mysql的高级查询语句
目录
一、本文前言
二、高效查询方式
1)指定指字段进行查看
2)对字段进行去重查看
3)where条件查询
4)and 和 or 进行逻辑关系的增加
5)查询取值列表中的数据
6)between的引用
7)like的查询方式
8)排序方式进行查询
三、运用函数查询
1)数据库中常用数学的函数
2)聚合函数
3)字符串函数
(1)去除字符 trim
(2) 截取 substr
(3)字段拼接
(4)返回字符长度 length
(5)替换 replace
四、高级查询语句
1)GROUP BY(用于分组和汇总)
(1)汇总统计
(2)汇总并对其指定字段(数字类)进行累加
(3)汇总并对其指定字段(数字类)进行累加,再进行降序
2)HAVING 过滤
3)别名设置查询
语法格式:
(1)字段别名
编辑
(2)表别名
4)表的自我连接
(1)无重复数值排名
(2)有重复数值排名
5)子查询语句
子查询运用升级
6)EXISTS
格式:
五、表连接查询
(1) 内连接 inner join
(2)左连接 left join
(3)右连接 right join
六、view 视图的运用
1)视图的创建
2) 视图提供的后续便捷操作
3)经典定义问题:视图能否插入数据
七、UNION 联级
1)UNION(合并后去重)
2)UNION ALL(合并后不去重)
八、多种方式求表与表的交集值
1)联级视图求交集值
2)内连接求交集值
(1)不去重求交集
(2)去重求交集
3)使用左连接求交集值
4)使用右连接求交集
5)使用子查询的方式求交集值
6)取非交集值
九、case 条件选择查询语句
十、正则表达式的运用
1)sql正则表达式的常见种类
2)sql正则运用
探究:空值(NULL)和无值(' ')的区别
一、本文前言
数据库是用来存储数据,更新,查询数据的工具,而查询数据是一个数据库最为核心的功能,数据库是用来承载信息,而信息是用来分析和查看的。所以掌握更为精细化的查询方式是很有必要的。本文将围绕数据的高级查询语句展开
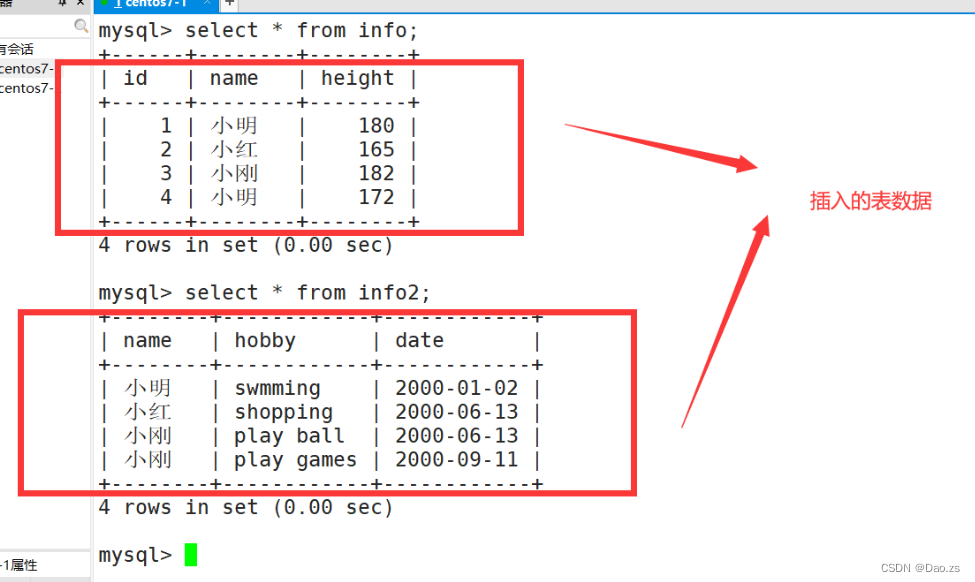
为了下面查询语句的运用,事先准备了两张表,后续也会根据查询功能的运用会对表进行一些变动,或则创建新表:
CREATE TABLE info (id int(4) ,name char(4),height double
) ;CREATE TABLE info2 (name char(4) hobby char(10) date char(10)
) ;
二、高效查询方式
1)指定指字段进行查看
select 字段1,字段2 from 表名;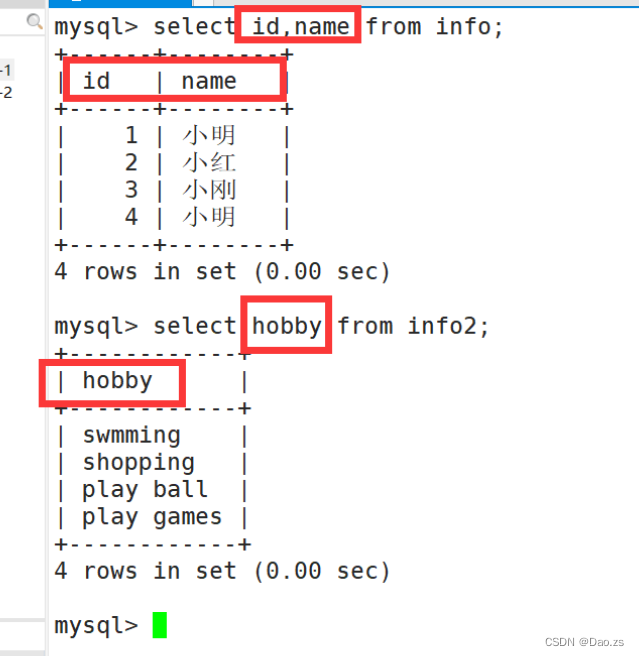
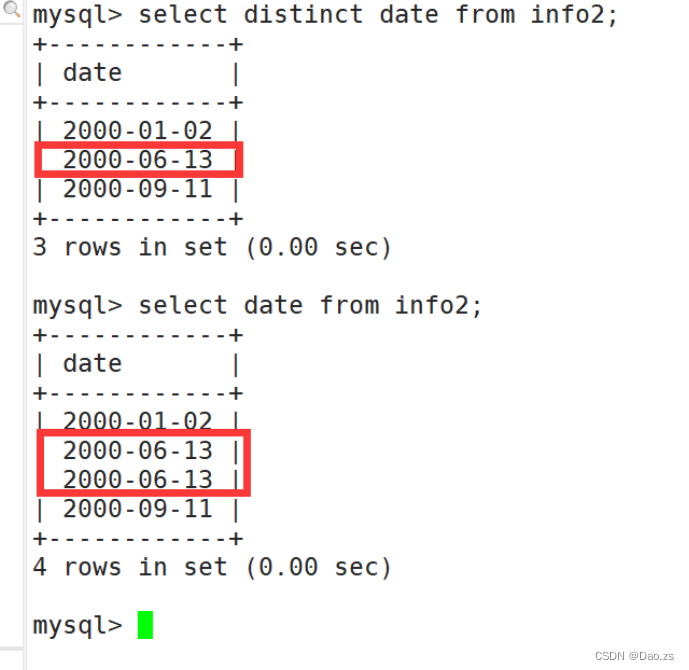
2)对字段进行去重查看
SELECT DISTINCT "字段" FROM "表名";
3)where条件查询
SELECT "字段" FROM 表名" WHERE "条件";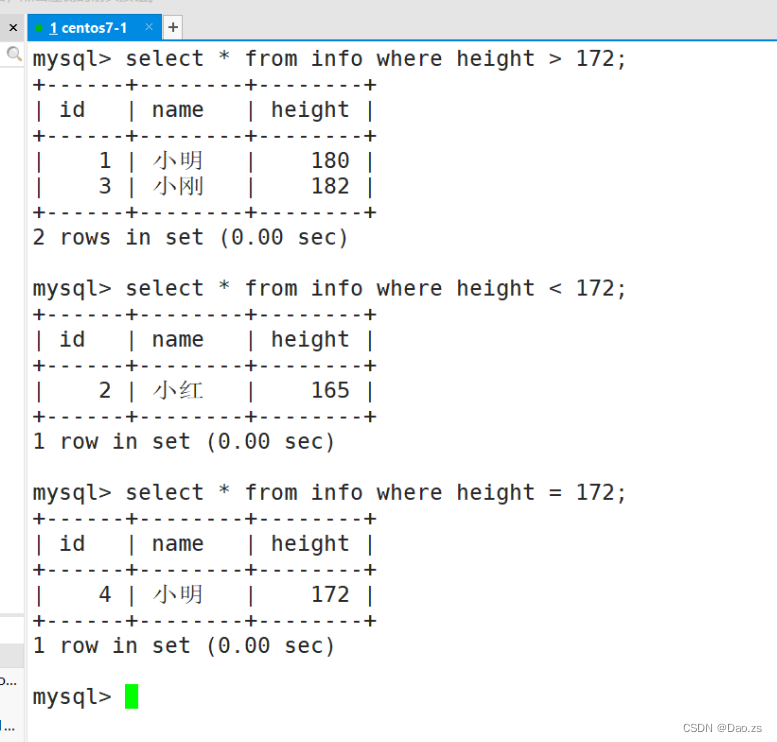
4)and 和 or 进行逻辑关系的增加
SELECT "字段" FROM "表名" WHERE "条件1" AND "条件2";
SELECT "字段" FROM "表名" WHERE "条件1" OR "条件2";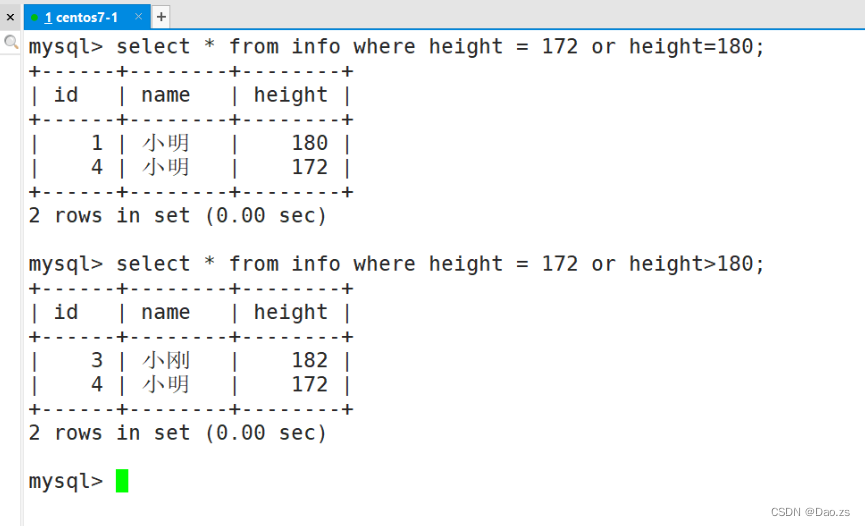
5)查询取值列表中的数据
SELECT "字段" FROM "表名" WHERE "字段" IN ('值1', '值2', ...); #in,遍历一个取值列表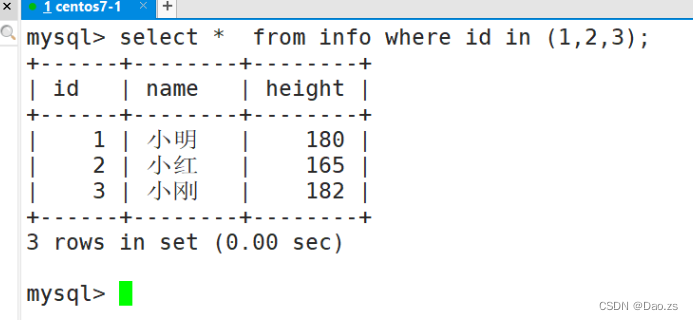
6)between的引用
SELECT "字段" FROM "表名" WHERE "字段" BETWEEN '值1' AND '值2';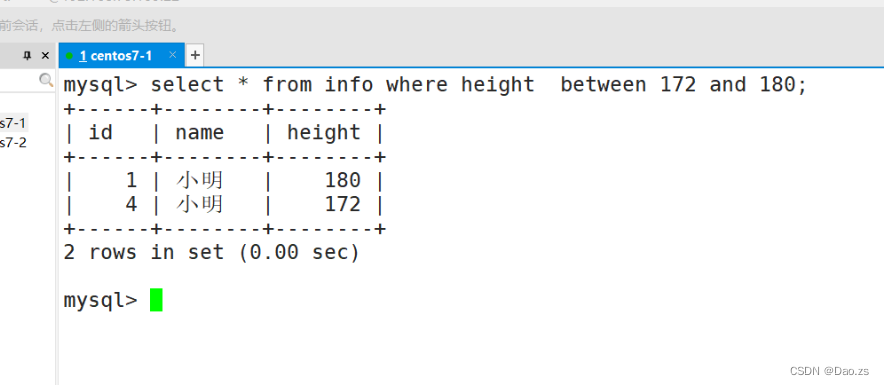
7)like的查询方式
like查询通常会与通配符配合使用
%:百分号表示零个、一一个或多个字符
_:划线表示单个字符
select * from info2 where hobby like '%ing';
select * from info2 where name like '小_';
select * from info2 where name like '_刚';select * from info2 where hobby like '%ay%';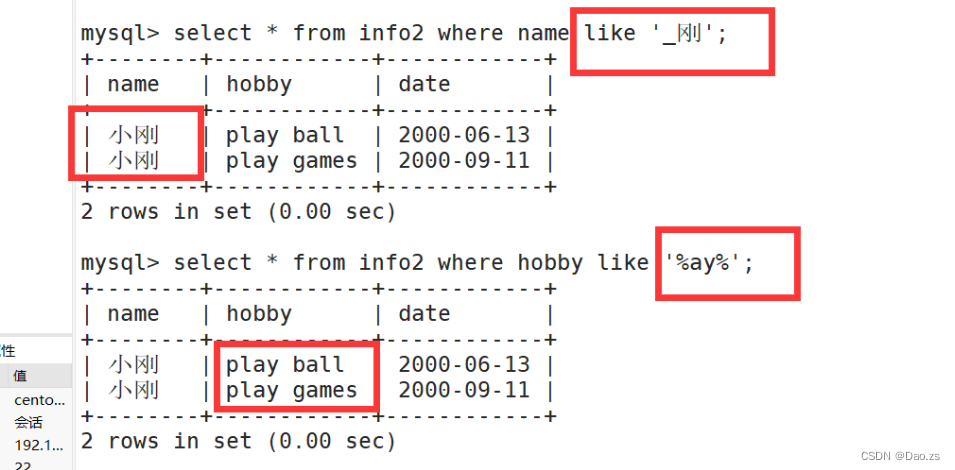
8)排序方式进行查询
order by,按关键字排序
注意:
- 一般对数值字段进行排序
- 如果对字符类型的字段进行排序,则会按首字母排序
SELECT "字段" FROM "表名" [WHERE "条件"] ORDER BY "字段" [ASC|DESC] ;#ASC是按照升序进行排序的,是默认的排序方式。#DESC是按降序方式进行排序。 select * from info order by height;select * from info order by height asc;select * from info order by height desc;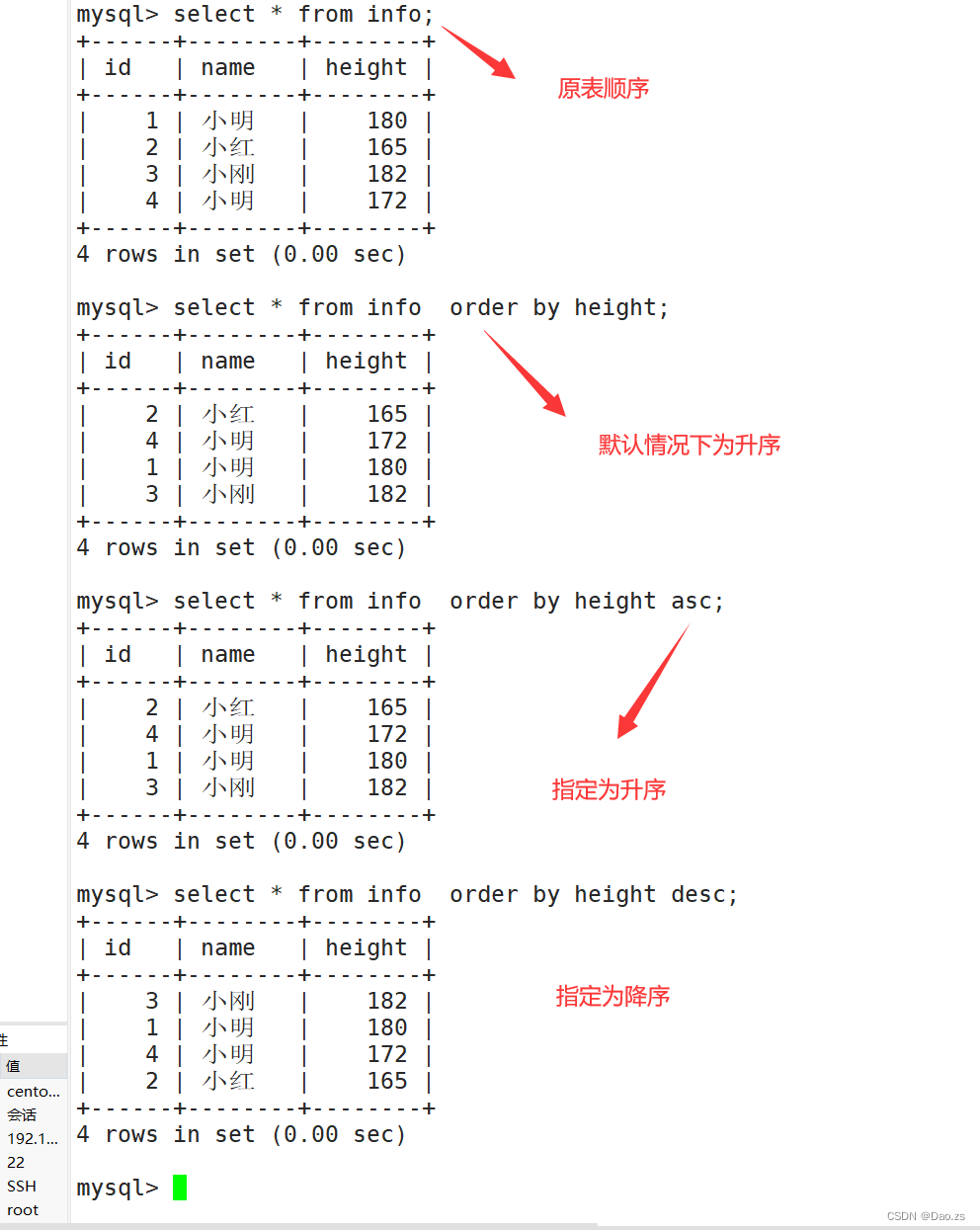
三、运用函数查询
1)数据库中常用数学的函数
| 数学函数 | 作用 |
| abs(x) | 返回x的绝对值 |
| rand() | 返回0到1的随机数 |
| mod(x, y) | 返回x除以y以后的余数 |
| power(x, y) | 返回x的y次方 |
| round(x) | 返回离x最近的整数 |
| round(x, y) | 保留x的y位小数四舍五入后的值 |
| sqrt(x) | 返回x的平方根 |
| truncate(x, y) | 返回数字x截断为y位小数的值 #不四舍五入 |
| ceil(x) | 返回大于或等于x的最小整数 |
| floor(x) | 返回小于或等于x的最大整数 |
| greatest(x1,x2,...) | 返回集合中最大的值 |
| least(x1,x2,...) | 返回集合中最小的值 |
SELECT abs(-1),rand(), mod(5,3) ,power(2,3);

