【Pytorch+torchvision】MNIST手写数字识别
深度学习入门项目,含代码详细解析
在本文中,我们将在
PyTorch中构建一个简单的卷积神经网络,并使用MNIST数据集训练它识别手写数字。 MNIST包含70,000张手写数字图像: 60,000张用于培训,10,000张用于测试。图像是灰度(即通道数为1),28x28像素,并且居中的,以减少预处理和加快运行。
目录
1.整体代码
2.代码解析
2.1参数设置
2.2数据集
2.3查看测试数据
2.4定义卷积神经网络编辑
2.5初始化网络与优化器
3.实验结果
1.整体代码
import torch
import torchvision
from torch.utils.data import DataLoader
import torch.nn as nn #torch.nn层中包含可训练的参数
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
#注意下面两行在matplotlib使用上出错时,加上可不出错
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'n_epochs = 3 #epoch的数量定义了将循环整个训练数据集的次数
batch_size_train = 64 #每次投喂的样本数量
batch_size_test = 1000
learning_rate = 0.01
momentum = 0.5 #优化器的超参数
log_interval = 10
random_seed = 1
torch.manual_seed(random_seed) #对于可重复的实验,须为任何使用随机数产生的东西设置随机种子
#训练集数据
train_loader = torch.utils.data.DataLoader(torchvision.datasets.MNIST('./data/', train=True, download=True, #加载该数据集(download=True)transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307,), (0.3081,))])), #Normalize()转换使用的值0.1307和0.3081是该数据集的全局平均值和标准偏差,这里将它们作为给定值batch_size=batch_size_train, shuffle=True)
#测试集数据
test_loader = torch.utils.data.DataLoader(torchvision.datasets.MNIST('./data/', train=False, download=True,transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size_test, shuffle=True) #使用size=1000对这个数据集进行测试
#查看一批测试数据由什么组成
examples = enumerate(test_loader) #enumerate指循环,类似for
batch_idx, (example_data, example_targets) = next(examples) #example_targets是图片实际对应的数字标签,example_data是指图片本身数据
print(example_targets)
print(example_data.shape) #输出torch.Size([1000, 1, 28, 28]),意味着我们有1000个例子的28x28像素的灰度(即没有rgb通道)#定义卷积神经网络
class Net(nn.Module):def __init__(self):super(Net, self).__init__()# batch*1*28*28(每次会送入batch个样本,输入通道数1(黑白图像),图像分辨率是28x28)# 下面的卷积层Conv2d的第一个参数指输入通道数,第二个参数指输出通道数(即用了几个卷积核),第三个参数指卷积核的大小self.conv1 = nn.Conv2d(1, 10, kernel_size=5) #因为图像为黑白的,所以输入通道为1,此时输出数据大小变为28-5+1=24.所以batchx1x28x28 -> batchx10x24x24self.conv2 = nn.Conv2d(10, 20, kernel_size=5) #第一个卷积层的输出通道数等于第二个卷积层是输入通道数。self.conv2_drop = nn.Dropout2d() #在前向传播时,让某个神经元的激活值以一定的概率p停止工作,可以使模型泛化性更强,因为它不会太依赖某些局部的特征self.fc1 = nn.Linear(320, 50) #由于下部分前向传播处理后,输出数据为20x4x4=320,传递给全连接层。# 输入通道数是320,输出通道数是50self.fc2 = nn.Linear(50, 10)#输入通道数是50,输出通道数是10,(即10分类(数字1-9),最后结果需要分类为几个就是几个输出通道数)。