集成学习:机器学习模型如何“博采众长”
前置概念
偏差
指模型的预测值与真实值之间的差异,它反映了模型的拟合能力。
方差
指模型在不同的训练集上产生的预测结果的差异,它反映了模型的稳定性。

在机器学习中,我们通常希望模型的偏差和方差都能够尽可能地小,从而达到更好的泛化能力。但是,偏差和方差的平衡是一个非常复杂的问题,很难通过简单的调参来解决。因此,在实际应用中,我们需要综合考虑模型的鲁棒性、准确性和泛化能力等多个指标,来评估模型的性能和可靠性。
拟合
模型过拟合指的是机器学习模型在训练集上表现很好,但在测试集或新数据上表现很差的情况。过拟合通常是由于模型过于复杂,或者训练数据过少、噪声过多等原因导致的。
欠拟合
模型欠拟合指的是机器学习模型在训练集和测试集上表现都不够好的情况。
决策树
决策树是一种基于树结构的分类算法,它通过构造一棵树来模拟决策过程。在决策树中,每个节点代表一个属性或特征,每个分支代表一个可能的取值,而每个叶子节点代表一个分类结果。决策树的工作原理是通过对数据集进行递归分割,将数据集划分为不同的子集,直到每个子集都属于同一类别或达到预定的停止条件。在分类时,将待分类样本从根节点开始,按照属性值依次向下遍历,直到到达叶子节点,即可得到分类结果。
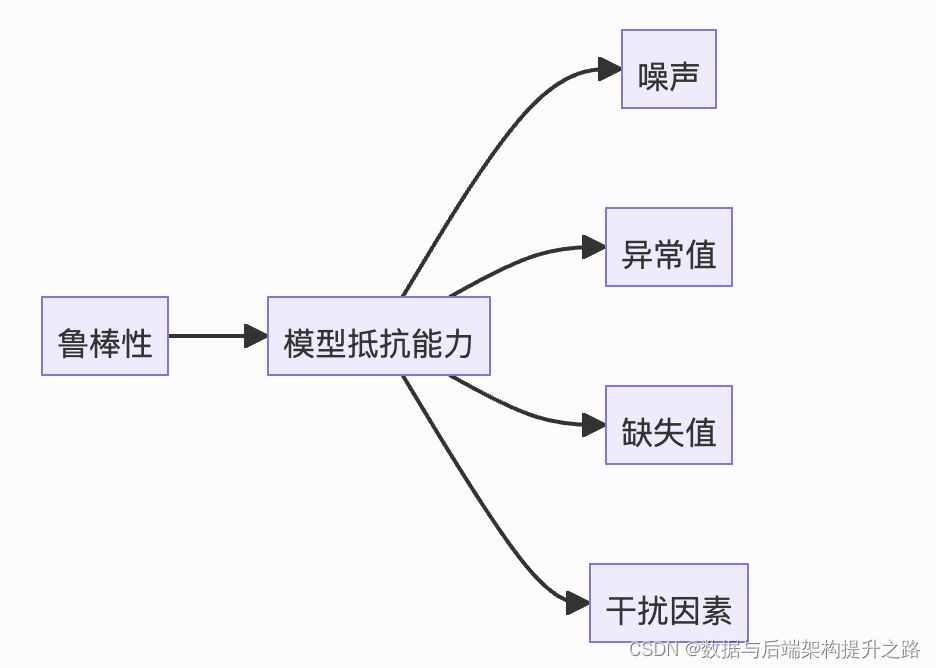
鲁棒性
指模型对于输入数据中的噪声、异常值、缺失值等干扰因素的抵抗能力。在机器学习中,我们通常希望模型能够对于不同的输入数据都能够产生稳定和一致的输出结果,我们可以通过数据清洗、特征选择、模型调参等方法来提高模型的鲁棒性,从而提高模型的性能和准确性。
集成学习
核心思想是训练出多个模型并将这些模型进行组合。根据分类器的训练方式和组合预测的方法。目标就是,减少机器学习模型的方差和偏差,找到机器学习模型在欠拟合和过拟合之间的最佳平衡点。集成学习中两种最重要的方法就是:降低偏差的 Boosting 和降低方差的Bagging。

