第八篇: K8S Prometheus Operator实现Ceph集群企业微信机器人告警
Prometheus Operator实现Ceph集群企业微信告警
实现方案
我们的k8s集群与ceph集群是部署在不同的服务器上,因此实现方案如下:
(1) ceph集群开启mgr内置的exporter服务,用于获取ceph集群的metrics
(2) k8s集群通过 Service + Endponit + ServiceMonitor建立ceph集群metrics与Prometheus之间的联系
- 建立一个 ServiceMonitor 对象,用于 Prometheus 添加监控项;
- 为 ServiceMonitor 对象关联 metrics 数据接口的一个 Service 对象;
- 确保 Service 对象可以正确获取到 Metrics 数据;
(3) 通过grafana监控ceph集群
(4) 配置企业微信告警
ceph集群开启内置exporter
Ceph Luminous 12.2.1的mgr中自带了Prometheus插件,内置了 Prometheus ceph exporter,可以使用Ceph mgr内置的exporter作为Prometheus的target。
在ceph集群机器上启动ceph exporter
ceph mgr module enable prometheus
查看Prometheus的服务端口是否启动, prometues exporter启动的端口是9283
netstat -nltp | grep mgr
通过 ceph -s可以看到ceph mgr进程是在哪台机器上启动的
(base) Ceph3 ➜ ~ ceph -scluster:id: 21217f8a-8597-4734-acf6-05e9251ce7behealth: HEALTH_OKservices:mon: 3 daemons, quorum Ceph1,Ceph3,Ceph2 (age 10d)mgr: Ceph3(active, since 2w), standbys: Ceph2, Ceph1mds: cephfs:1 {0=Ceph2=up:active} 2 up:standbyosd: 24 osds: 24 up (since 2w), 24 in (since 10M)rgw: 2 daemons active (Ceph1, Ceph2)task status:data:pools: 11 pools, 857 pgsobjects: 27.06M objects, 71 TiBusage: 216 TiB used, 133 TiB / 349 TiB availpgs: 856 active+clean1 active+clean+scrubbing+deepio:client: 1.3 MiB/s rd, 867 KiB/s wr, 7 op/s rd, 23 op/s wr
这里我们可以看到ceph mgr进程在Ceph3上启动, 在浏览器中输入对应的IP跟9283端口即可访问

点击蓝色Metrics后,可以看到所有的搜集的指标信息

k8s集群配置ServiceMonitor
k8s通过 Service + Endpoints 方式, 明确将外部ceph exporter服务映射为内部 Service.
Endpoints
Endpoints是将ceph exporter服务的节点所指向的服务映射到k8s内部服务,yaml配置文件如下
apiVersion: v1
kind: Endpoints
metadata:name: ceph-monitornamespace: monitoringlabels:app: monitor-ceph
subsets:
- addresses:- ip: 10.32.0.15ports:- name: httpport: 9283protocol: TCP
这里本质上获取服务的IP与Port
Service
Service是k8s内部的服务,可供k8s集群其他服务访问。这里yaml配置文件如下:
apiVersion: v1
kind: Service
metadata:name: ceph-monitornamespace: monitoringlabels:app: monitor-ceph
spec:type: ClusterIP clusterIP: Noneports:- name: httpport: 9283protocol: TCPtargetPort: 9283
这里需要注意:Service与Endpoints的name要保持一样,另外labels的命名要与name区分开,不要设置成一样,否则会导致咱们的服务无法访问。
ServiceMonitor
通过配置ServiceMonitor可以让Prometheus自动识别到ceph target. yaml文件如下:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:name: ceph-monitornamespace: monitoringlabels:release: prometheus
spec:endpoints:- port: httpinterval: 30sselector:matchLabels:app: monitor-cephnamespaceSelector:matchNames:- monitoring
这里的labels设置要与Prometheus对象中一致,否则可能会导致ceph的服务无法被Prometheus识别。
将上面三个配置写入到ceph-monitor.yaml文件,然后执行下述命令即可。
kubectl apply -f ceph-monitor.yaml

打开Prometheus网站可以发现Targets中已经可以监控到ceph集群了,接下来开始配置具体的监控内容和告警。
grafana配置ceph监控告警
配置监控规则方法
prometheus的监控规则文件在prometheus Pod中的路径:/etc/prometheus/rules/prometheus-prometheus-kube-prometheus-prometheus-rulefiles-0/