全连接层(Linear):y=x乘A的转置+bdef forward(self, x):x = F.relu(F.max_pool2d(self.conv1(x), 2)) # batch*10*24*24 -> batch*10*12*12(2*2的池化层会减半,步长为2)(激活函数ReLU不改变形状)x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2)) #此时输出数据大小变为12-5+1=8(卷积核大小为5)(2*2的池化层会减半)。所以 batchx10x12x12 -> batchx20x4x4。x = x.view(-1, 320) # batch*20*4*4 -> batch*320x = F.relu(self.fc1(x)) #进入全连接层x = F.dropout(x, training=self.training) #减少遇到过拟合问题,dropout层是一个很好的规范模型。x = self.fc2(x)#计算log(softmax(x))return F.log_softmax(x)
#初始化网络和优化器
#如果我们使用GPU进行训练,应使用例如network.cuda()将网络参数发送给GPU。将网络参数传递给优化器之前,将它们传输到适当的设备很重要,否则优化器无法以正确的方式跟踪它们。
network = Net()
optimizer = optim.SGD(network.parameters(), lr=learning_rate,momentum=momentum)
train_losses = []
train_counter = []
test_losses = []
test_counter = [i*len(train_loader.dataset) for i in range(n_epochs + 1)]
#每个epoch对所有训练数据进行一次迭代。加载单独批次由DataLoader处理
#训练函数
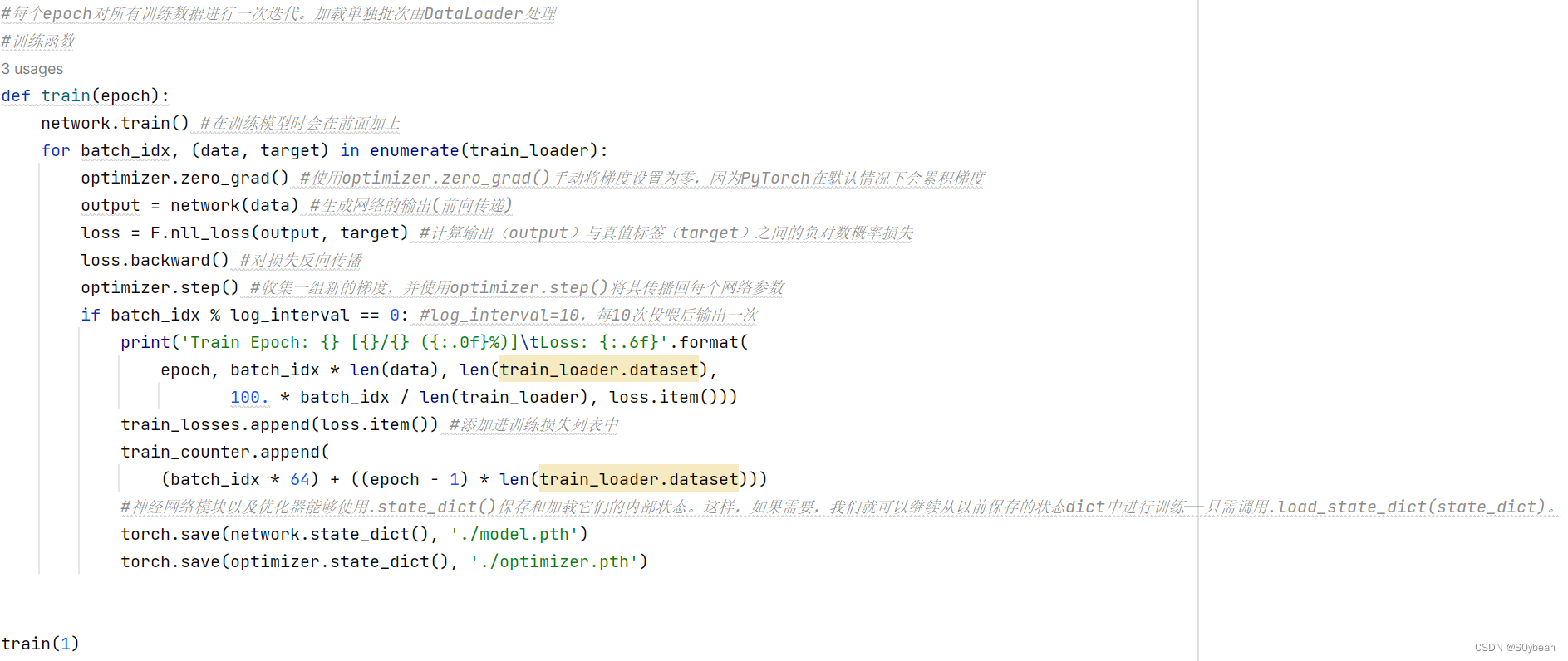
def train(epoch):network.train() #在训练模型时会在前面加上for batch_idx, (data, target) in enumerate(train_loader):optimizer.zero_grad() #使用optimizer.zero_grad()手动将梯度设置为零,因为PyTorch在默认情况下会累积梯度output = network(data) #生成网络的输出(前向传递)loss = F.nll_loss(output, target) #计算输出(output)与真值标签(target)之间的负对数概率损失loss.backward() #对损失反向传播optimizer.step() #收集一组新的梯度,并使用optimizer.step()将其传播回每个网络参数if batch_idx % log_interval == 0: #log_interval=10,每10次投喂后输出一次print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, batch_idx * len(data), len(train_loader.dataset),100. * batch_idx / len(train_loader), loss.item()))train_losses.append(loss.item()) #添加进训练损失列表中train_counter.append((batch_idx * 64) + ((epoch - 1) * len(train_loader.dataset)))#神经网络模块以及优化器能够使用.state_dict()保存和加载它们的内部状态。这样,如果需要,我们就可以继续从以前保存的状态dict中进行训练——只需调用.load_state_dict(state_dict)。torch.save(network.state_dict(), './model.pth')torch.save(optimizer.state_dict(), './optimizer.pth')train(1)#测试函数。总结测试损失,并跟踪正确分类的数字来计算网络的精度。
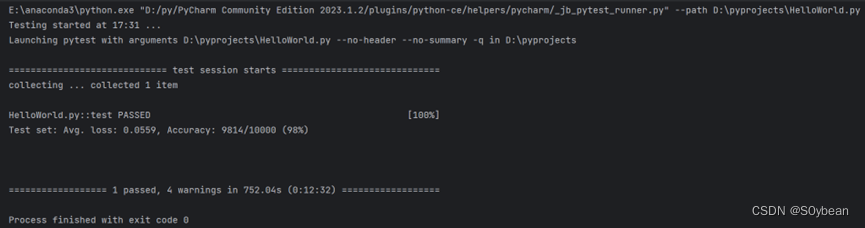
def test():network.eval() #在测试模型时在前面使用test_loss = 0correct = 0with torch.no_grad(): #使用上下文管理器no_grad(),我们可以避免将生成网络输出的计算结果存储在计算图(计算过程的构建,以便梯度反向传播等操作)中。