。数据类型只能是整数类型或字符串类型。不同的数据占用的字
节长度不同。
(4) end
end 只包含一部分,称为 zlend。占 1 个字节,值固定为 255,即二进制位为全 1,表示
一个 zipList 列表的结束。
3.10.3 listPack
对于 ziplist,实现复杂,为了逆序遍历,每个 entry 中包含前一个 entry 的长度,这样会
导致在 ziplist 中间修改或者插入 entry 时需要进行级联更新。在高并发的写操作场景下会极
度降低 Redis 的性能。为了实现更紧凑、更快的解析,更简单的实现,重写实现了 ziplist,
并命名为 listPack。
在 Redis 7.0 中,已经将 zipList 全部替换为了 listPack,但为了兼容性,在配置中也保留
了 zipList 的相关属性。
(1) 什么是 listPack
listPack 也是一个经过特殊编码的用于存储字符串或整数的双向链表。其底层数据结构
也由三部分构成:head、entries 与 end,且这三部分在内存上也是连续存放的。
listPack与zipList的重大区别在head与每个entry的结构上,表示列表结束的end与zipList
的 zlend 是相同的,占一个字节,且 8 位全为 1。
(2) head
head 由两部分构成:
totalBytes:占 4 个字节,用于存放 listPack 列表整体数据结构所占的字节数,包括
totalBytes 本身的长度。
elemNum:占 2 字节,用于存放列表包含的 entry 个数。其意义与 zipList 中 zllen 的相同。
与 zipList 的 head 相比,没有了记录最后一个 entry 偏移量的 zltail。
(3) entries
entries 也是 listPack 中真正的列表,由很多的列表元素 entry 构成。由于不同的元素类型、数值的不同,从而导致每个 entry 的长度不同。但与 zipList 的 entry 结构相比,listPack的 entry 结构发生了较大变化。
其中最大的变化就是没有了记录前一个 entry 长度的 prevlength,而增加了记录当前
entry 长度的 element-total-len。而这个改变仍然可以实现逆序遍历,但却避免了由于在列表
中间修改或插入 entry 时引发的级联更新。
每个 entry 仍由三部分构成:
encoding:该部分用于标志后面的 data 的具体类型。如果 data 为整数类型,encoding
长度可能会是 1、2、3、4、5 或 9 字节。不同的字节长度,其标识位不同。如果 data
为字符串类型,则 encoding 长度可能会是 1、2 或 5 字节。data 字符串不同的长度,对
应着不同的 encoding 长度。
data:真正存储的数据。数据类型只能是整数类型或字符串类型。不同的数据占用的字
节长度不同。
element-total-len:该部分用于记录当前 entry 的长度,用于实现逆序遍历。由于其特殊
的记录方式,使其本身占有的字节数据可能会是 1、2、3、4 或 5 字节。
3.10.4 skipList
(1) 什么是 skipList
skipList,跳跃列表,简称跳表,是一种随机化的数据结构,基于并联的链表,实现简单,查找效率较高。简单来说跳表也是链表的一种,只不过它在链表的基础上增加了跳跃功能。也正是这个跳跃功能,使得在查找元素时,能够提供较高的效率。
(2) skipList 原理
假设有一个带头尾结点的有序链表。
在该链表中,如果要查找某个数据,需要从头开始逐个进行比较,直到找到包含数据的那个节点,或者找到第一个比给定数据大的节点,或者找到最后尾结点,后两种都属于没有找到的情况。同样,当我们要插入新数据的时候,也要经历同样的查找过程,从而确定插入位置。
为了提升查找效率,在偶数结点上增加一个指针,让其指向下一个偶数结点。
这样所有偶数结点就连成了一个新的链表(简称高层链表),当然,高层链表包含的节点个数只是原来链表的一半。此时再想查找某个数据时,先沿着高层链表进行查找。当遇到第一个比待查数据大的节点时,立即从该大节点的前一个节点回到原链表中进行查找。例如,
若想插入一个数据 20,则先在(8,19,31,42)的链表中查找,找到第一个比 20 大的节点 31,然后再在高层链表中找到 31 节点的前一个节点 19,然后再在原链表中获取到其下一个节点值为 23。比 20 大,则将 20 插入到 19 节点与 23 节点之间。若插入的是 25,比节点23 大,则插入到 23 节点与 31 节点之间。
该方式明显可以减少比较次数,提高查找效率。如果链表元素较多,为了进一步提升查找效率,可以将原链表构建为三层链表,或再高层级链表。
层级越高,查找效率就会越高。
(3) 存在的问题
这种对链表分层级的方式从原理上看确实提升了查找效率,但在实际操作时就出现了问题:由于固定序号的元素拥有固定层级,所以列表元素出现增加或删除的情况下,会导致列表整体元素层级大调整,但这样势必会大大降低系统性能。
例如,对于划分两级的链表,可以规定奇数结点为高层级链表,偶数结点为低层级链表。对于划分三级的链表,可以按照节点序号与 3 取模结果进行划分。但如果插入了新的节点,或删除的原来的某些节点,那么定会按照原来的层级划分规则进行重新层级划分,那么势必会大大降低系统性能。
(4) 算法优化
为了避免前面的问题,skipList 采用了随机分配层级方式。即在确定了总层级后,每添
加一个新的元素时会自动为其随机分配一个层级。这种随机性就解决了节点序号与层级间的
固定关系问题。
上图演示了列表在生成过程中为每个元素随机分配层级的过程。从这个 skiplist 的创建
和插入过程可以看出,每一个节点的层级数都是随机分配的,而且新插入一个节点不会影响
到其它节点的层级数。只需要修改插入节点前后的指针,而不需对很多节点都进行调整。这
就降低了插入操作的复杂度。
skipList 指的就是除了最下面第 1 层链表之外,它会产生若干层稀疏的链表,这些链表
里面的指针跳过了一些节点,并且越高层级的链表跳过的节点越多。在查找数据的时先在高
层级链表中进行查找,然后逐层降低,最终可能会降到第 1 层链表来精确地确定数据位置。
在这个过程中由于跳过了一些节点,从而加快了查找速度。
3.10.5 quickList
(1) 什么是 quickList
quickList,快速列表,quickList 本身是一个双向无循环链表,它的每一个节点都是一个zipList。从Redis3.2版本开始,对于List的底层实现,使用quickList替代了zipList 和 linkedList。
zipList 与 linkedList 都存在有明显不足,而 quickList 则对它们进行了改进:吸取了 zipList
和 linkedList 的优点,避开了它们的不足。
quickList 本质上是 zipList 和 linkedList 的混合体。其将 linkedList 按段切分,每一段使用 zipList 来紧凑存储若干真正的数据元素,多个 zipList 之间使用双向指针串接起来。当然,对于每个 zipList 中最多可存放多大容量的数据元素,在配置文件中通过 list-max-ziplist-size属性可以指定。
(2) 检索操作
为了更深入的理解 quickList 的工作原理,通过对检索、插入、删除等操作的实现分析来
加深理解。
对于 List 元素的检索,都是以其索引 index 为依据的。quickList 由一个个的 zipList 构成,
每个 zipList 的 zllen 中记录的就是当前 zipList 中包含的 entry 的个数,即包含的真正数据元素
的个数。根据要检索元素的 index,从 quickList 的头节点开始,逐个对 zipList 的 zllen 做 sum
求和,直到找到第一个求和后 sum 大于 index 的 zipList,那么要检索的这个元素就在这个
zipList 中。
(3) 插入操作
由于 zipList 是有大小限制的,所以在 quickList 中插入一个元素在逻辑上相对就比较复杂
一些。假设要插入的元素的大小为 insertBytes,而查找到的插入位置所在的 zipList 当前的大
小为 zlBytes,那么具体可分为下面几种情况:
情况一:当 insertBytes + zlBytes <= list-max-ziplist-size 时,直接插入到 zipList 中相应位置
即可
情况二:当 insertBytes + zlBytes > list-max-ziplist-size,且插入的位置位于该 zipList 的首
部位置,此时需要查看该 zipList 的前一个 zipList 的大小 prev_zlBytes。
若 insertBytes + prev_zlBytes<= list-max-ziplist-size 时,直接将元素插入到前一个
zipList 的尾部位置即可
若 insertBytes + prev_zlBytes> list-max-ziplist-size 时,直接将元素自己构建为一个新
的 zipList,并连入 quickList 中
情况三:当 insertBytes + zlBytes > list-max-ziplist-size,且插入的位置位于该 zipList 的尾
部位置,此时需要查看该 zipList 的后一个 zipList 的大小 next_zlBytes。
若 insertBytes + next_zlBytes<= list-max-ziplist-size 时,直接将元素插入到后一个
zipList 的头部位置即可
若 insertBytes + next_zlBytes> list-max-ziplist-size 时,直接将元素自己构建为一个新
的 zipList,并连入 quickList 中
情况四:当 insertBytes + zlBytes > list-max-ziplist-size,且插入的位置位于该 zipList 的中间位置,则将当前 zipList 分割为两个 zipList 连接入 quickList 中,然后将元素插入到分割
后的前面 zipList 的尾部位置
(4) 删除操作
