TFRecords详解
内容目录
- TFRecords 是什么
- 序列化(Serialization)
- tf.data
- 图像序列化(Serializing Images)
- tf.Example
- 函数封装
- 小结
TFRecords 是什么
TPU拥有八个核心,充当八个独立的工作单元。我们可以通过将数据集分成多个文件或分片(shards),更有效地将数据传输给每个核心。这样,每个核心都可以在需要时获取数据的独立部分。
在TensorFlow中,用于分片的最方便的文件类型是TFRecord。TFRecord是一种包含字节串序列的二进制文件。数据在写入TFRecord之前需要被序列化(编码为字节串)。
在TensorFlow中,最方便的数据序列化方式是使用tf.Example封装数据。这是一种基于谷歌的protobufs的记录格式,但专为TensorFlow设计。它更或多或少地类似于带有一些类型注释的字典。
首先,我们将介绍如何使用TFRecords读取和写入数据。然后,我们将介绍如何使用tf.Example封装数据。
Protobufs(Protocol Buffers),也称为Protocol Buffers语言,是一种由Google开发的数据序列化格式。它可以用于结构化数据的序列化、反序列化以及跨不同平台和语言的数据交换。通过在一个结构体定义文件中定义数据结构,然后使用相应的编译器将其编译为特定语言的类,您可以方便地在不同的系统和编程语言之间共享和传输数据。
序列化(Serialization)
TFRecord是TensorFlow用于存储二进制数据的一种文件类型。TFRecord包含字节串序列。下面是一个非常简单的TFRecord示例:
import tensorflow as tf
import numpy as npPATH = '/kaggle/working/data.tfrecord'with tf.io.TFRecordWriter(path=PATH) as f:f.write(b'123') # write one recordf.write(b'xyz314') # write another recordwith open(PATH, 'rb') as f:print(f.read())

TFRecord是一系列字节,因此在将数据放入TFRecord之前,我们必须将数据转换为字节串。我们可以使用tf.io.serialize_tensor将张量转换为字节串,使用tf.io.parse_tensor将其转换回张量。在解析字符串并将其再次转换为张量时,保持张量的数据类型(在这种情况下为tf.uint8)非常重要,因为您必须在解析过程中指定该数据类型。
x = tf.constant([[1, 2], [3, 4]], dtype=tf.uint8)
print('x:', x, '\n')x_bytes = tf.io.serialize_tensor(x)
print('x_bytes:', x_bytes, '\n')print('x:', tf.io.parse_tensor(x_bytes, out_type=tf.uint8))

tf.data
那么如何将数据集写入TFRecord呢?如果您的数据集由字节串组成,您可以使用data.TFRecordWriter。要再次读取数据集,可以使用data.TFRecordsDataset。
from tensorflow.data import Dataset, TFRecordDataset
from tensorflow.data.experimental import TFRecordWriter# 创建一个小数据集
ds = Dataset.from_tensor_slices([b'abc', b'123'])# 写入数据
writer = TFRecordWriter(PATH)
writer.write(ds)# 读取数据集
ds_2 = TFRecordDataset(PATH)
for x in ds_2:print(x)
如果您的数据集由张量组成,请首先通过在数据集上映射tf.io.serialize_tensor来进行序列化。然后,在读取数据时,使用tf.io.parse_tensor来将字节串转换回张量。
features = tf.constant([[1, 2],[3, 4],[5, 6],
], dtype=tf.uint8)
ds = Dataset.from_tensor_slices(features)# 对张量进行序列化操作
# 通过使用 `map` 函数,可以在数据集中的每个张量上应用 `tf.io.serialize_tensor` 进行序列化操作。
ds_bytes = ds.map(tf.io.serialize_tensor)# 写入数据
writer = TFRecordWriter(PATH)
writer.write(ds_bytes)# 读取数据(反序列化)
ds_bytes_2 = TFRecordDataset(PATH)
ds_2 = ds_2.map(lambda x: tf.io.parse_tensor(x, out_type=tf.uint8))# They are the same!
for x in ds:print(x)
print()
for x in ds_2:print(x)