(with是使用的意思)for data, target in test_loader:output = network(data) #生成网络的输出(前向传递)# 将一批的损失相加test_loss += F.nll_loss(output, target, size_average=False).item() #NLLLoss 的输入是一个对数概率向量和一个目标标签pred = output.data.max(1, keepdim=True)[1] ## 找到概率最大的下标correct += pred.eq(target.data.view_as(pred)).sum() #预测正确的数量相加test_loss /= len(test_loader.dataset)test_losses.append(test_loss)print('\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(test_loss, correct, len(test_loader.dataset),100. * correct / len(test_loader.dataset)))test()#我们将在循环遍历n_epochs之前手动添加test()调用,以使用随机初始化的参数来评估我们的模型。
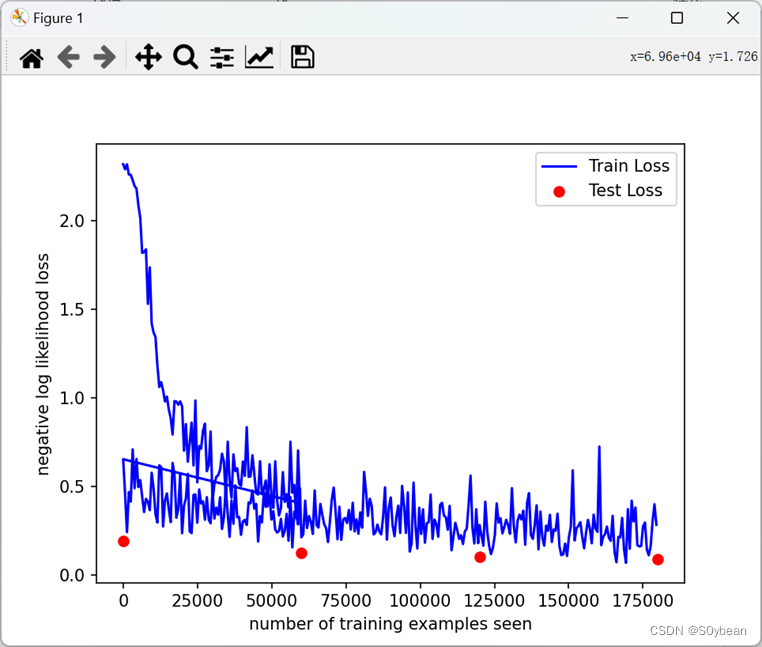
for epoch in range(1, n_epochs + 1):train(epoch)test()#评估模型的性能,画损失曲线
fig = plt.figure()
plt.plot(train_counter, train_losses, color='blue')
plt.scatter(test_counter, test_losses, color='red')
plt.legend(['Train Loss', 'Test Loss'], loc='upper right')
plt.xlabel('number of training examples seen')
plt.ylabel('negative log likelihood loss')
plt.show()#输出自己找的测试图片,比较模型的输出。
examples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples)
with torch.no_grad():output = network(example_data)
fig1 = plt.figure()
for i in range(6):plt.subplot(2,3,i+1)plt.tight_layout()plt.imshow(example_data[i][0], cmap='gray', interpolation='none')plt.title("Prediction: {}".format(output.data.max(1, keepdim=True)[1][i].item()))plt.xticks([])plt.yticks([])
plt.show()#继续对网络进行训练,并看看如何从第一次培训运行时保存的state_dicts中继续进行训练。我们将初始化一组新的网络和优化器。
continued_network = Net()
continued_optimizer = optim.SGD(network.parameters(), lr=learning_rate,momentum=momentum)network_state_dict = torch.load('model.pth') #见左侧项目列表,有该文件
continued_network.load_state_dict(network_state_dict) #使用.load_state_dict(),我们现在可以加载网络的内部状态,并在最后一次保存它们时优化它们。
optimizer_state_dict = torch.load('optimizer.pth') #见左侧项目列表,有该文件
continued_optimizer.load_state_dict(optimizer_state_dict)
#同样,运行一个训练循环应该立即恢复我们之前的训练。为了检查这一点,我们只需使用与前面相同的列表来跟踪损失值
for i in range(4,9):test_counter.append(i*len(train_loader.dataset))train(i)test()
#我们再次看到测试集的准确性从一个epoch到另一个epoch有了(运行更慢的,慢的多了)提高。
#输出自己找的测试图片,比较模型的输出。
examples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples)
with torch.no_grad():output = network(example_data)
fig1 = plt.figure()
for i in range(6):plt.subplot(2,3,i+1)plt.tight_layout()plt.imshow(example_data[i][0], cmap='gray', interpolation='none')plt.title("Prediction: {}".format(output.data.max(1, keepdim=True)[1][i].item()))plt.xticks([])plt.yticks([])
plt.show()2.代码解析
2.1参数设置

