ChatGPT模型采样算法详解
ChatGPT模型采样算法详解
ChatGPT所使用的模型——GPT(Generative Pre-trained Transformer)模型有几个参数,理解它们对文本生成任务至关重要。其中最重要的一组参数是temperature和top_p。二者控制两种不同的采样技术,用于因果语言模型(Causal language models)中预测给定上下文情景中下一个单词出现的概率。本文将重点讲解temperature和top_p的采样原理,以及它们对模型输出的影响。
文章目录
- 理解因果语言模型中的采样
- Top-k采样
- Top-p采样
- 温度采样
- 典型用例
- 总结
理解因果语言模型中的采样
假设我们训练了一个描述个人生活喜好的模型,我们想让它来补全“我喜欢漂亮的___”这个句子。一般语言模型会按照下图的流程来工作:

模型会查看所有可能的单词,并根据其概率分布从中采样,以预测下一个词。为了方便起见,假设模型的词汇量不大,只有:“大象”、“西瓜”、“鞋子”和“女孩”。通过下图的词汇概率我们可以发现,“女孩”的选中概率最高(p=0.664p=0.664p=0.664),“西瓜”的选中概率最低(p=0.032p=0.032p=0.032)。

上面的例子中,很明显“女孩”最可能被选中。因为人类对于单一问题在心智上习惯采用 “贪心策略”,即选择概率最高的事件。

贪心策略符合人类的心智,但是存在严重缺陷。
但是上面这种策略用在频繁交互的场景下会有一个显著缺陷——如果我们总是选择最可能的单词,那么这个词会反复不断被强化,因为现代语言模型中大多数模型的注意力只集中在最近的几个词(Token)上。这样生成的内容将非常的生硬和可预测,人们一眼就能看出是机器生成的且一点也不智能。
如何让我们的模型不那么具有确定性,让它生成的内容用词更加活跃呢?为此,我们引入了基于分布采样的生成采样算法。但是传统的采样方法会遇到了一个问题:如果我们有5万个候选词(Token),即使最后2.5万个极不可能出现的长尾词汇,它们的概率质量也可能会高达30%。这意味着,对于每个样本,我们有1/3的机会完全偏离原来的“主题”。又由于上面提到的注意力模型倾向于集中在最近出现的词上,这将导致不可恢复的错误级联,因为下一个词严重依赖于最近的错误词。
为了防止从尾部采样,最流行的方法是Top-k采样和温度采样。
Top-k采样
Top-k采样是对前面“贪心策略”的优化,它从排名前k的token种进行抽样,允许其他分数或概率较高的token也有机会被选中。在很多情况下,这种抽样带来的随机性有助于提高生成质量。

上图示例中,我们首先筛选似然值前三的token,然后根据似然值重新计算采样概率。
通过调整k的大小,即可控制采样列表的大小。“贪心策略”其实就是k=1的top-k采样。

Top-p采样
ChatGPT实际使用的不是Top-k采样,而是其改进版——Top-p采样。
Top-k有一个缺陷,那就是“k值取多少是最优的?”非常难确定。于是出现了动态设置token候选列表大小策略——即核采样(Nucleus Sampling)。下图展示了top-p值为0.9的Top-p采样效果:

