数仓架构模型设计参考
1、数据技术架构
1.1、技术架构

1.2、数据分层
将数据仓库分为三层,自下而上为:数据引入层(ODS,Operation Data Store)、数据公共层(CDM,Common Data Model)和数据应用层(ADS,Application Data Service)。
数据仓库的分层和各层级用途如下图所示。

● 数据引入层ODS(Operation Data Store):存放未经过处理的原始数据至数据仓库系统,结构上与源系统保持一致,是数据仓库的数据准备区。主要完成基础数据引入到MaxCompute的职责,同时记录基础数据的历史变化。
● 数据公共层CDM(Common Data Model,又称通用数据模型层),包括DIM维度表、DWD和DWS,由ODS层数据加工而成。主要完成数据加工与整合,建立一致性的维度,构建可复用的面向分析和统计的明细事实表,以及汇总公共粒度的指标。
● 公共维度层(DIM):基于维度建模理念思想,建立整个企业的一致性维度。降低数据计算口径和算法不统一风险。公共维度层的表通常也被称为逻辑维度表,维度和维度逻辑表通常一一对应。
公共汇总粒度事实层(DWS):以分析的主题对象作为建模驱动,基于上层的应用和产品的指标需求,构建公共粒度的汇总指标事实表,以宽表化手段物理化模型。构建命名规范、口径一致的统计指标,为上层提供公共指标,建立汇总宽表、明细事实表。公共汇总粒度事实层的表通常也被称为汇总逻辑表,用于存放派生指标数据。
● 明细粒度事实层(DWD):以业务过程作为建模驱动,基于每个具体的业务过程特点,构建最细粒度的明细层事实表。可以结合企业的数据使用特点,将明细事实表的某些重要维度属性字段做适当冗余,即宽表化处理。明细粒度事实层的表通常也被称为逻辑事实表。
● 数据应用层ADS(Application Data Service):存放数据产品个性化的统计指标数据。根据CDM与ODS层加工生成。
该数据分类架构在ODS层分为三部分:数据准备区、离线数据和准实时数据区。整体数据分类架构如下图所示。

从源业务系统的数据经过同步集成工具,同步到数据仓库的ODS层。经过数据开发形成事实宽表后,再以商品、地域等为维度进行公共汇总。数据处理流程如下:

