【C→C++】打开C++世界的大门
文章目录
- 前言
- 什么是C++
- C++的发展史
- C++的重要性
- 1. 使用广泛度
- 2. 工作领域的应用
- 1. C++关键字(C++98)
- 2. 命名空间
- 2.1 命名空间的定义
- 2.2 命名空间的使用
- 2.3 std命名空间的使用惯例
- 3. C++输入&输出
- 3.1 输入输出
- 3.2 说明
- 4. 缺省参数
- 4.1 缺省参数概念
- 4.2 缺省参数分类
- 5. 函数重载
- 5.1 函数重载概念
- 5.2 C++支持函数重载的原理--名字修饰
- 6. 引用
- 6.1 引用的概念
- 6.2 引用的特性
- 6.3 常引用
- 6.4 使用场景
- 1. 做参数(传参)
- 2. 做返回值
- 6.5 传值、传引用效率比较
- 1. 值和引用的作为参数的性能比较
- 2. 值和引用的作为返回值类型的性能比较
- 6.6 引用和指针的区别
- 7. 内联函数
- 7.1 概念
- 7.2 内联函数的特性
- 8. auto关键字(C++11)
- 8.1 类型别名思考
- 8.2 auto简介
- 8.3 auto的使用细则
- 8.4 auto不能推导的场景
- 9. 基于范围的for循环(C++11)
- 9.1 范围for的语法
- 9.2 范围for的使用条件
- 10. 指针空值nullptr(C++11)
这篇文章开始,我们进入C++的学习。

前言
什么是C++
C语言是结构化和模块化的语言,适合处理较小规模的程序。
对于复杂的问题,规模较大的程序,需要高度的抽象和建模,C语言则不合适。
为了解决软件危机, 20世纪80年代, 计算机界提出了OOP(object oriented programming:面向对象)思想,支持面向对象的程序设计语言应运而生。
1982年,Bjarne Stroustrup博士在C语言的基础上引入并扩充了面向对象的概念,发明了一种新的程序语言。为了表达该语言与C语言的渊源关系,命名为C++。
因此:C++是基于C语言而产生的,它既可以进行C语言的过程化程序设计,又可以进行以抽象数据类型为特点的基于对象的程序设计,还可以进行面向对象的程序设计。

C++的发展史
1979年,贝尔实验室的本贾尼等人试图分析unix内核的时候,试图将内核模块化,于是在C语言的基础上进行扩展,增加了类的机制,完成了一个可以运行的预处理程序,称之为C with classes。
语言的发展就像是练功打怪升级一样,也是逐步递进,由浅入深的过程。
我们先来看下C++的历史版本:
C++还在不断的向后发展。
但是:现在公司主流使用还是C++98和C++11,所以大家不用追求最新,重点将C++98和C++11掌握好,等工作后,随着对C++理解不断加深,有时间可以去琢磨下更新的特性。

C++的重要性
1. 使用广泛度
下图数据来自TIOBE编程语言社区2021年12月最新的排行榜,在30多年的发展中,C/C++几乎一致稳居前5:
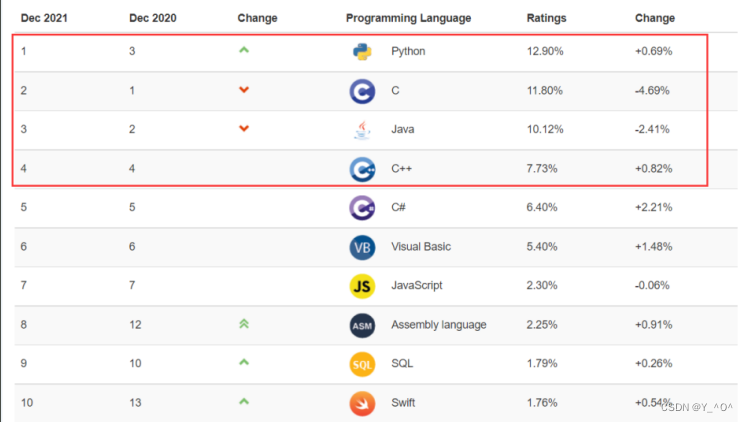
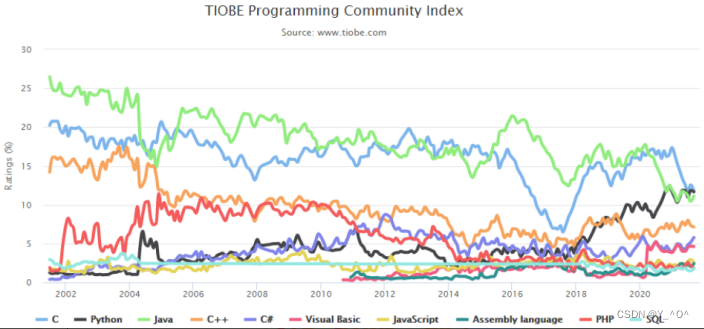
TIOBE 编程语言社区排行榜是编程语言流行趋势的一个指标,每月更新,这份排行榜的排名基于互联网上有经验的程序员、 课程和第三方厂商的数量。
排名使用著名的搜索引擎(诸如 Google、MSN、Yahoo!、Wikipedia、YouTube 以及 Baidu 等)进行计算。
注意:排名不能说明那个语言好,那个不好,每门编程语言都有适应自己的应用场景。
2. 工作领域的应用
- 操作系统及大型系统软件开发
所有操作系统几乎都是C/C++写的,许多大型软件背后几乎都是C++写的。
比如:Photoshop、Office、JVM(Java虚拟机)等,究其原因还是性能高,可以直接操控硬件。
- 服务器端开发
后台开发:主要侧重于业务逻辑的处理,即对于前端的请求,后端给出对应的响应,现在主流采用java,但内卷化比较严重,大厂可能会有C++后台开发,主要做一些基础组件,中间件、缓存、分布式存储等。
服务器端开发比后台开发更广泛,包含后台开发,一般对实时性要求比较高,比如游戏服务器、流媒体服务器、网络通讯等都是采用C++开发的。
- 游戏开发
PC平台几乎所有的游戏都是C++写的。
比如:魔兽世界、传奇、CS、跑跑卡丁车等。
市面上相当多的游戏引擎都是基于C++开发的,比如:Cocos2d、虚幻4、DirectX等。
三维游戏领域计算量非常庞大,底层的数学全都是矩阵变换,想要画面精美、内容丰富、游戏实时性高,这些高难度需求无疑只能选择C++语言。
比较知名的厂商:腾讯、网易、完美世界、巨人网络等。
- 嵌入式和物联网领域
嵌入式:就是把具有计算能力的主控板嵌入到机器装置或者电子装置的内部,从而能够控制这些装置。
比如:智能手环、摄像头、扫地机器人、智能音响等。
谈到嵌入式开发,大家最能想到的就是单片机开发(即在8位、16位或者32位单片机产品或者裸机上进行的开发),嵌入式开发除了单片机开发以外,还包含在soc片上、系统层面、驱动层面以及应用、中间件层面的开发。
常见的岗位有:嵌入式开发工程师、驱动开发工程师、系统开发工程师、Linux开发工程师、固件开发工程师等。
知名的一些厂商,比如:以华为、vivo、oppo、小米为代表的手机厂;以紫光展锐、乐鑫为代表的芯片厂;大疆、海康威视、大华、CVTE等具有自己终端业务厂商;以及海尔、海信、格力等传统家电行业。
随着5G的普及,物联网(即万物互联,)也成为了一种新兴势力,比如:阿里lot、腾讯lot、京东、百度、美团等都有硬件相关的事业部。
- 数字图像处理
数字图像处理中涉及到大量数学矩阵方面的运算,对CPU算力要求比较高,主要的图像处理算法库和开源库等都是C/C++写的,比如:OpenCV、OpenGL等,大名鼎鼎的Photoshop就是C++写的。
- 人工智能
一提到人工智能,大家首先想到的可能就是python,认为学习人工智能就要学习python,这个是误区,python中库比较丰富,使用python可以快速搭建神经网络、填入参数导入数据,然后就可以开始训练模型了。
但人工智能背后深度学习算法等核心内容还是用C++写的。
- 分布式应用
近年来随着移动互联网的兴起,各应用数据量业务量不断攀升;后端架构要不断提高性能和并发能力才能应对大信息时代的来临。
在分布式领域,好些分布式框架、文件系统、中间组件等都是C++开发的。对分布式计算影响极大的Hadoop生态的几个重量级组件:HDFS、zookeeper、HBase等,也都是基于Google用C++实现的GFS、Chubby、BigTable。包括分布式计算框架MapReduce也是Google先用C++实现了一套之后才有开源的java版本。
除了上述领域外,科学计算、浏览器、流媒体开发、网络软件等都是C++比较适合的场景,作为一名老牌语言的常青树,C++一直霸占编程语言前5名,肯定有其存在的价值。
接下来,我们正式进入C++的学习。
C++(兼容C)是在C的基础之上,容纳进去了面向对象编程思想,并增加了许多有用的库,以及编程范式等。
熟悉C语言之后,对C++学习有一定的帮助,本章节主要目标:
- 补充C语言语法的不足,以及C++是如何对C语言设计不合理的地方进行优化的,比如:作用域方面、IO方面、函数方面、指针方面、宏方面等。
- 为后续类和对象学习打基础。
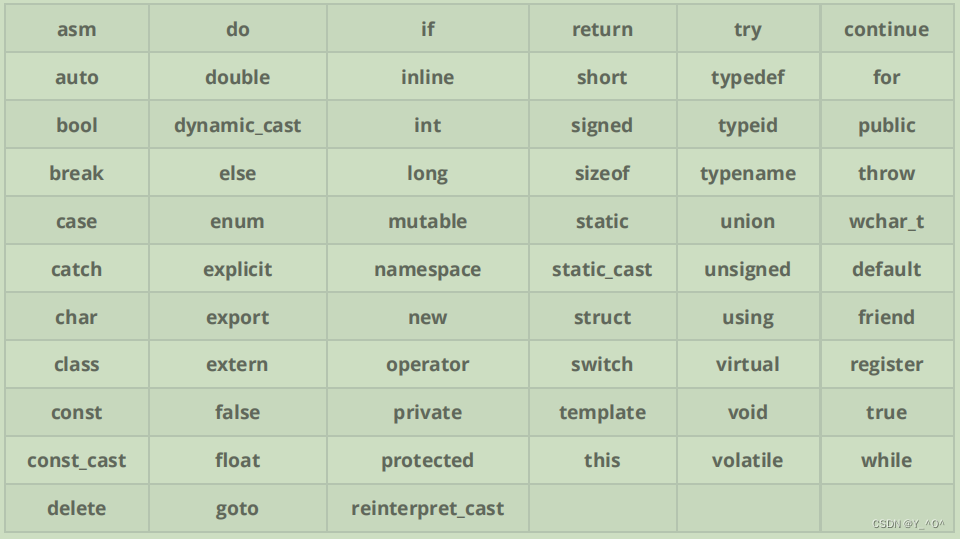
1. C++关键字(C++98)
C++总计63个关键字,C语言32个关键字。
ps:我们只是看一下C++有多少关键字,不对关键字进行具体的讲解。后面我们学到以后再细讲。
2. 命名空间
经过上面的了解,我们知道:
C++呢,其实就是之前的大佬感觉C语言存在一些不足,所以在C语言的基础上做了一些改进,并增加了一些新的东西。
那命名空间就是我们的大佬为C语言补的第一个坑:
在C/C++中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存在于全局作用域中,可能会导致很多冲突。
什么意思呢?举个栗子:
先来创建一个C++的项目:
跟创建C的项目一样,文件后缀CPP我们不要动就行了(创建C项目我们一般修改成.c后缀的)。
ps:.c就调C的编译器,.cpp就调C++的编译器。
那我们写了这样一段代码:
#include <stdio.h>
int rand = 10;int main()
{printf("%d\n", rand);return 0;
}
这是C版的代码,但我们说了C++是兼容C的。
这段代码有什么问题吗?
没有问题,我们打印了一个全局变量,名为rand。
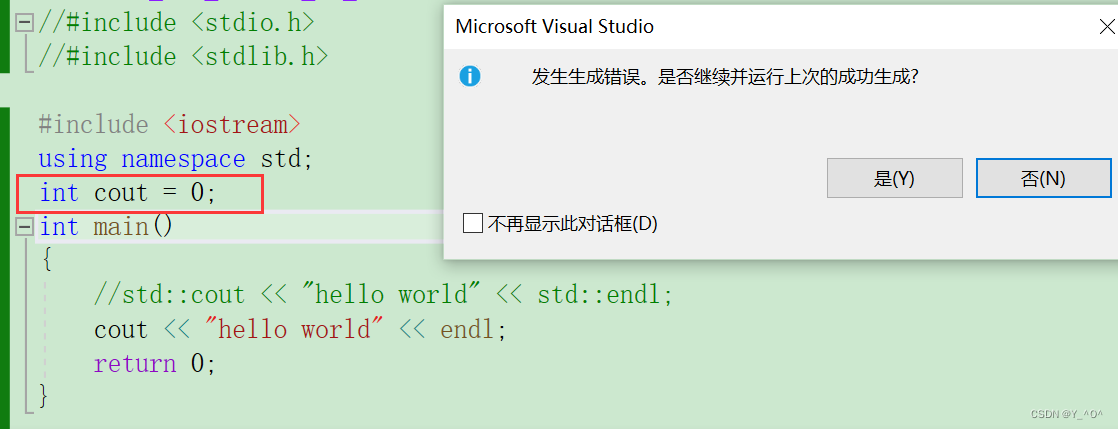
🆗,那我们再多包含一个头文件呢?
再次运行代码:
哦豁,发生错误了,怎么回事?
这里就发生了命名冲突。
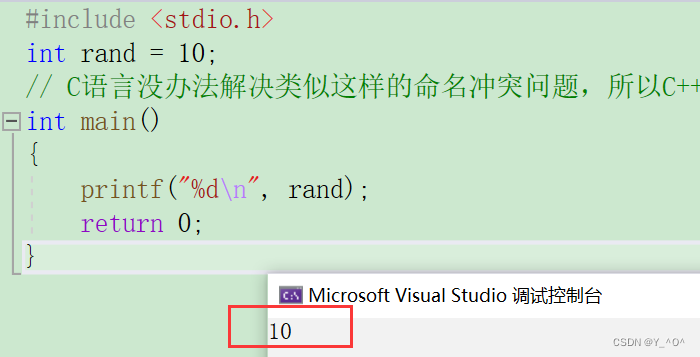

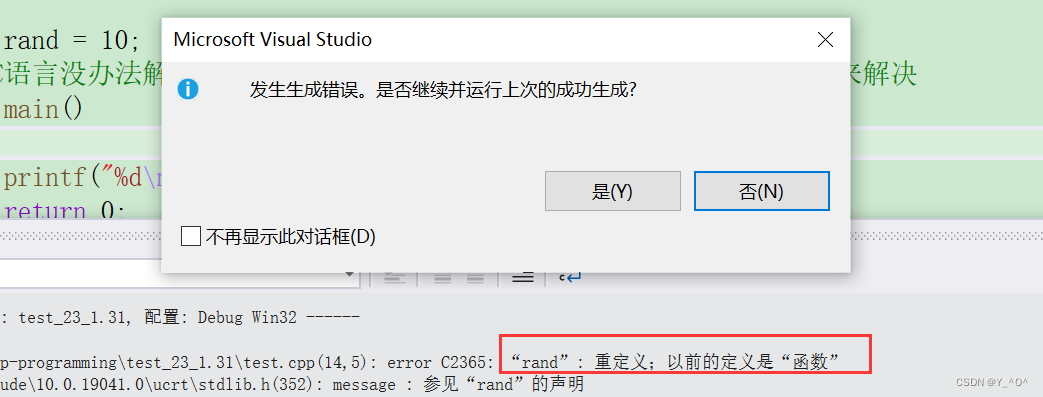
为什么我们加了一个头文件就发生命名冲突了呢?
其实编译器的提示已经很明显了:
如果大家以前了解过rand函数的话就知道它其实是库里面的一个函数,用来产生随机数的嘛。
需要包含的头文件就是<stdlib.h>,第一次之所以没事就是我们没有包对应的头文件。
那rand是我们定义的一个全局变量,现在也包含的rand()函数对应的头文件,所以我们打印的时候就在全局范围内找到了两个rand,所以就出错了。

类似的情况可能还有很多,我们只是举了其中一个例子。
所以这就是C语言的一个缺陷,C语言是不能很好的处理这种情况的,我们只能对我们自己定义的变量重新命名。
那我们的大佬是如何解决这个问题的呢?
C语言没办法解决类似这样的命名冲突问题,所以C++提出了namespace来解决。
namespace(命名空间)关键字的出现就是针对这种问题的,使用命名空间的目的是对标识符的名称进行本地化,以避免命名冲突或名字污染。
那大家先思考一下:
什么情况下同一个工程中出现多个同名的变量或函数不会发生命名冲突?
是不是只要它们在不同的域里,它们的作用域互不干扰就行了啊。
举个栗子:
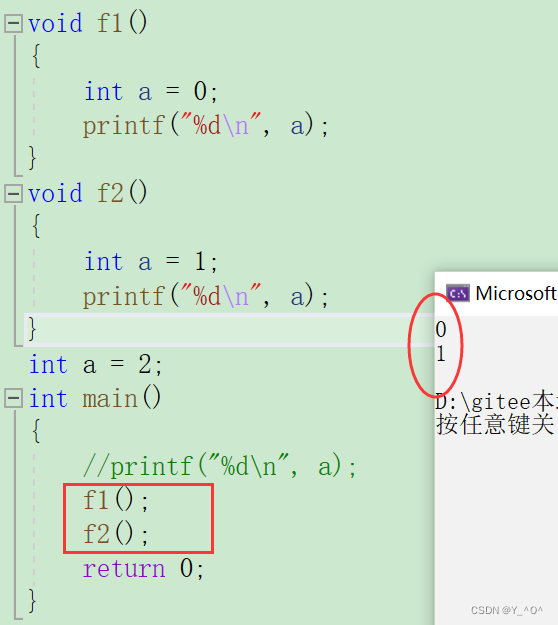
void f1()
{int a = 0;
}void f2()
{int a = 1;
}int main()
{return 0;
}
这样就没问题,因为虽然有两个a,但是它们两个都是局部变量,它们的作用域都是自己所在的函数,互不干扰,所以就没事。
那这时候如果我们在main函数里打印a其实是不行的:
为什么不行呢?
main函数要打印a的话首先就会在main函数对应局部域找a,当然它找不到,因为main函数里我们没有定义a,然后就会在全局去找,也找不到,因为我们定义的两个a都是局部的。
如果我们再定义一个全局的a就行了:
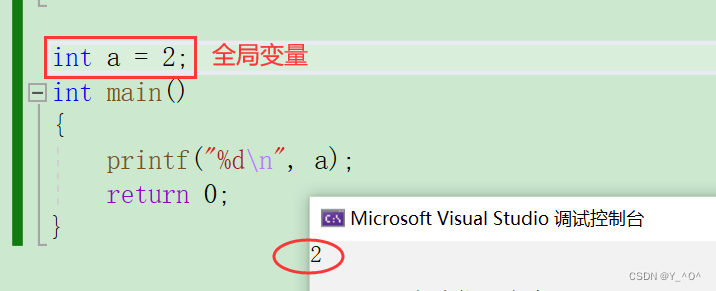
再来看一个问题:
如果我们现在在两个局部变量a所在的函数中打印a,打印的是全局的a还是局部的a?
🆗,当全局变量和局部变量名字相同时,局部优先嘛,这个我们之前C语言就提到过。
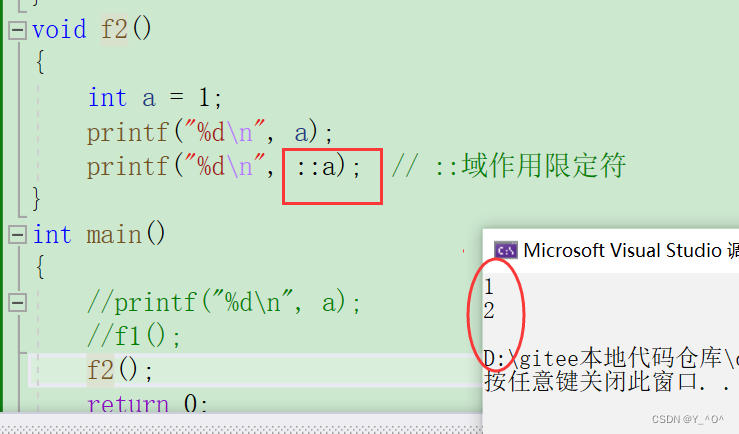
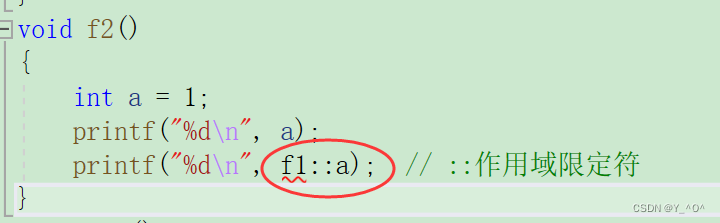
那现在我就想在函数f2()打印全局的a,有没有办法?
有的:
确实打印出来了,那那两个冒号是什么东西啊,为什么在a前面加了这个符号就打印全局a了?
🆗,::叫做 作用域限定符。
在a前面加上作用域限定符之后,打印a时就会直接在指定的作用域进行寻找,而::前面啥也不写,就代表限定的作用域是全局。
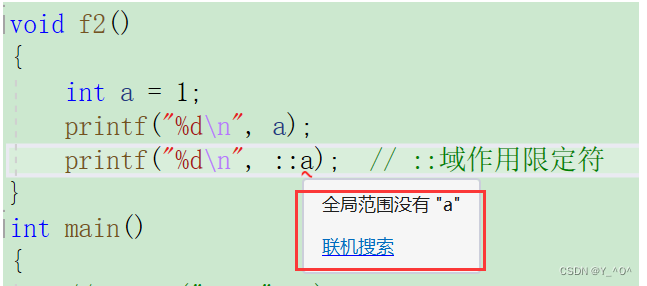
如果我们把全局的屏蔽掉:
就不行了。
另外这样是不行的:
不能指定另一个函数f1作为限定的域。
那了解了上面的内容,其实命名空间也是用类似的思想来避免这些冲突的。
2.1 命名空间的定义
我们还是通过例子来给大家讲解:

还来看这个,现在是存在命名冲突的:
C++提出的命名空间就是解决这种问题的。

怎么做呢?
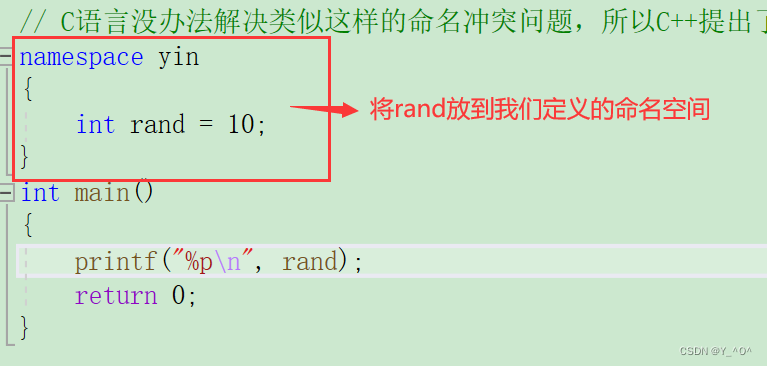
如果我们想解决这个命名冲突,就可以定义一个命名空间,将我们自己的rand放到命名空间里:
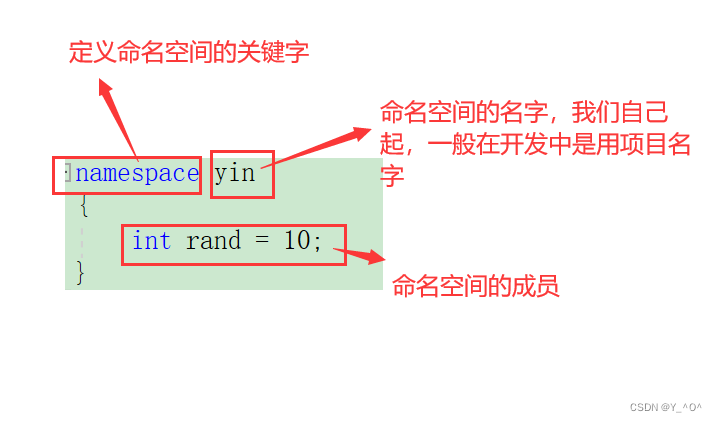
定义命名空间,需要使用到namespace关键字,后面跟命名空间的名字,然后接一对{}即可,{}中即为命名空间的成员。
那这样做就不会报错了吗?
是的。
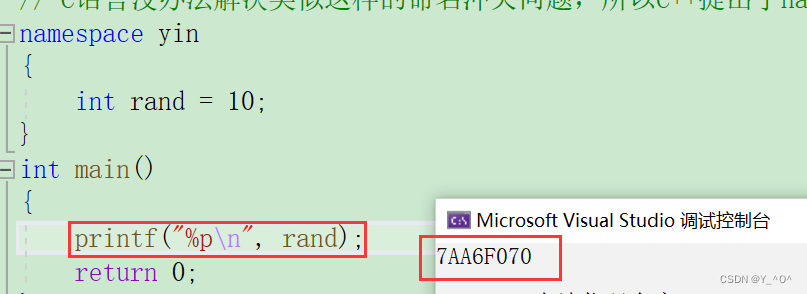
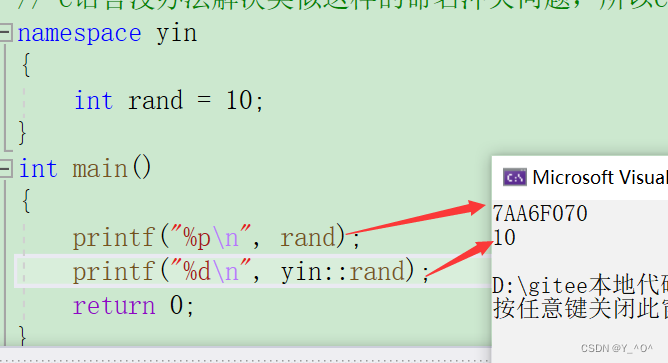
这次就成功的打印出来了rand的值,那打印出来的是个啥大家能看出来吗?
🆗,这里打印的其实是库里面的rand函数的地址(所以我改成了%P更合适一点),因为打印rand的时候会先在main函数所在的局部去找rand,但是没有,然后去全局找,就找到了库里面的rand,而我们自己定义的rand现在是在命名空间里的,所以不会找到,自然就没事了。
那我们现在如果想访问命名空间里的rand怎么办?
是不是用我们上面提到的作用域限定符就行了啊:
当然,在命名空间中,不止可以放变量:
命名空间中可以定义变量/函数/类型等等。

另外呢:
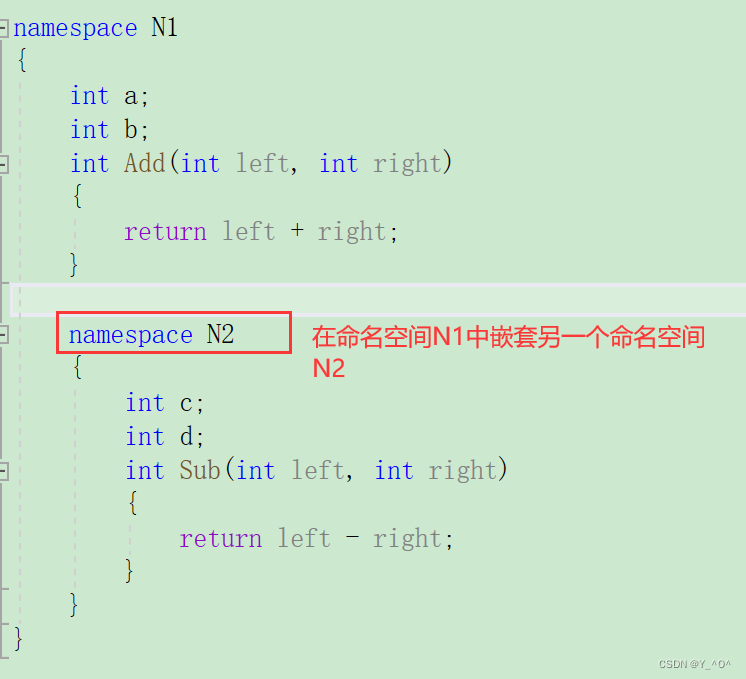
命名空间可以嵌套(多层嵌套)
那访问就应该这样:
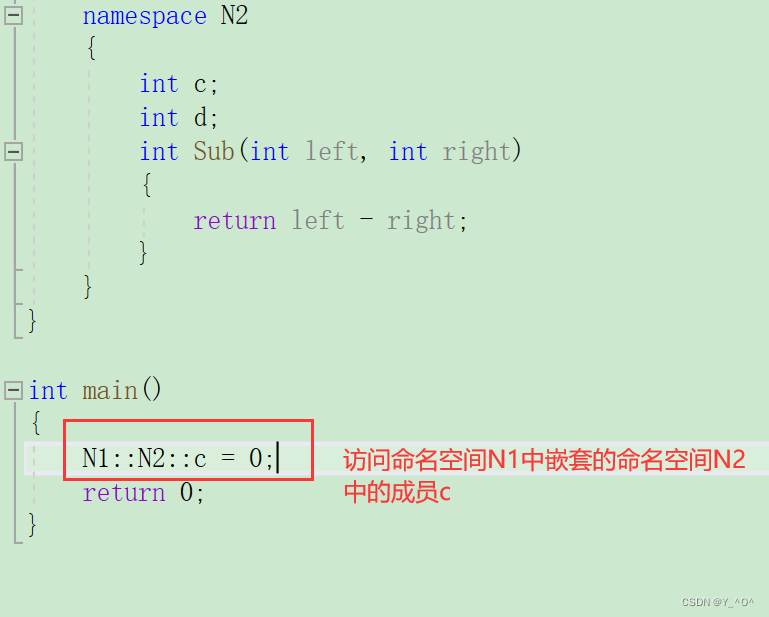
那大家再想一下:
命名空间是用来解决名字冲突的,那如果多个命名空间的名字撞了怎么办?
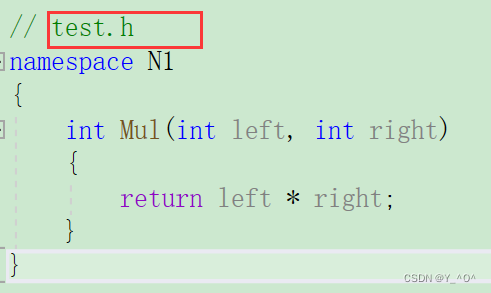
同一个工程中允许存在多个相同名称的命名空间,编译器最后会合成同一个命名空间中。
一个工程中的test.h和上面test.cpp中两个N1会被合并成一个。

2.2 命名空间的使用
通过上面的学习我们知道,命名空间的引入其实是为了解决命名冲突的问题。
那现在我们想使用命名空间里的某个成员,有哪些方法呢?
我们通过一个例子给大家介绍:
我们学习一门新的编程语言一般第一个程序都是“hello world”
接下来我们就来写一个C++版的“hello world”
那是不是很简单啊,写个main函数,然后打印一下就行了:
我们C语言打印用printf,C++里可以用cout(cout 用于在计算机屏幕上显示信息)。这个大家先了解一下就行了。
然后后面的endl其实就是换行。
这样就可以了吗?
运行发现还不行,为什么呢?
我们知道C语言使用printf打印需要包含头文件,那C++也一样,这里cout和endl想要使用的话也得包一个头文件,就是<iostream>

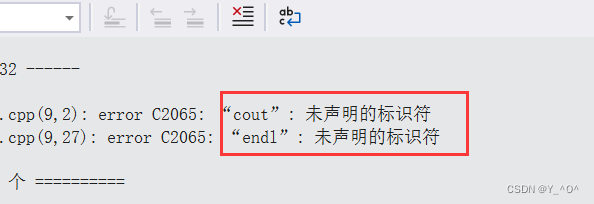

但我们发现现在还不行,怎么回事?
原因就在于C++为了避免我们自己命名的变量或者函数会与库里面的发生命名冲突,所以将标准库里面的东西都放到了一个命名空间——
std里。
那现在我们想使用命名空间std里的cout这些东西怎么办?
- 使用作用域限定符指定对应的命名空间
第一个方法就是用我们上面提到的作用域限定符::指定其对应的命名空间,这样我们的程序就会直接去对应的命名空间里寻找cout,那找到了,就可以用了:
这样就可以了。
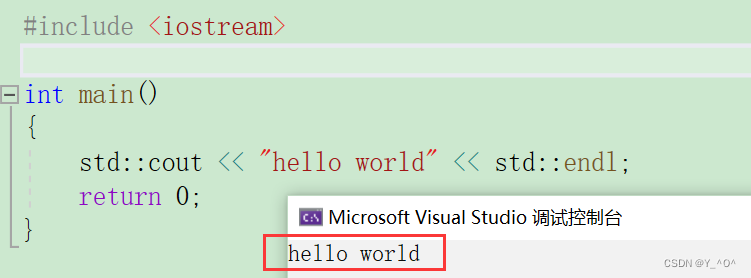
那还有没有其它方法呢?
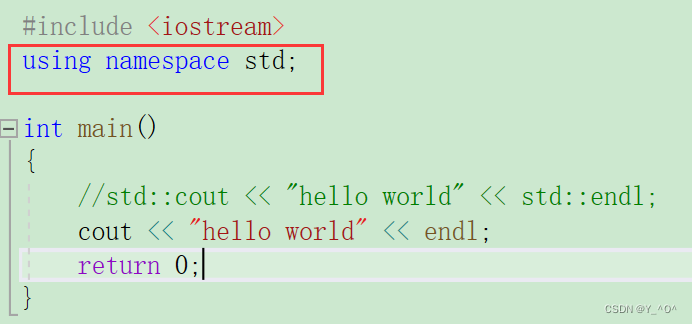
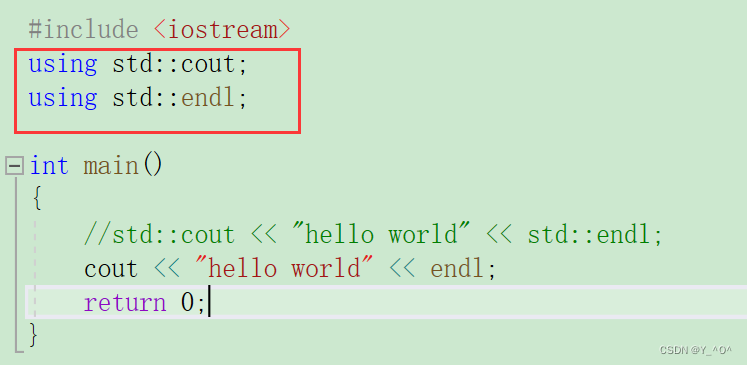
- 使用using namespace 命名空间名称 将该命名空间引入(全局展开)
这样就可以了,using namespace std;相当于把这个命名空间在全局范围内展开了。
所以现在不指定命名空间也可以用了。
但是这样做好不好呢?
是不是不太好啊,人家故意把这些东西封到命名空间中来防止命名冲突,我们这样直接全局展开的话是不是命令空间的存在就没什么意义了。
我们不小心再定义一个同名的变量啥的是不是就出现问题了。
所以呢,在一些项目中,我们一般不建议直接全局展开。
但是平时我们自己写一些练习,小程序之类的,图方便的话可以全局展开,自己注意一点就行了。
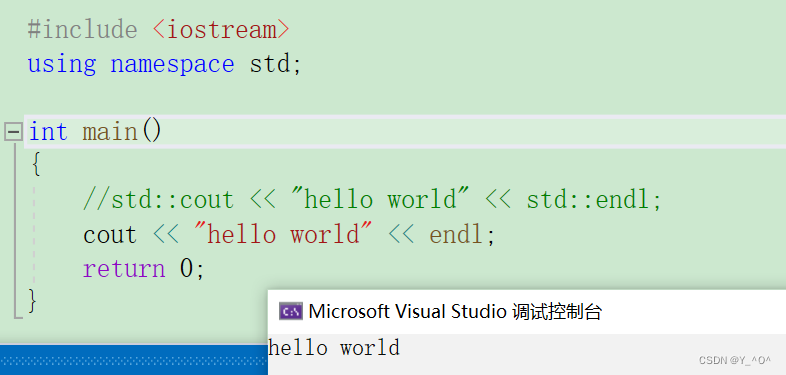
然后还有第3种方法:
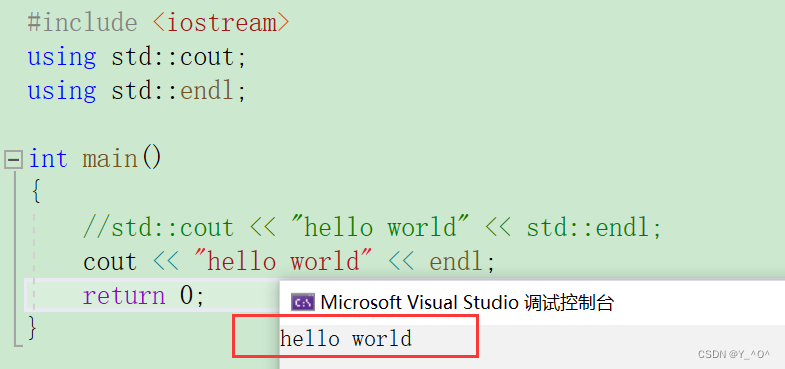
- 用哪个成员,就使用using引入哪个(部分展开)
std命名空间里是包含很多成员的,那我们现在如果只用到了cout和endl,我们就可以只把这两个引入程序中。
然后呢,就可以直接用了:
2.3 std命名空间的使用惯例
std是C++标准库的命名空间,如何展开std使用更合理呢?
- 在日常练习中,建议直接using namespace std即可,这样就很方便。
- using namespace std展开,标准库就全部暴露出来了,如果我们定义跟库重名的类型/对象/函数,就存在冲突问题。
该问题在日常练习中很少出现,但是项目开发中代码较多、规模大,就很容易出现。所以建议在项目开发中使用,像std::cout这样使用时指定命名空间 + using std: :cout展开常用的库对象/类型等方式。
3. C++输入&输出
新生婴儿会以自己独特的方式向这个崭新的世界打招呼,C++刚出来后,也算是一个新事物。

3.1 输入输出
那C++是否也应该向这个美好的世界来声问候呢?我们来看下C++是如何来实现问候的:
#include<iostream>
// std是C++标准库的命名空间名,C++将标准库的定义实现都放到这个命名空间中
using namespace std;
int main()
{cout << "Hello world!!!" << endl;return 0;
}
那其实我们上面已经实现过了,但是这里面用到的cout大家可能还不是很了解。
但是我们现在刚开始学习C++,还不能很好的理解这些东西。
cout 用于在计算机屏幕上显示信息,是C++中iostream 类型的对象,C++的输出是用“流”(stream)的方式实现的,流运算符的定义等信息是存放在C++的输入输出流库中的,因此如果在程序中使用cout和流运算符,就必须使用预处理命令把头文件stream包含到本文件中,即 < iostream > 库,该库定义的名字都在命名空间 std 中,所以 cout 全称是 std: :cout。
那上面还用到这个<<是啥啊。
<<是流插入运算符。
然后现在大家可以理解成这个cout就是控制台:
cout << "Hello world!!!" << endl;
我们的字符串"Hello world!!!"和换行endl流插入到控制台,流向控制台,然后就可以输出显示出来了。
那有输出了,肯定也要有输入,C++怎么输入呢?
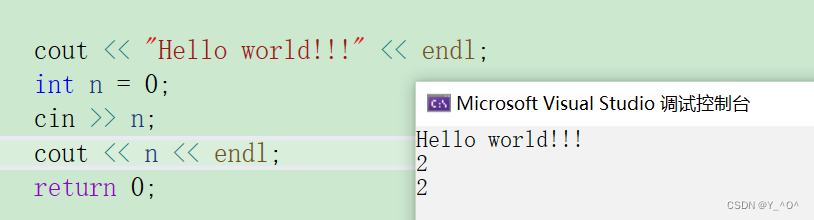
往屏幕上输出信息用cout,输入的话用cin。
那有流插入<<,就有流提取>>
所以C++,我们想输入一个数是这样的:
运行一下:
我们C语言输入一般用scanf,而且要指定格式,整型%d,字符%c…
而cin呢它可以做到自定识别变量类型。
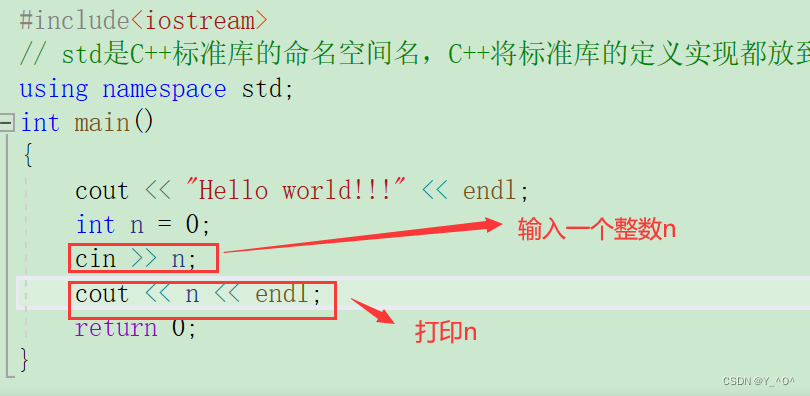
int main()
{int a;double b;char c;// 可以自动识别变量的类型cin >> a;cin >> b >> c;cout << a << endl;cout << b << " " << c << endl;return 0;
}