(1)深度学习中Epoch、Batch以及Batch size的设定 - 知乎 (zhihu.com)
Epoch(时期):将所有训练样本训练一次的过程
Batch:将整个训练样本分为若干个Batch
Batch_Size:每个Batch的样本数量
Iteration:训练一个Batch就是一个Iteration
(2)学习率一般设置为0.1或0.01
(3)Pytorch——momentum动量_momentum pytorch_Chukai123的博客-CSDN博客
Momentum作用:动量,跳出局部最优解。
引入momentum之后的权重更新:v=momentum∗v−Lr∗dw;w=w+v
V为速度一般初始为0
(4)log_interval=10:间隔10个Batch输出一次
(5)【pytorch】torch.manual_seed()用法详解_torch.seed_Xavier Jiezou的博客-CSDN博客
torch.manual_seed(seed):设置每次运行py文件生成的随机数相同。
2.2数据集

(1)torch.utils.data.DataLoader
Shuffle=True:打乱数据
(2)torchvision.datasets.MNIST
Root:MNIST数据集根目录
Train:true则从training.pt创建数据集,否则从test.pt创建
Download:true则从internet下载放在根目录
Transform:
torchvision.transforms 参数解读/中文使用手册_torchvision.transforms.functional.rotate_江南蜡笔小新的博客-CSDN博客
torchvision.transforms.ToTensor
将PIL图片或者numpy.ndarray转成Tensor类型的
torchvision.transforms.functional.normalize(tensor, mean, std)
根据给定的标准差和方差归一化tensor图片
参数:
- tensor(Tensor)—— 形状为(C,H,W)的Tensor图片
- mean(squence) —— 每个通道的均值,序列
- std (sequence) —— 每个通道的标准差,序列
返回:返回归一化后的Tensor图片。
2.3查看测试数据