而这些文件都是通过一个叫PrometheusRule的k8s资源生成的,PrometheusRule用于配置Promtheus的 Rule 规则文件,包括 recording rules 和 alerting,可以自动被 Prometheus 加载。
至于为什么 Prometheus 能够识别这个 PrometheusRule 资源对象呢?这就需要查看我们创建的 prometheus 这个资源对象了,里面有非常重要的一个属性 ruleSelector,用来匹配 rule 规则的过滤器,我们这里没有过滤,所以可以匹配所有的,假设要求匹配具有 prometheus=k8s 和 role=alert-rules 标签的 PrometheusRule 资源对象,则可以添加下面的配置:
ruleSelector:matchLabels:prometheus: k8srole: alert-rules
为了监控ceph集群,我们需要自定义一些报警规则,其实就是创建一个PrometheusRule的对象即可,然后Prometheus会自动识别。接下来我们重点关注我们需要创建的规则内容。
配置ceph监控规则
首先我们需要整理一下ceph集群一些非常重要的监控内容:
- ceph 几个重要的服务进程:mon, mgr, mds, osd, rgw
- ceph osd 的使用率
- ceph集群的状态
- ceph集群IO效率
PrometheusRule
PrometheusRule defines recording and alerting rules for a Prometheus instance
| Field | Description |
|---|---|
apiVersion string | monitoring.coreos.com/v1 |
kind string | PrometheusRule |
metadata Kubernetes meta/v1.ObjectMeta | Refer to the Kubernetes API documentation for the fields of the metadata field. |
spec PrometheusRuleSpec | Specification of desired alerting rule definitions for Prometheus. |
配置ceph监控规则
目前网上配置ceph的规则文章基本都没有用,大家都不懂什么意思,这里建议大家弄懂规则的制定方法。
这里有一些注意事项需要说一下:
-
PrometheusRule的metadata下的标签一定要配置一个与k8s集群中prometheus: ruleSelector下定义的相同的标签,否则配置的Rule无法被Prometheus识别
-
获取prometheus的yaml文件:kubectl get prometheus -n monitoring -o yaml > prometheus.yaml
-
找到ruleSelector section下的配置信息,例如:
ruleSelector:matchLabels:release: prometheus这里我们找到了标签:release,在配置rule时,填入即可。
-
-
配置的规则涉及的指标要从ceph exporter服务中获取。规则的设置方法如下:
- alert: CephClusterexpr: ceph_health_status > 0 # 规则的计算公式,需要使用相应的metrics,从ceph exporer服务中获取for: 3mlabels:severity: criticalstatus: 非常严重annotations:summary: "{{$labels.instance}}: Ceph集群状态异常"description: "{{$labels.instance}}:Ceph集群状态异常,当前状态为{{ $value }}"
expr的设计规则
PrometheusRule中的 expr字段用于定义监控规则的表达式。该表达式使用PromQL(Prometheus查询语言)来指定要监控的指标以及触发警报的条件。以下是PromQL的一些常用语法和使用方法的详细介绍:
-
指标选择器:
- 使用
<metric_name>选择特定的指标,例如:cpu_usage - 使用
<metric_name>{<label_name>="<label_value>"}选择带有特定标签值的指标,例如:cpu_usage{instance="server1", job="web"}
- 使用
-
二元操作符:
==:等于!=:不等于>:大于>=:大于等于<:小于<=:小于等于
-
逻辑操作符:
and:逻辑与or:逻辑或unless:逻辑非
-
函数:
rate(<metric_name>[<time_range>]):计算指标的速率,例如:rate(cpu_usage[5m])sum(<vector>):对指标向量进行求和,例如:sum(cpu_usage)avg(<vector>):对指标向量进行平均值计算,例如:avg(cpu_usage)
-
时间范围:
[<duration>]:指定一个时间范围,例如:[5m]表示过去5分钟的数据
ceph的监控规则
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:labels:prometheus: k8srole: alert-rulesrelease: prometheusname: ceph-rulesnamespace: monitoring
spec:groups:- name: cephrules:- alert: CephClusterexpr: ceph_health_status > 0for: 3mlabels:severity: criticalstatus: 非常严重annotations:summary: "{{$labels.instance}}: Ceph集群状态异常"description: "{{$labels.instance}}:Ceph集群状态异常,当前状态为{{ $value }}"- alert: CephOSDDownexpr: count(ceph_osd_up{} == 0.0) > 0for: 3mlabels:severity: criticalstatus: 非常严重annotations:summary: "{{$labels.instance}}: 有{{ $value }}个OSD挂掉了"description: "{{$labels.instance}}:{{ $labels.osd }}当前状态为{{ $labels.status }}"- alert: CephOSDOutexpr: count(ceph_osd_up{}) - count(ceph_osd_in{}) > 0for: 3mlabels:severity: criticalstatus: 非常严重annotations:summary: "{{$labels.instance}}: 有{{ $value }}个OSD Out"description: "{{$labels.instance}}:{{ $labels.osd }}当前状态为{{ $labels.status }}"- alert: CephOverSpaceexpr: ceph_cluster_total_used_bytes / ceph_cluster_total_bytes * 100 > 80for: 3mlabels:severity: criticalstatus: 非常严重annotations:summary: "{{$labels.instance}}:集群空间不足"description: "{{$labels.instance}}:当前空间使用率为{{ $value }}"- alert: CephMonDownexpr: count(ceph_mon_quorum_status{}) < 3for: 3mlabels:severity: criticalstatus: 非常严重annotations:summary: "{{$labels.instance}}:Mon进程异常"description: "{{$labels.instance}}: Mon进程Down"- alert: CephMgrDownexpr: sum(ceph_mgr_status{}) < 1.0for: 3mlabels:severity: criticalstatus: 非常严重annotations:summary: "{{$labels.instance}}:Mgr进程异常"description: "{{$labels.instance}}: Mgr进程Down"- alert: CephMdsDownexpr: sum(ceph_mds_metadata{}) < 3.0for: 3mlabels:severity: warningstatus: 告警annotations:summary: "{{$labels.instance}}:Mds进程异常"description: "{{$labels.instance}}: Mds进程Down"- alert: CephRgwDownexpr: sum(ceph_rgw_metadata{}) < 2.0for: 3mlabels:severity: warningstatus: 告警annotations:summary: "{{$labels.instance}}:Rgw进程异常"description: "{{$labels.instance}}: Rgw进程Down"- alert: CephOsdOverexpr: sum(ceph_osd_stat_bytes_used / ceph_osd_stat_bytes > 0.8) by (ceph_daemon) > 0for: 3mlabels:severity: warningstatus: 告警annotations:summary: "{{$labels.instance}}:High OSD Usage Alert"description: "{{$labels.instance}}: Some OSDs have usage above 80%"在k8s集群中配置生效,然后检查是否生效。如果没有生效,回去检查ruleSelector的标签是否配置正确
kubectl apply -f ceph_rules.yaml -n monitoring

