使用toad库进行机器学习评分卡全流程
1 加载数据
导入模块
import pandas as pd
from sklearn.metrics import roc_auc_score,roc_curve,auc
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
import numpy as np
import math
import xgboost as xgb
import toad
from toad.plot import bin_plot, badrate_plot
from matplotlib import pyplot as plt
from sklearn.preprocessing import StandardScaler
from toad.metrics import KS, F1, AUC
from toad.scorecard import ScoreCard
加载数据
# 加载数据
df = pd.read_csv('scorecard.txt')
print(df.info())
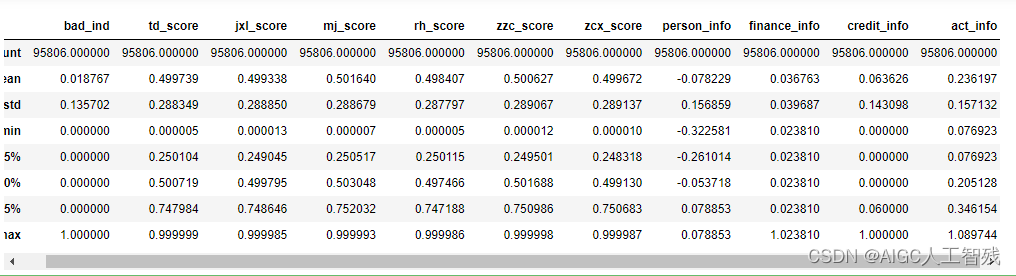
df.head()


df.describe()
数据划分
feature_list = list(df.columns)
feature_drop = ['bad_ind','uid','samp_type']
for lt in feature_drop:feature_list.remove(lt)
df_dev = df[df['samp_type']=='dev']
df_val = df[df['samp_type']=='val']
df_off = df[df['samp_type']=='off']
print(feature_list)
print('dev',df_dev.shape)
print('val',df_val.shape)
print('off',df_off.shape)

