Python 之 Pandas Series 数据结构
文章目录
- 一、Series 结构
- 二、数据结构 Series 创建
- 1. 创建
- 1.1 列表/数组作为数据源创建 Series
- 1.2 字典作为数据源创建 Series
- 1.3 通过标量创建
- 2. 参数说明
- 2.1 index 参数
- 2.2 name 参数
- 2.3 copy 参数
- 三、Series 的索引/切片
- 1. 下标索引
- 2. 标签索引
- 3. 切片
- 四、Series 数据结构的基本技巧
- 1. 查看前几条和后几条数据
- 2. 重新索引:reindex
- 3. 对齐运算
- 4. 删除和添加
一、Series 结构
- Series 结构,也称 Series 序列,是 Pandas 常用的数据结构之一,它是一种类似于一维数组的结构,由一组数据值(value)和一组标签组成,其中标签与数据值具有对应关系。
- 标签不必是唯一的,但必须是可哈希类型(也就是不可变类型,就像整型、字符串型等)。该对象既支持基于整数的索引,也支持基于标签的索引,并提供了许多方法来执行涉及索引的操作。ndarray 的统计方法已被覆盖,以自动排除缺失的数据(目前表示为 NaN)。
- Series 可以保存任何数据类型,比如整数、字符串、浮点数、Python 对象等,它的标签默认为整数,从 0 开始依次递增。
- Series 的结构图,如下所示:

- 通过标签我们可以更加直观地查看数据所在的索引位置。
- 在这里,我们引入 numpy 和 pandas 库,便于后续的操作。
import numpy as np
import pandas as pd
二、数据结构 Series 创建
- Series 的语法模板如下:
pd.Series(data=None, index=None, dtype=None, name=None, copy=False)
- 其参数含义如下:
- data 表示输入的数据,可以是列表、常量、ndarray 数组等,如果是字典,则保持参数顺序。
- index 表示索引值,必须是可散列的(也就是不可变数据类型,就像 str,bytes 和数值类型),并且与数据具有相同的长度,允许使用非唯一索引值。如果未提供,将默认为 RangeIndex(0,1,2,…,n)。
- dtype 表示输出系列的数据类型。如果未指定,将从数据中推断数据类型。
- name 是给 Series 定义一个名称。
- copy 表示对 data 进行拷贝,默认为 False,仅影响 Series 和 ndarray 数组。
1. 创建
1.1 列表/数组作为数据源创建 Series
- (1) 以列表作为数据创建 Series。
ar_list = [3,10,3,4,5]
print(type(ar_list))
s1 = pd.Series(ar_list)
print(s1)
print(type(s1))
#<class 'list'>
#0 3
#1 10
#2 3
#3 4
#4 5
#dtype: int64
#<class 'pandas.core.series.Series'>
- (2) 以数组作为数据创建 Series。
np_rand = np.arange(1,6)
s1 = pd.Series(np_rand)
s1
#0 1
#1 2
#2 3
#3 4
#4 5
#dtype: int32
- (3) 通过 index 和 values 属性取得对应的标签和值。
- 我们可以取出 Series 当中的所有标签值,默认为 RangeIndex(0,1,2,…,n)。
s1.index
#RangeIndex(start=0, stop=5, step=1)
- 当然,我们可以强制转化为列表输出。
list(s1.index)
#[0, 1, 2, 3, 4]
- 我们也取出 Series 的所有数据值,他们的数据类型为 ndarray。
print(s1.values, type(s1.values))
#[1 2 3 4 5] <class 'numpy.ndarray'>
- (4) 通过标签取得对应的值,或者修改对应的值。
- 我们可以输出 s1 当中索引为 1 的数据。
s1[1]
#2
- 我们也可以修改 s1 当中索引为 2 的数据。
s1[2] = 50
s1
#0 1
#1 2
#2 50
#3 4
#4 5
#dtype: int32
- 如果我们直接以负数作为索引值对 s1 进行操作,会直接报错,但可以通过新增索引和数据值进行操作。
- (5) 和列表索引区别。
- (a) 默认的索引 RangeIndex,不能使用负值,来表示从后往前找元素。
s1[-1] = 20
s1
# 0 1
# 1 2
# 2 50
# 3 4
# 4 5
#-1 20
#dtype: int64
- (b) 获取不存在的索引值对应数据,会报错,但是可以赋值,相当于新增数据。
s1[-1] = 20
print(s1)
print(s1.index)
# 0 1
# 1 2
# 2 50
# 3 4
# 4 5
#-1 20
#dtype: int64
#Int64Index([0, 1, 2, 3, 4, -1], dtype='int64')
- (c) 可以新增不同类型索引的数据,新增不同类型索引的数据,索引的类型会发生自动变化。
s1["a"] = 40
s1.index
#Index([0, 1, 2, 3, 4, -1, 'a'], dtype='object')
1.2 字典作为数据源创建 Series
- (1) 以字典作为数据创建 Series。
d = {'a': 1, 'b': 2, 'c': 3}
ser = pd.Series(data=d)
ser
#a 1
#b 2
#c 3
#dtype: int64
- (2) 通过 index 和 values 属性取得对应的标签和值。
- 具体可见如下例子。
ser.index
ser.values
#Index(['a', 'b', 'c'], dtype='object')
#array([1, 2, 3], dtype=int64)
- (3) 通过标签取得对应的值,或者修改对应的值。
- 和使用列表、数组创建 Series 一样,我们可以通过调用标签得到对应的数据。
ser['a']
#1
- 通过标签修改对应的数据。
ser["s"] = 50
#a 1
#b 2
#c 3
#s 50
#dtype: int64
- 如果标签非数值型,我们既可以用标签获取值,也可以用标签的下标获取值。
ser[0]
#1
- 负数表示从后往前进行索引。
ser[-1]
#50
- 也可以直接全部进行修改。
d = {'a': 1, 5: 2, 'c': 3}
ser1 = pd.Series(data=d)
ser1
#a 1
#5 2
#c 3
#dtype: int64
- 那么,当标签存在数值型的数据,就不可以使用标签的下标获取值,不然会直接报错。
- (4) 取得数据时,先进行标签的检查,如果标签中没有,再进行索引的检查,都不存在则报错。
1.3 通过标量创建
s = pd.Series(100,index=range(5))
s
#0 100
#1 100
#2 100
#3 100
#4 100
#dtype: int64
2. 参数说明
2.1 index 参数
- 索引值,必须是可散列的(不可变数据类型,例如 str,bytes 和数值类型),并且与数据具有相同的长度,允许使用非唯一索引值。如果未提供,将默认为 RangeIndex(0,1,2,…,n)。
- (1) 使用显式索引的方法定义索引标签。
- 当我们自定义索引标签(即显示索引)时,需要和数据长度一致。
data = np.array(['a','b','c','d'])
s = pd.Series(data,index=[100,101,102,103])
s
#100 a
#101 b
#102 c
#103 d
#dtype: object
(2) 从指定索引的字典构造序列。
d = {'a': 1, 'b': 2, 'c': 3}
ser = pd.Series(d, index=['a', 'b', 'c'])
ser
#a 1
#b 2
#c 3
#dtype: int64
- (3) 当传递的索引值未匹配对应的字典键时,使用 NaN(非数字)填充。
d = {'a': 1, 'b': 2, 'c': 3}
ser = pd.Series(data=d, index=['x', 'b', 'z'])
ser
#x NaN
#b 2.0
#z NaN
#dtype: float64
- 这里需要注意的是,索引是首先使用字典中的键构建的。在此之后,用给定的索引值对序列重新编制索引,因此我们得到所有 NaN。
- (4) 通过匹配的索引值,改变创建 Series 数据的顺序。
d = {'a': 1, 'b': 2, 'c': 3}
ser = pd.Series(data=d, index=['c', 'b', 'a'])
ser
#c 3
#b 2
#a 1
#dtype: int64
2.2 name 参数
- 我们可以给一个 Series 对象命名,也可以给一个 Series 数组中的索引列起一个名字,pandas 为我们设计好了对象的属性,并在设置了 name 属性值用来进行名字的设定。以下程序可以用来完成该操作。
dict_data1 = {"Beijing":2200,"Shanghai":2500,"Shenzhen":1700
}
data1 = pd.Series(dict_data1)
data1.name = "City_Data"
data1.index.name = "City_Name"
data1
#City_Name
#Beijing 2200
#Shanghai 2500
#Shenzhen 1700
#Name: City_Data, dtype: int64
- 序列的名称,如果是 DataFrame 的一部分,还包括列名。
- 如果用于形成数据帧,序列的名称将成为其索引或列名。每当使用解释器显示序列时,也会使用它。
2.3 copy 参数
- copy 表示对 data 进行拷贝,默认为 False,仅影响 Series 和 ndarray 数组。
- 我们以数组作为数据源,使用数组创建 Series。
np_rand = np.arange(1,6)
s1 = pd.Series(np_rand)
s1
#0 1
#1 2
#2 3
#3 4
#4 5
#dtype: int32
- 然后,我们改变 Series 标签为 1 的值,并在输出 Series 的对象 s1 的同时,输出数组对象 np_rand。
s1[1] = 50
print("s1:",s1)
print("np_rand:",np_rand)
#s1: 0 1
#1 50
#2 3
#3 4
#4 5
#dtype: int32
#np_rand: [ 1 50 3 4 5]
- 当源数据不是 Series 和 ndarray 类型时,我们以列表作为数据源,使用列表创建 Series。
my_list = [1,2,3,4,5,6]
s2 = pd.Series(my_list)
s2
#0 1
#1 2
#2 3
#3 4
#4 5
#5 6
#dtype: int64
- 然后,我们改变 Series 标签为 1 的值,并在输出 Series 的对象 s2 的同时,输出数组对象 my_list。
s2[1] = 50
print("s2:",s2)
print("my_list:",my_list)
#s2: 0 1
#1 50
#2 3
#3 4
#4 5
#5 6
#dtype: int64
#my_list: [1, 2, 3, 4, 5, 6]
三、Series 的索引/切片
1. 下标索引
- 下标索引类似于列表索引。
s = pd.Series(np.random.rand(5))
print(s)
print(s[3], type(s[3]), s[3].dtype)
#0 0.777657
#1 0.622071
#2 0.348129
#3 0.756216
#4 0.287849
#dtype: float64
#0.7562162366628223 <class 'numpy.float64'> float64
- 上面的位置索引和标签索引刚好一致,会使用标签索引。
- 当使用负值时,实际并不存在负数的标签索引。
2. 标签索引
- 当索引为 object 类型时,既可以使用标签索引也可以使用位置索引。
- Series 类似于固定大小的 dict,把 index 中的索引标签当做 key,而把 Series 序列中的元素值当做 value,然后通过 index 索引标签来访问或者修改元素值。
- 使用索标签访问单个元素值。
s = pd.Series(np.random.rand(5),index=list("abcde"))
print(s["b"], type(s["b"]), s["b"].dtype)
#0.26319645172526607 <class 'numpy.float64'> float64
- 使用索引标签访问多个元素值,注意需要选择多个标签的值,用 [[]] 来表示(相当于 [] 中包含一个列表)。
s = pd.Series([6,7,8,9,10],index = ['a','b','c','d','e'])
print(s)
print(s[['a','c','d']])
#a 6
#b 7
#c 8
#d 9
#e 10
#dtype: int64
#a 6
#c 8
#d 9
#dtype: int64
- 多标签会创建一个新的数组。
s1 = s[["b","a","e"]]
s1["b"] = 10
print("s1:",s1)
print("s源数据:",s)
#s1: b 10
#a 6
#e 10
#dtype: int64
#s源数据: a 6
#b 7
#c 8
#d 9
#e 10
#dtype: int64
3. 切片
- Series 使用标签切片运算与普通的 Python 切片运算不同,Series 使用标签切片时,其末端是包含的。
- Series 使用 python 切片运算即使用位置数值切片,其末端是不包含。
- 通过下标切片的方式访问 Series 序列中的数据,示例如下:
s = pd.Series(np.random.rand(10))
s
#0 0.927452
#1 0.235768
#2 0.516178
#3 0.277643
#4 0.697771
#5 0.273533
#6 0.133503
#7 0.185826
#8 0.687192
#9 0.316528
#dtype: float64
- 位置索引和标签索引刚好一致,使用切片时,如果是数值会认为是 python 切片运算,不包含末端。
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
print(s)
print(s[1:4])
#a 1
#b 2
#c 3
#d 4
#e 5
#dtype: int64
#b 2
#c 3
#d 4
#dtype: int64
- 如果想要获取最后三个元素,也可以使用下面的方式:
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
print(s[-3:])
#c 3
#d 4
#e 5
#dtype: int64
- 通过标签切片的方式访问 Series 序列中的数据,示例如下:
- 当 Series 使用标签切片时,其末端是包含的。
s1= pd.Series([6,7,8,9,10],index = ['a','b','c','d','e'])
s1["b":"d"]
#b 7
#c 8
#d 9
#dtype: int64
- 如果首尾端一致的话,就是该元素本身。
s1= pd.Series([6,7,8,9,10],index = ['e','d','a','b','a'])
s1
#c 8
#dtype: int64
- 在上面的索引方式,我们知道了位置索引和标签索引在 index 为数值类型时候的不同。
- 当 index 为数值类型的时候,使用位置索引会抛出 keyerror 的异常,也就是说当 index 为数值类型的时候,索引使用的是名称索引。
- 但是在切片的时候,有很大的不同,如果 index 为数值类型的时候,切片使用的是位置切片。
- 总的来说,当 index 为数值类型的时候:
- 进行索引的时候,相当于使用的是名称索引。
- 进行切片的时候,相当于使用的是位置切片。
四、Series 数据结构的基本技巧
1. 查看前几条和后几条数据
s = pd.Series(np.random.rand(15))
s
#0 0.819404
#1 0.552555
#2 0.792454
#3 0.215595
#4 0.824303
#5 0.970804
#6 0.997465
#7 0.519955
#8 0.354990
#9 0.758266
#dtype: float64
- s.head() 默认查看前 5 条数据,(其余的看括号内的数字)。
print(s.head())
print(s.head(1))
#0 0.819404
#1 0.552555
#2 0.792454
#3 0.215595
#4 0.824303
#dtype: float64
#0 0.819404
#dtype: float64
- s.tail() 默认查看后 5 条数据(其余的看括号内的数字)。
print(s.tail())
#5 0.970804
#6 0.997465
#7 0.519955
#8 0.354990
#9 0.758266
#dtype: float64
2. 重新索引:reindex
- 使用可选填充逻辑,使 Series 符合新索引。
- 将 NaN 放在上一个索引中没有值的位置。除非新索引等同于当前索引,并且生成新对象。
- 当新索引在上一个索引中不存在,生成新对象时,对应的值,设置为 NaN。
s = pd.Series(np.random.rand(5),index=list("abcde"))
s1 = s.reindex(list("cde"))
print("============s1=========")
print(s1)
print("============s=========")
print(s)
#============s1=========
#c 0.525886
#d 0.859566
#e 0.767330
#dtype: float64
#============s=========
#a 0.148972
#b 0.934014
#c 0.525886
#d 0.859566
#e 0.767330
#dtype: float64
3. 对齐运算
- 对其运算是数据清洗的重要过程,可以按索引对齐进行运算,如果没对齐的位置则补 NaN,最后也可以填充 NaN。
s1 = pd.Series(np.random.rand(3), index=["Kelly","Anne","T-C"])
s2 = pd.Series(np.random.rand(3), index=["Anne","Kelly","LiLy"])
print("==========s1=========")
print(s1)
print("==========s2=========")
print(s2)
print("==========s1+s2=========")
print(s1+s2)
#==========s1=========
#Kelly 0.481159
#Anne 0.066326
#T-C 0.916705
#dtype: float64
#==========s2=========
#Anne 0.090194
#Kelly 0.150472
#LiLy 0.220991
#dtype: float64
#==========s1+s2=========
#Anne 0.156520
#Kelly 0.631632
#LiLy NaN
#T-C NaN
#dtype: float64
4. 删除和添加
- s.drop() 是返回删除后的值,原值不改变,默认 inplace=False。
s = pd.Series(np.random.rand(5),index=list("abcde"))
s1 = s.drop("a")
print(s1)
print(s)
#b 0.918685
#c 0.613762
#d 0.142165
#e 0.309032
#dtype: float64
#a 0.630504
#b 0.918685
#c 0.613762
#d 0.142165
#e 0.309032
#dtype: float64
- 当 inplace 参数设置为 True 时,原值发生变化,返回 None。
s = pd.Series(np.random.rand(5),index=list("abcde"))
s1 = s.drop("a",inplace=True)
print(s1)
print(s)
#None
#b 0.946778
#c 0.733088
#d 0.793721
#e 0.681853
#dtype: float64
- 添加操作时,如果对应的标签没有就是添加,有就是修改。
s1 = pd.Series(np.random.rand(5),index=list("abcde"))
print(s1)
s1["s"] = 100
print(s1)
#a 0.743596
#b 0.778193
#c 0.036640
#d 0.324620
#e 0.282358
#dtype: float64
#a 0.743596
#b 0.778193
#c 0.036640
#d 0.324620
#e 0.282358
#s 100.000000
#dtype: float64
相关文章:
Python 之 Pandas Series 数据结构
文章目录一、Series 结构二、数据结构 Series 创建1. 创建1.1 列表/数组作为数据源创建 Series1.2 字典作为数据源创建 Series1.3 通过标量创建2. 参数说明2.1 index 参数2.2 name 参数2.3 copy 参数三、Series 的索引/切片1. 下标索引2. 标签索引3. 切片四、Series 数据结构的…...
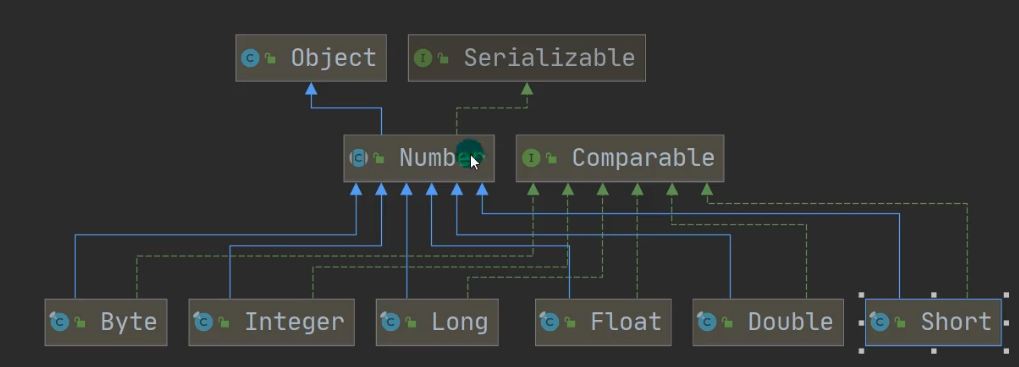
【java基础】Java常用类———包装类
包装类 wrapper 装箱与拆箱 装箱:基本类型->包装类; 拆箱: 包装类->基本类型 public class Integer01 {public static void main(String[] args) {//演示int <--> Integer 的装箱和拆箱//jdk5前是手动装箱和拆箱//手动装箱 in…...