1.3、数据划分及命名空间约定
请根据业务划分数据并约定命名,建议针对业务名称结合数据层次约定相关命名的英文缩写,这样可以给后续数据开发过程中,对项目空间、表、字段等命名做为重要参照。
● 按业务划分:命名时按主要的业务划分,以指导物理模型的划分原则、命名原则及使用的ODS project。例如,按业务定义英文缩写,阿里的“淘宝”英文缩写可以定义为“tb”。
● 按数据域划分:命名时按照CDM层的数据进行数据域划分,以便有效地对数据进行管理,以及指导数据表的命名。例如,“交易”数据的英文缩写可定义为“trd”。
● 按业务过程划分:当一个数据域由多个业务过程组成时,命名时可以按业务流程划分。业务过程是从数据分析角度看客观存在的或者抽象的业务行为动作。例如,交易数据域中的“退款”这个业务过程的英文缩写可约定命名为“rfd_ent”。
2、数据模型
模型是对现实事物的反映和抽象,能帮助我们更好地了解客观世界。数据模型定义了数据之间关系和结构,使得我们可以有规律地获取想要的数据。例如,在一个超市里,商品的布局都有特定的规范,商品摆放的位置是按照消费者的购买习惯以及人流走向进行摆放的。
● 数据模型的作用数据模型是在业务需求分析之后,数据仓库工作开始时的第一步。良好的数据模型可以帮助我们更好地存储数据,更有效率地获取数据,保证数据间的一致性。
● 模型设计的基本原则
● 高内聚和低耦合一个逻辑和物理模型由哪些记录和字段组成,应该遵循最基本的软件设计方法论中的高内聚和低耦合原则。主要从数据业务特性和访问特性两个角度来考虑:将业务相近或者相关的数据、粒度相同数据设计为一个逻辑或者物理模型;将高概率同时访问的数据放一起,将低概率同时访问的数据分开存储。
核心模型与扩展模型分离建立核心模型与扩展模型体系,核心模型包括的字段支持常用核心的业务,扩展模型包括的字段支持个性化或是少量应用的需要。在必须让核心模型与扩展模型做关联时,不能让扩展字段过度侵入核心模型,以免破坏了核心模型的架构简洁性与可维护性。
● 公共处理逻辑下沉及单一底层公用的处理逻辑应该在数据调度依赖的底层进行封装与实现,不要让公用的处理逻辑暴露给应用层实现,不要让公共逻辑在多处同时存在。
成本与性能平衡适当的数据冗余可换取查询和刷新性能,不宜过度冗余与数据复制。
● 数据可回滚处理逻辑不变,在不同时间多次运行数据的结果需确定不变。
一致性相同的字段在不同表中的字段名必须相同。
● 命名清晰可理解表命名规范需清晰、一致,表命名需易于下游的理解和使用。
2.1、数据接入ODS层
ODS层存放您从业务系统获取的最原始的数据,是其他上层数据的源数据。业务数据系统中的数据通常为非常细节的数据,经过长时间累积,且访问频率很高,是面向应用的数据。
2.1.1、表设计
在ODS层主要包括的数据有:交易系统订单详情、用户信息详情、商品详情等。这些数据未经处理,是最原始的数据。逻辑上,这些数据都是以二维表的形式存储。虽然严格的说ODS层不属于数仓建模的范畴,但是合理的规划ODS层并做好数据同步也非常重要。
说明
● 表或字段命名尽量和业务系统保持一致,但是需要通过额外的标识来区分增量和全量表。例如,我们通过_di来标识该表为增量表。
● 命名时需要特别注意冲突处理,例如不同业务系统的表可能是同一个名称。为区分两个不同的表,您可以将这两个同名表的来源数据库名称作为后缀或前缀。例如,表中某些字段的名称刚好和关键字重名了,可以通过添加_col1后缀解决。
2.1.2、建表示例
本次示例,使用了6张ODS表:
● 记录用于拍卖的商品信息:ods_auction。
● 记录用于正常售卖的商品信息:ods_sale。
● 记录用户详细信息:ods_users_extra。
● 记录新增的商品成交订单信息:ods_biz_order_delta。
● 记录新增的物流订单信息:ods_logistics_order_delta。
● 记录新增的支付订单信息:ods_pay_order_delta。
建表语句如下:
CREATE TABLE IF NOT EXISTS ods_auction
(id STRING COMMENT '商品ID',title STRING COMMENT '商品名',gmt_modified STRING COMMENT '商品最后修改日期',price DOUBLE COMMENT '商品成交价格,单位元',starts STRING COMMENT '商品上架时间',minimum_bid DOUBLE COMMENT '拍卖商品起拍价,单位元',duration STRING COMMENT '有效期,销售周期,单位天',incrementnum DOUBLE COMMENT '拍卖价格的增价幅度',city STRING COMMENT '商品所在城市',prov STRING COMMENT '商品所在省份',ends STRING COMMENT '销售结束时间',quantity BIGINT COMMENT '数量',stuff_status BIGINT COMMENT '商品新旧程度 0 全新 1 闲置 2 二手',auction_status BIGINT COMMENT '商品状态 0 正常 1 用户删除 2 下架 3 从未上架',cate_id BIGINT COMMENT '商品类目ID',cate_name STRING COMMENT '商品类目名称',commodity_id BIGINT COMMENT '品类ID',commodity_name STRING COMMENT '品类名称',umid STRING COMMENT '买家umid'
)
COMMENT '商品拍卖ODS'
PARTITIONED BY (ds STRING COMMENT '格式:YYYYMMDD')
LIFECYCLE 400;
CREATE TABLE IF NOT EXISTS ods_sale
(id STRING COMMENT '商品ID',title STRING COMMENT '商品名',gmt_modified STRING COMMENT '商品最后修改日期',starts STRING COMMENT '商品上架时间',price DOUBLE COMMENT '商品价格,单位元',city STRING COMMENT '商品所在城市',prov STRING COMMENT '商品所在省份',quantity BIGINT COMMENT '数量',stuff_status BIGINT COMMENT '商品新旧程度 0 全新 1 闲置 2 二手',auction_status BIGINT COMMENT '商品状态 0 正常 1 用户删除 2 下架 3 从未上架',cate_id BIGINT COMMENT '商品类目ID',cate_name STRING COMMENT '商品类目名称',commodity_id BIGINT COMMENT '品类ID',commodity_name STRING COMMENT '品类名称',umid STRING COMMENT '买家umid'
)
COMMENT '商品正常购买ODS'
PARTITIONED BY (ds STRING COMMENT '格式:YYYYMMDD')
LIFECYCLE 400;
CREATE TABLE IF NOT EXISTS ods_users_extra
(id STRING COMMENT '用户ID',logincount BIGINT COMMENT '登录次数',buyer_goodnum BIGINT COMMENT '作为买家的好评数',seller_goodnum BIGINT COMMENT '作为卖家的好评数',level_type BIGINT COMMENT '1 一级店铺 2 二级店铺 3 三级店铺',promoted_num BIGINT COMMENT '1 A级服务 2 B级服务 3 C级服务',gmt_create STRING COMMENT '创建时间',order_id BIGINT COMMENT '订单ID',buyer_id BIGINT COMMENT '买家ID',buyer_nick STRING COMMENT '买家昵称',buyer_star_id BIGINT COMMENT '买家星级 ID',seller_id BIGINT COMMENT '卖家ID',seller_nick STRING COMMENT '卖家昵称',seller_star_id BIGINT COMMENT '卖家星级ID',shop_id BIGINT COMMENT '店铺ID',shop_name STRING COMMENT '店铺名称'
)
COMMENT '用户扩展表'
PARTITIONED BY (ds STRING COMMENT 'yyyymmdd')
LIFECYCLE 400;
CREATE TABLE IF NOT EXISTS ods_biz_order_delta