说明我们的配置生效了,接下来开始在grafana中配置企业微信告警
Grafana配置企业微信告警
配置企业微信机器人
这里很简单,就不展开了。具体操作流程:找一个自己是群主的群聊,然后点击企业微信右上角的 ...并点击添加机器人,点击 新创建一个机器人,输入机器人名称及配置图片就生成好了。最后会得到一个链接: https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=xxx。
这里我配置了,但是无法直接在Grafana中配置webhook进行发送告警信息,这里需要使用第三方服务进行信息中转才能将消息发送到企业微信机器人。
部署中转服务
我在github上找到了两个项目:
第一个是 g2ww 我尝试了,并没有发送成功,总是报 40038, url长度错误。这里pass掉
第二个是 cloopy, 这个项目我测试成功。下面是我的处理流程:
step1 首先下载项目
git clone https://github.com/liozzazhang/message-transfer.git
step2 由于我使用的是k8s部署,所以这里要生成镜像部署,下面是生成的Dockerfile
FROM golang:latest AS buildCOPY . /go/src
WORKDIR /go/srcRUN CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go build -o /go/bin/cloopy *.goFROM alpineCOPY --from=build /go/bin/cloopy /cloopy
ENV TZ=Asia/Shanghai
CMD ["/cloopy"]
根据dockerfile生成镜像
docker build -t cloopy:latest .
step3 测试验证:镜像生成之后可以直接在本机上进行部署测试验证是否可以转发告警信息
docker run --rm -d -p 12345:12345 cloopy:latest
docker启动成功后,可以通过 docker logs -f $container_id 进行查看服务启动日志。
在grafana网页的添加Contact Points页面添加URL, URL格式为:http://10.66.17.96:12345/cloopy/grafana?webhook=https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=xxx

step4 测试通过后,开始编写k8s部署的yaml文件,如果使用域名的话,还需配置ingress
---
apiVersion: apps/v1
kind: Deployment
metadata:name: cloopynamespace: monitoringlabels:app: cloopy
spec:replicas: 1 selector:matchLabels:app: cloopytemplate:metadata:labels:app: cloopyspec:affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: kubernetes.io/hostnameoperator: Invalues:- master01- master02- master03containers:- name: cloopyimage: cloopy:latest# command:# - /bin/bash # - "./bin/monitor.sh"ports:- containerPort: 12345---
apiVersion: v1
kind: Service
metadata:name: cloopy namespace: monitoringlabels:app: cloopy
spec:ports:- name: httpport: 12345protocol: TCPtargetPort: 12345selector:app: cloopy type:LoadBalancer
------
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:name: cloopy namespace: monitoring
spec:ingressClassName: nginxrules:- host: webhook.com http:paths:- path: /pathType: Prefixbackend:service:name: cloopyport: number: 12345 path: /然后在k8s上进行部署即可: kubectl apply -f development.yaml。部署完成后,将grafana里URL测试环境的服务地址换成生产环境的域名或者IP再验证一下就可以了。
http://webhook.com/cloopy/grafana?webhook=https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=xxx
至此企业微信的Webhook便配置成功了。
配置企业微信
需要创建企业微信应用程序,并得到corp_id, secret_id, app_id。这几个变量要配置好。
然后将这几个变量配置到webcam下对应的变量就可以使用了,这个比较简单,但是其灵活性不如企业微信机器人。
配置告警规则
在配置告警规则时,我遇到了另外一个问题:通过AlertManager配置的rule无法在datasource Prometheus下进行告警,配置Alert时找不到这些告警内容,这里只能重新创建Alert Rule,然后再通过label进行绑定。