对于删除操作,只需要注意一点,在相应的 zipList 中删除元素后,该 zipList 中是否还有
元素。如果没有其它元素了,则将该 zipList 删除,将其前后两个 zipList 相连接。
3.10.6 key 与 value 中元素的数量
前面讲述的 Redis 的各种特殊数据结构的设计,不仅极大提升了 Redis 的性能,并且还使得 Redis 可以支持的 key 的数量、集合 value 中可以支持的元素数量可以非常庞大。
Redis 最多可以处理 232个 key(约 42 亿),并且在实践中经过测试,每个 Redis 实例至
少可以处理 2.5 亿个 key。
每个 Hash、List、Set、ZSet 集合都可以包含 232 个元素。
3.11 BitMap 操作命令
3.11.1 BitMap 简介
BitMap 是 Redis 2.2.0 版本中引入的一种新的数据类型。该数据类型本质上就是一个仅包含 0 和 1 的二进制字符串。而其所有相关命令都是对这个字符串二进制位的操作。用于描述该字符串的属性有三个:key、offset、bitValue。
key:BitMap 是 Redis 的 key-value 中的一种 Value 的数据类型,所以该 Value 一定有其对应的 key。
offset:每个 BitMap 数据都是一个字符串,字符串中的每个字符都有其对应的索引,该索引从 0 开始计数。该索引就称为每个字符在该 BitMap 中的偏移量 offset。这个 offset的值的范围是[0,232-1],即该 offset 的最大值为 4G-1,即 4294967295,42 亿多。
bitValue:每个 BitMap 数据中都是一个仅包含 0 和 1 的二进制字符串,每个 offset 位上的字符就称为该位的值 bitValue。bitValue 的值非 0 即 1。
3.11.2 setbit
格式:SETBIT key offset value
功能:为给定 key 的BitMap 数据的 offset 位置设置值为 value。其返回值为修改前该 offset
位置的 bitValue
说明:对于原 BitMap 字符串中不存在的 offset 进行赋值,字符串会自动伸展以确保它
可以将 value 保存在指定的 offset 上。当字符串值进行伸展时,空白位置以 0 填充。当然,设置的 value 只能是 0 或 1。不过需要注意的是,对使用较大 offset 的 SETBIT 操作来说,内存分配过程可能造成 Redis 服务器被阻塞。
3.11.3 getbit
格式:GETBIT key offset
功能:对 key 所储存的 BitMap 字符串值,获取指定 offset 偏移量上的位值 bitValue。
说明:当 offset 比字符串值的长度大,或者 key 不存在时,返回 0 。
3.11.4 bitcount
格式:BITCOUNT key [start] [end]
功能:统计给定字符串中被设置为 1 的 bit 位的数量。一般情况下,统计的范围是给定
的整个 BitMap 字符串。但也可以通过指定额外的 start 或 end 参数,实现仅对指定字节
范围内字符串进行统计,包括 start 和 end 在内。注意,这里的 start 与 end 的单位是
字节,不是 bit,并且从 0 开始计数。
说明:start 和 end 参数都可以使用负数值: -1 表示最后一个字节, -2 表示倒数第二个
字节,以此类推。另外,对于不存在的 key 被当成是空字符串来处理,因此对一个不存
在的 key 进行 BITCOUNT 操作,结果为 0 。
3.11.5 bitpos
格式:BITPOS key bit [start] [end]
功能:返回 key 指定的 BitMap 中第一个值为指定值 bit(非 0 即 1) 的二进制位的位置。
pos,即 position,位置。在默认情况下, 命令将检测整个 BitMap,但用户也可以通过
可选的 start 参数和 end 参数指定要检测的范围。
说明:start 与 end 的意义与 bitcount 命令中的相同。
3.11.6 bitop
格式:BITOP operation destkey key *key …+
功能:对一个或多个 BitMap 字符串 key 进行二进制位操作,并将结果保存到 destkey 上。
operation 可以是 AND 、 OR 、 NOT 、 XOR 这四种操作中的任意一种:
BITOP AND destkey key [key ...] :对一个或多个 BitMap 执行按位与操作,并将结果
保存到 destkey 。
BITOP OR destkey key [key ...] :对一个或多个 BitMap 执行按位或操作,并将结果保
存到 destkey 。
BITOP XOR destkey key [key ...] :对一个或多个 BitMap 执行按位异或操作,并将结
果保存到 destkey 。
BITOP NOT destkey key :对给定 BitMap 执行按位非操作,并将结果保存到 destkey 。
说明:
除了 NOT 操作之外,其他操作都可以接受一个或多个 BitMap 作为输入。
除了 NOT 操作外,其他对一个 BitMap 的操作其实就是一个复制。
如果参与运算的多个 BitMap 长度不同,较短的 BitMap 会以 0 作为补充位与较长BitMap 运算,且运算结果长度与较长 BitMap 的相同。
3.11.7 应用场景
由于 offset 的取值范围很大,所以其一般应用于大数据量的二值性统计。例如平台活跃用户统计(二值:访问或未访问)、支持率统计(二值:支持或不支持)、员工考勤统计(二值:上班或未上班)、图像二值化(二值:黑或白)等。
不过,对于数据量较小的二值性统计并不适合 BitMap,可能使用 Set 更为合适。当然,具体多少数据量适合使用 Set,超过多少数据量适合使用 BitMap,这需要根据具体场景进行具体分析。
例如,一个平台要统计日活跃用户数量。
如果使用 Set 来统计,只需上线一个用户,就将其用户 ID 写入 Set 集合即可,最后只需统计出 Set 集合中的元素个数即可完成统计。即 Set 集合占用内存的大小与上线用户数量成正比。假设用户 ID 为 m 位 bit 位,当前活跃用户数量为 n,则该 Set 集合的大小最少应该是m*n 字节。
如果使用 BitMap 来统计,则需要先定义出一个 BitMap,其占有的 bit 位至少为注册用户数量。只需上线一个用户,就立即使其中一个 bit 位置 1,最后只需统计出 BitMap 中 1 的个数即可完成统计。即 BitMap 占用内存的大小与注册用户数量成正比,与上线用户数量无关。假设平台具有注册用户数量为 N,则 BitMap 的长度至少为 N 个 bit 位,即 N/8 字节。何时使用 BitMap 更合适?令 m*n 字节 = N/8 字节,即 n = N/8/m = N/(8*m) 时,使用Set 集合与使用 BitMap 所占内存大小相同。以淘宝为例,其用户 ID 长度为 11 位(m),其注册用户数量为 8 亿(N),当活跃用户数量为 8 亿/(8*11) = 0.09 亿 = 9*106= 900 万,使用 Set与 BitMap 占用的内存是相等的。但淘宝的日均活跃用户数量为 8 千万,所以淘宝使用 BitMap更合适。
3.12 HyperLogLog 操作命令
3.12.1 HyperLogLog 简介
HyperLogLog 是 Redis 2.8.9 版本中引入的一种新的数据类型,其意义是 hyperlog log,超
级日志记录。该数据类型可以简单理解为一个 set 集合,集合元素为字符串。但实际上
HyperLogLog 是一种基数计数概率算法,通过该算法可以利用极小的内存完成独立总数的统
计。其所有相关命令都是对这个“set 集合”的操作。
HyperLogLog 算法是由法国人 Philippe Flajolet 博士研究出来的,Redis
的作者 Antirez 为了纪念 Philippe Flajolet 博士对组合数学和基数计算算
法分析的研究,在设计 HyperLogLog 命令的时候使用了 Philippe Flajolet
姓名的英文首字母 PF 作为前缀。遗憾的是 Philippe Flajolet 博士于 2011年 3 月 22 日因病在巴黎辞世。
HyperLogLog 算法是一个纯数学算法,我们这里不做研究。
3.12.2 pfadd
格式:PFADD key element *element …+
功能:将任意数量的元素添加到指定的 HyperLogLog 集合里面。如果内部存储被修改
了返回 1,否则返回 0。
3.12.3 pfcount
格式:PFCOUNT key *key …+
功能:该命令作用于单个 key 时,返回给定 key 的 HyperLogLog 集合的近似基数;该命
令作用于多个 key 时,返回所有给定 key 的 HyperLogLog 集合的并集的近似基数;如果
key 不存在,则返回 0。
3.12.4 pfmerge
格式:PFMERGE destkey sourcekey *sourcekey …+
功能:将多个 HyperLogLog 集合合并为一个 HyperLogLog 集合,并存储到 destkey 中,
合并后的 HyperLogLog 的基数接近于所有 sourcekey 的 HyperLogLog 集合的并集。
3.12.5 应用场景
HyperLogLog 可对数据量超级庞大的日志数据做不精确的去重计数统计。当然,这个不
精确的度在 Redis 官方给出的误差是 0.81%。这个误差对于大多数超大数据量场景是被允许
的。对于平台上每个页面每天的 UV 数据,非常适合使用 HyperLogLog 进行记录。
3.13 Geospatial 操作命令
3.13.1 Geospatial 简介
Geospatial,地理空间。
Redis 在 3.2 版本中引入了 Geospatial 这种新的数据类型。该类型本质上仍是一种集合,
只不过集合元素比较特殊,是一种由三部分构成的数据结构,这种数据结构称为空间元素:
经度:longitude。有效经度为[-180,180]。正的表示东经,负的表示西经。