Enumerate:将一个可遍历对象组合为一个索引序列
Next:返回迭代器的下一个项目
2.4定义卷积神经网络
Super:调用父类方法
卷积输出大小 = 输入分辨率 – 卷积核大小 + 1
输出通道数 = 使用卷积核数量
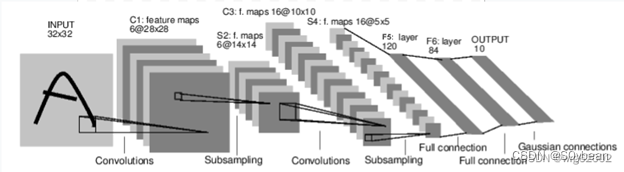
第一个全连接层输入分辨率如何确定?
28->24,24/2->12,12->8,8/2->4
这么说可能有些抽象,看下面的图就知道怎么来的了。
F.relu对应右侧图示的激活函数
PyTorch常用激活函数解析_f.leaky_relu_orientliu96的博客-CSDN博客
F.max_pool2d(,2):对卷积层进行最大池化,“2”为步长(2*2的池化层)
x.view:将tensor reshape成一维向量
F.log_softmax:归一化输出
2.5初始化网络与优化器

Optim.SGD:随机梯度下降
[i*len(train_loader.dataset) for i in range(n_epochs + 1)] 使用列表推导式构建一个样本数列表
F.nll_loss:NLLLoss 函数输入 input 之前,需要对 input 进行 log_softmax 处理,即将 input 转换成概率分布的形式,并且取对数,底数为 e。其损失函数为负对数似然。

3.实验结果


相关文章:
【Pytorch+torchvision】MNIST手写数字识别
深度学习入门项目,含代码详细解析 在本文中,我们将在PyTorch中构建一个简单的卷积神经网络,并使用MNIST数据集训练它识别手写数字。 MNIST包含70,000张手写数字图像: 60,000张用于培训,10,000张用于测试。图像是灰度(即…...

spring boot 集成rocketmq
集成Spring Boot和RocketMQ 在现代的微服务架构中,消息队列已经成为一种常见的异步处理模式,它能解决服务间的同步调用、耦合度高、流量高峰等问题。RocketMQ是阿里巴巴开源的一款消息中间件,性能优秀,功能齐全,被广泛…...

redis Hash类型命令
Redis中的Hash类型有多个常用命令可用于对Hash键进行操作。以下是一些常见的Redis Hash类型命令: HSET:设置Hash字段的值。 它将指定字段与相应的值关联起来,如果字段已经存在,则更新其值,如果字段不存在,…...

P1194 买礼物(最小生成树)(内附封面)
买礼物 题目描述 又到了一年一度的明明生日了,明明想要买 B B B 样东西,巧的是,这 B B B 样东西价格都是 A A A 元。 但是,商店老板说最近有促销活动,也就是: 如果你买了第 I I I 样东西࿰…...

oracle基础语法和备份恢复
Oracle总结 sql命令分类 1.DDL,数据定义语言,create创建/drop销毁 2.DCL,数据库控制语言,grant授权/revoke撤销 3.DML,数据操纵语言,insert/update/delete等sql语句 4.DQL,数据查询语言&am…...

【MATLAB第66期】#源码分享 | 基于MATLAB的PAWN全局敏感性分析模型(有条件参数和无条件参数)
【MATLAB第66期】#源码分享 | 基于MATLAB的PAWN全局敏感性分析模型(有条件参数和无条件参数) 文献参考 Pianosi, F., Wagener, T., 2015. A simple and efficient method for global sensitivity analysis based on cumulative distribution functions.…...

vue2过渡vue3技术差异点指南
基础点 reactive() 定义响应式变量(仅仅引用类型有效:对象数组map,set):reactive(),类似于data中return的数据 例子: import { reactive } from vueexport default {setup() {const state reactive({ count: 0 })function in…...
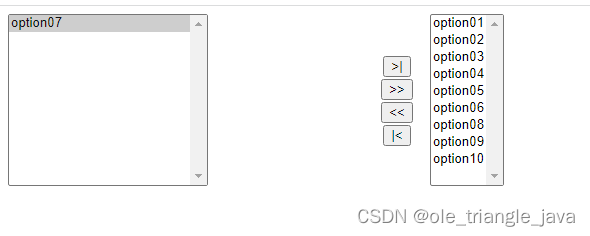
两个多选框(select)之间值的左右上下移动
<!DOCTYPE html> <html> <head><meta charset"utf-8"><title>两个多选框(select)之间值的左右上下移动</title> </head> <script src"https://cdn.bootcss.com/jquery/3.3.1/jquery.js"></script>&…...

【设计模式】——模板模式
什么是模板模式? 模板方法模式(Template Method Pattern),又叫模板模式(Template Pattern),在一个抽象类公开定义了执行它的方法的模板。它的子类可以按需要重写方法实现,但调用将以抽象类中定义的方式进行…...
工业机器视觉系统开发流程简介
需求分析和系统设计:与用户合作,明确系统的功能和性能需求,并设计系统的整体架构。 软、硬件选型:根据需求分析结果,选择适合的软、硬件设备,包括光学传感器、相机、光源、图像采集设备、处理器等。 软件…...

