通过基于pgsql的timescaleDB的time_bucket函数实现自定义聚合粒度
1、自己写的不完全满足要求的实现方式
with tb_tmp as (select *, //计算该时间距离第一天有多少天((extract(epoch from create_time) /3600/24)::integer) as ct_ifrom test.test_salary
)select min(a.create_time) as create_time,sum(a.salary)
from (select *,//移动数据使得3条数据为一组(ct_i - (select min(ct_i) % 3 from tb_tmp))/3 as circlefrom tb_tmp
) a
group by a.circle
order by create_time;with tb_tmp as (select *, extract (week from age(create_time, '1970-01-01')) as ct_ifrom test.test_salary
)select min(a.create_time) as create_time,sum(a.salary)
from (select *,(ct_i - (select min(ct_i::integer) % 3 from tb_tmp))/3 as circlefrom tb_tmp
) a
group by a.circle
order by create_time;select extract (year from timestamp age('2070-02-01', '1970-01-01'));select age('2070-02-01'::date)//年select *, extract (year from age(create_time, '1970-01-01')) as ct_ifrom test.test_salary;
//月select *, (extract (year from age(create_time, '1970-01-01')) - 1) * 12 + extract(month from create_time) -1 as ct_ifrom test_salary ;//周select *, ((extract(epoch from create_time) /3600/24/7)::integer) as ct_ifrom test_salary;//季度select *, extract (year from age(create_time, '1970-01-01')) * 4 + extract(quarter from create_time) as ct_ifrom test_salary;//日 select *, ((extract(epoch from create_time) /3600/24)::integer) as ct_ifrom test_salary;
2、第二种不完全实现方法,主要通过generate_series方法生成序列加上关联业务表实现自定义分组聚合
with ranges as (select tt.ss, tt.ee from (select the_time as ss, lead(t.the_time, 1) over (order by t.the_time) as ee from (select * from generate_series( '2020-01-01 00:00:00'::timestamp, '2024-01-01 00:00:00'::timestamp, '600 second'::interval) as the_time) t) tt
)
select r.ss,r.ee,department , sum(salary)
from ranges r
left join test.test_salary
t on t.create_time >= r.ss and t.create_time < r.ee
group by r.ss,r.ee,t.department
order by r.ss,r.ee,t.department ;3、通过time_bucket函数实现随意自定义的分组聚合,如n年,n季度,n月,n周,n天,n小时,n分钟,n秒,以及更复杂的每天的几点到几点,每周的周几到周几,每月的几号到本月或下月的几号
1)、按3天聚合,并且从指定的时间开始,默认是按照自然年,自然月,自然周的起始点开始的,如果不需要指定开始时间去掉第三个参数即可
select time_bucket('3 day', create_time, '2020-01-05'::timestamp) as tb,sum(salary) as salary from test.test_salary
where create_time >= '2020-01-05' and create_time <='2020-03-01'
group by tb
order by tb asc2)、实现每天9点到18点分组聚合
select department , create_time , time_bucket('1 day', create_time) + '9 hour' as tb,time_bucket('1 day', create_time) + '18 hour' as tb, salary from test.test_salary
where create_time < '2020-01-10' and extract(epoch from create_time::timestamp::time) >= 32400
and extract(epoch from create_time::timestamp::time) < 64800
order by create_time;3)、实现每周2到周五分组聚合
select time_bucket('1 week', create_time) + '1 day' as tb,time_bucket('1 week', create_time) + '4 day' as tb2 , sum(salary)
from test.test_salary
where create_time >= '2020-01-01' and create_time <='2020-05-01' and extract(dow from create_time::timestamp) >= 2 and extract(dow from create_time::timestamp) <=5
group by tb,tb2
order by tb,tb2 asc4)、实现本月2号到18号分组聚合
select tb1,sum(salary) from (select time_bucket('1 month', create_time)+ '1 day' tb1, create_time, salary from test.test_salarywhere create_time < '2021-01-01' and date_part('day',create_time) >= 2 and date_part('day',create_time) <=18 order by create_time) t
group by tb1;5)、实现本月18号到下月10分组聚合
select tb1,sum(salary) from ((select time_bucket('1 month', create_time) + '17 day' tb1, create_time, salary from test.test_salarywhere create_time < '2021-01-01' and date_part('day',create_time) >= 18 order by create_time)union all(select time_bucket('1 month', create_time) + '-1 month 17 day' tb1, create_time, salary from test.test_salarywhere create_time < '2021-01-01' and date_part('day', create_time) <= 10)order by tb1, create_time asc
) t
group by tb1;4、在我们使用time_bucket方法进行分组聚合获取数据时,我们会发现个问题,可能由于咱们的业务表中的数据并不是每个周期都有数据,比如咱们按月分组,但表中的数据没有2023-02的数据,那查询结果就直接没有2023-02这条数据,但有时我们的业务又需要补齐这条没有的数据,就2023-02的数据虽然是0但必须得有。这个时候另外一个方法就派上用场了。
time_bucket_gapfill:该方法可以补齐没有的数据,但它也有它的局限性,
第一:如果使用该方法,那么时间字段比如有where条件,也就是必须明确数据范围,也很好理解,如果明确,它也不知道该补齐哪些数据;
第二:该方法如果指定第三个参数,也就是指定从哪个时间开始分组的话不生效,比如咱们指定从02-02开始2天一个分组,那么02-02和02-03应该是一个组,02-04和02-05一个组,但这个方法还是会让02-01和02-02一个组不满足业务需求;
第三:该方法不支持增加一个时间间隔(interval),也就是上面sql中用到的time_bucket('1 month', create_time) + '-1 month 17 day'中的 + '-1 month 17 day'。
相关文章:

通过基于pgsql的timescaleDB的time_bucket函数实现自定义聚合粒度
1、自己写的不完全满足要求的实现方式 with tb_tmp as (select *, //计算该时间距离第一天有多少天((extract(epoch from create_time) /3600/24)::integer) as ct_ifrom test.test_salary )select min(a.create_time) as create_time,sum(a.salary) from (select *,//移动数据…...
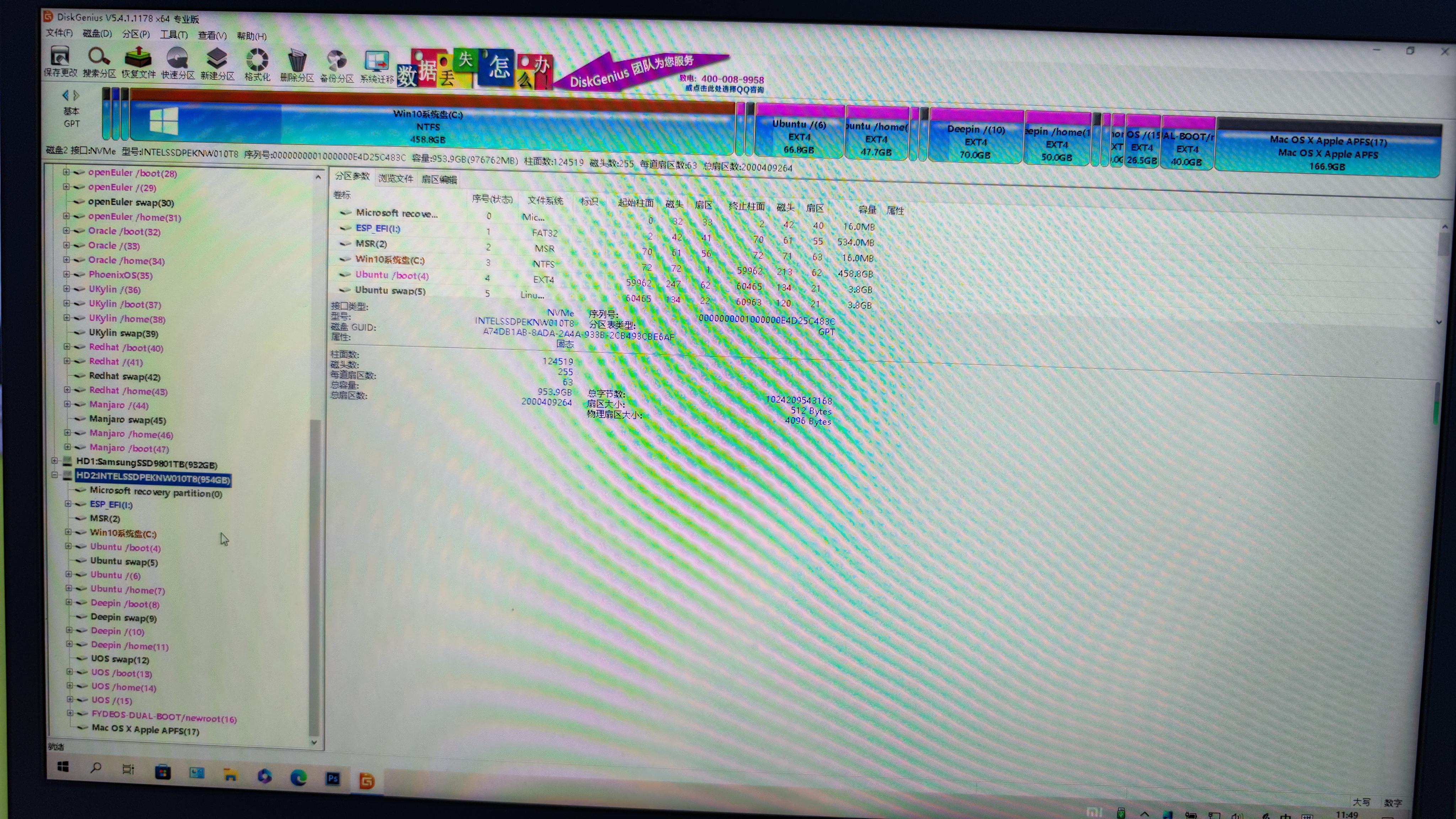
一台电脑安装26个操作系统(windows,macos,linux)
首先看看安装了哪些操作系统1-4: windows系统 四个5.Ubuntu6.deepin7.UOS家庭版8.fydeOS9.macOS10.银河麒麟11.红旗OS12.openSUSE Leap13.openAnolis14.openEuler(未安装桌面UI)15.中标麒麟(NeoKylin)16.centos17.debian Edu18.fedora19.oraclelinux20.R…...