纬度:latitude。有效纬度为[-85.05112878,85.05112878]。正的表示北纬,负的表示南
纬。
位置名称:为该经纬度所标注的位置所命名的名称,也称为该 Geospatial 集合的空间元
素名称。
通过该类型可以设置、查询某地理位置的经纬度,查询某范围内的空间元素,计算两空
间元素间的距离等。
3.13.2 geoadd
格式:GEOADD key longitude latitude member *longitude latitude member …+
功能:将一到多个空间元素添加到指定的空间集合中。
说明:当用户尝试输入一个超出范围的经度或者纬度时,该命令会返回一个错误。
3.13.3 geopos
格式:GEOPOS key member *member …+
功能:从指定的地理空间中返回指定元素的位置,即经纬度。
说明:因为 该命令接受可变数量元素作为输入,所以即使用户只给定了一个元素,命
令也会返回数组。
3.13.4 geodist
格式:GEODIST key member1 member2 [unit]
功能:返回两个给定位置之间的距离。其中 unit 必须是以下单位中的一种:
m :米,默认
km :千米
mi :英里
ft:英尺
说明:如果两个位置之间的其中一个不存在, 那么命令返回空值。另外,在计算距离
时会假设地球为完美的球形, 在极限情况下, 这一假设最大会造成 0.5% 的误差。
3.13.5 geohash
格式:GEOHASH key member *member …+
功能:返回一个或多个位置元素的 Geohash 值。
说明:GeoHash 是一种地址编码方法。他能够把二维的空间经纬度数据编码成一个字符
串。该值主要用于底层应用或者调试, 实际中的作用并不大。
3.13.6 georadius
格式:GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST]
[WITHHASH] [ASC|DESC] [COUNT count]
功能:以给定的经纬度为中心,返回指定地理空间中包含的所有位置元素中,与中心距
离不超过给定半径的元素。返回时还可携带额外的信息:
WITHDIST :在返回位置元素的同时,将位置元素与中心之间的距离也一并返回。
距离的单位和用户给定的范围单位保持一致。
WITHCOORD :将位置元素的经维度也一并返回。 WITHHASH:将位置元素的 Geohash 也一并返回,不过这个 hash 以整数形式表示
命令默认返回未排序的位置元素。 通过以下两个参数,用户可以指定被返回位置元素
的排序方式:
ASC :根据中心的位置,按照从近到远的方式返回位置元素。
DESC :根据中心的位置,按照从远到近的方式返回位置元素。
说明:在默认情况下, 该命令会返回所有匹配的位置元素。虽然用户可以使
用 COUNT <count> 选项去获取前 N 个匹配元素,但因为命令在内部可能会需要对所有
被匹配的元素进行处理,所以在对一个非常大的区域进行搜索时,即使使用 COUNT 选
项去获取少量元素,该命令的执行速度也可能会非常慢。
3.13.7 georadiusbymember
格式:GEORADIUSBYMEMBER key member radius m|km|ft|mi [WITHCOORD] [WITHDIST]
[WITHHASH] [ASC|DESC] [COUNT count]
功能:这个命令和 GEORADIUS 命令一样,都可以找出位于指定范围内的元素,但该命
令的中心点是由位置元素形式给定的,而不是像 GEORADIUS 那样,使用输入的经纬度
来指定中心点。
说明:返回结果中也是包含中心点位置元素的
3.13.8 应用场景
Geospatial 的意义是地理位置,所以其主要应用地理位置相关的计算。例如,微信发现中的“附近”功能,添加朋友中“雷达加朋友”功能;QQ 动态中的“附近”功能;钉钉中的“签到”功能等。
3.14 发布/订阅命令
3.14.1 消息系统
发布/订阅,即 pub/sub,是一种消息通信模式:发布者也称为消息生产者,生产和发送消息到存储系统;订阅者也称为消息消费者,从存储系统接收和消费消息。这个存储系统可以是文件系统 FS、消息中间件 MQ、数据管理系统 DBMS,也可以是 Redis。整个消息发布者、订阅者与存储系统称为消息系统。
消息系统中的订阅者订阅了某类消息后,只要存储系统中存在该类消息,其就可不断的接收并消费这些消息。当存储系统中没有该消息后,订阅者的接收、消费阻塞。而当发布者将消息写入到存储系统后,会立即唤醒订阅者。当存储系统放满时,不同的发布者具有不同的处理方式:有的会阻塞发布者的发布,等待可用的存储空间;有的则会将多余的消息丢失。
当然,不同的消息系统消息的发布/订阅方式也是不同的。例如 RocketMQ、Kafka 等消息中间件构成的消息系统中,发布/订阅的消息都是以主题 Topic 分类的。而 Redis 构成的消息系统中,发布/订阅的消息都是以频道 Channel 分类的。
3.14.2 subscribe
格式:SUBSCRIBE channel *channel …+
功能:Redis 客户端通过一个 subscribe 命令可以同时订阅任意数量的频道。在输出了订
阅了主题后,命令处于阻塞状态,等待相关频道的消息。
3.14.3 psubscribe
格式:PSUBSCRIBE pattern *pattern …+
功能:订阅一个或多个符合给定模式的频道。
说明:这里的模式只能使用通配符 *。例如,
it* 可以匹配所有以 it 开头的频道,像 it.news、
it.blog、it.tweets 等;news.*可以匹配所有以 news.开头的频道,像 news.global.today、
news.it 等。
3.14.4 publish
格式:PUBLISH channel message
功能:Redis 客户端通过一条 publish 命令可以发布一个频道的消息。返回值为接收到该消息的订阅者数量。
3.14.5 unsubscribe
格式:UNSUBSCRIBE *channel *channel …++
功能:Redis 客户端退订指定的频道。
说明:如果没有频道被指定,也就是一个无参数的 UNSUBSCRIBE 命令被执行,那么客
户端使用 SUBSCRIBE 命令订阅的所有频道都会被退订。在这种情况下,命令会返回一个
信息,告知客户端所有被退订的频道。
3.14.6 punsubscribe
格式:PUNSUBSCRIBE *pattern *pattern …++
功能:退订一个或多个符合给定模式的频道。
说明:这里的模式只能使用通配符 *。如果没有频道被指定,其效果与 SUBSCRIBE 命令
相同,客户端将退订所有订阅的频道。
3.14.7 pubsub
格式:PUBSUB <subcommand> [argument *argument …++
功能:PUBSUB 是一个查看订阅与发布系统状态的内省命令集,它由数个不同格式的子
命令组成,下面分别介绍这些子命令的用法。
(1) pubsub channels
格式:PUBSUB CHANNELS [pattern]
功能:列出当前所有的活跃频道。活跃频道指的是那些至少有一个订阅者的频道。
说明:pattern 参数是可选的。如果不给出 pattern 参数,将会列出订阅/发布系统中的
所有活跃频道。如果给出 pattern 参数,那么只列出和给定模式 pattern 相匹配的那些活
跃频道。pattern 中只能使用通配符*。
(2) pubsub numsub
格式:PUBSUB NUMSUB [channel-1 … channel-N]
功能:返回给定频道的订阅者数量。不给定任何频道则返回一个空列表。
(3) pubsub numpat
格式:PUBSUB NUMPAT
功能:查询当前 Redis 所有客户端订阅的所有频道模式的数量总和
3.15 Redis 事务
Redis 的事务的本质是一组命令的批处理。这组命令在执行过程中会被顺序地、一次性全部执行完毕,只要没有出现语法错误,这组命令在执行期间是不会被中断。
3.15.1 Redis 事务特性
Redis 的事务仅保证了数据的一致性,不具有像 DBMS 一样的 ACID 特性。
这组命令中的某些命令的执行失败不会影响其它命令的执行,不会引发回滚。即不具备原子性。
这组命令通过乐观锁机制实现了简单的隔离性。没有复杂的隔离级别。
这组命令的执行结果是被写入到内存的,是否持久取决于 Redis 的持久化策略,与事务无关。
3.15.2 Redis 事务实现
(1) 三个命令
Redis 事务通过三个命令进行控制。
muti:开启事务
exec:执行事务
discard:取消事务
(2) 基本使用
下面是定义并执行事务的用法:
事务执行后,再访问事务中定义的变量,其值是修改过后。
下面是定义但取消事务的举例:
事务取消后,事务中的命令是没有执行的。
3.15.3 Redis 事务异常处理
(1) 语法错误
当事务中的命令出现语法错误时,整个事务在 exec 执行时会被取消。exec 的提示是 exec 被忽略,事务被取消,因为之前的错误。此时访问 age 的值,发现其仍为 19,并没有变为事务中设置的 20。
(2) 执行异常
如果事务中的命令没有语法错误,但在执行过程中出现异常,该异常不会影响其它命令的执行。
以上事务中第 2 条命令在执行时出现异常。因为 score 并非是整型,无法被增加 20 的操作。但该异常并不会影响其前后命令的正确执行。查看 score 与 name 的值,发现是执行成功的结果。
3.15.4 Redis 事务隔离机制
(1) 为什么需要隔离机制
在并发场景下可能会出现多个客户端对同一个数据进行修改的情况。
例如:有两个客户端 C 左与 C 右,C 左需要申请 40 个资源,C 右需要申请 30 个资源。
它们首先查看了当前拥有的资源数量,即 resources 的值。它们查看到的都是 50,都感觉资
源数量可以满足自己的需求,于是修改资源数量,以占有资源。但结果却是资源出现了“超
卖”情况。
为了解决这种情况,Redis 事务通过乐观锁机制实现了多线程下的执行隔离。
(2) 隔离的实现
Redis 通过 watch 命令再配合事务实现了多线程下的执行隔离。
以上两个客户端执行的时间顺序为:

(3) 实现原理
其内部的执行过程如下:1) 当某一客户端对 key 执行了 watch 后,系统就会为该 key 添加一个 version 乐观锁,并初始化 version。例如初值为 1.0。
2) 此后客户端 C 左将对该 key 的修改语句写入到了事务命令队列中,虽未执行,但其将该key 的 value 值与 version 进行了读取并保存到了当前客户端缓存。此时读取并保存的是version 的初值 1.0。
3) 此后客户端 C 右对该 key 的值进行了修改,这个修改不仅修改了 key 的 value 本身,同时也增加了 version 的值,例如使其 version 变为了 2.0,并将该 version 记录到了该 key信息中。
4) 此后客户端 C 左执行 exec,开始执行事务中的命令。不过,其在执行到对该 key 进行修改的命令时,该命令首先对当前客户端缓存中保存的 version 值与当前 key 信息中的version 值。如果缓存 version 小于 key 的 version,则说明客户端缓存的 key 的 value 已经过时,该写操作如果执行可能会破坏数据的一致性。所以该写操作不执行。
相关文章:
消息中间件----内存数据库 Redis7(第3章 Redis 命令)
Redis 根据命令所操作对象的不同,可以分为三大类:对 Redis 进行基础性操作的命令,对 Key 的操作命令,对 Value 的操作命令。3.1 Redis 基本命令首先通过 redis-cli 命令进入到 Redis 命令行客户端,然后再运行下面的命令…...

