吴恩达深度学习笔记(八)——卷积神经网络(上)
一、卷积相关
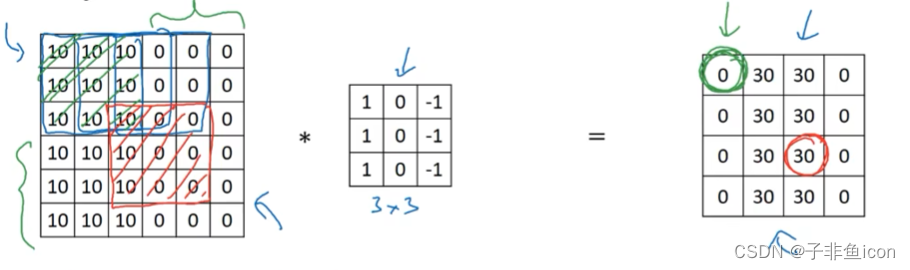
用一个f×f的过滤器卷积一个n×n的图像,假如padding为p,步幅为s,输出大小则为:
[n+2p−fs+1]×[n+2p−fs+1][\frac{n+2p-f}{s}+1]×[\frac{n+2p-f}{s}+1][sn+2p−f+1]×[sn+2p−f+1]
[]表示向下取整(floor)

大部分深度学习的方法对过滤器不做翻转等操作,直接相乘,更像是互相关,但约定俗成叫卷积运算。
二、三维卷积
图片的数字通道数必须和过滤器中的通道数相匹配。
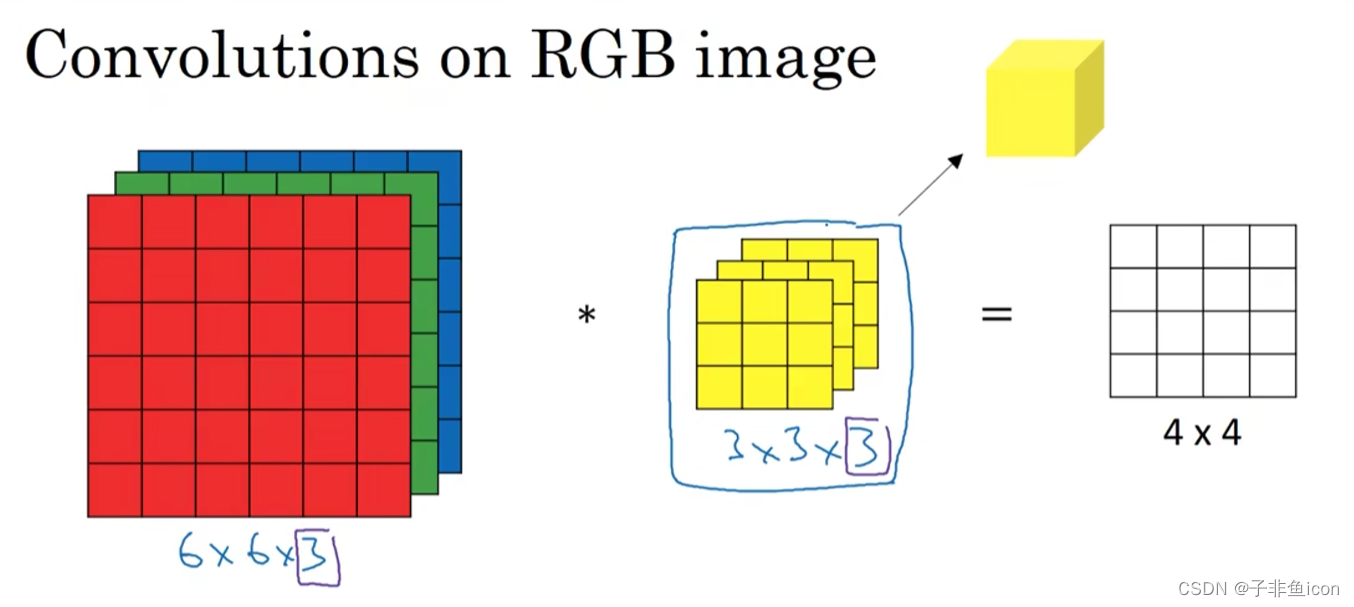
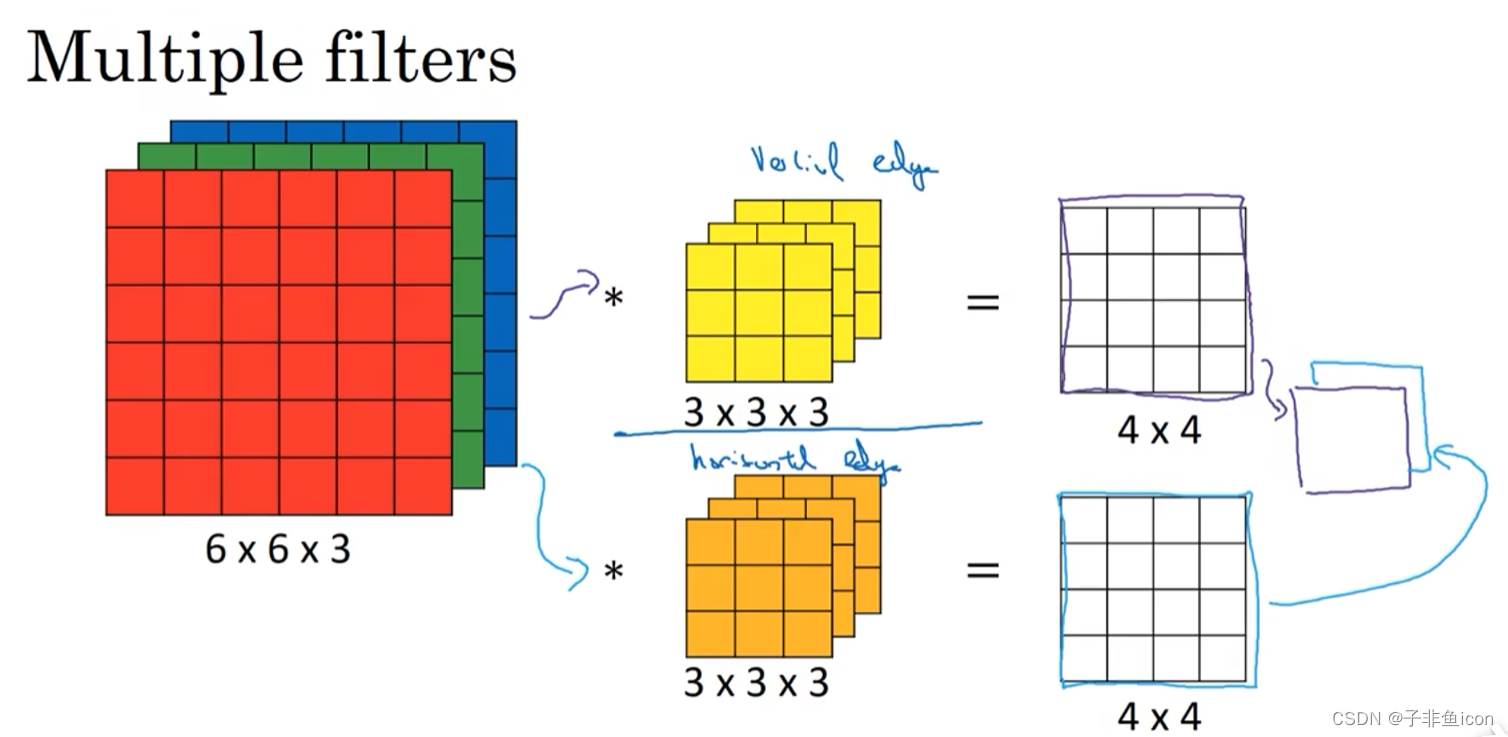
三维卷积相当于一个立方体与所有通道都乘起来然后求和。可以设计滤波器使得其得到单一通道,如红色的边缘特征。
卷积核通道数等于输入通道数,卷积核个数等于输出通道数。
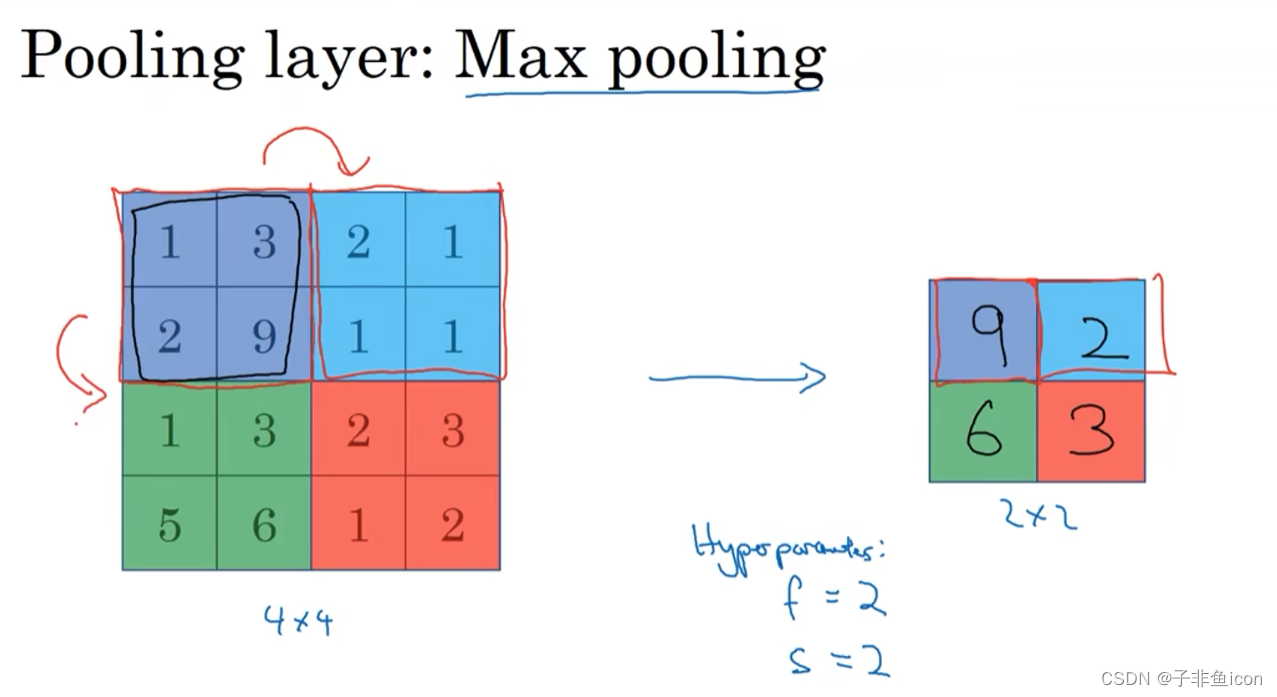
三、池化层
最大池化