【Unity3D】Renderer Feature简介
1 3D 项目迁移到 URP 项目后出现的问题 3D 项目迁移至 URP 项目后,会出现很多渲染问题,如:材质显示异常、GL 渲染不显示、多 Pass 渲染异常、屏幕后处理异常等问题。下面将针对这些问题给出一些简单的解决方案。 URP 官方教程和 API 详见→Un…...
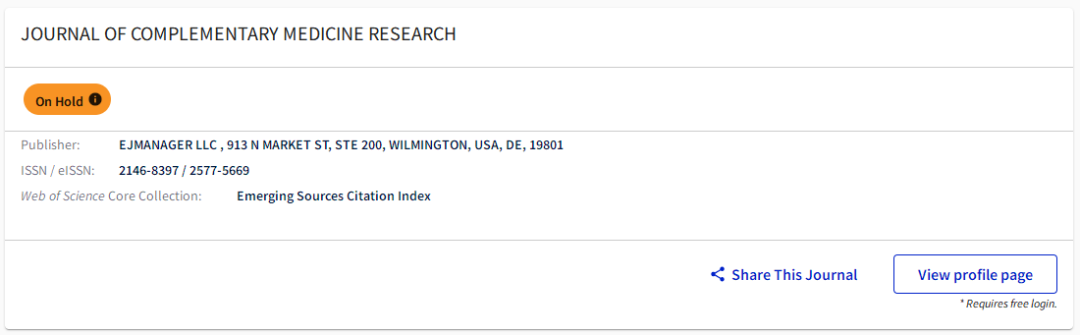
麻了!包含中科院TOP,共16本期刊被标记为“On Hold”状态!
近日,小编从科睿唯安旗下的“Master Journal List”官网查到,除了知名老牌期刊Chemosphere竟然被标记为“On Hold”状态,目前共有7本SCI期刊,1本SSCI期刊,8本ESCI期刊被标记为“On Hold”,究竟是怎么回事呢…...

2.Flink应用
2.1 数据流 DataStream:DataStream是Flink数据流的核心抽象,其上定义了对数据流的一系列操作DataStreamSource:DataStreamSource 是 DataStream 的 起 点 , DataStreamSource 在StreamExecutionEnvironment 中 创 建 ,…...
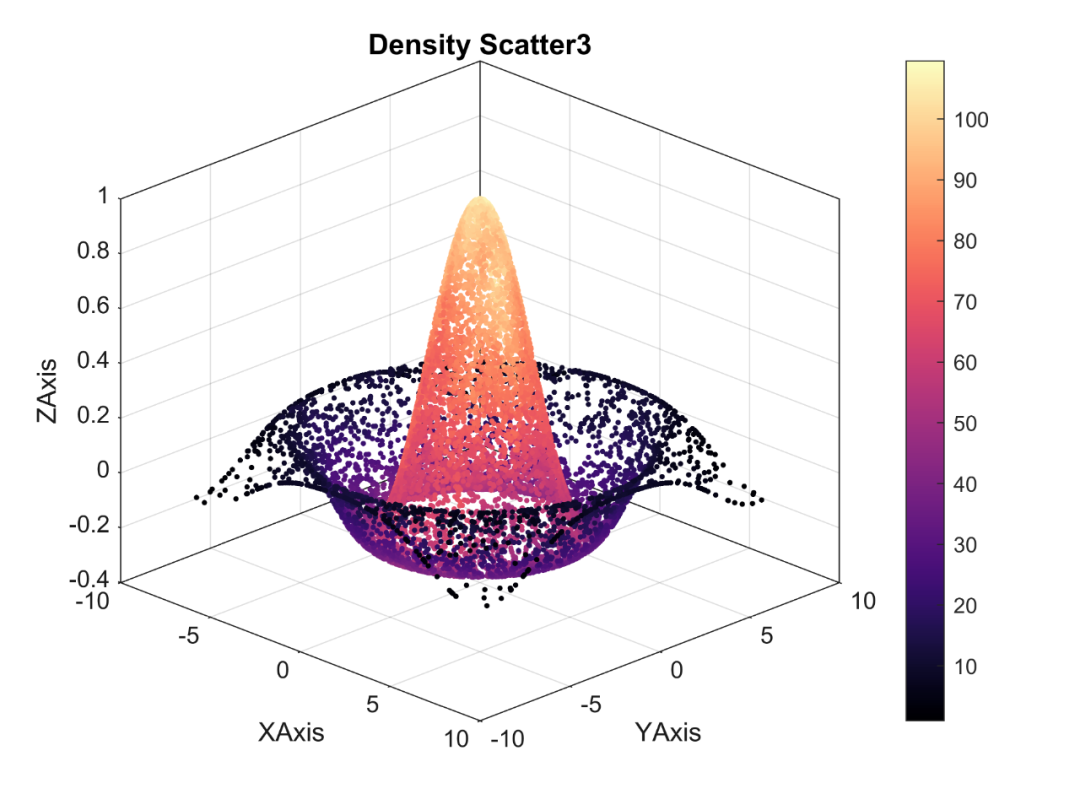
Matlab进阶绘图第25期—三维密度散点图
三维密度散点图本质上是一种特征渲染的三维散点图,其颜色表示某一点所在区域的密度信息。 除了作图,三维密度散点图绘制的关键还在于密度的计算。 当然,不管是作图还是密度的计算,这些在《Matlab论文插图绘制模板》和《Matlab点…...