简单数据分析
toad.detector.detect(df)
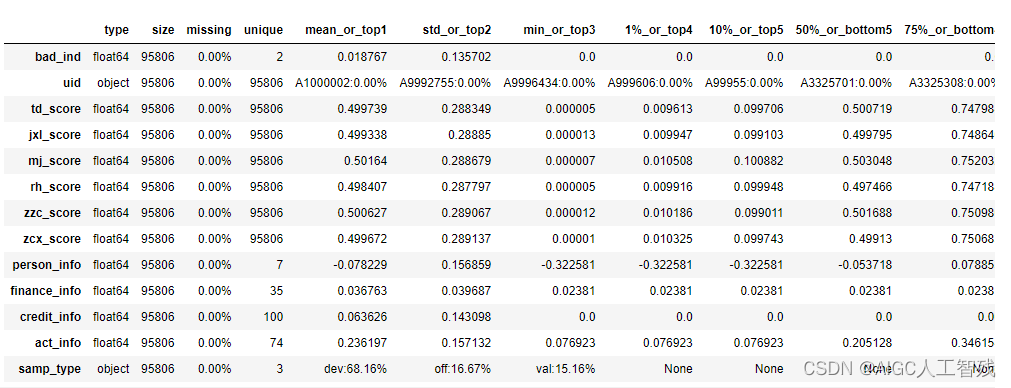
toad库能够同时处理数值型数据和分类型数据。由于没有缺失值,我们不用进行数据填充。
2 特征筛选
使用缺失率、IV和相关系数进行特征筛选。
# 根据缺失值、IV和相关系数进行特征筛选
dev_slt, drop_slt = toad.selection.select(df_dev, df_dev['bad_ind'], empty=0.7, iv=0.03, corr=0.7, return_drop=True, exclude=feature_drop)
print('keep:', dev_slt.shape,';drop empty:',drop_slt['empty'].shape,';drop iv:',drop_slt['iv'].shape,';drop_corr:',drop_slt['corr'].shape)
keep: (65304, 12) ;drop empty: (0,) ;drop iv: (1,) ;drop_corr: (0,)
3 卡方分箱
使用toad库,能够对所有特征切分节点,然后进行分箱
# 使用卡方分箱
# 使用卡方分箱
cmb = toad.transform.Combiner()
cmb.fit(dev_slt, dev_slt['bad_ind'], method='chi', min_samples=0.05, exclude=feature_drop)
bins = cmb.export()
print(bins)
{‘td_score’: [0.7989831262724624], ‘jxl_score’: [0.4197048501965005], ‘mj_score’: [0.3615303943747963], ‘zzc_score’: [0.4469861520889339], ‘zcx_score’: [0.7007847486465795], ‘person_info’: [-0.2610139784946237, -0.1286774193548387, -0.0537175627240143, 0.013863440860215, 0.0626602150537634, 0.078853046594982], ‘finance_info’: [0.0476190476190476], ‘credit_info’: [0.02, 0.04, 0.11], ‘act_info’: [0.1153846153846154, 0.141025641025641, 0.1666666666666666, 0.2051282051282051, 0.2692307692307692, 0.358974358974359, 0.3974358974358974, 0.5256410256410257]}
调整分箱
绘制Bivar图,观察该特征分享后是否单调性,不满足单调性需要调整分箱。
# 绘制bivar图,调整分箱
# 根据节点设置分箱
dev_slt2 = cmb.transform(dev_slt)
val2 = cmb.transform(df_val[dev_slt.columns])
off2 = cmb.transform(df_off[dev_slt.columns])# 观察分箱后的图像-act_info
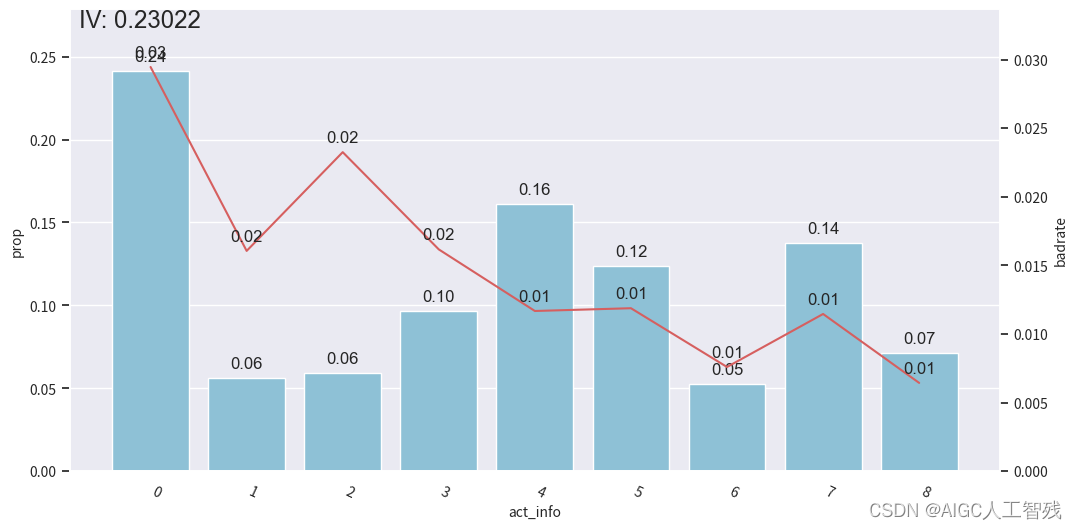
bin_plot(dev_slt2, x='act_info', target='bad_ind')
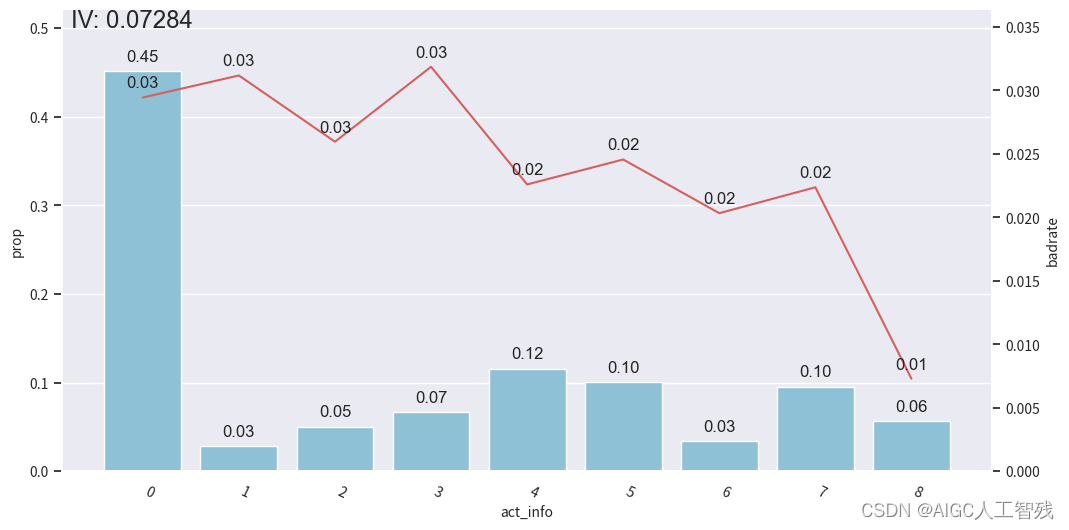
bin_plot(val2, x='act_info', target='bad_ind')
bin_plot(off2, x='act_info', target='bad_ind')
开发样本
测试样本
验证样本
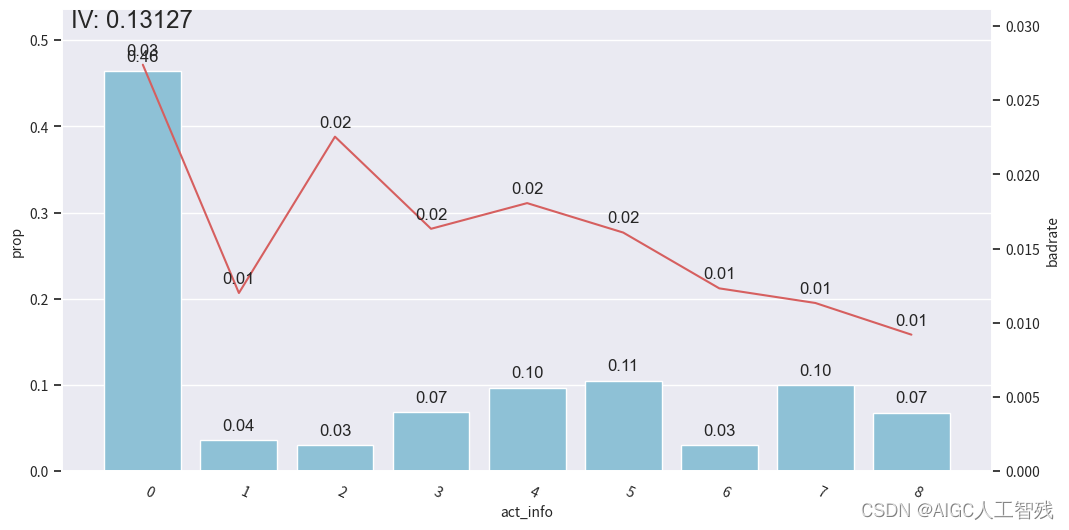
我们能看到前3箱出现上下波动,与整体的单调递减趋势不符,所以进行分箱合并。
# 没有呈现单调性,需要进行合并
bins['act_info']
[0.1153846153846154,
0.141025641025641,
0.1666666666666666,
0.2051282051282051,
0.2692307692307692,
0.358974358974359,
0.3974358974358974,
0.5256410256410257]
将其调整为3个分箱
adj_bins = {'act_info':[0.1666666666666666,0.358974358974359]}
cmb.set_rules(adj_bins)dev_slt3 = cmb.transform(dev_slt)
val3 = cmb.transform(df_val[dev_slt.columns])
off3 = cmb.transform(df_off[dev_slt.columns])# 观察分箱后的图像
bin_plot(dev_slt3, x='act_info', target='bad_ind')
bin_plot(val3, x='act_info', target='bad_ind')
bin_plot(off3, x='act_info', target='bad_ind')
开发样本
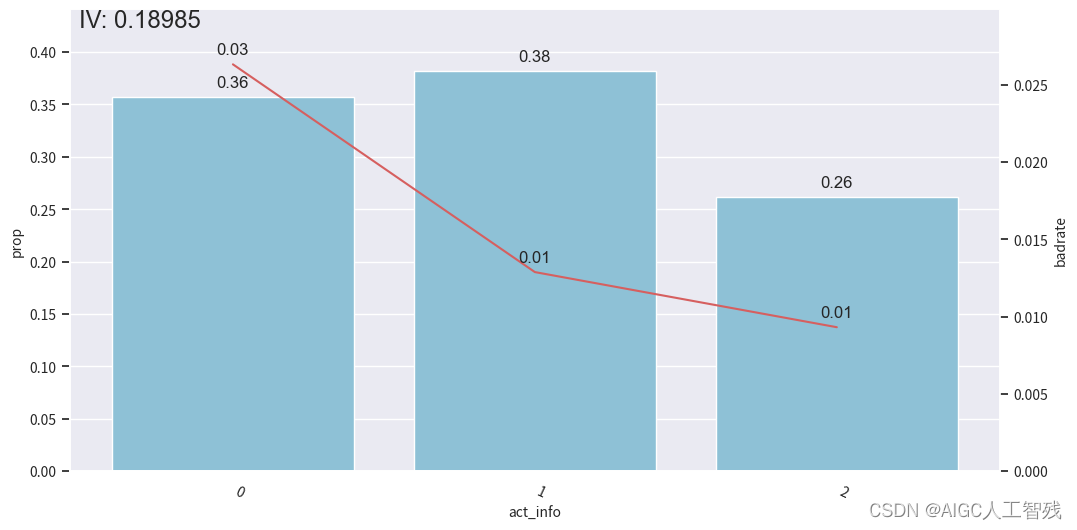
测试样本
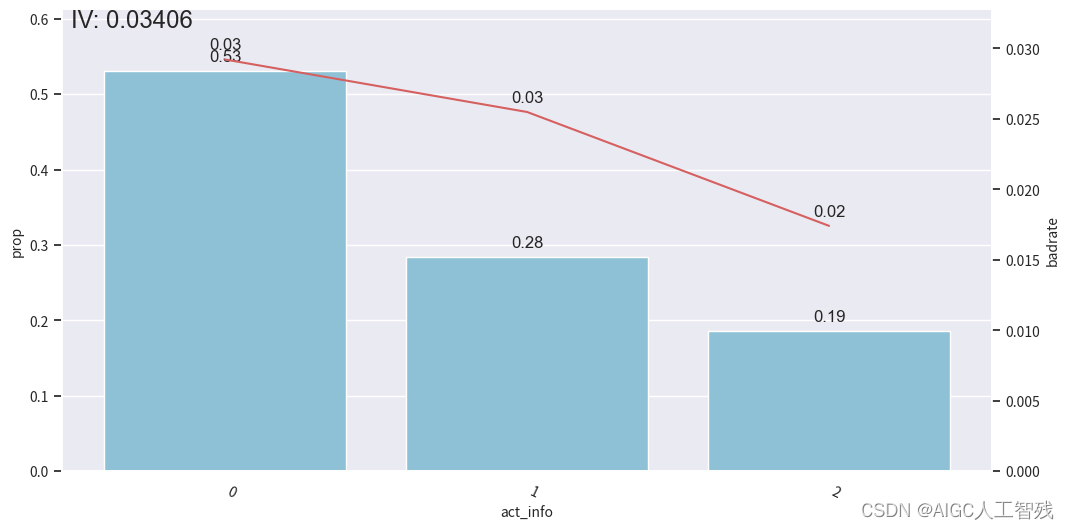
验证样本
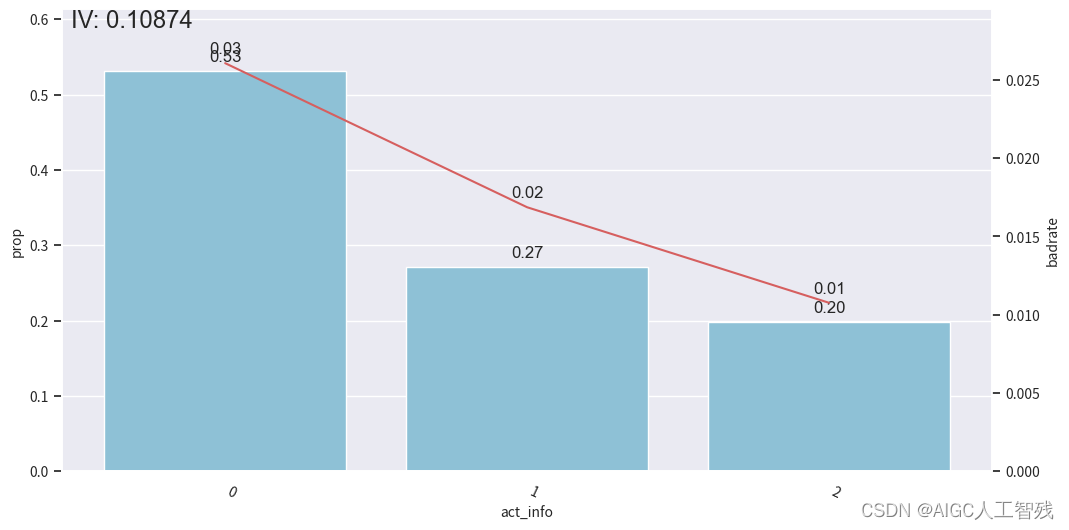
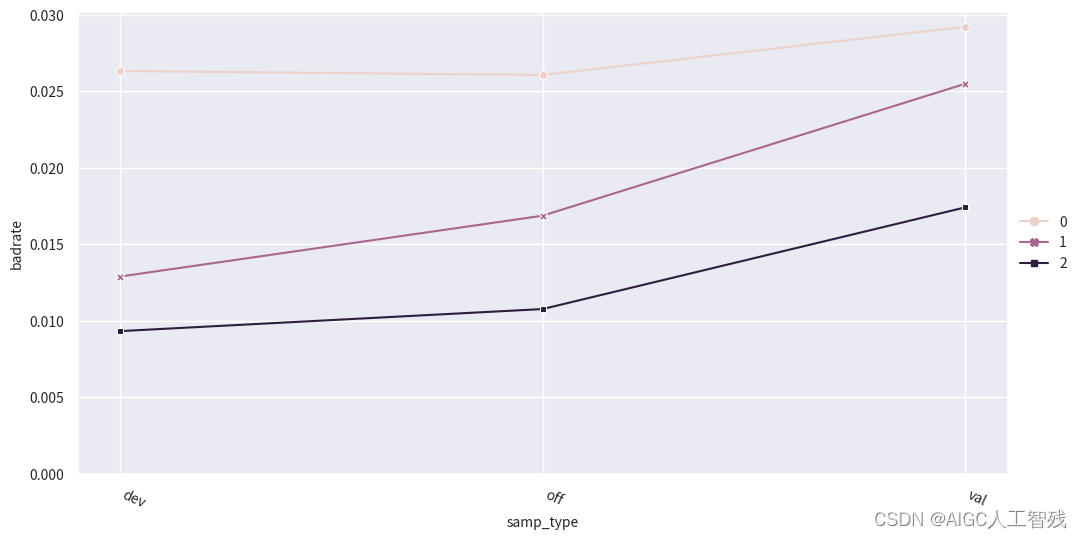
查看负样本占比关联图
# 绘制负样本占比关联图
data = pd.concat([dev_slt3, val3, off3], join='inner')
badrate_plot(data, x='samp_type', target='bad_ind', by='act_info')
其他特征分箱
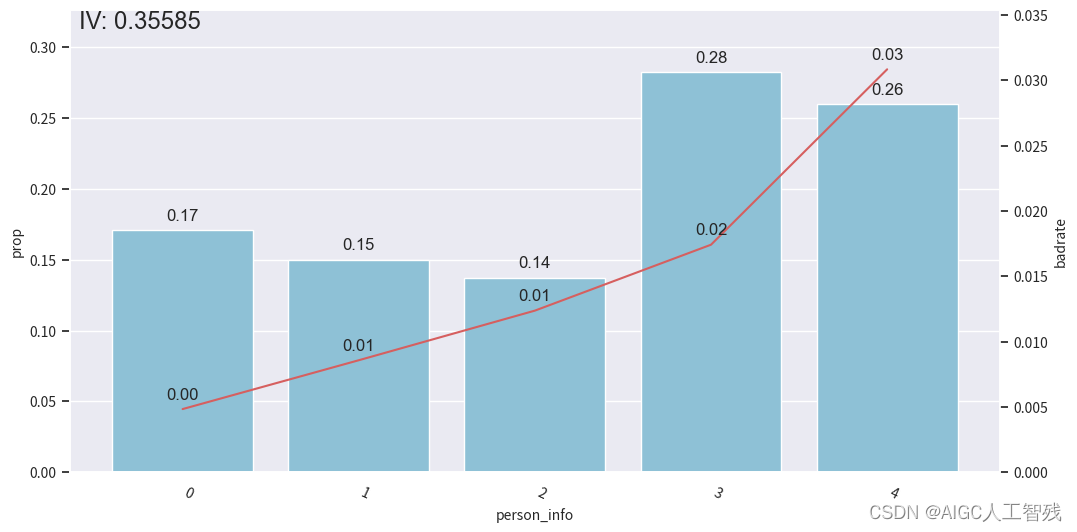
