【Linux06-基础IO】4.5万字的基础IO讲解
前言
本期分享基础IO的知识,主要有:
- 复习C语言文件操作
- 文件相关的系统调用
- 文件描述符fd
- 理解Linux下一切皆文件
- 缓冲区
- 文件系统
- 软硬链接
- 动静态库的理解和制作
- 动静态编译
博主水平有限,不足之处望请斧正!
C语言文件操作
#再谈文件
先回忆文件相关知识,结合已学操作系统知识,来构建共识:
- 文件 = 内容+属性
- 空文件也占空间(属性要占)
- 文件操作 = 对属性/内容的操作
- 标定一个文件,必须用 文件路径 + 文件名 的方式(具有唯一性)
- 没有指明文件路径时,默认在当前路径(进程的
cwd)进行文件访问
- 没有指明文件路径时,默认在当前路径(进程的
- 操作文件的一定是进程 (程序只有载入内存运行,才会执行文件操作)
- 文件只有被“打开”后才能访问
- “打开”:用户进程调用接口 ==> 操作系统“打开”文件
- 所以文件可分为:
- 被打开的文件
- 未被打开的文件
重点
- 操作文件的一定是进程(程序只有载入内存运行,文件操作才会被执行)
- 文件只有被“打开”(调用系统接口,系统来打开文件)之后才能操作
有了这些共识,我们可以得出结论:
文件操作 = 进程 操作 被打开文件(的内容/属性)
C语言文件接口使用
文件接口使用
写:
#include <stdio.h>#define FILE_NAME "log.txt"int main()
{//opt: r 读(不存在出错) / w写(不存在创建,存在则自动清空数据) // r+ 读写(不存在创建) / w+读写(不存在出错)// a 追加 / a+FILE* pf = fopen(FILE_NAME, "w");if(NULL == pf){perror("fopen");return 1;}int cnt = 5;while(cnt){fprintf(pf, "%s: %d\n", "Hello Bacon!", cnt--);}fclose(pf);return 0;
}
[bacon@VM-12-5-centos 2]$ make
gcc -o test test.c -std=c99
[bacon@VM-12-5-centos 2]$ ./test
[bacon@VM-12-5-centos 2]$ ls
log.txt makefile test test.c
[bacon@VM-12-5-centos 2]$ cat log.txt
Hello Bacon!: 5
Hello Bacon!: 4
Hello Bacon!: 3
Hello Bacon!: 2
Hello Bacon!: 1
读:
#include <stdio.h>#define FILE_NAME "log.txt"int main()
{FILE* pf = fopen(FILE_NAME, "r");if(NULL == pf){perror("fopen");return 1;}char buf[64];//fgets默认添加\0,因为C语言字符串以\0结尾,而fgets获取的是字符串//为什么要-1?以防极端情况fgets想添加\0添不上while(fgets(buf, sizeof(buf) - 1, pf) != NULL){printf("%s", buf); //log.txt内已经带了\n}fclose(pf);return 0;
}
Hello Bacon!: 5
Hello Bacon!: 4
Hello Bacon!: 3
Hello Bacon!: 2
Hello Bacon!: 1
用都会用,但感觉差口气儿。
理解文件接口
首先提出一个问题:C语言有文件接口,其他语言有吗?
一定有的。
为什么?因为文件在磁盘,磁盘是硬件,只有操作系统能访问硬件。
那我们又能知道,语言层面的文件接口,都必须调用系统接口。
为什么?因为操作系统对下管理硬件,对上通过提供系统调用的方式给用户良好的运行环境,任何人想访问硬件,都得过操作系统这关,它提供系统调用,我们就能访问;不提供,就不能。语言想进行文件操作,也只能通过系统调用。
- 任何人想访问硬件只能通过系统调用
- 学习文件接口,要学习不变的系统调用
文件相关的系统调用
open
NAMEopen, creat - open and possibly create a file or deviceSYNOPSIS#include <sys/types.h>#include <sys/stat.h>#include <fcntl.h>int open(const char *pathname, int flags);int open(const char *pathname, int flags, mode_t mode);
RETURN VALUEopen() and creat() return the new file descriptor, or -1 if an error occurred (in which case, errno is set appropriately).
先看第二个open:
- 作用:打开,或可能创建一个文件或设备
- 参数
pathname:要打开的文件路径flags:标记位(通过比特位传递选项)mode:权限
- 返回值:成功返回文件描述符
file descriptor,失败返回-1
为什么有两个open?
前者是不需要创建文件时用的,不需要给默认权限;后者是需要创建文件时用的,需要给默认权限mode
#通过比特位传递选项
#define ONE (1 << 0)
#define TWO (1 << 1)
#define THREE (1 << 2)
#define FOUR (1 << 3)void bitOption(int flags)
{if(flags & ONE) printf("ONE\n");if(flags & TWO) printf("TWO\n");if(flags & THREE) printf("THREE\n");if(flags & FOUR) printf("FOUR\n");
}int main()
{bitOption(ONE | TWO | FOUR);return 0;
}
对于open的flags,有几个宏:
O_RDONLY只读O_WRONLY只写O_RDWR读或写O_CREAT文件不存在则创建文件O_TRUNC文件存在则清空文件内容O_APPEND追加
close
NAMEclose - close a file descriptorSYNOPSIS#include <unistd.h>int close(int fd);
- 作用:关掉文件描述符对应的文件
- 参数
fd
- 返回值:成功返回0,失败返回-1
打开并关闭文件:
int main()
{int fd = open(FILE_NAME, O_WRONLY);if(fd == -1 ){perror("open");return 1;}close(fd);return 0;
}
[bacon@VM-12-5-centos 2]$ ./test
open: No such file or directory
怎么找不到呢?以写方式打开,默认不是会创建吗?
:我们不能把库函数那套照搬到系统调用上,“自动创建”是C库函数自己做的事。
int fd = open(FILE_NAME, O_WRONLY | O_CREAT);
给上了O_CREATE,我们现在要创建文件,却没给默认权限会怎么样?
[bacon@VM-12-5-centos 2]$ ./test
[bacon@VM-12-5-centos 2]$ ll
total 20
-rw--ws--T 1 bacon bacon 0 Jan 20 19:28 log.txt
-rw-rw-r-- 1 bacon bacon 68 Jan 20 10:48 makefile
-rwxrwxr-x 1 bacon bacon 8456 Jan 20 19:25 test
-rw-rw-r-- 1 bacon bacon 1354 Jan 20 19:25 test.c
根据权限也能知道,log.txt现在完全就是乱的。
正确用法:
int fd = open(FILE_NAME, O_WRONLY | O_CREAT, 0666);
[bacon@VM-12-5-centos 2]$ ./test
[bacon@VM-12-5-centos 2]$ ll
total 20
-rw-rw-r-- 1 bacon bacon 0 Jan 20 19:33 log.txt
-rw-rw-r-- 1 bacon bacon 68 Jan 20 10:48 makefile
-rwxrwxr-x 1 bacon bacon 8456 Jan 20 19:33 test
-rw-rw-r-- 1 bacon bacon 1360 Jan 20 19:33 test.c
log.txt经过umask,得到正确的权限。若我们不想要默认的umask,可以自己设置
NAMEumask - set file mode creation maskSYNOPSIS#include <sys/types.h>#include <sys/stat.h>mode_t umask(mode_t mask);
...
umask(0);
...
[bacon@VM-12-5-centos 2]$ ./test
[bacon@VM-12-5-centos 2]$ ll
total 20
-rw-rw-rw- 1 bacon bacon 0 Jan 20 19:40 log.txt
-rw-rw-r-- 1 bacon bacon 68 Jan 20 10:48 makefile
-rwxrwxr-x 1 bacon bacon 8512 Jan 20 19:39 test
-rw-rw-r-- 1 bacon bacon 1374 Jan 20 19:39 test.c
write
NAMEwrite - write to a file descriptorSYNOPSIS#include <unistd.h>ssize_t write(int fd, const void *buf, size_t count);
- 作用:向文件描述符写入
- 参数
fdbuf要被写入的数据count要写入的数据的字节个数
- 返回值:返回写入的字节个数
buf为什么是void*?数据类型是语言的事,操作系统眼里都是二进制!
向文件写入(不存在则创建,存在则清空):
int main()
{umask(0);int fd = open(FILE_NAME, O_WRONLY | O_CREAT | O_TRUNC, 0666);if(fd == -1){perror("open");return 1;}int cnt = 5;char outBuf[64];while(cnt){sprintf(outBuf, "%s %d\n", "Hello Bacon", cnt--);//第三个参数要不要+1把\0也写入文件?不用:\0结尾是C语言的事,和文件无关!write(fd, outBuf, strlen(outBuf)); }close(fd);return 0;
}
[bacon@VM-12-5-centos 2]$ ./test
[bacon@VM-12-5-centos 2]$ ll
total 24
-rw-rw-rw- 1 bacon bacon 70 Jan 20 21:32 log.txt
-rw-rw-r-- 1 bacon bacon 68 Jan 20 10:48 makefile
-rwxrwxr-x 1 bacon bacon 8664 Jan 20 21:32 test
-rw-rw-r-- 1 bacon bacon 1678 Jan 20 21:32 test.c
[bacon@VM-12-5-centos 2]$ cat log.txt
Hello Bacon 5
Hello Bacon 4
Hello Bacon 3
Hello Bacon 2
Hello Bacon 1
open(FILE_NAME, O_WRONLY | O_CREAT | O_TRUNC, 0666); = fopen(FILE_NAME, "w");
追加:
int fd = open(FILE_NAME, O_WRONLY | O_CREAT | O_APPEND, 0666);
[bacon@VM-12-5-centos 2]$ ./test
[bacon@VM-12-5-centos 2]$ ./test
[bacon@VM-12-5-centos 2]$ ./test
[bacon@VM-12-5-centos 2]$ cat log.txt
Hello Bacon 5
Hello Bacon 4
Hello Bacon 3
Hello Bacon 2
Hello Bacon 1
Hello Bacon 5
Hello Bacon 4
Hello Bacon 3
Hello Bacon 2
Hello Bacon 1
Hello Bacon 5
Hello Bacon 4
Hello Bacon 3
Hello Bacon 2
Hello Bacon 1
Hello Bacon 5
Hello Bacon 4
Hello Bacon 3
Hello Bacon 2
Hello Bacon 1
read
NAMEread - read from a file descriptorSYNOPSIS#include <unistd.h>ssize_t read(int fd, void *buf, size_t count);
- 作用:从文件描述符对应的文件读
- 参数
fdbuf被读入数据存放的地方count要读入数据的字节个数
- 返回值:返回成功读入的字节个数,返回0代表读到了文件结尾
从文件读:
int main()
{umask(0);int fd = open(FILE_NAME, O_RDONLY);if(fd == -1 ){perror("open");return 1;}char buf[1024];
b ssize_t read_ret = read(fd, buf, sizeof(buf) - 1);if(read_ret > 0) buf[read_ret] = 0; //我们读入字符串后,在结尾加上\0printf("%s\n", buf);close(fd);return 0;
}
[bacon@VM-12-5-centos 2]$ ./test
Hello Bacon 5
Hello Bacon 4
Hello Bacon 3
Hello Bacon 2
Hello Bacon 1
Hello Bacon 5
Hello Bacon 4
Hello Bacon 3
Hello Bacon 2
Hello Bacon 1
Hello Bacon 5
Hello Bacon 4
Hello Bacon 3
Hello Bacon 2
Hello Bacon 1
Hello Bacon 5
Hello Bacon 4
Hello Bacon 3
Hello Bacon 2
Hello Bacon 1#文件描述符fd
我们说“文件操作 = 进程 操作 被打开文件”,那就有个问题,当打开很多文件的时候,操作系统如何管理这些被打开的文件?一定是四步走:抽象、具象、组织、操作。我们说的文件操作,其实就是这四步中的“操作”。但其他我们还不清楚, 现在来谈谈文件的抽象、具象和组织。
文件的抽象
struct file{//文件的大部分属性
}
文件的具象和组织
先来看一个现象:
#define FILE_NAME(num) "log.txt"#numint main()
{int fd1 = open(FILE_NAME(1), O_WRONLY | O_CREAT, 0666);int fd2 = open(FILE_NAME(2), O_WRONLY | O_CREAT, 0666);int fd3 = open(FILE_NAME(3), O_WRONLY | O_CREAT, 0666);int fd4 = open(FILE_NAME(4), O_WRONLY | O_CREAT, 0666);printf("fd1 = %d\n", fd1);printf("fd2 = %d\n", fd2);printf("fd3 = %d\n", fd3);printf("fd4 = %d\n", fd4);close(fd1);close(fd2);close(fd3);close(fd4);return 0;
}
[bacon@VM-12-5-centos 2]$ ./mytest
fd1 = 3
fd2 = 4
fd3 = 5
fd4 = 6
从3开始?
为什么fd是从3开始, 既然是连续的整数,“0、1、2”哪去了?
我们研究fd,不妨也研究一下它的一种封装:
调用C语言的文件接口时必须用FILE* pf,调用系统调用时必须用int fd。而且前者底层脱不开后者,那这库函数想玩儿,必须用到fd,即FILE内一定有一个字段是fd!
很巧的是,默认打开的三个标准输入输出流恰好是FILE*类型。
NAMEstdin, stdout, stderr - standard I/O streamsSYNOPSIS#include <stdio.h>extern FILE *stdin;extern FILE *stdout;extern FILE *stderr;
其中会不会有什么联系?
#define FILE_NAME(num) "log.txt"#numint main()
{printf("fd of stdin = %d\n", stdin->_fileno); //获取FILE结构体内类似fd的字段printf("fd of stdout = %d\n", stdout->_fileno);//获取FILE结构体内类似fd的字段printf("fd of stderr = %d\n", stderr->_fileno);//获取FILE结构体内类似fd的字段int fd1 = open(FILE_NAME(1), O_WRONLY | O_CREAT, 0666);int fd2 = open(FILE_NAME(2), O_WRONLY | O_CREAT, 0666);int fd3 = open(FILE_NAME(3), O_WRONLY | O_CREAT, 0666);int fd4 = open(FILE_NAME(4), O_WRONLY | O_CREAT, 0666);printf("fd1 = %d\n", fd1);printf("fd2 = %d\n", fd2);printf("fd3 = %d\n", fd3);printf("fd4 = %d\n", fd4);close(fd1);close(fd2);close(fd3);close(fd4);return 0;
}
fd of stdin = 0
fd of stdout = 1
fd of stderr = 2
fd1 = 3
fd2 = 4
fd3 = 5
fd4 = 6
果然!“0、1、2”分别对应默认打开的三个标准输入输出流:stdin、stdout、stderr 。
连续整数?
我们也发现,被打开文件的描述符是连续的整数,这不禁让人想到数组的下标啊。
文件的具象和组织具体如图所示:
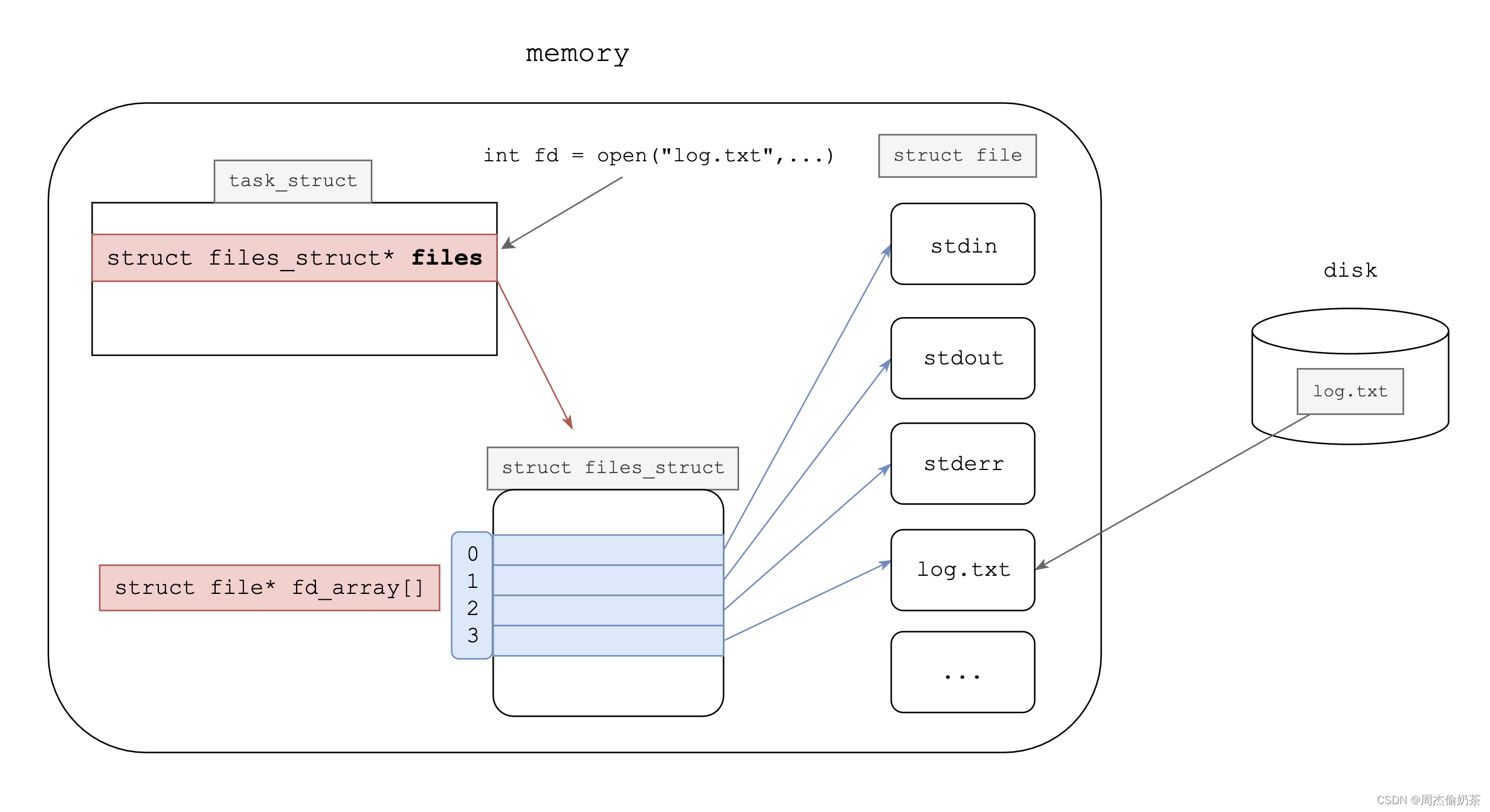
fd的本质就是数组的下标,是fd_array的下标。
将以上内容串联下,就能知道OS是怎么管理文件的了。
文件的管理
-
抽象、具象:
struct file(有文件的大部分属性) -
组织:
task_struct对象内有struct files_struct* files指向struct files_struct对象其中又有**
struct file* fd_array[],每一个元素都是一个FILE指针,它构建了进程(task_struct)和被打开文件(struct file)的映射关系,它的下标被称作文件描述符fd** -
操作:
open、close、write、read…
fd的分配规则
实践出真知。
int main()
{close(0);int fd = open("log.txt", O_WRONLY | O_CREAT, 0666);printf("fd = %d\n", fd);close(fd);return 0;
}
[bacon@VM-12-5-centos 3]$ ./mytest
fd = 0
int main()
{close(2);int fd = open("log.txt", O_WRONLY | O_CREAT, 0666);printf("fd = %d\n", fd);close(fd);return 0;
}
[bacon@VM-12-5-centos 3]$ ./mytest
fd = 2
分配规则:从小到大分配最小的未被占用fd。
再关1试试:
int main()
{close(1);int fd = open("log.txt", O_WRONLY | O_CREAT, 0666);printf("fd = %d\n", fd);close(fd);return 0;
}
[bacon@VM-12-5-centos 3]$ ./mytest
[bacon@VM-12-5-centos 3]$
关掉fd为1的文件就不打印结果了,为什么?
printf本质其实就是写入到fd为1的stdout内,然后读取stdout,输出到显示器上。需要注意,
系统默认stdout的fd为1。
也就是,即使我们把fd为1的stdout关掉,系统仍然会从fd为1的文件中读取并输出到显示器。
按这么说,关掉fd为1的stdout,我再打开log.txt,会从小到大找最小的未被占用fd,即 1,那我的log.txt岂不是成了系统眼里的stdout?
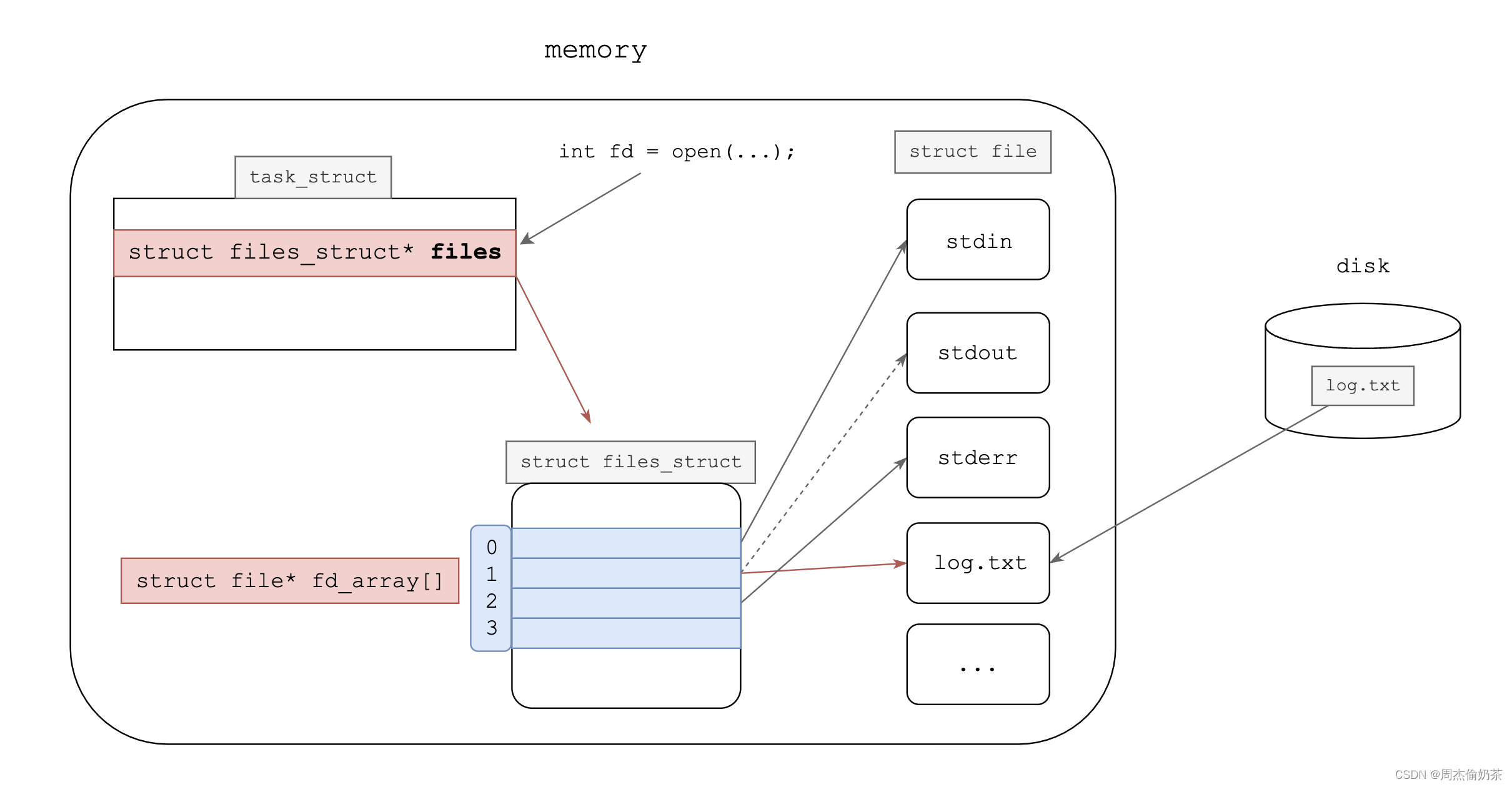
那也代表printf会向我的log.txt写入?
[bacon@VM-12-5-centos 3]$ ./mytest
[bacon@VM-12-5-centos 3]$ cat log.txt1
[bacon@VM-12-5-centos 3]$
文件里没有啊?其实这跟缓冲区有关,我们刷新一下就可以看到。
int main()
{close(1);int fd = open("log.txt", O_WRONLY | O_CREAT, 0666);printf("fd = %d\n", fd);fflush(stdout);close(fd);return 0;
}
[bacon@VM-12-5-centos 3]$ ./mytest
[bacon@VM-12-5-centos 3]$ cat log.txt
fd = 1
本来是输出到stdout(向stdout写入),一通操作后,输出到了log.txt(向log.txt写入),这就是重定向。
#重定向
是什么
改变向文件输入/输出的“方向”。
本质就是,修改struct file* fd_array中的元素(即更改某fd对应的FILE*指针)。
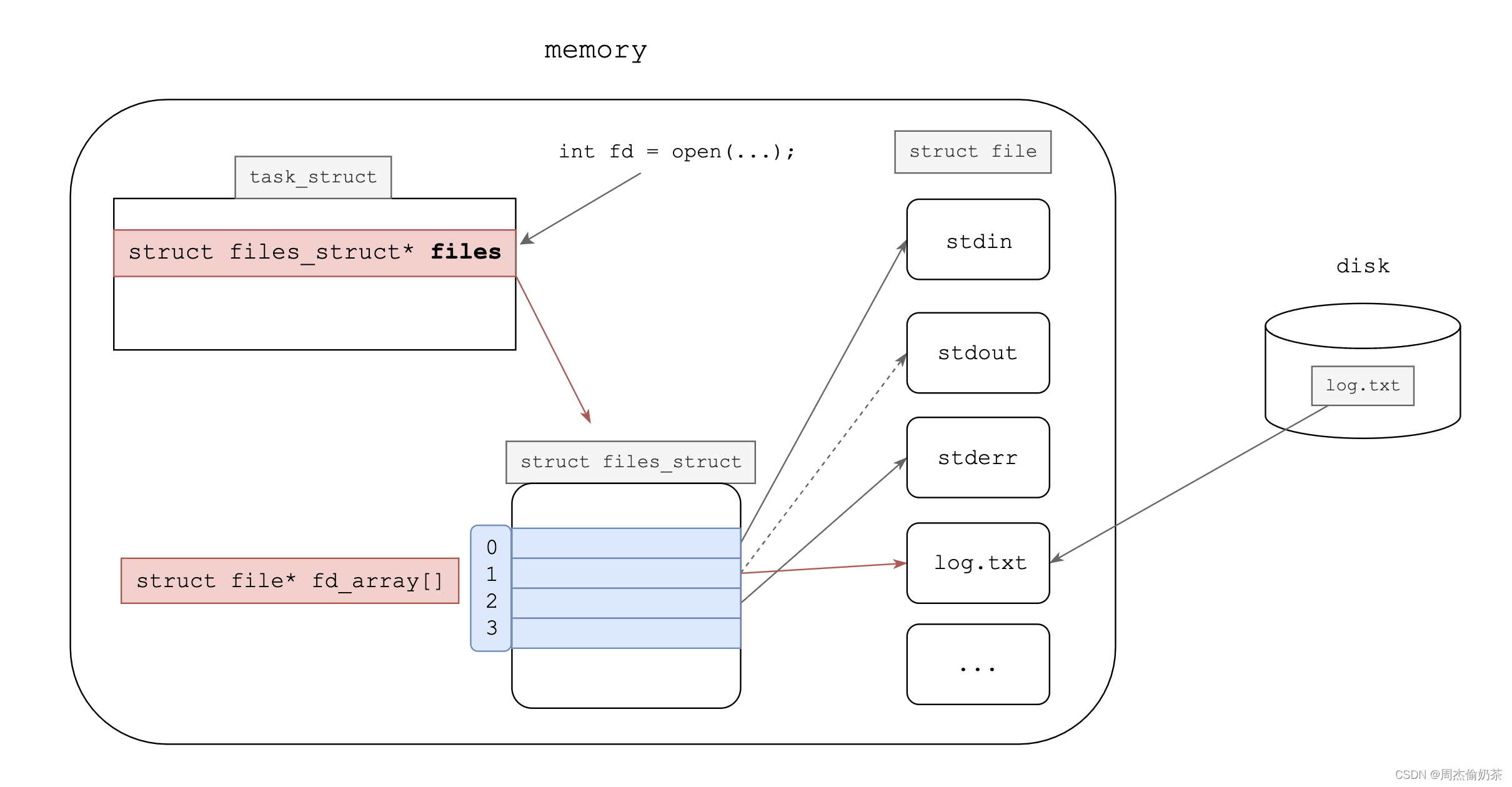
*1这个fd对应的指向原本是stdout,经过close和open,最终指向了log.txt1。
分类
>输出重定向>>追加重定 向<输入重定向
但是close + open有点挫
有没有别的办法进行重定向?有的
怎么做
可以通过一个系统调用dup2。
NAMEdup, dup2, dup3 - duplicate a file descriptorSYNOPSIS#include <unistd.h>int dup(int oldfd);int dup2(int oldfd, int newfd);#define _GNU_SOURCE /* See feature_test_macros(7) */#include <fcntl.h> /* Obtain O_* constant definitions */#include <unistd.h>int dup3(int oldfd, int newfd, int flags);
其中,dup2是我们最常用的,
dup2() makes newfd be the copy of oldfd, closing newfd first if necessary
- 作用:让
newfd对应元素变成oldfd对应元素的一份拷贝(fd_arrays[newfd] = fd_arrays[oldfd]) - 返回值:成功返回
newfd,失败返回-1
#define FILE_NAME "log.txt"int main()
{//原本输出(写入)到stdout,现在要输出(写入)到我自己的log.txtint fd = open(FILE_NAME, O_WRONLY | O_CREAT, 0666);int dup2_ret = dup2(fd, 1);assert(dup2_ret != -1);printf("fd = %d\n", fd);fflush(stdout);close(fd);return 0;
}
[bacon@VM-12-5-centos 3]$ ./mytest
[bacon@VM-12-5-centos 3]$ ls
log.txt makefile mytest mytest.c
[bacon@VM-12-5-centos 3]$ cat log.txt
fd = 3