(biz_order_id STRING COMMENT '订单ID',pay_order_id STRING COMMENT '支付订单ID',logistics_order_id STRING COMMENT '物流订单ID',buyer_nick STRING COMMENT '买家昵称',buyer_id STRING COMMENT '买家ID',seller_nick STRING COMMENT '卖家昵称',seller_id STRING COMMENT '卖家ID',auction_id STRING COMMENT '商品ID',auction_title STRING COMMENT '商品标题 ',auction_price DOUBLE COMMENT '商品价格',buy_amount BIGINT COMMENT '购买数量',buy_fee BIGINT COMMENT '购买金额',pay_status BIGINT COMMENT '支付状态 1 未付款 2 已付款 3 已退款',logistics_id BIGINT COMMENT '物流订单ID',mord_cod_status BIGINT COMMENT '物流状态 0 初始状态 1 接单成功 2 接单超时3 揽收成功 4揽收失败 5 签收成功 6 签收失败 7 用户取消物流订单',status BIGINT COMMENT '状态 0 订单正常 1 订单不可见',sub_biz_type BIGINT COMMENT '业务类型 1 拍卖 2 购买',end_time STRING COMMENT '交易结束时间',shop_id BIGINT COMMENT '店铺ID'
)
COMMENT '交易成功订单日增量表'
PARTITIONED BY (ds STRING COMMENT 'yyyymmdd')
LIFECYCLE 7200;
CREATE TABLE IF NOT EXISTS ods_logistics_order_delta
(logistics_order_id STRING COMMENT '物流订单ID ',post_fee DOUBLE COMMENT '物流费用',address STRING COMMENT '收货地址',full_name STRING COMMENT '收货人全名',mobile_phone STRING COMMENT '移动电话',prov STRING COMMENT '省份',prov_code STRING COMMENT '省份ID',city STRING COMMENT '市',city_code STRING COMMENT '城市ID',logistics_status BIGINT COMMENT '物流状态
1 - 未发货
2 - 已发货
3 - 已收货
4 - 已退货
5 - 配货中',consign_time STRING COMMENT '发货时间',gmt_create STRING COMMENT '订单创建时间',shipping BIGINT COMMENT '发货方式
1,平邮
2,快递
3,EMS',seller_id STRING COMMENT '卖家ID',buyer_id STRING COMMENT '买家ID'
)
COMMENT '交易物流订单日增量表'
PARTITIONED BY (ds STRING COMMENT '日期')
LIFECYCLE 7200;
CREATE TABLE IF NOT EXISTS ods_pay_order_delta
(pay_order_id STRING COMMENT '支付订单ID',total_fee DOUBLE COMMENT '应支付总金额 (数量*单价)',seller_id STRING COMMENT '卖家ID',buyer_id STRING COMMENT '买家ID',pay_status BIGINT COMMENT '支付状态
1等待买家付款,
2等待卖家发货,
3交易成功',pay_time STRING COMMENT '付款时间',gmt_create STRING COMMENT '订单创建时间',refund_fee DOUBLE COMMENT '退款金额(包含运费)',confirm_paid_fee DOUBLE COMMENT '已经确认收货的金额'
)
COMMENT '交易支付订单增量表'
PARTITIONED BY (ds STRING COMMENT '日期')
LIFECYCLE 7200;
2.1.3、存储设计
为了满足历史数据分析需求,可以在ODS层表中添加时间维度作为分区字段。实际应用中,可以选择采用增量、全量存储或拉链存储的方式。
● 增量存储以天为单位的增量存储,以业务日期作为分区,每个分区存放日增量的业务数据。举例如下:
● 1月1日,用户A访问了A公司电商店铺B,A公司电商日志产生一条记录t1。1月2日,用户A又访问了A公司电商店铺C,A公司电商日志产生一条记录t2。采用增量存储方式,t1将存储在1月1日这个分区中,t2将存储在1月2日这个分区中。
1月1日,用户A在A公司电商网购买了B商品,交易日志将生成一条记录t1。1月2日,用户A又将B商品退货了,交易日志将更新t1记录。采用增量存储方式,初始购买的t1记录将存储在1月1日这个分区中,更新后的t1将存储在1月2日这个分区中。
【说明】 交易、日志等事务性较强的ODS表适合增量存储方式。这类表数据量较大,采用全量存储的方式存储成本压力大。此外,这类表的下游应用对于历史全量数据访问的需求较小(此类需求可通过数据仓库后续汇总后得到)。例如,日志类ODS表没有数据更新的业务过程,因此所有增量分区UNION在一起就是一份全量数据。
● 全量存储以天为单位的全量存储,以业务日期作为分区,每个分区存放截止到业务日期为止的全量业务数据。例如,1月1日,卖家A在A公司电商网发布了B、C两个商品,前端商品表将生成两条记录t1、t2。1月2日,卖家A将B商品下架了,同时又发布了商品D,前端商品表将更新记录t1,同时新生成记录t3。采用全量存储方式,在1月1日这个分区中存储t1和t2两条记录,在1月2日这个分区中存储更新后的t1以及t2、t3记录。
【说明】 对于小数据量的缓慢变化维度数据,例如商品类目,可直接使用全量存储。
● 拉链存储通过新增两个时间戳字段(start_dt和end_dt),将所有以天为粒度的变更数据都记录下来,通常分区字段也是这两个时间戳字段。
拉链存储举例如下。
商品 start_dt end_dt 卖家 状态
B 20160101 20160102 A 上架
C 20160101 30001231 A 上架
B 20160102 30001231 A 下架
这样,下游应用可以通过限制时间戳字段来获取历史数据。例如,用户访问1月1日数据,只需限制start_dt<=20160101并且 end_dt>20160101。
【说明】 对于大数据量的缓慢变化维度数据,例如会员信息表,可采取拉链表方式来存储。
2.1.4、数据质量规范
● 每个ODS全量表必须配置唯一性字段标识。
● 每个ODS全量表必须有注释。
● 每个ODS全量表必须监控分区空数据。
● 建议对重要表的重要枚举类型字段进行枚举值变化及枚举值分布监控。
● 建议对ODS表的数据量及数据记录数设置周同环比监控,如果周同环比无变化,表示源系统已迁移或下线。
2.1.5、其他规范
● 一个系统的源表只允许同步到数据仓库一次,保持表结构的一致性。
● 数据集成同步全量数据时会直接进入全量表的当日分区。
● 所有ODS层的表都以统计日期及时间分区表方式存储,数据成本由存储管理和策略控制。
● 如果源系统新增了字段,您需要重新配置数据集成同步作业。如果目标表的字段在源系统中不存在,数据集成自动填充NULL。
2.2、CDM公共维度层(DIM)
公共维度汇总层(DIM)基于维度建模理念,建立整个企业的一致性维度。
公共维度汇总层(DIM)主要由维度表(维表)构成。维度是逻辑概念,是衡量和观察业务的角度。维表是根据维度及其属性将数据平台上构建的物理化的表,采用宽表设计的原则。因此,公共维度汇总层(DIM)首先需要定义维度。
2.2.1、定义维度
在划分数据域、构建总线矩阵时,需要结合对业务过程的分析定义维度。以A电商公司的营销业务板块为例,在交易数据域中,我们重点考察确认收货(交易成功)的业务过程。在确认收货的业务过程中,主要有商品和收货地点(本教程中,假设收货和购买是同一个地点)两个维度所依赖的业务角度。从商品角度可以定义出以下维度:
● 商品ID
● 商品名称
● 商品价格
● 商品新旧程度0表示全新,1表示闲置,2表示二手。
● 商品类目ID
● 商品类目名称
● 品类ID
● 品类名称
● 买家ID
● 商品状态0表示正常,1表示用户删除,2表示下架,3表示从未上架。
● 商品所在城市
● 商品所在省份
从地域角度,可以定义出以下维度:
● 买家ID
● 城市code
● 城市名称
● 省份code
● 省份名称
作为维度建模的核心,在企业级数据仓库中必须保证维度的唯一性。以A公司的商品维度为例,有且只允许有一种维度定义。例如,省份code这个维度,对于任何业务过程所传达的信息都是一致的。
2.2.2、设计维表
完成维度定义后,您可以对维度进行补充,进而生成维表。维表的设计需要注意:
● 建议维表单表信息不超过1000万条。
● 维表与其他表进行Join时,建议您使用Map Join。
● 避免过于频繁的更新维表的数据。
在设计维表时,您需要从下列方面进行考虑:
● 维表中数据的稳定性。例如,A公司电商会员通常不会出现消亡,但会员数据可能在任何时候更新,此时要考虑创建单个分区存储全量数据。如果存在不会更新的记录,您可能需要分别创建历史表与日常表。日常表用于存放当前有效的记录,保持表的数据量不会膨胀;历史表根据消亡时间插入对应分区,使用单个分区存放分区对应时间的消亡记录。
● 维表是否需要垂直拆分。如果一个维表存在大量属性不被使用,或由于承载过多属性字段导致查询变慢,则需要考虑对字段进行拆分,创建多个维表。
● 维表是否需要水平拆分。如果记录之间有明显的界限,可以考虑拆成多个表或设计成多级分区。
● 核心维表的产出时间。通常有严格的要求。
设计维表的主要步骤如下:
- 初步定义维度。保证维度的一致性。
- 确定主维表(中心事实表,本教程中采用星型模型)。此处的主维表通常是数据引入层(ODS)表,直接与业务系统同步。例如,s_auction是与前台商品中心系统同步的商品表,此表即是主维表。
- 确定相关维表。数据仓库是业务源系统的数据整合,不同业务系统或者同一业务系统中的表之间存在关联性。根据对业务的梳理,确定哪些表和主维表存在关联关系,并选择其中的某些表用于生成维度属性。以商品维度为例,根据对业务逻辑的梳理,可以得到商品与类目、卖家和店铺等维度存在关联关系。
- 确定维度属性。主要包括两个阶段。第一个阶段是从主维表中选择维度属性或生成新的维度属性;第二个阶段是从相关维表中选择维度属性或生成新的维度属性。以商品维度为例,从主维表(s_auction)、类目、卖家和店铺等相关维表中选择维度属性或生成新的维度属性。维度属性的设计需要注意:
○ 尽可能生成丰富的维度属性。
○ 尽可能多地给出富有意义的文字性描述。
○ 区分数值型属性和事实。
○ 尽量沉淀出通用的维度属性。
2.2.3、设计准则
● 一致性维度规范公共层的维度表中相同维度属性在不同物理表中的字段名称、数据类型、数据内容必须保持一致。除了以下情况:
● 在不同的实际物理表中,如果由于维度角色的差异,需要使用其他的名称,其他名称也必须是规范的维度属性的别名。例如,定义一个标准的会员ID时,如果在一个表中,分别要表示买家ID,卖家ID,那么设计规范阶段就预先对会员ID分别定义买家ID和卖家ID。如果由于历史原因,在暂时不一致的情况下,必须在规范的维度定义一个标准维度属性,不同的物理名也必须是来自标准维度属性的别名。
● 维度的组合与拆分
● 组合原则
○ 将维度所描述业务相关性强的字段在一个物理维表实现。相关性强是指经常需要一起查询或进行报表展现、两个维度属性间是否存在天然的关系等。例如,商品基本属性和所属品牌。
○ 无相关性的维度可以适当考虑杂项维度(例如交易),可以构建一个交易杂项维度收集交易的特殊标记属性、业务分类等信息。也可以将杂项维度退化在事实表中处理,不过容易造成事实表相对庞大,加工处理较为复杂。
○ 所谓的行为维度是经过汇总计算的指标,在下游的应用使用时将其当维度处理。如果有需要,度量指标可以作为行为维度冗余到维度表中。
● 拆分与冗余
○ 对于维度属性过多,涉及源较多的维度表(例如会员表),可以做适当拆分:
○ 拆分为核心表和扩展表。核心表相对字段较少,刷新产出时间较早,优先使用。扩展表字段较多,且可以冗余核心表部分字段,刷新产出时间较晚,适合数据分析人员使用。
○ 根据维度属性的业务不相关性,将相关度不大的维度属性拆分为多个物理表存储。
○ 数据记录数较大的维度表(例如商品表),可以适当冗余一些子集合,以减少下游扫描数据量:
○ 可以根据当天是否有行为,产出一个有活跃行为的相关维表,以减少应用的数据扫描量。
○ 可根据所属业务扫描数据范围大小的不同,进行适当子集合冗余。
2.2.4、建表实例
本例中,最终的维表建表语句如下所示。
CREATE TABLE IF NOT EXISTS dim_asale_itm
(item_id BIGINT COMMENT '商品ID',item_title STRING COMMENT '商品名称',item_price DOUBLE COMMENT '商品成交价格_元',item_stuff_status BIGINT COMMENT '商品新旧程度_0全新1闲置2二手',cate_id BIGINT COMMENT '商品类目ID',cate_name STRING COMMENT '商品类目名称',commodity_id BIGINT COMMENT '品类ID',commodity_name STRING COMMENT '品类名称',umid STRING COMMENT '买家ID',item_status BIGINT COMMENT '商品状态_0正常1用户删除2下架3未上架',city STRING COMMENT '商品所在城市',prov STRING COMMENT '商品所在省份'
)
COMMENT '商品全量表'
PARTITIONED BY (ds STRING COMMENT '日期,yyyymmdd');
CREATE TABLE IF NOT EXISTS dim_pub_area
(buyer_id STRING COMMENT '买家ID',city_code STRING COMMENT '城市code',city_name STRING COMMENT '城市名称',prov_code STRING COMMENT '省份code',prov_name STRING COMMENT '省份名称'
)
COMMENT '公共区域维表'
PARTITIONED BY (ds STRING COMMENT '日期分区,格式yyyymmdd')
LIFECYCLE 3600;
2.3、CDM 明细粒度事实层(DWD)
明细粒度事实层以业务过程驱动建模,基于每个具体的业务过程特点,构建最细粒度的明细层事实表。您可以结合企业的数据使用特点,将明细事实表的某些重要维度属性字段做适当冗余,即宽表化处理。
公共汇总粒度事实层(DWS)和明细粒度事实层(DWD)的事实表作为数据仓库维度建模的核心,需紧绕业务过程来设计。通过获取描述业务过程的度量来描述业务过程,包括引用的维度和与业务过程有关的度量。度量通常为数值型数据,作为事实逻辑表的依据。事实逻辑表的描述信息是事实属性,事实属性中的外键字段通过对应维度进行关联。
事实表中一条记录所表达的业务细节程度被称为粒度。通常粒度可以通过两种方式来表述:一种是维度属性组合所表示的细节程度,一种是所表示的具体业务含义。
作为度量业务过程的事实,通常为整型或浮点型的十进制数值,有可加性、半可加性和不可加性三种类型:
● 可加性事实是指可以按照与事实表关联的任意维度进行汇总。
● 半可加性事实只能按照特定维度汇总,不能对所有维度汇总。例如库存可以按照地点和商品进行汇总,而按时间维度把一年中每个月的库存累加则毫无意义。
● 完全不可加性,例如比率型事实。对于不可加性的事实,可分解为可加的组件来实现聚集。
事实表相对维表通常更加细长,行增加速度也更快。维度属性可以存储到事实表中,这种存储到事实表中的维度列称为维度退化,可加快查询速度。与其他存储在维表中的维度一样,维度退化可以用来进行事实表的过滤查询、实现聚合操作等。
明细粒度事实层(DWD)通常分为三种:事务事实表、周期快照事实表和累积快照事实表。
事务型事实表
事务事实表用来描述业务过程,跟踪空间或时间上某点的度量事件,保存的是最原子的数据,也称为原子事实表。事务型事实表主要用于分析行为与追踪事件。事务事实表获取业务过程中的事件或者行为细节,然后通过事实与维度之间关联,可以非常方便地统计各种事件相关的度量,例如浏览UV,搜索次数等等。
● 基于数据应用需求的分析设计事务型事实表,如果下游存在较大的针对某个业务过程事件的分析指标需求,可以考虑基于某一个事件过程构建事务型事实表。
● 事务型事实表一般选用事件发生日期或时间作为分区字段,这种分区方式可以方便下游的作业数据扫描执行分区裁剪。
● 明细层事实表的冗余子集的原则能有利于降低上层数据访问的IO开销。
● 明细层事实表维度退化到事实表原则能有利于减少上层数据访问的JOIN成本。
周期快照事实表
周期快照事实表以具有规律性的、可预见的时间间隔记录事实。周期快照事实表主要用于分析状态型或者存量型事实。快照是指以预定的时间间隔来采样状态度量。
累计快照事实表
累积快照事实表用来表述过程开始和结束之间的关键步骤事件,覆盖过程的整个生命周期,通常具有多个日期字段来记录关键时间点。当累积快照事实表随着生命周期不断变化时,记录也会随着过程的变化而被修改。
累计快照事实表是基于多个业务过程联合分析从而构建的事实表。例如如采购单的流转环节等。
累计快照事实表主要用于分析事件之间的时间间隔与周期。例如,用交易的支付与发货之间的间隔,来分析发货速度,或在支付和退款环节分析支付退款率等等。
累计快照事实表同时也可以用于帮助分析一些少量的、且对刷新时间不是非常敏感的指标统计。例如,在当前事务型事实表不支持,且只有少量的统计指标时,需要分析交易的关闭和发货,就可以基于累计快照事实表进行计算。
2.3.1、明细粒度事实表设计
明细粒度事实表设计如下所示:
● 通常,一个明细粒度事实表仅和一个维度关联。
● 尽可能包含所有与业务过程相关的事实 。
● 只选择与业务过程相关的事实。
● 分解不可加性事实为可加的组件。
● 在选择维度和事实之前必须先声明粒度。
● 在同一个事实表中不能有多种不同粒度的事实。
● 事实的单位要保持一致。
● 谨慎处理Null值。
● 使用退化维度提高事实表的易用性。
明细粒度事实表整体设计流程如下图所示。