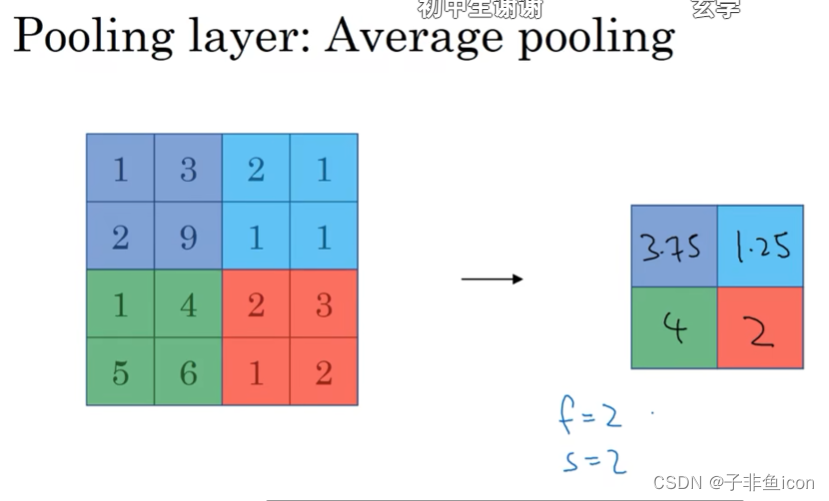
平均池化


四、为什么使用卷积
1.参数共享。


2.稀疏连接。


五、两个重要课后题





六、第一周课后作业
使用Pytorch来实现卷积神经网络,然后应用到手势识别中
代码:
import h5py
import time
import torch
import numpy as np
import torch.nn as nn
import matplotlib.pyplot as plt#import cnn_utilsdevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 加载数据集
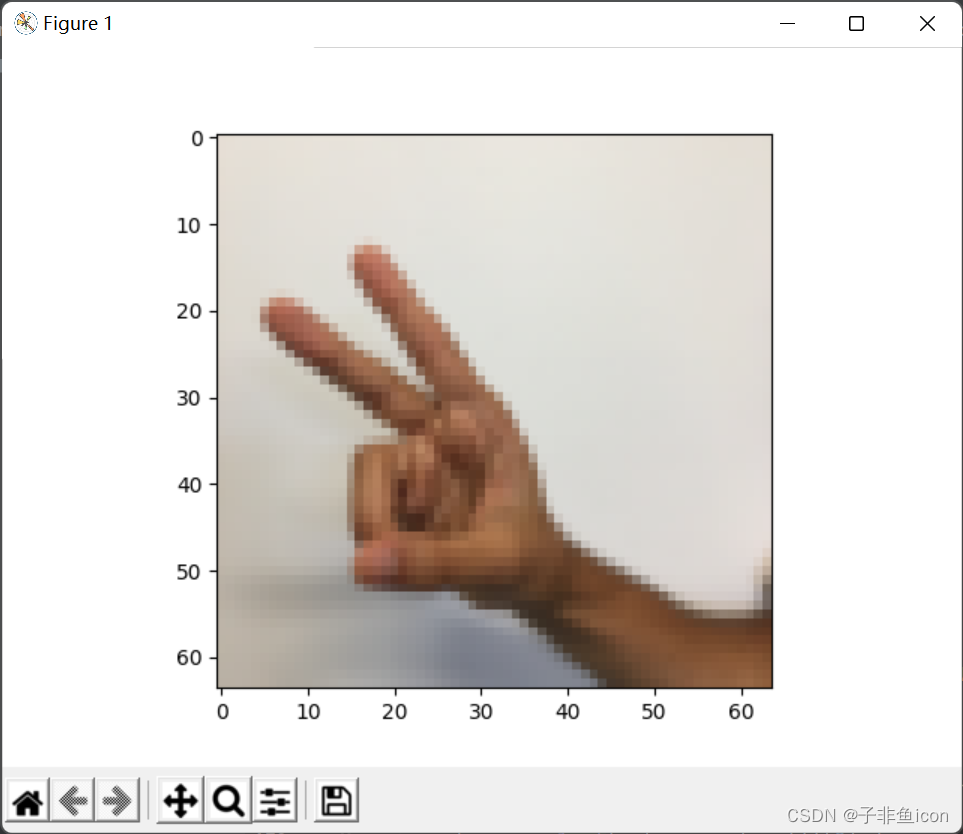
def load_dataset():train_dataset = h5py.File('datasets/train_signs.h5', "r")train_set_x_orig = np.array(train_dataset["train_set_x"][:]) # your train set featurestrain_set_y_orig = np.array(train_dataset["train_set_y"][:]) # your train set labelstest_dataset = h5py.File('datasets/test_signs.h5', "r")test_set_x_orig = np.array(test_dataset["test_set_x"][:]) # your test set featurestest_set_y_orig = np.array(test_dataset["test_set_y"][:]) # your test set labelsclasses = np.array(test_dataset["list_classes"][:]) # the list of classestrain_set_y_orig = train_set_y_orig.reshape((train_set_y_orig.shape[0], 1))test_set_y_orig = test_set_y_orig.reshape((test_set_y_orig.shape[0], 1))return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classesX_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()print(X_train_orig.shape) # (1080, 64, 64, 3),训练集1080张,图像大小是64*64
print(Y_train_orig.shape) # (1080, 1)
print(X_test_orig.shape) # (120, 64, 64, 3),测试集120张
print(Y_test_orig.shape) # (120, 1)
print(classes.shape) # (6,) 一共6种类别,0,1,2,3,4,5index = 6
plt.imshow(X_train_orig[index])
print ("y = " + str(np.squeeze(Y_train_orig[index,:])))
plt.show()# 把尺寸(H x W x C)转为(C x H x W) ,即通道在最前面;归一化数据集
X_train = np.transpose(X_train_orig, (0, 3, 1, 2))/255 # 将维度转为(1080, 3, 64, 64)
X_test = np.transpose(X_test_orig, (0, 3, 1, 2))/255 # 将维度转为(120, 3, 64, 64)
Y_train = Y_train_orig
Y_test = Y_test_orig# 转成Tensor方便后面的训练
X_train = torch.tensor(X_train, dtype=torch.float)
X_test = torch.tensor(X_test, dtype=torch.float)
Y_train = torch.tensor(Y_train, dtype=torch.float)
Y_test = torch.tensor(Y_test, dtype=torch.float)print(X_train.shape)
print(X_test.shape)
print(Y_train.shape)
print(Y_test.shape)# 使用交叉熵损失函数不用转化为独热编码