# 简化
def parse_serialized(serialized):return tf.io.parse_tensor(serialized, out_type=tf.uint8) # 修改 out_type 根据您的张量数据类型ds_3 = TFRecordDataset(PATH)ds_3 = ds_3.map(parse_serialized)for x in ds_3:print(x) #结果和上面一致
图像序列化(Serializing Images)
对图像进行序列化有多种方法:
- 使用tf.io.serialize_tensor进行原始编码,使用tf.io.parse_tensor进行解码。
- 使用tf.io.encode_jpeg进行JPEG编码,使用tf.io.decode_jpeg或tf.io.decode_and_crop_jpeg进行解码。
- 使用tf.io.encode_png进行PNG编码,使用tf.io.decode_png进行解码。
只需确保使用与您选择的编码器相对应的解码器。通常,在使用TPU时,使用JPEG编码对图像进行编码是一个不错的选择,因为这可以对数据进行一定程度的压缩,从而可能提高数据传输速度。
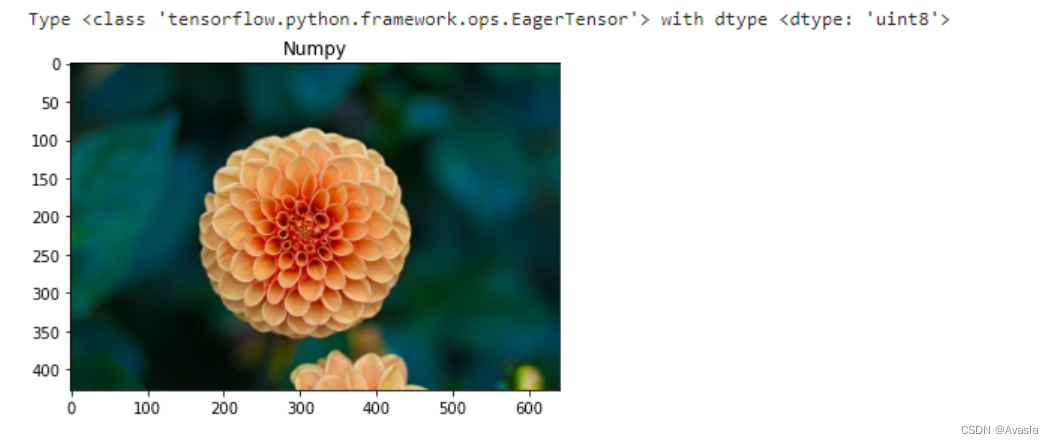
from sklearn.datasets import load_sample_image
import matplotlib.pyplot as plt# Load numpy array
image_raw = load_sample_image('flower.jpg')
print("Type {} with dtype {}".format(type(image_raw), image_raw.dtype))
plt.imshow(image_raw)
plt.title("Numpy")
plt.show()

