目标检测与跟踪 (3)- TensorRTYOLO V8性能优化与部署测试
系列文章目录
目标检测与跟踪 (1)- 机器人视觉与YOLO V8_Techblog of HaoWANG的博客-CSDN博客
目标检测与跟踪 (2)- YOLO V8配置与测试_Techblog of HaoWANG的博客-CSDN博客
目录
系列文章目录
前言
YOLO v8
TensorRT
一、TensorRT
1.1 原理
1.2 架构
1.3 功能
1.4 性能
1.5 GPU并行计算
二、安装&配置
1.下载
2.安装
3. 测试导出YOLO V8
4. 部署测试
前言
YOLO v8
YOLOv8 算法的核心特性和改动可以归结为如下:
1. 提供了一个全新的 SOTA 模型,包括 P5 640 和 P6 1280 分辨率的目标检测网络和基于 YOLACT 的实例分割模型。和 YOLOv5 一样,基于缩放系数也提供了 N/S/M/L/X 尺度的不同大小模型,用于满足不同场景需求
2. Backbone:
骨干网络和 Neck 部分可能参考了 YOLOv7 ELAN 设计思想,将 YOLOv5 的 C3 结构换成了梯度流更丰富的 C2f 结构,并对不同尺度模型调整了不同的通道数。
YOLO (You Only Look Once) is a real-time object detection system that is widely used in various applications such as self-driving cars, surveillance systems, and facial recognition software. YOLO V8 is the latest version of YOLO, released in 2022.
Here are some key features of YOLO V8:
- Improved accuracy: YOLO V8 has improved object detection accuracy compared to its predecessors, especially for objects with complex shapes and sizes.
- Real-time performance: YOLO V8 is designed for real-time object detection and can process images and videos at high frame rates.
- Multi-scale features: YOLO V8 uses multi-scale features to detect objects of different sizes and shapes.
- Improved bounding box regression: YOLO V8 has improved bounding box regression, which helps to more accurately detect the location and size of objects.
- New algorithms: YOLO V8 includes several new algorithms, such as spatial pyramid pooling and a new loss function, that improve object detection accuracy and speed.
- Support for multiple platforms: YOLO V8 can be run on a variety of platforms, including Windows, Linux, and Android.
If you're interested in using YOLO V8 for a specific project, you can find more information and resources on the YOLO website, including documentation, tutorials, and sample code.
TensorRT
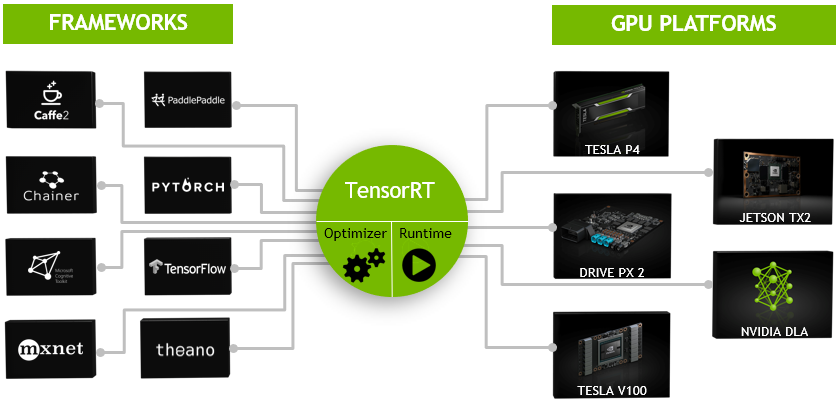
TensorRT是一个高性能的深度学习推理(Inference)优化器,可以为深度学习应用提供低延迟、高吞吐率的部署推理。TensorRT可用于对超大规模数据中心、嵌入式平台或自动驾驶平台进行推理加速。TensorRT现已能支持TensorFlow、Caffe、Mxnet、Pytorch等几乎所有的深度学习框架,将TensorRT和NVIDIA的GPU结合起来,能在几乎所有的框架中进行快速和高效的部署推理。
TensorRT 是一个C++库,从 TensorRT 3 开始提供C++ API和Python API,主要用来针对 NVIDIA GPU进行 高性能推理(Inference)加速。