Boosting 方法
有三种很受欢迎的算法,分别是 AdaBoost、GBDT 和 XGBoost
AdaBoost
它通过持续优化一个基模型,将新模型整合到原有模型中,并对样本进行加权,以减小模型预测误差。
GBDT(梯度提升决策树)
将梯度下降和 Boosting 方法结合的算法。它采用决策树模型,并定义一个损失函数,通过梯度下降来优化模型。
XGBoost(极端梯度提升)
对 GBDT 进一步优化的算法。它也采用决策树模型,并定义一个损失函数。与 GBDT 不同的是,XGBoost 利用泰勒展开式将损失函数展开到二阶,并利用二阶导数信息加快训练集的收敛速度
Bagging方法
是一种降低模型方差的集成学习方法,它通过随机抽取数据的方式,构建多个基模型,并将它们的结果进行集成,从而得到一个泛化能力更强的模型。Bagging方法有三种常见的算法:
决策树的Bagging
这种方法是基于决策树的Bagging,也称为树的聚合(Bagging of Tree)。它的基本思想是通过随机抽取数据和特征,构建多棵决策树,并将它们的结果进行集成。决策树具有显著的低偏差、高方差的特点,因此通过Bagging方法可以降低模型方差,提高模型的泛化能力。
随机森林算法
随机森林算法是一种基于决策树的Bagging方法,它在决策树的基础上引入了随机特征选择。具体来说,随机森林算法在每个节点上随机选择一部分特征进行划分,从而降低模型方差,提高模型的泛化能力。
极端随机森林算法
极端随机森林算法是一种基于决策树的Bagging方法,它在随机森林算法的基础上进一步引入了随机特征和随机阈值选择。具体来说,极端随机森林算法在每个节点上随机选择一部分特征和一个随机阈值进行划分,从而进一步降低模型方差,提高模型的泛化能力。
具体应用
“易速鲜花”运营部门提出了两个裂变思路。
方案一是选择一批热销商品,让老用户邀请朋友扫码下载 App 并成功注册,朋友越多,折扣越大。我们把这个方案命名为“疯狂打折”,它走的是友情牌。
方案二是找到一个朋友一起购买,第二件商品就可以免费赠送,这叫“买一送一”。 具体来说,方案一是让老用户邀请朋友扫码下载 App 并成功注册,朋友越多,折扣越大。
我们今天的目标就是根据这个数据集,来判断一个特定用户在特定的裂变促销之下,是否会转化。
预测代码如下:
import pandas as pd #导入Pandas
from sklearn.metrics import f1_score
from sklearn.tree import DecisionTreeClassifierdf_fission = pd.read_csv('易速鲜花裂变转化.csv') #载入数据
df_fission.head() #显示数据import matplotlib.pyplot as plt #导入pyplot模块
import seaborn as sns #导入Seaborn
fig = sns.countplot('是否转化', data=df_fission) #创建柱状计数图
fig.set_ylabel("数目") #Y轴标题
plt.show() #显示图像# 把二元类别文本数字化
df_fission['性别'].replace("女",0,inplace = True)
df_fission['性别'].replace("男",1,inplace=True)
# 显示数字类别
print("Gender unique values",df_fission['性别'].unique())
# 把多元类别转换成多个二元哑变量,然后贴回原始数据集
df_fission = pd.get_dummies(df_fission, drop_first = True)
df_fission # 显示数据集X = df_fission.drop(['用户码','是否转化'], axis = 1) # 构建特征集
y = df_fission.是否转化.values # 构建标签集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 0.2)
from sklearn.preprocessing import MinMaxScaler #导入归一化缩放器
scaler = MinMaxScaler() #创建归一化缩放器
X_train = scaler.fit_transform(X_train) #拟合并转换训练集数据