SELECT truncate(1.89,2);
SELECT truncate(1.89,1);
select ceil(1.76);
select floor(1.76);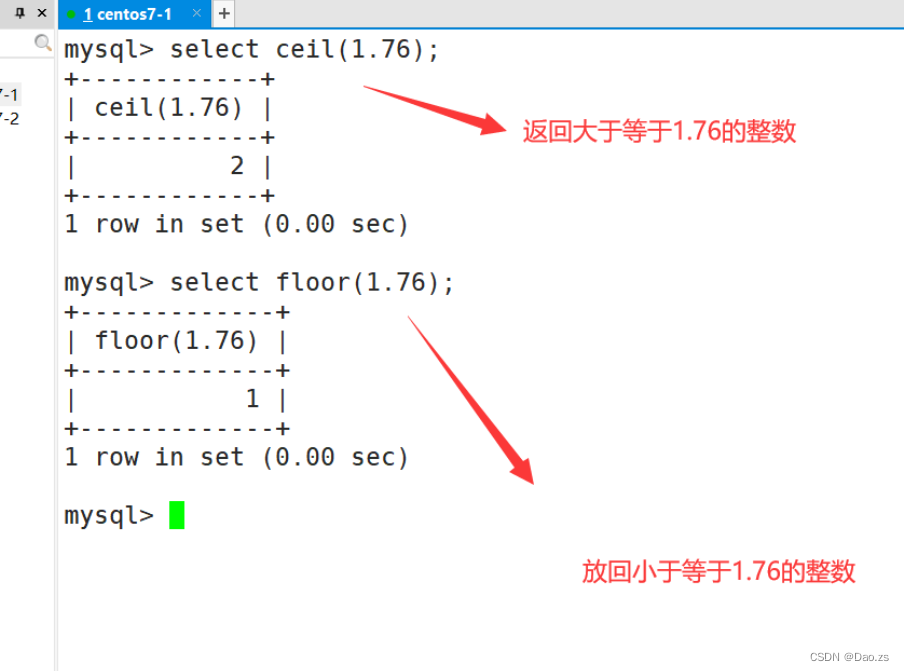
select greatest(1,2,3,55,12,55,61);
select least(1,2,3,55,12,55,61);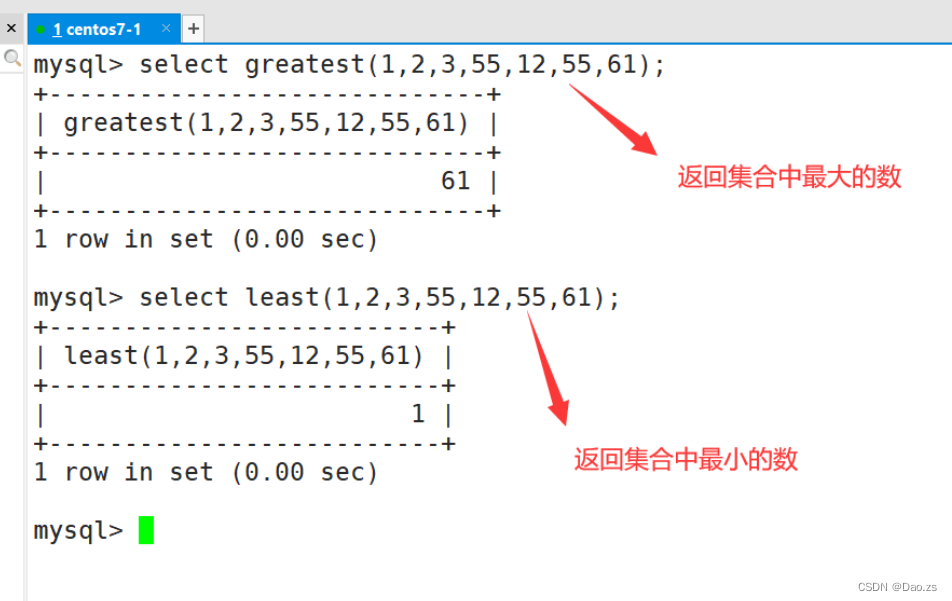
2)聚合函数
| 聚合函数 | 含义 |
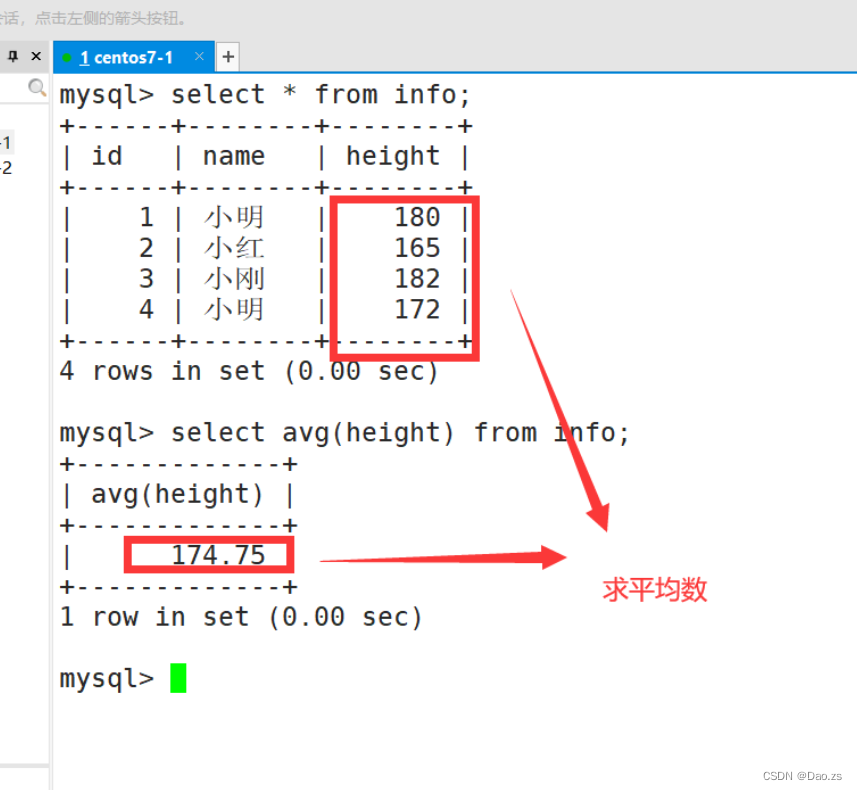
| avg() | 返回指定列的平均值 |
| count() | 返回指定列中非 NULL 值的个数 |
| min() | 返回指定列的最小值 |
| max() | 返回指定列的最大值 |
| sum(字段) | 返回指定列的所有值之和 |
select avg(height) from info;
select count(name) from info;
select count(*) from info;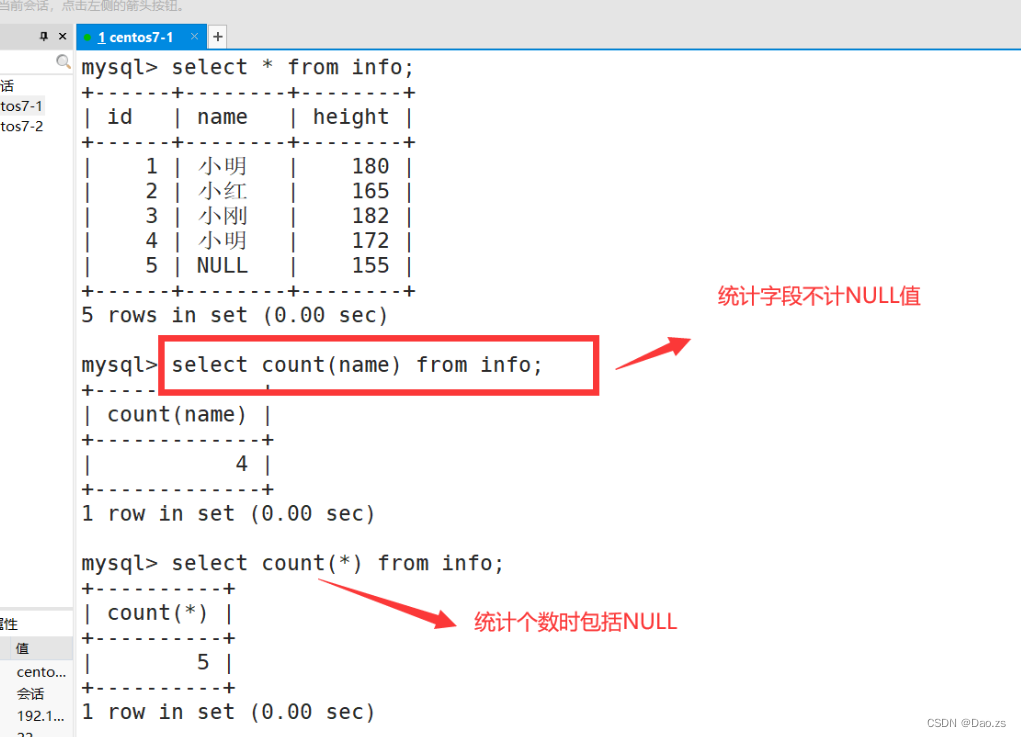
select max(height) from info;
select min(height) from info;
select sum(height) from info;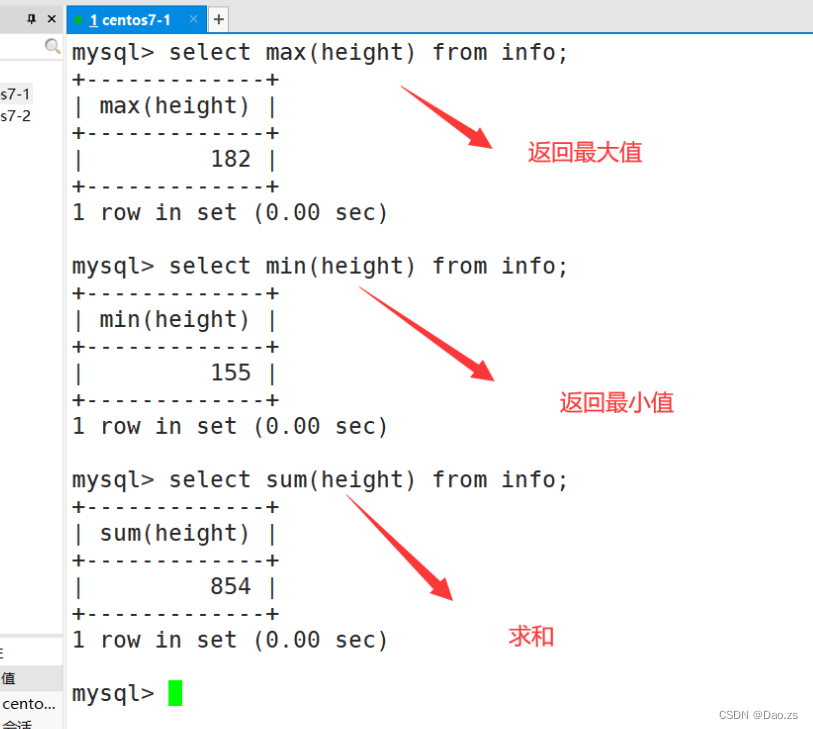
3)字符串函数
| 字符串函数 | 作用 |
| trim() | 返回去除指定格式的值 |
| concat(x,y) | 将提供的参数 x 和 y 拼接成一个字符串 |
| substr(x,y) | 获取从字符串 x 中的第 y 个位置开始的字符串,跟substring()函数作用相同 |
| substr(x,y,z) | 获取从字符串 x 中的第 y 个位置开始长度为 z 的字符串 |
| length(x) | 返回字符串 x 的长度 |
| replace(x,y,z) | 将字符串 z 替代字符串 x 中的字符串 y |
| upper(x) | 将字符串 x 的所有字母变成大写字母 |
| lower(x) | 将字符串 x 的所有字母变成小写字母 |
| left(x,y) | 返回字符串 x 的前 y 个字符 |
| right(x,y) | 返回字符串 x 的后 y 个字符 |
| repeat(x,y) | 将字符串 x 重复 y 次 |
| space(x) | 返回 x 个空格 |
| strcmp(x,y) | 比较 x 和 y,返回的值可以为-1,0,1 |
| reverse(x) | 将字符串 x 反转 |
(1)去除字符 trim
SELECT TRIM ([ [位置] [要移除的字符串] FROM ] 字符串);#[位置]:值可以为 LEADING (起头), TRAILING (结尾), BOTH (起头及结尾)。 #[要移除的字符串]:从字串的起头、结尾,或起头及结尾移除的字符串。缺省时为空格。select trim(leading 's' from 'swmming' );
select trim(trailing 'g' from 'swmming' );
select trim(both 'l' from 'lol' );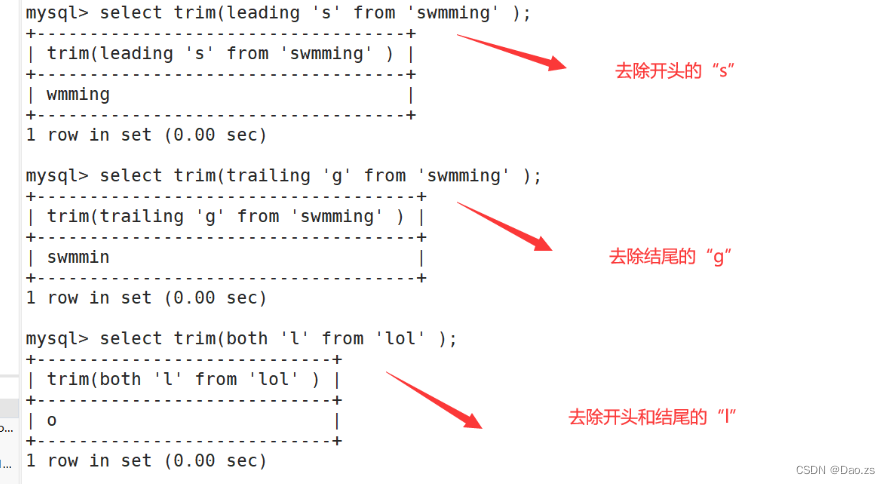
(2) 截取 substr
substr(x,y) #截取x字符串 从第y个开始,截取到末尾substr(x,y,z) #截取x字符串 从第y个开始截取 ,截取长度为zselect substr(hobby,2) from info2;
select substr(hobby,3) from info2;
select substr(hobby,2,5) from info2;select substr(hobby,4,6) from info2;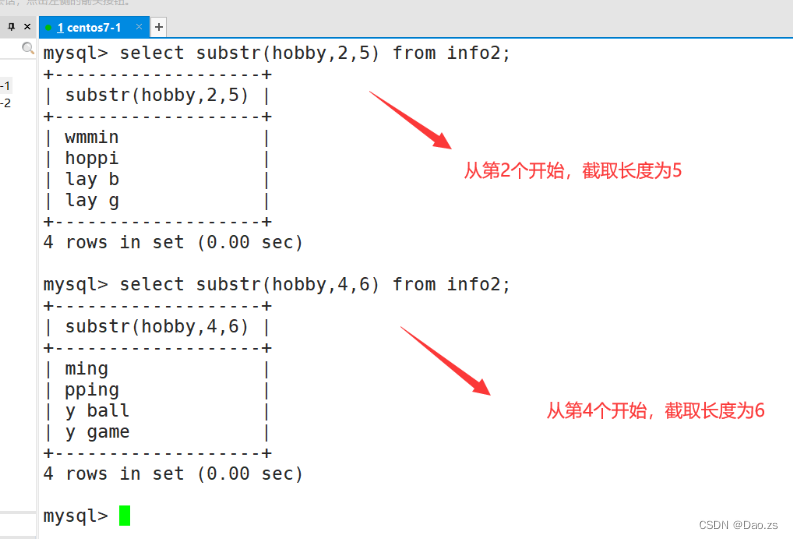
(3)字段拼接
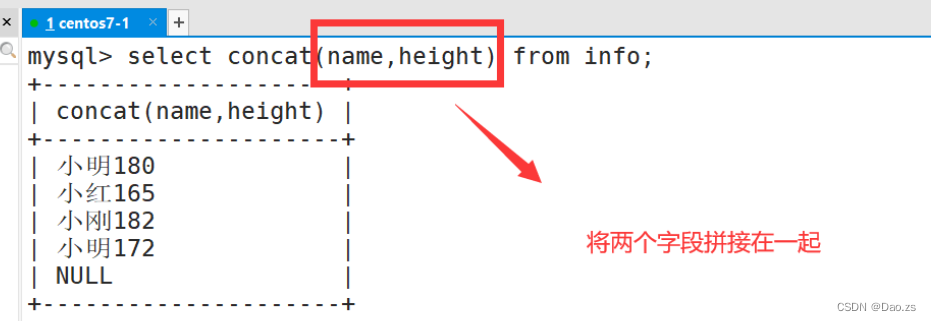
① concat(x,y)
select concat(name,height) from info;
② 使用 || 符号
#将info表中,name字段值和height字段值拼接在一起。select name || height from info;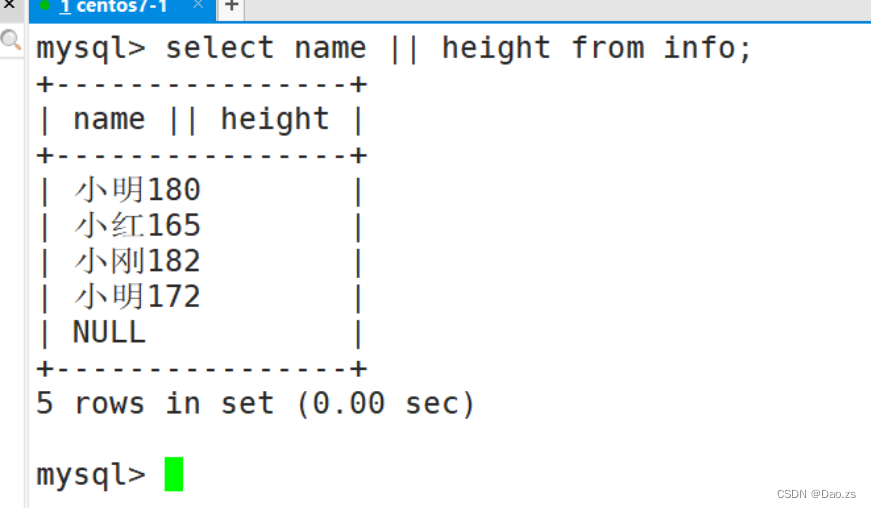
#将info表中,name字段值和height字段值拼接在一起,且中间加空格。select name || ' ' || height from info;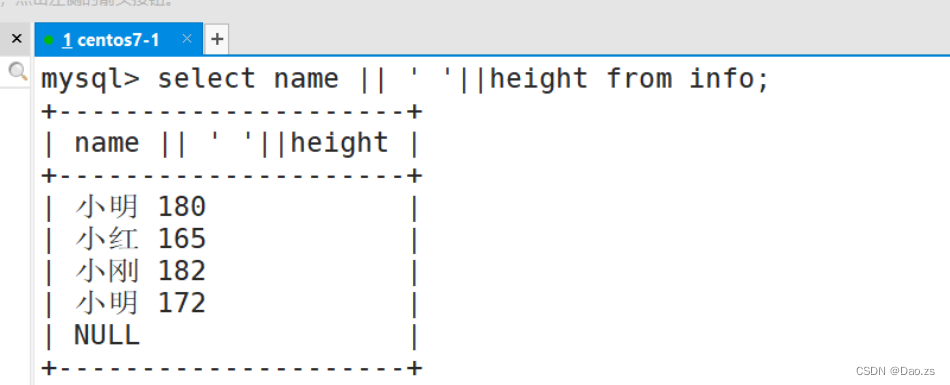
(4)返回字符长度 length
select length(hobby) from info2;
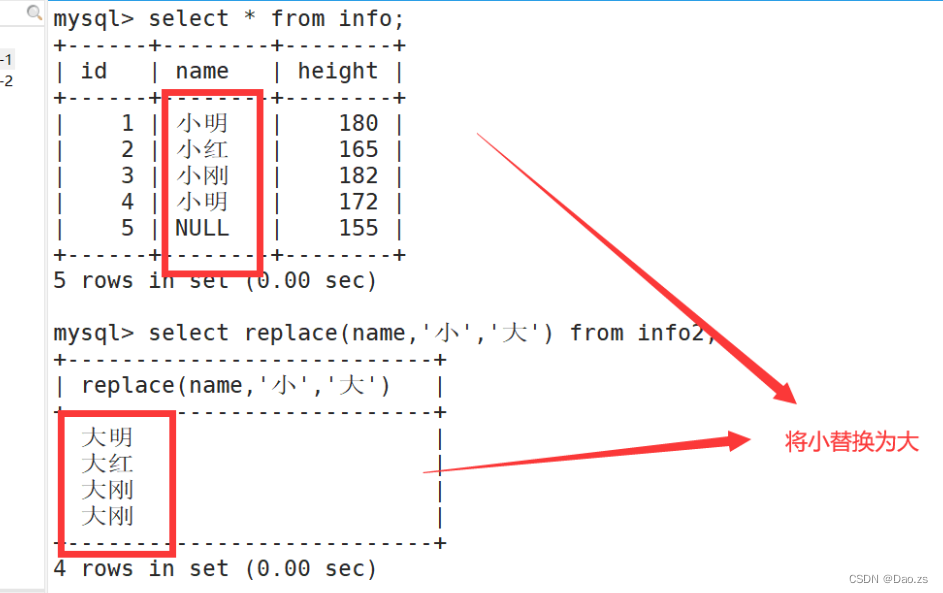
(5)替换 replace
select replace(name,'小','大') from info2;
四、高级查询语句
1)GROUP BY(用于分组和汇总)
对GROUPBY后面的字段的查询结果进行汇总分组,通常是结合聚合函数一起使用的
- "GROUP BY"有一个原则,凡是在"GROUP BY"后面出现的字段,必须在SELECT 后面出现
- 凡是在SELECT 后面出现的、且未在聚合函数中出现的字段,必须出现在"GROUP BY"后面
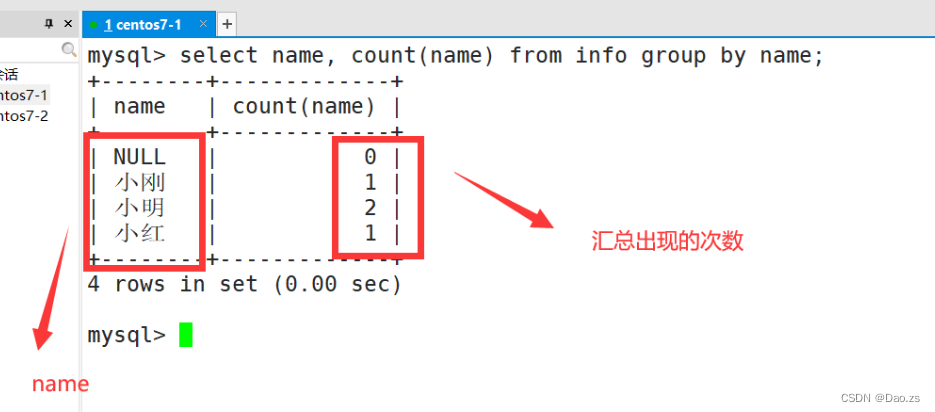
(1)汇总统计
select name, count(name) from info group by name;
(2)汇总并对其指定字段(数字类)进行累加
select name,sum(saving) from info3 group by name;