dockerfile文件
dockerfile文件内容 Form ip端口/centos:regular ENV JAVA_HOME /E:/Program Files/Java/jdk1.8.0_351 ENV PATH $JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH ENV LANG en_US.UTF-8 ENV LANGUAGE en_US:en ENV LC_ALL en_US.UTF-8 WORKDIR /opt COPY target/fast.jar /op…...

视觉SLAM ch11回环检测
回环检测的关键:如何有效的检测出相机经过同一个地方。如果成功的检测到可以为后端的位姿图提供更多有效数据,得到全局一致的估计。 回环检测提供了当前数据和所有历史数据的关联,还可以用回环检测进行重定位。 具体方法: 一&am…...
关于Ubuntu20.04文件系统思考
文章目录问题产生Ubuntu文件系统中普通用户可读写地址Ubuntu文件系统Ubuntu文件系统详解一级目录二级目录查找Ubuntu中软件安装位置Ubuntu修改文件权限问题产生 使用electron框架开发桌面端跨平台软件时,当开发完成的程序部署到Ubuntu上,系统无法产生日…...
内嵌于球的等边三棱柱
( A, B )---3*30*2---( 1, 0 )( 0, 1 ) 做一个网络让输入只有3个节点,每个训练集里有两张图片,让B的训练集全为0,排列组合A,观察迭代次数平均值的变化。共完成了64组,但只有12组不同的迭代次数。 差值结构 A-B 迭代次…...
论文解读 | [CVPR2020] ContourNet:向精确的任意形状场景文本检测迈出进一步
目录 1 研究背景和目的 1.1 主要贡献: 1.2 两个挑战: 2 ContourNet 3 方法论 3.1 Adaptive-RPN 3.2 LOTM 3.3 点重定位算法 4 实验和结果 论文地址:ContourNet: Taking a Further Step toward Accurate Arbitrary-shaped Scene Tex…...