X_test = scaler.transform(X_test) #转换测试集数据# 一、测试准确率是指在测试集上分类器正确分类的样本数占总样本数的比例。它是分类器性能的一个重要指标,但是它不能很好地反映分类器在不同类别上的表现。
#
#二、 F1分数是精确率和召回率的调和平均数,它综合了分类器的精确率和召回率,是一个更全面的分类器性能指标。
# 精确率是指分类器正确预测为正例的样本数占预测为正例的样本数的比例,召回率是指分类器正确预测为正例的样本数占实际为正例的样本数的比例。F
# 1分数越高,表示分类器的性能越好。#1.1 AdaBoost算法
from sklearn.ensemble import AdaBoostClassifier # 导入AdaBoost 模型
dt = DecisionTreeClassifier() # 选择决策树分类器作为AdaBoost 的基准算法
ada = AdaBoostClassifier(dt) # AdaBoost 模型
ada.fit(X_train, y_train) # 拟合模型
y_pred = ada.predict(X_test) # 进行预测
print("AdaBoost 测试准确率: {:.2f}%".format(ada.score(X_test, y_test)*100))
print("AdaBoost 测试F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))# 1.2 GBDT算法
from sklearn.ensemble import GradientBoostingClassifier # 导入梯度提升模型
gb = GradientBoostingClassifier() # 梯度提升模型
gb.fit(X_train, y_train) # 拟合模型
y_pred = gb.predict(X_test) # 进行预测
print(" 梯度提升测试准确率: {:.2f}%".format(gb.score(X_test, y_test)*100))
print(" 梯度提升测试F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))#1.3 XGBoost算法
from xgboost import XGBClassifier # 导入XGB 模型
xgb = XGBClassifier() # XGB 模型
xgb.fit(X_train, y_train) # 拟合模型
y_pred = xgb.predict(X_test) # 进行预测
print("XGB 测试准确率: {:.2f}%".format(xgb.score(X_test, y_test)*100))
print("XGB 测试F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))#2.1 决策树的Bagging
from sklearn.ensemble import BaggingClassifier # 导入Bagging 分类器
from sklearn.tree import DecisionTreeClassifier # 导入决策树分类器
from sklearn.metrics import (f1_score, confusion_matrix) # 导入评估指标
dt = BaggingClassifier(DecisionTreeClassifier()) # 只使用一棵决策树
dt.fit(X_train, y_train) # 拟合模型
y_pred = dt.predict(X_test) # 进行预测
print(" 决策树测试准确率: {:.2f}%".format(dt.score(X_test, y_test)*100))
print(" 决策树测试F1 分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))
bdt = BaggingClassifier(DecisionTreeClassifier()) # 树的Bagging
bdt.fit(X_train, y_train) # 拟合模型
y_pred = bdt.predict(X_test) # 进行预测
print(" 决策树Bagging 测试准确率: {:.2f}%".format(bdt.score(X_test, y_test)*100))