react-03-react-router-dom-路由
react-router-dom:react路由 印记中文:react-router-dom 1、路由原理 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>前端路由的基石_history</title> </head> <body><a hre…...
2自由度悬架LQR控制
目录 1 悬架系统 1.1 悬架结构示意图 1.2 悬架数学模型 1.3 路面激励 2.仿真分析 2.1simulink模型 2.2 仿真结果 2.3 结论 3. 总结 1 悬架系统 1.1 悬架结构示意图 1.2 悬架数学模型 其中:x1为悬架动扰度,x2为车身加速度,x3为轮胎…...
C语言返回类型为指针的一些经典题目(下)
续上一篇文章,上一篇文章题目都很经典,这一篇也不例外。一.返回类型为指针经典题目(下)1.代码(第六题)char *GetMemory3(int num) {char *p (char *)malloc(sizeof(char) * num);return p; } void Test3(void) {char *str NULL;str GetMemory3(100…...
OpenAI 官方api 阅读笔记
网站 API Key concepts Prompts and completions You input some text as a prompt, and the model will generate a text completion that attempts to match whatever context or pattern you gave it. Token 模型通过将文本分解成token来理解和处理, 处理token数量取…...
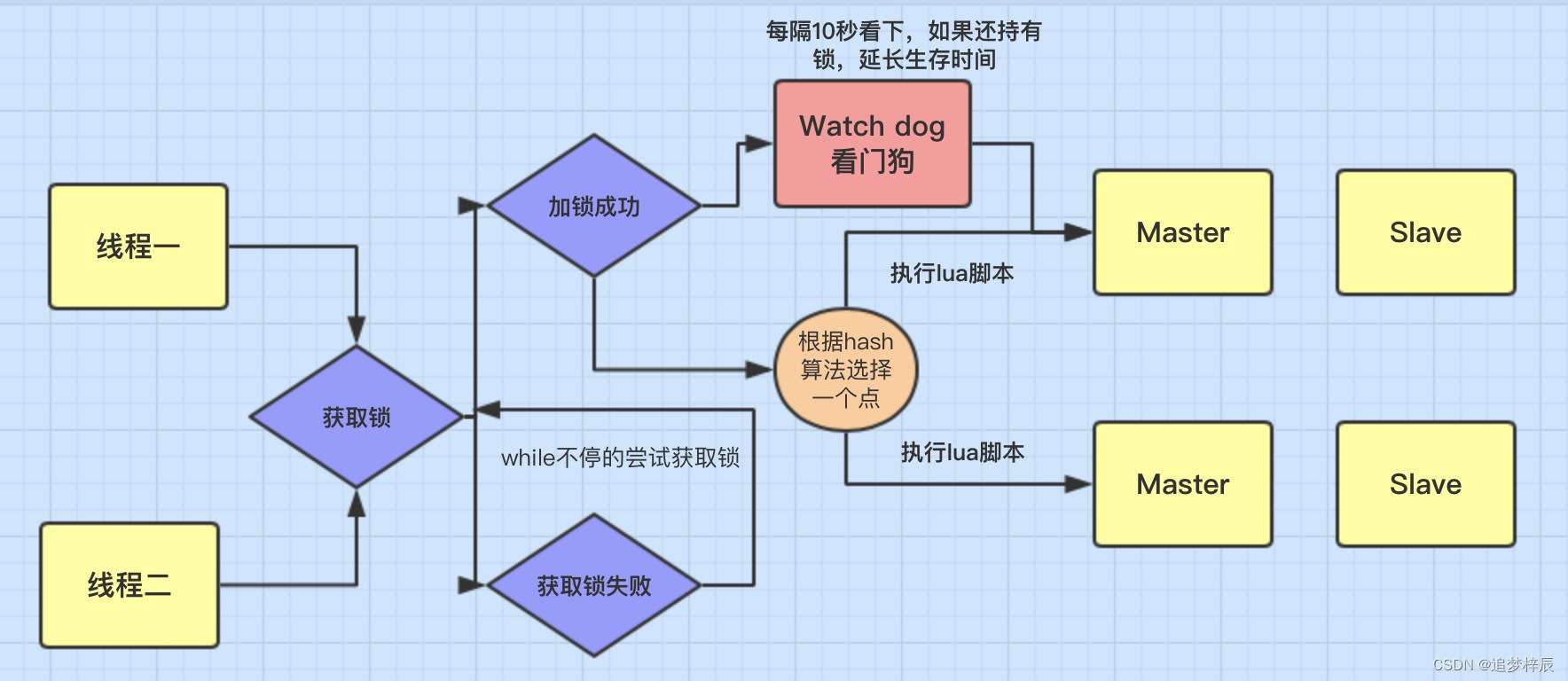
微服务项目【分布式锁】
创建Redisson模块 第1步:基于Spring Initialzr方式创建zmall-redisson模块 第2步:在zmall-redisson模块中添加相关依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</a…...
JavaWeb5-线程常用属性
目录 1.ID 2.名称 3.状态 4.优先级 5.是否守护线程 5.1.线程类型: ①用户线程(main线程默认是用户线程) ②守护线程(后台/系统线程) 5.2.守护线程作用 5.3.守护线程应用 5.4.守护线程使用 ①在用户线程&am…...