# LeNet模型
class ConvNet(nn.Module):def __init__(self):super(ConvNet, self).__init__()self.conv = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=8, kernel_size=4, padding=1, stride=1), # in_channels, out_channels, kernel_size 二维卷积nn.ReLU(),nn.MaxPool2d(kernel_size=8, stride=8, padding=4), # kernel_size=2, stride=2;原函数就是'kernel_size', 'stride', 'padding'的顺序nn.Conv2d(8, 16, 2, 1, 1),nn.ReLU(),nn.MaxPool2d(kernel_size=4, stride=4, padding=2))self.fc = nn.Sequential(nn.Linear(16*3*3, 6), # 16*3*3 向量长度为通道、高和宽的乘积nn.Softmax(dim=1))def forward(self, img):feature = self.conv(img)output = self.fc(feature.reshape(img.shape[0], -1)) # 全连接层块会将小批量中每个样本变平return outputnet = ConvNet()
print(net)# 定义损失函数
loss = nn.CrossEntropyLoss()# 训练模型
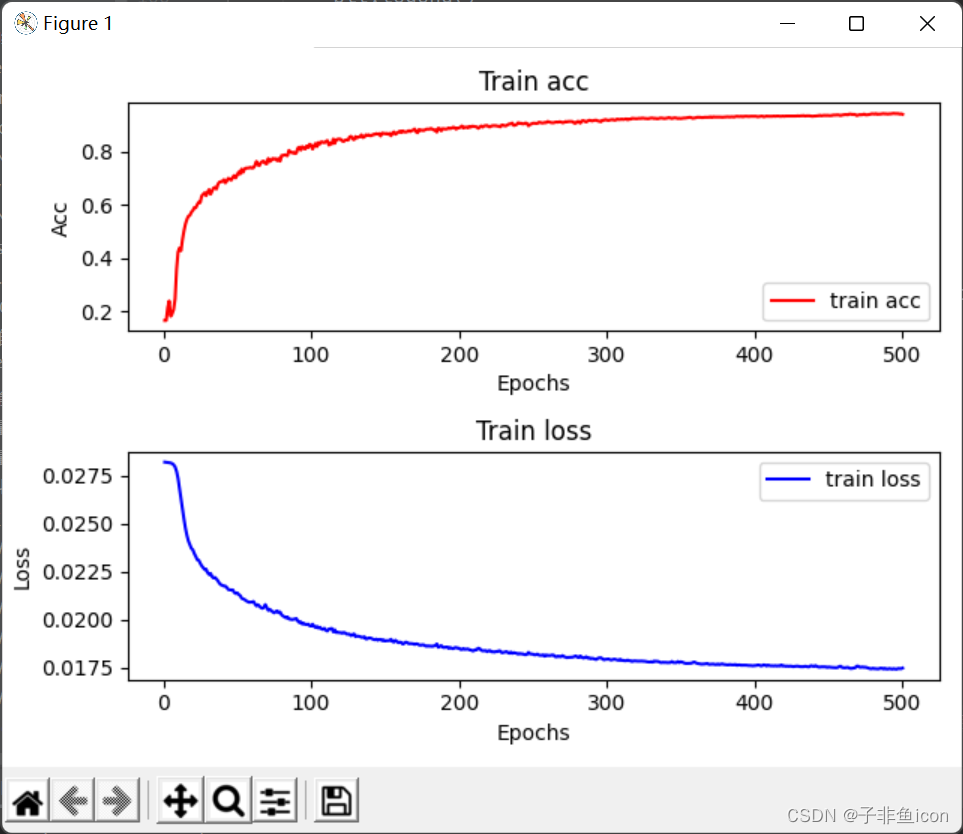
def model(net, X_train, Y_train, device, lr=0.001, batch_size=32, num_epochs=1500, print_loss=True, is_plot=True):net = net.to(device)print("training on ", device)# 定义优化器optimizer = torch.optim.Adam(net.parameters(), lr=lr, betas=(0.9, 0.999))# 将训练数据的特征和标签组合dataset = torch.utils.data.TensorDataset(X_train, Y_train)train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True)train_l_list, train_acc_list = [], []for epoch in range(num_epochs):train_l_sum, train_acc_sum, n = 0.0, 0.0, 0for X, y in train_iter:X = X.to(device)y = y.to(device)y_hat = net(X)y = y.squeeze(1).long() # .squeeze()用来将[batch_size,1]降维至[batch_size],.long用来将floatTensor转化为LongTensor,loss函数对类型有要求l = loss(y_hat, y).sum()# print(y.shape,y_hat.shape)# print(l)# 梯度清零optimizer.zero_grad()l.backward()optimizer.step()train_l_sum += l.item()train_acc_sum += (y_hat.argmax(dim=1) == y).sum().item()# print(y_hat.argmax(dim=1).shape,y.shape)n += y.shape[0]train_l_list.append(train_l_sum / n)train_acc_list.append(train_acc_sum / n)if print_loss and ((epoch + 1) % 10 == 0):print('epoch %d, loss %.4f, train acc %.3f' % (epoch + 1, train_l_sum / n, train_acc_sum / n))# 画图展示if is_plot:epochs_list = range(1, num_epochs + 1)plt.subplot(211)plt.plot(epochs_list, train_acc_list, label='train acc', color='r')plt.title('Train acc')plt.xlabel('Epochs')plt.ylabel('Acc')plt.tight_layout()plt.legend()plt.subplot(212)plt.plot(epochs_list, train_l_list, label='train loss', color='b')plt.title('Train loss')plt.xlabel('Epochs')plt.ylabel('Loss')plt.tight_layout()plt.legend()plt.show()return train_l_list, train_acc_list#开始时间
