JVM:运行时数据区域(白话文)
最近有时间在看一本<深入了解Java虚拟机>的书籍,这本书是一个中国人,名叫周志明的人写的。相比于其他翻译过来的技术书籍,这本书还是挺通俗易懂的。先前有和彬哥在聊,他说如果是自己一个人看的话会很枯燥,很难坚持下来,不妨边看边在公司内部做分享,遇到一些比较晦涩难懂的点可以收集起来和公司内部的人去讨论,大家一起学习。接下来,大家都知道,就有了这篇文章!
运行时数据区域
Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域。这些区域有各自的用途,以及创建和销毁的时间,有的区域随着虚拟机进程的启动而一直存在,有些区域则是依赖用户线程的启动和结束而建立和销毁。
根据《Java虚拟机规范》的规定,Java虚拟机所管理的内存将会包括以下几个运行时数据区域:
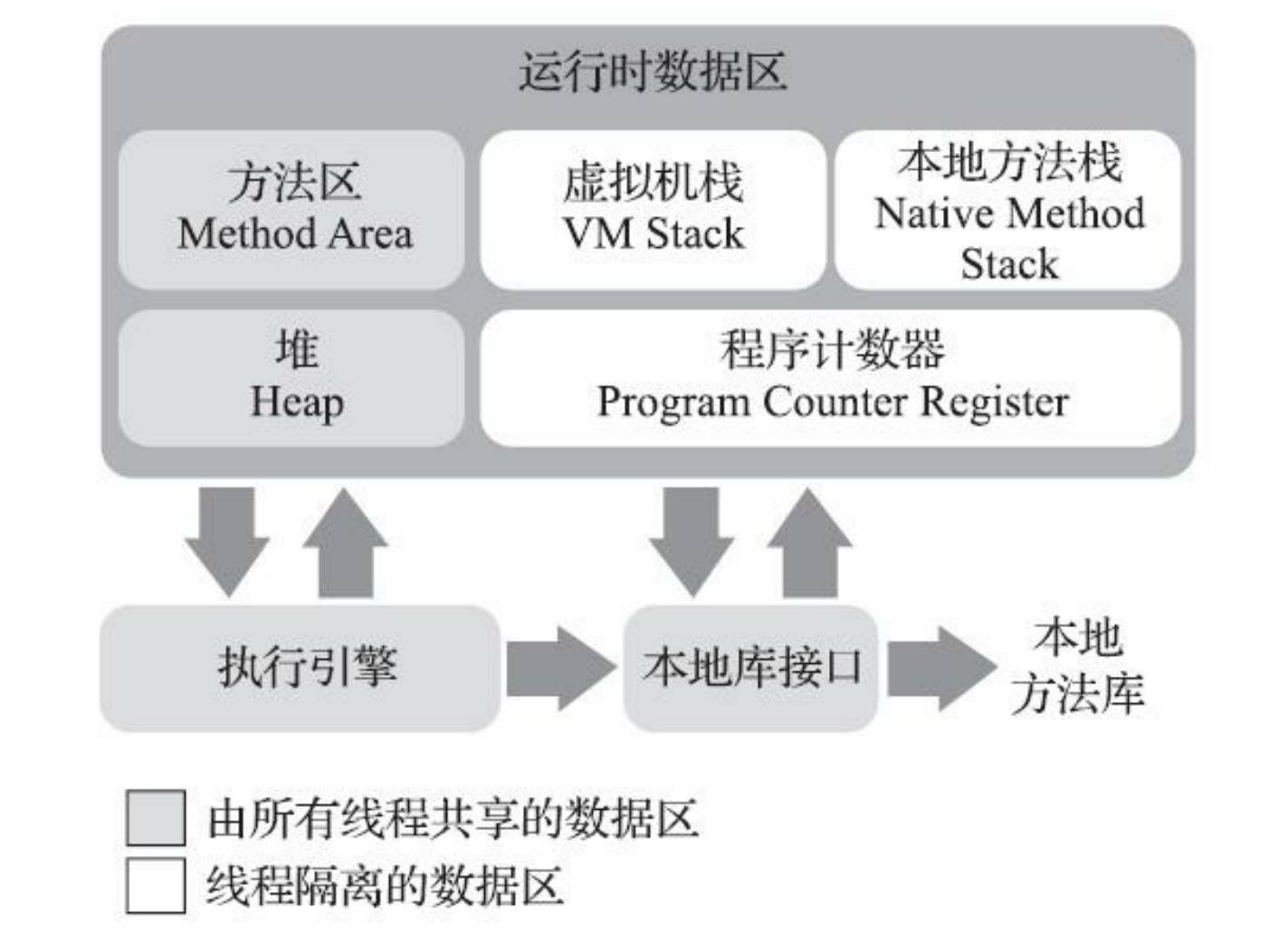
我理解它就是JVM对运行时数据区域一个概念模型,它代表了所有虚拟机的统一外观,但各款具体的Java虚拟机并不一定要完全照着概念模型的定义来进行设计,可能会通过一些更高效率的等价方式去实现它。
上图中,JVM 在线程共享与隔离的维度对JVM 内存划分为线程共享的数据区和线程隔离的数据区。
那你又似曾想过,线程共享数据区为什么划分为方法区和堆?线程私有数据区划分为程序计数器、java 虚拟机栈、本地方法栈呢?
实际上,我认为线程私有内存的区域划分是参考了操作系统的进程\线程运行时的内存布局。因为操作系统中,与线程相关联的内存就包括计数器和栈区;至于线程共享的呢,我认为是根据资源的动静态属性。也就是一些相对静态的数据,例如类结构,即使编译后的代码,而像java 对象大部分会发生变更。又或者以垃圾收集的主要部分进行分区。
线程私有的数据区
程序计数器
程序计数器(Program Counter Register)是一块较小的内存空间,它可以看作是当前线程所执行的字节码的行号指示器
为什么需要它?
由于Java虚拟机的多线程是通过线程轮流切换、分配处理器执行时间的方式来实现的,在任何一个确定的时刻,一个处理器只会执行一条线程中的指令。因此,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器变量,各条线程之间计数器互不影响,独立存储。
程序计数器是内存区域唯一一个在《Java虚拟机规范》中没有规定任何OutOfMemoryError情况的区域。
Java虚拟机栈
Java虚拟机栈是Java方法执行的线程内存模型:每个方法被执行的时候,Java虚拟机都会同步创建一个栈帧用于存储局部变量表、操作数栈、动态连接、方法出口等信息。每一个方法被调用直至执行完毕的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程