所以我将ceph下的规则又重新配置了一遍,我目前还没有找到好的方法进行yaml文件配置,等以后发现了再补充,目前是手动添加告警规则。
参考
如何用 Prometheus Operator 监控 K8s 集群外服务? - 掘金 (juejin.cn)
使用Operator管理Prometheus · Prometheus中文技术文档
Getting Started - Prometheus Operator (prometheus-operator.dev)
K8S集群部署kube-Prometheus监控Ceph(版本octopus)集群、并实现告警。_promethus基于ceph相关的告警规则_石头-豆豆的博客-CSDN博客
Prometheus Operator 配置PrometheusRule告警规则_prometheus runbook_url_富士康质检员张全蛋的博客-CSDN博客
prometheus-operator/Documentation/api.md at main · prometheus-operator/prometheus-operator · GitHub
相关文章:
第八篇: K8S Prometheus Operator实现Ceph集群企业微信机器人告警
Prometheus Operator实现Ceph集群企业微信告警 实现方案 我们的k8s集群与ceph集群是部署在不同的服务器上,因此实现方案如下: (1) ceph集群开启mgr内置的exporter服务,用于获取ceph集群的metrics (2) k8s集群通过 Service Endponit Ser…...

软件单元测试
单元测试目的和意义 对于非正式的软件(其特点是功能比较少,后续也不有新特性加入,不用负责维护),我们可以使用debug单步执行,内存修改,检查对应的观测点是否符合要求来进行单元测试,…...

Redis | 集群模式
Redis | 集群模式 随着互联网应用规模的不断扩大,单一节点的数据库性能已经无法满足大规模应用的需求。为了提高数据库的性能和可扩展性,分布式数据库成为了解决方案之一。Redis 作为一个高性能的内存数据库,自然也有了自己的分布式部署方式…...
8.3day04git+数据结构
文章目录 git版本控制学习高性能的单机管理主机的心跳服务算法题 git版本控制学习 一个免费开源,分布式的代码版本控制系统,帮助开发团队维护代码 作用:记录代码内容,切换代码版本,多人开发时高效合并代码内容 安装g…...
04-5_Qt 5.9 C++开发指南_QComboBox和QPlainTextEdit
文章目录 1. 实例功能概述2. 源码2.1 可视化UI设计2.2 widget.h2.3 widget.cpp 1. 实例功能概述 QComboBox 是下拉列表框组件类,它提供一个下拉列表供用户选择,也可以直接当作一个QLineEdit 用作输入。OComboBox 除了显示可见下拉列表外,每个…...