top-p值通常设置为比较高的值(如0.75),目的是限制低概率token的长尾。我们可以同时使用top-k和top-p。如果k和p同时启用,则p在k之后起作用。
温度采样
温度采样受统计热力学的启发,高温意味着更可能遇到低能态。在概率模型中,logits扮演着能量的角色,我们可以通过将logits除以温度来实现温度采样,然后将其输入Softmax并获得采样概率。
越低的温度使模型对其首选越有信心,而高于1的温度会降低信心。0温度相当于argmax似然,而无限温度相当于于均匀采样。
温度采样中的温度与玻尔兹曼分布有关,其公式如下所示:
ρi=1Qe−ϵi/kT=e−ϵi/kT∑j=1Me−ϵj/kT\rho_i = \frac{1}{Q}e^{-\epsilon_i/kT}=\frac{e^{-\epsilon_i/kT}}{\sum_{j=1}^M e^{-\epsilon_j/kT}} ρi=Q1e−ϵi/kT=∑j=1Me−ϵj/kTe−ϵi/kT
其中 ρi\rho_iρi 是状态 iii 的概率,ϵi\epsilon_iϵi 是状态 iii 的能量, kkk 是波兹曼常数,TTT 是系统的温度,MMM 是系统所能到达的所有量子态的数目。
有机器学习背景的朋友第一眼看到上面的公式会觉得似曾相识。没错,上面的公式跟Softmax函数Softmax(zi)=ezi∑c=1CezcSoftmax(z_i) = \frac{e^{z_i}}{\sum_{c=1}^Ce^{z_c}}Softmax(zi)=∑c=1Cezcezi 很相似,本质上就是在Softmax函数上添加了温度(T)这个参数。Logits根据我们的温度值进行缩放,然后传递到Softmax函数以计算新的概率分布。
上面“我喜欢漂亮的___”这个例子中,初始温度T=1T=1T=1,我们直观看一下 TTT 取不同值的情况下,概率会发生什么变化:

通过上图我们可以清晰地看到,随着温度的降低,模型愈来愈越倾向选择”女孩“;另一方面,随着温度的升高,分布变得越来越均匀。当T=50T=50T=50时,选择”西瓜“的概率已经与选择”女孩“的概率相差无几了。

通常来说,温度与模型的“创造力”有关。但事实并非如此。温度只是调整单词的概率分布。其最终的宏观效果是,在较低的温度下,我们的模型更具确定性,而在较高的温度下,则不那么确定。
典型用例
temperature = 0.0
temperature=0会消除输出的随机性,这会使得GPT的回答稳定不变。
较低的温度适用于需要稳定性、最可能输出(实际输出、分类等)的情况。
temperature = 1.0
temperature=1每次将产生完全不同的输出,且有时输出的结果会非常搞笑。因此,即便是开放式任务,也应该谨慎使用temperature=1。对于故事创作或创意文案生成等任务,温度值设为0.7到0.9之间更为合适。
temperature = 0.75
通常,温度设在0.70–0.90之间是创造性任务最常见的温度。
虽然存在一些关于温度设置的一般性建议,但没有什么是一成不变的。作为GPT-3最重要的设置之一,实际使用中建议多一试下,看看不同设置对输出效果的影响。
总结
本文详细为大家阐述了temperature和top_p的采样原理,以及它们对模型输出的影响。实际使用中建议只修改其中一个的值,不要两个同时修改。
temperature可以简单得将其理解为“熵”,控制输出的混乱程度(随机性),而top-p可以简单将其理解为候选词列表大小,控制模型所能看到的候选词的多少。实际使用中大家要多尝试不同的值,从而获得最佳输出效果。
另外还有两个参数——frequency_penalty 和 presence_penalty 对生成输出也有较大影响,请参考《ChatGPT模型中的惩罚机制》。
相关文章:
ChatGPT模型采样算法详解
ChatGPT模型采样算法详解 ChatGPT所使用的模型——GPT(Generative Pre-trained Transformer)模型有几个参数,理解它们对文本生成任务至关重要。其中最重要的一组参数是temperature和top_p。二者控制两种不同的采样技术,用于因果…...
【Unity3d】Unity与iOS通信
在unity开发或者sdk开发经常需要用到unity与oc之间进行交互,这里把它们之间通信代码整理出来。 Unity调用Objective-C 主要分三个步骤: (一)、在xcode中定义要被unity调用的函数 新建一个类,名字可以任意,比如UnityBridge&…...