print(" 决策树Bagging 测试F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))#2.2 随机森林算法
from sklearn.ensemble import RandomForestClassifier # 导入随机森林模型
rf = RandomForestClassifier() # 随机森林模型
rf.fit(X_train, y_train) # 拟合模型
y_pred = rf.predict(X_test) # 进行预测
print(" 随机森林测试准确率: {:.2f}%".format(rf.score(X_test, y_test)*100))
print(" 随机森林测试F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))#2.3 极端随机森林算法
from sklearn.ensemble import ExtraTreesClassifier # 导入极端随机森林模型
ext = ExtraTreesClassifier() # 极端随机森林模型
ext.fit(X_train, y_train) # 拟合模型
y_pred = ext.predict(X_test) # 进行预测
print(" 极端随机森林测试准确率: {:.2f}%".format(ext.score(X_test, y_test)*100))
print(" 极端随机森林测试F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))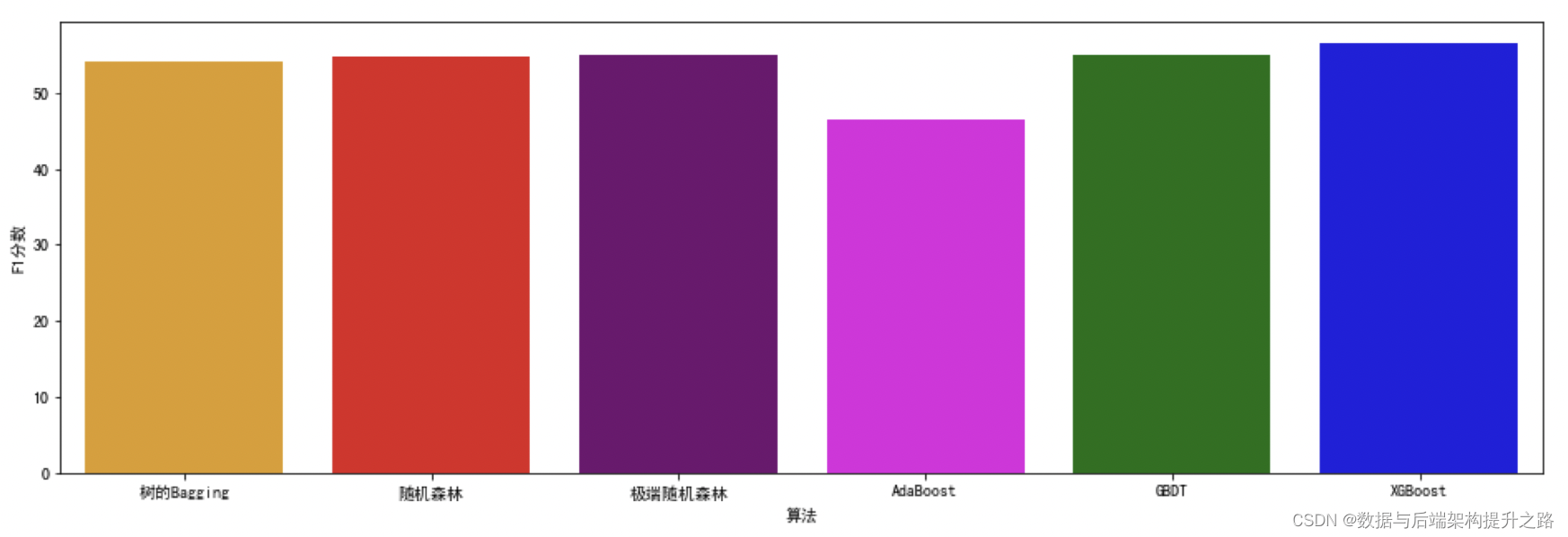
相关文章:
集成学习:机器学习模型如何“博采众长”
前置概念 偏差 指模型的预测值与真实值之间的差异,它反映了模型的拟合能力。 方差 指模型在不同的训练集上产生的预测结果的差异,它反映了模型的稳定性。 方差和偏差对预测结果所造成的影响 在机器学习中,我们通常希望模型的偏差和方差都…...
排序算法(二)
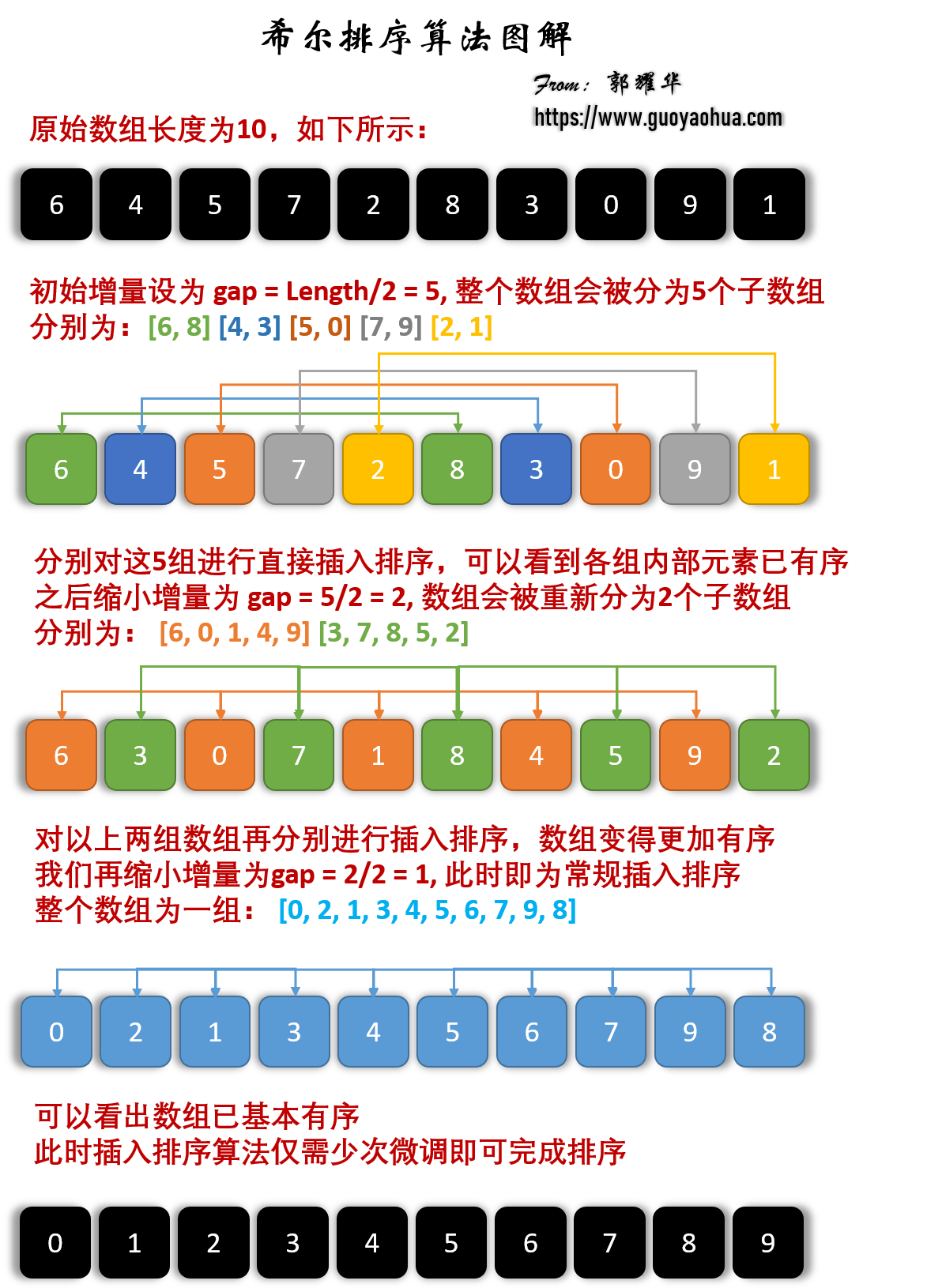
1.希尔排序-Shell Sort 1.算法原理 将未排序序列按照增量gap的不同分割为若干个子序列,然后分别进行插入排序,得到若干组排好序的序列; 缩小增量gap,并对分割为的子序列进行插入排序;最后一次的gap1,即整个…...
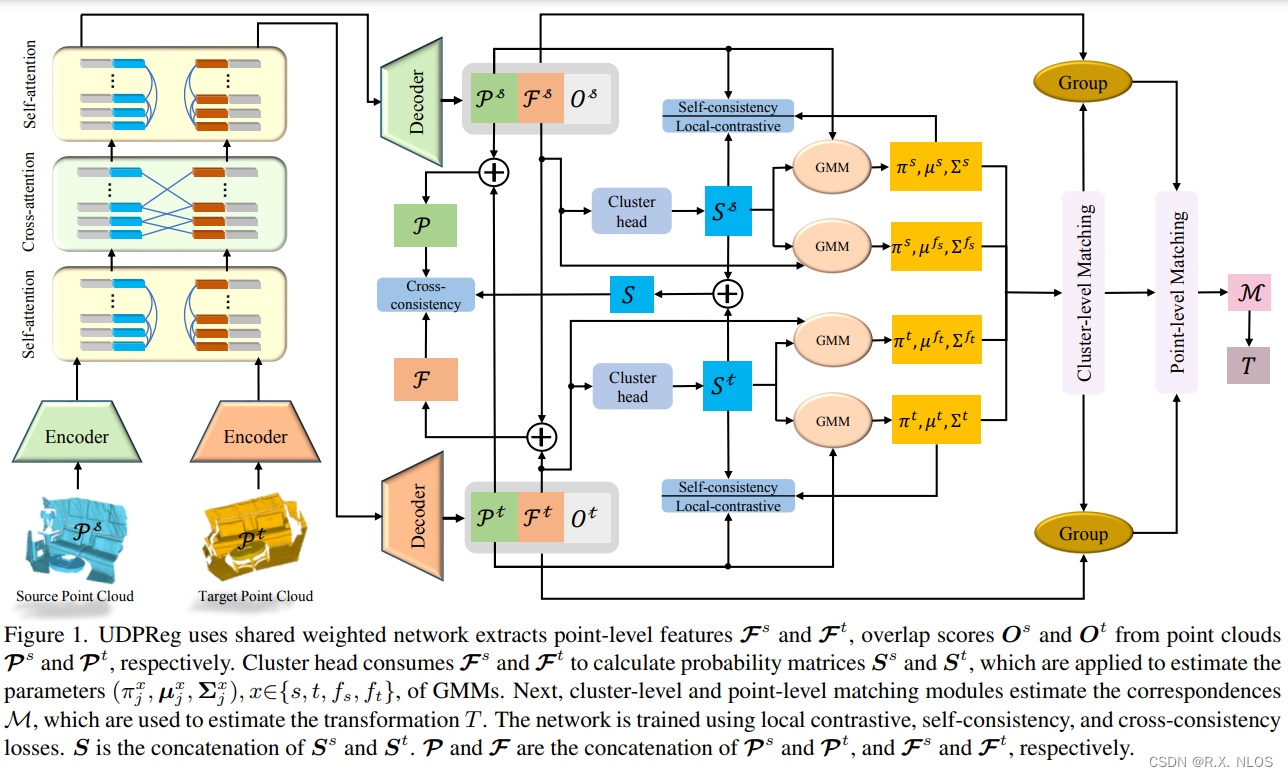
CVPR 2023 | 无监督深度概率方法在部分点云配准中的应用
注1:本文系“计算机视觉/三维重建论文速递”系列之一,致力于简洁清晰完整地介绍、解读计算机视觉,特别是三维重建领域最新的顶会/顶刊论文(包括但不限于 Nature/Science及其子刊; CVPR, ICCV, ECCV, NeurIPS, ICLR, ICML, TPAMI, IJCV 等)。本次介绍的论文是:2023年,CVPR,…...
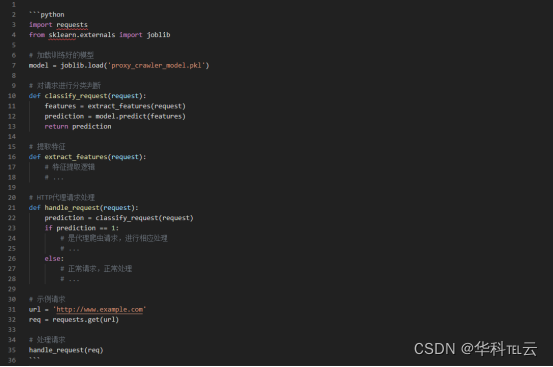
HTTP隧道识别与防御:机器学习的解决方案
随着互联网的快速发展,HTTP代理爬虫已成为数据采集的重要工具。然而,随之而来的是恶意爬虫对网络安全和数据隐私的威胁。为了更好地保护网络环境和用户数据,我们进行了基于机器学习的HTTP代理爬虫识别与防御的研究。以增强对HTTP代理爬虫的识…...
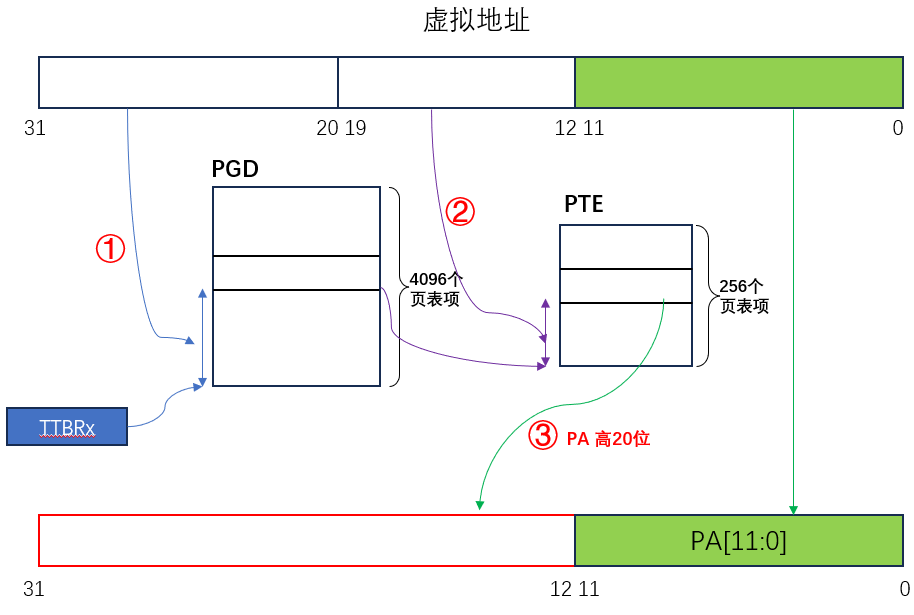
【MMU】认识 MMU 及内存映射的流程
MMU(Memory Manager Unit),是内存管理单元,负责将虚拟地址转换成物理地址。除此之外,MMU 实现了内存保护,进程无法直接访问物理内存,防止内存数据被随意篡改。 目录 一、内存管理体系结构 1、…...
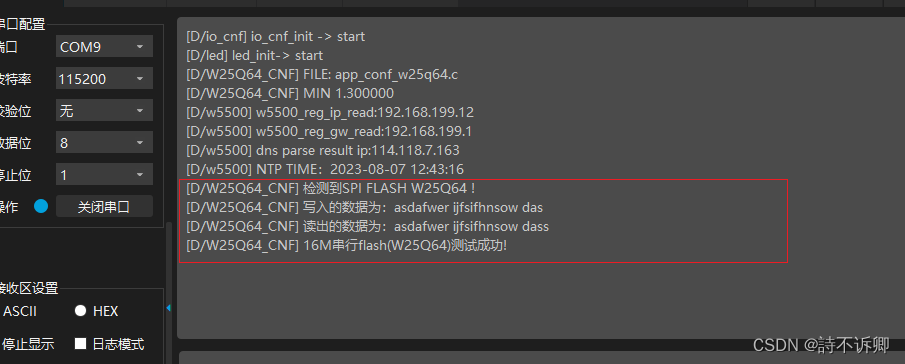
Clion开发Stm32之存储模块(W25Q64)驱动编写
前言 涵盖之前文章: Clion开发STM32之HAL库SPI封装(基础库) W25Q64驱动 头文件 #ifndef F1XX_TEMPLATE_MODULE_W25Q64_H #define F1XX_TEMPLATE_MODULE_W25Q64_H#include "sys_core.h" /* Private typedef ---------------------------------------------------…...