(3)汇总并对其指定字段(数字类)进行累加,再进行降序
select name,sum(saving) from info3 group by name order by sum(saving) desc;
2)HAVING 过滤
- 用来过滤由"GROUP BY"语句返回的记录集,通常与"GROUP BY"语句联合使用
- HAVING语句的存在弥补了WHERE 关键字不能与聚合函数联合使用的不足
- where只能对原表中的字段进行筛选,不能对group by后的结果进行筛选
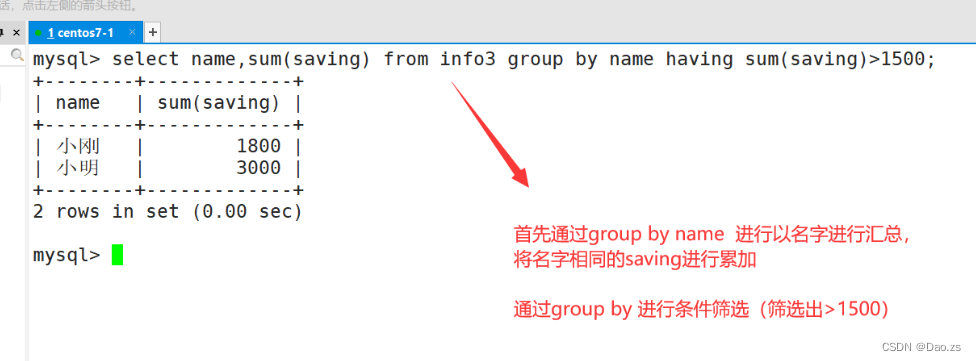
SELECT 字段1,SUM(字段2) FROM "表格名" GROUP BY 字段1 HAVING(函数条件) ;
select name,sum(saving) from info3 group by name having sum(saving)>1500;
3)别名设置查询
语法格式:
SELECT 字段1,字段2 AS 字段2的别名 from 表名; #AS可以省略不写(1)字段别名
select name,sum(saving) as total_saving from info3 group by name having sum(saving)>1000;
select name,sum(saving) as total_saving from info3 group by name having total_saving>1000;
(2)表别名
SELECT 表格别名.字段1 [AS] 字段别名 FROM 表格名 [AS] 表格别名; #AS可以省略不写
4)表的自我连接
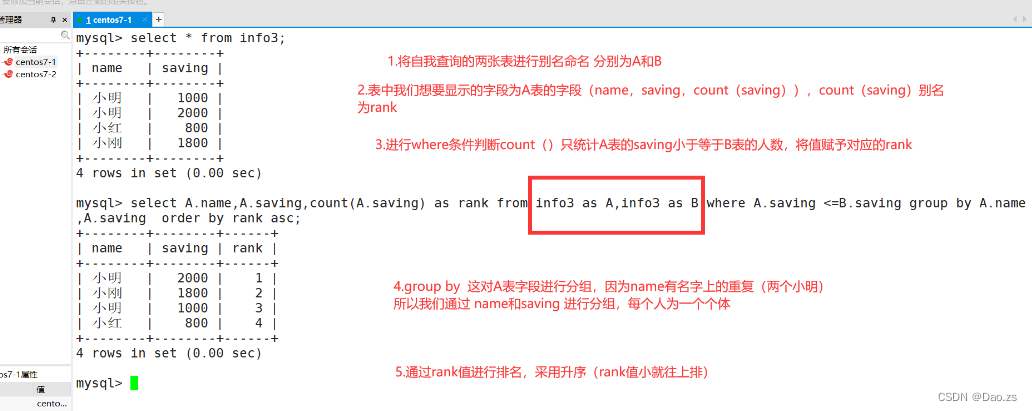
(1)无重复数值排名
对下面的表进行saving比较并且进行排名通过表的自我连接进行实现