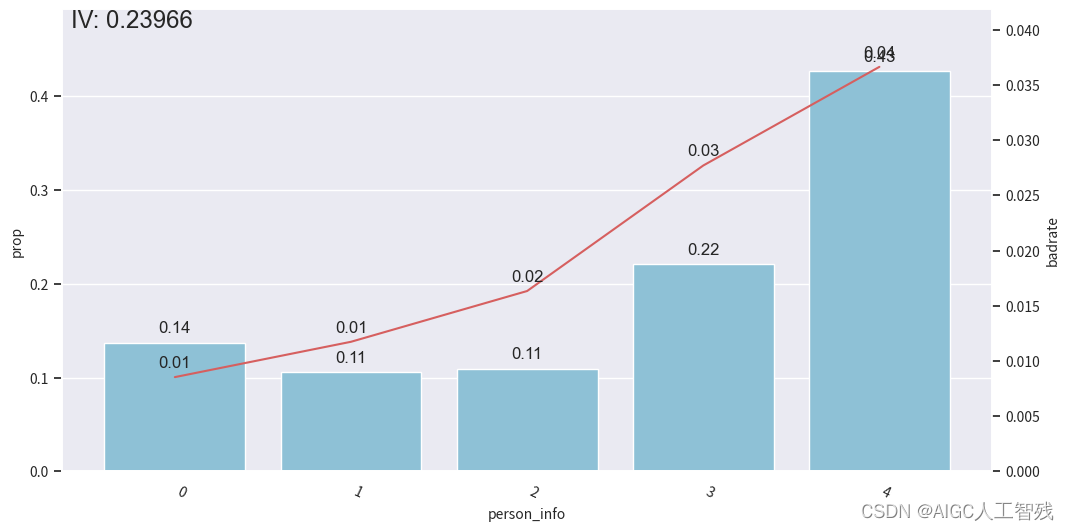
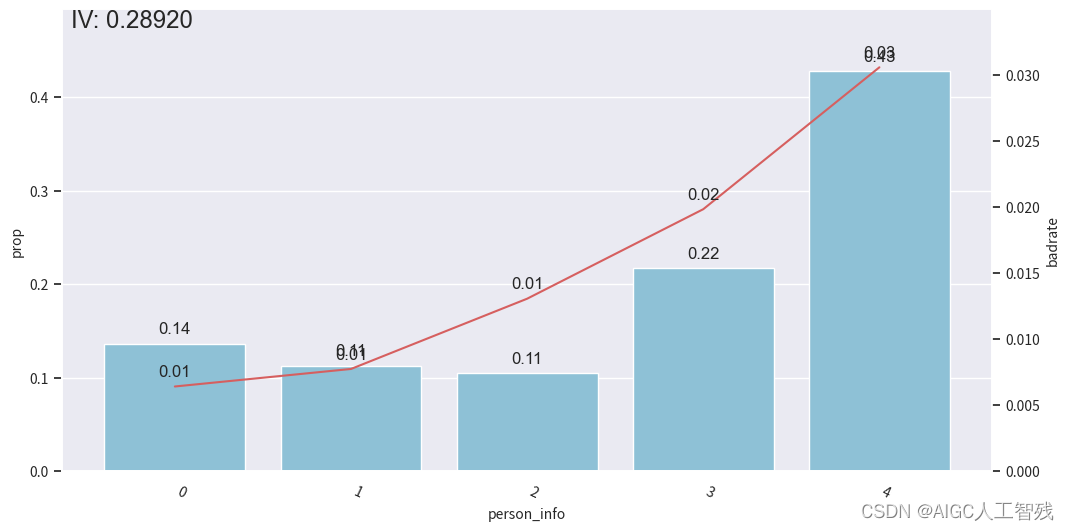
person_info特征分箱
bins['person_info']
[-0.2610139784946237,
-0.1286774193548387,
-0.0537175627240143,
0.013863440860215,
0.0626602150537634,
0.078853046594982]
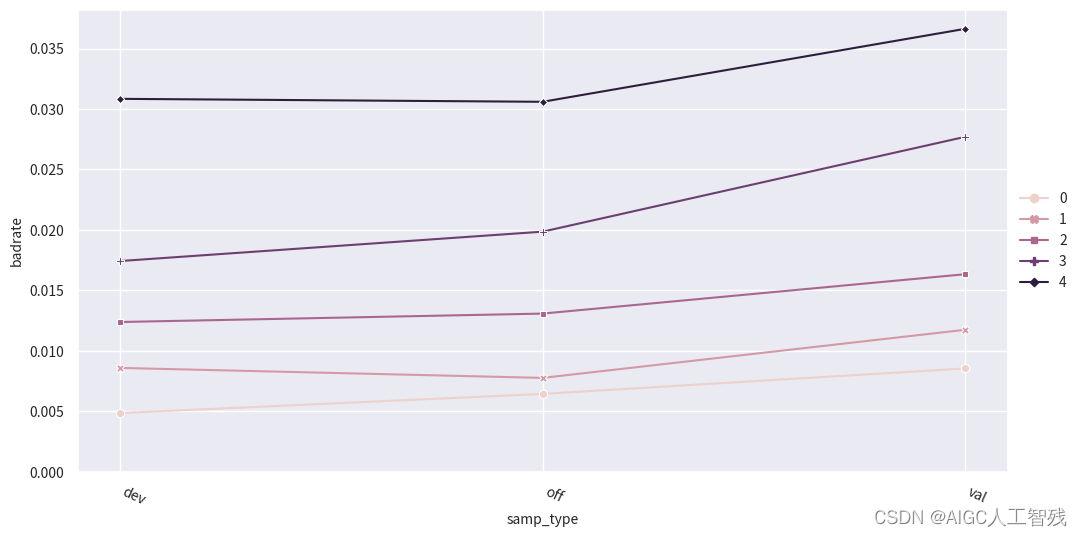
adj_bins = {'person_info':[-0.2610139784946237,-0.1286774193548387,-0.0537175627240143,0.078853046594982]}
cmb.set_rules(adj_bins)dev_slt3 = cmb.transform(dev_slt)
val3 = cmb.transform(df_val[dev_slt.columns])
off3 = cmb.transform(df_off[dev_slt.columns])data = pd.concat([dev_slt3, val3, off3], join='inner')
badrate_plot(data, x='samp_type', target='bad_ind', by='person_info')
# 观察分箱后的图像
bin_plot(dev_slt3, x='person_info', target='bad_ind')
bin_plot(val3, x='person_info', target='bad_ind')
bin_plot(off3, x='person_info', target='bad_ind')
bins['person_info']
负样本占比关联图
开发样本
测试样本
验证样本
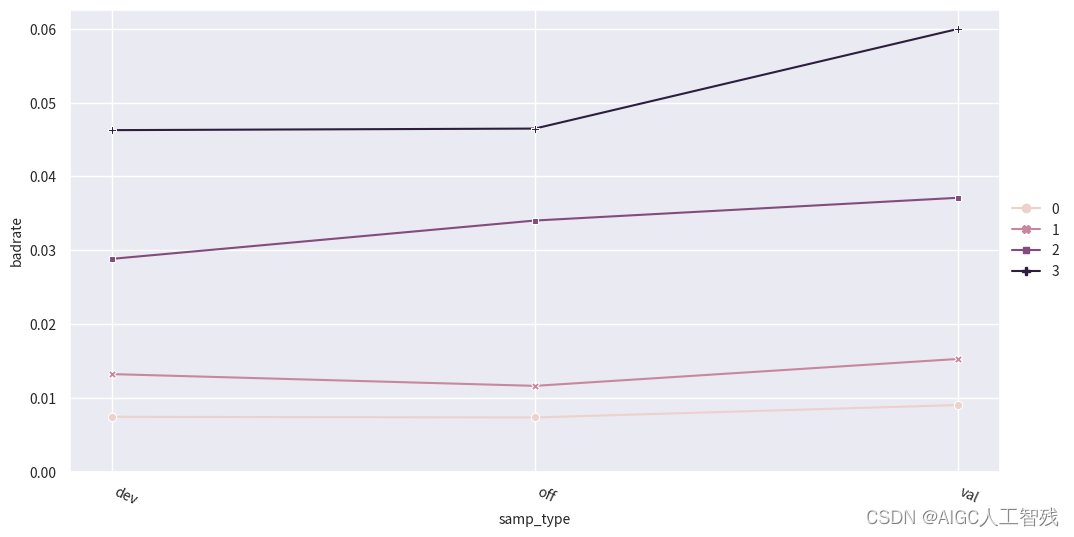
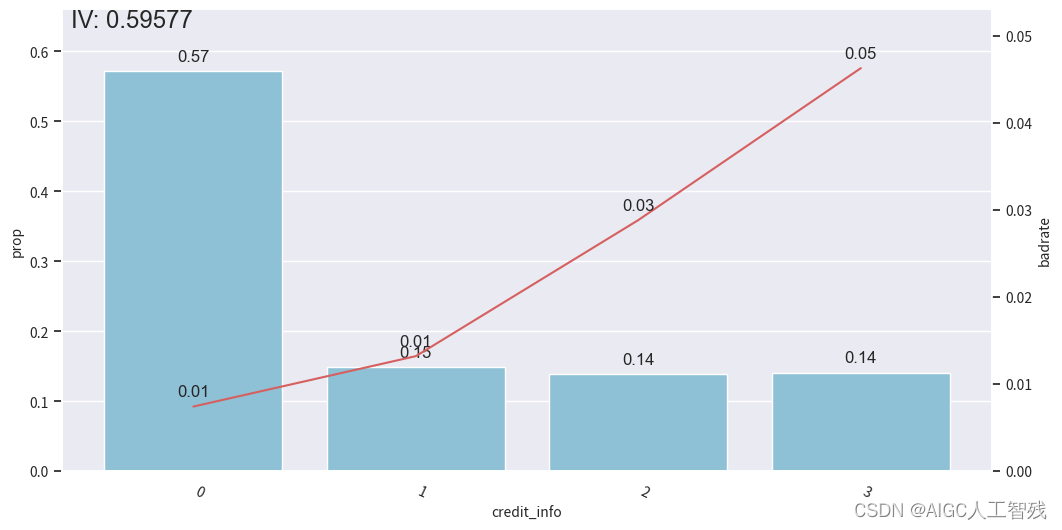
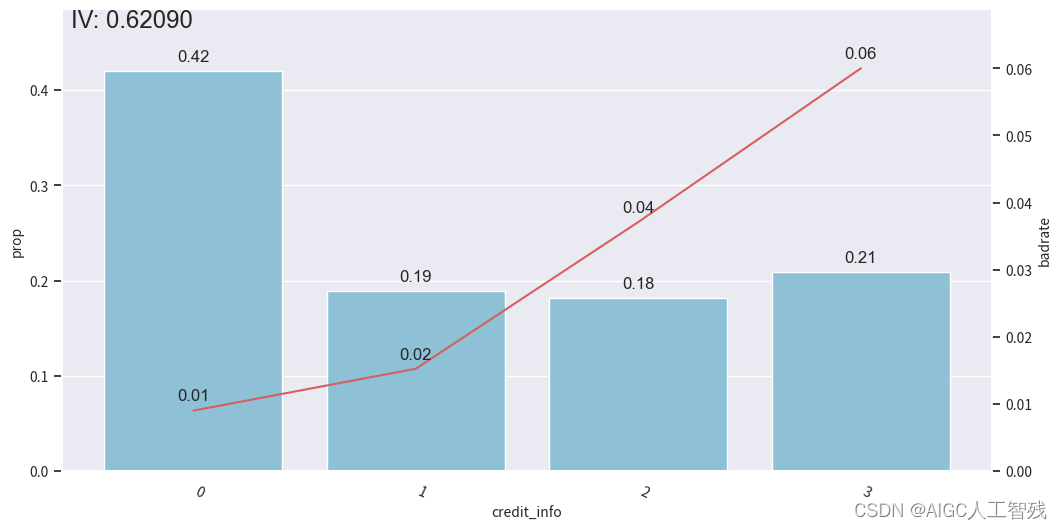
credit_info特征
# credit_info
badrate_plot(data, x='samp_type', target='bad_ind', by='credit_info')# 观察分箱后的图像
bin_plot(dev_slt3, x='credit_info', target='bad_ind')
bin_plot(val3, x='credit_info', target='bad_ind')
bin_plot(off3, x='credit_info', target='bad_ind')
bins['credit_info']
负样本占比
开发样本
测试样本
验证样本
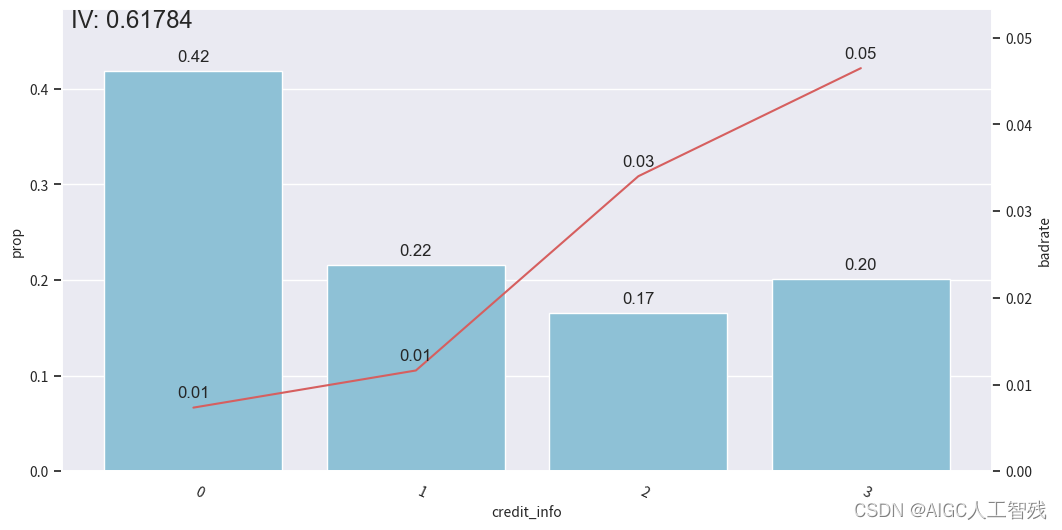
其他特征分箱分为两个,所以不需要单独看。
4 WOE编码,并验证IV
# WOE编码,验证IV
woet = toad.transform.WOETransformer()
dev_woe = woet.fit_transform(dev_slt3, dev_slt3['bad_ind'], exclude=feature_drop)
val_woe = woet.transform(val3[dev_slt3.columns])
off_woe = woet.transform(off3[dev_slt3.columns])
data_woe = pd.concat([dev_woe, val_woe,off_woe])
# 计算PSI
psi_df = toad.metrics.PSI(dev_woe,val_woe).sort_values(0)
psi_df = psi_df.reset_index()
psi_df = psi_df.rename(columns={'index':'feature', 0:'psi'})
psi_df
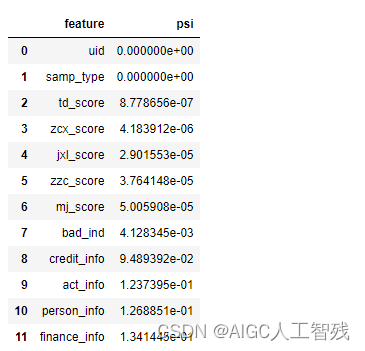
一般删除psi大于0.1的特征,但我们这里调整为0.13。
psi_013 = list(psi_df[psi_df.psi<0.13].feature)
# psi_013.extend(feature_drop)
data_psi = data_woe[psi_013]
dev_woe_psi = dev_woe[psi_013]
val_woe_psi = val_woe[psi_013]
off_woe_psi = off_woe[psi_013]
print(data_psi.shape)
(95806, 11)
由于卡方分箱后部分变量的IV降低,且整体相关程度增大,需要再次筛选特征。
dev_woe_psi2,drop_lst = toad.selection.select(dev_woe_psi, dev_woe_psi['bad_ind'], empty=0.6, iv=0.001, corr=0.5, return_drop=True, exclude=feature_drop)
print('keep:',dev_woe_psi2.shape,';drop empty:',drop_lst['empty'].shape,';drop iv:',drop_lst['iv'].shape,';drop corr:',drop_lst['corr'].shape)
keep: (65304, 7) ;drop empty: (0,) ;drop iv: (4,) ;drop corr: (0,)
5 再次特征筛选
使用逐步回归进行特征筛选,这里为线性回归模型,并选择KS作为评价指标。
# 特征筛选,使用逐步回归法进行筛选
dev_woe_psi_stp = toad.selection.stepwise(dev_woe_psi2,dev_woe_psi2['bad_ind'],exclude=feature_drop,direction='both',criterion='ks',estimator='ols',intercept=False)
val_woe_psi_stp = val_woe_psi[dev_woe_psi_stp.columns]