RDD的持久化【博学谷学习记录】
RDD的缓存缓存: 一般当一个RDD的计算非常的耗时|昂贵(计算规则比较复杂),或者说这个RDD需要被重复(多方)使用,此时可以将这个RDD计算完的结果缓存起来, 便于后续的使用, 从而提升效率通过缓存也可以提升RDD的容错能力, 当后续计算失败后, 尽量不让RDD进行回溯所有的依赖链条, 从…...

Python3 正则表达式
Python3 正则表达式 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。 Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。 re 模块使 Python 语言拥有全部的正则表达式功能。 compile 函数根…...

Qt-基础
Qt1. 概念其他概念对话框模态对话框与非模态对话框事件事件拦截/过滤事件例子鼠标/屏幕使用界面功能qt-designer工具debug目录结构mainwindow控件窗口QMainWindow事件2. 项目概览QOBJECT tree 对象树3. 信号和槽信号函数关联自定义信号和槽函数自定义信号和槽函数1自定义信号和…...

ABB机器人将实时坐标发送给西门子PLC的具体方法示例
ABB机器人将实时坐标发送给西门子PLC的具体方法示例 本次以PROFINET通信为例进行说明,演示ABB机器人将实时坐标发送给西门子PLC的具体方法。 首先,要保证ABB机器人和PLC的信号地址分配已经完成,具体的内容可参考以下链接: S7-1200PLC与ABB机器人进行PROFINET通信的具体方法…...