start_time = time.clock()
#开始训练
train_l_list, train_acc_list = model(net, X_train, Y_train, device, lr=0.0009, batch_size=64, num_epochs=500, print_loss=True, is_plot=True)
#结束时间
end_time = time.clock()
#计算时差
print("CPU的执行时间 = " + str(end_time - start_time) + " 秒" )#计算分类准确率
def evaluate_accuracy(X_test, Y_test, net, device=None):if device is None and isinstance(net, torch.nn.Module):# 如果没指定device就使用net的devicedevice = list(net.parameters())[0].device # 未指定的话,就是cpuX_test = X_test.to(device)Y_test = Y_test.to(device)acc = (net(X_test).argmax(dim=1) == Y_test.squeeze()).sum().item()acc = acc / X_test.shape[0]return accaccuracy_train = evaluate_accuracy(X_train, Y_train, net)
print("训练集的准确率:", accuracy_train)accuracy_test = evaluate_accuracy(X_test, Y_test, net)
print("测试集的准确率:", accuracy_test)
输出:
(1080, 64, 64, 3)
(1080, 1)
(120, 64, 64, 3)
(120, 1)
(6,)
y = 2
torch.Size([1080, 3, 64, 64])
torch.Size([120, 3, 64, 64])
torch.Size([1080, 1])
torch.Size([120, 1])
ConvNet((conv): Sequential((0): Conv2d(3, 8, kernel_size=(4, 4), stride=(1, 1), padding=(1, 1))(1): ReLU()(2): MaxPool2d(kernel_size=8, stride=8, padding=4, dilation=1, ceil_mode=False)(3): Conv2d(8, 16, kernel_size=(2, 2), stride=(1, 1), padding=(1, 1))(4): ReLU()(5): MaxPool2d(kernel_size=4, stride=4, padding=2, dilation=1, ceil_mode=False))(fc): Sequential((0): Linear(in_features=144, out_features=6, bias=True)(1): Softmax(dim=1))
)
training on cuda
epoch 10, loss 0.0274, train acc 0.423
epoch 20, loss 0.0236, train acc 0.580
epoch 30, loss 0.0224, train acc 0.649
epoch 40, loss 0.0218, train acc 0.689
epoch 50, loss 0.0214, train acc 0.713
epoch 60, loss 0.0209, train acc 0.739
epoch 70, loss 0.0206, train acc 0.755
epoch 80, loss 0.0202, train acc 0.786
epoch 90, loss 0.0201, train acc 0.795
epoch 100, loss 0.0197, train acc 0.825
epoch 110, loss 0.0194, train acc 0.839
epoch 120, loss 0.0193, train acc 0.847