表的自我连接达到排名的原理分析及操作思路:
- 以上面的数据表为例,假设共有四个人,他们手中的金额各不相同。我们已经进行表的自我连接
- 使用count计数,只计数大于等于自身手上金额的人数,比如2000的小明,大于等于他的人数只有1个,就计数值也可以当作他的排名
- 再比如800的小红,大于等于她的有4个人,就该计数值为4,同理可以证明她排名第四
select A.name,A.saving,count(A.saving) as rank from info3 as A,info3 as B where A.saving <=B.saving group by A.name,A.saving order by rank asc;
(2)有重复数值排名
新需求表:
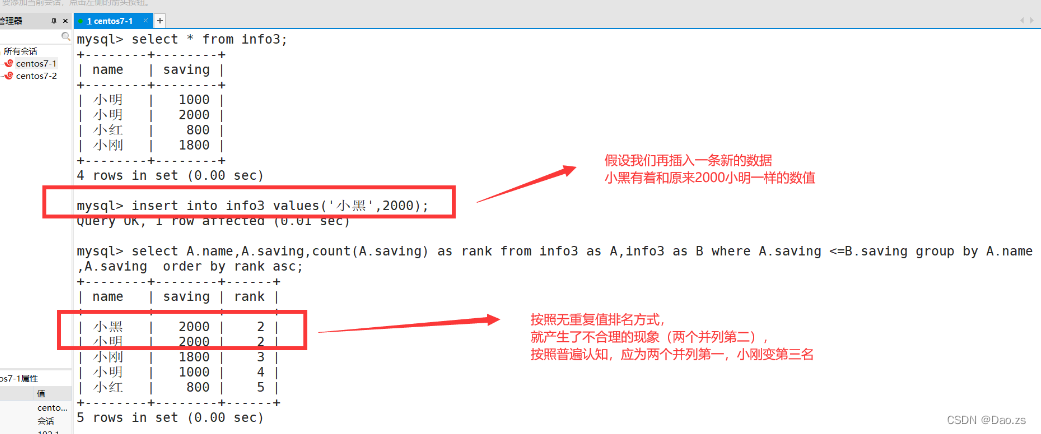
select A.name,A.saving,count(A.saving) as rank from info3 as A,info3 as B where A.saving < B.saving or (A.name=B.nameme and A.saving=B.saving) group by A.name,A.saving order by rank asc;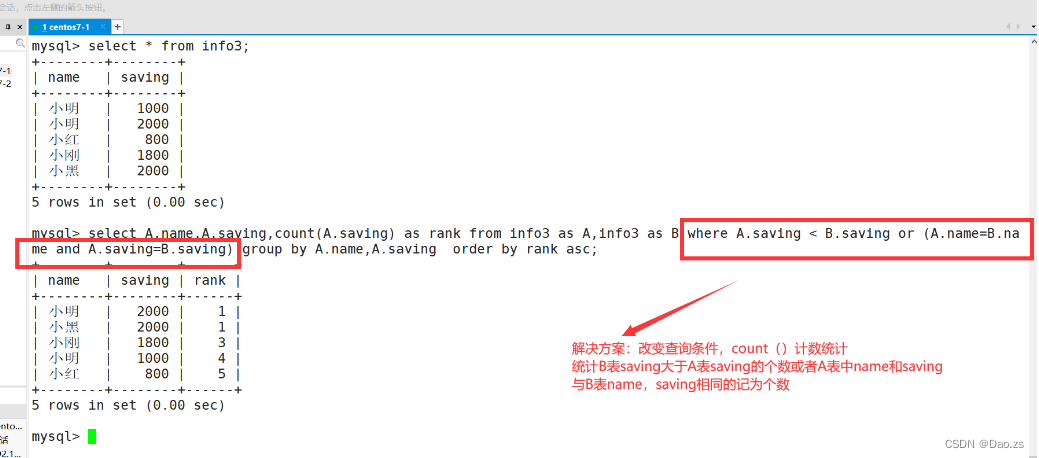
5)子查询语句
子查询:连接表格,在WHERE 子句或HAVING 子句中插入另一个SQL语句
SELECT "字段1" FROM "表格1" WHERE "字段2" [比较运算符] #外查询(SELECT "字段1" FROM "表格2" WHERE "条件") ; #内查询普通的表数据连接:
select * from info as A, info3 as B where A.name=B.name;
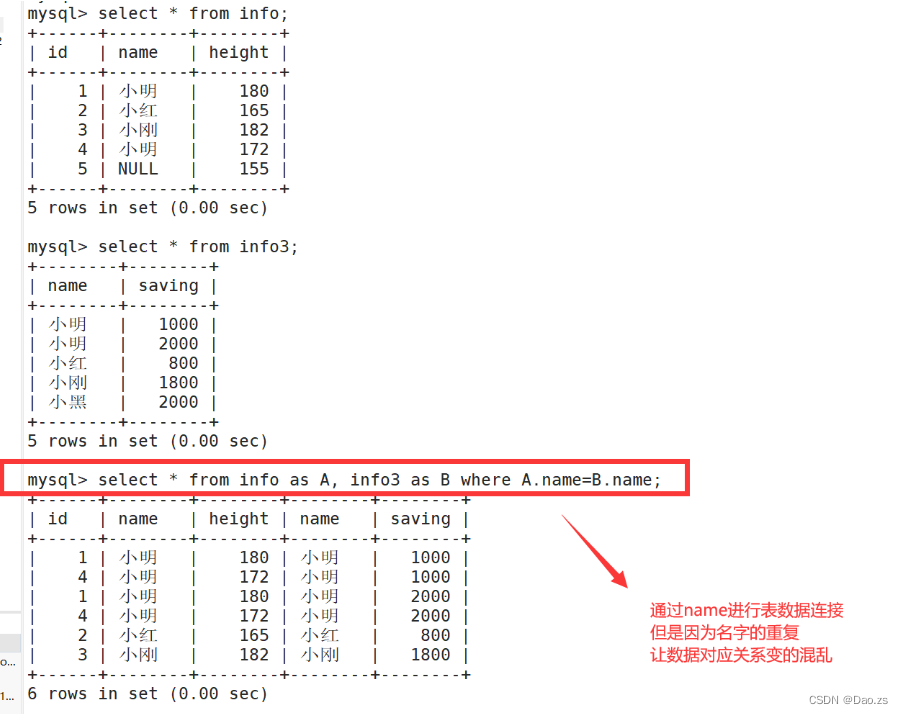
子查询加入表连接 :
select * from info where name in(select name from info3 where saving > 1000);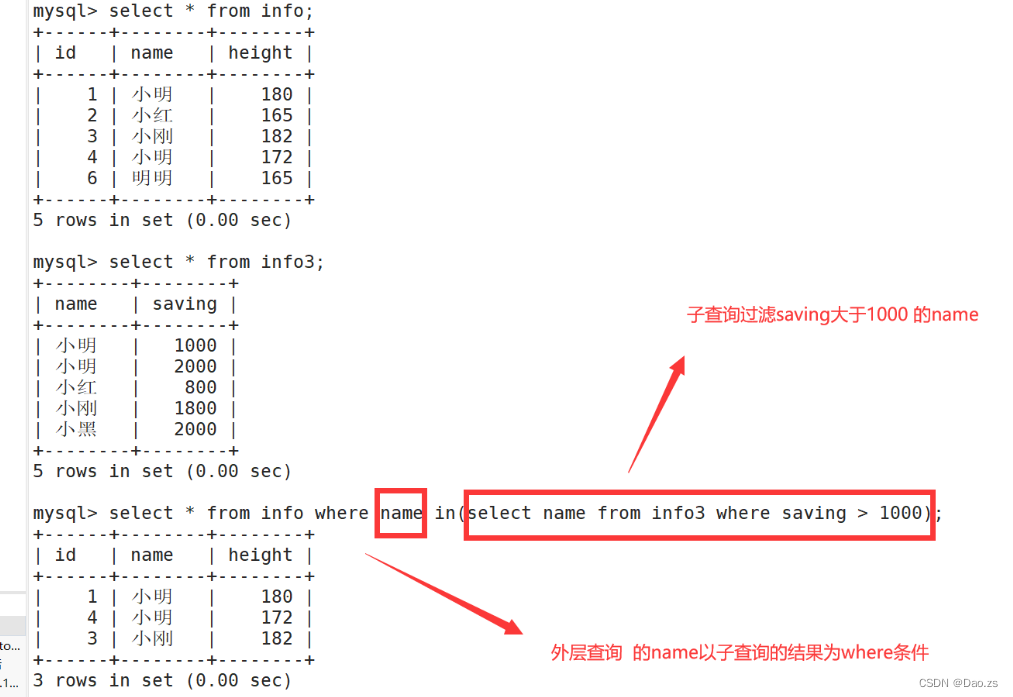
子查询运用升级
求“北京地区”的所有saving值之和
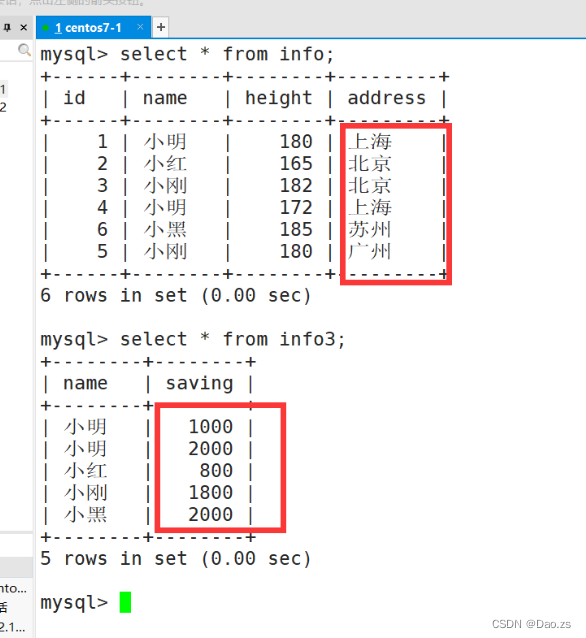
select sum(saving) from info3 where name in (select name from info where address='北京');