干货分享|数据可视化报表制作技巧
脑中想得再好,也要看最终的效果呈现。但偏偏有些用户分析思维不差,就是数据分析报表的制作拖了后腿,导致始终无法完美呈现数据可视化分析效果。本文将总结奥威BI软件上的常用的数据可视化报表制作技巧,供大家随时查阅。 BI数据可…...

Longhorn,企业级云原生容器分布式存储 - 备份与恢复
Longhorn,企业级云原生容器分布式存储 - 备份与恢复快照手动快照周期性快照和备份使用 Longhorn UI 设置周期性快照使用 StorageClass 设置 Recurring Jobs分离卷时允许 Recurring Job容灾卷创建容灾(DR)卷备份设置备份目标使用阿里云OSS备份存储准备工作为 S3 兼容…...

亿级高并发电商项目-- 实战篇 --万达商城项目 十(安装与配置Elasticsearch和kibana、编写搜索功能、向ES同步数据库商品数据)
亿级高并发电商项目-- 实战篇 --万达商城项目搭建 一 (商家端与用户端功能介绍、项目技术架构、数据库表结构等设计) 亿级高并发电商项目-- 实战篇 --万达商城项目搭建 一 (商家端与用户端功能介绍、项目技术架构、数据库表结构等设计&#x…...
windwos安装spring-cloud-alibaba-nacos
windwos安装spring-cloud-alibaba-nacos前言一、预备环境二、下载源码或者安装包1.启动2.关闭总结前言 这个快速开始手册是帮忙您快速在您的电脑上,下载、安装并使用 Nacos。 一、预备环境 Nacos 依赖 Java 环境来运行。如果您是从代码开始构建并运行Nacos&#x…...

Spring Boot 项目如何统一结果,统一异常,统一日志
1 统一结果返回目前的前后端开发大部分数据的传输格式都是json,因此定义一个统一规范的数据格式有利于前后端的交互与UI的展示。1.1 统一结果的一般形式是否响应成功;响应状态码;状态码描述;响应数据;其他标识符&#…...

Ubuntu下用Lean源码编译openwrt及一行命令u盘启动openwrt安装x86硬盘上
Ubuntu下用Lean源码编译openwrt 源码地址:https://github.com/coolsnowwolf/lede 1:首先微软云服务器装好 Ubuntu 64bit,推荐 Ubuntu 20.04 LTS x64,免费一年。ip设置在地球某处。总结就是每一步需要下载的都得下载完,…...