from IPython.display import Image# jpeg encode / decode
image_jpeg = tf.io.encode_jpeg(image_raw)
print("Type {} with dtype {}".format(type(image_jpeg), image_jpeg.dtype))
print("Sample: {}".format(image_jpeg.numpy()[:25])) #显示前25个编码后的字节
Image(image_jpeg.numpy())
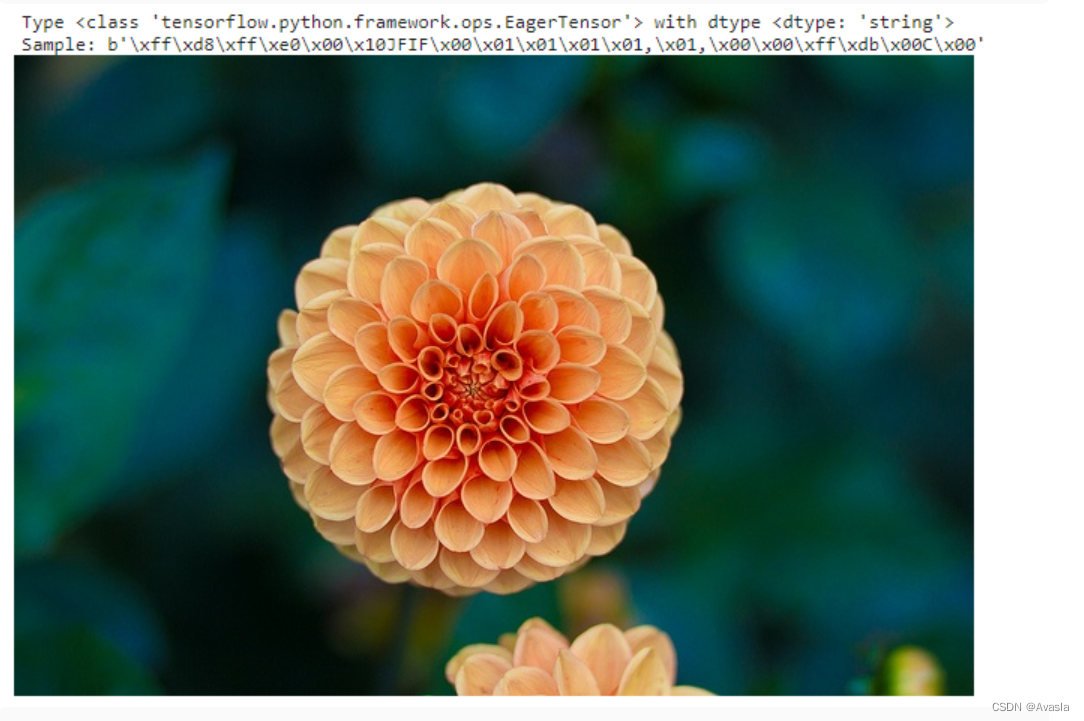
image_raw_2 = tf.io.decode_jpeg(image_jpeg)print("Type {} with dtype {}".format(type(image_raw_2), image_raw_2.dtype))
plt.imshow(image_raw_2)
plt.title("Numpy")
plt.show()
tf.Example
如果您有结构化数据,比如成对的图像和标签,该怎么办?TensorFlow还包括用于结构化数据的API,即tf.Example。它们基于谷歌的Protocol Buffers。
一个单独的Example旨在表示数据集中的一个实例,比如一个(图像、标签)对。每个Example都有Features,这被描述为特征名称和值的字典。一个值可以是BytesList、FloatList或Int64List,每个值都包装为单独的Feature。没有用于张量的值类型;相反,使用tf.io.serialize_tensor对张量进行序列化,通过numpy方法获取字节串,并将其编码为BytesList。
以下是我们如何对带有标签的图像数据进行编码的示例:
from tensorflow.train import BytesList, FloatList, Int64List
from tensorflow.train import Example, Features, Feature# The Data
image = tf.constant([ # this could also be a numpy array[0, 1, 2],[3, 4, 5],[6, 7, 8],
])
label = 0
class_name = "Class A"# Wrap with Feature as a BytesList, FloatList, or Int64List
image_feature = Feature(bytes_list=BytesList(value=[tf.io.serialize_tensor(image).numpy(),])
)
label_feature = Feature(int64_list=Int64List(value=[label]),
)
class_name_feature = Feature(bytes_list=BytesList(value=[class_name.encode()])
)# Create a Features dictionary
features = Features(feature={'image': image_feature,'label': label_feature,'class_name': class_name_feature,
})# Wrap with Example
example = Example(features=features)print(example)

查看标签内容
![![[Pasted image 20230810140233.png]]![[Pasted image 20230810140309.png]]](https://img-blog.csdnimg.cn/d51faf40c20d4d288129ae47561d8fa8.png)
一旦所有内容都被编码为一个示例(Example),可以使用SerializeToString方法将其序列化。
![![[Pasted image 20230810140347.png]]](https://img-blog.csdnimg.cn/101e5f6972094aa1b2f6eaa93121e756.png)
函数封装
def make_example(image, label, class_name):image_feature = Feature(bytes_list=BytesList(value=[tf.io.serialize_tensor(image).numpy(),]))label_feature = Feature(int64_list=Int64List(value=[label,]))class_name_feature = Feature(bytes_list=BytesList(value=[class_name.encode(),]))features = Features(feature={'image': image_feature,'label': label_feature,'class_name': class_name_feature,})example = Example(features=features)return example.SerializeToString()
函数使用如下:
example = make_example(image=np.array([[1, 2], [3, 4]]),label=1,class_name="Class B",
)print(example)
![![[Pasted image 20230810140530.png]]](https://img-blog.csdnimg.cn/e0417b0185b54e3baf64a8353f9b6d66.png)
小结
整个过程可能如下所示:
- 使用
tf.data.Dataset构建数据集。您可以使用from_generator或from_tensor_slices方法。 - 通过使用
make_example遍历数据集来序列化数据集。 - 使用
io.TFRecordWriter或data.TFRecordWriter将数据集写入TFRecords。
然而,请注意,如果要在数据集的map方法中使用make_example之类的函数,您需要首先使用tf.py_function对其进行包装,因为TensorFlow以图模式执行数据集变换。您可以编写类似以下的代码:
ds_bytes = ds.map(lambda image, label: tf.py_function(func=make_example, inp=[image, label], Tout=tf.string))
其他资料
API文档tf.data.Dataset | TensorFlow v2.13.0。
相关文章:
TFRecords详解
内容目录 TFRecords 是什么序列化(Serialization)tf.data 图像序列化(Serializing Images)tf.Example函数封装 小结 TFRecords 是什么 TPU拥有八个核心,充当八个独立的工作单元。我们可以通过将数据集分成多个文件或分片(shards)…...
【多维定向滤波器组和表面波】表面变换:用于高效表示多维 s 的多分辨率变换(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