fd_array[1] = fd_array[fd]
以上是输出重定向,其他两个重定向也很简单。
追加重定向:
#define FILE_NAME "log.txt"int main()
{int fd = open(FILE_NAME, O_WRONLY | O_CREAT | O_APPEND, 0666);dup2(fd, 1);printf("fd = %d\n", fd);fflush(stdout);close(fd);return 0;
}
[bacon@VM-12-5-centos 3]$ cat log.txt
fd = 3
[bacon@VM-12-5-centos 3]$ ./mytest
[bacon@VM-12-5-centos 3]$ ./mytest
[bacon@VM-12-5-centos 3]$ ./mytest
[bacon@VM-12-5-centos 3]$ cat log.txt
fd = 3
fd = 3
fd = 3
fd = 3
输入重定向:
int main()
{//输入重定向:原本从stdin输入(读),现在从我自己的log.txt输入(读)int fd = open(FILE_NAME, O_RDONLY, 0666);if(fd < 0){perror("open");return -1;}dup2(fd, 0);char line[64];while(1){printf("> ");if(fgets(line, sizeof(line), stdin) == NULL) break;printf("%s", line);}close(fd);return 0;
}
[bacon@VM-12-5-centos 3]$ cat log.txt
hello world!
I'm Bacon!
[bacon@VM-12-5-centos 3]$ ./mytest
> hello world!
> I'm Bacon!
> [bacon@VM-12-5-centos 3]$
#把重定向加入shell
shell的原理是程序替换,所以重定向的工作一定是子进程来做,而父进程只需要规定子进程如何重定向。
实现一个redirCheck函数,获取命令中的重定向信息,交给子进程来真正重定向。
redirCheck实现思路:
- 全局变量
redirType保存重定向的类型 - 全局变量
redirFile保存要重定向至的文件名 - 父进程调用
redirCheck函数来获取前两者(子进程也能共享到) ,并处理输入的命令- 处理命令:将重定向标识置空
arg交给shell处理- 后面的文件名保存,不需要交给
shell(重定向标识置空后,不会读取到文件名了)
- 处理命令:将重定向标识置空
#include <stdio.h>
#include <ctype.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <sys/wait.h>
#include <assert.h>
#include <string.h>
#include <errno.h>#define NUM 1024
#define OPT_NUM 32#define NONE_REDIR 0
#define INPUT_REDIR 1
#define APPEND_REDIR 2
#define OUTPUT_REDIR 3#define trimSpace(start) do{\while(isspace(*start)) ++start; \
}while(0)char lineCommand[NUM];
char* myargv[OPT_NUM];
int lastCode = 0;
int lastSig = 0;//重定向信息
int redirType = NONE_REDIR;
char* redirFile = NULL;//重定向检查:
//1. 获取重定向信息:重定向类型和重定向的文件
//2. 处理命令,将arg和文件名分离,arg需要给shell用,文件名保存即可
//"ls -a -l > myfile" ==> "ls -a -l \0 myfile"
void redirCheck(char* commands)
{assert(commands); char* start = commands;char* end = commands + strlen(commands);while(start < end){if(*start == '>') //确定重定向类型{*start = '\0'; //切割arg和文件++start;if(*start == '>') //追加重定向{redirType = APPEND_REDIR;++start; //跳过第二个'>'}else //输出重定向{redirType = OUTPUT_REDIR; //获取重定向类型}trimSpace(start); //宏函数过滤空格redirFile = start; //获取重定向文件break;}else if(*start == '<'){*start = '\0';++start;trimSpace(start);redirType = INPUT_REDIR;redirFile = start;break;}else {++start;}}
}int main()
{while(1){redirType = NONE_REDIR;redirFile = NULL;printf("[%s@%s]# ", getenv("USER"), getenv("HOSTNAME"));fflush(stdout);char* ret = fgets(lineCommand, sizeof(lineCommand) - 1, stdin); assert(ret != NULL); lineCommand[strlen(lineCommand) - 1] = 0;redirCheck(lineCommand);myargv[0] = strtok(lineCommand, " ");int i = 1;while(myargv[i++] = strtok(NULL, " "));if(myargv[0] != NULL && strcmp(myargv[0], "cd") == 0){if(myargv[1] != NULL) chdir(myargv[1]);continue;}if(myargv[0] != NULL && myargv[1] != NULL && strcmp(myargv[0], "echo") == 0){if(strcmp(myargv[1], "$?") == 0){printf("exitCode = %d | exitSig = %d\n", lastCode, lastSig);}else {printf("%s\n", myargv[1]);}continue;}pid_t id = fork();assert(id != -1);if(id == 0){//重定向switch(redirType){case NONE_REDIR:break;case INPUT_REDIR:{int fd = open(redirFile, O_RDONLY);if(fd < 0){perror("open redirFile");exit(errno);}dup2(fd, 0);}break;case OUTPUT_REDIR:case APPEND_REDIR: {int flags = O_WRONLY | O_CREAT; if(redirType == APPEND_REDIR) flags |= O_APPEND;else flags |= O_TRUNC;int fd = open(redirFile, flags, 0666);if(fd < 0){perror("open redirFile");exit(errno);}dup2(fd, 1);}break;default:printf("something wrong...\n");break;}execvp(myargv[0], myargv);exit(1);}int status = 0;pid_t wait_ret = waitpid(id, &status, 0);assert(wait_ret > 0);lastCode = (status >> 8) & 0xFF;lastSig = status & 0x7F;}return 0;
}
[bacon@VM-12-5-centos myshell]$ ./myshell
[bacon@VM-12-5-centos]# ls -a > log.txt
[bacon@VM-12-5-centos]# ls
log.txt makefile myshell myshell.c
[bacon@VM-12-5-centos]# cat log.txt
.
..
log.txt
makefile
myshell
myshell.c
[bacon@VM-12-5-centos]# ls -a -l >> log.txt
[bacon@VM-12-5-centos]# cat log.txt
.
..
log.txt
makefile
myshell
myshell.c
total 40
drwxrwxr-x 2 bacon bacon 4096 Jan 26 20:29 .
drwxrwxr-x 6 bacon bacon 4096 Jan 26 17:49 ..
-rw-rw-r-- 1 bacon bacon 40 Jan 26 20:29 log.txt
-rw-rw-r-- 1 bacon bacon 115 Jan 19 10:26 makefile
-rwxrwxr-x 1 bacon bacon 13824 Jan 26 20:29 myshell
-rw-rw-r-- 1 bacon bacon 4650 Jan 26 20:29 myshell.c
[bacon@VM-12-5-centos]# cat < log.txt
.
..
log.txt
makefile
myshell
myshell.c
total 40
drwxrwxr-x 2 bacon bacon 4096 Jan 26 20:29 .
drwxrwxr-x 6 bacon bacon 4096 Jan 26 17:49 ..
-rw-rw-r-- 1 bacon bacon 40 Jan 26 20:29 log.txt
-rw-rw-r-- 1 bacon bacon 115 Jan 19 10:26 makefile
-rwxrwxr-x 1 bacon bacon 13824 Jan 26 20:29 myshell
-rw-rw-r-- 1 bacon bacon 4650 Jan 26 20:29 myshell.c
子进程重定向会不会影响父进程的struct files_struct?
不影响,struct files_struct是进程相关的数据结构,而进程间具有独立性。
需要注意的是,创建子进程时并不会为子进程把所有已打开文件再拷贝一份,因为进程管理是进程管理,文件管理是文件管理。
子进程执行程序替换会不会影响因重定向打开的文件?
不影响,程序替换只是用磁盘上的代码和数据替换进程原来的代码和数据, 跟这些内核数据结构没有任何关系。

