【BASH】回顾与知识点梳理(十)
【BASH】回顾与知识点梳理 十
- 十. 文件的格式化与相关处理
- 10.1 格式化打印: printf
- 10.2 awk:好用的数据处理工具
- awk 的逻辑运算字符
- 10.3 文件比对工具
- diff
- cmp
- patch
- 10.4 文件打印准备: pr
该系列目录 --> 【BASH】回顾与知识点梳理(目录)
十. 文件的格式化与相关处理
接下来让我们来将文件进行一些简单的编排吧!底下这些动作可以将你的讯息进行排版的动作, 不需要重新以 vim 去编辑,透过数据流重导向配合底下介绍的 printf 功能,以及 awk 指令, 就可以让你的讯息以你想要的模样来输出了!试看看吧!
10.1 格式化打印: printf
在很多时候,我们可能需要将自己的数据给他格式化输出的! 举例来说,考试卷分数的输出,姓名与科目及分数之间,总是可以稍微作个比较漂亮的版面配置吧? 例如我想要输出底下的样式:
Name Chinese English Math Average
DmTsai 80 60 92 77.33
VBird 75 55 80 70.00
Ken 60 90 70 73.33
上表的数据主要分成五个字段,各个字段之间可使用 tab 或空格键进行分隔。 请将上表的资料转存成为 printf.txt 档名,等一下我们会利用这个文件来进行几个小练习的。 因为每个字段的原始数据长度其实并非是如此固定的 (Chinese 长度就是比 Name 要多), 而我就是想要如此表示出这些数据,此时,就得需要打印格式管理员 printf 的帮忙了! printf 可以帮我们将资料输出的结果格式化,而且而支持一些特殊的字符~底下我们就来看看!
printf '打印格式' 实际内容
选项与参数:
关于格式方面的几个特殊样式:\a 警告声音输出\b 退格键(backspace)\f 清除屏幕 (form feed)\n 输出新的一行\r 亦即 Enter 按键\t 水平的 [tab] 按键\v 垂直的 [tab] 按键\xNN NN 为两位数的数字,可以转换数字成为字符。
关于 C 程序语言内,常见的变数格式%ns 那个 n 是数字, s 代表 string ,亦即多少个字符;%ni 那个 n 是数字, i 代表 integer ,亦即多少整数字数;%N.nf 那个 n 与 N 都是数字, f 代表 floating (浮点),如果有小数字数,假设我共要十个位数,但小数点有两位,即为 %10.2f 啰!
接下来我们来进行几个常见的练习。假设所有的数据都是一般文字 (这也是最常见的状态),因此最常用来分隔数据的符号就是 [Tab] 啦!因为 [Tab] 按键可以将数据作个整齐的排列!那么如何利用printf 呢?参考底下这个范例:
# 范例一:将刚刚上头数据的文件 (printf.txt) 内容仅列出姓名与成绩:(用 [tab] 分隔)
[root@node-135 yurq]# printf '%s\t %s\t %s\t %s\t %s\t \n' $(cat printf.txt)
Name Chinese English Math Average
DmTsai 80 60 92 77.33
VBird 75 55 80 70.00
Ken 60 90 70 73.33
由于 printf 并不是管线命令,因此我们得要透过类似上面的功能,将文件内容先提出来给 printf 作为后续的资料才行。 如上所示,我们将每个数据都以 [tab] 作为分隔,但是由于 Chinese 长度太长,导致 English 中间多了一个 [tab] 来将资料排列整齐!啊~结果就看到资料对齐结果的差异了!
另外,在 printf 后续的那一段格式中,%s 代表一个不固定长度的字符串,而字符串与字符串中间就以 \t 这个 [tab] 分隔符来处理!你要记得的是,由于 \t 与 %s 中间还有空格,因此每个字符串间会有一个 [tab] 与一个空格键的分隔喔!
既然每个字段的长度不固定会造成上述的困扰,那我将每个字段固定就好啦!没错没错!这样想非常好! 所以我们就将数据给他进行固定字段长度的设计吧!
# 范例二:将上述资料关于第二行以后,分别以字符串、整数、小数点来显示:
[root@node-135 yurq]# printf '%10s %5i %5i %5i %8.2f \n' $(cat printf.txt | grep -v Name)DmTsai 80 60 92 77.33VBird 75 55 80 70.00Ken 60 90 70 73.33
上面这一串格式想必您看得很辛苦!没关系!一个一个来解释!上面的格式共分为五个字段, %10s 代表的是一个长度为 10 个字符的字符串字段,%5i 代表的是长度为 5 个字符的数字字段,至于那个%8.2f则代表长度为 8 个字符的具有小数点的字段,其中小数点有两个字符宽度。我们可以使用底下的说明来介绍%8.2f的意义:
字符宽度: 12345678
%8.2f 意义: 00000.00
如上所述,全部的宽度仅有 8 个字符,整数部分占有 5 个字符,小数点本身 (.) 占一位,小数点下的位数则有两位。 这种格式经常使用于数值程序的设计中!这样了解乎?自己试看看如果要将小数点位数变成 1 位又该如何处理?
printf 除了可以格式化处理之外,他还可以依据 ASCII 的数字与图形对应来显示数据喔! 举例来说 16 进位的 45 可以得到什么 ASCII 的显示图 (其实是字符啦)?
范例三:列出 16 进位数值 45 代表的字符为何?
[dmtsai@study ~]$ printf '\x45\n'
E
# 这东西也很好玩~他可以将数值转换成为字符,如果你会写 script 的话,
# 可以自行测试一下,由 20~80 之间的数值代表的字符是啥喔! ^_^
printf 的使用相当的广泛喔!包括等一下后面会提到的 awk 以及在 C 程序语言当中使用的屏幕输出,都是利用 printf 呢!鸟哥这里也只是列出一些可能会用到的格式而已,有兴趣的话,可以自行多作一些测试与练习喔! ^_^
打印格式化这个 printf 指令,乍看之下好像也没有什么很重要的~ 不过,如果你需要自行撰写一些软件,需要将一些数据在屏幕上头漂漂亮亮的输出的话, 那么 printf 可也是一个很棒的工具喔!
10.2 awk:好用的数据处理工具
awk 也是一个非常棒的数据处理工具!相较于 sed 常常作用于一整个行的处理, awk 则比较倾向于一行当中分成数个『字段』来处理。因此,awk 相当的适合处理小型的数据数据处理呢!awk 通常运作的模式是这样的:
[dmtsai@study ~]$ awk '条件类型 1{动作 1} 条件类型 2{动作 2} ...' filename