epoch 130, loss 0.0191, train acc 0.857
epoch 140, loss 0.0190, train acc 0.860
epoch 150, loss 0.0189, train acc 0.868
epoch 160, loss 0.0188, train acc 0.878
epoch 170, loss 0.0187, train acc 0.886
epoch 180, loss 0.0186, train acc 0.885
epoch 190, loss 0.0185, train acc 0.886
epoch 200, loss 0.0185, train acc 0.890
epoch 210, loss 0.0184, train acc 0.895
epoch 220, loss 0.0184, train acc 0.894
epoch 230, loss 0.0183, train acc 0.900
epoch 240, loss 0.0182, train acc 0.909
epoch 250, loss 0.0182, train acc 0.907
epoch 260, loss 0.0181, train acc 0.914
epoch 270, loss 0.0181, train acc 0.909
epoch 280, loss 0.0180, train acc 0.914
epoch 290, loss 0.0180, train acc 0.916
epoch 300, loss 0.0179, train acc 0.919
epoch 310, loss 0.0179, train acc 0.923
epoch 320, loss 0.0178, train acc 0.924
epoch 330, loss 0.0178, train acc 0.927
epoch 340, loss 0.0178, train acc 0.926
epoch 350, loss 0.0178, train acc 0.925
epoch 360, loss 0.0177, train acc 0.928
epoch 370, loss 0.0177, train acc 0.931
epoch 380, loss 0.0176, train acc 0.931
epoch 390, loss 0.0176, train acc 0.932
epoch 400, loss 0.0176, train acc 0.933
epoch 410, loss 0.0176, train acc 0.933
epoch 420, loss 0.0176, train acc 0.933
epoch 430, loss 0.0176, train acc 0.934
epoch 440, loss 0.0175, train acc 0.934
epoch 450, loss 0.0175, train acc 0.936
epoch 460, loss 0.0175, train acc 0.939
epoch 470, loss 0.0176, train acc 0.938
epoch 480, loss 0.0175, train acc 0.943
epoch 490, loss 0.0174, train acc 0.942
epoch 500, loss 0.0175, train acc 0.941
CPU的执行时间 = 67.5224961 秒
训练集的准确率: 0.9425925925925925
测试集的准确率: 0.8333333333333334七、经典网络
LeNet:
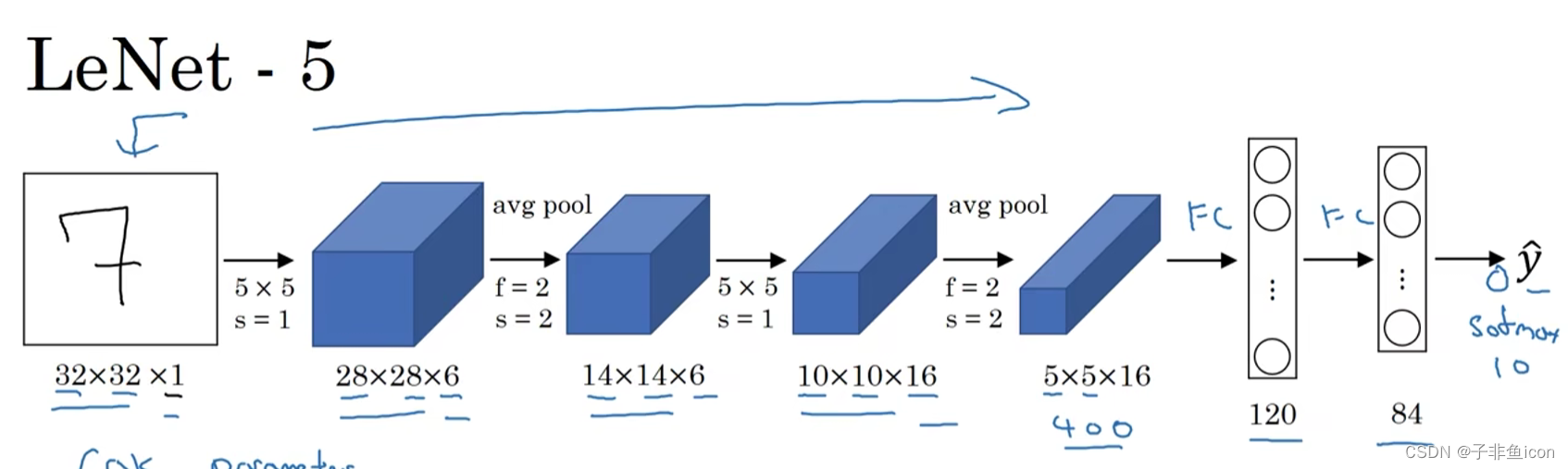
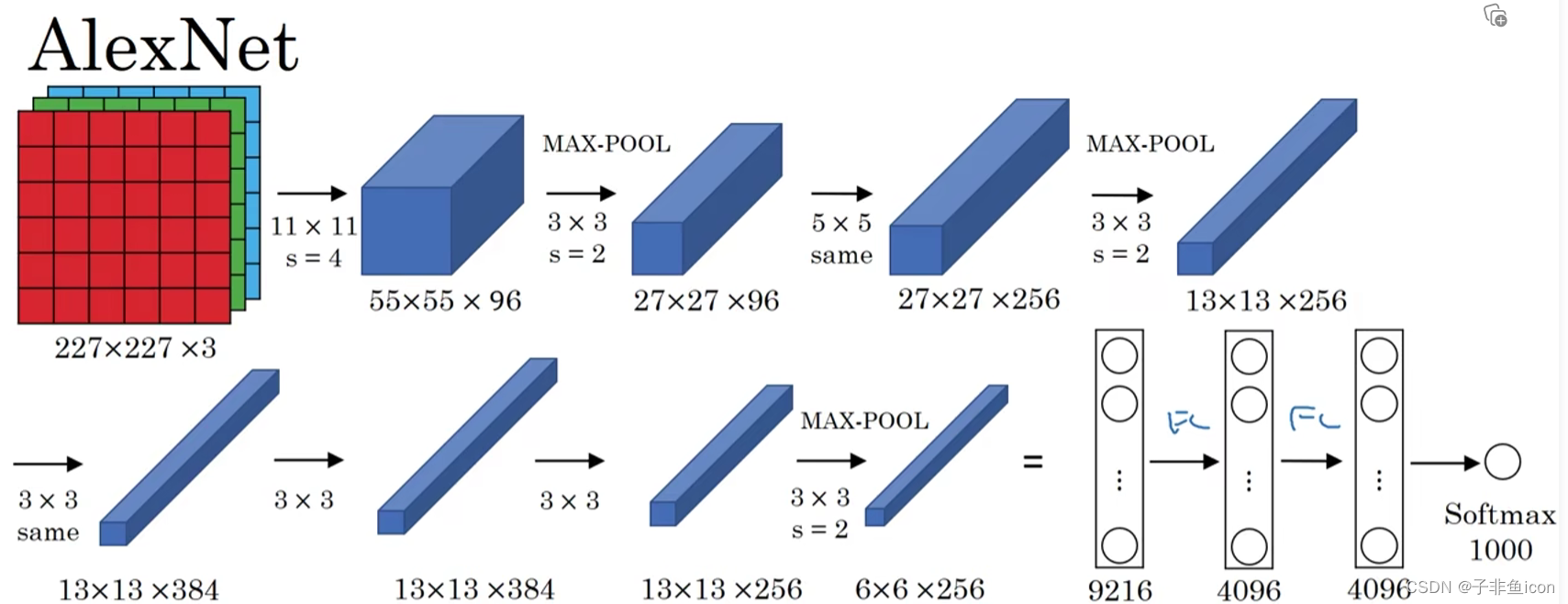
AlexNet
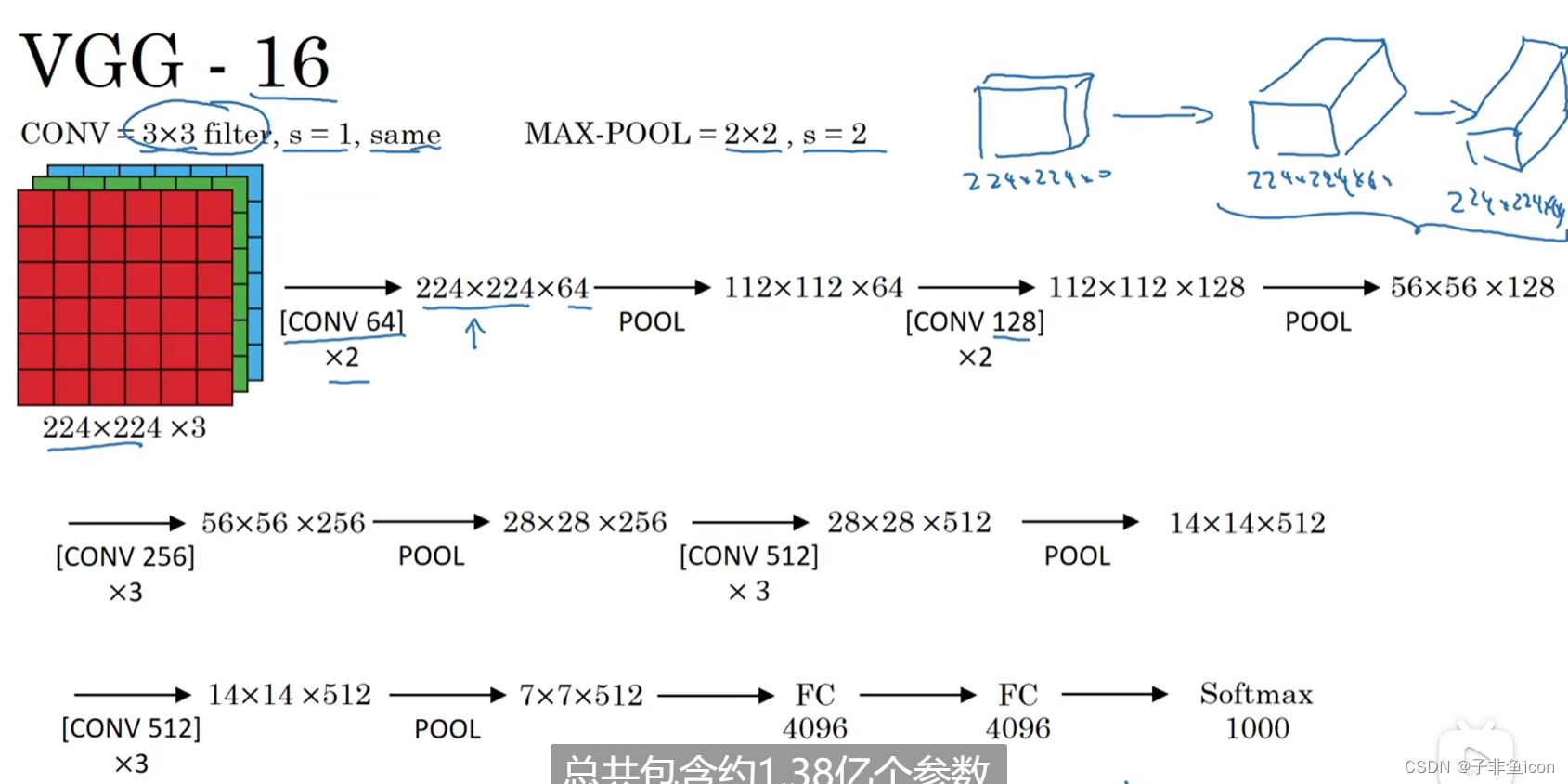
VGG-16
八、残差网络
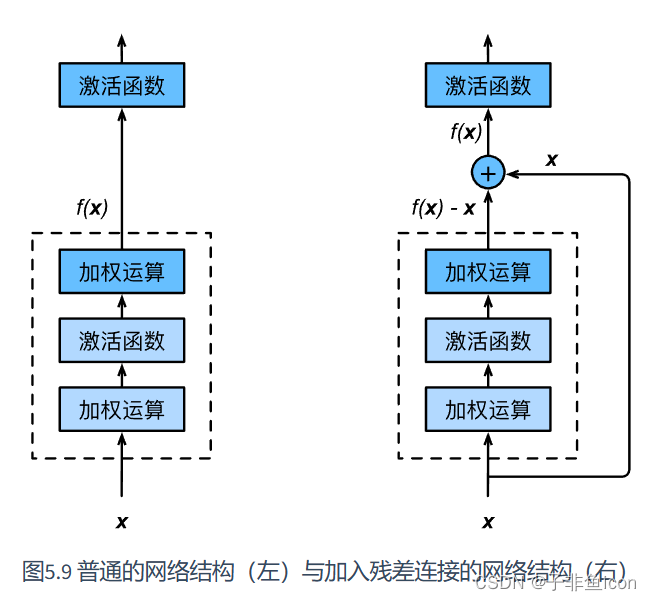
残差网络起作用的主要原因是:这些残差块学习恒等函数非常容易,能确定网络性能不会受到影响,很多时候甚至可以提高效率,或者说至少不会降低网络的效率,因此,创建类似残差网络可以提升网络性能。
九、1×1卷积(Network in Network)
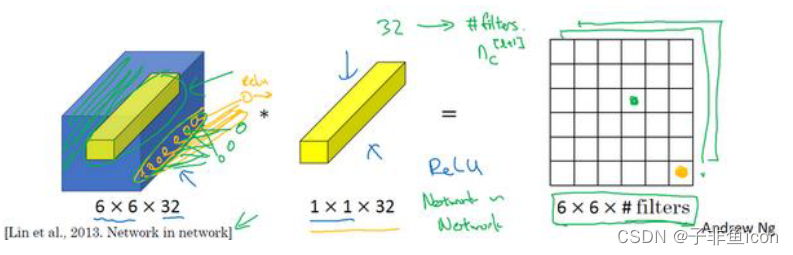
这个1x1×32过滤器中的32个数字可以这样理解,一个神经元的输入是32个数字(输入图片中左下角位置32个通道中的数字),即相同高度和宽度上某一切片上的32个数字,这32个数字具有不同通道,乘以32个权重(将过滤器中的32个数理解为权重),然后应用ReLU非线性函数,输出相应的结果。