JavaScript Number 对象
JavaScript 是一门非常强大的编程语言,它提供了许多内置对象来帮助开发者在编写 JavaScript 应用时更轻松地处理数据。其中一个非常有用的对象是 JavaScript Number 对象,它可以帮助我们处理数值类型的数据,例如整数和浮点数。在本文中&#…...
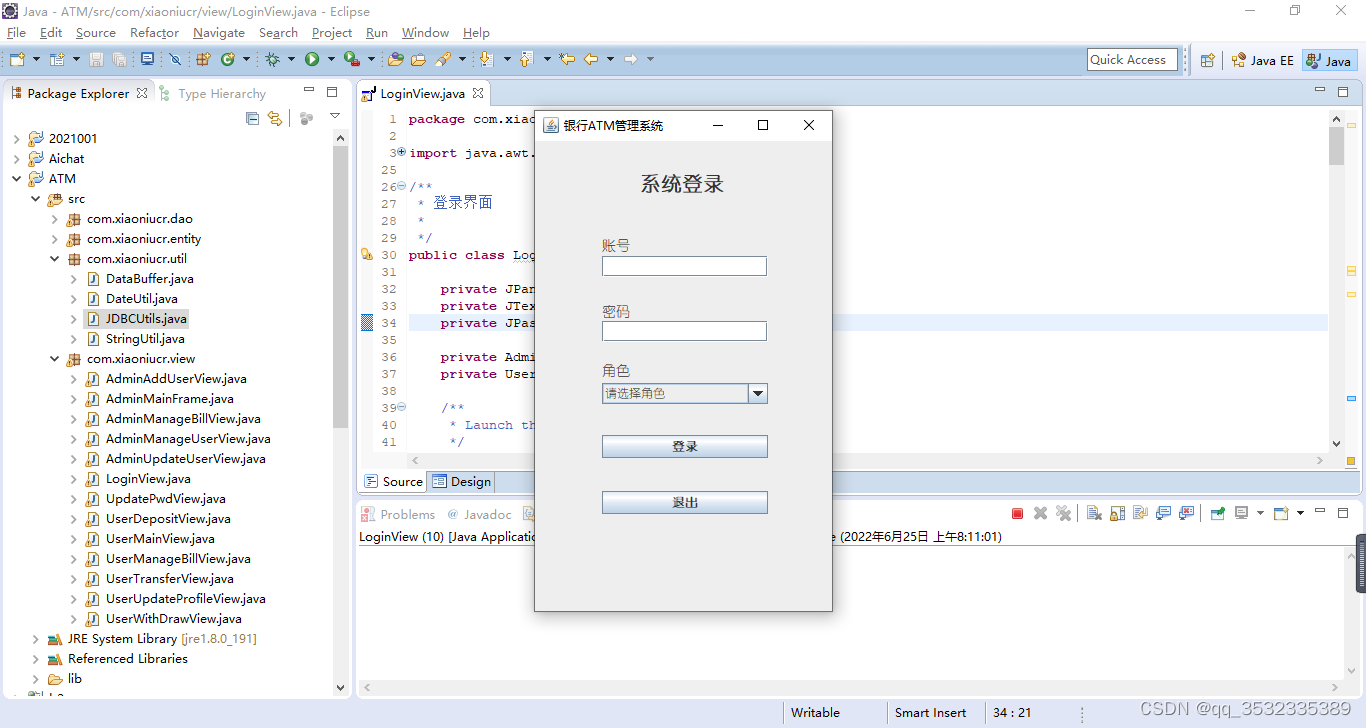
【原创】java+swing+mysql银行ATM管理系统
本文主要介绍使用javaswingmysql去设计一个银行ATM管理系统,模仿实现存款、取款、转账、余额查询等功能。 功能分析: 隐含ATM管理系统一般分为管理员和用户角色,管理员可以进行用户管理、账单管理,用户可以进行转取存款等功能如…...

博弈论--总结
博弈分类 按照是否对外产出或消耗 零和博弈:博弈过程作为整体对外无产出也无消耗。非零和博弈:博弈过程作为整体对外有产出或有消耗。 按照博弈参与人数 1人博弈2人博弈3人博弈n人博弈 按照博弈是否重复 注:同一规则的同一博弈过程反复…...
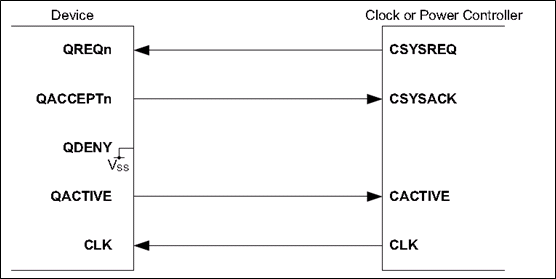
AMBA低功耗接口规范(Low Power Interface Spec)
1.简介 AMBA提供的低功耗接口,用于实现power控制功能。目前AMBA里面包含2种低功耗接口: Q-Channel:实现简单的power控制,如上电,下电。 P-Channel:实现复杂的power控制,如全上电,半上…...
matlab-汽车四分之一半主动悬架模糊控制
1、内容简介汽车四分之一半主动悬架模糊控制651-可以交流、咨询、答疑2、内容说明半主动悬架汽车 1/4 动力学模型建立 本章主要对悬架类型进行简要介绍,并对其进行对比分析,提出半主动悬架的优越性,论述半主动悬架的工作原理,并对…...
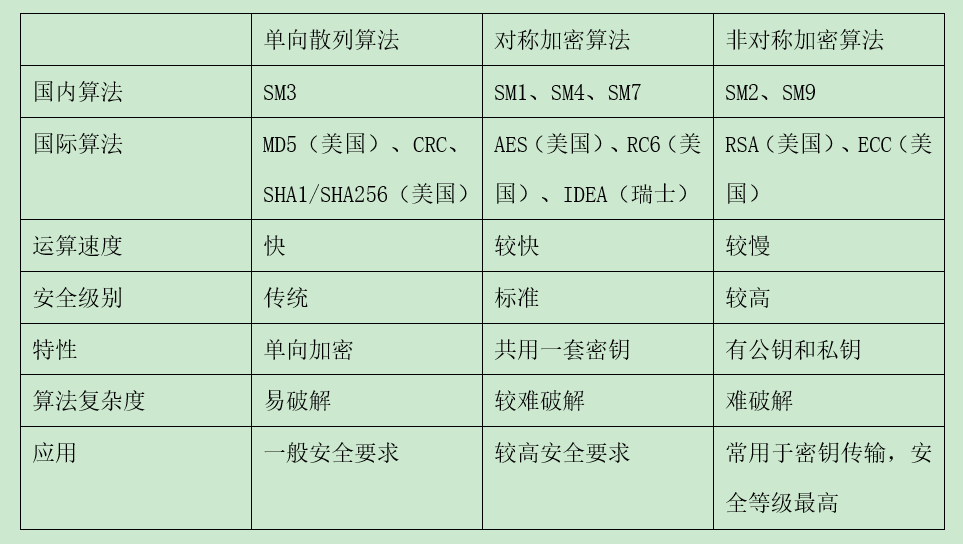
【安全加密】通信加密算法介绍
加密常用于通信中,如战争中电台通讯有明码和密码,密码需要不断更换密码本;另外,商用软件也需要用到加密技术,如根据电脑的mac地址设置权限,防止软件被恶意传播。 文章目录一、介绍1. 单向散列/哈希算法2. 对…...