一、TensorRT
TensorRT(TensorRT™)是英伟达(NVIDIA)开发的一个高性能推理优化器,旨在加速深度学习模型的推理过程。它针对英伟达GPU进行了优化,利用深度神经网络(DNN)推理的并行计算能力,提供了快速且高效的推理解决方案。下面我将详细介绍TensorRT的原理、架构、功能和性能。
(TensorRT(1)-介绍-使用-安装 | arleyzhang)
1.1 原理
TensorRT的核心原理是通过优化和精简深度学习模型,以提高推理的速度和效率。它使用了三个关键技术:
- 网络层融合(Layer Fusion):TensorRT通过将多个网络层融合成一个更大的层,减少了内存访问和计算的开销。这种融合可以消除层之间的中间结果,从而减少了内存传输和存储需求,提高了推理的速度。
- 精确度校准(Precision Calibration):TensorRT可以通过在模型推理之前对模型进行精确度校准,将浮点数参数转换为定点数参数,从而降低了内存带宽和计算的需求。这种定点计算可以在保持模型精度的同时,提高推理的速度。
- 动态张量内存(Dynamic Tensor Memory):TensorRT根据模型的需求动态分配内存,避免了不必要的内存分配和拷贝操作。这种动态内存管理减少了内存开销,提高了推理的效率。
1.2 架构
TensorRT的架构可以分为四个主要组件:
- 解析器(Parser):解析器负责将训练好的深度学习模型从常见的模型格式(如Caffe、TensorFlow、ONNX等)加载到TensorRT中进行优化和推理。
- 优化器(Optimizer):优化器是TensorRT的核心组件,它通过网络层融合、精确度校准和动态张量内存等技术对深度学习模型进行优化。优化器会分析模型的结构,并根据硬件特性和性能要求对模型进行优化,以提高推理的速度和效率。
- 推理引擎(Inference Engine):推理引擎是TensorRT的推理核心,它将优化后的模型转换为可在GPU上执行的计算图。推理引擎使用GPU的并行计算能力对模型进行高效的推理,实现快速的预测。
- 插件(Plugin):插件是TensorRT的可扩展组件,它允许用户自定义和添加额外的层、操作或功能。用户可以根据自己的需求编写插件,并将其集成到TensorRT中,以扩展其功能。
1.3 功能
TensorRT提供了丰富的功能,用于优化和加速深度学习模型的推理过程,包括:
- 网络优化:TensorRT可以自动优化和精简深度学习模型,减少模型的计算和存储需求,提高推理的速度和效率。
- 精确度控制:TensorRT支持定点计算和混合精度计算,可以在保持模型精度的同时提高推理的速度。
- 动态形状支持:TensorRT可以处理具有动态形状(Dynamic Shapes)的模型,适用于一些需要在运行时根据输入数据进行形状变化的场景。
1.4 性能
TensorRT在推理性能方面表现出色,具有以下特点:
- 高速推理:TensorRT通过使用GPU的并行计算能力和优化的推理引擎,实现了快速的推理速度。相比于传统的深度学习框架,TensorRT可以显著提高模型的推理性能。
- 低延迟:TensorRT通过优化和精简模型的计算图,减少了内存访问和计算的开销,从而降低了推理的延迟。这对于实时应用和对延迟敏感的任务非常重要。
- 高吞吐量:TensorRT可以充分利用GPU的并行计算能力,实现高吞吐量的推理。这意味着可以同时处理多个输入数据,并获得更高的推理效率。
总而言之,TensorRT是一个针对深度学习模型推理优化的高性能引擎。它通过网络层融合、精确度校准和动态张量内存等技术,提供了快速、高效的推理解决方案。TensorRT在加速推理速度、降低延迟和提高吞吐量方面具有显著优势,特别适用于对性能要求较高的应用场景。
1.5 GPU并行计算
TensorRT的推理引擎充分利用了GPU的并行计算能力,以实现高效的推理。下面是TensorRT推理引擎如何利用GPU并行计算能力的几个关键方面:
- 并行计算图: TensorRT将优化后的模型转换为适用于GPU并行计算的计算图。在这个计算图中,不同的操作可以并行执行,以最大程度地利用GPU的多个计算单元。这样可以实现高效的并行推理,提高推理速度。
- 流水线并行: TensorRT推理引擎利用计算和数据传输之间的时间差异,实现流水线并行。它将不同的计算任务划分为多个阶段,并同时执行这些阶段。这种流水线并行可以减少计算和数据传输之间的等待时间,提高GPU的利用率,从而加速推理过程。
- 批处理并行: TensorRT推理引擎支持批处理并行,即同时处理多个输入数据。在批处理中,多个输入数据可以并行地在GPU上进行计算,从而实现更高的吞吐量。这种并行计算可以大大提高推理效率,特别是对于具有大量输入数据的场景。
- 权重共享: 在某些情况下,多个模型层可以共享相同的权重。TensorRT推理引擎利用这一特性,通过共享权重来减少计算和内存访问的开销。共享权重可以减少冗余计算,提高推理速度。
- Tensor核心计算: TensorRT推理引擎使用专门的Tensor核心计算单元,在GPU上执行高效的张量操作。这些Tensor核心计算单元可以同时处理多个数据元素,实现高度并行的计算,从而提高推理速度。
通过这些并行计算技术,TensorRT推理引擎能够充分发挥GPU的并行计算能力,实现高效的推理。并行计算图、流水线并行、批处理并行、权重共享以及Tensor核心计算等方法的结合,可以显著提高模型的推理性能,并满足对于实时性、低延迟和高吞吐量的要求。
二、安装&配置
1.下载
TensorRT SDK | NVIDIA DeveloperHelps developers to optimize inference, reduce latency, and deliver high throughput for inference applications.https://developer.nvidia.com/tensorrt
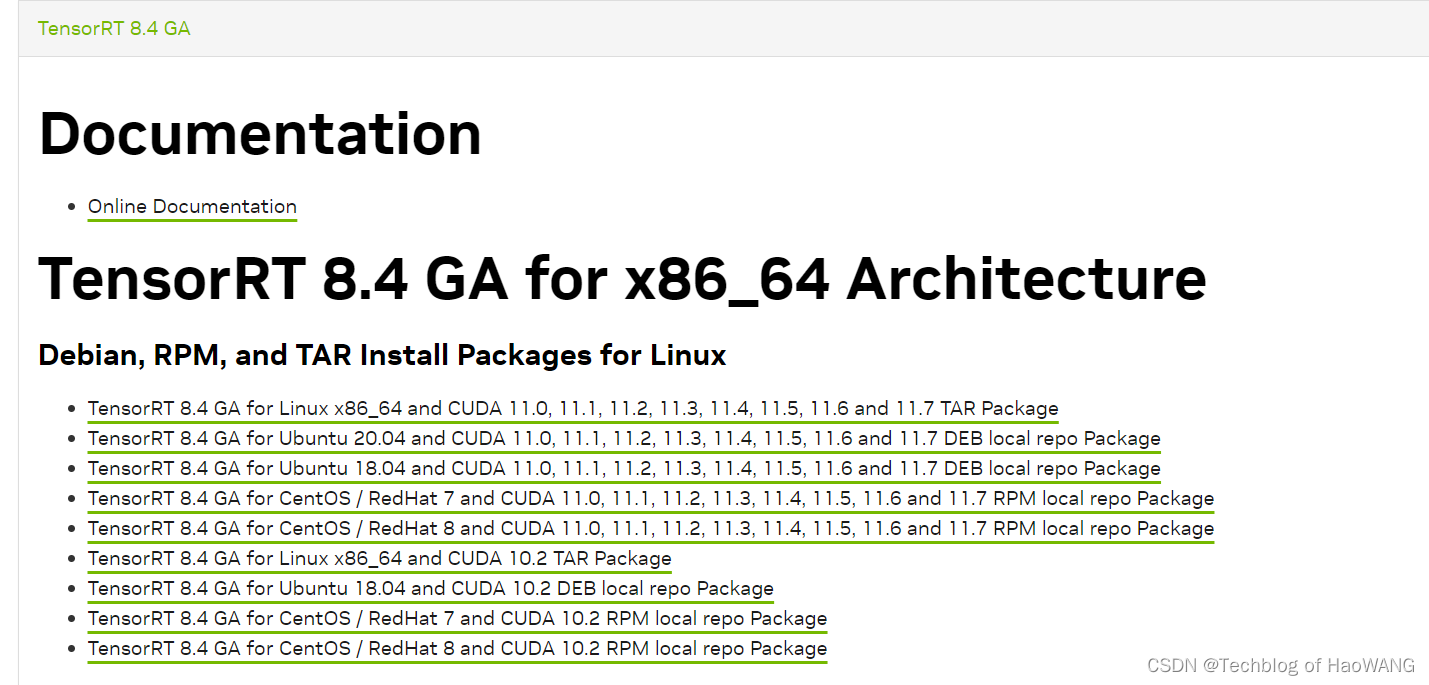
最新版本为tensorRT8 GA,根据系统下载适合的tensorRT版本:
https://developer.nvidia.com/nvidia-tensorrt-download