-
局部变量表:编译期可知的各种Java虚拟机基本数据类型(boolean、int、double等)、对象引用(reference类型,它并不等同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或者其他与此对象相关的位置)和returnAddress 类型(指向了一条字节码指令的地址)。说的通俗一点就是用于存放方法参数和方法内部定义的局部变量
-
操作数栈:用户方法内临时运算,暂存中间结果(2+4*5)
-
动态链接:
在A.java文件中,比如A.java依赖于B.java,那么在A.class的静态常量池中如何表示ClassB的地址呢,就是通过一个符号,比如字面量"abc"来表示ClassB所在的地址。 在类加载解析阶段,是有一步就是把符号引用转为直接引用的步骤。就是把"abc" 符号引用转换成classB的实际地址,也就是直接引用。实际上,我理解当时只是转换了已知的一部分,比如类的符号引用、字段的符号引用、部分方法的符号引用等。还存在一部分在类加载时也无法转换,比如ClassA某个方法中调用了某个多态的方法。多态的实现类是需要在运行时才可以确定。那如何解决这个问题?就是动态链接
每一个栈帧内部都包含一个指向运行时常量池中该栈帧所属方法的引用,包含这个引用的目的就是为了支持当前方法的代码能够实现动态链接。
动态链接就是将指令中的符号引用转化为真实的方法地址。
在《Java虚拟机规范》中,对这个内存区域规定了两类异常状况:如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverflowError异常;如果Java虚拟机栈容量可以动态扩展,当栈扩展时无法申请到足够的内存会抛出OutOfMemoryError异常。
本地方法栈
本地方法栈(Native Method Stacks)与虚拟机栈所发挥的作用是非常相似的,其区别只是虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则是为虚拟机使用到的本地(Native)方法服务。
《Java虚拟机规范》对本地方法栈中方法使用的语言、实现方式与数据结构并没有任何强制规定,因此具体的虚拟机可以根据需要自由实现它,甚至有的Java虚拟机(譬如Hot-Spot虚拟机)直接就把本地方法栈和虚拟机栈合二为一。与虚拟机栈一样,本地方法栈也会在栈深度溢出或者栈扩展失败时分别抛出StackOverflowError和OutOfMemoryError异常。
线程共享的区域
Java堆
堆内存区域的唯一目的就是存放对象实例,Java世界里“几乎”所有的对象实例都在这里分配内存。
《Java虚拟机规范》中对Java堆的描述是:“所有的对象实例以及数组都应当在堆上分配
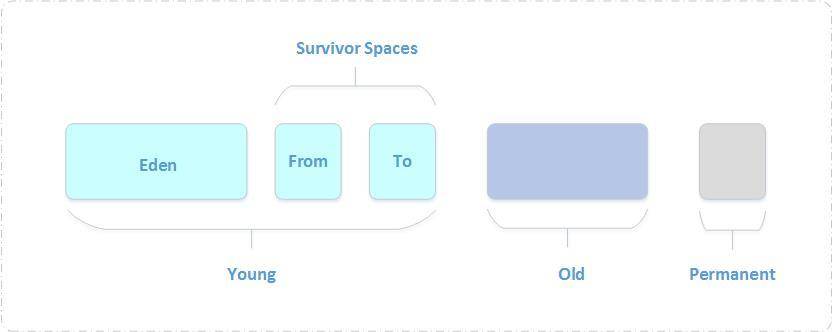
为什么堆又分为“新生代”、“老年代”?新生代又分“Eden空间”、“S0”、“S1”?
从回收内存的角度看,由于现代垃圾收集器大部分都是基于分代收集理论设计的,实际上,这些区域划分仅仅是一部分垃圾收集器的共同特性或者说设计风格而已,而非某个Java虚拟机具体实现的固有内存布局,更不是《Java虚拟机规范》里对Java堆的进一步细致划分。
不少资料上经常写着类似于“Java虚拟机的堆内存分为新生代、老年代、永久代、Eden、Survivor……”这样的内容。在十年之前(以G1收集器的出现为分界),作为业界绝对主流的HotSpot虚拟机,它内部的垃圾收集器全部都基于“经典分代”来设计,需要新生代、老年代收集器搭配才能工作,在这种背景下,上述说法还算是不会产生太大歧义。但是到了今天,垃圾收集器技术与十年前已不可同日而语,HotSpot里面也出现了不采用分代设计的新垃圾收集器,再按照上面的提法就有很多需要商榷的地方了。
是否还存在其他角度的划分呢?
从分配内存的角度看,所有线程共享的Java堆中可以划分出多个线程私有的分配缓冲区(Thread Local Allocation Buffer,TLAB),以提升对象分配时的效率。不过无论从什么角度,无论如何划分,都不会改变Java堆中存储内容的共性,无论是哪个区域,存储的都只能是对象的实例,将Java堆细分的目的只是为了更好地回收内存,或者更快地分配内存
根据《Java虚拟机规范》的规定,Java堆可以处于物理上不连续的内存空间中,但在逻辑上它应该被视为连续的(虚拟内存),这点就像我们用磁盘空间去存储文件一样,并不要求每个文件都连续存放。但对于大 对象(典型的如数组对象),多数虚拟机实现出于实现简单、存储高效的考虑,很可能会要求连续的内存空间。
Java堆既可以被实现成固定大小的,也可以是可扩展的,不过当前主流的Java虚拟机都是按照可扩展来实现的(通过参数-Xmx和-Xms设定)。如果在Java堆中没有内存完成实例分配,并且堆也无法再扩展时,Java虚拟机将会抛出OutOfMemoryError异常。
方法区
方法区(Method Area)用于存储已被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等数据。
《Java虚拟机规范》中把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫作“非堆”(Non-Heap),目的是与Java堆区 分开来。
Java8 之前,Hotspot对方法区的实现为什么是永久代?又或者说如何对方法区进行回收?
在JDK 8以前,很多人都喜欢把方法区称呼为“永久代”(Permanent Generation),或将两者混为一谈。本质上这两者并不是等价的,因为仅仅是当时的HotSpot虚拟机设计团队选择把收集器的分代设计扩展至方法区,或者说使用永久代来实现方法区而已,这样使得HotSpot的垃圾收集器能够像管理Java堆一样管理这部分内存,省去专门为方法区编写内存管理代码的工作。
其他虚拟机如BEA JRockit、IBM J9 是不存在永久代的概念的。
原则上如何实现方法区属于虚拟机实现细节,不受《Java虚拟机规范》管束,并不要求统一。
Hotspot为什么放弃永久代的实现