45.113.201.X服务器远程不上是什么原因,有什么办法解决?
45.113.201.1远程登录不上可能有多种原因导致,以下是一些常见的问题和解决方法: 网络连接问题:确保本地网络连接正常,尝试通过其他设备或网络连接服务器,确认是否是网络问题导致无法远程登录。 IP地址或端口错误&…...

微信小程序 地图map(电子围栏圆形和多边形)
正常情况下是没有手机上画电子围栏的,公共平台上我也没找到,所以走了一个歪点子,就是给地图添加点击事件,记录点的位置,在画到电子围栏上就是添加电子围栏了,如果只是显示电子围栏就简单了 一、多边形电子…...

Dockerfile 文件
dockerfile是一个文本文件,包含一条条指令,每条指令都会构建一层镜,一般分为四部分:基础镜像信息、维护者信息、镜像操作指令和容器启动时执行指令,#为 Dockerfile 中的注释。 docker build 基于dockerfile制作镜像 OPTIONS参数 …...
ssm学院党员管理系统源码和论文PPT
ssm学院党员管理系统源码和论文PPT002 开发工具:idea 数据库mysql5.7(mysql5.7最佳) 数据库链接工具:navcat,小海豚等 开发技术:java ssm tomcat8.5 选题意义、价值和目标: 随着鄂尔多斯应用技术学院招生规模的不断扩大&…...

文件数字水印,附一种纯文本隐写术数字水印方法
数字水印(Digital Watermark)是一种在数字媒体文件中嵌入隐藏信息的技术。这些数字媒体可以是图片、音频、视频或文本等。数字水印不会对原始文件造成明显的视觉或听觉变化,但可以在一定程度上保护知识产权,追踪数据来源ÿ…...
 使用Vue开发chrome插件)
测试开发(一) 使用Vue开发chrome插件
目录 一、引言 二、功能说明 三、【配置】操作演示 四、【请求拦截】演示 不断访问博客&#x...

游戏行业实战案例 4 :在线时长分析
【面试题】某游戏数据后台设有「登录日志」和「登出日志」两张表。 「登录日志」记录各玩家的登录时间和登录时的角色等级。 「登出日志」记录各玩家的登出时间和登出时的角色等级。 其中,「角色id」字段唯一识别玩家。 游戏开服前两天( 2022-08-13 至 …...

记一次图片压缩引发的生产问题
省流: 死循环导致没有commit(提交事务),transaction一直没有结束。 正文: 调用接口报错: jdbc报错: MySQLTransactionRollbackException: Lock wait timeout exceeded; try restarting tran…...
mybatis-flex探索
mybatis古今未来 最近无意之中发现了一个非常棒的持久层框架mybatis-flex,迫不及待研究了一下 发现简直就是我的梦中情框,之前写ibatis,后来写mybatis,接着写mybatis-plus,接着研究mybatis-flex ibatis ibatis是apa…...

用ClickHouse 文件表引擎快速查询分析文件数据
有时我们需要快速查询分析文件数据,正常流程需要在数据库中创建表,然后利用工具或编码导入数据,这时才能在数据库中查询分析。利用ClickHouse文件引擎可以快速查询文件数据。本文首先介绍ClickHouse文件引擎,然后介绍如何快速实现…...

esp8266httpclient_get_post使用
esp8266httpclient_get_post使用 #include<ESP8266WiFi.h> #include <ESP8266HTTPClient.h>//const char *ssid "AxxxIFI"; const char *password "xxxs879xxx68";const char* ssid "IT-nxxxang";const char* URL "http://…...