2.安装
1、 解压缩
tar xzvf TensorRT-X2、 安装TensorRT wheel 文件,根据python版本选择,这里是python3.7
cd TensorRT-X/python
pip install tensorrt-X.whl3、 安装graphsurgeon wheel文件
cd TensorRT-X/python
pip install graphsurgeon-X.whl4、 配置环境变量
export PATH=$PATH:/usr/local/cuda-11.1/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-11.1/lib64
export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/cuda-11.1/lib64
source /etc/profile5、有时需要设置
export LD_LIBRARY_PATH=/home/XX/TensorRT-X/lib:$LD_LIBRARY_PATH
source ~/.bashrc3. 测试导出YOLO V8
安装依赖
pip install onnx==1.12.0
pip install onnx-simplifier==0.4.0
pip install coloredlogs==15.0.1
pip install humanfriendly==10.0
pip install onnxruntime-gpu==1.12.0
pip isntall onnxsim-no-ort==0.4.0
pip install opencv-python==4.5.2.52(注意cv2一定不能用4.6.0)
pip install protobuf==3.19.4
pip install setuptools==63.2.0
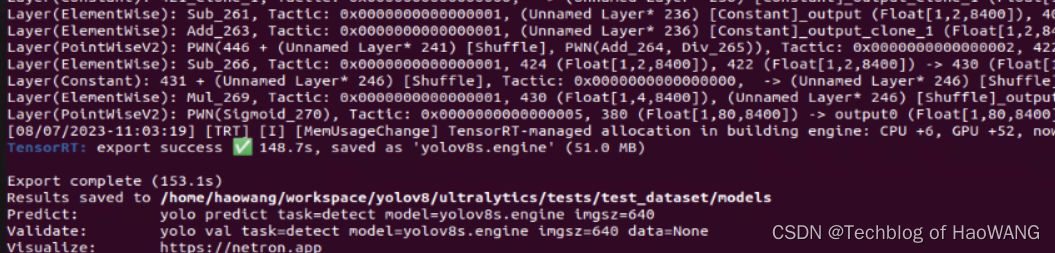
导出测试:
yolo export model=yolov8n.pt format=engine device=0 # export official model
yolo export model=path/to/best.pt format=onnx # export custom trained model
4. 部署测试
模型1:yolov8l.pt
TRT模型:yolov8l.engine
import cv2
from ultralytics import YOLO# Load the YOLOv8 model
model = YOLO('yolov8l.engine')# Open the video file
video_path = "path/to/your/video/file.mp4"cap = cv2.VideoCapture(0)# Loop through the video frames
while cap.isOpened():# Read a frame from the videosuccess, frame = cap.read()if success:# Run YOLOv8 tracking on the frame, persisting tracks between framesresults = model.track(frame, persist=True)# Visualize the results on the frameannotated_frame = results[0].plot()# Display the annotated framecv2.imshow("YOLOv8 Tracking", annotated_frame)# Break the loop if 'q' is pressedif cv2.waitKey(1) & 0xFF == ord("q"):breakelse:# Break the loop if the end of the video is reachedbreak# Release the video capture object and close the display window
cap.release()
cv2.destroyAllWindows()
对比: watch -n 1 nvidia-smi
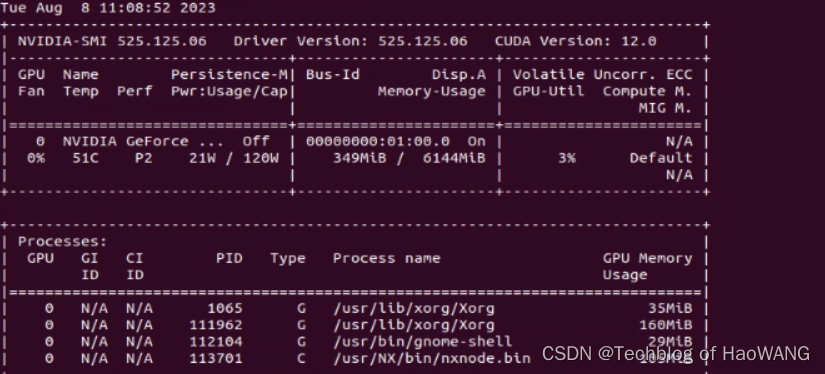
结果