SpringBoot动态切换数据源
SpringBoot整合多数据源,动态添加新数据源并切换 1.需求2.创建数据源配置类3.切换数据源4.切换数据源管理类5.使用案例5.AOP切面拦截 1.需求 低代码服务需要给多套系统进行功能配置,要求表结构必须生成在对应系统的数据库中,所以表结构的生成…...

[C++项目] Boost文档 站内搜索引擎(4): 搜索的相关接口的实现、线程安全的单例index接口、cppjieba分词库的使用、综合调试...
有关Boost文档搜索引擎的项目的前三篇文章, 已经分别介绍分析了: 项目背景: 🫦[C项目] Boost文档 站内搜索引擎(1): 项目背景介绍、相关技术栈、相关概念介绍…文档解析、处理模块parser的实现: 🫦[C项目] Boost文档 站内搜索引擎(2): 文档文本解析模块…...

SAP ABAP元素域值描述通过函数(DD_DOMVALUE_TEXT_GET)获取
代码如下: PERFORM FRM_GET_DOMVALUE_TEXT USING ZMMD_ZFLZQ <GFS_DATA>-ZFLZQ CHANGING <GFS_DATA>-ZZQTEXT .IF <GFS_DATA>-ZXYLX IS NOT INITIAL .PERFORM FRM_GET_DOMVALUE_TEXT USING ZMMD_ZXYLX <GFS_DATA>-ZXYLX CHANGING <GFS_…...