Sqlserver_Oracle_Mysql_Postgresql不同关系型数据库之主从延迟的理解和实验
关系型数据库主从节点的延迟是否和隔离级别有关联,个人认为两者没有直接关系,主从延迟在关系型数据库中一般和这两个时间有关:事务日志从主节点传输到从节点的时间事务日志在从节点的应用时间 事务日志从主节点传输到从节点的时间࿰…...
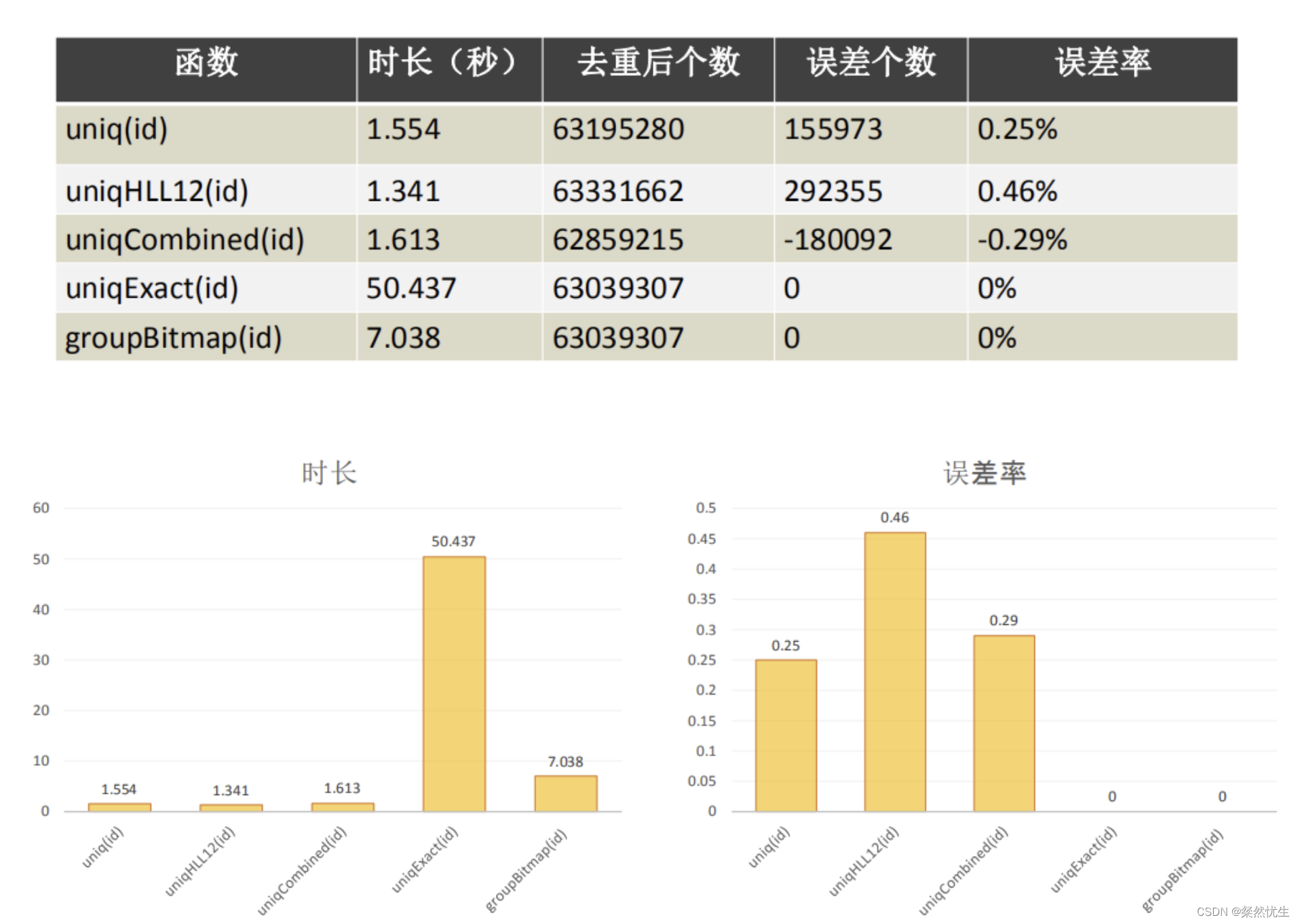
Clickhouse学习系列——一条SQL完成gourp by分组与不分组数值计算
笔者在近一两年接触了Clickhouse数据库,在项目中也进行了一些实践,但一直都没有一些技术文章的沉淀,近期打算做个系列,通过一些具体的场景将Clickhouse的用法进行沉淀和分享,供大家参考。 首先我们假设一个Clickhouse数…...

做好“关键基础设施提供商”角色,亚马逊云科技加快生成式AI落地
一场关于生产力的革命已在酝酿之中。全球管理咨询公司麦肯锡在最近的报告《生成式人工智能的经济潜力:下一波生产力浪潮》中指出,生成式AI每年可能为全球经济增加2.6万亿到4.4万亿美元的价值。在几天前的亚马逊云科技纽约峰会中,「生成式AI」…...

如何使用 ChatGPT 规划家居装修
你正在计划家庭装修项目,但不确定从哪里开始?ChatGPT 随时为你提供帮助。从集思广益的设计理念到估算成本,ChatGPT 可以简化你的家居装修规划流程。在本文中,我们将讨论如何使用 ChatGPT 有效地规划家居装修,以便你的项…...

题解 | #1002.Random Nim Game# 2023杭电暑期多校7
1002.Random Nim Game 诈骗博弈题 题目大意 Nim是一种双人数学策略游戏,玩家轮流从不同的堆中移除棋子。在每一轮游戏中,玩家必须至少取出一个棋子,并且可以取出任意数量的棋子,条件是这些棋子都来自同一个棋子堆。走最后一步棋…...