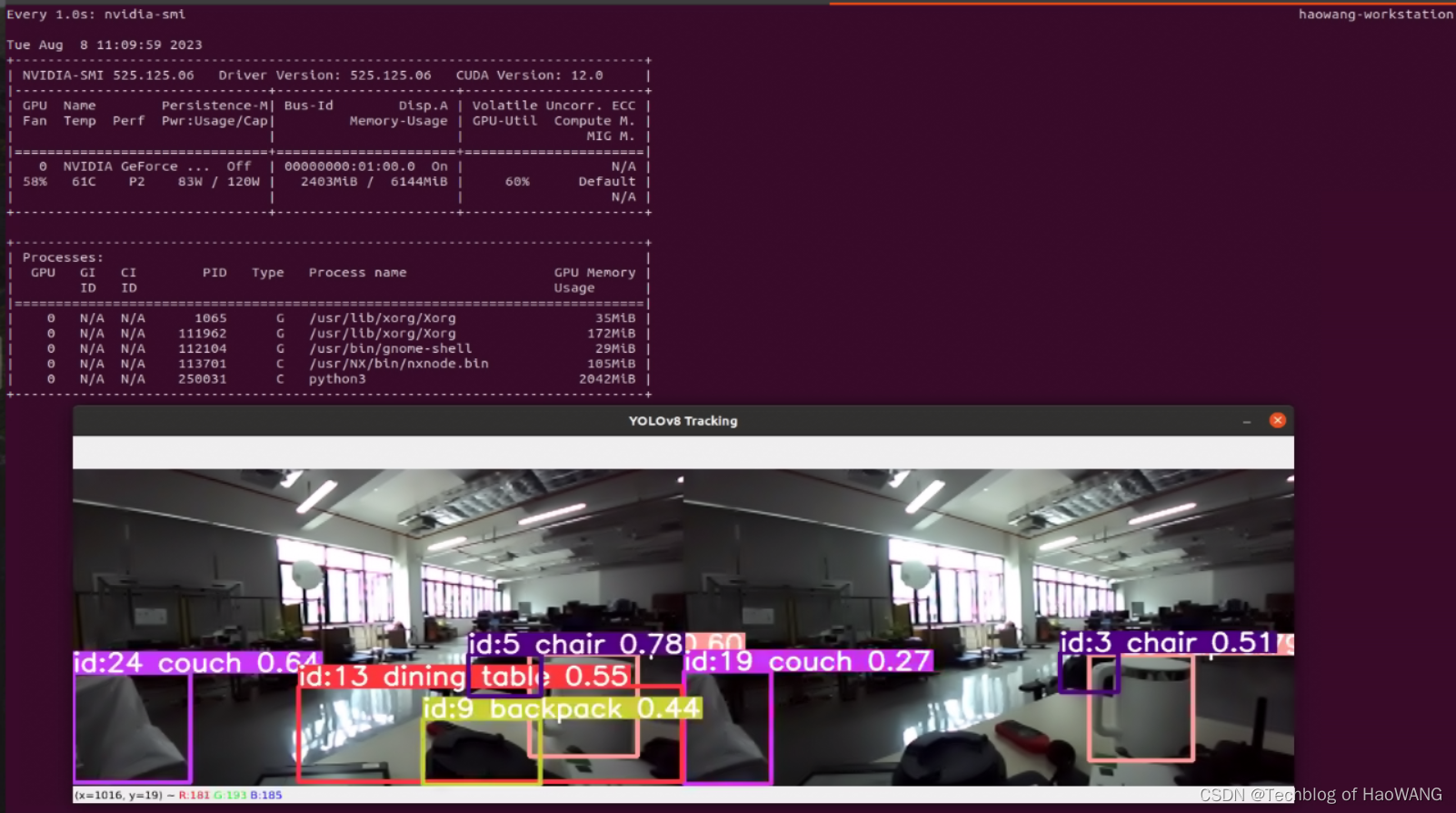
模型加载速度和检测效果有较大程度提升,并且帧率和占用也维持在合理水平,TensorRT模型优化和部署性能优异。
相关文章:
目标检测与跟踪 (3)- TensorRTYOLO V8性能优化与部署测试
系列文章目录 目标检测与跟踪 (1)- 机器人视觉与YOLO V8_Techblog of HaoWANG的博客-CSDN博客 目标检测与跟踪 (2)- YOLO V8配置与测试_Techblog of HaoWANG的博客-CSDN博客 目录 系列文章目录 前言 YOLO v8 TensorRT 一、…...
SAS-数据集SQL垂直(纵向)合并
一、SQL垂直合并的基本语法 一个selectt对应一个表,select之间用set-operator连接,set-operator包括:except(期望)、intersect(相交)、union(合并),outer un…...
SpringBoot3 整合Prometheus + Grafana
通过Prometheus Grafana对线上应用进行观测、监控、预警… 健康状况【组件状态、存活状态】Health运行指标【cpu、内存、垃圾回收、吞吐量、响应成功率…】Metrics… 1. SpringBoot Actuator 1. 基本使用 1. 场景引入 <dependency><groupId>org.springframew…...
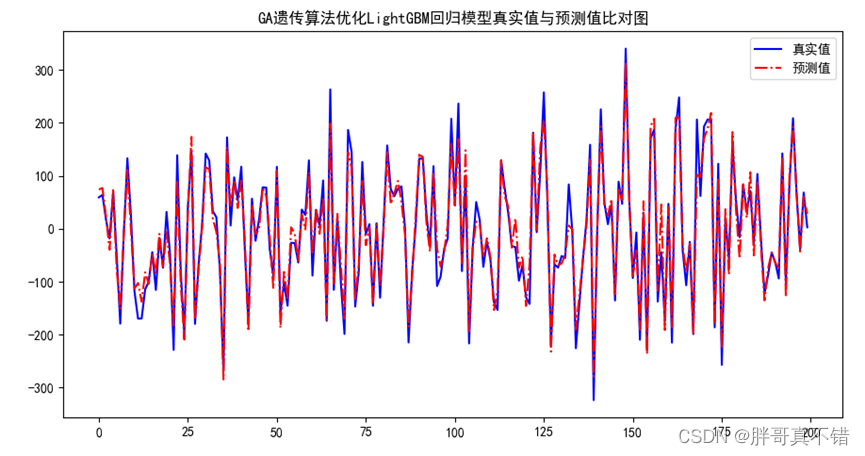
Python实现GA遗传算法优化LightGBM回归模型(LGBMRegressor算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。 1.项目背景 遗传算法(Genetic Algorithm,GA)最早是由美国的 John holland于20世…...
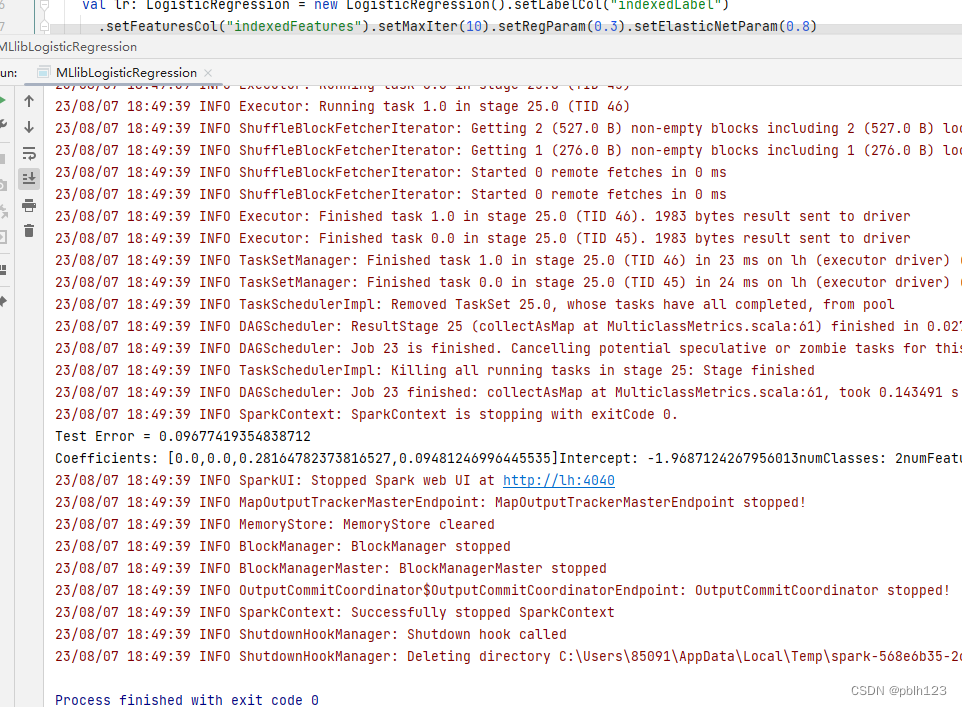
【基于IDEA + Spark 3.4.1 + sbt 1.9.3 + Spark MLlib 构建逻辑回归鸢尾花分类预测模型】
逻辑回归进行鸢尾花分类的案例 背景说明: 基于IDEA Spark 3.4.1 sbt 1.9.3 Spark MLlib 构建逻辑回归鸢尾花分类预测模型,这是一个分类模型案例,通过该案例,可以快速了解Spark MLlib分类预测模型的使用方法。 依赖 ThisBui…...
资深测试老鸟整理,性能测试-常见调优详细,卷起来...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 常见的一些性能缺…...
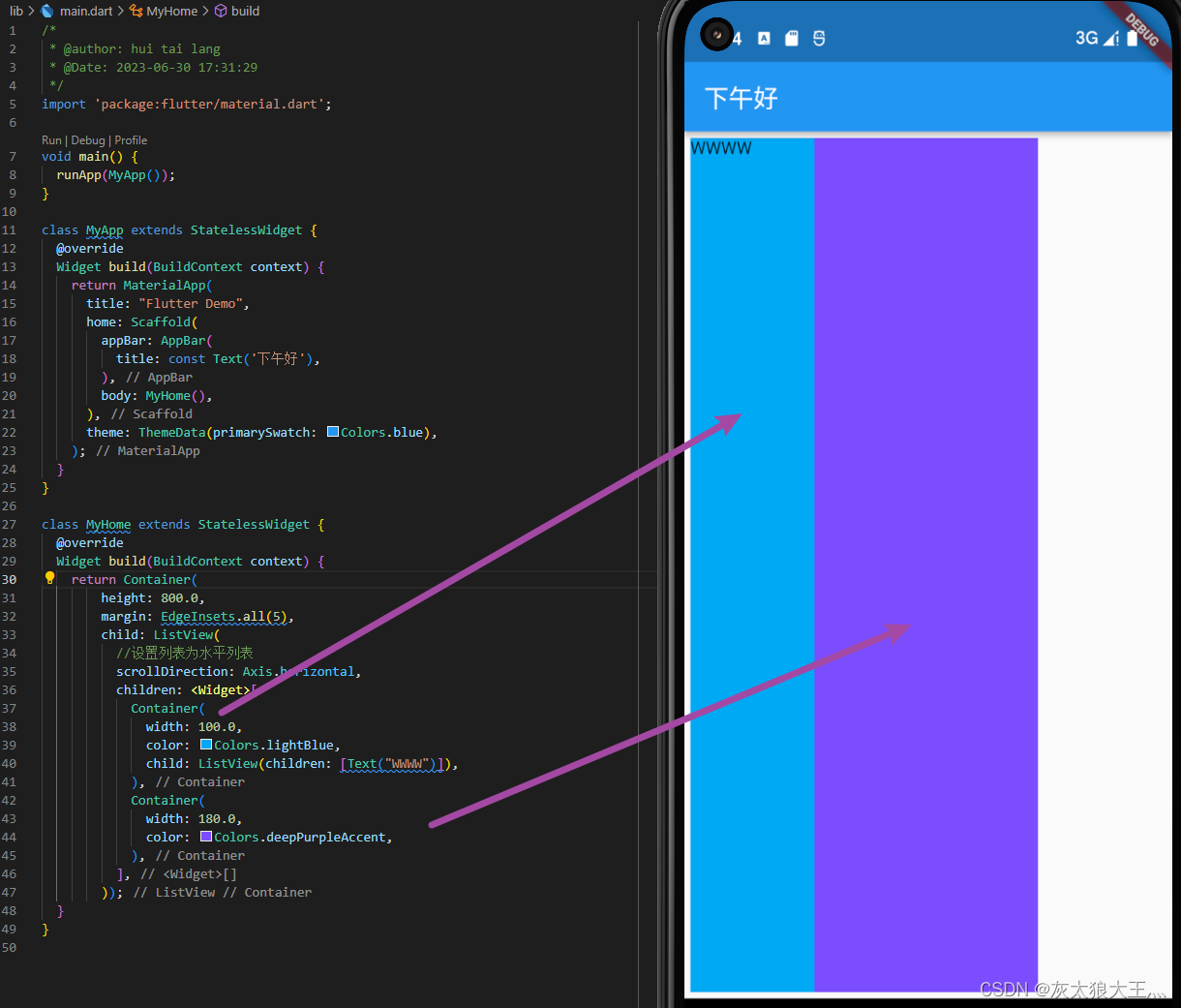
【第五章 flutter学习之flutter进阶组件-上篇】
文章目录 一、列表组件1.常规列表2.动态列表 二、FridView组件三、Stack层叠组件四、AspectRatio Card CircleAvatar组件五、按钮组件六、Stack组件七、Wrap组件八、StatefulWidget有状态组件总结 一、列表组件 1.常规列表 children: const <Widget>[ListTile(leading: …...