1×1卷积压缩信道数量并减少计算
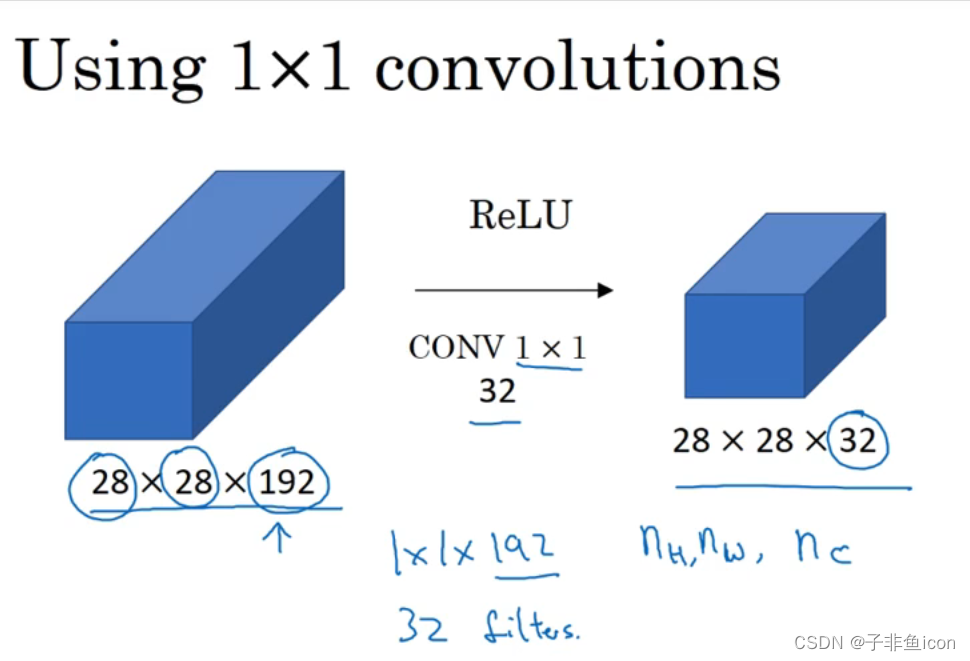
1x1卷积层就是这样实现了一些重要功能的(doing something pretty non-trivial),它给神经网络添加了一个非线性函数,从而减少或保持输入层中的通道数量不变,当然如果你愿意,也可以增加通道数量。
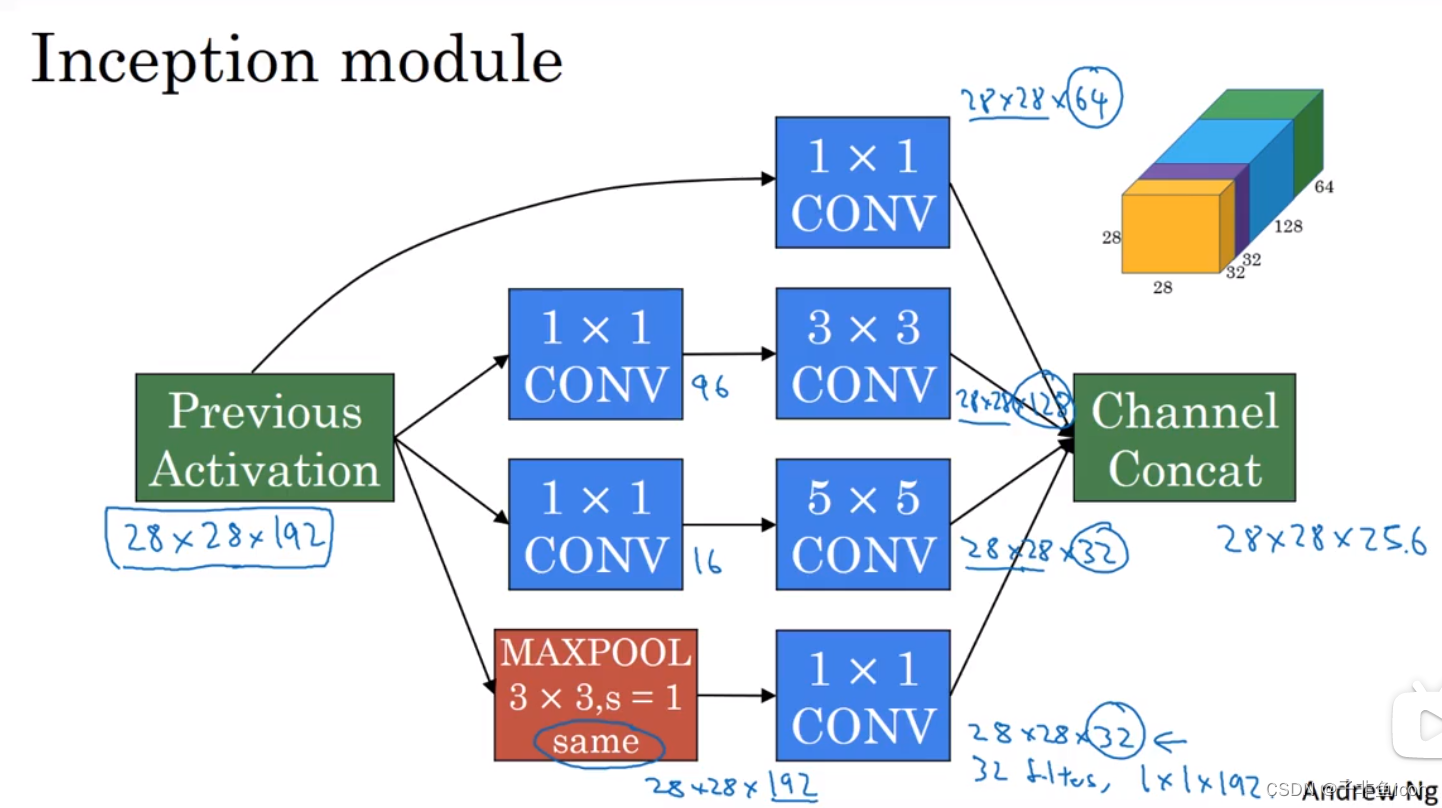
十、谷歌Inception网络
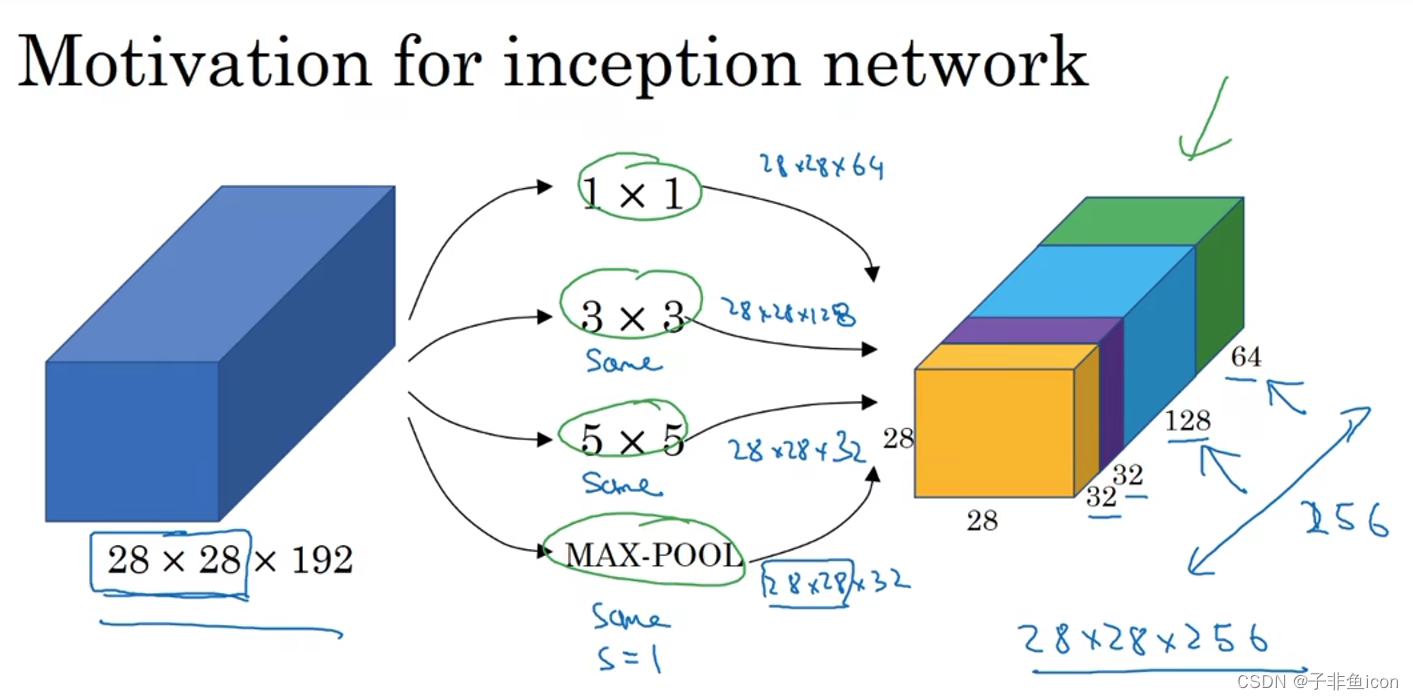
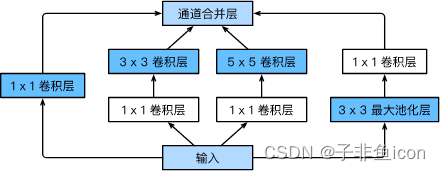
Inception块里有4条并行的线路。前3条线路使用窗口大小分别是1×1、3×3和5×5的卷积层来抽取不同空间尺寸下的信息,其中中间2个线路会对输入先做1×1卷积来减少输入通道数,以降低模型复杂度。第四条线路则使用3×3最大池化层,后接1×1卷积层来改变通道数。4条线路都使用了合适的填充来使输入与输出的高和宽一致。最后我们将每条线路的输出在通道维上连结,并输入接下来的层中去。
十一、迁移学习
如果你有大量数据,你应该做的就是用开源的网络和它的权重,把这、所有的仪重当作初始化,然后训练整个网络。再次注意,如果这是一个1000节点的softmax,而你只有三个输出,你需要你自己的softmax输出层来输出你要的标签。
如果你有越多的标定的数据,可以训练越多的层。极端情况下,你可以用下载的权重只作为初始化,用它们来代替随机初始化,接着你可以用梯度下降训练,更新网络所有层的所有权重。
十二、第二周重要课后作业