awk 后面接两个单引号并加上大括号 {} 来设定想要对数据进行的处理动作。 awk 可以处理后续接的文件,也可以读取来自前个指令的 standard output 。 但如前面说的, awk 主要是处理『每一行的字段内的数据』,而默认的『字段的分隔符为 "空格键" 或 "[tab]键" 』!举例来说,我们用 last 可以将登入者的数据取出来,结果如下所示:
[root@node-135 yurq]# last -n 5
root pts/0 192.168.17.1 Mon Aug 7 13:21 still logged in
root pts/1 192.168.17.1 Fri Aug 4 17:38 - 08:56 (2+15:18)
root pts/0 192.168.17.1 Fri Aug 4 17:37 - 08:56 (2+15:19)
root tty1 Fri Aug 4 17:36 still logged in
reboot system boot 3.10.0-1160.92.1 Fri Aug 4 17:36 - 13:44 (2+20:08)wtmp begins Fri Jul 14 17:42:53 2023
若我想要取出账号与登入者的 IP ,且账号与 IP 之间以 [tab] 隔开,则会变成这样:
[root@node-135 yurq]# last -n 5 | awk '{print $1 "\t" $3}'
root 192.168.17.1
root 192.168.17.1
root 192.168.17.1
root Fri
reboot bootwtmp Fri
上表是 awk 最常使用的动作!透过 print 的功能将字段数据列出来!字段的分隔则以空格键或 [tab] 按键来隔开。 因为不论哪一行我都要处理,因此,就不需要有 “条件类型” 的限制!我所想要的是第一栏以及第三栏, 但是,第五行的内容怪怪的~这是因为数据格式的问题啊!所以啰~使用 awk 的时候,请先确认一下你的数据当中,如果是连续性的数据,请不要有空格或 [tab] 在内,否则,就会像这个例子这样,会发生误判喔!
另外,由上面这个例子你也会知道,在 awk 的括号内,每一行的每个字段都是有变量名称的,那就是 $1, $2… 等变量名称。以上面的例子来说,dmtsai 是 $1 ,因为他是第一栏嘛!至于 192.168.1.100 是第三栏, 所以他就是 $3 啦!后面以此类推~呵呵!还有个变数喔!那就是 $0 ,$0 代表『一整列资料』的意思~以上面的例子来说,第一行的 $0 代表的就是『dmtsai … 』那一行啊! 由此可知,刚刚上面五行当中,整个 awk 的处理流程是:
- 读入第一行,并将第一行的资料填入 $0, $1, $2… 等变数当中;
- 依据 “条件类型” 的限制,判断是否需要进行后面的 “动作”;
- 做完所有的动作与条件类型;
- 若还有后续的『行』的数据,则重复上面 1~3 的步骤,直到所有的数据都读完为止。
经过这样的步骤,你会晓得, awk 是『以行为一次处理的单位』, 而『以字段为最小的处理单位』。好了,那么 awk 怎么知道我到底这个数据有几行?有几栏呢?这就需要 awk 的内建变量的帮忙啦~
| 变量名称 | 代表意义 |
|---|---|
| NF | 每一行 ($0) 拥有的字段总数 |
| NR | 目前 awk 所处理的是『第几行』数据 |
| FS | 目前的分隔字符,默认是空格键 |
我们继续以上面 last -n 5 的例子来做说明,如果我想要:
- 列出每一行的账号(就是 $1);
- 列出目前处理的行数(就是 awk 内的 NR 变量)
- 并且说明,该行有多少字段(就是 awk 内的 NF 变量)
要注意喔,awk 后续的所有动作是以单引号『
'』括住的,由于单引号与双引号都必须是成对的, 所以, awk 的格式内容如果想要以 print 打印时,记得非变量的文字部分,包含上一小节 printf 提到的格式中,都需要使用双引号来定义出来喔!因为单引号已经是 awk 的指令固定用法了!
[root@node-135 yurq]# last -n 5| awk '{print $1 "\t lines: " NR "\t columns: " NF}'
root lines: 1 columns: 10
root lines: 2 columns: 10
root lines: 3 columns: 10
root lines: 4 columns: 9
reboot lines: 5 columns: 11lines: 6 columns: 0
wtmp lines: 7 columns: 7
注意喔,
在 awk 内的 NR, NF 等变量要用大写,且不需要有钱字号 $ 啦!
这样可以了解 NR 与 NF 的差别了吧?好了,底下来谈一谈所谓的 “条件类型” 了吧!
awk 的逻辑运算字符
既然有需要用到 “条件” 的类别,自然就需要一些逻辑运算啰~例如底下这些:
| 运算单元 | 代表意义 |
|---|---|
| > | 大于 |
| < | 小于 |
| >= | 大于或等于 |
| <= | 小于或等于 |
| == | 等于 |
| != | 不等于 |
值得注意的是那个『 == 』的符号,因为
- 逻辑运算上面亦即所谓的大于、小于、等于等判断式上面,习惯上是以『 == 』来表示;
- 如果是直接给予一个值,例如变量设定时,就直接使用 = 而已。
好了,我们实际来运用一下逻辑判断吧!举例来说,在 /etc/passwd 当中是以冒号 “:” 来作为字段的分隔, 该文件中第一字段为账号,第三字段则是 UID。那假设我要查阅,第三栏小于 10 以下的数据,并且仅列出账号与第三栏, 那么可以这样做:
[root@node-135 yurq]# awk '{FS=":"} $3<10 {print $1 "\t" $3}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin 1
daemon 2
...
有趣吧!不过,怎么第一行没有正确的显示出来呢?这是因为我们读入第一行的时候,那些变数 $1, $2… 默认还是以空格键为分隔的,所以虽然我们定义了 FS=“:” 了, 但是却仅能在第二行后才开始生效。那么怎么办呢?我们可以预先设定 awk 的变量啊! 利用 BEGIN 这个关键词喔!这样做:
[root@node-135 yurq]# cat /etc/passwd | awk 'BEGIN {FS=":"} $3 < 10 {print $1 "\t " $3}'
root 0
bin 1
...