#引用计数
肯定存在多个进程同时打开一个文件的情况,这时如果某个进程退出了,对文件有什么影响?
这就要提到引用计数。对于某个文件file,其引用计数ref_count表示的是有多少地方指向自己,也就是引用自己。
-
3个进程引用自己,
ref_count= 3,文件不关闭此时其中的一个进程退出…
-
2个进程引用自己,
ref_count = 2,文件不关闭再有一个退出…
-
ref_count = 1,文件不关闭再有一个退出…
-
ref_count = 0,文件关闭。
比如某个进程close,OS只是会--ref_count。
从中我们可以体会多个进程打开文件是怎么个样子了。
如何理解Linux下一切皆文件?
拿硬件举例:

- 我们通过冯诺依曼体系结构可以知道,想要操作键盘磁盘这类外设的数据,必须读取到内存,处理完后再写入回去,这中操作也叫
IO。 - 操作系统要管理硬件,就需要抽象、具象、组织、操作
- 抽象方面,各个硬件分别有自己的抽象
- 操作方面,各个硬件为了能操作硬件的数据,都要提供读写方法(若某个设备不需要读/写方法,可以读/写方法内可以什么都不做)
- *这些硬件的读写方法,其实就在其驱动程序里
- 对于这些硬件,操作系统怎么看?
- 全部看做文件,属性都按需抽象出来!管你来的是哪个硬件,属性该填的填,至于你们的读写,你自己提供,我只需要用一个指针找到你提供的,用现成的
最后一步,全部看做文件,也就是图中struct file这一层,就叫做**VFS(virtual file system)**,虚拟文件系统。很像是一种封装:虚拟文件系统让我们不需要关心底层硬件管理的各种不同细节,也能让上层的软件,能够用单一的方式,来跟底层不同的硬件沟通。
为什么说Linux下,一切皆是文件?因为有VFS来“统一度量衡”。
我们可以看看源码的细节,来验证我们上面的说法。
struct file 内是有指针指向文件操作方法的
struct file {...const struct file_operations *f_op;...
}
struct file_operations {struct module *owner;loff_t (*llseek) (struct file *, loff_t, int);ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);ssize_t (*aio_read) (struct kiocb *, const struct iovec *, unsigned long, loff_t);ssize_t (*aio_write) (struct kiocb *, const struct iovec *, unsigned long, loff_t);int (*readdir) (struct file *, void *, filldir_t);unsigned int (*poll) (struct file *, struct poll_table_struct *);int (*ioctl) (struct inode *, struct file *, unsigned int, unsigned long);long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long);long (*compat_ioctl) (struct file *, unsigned int, unsigned long);int (*mmap) (struct file *, struct vm_area_struct *);int (*open) (struct inode *, struct file *);int (*flush) (struct file *, fl_owner_t id);int (*release) (struct inode *, struct file *);int (*fsync) (struct file *, struct dentry *, int datasync);int (*aio_fsync) (struct kiocb *, int datasync);int (*fasync) (int, struct file *, int);int (*lock) (struct file *, int, struct file_lock *);ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long);int (*check_flags)(int);int (*flock) (struct file *, int, struct file_lock *);ssize_t (*splice_write)(struct pipe_inode_info *, struct file *, loff_t *, size_t, unsigned int);ssize_t (*splice_read)(struct file *, loff_t *, struct pipe_inode_info *, size_t, unsigned int);int (*setlease)(struct file *, long, struct file_lock **);
};
其他我们没学过,
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
这两个我们是知道的。
#缓冲区
先来看一个现象。
int main()
{//Cprintf("I'm printf\n");fprintf(stdout, "I'm fprintf\n");fputs("I'm fputs\n", stdout);//system callconst char* msg = "I'm write\n";write(1, msg, strlen(msg));return 0;
}
[bacon@VM-12-5-centos 5-buffer]$ ./test
I'm printf
I'm fprintf
I'm fputs
I'm write
这都没问题,但是……
int main()
{//Cprintf("I'm printf\n");fprintf(stdout, "I'm fprintf\n");fputs("I'm fputs\n", stdout);//system callconst char* msg = "I'm write\n";write(1, msg, strlen(msg));fork();return 0;
}
[bacon@VM-12-5-centos 5-buffer]$ ./test
I'm printf
I'm fprintf
I'm fputs
I'm write
[bacon@VM-12-5-centos 5-buffer]$ ./test > log.txt
[bacon@VM-12-5-centos 5-buffer]$ cat log.txt
I'm write
I'm printf
I'm fprintf
I'm fputs
I'm printf
I'm fprintf
I'm fputs
fork后打印是正常的,但是重定向怎么不对劲?
我们得先了解缓冲区。
是什么
一段内存。
为什么
我们可以通过寄特产的例子来理解:
广东人张三和东北人李四是网友,一天张三想寄点特产给李四,两种方案:
- 自己骑自己的单车,自己送,花上几个月
- 放到楼下顺丰快递点,顺丰送,只需要下个楼的时间
自然是后者好,因为前者太浪费自己的时间。快递行业的意义其实就在其中:节省发送者的时间。
把寄特产换成写文件:
- 张三就是进程,要把数据从内存输出到磁盘
- 李四就是文件,在磁盘中等待被写入
张三要寄特产,即进程要输出到磁盘时
- 进程自己访问,就相当于自己骑单车从广东到东北
- 拷贝到缓冲区让缓冲区定期刷新,就相当于找顺丰帮忙寄
那么为什么要有缓冲区也明了了:节省进程访问外设的时间。
不对啊,拷贝到缓冲区?我可没干这事啊!
与其说我们用的IO接口,如fwrite是写入到文件的函数,不如说它们是拷贝函数——从进程拷贝到“缓冲区”或外设中。
还有个问题,我把特产给顺丰,他什么时候给我送呢?
我把数据拷贝到缓冲区,它什么时候给我刷新呢?
缓冲区的刷新策略
缓冲区是为了节省进程时间,那我们看,一坨数据,怎么刷新到外设最能体现缓冲区的意义?
少量多次 or 多量少次?
自然是后者。就是访问外外设这个操作慢,最大程度减少外设访问,即多量少次地刷新,才最节省时间。
但也不能无脑减少外设访问,比如显示器:我们习惯按行看,它等半天给你突然刷一整屏,不合理。
所以,虽然最大程度减少外设访问才最节省时间,但不同场景也需要不同的刷新策略:
- 无缓冲:立即刷新
- 行缓冲:按行刷新(如显示器)
- 全缓冲:缓冲区慢刷新(如磁盘文件)
- *用户强制刷新(如调用
fflush) - *进程退出
说这么多,对缓冲区有一定认识了,但很重要的一个,位置,还不知道。
缓冲区的位置
[bacon@VM-12-5-centos 5-buffer]$ ./test
I'm printf
I'm fprintf
I'm fputs
I'm write
[bacon@VM-12-5-centos 5-buffer]$ ./test > log.txt
[bacon@VM-12-5-centos 5-buffer]$ cat log.txt
I'm write
I'm printf
I'm fprintf
I'm fputs
I'm printf
I'm fprintf
I'm fputs
可以告诉大家,这种现象,就是和缓冲区有关。但我们现有知识分析不出个所以然,能确定的是:缓冲区一定不在内核(否则write也会打印两次)。
所以,我们先前讨论的缓冲区,都是用户级语言层面的缓冲区(如stdin、stdout、stderr内就有)。
而stdin、stdout、stderr都是FILE类型,那也说明,语言层面的缓冲区就在FILE内!
回想一下,我们fflush手动刷新缓冲区,是不是要传递FILE指针?我们关闭文件(文件关闭后会刷新缓冲区),是不是要传递FILE指针?是的,这里也对应上了。
[bacon@VM-12-5-centos 6-basic_IO]$ vim /usr/include/stdio.h

[bacon@VM-12-5-centos 6-basic_IO]$ vim /usr/include/libio.h

*这一堆指针,维护的就是语言层面的缓冲区
有了语言层面缓冲区的理解,就解释“fork后打印是正常的,但是重定向不对劲?”这个现象了。
int main()
{//Cprintf("I'm printf\n");fprintf(stdout, "I'm fprintf\n");fputs("I'm fputs\n", stdout);//system callconst char* msg = "I'm write\n";write(1, msg, strlen(msg));fork();return 0;
}
[bacon@VM-12-5-centos 5-buffer]$ ./test
I'm printf
I'm fprintf
I'm fputs
I'm write
[bacon@VM-12-5-centos 5-buffer]$ ./test > log.txt
[bacon@VM-12-5-centos 5-buffer]$ cat log.txt
I'm write
I'm printf
I'm fprintf
I'm fputs
I'm printf
I'm fprintf
I'm fputs
缓冲区在被打开的文件中
-
没有重定向看到4条信息:
- 向
stdout写入,刷新策略:行缓冲 - C接口中,\n使得缓冲区刷新
- fork前刷新,数据不在缓冲区内
- fork创建子进程,stdout被父子进程共享
- 而后整个程序跑完,也就是fork后紧跟着的就是父/子进程退出,需要进行缓冲区刷新(即修改)
- 本来要对缓冲区修改,但缓冲区没有数据,不会进行修改的操作,不会发生写实拷贝
- 平平淡淡打印4条信息
- 向
-
重定向了看到7条信息:
- 向
普通文件写入,刷新策略:全缓冲 - C接口中,\n无法使得缓冲区刷新,数据量也达不到全缓冲的条件
- 没有刷新,数据还在缓冲区内
- fork创建子进程,log.txt被父子进程共享
- 而后整个程序跑完,也就是fork后紧跟着的就是父/子进程退出,需要进行缓冲区刷新(即修改)
- 对共享的被打开文件的缓冲区修改 = 写时拷贝!
- 这也代表,父子进程虽然共享被打开的文件,但是被打开文件的缓冲区已经又拷贝了一份,父子进程各有一份缓冲区,退出时分别刷新
- 所以出人意料地,C接口在父子进程退出时分别打印了一次,总共6次,加上系统调用1次,最终打印了7条信息
- 向
-
write“不问世事”?
:write并不用FILE,而是用fd,也就是write不会用到语言层面提供的缓冲区
简单来说:
-
fork:创建了子进程,父子进程退出分别会刷新自己的缓冲区。而刷新本质是一种拷贝,也就是修改
-
未重定向:要写入的文件是显示器文件,默认行刷新。
\n使stdout的数据立即刷新,父子进程共享的缓冲区,在退出时想刷新,也并不会发生写实拷贝,因为缓冲区内没数据
-
重定向:要写入的文件是普通文件,默认全刷新。
\n不能使stdout的数据立即刷新,父子进程共享的缓冲区,在退出时想刷新,会发生写实拷贝,因为缓冲区内有数据
-
只有C语言接口发生写实拷贝?
- C:
struct file stdout内申请的缓存区空间被父子进程共享且要被写入,缓冲区发生写时拷贝。父子进程退出时分别刷新自己的缓冲区,最终打印双份信息 - 系统调用:通过
fd来写入stdout,没有C提供的缓冲区
- C:
光说不练假把式,来自己搞一个行缓冲的缓冲区玩玩。
#自己封装行缓冲的缓冲区
makefile
main:main.c myclib.cgcc -o $@ $^ -std=c99.PHONY:clean
clean:rm -f main
#include <unistd.h>
#include <stdlib.h>
#include <errno.h>
#include <string.h>
#include <assert.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>#define SIZE 1024
#define SYNC_NOW (1 << 1)
#define SYNC_LINE (1 << 2)
#define SYNC_FULL (1 << 3)typedef struct myFILE
{int flags; //标记位:刷新方式int fileno;int cap; //缓冲区容量int size; //缓冲区大小char buffer[SIZE];
}myFILE;myFILE* myfopen(const char* pathName, const char* mode);
void myfwrite(const void* ptr, int num, myFILE* pf);
void myfclose(myFILE* pf);
void myfflush(myFILE* pf);
#include "myclib.h"myFILE* myfopen(const char* pathName, const char* mode)
{//获取打开模式int openFlags = 0;int defalutMode = 0666;if(strcmp(mode, "r") == 0)openFlags |= O_RDONLY;else if(strcmp(mode, "w") == 0)openFlags |= (O_WRONLY | O_CREAT | O_TRUNC);else if(strcmp(mode, "a") == 0)openFlags |= (O_WRONLY | O_CREAT | O_APPEND);//根据是否需要创建文件,来调用不同的openint fd = 0;if(openFlags & O_RDONLY)fd = open(pathName, openFlags);else fd = open(pathName, openFlags, defalutMode);if(fd < 0){const char* errMsg = strerror(errno);write(2, errMsg, strlen(errMsg));return NULL;}//开辟并设置myFILE对象myFILE* pf = (myFILE*)malloc(sizeof(myFILE));assert(pf);pf->flags = SYNC_LINE; //默认行刷新pf->fileno = fd;pf->cap = SIZE;pf->size = 0;memset(pf->buffer, 0, SIZE);return pf;
}void myfwrite(const void* ptr, int num, myFILE* pf)
{//1. 写入缓冲区memcpy(pf->buffer + pf->size, ptr, num); //不考虑缓冲区溢出pf->size += num;//2. 判断是否需要刷新if(pf->flags & SYNC_NOW){write(pf->fileno, pf->buffer, pf->size);pf->size = 0;}else if(pf->flags & SYNC_FULL){if(pf->size == pf->cap){write(pf->fileno, pf->buffer, pf->size);pf->size = 0;}}else if(pf->flags & SYNC_LINE){if(pf->buffer[pf->size - 1] == '\n'){write(pf->fileno, pf->buffer, pf->size);pf->size = 0;}}
}void myfclose(myFILE* pf)
{myfflush(pf);close(pf->fileno);
}void myfflush(myFILE* pf)
{if(pf->size > 0)write(pf->fileno, pf->buffer, pf->size);fsync(pf->fileno); //强制进行外设刷新,下文会提到pf->size = 0; //惰性删除(后来的数据会覆盖)
}
#include "myclib.h"int main()
{myFILE* pf = myfopen("./log.txt", "w");assert(pf);int cnt = 5;const char* msg = "testing myclib...\n";while(1){myfwrite(msg, strlen(msg), pf);sleep(1);--cnt;if(cnt == 0) break;}myfclose(pf);return 0;
}

#include "myclib.h"int main()
{myFILE* pf = myfopen("./log.txt", "w");assert(pf);int cnt = 5;const char* msg = "testing myclib...";while(1){myfwrite(msg, strlen(msg), pf);sleep(1);--cnt;if(cnt == 0) break;}myfclose(pf);return 0;
}
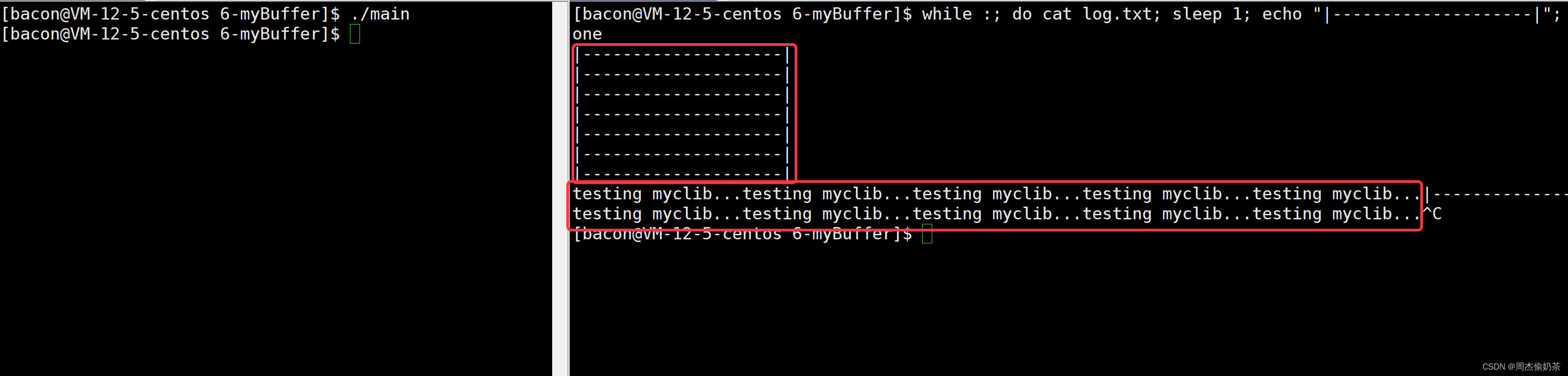
不对不对,刚刚说“系统调用:通过fd来写入stdout,没有C提供的缓冲区”,按这个说法,write没有缓冲区,直接写到磁盘上的文件?按理来说不可能,因为这样效率也太低了呀!是的,操作系统层面也有自己的缓冲区。
所以我们就能把缓冲区分两种。
分类
- 语言层面的缓冲区(上面谈的一大堆都是关于语言层面的缓冲区)
- 系统层面的内核缓冲区
系统调用fsync
NAMEfsync, fdatasync - synchronize a file's in-core state with storage deviceSYNOPSIS#include <unistd.h>int fsync(int fd);
可以将文件的内核状态同步到存储设备,也就是刷新内核缓冲区。我们自己封装的语言级缓冲区就用到了:
void myfflush(myFILE* pf)
{if(pf->size > 0)write(pf->fileno, pf->buffer, pf->size);fsync(pf->fileno); //强制进行外设刷新,下文会提到pf->size = 0;
}
至于内核缓冲区的刷新策略,就不是我们能决定的了;位置我们也没有过多了解的必要。
学习了缓冲区,我们对IO操作的理解就更深刻了。
IO操作的流程
语言接口output操作:
- 信息写入struct file对象中的语言缓冲区
- 语言缓冲区按刷新策略刷新到内核缓冲区
- 内核缓冲区自主决定何时刷新到外设
系统调用output操作:
- 信息写入内核缓冲区
- 内核缓冲区自主决定何时刷新到外设
至此,通过对文件的深入理解,“基础IO”对我们来说真的就是“基础”了。现在看,学C语言时对文件的理解简直太浅显,有了现在的理解,还会怕IO操作玩不明白嘛!
先前我们谈论的都是被打开的文件,那没打开的文件呢?能肯定的是,它们肯定在磁盘上静静地躺着。
那磁盘上的这么老多文件都是怎么管理的呢?可以理解为“静态管理”,按规则将文件们放到各自的位置。这一整个管理的体系就叫文件系统。
文件系统
是什么
文件系统是一种在存储设备上管理文件的软件系统。
- 从系统角度来看,文件系统是对文件存储设备的空间进行组织和分配
- 具体地说,它负责为用户建立文件,存入、读出、修改、转储文件,控制文件的存取,当用户不再使用时撤销文件等。
磁盘的物理结构
磁盘是计算机中唯一的机械结构,而且还是外部设备,所以它相对其他设备非常慢。
*虽然我们自己很少用很少见磁盘了,但因为性价比高,不会像ssd那样过多访问可能被击穿等等原因,很多企业仍主要用磁盘