JVM调优及垃圾回收GC
一、说一说JVM的内存模型。JVM的运行时内存也叫做JVM堆,从GC的角度可以将JVM分为新生代、老年代和永久代。其中新生代默认占1/3堆内存空间,老年代默认占2/3堆内存空间,永久代占非常少的对内存空间。新生代又分为Eden区、SurvivorFrom区和Surv…...

JAVA练习53-打乱数组
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 前言 一、题目-打乱数组 1.题目描述 2.思路与代码 2.1 思路 2.2 代码 总结 前言 提示:这里可以添加本文要记录的大概内容: 2月17日练习内…...
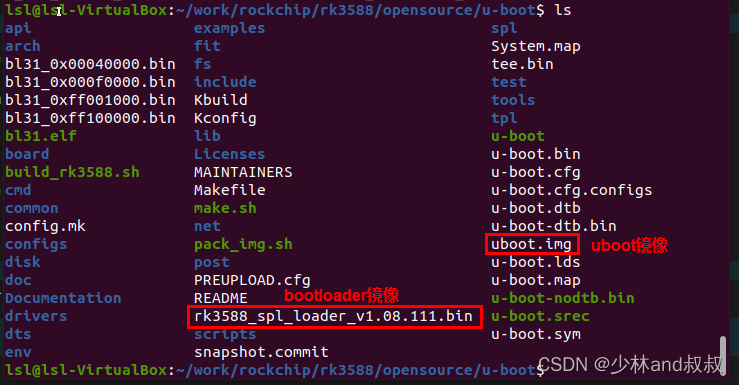
基于RK3588的嵌入式linux系统开发(三)——Uboot镜像文件合成
本章uboot镜像文件的合成包括官网必备文件rkbin下载和uboot镜像文件合成两部分内容,具体分别如下所述。 (一)下载rkbin文件包 以上uboot编译生成的uboot镜像不能直接烧录到板卡中运行,需要与atf、bl31、ddr配置文件等必备文件合成…...
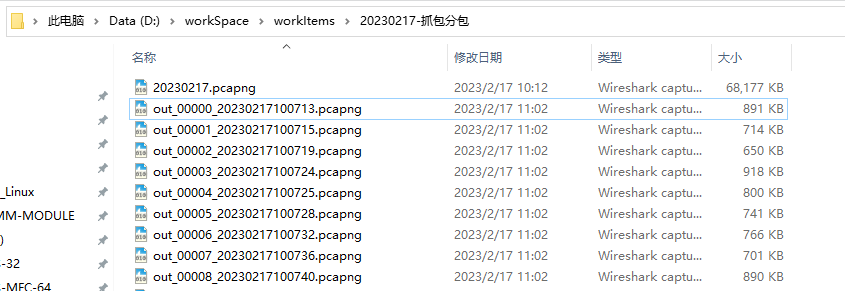
wireshark抓包后通过工具分包
分包说明:关于现场问题分析,一般都是通过日志,这个属于程序中加的打印,或存数据库,或者存文本形式,这种一般比较符合程序逻辑;还有一种就是涉及到网络通信方面的,需要通过抓包来分析…...