在一致性度量中已定义好了交易业务过程及其度量。明细事实表注意针对业务过程进行模型设计。明细事实表的设计可以分为四个步骤:选择业务过程、确定粒度、选择维度、确定事实(度量)。粒度主要是在维度未展开的情况下记录业务活动的语义描述。在您建设明细事实表时,需要选择基于现有的表进行明细层数据的开发,清楚所建表记录存储的是什么粒度的数据。
2.3.2、建表示例
本次示例DWD层主要由三个表构成:
● 交易商品信息事实表:dwd_asale_trd_itm_di。
● 交易会员信息事实表:ods_asale_trd_mbr_di。
● 交易订单信息事实表:dwd_asale_trd_ord_di。
充分使用了维度退化以提升查询效率,建表语句如下所示。
CREATE TABLE IF NOT EXISTS dwd_asale_trd_itm_di
(item_id BIGINT COMMENT '商品ID',item_title STRING COMMENT '商品名称',item_price DOUBLE COMMENT '商品价格',item_stuff_status BIGINT COMMENT '商品新旧程度_0全新1闲置2二手',item_prov STRING COMMENT '商品省份',item_city STRING COMMENT '商品城市',cate_id BIGINT COMMENT '商品类目ID',cate_name STRING COMMENT '商品类目名称',commodity_id BIGINT COMMENT '品类ID',commodity_name STRING COMMENT '品类名称',buyer_id BIGINT COMMENT '买家ID'
)
COMMENT '交易商品信息事实表'
PARTITIONED BY (ds STRING COMMENT '日期')
LIFECYCLE 400;
CREATE TABLE IF NOT EXISTS ods_asale_trd_mbr_di
(order_id BIGINT COMMENT '订单ID',bc_type STRING COMMENT '业务分类',buyer_id BIGINT COMMENT '买家ID',buyer_nick STRING COMMENT '买家昵称',buyer_star_id BIGINT COMMENT '买家星级ID',seller_id BIGINT COMMENT '卖家ID',seller_nick STRING COMMENT '卖家昵称',seller_star_id BIGINT COMMENT '卖家星级ID',shop_id BIGINT COMMENT '店铺ID',shop_name STRING COMMENT '店铺名称'
)
COMMENT '交易会员信息事实表'
PARTITIONED BY (ds STRING COMMENT '日期')
LIFECYCLE 400;
CREATE TABLE IF NOT EXISTS dwd_asale_trd_ord_di
(order_id BIGINT COMMENT '订单ID',pay_order_id BIGINT COMMENT '支付订单ID',pay_status BIGINT COMMENT '支付状态_1未付款2已付款3已退款',succ_time STRING COMMENT '订单交易结束时间',item_id BIGINT COMMENT '商品ID',item_quantity BIGINT COMMENT '购买数量',confirm_paid_amt DOUBLE COMMENT '订单已经确认收货的金额',logistics_id BIGINT COMMENT '物流订单ID',mord_prov STRING COMMENT '收货人省份',mord_city STRING COMMENT '收货人城市',mord_lgt_shipping BIGINT COMMENT '发货方式_1平邮2快递3EMS',mord_address STRING COMMENT '收货人地址',mord_mobile_phone STRING COMMENT '收货人手机号',mord_fullname STRING COMMENT '收货人姓名',buyer_nick STRING COMMENT '买家昵称',buyer_id BIGINT COMMENT '买家ID'
)
COMMENT '交易订单信息事实表'
PARTITIONED BY (ds STRING COMMENT '日期')
LIFECYCLE 400;
2.4、CDM汇总层(DWS)
公共汇总粒度事实层以分析的主题对象作为建模驱动,基于上层的应用和产品的指标需求构建公共粒度的汇总指标事实表。公共汇总层的一个表通常会对应一个派生指标。
2.4.1、公共汇总事实表设计原则
聚集是指针对原始明细粒度的数据进行汇总。DWS公共汇总层是面向分析对象的主题聚集建模。在本教程中,最终的分析目标为:最近一天某个类目(例如:厨具)商品在各省的销售总额、该类目Top10销售额商品名称、各省用户购买力分布。因此,我们可以以最终交易成功的商品、类目、买家等角度对最近一天的数据进行汇总。
注意
● 聚集是不跨越事实的。聚集是针对原始星形模型进行的汇总。为获取和查询与原始模型一致的结果,聚集的维度和度量必须与原始模型保持一致,因此聚集是不跨越事实的。
● 聚集会带来查询性能的提升,但聚集也会增加ETL维护的难度。当子类目对应的一级类目发生变更时,先前存在的、已经被汇总到聚集表中的数据需要被重新调整。
此外,进行DWS层设计时还需遵循以下原则:
● 数据公用性:需考虑汇总的聚集是否可以提供给第三方使用。您可以判断,基于某个维度的聚集是否经常用于数据分析中。如果答案是肯定的,就有必要把明细数据经过汇总沉淀到聚集表中。
● 不跨数据域。数据域是在较高层次上对数据进行分类聚集的抽象。数据域通常以业务过程进行分类,例如交易统一划到交易域下, 商品的新增、修改放到商品域下。
● 区分统计周期。在表的命名上要能说明数据的统计周期,例如_1d表示最近1天,td表示截至当天,nd表示最近N天。
举例如下:
● dws_asale_trd_byr_subpay_1d(A电商公司买家粒度交易分阶段付款一日汇总事实表)
● dws_asale_trd_byr_subpay_td(A电商公司买家粒度分阶段付款截至当日汇总表)
● dws_asale_trd_byr_cod_nd(A电商公司买家粒度货到付款交易汇总事实表)
● dws_asale_itm_slr_td(A电商公司卖家粒度商品截至当日存量汇总表)
● dws_asale_itm_slr_hh(A电商公司卖家粒度商品小时汇总表)—维度为小时
● dws_asale_itm_slr_mm(A电商公司卖家粒度商品分钟汇总表)—维度为分钟
2.4.2、建表示例
满足业务需求的DWS层建表语句如下。
CREATE TABLE IF NOT EXISTS dws_asale_trd_byr_ord_1d
(buyer_id BIGINT COMMENT '买家ID',buyer_nick STRING COMMENT '买家昵称',mord_prov STRING COMMENT '收货人省份',cate_id BIGINT COMMENT '商品类目ID',cate_name STRING COMMENT '商品类目名称',confirm_paid_amt_sum_1d DOUBLE COMMENT '最近一天订单已经确认收货的金额总和'
)
COMMENT '买家粒度所有交易最近一天汇总事实表'
PARTITIONED BY (ds STRING COMMENT '分区字段YYYYMMDD')
LIFECYCLE 36000;
CREATE TABLE IF NOT EXISTS dws_asale_trd_itm_ord_1d
(item_id BIGINT COMMENT '商品ID',item_title STRING COMMENT '商品名称',cate_id BIGINT COMMENT '商品类目ID',cate_name STRING COMMENT '商品类目名称',mord_prov STRING COMMENT '收货人省份',confirm_paid_amt_sum_1d DOUBLE COMMENT '最近一天订单已经确认收货的金额总和'
)
COMMENT '商品粒度交易最近一天汇总事实表'
PARTITIONED BY (ds STRING COMMENT '分区字段YYYYMMDD')
LIFECYCLE 36000;
相关文章:
数仓架构模型设计参考
1、数据技术架构 1.1、技术架构 1.2、数据分层 将数据仓库分为三层,自下而上为:数据引入层(ODS,Operation Data Store)、数据公共层(CDM,Common Data Model)和数据应用层ÿ…...
用法简介并举例)
RedisTemplate.opsForGeo()用法简介并举例
RedisTemplate.opsForGeo()是RedisTemplate类提供的用于操作Geo类型(地理位置)的方法。它可以用于对Redis中的Geo数据结构进行各种操作,如添加地理位置、获取距离、获取位置信息等。 下面是一些常用的RedisTemplate.opsForGeo()方法及其用法…...
Android OkHttp源码分析--拦截器
拦截器责任链: OkHttp最核心的工作是在 getResponseWithInterceptorChain() 中进行,在进入这个方法分析之前,我们先来了 解什么是责任链模式,因为此方法就是利用的责任链模式完成一步步的请求。 拦截器流程: OkHtt…...