C++设计模式之桥接设计模式
文章目录 C桥接设计模式什么是桥接设计模式该模式有什么优缺点优点缺点 如何使用 C桥接设计模式 什么是桥接设计模式 桥接设计模式是一种结构型设计模式,它可以将抽象接口和实现分离开来,以便它们可以独立地变化和扩展。 该模式有什么优缺点 优点 灵…...
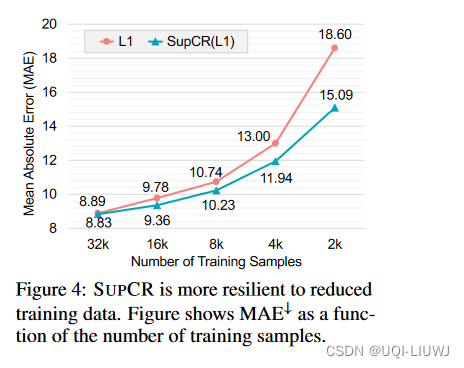
论文笔记:SUPERVISED CONTRASTIVE REGRESSION
2022arxiv的论文,没有中,但一作是P大图班本MIT博,可信度应该还是可以的 0 摘要 深度回归模型通常以端到端的方式进行学习,不明确尝试学习具有回归意识的表示。 它们的表示往往是分散的,未能捕捉回归任务的连续性质。…...

Java 多线程并发 CAS 技术详解
一、CAS概念和应用背景 CAS的作用和用途 CAS(Compare and Swap)是一种并发编程中常用的技术,用于解决多线程环境下的并发访问问题。CAS操作是一种原子操作,它可以提供线程安全性,避免了使用传统锁机制所带来的性能开…...
如何压缩高清PDF文件大小?将PDF文件压缩到最小的三个方法
PDF格式是一种非常常用的文档格式,但是有时候我们需要将PDF文件压缩为更小的大小以便于传输和存储。在本文中,我们将介绍三种PDF压缩的方法,包括在线PDF压缩、利用软件PDF压缩以及使用WPS缩小pdf。 首先,在线PDF压缩是最常用的方…...
)
04 统计语言模型(n元语言模型)
博客配套视频链接: https://space.bilibili.com/383551518?spm_id_from=333.1007.0.0 b 站直接看 配套 github 链接:https://github.com/nickchen121/Pre-training-language-model 配套博客链接:https://www.cnblogs.com/nickchen121/p/15105048.html 预训练 预先训练 我们…...

Linux各目录详解
Linux文件系统是一个树状结构,由多个目录(或文件夹)组成。以下是常见的Linux目录及其功能的详细解释: /(根目录):在Linux文件系统中,所有其他目录和文件都是从根目录派生的。所有的存…...

SkyWalking 10.2.0 SWCK 配置过程
SkyWalking 10.2.0 & SWCK 配置过程 skywalking oap-server & ui 使用Docker安装在K8S集群以外,K8S集群中的微服务使用initContainer按命名空间将skywalking-java-agent注入到业务容器中。 SWCK有整套的解决方案,全安装在K8S群集中。 具体可参…...

ubuntu搭建nfs服务centos挂载访问
在Ubuntu上设置NFS服务器 在Ubuntu上,你可以使用apt包管理器来安装NFS服务器。打开终端并运行: sudo apt update sudo apt install nfs-kernel-server创建共享目录 创建一个目录用于共享,例如/shared: sudo mkdir /shared sud…...

Java 8 Stream API 入门到实践详解
一、告别 for 循环! 传统痛点: Java 8 之前,集合操作离不开冗长的 for 循环和匿名类。例如,过滤列表中的偶数: List<Integer> list Arrays.asList(1, 2, 3, 4, 5); List<Integer> evens new ArrayList…...

【第二十一章 SDIO接口(SDIO)】
第二十一章 SDIO接口 目录 第二十一章 SDIO接口(SDIO) 1 SDIO 主要功能 2 SDIO 总线拓扑 3 SDIO 功能描述 3.1 SDIO 适配器 3.2 SDIOAHB 接口 4 卡功能描述 4.1 卡识别模式 4.2 卡复位 4.3 操作电压范围确认 4.4 卡识别过程 4.5 写数据块 4.6 读数据块 4.7 数据流…...