举个栗子~Tableau 技巧(251):统一多个工作表的坐标轴范围
在工作汇报场景,有一个很常见、很多数据粉反馈的需求:同一看板上的两个图表,因为轴范围不一致(如下图),很难直观比较。有什么办法可以统一它们的坐标轴范围呢? 类似需求,不论两个还是…...

Centos7 调整磁盘空间
1. 查看磁盘空间占用情况: df -h 可以看到 /home 有很多剩余空间,占了绝大部分, 而我又很少把文件放在home下。 2. 备份 /home 下的内容: cp -r /home/ /homebak/ 3. 关闭home进程: fuser -m -v -i -k /home 报错: -bash: fuser…...

小菜版考试系统——“C”
各位CSDN的uu们你们好呀,今天,小雅兰的内容是小菜版考试系统,最近一直在忙C语言课程设计的事,那么,就请uu们看看我的学习成果吧。 课程设计任务 摘要 题目分析 流程图 关键程序代码 程序运行结果 结论与心得 参…...
Twitter被封号了?最详细的申诉教程在此
由于Twitter检测系统是十分敏感的,所以在运营的时候很容易莫名就出现“此账号被封禁”或者“此账号被冻结”的情况。出现这种情况大多是因为账号发送了垃圾信息、面临安全风险、发太多广告或者太久没上线被判为机器人这几个原因。被封号后,我们可以通过向…...

Docker 安装配置
本章背景知识 本章主要介绍在 Centos 操作系统平台上进行安装和配置Docker Engine。 环境准备 1、操作系统支持。 CentOS、Debian、Fedora、Raspbian、RHEL、SLES、Ubuntu、Binaries 2、启用yum 软件仓库源。 centos-extras 编者注:Centos 默认已经开启cento…...
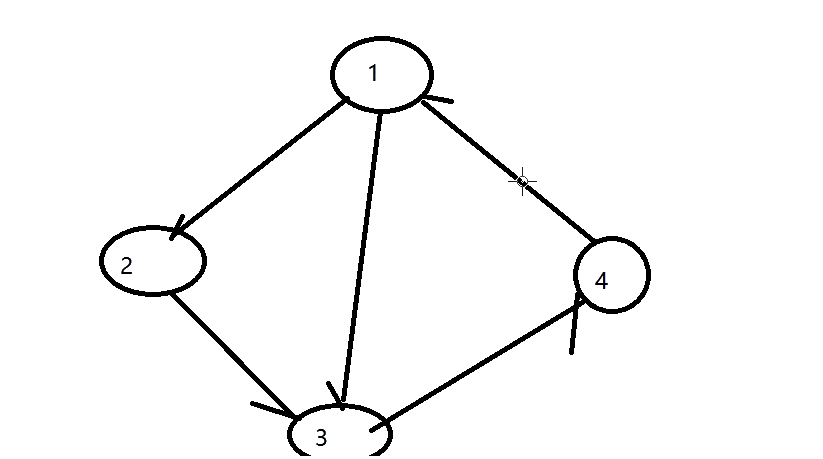
死锁检测组件-设想
死锁检测组件-设想 现在有三个临界资源和三把锁绑定了,三把锁又分别被三个线程占用。(不用关注临界资源,因为锁和临界资源是绑定的) 但现在出现这种情况:线程1去申请获取锁2,线程2申请获取锁3,…...