3.2 说明
- 使用cout标准输出对象(控制台)和cin标准输入对象(键盘)时,必须包含< iostream >头文件以及按命名空间使用方法使用std。
- cout和cin是全局的流对象,endl是特殊的C++符号,表示换行输出,他们都包含在包含< iostream >头文件中。
- <<是流插入运算符,>>是流提取运算符。
- 使用C++输入输出更方便,不需要像printf/scanf输入输出时那样,需要手动控制格式。
C++的输入输出可以自动识别变量类型。- 实际上cout和cin分别是ostream和istream类型的对象,>>和<<也涉及运算符重载等知识,
这些知识我们我们后续才会学习,所以我们这里只是简单学习他们的使用。后面我们还有有一个章节更深入的学习IO流用法及原理。注意:早期标准库将所有功能在全局域中实现,声明在.h后缀的头文件中,使用时只需包含对应头文件即可,后来将其实现在std命名空间下,为了和C头文件区分,也为了正确使用命名空间,规定C++头文件不带.h;旧编译器(vc 6.0)中还支持<iostream.h>格式,后续编译器已不支持,因此推荐使用+std的方式。
ps:
关于cout和cin还有很多更复杂的用法,比如控制浮点数输出精度,控制整形输出进制格式等等。因为C++兼容C语言的用法(也就是说必要时我们可以直接使用C的方式),这些又用的不是很多,我们这里就不展开学习了。后续如果有需要,我们再配合文档学习。
4. 缺省参数
缺省参数其实也是C++补的C语言的一个坑。
4.1 缺省参数概念
我们先来回忆一下:
C语言中的函数,如果我们自定义一个函数,函数有一个或多个参数,那我们调用的时候是不是就必须传参啊,形参有几个,实参我们就需要传几个。
那C++引入了缺省参数,是什么呢?
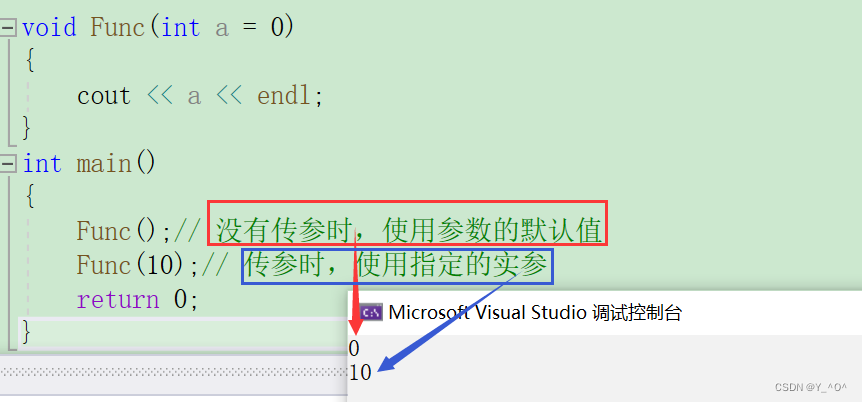
缺省参数是声明或定义函数时为函数的参数指定一个缺省值(默认值)。
在调用该函数时,如果没有指定实参则采用该形参的缺省值,否则使用指定的实参。
举个栗子:
void Func(int a = 0)
{cout << a << endl;
}
int main()
{Func();// 没有传参时,使用参数的默认值Func(10);// 传参时,使用指定的实参return 0;
}
我们两次调用Func函数(指定参数a的缺省值为0),第一次调用不传参,第二次实参为10。
我们运行一下:
🆗,这就是缺省参数。
4.2 缺省参数分类
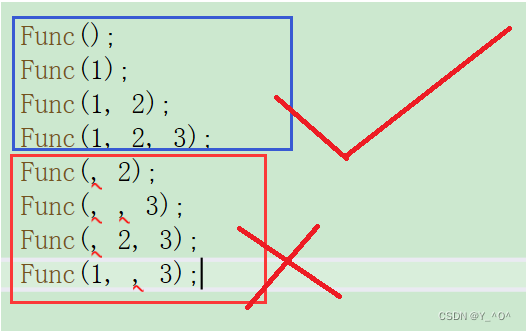
- 全缺省参数
即函数有一个或多个参数,全部都有缺省值。
void Func(int a = 10, int b = 20, int c = 30){cout<<"a = "<<a<<endl;cout<<"b = "<<b<<endl;cout<<"c = "<<c<<endl;}
那这时我们传参可以怎么传呢?
int main()
{Func();Func(1);Func(1, 2);Func(1, 2, 3);return 0;
}

这样都是可以的,但是注意,不要这样搞⚠:
2. 半缺省参数
即有多个参数时,可以有的给缺省值,有的不给。
像这样:
void Func(int a, int b = 10, int c = 20)
{cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl;
}
那我们传参就有这几种方式:
int main()
{Func(1);Func(1, 2);Func(1, 2, 3);return 0;
}

但是要注意:
- 半缺省参数必须从右往左依次来给出,不能间隔着给
既不能像这样:
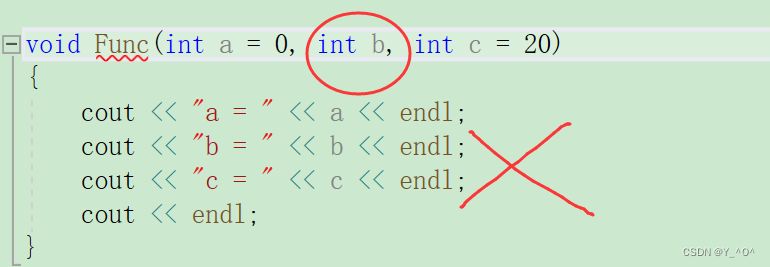

- 缺省参数不能在函数声明和定义中同时出现
//a.hvoid Func(int a = 10);// a.cppvoid Func(int a = 20){}
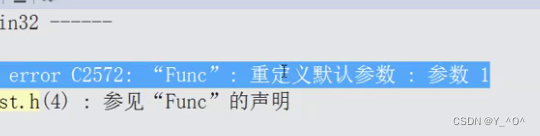
注意:如果声明与定义位置同时出现,且恰巧两个位置提供的值不同,那编译器就无法确定到底该用那个缺省值。
当然,即使两个地方值给的一样,也照样会报上面那个错误。
另外需要注意,如果有函数声明的话,缺省参数要在声明的时候给。
- 缺省值必须是常量或者全局变量(一般不用全局变量)
- C语言不支持缺省参数(编译器不支持)
5. 函数重载
自然语言中,一个词可以有多重含义,人们可以通过上下文来判断该词真实的含义,即该词被重载了。
5.1 函数重载概念
在C++中呢引入了函数重载,这个也是C语言所没有的,那什么是函数重载呢?
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数的个数 或 参数的类型 或 参数类型的顺序)不同,常用来处理实现功能类似但数据类型不同的问题。
- 参数类型不同
首先来看函数重载的第一种情况:参数类型不同。即函数名和参数个数都是一样的,只是参数类型不同。
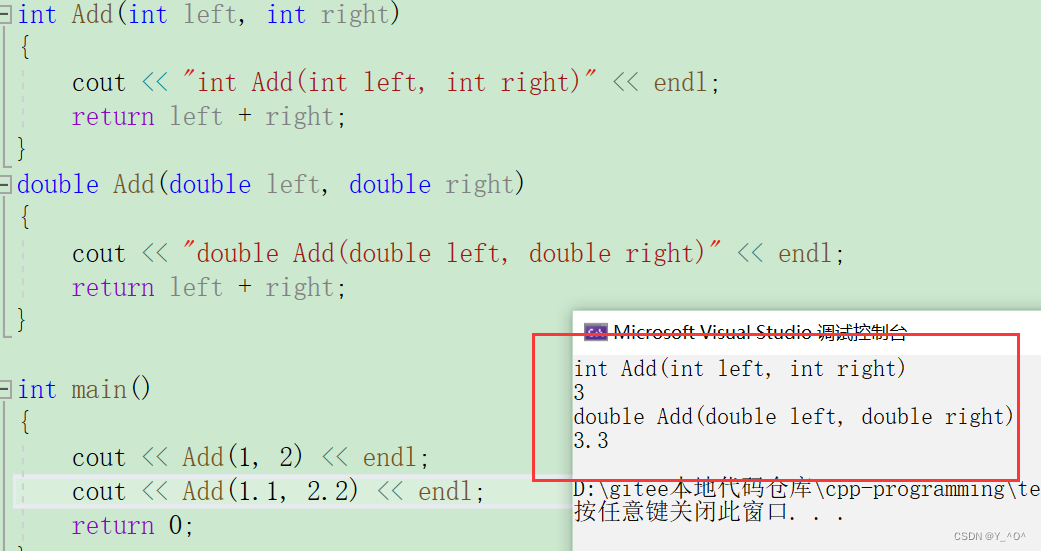
int Add(int left, int right)
{cout << "int Add(int left, int right)" << endl;return left + right;
}
double Add(double left, double right)
{cout << "double Add(double left, double right)" << endl;return left + right;
}
像这样两个函数,它们的函数名完全相同,唯一的区别就是参数类型和返回类型不同。
🆗,那大家都知道这样的情况在C语言中肯定是会报错的。
那C语言中我们想解决这个错误就只能改动一下,让这两个函数的名字不再相同。

但是C++引入了函数重载就支持这种情况的出现了:
这样看起来我们是调用的同一个函数,但是程序会自动根据我们传的参数类型进行匹配,如何匹配我们后面也会介绍到。
在有些时候还是很方便的。

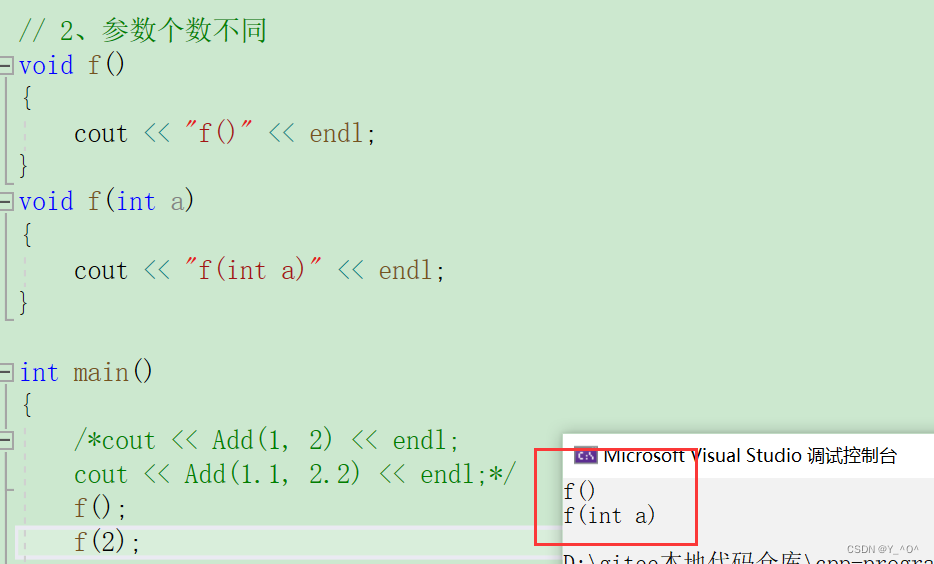
- 参数个数不同
第二种情况:函数名和返回类型都相同,但是参数的个数不同。
// 2、参数个数不同
void f()
{cout << "f()" << endl;
}
void f(int a)
{cout << "f(int a)" << endl;
}
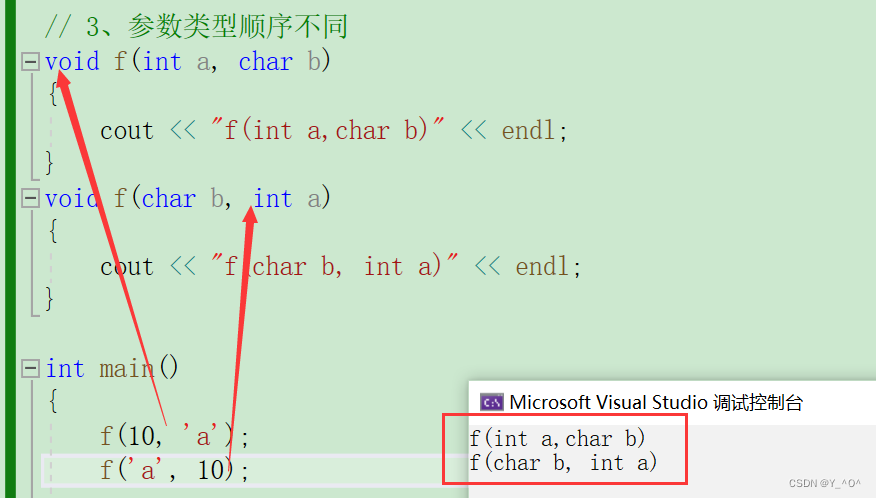
- 参数类型顺序不同
第三种:参数类型的顺序不同,什么意思呢,比如下面这种情况:
void f(int a, char b)
{cout << "f(int a,char b)" << endl;
}
void f(char b, int a)
{cout << "f(char b, int a)" << endl;
}
参数的类型都是int和char,但是顺序不一样。
5.2 C++支持函数重载的原理–名字修饰
首先大家思考一个问题:
我们上面提到C++中出现函数重载情况的时候,我们去调用时程序会根据我们传的参数类型去匹配对应的函数。
那大家想一下,相比C语言的函数调用过程,这个匹配的过程会不会导致程序变慢,或者说让运行时间变长呢?
🆗,是不会的哦。
因为这个匹配的过程其实是在编译期间就完成的,所以不会对运行时间造成影响。
我们之前专门有一篇文章讲解C/C++程序一步步变成可执行程序的过程,大家忘了的话可以回顾一下链接: link
那我们继续,那在编译期间,编译器是如何对这些重载函数进行区分和匹配呢?
🆗,那原因呢就在于C++做了一件事情,就是对函数名进行了名字修饰。
而C语言是不会进行这样的处理的,因为C语言不允许函数重载,即C程序中不会出现同名函数的,所以C语言可以直接通过函数名去匹配对应的函数,一旦出现同名函数,那这时就发生冲突了,就报错了。
那具体C++是怎么对函数名进行修饰的?
那其实每个编译器都有自己的函数名修饰规则,这取决于编译器的实现者。
由于Windows下vs的修饰规则过于复杂:
可以给大家看一下在vs上C的函数名和C++修饰之后的函数名的对比:
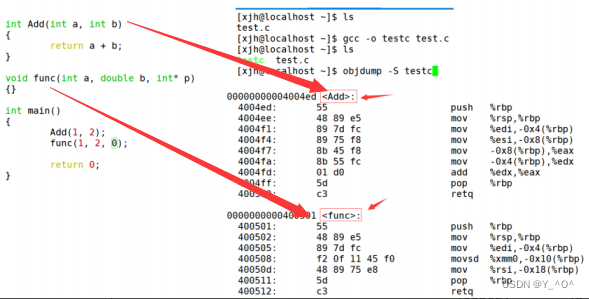
相比于Windows下vs的修饰规则,Linux下g++的修饰规则简单易懂,下面我们可以看看g++对函数修饰后的名字:
- 采用C语言编译器编译后结果(gcc)
结论:在linux下,采用gcc编译完成后,函数名字没有发生改变。- 采用C++编译器编译后结果(g++)
结论:在linux下,采用g++编译完成后,函数名字的修饰发生改变,编译器将函数参数类型信息添加到修改后的名字中。
我们可以看出gcc的函数修饰后名字不变。而g++的函数修饰后变成【_Z+函数长度+函数名+类型首字母】
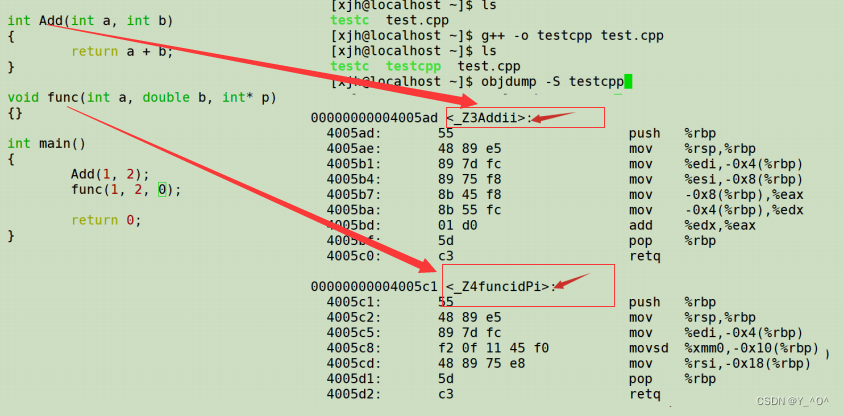
Windows下名字修饰规则
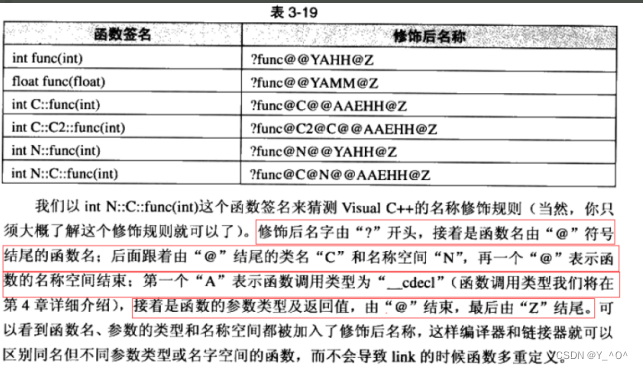
对比Linux会发现,windows下vs编译器对函数名字修饰规则相对复杂难懂,但道理都是类似的,我们就不做细致的研究了。
通过这里就理解了C语言没办法支持重载,因为同名函数没办法区分。而C++是通过函数修饰规则来区分,只要参数不同,修饰出来的名字就不一样,就支持了重载。
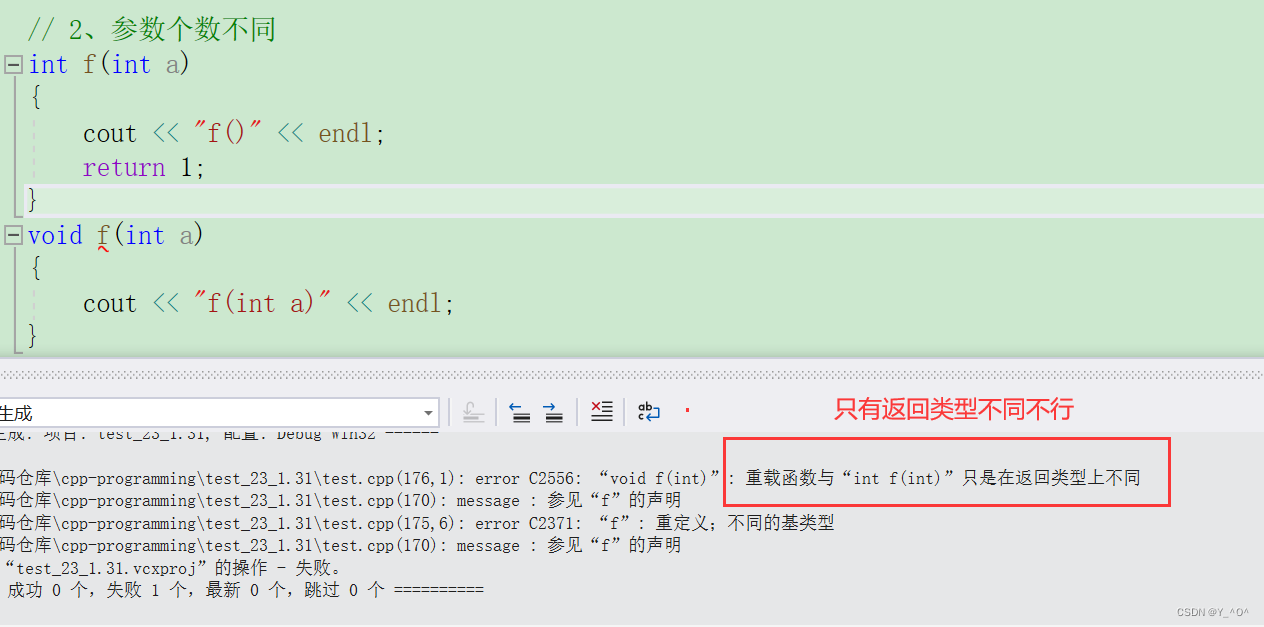
最后大家再思考一个问题:如果两个函数只有函数返回值类型不同,能否构成重载?
是不行的。
为什么不行?
因为我们在调用的时候,是不是不能分辨出返回类型是啥啊,这样是不合理的。
所以:
如果两个函数函数名和参数是一样的,只有返回值不同是不能构成重载的,因为调用时编译器没办法区分。