磁头就像笔,盘面就像纸。运转时,盘片高速旋转,磁头悬在盘面上,不直接和盘面接触。这个场景就像一架波音747在离地1米的距离高速飞行,所以一粒灰尘都很可能超过“1米”,造成磕碰导致的盘片损毁。
在背面,还有硬件电路和伺服系统,可以控制磁头和盘片等,实现寻址等功能。
那到底磁盘到底是怎样存储数据的,怎样表示“0、1”的?
可以这样理解:盘面上有很多个小小磁铁,每个磁铁有N、S极,通过磁头充磁、消磁,可以对它们的南北极调转,从而达到“0、1”的效果。
充磁消磁可以通过加热的方式实现。磁盘内具体是通过电子流动来实现。
有兴趣的朋友可以看看磁盘是怎么运转的
磁盘的存储结构
了解存储结构,肯定要具体到某个盘面来讨论。
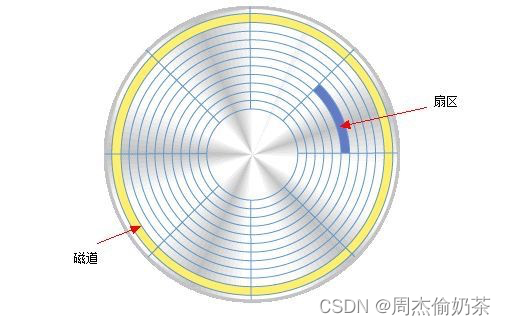
就是一圈圈同心圆组成的,“同心圆”叫磁道,分割出的一块块扇形区域就叫扇区。
磁盘寻址的时候,基本单位就是扇区(一般512bytes)。一块一块的,这也是为什么有“块设备文件”。
#CHS寻址模式
那在一面上,是怎么定位一个扇区的?
首先要确定磁道(某圈),接着通过磁道找到对应的扇区(某圈上的某部分)。
那是如何定位某个磁道的?
磁头的来回摆动就能定位。
又是如何通过磁道找到对应扇区的?
盘片的旋转就能配合磁头找到对应扇区。在盘片一次旋转的时间(单位时间)内,通过磁头找到扇区并读取数据。
上面这一点也是磁盘的技术难点:提高转速,将单位时间缩短不难;难的是让磁头读取数据的能力跟上缩短的单位时间。
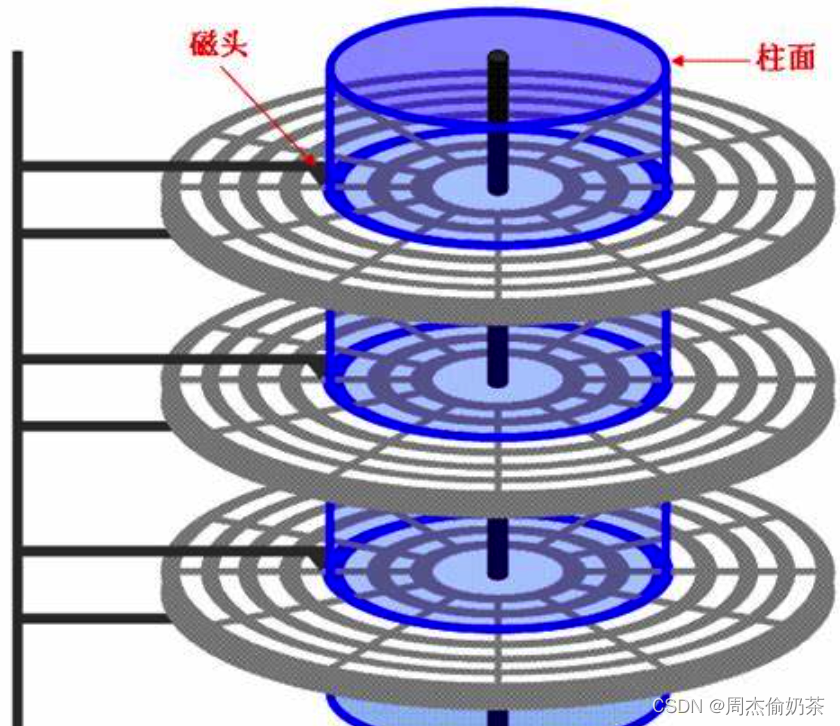
需要提一下柱面的概念:不同盘片上半径相同的所有磁道,立体地看就像圆柱,故称柱面。(其实就是磁道)
但是这个概念好像没有存在的必要吧?
并不是的,因为每面一个的磁头并不能各动各的,一个动全都一起动。**那么当磁头定位好、准备寻找扇区的时候,所有磁头就能一起出动,一找就是n个磁头一起找,效率MAX。**所以这个柱面的概念是有必要的。
聊到这,我们可以下结论了,在磁盘中到底如何定位一个扇区?
:先移动磁头,找到对应磁道(柱面);再让盘片旋转,所有面的磁头一起找目标扇区。
- 柱面 =
cylinder - 磁头 =
head - 扇区 =
sector
这就是CHS寻址模式。
磁盘的逻辑结构
讲磁盘的逻辑结构,可以先看看磁带。

磁带的存储介质是一种黑色的塑料材质,卷起来像挖掉中心的圆,这个圆又是很多同心圆组成。**把它们扯出来,拉直,其实是一条塑料。**这磁带像不像磁盘的盘片?那磁盘的结构也是和这磁带一样,“扯出来拉直是一条”?是的,
磁盘的逻辑结构是线性结构。
虽然磁盘物理上是圆形的,但我们可以把它想象成线性的。
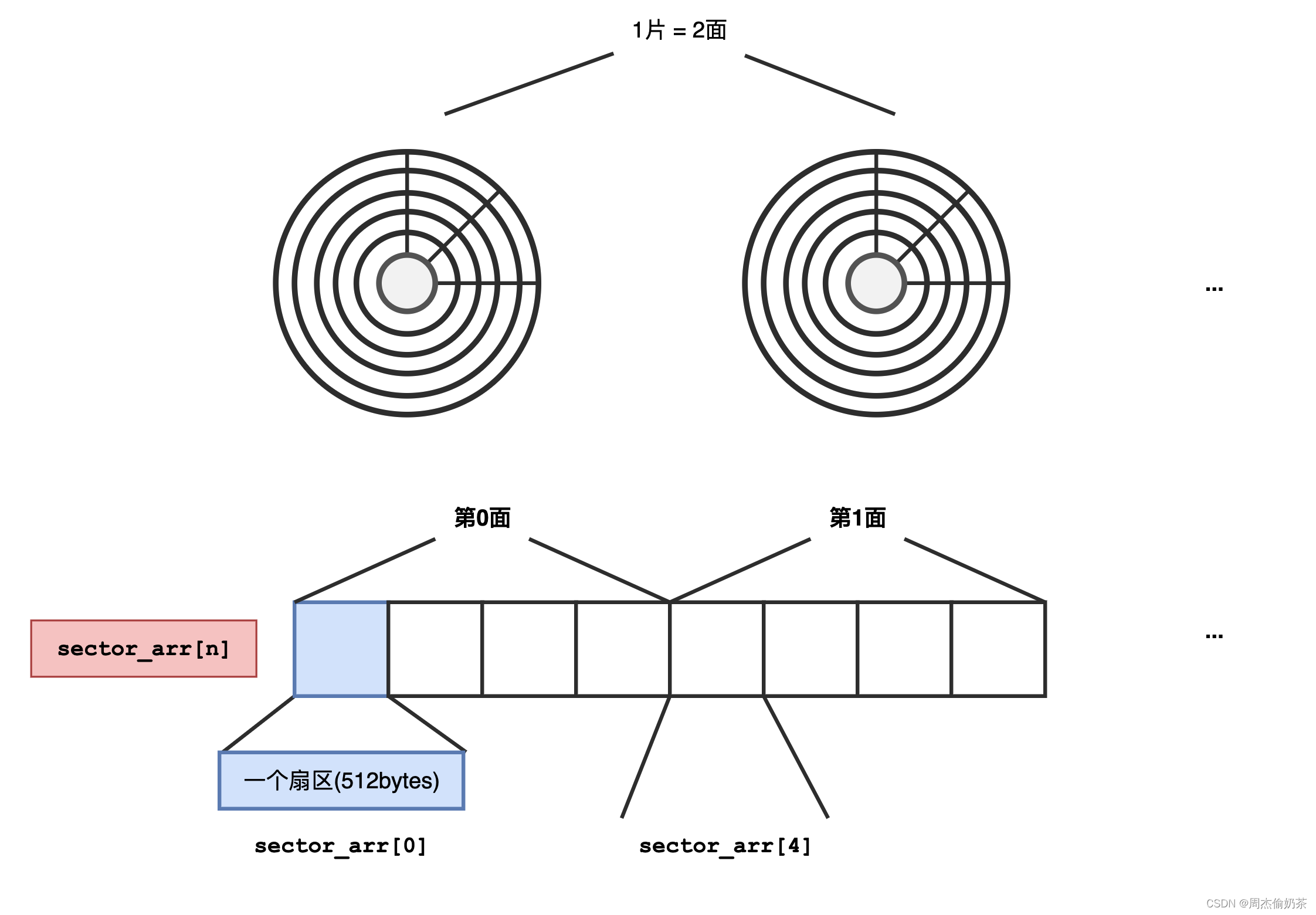
上图就很好地表示了对磁盘的抽象,逻辑结构变成了一个数组,我们将磁盘看作一个sector_arr[],每一个元素是一个扇区。所以要找到一个扇区,只要知道这个扇区的下标。这样的下标也叫逻辑块地址(Logic Block Address)。说白了,这个数组的下标(逻辑块地址)标识了一个数据区块。
逻辑是逻辑,你终究还得存到物理结构中,LBA地址如何对应上CHS寻址模式?
比如,现有一个磁盘
- 盘面 = 4
- 每面的磁道 = 10
- 每个磁道上的扇区 = 100
- 扇区大小 = 512bytes
LBA地址,sector_arr[123],对应到物理结构上是什么样?
这个磁盘大小是4 * 10 * 100 * 512 bytes,sector_arr的下标范围是4 * 10 * 100。
也可得每一个盘面有1000个扇区。
- 第几号盘面?123 / 1000 = 0——第0号盘面
- 第几号磁道? 123 / 100 = 1——第1号磁道
- 第几号扇区?123 % 100 = 23——第23号扇区
sector_arr[123] == 第0号盘面中第1号磁道的第23号扇区
如上,我们的逻辑结构就能和物理结构搭起来了。
而且,我们也能对磁盘来一套管理组合拳:抽象、具象、组织、操作。
管理也到位了。
但,为什么要通过逻辑结构抽象出LBA地址,直接CHS不行吗?
- 便于管理(数组肯定比一个三维结构好管理)
- 对OS的代码和硬件解耦(硬件的底层变了也不影响我OS的代码,只要你能转换我给你的LBA地址)
磁盘的单次读取
512bytes太小了,经过测试,性能不高,所以,
磁盘单次读取一般是4KB。
不会有点浪费吗,万一我只访问1bit的数据呢?
这其实是一种以空间换时间的做法:
-
对于OS来说,一次读取4KB的性能好(提高IO的效率)
-
是一种数据预加载,提高cpu缓存命中率,效率更高
*局部性原理:访问某一部分数据,它周围的数据很有可能也要被访问。
内存其实也是以为4KB为单位,每个单位称为页框。
磁盘中的文件(尤其是可执行文件),都是被划分成4KB的块,这样的块称为页帧。
分区和分组
即便如此,4KB对于动辄500GB的磁盘来说还是太小。
解决:先分区,再分组(本质是分治,管理好最小子问题,就能管理整个问题)。
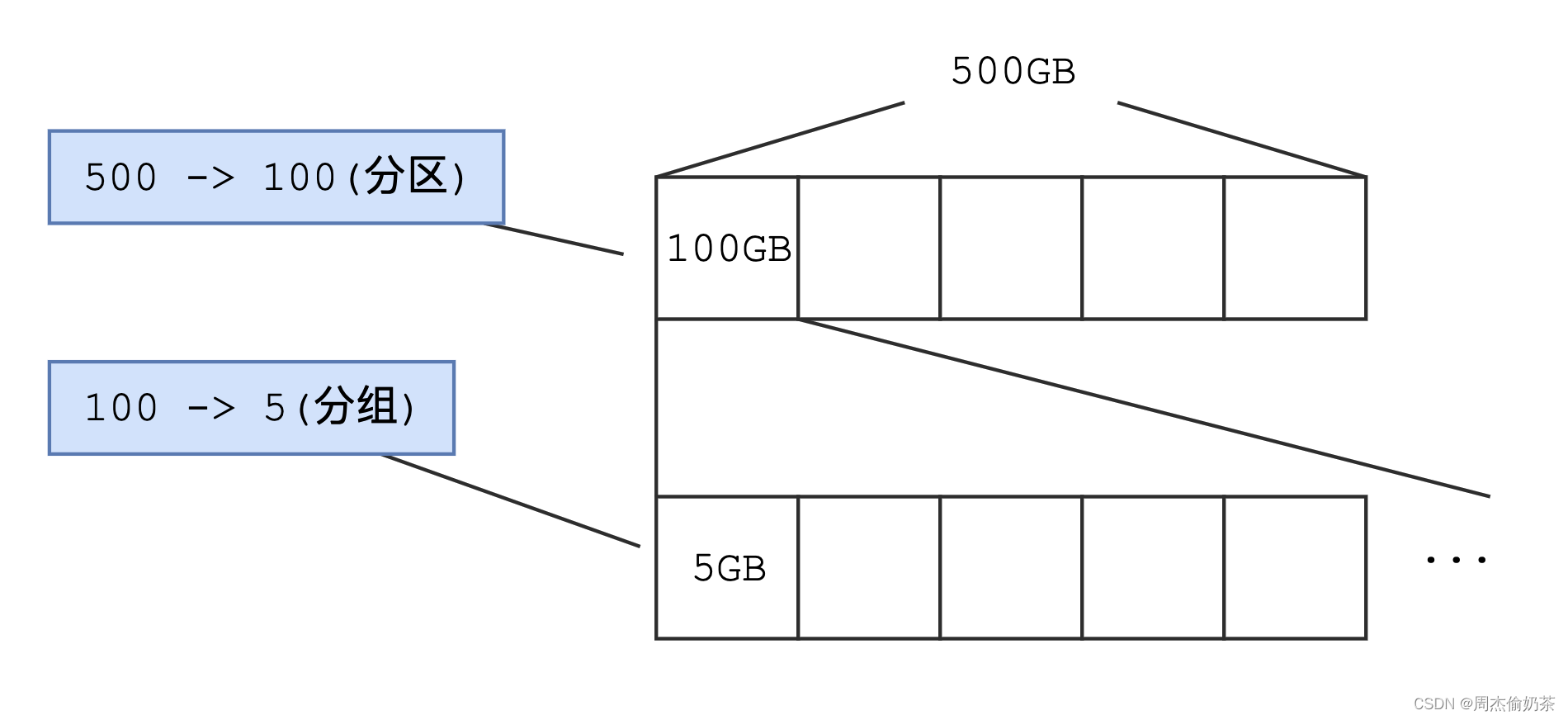
那这也代表,对于这么大的磁盘,想讨论文件系统,只需要讨论这5GB中的构成就够了。
分区:
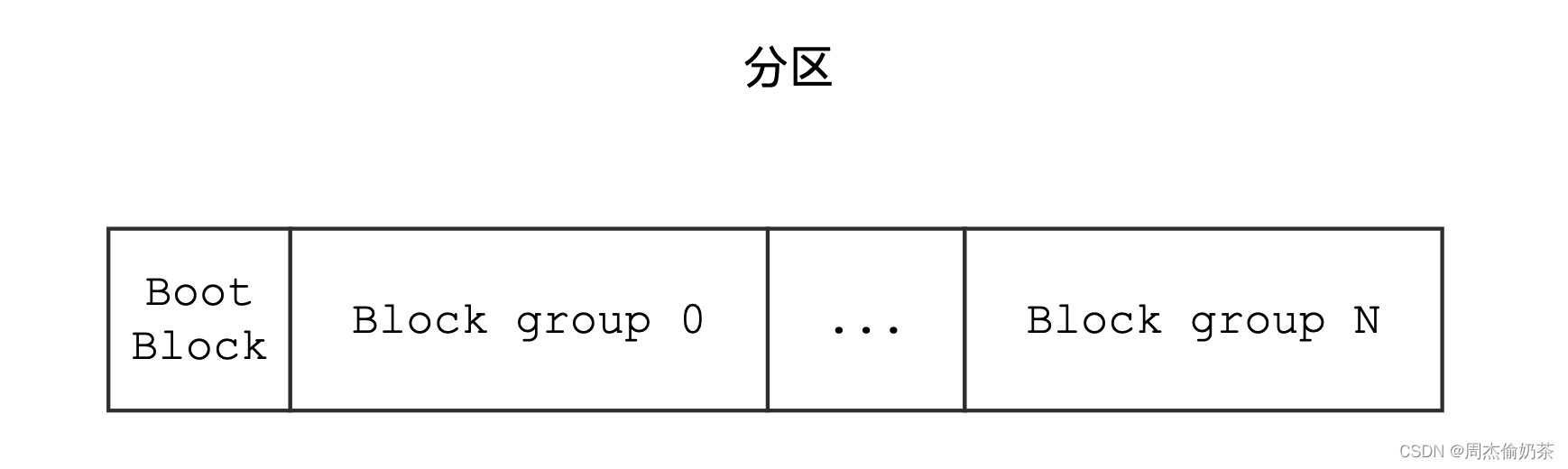
分组:

- Super Block:保存的是整个分区的文件系统的信息
- 它属于整个分区,所以对于每个分组来说,不是必须有的
- 每个分组都保存一份可以理解成备份,能实现文件系统的恢复
- Group Descriptor Table:保存分组的属性信息
- Inode BitMap:保存分组内部inode的使用情况(对应位置的inode是否被使用)
- Block BitMap:保存分组内部Block的使用情况(对应位置的Data Block是否被使用)
- Inode Table:保存分组内可用(已使用+未使用)的inode
- Data Blocks:保存分组内部所有文件的数据块(可动态变化)
#inode
是什么
索引节点,存储了文件的很多属性,在文件系统中非常重要。
之前我们提到过,文件 = 属性 + 内容,在Linux中二者是分开存储的
- 文件的几乎所有属性保存在自己的大小不变的
inode中(文件名并不存在inode) - 文件的内容保存在
Data Blocks
也就是说,某一个文件的属性保存在Inode Table中的某一个Inode,内容则保存在Data Blocks中的n个数据块中。
那我们看一个场景:在Linux下创建一个文件。
需要先找Inode Table中未使用的inode,再找Data Blocks中未使用的数据块。BitMap就是干这事的。
Inode BitMap通过某个比特位的0/1,来表示对应位置的Inode是否被使用,如
0 0 0 1 0 1 1 0
未使用 未使用 未使用 已使用 未使用 已使用 已使用 未使用
Block BitMap同理。
那整个分组有多少个Data Block,已经使用了多少,还有没少没被使用……这些问题又如何解决?
组描述表Group Descriptor Table内就保存了这些数据。
而文件需要区分彼此的inode,因此每个inode都有自己的id。
[bacon@VM-12-5-centos 7-file_system]$ ls -li
total 4
922143 drwxrwxr-x 2 bacon bacon 4096 Feb 17 08:40 dir
922141 -rw-rw-r-- 1 bacon bacon 0 Feb 17 08:39 log1.txt
922142 -rw-rw-r-- 1 bacon bacon 0 Feb 17 08:40 log2.txt
*ls -i可以显示文件inode的id。
这个inode的编号有什么用?查找文件时就是通过inode的编号来查找。
找到了一个文件,想获取它的内容,可以到Data Blocks去拿,但是怎么确定这么多数据块中,哪些是和我这个文件有关的呢?
inode中,有一个字段保存了相关属性
struct inode
{int id;mode_t mode;...int blocks[15]; //保存数据块编号...
}
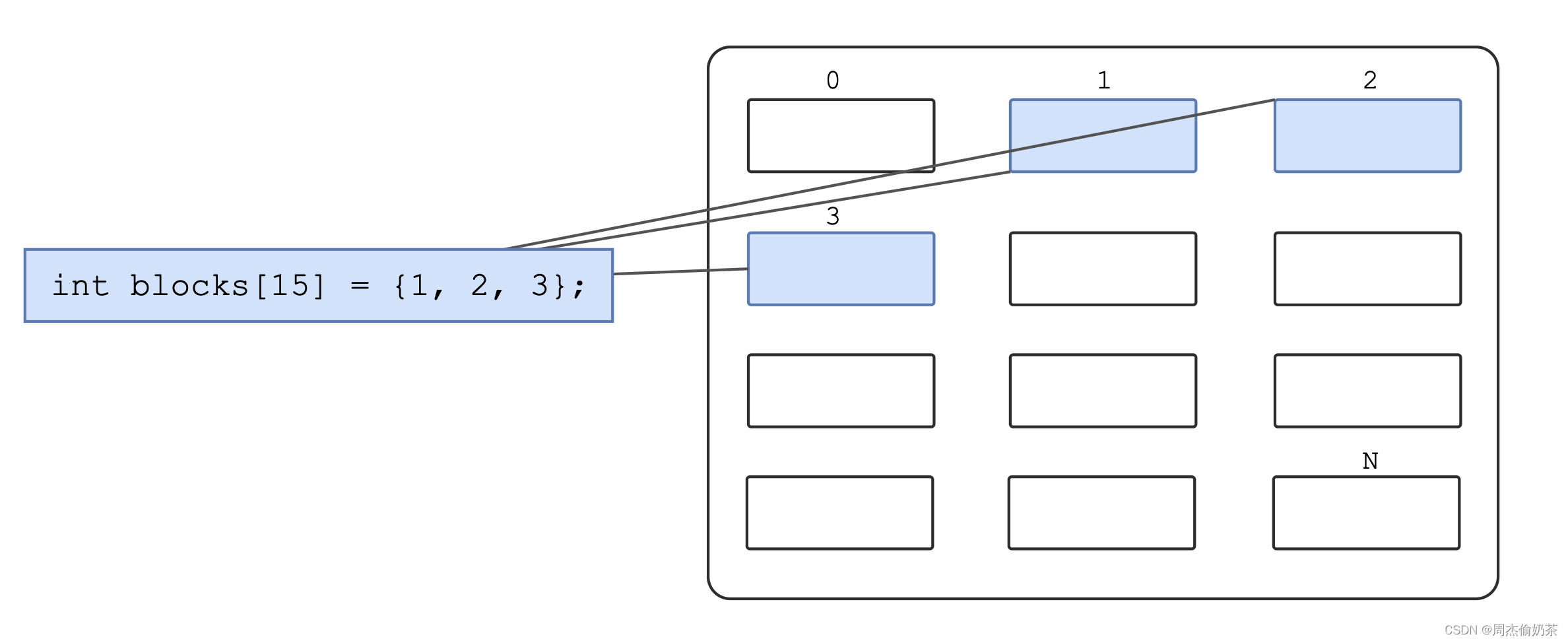
如此就能确认哪些数据块和当前文件有关。但这样能标识的数据块还是太少(15 * 4KB / 1024B = 60KB)。
其实不然,谁说数据块里只能保存文件内容?数据块内也能保存其他数据块编号!(多级索引)
所以文件和inode、Data Blocks间一定有方式建立关系。
基于文件系统,重新理解文件
有了上面的认识,对于创建文件也有了新的理解。
创建一个文件:
- Inode BitMap中某个位置从0变成1
- 根据BitMap中的位置,找到Inode Table中对应位置的inode,把文件属性填入
- 如果需要写入:数据写入Data Blocks,Block BitMap中对应位置的比特位从0变成1
- inode中填入数据块编号(建立inode和Data Blocks间的联系)
- 返回inode编号
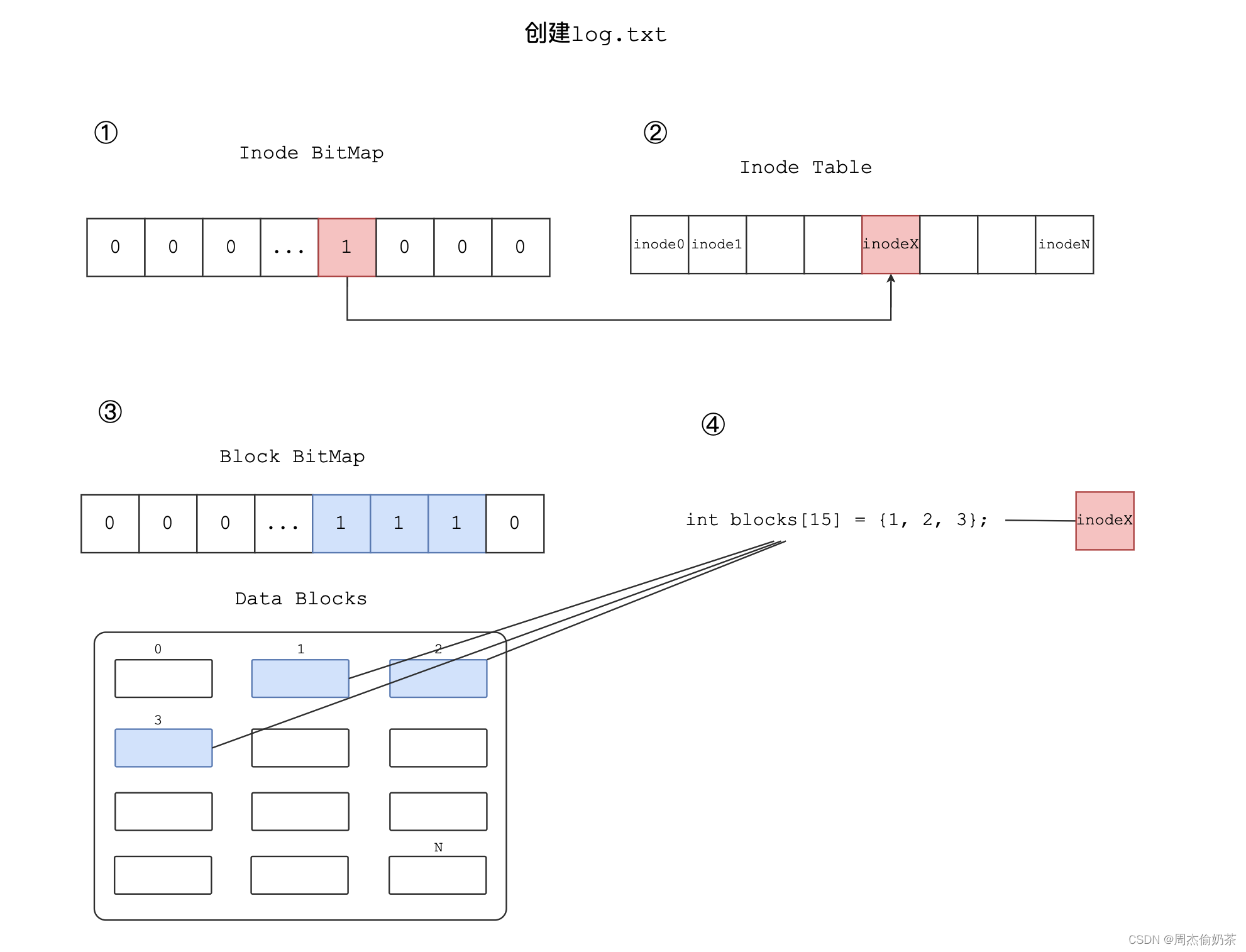
同理,读取一个文件:
- 根据文件inode编号找到Inode Table中属于此文件的inode
- 通过inode中保存的数据块编号,找到数据块
- 读取
同理,删除一个文件:
- Inode BitMap中某个位置从1变成0
- Block BitMap中标识此文件数据块的比特位从1变成0
这是一种惰性删除,下次有别的文件来,会将原本的属性、内容都覆盖掉。哪些是自己的数据,下一个来的文件自己也清楚。
以前可能看见过恢复数据这样的操作,跟这里的惰性删除就有关系。
等等,你刚刚说“查找文件时就是通过inode的编号来查找”。
但,我们Linux用了这么久,文件相关的操作一直都用的是文件名,这个inode编号?……
[bacon@VM-12-5-centos 7-file_system]$ ls -li
total 1
922143 drwxrwxr-x 2 bacon bacon 4096 Feb 17 08:40 dir
[bacon@VM-12-5-centos 7-file_system]$ ls 922143
ls: cannot access 922143: No such file or directory
没用啊?
任何一个文件,一定在某个目录下。目录是文件,那么目录也有自己的数据块,里边存什么呢?
目录的数据块中,存的是文件名和inode编号的映射关系。
同一目录下,不能有同名文件。那么在某个目录下,文件名就是唯一的key值,可以通过这个key值索引到inode。
文件名对人友好,便于区分和管理,但对计算机来说,inode编号更简单。
:表面上,我们是用文件名来进行各种查找和其他操作;本质上,还是通过inode编号。
我们以前讲权限的时候,谈到“要在某个目录下创建文件必须要有这个目录的写入权限”,为什么?
因为查找文件时就是通过inode的编号来查找,在某个目录下通过文件名创建文件,需要写入文件名和inode编号的映射关系,也就需要对这个目录的数据块写入。
“要读文件,必须有这个目录的读取权限”,为什么?
因为查找文件时就是通过inode的编号来查找,读取某个目录下的某个文件,需要知道文件名和inode编号的映射关系,也就需要读取这个目录中数据块的内容。
所以创建文件和删除文件最后一步还要对目录的数据块进行操作。
以上的这些储备,其实可以让我们更好地学习软硬链接。
#软硬链接
先见见猪跑,创建一个软链接。
[bacon@VM-12-5-centos 8-link]$ touch myfile.txt
[bacon@VM-12-5-centos 8-link]$ ln -s myfile.txt soft_file.link
[bacon@VM-12-5-centos 8-link]$ ls -li
total 0
922145 -rw-rw-r-- 1 bacon bacon 0 Feb 17 11:53 myfile.txt
922146 lrwxrwxrwx 1 bacon bacon 10 Feb 17 11:53 soft_file.link -> myfile.txt
再来一个硬链接。
[bacon@VM-12-5-centos 8-link]$ ln myfile.txt hard_file.link
[bacon@VM-12-5-centos 8-link]$ ll -i
total 0
922145 -rw-rw-r-- 2 bacon bacon 0 Feb 17 11:53 hard_file.link
922145 -rw-rw-r-- 2 bacon bacon 0 Feb 17 11:53 myfile.txt
922146 lrwxrwxrwx 1 bacon bacon 10 Feb 17 11:53 soft_file.link -> myfile.txt
一个inode对应一个文件名,但这里hard_file.link和myfile.txt的inode编号居然是一样的,而且权限后的数字也变了。
- 有独立inode的链接文件被称作原文件的软链接
- 没有独立inode的链接文件被称作原文件的硬链接
现在你脑子里肯定有各种疑惑,软硬链接到底做了什么,权限后的数字又是什么?别急,我们一步步来。
硬链接做了什么?
[bacon@VM-12-5-centos 8-link]$ ll -i
total 0
922145 -rw-rw-r-- 2 bacon bacon 0 Feb 17 11:53 hard_file.link
922145 -rw-rw-r-- 2 bacon bacon 0 Feb 17 11:53 myfile.txt
922146 lrwxrwxrwx 1 bacon bacon 10 Feb 17 11:53 soft_file.link -> myfile.txt
[bacon@VM-12-5-centos 8-link]$ echo "hello bacon" >> myfile.txt
[bacon@VM-12-5-centos 8-link]$ echo "hello bacon" >> myfile.txt
[bacon@VM-12-5-centos 8-link]$ ll -i
total 8
922145 -rw-rw-r-- 2 bacon bacon 24 Feb 17 12:03 hard_file.link
922145 -rw-rw-r-- 2 bacon bacon 24 Feb 17 12:03 myfile.txt
922146 lrwxrwxrwx 1 bacon bacon 10 Feb 17 11:53 soft_file.link -> myfile.txt
[bacon@VM-12-5-centos 8-link]$ cat myfile.txt
hello bacon
hello bacon
[bacon@VM-12-5-centos 8-link]$ cat hard_file.link
hello bacon
hello bacon
根据以上的现象,我们可以确定:硬链接没有新增文件(inode没有给硬链接分配其inode)。既然如此,硬链接文件用的肯定是别人的inode和数据块。
是什么
没错,硬链接的本质,其实就是在目录的数据块中写入一对新的“inode编号和文件名映射关系”(键值对):
- 原文件:922145 <==> myfile.txt
- 硬链接文件:922145 <==> hard_file.link
那权限后的数字是什么?
是inode中的一个计数器,其实就是引用计数,表示了当前inode的硬链接数。
[bacon@VM-12-5-centos 8-link]$ rm myfile.txt
[bacon@VM-12-5-centos 8-link]$ ll -i
total 4
922145 -rw-rw-r-- 1 bacon bacon 24 Feb 17 12:03 hard_file.link
922146 lrwxrwxrwx 1 bacon bacon 10 Feb 17 11:53 soft_file.link -> myfile.txt
删除原文件,相当于引用计数–,还剩下1。我们也能得出一个结论:
文件的硬链接数 减至0,文件才算真正删除。
但,新建一个文件时,硬链接数怎么也是1?
因为文件本身就具有文件名和inode编号的映射关系,也算是硬链接。
诶?那这一通操作,不就是重命名吗?
是的,mv重命名的本质就是向目标目录的数据块中写入一对新的映射关系,再将原来的删除。
再来看看软链接。

删除之后,被soft_file.link链接的这个文件本质上还是存在的,但是它这里一直闪烁表示失效,
[bacon@VM-12-5-centos 8-link]$ cat soft_file.link
cat: soft_file.link: No such file or directory
想操作也说找不到。为什么呢?
软链接的本质,其实就是在目录的数据块中写入一对新的“文件名(路径)和文件名映射关系”
不是用inode编号链接(建立映射)的,而是通过文件名(路径)链接。
因此,删除原文件后,软链接保存的路径找不到原文件,就失效了。按这道理,我们重新创建一个文件,让软链接保存的路径能找到文件,就又可以了?
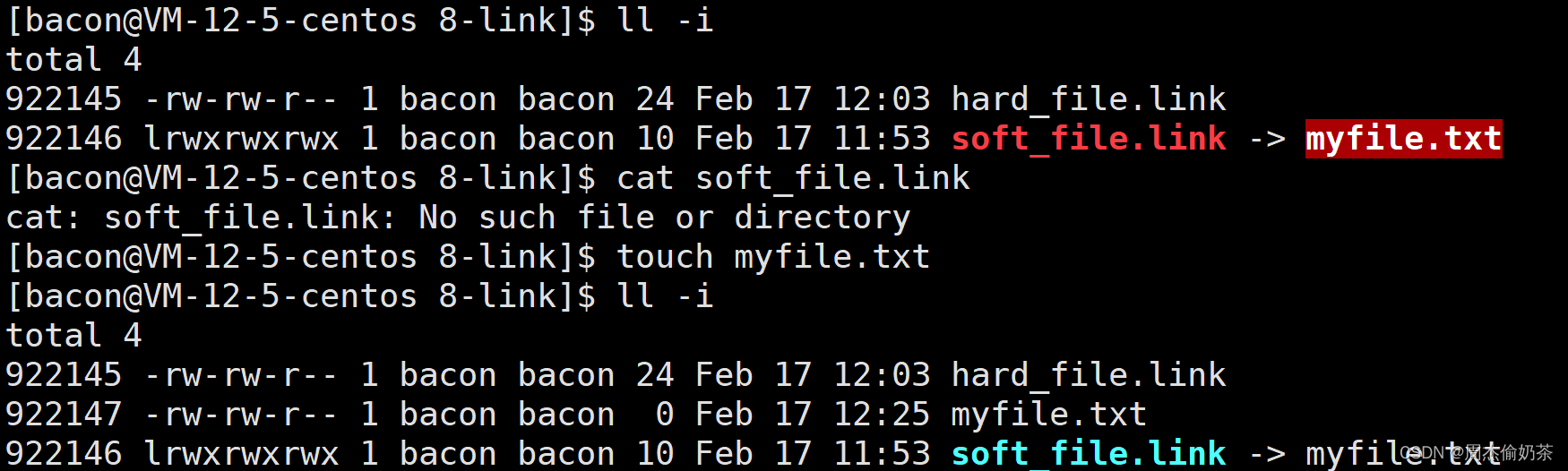
是的,只不过这个文件已经是一个全新的文件了。
作用
软链接的作用:“快捷方式”。
windows下:

Linux下:
#在./bin/exe/a/b/c/test下写了一个打印hello link的小程序
[bacon@VM-12-5-centos 8-link]$ mkdir -p ./bin/exe/a/b/c/test
[bacon@VM-12-5-centos 8-link]$ cd ./bin/exe/a/b/c/test/
[bacon@VM-12-5-centos test]$ touch test.c
[bacon@VM-12-5-centos test]$ vim test.c
[bacon@VM-12-5-centos test]$ gcc -o test test.c
[bacon@VM-12-5-centos test]$ ll
total 16
-rwxrwxr-x 1 bacon bacon 8360 Feb 17 14:56 test
-rw-rw-r-- 1 bacon bacon 77 Feb 17 14:56 test.c
[bacon@VM-12-5-centos test]$ cd -
/home/bacon/linux/6-basic_IO/8-link
#回到/home/bacon/linux/6-basic_IO/8-link,想执行一下test却很费劲
[bacon@VM-12-5-centos 8-link]$ ./bin/exe/a/b/c/test/test
hello link
#软链接
[bacon@VM-12-5-centos 8-link]$ ln -s ./bin/exe/a/b/c/test/test test
[bacon@VM-12-5-centos 8-link]$ ll
total 4
drwxrwxr-x 3 bacon bacon 4096 Feb 17 14:55 bin
lrwxrwxrwx 1 bacon bacon 25 Feb 17 14:59 test -> ./bin/exe/a/b/c/test/test
[bacon@VM-12-5-centos 8-link]$ ./test
hello link
硬链接的作用:作目录树状结构中的“父指针”。
[bacon@VM-12-5-centos 2]$ touch file.txt
[bacon@VM-12-5-centos 2]$ mkdir dir
[bacon@VM-12-5-centos 2]$ ll
total 4
drwxrwxr-x 2 bacon bacon 4096 Feb 17 15:11 dir
-rw-rw-r-- 1 bacon bacon 0 Feb 17 15:11 file.txt
file.txt的硬链接数是1可以理解,但为什么同样是新建,dir却是2?这就要把.和..拉出来讲讲了。
[bacon@VM-12-5-centos 2]$ ll -i
total 4
922157 drwxrwxr-x 2 bacon bacon 4096 Feb 17 15:11 dir
922156 -rw-rw-r-- 1 bacon bacon 0 Feb 17 15:11 file.txt
[bacon@VM-12-5-centos 2]$ cd dir
[bacon@VM-12-5-centos dir]$ ll -ai
total 8
922157 drwxrwxr-x 2 bacon bacon 4096 Feb 17 15:11 .
922155 drwxrwxr-x 3 bacon bacon 4096 Feb 17 15:11 ..
. 其实就又是一个硬链接。