off_woe_psi_stp = off_woe_psi[dev_woe_psi_stp.columns]
data_woe_psi_std = pd.concat([dev_woe_psi_stp, val_woe_psi_stp, off_woe_psi_stp])
print(data_woe_psi_std.shape)
print(data_woe_psi_std.columns)
(95806, 6)
Index([‘uid’, ‘samp_type’, ‘bad_ind’, ‘credit_info’, ‘act_info’,
‘person_info’],
dtype=‘object’)
6 模型训练
定义逻辑回归模型和XGBoost模型的函数
# 进行模型训练
def lr_model(x,y,valx,valy,offx,offy,c):model = LogisticRegression(C=c, class_weight='balanced')model.fit(x,y)# devy_pred = model.predict_proba(x)[:,1]fpr_dev, tpr_dev, _ = roc_curve(y,y_pred)dev_ks = abs(fpr_dev-tpr_dev).max()print('dev_ks:',dev_ks)y_pred = model.predict_proba(valx)[:,1]fpr_val, tpr_val, _ = roc_curve(valy,y_pred)val_ks = abs(fpr_val-tpr_val).max()print('val_ks:',val_ks)y_pred = model.predict_proba(offx)[:,1]fpr_off, tpr_off, _ = roc_curve(offy,y_pred)off_ks = abs(fpr_off-tpr_off).max()print('off_ks:',off_ks)plt.plot(fpr_dev, tpr_dev, label='dev')plt.plot(fpr_val, tpr_val, label='val')plt.plot(fpr_off, tpr_off, label='off')plt.plot([0,1],[0,1],'k--')plt.xlabel('False positive rate')plt.ylabel('True positive rate')plt.title('lr model ROC Curve')plt.legend(loc='best')plt.show()# xgb模型
def xgb_model(x,y,valx,valy,offx,offy):model = xgb.XGBClassifier(learning_rate=0.05,n_estimators=400,max_depth=2,min_child_weight = 1,subsample=1,nthread=-1,scale_pos_weight=1,random_state=1,n_jobs=-1,reg_lambda=300)model.fit(x,y)# devy_pred = model.predict_proba(x)[:,1]fpr_dev, tpr_dev, _ = roc_curve(y,y_pred)dev_ks = abs(fpr_dev-tpr_dev).max()print('dev_ks:',dev_ks)y_pred = model.predict_proba(valx)[:,1]fpr_val, tpr_val, _ = roc_curve(valy,y_pred)val_ks = abs(fpr_val-tpr_val).max()print('val_ks:',val_ks)y_pred = model.predict_proba(offx)[:,1]fpr_off, tpr_off, _ = roc_curve(offy,y_pred)off_ks = abs(fpr_off-tpr_off).max()print('off_ks:',off_ks)plt.plot(fpr_dev, tpr_dev, label='dev')plt.plot(fpr_val, tpr_val, label='val')plt.plot(fpr_off, tpr_off, label='off')plt.plot([0,1],[0,1],'k--')plt.xlabel('False positive rate')plt.ylabel('True positive rate')plt.title('xgb model ROC Curve')plt.legend(loc='best')plt.show()
定义模型函数的使用函数,在函数中分别进行正向调用和逆向调用,验证模型的效果上限。如逆向模型训练集KS值明显小于正向模型训练集KS值,说明当前时间外样本分布与开发样本差异较大,需要重新划分样本集。
start_train(data_woe_psi_std,target='bad_ind', exclude=feature_drop)
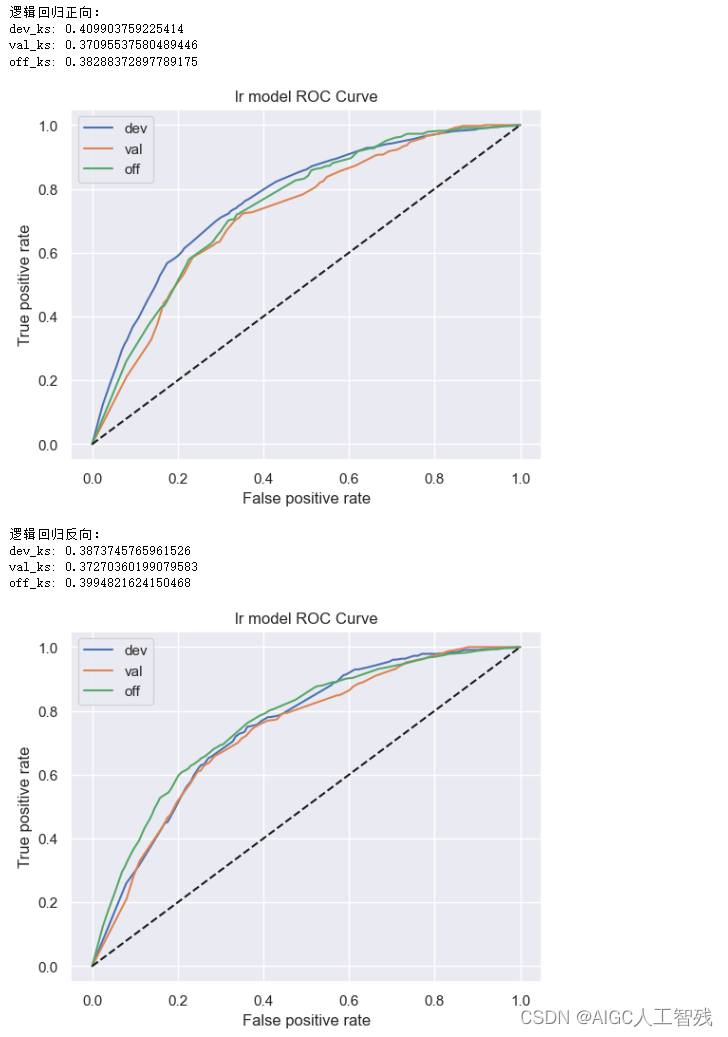
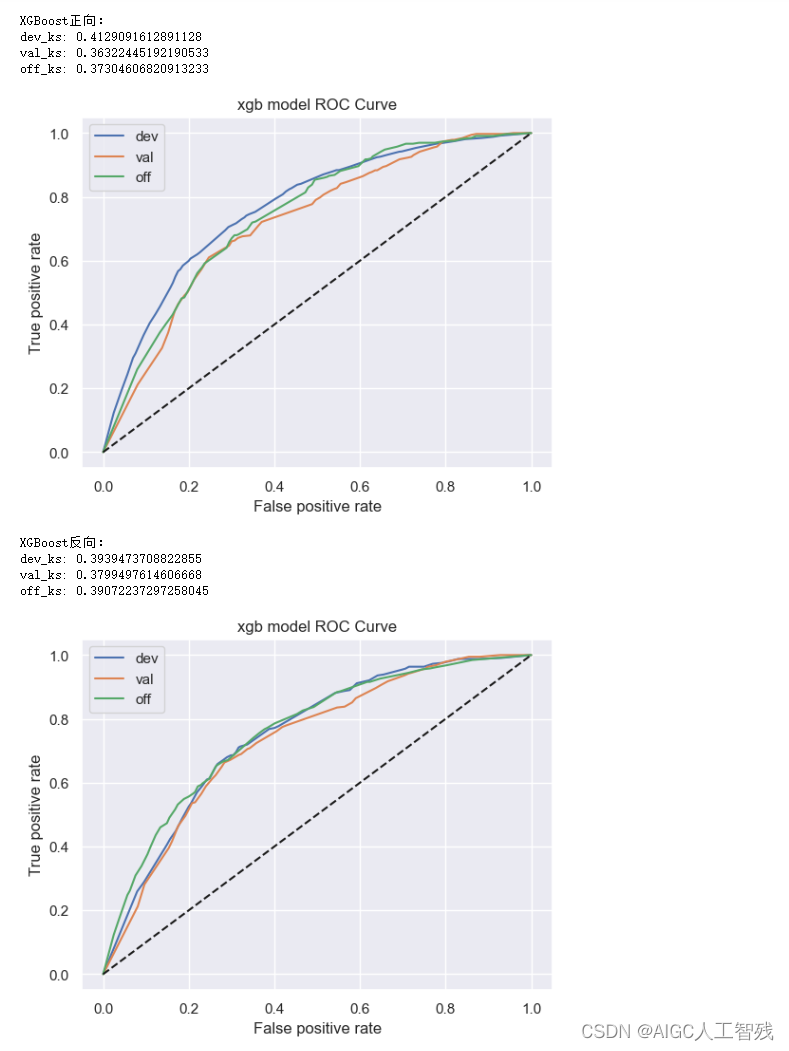
- XGBoost的效果没有好于逻辑回归模型,因此特征不需要进行再组合;
- 反向lr模型的结果没有显著好于正向调用的结果,因此该模型在当前特征空间下没有优化的空间;
- lr正向训练和反向训练的ks值在5%以内,所以不需要调整时间稳定性较差的变量。
计算训练集、测试集和验证集的ks、F1和auc值
7 计算指标评估模型,生成模型报告
# 分别计算ks,F1和auc值
target = 'bad_ind'
lt = list(data_woe_psi_std.columns)
for i in feature_drop:lt.remove(i)devv = data_woe_psi_std[data_woe_psi_std['samp_type']=='dev']
vall = data_woe_psi_std[data_woe_psi_std['samp_type']=='val']