编程作业:
参考链接:https://blog.csdn.net/u013733326/article/details/80250818
笑脸识别
下一次放假的时候,你决定和你的五个朋友一起度过一个星期。这是一个非常好的房子,在附近有很多事情要做,但最重要的好处是每个人在家里都会感到快乐,所以任何想进入房子的人都必须证明他们目前的幸福状态。
作为一个深度学习的专家,为了确保“快乐才开门”规则得到严格的应用,你将建立一个算法,它使用来自前门摄像头的图片来检查这个人是否快乐,只有在人高兴的时候,门才会打开。

你收集了你的朋友和你自己的照片,被前门的摄像头拍了下来。数据集已经标记好了。

代码:
import h5py
import time
import torch
import numpy as np
import torch.nn as nn
import matplotlib.pyplot as pltdevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 加载数据集
def load_dataset():train_dataset = h5py.File('datasets/train_happy.h5', "r")train_set_x_orig = np.array(train_dataset["train_set_x"][:]) # your train set featurestrain_set_y_orig = np.array(train_dataset["train_set_y"][:]) # your train set labelstest_dataset = h5py.File('datasets/test_happy.h5', "r")test_set_x_orig = np.array(test_dataset["test_set_x"][:]) # your test set featurestest_set_y_orig = np.array(test_dataset["test_set_y"][:]) # your test set labelsclasses = np.array(test_dataset["list_classes"][:]) # the list of classestrain_set_y_orig = train_set_y_orig.reshape((train_set_y_orig.shape[0], 1))test_set_y_orig = test_set_y_orig.reshape((test_set_y_orig.shape[0], 1))return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classesX_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()print(X_train_orig.shape) # (600, 64, 64, 3),训练集600张,图像大小是64*64
print(Y_train_orig.shape) # (600, 1)
print(X_test_orig.shape) # (150, 64, 64, 3),测试集150张
print(Y_test_orig.shape) # (150, 1)
print(classes.shape) # (2,) 一共2种类别,0:not happy; 1:happyindex = 5
plt.imshow(X_train_orig[index])
print ("y = " + str(np.squeeze(Y_train_orig[index,:])))
#plt.show()# 把尺寸(H x W x C)转为(C x H x W) ,即通道在最前面;归一化数据集
X_train = np.transpose(X_train_orig, (0, 3, 1, 2))/255 # 将维度转为(600, 3, 64, 64)
X_test = np.transpose(X_test_orig, (0, 3, 1, 2))/255 # 将维度转为(150, 3, 64, 64)
Y_train = Y_train_orig
Y_test = Y_test_orig# 转成Tensor方便后面的训练(不然会数据类型报错)
X_train = torch.tensor(X_train, dtype=torch.float)
X_test = torch.tensor(X_test, dtype=torch.float)
Y_train = torch.tensor(Y_train, dtype=torch.float)
Y_test = torch.tensor(Y_test, dtype=torch.float)print(X_train.shape)
print(X_test.shape)
print(Y_train.shape)
print(Y_test.shape)# 构建网络结构(包含BN)
class ConvNet(nn.Module):def __init__(self):super(ConvNet, self).__init__()self.conv = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=32, kernel_size=7, padding=3, stride=1), # in_channels, out_channels, kernel_size 二维卷积nn.BatchNorm2d(32), # 对输出按通道C批量规范化;γ和β可学习nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2), # kernel_size=2, stride=2;原函数就是'kernel_size', 'stride', 'padding'的顺序)self.fc = nn.Sequential(nn.Linear(32*32*32, 1), # 16*3*3 向量长度为通道、高和宽的乘积nn.Sigmoid() # S要大写;区别于torch.sigmoid())def forward(self, img):feature = self.conv(img)output = self.fc(feature.reshape(img.shape[0], -1)) # 全连接层块会将小批量中每个样本变平return outputnet = ConvNet()
print(net)# 定义损失函数
#loss = nn.MSELoss()
loss = nn.BCELoss(reduction = 'sum') # 0,1的交叉损失熵;返回loss的和# 训练模型
def model(net, X_train, Y_train, device, lr=0.001, batch_size=32, num_epochs=1500, print_loss=True, is_plot=True):net = net.to(device)print("training on ", device)# 定义优化器optimizer = torch.optim.Adam(net.parameters(), lr=lr, betas=(0.9, 0.999))# 将训练数据的特征和标签组合dataset = torch.utils.data.TensorDataset(X_train, Y_train)train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True)train_l_list, train_acc_list = [], []for epoch in range(num_epochs):train_l_sum, train_acc_sum, n = 0.0, 0.0, 0for X, y in train_iter:X = X.to(device)y = y.to(device)y_hat = net(X)#.squeeze(-1)## 交叉熵损失函数中需要 .squeeze()用来将[batch_size,1]降维至[batch_size],.long用来将floatTensor转化为LongTensor,loss函数对类型有要求l = loss(y_hat, y) #.sum()# print(y.shape,y_hat.shape)# print(l)# 梯度清零optimizer.zero_grad()l.backward()optimizer.step()train_l_sum += l.item()train_acc_sum += (torch.round(y_hat) == y).sum().item()# print(y_hat.argmax(dim=1).shape,y.shape)n += y.shape[0]train_l_list.append(train_l_sum / n)train_acc_list.append(train_acc_sum / n)if print_loss and ((epoch + 1) % 10 == 0):print('epoch %d, loss %.4f, train acc %.3f' % (epoch + 1, train_l_sum / n, train_acc_sum / n))# 画图展示if is_plot:epochs_list = range(1, num_epochs + 1)plt.subplot(211)plt.plot(epochs_list, train_acc_list, label='train acc', color='r')plt.title('Train acc')plt.xlabel('Epochs')plt.ylabel('Acc')plt.tight_layout()plt.legend()plt.subplot(212)plt.plot(epochs_list, train_l_list, label='train loss', color='b')plt.title('Train loss')plt.xlabel('Epochs')plt.ylabel('Loss')plt.tight_layout()plt.legend()plt.show()return train_l_list, train_acc_list#开始时间
start_time = time.clock()
#开始训练
train_l_list, train_acc_list = model(net, X_train, Y_train, device, lr=0.0009, batch_size=64, num_epochs=100, print_loss=True, is_plot=True)
#结束时间
end_time = time.clock()
#计算时差
print("CPU的执行时间 = " + str(end_time - start_time) + " 秒" )#计算分类准确率
def evaluate_accuracy(X_test, Y_test, net, device=None):if device is None and isinstance(net, torch.nn.Module):# 如果没指定device就使用net的devicedevice = list(net.parameters())[0].device # 未指定的话,就是cpuX_test = X_test.to(device)Y_test = Y_test.to(device)#print(net(X_test).shape,Y_test.shape)acc = (torch.round(net(X_test)) == Y_test).sum().item()acc = acc / X_test.shape[0]return accaccuracy_train = evaluate_accuracy(X_train, Y_train, net)
print("训练集的准确率:", accuracy_train)accuracy_test = evaluate_accuracy(X_test, Y_test, net)
print("测试集的准确率:", accuracy_test)
结果:
D:\Anaconda3\envs\pytorch\python.exe "D:/PyCharm files/deep learning/吴恩达/L4W2/L4W2_TRY.py"
(600, 64, 64, 3)
(600, 1)
(150, 64, 64, 3)
(150, 1)
(2,)
y = 1
torch.Size([600, 3, 64, 64])
torch.Size([150, 3, 64, 64])
torch.Size([600, 1])
torch.Size([150, 1])
ConvNet((conv): Sequential((0): Conv2d(3, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU()(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(fc): Sequential((0): Linear(in_features=32768, out_features=1, bias=True)(1): Sigmoid())
)
training on cuda
epoch 10, loss 0.0950, train acc 0.973
epoch 20, loss 0.0580, train acc 0.982
epoch 30, loss 0.0935, train acc 0.962
epoch 40, loss 0.0150, train acc 0.997
epoch 50, loss 0.0082, train acc 1.000
epoch 60, loss 0.0056, train acc 1.000
epoch 70, loss 0.0073, train acc 1.000
epoch 80, loss 0.0030, train acc 1.000
epoch 90, loss 0.0088, train acc 0.998
epoch 100, loss 0.0024, train acc 1.000
CPU的执行时间 = 40.573377799999996 秒
训练集的准确率: 1.0
测试集的准确率: 0.98
发现跟参考链接一样,很快就达到了较高的准确率。
相关文章:
吴恩达深度学习笔记(八)——卷积神经网络(上)
一、卷积相关 用一个ff的过滤器卷积一个nn的图像,假如padding为p,步幅为s,输出大小则为: [n2p−fs1][n2p−fs1][\frac{n2p-f}{s}1][\frac{n2p-f}{s}1][sn2p−f1][sn2p−f1] []表示向下取整(floor) 大部分深度学习…...
14 基数排序(桶排序)
文章目录1 基数排序基本思想2 基数排序的代码实现2.1 java2.2 scala3 基数排序总结1 基数排序基本思想 1) 基数排序(radix sort)属于“分配式排序”(distribution sort),又称“桶子法”(bucket sort&#…...

汉明距离Java解法
两个整数之间的 汉明距离 指的是这两个数字对应二进制位不同的位置的数目。 给你两个整数 x 和 y,计算并返回它们之间的汉明距离。 例: 输入:x 1, y 4 输出:2 解释: 1 (0 0 0 1) 4 (0 1 0 0) ↑ ↑ 上…...
Netty服务端请求接受过程源码剖析
目标 服务器启动后,客户端进行连接,服务器端此时要接受客户端请求,并且返回给客户端想要的请求,下面我们的目标就是分析Netty 服务器端启动后是怎么接受到客户端请求的。我们的代码依然与上一篇中用同一个demo, 用io.…...

金三银四春招特供|高质量面试攻略
🔰 全文字数 : 1万5千 🕒 阅读时长 : 20min 📋 关键词 : 求职规划、面试准备、面试技巧、谈薪职级 👉 公众号 : 大摩羯先生 本篇来聊聊一个老生常谈的话题————“面试”。利用近三周工作午休时间整理了这篇洋洋洒洒却饱含真诚…...
搭建Hexo博客-第4章-绑定自定义域名
搭建Hexo博客-第4章-绑定自定义域名 搭建Hexo博客-第4章-绑定自定义域名 搭建Hexo博客-第4章-绑定自定义域名 在这一篇文章中,我将会介绍如何给博客绑定你自己的域名。其实绑定域名本应该很简单的,但我当初在这上走了不少弯路,所以我觉得有…...

lightdb-sql拦截
文章目录LightDB - sql 审核拦截一 简介二 参数2.1 lightdb_sql_mode2.2 lt_firewall.lightdb_business_time三 规则介绍及使用3.1 select_without_where3.1.1 案例3.2 update_without_where/delete_without_where3.2.1 案例3.3 high_risk_ddl3.3.1 案例LightDB - sql 审核拦截…...
二进制中1的个数-剑指Offer-java位运算
一、题目描述编写一个函数,输入是一个无符号整数(以二进制串的形式),返回其二进制表达式中数字位数为 1 的个数(也被称为 汉明重量).)。提示:请注意,在某些语言(如 Java&…...