6. 引用
6.1 引用的概念
那C++的引用又是什么东西呢?
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,一个变量若存在引用,则它和它引用的变量共用同一块内存空间。
比如:武松,别名有武二郎,天伤星,行者等。

那如何定义一个变量的引用呢?
语法:类型& 引用变量名(对象名) = 引用实体;
举个栗子:
int main()
{int a = 5;int& b = a;return 0;
}
这里b就是a的一个引用。
b就相当于a的一个别名,它们共用同一块内存空间。
a和b的关系就好比武二郎和行者,都是指的武松。
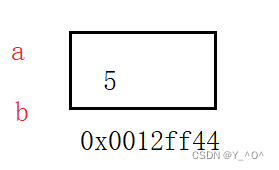
我们可以验证一下:
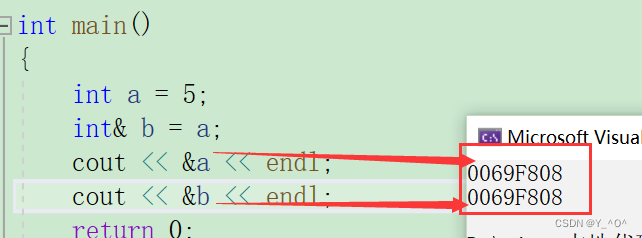
a和b的地址是一样的。
那我们可不可以给a再取一个别名:
当然可以,就像武松他可以有好几个绰号。
那c是a的一个引用(别名),那我们可不可以给c定义一个引用?
也是可以的。
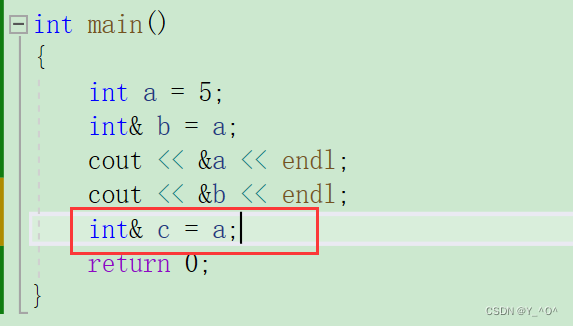
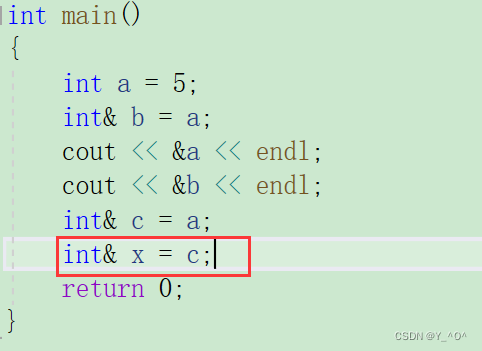
就相当于我们给同一块空间起了很多个名字。
注意:
引用类型必须和引用实体是同种类型的
整形变量的引用是int&
字符变量的引用是char&
整形指针变量的引用就是int*&
6.2 引用的特性
- 引用在定义时必须初始化

我们定义一个引用,必须对它进行初始化。

- 一个变量可以有多个引用
这个我们在上面就提到了嘛,就好比一个人可以有很多别名。
b、c、d都是a的引用。

- 引用一旦引用一个实体之后,就不能再引用其他实体
什么意思呢?举个栗子:
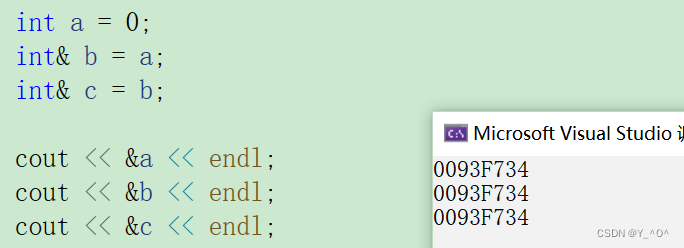
现在b、c都是a的引用,当然的地址都是一样的:
那我们现在做这样一个事情:
我们新定义一个变量x,把x赋给c(c是a的引用),那现在c会变成x的引用嘛?
不会的,我们上面说了,一个引用在引用一个实体之后,就不能再引用其他实体了,就可以理解为行者已经是武松的绰号了,就不能再成为别人的绰号了。
我们看到b、c地址并没有改变,还是a的引用。
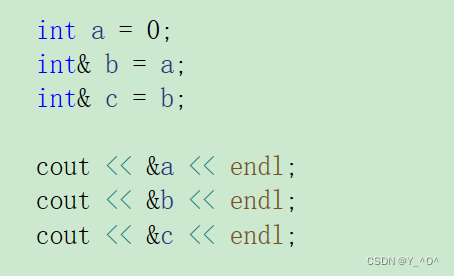
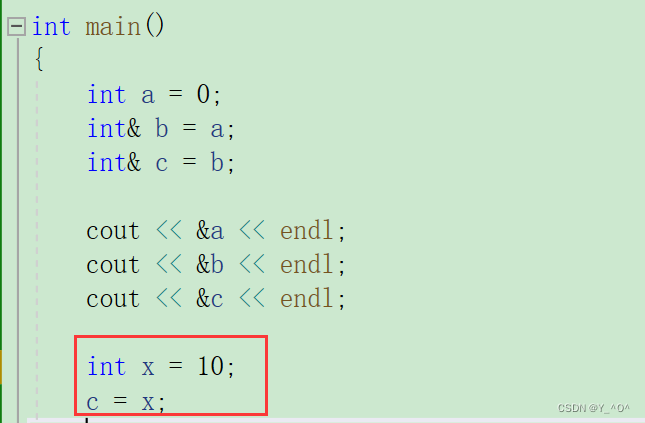
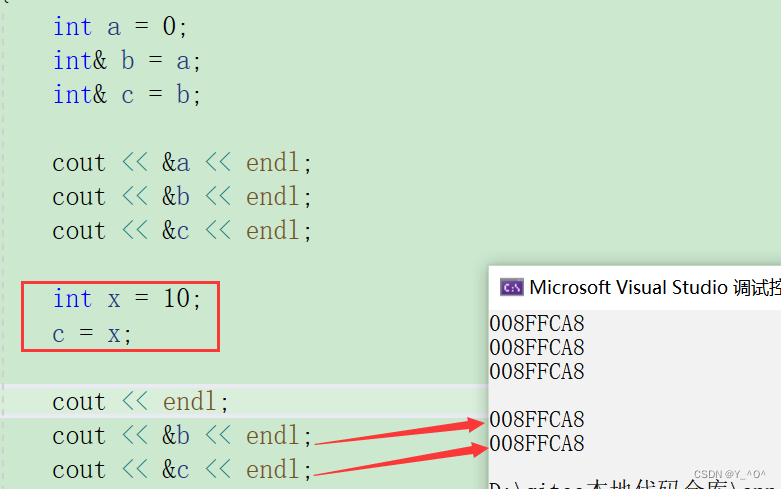
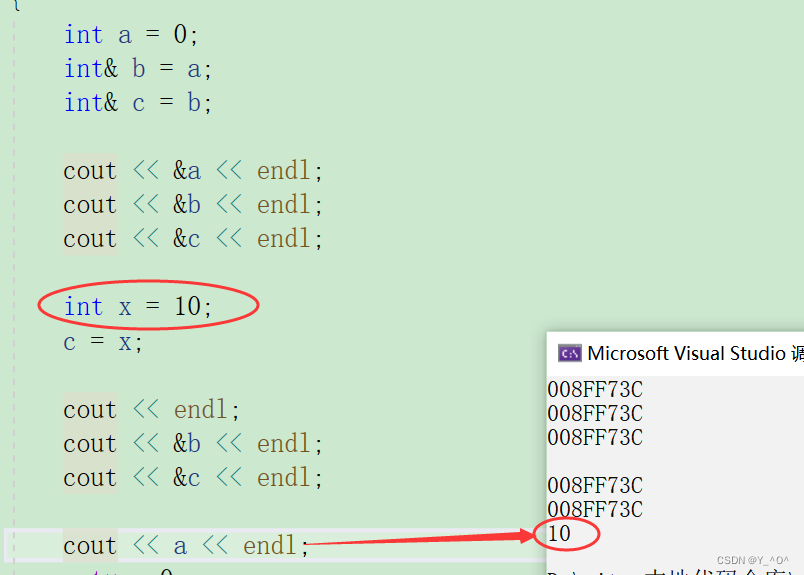
那c = x;起到的效果是啥呢?
c是a的引用,可以理解为c就是a,那
c = x;就是把c的值10赋给了a,所以我们现在打印a:
a就是10了。
当然b、c就也是10 了。
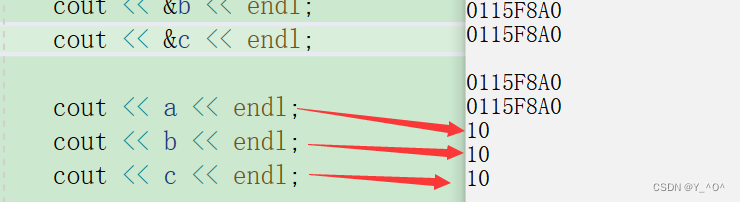
6.3 常引用
一起来看:
int a = 1;int& b = a;
定义一个整型变量a,然后给a取了一个别名b,这没问题吧。
然后再看:
const int x = 5;int& y = x;
这样可以吗?
🆗,不行。
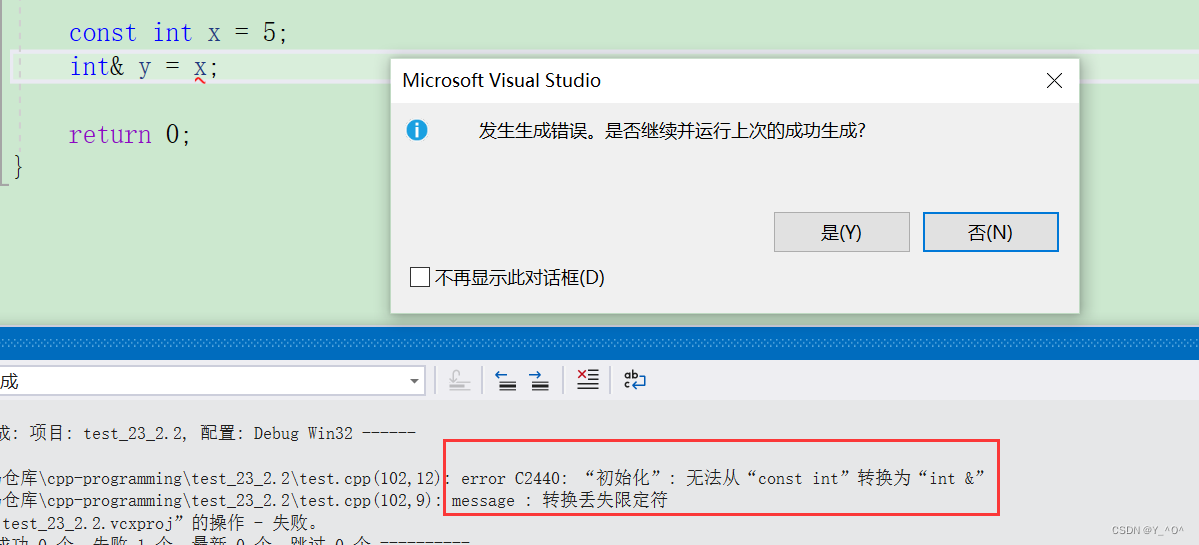
为什么呢?
对于引用,还有指针来说,对它们进行赋值和初始化时,权限可以缩小,但不能放大。
什么意思呢?
这里的x是被const修饰的,一个变量被const修饰后就具有了常属性,就不能再被改变了,这也是我们之前C语言的知识了。
但是现在我们想要给它起一个别名(引用)y,而y是没有被const修饰的,也就是说y是可以被改变的,但是它引用的实体却是不可变的。
这是不是相当于给它的权限放大了,所以这样不行。
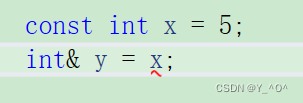
那我们说指针也具有这样的特性,我们也举个栗子:
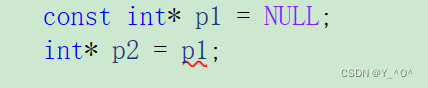
const修饰*p1,即p1指向的内容不能被修改,但p2是可以被修改的,所以想把p1赋给p2就是不行的。
这两个就是典型的放大权限的例子:

那我们怎么才能够成功赋值呢?
是不是让他们的权限一样大就行了:
这样就可以了。
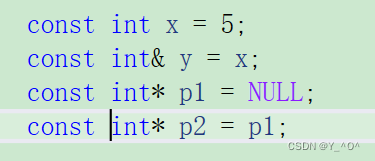
那这种可不可以:
可以嘛,权限缩小是可以的。

再来看这个对不对:
int Count()
{int n = 0;n++;return n;
}
int main()
{int& ret = Count();return 0;
}

不行,因为这里返回的(ret接收的)是一个临时变量,临时变量具有常属性(不能被修改),所以这里也相当于放大权限了。
至于这里为什么返回的是临时变量,如果大家不明白,先不急,下面使用场景的第二个(做返回值)会对Count函数如何返回进行分析。
那这里也是加一个const就好了:

🆗,我们再来看一个场景:

这个行不行?
首先答案肯定是不行。
拿为什么呢?
大家可能会想,这类型都不一样,肯定不行了。
我刚开始也是这么想的,但是:

欸,为什么啊?
为什么加一个const就可以了呢?x就可以成为i的引用(别名)了吗?
那原因在于:
大家要知道,类型转换是会产生临时变量的,不管是强制类型转换,还是隐式类型转换,都是会产生临时变量的。
举个例子:
这里是直接把x转换成浮点型赋给y 了吗?
🆗,不是的,这里会产生一个临时变量,临时变量的值就是x转换成double类型的值,然后把这个临时变量赋值给y。
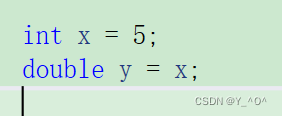
那我们回过头来看这个程序:
应该是怎么样的:是会产生一个临时变量接收i转换为double类型的值,所以x其实是这个double类型的临时变量的引用,但是报错了,因为临时变量具有常性,所以我们加了一个const之后就好了。

