JVM从跨平台到跨专业 Ⅲ -- 类加载与字节码技术【下】
文章目录
- 编译期处理
- 默认构造器
- 自动拆装箱
- 泛型集合取值
- 可变参数
- foreach 循环
- switch 字符串
- switch 枚举
- 枚举类
- try-with-resources
- 方法重写时的桥接方法
- 匿名内部类
- 类加载阶段
- 加载
- 链接
- 初始化
- 相关练习和应用
- 类加载器
- 类与类加载器
- 启动类加载器
- 拓展类加载器
- 双亲委派模式
- 自定义类加载器
- 拓:线程上下文类加载器
- 运行期优化
- 即时编译
- 分层编译
- 方法内联
- 字段优化
- 反射优化
编译期处理
所谓的 语法糖 ,其实就是指 java 编译器把 .java 源码编译为 .class 字节码的过程中,自动生成和转换的一些代码,主要是为了减轻程序员的负担,算是 java 编译器给我们的一个额外福利
注意,以下代码的分析,借助了 javap 工具,idea 的反编译功能,idea 插件 jclasslib 等工具。另外, 编译器转换的结果直接就是 class 字节码,只是为了便于阅读,给出了 几乎等价 的 java 源码方式,并不是编译器还会转换出中间的 java 源码,切记。
默认构造器
public class Candy1 {}
经过编译期优化后;
public class Candy1 {//这个无参构造器是java编译器帮我们加上的public Candy1() {//即调用父类 Object 的无参构造方法,即调用 java/lang/Object." <init>":()Vsuper();}
}
自动拆装箱
基本类型和其包装类型的相互转换过程,称为拆装箱
在JDK 5以后,它们的转换可以在编译期自动完成
public class Demo2 {public static void main(String[] args) {Integer x = 1;int y = x;}
}
转换过程如下;
public class Demo2 {public static void main(String[] args) {//基本类型赋值给包装类型,称为装箱Integer x = Integer.valueOf(1);//包装类型赋值给基本类型,称谓拆箱int y = x.intValue();}
}
泛型集合取值
泛型也是在 JDK 5 开始加入的特性,但 java 在编译泛型代码后会执行 泛型擦除 的动作,即泛型信息在编译为字节码之后就丢失了,实际的类型都当做了 Object 类型来处理:
public class Demo3 {public static void main(String[] args) {List<Integer> list = new ArrayList<>();list.add(10); //实际调用的是add(Objcet o)Integer x = list.get(0); //实际调用的是get(Object o)}
}
对应字节码:
Code:stack=2, locals=3, args_size=10: new #2 // class java/util/ArrayList3: dup4: invokespecial #3 // Method java/util/ArrayList."<init>":()V7: astore_18: aload_19: bipush 1011: invokestatic #4 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;//这里进行了泛型擦除,实际调用的是add(Objcet o)14: invokeinterface #5, 2 // InterfaceMethod java/util/List.add:(Ljava/lang/Object;)Z19: pop20: aload_121: iconst_0//这里也进行了泛型擦除,实际调用的是get(Object o) 22: invokeinterface #6, 2 // InterfaceMethod java/util/List.get:(I)Ljava/lang/Object;
//这里进行了类型转换,将Object转换成了Integer27: checkcast #7 // class java/lang/Integer30: astore_231: return
所以在取值时,编译器真正生成的字节码中,还要额外做一些类型转换的操作:
//需要将Object转化为Integer
Integer x = (Integer) list.get(0);
如果前面的x变量类型修改为int基本类型,则还有自动拆箱的操作:
//需要将Object转化为Integer,并执行拆箱操作
int x = (Integer) list.get(0).intValue();
注意:
①擦除的是字节码上的泛型信息,可以看到LocalVariableTypeTable仍然保留了方法参数泛型的信息