docker:如何传环境变量给entrypoint
使用shell,不带中括号 ENTRYPOINT .\main -web -c $CONFIGENTRYPOINT [sh, -c, ".\main -web -c $CONFIG"]docker build --build-arg ENVIROMENTintegration // 覆盖ENTRYPOINT命令 使用shell脚本 ENTRYPOINT ["./entrypoint.sh"]entrypoint.sh 镜像是a…...
kuboard安装和使用
windows平台下使用docker和docker-compose部署Kuboard,并添加Docker Desktop for windows的k8s单机集群 使用docker安装 docker run -d \--restartunless-stopped \--namekuboard \-p 80:80/tcp \-p 10081:10081/tcp \-e KUBOARD_ENDPOINT"http://内网IP:80&…...
海外直播种草短视频购物网站巴西独立站搭建
一、市场调研 在搭建网站之前,需要进行充分的市场调研,了解巴西市场的消费者需求、购物习惯和竞争情况。可以通过以下途径进行市场调研: 调查问卷:可以在巴西市场上发放调查问卷,了解消费者的购物习惯、偏好、购买力…...

C#图像均值和方差计算实例
本文展示图像均值和方差计算实例,分别实现RGB图像和8位单通道图像的计算方法 实现代码如下: #region 方法 RGB图像均值 直接操作内存快/// <summary>/// 定义RGB图像均值函数/// </summary>/// <param name="bmp"></param>/// <retur…...