线程池的使用
为什么要使用线程池 复习一下创建线程的几种方式: 继承Thread 实现Runnable 实现Callable 但是如果频繁的创建/销毁线程,就会造成资源浪费。这时候就需要将线程创建好之后存起来,以后要用取出来,用完后再放回去。 注意 ÿ…...
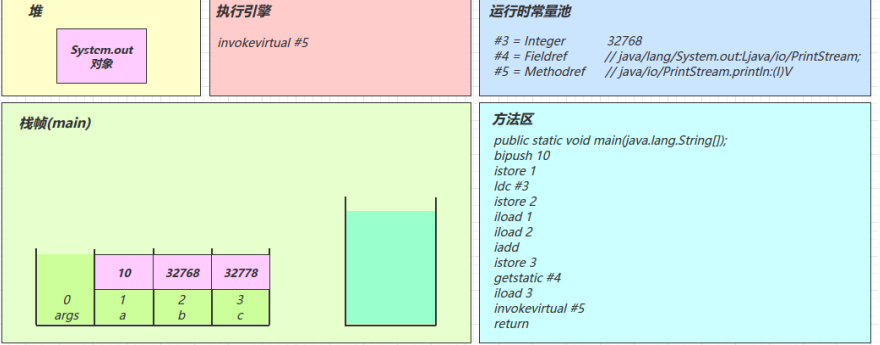
字节码指令
目录 2.1 入门 2.2 javap 工具 2.3 图解方法执行流程 1)原始 java 代码 2)编译后的字节码文件 3)常量池载入运行时常量池 4)方法字节码载入方法区 5)main 线程开始运行,分配栈帧内存 6)…...

TLS/SSL证书彻底扫盲
证书格式 pem Privacy Enhanced Mail文本格式,以 -----BEGIN CERTIFICATE----- 开头,以-----END CERTIFICATE-----结尾 der 二进制格式,只保存证书,不保存私钥java和window服务器常见 pfx/p12 Predecessor of PKCS#12二进制格式&…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...

屋顶变身“发电站” ,中天合创屋面分布式光伏发电项目顺利并网!
5月28日,中天合创屋面分布式光伏发电项目顺利并网发电,该项目位于内蒙古自治区鄂尔多斯市乌审旗,项目利用中天合创聚乙烯、聚丙烯仓库屋面作为场地建设光伏电站,总装机容量为9.96MWp。 项目投运后,每年可节约标煤3670…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

Redis数据倾斜问题解决
Redis 数据倾斜问题解析与解决方案 什么是 Redis 数据倾斜 Redis 数据倾斜指的是在 Redis 集群中,部分节点存储的数据量或访问量远高于其他节点,导致这些节点负载过高,影响整体性能。 数据倾斜的主要表现 部分节点内存使用率远高于其他节…...

安宝特案例丨Vuzix AR智能眼镜集成专业软件,助力卢森堡医院药房转型,赢得辉瑞创新奖
在Vuzix M400 AR智能眼镜的助力下,卢森堡罗伯特舒曼医院(the Robert Schuman Hospitals, HRS)凭借在无菌制剂生产流程中引入增强现实技术(AR)创新项目,荣获了2024年6月7日由卢森堡医院药剂师协会࿰…...
 + 力扣解决)
LRU 缓存机制详解与实现(Java版) + 力扣解决
📌 LRU 缓存机制详解与实现(Java版) 一、📖 问题背景 在日常开发中,我们经常会使用 缓存(Cache) 来提升性能。但由于内存有限,缓存不可能无限增长,于是需要策略决定&am…...

【Linux】自动化构建-Make/Makefile
前言 上文我们讲到了Linux中的编译器gcc/g 【Linux】编译器gcc/g及其库的详细介绍-CSDN博客 本来我们将一个对于编译来说很重要的工具:make/makfile 1.背景 在一个工程中源文件不计其数,其按类型、功能、模块分别放在若干个目录中,mak…...

华为OD机试-最短木板长度-二分法(A卷,100分)
此题是一个最大化最小值的典型例题, 因为搜索范围是有界的,上界最大木板长度补充的全部木料长度,下界最小木板长度; 即left0,right10^6; 我们可以设置一个候选值x(mid),将木板的长度全部都补充到x,如果成功…...

Kubernetes 网络模型深度解析:Pod IP 与 Service 的负载均衡机制,Service到底是什么?
Pod IP 的本质与特性 Pod IP 的定位 纯端点地址:Pod IP 是分配给 Pod 网络命名空间的真实 IP 地址(如 10.244.1.2)无特殊名称:在 Kubernetes 中,它通常被称为 “Pod IP” 或 “容器 IP”生命周期:与 Pod …...

DiscuzX3.5发帖json api
参考文章:PHP实现独立Discuz站外发帖(直连操作数据库)_discuz 发帖api-CSDN博客 简单改造了一下,适配我自己的需求 有一个站点存在多个采集站,我想通过主站拿标题,采集站拿内容 使用到的sql如下 CREATE TABLE pre_forum_post_…...