反向传播与梯度下降详解
一,前向传播与反向传播 1.1,神经网络训练过程 神经网络训练过程是: 先通过随机参数“猜“一个结果(模型前向传播过程),这里称为预测结果 a a a;然后计算 a a a 与样本标签值...
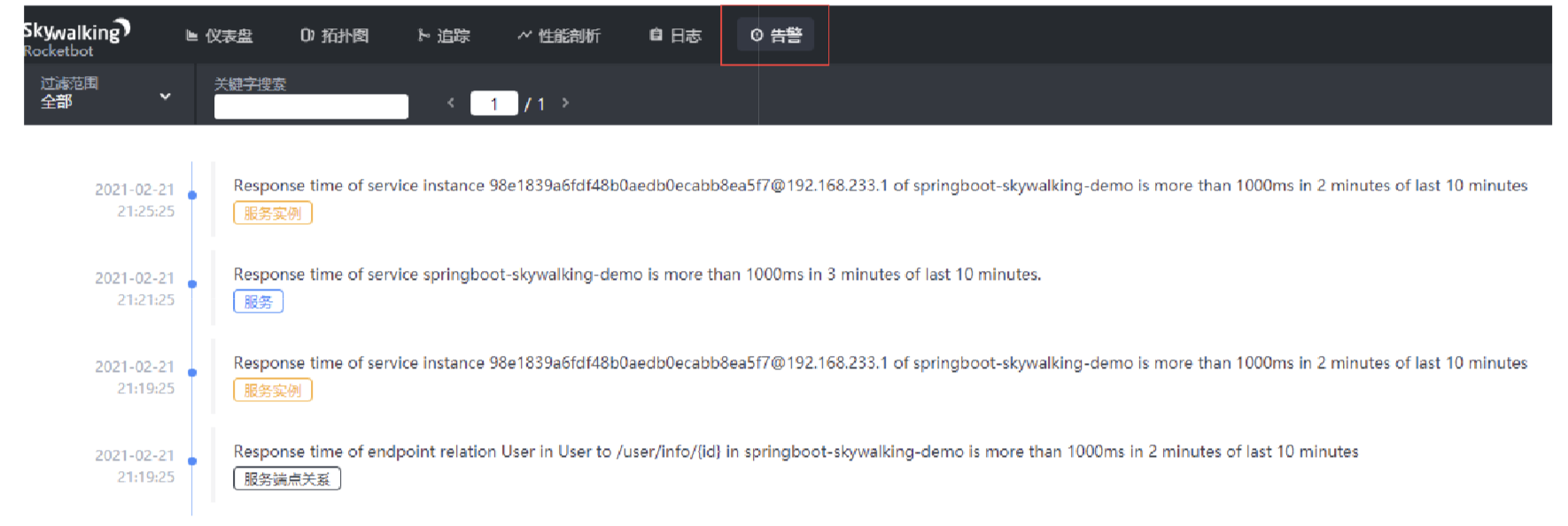
Skywalking ui页面功能介绍
菜单栏 仪表盘:查看被监控服务的运行状态; 拓扑图:以拓扑图的方式展现服务之间的关系,并以此为入口查看相关信息; 追踪:以接口列表的方式展现,追踪接口内部调用过程; 性能剖析&am…...
哪里可以找到免费的 PDF 阅读编辑器?7 个免费 PDF 阅读编辑器分享
如果您曾经需要编辑 PDF,您可能会发现很难找到免费的 PDF 编辑器。幸运的是,您可以使用在线资源来编辑该文档,而无需为软件付费。 在本文中,我将介绍七种不同的 PDF 编辑器,它们至少可以让您免费编辑几个文件。我通过…...
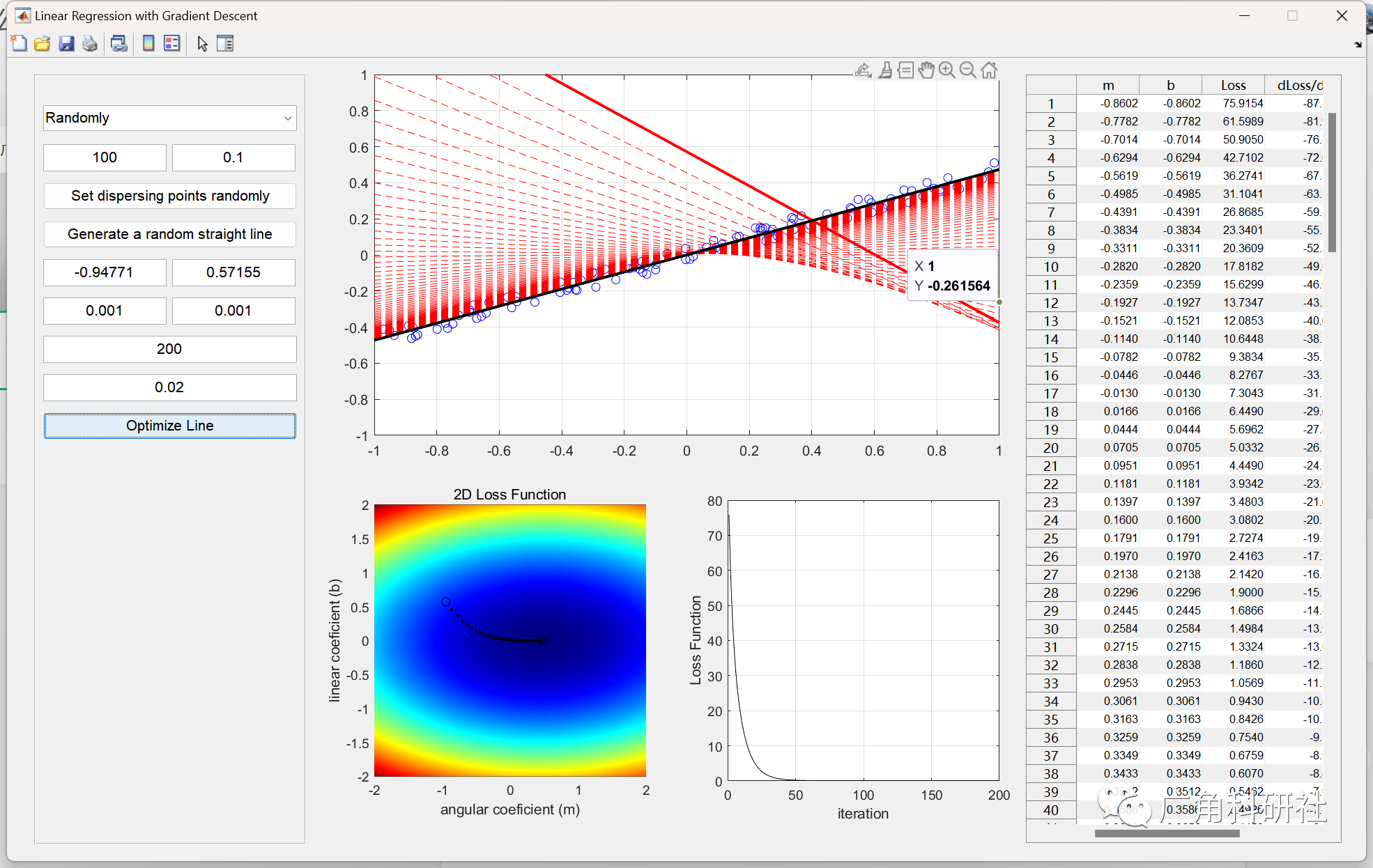
使用梯度下降的线性回归(Matlab代码实现)