6.4 使用场景
那引用的使用场景有哪些呢?我们一起来看一看:
1. 做参数(传参)
我们先来回忆一个问题:C语言中要想交换两个整型变量,我们是怎么做的?
🆗,我们知道形参是实参的一份临时拷贝,形参的改变不影响实参,所以呢?
我们要传变量的地址过去:
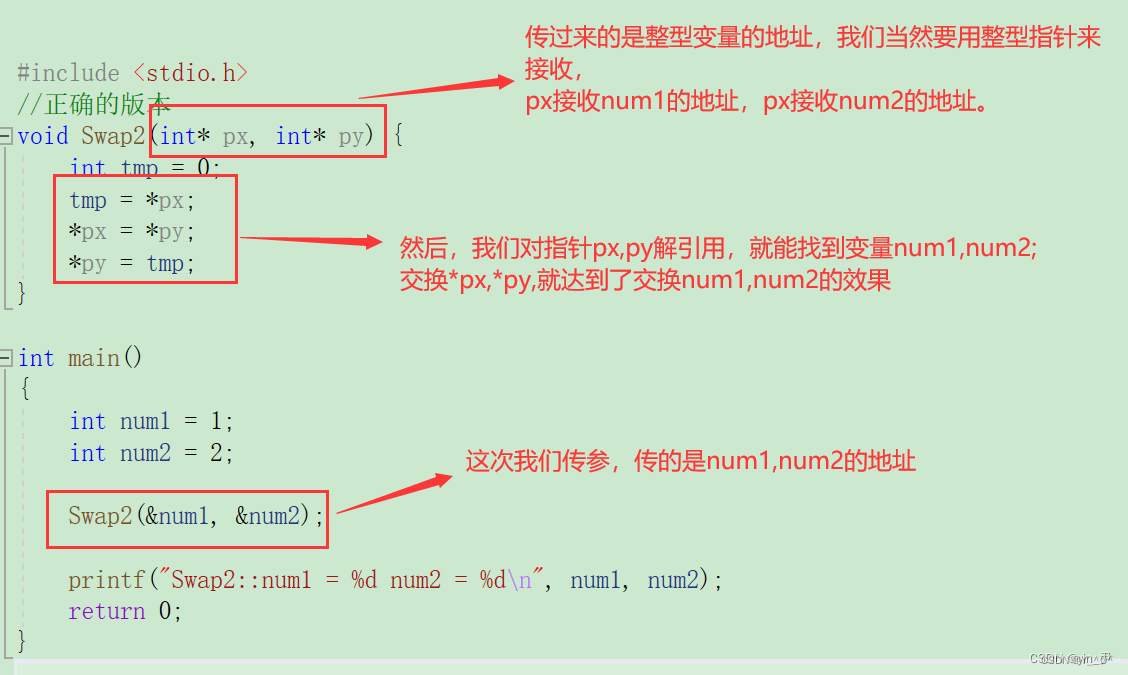
那现在C++引入了引用之后,我们是不是就不用这么麻烦,再传地址过去了啊:
借助引用是不是也能轻松搞定啊:
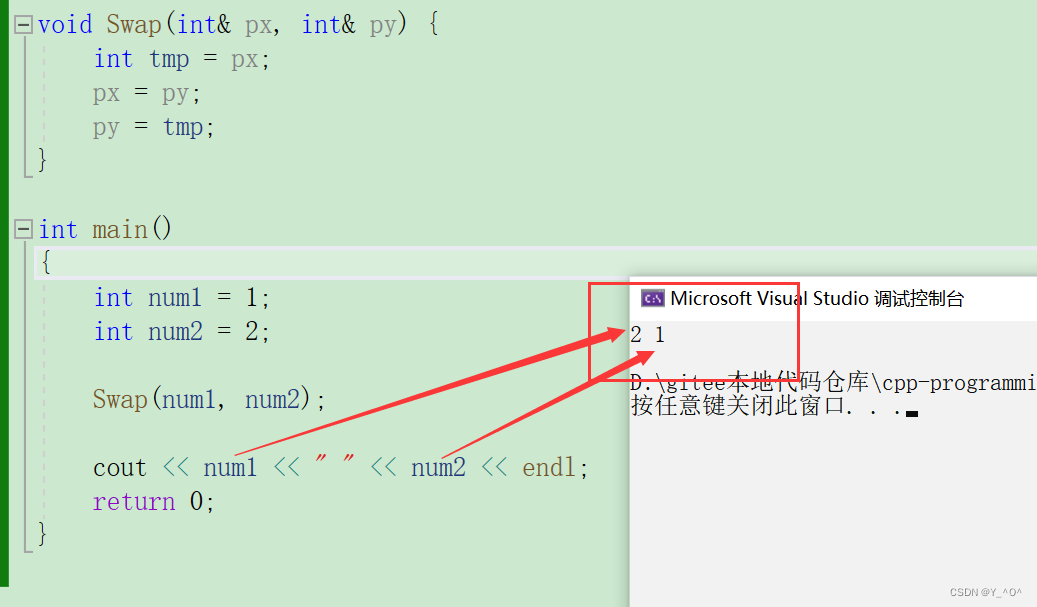
void Swap(int& px, int& py) {int tmp = px;px = py;py = tmp;
}int main()
{int num1 = 1;int num2 = 2;Swap(num1, num2);cout << num1 << " " << num2 << endl;return 0;
}
我们用两个变量的引用进行交换,是不是就行了啊:
2. 做返回值
那在讲引用做返回值之前,我们首先要做一些铺垫:
我们先来看这样一个程序:
int Count()
{int n = 0;n++;return n;
}
int main()
{int ret = Count();return 0;
}
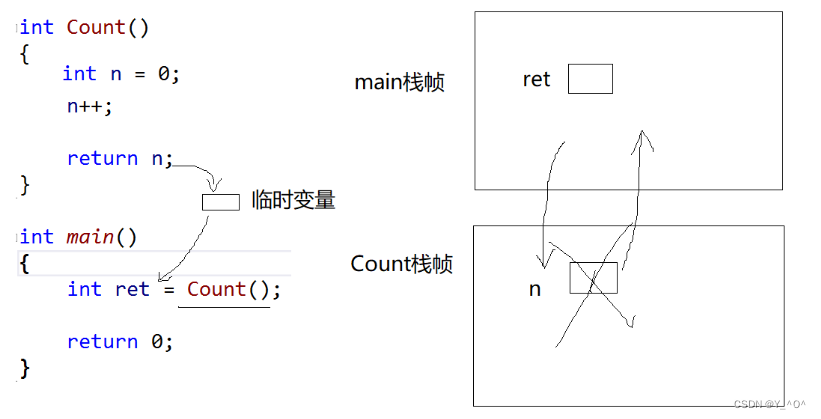
一个很简单的程序,main函数调用Count函数,返回值n赋给了变量ret。
那问大家一个问题:在这个过程中,Count函数返回的n是直接就赋给了ret吗?
🆗,不是的,不能够这样做。
为什么呢?
因为n是不是Count函数中创建的一个局部变量啊,它是存在Count函数的栈帧里的,当函数调用结束,n是不是随着Count函数的栈帧一起被销毁了。当然这里的销毁不是说这块空间不存在了,是归还给操作系统了,但是我们就没有这块空间的使用权了。
所以,函数调用结束我们还能把n这块空间的值赋给ret吗,是不是不行啊。
那这个过程是如何将这个返回值安全的给到ret呢?
那如果大家了解过函数栈帧的创建和销毁就应该知道,这个地方在销毁之前,会产生一个临时变量,来保存要返回的n的值(当要返回的数据比较小的时候,这个临时变量通常是一个寄存器,比较大的时候就不一定是寄存器了)。
然后就算调用结束,n被销毁了,我们也保留了返回值可以赋给main函数的ret。
理解了上一个程序,我们再来看一个:
int Count()
{static int n = 0;n++;return n;
}
int main()
{int ret = Count();return 0;
}
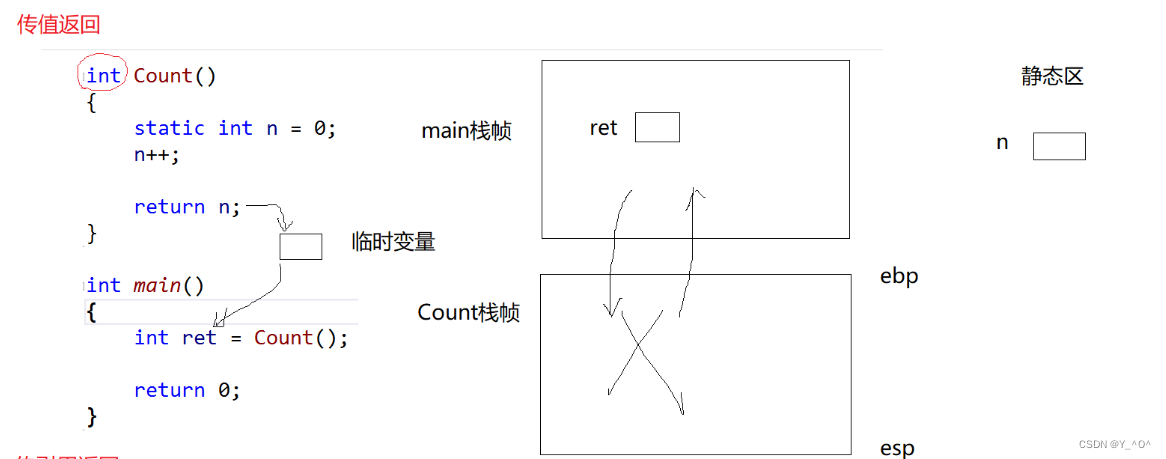
与上面的程序相比,唯一的区别就是这次Count函数里的变量n是被static修饰的。
如果大家不太了解或者忘记了static关键字的作用,可以复习一下链接: link
局部变量被static修饰后,将存储在静态区,出作用域后将不会被销毁,而是保留在静态区,生命周期改变(本质上改变了存储类型),这时它的生命周期就是程序的声明周期。
也就是说,这次变量n就不再是保存在函数Count的栈帧里了,而是在静态区,即使函数调用结束栈帧销毁,变量n也依然存在。
哦豁,那这样的话,是不是就可以直接用n去返回了呀。
但实际不是的,编译器在这里是傻瓜式的处理,他不管函数栈帧销毁后n是否存在,所做的处理都是一样的,都是利用一个临时变量去返回。
那既然编译器没有对第二种场景进行优化,那这个权力是不是就给到了我们自己手里啊?
我们能不能想个办法进行一个好的处理呢?
因为既然这个地方函数栈帧销毁后n还在静态区存在,那是不是没必要再去借助寄存器来返回啊?
那我们可以怎么做呢?
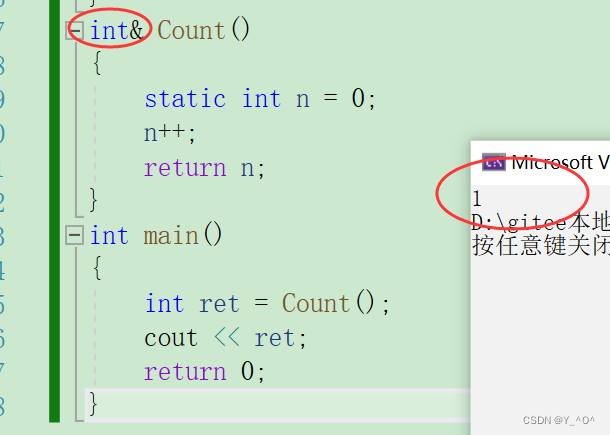
🆗,很简单,只需把返回值类型改成n的引用就行了:
那这时返回n的引用,我们说引用和它引用的实体是不是占用同一块空间啊,相当于返回的是n的一个别名,那其实可以认为我们就直接返回n了,就像武二郎和行者都是武松。
那我们再来看一个程序:
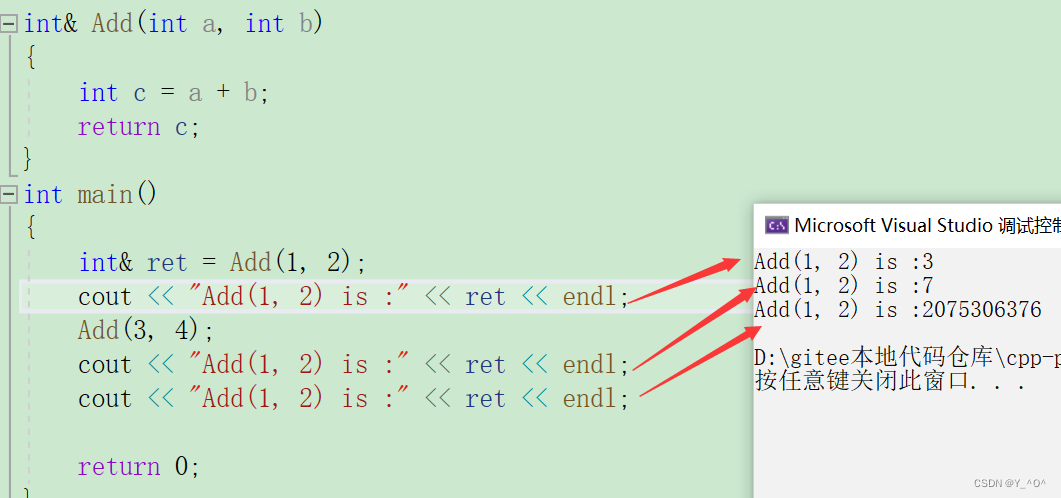
int& Add(int a, int b)
{int c = a + b;return c;
}
int main()
{int& ret = Add(1, 2);Add(3, 4);cout << "Add(1, 2) is :" << ret << endl;cout << "Add(1, 2) is :" << ret << endl;return 0;
}
大家分析一下,思考一下结果是啥?
为什么是这样的结果?
首先不管结果是啥,大家要能够看出来这段代码是有问题的。
什么问题呢?
函数Add中的c是局部变量,是创建在函数栈帧上的,函数调用结束就随着函数栈帧销毁了(这块空间归还给操作系统了),但是,我们最后返回了变量c的引用(别名),而且main函数也用了一个引用来接收,相当于给c的别名(引用)有起了一个别名,即ret也是c的一个引用,那也可以认为ret就是c。
那然后我们去打印ret,就相当于去拿c这块空间的值了,但是这块空间已经归还给操作系统了,已经不属于我们了,此时我们再去访问其实已经是非法的行为了。
但是我们看到也打印出来3 了,这是因为这块空间归还之后,操作系统有可能还没有去清理这块空间,所以我们再去拿还是拿到了原来算出来的3,那如果操作系统进行了一些处理,我们拿到什么可能就不知道了,可能就是随机值了。
就像我们后面又调用了一次,然后打印是7,后面又打印就是一个随机值了。
所以想告诉大家的是:
这里的结果打印出来是几并不重要,可能在不同的编译器上,不同的平台上,就有所差异。
这个结果是未定义的,因为这本身就是一种错误的,非法的行为。
重点是大家要明白这个程序是错误的,这种情况是不能返回引用的。
所以最后总结一下:
如果函数返回时,出了函数作用域,返回对象还在(还没还给系统),则可以使用引用返回(比如:静态的、全局的、malloc的等等),如果已经还给系统了,则必须使用传值返回,若还返回引用,则结果是未定义的。
6.5 传值、传引用效率比较
以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,与传引用相比,效率是比较低的,尤其是当参数或者返回值类型非常大时,效率就更低。
接下来我们就通过两个程序来对比一下:
1. 值和引用的作为参数的性能比较
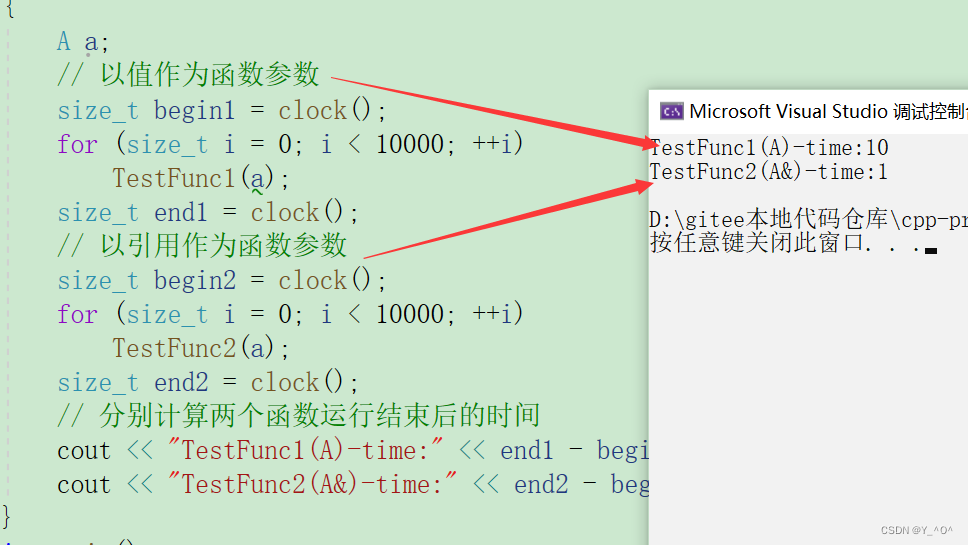
首先对比一下以值作为函数参数和以引用作为函数参数效率的对比:
#include <time.h>
struct A{ int a[10000]; };
void TestFunc1(A a){}
void TestFunc2(A& a){}
void TestRefAndValue()
{A a;// 以值作为函数参数size_t begin1 = clock();for (size_t i = 0; i < 10000; ++i)TestFunc1(a);size_t end1 = clock();// 以引用作为函数参数size_t begin2 = clock();for (size_t i = 0; i < 10000; ++i)TestFunc2(a);size_t end2 = clock();
// 分别计算两个函数运行结束后的时间cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;
}
程序有些地方大家不懂不用管,我们只是对比一下它们的效率。
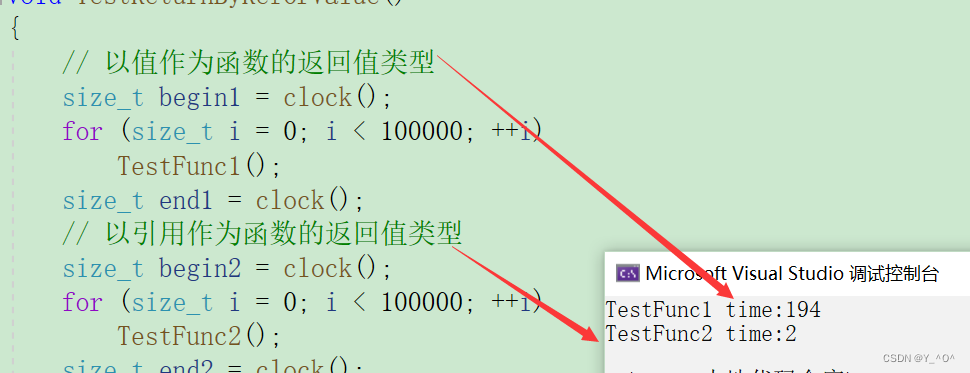
2. 值和引用的作为返回值类型的性能比较
#include <time.h>
struct A{ int a[10000]; };
A a;
// 值返回
A TestFunc1() { return a;}
// 引用返回
A& TestFunc2(){ return a;}
void TestReturnByRefOrValue()
{// 以值作为函数的返回值类型size_t begin1 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc1();size_t end1 = clock();// 以引用作为函数的返回值类型size_t begin2 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc2();size_t end2 = clock();// 计算两个函数运算完成之后的时间cout << "TestFunc1 time:" << end1 - begin1 << endl;cout << "TestFunc2 time:" << end2 - begin2 << endl;
}
6.6 引用和指针的区别
下面我们来看一下引用和指针的区别:
首先从语法概念上来说:
引用就是一个别名,没有独立空间,和其引用实体共用同一块空间;
而指针是占用空间的,32位平台上4个字节,64位平台上8个字节,是用来存放地址的。
但是呢?
在实际的底层实现上,引用也是有空间的,因为引用其实就是利用指针来实现的。
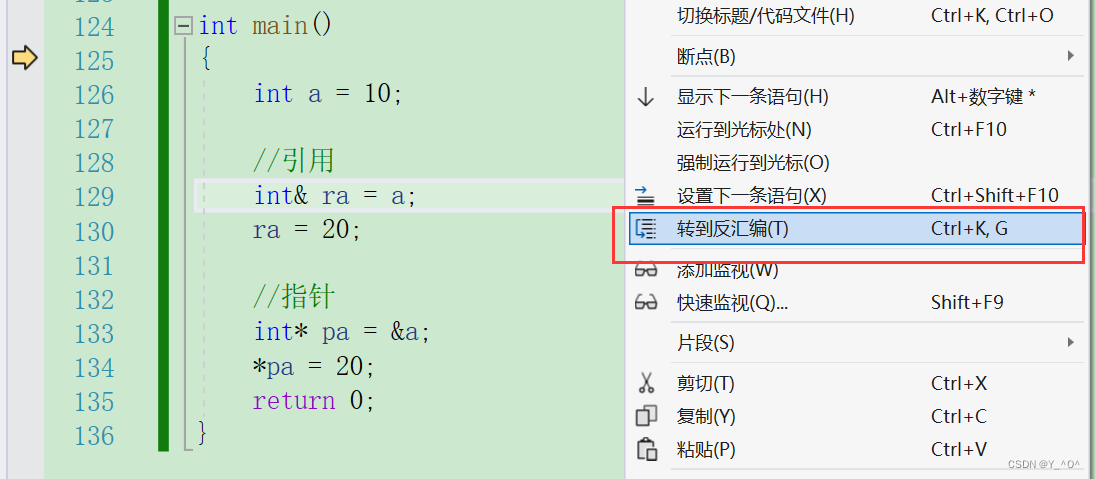
看这样一段代码:
int main()
{int a = 10;//引用int& ra = a;ra = 20;//指针int* pa = &a;*pa = 20;return 0;
}
我们通过调试来看一下它们的汇编代码:
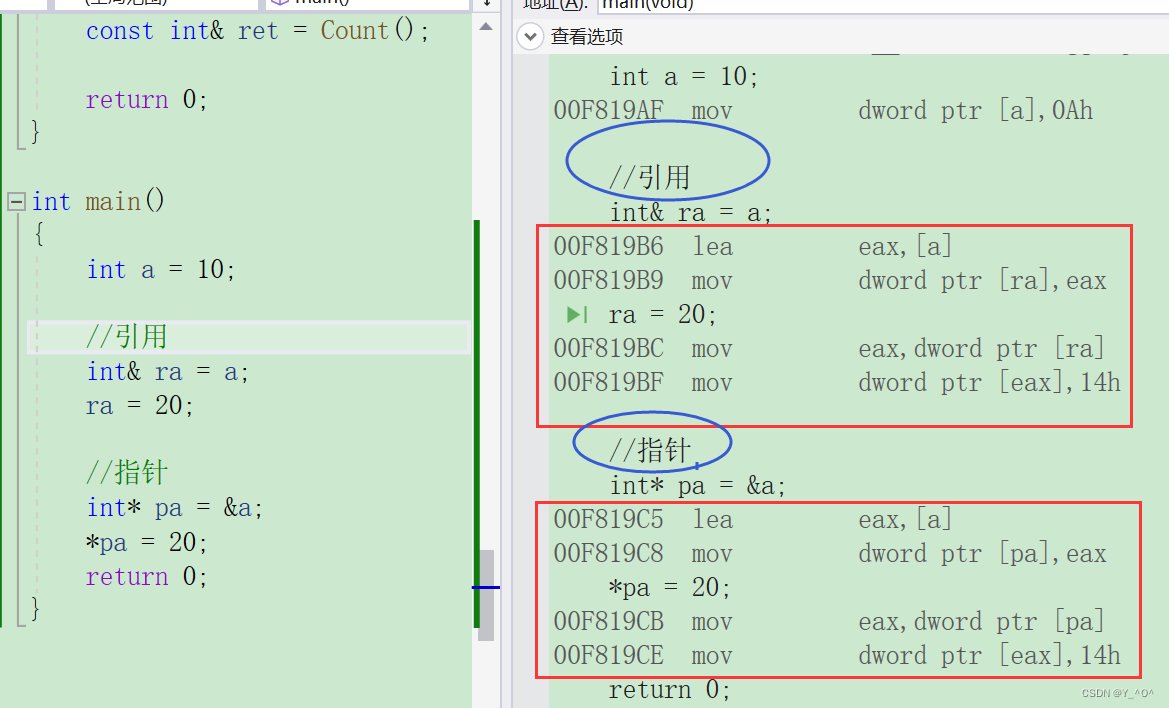
可以看到,它们产生的汇编代码都是一样的。
总结一下,指针和引用的区别:
- 概念上:引用是定义一个变量的别名,指针存储一个变量地址。
- 引用在定义时必须初始化,指针没有要求(当然最好进行初始化)
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体
- 没有NULL引用,但有NULL指针
- 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节,64位8个字节)
- 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
- 有多级指针,但是没有多级引用
- 访问实体方式不同,指针需要显式解引用,引用则是编译器自己处理
- 引用比指针使用起来相对更安全
7. 内联函数
除了上面的内容,我们C++的祖师爷呢还觉得C语言中的宏也不是很好:
我们在C语言的预处理那一章也有比较详细的学习过宏,也分析了宏的缺点:
当然宏也是有一些优点的:
比如我们定义一个宏函数(当然它不是一个真正的函数),它也可以完成一个函数的功能,但是呢它不用像真正的函数那样建立函数栈帧。
补充:C++中建议用const和枚举enum代替宏定义的常量
从宏的这些优缺点出发,C++又引入了一个新的概念——内联函数。
7.1 概念
那什么是内联函数呢?
以inline修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数调用建立栈帧的开销,内联函数提升程序运行的效率。
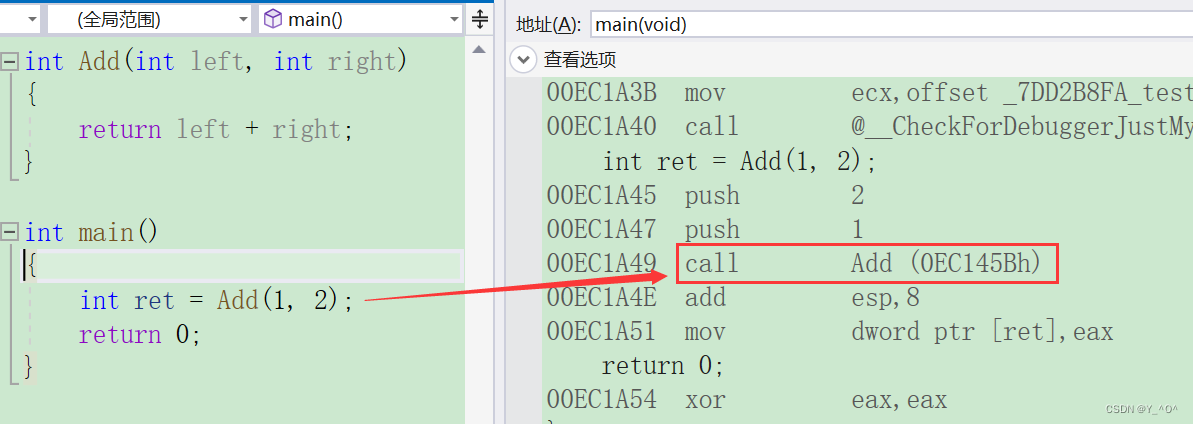
如果是定义一个普通的函数:
我们调试看它的汇编:
大家可能对汇编不太懂,但是看到这个call 函数名(地址)其实就是去调用这个函数建立栈帧了。