鸿蒙边缘计算网关正式开售
IDO-IPC3528鸿蒙边缘计算网关基于RK3568研发设计,采用22nm先进工艺制程,四核A55 CPU,主频高达2.0GHz,支持高达8GB高速LPDDR4,1T算力NPU,4K H.265/H264硬解码;视频输出接口HDMI2.0,双…...

Bytebase 2.5.0 - VCS 集成支持 Azure DevOps,支持达梦数据库
🚀 新功能 VCS 集成支持 Azure DevOps。研发版本支持达梦数据库。允许用户设置需要重新登录的频率。支持选择并导出数据库变更历史。新增 MySQL Schema 设计器。支持字段模板库。 🎄 改进 在 SQL 编辑器中,优化 MongoDB 的查询结果。优化 …...

tomcat通过systemctl启动时报错Cannot find /usr/local/tomcat/bin/setclasspath.sh
解决方法,检查自己的CATALINA_HOME和TOMCAT_HOME配置情况 我的配置在/etc/profile下的如下 使其立即生效 后将/usr/lib/systemd/system/tomcat.service中的CATALINA_HOME和TOMCAT_HOME和/etc/profile改一致 重新加载再重启解决 解决方法,检查自己的C…...
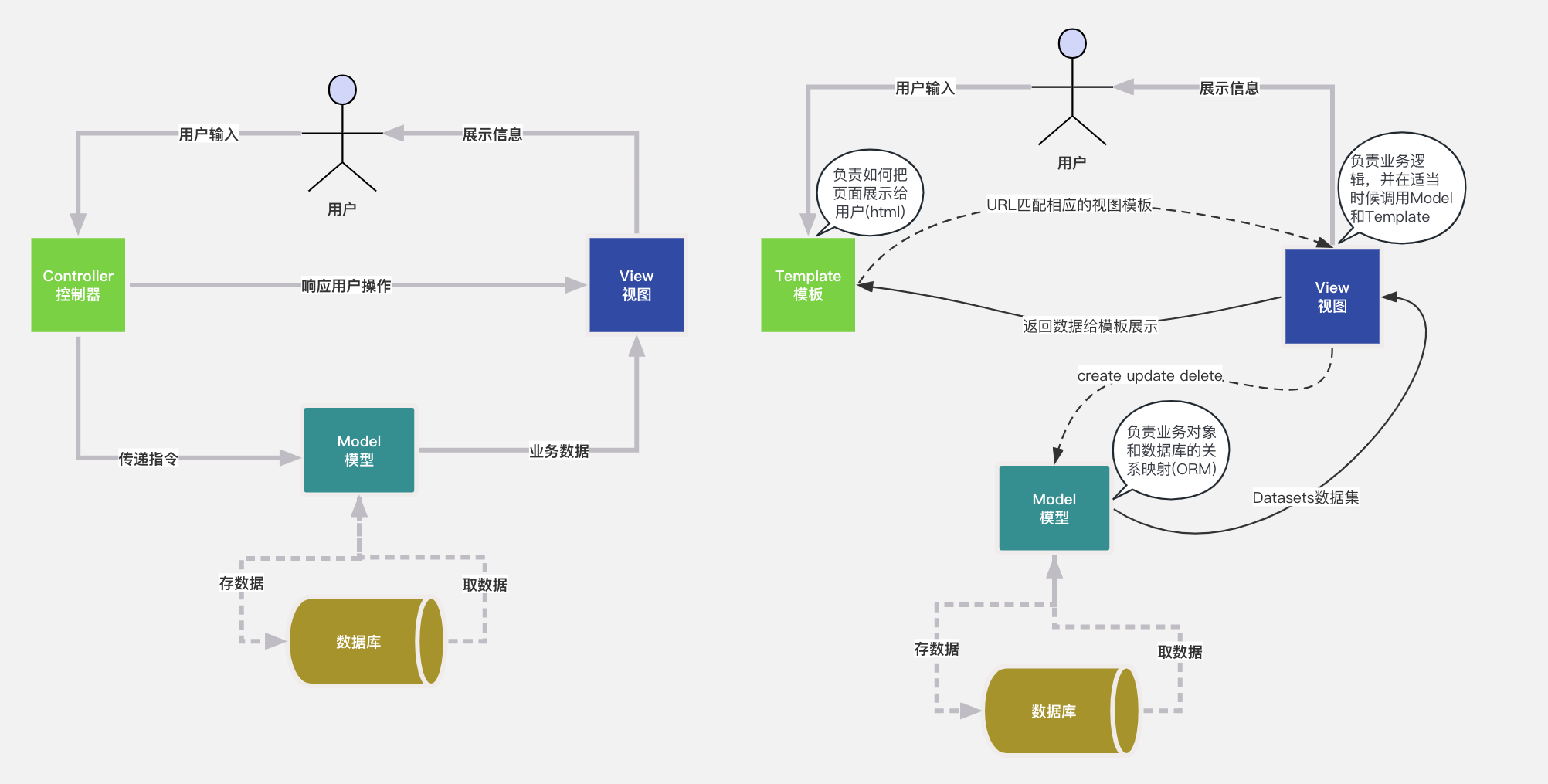
Django架构图
1. Django 简介 基本介绍 Django 是一个由 Python 编写的一个开放源代码的 Web 应用框架 使用 Django,只要很少的代码,Python 的程序开发人员就可以轻松地完成一个正式网站所需要的大部分内容,并进一步开发出全功能的 Web 服务 Django 本身…...