目录 💥1 概述 📚2 运行结果 🎉3 参考文献 👨💻4 Matlab代码 💥1 概述 梯度下降法,是一种基于搜索的最优化方法,最用是最小化一个损失函数。梯度下降是迭代法的一种,可以用于求…...
在Ubuntu上设置MySQL可以远程登录
在Ubuntu上设置MySQL可以远程登录一.设置数据库二.设置防火墙由于Ubuntu查看修改MySQL不是很方便,想着在虚拟机安装的Windows系统或者局域网中的其他电脑上去查看Ubuntu系统上的数据库,这样省事一些,我电脑安装的数据库是MySQL8。一.设置数据…...
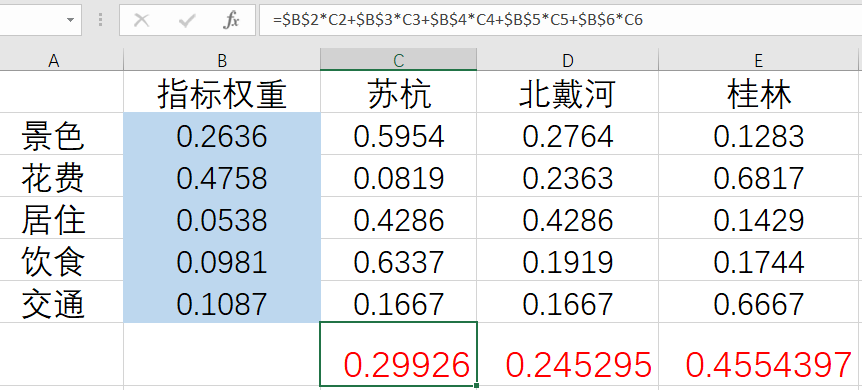
清风1.层次分析法
一.流程1.建立评价体系2.建立判断矩阵2.1 A-C-C矩阵从准则层对目标层的特征向量上看,花费的权重最大算术平均法求权重的结果为:0.26230.47440.05450.09850.1103几何平均法求权重的结果为:0.26360.47730.05310.09880.1072特征值法求权重的结果…...