linux shell 入门学习笔记3 shebang
shebang 计算机程序中,shebang指的是出现在文本文件的第一行前两个字符#! 在Unix系统中,程序会分析shebang后面的内容,作为解释器的指令,例如 以#!/bin/sh 开头的文件,程序在执行的时候会调用/bin/sh,也就…...
)
写作小课堂:简历模版【A4纸正反两面】(20230219)
文章目录 I 联系方式II 个人信息III 求职意向IV 工作经验2018年-11月-至今全城淘信息技术服务有限公司2017年07月-2018年-11月湖南微流网络科技有限公司2014年06月-2017年07月湖南高阳通联信息技术有限公司V 项目经验2018年11月-至今全城淘淘管家2017年10月-2018年11月ASO(机刷…...
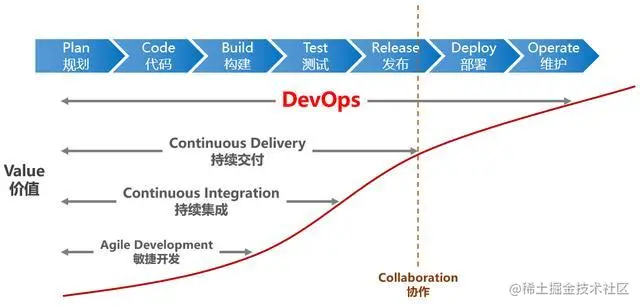
一文搞懂 DevOps
前言 DevOps作为一个热门的概念,近年来频频出现在各大技术社区和媒体的文章中,备受行业大咖的追捧,也吸引了很多吃瓜群众的围观。 那么,DevOps是什么呢? 有人说它是一种方法,也有人说它是一种工具&#…...