offf = data_woe_psi_std[data_woe_psi_std['samp_type']=='off']
x,y=devv[lt], devv[target]
valx,valy = vall[lt],vall[target]
offx,offy = offf[lt], offf[target]
lr = LogisticRegression()
lr.fit(x,y)prob_dev = lr.predict_proba(x)[:,1]
print('训练集')
print('F1:',F1(prob_dev,y))
print('KS:',KS(prob_dev,y))
print('AUC:',AUC(prob_dev,y))prob_val = lr.predict_proba(valx)[:,1]
print('测试集')
print('F1:',F1(prob_val,valy))
print('KS:',KS(prob_val,valy))
print('AUC:',AUC(prob_val,valy))prob_off = lr.predict_proba(offx)[:,1]
print('验证集')
print('F1:',F1(prob_off,offy))
print('KS:',KS(prob_off,offy))
print('AUC:',AUC(prob_off,offy))# 验证集的模型PSI和特征PSI
print('模型PSI:', toad.metrics.PSI(prob_dev,prob_off))
print('特征PSI:\n', toad.metrics.PSI(x,offx).sort_values(0))
训练集
F1: 0.02962459026532253
KS: 0.40665138719594446
AUC: 0.7683462756870743
测试集
F1: 0.03395860284605433
KS: 0.3709553758048945
AUC: 0.723771920780572
验证集
F1: 0
KS: 0.38288372897789186
AUC: 0.7447410631197128
模型PSI: 0.3372146799079187
特征PSI:
credit_info 0.098585
act_info 0.124820
person_info 0.127210
dtype: float64
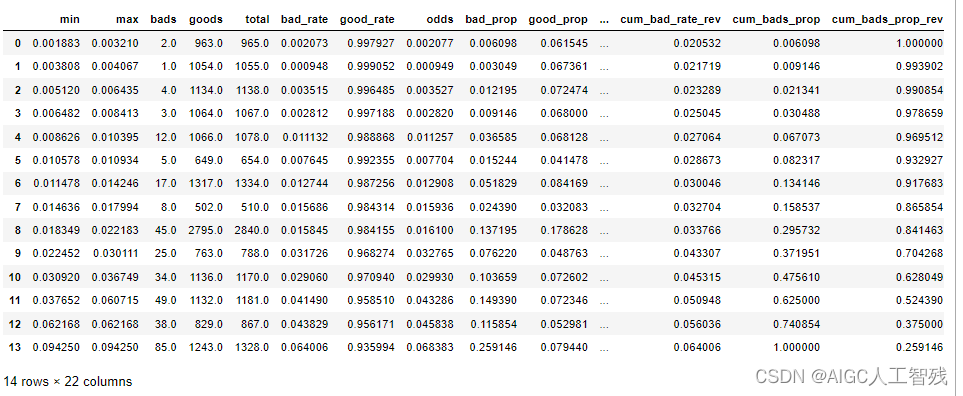
生成验证集的ks报告
toad.metrics.KS_bucket(prob_off, offy, bucket=15, method='quantile')
8 生成评分卡
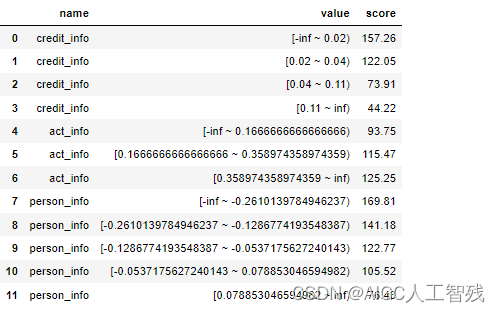
# 用toad生成评分卡
card = ScoreCard(combiner=cmb,transer=woet, C=0.1,class_weight='balanced',base_score=600,base_odds=35,pdo=60,rate=2)
card.fit(x,y)
final_card = card.export(to_frame=True)
final_card
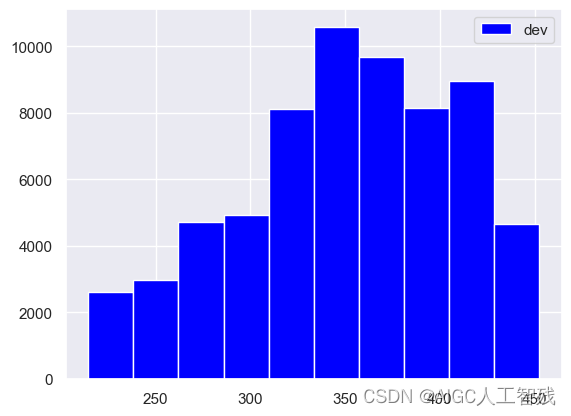
对训练集、测试集和验证集应用评分卡,预测用户的分数。这里要注意要传入原始数据,不要传入woe编码转化后和分箱后的数据。
# 评分卡进行预测
df_dev['score'] = card.predict(df_dev)
df_val['score'] = card.predict(df_val)
df_off['score'] = card.predict(df_off)
plt.hist(df_dev['score'], label = 'dev',color='blue', bins = 10)
plt.legend()
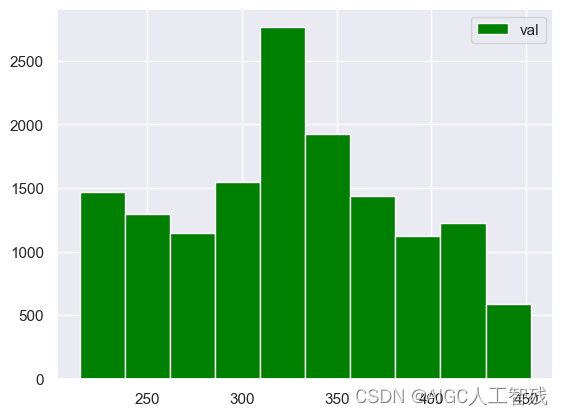
plt.hist(df_val['score'], label = 'val',color='green', bins = 10)
plt.legend()
plt.hist(df_off['score'], label = 'off',color='orange', bins = 10)
plt.legend()
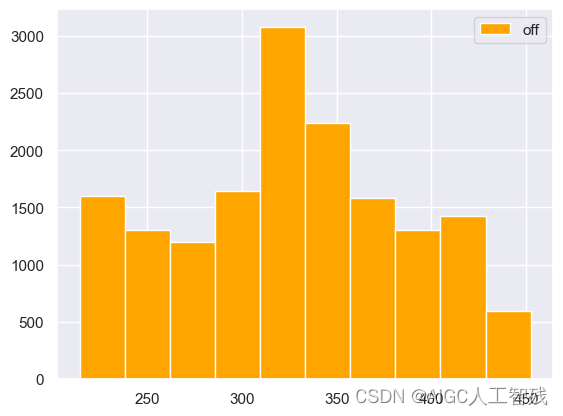
三组评分数据在一个图中
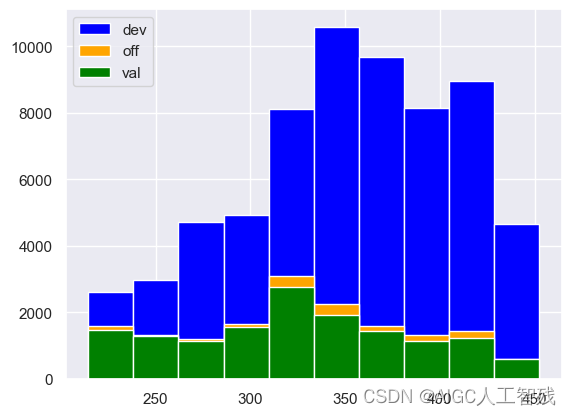
plt.hist(df_dev['score'], label = 'dev',color='blue', bins = 10)
plt.hist(df_off['score'], label = 'off',color='orange', bins = 10)
plt.hist(df_val['score'], label = 'val',color='green', bins = 10)
plt.legend()
相关文章:
使用toad库进行机器学习评分卡全流程
1 加载数据 导入模块 import pandas as pd from sklearn.metrics import roc_auc_score,roc_curve,auc from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression import numpy as np import math import xgboost as xgb …...
)
Python数据容器——列表(list)
数据容器入门 Python中的数据容器: 一种可以容纳多份数据的数据类型,容纳的每一份数据称之为1个元素 每一个元素,可以是任意类型的数据,如字符串、数字、布尔等。 数据容器根据特点的不同,如:是否支持重复元…...
Linux CEF(Chromium Embedded Framework)源码下载编译详细记录
Linux CEF(Chromium Embedded Framework)源码下载编译 背景 由于CEF默认的二进制分发包不支持音视频播放,需要自行编译源码,将ffmpeg开关打开才能支持。这里介绍的是Linux平台下的CEF源码下载编译过程。 前置条件 下载的过程非…...