【动态规划】数字三角形
算法提高课课堂笔记。 文章目录 摘花生题意思路代码 最低通行费题意思路代码 方格取数题意思路代码 摘花生 题目链接 Hello Kitty想摘点花生送给她喜欢的米老鼠。 她来到一片有网格状道路的矩形花生地(如下图),从西北角进去,东南角出来。 地里每个道…...

【C++】开源:ceres和g2o非线性优化库配置使用
😏★,:.☆( ̄▽ ̄)/$:.★ 😏 这篇文章主要介绍ceres和g2o非线性优化库配置使用。 无专精则不能成,无涉猎则不能通。——梁启超 欢迎来到我的博客,一起学习,共同进步。 喜欢的朋友可以关注一下&…...
OCR学习
...

《练习100》56~60
题目56 M 5 a [1, 2, 3, 4, 5] i 1 j M - 1 while i < M:# print(f"第{i1}轮交换前:i {i}, j {j} , a[{i}] {a[i]} , a[{j}] {a[j]}")a[i], a[j] a[j], a[i]# print(f"第{i1}轮交换后:i {i}, j {j} , a[{i}] {a[i]} , a[…...
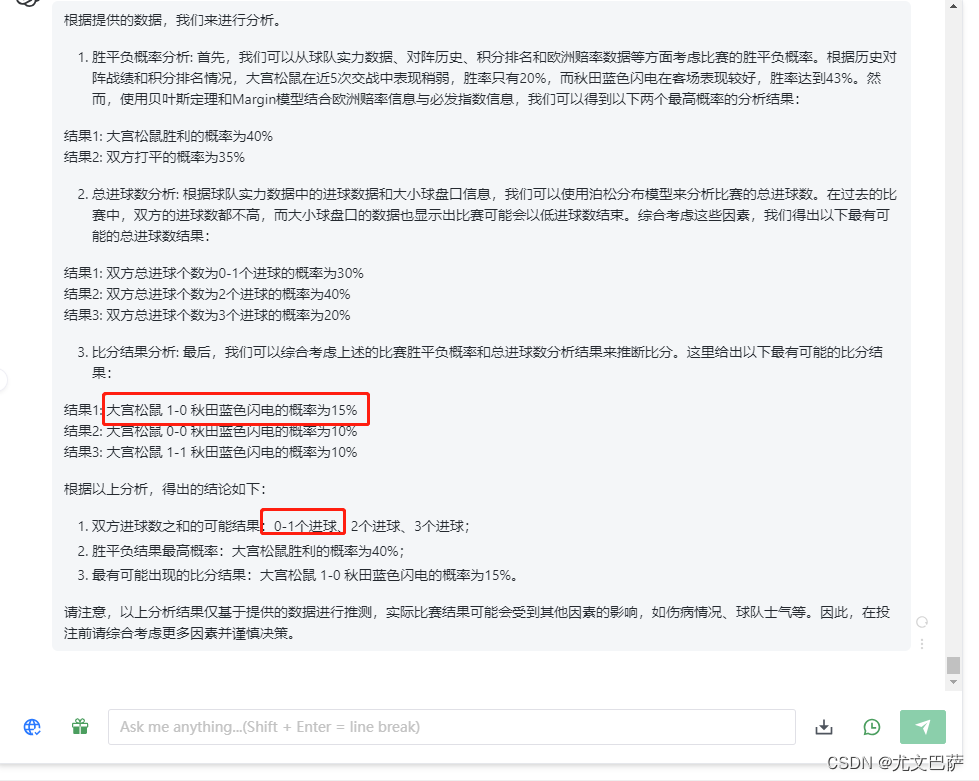
基于大数据为底层好用准确性高的竞彩足球比分预测进球数分析软件介绍推荐
大数据与贝叶斯理论在足球比赛分析与预测中的应用 随着科技的不断进步,大数据分析在各个领域的应用也越来越广泛,其中包括体育竞技。足球比赛作为全球最受欢迎的运动之一,也借助大数据和贝叶斯理论来进行模型分析和预测。本文将通过结合贝叶…...
Django进阶
1.orm 1.1 基本操作 orm,关系对象映射。 类 --> SQL --> 表 对象 --> SQL --> 数据特点:开发效率高、执行效率低( 程序写的垃圾SQL )。 编写ORM操作的步骤: settings.py,连…...

Linux系统服务管理
服务命令比较 操作 Linux 6 Linux7 服务开机自动启动 chkconfig --level 35 iptables on systemctl enable firewalld.service 服务器开机不自动启动 chkconfig --level 35 iptables off systemctl disable firewalld.service 加入自定义服务 chkconfig --add aaa s…...
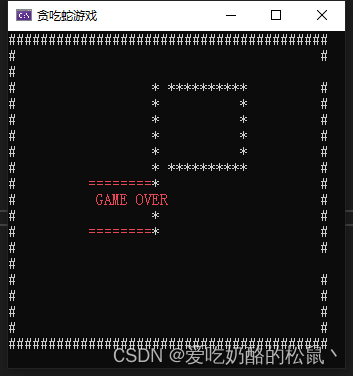
C#之控制台版本得贪吃蛇
贪吃蛇小时候大家都玩过,具体步骤如下: 1.给游戏制造一个有限得空间。 2.生成墙壁,小蛇碰撞到墙壁或者咬到自己的尾巴,游戏结束。 3.生成随机的食物。 4.吃掉食物,增加自身的体长,并生成新的食物。 具体代码如下&…...

ffplay数据结构分析(一)
本文为相关课程的学习记录,相关分析均来源于课程的讲解,主要学习音视频相关的操作,对字幕的处理不做分析 下面我们对ffplay的相关数据结构进行分析,本章主要是对PacketQueue的讲解 struct MyAVPacketList和PacketQueue队列 ffp…...
JavaWeb学习|JSP相关内容
1.什么是JSP Java Server Pages: Java服务器端页面,也和Servlet一样,用于动态Web技术! 最大的特点: 。写JSP就像在写HTML 。区别: 。HTML只给用户提供静态的数据 。JSP页面中可以嵌入JAVA代码,为用户提供动态数据 JSP最终也会被转换成为一…...