kubernetes教程 --组件详细介绍
组件详细介绍 NameSpace 在 Kubernetes 中,名字空间(Namespace) 提供一种机制,将同一集群中的资源划分为相互隔离的组。 同一名字空间内的资源名称要唯一,但跨名字空间时没有这个要求。 名字空间作用域仅针对带有名字…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...

阿里云ACP云计算备考笔记 (5)——弹性伸缩
目录 第一章 概述 第二章 弹性伸缩简介 1、弹性伸缩 2、垂直伸缩 3、优势 4、应用场景 ① 无规律的业务量波动 ② 有规律的业务量波动 ③ 无明显业务量波动 ④ 混合型业务 ⑤ 消息通知 ⑥ 生命周期挂钩 ⑦ 自定义方式 ⑧ 滚的升级 5、使用限制 第三章 主要定义 …...

学校招生小程序源码介绍
基于ThinkPHPFastAdminUniApp开发的学校招生小程序源码,专为学校招生场景量身打造,功能实用且操作便捷。 从技术架构来看,ThinkPHP提供稳定可靠的后台服务,FastAdmin加速开发流程,UniApp则保障小程序在多端有良好的兼…...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...

剑指offer20_链表中环的入口节点
链表中环的入口节点 给定一个链表,若其中包含环,则输出环的入口节点。 若其中不包含环,则输出null。 数据范围 节点 val 值取值范围 [ 1 , 1000 ] [1,1000] [1,1000]。 节点 val 值各不相同。 链表长度 [ 0 , 500 ] [0,500] [0,500]。 …...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...

【配置 YOLOX 用于按目录分类的图片数据集】
现在的图标点选越来越多,如何一步解决,采用 YOLOX 目标检测模式则可以轻松解决 要在 YOLOX 中使用按目录分类的图片数据集(每个目录代表一个类别,目录下是该类别的所有图片),你需要进行以下配置步骤&#x…...

全面解析各类VPN技术:GRE、IPsec、L2TP、SSL与MPLS VPN对比
目录 引言 VPN技术概述 GRE VPN 3.1 GRE封装结构 3.2 GRE的应用场景 GRE over IPsec 4.1 GRE over IPsec封装结构 4.2 为什么使用GRE over IPsec? IPsec VPN 5.1 IPsec传输模式(Transport Mode) 5.2 IPsec隧道模式(Tunne…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...