[bacon@VM-12-5-centos dir]$ mkdir another_dir
[bacon@VM-12-5-centos dir]$ cd ..
[bacon@VM-12-5-centos 2]$ tree
.
|-- dir
| `-- another_dir
`-- file.txt2 directories, 1 file
[bacon@VM-12-5-centos 2]$ ll -i
total 4
922157 drwxrwxr-x 3 bacon bacon 4096 Feb 17 15:29 dir
922156 -rw-rw-r-- 1 bacon bacon 0 Feb 17 15:11 file.txt
当我们在dir内创建another_dir,dir的硬链接数变成了3?
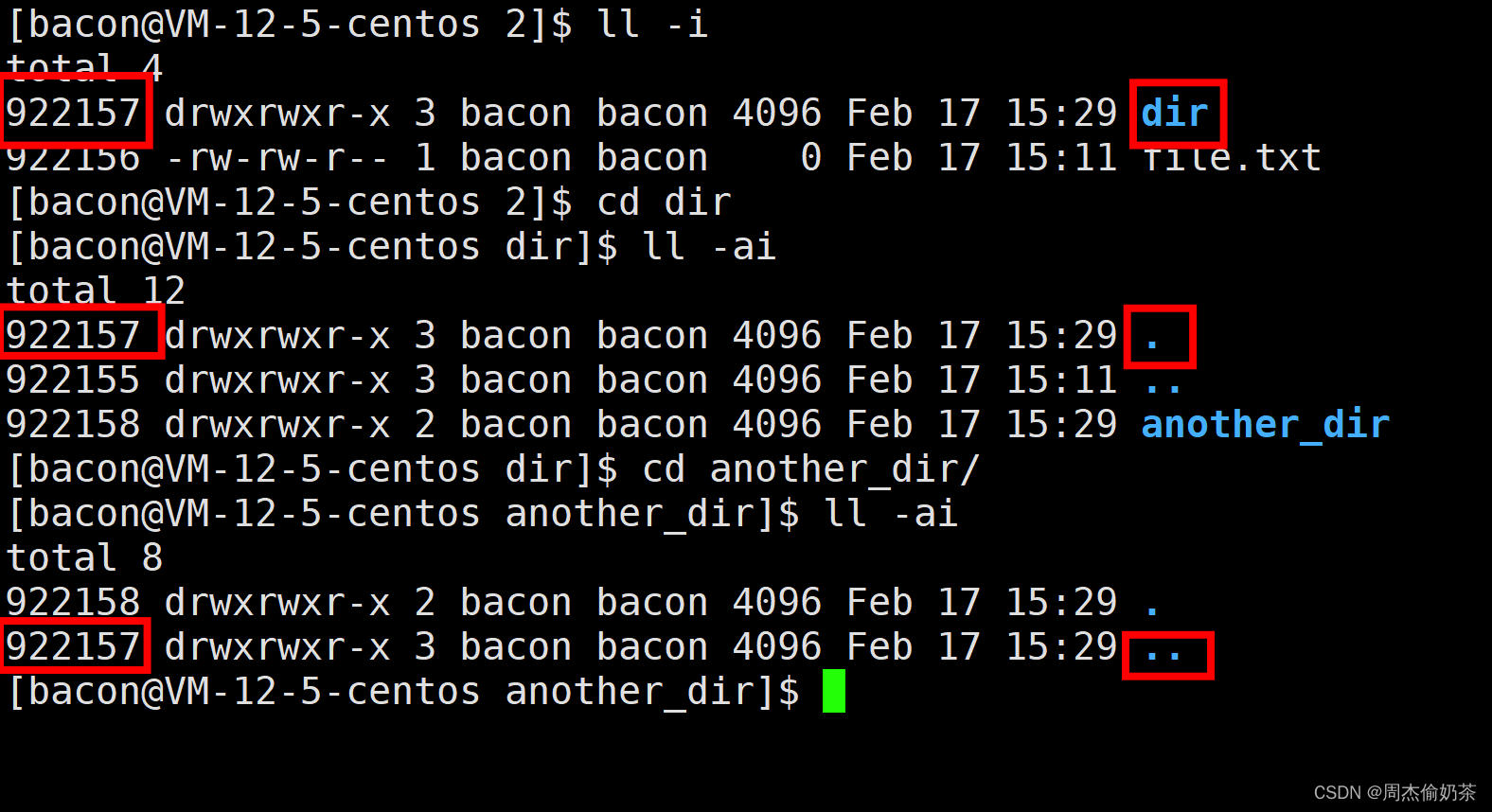
..也是一层链接!
但是并不能给目录建立硬链接。
[bacon@VM-12-5-centos 2]$ ls
dir file.txt
[bacon@VM-12-5-centos 2]$ ln dir hardlink_for_dir
ln: ‘dir’: hard link not allowed for directory
为什么?
为一个目录创建硬链接,也就必须对其子目录和子文件创建硬链接,也必须对其子目录的子目录和子目录的子文件创建硬链接,也必须……这一趟下来可太复杂了,也很容易死循环。比如根目录的某个下级目录中有根目录的硬链接,当我们访问这个硬链接,会走进根目录,走进根目录最终又会走到这个下级目录,又会走到根目录的硬链接……
不对啊,.和..不正是给目录建立的硬链接吗,这不是自相矛盾吗?
这俩货 是特殊情况,也是OS自己来设置的,所以百分百放心不会有问题。
最后我们再解释一下文件的AMC时间。
#文件的AMC时间
- Access:文件最后访问时间
- Modify:文件属性最后修改时间
- Change:文件内容最后修改时间
[bacon@VM-12-5-centos 3]$ touch test.txt
[bacon@VM-12-5-centos 3]$ stat test.txt File: ‘test.txt’Size: 0 Blocks: 0 IO Block: 4096 regular empty file
Device: fd01h/64769d Inode: 922160 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1003/ bacon) Gid: ( 1003/ bacon)
#新建后,三个时间是统一的
Access: 2023-02-17 15:58:34.797701756 +0800
Modify: 2023-02-17 15:58:34.797701756 +0800
Change: 2023-02-17 15:58:34.797701756 +0800Birth: -
#更改了文件属性
[bacon@VM-12-5-centos 3]$ chmod o-r test.txt
[bacon@VM-12-5-centos 3]$ stat test.txt File: ‘test.txt’Size: 0 Blocks: 0 IO Block: 4096 regular empty file
Device: fd01h/64769d Inode: 922160 Links: 1
Access: (0660/-rw-rw----) Uid: ( 1003/ bacon) Gid: ( 1003/ bacon)
Access: 2023-02-17 15:58:34.797701756 +0800
Modify: 2023-02-17 15:58:34.797701756 +0800
#Change时间对应更新
Change: 2023-02-17 15:58:59.508849528 +0800Birth: -
#更改了文件内容
[bacon@VM-12-5-centos 3]$ echo "hello Modify" >> test.txt
[bacon@VM-12-5-centos 3]$ stat test.txt File: ‘test.txt’Size: 13 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 922160 Links: 1
Access: (0660/-rw-rw----) Uid: ( 1003/ bacon) Gid: ( 1003/ bacon)
Access: 2023-02-17 15:59:27.807018723 +0800
#更改了文件内容,所以Modify时间更新
Modify: 2023-02-17 15:59:26.462010682 +0800
#但是没再改文件属性,Change时间却更新?
Change: 2023-02-17 15:59:26.462010682 +0800Birth: -
为什么?因为改了文件内容,文件属性也很可能更改了。
[bacon@VM-12-5-centos 3]$ stat test.txt File: ‘test.txt’Size: 13 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 922160 Links: 1
Access: (0660/-rw-rw----) Uid: ( 1003/ bacon) Gid: ( 1003/ bacon)
Access: 2023-02-17 15:59:27.807018723 +0800
Modify: 2023-02-17 15:59:26.462010682 +0800
Change: 2023-02-17 15:59:26.462010682 +0800Birth: -
#访问文件
[bacon@VM-12-5-centos 3]$ cat test.txt
hello Modify
[bacon@VM-12-5-centos 3]$ stat test.txt File: ‘test.txt’Size: 13 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 922160 Links: 1
Access: (0660/-rw-rw----) Uid: ( 1003/ bacon) Gid: ( 1003/ bacon)
#Access时间没更新
Access: 2023-02-17 15:59:27.807018723 +0800
Modify: 2023-02-17 15:59:26.462010682 +0800
Change: 2023-02-17 15:59:26.462010682 +0800Birth: -
#访问文件
[bacon@VM-12-5-centos 3]$ cat test.txt
hello Modify
#访问文件
[bacon@VM-12-5-centos 3]$ cat test.txt
hello Modify
#访问文件
[bacon@VM-12-5-centos 3]$ cat test.txt
hello Modify
[bacon@VM-12-5-centos 3]$ stat test.txt File: ‘test.txt’Size: 13 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 922160 Links: 1
Access: (0660/-rw-rw----) Uid: ( 1003/ bacon) Gid: ( 1003/ bacon)
#Access时间还是没更新
Access: 2023-02-17 15:59:27.807018723 +0800
Modify: 2023-02-17 15:59:26.462010682 +0800
Change: 2023-02-17 15:59:26.462010682 +0800
怎么回事?如果真的每次访问都更新一下Access时间,就意味着每次访问都要对磁盘上的数据更改,效率太低。所以Access的更新策略优化成了“一定时间/一定次数后更新”。
#动静态库
概念回顾
以前学习这部分,主要的概念就是动静态链接。
静态链接:程序编译的时候就将静态库的代码链接(拷贝)进可执行程序,执行时无需链接
动态链接:程序执行时才去链接动态库的代码(多个程序可以共享同一动态库的代码)
- 链接动态库的可执行文件中,只需要保存所用函数的地址表,而不是函数对应的机器码。
- 可执行程序执行前,会根据地址表把磁盘上动态库中的代码拷贝到内存,这个行为称动态链接
具体见这篇文章:【Linux03-基本工具之GCC】Linux下的C语言编译器
库的本质
以前,张三想用我写的一些接口,但我不想把源码暴露给他,就给他.o可重定向目标文件和.h头文件,他也能正常用。可是,一旦源文件多了,.o也多了,非常不方便。
最后,人们决定将多个.o文件组合到一起,打包形成一个文件,这个文件就是库。
而库的打包方式等,又决定了库的类型(动/静态库)。
了解了库的本质,我们可以更深入地学习动静态库和动静态链接。
静态库
我们提到,库的本质就是将多个.o文件打包,如何打包呢?这里要提到一个命令:ar。
- 作用:
ar是archive的缩写,意为归档。这个命令是GNU的归档命令。可以打包.o文件 - 选项
-r=replace-c=create
my_add.h
#pragma once #include <stdio.h>int Add(int x, int y);
my_add.c
#include "my_add.h"int Add(int x, int y)
{printf("%d + %d = ", x, y);return x + y;
}
my_sub.h
#pragma once #include <stdio.h>int Sub(int x, int y);
my_sub.c
#include "my_sub.h"int Sub(int x, int y)
{printf("%d - %d = ", x, y);return x - y;
}
makefile
libmycal.a:my_add.o my_sub.oar -rc $@ $^
my_add.o:my_add.cgcc -c my_add.c
my_sub.o:my_sub.cgcc -c my_sub.c.PHONY:clean
clean:rm -f *.o libmycal.a
bash
[bacon@VM-12-5-centos 9-lib]$ make
gcc -c my_add.c
gcc -c my_sub.c
ar -rc libmycal.a my_add.o my_sub.o
[bacon@VM-12-5-centos 9-lib]$ file libmycal.a
libmycal.a: current ar archive #libmycal.a是归档文件
如此就有了一个静态库。那么如何交付呢
交付库 = 打包压缩(动/静态库文件 + 对应的头文件)
先来打包:
libmycal.a:my_add.o my_sub.oar -rc $@ $^
my_add.o:my_add.cgcc -c my_add.c
my_sub.o:my_sub.cgcc -c my_sub.c.PHONY:releasemkdir -p mylib/includemkdir -p mylib/lib cp -f *.h mylib/includecp -f *.a mylib/lib.PHONY:clean
clean:rm -f *.o libmycal.a
[bacon@VM-12-5-centos 9-lib]$ make release
mkdir -p mylib/include
mkdir -p mylib/lib
cp -f *.h mylib/include
cp -f *.a mylib/lib
[bacon@VM-12-5-centos 9-lib]$ ll
total 36
...
drwxrwxr-x 4 bacon bacon 4096 Feb 17 19:33 mylib
...
[bacon@VM-12-5-centos 9-lib]$ tree mylib
mylib
|-- include
| |-- my_add.h
| `-- my_sub.h
`-- lib`-- libmycal.a2 directories, 3 files
再来压缩:
[bacon@VM-12-5-centos 9-lib]$ tar czf mylib.tgz mylib
[bacon@VM-12-5-centos 9-lib]$ ll
total 40
...
-rw-rw-r-- 1 bacon bacon 945 Feb 17 19:36 mylib.tgz
...
这时,只需要把mylib.tgz发给张三就可以了。
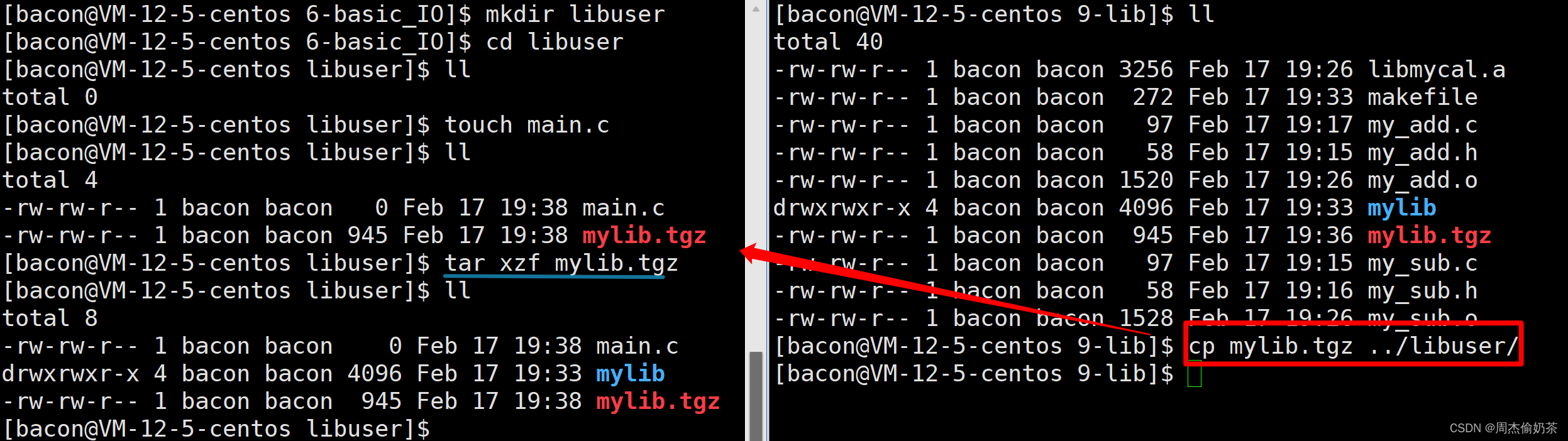
解压完后,还要安装。安装的本质其实是拷贝:
- 把头文件拷贝到系统的头文件路径中
- 把库文件拷贝到系统的库文件路径中
但我们先不安装,直接用。
第一种方案:指明路径
[bacon@VM-12-5-centos libuser]$ gcc -o cal main.c
main.c:1:20: fatal error: my_add.h: No such file or directory#include "my_add.h"^
compilation terminated.
使用一下,发现找不到头文件。
头文件默认搜索顺序:. ==> 系统默认路径
但头文件在./mylib/include,并不在.,也不在系统默认路径。
解决:指定头文件搜索路径——gcc -I ./mylib/include
[bacon@VM-12-5-centos libuser]$ gcc -o cal main.c -I ./mylib/include/
/tmp/ccbnzfvK.o: In function `main':
main.c:(.text+0xf): undefined reference to `Add'
main.c:(.text+0x2f): undefined reference to `Sub'
collect2: error: ld returned 1 exit status
但链接的时候又找不到Add定义,说明是库找不到。
解决:指定库文件搜索路径——gcc -L ./mylib/lib
[bacon@VM-12-5-centos libuser]$ gcc -o cal main.c -I ./mylib/include/ -L ./mylib/lib
/tmp/ccpjHdMn.o: In function `main':
main.c:(.text+0xf): undefined reference to `Add'
main.c:(.text+0x2f): undefined reference to `Sub'
collect2: error: ld returned 1 exit status
还不行?其实,想要链接第三方库(非/usr/bin/lib下的库),必须要指明库名。
不对啊,我们以前用标准库都不用指明库名呢?
仅仅使用C标准库,gcc能识别;用C++的标准库,g++也能识别。但第三方库,对于编译器来说无法识别,必须指明库名。
解决:指定库文件名称——gcc -l libmycal.a
[bacon@VM-12-5-centos libuser]$ gcc -o cal main.c -I ./mylib/include/ -L ./mylib/lib -l libmycal.a
/usr/bin/ld: cannot find -llibmycal.a
collect2: error: ld returned 1 exit status
还不行???别忘了,库名称是去掉前缀lib和后缀.a/.so。
bacon@VM-12-5-centos libuser]$ gcc -o cal main.c -I ./mylib/include/ -L ./mylib/lib -l mycal
[bacon@VM-12-5-centos libuser]$ ll
total 20
-rwxrwxr-x 1 bacon bacon 8480 Feb 17 20:00 cal
-rw-rw-r-- 1 bacon bacon 136 Feb 17 19:45 main.c
drwxrwxr-x 4 bacon bacon 4096 Feb 17 19:33 mylib
[bacon@VM-12-5-centos libuser]$ ./cal
10 + 20 = 30
10 - 20 = -10
完事。
[bacon@VM-12-5-centos libuser]$ ./cal
10 + 20 = 30
10 - 20 = -10
[bacon@VM-12-5-centos libuser]$ file cal
cal: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.32, BuildID[sha1]=c23e0c892d73684e3d2ae775a9d405551526cc52, not stripped
咱们用的是静态库,但还是动态链接?虽然gcc默认动态链接,但这只是建议动态链接。 到底什么链接还是得看具体给了什么库。
- 只有动态:动态链接
- 只有静态:静态链接
- 动静都有:动态链接
我们用了printf,需要C语言的库。尽管系统内可能动静态库都有,但gcc默认用动态库,所以整体就是动态链接。
第二种方案:安装
[bacon@VM-12-5-centos mylib]$ ll
total 8
drwxrwxr-x 2 bacon bacon 4096 Feb 17 19:33 include
drwxrwxr-x 2 bacon bacon 4096 Feb 17 19:33 lib
#拷贝头文件到系统默认路径
[bacon@VM-12-5-centos mylib]$ sudo cp ./include/* /usr/include
[bacon@VM-12-5-centos mylib]$ ls /usr/include/my_add.h
/usr/include/my_add.h
#拷贝库文件到系统默认路径
[bacon@VM-12-5-centos mylib]$ sudo cp ./lib/* /lib64/
[bacon@VM-12-5-centos mylib]$ ls /lib64/libmycal.a
/lib64/libmycal.a
[bacon@VM-12-5-centos libuser]$ gcc main.c
/tmp/ccnB76rp.o: In function `main':
main.c:(.text+0xf): undefined reference to `Add'
main.c:(.text+0x2f): undefined reference to `Sub'
collect2: error: ld returned 1 exit status
还是不行:即便能在默认路径找了,但是库很多,还是无法确定要链接哪个,得指定库名。
[bacon@VM-12-5-centos libuser]$ gcc main.c -l mycal
[bacon@VM-12-5-centos libuser]$ ll
total 20
-rwxrwxr-x 1 bacon bacon 8480 Feb 17 20:20 a.out
-rw-rw-r-- 1 bacon bacon 136 Feb 17 19:45 main.c
drwxrwxr-x 4 bacon bacon 4096 Feb 17 19:33 mylib
[bacon@VM-12-5-centos libuser]$ ./a.out
10 + 20 = 30
10 - 20 = -10
做完测试,还是要把这些东西删掉,免得污染。
[bacon@VM-12-5-centos libuser]$ sudo rm /usr/include/my_*
[bacon@VM-12-5-centos libuser]$ sudo rm /usr/lib64/libmycal.a
这个过程,就叫卸载。
动态库
相比静态库,仅多了一个选项:-fPIC。作用是,在编译生成.o文件时,产生位置无关码(position independent code)。
[bacon@VM-12-5-centos 2]$ cat makefile
libmycal.so:my_add.o my_sub.ogcc -shared -o $@ $^
my_add.o:my_add.cgcc -c -fPIC my_add.c
my_sub.o:my_sub.cgcc -c -fPIC my_sub.c.PHONY:release
release:mkdir -p mylib/includemkdir -p mylib/lib cp -f *.h mylib/includecp -f *.so mylib/lib.PHONY:clean
clean:rm -rf *.o libmycal.so mylib
[bacon@VM-12-5-centos 2]$ make
gcc -c -fPIC my_add.c
gcc -c -fPIC my_sub.c
gcc -shared -o libmycal.so my_add.o my_sub.o [bacon@VM-12-5-centos 2]$ clear
[bacon@VM-12-5-centos 2]$ make release
mkdir -p mylib/include
mkdir -p mylib/lib
cp -f *.h mylib/include
cp -f *.so mylib/lib
[bacon@VM-12-5-centos 2]$ ll
total 40
...
drwxrwxr-x 4 bacon bacon 4096 Feb 17 20:48 mylib
...
[bacon@VM-12-5-centos 2]$ tree mylib/
mylib/
|-- include
| |-- my_add.h
| `-- my_sub.h
`-- lib`-- libmycal.so2 directories, 3 files
[bacon@VM-12-5-centos 2]$ cp -rf mylib ../../libuser
[bacon@VM-12-5-centos libuser]$ pwd
/home/bacon/linux/6-basic_IO/libuser
[bacon@VM-12-5-centos libuser]$ gcc -o cal main.c -Imylib/include -Lmylib/lib -lmycal
[bacon@VM-12-5-centos libuser]$ ll
total 20
-rwxrwxr-x 1 bacon bacon 8432 Feb 17 20:57 cal
-rw-rw-r-- 1 bacon bacon 136 Feb 17 20:56 main.c
drwxrwxr-x 4 bacon bacon 4096 Feb 17 20:56 mylib
[bacon@VM-12-5-centos libuser]$ ./cal
./cal: error while loading shared libraries: libmycal.so: cannot open shared object file: No such file or directory
发现加载动态库的时候有问题。
[bacon@VM-12-5-centos libuser]$ ldd callinux-vdso.so.1 => (0x00007ffffe9aa000)libmycal.so => not foundlibc.so.6 => /lib64/libc.so.6 (0x00007fce6e43e000)/lib64/ld-linux-x86-64.so.2 (0x00007fce6e80c000)
库文件的路径和名称我都交代了啊,怎么还找不到?
我们是给gcc交代的,但是当程序编译完,就没gcc的事儿了,运行前动态链接还得找OS。OS和shell也得知道库在哪里。
我们的库不在系统路径下,所以运行前OS找不到这个库。
解决1:把我们的路径追加到环境变量LD_LIBRARY_PATH,shell运行时会自动到这里找
[bacon@VM-12-5-centos libuser]$ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/bacon/linux/6-basic_IO/libuser/mylib/lib
[bacon@VM-12-5-centos libuser]$ echo $LD_LIBRARY_PATH
:/home/bacon/.VimForCpp/vim/bundle/YCM.so/el7.x86_64:/home/bacon/linux/6-basic_IO/libuser/mylib/lib
[bacon@VM-12-5-centos libuser]$ gcc -o cal main.c -Imylib/include -Lmylib/lib -lmycal
[bacon@VM-12-5-centos libuser]$ ll
total 20
-rwxrwxr-x 1 bacon bacon 8432 Feb 17 21:08 cal
-rw-rw-r-- 1 bacon bacon 136 Feb 17 20:56 main.c
drwxrwxr-x 4 bacon bacon 4096 Feb 17 20:56 mylib
[bacon@VM-12-5-centos libuser]$ ./cal
10 + 20 = 30
10 - 20 = -10
完事。
但这样导的环境变量是临时的,用来测试一下还行,长久用还得每次导,不方便。
解决2:拷贝到系统路径下
不演示了。
解决3:在/etc/ld.so.conf.d添加配置文件
*shell也会在这里的配置文件中找
[bacon@VM-12-5-centos libuser]$ cd /etc/ld.so.conf.d
[bacon@VM-12-5-centos ld.so.conf.d]$ sudo touch test.conf
[bacon@VM-12-5-centos ld.so.conf.d]$ ll
total 16
-rw-r--r-- 1 root root 26 Feb 24 2022 bind-export-x86_64.conf
-rw-r--r-- 1 root root 19 Aug 9 2019 dyninst-x86_64.conf
-r--r--r-- 1 root root 63 Jun 28 2022 kernel-3.10.0-1160.71.1.el7.x86_64.conf
-rw-r--r-- 1 root root 17 Oct 2 2020 mariadb-x86_64.conf
-rw-r--r-- 1 root root 0 Feb 17 21:14 test.conf
在test.conf中,添加我们的库的路径。
[bacon@VM-12-5-centos ld.so.conf.d]$ cat test.conf
/home/bacon/linux/6-basic_IO/libuser/mylib/lib
[bacon@VM-12-5-centos libuser]$ ./cal
./cal: error while loading shared libraries: libmycal.so: cannot open shared object file: No such file or directory
[bacon@VM-12-5-centos libuser]$ ldd cal linux-vdso.so.1 => (0x00007ffedcda4000)libmycal.so => not foundlibc.so.6 => /lib64/libc.so.6 (0x00007fc53ebba000)/lib64/ld-linux-x86-64.so.2 (0x00007fc53ef88000)
还是找不到……因为配置文件还没更新。
使用ldconfig(加载配置文件)命令即可。
[bacon@VM-12-5-centos ld.so.conf.d]$ sudo ldconfig
[bacon@VM-12-5-centos etc]$ cd /home/bacon/linux/6-basic_IO/libuser
[bacon@VM-12-5-centos libuser]$ ldd callinux-vdso.so.1 => (0x00007ffe7855f000)libmycal.so => /home/bacon/linux/6-basic_IO/libuser/mylib/lib/libmycal.so (0x00007fa5450db000)libc.so.6 => /lib64/libc.so.6 (0x00007fa544d0d000)/lib64/ld-linux-x86-64.so.2 (0x00007fa5452dd000)
[bacon@VM-12-5-centos libuser]$ ./cal
10 + 20 = 30
10 - 20 = -10
完事。
解决4:软链接
#把配置文件去掉
[bacon@VM-12-5-centos ld.so.conf.d]$ sudo rm -f test.conf
[bacon@VM-12-5-centos ld.so.conf.d]$ ll
total 16
-rw-r--r-- 1 root root 26 Feb 24 2022 bind-export-x86_64.conf
-rw-r--r-- 1 root root 19 Aug 9 2019 dyninst-x86_64.conf
-r--r--r-- 1 root root 63 Jun 28 2022 kernel-3.10.0-1160.71.1.el7.x86_64.conf
-rw-r--r-- 1 root root 17 Oct 2 2020 mariadb-x86_64.conf
[bacon@VM-12-5-centos ld.so.conf.d]$ sudo ldconfig
[bacon@VM-12-5-centos ld.so.conf.d]$ cd -
/home/bacon/linux/6-basic_IO/libuser
#无法找到动态库
[bacon@VM-12-5-centos libuser]$ ./cal
./cal: error while loading shared libraries: libmycal.so: cannot open shared object file: No such file or directory
[bacon@VM-12-5-centos libuser]$ ldd callinux-vdso.so.1 => (0x00007ffd4b1e1000)libmycal.so => not foundlibc.so.6 => /lib64/libc.so.6 (0x00007fd56a245000)/lib64/ld-linux-x86-64.so.2 (0x00007fd56a613000)
#软链接
[bacon@VM-12-5-centos libuser]$ ln -s ~/linux/6-basic_IO/libuser/mylib/lib/libmycal.so libmycal.so
[bacon@VM-12-5-centos libuser]$ ll
total 20
-rwxrwxr-x 1 bacon bacon 8432 Feb 17 21:08 cal
lrwxrwxrwx 1 bacon bacon 58 Feb 17 21:29 libmycal.so -> /home/bacon/linux/6-basic_IO/libuser/mylib/lib/libmycal.so
-rw-rw-r-- 1 bacon bacon 136 Feb 17 20:56 main.c
drwxrwxr-x 4 bacon bacon 4096 Feb 17 20:56 mylib
[bacon@VM-12-5-centos libuser]$ ./cal
10 + 20 = 30
10 - 20 = -10
运行时找在当前路径下找libmycal.so,会软链接至/home/bacon/linux/6-basic_IO/libuser/mylib/lib/libmycal.so。
完事。
#安装第三方库
来一个黑框框图形化界面的库。
先下载:
[bacon@VM-12-5-centos ~]$ sudo yum install ncurses-devel
检查一下是有的:
[bacon@VM-12-5-centos test]$ ls /usr/include/ncurses.h -l
lrwxrwxrwx 1 root root 8 Feb 18 09:42 /usr/include/ncurses.h -> curses.h
写个hello world:
#include <string.h>
#include <ncurses.h>int main(){initscr();raw();noecho();curs_set(0);const char* c = "Hello, World!";mvprintw(LINES/2,(COLS-strlen(c))/2,c);refresh();getch();endwin();return 0;
}
编译:
[bacon@VM-12-5-centos test]$ gcc -o test test.c -lncurses
效果:
理解动静态编译
静态编译
使用静态库、静态链接的编译行为称静态编译。
静态库的链接
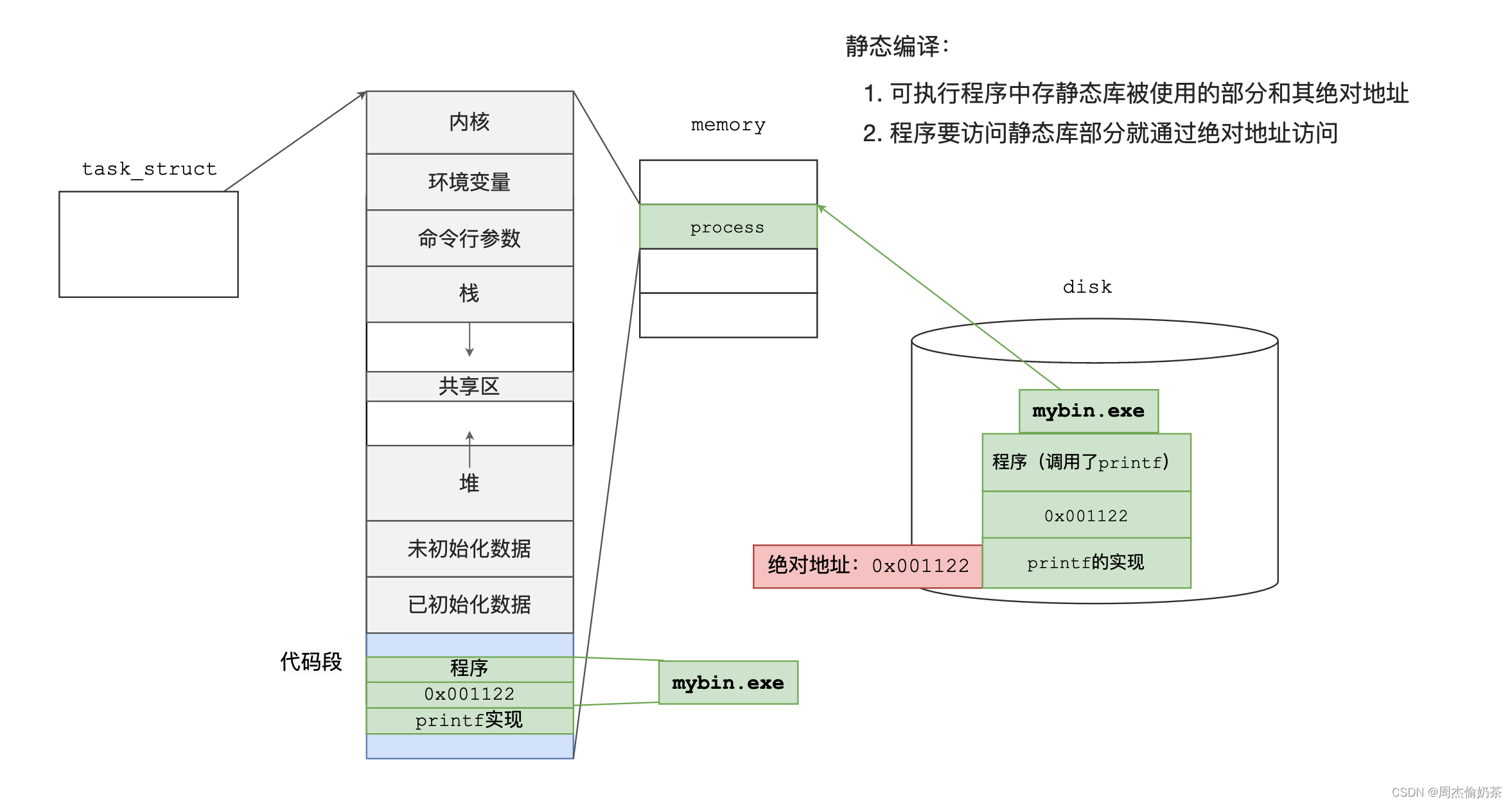
静态库会在编译时拷贝(链接)到可执行程序。
静态库的“加载”
其实静态库不需要加载,它就嵌在可执行程序中。
类似绝对编址:编译时,静态库的代码具体在哪里,已经根据虚拟地址空间的内存划分规则被写死了。
运行时静态库的访问
那这样的可执行程序运行时,静态库的代码在哪里呢?
只能是虚拟地址空间中的代码段区域。往后进程访问静态库中的代码(如printf),都是通过绝对地址,找到printf的入口。
usec.c
#include <stdio.h>int main()
{printf("hello wolrd!\n");return 0;
}
[bacon@VM-12-5-centos test]$ gcc -static -o s_usec usec.c
[bacon@VM-12-5-centos test]$ lld s_usec
-bash: lld: command not found
[bacon@VM-12-5-centos test]$ ldd s_usec not a dynamic executable #静态链接,不保存相对地址
静态编译:
- 可执行程序中存静态库被使用的部分和其绝对地址
- 程序要访问静态库部分就通过绝对地址访问
动态编译
使用动态库,动态链接的编译行为称动态编译。
动态库的链接
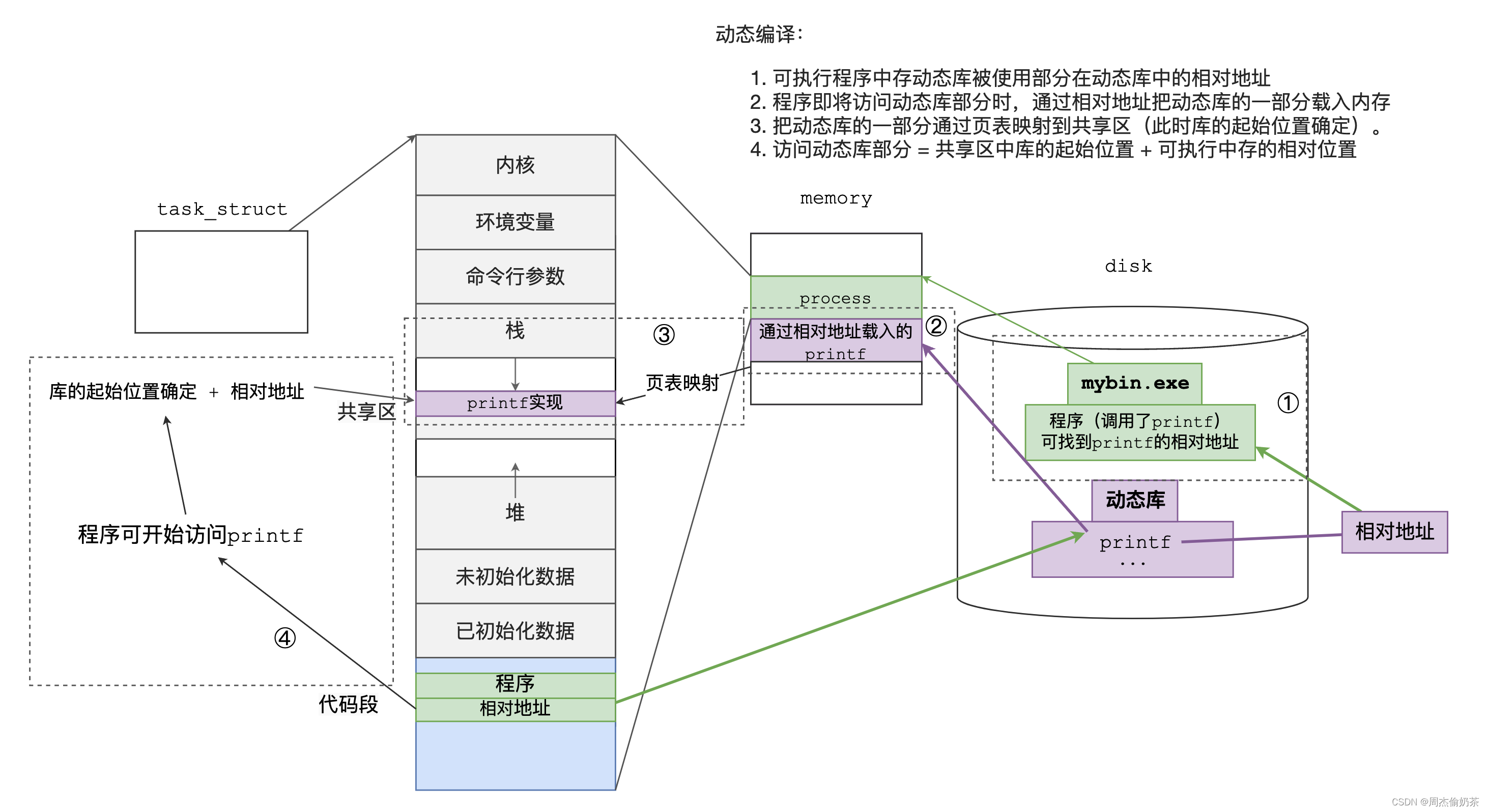
我们前面提到的-fPIC产生位置无关码,其实就是一种相对编址。
可执行程序中会保存位置无关码。这些相对地址是动态库中被使用部分在动态库中的相对地址。
动态库的加载
程序载入内存时,通过相对地址把动态库的一部分载入代码段
动态库的访问
程序即将访问动态库部分时,通过相对地址把动态库的一部分载入代码段
[bacon@VM-12-5-centos test]$ gcc -o usec usec.c
#动态链接,可执行内保存相对地址
[bacon@VM-12-5-centos test]$ ldd useclinux-vdso.so.1 => (0x00007ffef80f4000)libc.so.6 => /lib64/libc.so.6 (0x00007f6026e16000) #printf的相对地址/lib64/ld-linux-x86-64.so.2 (0x00007f60271e4000)
动态编译:
- 可执行程序中存动态库被使用部分在动态库中的相对地址
- 程序即将访问动态库部分时,通过相对地址把动态库的一部分载入内存
- 把动态库的一部分通过页表映射到共享区(此时库的起始位置确定)。
- 访问动态库部分 = 共享区中库的起始位置 + 可执行中存的相对位置
为什么编译源文件要加-fPIC?这样编译出来的.o中,函数地址都是相对地址(位置无关码)了。
为什么打包成库时要加-shared?这样打包出来的库文件就是动态库格式。
可算结束了,这一章节可真不简单。
表层需要讲的其实就是文件描述符、软硬链接、动静态库,但底层牵扯的知识又很多。只有把背后的知识了解清楚,我们才能真正理解表层内容。
很高兴你能看到这,本期的分享告一段落了。
这里是培根的blog,期待与你共同进步
下期见~
相关文章:
【Linux06-基础IO】4.5万字的基础IO讲解
前言 本期分享基础IO的知识,主要有: 复习C语言文件操作文件相关的系统调用文件描述符fd理解Linux下一切皆文件缓冲区文件系统软硬链接动静态库的理解和制作动静态编译 博主水平有限,不足之处望请斧正! C语言文件操作 #再谈文件…...