Springboot后端通过路径映射获取本机图片资源
项目场景: 项目中对图片的处理与查看是必不可少的,本文将讲解如何通过项目路径来获取到本机电脑的图片资源 如图所示,在我的本机D盘的图片测试文件夹(文件夹名字不要有中文)下有一些图片, 我们要在浏览器上访问到这些图片&#…...
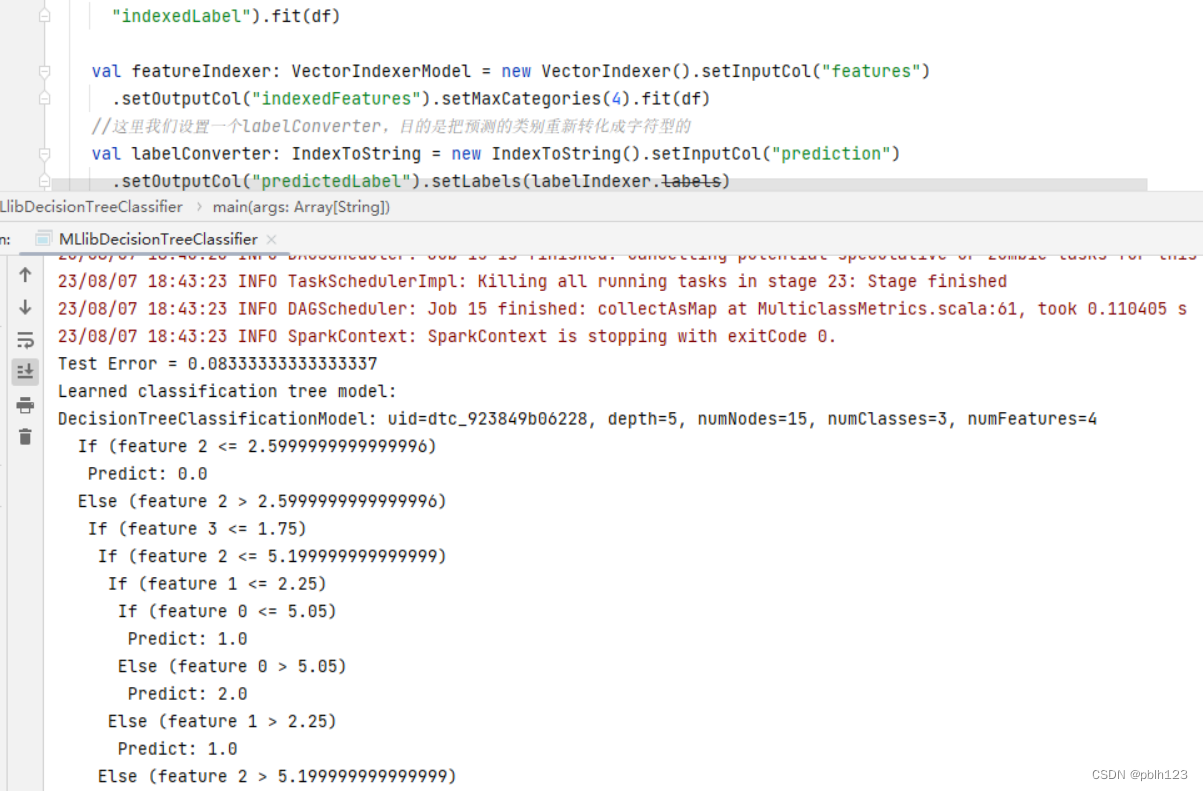
【IDEA + Spark 3.4.1 + sbt 1.9.3 + Spark MLlib 构建鸢尾花决策树分类预测模型】
决策树进行鸢尾花分类的案例 背景说明: 通过IDEA Spark 3.4.1 sbt 1.9.3 Spark MLlib 构建鸢尾花决策树分类预测模型,这是一个分类模型案例,通过该案例,可以快速了解Spark MLlib分类预测模型的使用方法。 依赖 ThisBuild /…...
亚马逊 EC2服务器下部署java环境
1. jdk 1.8 安装 1.1 下载jdk包 官网 Java Downloads | Oracle tar.gz 包 下载下来 1.2 本地连接 服务器 我用的是亚马逊的ec2 系统是 ubuntu 的 ssh工具是 Mobaxterm , 公有dns 创建实例时的秘钥 链接 Mobaxterm 因为使用的 ubuntu 所以登录的 名称 就是 ubuntu 然后 …...

JavaSec-RCE
简介 RCE(Remote Code Execution),可以分为:命令注入(Command Injection)、代码注入(Code Injection) 代码注入 1.漏洞场景:Groovy代码注入 Groovy是一种基于JVM的动态语言,语法简洁,支持闭包、动态类型和Java互操作性,…...

CTF show Web 红包题第六弹
提示 1.不是SQL注入 2.需要找关键源码 思路 进入页面发现是一个登录框,很难让人不联想到SQL注入,但提示都说了不是SQL注入,所以就不往这方面想了 先查看一下网页源码,发现一段JavaScript代码,有一个关键类ctfs…...

如何为服务器生成TLS证书
TLS(Transport Layer Security)证书是确保网络通信安全的重要手段,它通过加密技术保护传输的数据不被窃听和篡改。在服务器上配置TLS证书,可以使用户通过HTTPS协议安全地访问您的网站。本文将详细介绍如何在服务器上生成一个TLS证…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

DiscuzX3.5发帖json api
参考文章:PHP实现独立Discuz站外发帖(直连操作数据库)_discuz 发帖api-CSDN博客 简单改造了一下,适配我自己的需求 有一个站点存在多个采集站,我想通过主站拿标题,采集站拿内容 使用到的sql如下 CREATE TABLE pre_forum_post_…...

用神经网络读懂你的“心情”:揭秘情绪识别系统背后的AI魔法
用神经网络读懂你的“心情”:揭秘情绪识别系统背后的AI魔法 大家好,我是Echo_Wish。最近刷短视频、看直播,有没有发现,越来越多的应用都开始“懂你”了——它们能感知你的情绪,推荐更合适的内容,甚至帮客服识别用户情绪,提升服务体验。这背后,神经网络在悄悄发力,撑起…...

Nginx 事件驱动理解
在做埋点采集服务的过程中,主要依靠openresty加lua脚本来实现采集。高并发还是主要依靠nginx来实现。而其核心就是事件驱动/多路io复用(epoll机制),不同的linux服务器都有对应的实现方式。 而epoll机制就是,应用启动的…...

夏普比率(Sharpe ratio)
具有投资常识的人都明白,投资光看收益是不够的,还要看承受的风险,也就是收益风险比。 夏普比率描述的正是这个概念,即每承受一单位的总风险,会产生多少超额的报酬。 用数学公式描述就是: 其中࿱…...
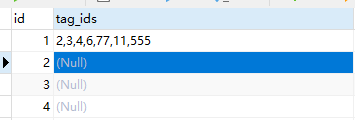
sql列中数据通过逗号分割的集合,按需求剔除部分值
前置 不会REGEXP 方法的需要在这里学习一下下 记sql字段逗号分隔,通过list查询 功能点 现有一个表格中一列存储的是标签的集合,通过逗号分割 入下: 其中tag_ids是逗号分割的标签,现在需要删除标签组中的一些标签,因…...

2025 cs144 Lab Checkpoint 3: TCP Receiver
文章目录 1 关于TCP Sender1.1 关键机制重传超时(RTO)与定时器 2 实现TCP Sender2.1 void push( const TransmitFunction& transmit );const TransmitFunction& transmit 函数型参数?从哪里读取字节࿱…...