现在回头来看,当年使用永久代来实现方法区的决定并不是一个好主意,这种设计导致了Java应用更容易遇到内存溢出的问题(永久代有-XX:MaxPermSize的上限,即使不设置也有默认大小,而J9和JRockit只要没有触碰到进程可用内存的上限,就不会出问题(怎么理解呢?),而且有极少数方法(例如String::intern())会因永久代的原因而导致不同虚拟机下有不同的表现。当Oracle收购BEA获得了JRockit的所有权后,准备把JRockit中的优秀功能,譬如Java Mission Control管理工具,移植到HotSpot 虚拟机时,但因为两者对方法区实现的差异而面临诸多困难。考虑到HotSpot未来的发展,在JDK 6的时候HotSpot开发团队就有放弃永久代,逐步改为采用本地内存(Native Memory)来实现方法区的计划了,到了JDK 7的HotSpot,已经把原本放在永久代的字符串常量池、静态变量等移出到堆中,而到了JDK 8,终于完全废弃了永久代的概念,改用与JRockit、J9一样在本地内存中实现的元空间(Meta- space)来代替,把JDK 7中永久代还剩余的内容(主要是类型信息)全部移到元空间中。(放弃某一个东西不是一步到位的。)
PS:元空间和直接内存使用的都是本地内存,不受到JVM进程内存大小的限制。只受限于本机总内存
《Java虚拟机规范》对方法区的约束是非常宽松的,除了和Java堆一样不需要连续的内存和可以选择固定大小或者可扩展外,甚至还可以选择不实现垃圾收集。相对而言,垃圾收集行为在这个区域的确是比较少出现的,但并非数据进入了方法区就如永久代的名字一样“永久”存在了。这区域的内存回收目标主要是针对常量池的回收和对类型的卸载,一般来说这个区域的回收效果比较难令人满意,尤其是类型的卸载,条件相当苛刻,但是这部分区域的回收有时又确实是必要的
根据《Java虚拟机规范》的规定,如果方法区无法满足新的内存分配需求时,将抛出OutOfMemoryError异常。
运行时常量池
运行时常量池(Runtime Constant Pool)是方法区的一部分。Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池表(Constant Pool Table),用于存放编译期生成的各种字面量与符号引用,这部分内容将在类加载后存放到方法区的运行时常量池中。
public class cn.comein.config.RedisKeyListen extends redis.clients.jedis.JedisPubSubminor version: 0major version: 52flags: ACC_PUBLIC, ACC_SUPER
Constant pool:
// 比如方法中创建一个对象 new\invoke --> 可以理解是一个类的字典#1 = Methodref #13.#38 // redis/clients/jedis/JedisPubSub."<init>":()V#2 = Fieldref #11.#39 // cn/comein/config/RedisKeyListen.log:Lorg/slf4j/Logger;#3 = String #40 // 收到redisKey过期消息,channel: {}, messageKey: {}#4 = InterfaceMethodref #41.#42 // org/slf4j/Logger.info:#5 = Class #43 // cn/comein/common/keylisten/ExpireKeyVo#6 = Methodref #5.#38 // cn/comein/common/keylisten/ExpireKeyVo."<init>":()V#7 = Methodref #5.#44 // cn/comein/common/keylisten/ExpireKeyVo.setChannel:#8 = Methodref #5.#45 // cn/comein/common/keylisten/ExpireKeyVo.setKey:#9 = Fieldref #11.#46 // #10 = InterfaceMethodref #47.#48 // org/springframework/context/ApplicationContext.publishEvent:#11 = Class #49 // cn/comein/config/RedisKeyListen#12 = Methodref #50.#51 // org/slf4j/LoggerFactory.getLogger:#13 = Class #52 // redis/clients/jedis/JedisPubSub#14 = Utf8 log#15 = Utf8 Lorg/slf4j/Logger;
{public void onMessage(java.lang.String, java.lang.String);descriptor: (Ljava/lang/String;Ljava/lang/String;)Vflags: ACC_PUBLICCode:stack=4, locals=4, args_size=30: getstatic #2 // Field log:Lorg/slf4j/Logger;3: ldc #3 // String 收到redisKey过期消息,channel: {}, messageKey: {}5: aload_16: aload_27: invokeinterface #4, 4 // InterfaceMethod org/slf4j/Logger.info:12: new #5 // class cn/comein/common/keylisten/ExpireKeyVo15: dup16: invokespecial #6 // Method cn/comein/common/keylisten/ExpireKeyVo."<init>":()V19: astore_3
既然每个class 都有一个静态常量池,那加载到jvm 时是否每一个class文件都对应一个运行时常量池?
我在网上找了一些资料,答案参其不齐,有的说不是,有的说是。后来我看了JVM 规范中对运行时常量池的描述,答案也有点模糊,不太确定,初步的答案时肯定的。