深入理解JavaScript设计模式之单例模式
目录 什么是单例模式为什么需要单例模式常见应用场景包括 单例模式实现透明单例模式实现不透明单例模式用代理实现单例模式javaScript中的单例模式使用命名空间使用闭包封装私有变量 惰性单例通用的惰性单例 结语 什么是单例模式 单例模式(Singleton Pattern&#…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

【Zephyr 系列 10】实战项目:打造一个蓝牙传感器终端 + 网关系统(完整架构与全栈实现)
🧠关键词:Zephyr、BLE、终端、网关、广播、连接、传感器、数据采集、低功耗、系统集成 📌目标读者:希望基于 Zephyr 构建 BLE 系统架构、实现终端与网关协作、具备产品交付能力的开发者 📊篇幅字数:约 5200 字 ✨ 项目总览 在物联网实际项目中,**“终端 + 网关”**是…...
Linux部署私有文件管理系统MinIO
最近需要用到一个文件管理服务,但是又不想花钱,所以就想着自己搭建一个,刚好我们用的一个开源框架已经集成了MinIO,所以就选了这个 我这边对文件服务性能要求不是太高,单机版就可以 安装非常简单,几个命令就…...
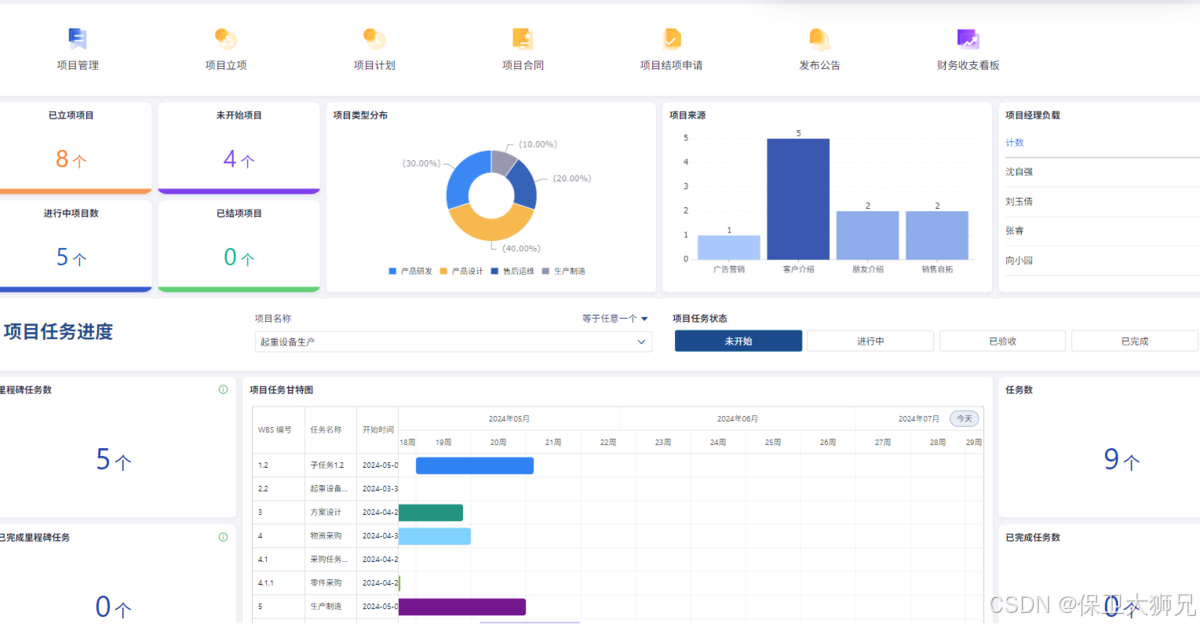
项目进度管理软件是什么?项目进度管理软件有哪些核心功能?
无论是建筑施工、软件开发,还是市场营销活动,项目往往涉及多个团队、大量资源和严格的时间表。如果没有一个系统化的工具来跟踪和管理这些元素,项目很容易陷入混乱,导致进度延误、成本超支,甚至失败。 项目进度管理软…...

MyBatis-Plus 常用条件构造方法
1.常用条件方法 方法 说明eq等于 ne不等于 <>gt大于 >ge大于等于 >lt小于 <le小于等于 <betweenBETWEEN 值1 AND 值2notBetweenNOT BETWEEN 值1 AND 值2likeLIKE %值%notLikeNOT LIKE %值%likeLeftLIKE %值likeRightLIKE 值%isNull字段 IS NULLisNotNull字段…...