很有趣吧!而除了 BEGIN 之外,我们还有 END 呢!另外,如果要用 awk 来进行『计算功能』呢?以底下的例子来看, 假设我有一个薪资数据表档名为 pay.txt ,内容是这样的:
[root@node-135 yurq]# cat pay.txt
Name 1st 2nd 3th
VBird 23000 24000 25000
DMTsai 21000 20000 23000
Bird2 43000 42000 41000
如何帮我计算每个人的总额呢?而且我还想要格式化输出喔!我们可以这样考虑:
- 第一行只是说明,所以第一行不要进行加总 (NR==1 时处理);
- 第二行以后就会有加总的情况出现 (NR>=2 以后处理)
[root@node-135 yurq]# cat ./pay.txt | awk 'NR==1{printf "%10s %10s %10s %10s %10s\n",$1,$2,$3,$4,"Total"}
NR>=2{total= $4+$2+$3;printf "%10s %10i %10i %10i %10.2f\n",$1,$2,$3,$4,total}'Name 1st 2nd 3th TotalVBird 23000 24000 25000 72000.00DMTsai 21000 20000 23000 64000.00Bird2 43000 42000 41000 126000.00
上面的例子有几个重要事项应该要先说明的:
- awk 的指令间隔:所有 awk 的动作,亦即在 {} 内的动作,如果有需要多个指令辅助时,可利用分号『
;』间隔, 或者直接以 [Enter] 按键来隔开每个指令,例如上面的范例中,鸟哥共按了三次 [enter] 喔! - 逻辑运算当中,如果是『
等于』的情况,则务必使用两个等号『==』! - 格式化输出时,在 printf 的格式设定当中,务必加上
\n,才能进行分行! - 与 bash shell 的变量不同,在 awk 当中,
变量可以直接使用,不需加上 $符号。
利用 awk 这个玩意儿,就可以帮我们处理很多日常工作了呢!真是好用的很~ 此外, awk 的输出格式当中,常常会以 printf 来辅助,所以, 最好你对 printf 也稍微熟悉一下比较好啦!另外, awk 的动作内 {} 也是支持 if (条件) 的喔! 举例来说,上面的指令可以修订成为这样:
[dmtsai@study ~]$ cat pay.txt | \
> awk '{if(NR==1) printf "%10s %10s %10s %10s %10s\n",$1,$2,$3,$4,"Total"}
> NR>=2{total = $2 + $3 + $4
> printf "%10s %10d %10d %10d %10.2f\n", $1, $2, $3, $4, total}'
awk'{if(condition) {command1}else{command2}}'[input_file]
[root@node-135 yurq]# cat ./pay.txt | awk '{if(NR==1){printf "%10s %10s %10s %10s %10s\n",$1,$2,$3,$4,"Total"}
else{total= $4+$2+$3;printf "%10s %10i %10i %10i %10.2f\n",$1,$2,$3,$4,total}}'Name 1st 2nd 3th TotalVBird 23000 24000 25000 72000.00DMTsai 21000 20000 23000 64000.00Bird2 43000 42000 41000 126000.00
你可以仔细的比对一下上面两个输入有啥不同~从中去了解两种语法吧!我个人是比较倾向于使用第一种语法, 因为会比较有统一性啊! ^_^
除此之外, awk 还可以帮我们进行循环计算喔!真是相当的好用!不过,那属于比较进阶的单独课程了, 我们这里就不再多加介绍。如果你有兴趣的话,请务必参考延伸阅读中的相关连结喔
10.3 文件比对工具
什么时候会用到文件的比对啊?通常是『同一个软件包的不同版本之间,比较配置文件与原始档的差异』。 很多时候所谓的文件比对,通常是用在 ASCII 纯文本档的比对上的!那么比对文件的指令有哪些?最常见的就是 diff 啰! 另外,除了 diff 比对之外,我们还可以藉由 cmp 来比对非纯文本档!同时,也能够藉由 diff 建立的分析檔, 以处理补丁 (patch) 功能的文件呢!就来玩玩先!
diff
diff 就是用在比对两个文件之间的差异的,并且是以行为单位来比对的!一般是用在 ASCII 纯文本档的比对上。 由于是以行为比对的单位,因此 diff 通常是用在同一的文件(或软件)的新旧版本差异上! 举例来说,假如我们要将 /etc/passwd 处理成为一个新的版本,处理方式为: 将第四行删除,第六行则取代成为『no six line』,新的文件放置到 /tmp/test 里面,那么应该怎么做?
[root@node-135 yurq]# cp /etc/passwd passwd.old
[root@node-135 yurq]# cat /etc/passwd | sed -e '4d' -e '6c no six line' > passwd.new
[root@node-135 yurq]# nl passwd.old1 root:x:0:0:root:/root:/bin/bash2 bin:x:1:1:bin:/bin:/sbin/nologin3 daemon:x:2:2:daemon:/sbin:/sbin/nologin4 adm:x:3:4:adm:/var/adm:/sbin/nologin5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin6 sync:x:5:0:sync:/sbin:/bin/sync7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
...
[root@node-135 yurq]# nl passwd.new1 root:x:0:0:root:/root:/bin/bash2 bin:x:1:1:bin:/bin:/sbin/nologin3 daemon:x:2:2:daemon:/sbin:/sbin/nologin4 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin5 "no six line"6 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
...# 注意一下, sed 后面如果要接超过两个以上的动作时,每个动作前面得加 -e 才行!