那我们现在把它改成内联函数:

如果在上述函数前增加inline关键字将其改成内联函数,在编译期间编译器会用函数体替换函数的调用。
我们再来看一下反汇编:
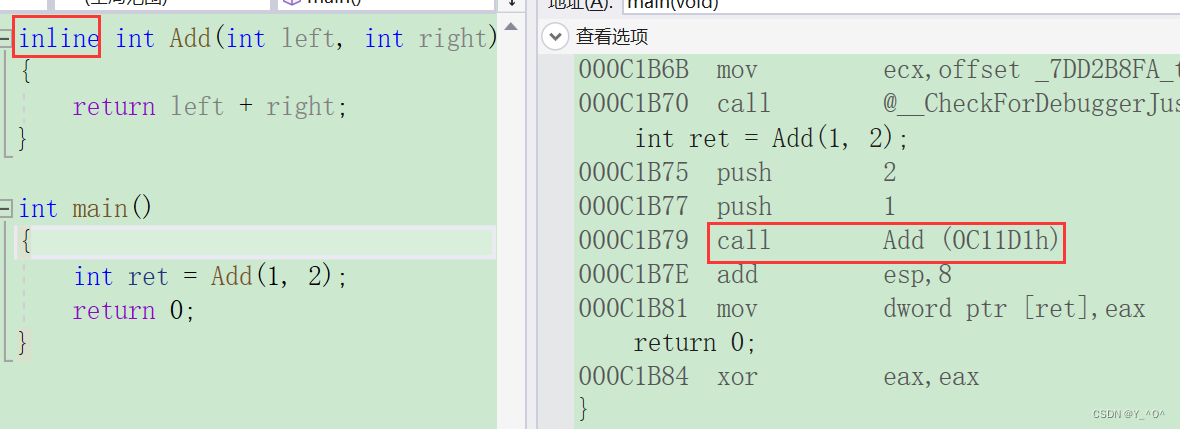
怎么没起作用啊。
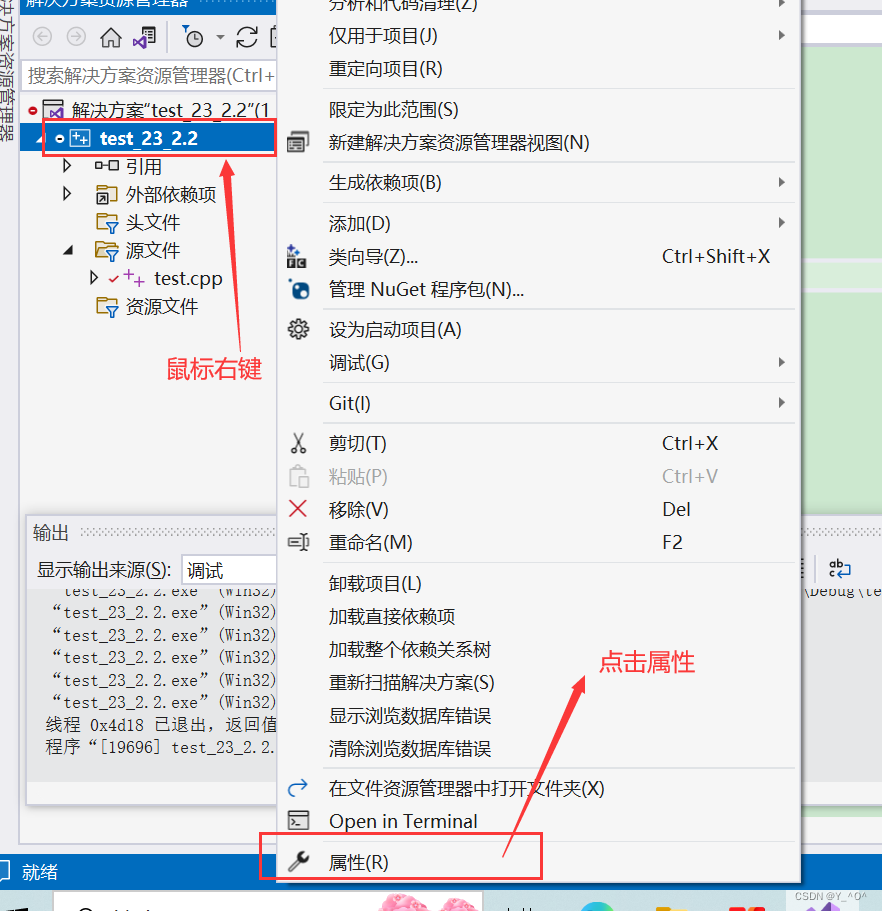
怎么样让它起作用呢?
🆗,它在release版本下面会起作用,或者在debug版本下需要我们进行一下设置:
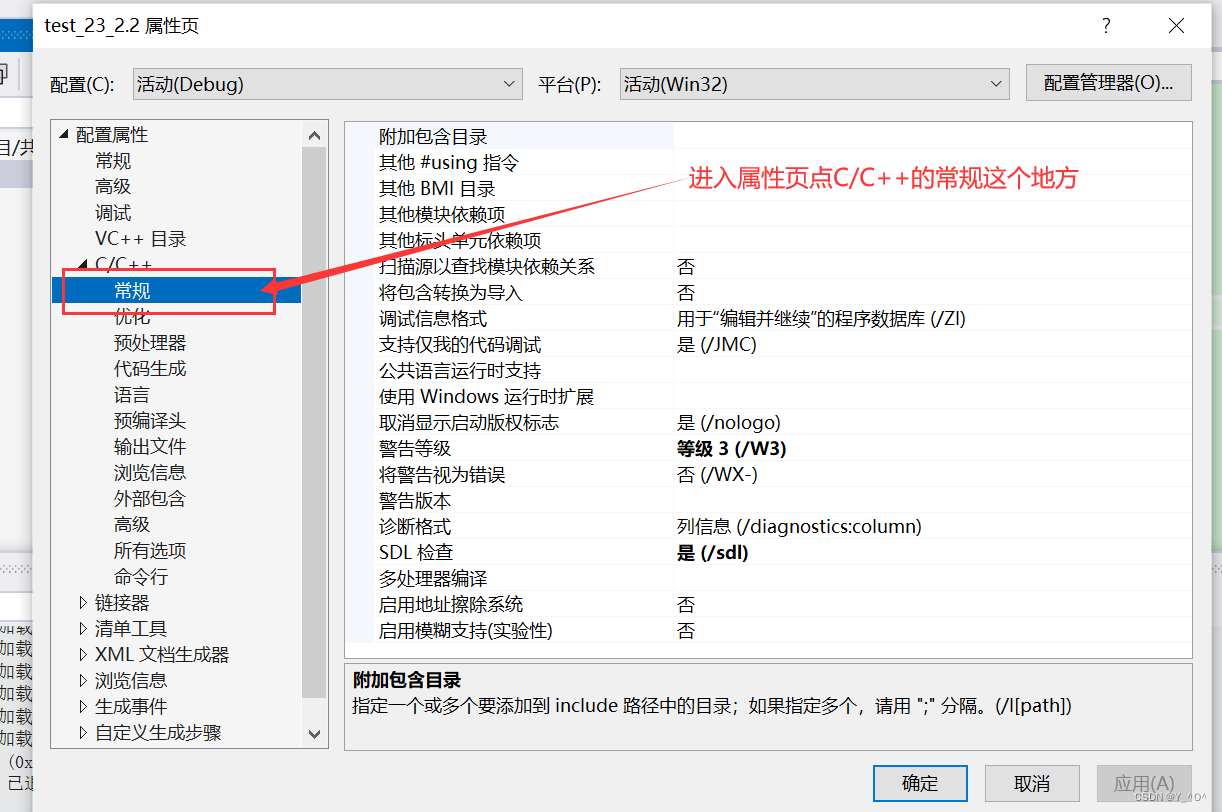
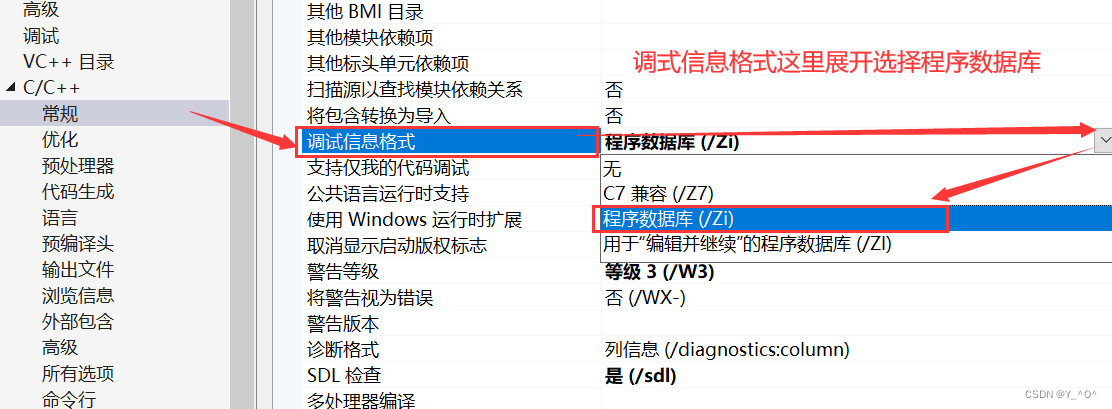
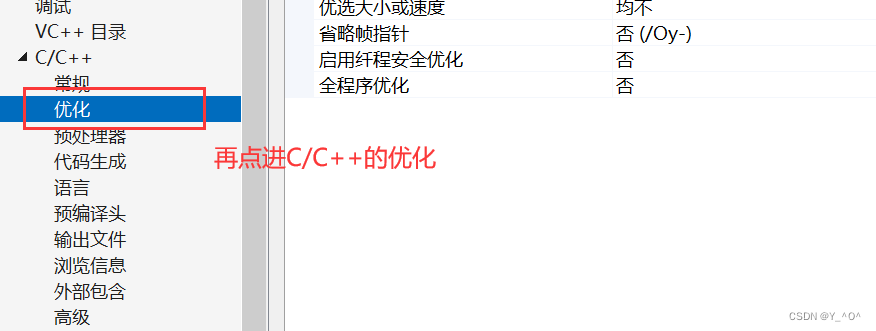
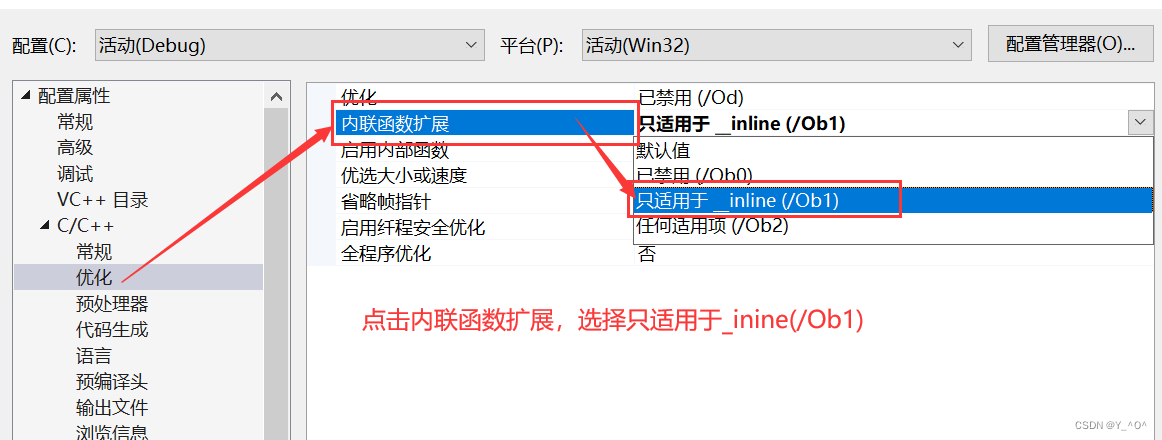
然后我们再来看:
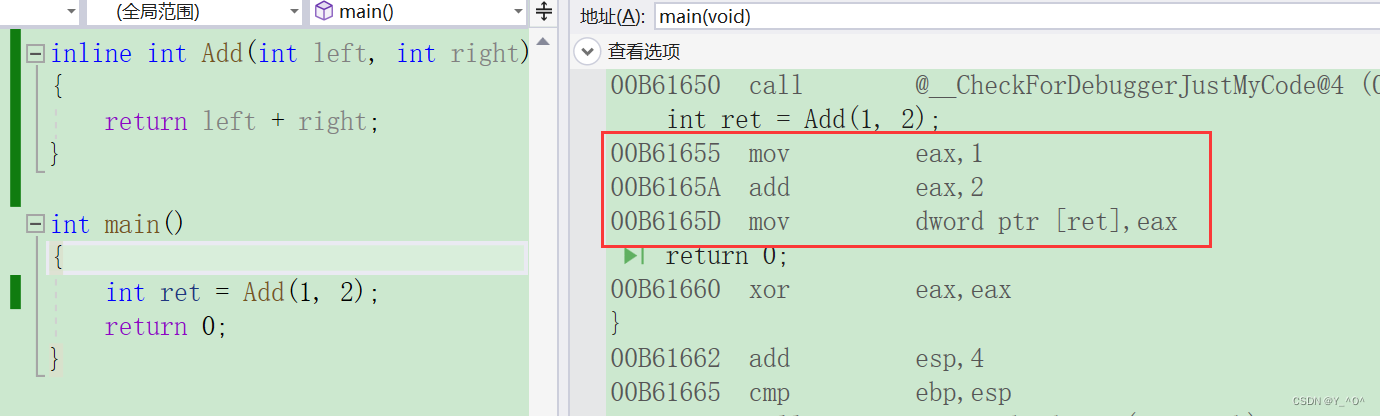
这次是不是就没有call Add那个指令了,说明我们的内联函数就起作用了,就没有函数调用建立栈帧的开销了。
7.2 内联函数的特性
- inline是一种以空间换时间的做法,如果编译器将函数当成内联函数处理,在编译阶段,会用函数体替换函数调用。
缺陷:可能会使目标文件变大,
优势:少了调用开销,提高程序运行效率。
简单解释一下:
这里说的这个空间换时间,不是说程序运行时占用的空间会变大,而是最终产生的可执行程序可能会变大。
因为C++编译器会在调用内联函数的地方将函数直接展开,这样的话与普通的调用相比,产生的指令就可能变多,所以最终生成的可执行程序可能会变大。
- inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同,一般建议:将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略inline特性。
下图为《C++prime》第五版关于inline的建议:

也就是说:
不是所有的内联函数最终都会按照内联函数进行处理的,一般规模较小并且频繁使用的的我们才实现成内联函数,否则即使我们实现成内联函数,编译器也不一定会按照内联函数进行处理。
举个例子:
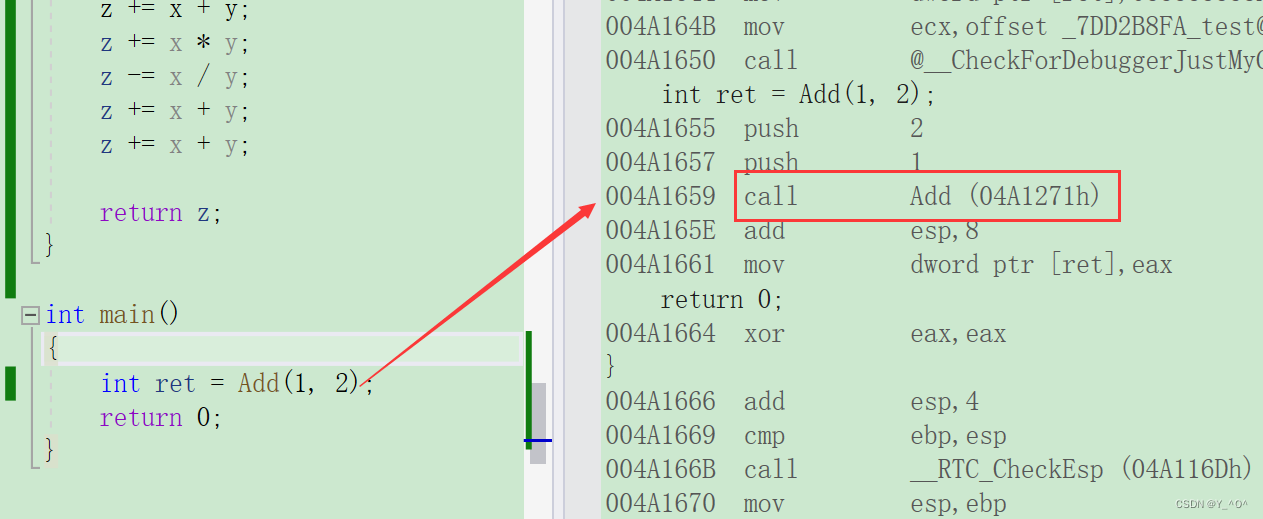
刚才的Add函数我们用inline修饰后调试发现确实按照内联函数处理了,那如果我们现在在Add函数中再多增加一些语句,有可能就不再按内联函数执行了:
我们再来调试观察一下:
是不是又有call Add了。
- 内联函数不能声明和定义分离,分离会导致链接错误
因为内联函数编译期间就会在函数调用的地方被展开,不会像普通的函数调用那样call一个地址然后跳转调用,就没有函数地址了(可以认为内联函数不会产生地址进符号表),这样链接的时候就会找不到。
所以内联函数如果有声明的话,把声明定义放一起。
8. auto关键字(C++11)
8.1 类型别名思考
随着不断地学习,往后我们的程序会越来越复杂,程序中用到的类型也可能越来越复杂,经常体现在:
- 类型难于拼写
- 含义不明确导致容易出错
比如:
这个
std::map<std::string,std::string>::iterator就是一个类型,现在我们还看不懂,还没学到。
这个类型就很长,我们写的时候就很容易可能会写错,怎么简化呢?
大家可能会想到用typedef去取一个别名。
这确实是一个方法。
使用typedef给类型取别名确实可以简化代码,但是typedef也存在一些不好的地方。比如:
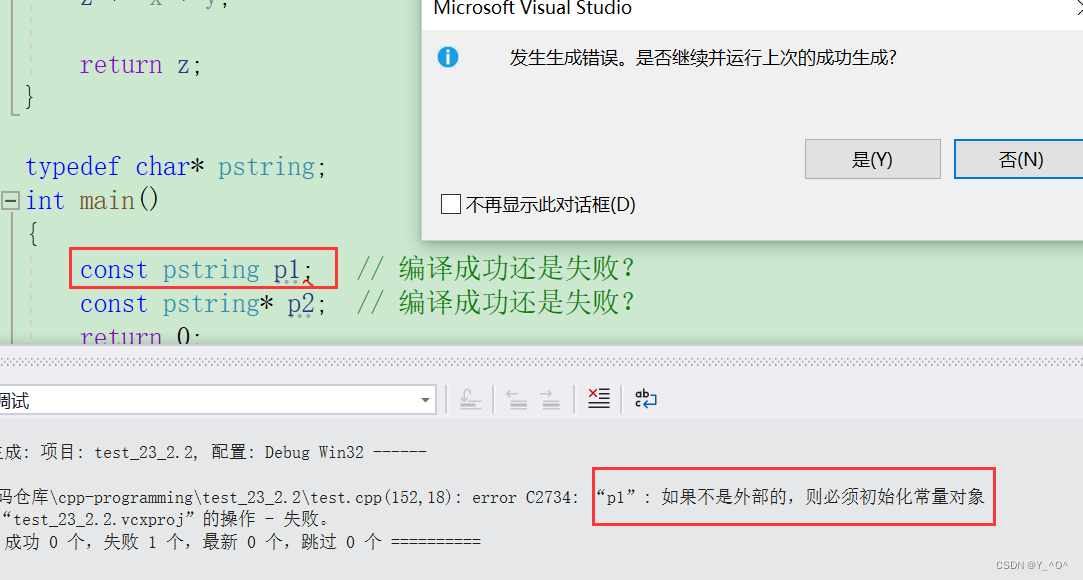
typedef char* pstring;
int main()
{const pstring p1; // 编译成功还是失败?const pstring* p2; // 编译成功还是失败?return 0;
}
大家看定义这两个变量有没有什么问题?
🆗,p1这里有错误,为什么呢?
我们自己分析肯定认为p1是这样的?
const char* p1
那这肯定没什么问题嘛,p1是一个字符指针,const 修饰*p1,那就是p1指向的内容不能被改变罢了。
但是,由于这里typedef char* pstring;的缘故,实际上是这样的:
char* const p1;
即const修饰p1,p1不能被修改,而const修饰的变量是必须初始化的,但这里我们没初始化,所以就报错了。
初始化一下就不报错了。