vue- 创建wms-web项目
vue 发展历程 安装vite 第一步 创建wms-web项目 第二步 打开文件夹并安装所有开发环境的依赖 都可以放静态资源 public>vite.svg 不会重新编译成其他名字 assets>vue.svg 会重新编译成一个随机的名称 重新编译 启动 第三步 spa 单页渲染 第四步 安装路由 第五步 …...
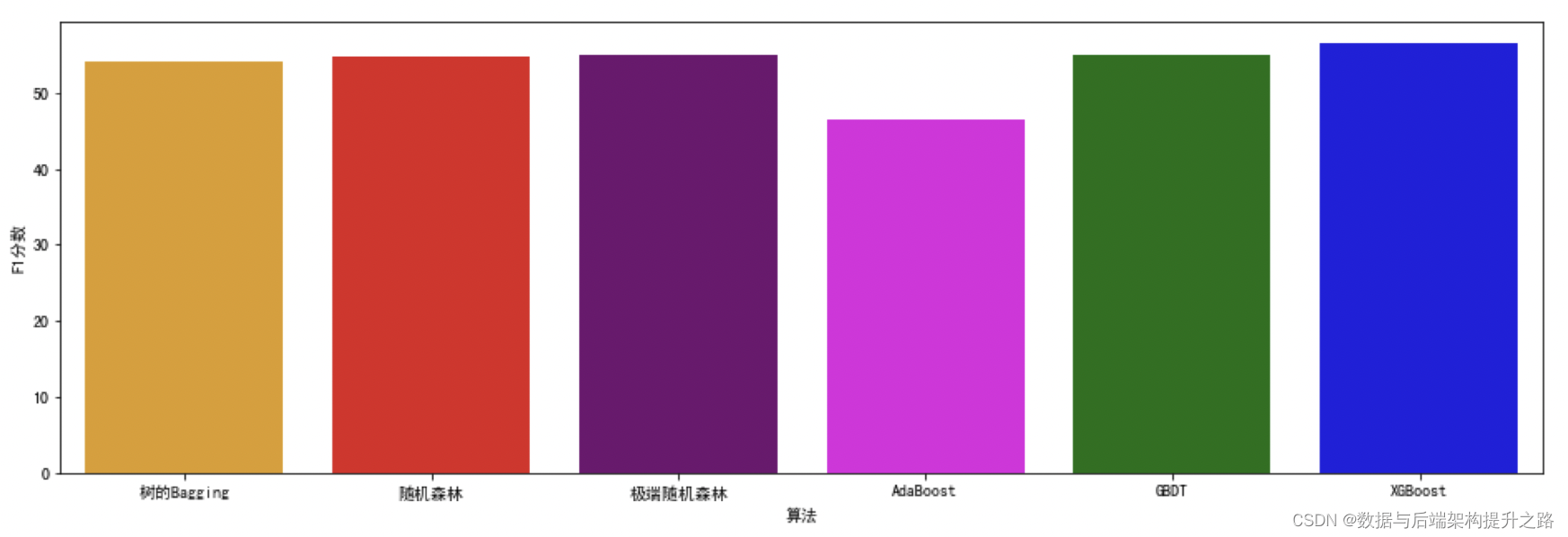
集成学习:机器学习模型如何“博采众长”
前置概念 偏差 指模型的预测值与真实值之间的差异,它反映了模型的拟合能力。 方差 指模型在不同的训练集上产生的预测结果的差异,它反映了模型的稳定性。 方差和偏差对预测结果所造成的影响 在机器学习中,我们通常希望模型的偏差和方差都…...
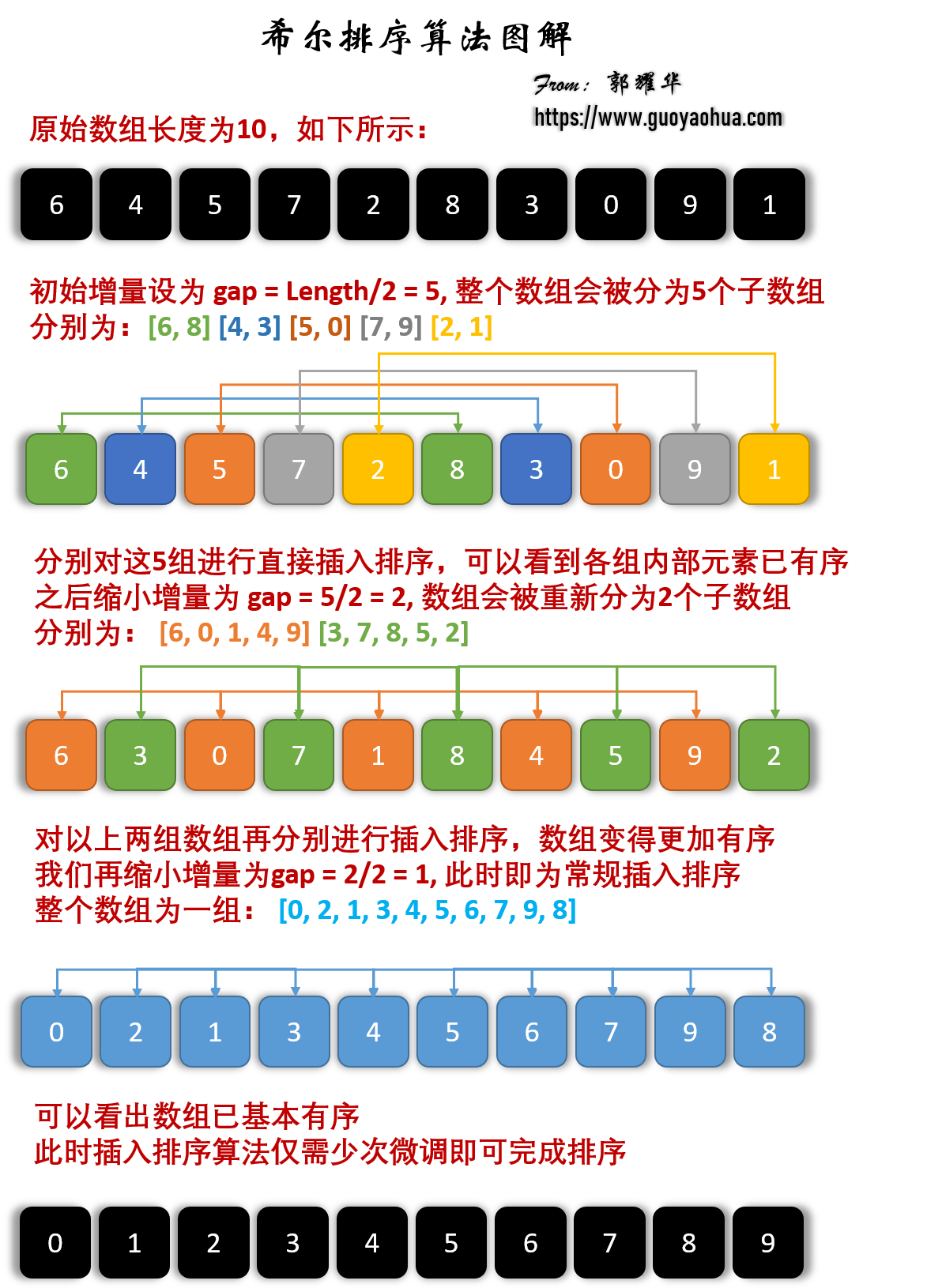
排序算法(二)
1.希尔排序-Shell Sort 1.算法原理 将未排序序列按照增量gap的不同分割为若干个子序列,然后分别进行插入排序,得到若干组排好序的序列; 缩小增量gap,并对分割为的子序列进行插入排序;最后一次的gap1,即整个…...
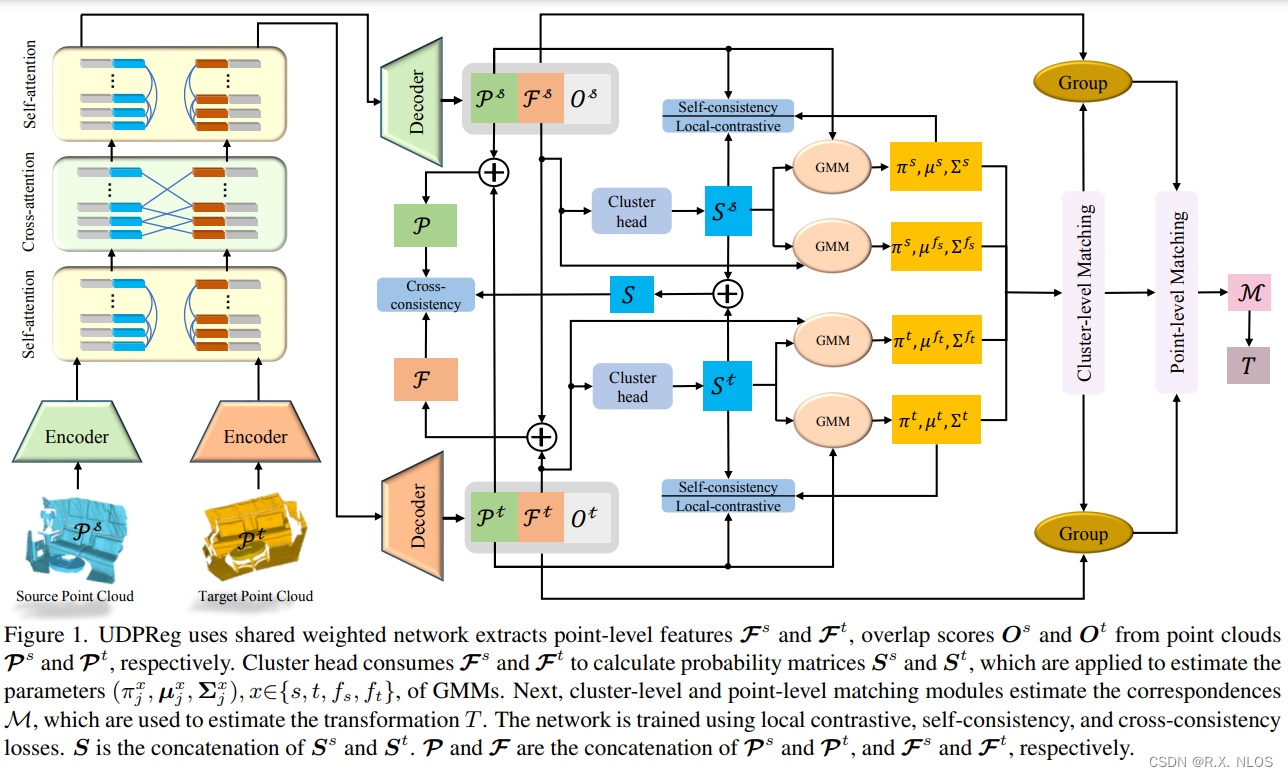
CVPR 2023 | 无监督深度概率方法在部分点云配准中的应用
注1:本文系“计算机视觉/三维重建论文速递”系列之一,致力于简洁清晰完整地介绍、解读计算机视觉,特别是三维重建领域最新的顶会/顶刊论文(包括但不限于 Nature/Science及其子刊; CVPR, ICCV, ECCV, NeurIPS, ICLR, ICML, TPAMI, IJCV 等)。本次介绍的论文是:2023年,CVPR,…...