学自动化测试可以用这几个练手项目
练手项目的业务逻辑比较简单,只适合练手,不能代替真实项目。 学习自动化测试最难的是没有合适的项目练习。 测试本身既要讲究科学,又有艺术成分,单单学几个 api 的调用很难应付工作中具体的问题。 你得知道什么场景下需要添加显…...
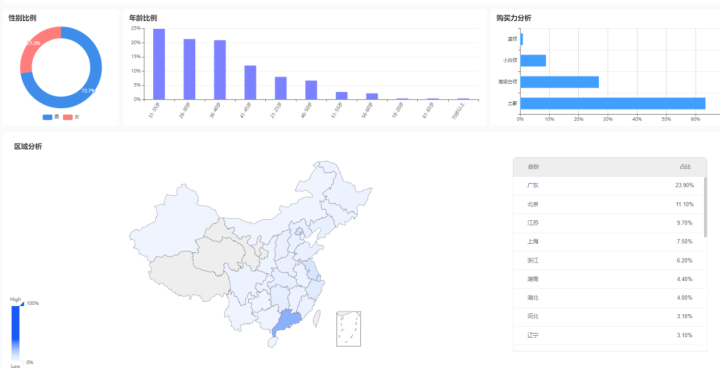
2023年保健饮品行业分析:市场规模不断攀升,年度销额增长近140%
随着人们健康意识的不断增强,我国保健品市场需求持续增长,同时,保健饮品的市场规模也在不断攀升。 根据鲸参谋电商数据显示,2022年度,京东平台上保健饮品的年度销量超60万件,同比增长了约124%;该…...

2023-02-17 学习记录--TS-邂逅TS(一)
TS-邂逅TS(一) 不积跬步,无以至千里;不积小流,无以成江海。💪🏻 一、TypeScript在线编译器 https://www.typescriptlang.org/play/ 二、类型 1、普通类型 number(数值型ÿ…...
SpringMVC创建异步回调请求的4种方式
首先要明确一点,同步请求和异步请求对于客户端用户来讲是一样的,都是需客户端等待返回结果。不同之处在于请求到达服务器之后的处理方式,下面用两张图解释一下同步请求和异步请求在服务端处理方式的不同:同步请求异步请求两个流程…...
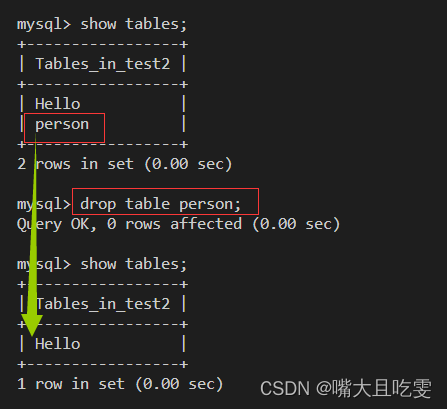
MySQL(二)表的操作
一、创建表 CREATE TABLE table_name ( field1 datatype, field2 datatype, field3 datatype ) character set 字符集 collate 校验规则 engine 存储引擎; 说明: field 表示列名 datatype 表示列的类型 character set 字符集,如…...
SpringCloud - 入门
目录 服务架构演变 单体架构 分布式架构 分布式架构要考虑的问题 微服务 初步认识 案例Demo 服务拆分注意事项 服务拆分示例 服务调用 服务架构演变 单体架构 将业务的所有功能集中在一个项目中开发,打成一个包部署优点: 架构简单部署成本低缺…...

进一步了解C++函数的各种参数以及重载,了解C++部分的内存模型,C++独特的引用方式,巧妙替换指针,初步了解类与对象。满满的知识,希望大家能多多支持
C的编程精华,走过路过千万不要错过啊!废话少说,我们直接进入正题!!!! 函数高级 C的函数提高 函数默认参数 在C中,函数的形参列表中的形参是可以有默认值的。 语法:返…...
Chapter6:机器人SLAM与自主导航
ROS1{\rm ROS1}ROS1的基础及应用,基于古月的课,各位可以去看,基于hawkbot{\rm hawkbot}hawkbot机器人进行实际操作。 ROS{\rm ROS}ROS版本:ROS1{\rm ROS1}ROS1的Melodic{\rm Melodic}Melodic;实际机器人:Ha…...

Sass的使用要点
Sass 是一个 CSS 预处理器,完全兼容所有版本的 CSS。实际上,Sass 并没有真正为 CSS 语言添加任何新功能。只是在许多情况下可以可以帮助我们减少 CSS 重复的代码,节省开发时间。 一、注释 方式一:双斜线 // 方式二:…...

计算机启动过程,从按下电源按钮到登录界面的详细步骤
1、背景 自接触计算机以来,一直困扰着我一个问题。当我们按下电脑的开机键后,具体发生了哪些过程呢?计算机启动的具体步骤是什么? 计算机启动过程通常分为五个步骤:电源自检、BIOS自检、引导设备选择、引导程序加载和…...
LeetCode 刷题之 BFS 广度优先搜索【Python实现】
1. BFS 算法框架 BFS:用来搜索 最短路径 比较合适,如:求二叉树最小深度、最少步数、最少交换次数,一般与 队列 搭配使用,空间复杂度比 DFS 大很多DFS:适合搜索全部的解,如:寻找最短…...
Hadoop01【尚硅谷】
大数据学习笔记 大数据概念 大数据:指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。 主要解决,海量数据的存储…...

LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器的上位机配置操作说明
LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器专为工业环境精心打造,完美适配AGV和无人叉车。同时,集成以太网与语音合成技术,为各类高级系统(如MES、调度系统、库位管理、立库等)提供高效便捷的语音交互体验。 L…...

Vue3 + Element Plus + TypeScript中el-transfer穿梭框组件使用详解及示例
使用详解 Element Plus 的 el-transfer 组件是一个强大的穿梭框组件,常用于在两个集合之间进行数据转移,如权限分配、数据选择等场景。下面我将详细介绍其用法并提供一个完整示例。 核心特性与用法 基本属性 v-model:绑定右侧列表的值&…...

可靠性+灵活性:电力载波技术在楼宇自控中的核心价值
可靠性灵活性:电力载波技术在楼宇自控中的核心价值 在智能楼宇的自动化控制中,电力载波技术(PLC)凭借其独特的优势,正成为构建高效、稳定、灵活系统的核心解决方案。它利用现有电力线路传输数据,无需额外布…...

AtCoder 第409场初级竞赛 A~E题解
A Conflict 【题目链接】 原题链接:A - Conflict 【考点】 枚举 【题目大意】 找到是否有两人都想要的物品。 【解析】 遍历两端字符串,只有在同时为 o 时输出 Yes 并结束程序,否则输出 No。 【难度】 GESP三级 【代码参考】 #i…...

12.找到字符串中所有字母异位词
🧠 题目解析 题目描述: 给定两个字符串 s 和 p,找出 s 中所有 p 的字母异位词的起始索引。 返回的答案以数组形式表示。 字母异位词定义: 若两个字符串包含的字符种类和出现次数完全相同,顺序无所谓,则互为…...

laravel8+vue3.0+element-plus搭建方法
创建 laravel8 项目 composer create-project --prefer-dist laravel/laravel laravel8 8.* 安装 laravel/ui composer require laravel/ui 修改 package.json 文件 "devDependencies": {"vue/compiler-sfc": "^3.0.7","axios": …...

GO协程(Goroutine)问题总结
在使用Go语言来编写代码时,遇到的一些问题总结一下 [参考文档]:https://www.topgoer.com/%E5%B9%B6%E5%8F%91%E7%BC%96%E7%A8%8B/goroutine.html 1. main()函数默认的Goroutine 场景再现: 今天在看到这个教程的时候,在自己的电…...

基于Java+VUE+MariaDB实现(Web)仿小米商城
仿小米商城 环境安装 nodejs maven JDK11 运行 mvn clean install -DskipTestscd adminmvn spring-boot:runcd ../webmvn spring-boot:runcd ../xiaomi-store-admin-vuenpm installnpm run servecd ../xiaomi-store-vuenpm installnpm run serve 注意:运行前…...

CVPR2025重磅突破:AnomalyAny框架实现单样本生成逼真异常数据,破解视觉检测瓶颈!
本文介绍了一种名为AnomalyAny的创新框架,该方法利用Stable Diffusion的强大生成能力,仅需单个正常样本和文本描述,即可生成逼真且多样化的异常样本,有效解决了视觉异常检测中异常样本稀缺的难题,为工业质检、医疗影像…...

0x-3-Oracle 23 ai-sqlcl 25.1 集成安装-配置和优化
是不是受够了安装了oracle database之后sqlplus的简陋,无法删除无法上下翻页的苦恼。 可以安装readline和rlwrap插件的话,配置.bahs_profile后也能解决上下翻页这些,但是很多生产环境无法安装rpm包。 oracle提供了sqlcl免费许可,…...