原型模式与享元模式:提升系统性能的利器
原型模式和享元模式,前者是在创建多个实例时,对创建过程的性能进行调优;后者是用减 少创建实例的方式,来调优系统性能。这么看,你会不会觉得两个模式有点相互矛盾呢? 在有些场景下,我们需要重复…...

uniapp封装手写签名
组件代码 cat-signature <template><view v-if"visibleSync" class"cat-signature" :class"{visible:show}" touchmove.stop.prevent"moveHandle"><view class"mask" tap"close" /><view c…...

掌握 JVM 调优命令
常用命令 1、jps查看当前 java 进程2、jinfo实时查看和调整 JVM 配置参数3、jstat查看虚拟机统计信息4、jstack查看线程堆栈信息5、jmap查看堆内存的快照信息 JVM 日常调优总结起来就是:首先通过 jps 命令查看当前进程,然后根据 pid 通过 jinfo 命令查看…...
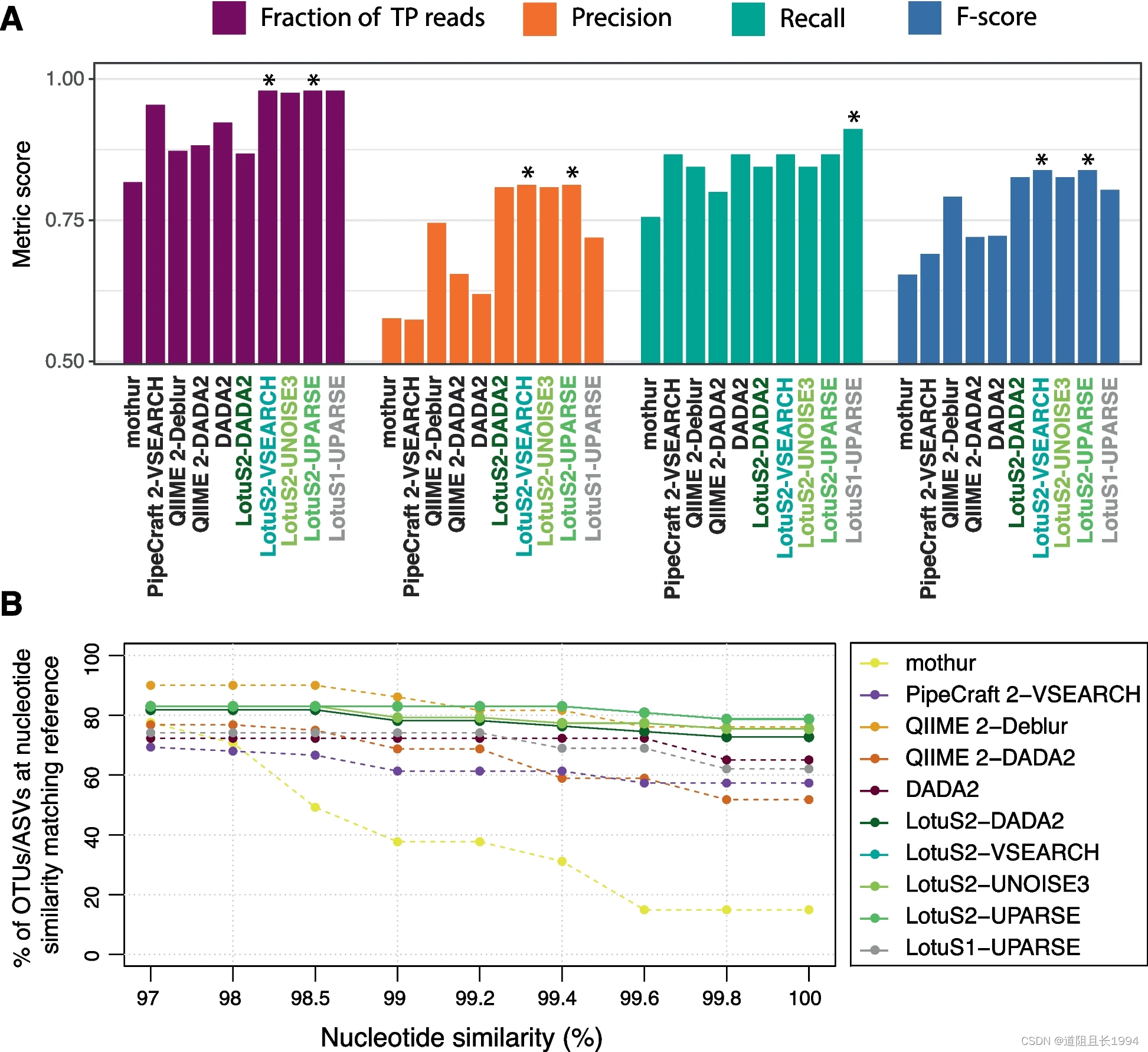
扩增子分析流程——Lotus2: 一行命令完成所有分析
为什么介绍lotus2 因为快,作者比较了lotus2流程和qiime2、dada2、vsearch等,lotus2的速度最快、占用内存最小。 因为方便,只需要一行代码,即可完成全部分析。 lotus2 -i Example/ -m Example/miSeqMap.sm.txt -o myTestRun而且分…...