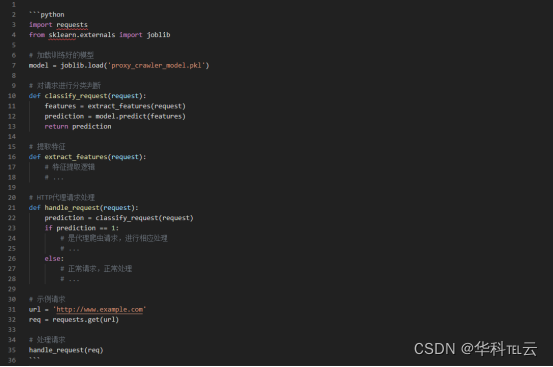
HTTP隧道识别与防御:机器学习的解决方案
随着互联网的快速发展,HTTP代理爬虫已成为数据采集的重要工具。然而,随之而来的是恶意爬虫对网络安全和数据隐私的威胁。为了更好地保护网络环境和用户数据,我们进行了基于机器学习的HTTP代理爬虫识别与防御的研究。以增强对HTTP代理爬虫的识…...
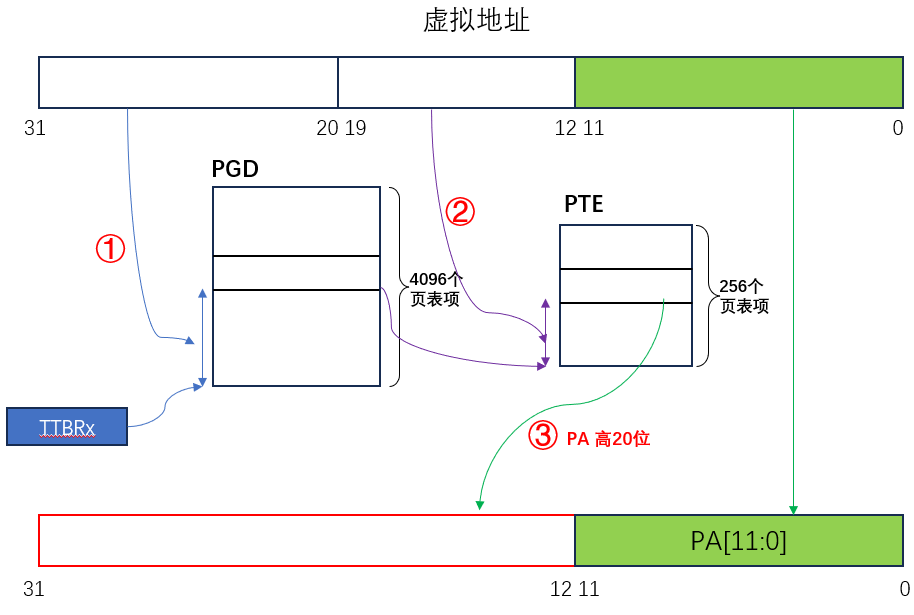
【MMU】认识 MMU 及内存映射的流程
MMU(Memory Manager Unit),是内存管理单元,负责将虚拟地址转换成物理地址。除此之外,MMU 实现了内存保护,进程无法直接访问物理内存,防止内存数据被随意篡改。 目录 一、内存管理体系结构 1、…...
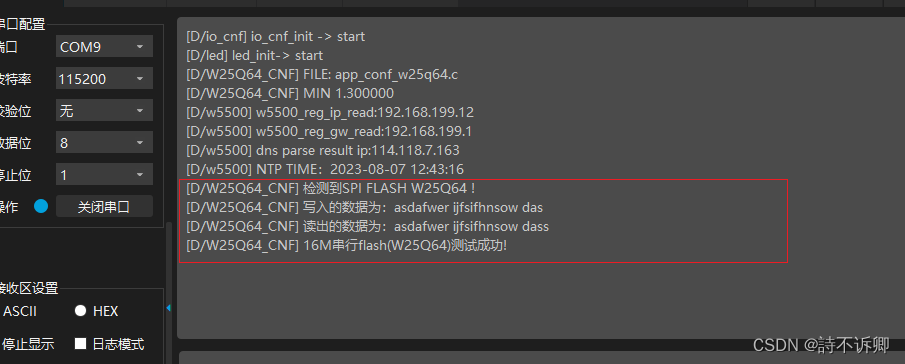
Clion开发Stm32之存储模块(W25Q64)驱动编写
前言 涵盖之前文章: Clion开发STM32之HAL库SPI封装(基础库) W25Q64驱动 头文件 #ifndef F1XX_TEMPLATE_MODULE_W25Q64_H #define F1XX_TEMPLATE_MODULE_W25Q64_H#include "sys_core.h" /* Private typedef ---------------------------------------------------…...