「首席架构师推荐」免费数据可视化软件你喜欢哪一个?
数据可视化,是关于数据视觉表现形式的科学技术研究。其中,这种数据的视觉表现形式被定义为,一种以某种概要形式抽提出来的信息,包括相应信息单位的各种属性和变量。它是一个处于不断演变之中的概念,其边界在不断地扩大…...

深度学习术语解释:backbone、head、neck,etc
backbone:翻译为主干网络的意思,既然说是主干网络,就代表其是网络的一部分,那么是哪部分呢?这个主干网络大多时候指的是提取特征的网络,其作用就是提取图片中的信息,共后面的网络使用。这些网络…...
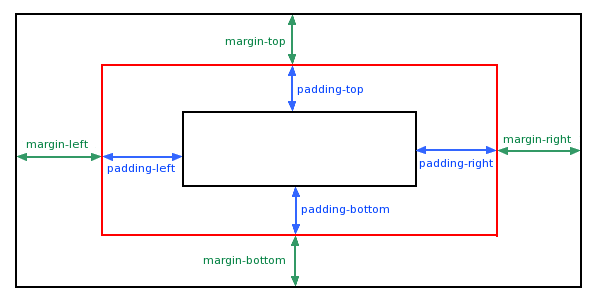
基础篇—CSS margin(外边距)解析
什么是CSS margin(外边距)? CSS margin(外边距)属性定义元素周围的空间。 属性描述margin简写属性。在一个声明中设置所有外边距属性。margin-bottom设置元素的下外边距。margin-left设置元素的左外边距。margin-right设置元素的右外边距。margin-top设置元素的上外边距。mar…...

ChatGPT或将引发新一轮失业潮?是真的吗?
最近,要说有什么热度不减的话题,那ChatGPT必然榜上有名。据悉是这是由美国人工智能研究实验室OpenAI开发的一种全新聊天机器人模型,它能够通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动,并协助人类…...
【Selenium学习】Selenium 中特殊元素操作
1.鼠标定位操作鼠标悬停,即当光标与其名称表示的元素重叠时触发的事件,在 Selenium 中将键盘鼠标操作封装在 Action Chains 类中。Action Chains 类的主要应用场景为单击鼠标、双击鼠标、鼠标拖曳等。部分常用的方法使用分类如下:• click(on…...

Spark相关的依赖冲突,后期持续更新总结
Spark相关的依赖冲突持续更新总结 Spark-Hive_2.11依赖报错 这个依赖是Spark开启支持hive SQL解析,其中2.11是Spark对应的Scala版本,如Spark2.4.7,对应的Scala版本是2.11.12;这个依赖会由于Spark内部调用的依赖guava的版本问题出…...

【每日一题Day122】LC1237找出给定方程的正整数解 | 双指针 二分查找
找出给定方程的正整数解【LC1237】 给你一个函数 f(x, y) 和一个目标结果 z,函数公式未知,请你计算方程 f(x,y) z 所有可能的正整数 数对 x 和 y。满足条件的结果数对可以按任意顺序返回。 尽管函数的具体式子未知,但它是单调递增函数&#…...
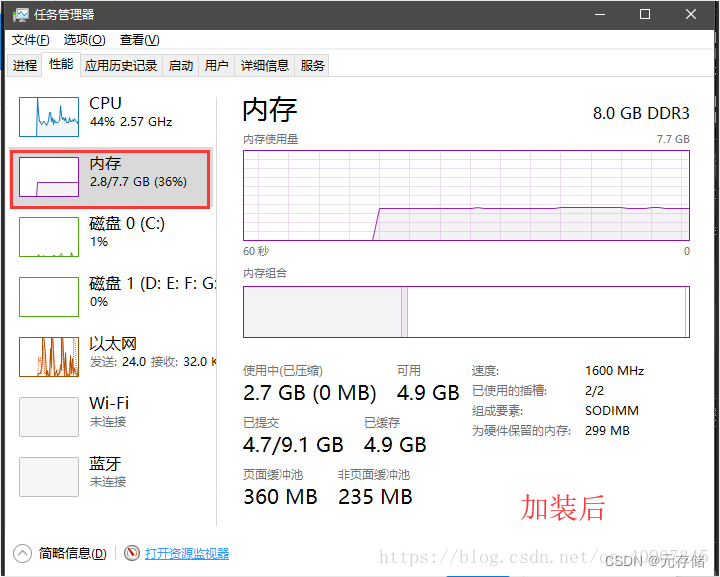
笔记本加装固态和内存条教程(超详细)
由于笔记本是几年前买的了,当时是4000,现在用起来感到卡顿,启动、运行速度特别慢,就决定换个固态硬盘,加个内存条,再给笔记本续命几年。先说一下加固态硬盘SSD的好处:1.启动快 2.读取延迟小 3.写…...