Adaptive AUTOSAR—— Communication Management 3.1
9 Communication Management 9.1 What is Communication Management? 通信管理是自适应平台架构中的一个功能集群。 作为一个功能集群,通信管理向应用程序提供了一个C++ API,实现了面向服务的通信。服务是一个由应用程序提供的功能单元,可以在运行时被另一个应用程序动态…...
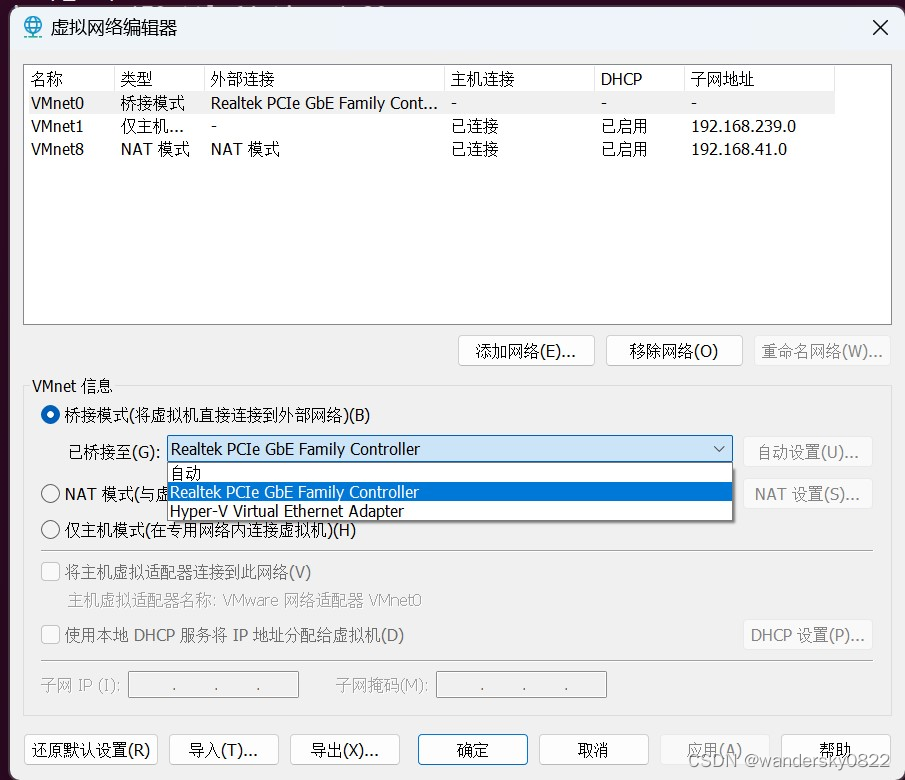
VMnet0 桥接设置
VMnet0 一定要设置为你的硬件物理网卡,不能设置自动,不然后,网线一断,就再也连不上了。必须重启电脑才能连上,这个问题找了很久才找到。 下面有个hyper-V虚拟网卡,如果选自动的话,物理网卡一掉…...