c++协程库理解—ucontext组件实践
文章目录1.干货写在前面2.ucontext初接触3.ucontext组件到底是什么4.小试牛刀-使用ucontext组件实现线程切换5.使用ucontext实现自己的线程库6.最后一步-使用我们自己的协程库1.干货写在前面 协程是一种用户态的轻量级线程 首先我们可以看看有哪些语言已经具备协程语义&#x…...

英语基础-状语
1. 课前引语 1. 形容词使用场景 (1). 放在系动词后面作表语 The boy is handsome. (2). 放在名词前面做定语 I like this beautiful girl. (3). 放在宾语后面做补语 You make your father happy. 总结:形容词无论做什么,都离不开名词,…...

目标检测笔记(八):自适应缩放技术Letterbox完整代码和结果展示
文章目录自适应缩放技术Letterbox介绍自适应缩放技术Letterbox流程自适应缩放Letterbox代码运行结果自适应缩放技术Letterbox介绍 由于数据集中存在多种不同和长宽比的样本图,传统的图片缩放方法按照固定尺寸来进行缩放会造成图片扭曲变形的问题。自适应缩放技术通…...

2023年全国最新高校辅导员精选真题及答案1
百分百题库提供高校辅导员考试试题、辅导员考试预测题、高校辅导员考试真题、辅导员证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 一、选择题 11.李某与方某签订房屋租赁合同期间,李某欲购买租赁房屋ÿ…...

【Python】Python读写Excel表格
简要版,更多功能参考资料1。1 Excel文件保存格式基础概念此处不提,详见资料1。Excel的文件保存格式有两种: xls 和 xlsx。如果你看不到文件后缀,按下图设置可见。xls是Office 2003及之前版本的表格的默认保存格式。xlsx 是 Excel …...
Python每日一练(20230218)
目录 1. 旋转图像 2. 解码方法 3. 二叉树最大路径和 1. 旋转图像 给定一个 n n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。 你必须在原地旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要 使用另一个矩阵来旋转图像…...
基于SSM框架的狼途汽车门店管理系统的设计与实现
基于SSM框架的狼途汽车门店管理系统的设计与实现 ✌全网粉丝20W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式🍅 一、…...

视频监控流程图3
<html> <head> <meta http-equiv"Content-Type" content"text/html; charsetUTF-8"/> <link rel"stylesheet" type"text/css" href"visio.css"/> <title> 视频监控流程图 </title> <…...
 2.14.3 CANFD协议介绍)
Linux ARM平台开发系列讲解(CAN) 2.14.3 CANFD协议介绍
1. 概述 前面章节介绍了CAN2.0协议,CAN现在主要是用在汽车领域,随着CAN的发展, 又衍生除了CANFD协议,该协议是在CAN的基础之上进行了升级,CAN2.0的最高速率是1Mbps,有限的速率导致CAN总线上负载率变高,所以CANFD就出现了,CANFD目前最高支持10Mbps。除此之外,CANFD还拥…...

参考 | 给C盘 “搬家“
参考 | 给C盘 “搬家” 将在C盘准备 “搬家” 的 文件/文件夹 完整路径 copy 下来 e.g. 路径一 “C:\Users\你的用户名\AppData\Roaming\kingsoft” 将这个 文件/文件夹 CTRLX 剪切下来 注意: 剪切后, 不需要自己重新新建, 直接执行第三步 将这个 文件/文件夹 CTRLV 粘贴到你要…...
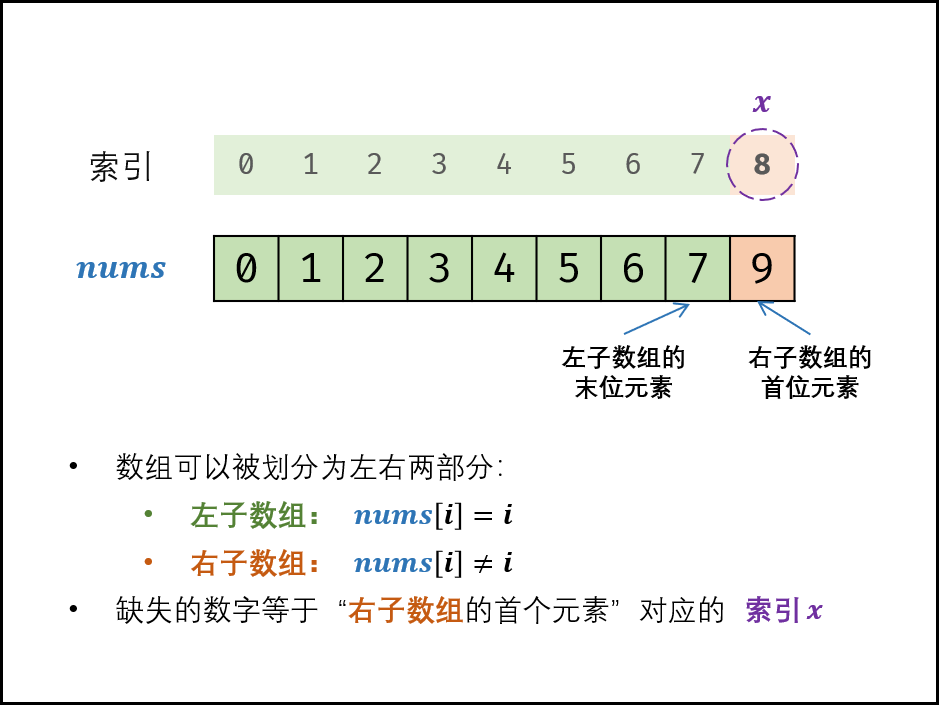
剑指 Offer 53 - II. 0~n-1中缺失的数字
原题链接 难度:easy\color{Green}{easy}easy 题目描述 一个长度为n-1的递增排序数组中的所有数字都是唯一的,并且每个数字都在范围0~n-1之内。在范围0~n-1内的n个数字中有且只有一个数字不在该数组中,请找出这个数字…...

分布式id
一、分布式系统 1.1 分布式系统的定义和应用场景 分布式系统是由多个独立的计算机节点协同工作,以共同完成一个任务的系统。这些节点通过网络进行通信和协调,共享计算和存储资源,从而实现对更大规模问题的处理和更高系统可用性的要求。 分…...

创意编程py模拟题
前言:好久没写博客了,来水好好写一篇 注:本篇文章为py,不是c 1、敲七 版本1 题目: 题目描述 输出7和7的倍数,还有包含7的数字例如(17,27,37…70,71&#…...
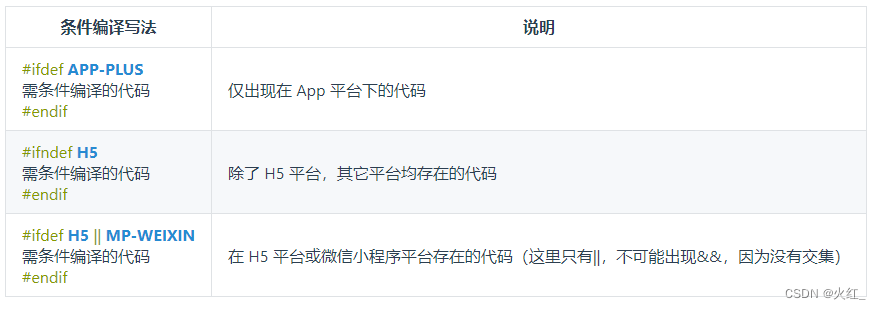
uniapp中条件编译
官方:https://uniapp.dcloud.net.cn/tutorial/platform.html#%E8%B7%A8%E7%AB%AF%E5%85%BC%E5%AE%B9 #ifndef H5 代码段… #endif 表示除了H5其他都可以编译 #ifdef H5 代码段… #endef 表示只能编译H5,其他的都不能编译 其他编译平台请查看官方文档。 …...

封装 YoloV5 detect.py 成 Python 库以供 python 程序使用
本项目地址 Github 本项目地址 Github Introduction YoloV5 作为 YoloV4 之后的改进型,在算法上做出了优化,检测的性能得到了一定的提升。其特点之一就是权重文件非常的小,可以在一些配置更低的移动设备上运行,且提高速度的同时…...

PostgreSQL , PostGIS , 球坐标 , 平面坐标 , 球面距离 , 平面距离
标签 PostgreSQL , PostGIS , 球坐标 , 平面坐标 , 球面距离 , 平面距离 背景 PostGIS中有两种常用的空间类型geometry和geography,这两种数据类型有什么差异,应该如何选择? 对于GIS来说,首先是坐标系,有两种&#…...

K3S 系列文章-5G IoT 网关设备 POD 访问报错 DNS ‘i/o timeout‘分析与解决
开篇 《K3s 系列文章》《Rancher 系列文章》 问题概述 20220606 5G IoT 网关设备同时安装 K3S Server, 但是 POD 却无法访问互联网地址,查看 CoreDNS 日志提示如下: ... [ERROR] plugin/errors: 2 update.traefik.io. A: read udp 10.42.0.3:38545-&…...

社会工程学介绍
目录前言手段和术语假托在线聊天/电话钓鱼下饵(Baiting)等价交换同情心尾随(Tailgating or Piggybacking)社交工程学的演进钓鱼式攻击电脑蠕虫垃圾邮件特别人物总结前言 在信息安全方面,社会工程学是指对人进行心理操…...

干货 | 有哪些安慰剂按钮的设计?
仔细观察我们的生活,你会发现处处都是安慰剂按钮,ATM的点钞声、开启空调的呼呼声,这些都对用户心里产生了有意的引导作用,当你打开了空调按钮,先播放声音会让你感觉你按下的按钮起到了作用。 我们的大脑不喜欢杂乱无章…...

golang循环变量捕获问题
在 Go 语言中,当在循环中启动协程(goroutine)时,如果在协程闭包中直接引用循环变量,可能会遇到一个常见的陷阱 - 循环变量捕获问题。让我详细解释一下: 问题背景 看这个代码片段: fo…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...

QMC5883L的驱动
简介 本篇文章的代码已经上传到了github上面,开源代码 作为一个电子罗盘模块,我们可以通过I2C从中获取偏航角yaw,相对于六轴陀螺仪的yaw,qmc5883l几乎不会零飘并且成本较低。 参考资料 QMC5883L磁场传感器驱动 QMC5883L磁力计…...

前端导出带有合并单元格的列表
// 导出async function exportExcel(fileName "共识调整.xlsx") {// 所有数据const exportData await getAllMainData();// 表头内容let fitstTitleList [];const secondTitleList [];allColumns.value.forEach(column > {if (!column.children) {fitstTitleL…...
-----深度优先搜索(DFS)实现)
c++ 面试题(1)-----深度优先搜索(DFS)实现
操作系统:ubuntu22.04 IDE:Visual Studio Code 编程语言:C11 题目描述 地上有一个 m 行 n 列的方格,从坐标 [0,0] 起始。一个机器人可以从某一格移动到上下左右四个格子,但不能进入行坐标和列坐标的数位之和大于 k 的格子。 例…...
)
python爬虫:Newspaper3k 的详细使用(好用的新闻网站文章抓取和解析的Python库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Newspaper3k 概述1.1 Newspaper3k 介绍1.2 主要功能1.3 典型应用场景1.4 安装二、基本用法2.2 提取单篇文章的内容2.2 处理多篇文档三、高级选项3.1 自定义配置3.2 分析文章情感四、实战案例4.1 构建新闻摘要聚合器…...

WordPress插件:AI多语言写作与智能配图、免费AI模型、SEO文章生成
厌倦手动写WordPress文章?AI自动生成,效率提升10倍! 支持多语言、自动配图、定时发布,让内容创作更轻松! AI内容生成 → 不想每天写文章?AI一键生成高质量内容!多语言支持 → 跨境电商必备&am…...

ios苹果系统,js 滑动屏幕、锚定无效
现象:window.addEventListener监听touch无效,划不动屏幕,但是代码逻辑都有执行到。 scrollIntoView也无效。 原因:这是因为 iOS 的触摸事件处理机制和 touch-action: none 的设置有关。ios有太多得交互动作,从而会影响…...
的原因分类及对应排查方案)
JVM暂停(Stop-The-World,STW)的原因分类及对应排查方案
JVM暂停(Stop-The-World,STW)的完整原因分类及对应排查方案,结合JVM运行机制和常见故障场景整理而成: 一、GC相关暂停 1. 安全点(Safepoint)阻塞 现象:JVM暂停但无GC日志,日志显示No GCs detected。原因:JVM等待所有线程进入安全点(如…...

Android 之 kotlin 语言学习笔记三(Kotlin-Java 互操作)
参考官方文档:https://developer.android.google.cn/kotlin/interop?hlzh-cn 一、Java(供 Kotlin 使用) 1、不得使用硬关键字 不要使用 Kotlin 的任何硬关键字作为方法的名称 或字段。允许使用 Kotlin 的软关键字、修饰符关键字和特殊标识…...