深入讲解Kubernetes架构-租约
分布式系统通常需要租约(Lease);租约提供了一种机制来锁定共享资源并协调集合成员之间的活动。 在 Kubernetes 中,租约概念表示为 coordination.k8s.io API 组中的 Lease 对象, 常用于类似节点心跳和组件级领导者选举等…...
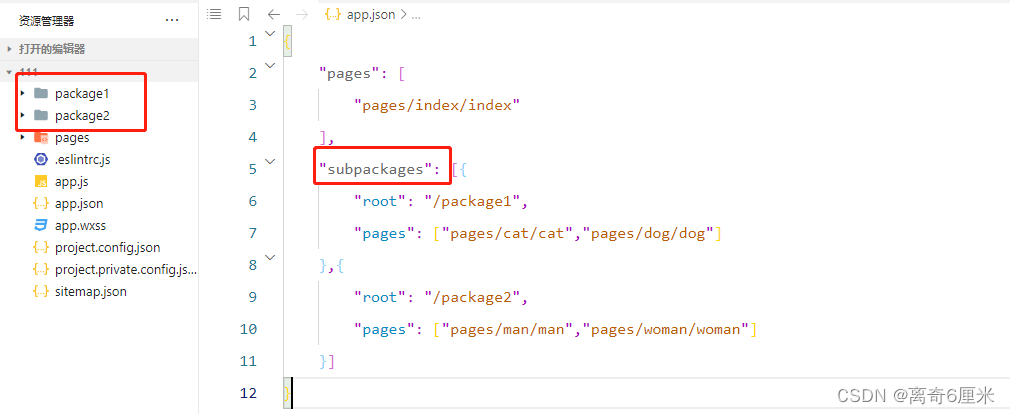
微信小程序学习第11天——Vant Weapp组件库、API Promise化、全局数据共享Mobx、分包
目录一、小程序对npm 的限制二、使用Vant Weapp组件库1、安装组件2、使用组件3、定制全局样式三、API Promise化1、下载miniprogram-api-promise2、引入3、使用四、全局数据共享五、分包1、分包概念2、使用分包3、独立分包4、分包预下载一、小程序对npm 的限制 在小程序中使用…...
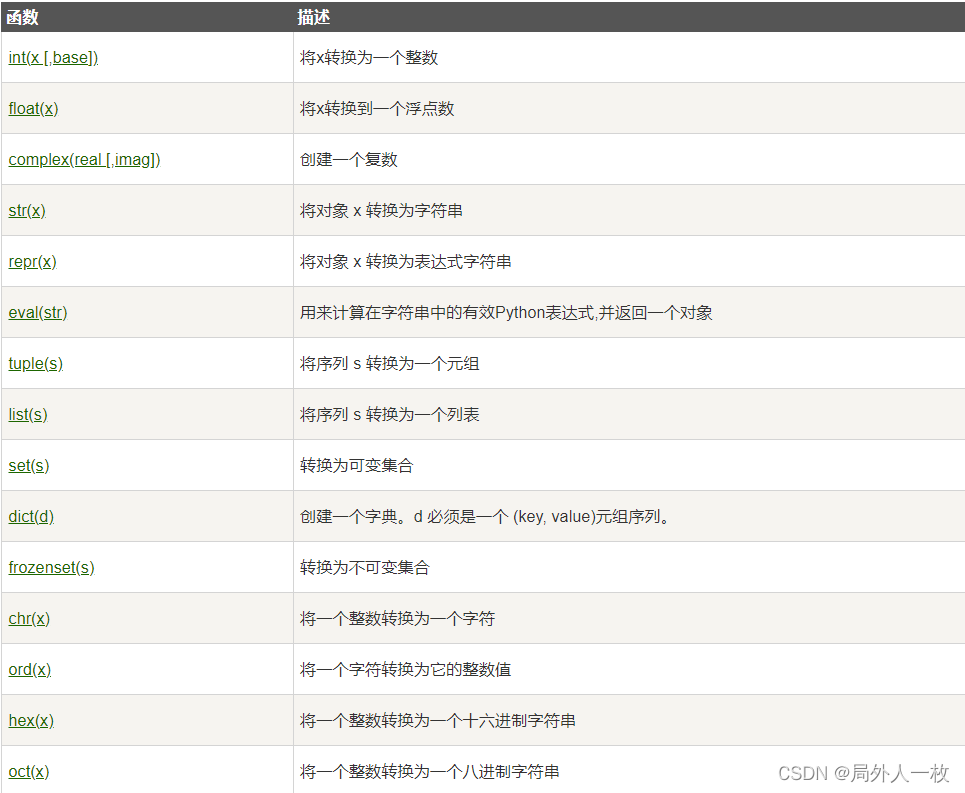
Python3-基本数据类型
Python3 基本数据类型 Python 中的变量不需要声明。每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。 在 Python 中,变量就是变量,它没有类型,我们所说的"类型"是变量所指的内存中对象的类型。 等号&…...