微服务 云原生:搭建 Harbor 私有镜像仓库
Harbor官网 写在文前: 本文中用到机器均为虚拟机 CentOS-7-x86_64-Minimal-2009 镜像。 基础设施要求 虚拟机配置达到最低要求即可,本次系统中使用 docker 24.0.4、docker-compose 1.29.2。docker 及 docker-compose 的安装可以参考上篇文章 微服务 &am…...

Ceph入门到精通-远程开发Windows下使用SSH密钥实现免密登陆Linux服务器
工具: win10、WinSCP 服务器生成ssh密钥: 打开终端,使账号密码登录,输入命令 ssh-keygen -t rsa Winscp下载 Downloading WinSCP-6.1.1-Setup.exe :: WinSCP window 生成密钥 打开powershell ssh-keygen -t rsa 注意路径 …...
APP外包开发的开发语言对比
在开发iOS APP时有两种语言可以选择,Swift(Swift Programming Language)和 Objective-C(Objective-C Programming Language),它们是两种不同的编程语言,都被用于iOS和macOS等苹果平台的软件开发…...
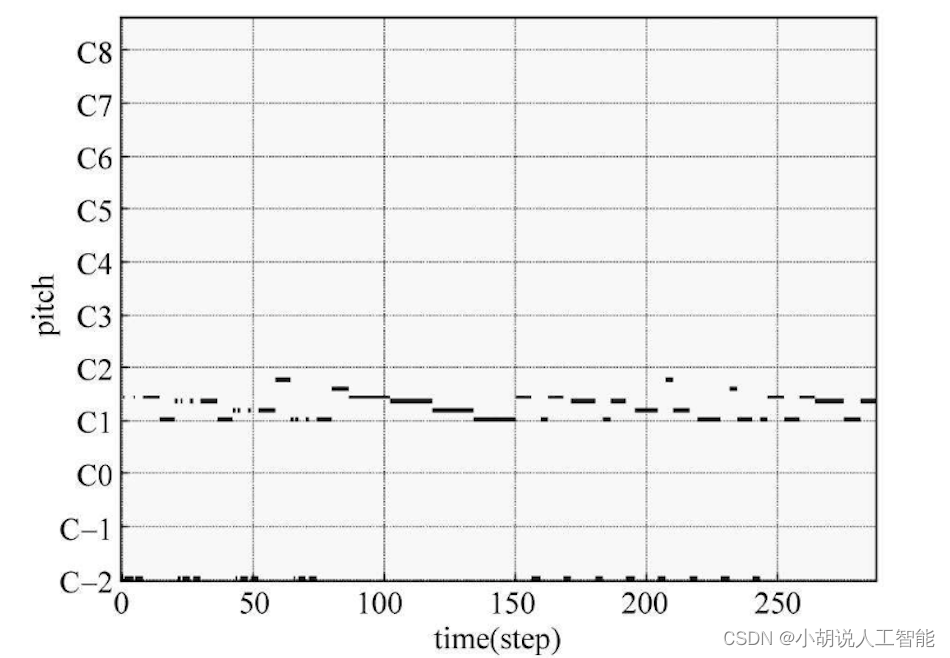
基于Python++PyQt5马尔科夫模型的智能AI即兴作曲—深度学习算法应用(含全部工程源码+测试数据)
目录 前言总体设计系统整体结构图系统流程图 运行环境Python 环境PC环境配置 模块实现1. 钢琴伴奏制作1)和弦的实现2)和弦级数转为当前调式音阶3)根据预置节奏生成伴奏 2. 乐句生成1)添加音符2)旋律生成3)节…...