那么遇到这种情况,我就有个习惯,我会尝试站在设计者的角度去思考,也就是如果是我,我会怎么去设计、怎么去实现他!
.class文件中静态的常量池中是有索引的,每个class 的常量池都是从0开始编号,有的常量池项还持有其它常量池项的引用,指向另一个常量池项;方法指令中也存在会指向某一个常量池项。如果在类加载后都公用一个全局的运行时常量池,那么每个静态常量池中编号和索引,以及方法中的指令索引也要修改,这看来似乎不太现实。分开还更容易维护,比如在方法区中开辟一块内存专门存储运行时常量池。可以理解这一整块运行时常量池是一个map,key 是类的全限定名,value 是每个class 对应的运行时常量池。
另外,这个内存区域,一般来说,除了保存Class文件中描述的符号引用外,还会把由符号引用翻译出来的直接引用也存储在运行时常量池中。
运行时常量池相对于Class文件常量池的另外一个重要特征是具备动态性,Java语言并不要求常量一定只有编译期才能产生,也就是说,并不是只有Class文件中常量池的内容才能进入方法区运行时常量池,运行期间也可以将新的常量放入池中,这种特性被开发人员利用得比较多的便是String类的intern()方法。
既然运行时常量池是方法区的一部分,自然受到方法区内存的限制,当常量池无法再申请到内存时会抛出OutOfMemoryError异常。
字符串常量池
我在学习过程中会对字符串常量池和运行时常量池所存储的东西有所混淆,不知道你们有没有。尽管你们没有,我觉得我还是有必要说一下,当作个记录笔记吧。
为什么搞一个字符串常量池?
字符串的分配,和其他的对象分配一样,耗费高昂的时间与空间代价,作为最基础的数据类型,大量频繁的创建字符串,极大程度地影响程序的性能。另外字符串是不可变的,可以不用担心数据冲突进行共享,所以JVM团队为了重用String对象而单独给它开辟了一块空间,叫做字符串常量池,Java1.6之前在方法区中,1.7 后移到了堆中。
注意:字符串常量池保存的是String对象的引用,String对象本身存在于堆上的其他位置。
字符串常量池在底层就是一个 StringTable,可以简单理解 map(Set),key 是该字符串的字面量,value 是指向堆中对象的引用。
很多面试官在面试的时候喜欢问这个一个问题:“String s = new String(“xyz”);创建了多少个String实例”?
很多人都会说是一个或者两个,两个的话分别是一个是字符串字面量"xyz"所对应的、驻留(intern)在一个全局共享的字符串常量池中的实例,另一个是通过new String(String)创建并初始化的、内容与"xyz"相同的实例。
也有很多人说这样的说法不太准确,甚至认为这个问题问法有问题的。
因为根据 R大的这篇文章,在这条语句所在的类被加载时,字符串池中已经存在字符串字面量"xyz"所对应的常量池的对象了,如果是这样的话,当指令真正执行这个的时候,任何时候都是只创建了一个对象,就是 new 这个。
后来我又通过查阅资料,JVM规范里明确指定 resolve 阶段可以是lazy的。什么意思呢?就HotSpot VM的实现来说,加载类的时候,那些字符串字面量会进入到当前类的运行时常量池,不会进入全局的字符串常量池(即在StringTable中并没有相应的引用,在堆中也没有对应的对象产生),而是在执行到该行代码指令时,才开始对字符串字面量"xyz"创建对象,并把引用放入到常量池中,接着再通过new String(String)创建并初始化的、内容与"xyz"相同的实例。
从StackOverflow找到这个问题的:https://www.zhihu.com/question/55994121/answer/147296098
public class Test {public static void main(String[] args) {test('h', 'e', 'l', 'l', 'o');}static void test(char... arg) {String s1 = new String(arg);String s2 = s1.intern();System.out.println('"'+s1+'"'+(s1!=s2? " existed": " did not exist")+" in the pool before");System.out.println("hello");}
}
// String的 intern 方法干了什么?
// DK7中,如果常量池中已经有了这个字符串,那么直接返回常量池中它的引用,如果没有,那就将它的引用保存一份到字符串常量池,然后直接返回这个引用。
直接内存
直接内存(Direct Memory)并不是虚拟机运行时数据区的一部分,也不是《Java虚拟机规范》中定义的内存区域。但是这部分内存也被频繁地使用,而且也可能导致OutOfMemoryError异常出现,所以我放到这里一起来了解一下。
在JDK 1.4中新加入了NIO(New Input/Output)类,引入了一种基于通道(Channel)与缓冲区(Buffer)的I/O方式,它可以使用Native函数库直接分配堆外内存,然后通过一个存储在Java堆里面的DirectByteBuffer对象作为这块内存的引用进行操作。这样能在一些场景中显著提高性能,因为避免了在Java堆和Native堆中来回复制数据。
显然,本机直接内存的分配不会受到Java堆大小的限制,但是,既然是内存,则肯定还是会受到本机总内存大小,一般服务管理员配置虚拟机参数时,会根据实际内存去设置-Xmx等参数信息,但经常忽略掉直接内存,使得各个内存区域总和大于物理内存限制,从而导致动态扩展时出现OutOfMemoryError异常。
相关文章:
JVM:运行时数据区域(白话文)
最近有时间在看一本<深入了解Java虚拟机>的书籍,这本书是一个中国人,名叫周志明的人写的。相比于其他翻译过来的技术书籍,这本书还是挺通俗易懂的。先前有和彬哥在聊,他说如果是自己一个人看的话会很枯燥,很难坚…...