在编程时,常常需要把表达式的值赋值给变量,这就要求在声明变量的时候清楚地知道表达式的类型。
然而有时候要做到这点并非那么容易,因此C++11给auto赋予了新的含义。
8.2 auto简介
在早期C/C++中auto的含义是:使用auto修饰的变量,是具有自动存储器的局部变量,但遗憾的是一直没有人去使用它,大家可以思考下为什么?
C++11中,标准委员会赋予了auto全新的含义即:
auto不再是一个存储类型指示符,而是作为一个新的类型指示符来指示编译器,auto声明的变量在编译阶段编译器会根据初始化表达式来推导auto代表的实际类型。
举一些例子:
定义一个整型变量a,变量b要想接收a,也应该定义成int类型,这没什么问题。
但是,现在我们就可以这样写:
那这时b的类型就不是我们显示指定的,而是根据a自动推导出来的。
当然,其它类型的数据也可以:
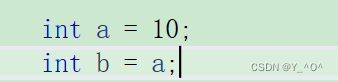

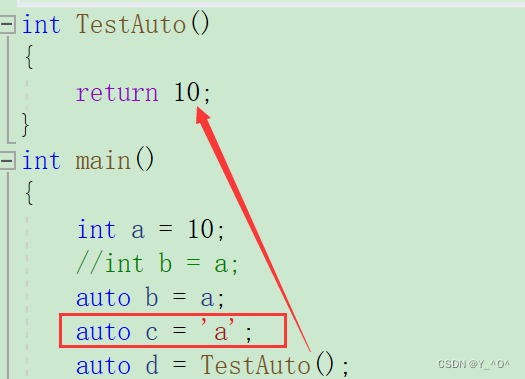
我们也可以验证一下b,c,d推断出来的类型对不对:

另外:
使用auto定义变量时必须对其进行初始化
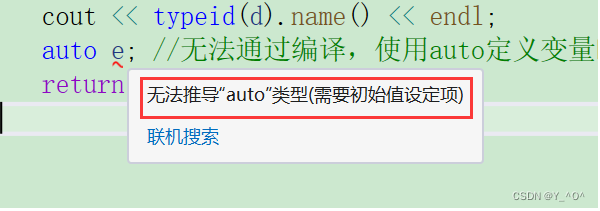
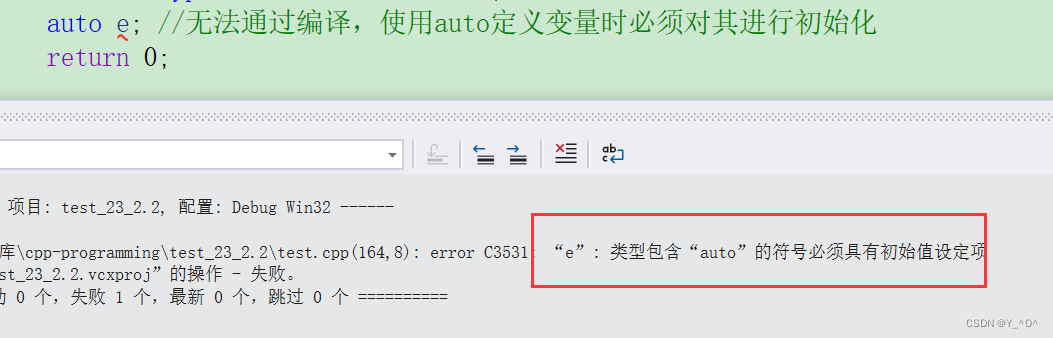
【注意】⚠:
使用auto定义变量时必须对其进行初始化,在编译阶段编译器需要根据初始化表达式来推导auto的实际类型。因此auto并非是一种“类型”的声明,而是一个类型声明时的“占位符”,编译器在编译期会将auto替换为变量实际的类型。
8.3 auto的使用细则
- auto与指针和引用结合起来使用
用auto声明指针类型时,用auto和auto*都可以,但用auto声明引用类型时则必须加&
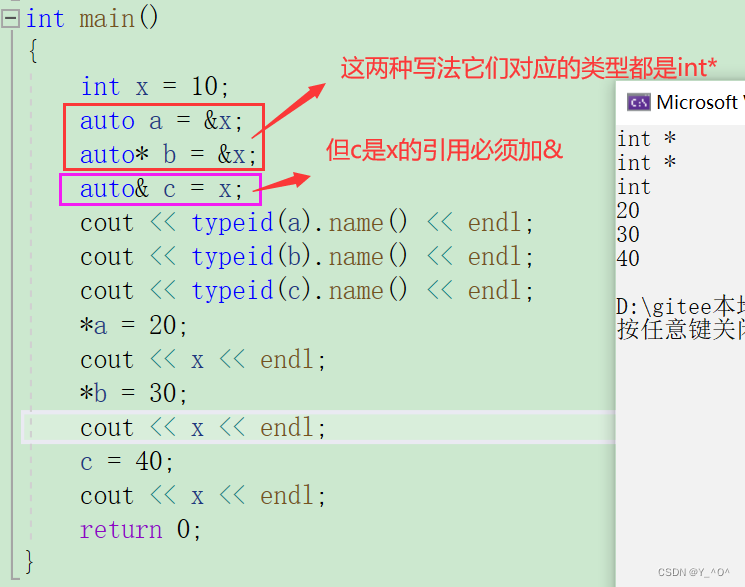
int main()
{int x = 10;auto a = &x;auto* b = &x;auto& c = x;cout << typeid(a).name() << endl;cout << typeid(b).name() << endl;cout << typeid(c).name() << endl;*a = 20;*b = 30;c = 40;return 0;
}
2. 在同一行定义多个变量
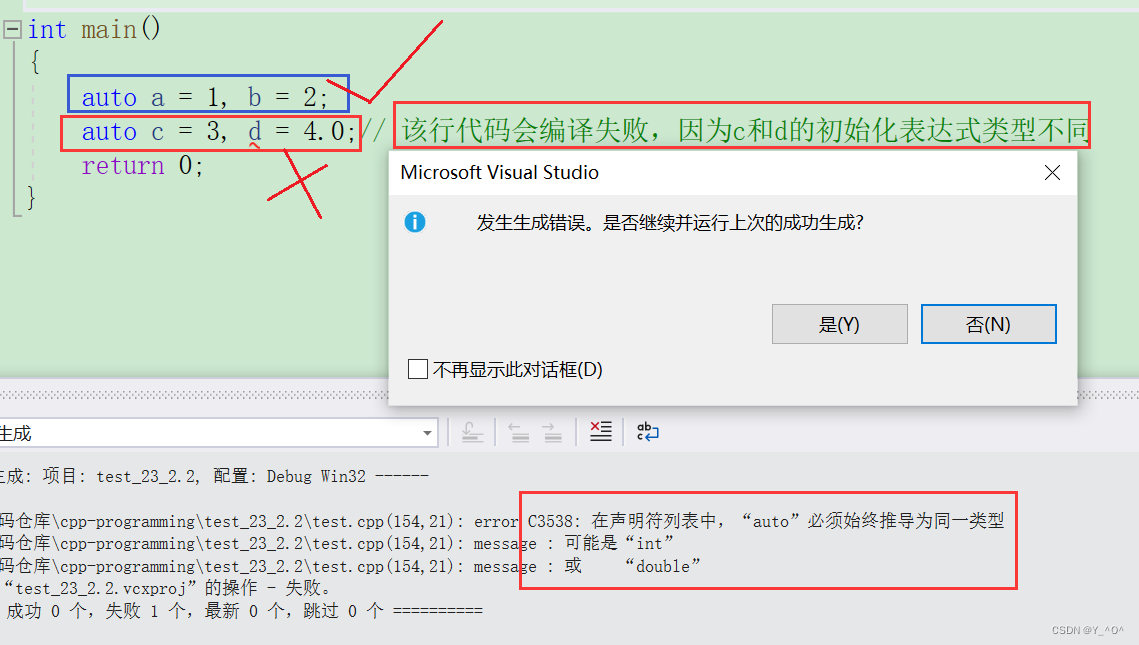
当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译器实际只对第一个类型进行推导,然后用推导出来的类型定义其他变量。
int main()
{auto a = 1, b = 2;auto c = 3, d = 4.0;// 该行代码会编译失败,因为c和d的初始化表达式类型不同return 0;
}
8.4 auto不能推导的场景
- auto声明的变量不能作为函数的参数
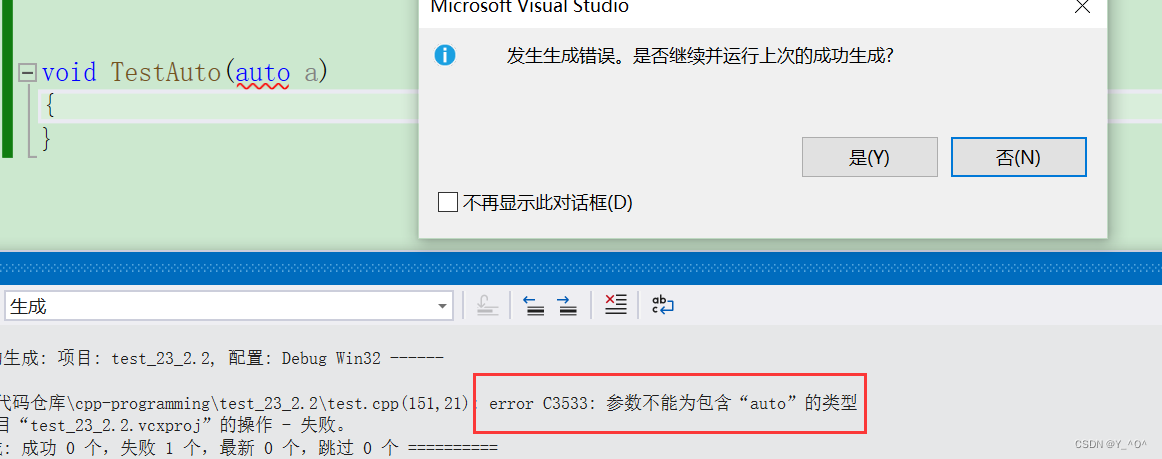
auto不能作为形参类型,因为编译器无法对其实际类型进行推导。
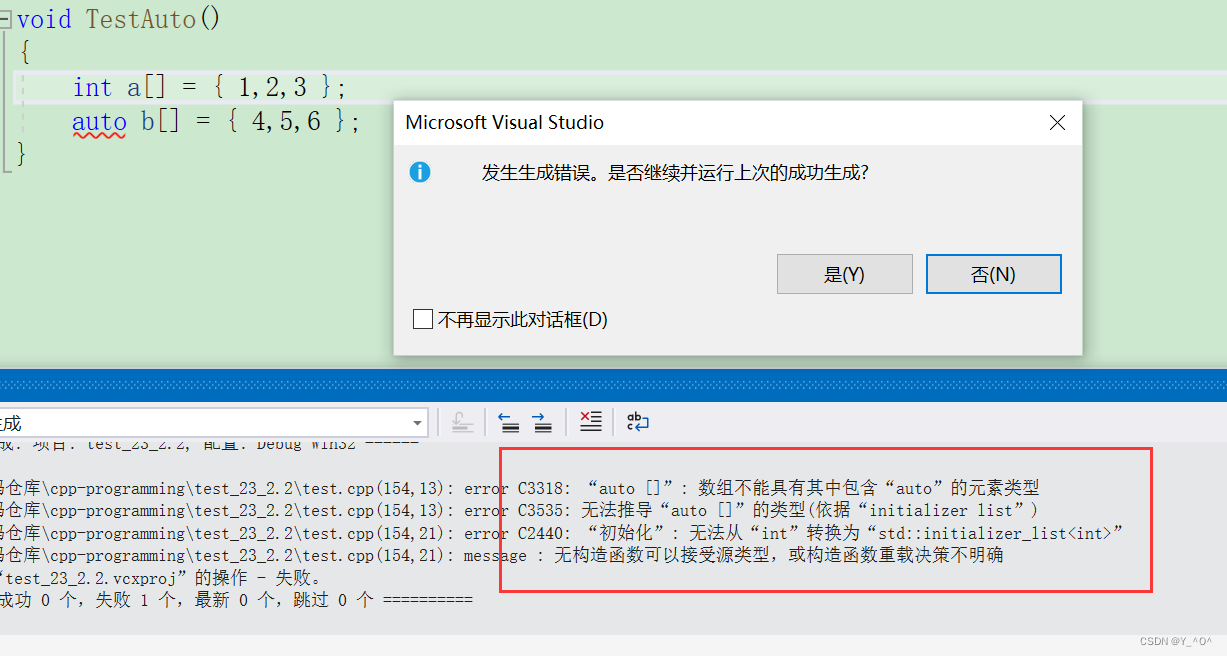
- auto不能直接用来声明数组
- 为了避免与C++98中的auto发生混淆,C++11只保留了auto作为类型指示符的用法
- auto在实际中最常见的优势用法就是跟以后会讲到的C++11提供的新式for循环,还有lambda表达式等进行配合使用
auto在C++11提供的新式for循环的应用我们下面就会讲到。
9. 基于范围的for循环(C++11)
在我们之前学的C语言以及C++98中如果要遍历一个数组,我们一般都是这样做的:
int main()
{int array[] = { 1, 2, 3, 4, 5 };for (int* p = array; p < array + sizeof(array) / sizeof(array[0]); ++p)cout << *p << " ";return 0;
}
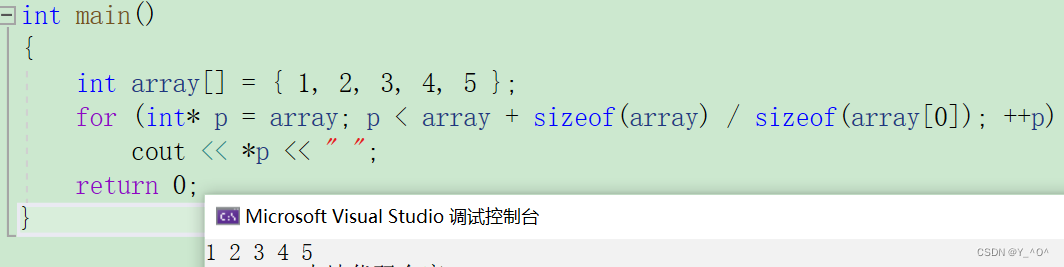
对于一个有范围的集合而言,由程序员来说明循环的范围是多余的,有时候还会容易犯错误。
因此C++11中引入了基于范围的for循环。
9.1 范围for的语法
for循环后的括号由冒号“ :”分为两部分:第一部分是范围内用于迭代的变量,第二部分则表示被迭代的范围。
int main()
{int array[] = { 1, 2, 3, 4, 5 };for (auto e : array)cout << e << " ";return 0;
}
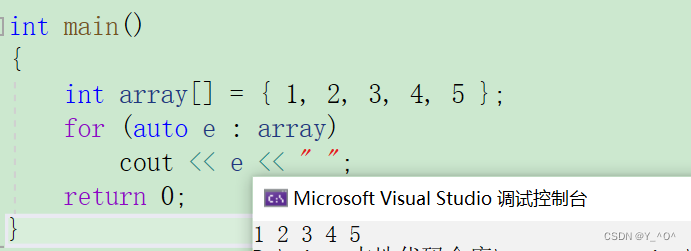
这样它会自动取数组中的元素赋给e变量,并自动判断结束。
当然这里其实用int就行,但我们刚刚学了auto,用auto的话,如果数组是double或其它类型的元素,我们是不是也可以直接遍历不用改代码啊。
那如果我们现在想改变数组元素的值,可以这样写吗?
int main()
{int array[] = { 1, 2, 3, 4, 5 };for (auto i : array){i *= 2;cout << i << " ";}for (auto e : array)cout << e << " ";return 0;
}
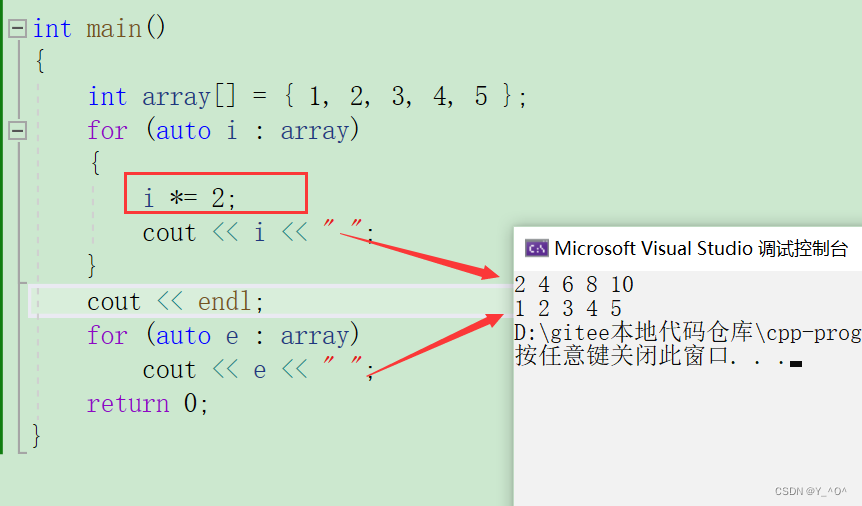
大家看出来了吗?是不是不行啊!
我们上面说了,它是把数组的元素赋值给了前面的遍历i和e,i和e相当于是数组元素的拷贝,所以我们改变i的值,并不会影响数组元素的值。
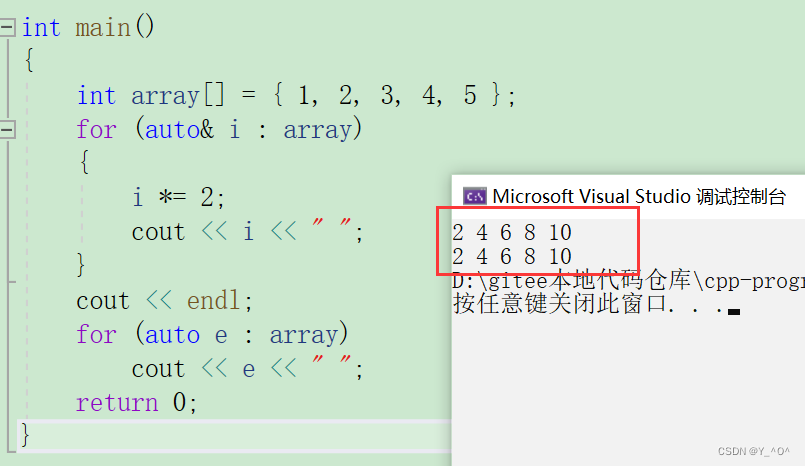
如果想改变数组元素,我们可以这样做:
int main()
{int array[] = { 1, 2, 3, 4, 5 };for (auto& i : array){i *= 2;cout << i << " ";}cout << endl;for (auto e : array)cout << e << " ";return 0;
}
看出来区别了吗?
i是数组元素的引用(别名),那改变i是不是就相当于改变数组元素了。