Sublime Text 4 Build 4151 4152 发布及注册方法
Sublime Text 是一个商业代码编辑器。它原生支持许多编程语言和标记语言,用户可以通过插件来扩展它的功能,这些插件通常是由社区建立的,并以自由软件许可证的形式维护。为了方便插件,Sublime Text 有一个 Python API。 Sublime T…...

第八篇: K8S Prometheus Operator实现Ceph集群企业微信机器人告警
Prometheus Operator实现Ceph集群企业微信告警 实现方案 我们的k8s集群与ceph集群是部署在不同的服务器上,因此实现方案如下: (1) ceph集群开启mgr内置的exporter服务,用于获取ceph集群的metrics (2) k8s集群通过 Service Endponit Ser…...

软件单元测试
单元测试目的和意义 对于非正式的软件(其特点是功能比较少,后续也不有新特性加入,不用负责维护),我们可以使用debug单步执行,内存修改,检查对应的观测点是否符合要求来进行单元测试,…...

Redis | 集群模式
Redis | 集群模式 随着互联网应用规模的不断扩大,单一节点的数据库性能已经无法满足大规模应用的需求。为了提高数据库的性能和可扩展性,分布式数据库成为了解决方案之一。Redis 作为一个高性能的内存数据库,自然也有了自己的分布式部署方式…...
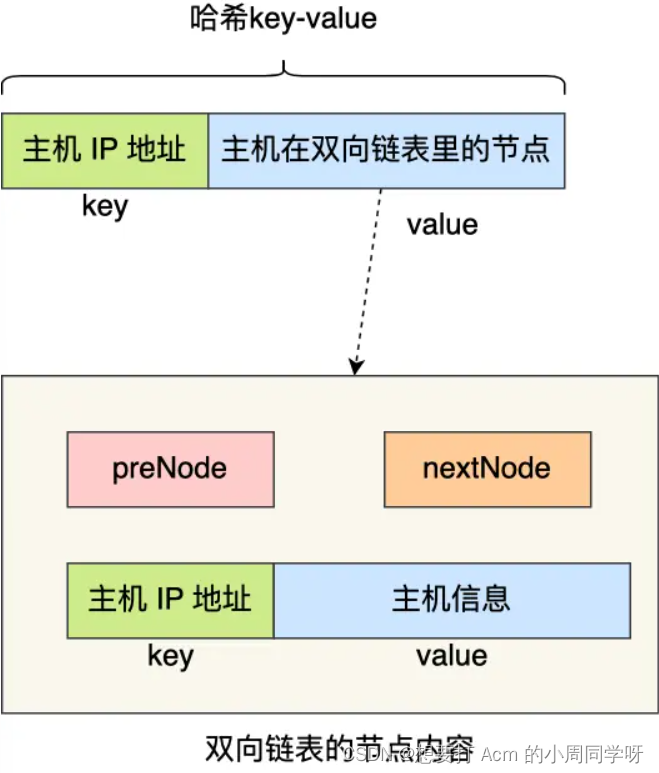
8.3day04git+数据结构
文章目录 git版本控制学习高性能的单机管理主机的心跳服务算法题 git版本控制学习 一个免费开源,分布式的代码版本控制系统,帮助开发团队维护代码 作用:记录代码内容,切换代码版本,多人开发时高效合并代码内容 安装g…...
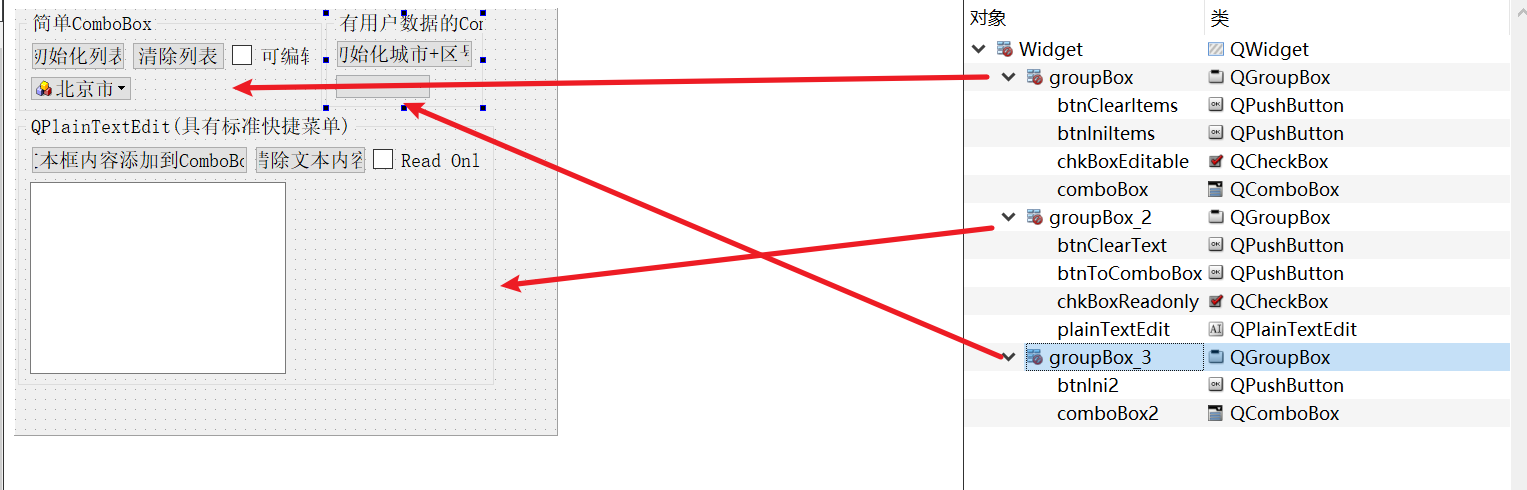
04-5_Qt 5.9 C++开发指南_QComboBox和QPlainTextEdit
文章目录 1. 实例功能概述2. 源码2.1 可视化UI设计2.2 widget.h2.3 widget.cpp 1. 实例功能概述 QComboBox 是下拉列表框组件类,它提供一个下拉列表供用户选择,也可以直接当作一个QLineEdit 用作输入。OComboBox 除了显示可见下拉列表外,每个…...