接下来讨论一下关于 diff 的用法吧
diff [-bBi] from-file to-file
选项与参数:
from-file :一个档名,作为原始比对文件的档名;
to-file :一个档名,作为目的比对文件的档名;
注意,from-file 或 to-file 可以 - 取代,那个 - 代表『Standard input』之意。
-a :diff 只会逐行比较文本文件
-b :忽略一行当中,仅有多个空白的差异(例如 "about me" 与 "about me" 视为相同
-B :忽略空白行的差异。
-i :忽略大小写的不同。
-N/--new-file : 在比较目录时,若文件A仅出现在某个目录中,预设会显示:Only in目录文件A若使用-N参数,则diff会将文件A与一个空白的文件比较。
-r :比较子目录中的文件
-u :以合并的方式来显示文件内容的不同
[root@node-135 yurq]# diff /etc/passwd test
4d3 <==左边第四行被删除 (d) 掉了,基准是右边的第三行
< adm:x:3:4:adm:/var/adm:/sbin/nologin <==这边列出左边(<)文件被删除的那一行内容
6c5 <==左边文件的第六行被取代 (c) 成右边文件的第五行
< sync:x:5:0:sync:/sbin:/bin/sync <==左边(<)文件第六行内容
---
> "no six line" <==右边(>)文件第五行内
# 很聪明吧!用 diff 就把我们刚刚的处理给比对完毕了!
用 diff 比对文件真的是很简单喔!不过,你不要用 diff 去比对两个完全不相干的文件,因为比不出个啥咚咚! 另外, diff 也可以比对整个目录下的差异喔!举例来说,我们想要了解一下不同的开机执行等级 (runlevel) 内容有啥不同?假设你已经知道执行等级 0 与 5 的启动脚本分别放置到/etc/rc0.d 及 /etc/rc5.d , 则我们可以将两个目录比对一下:
[root@node-135 yurq]# diff /etc/rc0.d/ /etc/rc5.d/
Only in /etc/rc0.d/: K90network
Only in /etc/rc5.d/: S10network
[root@node-135 yurq]# ll /etc/rc0.d/
total 0
lrwxrwxrwx. 1 root root 20 Jul 14 17:28 K50netconsole -> ../init.d/netconsole
lrwxrwxrwx. 1 root root 17 Jul 14 17:28 K90network -> ../init.d/network
[root@node-135 yurq]# ll /etc/rc5.d/
total 0
lrwxrwxrwx. 1 root root 20 Jul 14 17:28 K50netconsole -> ../init.d/netconsole
lrwxrwxrwx. 1 root root 17 Jul 14 17:28 S10network -> ../init.d/network
我们的 diff 很聪明吧!还可以比对不同目录下的相同文件名的内容,这样真的很方便喔~
cmp
相对于 diff 的广泛用途, cmp 似乎就用的没有这么多了~ cmp 主要也是在比对两个文件,他主要利用『字节』单位去比对, 因此,当然也可以比对 binary file 啰~(还是要再提醒喔, diff 主要是以『行』为单位比对, cmp 则是以『字节』为单位去比对,这并不相同!)
cmp [-l] file1 file2
选项与参数:
-l :将所有的不同点的字节处都列出来。因为 cmp 预设仅会输出第一个发现的不同点。
#范例一:用 cmp 比较一下 passwd.old 及 passwd.new
[dmtsai@study testpw]$ cmp passwd.old passwd.new
passwd.old passwd.new differ: char 106, line 4
看到了吗?第一个发现的不同点在第四行,而且字节数是在第 106 个字节处!这个 cmp 也可以用来比对 binary 啦! ^_^
patch
patch 这个指令与 diff 可是有密不可分的关系啊!我们前面提到,diff 可以用来分辨两个版本之间的差异, 举例来说,刚刚我们所建立的 passwd.old 及 passwd.new 之间就是两个不同版本的文件。 那么,如果要『升级』呢?就是『将旧的文件升级成为新的文件』时,应该要怎么做呢? 其实也不难啦!就是『先比较先旧版本的差异,并将差异档制作成为补丁档,再由补丁档更新旧文件』即可。 举例来说,我们可以这样做测试:
#范例一:以 /tmp/testpw 内的 passwd.old 与 passwd.new 制作补丁文件
[dmtsai@study testpw]$ diff -Naur passwd.old passwd.new > passwd.patch
[dmtsai@study testpw]$ cat passwd.patch
--- passwd.old 2015-07-14 22:37:43.322535054 +0800 <==新旧文件的信息
+++ passwd.new 2015-07-14 22:38:03.010535054 +0800
@@ -1,9 +1,8 @@ <==新旧文件要修改数据的界定范围,旧档在 1-9 行,新檔在 1-8 行
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
-adm:x:3:4:adm:/var/adm:/sbin/nologin <==左侧文件删除
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
-sync:x:5:0:sync:/sbin:/bin/sync <==左侧文件删除
+no six line <==右侧新档加入
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
一般来说,使用 diff 制作出来的比较文件通常使用扩展名为 .patch 啰。至于内容就如同上面介绍的样子。 基本上就是以行为单位,看看哪边有一样与不一样的,找到一样的地方,然后将不一样的地方取代掉! 以上面表格为例,新文件看到 - 会删除,看到 + 会加入!好了,那么如何将旧的文件更新成为新的内容呢? 就是将 passwd.old 改成与 passwd.new 相同!可以这样做:
# 因为 CentOS 7 预设没有安装 patch 这个软件,因此得要依据之前介绍的方式来安装一下软件!
# 请记得拿出原本光盘并放入光驱当中,这时才能够使用底下的方式来安装软件!
[dmtsai@study ~]$ su -
[root@study ~]# mount /dev/sr0 /mnt
[root@study ~]# rpm -ivh /mnt/Packages/patch-2.*
[root@study ~]# umount /mnt
[root@study ~]# exit
# 透过上述的方式可以安装好所需要的软件,且无须上网。接下来让我们开始操作 patch 啰!
[dmtsai@study ~]$ patch -pN < patch_file <==更新
[dmtsai@study ~]$ patch -R -pN < patch_file <==还原
选项与参数:
-p :后面可以接『取消几层目录』的意思。
-R :代表还原,将新的文件还原成原来旧的版本。# 范例二:将刚刚制作出来的 patch file 用来更新旧版数据
[dmtsai@study testpw]$ patch -p0 < passwd.patch
patching file passwd.old
[dmtsai@study testpw]$ ll passwd*
-rw-rw-r--. 1 dmtsai dmtsai 2035 Jul 14 22:38 passwd.new
-rw-r--r--. 1 dmtsai dmtsai 2035 Jul 14 23:30 passwd.old <==文件一模一样!# 范例三:恢复旧文件的内容
[dmtsai@study testpw]$ patch -R -p0 < passwd.patch
[dmtsai@study testpw]$ ll passwd*
-rw-rw-r--. 1 dmtsai dmtsai 2035 Jul 14 22:38 passwd.new
-rw-r--r--. 1 dmtsai dmtsai 2092 Jul 14 23:31 passwd.old
# 文件就这样恢复成为旧版本啰
为什么这里会使用 -p0 呢?因为我们在比对新旧版的数据时是在同一个目录下, 因此不需要减去目录啦!如果是使用整体目录比对 (diff 旧目录 新目录) 时, 就得要依据建立 patch 文件所在目录来进行目录的删减啰!
[root@node-135 yurq]# mkdir passwd
[root@node-135 home]# mv passwd.patch yurq/passwd/
[root@node-135 home]# cd yurq/passwd
[root@node-135 passwd]# ll
total 4
-rw-r--r-- 1 root root 480 Aug 7 16:01 passwd.patch
[root@node-135 passwd]# patch -p1 <passwd.patch
can't find file to patch at input line 3
Perhaps you used the wrong -p or --strip option?
The text leading up to this was:
--------------------------
|--- passwd.old 2023-08-07 16:00:40.526592964 +0800
|+++ passwd.new 2023-08-07 16:00:46.262620988 +0800
--------------------------
File to patch:
可能是这么用的吧
10.4 文件打印准备: pr
如果你曾经使用过一些图形接口的文字处理软件的话,那么很容易发现,当我们在打印的时候, 可以同时选择与设定每一页打印时的标头吧!也可以设定页码呢!那么,如果我是在 Linux 底下打印纯文本档呢?可不可以具有标题啊?可不可以加入页码啊?呵呵!当然可以啊!使用 pr 就能够达到这个功能了。不过, pr 的参数实在太多了,鸟哥也说不完,一般来说,鸟哥都仅使用最简单的方式来处理而已。举例来说,如果想要打印 /etc/man_db.conf 呢?
[dmtsai@study ~]$ pr /etc/man_db.conf
2014-06-10 05:35 /etc/man_db.conf Page 1
#
#
# This file is used by the man-db package to configure the man and cat paths.
# It is also used to provide a manpath for those without one by examining
# configure script
...
上面特殊字体那一行呢,其实就是使用 pr 处理后所造成的标题啦!标题中会有『文件时间』、『文件档名』及『页码』三大项目。 更多的 pr 使用,请参考 pr 的说明啊! ^_^
该系列目录 --> 【BASH】回顾与知识点梳理(目录)
相关文章:
)
【BASH】回顾与知识点梳理(十)
【BASH】回顾与知识点梳理 十 十. 文件的格式化与相关处理10.1 格式化打印: printf10.2 awk:好用的数据处理工具awk 的逻辑运算字符 10.3 文件比对工具diffcmppatch 10.4 文件打印准备: pr 该系列目录 --> 【BASH】回顾与知识点梳理&#…...
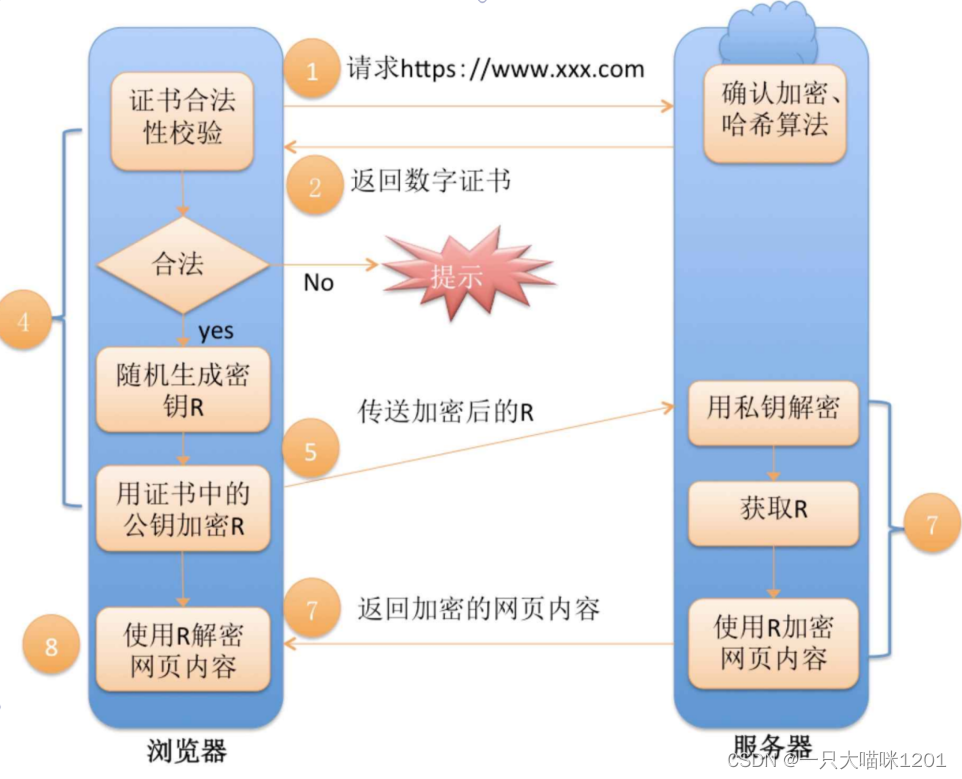
【网络】应用层——HTTPS协议
🐱作者:一只大喵咪1201 🐱专栏:《网络》 🔥格言:你只管努力,剩下的交给时间! HTTPS协议 🍉HTTP的不安全性🍉认识HTTPS协议🍓加密解密ἵ…...
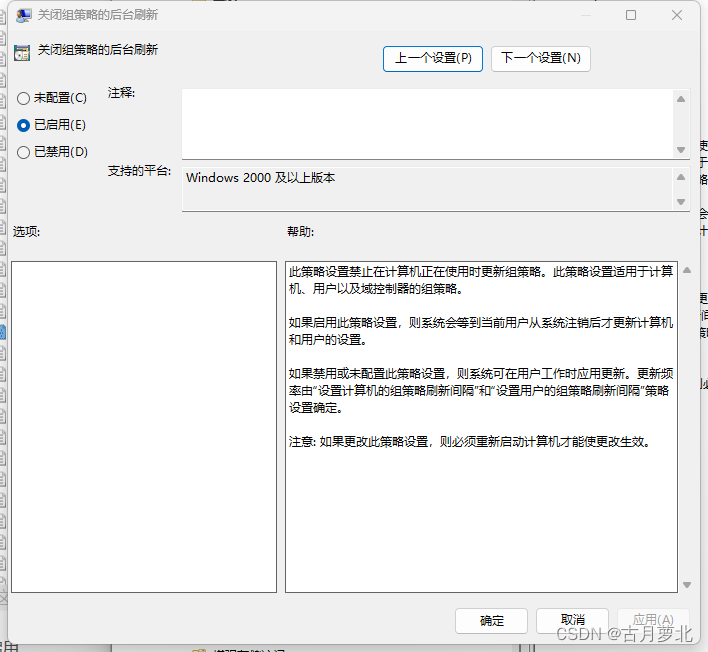
Windows新版文件资源管理器经常在后台弹出的临时解决方案
禁用组策略自动刷新 运行gpedit.msc找到计算机配置->管理模板->系统->组策略找到 “关闭组策略的后台刷新”启用 参考 https://answers.microsoft.com/en-us/windows/forum/all/windows-11-most-recently-opened-explorer-window/26e097bd-1eba-4462-99bd-61597b5…...
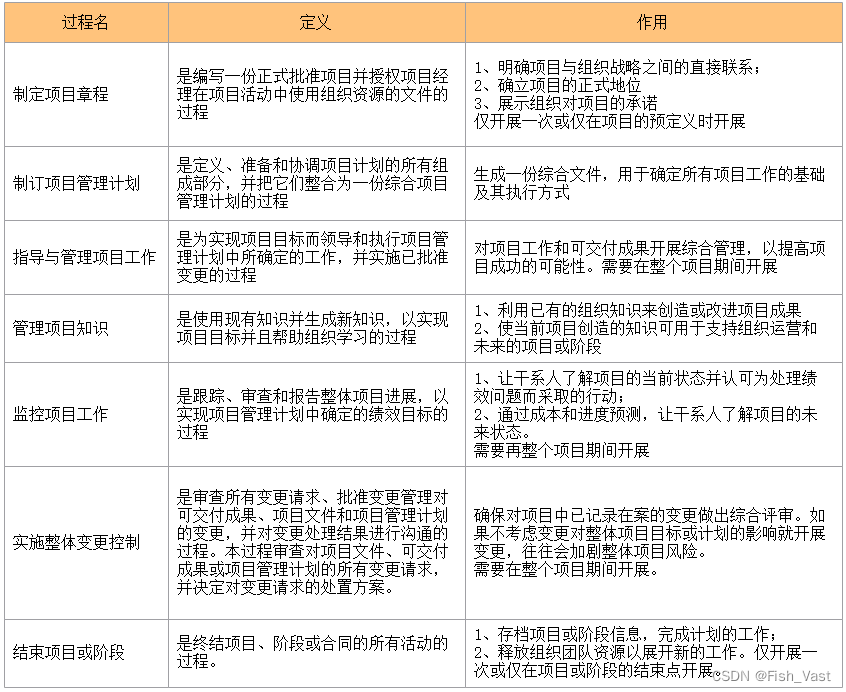
软考高项(八)项目整合管理 ★重点集萃★
👑 个人主页 👑 :😜😜😜Fish_Vast😜😜😜 🐝 个人格言 🐝 :🧐🧐🧐说到做到,言出必行&am…...