RPA落地指南:什么是RPA
什么是RPA RPA在企业中起什么作用并扮演什么角色呢?想要充分了解RPA,我们需要知道RPA的相关概念、特点、功能以及能解决的问题。接下来对这些内容进行详细介绍。 1.1 RPA的3个核心概念 RPA的中文译名是“机器人流程自动化”,顾名思义&…...
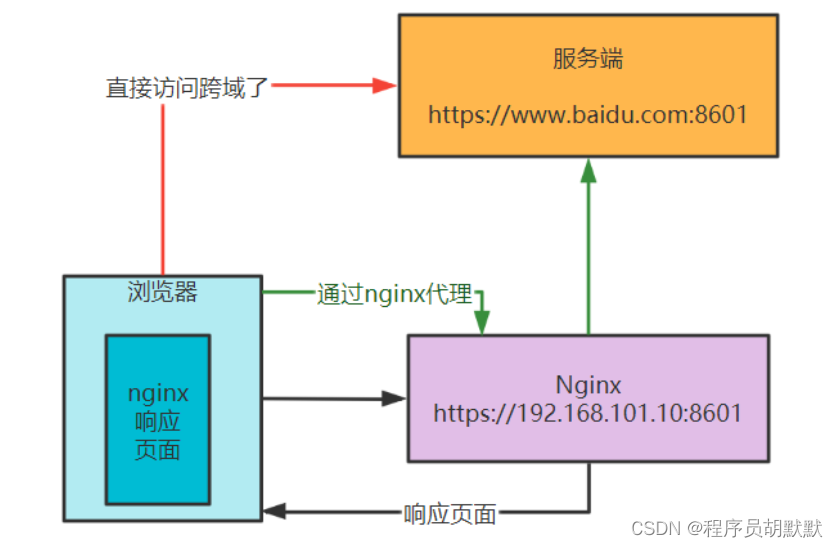
跨域问题的三种解决办法
我们平时对于前后端联调的项目,以下的错误是经常常见的,我们查看浏览器报错: Access to XMLHttpRequest at http://localhost:63110/system/dictionary/all fromorigin http://localhost:8601 has been blocked by CORS policy: No Access…...