Unity安卓构建实战指南:解决APK真机安装闪退与构建失败
1. 这不是一本“从零开始”的书,而是一份你真正上手Unity安卓游戏开发前必须撕开的说明书我带过三届Unity实习工程师,也帮二十多个独立开发者把Demo打包进Google Play。每次看到新人在“安卓构建失败”报错里反复挣扎,或者对着“IL2CPP编译卡…...

从分立逻辑到单片机:基于ATmega8的MIDI通道分析仪设计与实现
1. 项目概述:从分立逻辑到单片机的MIDI通道分析仪进化史二十年前,当我在《Elektor》杂志上发表第一版MIDI通道分析仪时,整个数字音乐世界还处于一个相当“硬核”的阶段。那个版本的设计,用今天的话来说,简直就是一场“…...

基于声卡与电流互感器的安全交流功率测量系统设计与实践
1. 项目概述:用声卡安全测量交流功率我一直对各种测量技术抱有浓厚的兴趣,毕竟“测量即认知”这句老话在今天依然适用。对于电力消耗和产出,没有什么比直接测量更能说明问题了。交流功率的测量,核心在于同时获取电压和电流的瞬时值…...
到panic:深入Linux 5.4内核,看异常处理如何层层递进)
从BUG()到panic:深入Linux 5.4内核,看异常处理如何层层递进
从BUG()到panic:Linux内核异常处理的防御体系全解析当你在深夜调试一个内核模块时,突然屏幕刷出一串红色警告——这可能是每个Linux内核开发者都经历过的噩梦时刻。但你是否想过,从第一行警告出现到系统完全崩溃,内核究竟经历了怎…...

开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南
开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南 【免费下载链接】Tkinter-Designer An easy and fast way to create a Python GUI 🐍 项目地址: https://gitcode.com/gh_mirrors/tk/Tkinter-Designer 在Python GUI开发…...
)
Windows10下V-REP教育版安装保姆级教程(附百度网盘资源与避坑点)
Windows10系统V-REP教育版完整安装指南:从下载到实战避坑在机器人仿真和自动化控制领域,V-REP(现更名为CoppeliaSim)作为一款功能强大的跨平台机器人仿真软件,已经成为众多工科学生和研究人员的首选工具。特别是其教育…...

基于雷达与光敏传感器的低功耗智能窗防设备设计与实现
1. 项目概述:一个基于雷达与光敏的智能窗防设备几年前,我因为一次短暂的出差,家里空置了几天,回来后就一直琢磨着怎么给家里的窗户加点“动静”。市面上的智能安防摄像头固然好,但要么需要复杂的布线,要么云…...

如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型
如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型 【免费下载链接】DeepPurpose A Deep Learning Toolkit for DTI, Drug Property, PPI, DDI, Protein Function Prediction (Bioinformatics) 项目地址: https://gitcode.com/gh_mirrors/de…...

终极指南:用AlwaysOnTop免费开源工具彻底改变你的Windows工作方式
终极指南:用AlwaysOnTop免费开源工具彻底改变你的Windows工作方式 【免费下载链接】AlwaysOnTop Make a Windows application always run on top 项目地址: https://gitcode.com/gh_mirrors/al/AlwaysOnTop 你是否经常在多个窗口间来回切换,浪费宝…...

终极指南:三步搞定Windows系统安卓APK文件安装,告别模拟器时代
终极指南:三步搞定Windows系统安卓APK文件安装,告别模拟器时代 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为电脑无法直接运行手机应用…...