基于python+django开发的学生信息管理系统
基于pythondjangovue.js开发的学生信息管理系统,师弟的课程作业 功能介绍 平台采用B/S结构,后端采用主流的Python语言进行开发,前端采用主流的Vue.js进行开发。 功能包括:学生管理、班级管理、用户管理、日志管理、系统信息模块…...
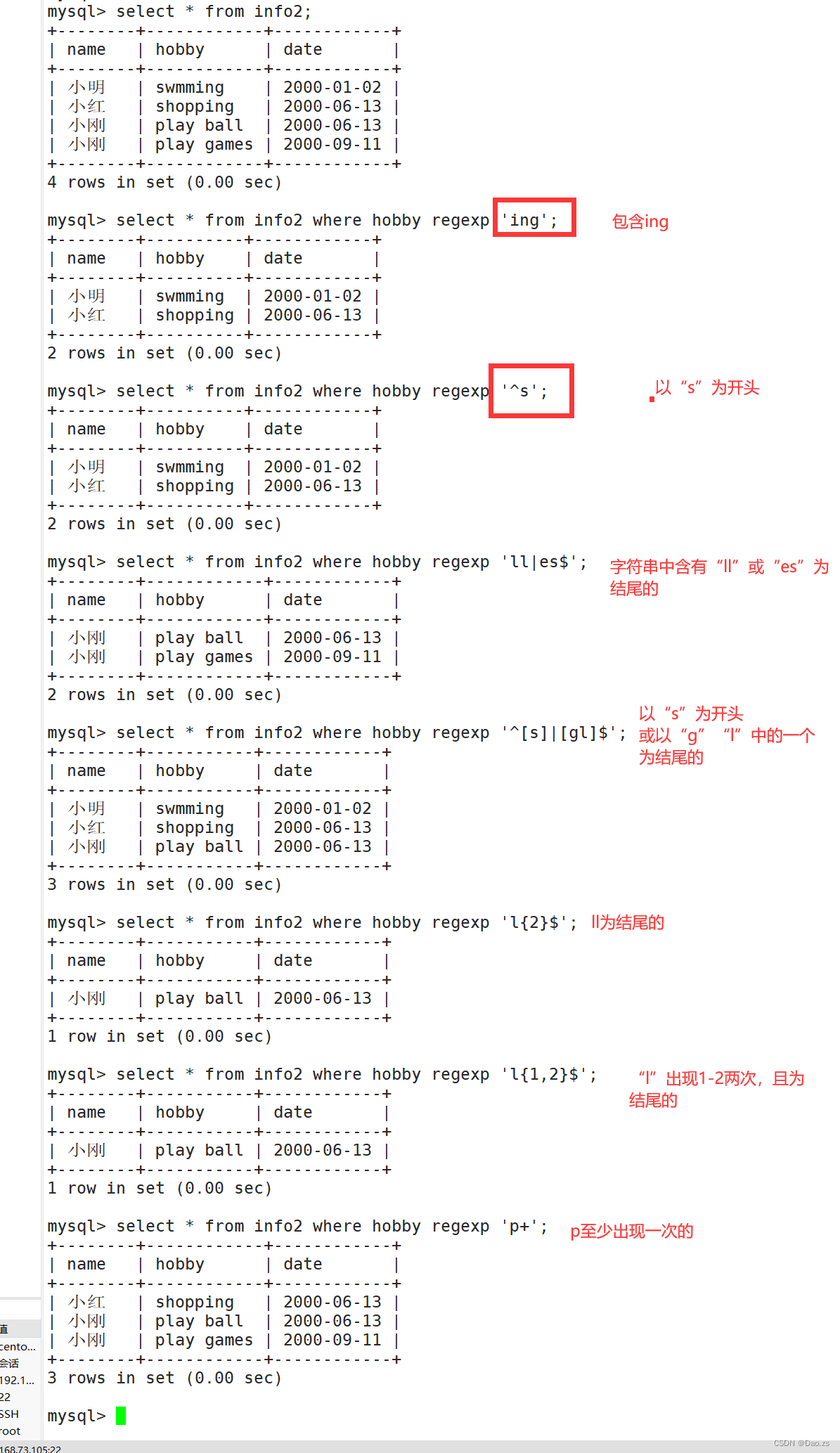
mysql的高级查询语句
目录 一、本文前言 二、高效查询方式 1)指定指字段进行查看 2)对字段进行去重查看 3)where条件查询 4)and 和 or 进行逻辑关系的增加 5)查询取值列表中的数据 6)between的引用 7)like…...
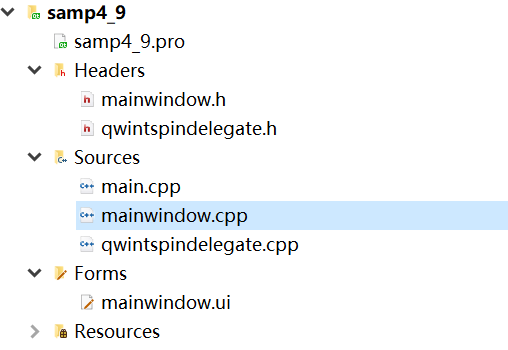
04-8_Qt 5.9 C++开发指南_QTableWidget的使用
文章目录 1. QTableWidget概述2. 源码2.1 可视化UI设计2.2 程序框架2.3 qwintspindelegate.h2.4 qwintspindelegate.cpp2.5 mainwindow.h2.6 mainwindow.cpp 1. QTableWidget概述 QTableWidget是Qt中的表格组件类。在窗体上放置一个QTableWidget 组件后,可以在 PropertyEditor…...