Android中简单封装Livedata工具类
Android中简单封装Livedata工具类 前言: 之前讲解过livedata和viewmodel的简单使用,也封装过room工具类,本文是对livedata的简单封装和使用,先是封装了一个简单的工具类,然后实现了一个倒计时工具类的封装. 1.LiveD…...
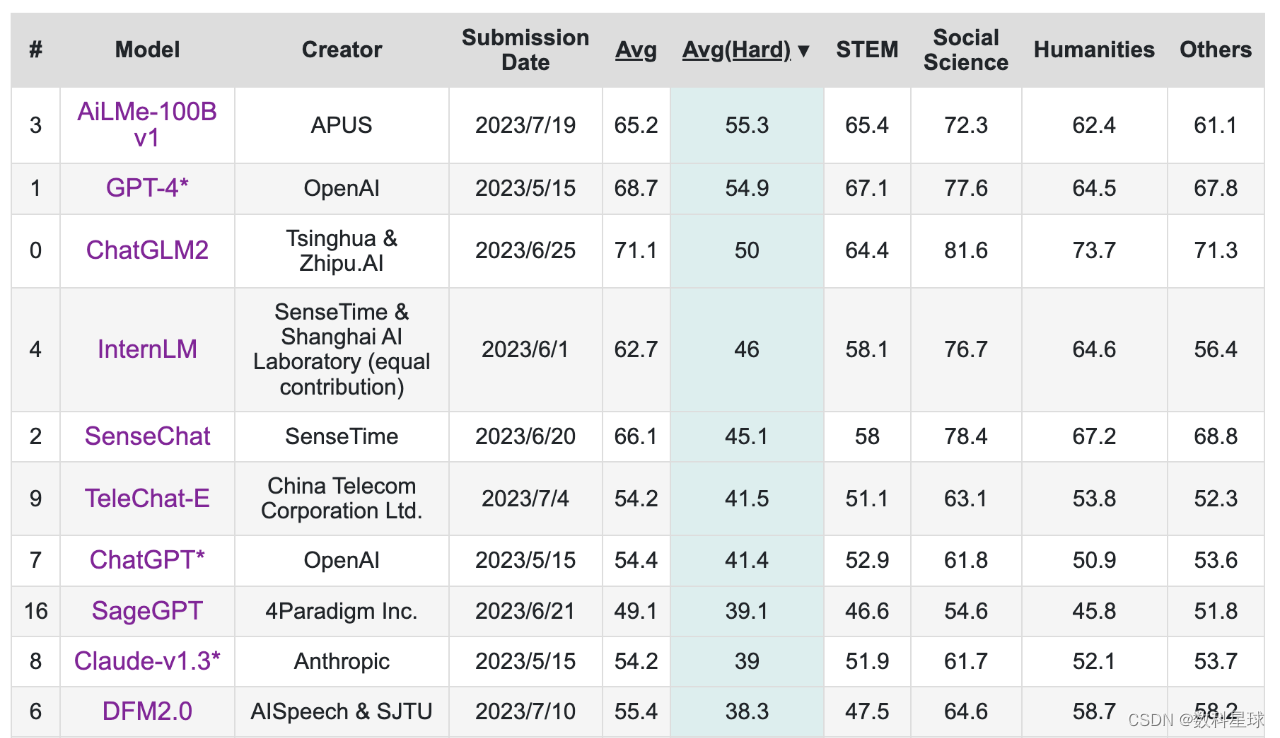
国内大模型在局部能力上已超ChatGPT
中文大模型正在后来居上,也必须后来居上。 数科星球原创 作者丨苑晶 编辑丨大兔 从GPT3.5彻底出圈后,大模型的影响力开始蜚声国际。一段时间内,国内科技公司可谓被ChatGPT按在地上打,毫无还手之力。 彼时,很多企业…...

监控设置ip地址怎么设置
监控设备的IP地址设置是保障监控系统正常工作的基础。通过设置IP地址,我们可以确定监控设备在局域网内的位置,并远程访问监控设备进行实时查看、存储视频等操作。下面虎观代理小二二将介绍具体步骤。 方法一: 和电脑连接在一起,…...

stm32G473的flash模式是单bank还是双bank?
今天突然有人stm32G473的flash模式是单bank还是双bank?由于时间太久,我真忘记了。搜搜发现,还真有人和我一样。见下面的链接:https://shequ.stmicroelectronics.cn/forum.php?modviewthread&tid644563 根据STM32G4系列参考手…...

visual studio 2022更改主题为深色
visual studio 2022更改主题为深色 点击visual studio 上方的 工具-> 选项 在选项窗口中,选择 环境 -> 常规 ,将其中的颜色主题改成深色 点击确定,更改完成...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...

【AI学习】三、AI算法中的向量
在人工智能(AI)算法中,向量(Vector)是一种将现实世界中的数据(如图像、文本、音频等)转化为计算机可处理的数值型特征表示的工具。它是连接人类认知(如语义、视觉特征)与…...

Ascend NPU上适配Step-Audio模型
1 概述 1.1 简述 Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤)&#x…...

基于Java+MySQL实现(GUI)客户管理系统
客户资料管理系统的设计与实现 第一章 需求分析 1.1 需求总体介绍 本项目为了方便维护客户信息为了方便维护客户信息,对客户进行统一管理,可以把所有客户信息录入系统,进行维护和统计功能。可通过文件的方式保存相关录入数据,对…...

【JVM面试篇】高频八股汇总——类加载和类加载器
目录 1. 讲一下类加载过程? 2. Java创建对象的过程? 3. 对象的生命周期? 4. 类加载器有哪些? 5. 双亲委派模型的作用(好处)? 6. 讲一下类的加载和双亲委派原则? 7. 双亲委派模…...
32单片机——基本定时器
STM32F103有众多的定时器,其中包括2个基本定时器(TIM6和TIM7)、4个通用定时器(TIM2~TIM5)、2个高级控制定时器(TIM1和TIM8),这些定时器彼此完全独立,不共享任何资源 1、定…...

土建施工员考试:建筑施工技术重点知识有哪些?
《管理实务》是土建施工员考试中侧重实操应用与管理能力的科目,核心考查施工组织、质量安全、进度成本等现场管理要点。以下是结合考试大纲与高频考点整理的重点内容,附学习方向和应试技巧: 一、施工组织与进度管理 核心目标: 规…...