篇九:组合模式:树形结构的力量
篇九:“组合模式:树形结构的力量” 开始本篇文章之前先推荐一个好用的学习工具,AIRIght,借助于AI助手工具,学习事半功倍。欢迎访问:http://airight.fun/。 另外有2本不错的关于设计模式的资料,…...
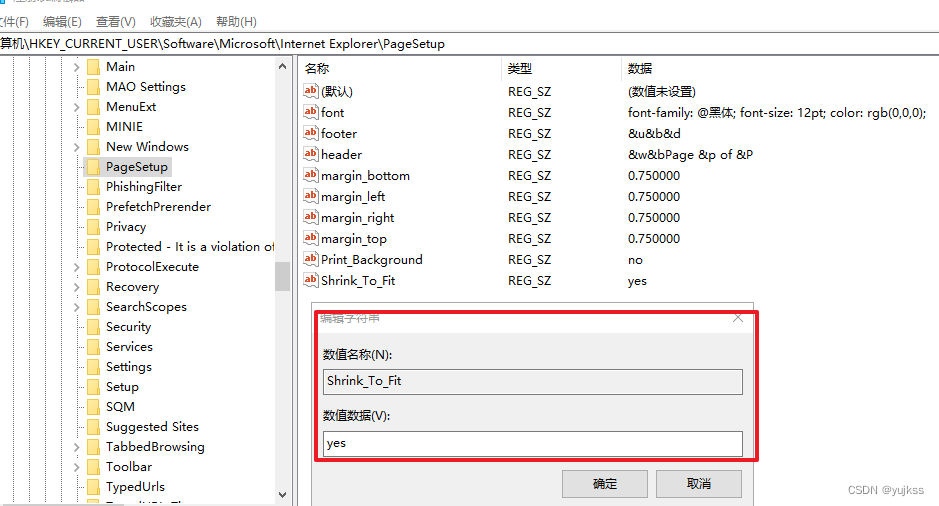
【注册表】windows系统注册表常用修改方案
文章目录 ◆ 修改IE浏览器打印页面参数设置◆气泡屏幕保护◆彩带屏幕保护程序◆过滤IP(适用于WIN2000)◆禁止显示IE的地址栏◆禁止更改IE默认的检查(winnt适用)◆允许DHCP(winnt适用)◆局域网自动断开的时间(winnt适用)◆禁止使用“重置WEB设置”◆禁止更…...

ant-design-vue 4.x升级问题-样式丢失问题
[vue] ant-design-vue 4.x升级问题-样式丢失问题 项目环境问题场景解决方案 该文档是在升级ant-design-vue到4.x版本的时候遇到的问题 项目环境 "vue": "^3.3.4", "ant-design-vue": "^4.0.0", "vite": "^4.4.4&quo…...

【果树农药喷洒机器人】Part3:变量喷药系统工作原理介绍
本专栏介绍:免费专栏,持续更新机器人实战项目,欢迎各位订阅关注。 关注我,带你了解更多关于机器人、嵌入式、人工智能等方面的优质文章! 文章目录 一、变量喷药系统工作原理二、液压通路设计与控制系统封装2.1液压通路…...

GoogLeNet创新点总结
GoogLeNet是一种深度卷积神经网络架构,于2014年由Google团队提出,是ILSVRC(ImageNet Large Scale Visual Recognition Challenge)比赛的冠军模型,其创新点主要集中在以下几个方面: Inception模块&#…...
)
不同路径1、2、3合集(980. 不同路径 III)
不同路径一 矩形格,左上角 到 右下角。 class Solution {int [] directX new int[]{-1,1,0,0};int [] directY new int[]{0,0,-1,1};int rows;int cols;public int uniquePathsIII(int[][] grid) {if (grid null || grid.length 0 || grid[0].length 0) {ret…...

【云原生】Yaml文件详解
目录 一、YAML 语法格式1.1查看 api 资源版本标签1.2 写一个yaml文件demo1.3 详解k8s中的port 一、YAML 语法格式 Kubernetes 支持 YAML 和 JSON 格式管理资源对象JSON 格式:主要用于 api 接口之间消息的传递YAML格式:用于配置和管理,YAML 是…...