《golang设计模式》第二部分·结构型模式-01-适配器模式(Adapter)
文章目录 1. 概念1.1 角色1.2 应用场景1.2 类图 2. 代码示例2.1 设计2.2 代码2.3 示例类图 1. 概念 定义一个适配器,帮助原本不能实现接口的类“实现”该接口 1.1 角色 目标(Target):客户端调用的目标接口 被适配者(…...

机器学习概述及其主要算法
目录 1、什么是机器学习 2、数据集 2.1、结构 3、算法分类 4、算法简介 4.1、K-近邻算法 4.2、贝叶斯分类 4.3、决策树和随机森林 4.4、逻辑回归 4.5、神经网络 4.6、线性回归 4.7、岭回归 4.8、K-means 5、机器学习开发流程 6、学习框架 1、什么是机器学习 机器…...

识jvm堆栈中一个数据类型是否为为引用类型,目前虚拟机实现中是如何做的?
调用栈里的引用类型数据是GC的根集合(root set)的重要组成部分;找出栈上的引用是GC的根枚举(root enumeration)中不可或缺的一环。 要看JVM选择用什么方式。通常这个选择会影响到GC的实现。 如果JVM选择不记录任何这种…...

Bug合集
这里会收藏后面所遇到的bug并附上具有参考的意义的博客,会持续更新 Java 1、SpringBoot升级2.6.0以上后,Swagger出现版本不兼容报错。 Failed to start bean ‘documentationPluginsBootstrapper‘; nested exception is java.lang.NullPo…...
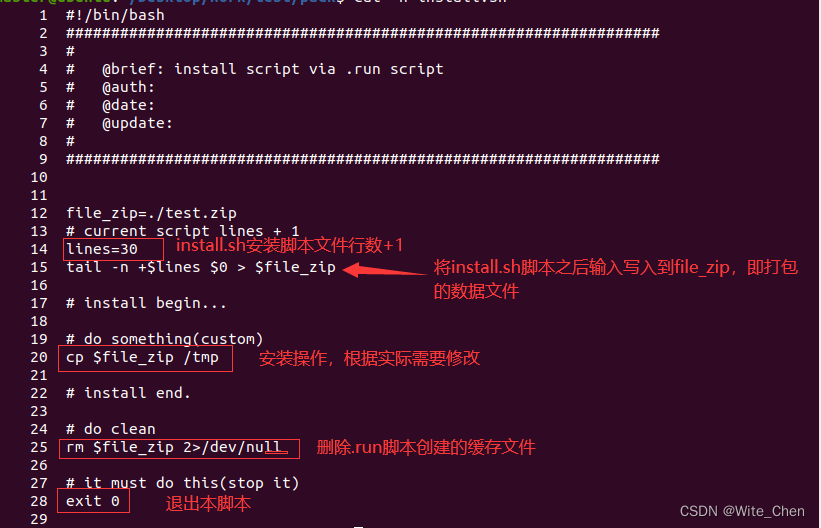
linux下.run安装脚本制作
1、安装文件(install.sh) PS: .run安装包内部执行脚本文件 2、资源文件(test.zip) PS: 待安装程序源文件 3、制作.run脚本(install.run) cat install.sh test.zip > install.run chmod ax install.run...
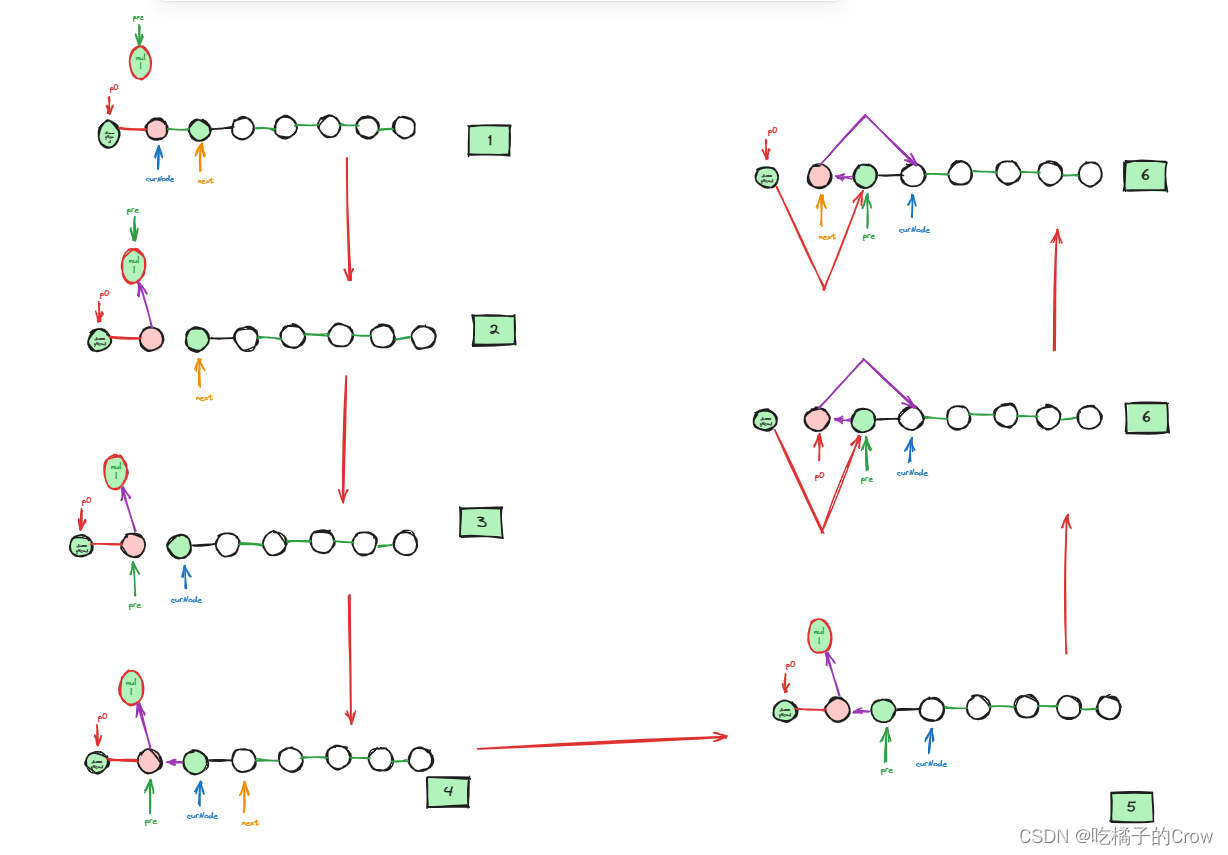
面试热题(翻转k个链表)
给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。 k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。 你不能只是单纯的改变节点内部的值&a…...
每天10个小知识点)
前端面试的性能优化部分(4)每天10个小知识点
目录 系列文章目录前端面试的性能优化部分(1)每天10个小知识点前端面试的性能优化部分(2)每天10个小知识点前端面试的性能优化部分(3)每天10个小知识点前端面试的性能优化部分(4)每天…...