Go语言并发编程(千锋教育)
Go语言并发编程(千锋教育) 视频地址:https://www.bilibili.com/video/BV1t541147Bc?p14 作者B站:https://space.bilibili.com/353694001 源代码:https://github.com/rubyhan1314/go_goroutine 1、基本概念 1.1、…...

CSS革命:用Sass/SCSS引领前端创新
目录 前言SCSSSassSass 和 SCSS 的区别 前言 在现代的前端开发中,CSS已成为呈现网页和应用程序样式的核心。然而,原生的CSS语法在大型项目中可能变得混乱、冗长且难以维护。 为了解决这些问题,SCSS(Sass CSS)和Sass&am…...

MAPPO 算法的深度解析与应用和实现
【论文研读】 The Surprising Effectiveness of PPO in Cooperative Multi-Agent Games 说明: 来源:36th Conference on Neural Information Processing Systems (NeurIPS 2022) Track on Datasets and Benchmarks. 是NIPS文章,质量有保障&…...

API接口的涉及思路以及部分代码
在现代软件开发中,API(Application Programming Interface)接口扮演了一个至关重要的角色。通过API接口,不同的应用程序、系统或服务之间可以进行数据交换和相互调用,实现功能的扩展和集成。本文将探讨API接口的设计思…...

Stable Diffusion无需代码连接QQ邮箱的方法
Stable Diffusion用户使用场景: 电商商家在产品测试阶段,通过微信社群日常收集用户对产品设计的反馈,包括对产品的修改建议或外观设计等,并将这些反馈上传至集简云小程序。然后,他们使用Stable Diffusion AI工具生成图…...

Excel表格(一)
1.单一栏的宽度和高度设置 2.大标题的跨栏居中 3.让单元格内的文字------自动适应 4.序号递增 5.货币符号 6.日期格式的选择 选到单元格,选中对应的日期格式 7.自动求和的计算 然后在按住回车键即可求出当前行的金额 点击自动求和 8.冻结表格栏 9.排序 1.单栏排序 …...

详细介绍渗透测试与漏洞扫描