②使用反射,我们可以获得方法的参数和返回值的泛型信息,但是方法内局部变量的泛型信息我们是拿不到的:
public Set<Integer> test(List<String> list, Map<Integer, Object> map) {
}
Method test = Candy3.class.getMethod("test", List.class, Map.class);
Type[] types = test.getGenericParameterTypes();
for (Type type : types) {if (type instanceof ParameterizedType) {ParameterizedType parameterizedType = (ParameterizedType) type;System.out.println("原始类型 - " + parameterizedType.getRawType());Type[] arguments = parameterizedType.getActualTypeArguments();for (int i = 0; i < arguments.length; i++) {System.out.printf("泛型参数[%d] - %s\n", i, arguments[i]);}}
}
输出;
原始类型 - interface java.util.List
泛型参数[0] - class java.lang.String
原始类型 - interface java.util.Map
泛型参数[0] - class java.lang.Integer
泛型参数[1] - class java.lang.Object
可变参数
可变参数也是 JDK 5 开始加入的新特性,例如:
public class Demo4 {public static void foo(String... args) {//将args赋值给arr,可以看出String...实际就是String[] String[] arr = args;System.out.println(arr.length);}public static void main(String[] args) {foo("hello", "world");}
}
可变参数 String… args 其实是一个 String[] args ,从代码中的赋值语句中就可以看出来。 同 样 java 编译器会在编译期间将上述代码变换为:
public class Demo4 {public Demo4 {}public static void foo(String[] args) {String[] arr = args;System.out.println(arr.length);}public static void main(String[] args) {foo(new String[]{"hello", "world"});}
}
注意:如果调用的是foo(),即未传递参数时,等价代码为foo(new String[]{}),创建了一个空数组,而不是直接传递的null
foreach 循环
仍是 JDK 5 开始引入的语法糖,数组的循环:
public class Demo5 {public static void main(String[] args) {//数组赋初值的简化写法也是一种语法糖。int[] arr = {1, 2, 3, 4, 5};for(int x : arr) {System.out.println(x);}}
}
编译器会帮我们转换为;
public class Demo5 {public Demo5 {}public static void main(String[] args) {int[] arr = new int[]{1, 2, 3, 4, 5};for(int i=0; i<arr.length; ++i) {int x = arr[i];System.out.println(x);}}
}
如果是集合使用foreach:
public class Demo5 {public static void main(String[] args) {List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);for (Integer x : list) {System.out.println(x);}}
}
集合要使用foreach,需要该集合类实现了Iterable接口,因为集合的遍历需要用到迭代器Iterator:
public class Demo5 {public Demo5 {}public static void main(String[] args) {List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);//获得该集合的迭代器Iterator<Integer> iterator = list.iterator();while(iterator.hasNext()) {Integer x = (Integer)iterator.next();System.out.println(x);}}
}
注意:
foreach 循环写法,能够配合数组,以及所有实现了 Iterable 接口的集合类一起使用,其中Iterable 用来获取集合的迭代器( Iterator )
switch 字符串
从 JDK 7 开始,switch 可以作用于字符串和枚举类,这个功能其实也是语法糖,例如:
public class Demo6 {public static void main(String[] args) {String str = "hello";switch (str) {case "hello" :System.out.println("h");break;case "world" :System.out.println("w");break;default:break;}}
}
在编译器中执行的操作:
public class Demo6 {public Demo6() {}public static void main(String[] args) {String str = "hello";int x = -1;//通过字符串的hashCode+value来判断是否匹配switch (str.hashCode()) {//hello的hashCodecase 99162322 ://再次比较,因为字符串的hashCode有可能相等if(str.equals("hello")) {x = 0;}break;//world的hashCodecase 11331880 :if(str.equals("world")) {x = 1;}break;default:break;}//用第二个switch在进行输出判断switch (x) {case 0:System.out.println("h");break;case 1:System.out.println("w");break;default:break;}}
}
过程说明:
- 在编译期间,单个的switch被分为了两个
- 第一个用来匹配字符串,并给x赋值
- 字符串的匹配用到了字符串的hashCode,还用到了equals方法
- 使用hashCode是为了提高比较效率,使用equals是防止有hashCode冲突(如BM和C.)
- 第二个用来根据x的值来决定输出语句
- 第一个用来匹配字符串,并给x赋值
switch 枚举
public class Demo7 {public static void main(String[] args) {SEX sex = SEX.MALE;switch (sex) {case MALE:System.out.println("man");break;case FEMALE:System.out.println("woman");break;default:break;}}
}enum SEX {MALE, FEMALE;
}
编译器中执行的代码如下;
public class Demo7 {/** * 定义一个合成类(仅 jvm 使用,对我们不可见) * 用来映射枚举的 ordinal 与数组元素的关系 * 枚举的 ordinal 表示枚举对象的序号,从 0 开始 * 即 MALE 的 ordinal()=0,FEMALE 的 ordinal()=1 */ static class $MAP {//数组大小即为枚举元素个数,里面存放了case用于比较的数字static int[] map = new int[2];static {//ordinal即枚举元素对应所在的位置,MALE为0,FEMALE为1map[SEX.MALE.ordinal()] = 1;map[SEX.FEMALE.ordinal()] = 2;}}public static void main(String[] args) {SEX sex = SEX.MALE;//将对应位置枚举元素的值赋给x,用于case操作int x = $MAP.map[sex.ordinal()];switch (x) {case 1:System.out.println("man");break;case 2:System.out.println("woman");break;default:break;}}
}enum SEX {MALE, FEMALE;
}
枚举类
JDK 7 新增了枚举类,以前面的性别枚举为例:
enum SEX {MALE, FEMALE;
}
转换后的代码;
public final class Sex extends Enum<Sex> { //对应枚举类中的元素public static final Sex MALE; public static final Sex FEMALE; private static final Sex[] $VALUES;static { //调用构造函数,传入枚举元素的值及ordinalMALE = new Sex("MALE", 0); FEMALE = new Sex("FEMALE", 1); $VALUES = new Sex[]{MALE, FEMALE}; }//调用父类中的方法private Sex(String name, int ordinal) { super(name, ordinal); }public static Sex[] values() { return $VALUES.clone(); }public static Sex valueOf(String name) { return Enum.valueOf(Sex.class, name); } }
try-with-resources
JDK 7 开始新增了对需要关闭的资源处理的特殊语法try-with-resources;
try(资源变量 = 创建资源对象) {} catch() {}其中资源对象需要实现 AutoCloseable 接口,例如 InputStream 、 OutputStream 、 Connection 、 Statement 、 ResultSet 等接口都实现了 AutoCloseable ,使用 try-with- resources 可以不用写 finally 语句块,编译器会帮助生成关闭资源代码,例如:
public class Candy9 { public static void main(String[] args) {try(InputStream is = new FileInputStream("d:\\1.txt")){ System.out.println(is); } catch (IOException e) { e.printStackTrace(); } }
}
会被转换为:
public class Candy9 { public Candy9() { }public static void main(String[] args) { try {InputStream is = new FileInputStream("d:\\1.txt");Throwable t = null; try {System.out.println(is); } catch (Throwable e1) { // t 是我们代码出现的异常 t = e1; throw e1; } finally {// 判断了资源不为空 if (is != null) { // 如果我们代码有异常if (t != null) { try {is.close(); } catch (Throwable e2) { // 如果 close 出现异常,作为被压制异常添加t.addSuppressed(e2); } } else { // 如果我们代码没有异常,close 出现的异常就是最后 catch 块中的 e is.close(); } } } } catch (IOException e) {e.printStackTrace(); } }
}
为什么要设计一个 addSuppressed(Throwable e) (添加被压制异常)的方法呢?
这是为了防止异常信息的丢失(想想 try-with-resources 生成的 fianlly 中如果抛出了异常):
public class Test6 { public static void main(String[] args) { try (MyResource resource = new MyResource()) { int i = 1/0; } catch (Exception e) { e.printStackTrace(); } }
}
class MyResource implements AutoCloseable { public void close() throws Exception { throw new Exception("close 异常"); }
}
输出:
java.lang.ArithmeticException: / by zero at test.Test6.main(Test6.java:7) Suppressed: java.lang.Exception: close 异常 at test.MyResource.close(Test6.java:18) at test.Test6.main(Test6.java:6)
如以上代码所示,两个异常信息都不会丢。
方法重写时的桥接方法
我们都知道,方法重写时对返回值分两种情况:
- 父子类的返回值完全一致
- 子类返回值可以是父类返回值的子类
class A { public Number m() { return 1; }
}
class B extends A { @Override // 子类 m 方法的返回值是 Integer 是父类 m 方法返回值 Number 的子类 public Integer m() { return 2; }
}
对于子类,java 编译器会做如下处理:
class B extends A { public Integer m() { return 2; }// 此桥接方法才是真正重写了父类 public Number m() 方法 public synthetic bridge Number m() { // 调用 public Integer m() return m(); }
}
其中桥接方法(也可以叫做合成方法)比较特殊,仅对 java 虚拟机可见,并且与原来的 public Integer m() 没有命名冲突,可以用下面反射代码来验证:
public static void main(String[] args) {for(Method m : B.class.getDeclaredMethods()) {System.out.println(m);}}
结果:
public java.lang.Integer cn.ali.jvm.test.B.m()
public java.lang.Number cn.ali.jvm.test.B.m()
匿名内部类
源代码:
public class Candy10 {public static void main(String[] args) {Runnable runnable = new Runnable() {@Overridepublic void run() {System.out.println("running...");}};}
}
转换后的代码:
public class Candy10 {public static void main(String[] args) {// 用额外创建的类来创建匿名内部类对象Runnable runnable = new Candy10$1();}
}// 创建了一个额外的类,实现了 Runnable 接口
final class Candy10$1 implements Runnable {public Demo8$1() {}@Overridepublic void run() {System.out.println("running...");}
}
引用局部变量的匿名内部类,源代码:
public class Candy11 { public static void test(final int x) { Runnable runnable = new Runnable() { @Override public void run() { System.out.println("ok:" + x); } }; }
}
转换后代码:
// 额外生成的类
final class Candy11$1 implements Runnable { int val$x; Candy11$1(int x) { this.val$x = x; }public void run() { System.out.println("ok:" + this.val$x); }
}public class Candy11 { public static void test(final int x) { Runnable runnable = new Candy11$1(x); }
}
注意:
这同时解释了为什么匿名内部类引用局部变量时,局部变量必须是 final 的:因为在创建Candy11$1对象时,将 x 的值赋值给了Candy11$1对象的val$x属性,所以 x 不应该再发生变化了,如果变化,那么val$x属性没有机会再跟着一起变化
注意上面代码中,有些变量中含有
$符号,这些符号一般会在jvm内部使用,方便jvm的操作。java源代码中不会出现这种符号。
类加载阶段
加载
- 将类的字节码载入方法区(1.8后为元空间,在本地内存中)中,其内部采用 C++ 的 instanceKlass 来描述 java 类,它的重要 field 有:
_java_mirror即 java 的类镜像,例如对 String 来说,它的镜像类就是 String.class,作用是把 klass 暴露给 java 使用_super即父类_fields即成员变量_methods即方法_constants即常量池_class_loader即类加载器_vtable虚方法表_itable接口方法
- 如果这个类还有父类没有加载,先加载父类
- 加载和链接可能是交替运行的
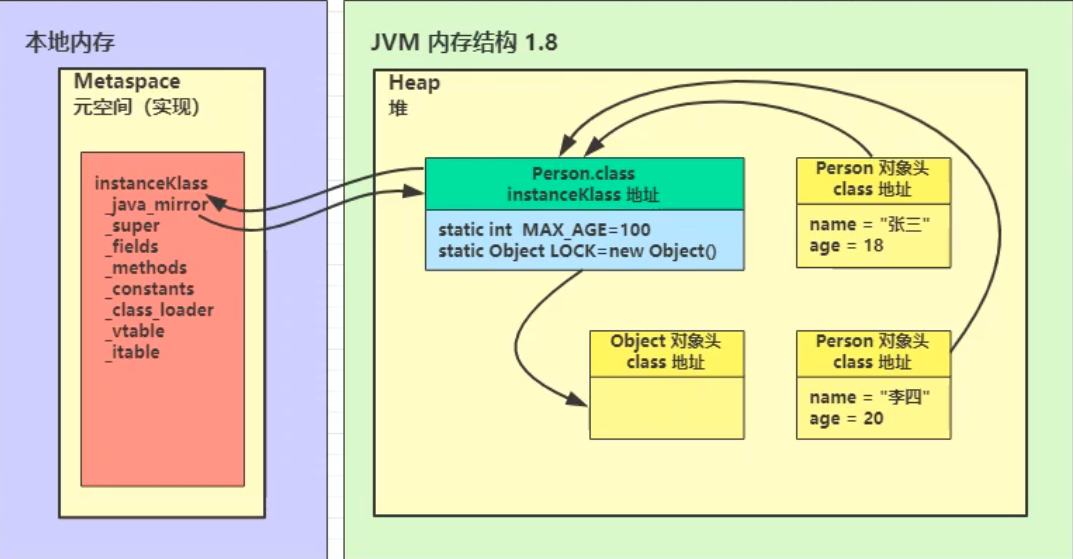
instanceKlass保存在方法区。JDK 8以后,方法区位于元空间中,而元空间又位于本地内存中_java_mirror则是保存在堆内存中InstanceKlass和*.class(JAVA镜像类)互相保存了对方的地址- 类的对象在对象头中保存了
*.class的地址(也就是说类型指针)。让对象可以通过其找到方法区中的instanceKlass,从而获取类的各种信息
注意:
①instanceKlass 这样的【元数据】是存储在方法区(1.8 后的元空间内),但 _java_mirror 是存储在堆中
②可以通过前面介绍的 HSDB 工具查看
链接
链接阶段可以分为三个小的步骤:
-
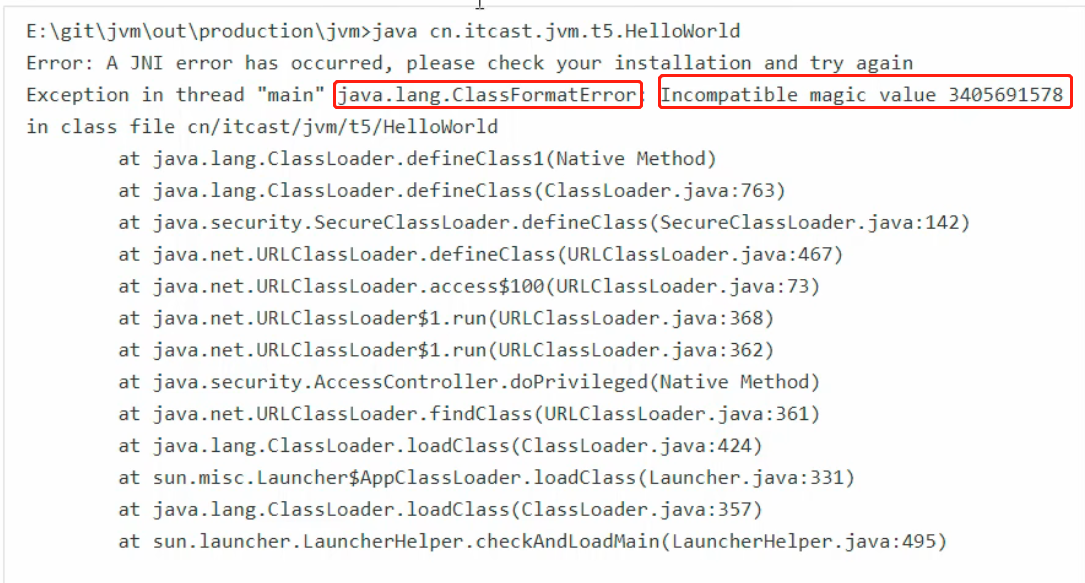
验证:验证类是否符合 JVM规范、安全性检查我们可以试验一下:用 UE 等支持二进制的编辑器修改 HelloWorld.class 的魔数,在控制台运行,结果如下:
-
准备:为 static 变量分配空间,设置默认值- static变量在JDK 7以前是存储与instanceKlass末尾。但在JDK 7以后就存储在_java_mirror末尾了
- static变量在分配空间和赋值是在两个阶段完成的。分配空间在准备阶段完成,赋值在初始化阶段完成(在类的构造方法中)
- 如果 static 变量是 final 的基本类型,以及字符串常量,那么编译阶段值就确定了,赋值在准备阶段完成
- 如果 static 变量是 final 的,但属于引用类型,那么赋值也会在初始化阶段完成(在类的构造方法中)
-
解析:将常量池中的符号引用解析为直接引用- 符号引用也就是说仅仅是一个符号,并不知道这个符号对应着内存的哪一块空间,但是经过了解析之后变成了直接引用,就知道这些引用的是哪一块位置了。
怎么理解解析这一步骤呢,我们可以通过一段代码来看看:
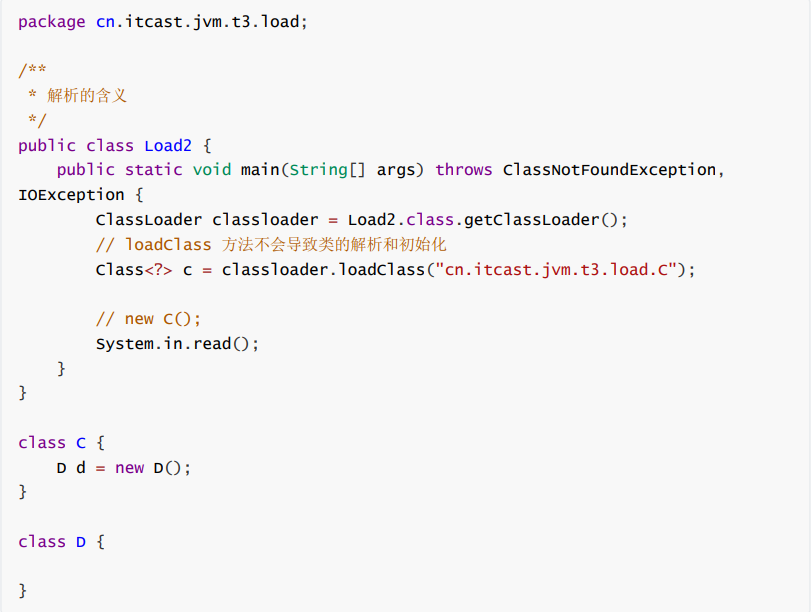
我们看看load.C的常量池:
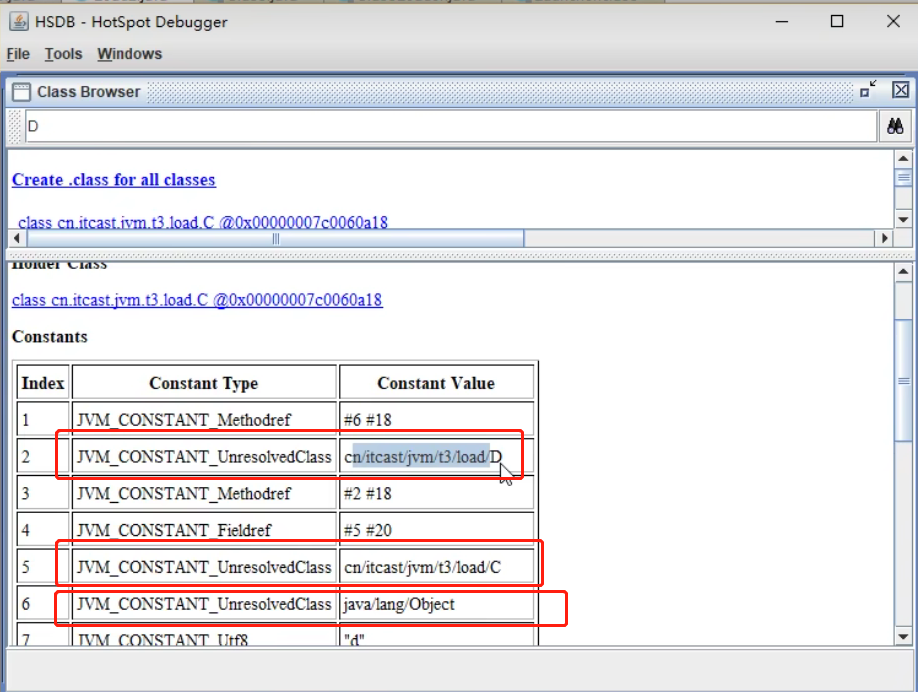
我们可以看到JVM_CONSTANT_UnresolvedClass,是一个未经解析的类,也就是说后面的类D仅仅是一个符号,既没有加载也没有解析。
而如果我们使用的是new C(),我们再来看load.C的常量池;
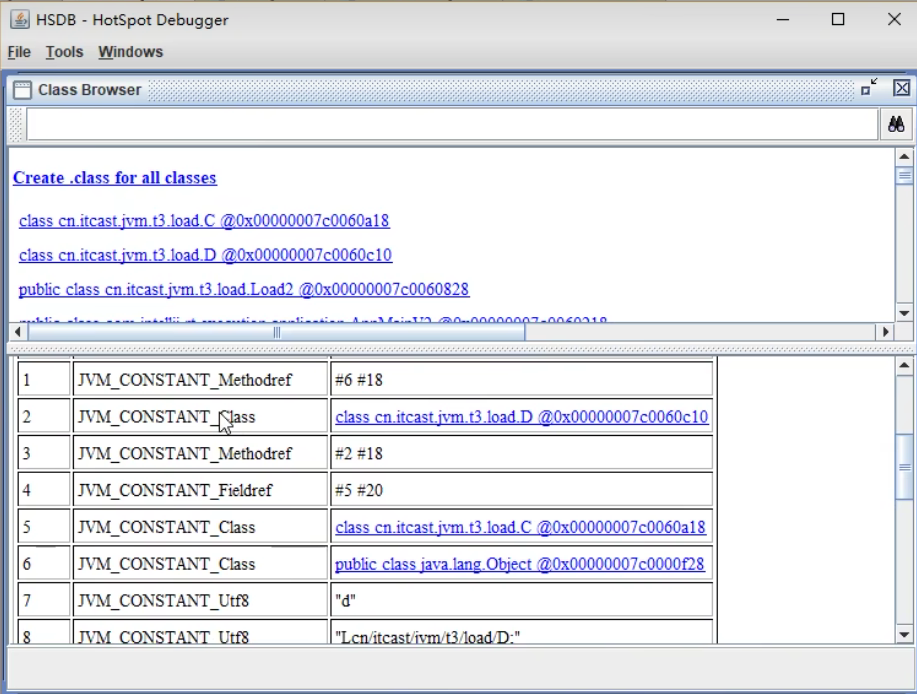
可以看到我们的类D已经被解析了拥有了地址。
初始化
初始化阶段就是执行类构造器<cinit>()V方法的过程,虚拟机会保证这个类的『构造方法』的线程安全
<cinit>()V方法是由编译器自动收集类中的所有类变量的赋值动作和静态语句块(static{}块)中的语句合并产生的
注意:
编译器收集的顺序是由语句在源文件中出现的顺序决定的,静态语句块中只能访问到定义在静态语句块之前的变量,定义在它之后的变量,在前面的静态语句块可以赋值,但是不能访问,如:

发生时机
类的初始化的懒惰的,以下情况会初始化:
- main 方法所在的类,总会被首先初始化
- 首次访问这个类的静态变量或静态方法时
- 子类初始化,如果父类还没初始化,会引发
- 子类访问父类的静态变量,只会触发父类的初始化
- Class.forName
- new 会导致初始化
以下情况不会初始化:
- 访问类的 static final 静态常量(基本类型和字符串)
- 前面我们说过,在类的链接阶段就完成了
- 类对象.class 不会触发初始化
- 创建该类对象的数组
- 类加载器的.loadClass方法
- Class.forNamed的参数2为false时
验证类是否被初始化,可以看改类的静态代码块是否被执行
验证
实验时先全部注释,每次只执行其中一个,然后看类的静态代码块是否被执行:
public class Load1 {static {System.out.println("main init");}public static void main(String[] args) throws ClassNotFoundException {// 1. 静态常量(基本类型和字符串)不会触发初始化
// System.out.println(B.b);// 2. 类对象.class 不会触发初始化
// System.out.println(B.class);// 3. 创建该类的数组不会触发初始化
// System.out.println(new B[0]);// 4. 不会初始化类 B,但会加载 B、A
// ClassLoader cl = Thread.currentThread().getContextClassLoader();
// cl.loadClass("cn.ali.jvm.test.classload.B");// 5. 不会初始化类 B,但会加载 B、A
// ClassLoader c2 = Thread.currentThread().getContextClassLoader();
// Class.forName("cn.ali.jvm.test.classload.B", false, c2);// 1. 首次访问这个类的静态变量或静态方法时
// System.out.println(A.a);// 2. 子类初始化,如果父类还没初始化,会引发
// System.out.println(B.c);// 3. 子类访问父类静态变量,只触发父类初始化
// System.out.println(B.a);// 4. 会初始化类 B,并先初始化类 A
// Class.forName("cn.ali.jvm.test.classload.B");}}class A {static int a = 0;static {System.out.println("a init");}
}
class B extends A {final static double b = 5.0;static boolean c = false;static {System.out.println("b init");}
}
相关练习和应用
从字节码分析,使用 a,b,c 这三个常量是否会导致 E 初始化;
public class Load2 {public static void main(String[] args) {System.out.println(E.a);System.out.println(E.b);// 会导致 E 类初始化,因为 Integer 是包装类System.out.println(E.c);}
}class E {public static final int a = 10;public static final String b = "hello";public static final Integer c = 20;static {System.out.println("E cinit");}
}
典型应用 - 完成懒惰初始化单例模式
public class Singleton {private Singleton() { } // 内部类中保存单例private static class LazyHolder { static final Singleton INSTANCE = new Singleton(); }// 第一次调用 getInstance 方法,才会导致内部类加载和初始化其静态成员 public static Singleton getInstance() { return LazyHolder.INSTANCE; }
}
以上的实现特点是:
- 懒惰实例化
- 初始化时的线程安全是有保障的
类加载器
Java虚拟机设计团队有意把类加载阶段中的“通过一个类的全限定名来获取描述该类的二进制字节流”这个动作放到Java虚拟机外部去实现,以便让应用程序自己决定如何去获取所需的类。实现这个动作的代码被称为“类加载器”(ClassLoader)
类与类加载器
类加载器虽然只用于实现类的加载动作,但它在Java程序中起到的作用却远超类加载阶段
对于任意一个类,都必须由加载它的类加载器和这个类本身一起共同确立其在Java虚拟机中的唯一性,每一个类加载器,都拥有一个独立的类名称空间。这句话可以表达得更通俗一些:比较两个类是否“相等”,只有在这两个类是由同一个类加载器加载的前提下才有意义,否则,即使这两个类来源于同一个Class文件,被同一个Java虚拟机加载,只要加载它们的类加载器不同,那这两个类就必定不相等
以JDK 8为例:
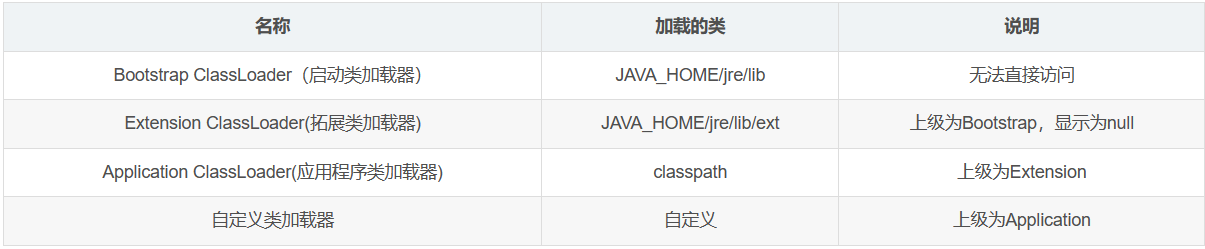
Extension ClassLoader(拓展类加载器)去getParent的时候得到的是个null,因为Bootstrap ClassLoader(启动类加载器)是用C++写的,不会让我们的Java代码直接访问。
启动类加载器
可通过在控制台输入指令,使得类被启动类加器加载
例如:
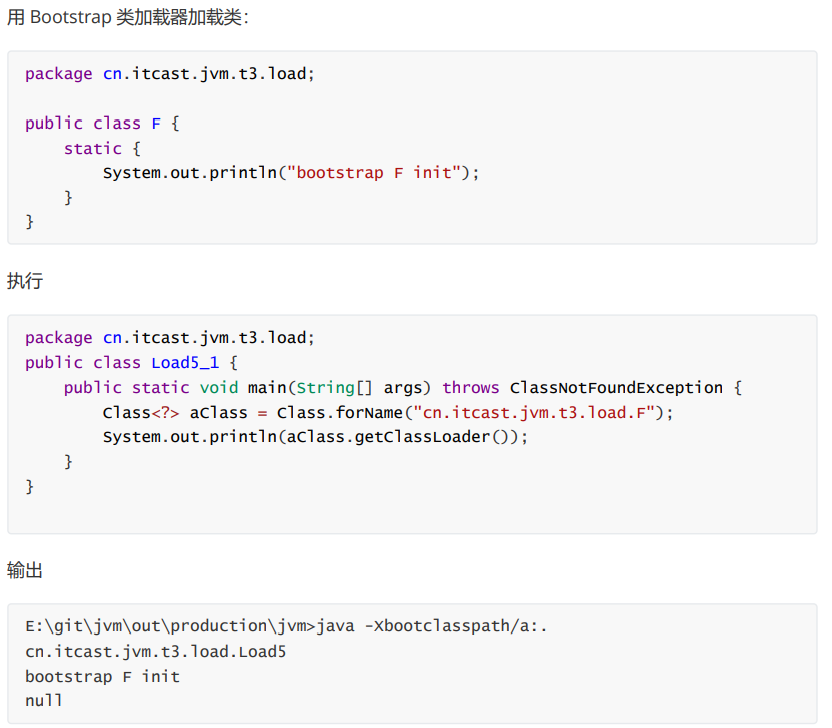
注意:

拓展类加载器
如果classpath和JAVA_HOME/jre/lib/ext 下有同名类,加载时会使用拓展类加载器加载。当应用程序类加载器发现拓展类加载器已将该同名类加载过了,则不会再次加载
其本质就是双亲委派模式的应用
双亲委派模式
双亲委派模式,即调用类加载器ClassLoader 的 loadClass 方法时,查找类的规则。总的来说就是委派上级来优先做类的加载,上级没有再自己来完成类的加载。
要注意这四种类加载器并没有继承的关系,只是级别不一样
loadClass源码;
protected Class<?> loadClass(String name, boolean resolve)throws ClassNotFoundException
{synchronized (getClassLoadingLock(name)) {// 首先查找该类是否已经被该类加载器加载过了Class<?> c = findLoadedClass(name);//如果没有被加载过if (c == null) {long t0 = System.nanoTime();try {//看是否被它的上级加载器加载过了 Extension的上级是Bootstarp,但它显示为nullif (parent != null) {c = parent.loadClass(name, false);} else {//看是否被启动类加载器加载过c = findBootstrapClassOrNull(name);}} catch (ClassNotFoundException e) {// ClassNotFoundException thrown if class not found// from the non-null parent class loader//捕获异常,但不做任何处理}if (c == null) {//如果还是没有找到,先让拓展类加载器调用findClass方法去找到该类,如果还是没找到,就抛出异常//然后让应用类加载器去找classpath下找该类long t1 = System.nanoTime();c = findClass(name);// 记录时间sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);sun.misc.PerfCounter.getFindClasses().increment();}}if (resolve) {resolveClass(c);}return c;}
}
自定义类加载器
使用场景:
- 想加载非 classpath 随意路径中的类文件
- 通过接口来使用实现,希望解耦时,常用在框架设计
- 这些类希望予以隔离,不同应用的同名类都可以加载,不冲突,常见于 tomcat 容器
步骤:
- 继承ClassLoader父类
- 要遵从双亲委派机制,重写 findClass 方法
- 不是重写loadClass方法,否则不会走双亲委派机制
- 读取类文件的字节码
- 调用父类的 defineClass 方法来加载类
- 使用者调用该类加载器的 loadClass 方法
破坏双亲委派模式
- 双亲委派模型的第一次“被破坏”其实发生在双亲委派模型出现之前——即JDK1.2面世以前的“远古”时代
- 建议用户重写findClass()方法,在类加载器中的loadClass()方法中也会调用该方法
- 双亲委派模型的第二次“被破坏”是由这个模型自身的缺陷导致的
- 如果有基础类型又要调用回用户的代码,此时也会破坏双亲委派模式
- 双亲委派模型的第三次“被破坏”是由于用户对程序动态性的追求而导致的
- 这里所说的“动态性”指的是一些非常“热”门的名词:代码热替换(Hot Swap)、模块热部署(Hot Deployment)等
拓:线程上下文类加载器
我们在使用 JDBC 时,都需要加载 Driver 驱动,不知道你注意到没有,不写:
Class.forName("com.mysql.jdbc.Driver")
也是可以让 com.mysql.jdbc.Driver 正确加载的,你知道是怎么做的吗?
让我们追踪一下源码:
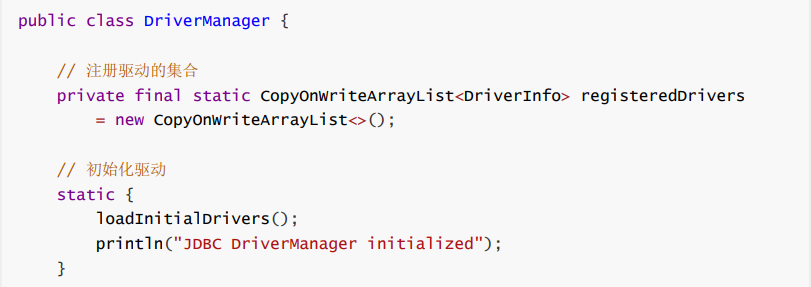
先不看别的,看看 DriverManager 的类加载器:
System.out.println(DriverManager.class.getClassLoader());
打印 null,表示它的类加载器是 Bootstrap ClassLoader,会到 JAVA_HOME/jre/lib 下搜索类,但 JAVA_HOME/jre/lib 下显然没有 mysql-connector-java-5.1.47.jar 包,这样问题来了,在DriverManager 的静态代码中,怎么能正确加载 com.mysql.jdbc.Driver 呢?
继续看 loadInitialDrivers() 方法:

先看 2)发现它最后是使用 Class.forName 完成类的加载和初始化,关联的是应用程序类加载器,因此可以顺利完成类加载
再看 1)它就是大名鼎鼎的 Service Provider Interface (SPI)
约定如下,在 jar 包的 META-INF/services 包下,以接口全限定名名为文件,文件内容是实现类名称
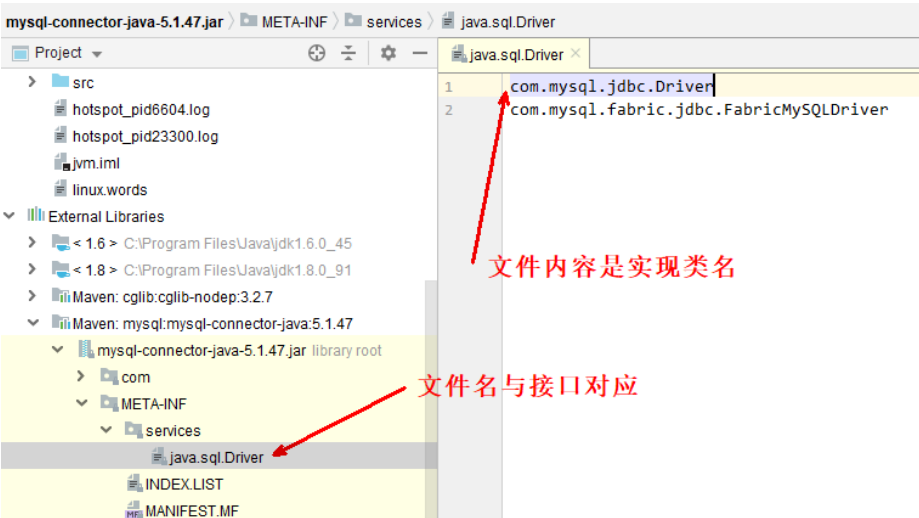
这样就可以使用:
ServiceLoader<接口类型> allImpls = ServiceLoader.load(接口类型.class);
Iterator<接口类型> iter = allImpls.iterator();
while(iter.hasNext()) {iter.next();
}
来得到实现类,体现的是【面向接口编程+解耦】的思想,在下面一些框架中都运用了此思想:
- JDBC
- Servlet 初始化器
- Spring 容器
- Dubbo(对 SPI 进行了扩展)
接着看 ServiceLoader.load 方法:
public static <S> ServiceLoader<S> load(Class<S> service) {// 获取线程上下文类加载器ClassLoader cl = Thread.currentThread().getContextClassLoader();return ServiceLoader.load(service, cl);
}
线程上下文类加载器是当前线程使用的类加载器,默认就是应用程序类加载器,它内部又是由Class.forName 调用了线程上下文类加载器完成类加载,具体代码在 ServiceLoader 的内部类LazyIterator 中:
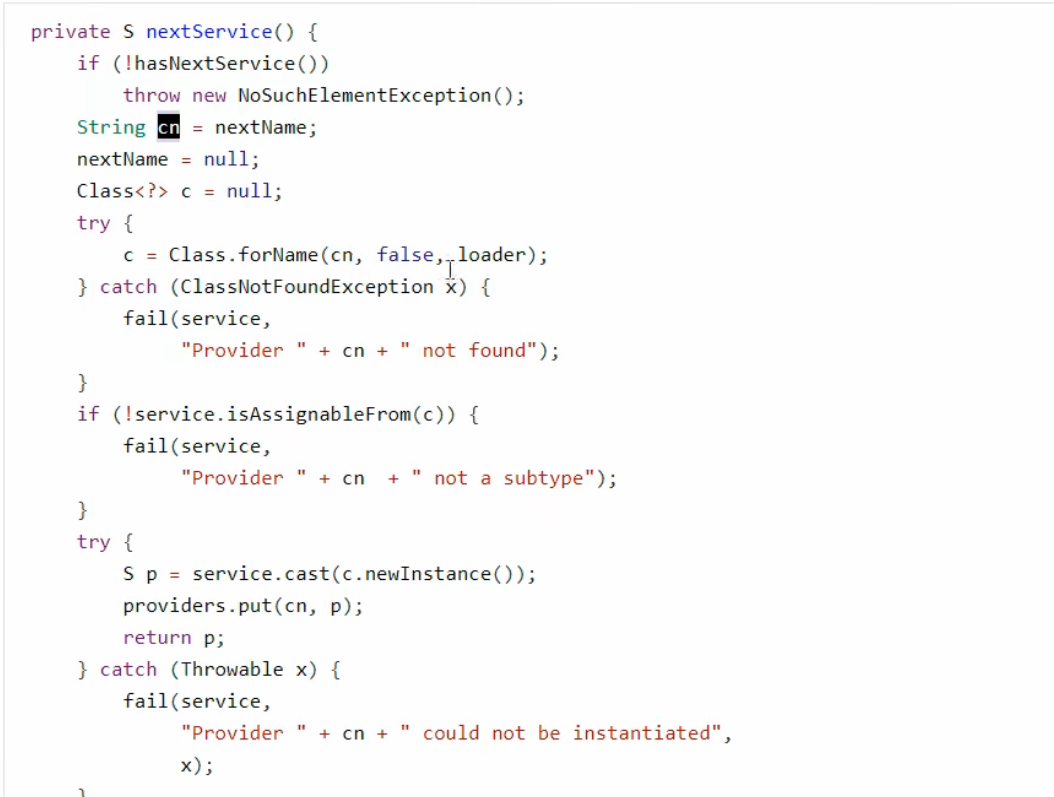
运行期优化
即时编译
分层编译
JVM 将执行状态分成了 5 个层次:
- 0层:解释执行,用解释器将字节码翻译为机器码
- 1层:使用 C1 即时编译器编译执行(不带 profiling)
- 2层:使用 C1 即时编译器编译执行(带基本的profiling)
- 3层:使用 C1 即时编译器编译执行(带完全的profiling)
- 4层:使用 C2 即时编译器编译执行
profiling 是指在运行过程中收集一些程序执行状态的数据,例如【方法的调用次数】,【循环的 回边次数】等
即时编译器(JIT)与解释器的区别
- 解释器
- 将字节码解释为机器码,下次即使遇到相同的字节码,仍会执行重复的解释
- 是将字节码解释为针对所有平台都通用的机器码
- 即时编译器
- 将一些字节码编译为机器码,并存入 Code Cache,下次遇到相同的代码,直接执行,无需再编译
- 根据平台类型,生成平台特定的机器码
对于大部分的不常用的代码,我们无需耗费时间将其编译成机器码,而是采取解释执行的方式运行;另一方面,对于仅占据小部分的热点代码,我们则可以将其编译成机器码,以达到理想的运行速度。 执行效率上简单比较一下 Interpreter(解释器) < C1 < C2,总的目标是发现热点代码(hotspot名称的由 来),并优化这些热点代码
我们来看一段代码:
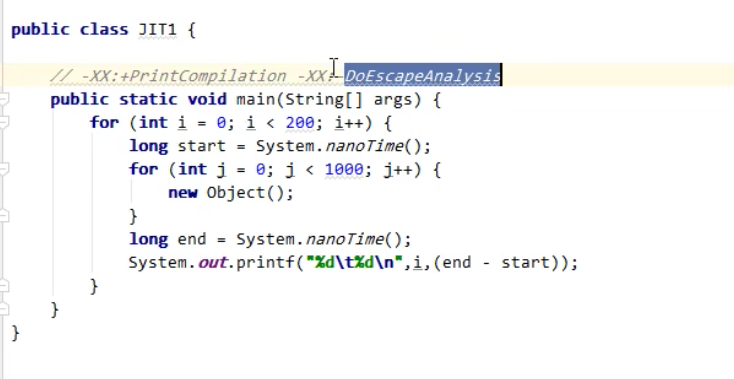
大致就是每创建1000个对象记一次时间,重复200次,我们发现在第145次之后创建时间会有一个明显的锐减:

这里就使用了一种优化手段称之为【逃逸分析】,它会分析这个new Object出来的对象在循环外面是否会被用到、会不会被其它方法所引用,结果发现没有。也就是说这个对象不会逃逸,外层用不到,既然用不到那么就没有必要创建它。
之所以后来消耗的时间这么短是因为JIT进行了逃逸分析之后,把对象创建的字节码给替换掉了,干脆不创建对象(C2编译器为了优化可能会把原本的字节码改得面目全非)。
可以使用 -XX:-DoEscapeAnalysis 关闭逃逸分析
逃逸分析是C2 即时编译器做出的优化
参考文档:
https://docs.oracle.com/en/java/javase/12/vm/java-hotspot-virtual-machine-performance-enhancements.html#GUID-D2E3DC58-D18B-4A6C-8167-4A1DFB4888E4
方法内联
也属于即时编译器优化手段的一种
private static int square(final int i) {return i * i;
}
System.out.println(square(9));
如果发现 square 是热点方法,并且长度不太长时,会进行内联,所谓的内联就是把方法内代码拷贝、粘贴到调用者的位置:
System.out.println(9 * 9);
还能够进行常量折叠(constant folding)的优化:
System.out.println(81);
注意:
C++是否为内联函数由自己决定,Java由编译器决定。Java不支持直接声明为内联函数的,如果想让他内联,你只能够向编译器提出请求: 关键字final修饰 用来指明那个函数是希望被JVM内联的,如
public final void doSomething() { // to do something
}
总的来说,一般的函数都不会被当做内联函数,只有声明了final后,编译器才会考虑是不是要把你的函数变成内联函数
相关jvm命令:
-XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining (解锁隐藏参数)打印inlining 信息
-XX:CompileCommand=dontinline,*JIT2.square 禁止某个方法 inlining
-XX:+PrintCompilation 打印编译信息
*JIT2.square*通配任意报名- JIT2匹配类
- square匹配JIT2类中的方法
字段优化
针对成员变量或者是静态成员变量的读写操作优化。
都是通过即时编译器优化生成的IR图来精简最后的机器码(在生成机器码前就好像人浏览了一遍代码,通过前后关联情况手动消除了一些重复或无效的代码),去掉无效代码,减少在code cache中存储的机器码的大小,节省内存,提高程序运行速度。
主要包括:
- 缓存读取、
- 去除重复操作、
- 分支优化、
- 不可达分支消除
对象字段读取优化
- 优化一:缓存读取

- 优化二:去重去不可达分支,可达分支优化
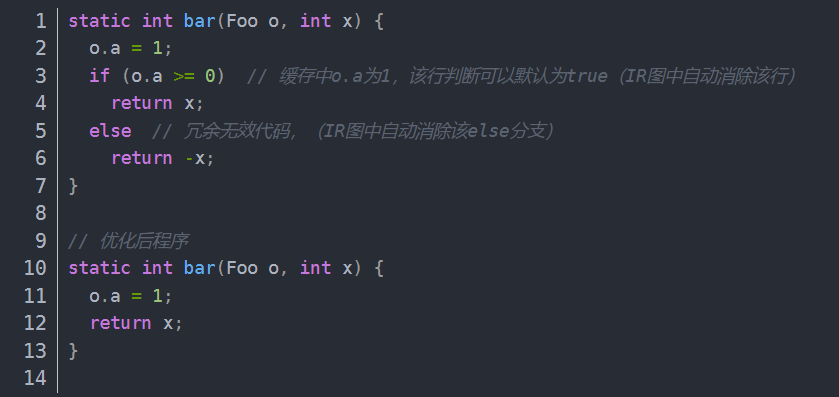
对象字段存储优化
同一个字段先后被存储两次,两次操作中间没有对该字段的读取操作,没有被方法调用或者没有被间接存储到其他字段,JVM会消除第一处的冗余赋值指令(Volatile同样可以阻止该优化,强制属性值实时刷入内存);
class Foo {int a = 0; // 冗余重复代码,被优化(IR图中被去除)void bar() {a = 1; // 冗余重复代码,被优化(IR图中被去除)a = 2; // 最终执行的赋值语句}
}// 优化后程序
class Foo { void bar() {a = 2; // 最终执行的赋值语句}
}
局部变量死存储优化
与对象的字段值一样包含去除重复或者无效代码,优化分支选择。
// 重复代码消除
int bar(int x, int y) {int t = x*y; // 重复冗余代码,IR图中被去除t = x+y;return t;
}// 分支代码优化
int bar(boolean f, int x, int y) {int t = x*y; // 编译后此处为int t ,具体赋值操作留到if程序块中if (f)t = x+y;return t; // 如果走这条路才会对t进行第一行的赋值操作(int t = x*y) 并返回
}// 不可达分支
int bar(int x) {if (false) // 不可达分支,IR图中不会被编译return x;elsereturn -x;
}
注意:
可能出现异常时,无法进行字段优化
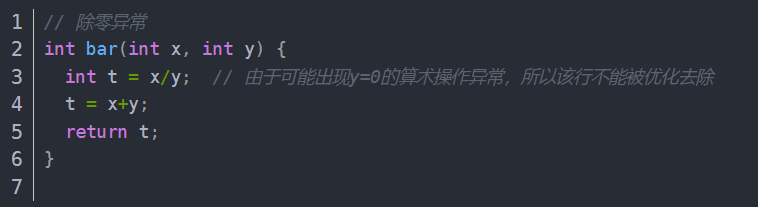
反射优化
public class Reflect1 {public static void foo() {System.out.println("foo...");}public static void main(String[] args) throws NoSuchMethodException, InvocationTargetException, IllegalAccessException {Method foo = Demo3.class.getMethod("foo");for(int i = 0; i<=16; i++) {foo.invoke(null);}}
}
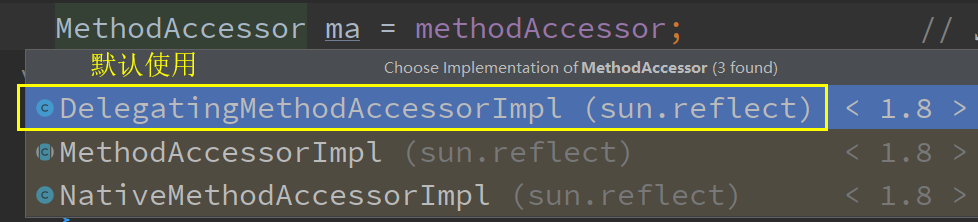
foo.invoke 前面 0 ~ 15 次调用使用的是 MethodAccessor 的 NativeMethodAccessorImpl 实现
invoke方法源码:
@CallerSensitive
public Object invoke(Object obj, Object... args)throws IllegalAccessException, IllegalArgumentException,InvocationTargetException
{if (!override) {if (!Reflection.quickCheckMemberAccess(clazz, modifiers)) {Class<?> caller = Reflection.getCallerClass();checkAccess(caller, clazz, obj, modifiers);}}//MethodAccessor是一个接口,有3个实现类,其中有一个是抽象类MethodAccessor ma = methodAccessor; // read volatileif (ma == null) {ma = acquireMethodAccessor();}return ma.invoke(obj, args);
}
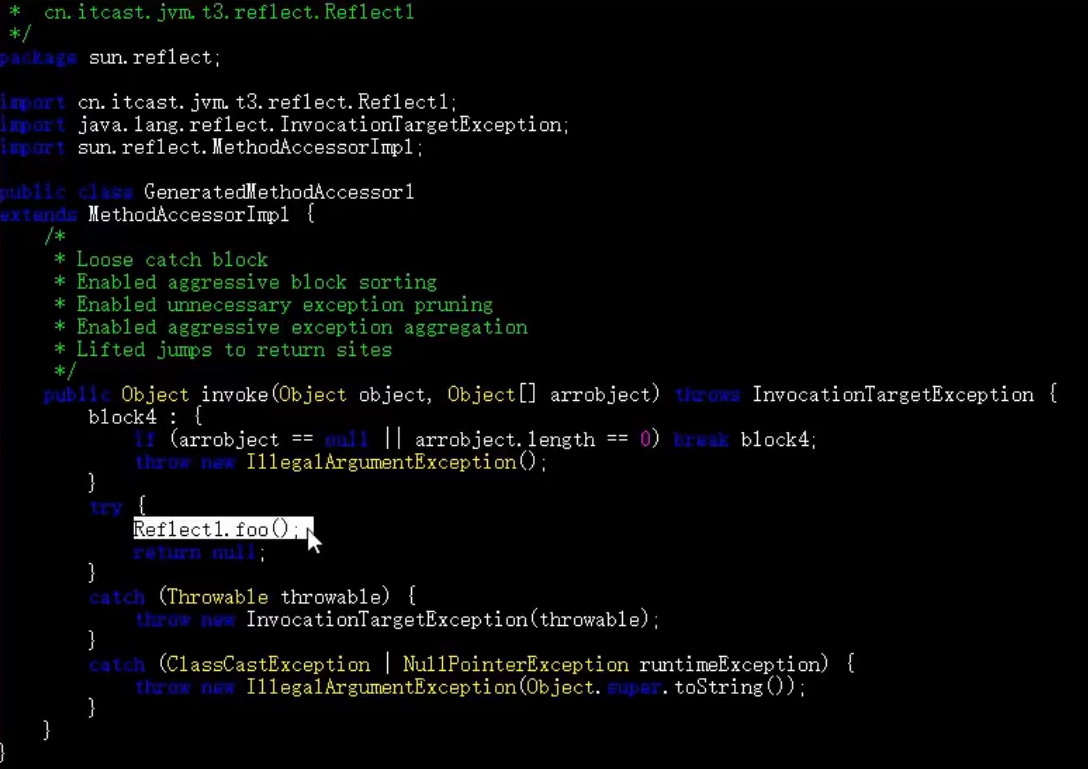
会由DelegatingMehodAccessorImpl去调用NativeMethodAccessorImpl
NativeMethodAccessorImpl源码;
class NativeMethodAccessorImpl extends MethodAccessorImpl {private final Method method;private DelegatingMethodAccessorImpl parent;private int numInvocations;NativeMethodAccessorImpl(Method var1) {this.method = var1;}//每次进行反射调用,会让numInvocation与ReflectionFactory.inflationThreshold的值(15)进行比较,并使使得numInvocation的值加一//如果numInvocation>ReflectionFactory.inflationThreshold,则会调用本地方法invoke0方法public Object invoke(Object var1, Object[] var2) throws IllegalArgumentException, InvocationTargetException {if (++this.numInvocations > ReflectionFactory.inflationThreshold() && !ReflectUtil.isVMAnonymousClass(this.method.getDeclaringClass())) {MethodAccessorImpl var3 = (MethodAccessorImpl)(new MethodAccessorGenerator()).generateMethod(this.method.getDeclaringClass(), this.method.getName(), this.method.getParameterTypes(), this.method.getReturnType(), this.method.getExceptionTypes(), this.method.getModifiers());this.parent.setDelegate(var3);}return invoke0(this.method, var1, var2);}void setParent(DelegatingMethodAccessorImpl var1) {this.parent = var1;}private static native Object invoke0(Method var0, Object var1, Object[] var2);
}
//ReflectionFactory.inflationThreshold()方法的返回值
private static int inflationThreshold = 15;
- 一开始if条件不满足,就会调用本地方法invoke0
- 随着numInvocation的增大,当它大于ReflectionFactory.inflationThreshold的值16时,就会本地方法访问器替换为一个运行时动态生成的访问器,来提高效率
- 这时会从反射调用变为正常调用,即直接调用 Reflect1.foo()
相关文章:
JVM从跨平台到跨专业 Ⅲ -- 类加载与字节码技术【下】
文章目录编译期处理默认构造器自动拆装箱泛型集合取值可变参数foreach 循环switch 字符串switch 枚举枚举类try-with-resources方法重写时的桥接方法匿名内部类类加载阶段加载链接初始化相关练习和应用类加载器类与类加载器启动类加载器拓展类加载器双亲委派模式自定义类加载器…...