ffmpeg下载安装教程
ffmpeg官网下载地址https://ffmpeg.org/download.html 这里以windows为例,鼠标悬浮到windows图标上,再点击 Windows builds from gyan.dev 或者直接打开 https://www.gyan.dev/ffmpeg/builds/ 下载根据个人需要下载对应版本 解压下载的文件,并复制bin所在目录 新打开一个命令…...
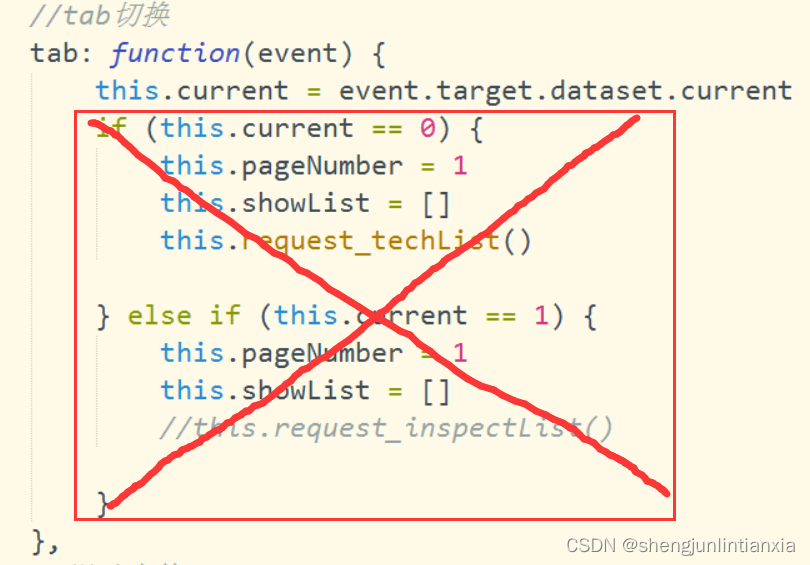
uniapp之当你问起“tab方法触发时eventchange也跟着触发了咋办”时
我相信没有大佬会在这个问题上卡两个小时吧,记下来大家就当看个乐子了。 当时问题就是,点击tab头切换的时候,作为tab滑动事件的eventchange同时触发了,使得接口请求了两次 大概是没睡好,我当时脑子老想着怎么阻止它冒…...
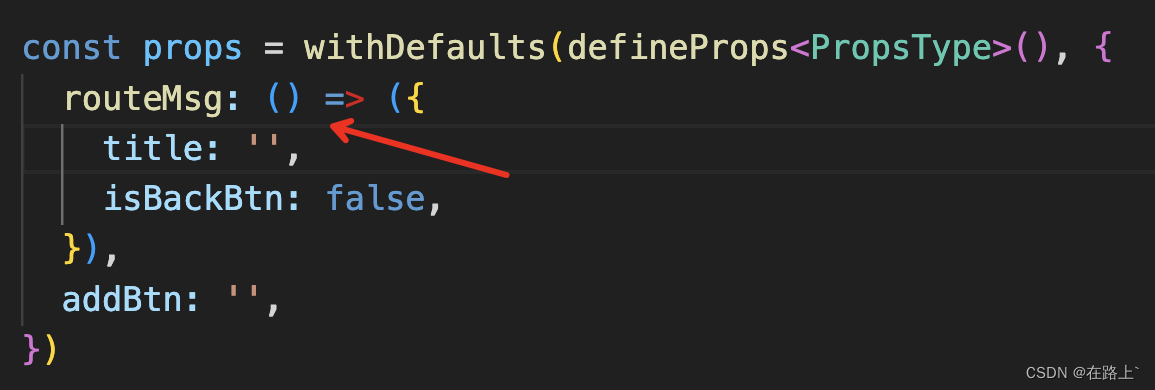
TS 踩坑之路(四)之 Vue3
一、在使用定义默认值withDefaults和defineProps 组合时,默认值设置报错 代码案例 报错信息 不能将类型“{ isBackBtn: false; }”分配给类型“(props: PropsType) > RouteMsgType”。 对象字面量只能指定已知属性,并且“isBackBtn”不在类型“(pro…...

网络六边形受到攻击
大家读完觉得有帮助记得关注和点赞!!! 抽象 现代智能交通系统 (ITS) 的一个关键要求是能够以安全、可靠和匿名的方式从互联车辆和移动设备收集地理参考数据。Nexagon 协议建立在 IETF 定位器/ID 分离协议 (…...

定时器任务——若依源码分析
分析util包下面的工具类schedule utils: ScheduleUtils 是若依中用于与 Quartz 框架交互的工具类,封装了定时任务的 创建、更新、暂停、删除等核心逻辑。 createScheduleJob createScheduleJob 用于将任务注册到 Quartz,先构建任务的 JobD…...

HBuilderX安装(uni-app和小程序开发)
下载HBuilderX 访问官方网站:https://www.dcloud.io/hbuilderx.html 根据您的操作系统选择合适版本: Windows版(推荐下载标准版) Windows系统安装步骤 运行安装程序: 双击下载的.exe安装文件 如果出现安全提示&…...

【C语言练习】080. 使用C语言实现简单的数据库操作
080. 使用C语言实现简单的数据库操作 080. 使用C语言实现简单的数据库操作使用原生APIODBC接口第三方库ORM框架文件模拟1. 安装SQLite2. 示例代码:使用SQLite创建数据库、表和插入数据3. 编译和运行4. 示例运行输出:5. 注意事项6. 总结080. 使用C语言实现简单的数据库操作 在…...

全面解析各类VPN技术:GRE、IPsec、L2TP、SSL与MPLS VPN对比
目录 引言 VPN技术概述 GRE VPN 3.1 GRE封装结构 3.2 GRE的应用场景 GRE over IPsec 4.1 GRE over IPsec封装结构 4.2 为什么使用GRE over IPsec? IPsec VPN 5.1 IPsec传输模式(Transport Mode) 5.2 IPsec隧道模式(Tunne…...