SpringBoot动态切换数据源
SpringBoot整合多数据源,动态添加新数据源并切换 1.需求2.创建数据源配置类3.切换数据源4.切换数据源管理类5.使用案例5.AOP切面拦截 1.需求 低代码服务需要给多套系统进行功能配置,要求表结构必须生成在对应系统的数据库中,所以表结构的生成…...

[C++项目] Boost文档 站内搜索引擎(4): 搜索的相关接口的实现、线程安全的单例index接口、cppjieba分词库的使用、综合调试...
有关Boost文档搜索引擎的项目的前三篇文章, 已经分别介绍分析了: 项目背景: 🫦[C项目] Boost文档 站内搜索引擎(1): 项目背景介绍、相关技术栈、相关概念介绍…文档解析、处理模块parser的实现: 🫦[C项目] Boost文档 站内搜索引擎(2): 文档文本解析模块…...
。】2022-5-15)
【根据当天日期输出明天的日期(需对闰年做判定)。】2022-5-15
缘由根据当天日期输出明天的日期(需对闰年做判定)。日期类型结构体如下: struct data{ int year; int month; int day;};-编程语言-CSDN问答 struct mdata{ int year; int month; int day; }mdata; int 天数(int year, int month) {switch (month){case 1: case 3:…...

C++实现分布式网络通信框架RPC(3)--rpc调用端
目录 一、前言 二、UserServiceRpc_Stub 三、 CallMethod方法的重写 头文件 实现 四、rpc调用端的调用 实现 五、 google::protobuf::RpcController *controller 头文件 实现 六、总结 一、前言 在前边的文章中,我们已经大致实现了rpc服务端的各项功能代…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...
)
是否存在路径(FIFOBB算法)
题目描述 一个具有 n 个顶点e条边的无向图,该图顶点的编号依次为0到n-1且不存在顶点与自身相连的边。请使用FIFOBB算法编写程序,确定是否存在从顶点 source到顶点 destination的路径。 输入 第一行两个整数,分别表示n 和 e 的值(1…...

3-11单元格区域边界定位(End属性)学习笔记
返回一个Range 对象,只读。该对象代表包含源区域的区域上端下端左端右端的最后一个单元格。等同于按键 End 向上键(End(xlUp))、End向下键(End(xlDown))、End向左键(End(xlToLeft)End向右键(End(xlToRight)) 注意:它移动的位置必须是相连的有内容的单元格…...

HashMap中的put方法执行流程(流程图)
1 put操作整体流程 HashMap 的 put 操作是其最核心的功能之一。在 JDK 1.8 及以后版本中,其主要逻辑封装在 putVal 这个内部方法中。整个过程大致如下: 初始判断与哈希计算: 首先,putVal 方法会检查当前的 table(也就…...

LangChain知识库管理后端接口:数据库操作详解—— 构建本地知识库系统的基础《二》
这段 Python 代码是一个完整的 知识库数据库操作模块,用于对本地知识库系统中的知识库进行增删改查(CRUD)操作。它基于 SQLAlchemy ORM 框架 和一个自定义的装饰器 with_session 实现数据库会话管理。 📘 一、整体功能概述 该模块…...

Linux 中如何提取压缩文件 ?
Linux 是一种流行的开源操作系统,它提供了许多工具来管理、压缩和解压缩文件。压缩文件有助于节省存储空间,使数据传输更快。本指南将向您展示如何在 Linux 中提取不同类型的压缩文件。 1. Unpacking ZIP Files ZIP 文件是非常常见的,要在 …...

如何更改默认 Crontab 编辑器 ?
在 Linux 领域中,crontab 是您可能经常遇到的一个术语。这个实用程序在类 unix 操作系统上可用,用于调度在预定义时间和间隔自动执行的任务。这对管理员和高级用户非常有益,允许他们自动执行各种系统任务。 编辑 Crontab 文件通常使用文本编…...

STM32HAL库USART源代码解析及应用
STM32HAL库USART源代码解析 前言STM32CubeIDE配置串口USART和UART的选择使用模式参数设置GPIO配置DMA配置中断配置硬件流控制使能生成代码解析和使用方法串口初始化__UART_HandleTypeDef结构体浅析HAL库代码实际使用方法使用轮询方式发送使用轮询方式接收使用中断方式发送使用中…...