一、概念 渗透测试: 渗透测试并没有一个标准的定义,国外一些安全组织达成共识的通用说法;通过模拟恶意黑客的攻击方法,来评估计算机网络系统安全的一种评估方法。这个过程包括对系统的任何弱点、技术缺陷或漏洞的主动的主动分析…...
Scikit-learn聚类方法代码批注及相关练习
一、代码批注 代码来自:https://scikit-learn.org/stable/auto_examples/cluster/plot_dbscan.html#sphx-glr-auto-examples-cluster-plot-dbscan-py import numpy as np from sklearn.cluster import DBSCAN from sklearn import metrics from sklearn.datasets …...

C#程序的启动显示方案(无窗口进程发送消息) - 开源研究系列文章
今天继续研究C#的WinForm的实例显示效果。 我们上次介绍了Winform窗体的唯一实例运行代码(见博文:基于C#的应用程序单例唯一运行的完美解决方案 - 开源研究系列文章 )。这就有一个问题,程序已经打开了,这时候再次运行该应用程序,…...

java泛型和通配符的使用
泛型机制 本质是参数化类型(与方法的形式参数比较,方法是参数化对象)。 优势:将类型检查由运行期提前到编译期。减少了很多错误。 泛型是jdk5.0的新特性。 集合中使用泛型 总结: ① 集合接口或集合类在jdk5.0时都修改为带泛型的结构② 在实例化集合类时…...
【网络】自定义协议 | 序列化和反序列化 | 以tcpServer为例
本文首发于 慕雪的寒舍 以tcpServer的计算器服务为例,实现一个自定义协议 阅读本文之前,请先阅读 tcpServer 本文完整代码详见 Gitee 1.重谈tcp 注意,当下所对tcp的描述都是以简单、方便理解起见,后续会对tcp协议进行深入解读 …...
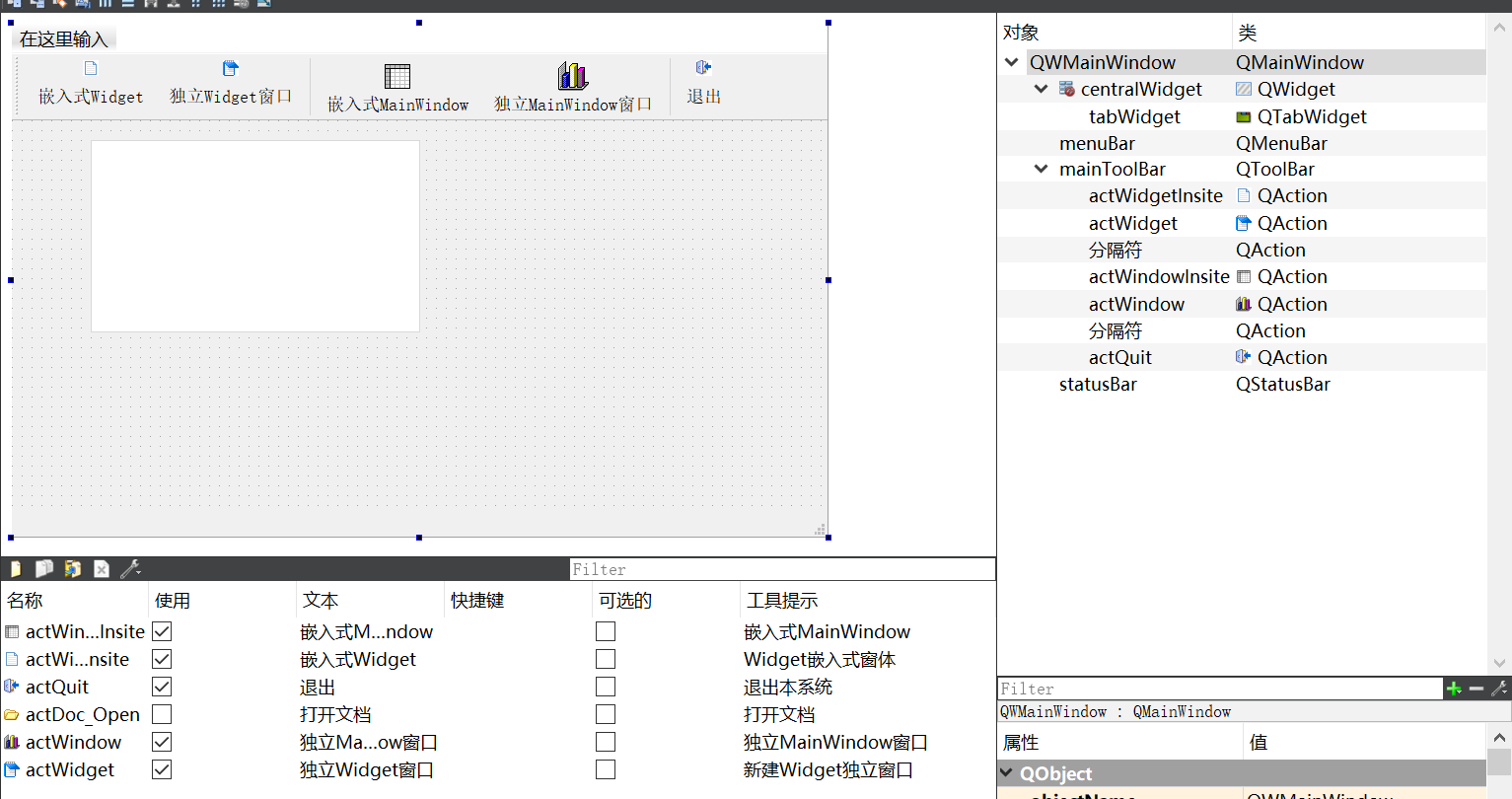
06-3_Qt 5.9 C++开发指南_多窗体应用程序的设计(主要的窗体类及其用途;窗体类重要特性设置;多窗口应用程序设计)
文章目录 1. 主要的窗体类及其用途2. 窗体类重要特性的设置2.1 setAttribute()函数2.2 setWindowFlags()函数2.3 setWindowState()函数2.4 setWindowModality()函数2.5 setWindowOpacity()函数 3. 多窗口应用程序设计3.1 主窗口设计3.2 QFormDoc类的设计3.3 QFormDoc类的使用3.…...