【Spring】创建一个Spring项目与Bean对象的存储
目录 一、创建Spring项目 1、创建Maven项目 2、配置maven国内源 3、引入spring依赖 4、添加启动类 二、将Bean对象存储到Spring(IoC容器) 1、创建Bean对象 2、将Bean存储到spring(容器)中 3、获取Bean对象 3.1、Applicatio…...
Docker的入门与使用
什么是Docker? docker官网 简介与概述 Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从 Apache2.0 协议开源。 Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上&#x…...
Smart HTML Elements 16.1 Crack
Smart HTML Elements 是一个现代 Vanilla JS 和 ES6 库以及下一代前端框架。企业级 Web 组件包括辅助功能(WAI-ARIA、第 508 节/WCAG 合规性)、本地化、从右到左键盘导航和主题。与 Angular、ReactJS、Vue.js、Bootstrap、Meteor 和任何其他框架集成。 智…...
[分享]STM32G070 串口 乱码 解决方法
硬件 NUCLEO-G070RB 工具 cubemx 解决方法 7bit 改为 8bit printf 配置方法 添加头文件 #include <stdio.h> 添加重定向代码 #ifdef __GNUC__#define PUTCHAR_PROTOTYPE int __io_putchar(int ch)#else#define PUTCHAR_PROTOTYPE int fputc(int ch, FILE *f)#endi…...
)
[代码案例]学会python读写各类文件的操作(excel,txt,mat)
简介 python读写三类文件 excel文件 txt文件 mat文件 代码 """Description: python 读写各类文件 操作 """ import scipy as scipy from scipy.io import loadmat import xlwt import xlrd 读写excel文件workbook xlrd.open_workbook(test1.…...

【LeetCode】练习习题集【4月 - 7 月】
LEETCODE习题集【4月-7月总结】 简单 数组部分 1.重复数 题目: 在一个长度u为 n 的数组 nums 里的所有数字都在 0~n-1 的范围内。数组中某些数字是重复的,但不知道有几个数字重复了,也不知道每个数字重复了几次。请找出数组中…...

C# 子类强制转换为父类异常,引出的C#Dll加载机制,以及同类名同命名空间同dll程序集在C#中是否为同一个类的研究。
已知,子类B继承自父类A,但是在代码运行时,B类强制转换为A类,却报代码转换异常。 很奇怪的问题吧,不过这个也是难得机会,去研究C#运行的底层原理。 下面是报错的代码片段。 string className _shapeRefle…...

【网络】每天掌握一个Linux命令 - iftop
在Linux系统中,iftop是网络管理的得力助手,能实时监控网络流量、连接情况等,帮助排查网络异常。接下来从多方面详细介绍它。 目录 【网络】每天掌握一个Linux命令 - iftop工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景…...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...

(十)学生端搭建
本次旨在将之前的已完成的部分功能进行拼装到学生端,同时完善学生端的构建。本次工作主要包括: 1.学生端整体界面布局 2.模拟考场与部分个人画像流程的串联 3.整体学生端逻辑 一、学生端 在主界面可以选择自己的用户角色 选择学生则进入学生登录界面…...

从WWDC看苹果产品发展的规律
WWDC 是苹果公司一年一度面向全球开发者的盛会,其主题演讲展现了苹果在产品设计、技术路线、用户体验和生态系统构建上的核心理念与演进脉络。我们借助 ChatGPT Deep Research 工具,对过去十年 WWDC 主题演讲内容进行了系统化分析,形成了这份…...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...
【机器视觉】单目测距——运动结构恢复
ps:图是随便找的,为了凑个封面 前言 在前面对光流法进行进一步改进,希望将2D光流推广至3D场景流时,发现2D转3D过程中存在尺度歧义问题,需要补全摄像头拍摄图像中缺失的深度信息,否则解空间不收敛…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

Python如何给视频添加音频和字幕
在Python中,给视频添加音频和字幕可以使用电影文件处理库MoviePy和字幕处理库Subtitles。下面将详细介绍如何使用这些库来实现视频的音频和字幕添加,包括必要的代码示例和详细解释。 环境准备 在开始之前,需要安装以下Python库:…...

Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信
文章目录 Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信前言一、网络通信基础概念二、服务端与客户端的完整流程图解三、每一步的详细讲解和代码示例1. 创建Socket(服务端和客户端都要)2. 绑定本地地址和端口&#x…...

保姆级教程:在无网络无显卡的Windows电脑的vscode本地部署deepseek
文章目录 1 前言2 部署流程2.1 准备工作2.2 Ollama2.2.1 使用有网络的电脑下载Ollama2.2.2 安装Ollama(有网络的电脑)2.2.3 安装Ollama(无网络的电脑)2.2.4 安装验证2.2.5 修改大模型安装位置2.2.6 下载Deepseek模型 2.3 将deepse…...