el-checkbox修改选中和未选中的值
由于在checkbox选中的时候,默认的是为true和false。 后端定义的绑定字段不是为布尔值,而是为0,1 解决办法 <el-checkbox v-model"model.status" :true-label"1" :false-label"0"> </el-checkbox>…...

完整版:TCP、UDP报文格式
目录 TCP报文格式 报文格式 报文示例 UDP报文格式 报文格式 报文示例 TCP报文格式 报文格式 图1 TCP首部格式 字段长度含义Source Port16比特源端口,标识哪个应用程序发送。Destination Port16比特目的端口,标识哪个应用程序接收。Sequence Numb…...

如何远程连接云服务器oracle数据库
要远程连接云服务器上的Oracle数据库,可以按照以下步骤进行操作: 1. 确保你的云服务器已经安装了Oracle数据库,并且启动了数据库服务。 2. 登录到云服务器的操作系统。可以使用SSH工具(如PuTTY)连接到云服务器,使用管理员权限登录…...

“深入剖析JVM内部机制:探秘Java虚拟机的运行原理“
标题:深入剖析JVM内部机制:探秘Java虚拟机的运行原理 摘要:本文将深入剖析Java虚拟机(JVM)的内部机制,探秘其运行原理。我们将从JVM的结构、内存管理、垃圾回收、即时编译等方面展开讨论,并通过…...
尚品汇总结十:秒杀模块(面试专用)
1、需求分析 所谓“秒杀”,就是商家发布一些超低价格的商品,所有买家在同一时间网上抢购的一种销售方式。通俗一点讲就是商家为促销等目的组织的网上限时抢购活动。由于商品价格低廉,往往一上架就被抢购一空,有时只用一秒钟。 秒…...

什么是设计模式?
目录 概述: 什么是模式!! 为什么学习模式!! 模式和框架的比较: 设计模式研究的历史 关于pattern的历史 Gang of Four(GoF) 关于”Design”Pattern” 重提:指导模式设计的三个概念 1.重用(reuse)…...
结构体的进阶应用)
基于算法竞赛的c++编程(28)结构体的进阶应用
结构体的嵌套与复杂数据组织 在C中,结构体可以嵌套使用,形成更复杂的数据结构。例如,可以通过嵌套结构体描述多层级数据关系: struct Address {string city;string street;int zipCode; };struct Employee {string name;int id;…...

k8s从入门到放弃之Ingress七层负载
k8s从入门到放弃之Ingress七层负载 在Kubernetes(简称K8s)中,Ingress是一个API对象,它允许你定义如何从集群外部访问集群内部的服务。Ingress可以提供负载均衡、SSL终结和基于名称的虚拟主机等功能。通过Ingress,你可…...

UE5 学习系列(三)创建和移动物体
这篇博客是该系列的第三篇,是在之前两篇博客的基础上展开,主要介绍如何在操作界面中创建和拖动物体,这篇博客跟随的视频链接如下: B 站视频:s03-创建和移动物体 如果你不打算开之前的博客并且对UE5 比较熟的话按照以…...

【第二十一章 SDIO接口(SDIO)】
第二十一章 SDIO接口 目录 第二十一章 SDIO接口(SDIO) 1 SDIO 主要功能 2 SDIO 总线拓扑 3 SDIO 功能描述 3.1 SDIO 适配器 3.2 SDIOAHB 接口 4 卡功能描述 4.1 卡识别模式 4.2 卡复位 4.3 操作电压范围确认 4.4 卡识别过程 4.5 写数据块 4.6 读数据块 4.7 数据流…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

【碎碎念】宝可梦 Mesh GO : 基于MESH网络的口袋妖怪 宝可梦GO游戏自组网系统
目录 游戏说明《宝可梦 Mesh GO》 —— 局域宝可梦探索Pokmon GO 类游戏核心理念应用场景Mesh 特性 宝可梦玩法融合设计游戏构想要素1. 地图探索(基于物理空间 广播范围)2. 野生宝可梦生成与广播3. 对战系统4. 道具与通信5. 延伸玩法 安全性设计 技术选…...

Mac下Android Studio扫描根目录卡死问题记录
环境信息 操作系统: macOS 15.5 (Apple M2芯片)Android Studio版本: Meerkat Feature Drop | 2024.3.2 Patch 1 (Build #AI-243.26053.27.2432.13536105, 2025年5月22日构建) 问题现象 在项目开发过程中,提示一个依赖外部头文件的cpp源文件需要同步,点…...

JS手写代码篇----使用Promise封装AJAX请求
15、使用Promise封装AJAX请求 promise就有reject和resolve了,就不必写成功和失败的回调函数了 const BASEURL ./手写ajax/test.jsonfunction promiseAjax() {return new Promise((resolve, reject) > {const xhr new XMLHttpRequest();xhr.open("get&quo…...

什么是VR全景技术
VR全景技术,全称为虚拟现实全景技术,是通过计算机图像模拟生成三维空间中的虚拟世界,使用户能够在该虚拟世界中进行全方位、无死角的观察和交互的技术。VR全景技术模拟人在真实空间中的视觉体验,结合图文、3D、音视频等多媒体元素…...

前端调试HTTP状态码
1xx(信息类状态码) 这类状态码表示临时响应,需要客户端继续处理请求。 100 Continue 服务器已收到请求的初始部分,客户端应继续发送剩余部分。 2xx(成功类状态码) 表示请求已成功被服务器接收、理解并处…...