(力扣)用两个栈实现队列
这里是栈的源代码:栈和队列的实现 当然,自己也可以写一个栈来用,对题目来说不影响,只要符合栈的特点就行。 题目: 请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(push、pop、pe…...

【自动化测试框架】关于unitttest你需要知道的事
一、UnitTest单元测试框架提供了那些功能 1.提供用例组织和执行 如何定义一条“测试用例”? 如何灵活地控制这些“测试用例”的执行? 2.提供丰定的断言方法 当测试用例的执行结果与预期结果不一致时,判定测试用例失败。在自动化测试中,通过“断言”…...
手机便签中可以打勾的圆圈或小方块怎么弄?
在日常的生活和工作中,很多网友除了使用手机便签来记录灵感想法、读书笔记、各种琐事、工作事项外,还会用它来记录一些清单,例如待办事项清单、读书清单、购物清单、旅行必备物品清单等。 在按照记录的清单内容来执行的时候,为了…...

【Linux】gdb 的使用
目录 1. 使用 gdb 的前置工作 2. 如何使用 gdb 进行调试 1、如何看到我的代码 2、如何打断点 3、怎么运行程序 4、如何进行逐过程调试 5、如何进行逐语句调试 6、如何监视变量值 7、如何跳到指定位置 8、运行完一个函数 9、怎么跳到下一个断点 10、如何禁用/开启…...
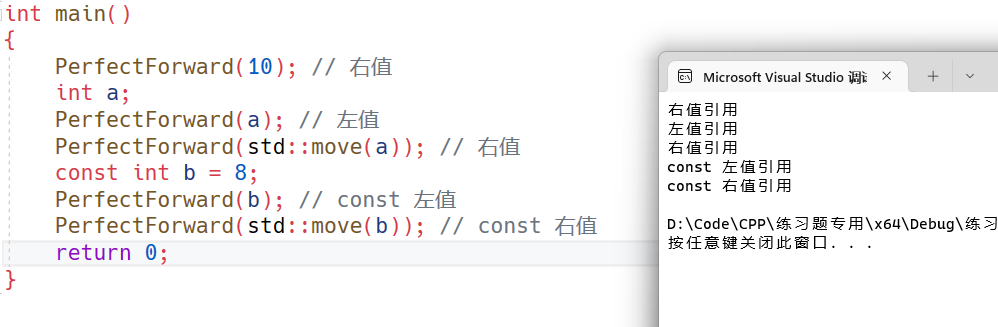
C++11之右值引用
C11之右值引用 传统的C语法中就有引用的语法,而C11中新增了的 右值引用(rvalue reference)语法特性,所以从现在开始我们之前学习的引用就叫做左值引用(lvalue reference)。无论左值引用还是右值引用&#…...