注意⚠:
与普通循环类似,可以用continue来结束本次循环,也可以用break来跳出整个循环。
9.2 范围for的使用条件
- for循环迭代的范围必须是确定的
对于数组而言,就是数组中第一个元素和最后一个元素的范围;对于类而言,应该提供begin和end的方法,begin和end就是for循环迭代的范围。
比如这种情况就不能用范围for:
void TestFor(int array[])
{for(auto& e : array)cout<< e <<endl;
}
这里我们能看出来是数组传参,数组传参我们指道其实是传的首元素地址,这里虽然用数组接收,但其本质上还是个指针。
🆗,其它还有与范围for相关的知识我们会在后面的学习中讲到,因为有些知识我们现在还没办法很好的理解。
10. 指针空值nullptr(C++11)
在良好的C/C++编程习惯中,声明一个变量时最好给该变量一个合适的初始值,否则可能会出现不可预料的错误,比如未初始化的指针。
如果一个指针没有合法的指向,我们基本都是按照如下方式对其进行初始化:
int* p1 = NULL;
NULL就是空指针嘛,我们学过C语言知道其实NULL就是把0强制类型转换为void*的指针了,实际是一个宏。
那我们来看这样一个代码:
void f(int)
{cout << "f(int)" << endl;
}
void f(int*)
{cout << "f(int*)" << endl;
}
int main()
{f(0);f(NULL);return 0;
}
这两次函数调用会如何匹配?
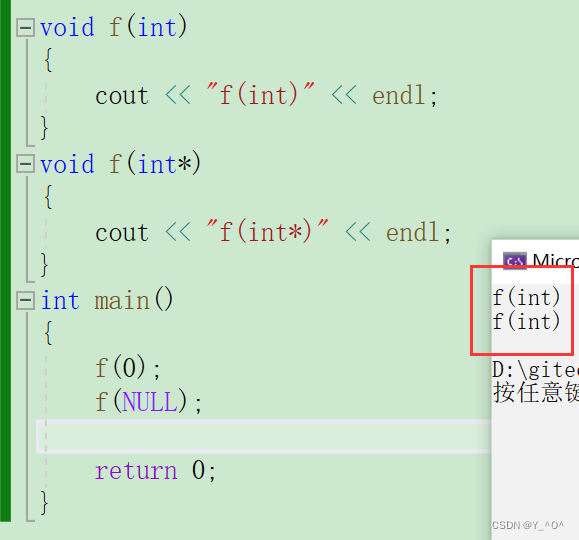
欸,NULL不是指针嘛,为什么
f(NULL);调用的也是第一个函数呢?
原因在于NULL在C++ 中的定义发生了一些改变。
NULL实际是一个宏,在传统的C头文件(stddef.h)中,可以看到如下代码:
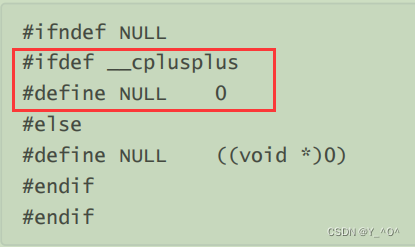
意思呢就是在C++中NULL其实就是0。
所以要想NULL调用第二个函数:
在C++98中,字面常量0既可以是一个整形数字,也可以是无类型的指针(void*)常量,但是编译器默认情况下将其看成是一个整形常量,如果要将其按照指针方式来使用,必须对其进行强转。
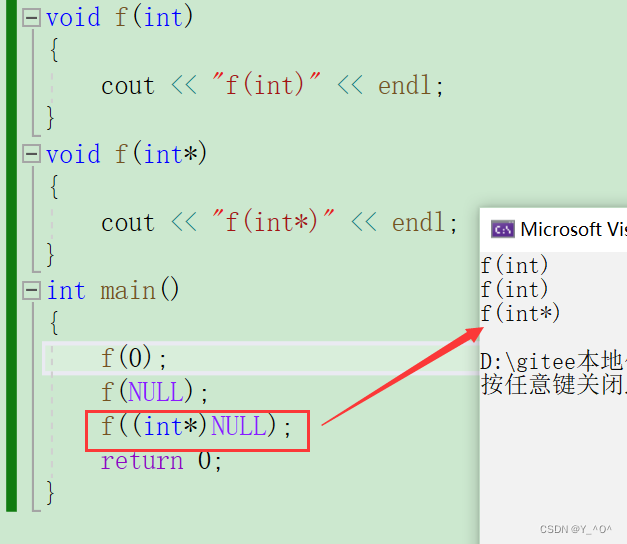
那由于以上这些原因呢,C++11引入了一个新关键字nullptr来表示空指针:
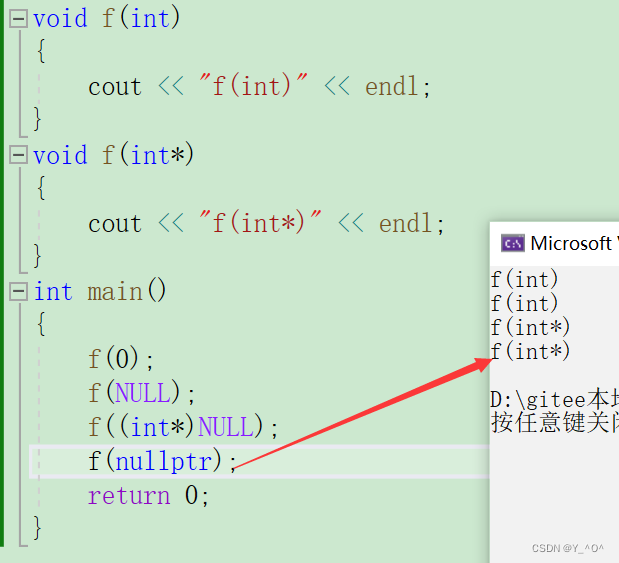
- 在使用nullptr表示指针空值时,不需要包含头文件,因为nullptr是C++11作为新关键字引入的。
- 在C++11中,sizeof(nullptr) 与 sizeof((void*)0)所占的字节数相同。
- 为了提高代码的健壮性,在后续表示指针空值时建议最好使用nullptr。
🆗,那这篇文章的内容就到这里,欢迎大家指正。下一篇文章开始,我们就进入C++类和对象的学习了!!!

相关文章:
【C→C++】打开C++世界的大门
文章目录前言什么是CC的发展史C的重要性1. 使用广泛度2. 工作领域的应用1. C关键字(C98)2. 命名空间2.1 命名空间的定义2.2 命名空间的使用2.3 std命名空间的使用惯例3. C输入&输出3.1 输入输出3.2 说明4. 缺省参数4.1 缺省参数概念4.2 缺省参数分类5. 函数重载5.1 函数重载…...
点云深度学习系列博客(四): 注意力机制原理概述
目录 1. 注意力机制由来 2. Nadaraya-Watson核回归 3. 多头注意力与自注意力 4. Transformer模型 Reference 随着Transformer模型在NLP,CV甚至CG领域的流行,注意力机制(Attention Mechanism)被越来越多的学者所注意,将…...

设置Visual Studio 2022背景图
前言 编写代码时界面舒服,自己喜欢很重要。本篇文章将会介绍VS2022壁纸的一些设置,主题的更改以及如何设计界面。 理想的界面应该是这样的 接下来我们来一步步学习如何将界面设计成这样 一、壁纸插件下载 1.拓展->点击拓展管理 2.右上角搜索backgro…...
1. 用Qt开发的十大理由
用Qt的十大理由 原因最主要的是很多大公司都在用,有钱景。 先来看看各大公司的评价: 奔驰:们用 Qt 开发了绝大部分的UI体验和软件,包括屏幕动画,屏幕间的过渡和小组件。 FORMLABS:凭借Qt的快速迭代&…...

俄罗斯方块游戏代码
♥️作者:小刘在C站 ♥️个人主页:小刘主页 ♥️每天分享云计算网络运维课堂笔记,努力不一定有收获,但一定会有收获加油!一起努力,共赴美好人生! ♥️夕阳下,是最美的,绽…...

设计模式相关面试题
文章目录面向对象编程中,都有哪些设计原则?设计模式的分类 ?单例模式的特点是什么?单例模式有哪些实现?什么是简单⼯⼚模式什么是抽象⼯⼚模式?什么是⼯⼚⽅法模式?什么是代理模式?S…...
构建Jenkins 2.340持续集成环境
一、前言 本文学习自:2022版Jenkins教程(从配置到实战) 如有不妥,欢迎指正 二、构建资料 已经包括了本文档使用的所有所需的安装包 三、安装docker 1、解压docker docker-20.10.10.tgz2、复制文件 cp docker/* /usr/bin/3、编写启动文…...

Ubuntu/Centos下OpenJ9 POI输出Excel的Bug
项目更换 JDK为 OpenJ9 后, 使用 POI 导出 Excel 遇到的问题 OpenJ9 版本信息 /opt/jdk/jdk-11.0.178/bin/java -version openjdk version "11.0.17" 2022-10-18 IBM Semeru Runtime Open Edition 11.0.17.0 (build 11.0.178) Eclipse OpenJ9 VM 11.0.17.0 (build …...

链接脚本学习笔记
IAR 一般步骤 链接器用于链接过程。它通常执行以下过程(请注意,某些步骤可以通过命令行选项或链接器配置文件中的指令关闭): 1.确定应用程序中要包含哪些模块。始终包含对象文件中提供的模块。仅当库文件中的模块为从包含的模块…...

NLP顶会近三年小众研究领域
ACL 2022 编码器和解码器框架、自然语言生成、知识i神经元、抽取式文本摘要、预训练语言模型、零样本神经机器翻译等。 2021 新闻标题生成任务等。跨语言命名实体识别、代码搜索、音乐生成、Hi-Transformer、预训练语言模型、语义交互等。 EMNLP 2021 代码摘要生成、隐私…...
[electron] 一 vue3.2+vite+electron 项目集成
一 开发环境系统:windows开发工具: git , vscode,termial环境依赖: node, npm 二 步骤2.1 通过vite 创建vue项目通过 终端执行命令,选择 模板 vuenpm init vite cd 项目目录 npm install npm run dev2.2 集成 electro…...
ESP32 Arduino(十二)lvgl移植使用
一、简介LVGL全程LittleVGL,是一个轻量化的,开源的,用于嵌入式GUI设计的图形库。并且配合LVGL模拟器,可以在电脑对界面进行编辑显示,测试通过后再移植进嵌入式设备中,实现高效的项目开发。SquareLine Studi…...

js一数组按照另一数组进行排序
有时我们需要一个数组按另一数组的顺序来进行排序,总结一下方法,同时某些场景也会用到。 首先一个数组相对简单的情况: var arr1 [52,23,36,11,09]; var arr2 [23,09,11,36,52]; // 要求arr1按照arr2的顺序来排序,可以看到两个…...

JavaScript 类继承
JavaScript 类继承是面向对象编程的一个重要概念,它允许一个类从另一个类继承属性和方法。通过使用继承,可以避免代码重复,并可以在现有类的基础上扩展新功能。 在 JavaScript 中,您可以使用关键字 extends 来实现类继承。例如&a…...
MySQL相关面试题
文章目录union 和 unionAll 的区别?drop、delete与truncate的区别 ?sql 语句如何优化 ?什么是事务 ?事务的四个特性(ACID) ?事务的隔离级别?索引主要有哪几种分类 ?什么时候适合添加索引&#x…...
Python创意作品说明怎么写,python创意编程作品集
大家好,小编来为大家解答以下问题,Python创意作品说明怎么写,python创意编程作品集,现在让我们一起来看看吧! 1、有哪些 Python 经典书籍 书名:深度学习入门 作者:[ 日] 斋藤康毅 …...
icomoon字体图标的使用
很久之前就学习过iconfont图标的使用,今天又遇到一个用icomoon字体图标写的案例,于是详细学习了一下,现整理如下。 一、下载 1.网址: https://icomoon.io/#home 2.点击IcoMoon App。 3.点击 https://icomoon.io/app 4.进入IcoM…...
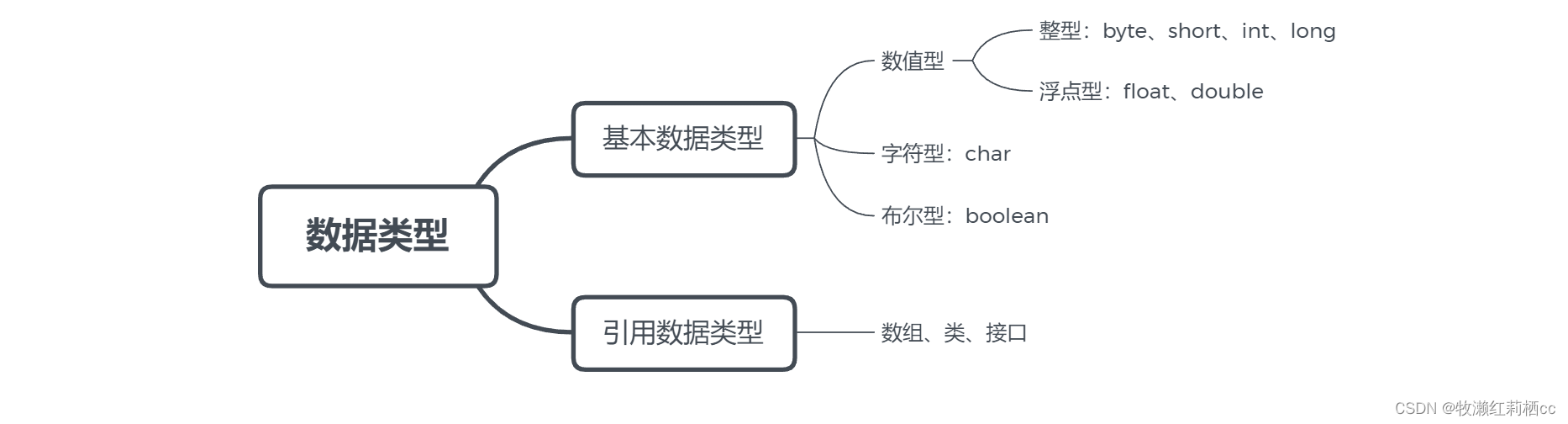
Java · 常量介绍 · 变量类型转换 · 理解数值提升 · int 和 Stirng 之间的相互转换
书接上回 Java 变量介绍 我们继续学习以下内容. 四、常量字面值常量final 关键字修饰的常量五、理解类型转换int 和 long/double 相互赋值int 和 boolean 相互赋值int 字面值常量给 byte 赋值强制类型转换类型转换小结六、理解数值提升int 和 long 混合运算byte 和 byte 的运算…...
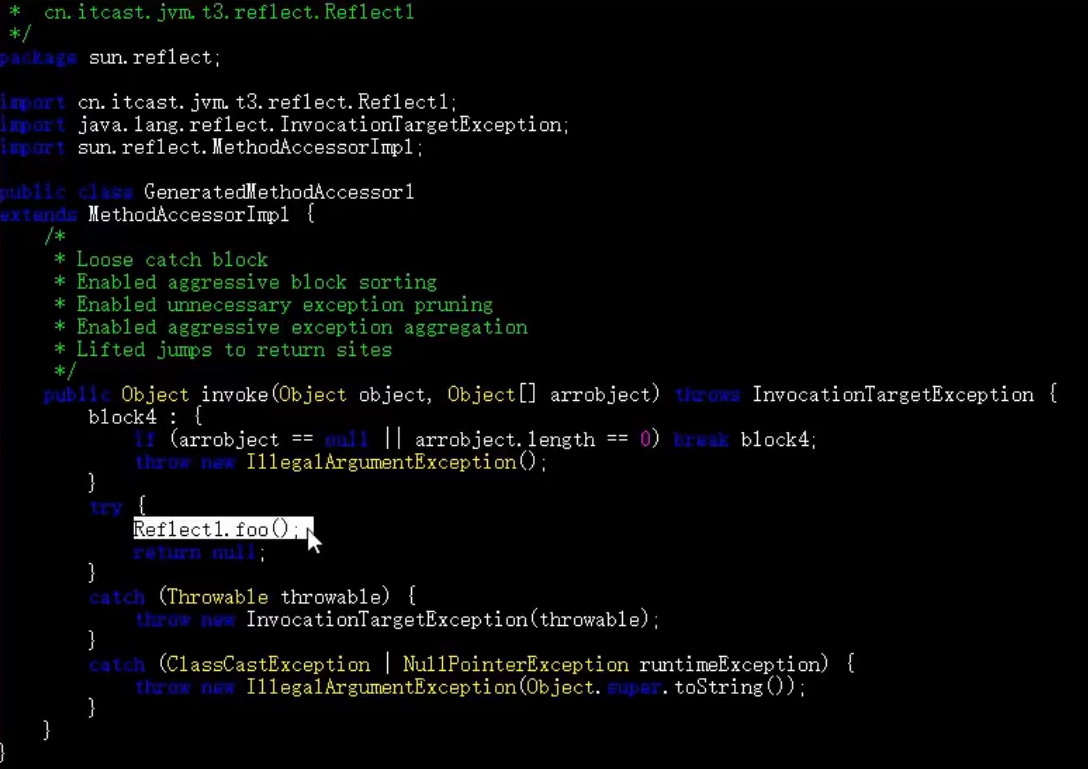
JVM从跨平台到跨专业 Ⅲ -- 类加载与字节码技术【下】
文章目录编译期处理默认构造器自动拆装箱泛型集合取值可变参数foreach 循环switch 字符串switch 枚举枚举类try-with-resources方法重写时的桥接方法匿名内部类类加载阶段加载链接初始化相关练习和应用类加载器类与类加载器启动类加载器拓展类加载器双亲委派模式自定义类加载器…...

ucore的字符输出
ucore的字符输出有cga,lpt,和串口。qemu模拟出来显示器连接到cga中。 cga cga的介绍网站:https://en.wikipedia.org/wiki/Color_Graphics_Adapter cga是显示卡,内部有个叫6845的芯片。cga卡把屏幕划分成一个一个单元格,每个单元格显示一个a…...
详解)
后进先出(LIFO)详解
LIFO 是 Last In, First Out 的缩写,中文译为后进先出。这是一种数据结构的工作原则,类似于一摞盘子或一叠书本: 最后放进去的元素最先出来 -想象往筒状容器里放盘子: (1)你放进的最后一个盘子(…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

【HarmonyOS 5.0】DevEco Testing:鸿蒙应用质量保障的终极武器
——全方位测试解决方案与代码实战 一、工具定位与核心能力 DevEco Testing是HarmonyOS官方推出的一体化测试平台,覆盖应用全生命周期测试需求,主要提供五大核心能力: 测试类型检测目标关键指标功能体验基…...

UE5 学习系列(三)创建和移动物体
这篇博客是该系列的第三篇,是在之前两篇博客的基础上展开,主要介绍如何在操作界面中创建和拖动物体,这篇博客跟随的视频链接如下: B 站视频:s03-创建和移动物体 如果你不打算开之前的博客并且对UE5 比较熟的话按照以…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...

成都鼎讯硬核科技!雷达目标与干扰模拟器,以卓越性能制胜电磁频谱战
在现代战争中,电磁频谱已成为继陆、海、空、天之后的 “第五维战场”,雷达作为电磁频谱领域的关键装备,其干扰与抗干扰能力的较量,直接影响着战争的胜负走向。由成都鼎讯科技匠心打造的雷达目标与干扰模拟器,凭借数字射…...

Web 架构之 CDN 加速原理与落地实践
文章目录 一、思维导图二、正文内容(一)CDN 基础概念1. 定义2. 组成部分 (二)CDN 加速原理1. 请求路由2. 内容缓存3. 内容更新 (三)CDN 落地实践1. 选择 CDN 服务商2. 配置 CDN3. 集成到 Web 架构 …...

AGain DB和倍数增益的关系
我在设置一款索尼CMOS芯片时,Again增益0db变化为6DB,画面的变化只有2倍DN的增益,比如10变为20。 这与dB和线性增益的关系以及传感器处理流程有关。以下是具体原因分析: 1. dB与线性增益的换算关系 6dB对应的理论线性增益应为&…...

A2A JS SDK 完整教程:快速入门指南
目录 什么是 A2A JS SDK?A2A JS 安装与设置A2A JS 核心概念创建你的第一个 A2A JS 代理A2A JS 服务端开发A2A JS 客户端使用A2A JS 高级特性A2A JS 最佳实践A2A JS 故障排除 什么是 A2A JS SDK? A2A JS SDK 是一个专为 JavaScript/TypeScript 开发者设计的强大库ÿ…...