ucore的字符输出
ucore的字符输出有cga,lpt,和串口。qemu模拟出来显示器连接到cga中。 cga cga的介绍网站:https://en.wikipedia.org/wiki/Color_Graphics_Adapter cga是显示卡,内部有个叫6845的芯片。cga卡把屏幕划分成一个一个单元格,每个单元格显示一个a…...

【ESP 保姆级教程】玩转emqx数据集成篇① ——认识数据集成
忘记过去,超越自己 ❤️ 博客主页 单片机菜鸟哥,一个野生非专业硬件IOT爱好者 ❤️❤️ 本篇创建记录 2023-02-10 ❤️❤️ 本篇更新记录 2023-02-10 ❤️🎉 欢迎关注 🔎点赞 👍收藏 ⭐️留言📝🙏 此博客均由博主单独编写,不存在任何商业团队运营,如发现错误,请…...
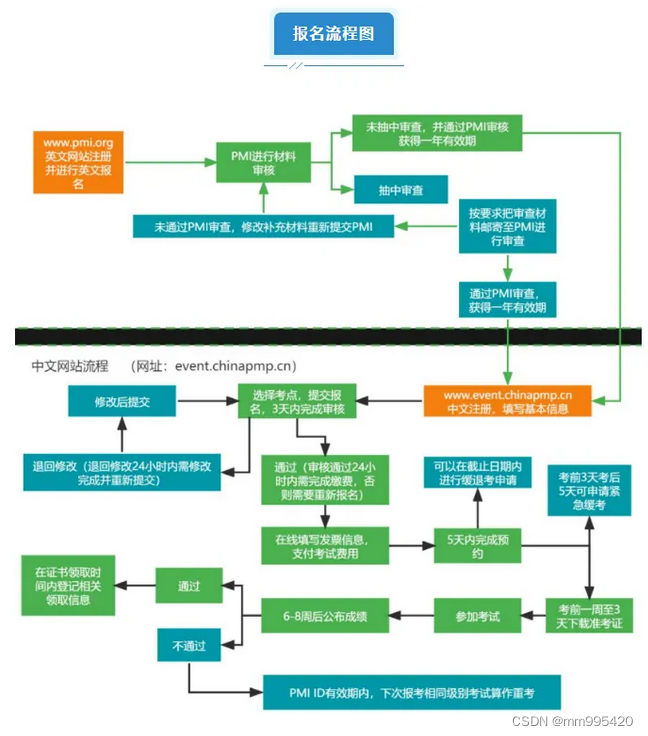
PMP报考条件?
PMP已经被认为是项目管理专业身份的象征,项目经理人取得的重要资质。 PMP考试一般每年在中国大陆地区,会进行四次考试,今天就来详细说一说PMP考试的时间线。 01考试时间PMP考试在中国大陆一年开展四次,分别在每年的3月、6月、9月…...
Vite+Vue3实现版本更新检查,实现页面自动刷新
ViteVue3实现版本更新检查,实现页面自动刷新1、使用Vite插件打包自动生成版本信息2、Vite.config.ts配置3、配置环境变量4、路由配置现有一个需求就是实现管理系统的版本发版,网页实现自动刷新页面获取最新版本 搜索了一下,轮询的方案有点浪费…...

LeetCode刷题模版:292、295、297、299-301、303、304、309、310
目录 简介292. Nim 游戏295. 数据流的中位数297. 二叉树的序列化与反序列化【未理解】299. 猜数字游戏300. 最长递增子序列301. 删除无效的括号【未理解】303. 区域和检索 - 数组不可变304. 二维区域和检索 - 矩阵不可变309. 最佳买卖股票时机含冷冻期310. 最小高度树【未理解】…...

20、CSS中单位:【px和%】【em和rem】【vw|vh|vmin|vmax】的区别
CSS中的px 和 % px (pixels) 是固定单位,也可以叫基本单位,代表像素,可以确保元素的大小不受屏幕分辨率的影响。 % (percentage) 是相对单位,代表元素大小相对于其父元素或视口(viewport)的大小的百分比。使用百分比可…...

第五节 字符设备驱动——点亮LED 灯
通过字符设备章节的学习,我们已经了解了字符设备驱动程序的基本框架,主要是掌握如何申请及释放设备号、添加以及注销设备,初始化、添加与删除cdev 结构体,并通过cdev_init 函数建立cdev 和file_operations 之间的关联,…...
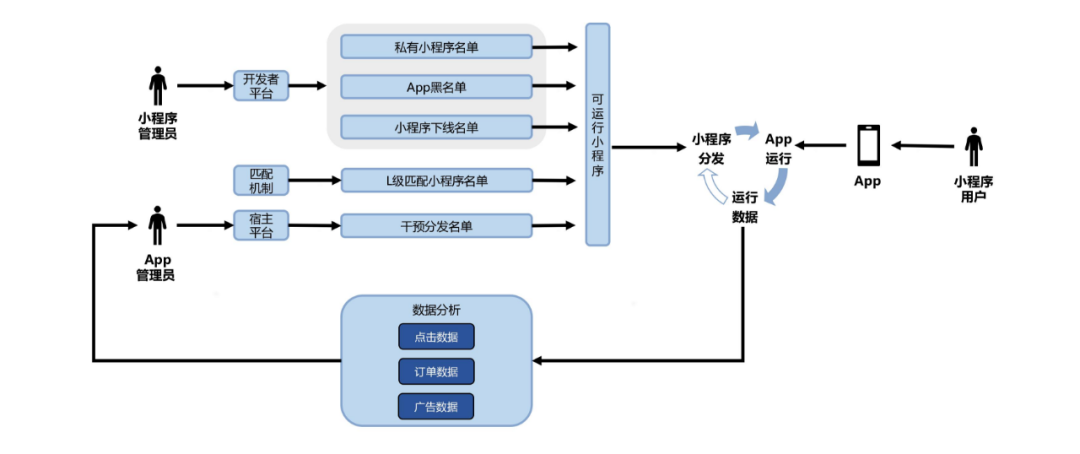
浅谈小程序开源业务架构建设之路
一、业务介绍 1.1 小程序开源整体介绍 百度从做智能小程序的第一天开始就打造真正开源开放的生态,我们的愿景是:定义移动时代最佳体验,建设智能小程序行业标准,打破孤岛,共建开源、开放、繁荣的小程序行业生态。百度…...
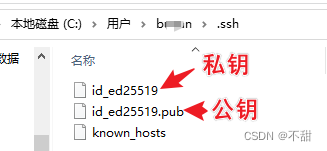
git、gitee、github关系梳理及ssh不对称加密大白话解释
温馨提示:本文不会讲解如何下载、安装git,也不会讲解如何注册、使用gitee或GitHub,这些内容网上一大把,B站上的入门课程也很多,自己看看就好了。 本文仅对 git、gitee、github的关系梳理及ssh公钥私钥授权原理用白话讲…...