6)EXISTS
- 用来测试内查询有没有产生任何结果,类似布尔值是否为真。
- 如果内查询有结果的话,系统就会执行外查询中的SQL语句。若是没有结果的话,那整个SQL语句就不会产生任何结果
格式:
SELECT "字段1" FROM "表格1" WHERE EXISTS (SELECT * FROM "表格2" WHERE "条件");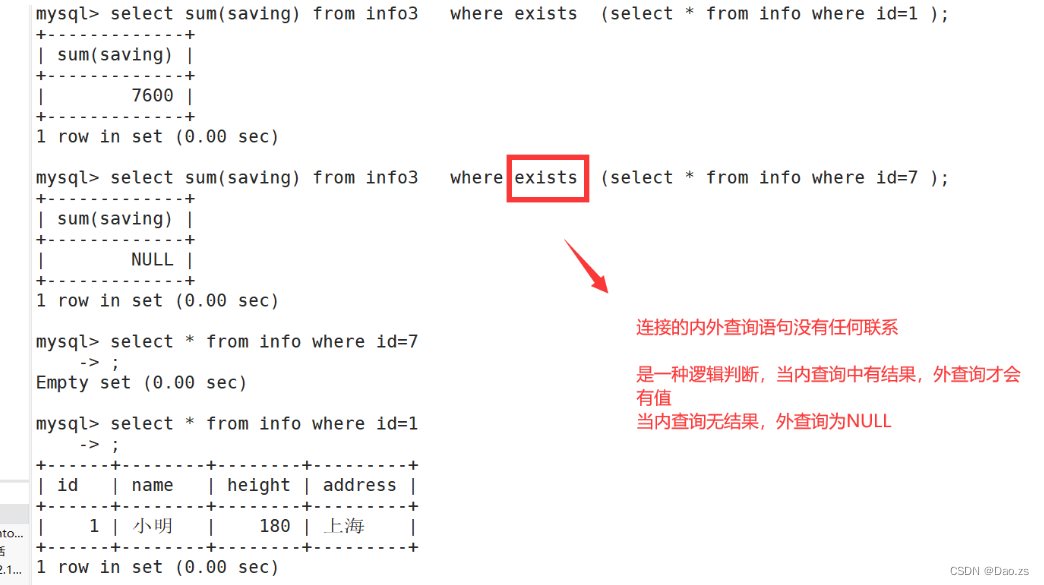
五、表连接查询
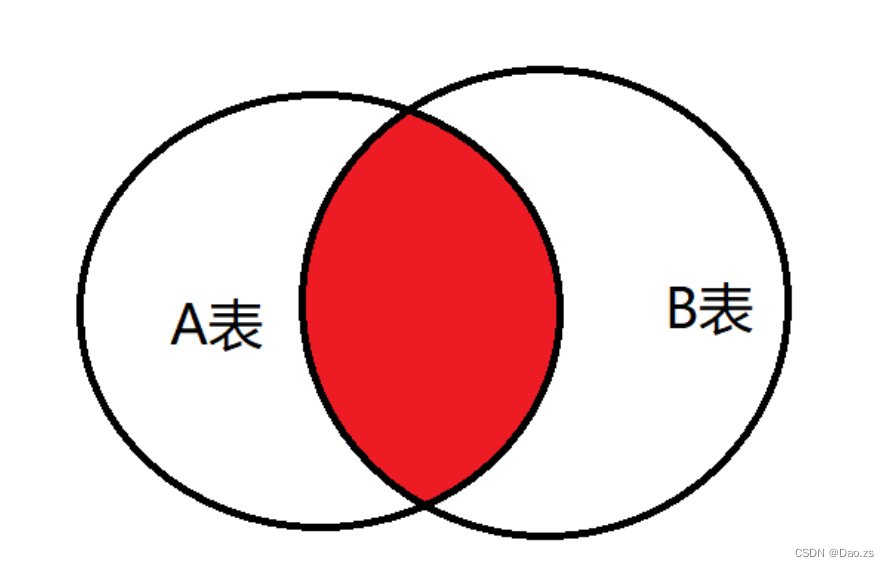
MYSQL数据库中常用的表连接有三种:
- inner join(内连接):只返回两个表中联结字段相等的行(有交集的值
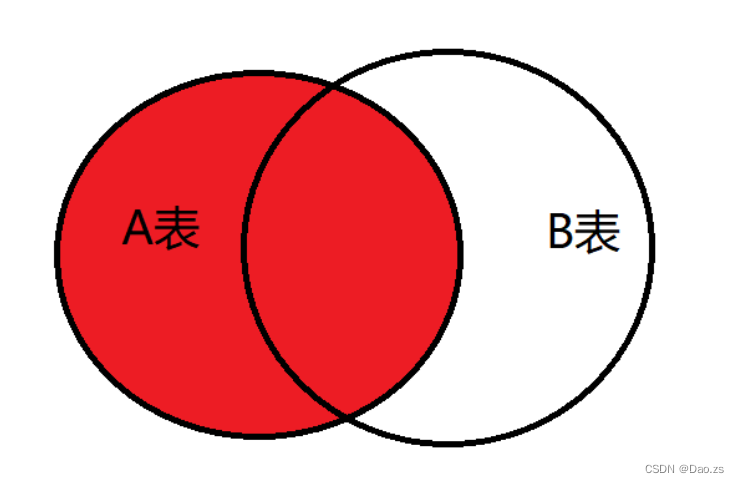
- left join(左连接):返回包括左表中的所有记录和右表中联结字段相等的记录
- A left join B : A为左表,B为右表
- right join(右连接):返回包括右表中的所有记录和左表中联结字段相等的记录
- A right join B: A为左表 ,B为右表

(1) 内连接 inner join
select * from info A inner join info3 B on A.name = B.name;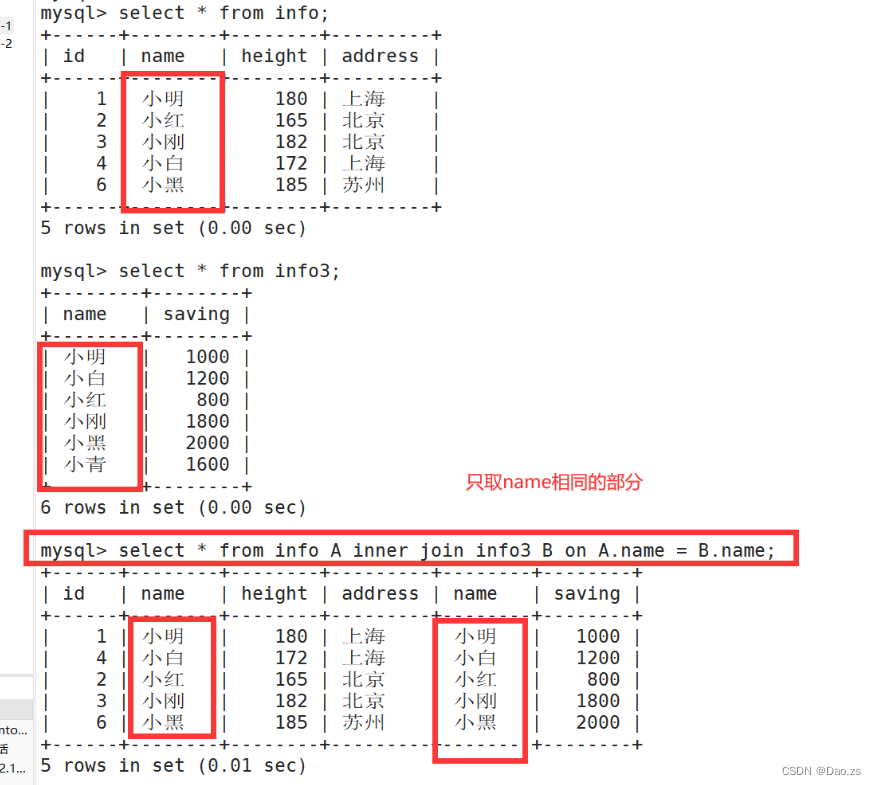
其他实现内连接的方式:
select * from info A, info3 B where A.name=B.name;select * from info A inner join info3 B using(name);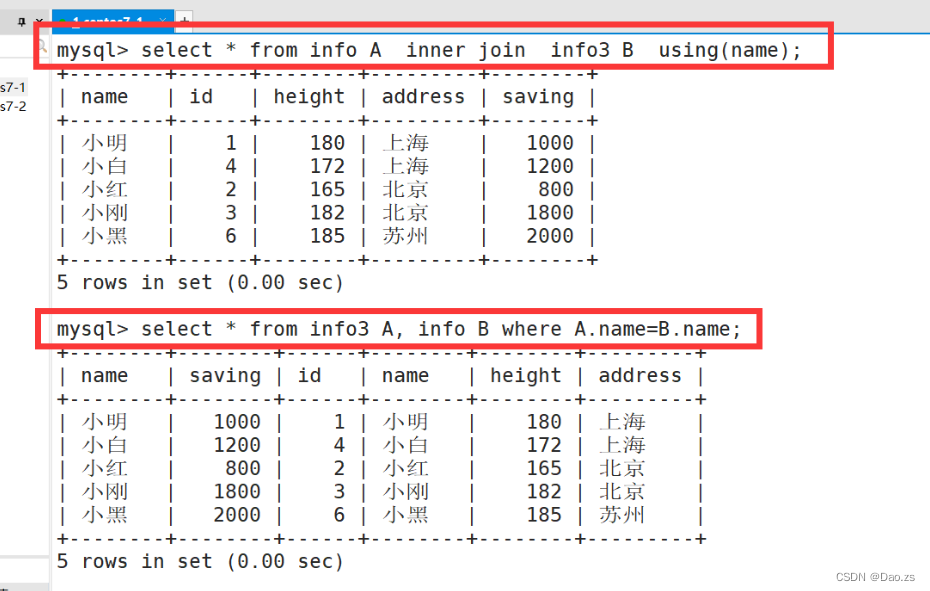
(2)左连接 left join
select * from info A LEFT JOIN info3 B on A.name=B.name;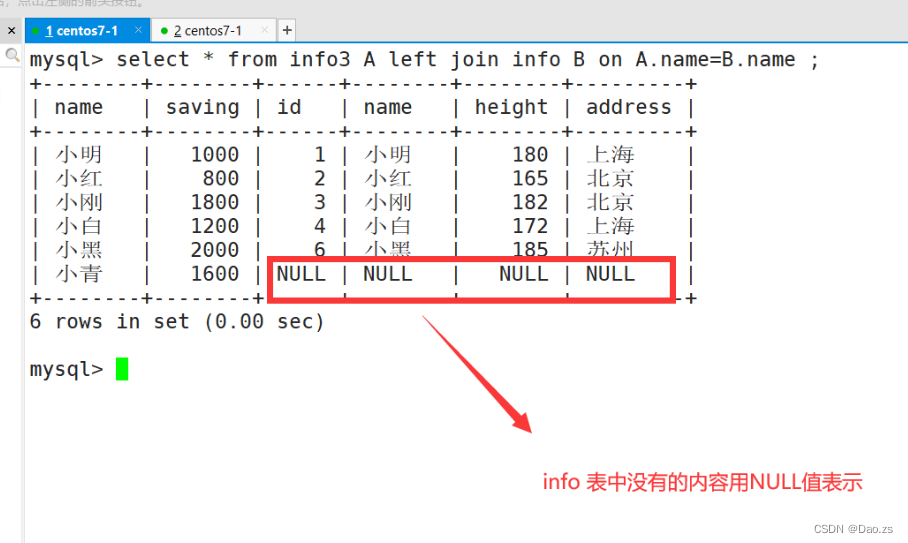
(3)右连接 right join
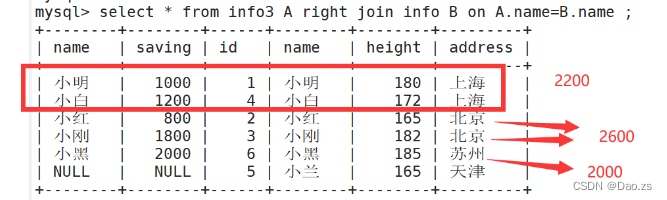
select * from info3 A right join info B on A.name=B.name ;