企业如何增强终端安全?
在数字化转型加速的今天,企业的业务运行越来越依赖于终端设备。从员工的笔记本电脑、智能手机,到工厂里的物联网设备、智能传感器,这些终端构成了企业与外部世界连接的 “神经末梢”。然而,随着远程办公的常态化和设备接入的爆炸式…...

GruntJS-前端自动化任务运行器从入门到实战
Grunt 完全指南:从入门到实战 一、Grunt 是什么? Grunt是一个基于 Node.js 的前端自动化任务运行器,主要用于自动化执行项目开发中重复性高的任务,例如文件压缩、代码编译、语法检查、单元测试、文件合并等。通过配置简洁的任务…...
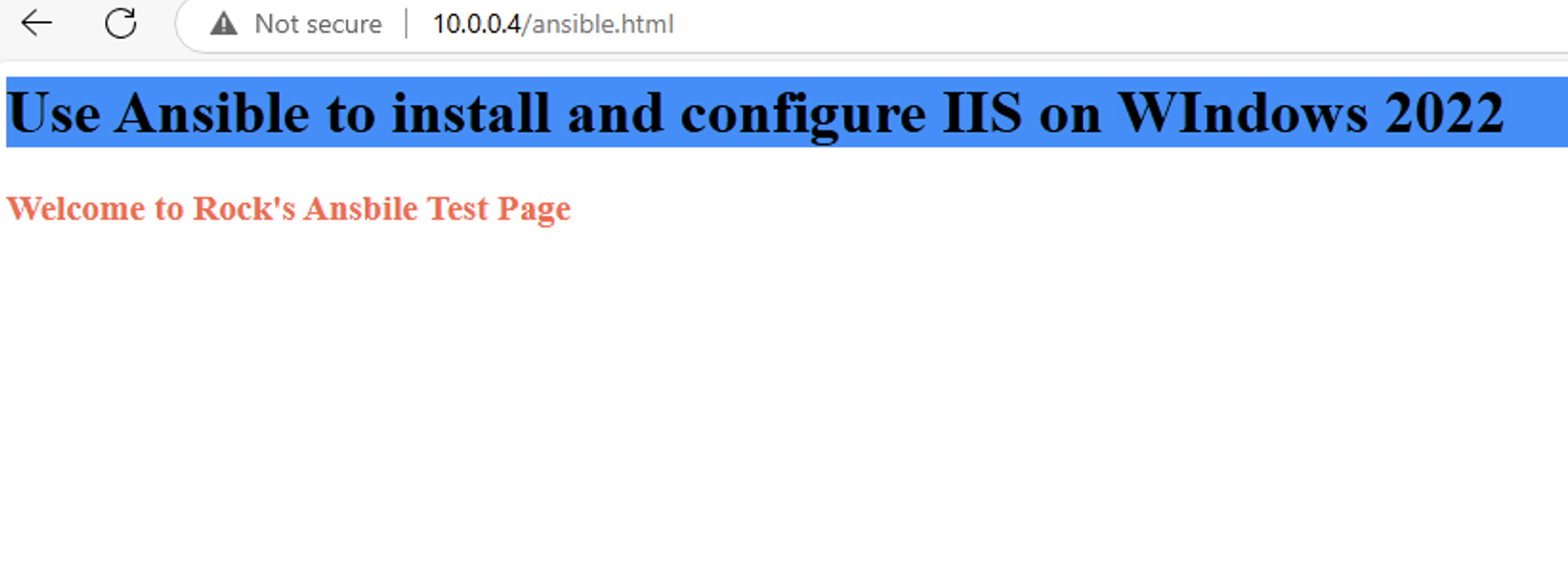
通过 Ansible 在 Windows 2022 上安装 IIS Web 服务器
拓扑结构 这是一个用于通过 Ansible 部署 IIS Web 服务器的实验室拓扑。 前提条件: 在被管理的节点上安装WinRm 准备一张自签名的证书 开放防火墙入站tcp 5985 5986端口 准备自签名证书 PS C:\Users\azureuser> $cert New-SelfSignedCertificate -DnsName &…...

LangFlow技术架构分析
🔧 LangFlow 的可视化技术栈 前端节点编辑器 底层框架:基于 (一个现代化的 React 节点绘图库) 功能: 拖拽式构建 LangGraph 状态机 实时连线定义节点依赖关系 可视化调试循环和分支逻辑 与 LangGraph 的深…...
前端开发者常用网站
Can I use网站:一个查询网页技术兼容性的网站 一个查询网页技术兼容性的网站Can I use:Can I use... Support tables for HTML5, CSS3, etc (查询浏览器对HTML5的支持情况) 权威网站:MDN JavaScript权威网站:JavaScript | MDN...