c++提高篇——string容器
一、string基本概念 string是C风格的字符串,而string本质上是一个类。 与c语言不同,string是一个类,类内部封装了char*,管理这个字符串,是一个char型的容器。在根本上与c语言字符串是一致的。 在string类内部封装了很…...
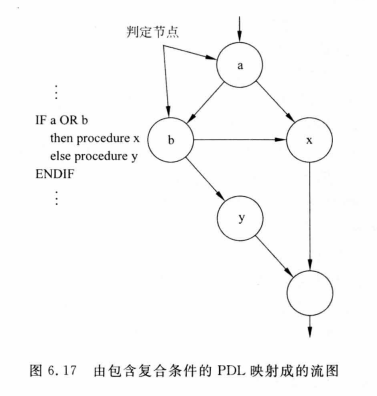
[软件工程导论(第六版)]第6章 详细设计(复习笔记)
文章目录6.1 结构程序设计6.2 人机界面设计6.3 过程设计的工具6.3.1 程序流程图(程序框图)6.3.2 盒图(N-S图)6.3.3 PAD图(问题分析图)6.3.4 判定表6.3.5 判断树6.3.6 过程设计语言6.4 面向数据结构的设计方…...
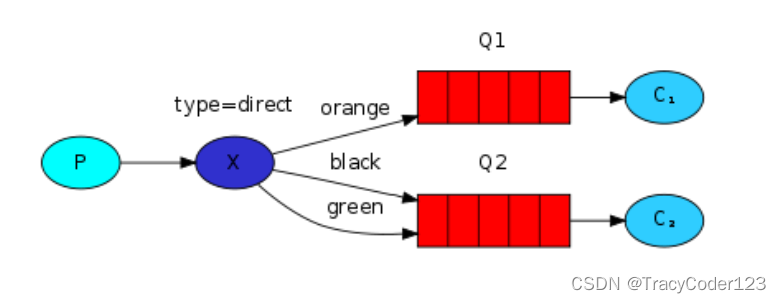
RabbitMQ核心内容:实战教程(java)
文章目录一、安装二、入门1.分类2.核心概念3.工作原理4.六大模式三、模式一:"Hello World!"1.依赖2.生产者代码3.消费者代码四、模式二:Work Queues1.工作原理2.工具类代码:连接工厂3.消费者代码4.生产者代码5.分发策略不公平分发预…...
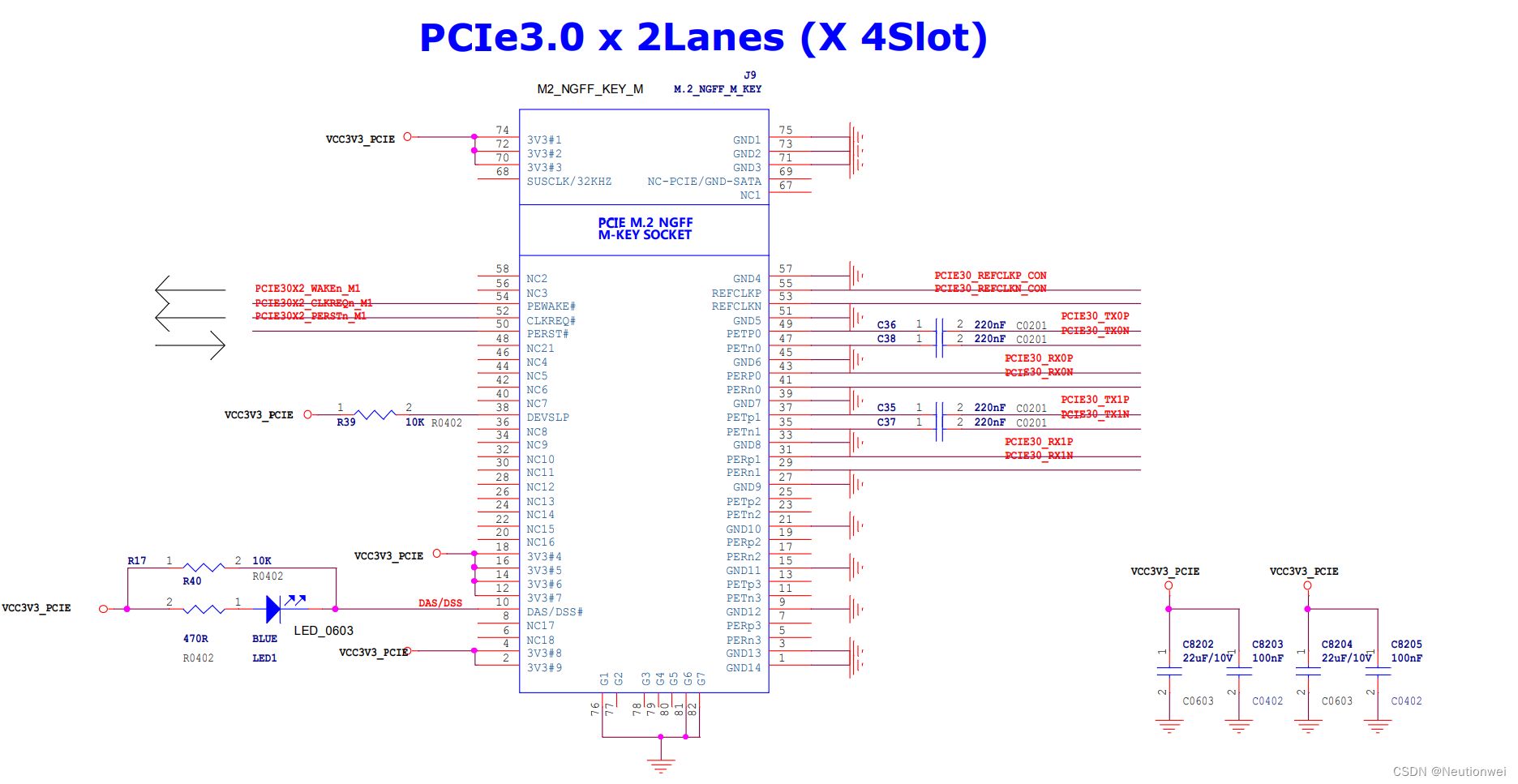
RK356x U-Boot研究所(命令篇)3.7 pci与nvme命令的用法
平台U-Boot 版本Linux SDK 版本RK356x2017.09v1.2.3文章目录 一、设备树与config配置二、pci命令的定义三、nvme命令的定义四、pci与nvme命令的用法3.1 pci总线扫描3.2 nvme设备信息3.3 nvme设备读写一、设备树与config配置 RK3568支持PCIe接口,例如ROC-RK3568-PC: 原理图如…...