Sqlserver_Oracle_Mysql_Postgresql不同关系型数据库之主从延迟的理解和实验
关系型数据库主从节点的延迟是否和隔离级别有关联,个人认为两者没有直接关系,主从延迟在关系型数据库中一般和这两个时间有关:事务日志从主节点传输到从节点的时间事务日志在从节点的应用时间 事务日志从主节点传输到从节点的时间࿰…...
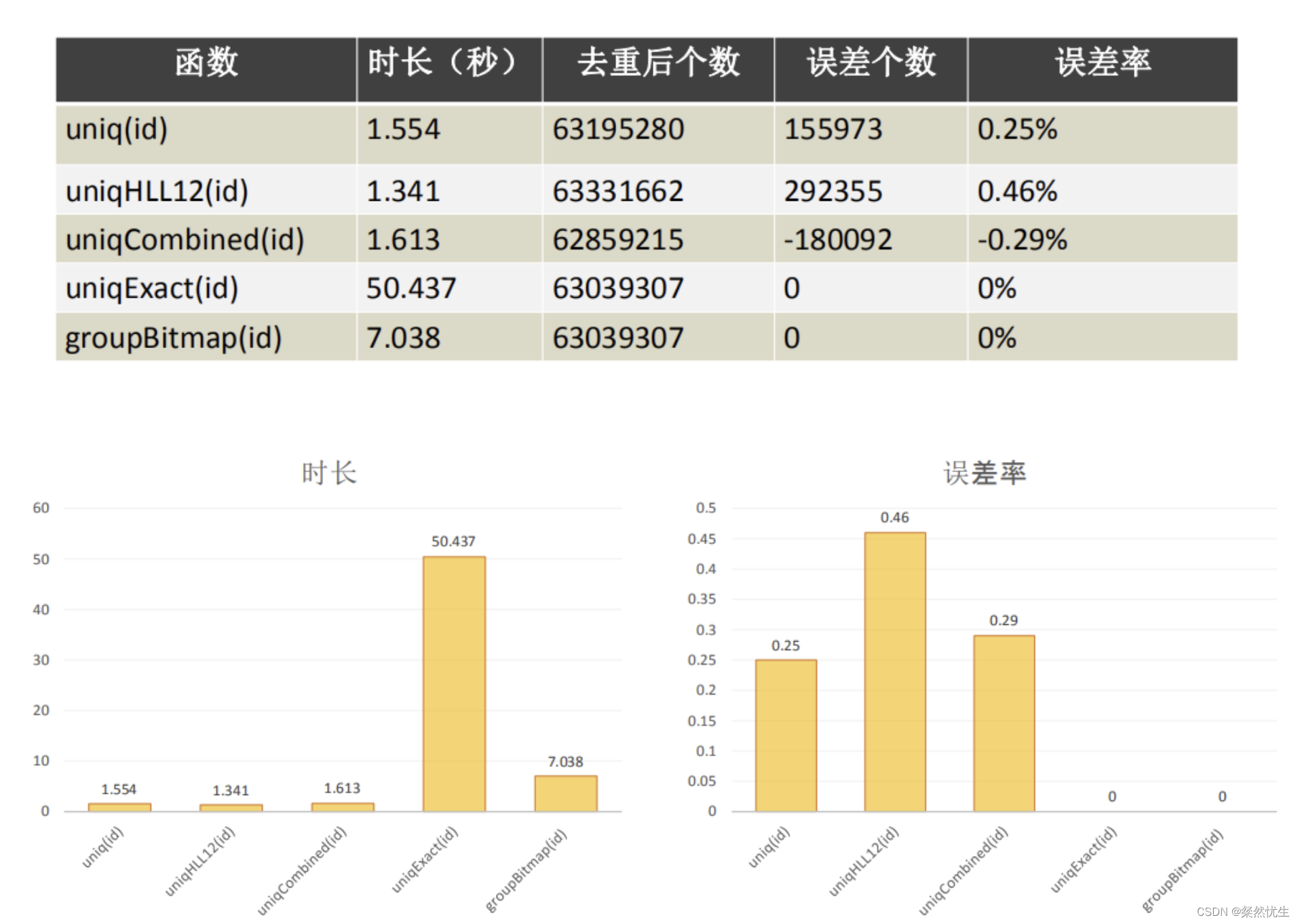
Clickhouse学习系列——一条SQL完成gourp by分组与不分组数值计算
笔者在近一两年接触了Clickhouse数据库,在项目中也进行了一些实践,但一直都没有一些技术文章的沉淀,近期打算做个系列,通过一些具体的场景将Clickhouse的用法进行沉淀和分享,供大家参考。 首先我们假设一个Clickhouse数…...

做好“关键基础设施提供商”角色,亚马逊云科技加快生成式AI落地
一场关于生产力的革命已在酝酿之中。全球管理咨询公司麦肯锡在最近的报告《生成式人工智能的经济潜力:下一波生产力浪潮》中指出,生成式AI每年可能为全球经济增加2.6万亿到4.4万亿美元的价值。在几天前的亚马逊云科技纽约峰会中,「生成式AI」…...

如何使用 ChatGPT 规划家居装修
你正在计划家庭装修项目,但不确定从哪里开始?ChatGPT 随时为你提供帮助。从集思广益的设计理念到估算成本,ChatGPT 可以简化你的家居装修规划流程。在本文中,我们将讨论如何使用 ChatGPT 有效地规划家居装修,以便你的项…...

题解 | #1002.Random Nim Game# 2023杭电暑期多校7
1002.Random Nim Game 诈骗博弈题 题目大意 Nim是一种双人数学策略游戏,玩家轮流从不同的堆中移除棋子。在每一轮游戏中,玩家必须至少取出一个棋子,并且可以取出任意数量的棋子,条件是这些棋子都来自同一个棋子堆。走最后一步棋…...

篇九:组合模式:树形结构的力量
篇九:“组合模式:树形结构的力量” 开始本篇文章之前先推荐一个好用的学习工具,AIRIght,借助于AI助手工具,学习事半功倍。欢迎访问:http://airight.fun/。 另外有2本不错的关于设计模式的资料,…...
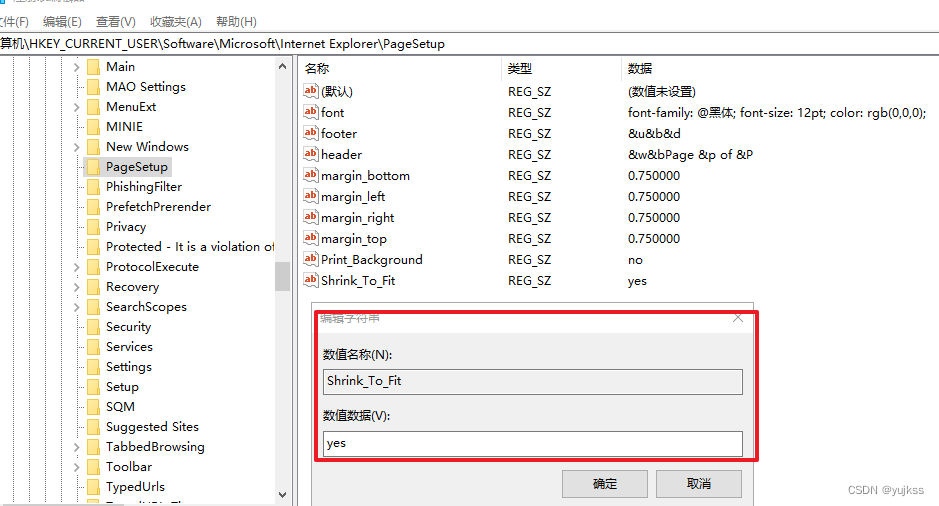
【注册表】windows系统注册表常用修改方案
文章目录 ◆ 修改IE浏览器打印页面参数设置◆气泡屏幕保护◆彩带屏幕保护程序◆过滤IP(适用于WIN2000)◆禁止显示IE的地址栏◆禁止更改IE默认的检查(winnt适用)◆允许DHCP(winnt适用)◆局域网自动断开的时间(winnt适用)◆禁止使用“重置WEB设置”◆禁止更…...

ant-design-vue 4.x升级问题-样式丢失问题
[vue] ant-design-vue 4.x升级问题-样式丢失问题 项目环境问题场景解决方案 该文档是在升级ant-design-vue到4.x版本的时候遇到的问题 项目环境 "vue": "^3.3.4", "ant-design-vue": "^4.0.0", "vite": "^4.4.4&quo…...

【果树农药喷洒机器人】Part3:变量喷药系统工作原理介绍
本专栏介绍:免费专栏,持续更新机器人实战项目,欢迎各位订阅关注。 关注我,带你了解更多关于机器人、嵌入式、人工智能等方面的优质文章! 文章目录 一、变量喷药系统工作原理二、液压通路设计与控制系统封装2.1液压通路…...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

【Java学习笔记】Arrays类
Arrays 类 1. 导入包:import java.util.Arrays 2. 常用方法一览表 方法描述Arrays.toString()返回数组的字符串形式Arrays.sort()排序(自然排序和定制排序)Arrays.binarySearch()通过二分搜索法进行查找(前提:数组是…...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...

智能在线客服平台:数字化时代企业连接用户的 AI 中枢
随着互联网技术的飞速发展,消费者期望能够随时随地与企业进行交流。在线客服平台作为连接企业与客户的重要桥梁,不仅优化了客户体验,还提升了企业的服务效率和市场竞争力。本文将探讨在线客服平台的重要性、技术进展、实际应用,并…...

MySQL中【正则表达式】用法
MySQL 中正则表达式通过 REGEXP 或 RLIKE 操作符实现(两者等价),用于在 WHERE 子句中进行复杂的字符串模式匹配。以下是核心用法和示例: 一、基础语法 SELECT column_name FROM table_name WHERE column_name REGEXP pattern; …...

全志A40i android7.1 调试信息打印串口由uart0改为uart3
一,概述 1. 目的 将调试信息打印串口由uart0改为uart3。 2. 版本信息 Uboot版本:2014.07; Kernel版本:Linux-3.10; 二,Uboot 1. sys_config.fex改动 使能uart3(TX:PH00 RX:PH01),并让boo…...

【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

算法岗面试经验分享-大模型篇
文章目录 A 基础语言模型A.1 TransformerA.2 Bert B 大语言模型结构B.1 GPTB.2 LLamaB.3 ChatGLMB.4 Qwen C 大语言模型微调C.1 Fine-tuningC.2 Adapter-tuningC.3 Prefix-tuningC.4 P-tuningC.5 LoRA A 基础语言模型 A.1 Transformer (1)资源 论文&a…...