【PHP的设计模式】
PHP的设计模式 一、策略模式二、工厂模式三、单例模式四、注册模式五、适配器模式六、观察者模式 一、策略模式 策略模式是对象的行为模式,用意是对一组算法的封装。动态的选择需要的算法并使用。 策略模式指的是程序中涉及决策控制的一种模式。策略模式功能非常强…...
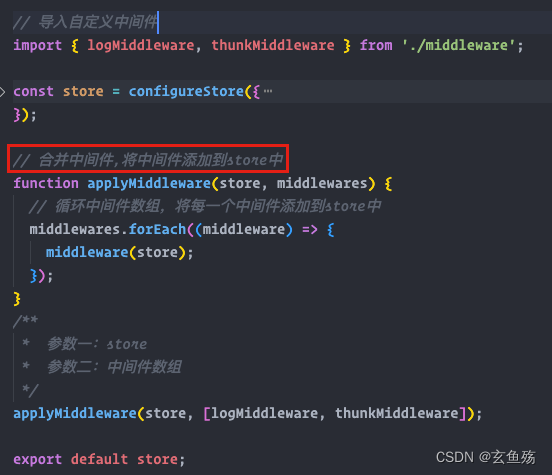
React 之 Redux - 状态管理
一、前言 1. 纯函数 函数式编程中有一个非常重要的概念叫纯函数,JavaScript符合函数式编程的范式,所以也有纯函数的概念 确定的输入,一定会产生确定的输出 函数在执行过程中,不能产生副作用 2. 副作用 表示在执行一个函数时&a…...

OpenLayers 可视化之热力图
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 热力图(Heatmap)又叫热点图,是一种通过特殊高亮显示事物密度分布、变化趋势的数据可视化技术。采用颜色的深浅来显示…...

通过Wrangler CLI在worker中创建数据库和表
官方使用文档:Getting started Cloudflare D1 docs 创建数据库 在命令行中执行完成之后,会在本地和远程创建数据库: npx wranglerlatest d1 create prod-d1-tutorial 在cf中就可以看到数据库: 现在,您的Cloudfla…...

ssc377d修改flash分区大小
1、flash的分区默认分配16M、 / # df -h Filesystem Size Used Available Use% Mounted on /dev/root 1.9M 1.9M 0 100% / /dev/mtdblock4 3.0M...

FastAPI 教程:从入门到实践
FastAPI 是一个现代、快速(高性能)的 Web 框架,用于构建 API,支持 Python 3.6。它基于标准 Python 类型提示,易于学习且功能强大。以下是一个完整的 FastAPI 入门教程,涵盖从环境搭建到创建并运行一个简单的…...

电脑插入多块移动硬盘后经常出现卡顿和蓝屏
当电脑在插入多块移动硬盘后频繁出现卡顿和蓝屏问题时,可能涉及硬件资源冲突、驱动兼容性、供电不足或系统设置等多方面原因。以下是逐步排查和解决方案: 1. 检查电源供电问题 问题原因:多块移动硬盘同时运行可能导致USB接口供电不足&#x…...

【快手拥抱开源】通过快手团队开源的 KwaiCoder-AutoThink-preview 解锁大语言模型的潜力
引言: 在人工智能快速发展的浪潮中,快手Kwaipilot团队推出的 KwaiCoder-AutoThink-preview 具有里程碑意义——这是首个公开的AutoThink大语言模型(LLM)。该模型代表着该领域的重大突破,通过独特方式融合思考与非思考…...

el-switch文字内置
el-switch文字内置 效果 vue <div style"color:#ffffff;font-size:14px;float:left;margin-bottom:5px;margin-right:5px;">自动加载</div> <el-switch v-model"value" active-color"#3E99FB" inactive-color"#DCDFE6"…...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...

如何在看板中有效管理突发紧急任务
在看板中有效管理突发紧急任务需要:设立专门的紧急任务通道、重新调整任务优先级、保持适度的WIP(Work-in-Progress)弹性、优化任务处理流程、提高团队应对突发情况的敏捷性。其中,设立专门的紧急任务通道尤为重要,这能…...

(二)原型模式
原型的功能是将一个已经存在的对象作为源目标,其余对象都是通过这个源目标创建。发挥复制的作用就是原型模式的核心思想。 一、源型模式的定义 原型模式是指第二次创建对象可以通过复制已经存在的原型对象来实现,忽略对象创建过程中的其它细节。 📌 核心特点: 避免重复初…...