六、view 视图的运用
视图:可以被当作是虚拟表或存储查询
- 视图跟表格的不同是,表格中有实际储存数据记录,而视图是建立在表格之上的一个架构,它本身并不实际储存数据记录
- 临时表在用户退出或同数据库的连接断开后就自动消失了,而视图不会消失
- 视图不含有数据,只存储它的定义,它的用途一般可以简化复杂的查询。 比如你要对几个表进行连接查询,而且还要进行统计排序等操作,写SQL语句会很麻烦的,用视图将几个表联结起来,然后对这个视图进行查询操作,就和对一个表查询一样,很方便
格式:
CREATE VIEW "视图表名" AS "SELECT 语句"; #创建视图表
DROP VIEW "视图表名"; #删除视图表1)视图的创建
创建需求:独立创建一个视图,用来统计info和info3 两张表之间,先对name进行address的汇总,再计算地区的saving之和 。要求体现出address 和sum(sving) 两个字段
create view v_address_saving as select A.address,sum(B.saving) total_saving from info A inner join info3 B on A.name=B.name group by address;
视图创建的数据验证:
2) 视图提供的后续便捷操作
视图的好处:创建视图的过程虽然和高级查询语句(通过两个select语句进行组合条件划分生成派生表)一样,过程是复杂的,但是如果该查询操作是需要经常使用的,创建视图就很有必要,不仅能简化查询过程,还能对该查询进行进一步操作,而且十分简便
进一步需求: 需要计算出苏州和上海两个地区的saving之和
select sum(total_saving) as suzhou_shanghai_saving from v_address_saving where address='苏州'or address='上海';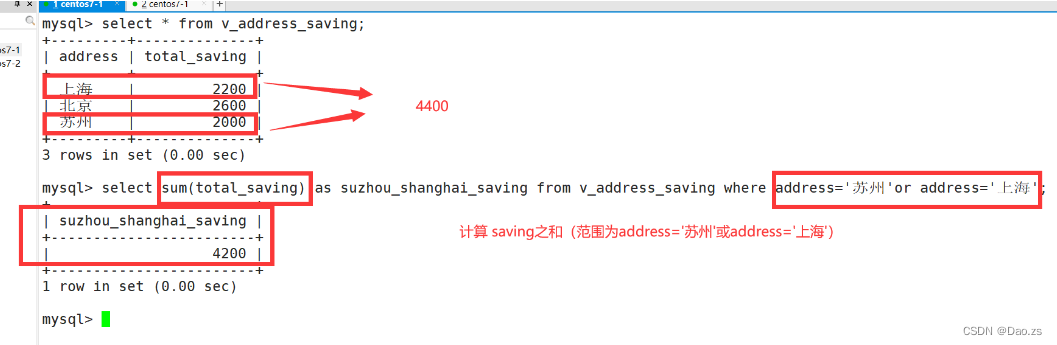
3)经典定义问题:视图能否插入数据
视图能否插入数据,要看情况而定:
(1)如果视图表是两个表的连接查询(比如视图的A字段来自A表,B字段来自B表,数据是无法插入的)。因为表结构和原表不一致。视图中的字段是根据原表中某个字段,通过函数运算,产生的新字段,而没有真正能够存储的字段,所以该数据是无法插入的
(2)如果视图表结构与原表保持一致,数据是可以插入的,插入的数据是存储在原表中,视图所更新出的数据,其实是映射原表的数据
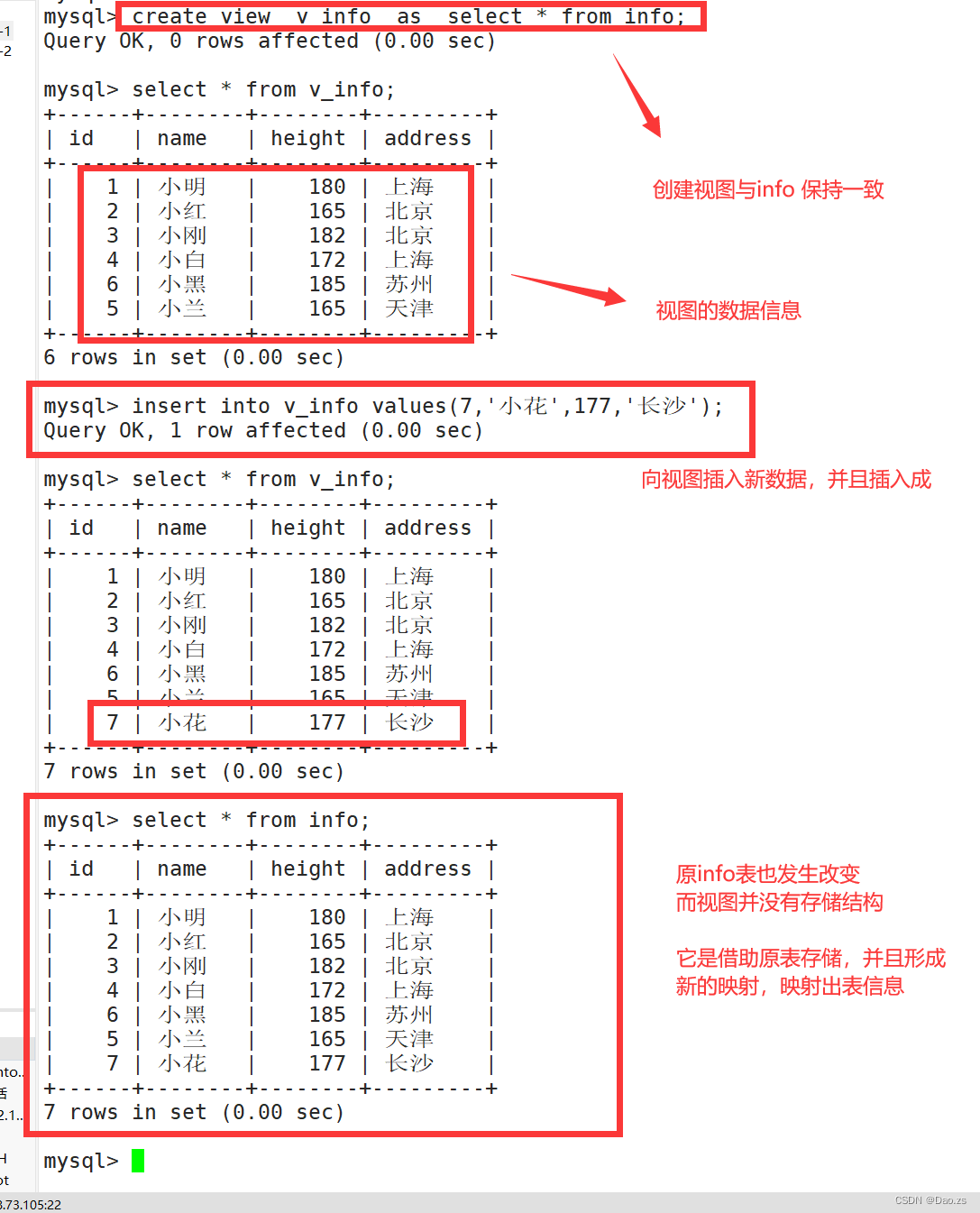
show create view 分析创建视图的过程:

七、UNION 联级
UNION联集:将两个SQL语句的结果合并起来,两个SQL语句所产生的字段需要是同样的数据记录种类
1)UNION(合并后去重)
生成结果的数据记录值将没有重复,且按照字段的顺序进行排序。#合并后去重
格式:[select 语句1] UNION [select 语句2];
select name from info union select name from info3;
2)UNION ALL(合并后不去重)
select name from info union all select name from info3;
八、多种方式求表与表的交集值
1)联级视图求交集值
create view v_info as select distinct name from info union all select distinct name from info3;
select name,count(*) from v_info group by name;select name from v_info group by name having count(*) >1;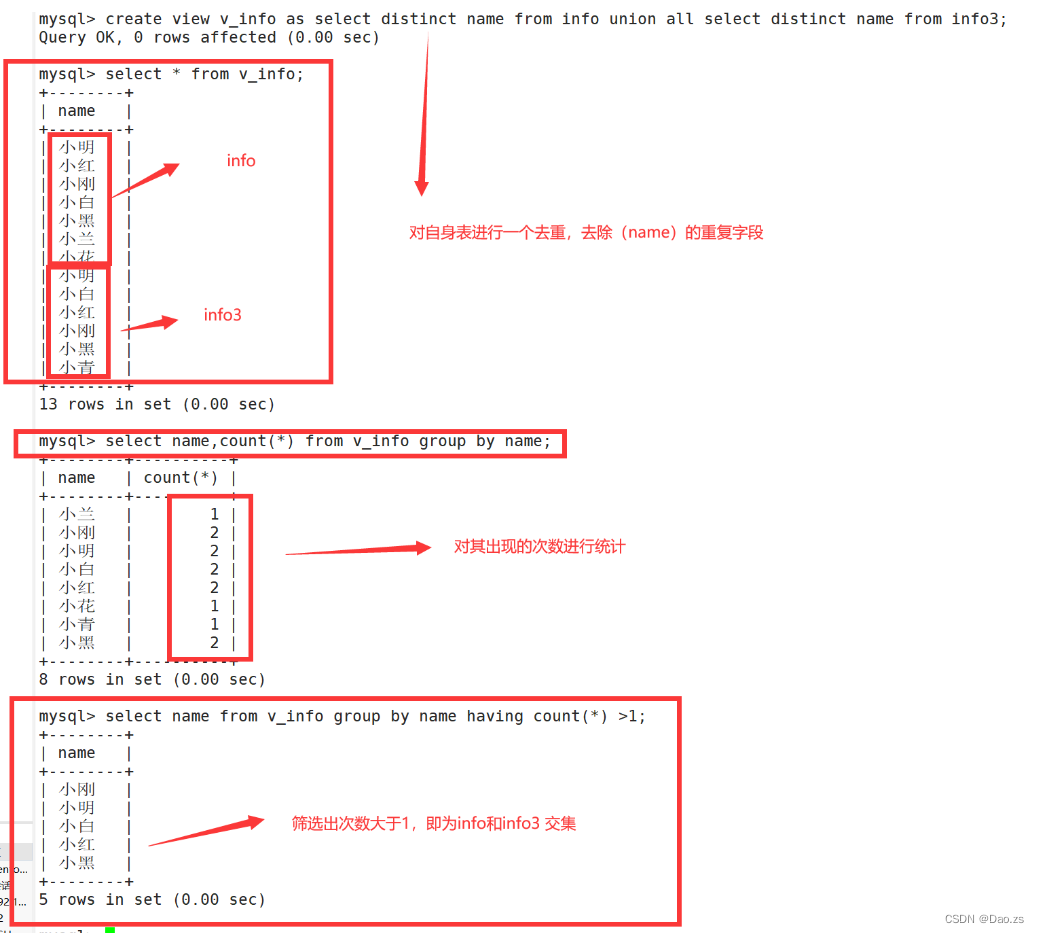
2)内连接求交集值
(1)不去重求交集
select A.name from info A inner join info3 B on A.name=B.name;
select A.name from info A inner join info3 B using(name);
(2)去重求交集
select distinct A.name from info A inner join info3 B using(name);
3)使用左连接求交集值
select * from info A left join info3 B using(name);
select distinct A.name from info A left join info3 B using(name) where B.name is not null;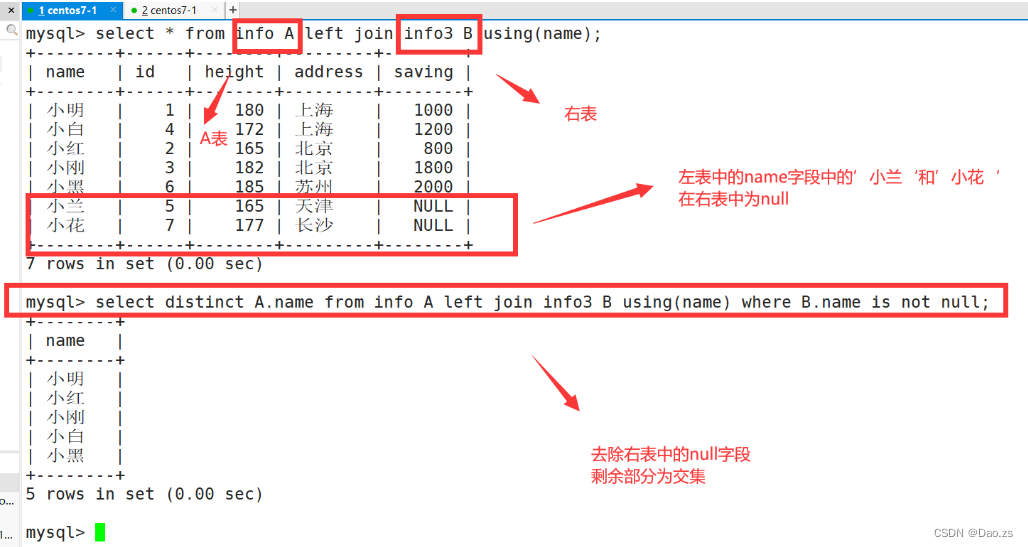
4)使用右连接求交集
#使用右连接查出store_name字段的交集值,之后去重select * from info A right join info3 B using(name);select distinct A.name from info A right join info3 B using(name) where A.name is not null;或select distinct A.name from info A right join info3 B on A.name=B.name where A.name is not null;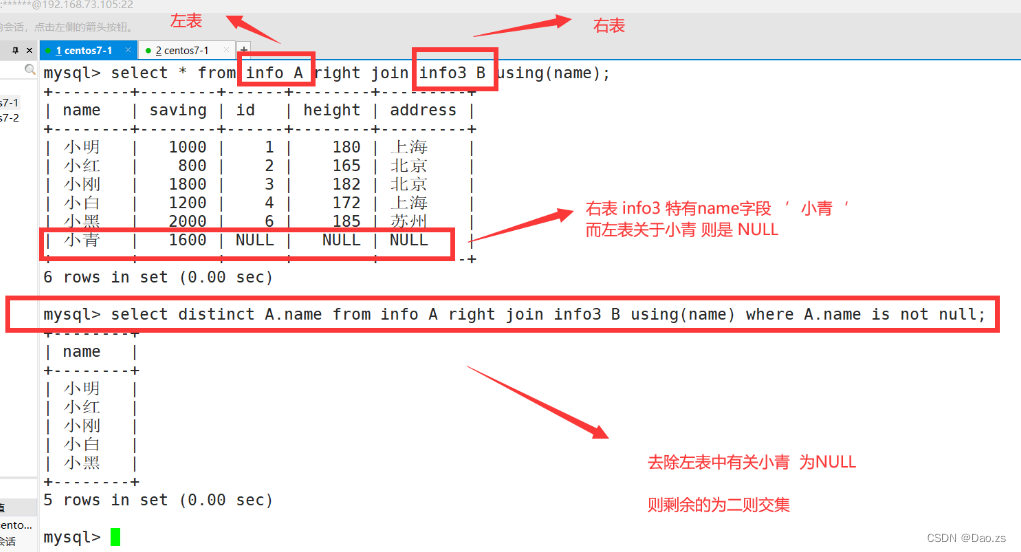
5)使用子查询的方式求交集值
select distinct name from info where name in (select name from info3);
6)取非交集值
(1)联级方法中 count(*)<=1
(2)左右内连接 将is not null 改为 is null
(3)子查询 外连接查询 not in (内连接查询)
九、case 条件选择查询语句
SELECT CASE ("字段名")WHEN "条件1" THEN "结果1"WHEN "条件2" THEN "结果2"[ELSE "结果N"]ENDFROM "表名";# "条件"可以是一个数值或是公式。ELSE子句则并不是必须的。mysql> select address,case address-> when '上海' then height-10-> when '北京' then height+5-> else height+10-> end-> "new_height",name-> from info;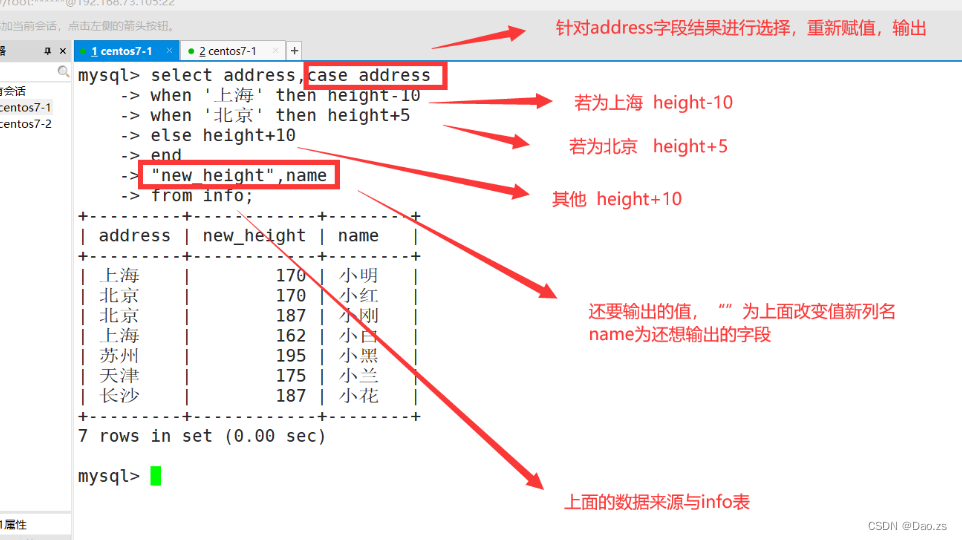
十、正则表达式的运用
1)sql正则表达式的常见种类
| 正则符号 | 作用 |
| ^ | 匹配文本的开始字符 |
| $ | 匹配文本的结束字符 |
| . | 匹配任何单个字符 |
| * | 匹配零个或多个在它前面的字符 |
| + | 匹配前面的字符 1 次或多次 |
| 字符串 | 匹配包含指定的字符串 |
| l | 或,“|”前面的不成立时,就匹配后面的字符串 |
| [...] | 匹配字符集合中的任意一个字符 |
| [^...] | 匹配不在括号中的任何字符 |
| {n} | 匹配前面的字符串 n 次 |
| {n,m} | 匹配前面的字符串至少 n 次,至多m 次 |
2)sql正则运用
格式:
select "字段" from "表名" where "字段" regexp '正则表达式';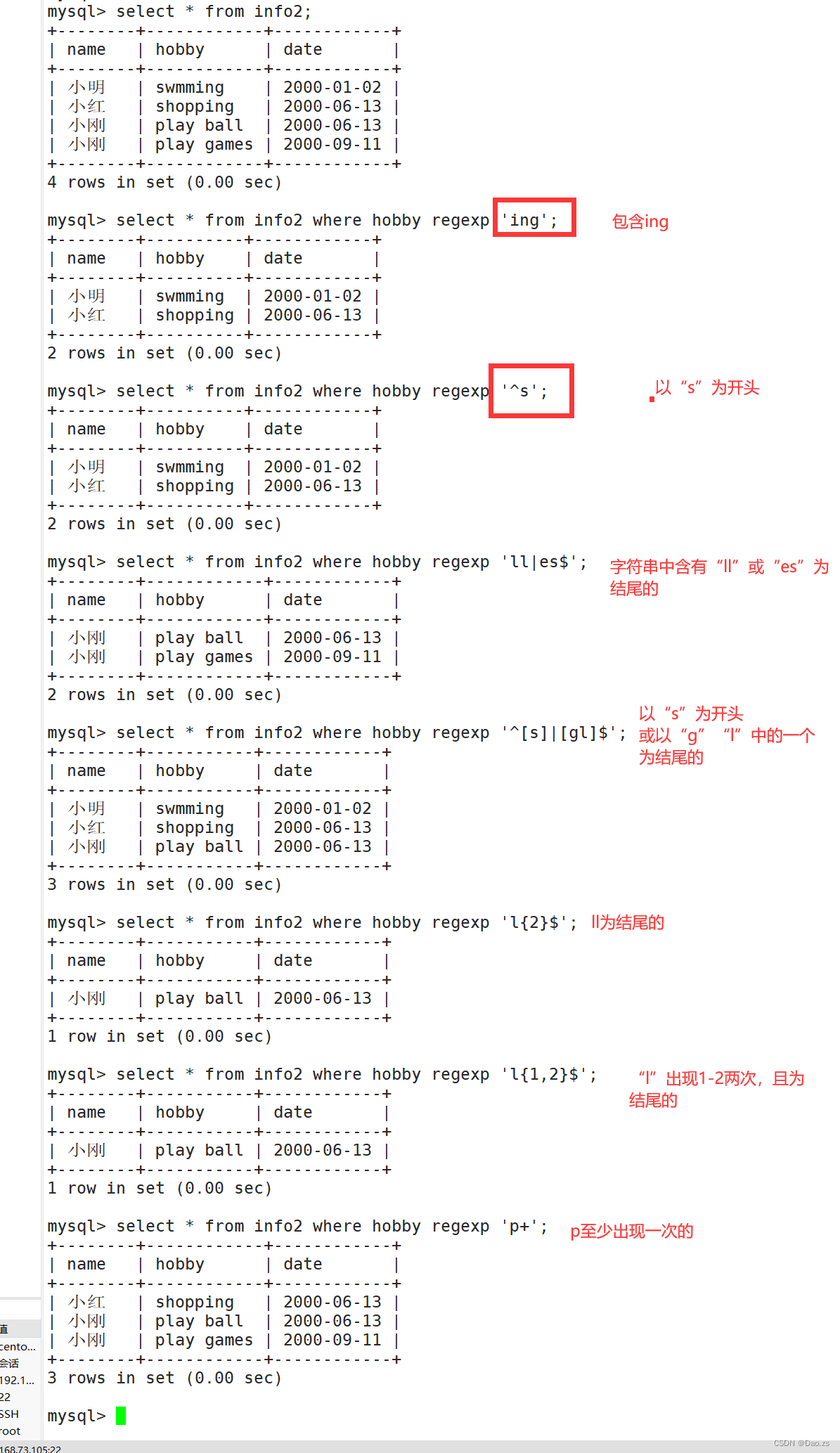
探究:空值(NULL)和无值(' ')的区别
无值的长度为0,不占用空间;而NULL值的长度是NULL,是占用空间的
IS NULL或者IS NOT NULL,是用来判断字段是不是为NULL或者不是NULL,不能查出是不是无值的
无值的判断使用=' '或者< >' '来处理。<>代表不等于
在通过 count ()指定字段统计有多少行数时,如果遇到NULL值会自动忽略掉,遇到无值会加入到记录中进行计算
相关文章:
mysql的高级查询语句
目录 一、本文前言 二、高效查询方式 1)指定指字段进行查看 2)对字段进行去重查看 3)where条件查询 4)and 和 or 进行逻辑关系的增加 5)查询取值列表中的数据 6)between的引用 7)like…...
04-8_Qt 5.9 C++开发指南_QTableWidget的使用
文章目录 1. QTableWidget概述2. 源码2.1 可视化UI设计2.2 程序框架2.3 qwintspindelegate.h2.4 qwintspindelegate.cpp2.5 mainwindow.h2.6 mainwindow.cpp 1. QTableWidget概述 QTableWidget是Qt中的表格组件类。在窗体上放置一个QTableWidget 组件后,可以在 PropertyEditor…...

《golang设计模式》第二部分·结构型模式-01-适配器模式(Adapter)
文章目录 1. 概念1.1 角色1.2 应用场景1.2 类图 2. 代码示例2.1 设计2.2 代码2.3 示例类图 1. 概念 定义一个适配器,帮助原本不能实现接口的类“实现”该接口 1.1 角色 目标(Target):客户端调用的目标接口 被适配者(…...

机器学习概述及其主要算法
目录 1、什么是机器学习 2、数据集 2.1、结构 3、算法分类 4、算法简介 4.1、K-近邻算法 4.2、贝叶斯分类 4.3、决策树和随机森林 4.4、逻辑回归 4.5、神经网络 4.6、线性回归 4.7、岭回归 4.8、K-means 5、机器学习开发流程 6、学习框架 1、什么是机器学习 机器…...

识jvm堆栈中一个数据类型是否为为引用类型,目前虚拟机实现中是如何做的?
调用栈里的引用类型数据是GC的根集合(root set)的重要组成部分;找出栈上的引用是GC的根枚举(root enumeration)中不可或缺的一环。 要看JVM选择用什么方式。通常这个选择会影响到GC的实现。 如果JVM选择不记录任何这种…...