微信头像昵称获取能力的变化导致了我半年没更新小程序
背景 2022年9月份,微信更改了获取头像昵称的规则,回收了原有 wx.getUserProfile 中的部分能力,为了减小对【微点记账】小程序的影响,长达半年未做任何更新,今天为了增加这个聊天机器人的功能,不得不重新查…...
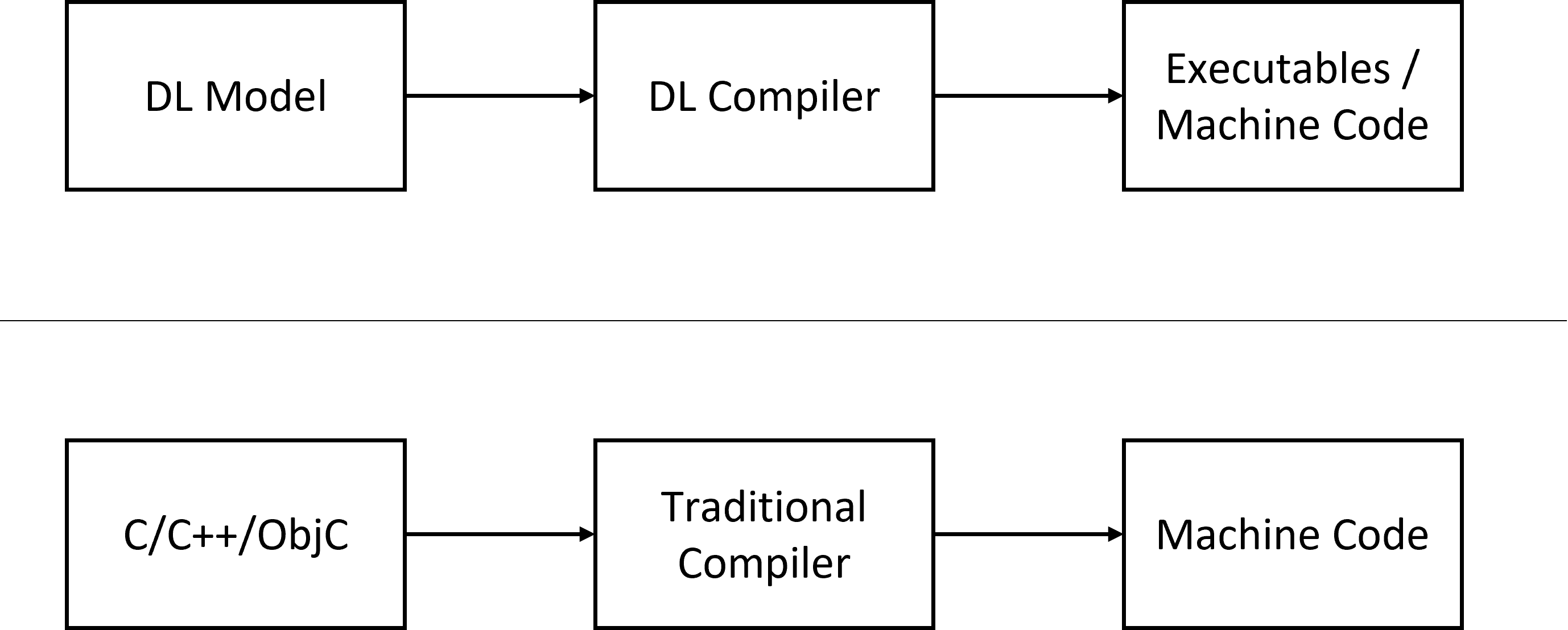
【深度学习编译器系列】1. 为什么需要深度学习编译器?
本系列是自学深度学习编译器过程中的一些笔记和总结,参考文献在文末。 1. 概述 深度学习(DL)编译器的产生有两方面的因素:深度学习模型的广泛应用,以及深度学习芯片的层出不穷。 一方面,我们现在有非常多…...
数据结构与算法总结整理(超级全的哦!)
数据结构与算法基础大O表示法时间复杂度大O表示法时间复杂度排序:最坏时间复杂度时间复杂度的几条基本计算规则内存工作原理什么是内存内存主要分为三种存储器随机存储器(RAM)只读存储器(ROM)高速缓存(Cach…...