UDP协议详解
目录 前言: 再谈协议 UDP协议 比较知名的校验和 小结: 前言: UDP和TCP作为传输层非常知名的两个协议,那么将数据从应用层到传输层数据是怎样进行打包的?具体都会增加一些什么样的报头,下面内容详细介绍…...
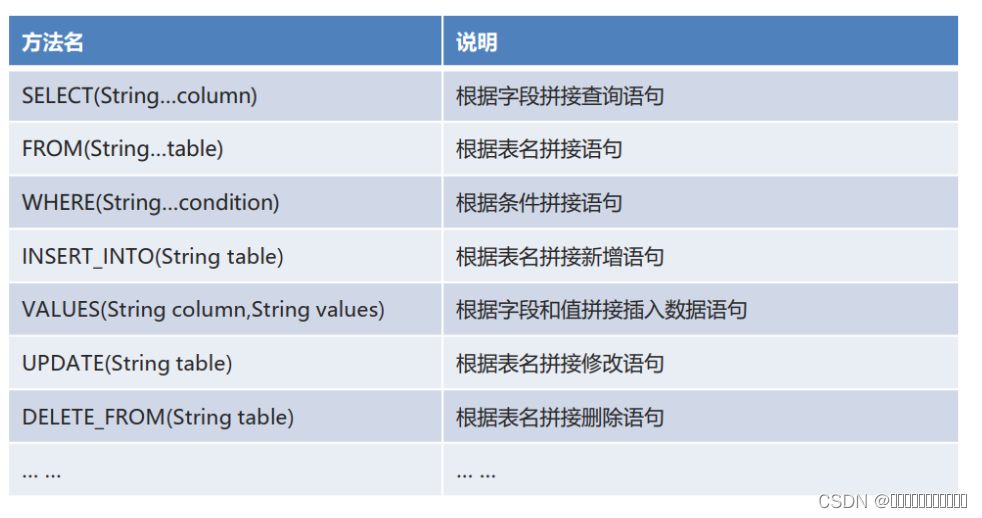
Myb atis基础3
Mybatis注解开发单表操作Mybatis的常用注解Mybatis的增删改查MyBatis注解开发的多表操作MyBatis的注解实现复杂映射开发一对一查询一对多查询多对多查询构建sqlsql构建对象介绍查询功能的实现新增功能的实现修改功能的实现删除功能的实现Mybatis注解开发单表操作 Mybatis的常用…...

VHDL语言基础-时序逻辑电路-寄存器
目录 寄存器的设计: 多位寄存器: 多位寄存器的VHDL描述: 移位寄存器: 串进并出的移位寄存器的VHDL描述: 寄存器的设计: 多位寄存器: 一个D触发器就是一位寄存器,如果需要多位寄存器&…...

高通开发系列 - linux kernel更新msm-3.18升至msm-4.9
By: fulinux E-mail: fulinux@sina.com Blog: https://blog.csdn.net/fulinus 喜欢的盆友欢迎点赞和订阅! 你的喜欢就是我写作的动力! 目录 linux kernel更新msm-3.18升至msm-4.9第一周处理的内容:第二周处理的内容第三周处理的内容linux kernel更新msm-3.18升至msm-4.9 第…...

【Tensorflow2.0】tensorflow中的Dense函数解析
目录1 作用2 例子3 与torch.nn.Linear的区别4 参考文献1 作用 注意此处Tensorflow版本是2.0。 由于本人是Pytorch用户,对Tensorflow不是很熟悉,在读到用tf写的代码时就很是麻烦。如图所示,遇到了如下代码: h Dense(unitsadj_di…...

PyTorch学习笔记:data.RandomSampler——数据随机采样
PyTorch学习笔记:data.RandomSampler——数据随机采样 torch.utils.data.RandomSampler(data_source, replacementFalse, num_samplesNone, generatorNone)功能:随即对样本进行采样 输入: data_source:被采样的数据集合replace…...

设计模式(七)----创建型模式之建造者模式
1、概述 将一个复杂对象的构建与表示分离,使得同样的构建过程可以创建不同的表示。 分离了部件的构造(由Builder来负责)和装配(由Director负责)。 从而可以构造出复杂的对象。这个模式适用于:某个对象的构建过程复杂的情况。 由于实现了构建和装配的解…...
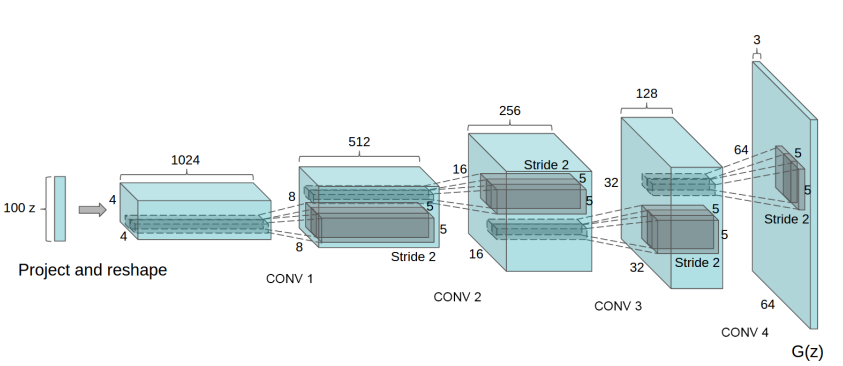
DCGAN
DCGAN的论文地址[https://arxiv.org/pdf/1511.06434.pdf]。DCGAN是GAN的一个变体,DCGAN就是将CNN和原始的GAN结合到一起,生成网络和鉴别网络都运用到了深度卷积神经网络。DCGAN提高了基础GAN的稳定性和生成结果质量。DCGAN主要是在网络架构上改进了原始的…...

【速通版】吴恩达机器学习笔记Part3
目录 1.多元线性回归 a.特征缩放 可行的缩放方式: 1.除以最大值: 2.mean normalization: 3.Z-score normalization b.learning curve: c.learning rate: 2.多项式回归 3.classification logistics regression 1.多元线性回归 其意义很…...

【leetcode】跳跃游戏
一、题目描述 给定一个非负整数数组 nums ,你最初位于数组的 第一个下标 。 数组中的每个元素代表你在该位置可以跳跃的最大长度。 判断你是否能够到达最后一个下标。 示例 1: 输入:nums [2,3,1,1,4] 输出:true 解释&#x…...

若依框架深度定制实战:从模块设计到企业级应用优化
1. 若依框架企业级定制入门指南 第一次接触若依框架时,我就被它"开箱即用"的特性惊艳到了。这个基于Spring Boot和MyBatis的快速开发平台,确实能帮开发者节省大量重复劳动。但真正把它用进企业级项目时,我发现原版框架就像毛坯房&a…...

Spring Boot 环境变量配置详解:从 IDEA 到 Docker 部署
Spring Boot 环境变量配置详解:从 IDEA 到 Docker 部署 文章目录Spring Boot 环境变量配置详解:从 IDEA 到 Docker 部署一、问题背景1.1 环境二、问题分析2.1 现象描述2.2 根本原因1. Spring Boot RelaxedBinding 机制2. Linux 环境变量大小写敏感3. 为什…...

Steam成就数据自主管理:技术深度解析与实战应用
Steam成就数据自主管理:技术深度解析与实战应用 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager 你是否曾因某个隐藏成就的触发条件过于苛刻而反…...

3步让你的PyTorch模型在Intel CPU提速50%:开发者实战指南
3步让你的PyTorch模型在Intel CPU提速50%:开发者实战指南 【免费下载链接】intel-extension-for-pytorch A Python package for extending the official PyTorch that can easily obtain performance on Intel platform 项目地址: https://gitcode.com/GitHub_Tre…...

别再死记硬背真值表了!用Simulink亲手搭建一个SR触发器,理解双稳态存储的底层逻辑
用Simulink亲手搭建SR触发器:从零理解双稳态存储的工程逻辑 记得第一次在数字电路课本上看到SR触发器的真值表时,那种困惑感至今难忘。S、R、Q、Q这些符号在纸上跳来跳去,而"双稳态"、"锁存"这些概念就像天书一样抽象。直…...

终极指南:如何在PC上通过yuzu模拟器流畅运行任天堂Switch游戏
终极指南:如何在PC上通过yuzu模拟器流畅运行任天堂Switch游戏 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu yuzu是目前最流行的开源任天堂Switch模拟器,它允许用户在PC上体验Switch平台的…...
)
Keil MDK5.34安装包+破解工具一站式配置指南(附资源下载链接)
Keil MDK5.34 从零配置到项目实战全流程指南 开发环境搭建基础篇 对于刚接触嵌入式开发的工程师来说,Keil MDK作为ARM架构的主流开发工具链,其安装配置往往是第一个需要跨越的门槛。不同于普通软件的"下一步式"安装,MDK环境搭建涉及…...

多显示器DPI精准调节:效率倍增的显示一致性解决方案
多显示器DPI精准调节:效率倍增的显示一致性解决方案 【免费下载链接】SetDPI 项目地址: https://gitcode.com/gh_mirrors/se/SetDPI 在当今多屏办公环境中,你是否曾经历过这样的尴尬:主显示器文字清晰锐利,副显示器却模糊…...
)
易语言DLL注入工具(含完整源码+窗口Hook实战示例)
温馨提示:文末有联系方式产品核心功能概述 本工具是一款采用易语言开发的Windows平台DLL注入解决方案,支持将指定动态链接库注入至目标进程,并对目标窗口实施消息钩取(Hook),实现UI层行为拦截与增强。 内置…...

DeerFlow深度研究框架:四大核心能力与企业级应用实践
DeerFlow深度研究框架:四大核心能力与企业级应用实践 【免费下载链接】deer-flow DeerFlow is a community-driven framework for deep research, combining language models with tools like web search, crawling, and Python execution, while contributing back…...