Bug合集
这里会收藏后面所遇到的bug并附上具有参考的意义的博客,会持续更新 Java 1、SpringBoot升级2.6.0以上后,Swagger出现版本不兼容报错。 Failed to start bean ‘documentationPluginsBootstrapper‘; nested exception is java.lang.NullPo…...
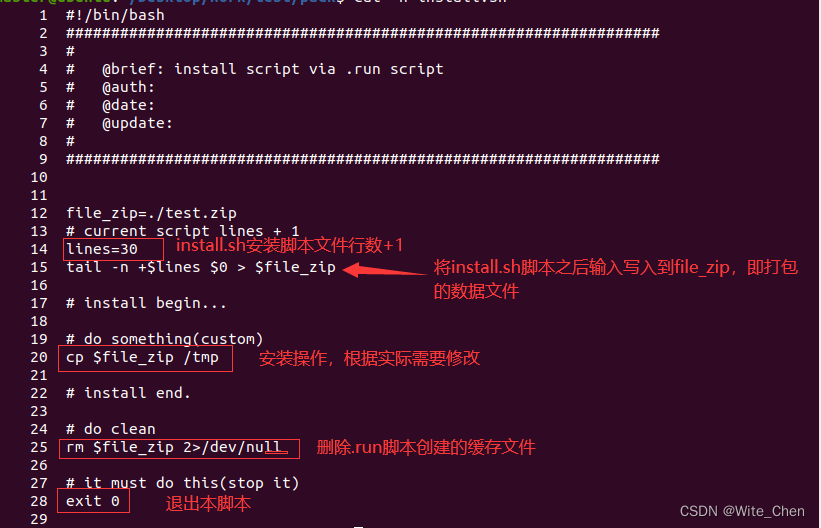
linux下.run安装脚本制作
1、安装文件(install.sh) PS: .run安装包内部执行脚本文件 2、资源文件(test.zip) PS: 待安装程序源文件 3、制作.run脚本(install.run) cat install.sh test.zip > install.run chmod ax install.run...
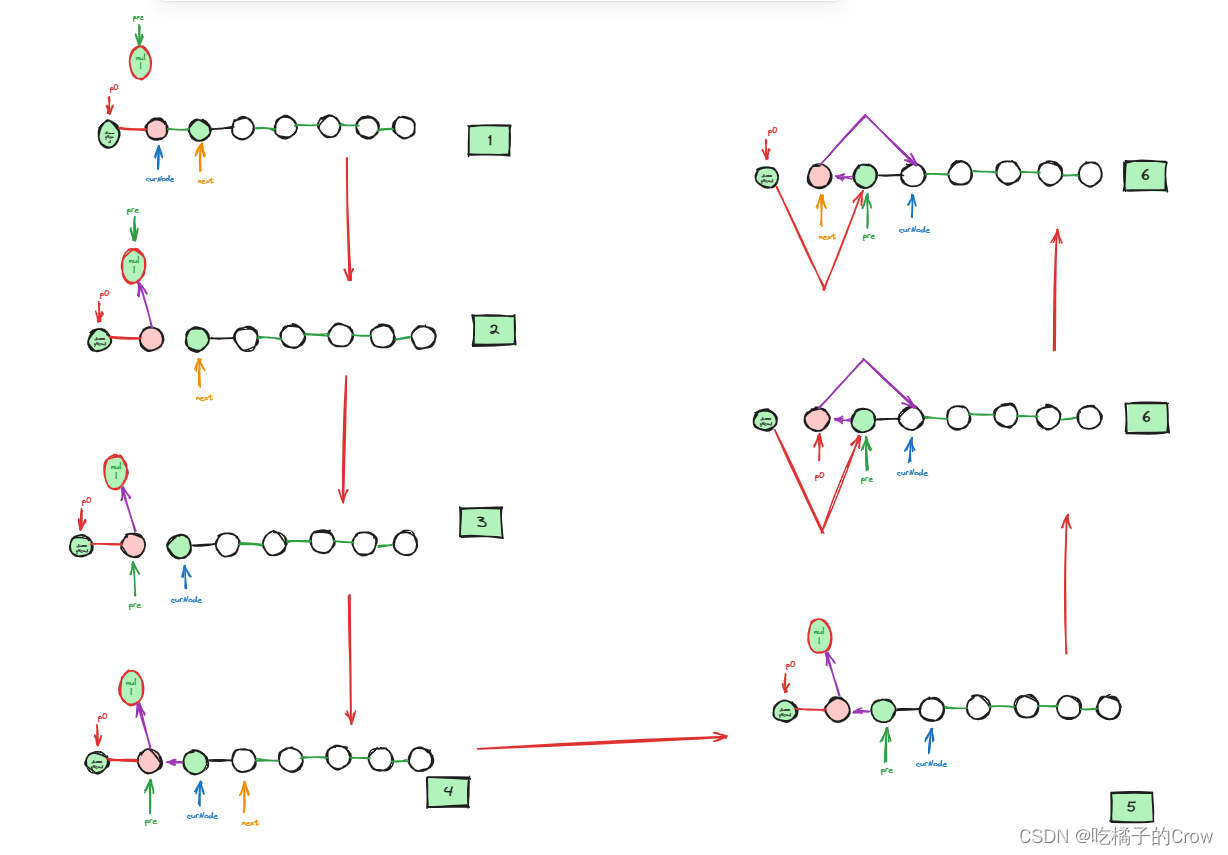
面试热题(翻转k个链表)
给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。 k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。 你不能只是单纯的改变节点内部的值&a…...
每天10个小知识点)
前端面试的性能优化部分(4)每天10个小知识点
目录 系列文章目录前端面试的性能优化部分(1)每天10个小知识点前端面试的性能优化部分(2)每天10个小知识点前端面试的性能优化部分(3)每天10个小知识点前端面试的性能优化部分(4)每天…...

el-checkbox修改选中和未选中的值
由于在checkbox选中的时候,默认的是为true和false。 后端定义的绑定字段不是为布尔值,而是为0,1 解决办法 <el-checkbox v-model"model.status" :true-label"1" :false-label"0"> </el-checkbox>…...

完整版:TCP、UDP报文格式
目录 TCP报文格式 报文格式 报文示例 UDP报文格式 报文格式 报文示例 TCP报文格式 报文格式 图1 TCP首部格式 字段长度含义Source Port16比特源端口,标识哪个应用程序发送。Destination Port16比特目的端口,标识哪个应用程序接收。Sequence Numb…...

如何远程连接云服务器oracle数据库
要远程连接云服务器上的Oracle数据库,可以按照以下步骤进行操作: 1. 确保你的云服务器已经安装了Oracle数据库,并且启动了数据库服务。 2. 登录到云服务器的操作系统。可以使用SSH工具(如PuTTY)连接到云服务器,使用管理员权限登录…...

“深入剖析JVM内部机制:探秘Java虚拟机的运行原理“
标题:深入剖析JVM内部机制:探秘Java虚拟机的运行原理 摘要:本文将深入剖析Java虚拟机(JVM)的内部机制,探秘其运行原理。我们将从JVM的结构、内存管理、垃圾回收、即时编译等方面展开讨论,并通过…...
尚品汇总结十:秒杀模块(面试专用)
1、需求分析 所谓“秒杀”,就是商家发布一些超低价格的商品,所有买家在同一时间网上抢购的一种销售方式。通俗一点讲就是商家为促销等目的组织的网上限时抢购活动。由于商品价格低廉,往往一上架就被抢购一空,有时只用一秒钟。 秒…...

什么是设计模式?
目录 概述: 什么是模式!! 为什么学习模式!! 模式和框架的比较: 设计模式研究的历史 关于pattern的历史 Gang of Four(GoF) 关于”Design”Pattern” 重提:指导模式设计的三个概念 1.重用(reuse)…...
Node.js |(三)Node.js API:path模块及Node.js 模块化 | 尚硅谷2023版Node.js零基础视频教程
学习视频:尚硅谷2023版Node.js零基础视频教程,nodejs新手到高手 文章目录 📚path模块📚Node.js模块化🐇介绍🐇模块暴露数据⭐️模块初体验⭐️暴露数据 🐇导入文件模块🐇导入文件夹的…...

Netty自定义编码解码器
上次通信的时候用的是自带的编解码器,今天自己实现一下自定义的。 1、自定义一下协议 //协议类 Data public class Protocol<T> implements Serializable {private Long id System.currentTimeMillis();private short msgType;// 假设1为请求 2为响应privat…...
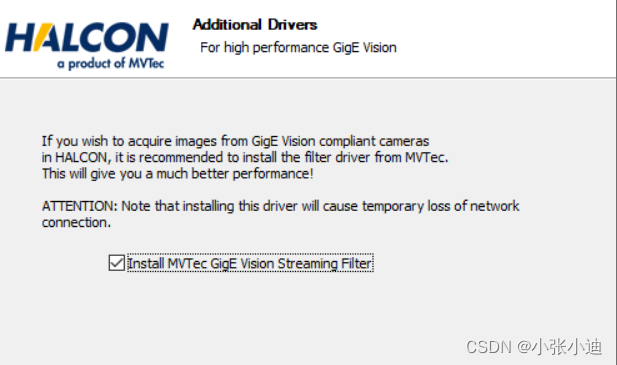
HOperatorSet.OpenFramegrabber “GigEVision“
HOperatorSet.OpenFramegrabber "GigEVision"访问失败 直接跳出 但其他算子可以访问 重装halcon x86...

图的遍历DFSBFS-有向图无向图
西江月・证明 即得易见平凡,仿照上例显然。留作习题答案略,读者自证不难。 反之亦然同理,推论自然成立。略去过程Q.E.D.,由上可知证毕。 有向图的遍历可以使用深度优先搜索(DFS)和广度优先搜索(…...
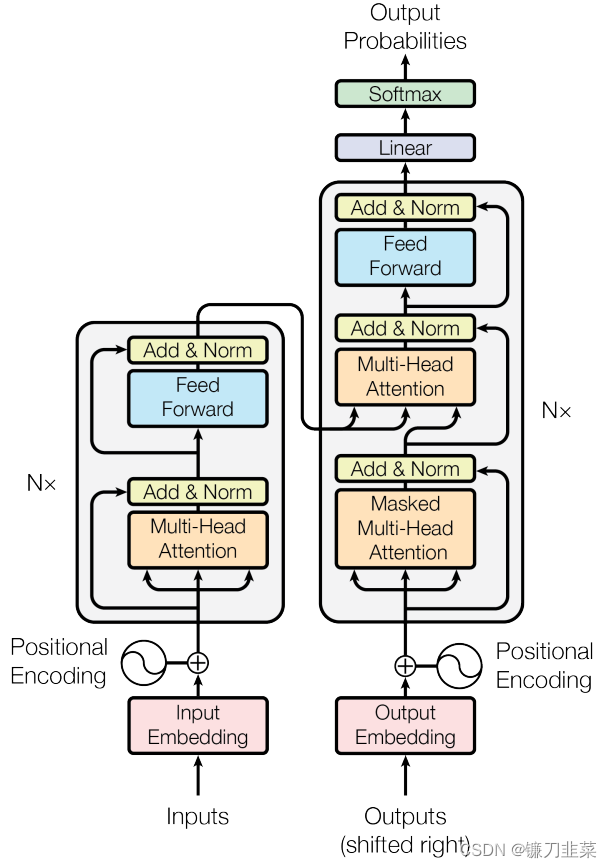
【NLP】深入浅出全面回顾注意力机制
深入浅出全面回顾注意力机制 1. 注意力机制概述2. 举个例子:使用PyTorch带注意力机制的Encoder-Decoder模型3. Transformer架构回顾3.1 Transformer的顶层设计3.2 Encoder与Decoder的输入3.3 高并发长记忆的实现self-attention的矩阵计算形式多头注意力(…...

第19节 Node.js Express 框架
Express 是一个为Node.js设计的web开发框架,它基于nodejs平台。 Express 简介 Express是一个简洁而灵活的node.js Web应用框架, 提供了一系列强大特性帮助你创建各种Web应用,和丰富的HTTP工具。 使用Express可以快速地搭建一个完整功能的网站。 Expre…...

macOS多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用
文章目录 问题现象问题原因解决办法 问题现象 macOS启动台(Launchpad)多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用。 问题原因 很明显,都是Google家的办公全家桶。这些应用并不是通过独立安装的…...

cf2117E
原题链接:https://codeforces.com/contest/2117/problem/E 题目背景: 给定两个数组a,b,可以执行多次以下操作:选择 i (1 < i < n - 1),并设置 或,也可以在执行上述操作前执行一次删除任意 和 。求…...

【分享】推荐一些办公小工具
1、PDF 在线转换 https://smallpdf.com/cn/pdf-tools 推荐理由:大部分的转换软件需要收费,要么功能不齐全,而开会员又用不了几次浪费钱,借用别人的又不安全。 这个网站它不需要登录或下载安装。而且提供的免费功能就能满足日常…...

Java编程之桥接模式
定义 桥接模式(Bridge Pattern)属于结构型设计模式,它的核心意图是将抽象部分与实现部分分离,使它们可以独立地变化。这种模式通过组合关系来替代继承关系,从而降低了抽象和实现这两个可变维度之间的耦合度。 用例子…...

MySQL 知识小结(一)
一、my.cnf配置详解 我们知道安装MySQL有两种方式来安装咱们的MySQL数据库,分别是二进制安装编译数据库或者使用三方yum来进行安装,第三方yum的安装相对于二进制压缩包的安装更快捷,但是文件存放起来数据比较冗余,用二进制能够更好管理咱们M…...

MinIO Docker 部署:仅开放一个端口
MinIO Docker 部署:仅开放一个端口 在实际的服务器部署中,出于安全和管理的考虑,我们可能只能开放一个端口。MinIO 是一个高性能的对象存储服务,支持 Docker 部署,但默认情况下它需要两个端口:一个是 API 端口(用于存储和访问数据),另一个是控制台端口(用于管理界面…...

C语言中提供的第三方库之哈希表实现
一. 简介 前面一篇文章简单学习了C语言中第三方库(uthash库)提供对哈希表的操作,文章如下: C语言中提供的第三方库uthash常用接口-CSDN博客 本文简单学习一下第三方库 uthash库对哈希表的操作。 二. uthash库哈希表操作示例 u…...
Golang——7、包与接口详解
包与接口详解 1、Golang包详解1.1、Golang中包的定义和介绍1.2、Golang包管理工具go mod1.3、Golang中自定义包1.4、Golang中使用第三包1.5、init函数 2、接口详解2.1、接口的定义2.2、空接口2.3、类型断言2.4、结构体值接收者和指针接收者实现接口的区别2.5、一个结构体实现多…...

论文阅读笔记——Muffin: Testing Deep Learning Libraries via Neural Architecture Fuzzing
Muffin 论文 现有方法 CRADLE 和 LEMON,依赖模型推理阶段输出进行差分测试,但在训练阶段是不可行的,因为训练阶段直到最后才有固定输出,中间过程是不断变化的。API 库覆盖低,因为各个 API 都是在各种具体场景下使用。…...