DPDK — MALLOC 堆内存管理组件
目录 文章目录 目录MALLOC 堆内存管理组件rte_malloc() 接口malloc_heap 结构体malloc_elem 结构体内存初始化流程内存申请流程内存释放流程MALLOC 堆内存管理组件 MALLOC(堆内存管理组件)基于 hugetlbfs 内核文件系统来实现,能够从 HugePage 中分配一块连续的物理大页内存…...

分享113个HTML艺术时尚模板,总有一款适合您
分享113个HTML艺术时尚模板,总有一款适合您 113个HTML艺术时尚模板下载链接:https://pan.baidu.com/s/1ReoPNIRjkYov-SjsPo0vhg?pwdjk4a 提取码:jk4a Python采集代码下载链接:采集代码.zip - 蓝奏云 女性化妆用品网页模板 粉…...

2023年美赛C题Wordle预测问题一建模及Python代码详细讲解
相关链接 (1)2023年美赛C题Wordle预测问题一建模及Python代码详细讲解 (2)2023年美赛C题Wordle预测问题二建模及Python代码详细讲解 (3)2023年美赛C题Wordle预测问题三、四建模及Python代码详细讲解 &…...

通过Wrangler CLI在worker中创建数据库和表
官方使用文档:Getting started Cloudflare D1 docs 创建数据库 在命令行中执行完成之后,会在本地和远程创建数据库: npx wranglerlatest d1 create prod-d1-tutorial 在cf中就可以看到数据库: 现在,您的Cloudfla…...

iPhone密码忘记了办?iPhoneUnlocker,iPhone解锁工具Aiseesoft iPhone Unlocker 高级注册版分享
平时用 iPhone 的时候,难免会碰到解锁的麻烦事。比如密码忘了、人脸识别 / 指纹识别突然不灵,或者买了二手 iPhone 却被原来的 iCloud 账号锁住,这时候就需要靠谱的解锁工具来帮忙了。Aiseesoft iPhone Unlocker 就是专门解决这些问题的软件&…...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...

【项目实战】通过多模态+LangGraph实现PPT生成助手
PPT自动生成系统 基于LangGraph的PPT自动生成系统,可以将Markdown文档自动转换为PPT演示文稿。 功能特点 Markdown解析:自动解析Markdown文档结构PPT模板分析:分析PPT模板的布局和风格智能布局决策:匹配内容与合适的PPT布局自动…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

今日科技热点速览
🔥 今日科技热点速览 🎮 任天堂Switch 2 正式发售 任天堂新一代游戏主机 Switch 2 今日正式上线发售,主打更强图形性能与沉浸式体验,支持多模态交互,受到全球玩家热捧 。 🤖 人工智能持续突破 DeepSeek-R1&…...

LeetCode - 199. 二叉树的右视图
题目 199. 二叉树的右视图 - 力扣(LeetCode) 思路 右视图是指从树的右侧看,对于每一层,只能看到该层最右边的节点。实现思路是: 使用深度优先搜索(DFS)按照"根-右-左"的顺序遍历树记录每个节点的深度对于…...

智能AI电话机器人系统的识别能力现状与发展水平
一、引言 随着人工智能技术的飞速发展,AI电话机器人系统已经从简单的自动应答工具演变为具备复杂交互能力的智能助手。这类系统结合了语音识别、自然语言处理、情感计算和机器学习等多项前沿技术,在客户服务、营销推广、信息查询等领域发挥着越来越重要…...

IP如何挑?2025年海外专线IP如何购买?
你花了时间和预算买了IP,结果IP质量不佳,项目效率低下不说,还可能带来莫名的网络问题,是不是太闹心了?尤其是在面对海外专线IP时,到底怎么才能买到适合自己的呢?所以,挑IP绝对是个技…...
免费数学几何作图web平台
光锐软件免费数学工具,maths,数学制图,数学作图,几何作图,几何,AR开发,AR教育,增强现实,软件公司,XR,MR,VR,虚拟仿真,虚拟现实,混合现实,教育科技产品,职业模拟培训,高保真VR场景,结构互动课件,元宇宙http://xaglare.c…...